⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
IDEA: Image Description Enhanced CLIP-Adapter
Authors:Zhipeng Ye, Feng Jiang, Qiufeng Wang, Kaizhu Huang, Jiaqi Huang
CLIP (Contrastive Language-Image Pre-training) has attained great success in pattern recognition and computer vision. Transferring CLIP to downstream tasks (e.g. zero- or few-shot classification) is a hot topic in multimodal learning. However, current studies primarily focus on either prompt learning for text or adapter tuning for vision, without fully exploiting the complementary information and correlations among image-text pairs. In this paper, we propose an Image Description Enhanced CLIP-Adapter (IDEA) method to adapt CLIP to few-shot image classification tasks. This method captures fine-grained features by leveraging both visual features and textual descriptions of images. IDEA is a training-free method for CLIP, and it can be comparable to or even exceeds state-of-the-art models on multiple tasks. Furthermore, we introduce Trainable-IDEA (T-IDEA), which extends IDEA by adding two lightweight learnable components (i.e., a projector and a learnable latent space), further enhancing the model’s performance and achieving SOTA results on 11 datasets. As one important contribution, we employ the Llama model and design a comprehensive pipeline to generate textual descriptions for images of 11 datasets, resulting in a total of 1,637,795 image-text pairs, named “IMD-11”. Our code and data are released at https://github.com/FourierAI/IDEA.
CLIP(对比语言-图像预训练)在模式识别和计算机视觉领域取得了巨大的成功。将CLIP应用于下游任务(例如零样本或小样本分类)是多模态学习的热门话题。然而,当前的研究主要集中于文本的提示学习或视觉的适配器调整,而没有充分利用图像-文本对之间的互补信息和关联。在本文中,我们提出了一种图像描述增强CLIP适配器(IDEA)方法,将CLIP适应于小样本图像分类任务。该方法通过利用图像的视觉特征和文本描述来捕获细微特征。IDEA是一种无训练的CLIP方法,它在多个任务上的表现可与或超过最新模型。此外,我们引入了可训练IDEA(T-IDEA),它通过添加两个轻量级可学习组件(即投影器和可学习潜在空间)来扩展IDEA,进一步提高了模型的性能,并在11个数据集上实现了最新结果。作为一个重要贡献,我们采用了Llama模型,并设计了一个全面的流程来生成这11个数据集的图像文本描述,共产生1,637,795个图像-文本对,名为“IMD-11”。我们的代码和数据已发布在https://github.com/FourierAI/IDEA上。
论文及项目相关链接
Summary
CLIP在模式识别和计算机视觉领域取得了巨大成功,其在下游任务(如零样本或小样本分类)的迁移学习已成为多模态学习的热门话题。然而,当前研究主要关注文本提示学习或视觉适配器调整,未充分利用图像文本对之间的互补信息和相关性。本文提出了一种基于图像描述增强的CLIP适配器(IDEA)方法,用于适应小样本图像分类任务。该方法通过利用视觉特征和图像文本描述来捕捉精细特征。IDEA是一种针对CLIP的无训练方法,在多个任务上的性能可与或超越现有最先进的模型。此外,本文还介绍了通过添加两个轻量级学习组件(即投影器和可学习潜在空间)对IDEA进行扩展的可训练IDEA(T-IDEA),进一步提高了模型性能,并在11个数据集上实现了最新结果。同时,本文利用Llama模型设计了一个全面的管道来生成11个数据集的图像文本描述,产生了总计163万7千7百9十五个图像文本对,名为“IMD-11”。
Key Takeaways
- CLIP在模式识别和计算机视觉领域表现出卓越性能。
- 在下游任务(如小样本分类)的迁移学习是CLIP的热门应用方向。
- 当前研究未充分利用图像和文本之间的互补信息和相关性。
- IDEA方法通过结合视觉特征和图像文本描述,适应小样本图像分类任务。
- IDEA是一种针对CLIP的无训练方法,性能优越。
- T-IDEA通过添加学习组件进一步提高模型性能,并在多个数据集上实现最新结果。
点此查看论文截图

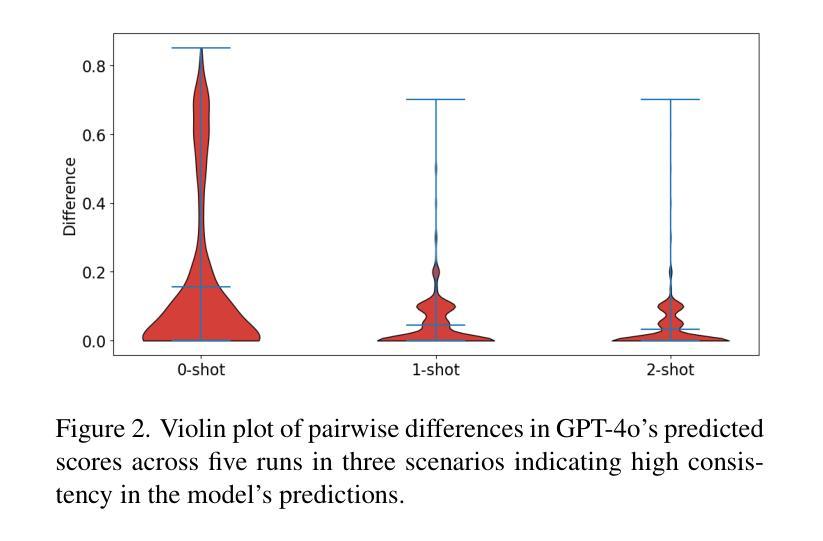
Exploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Authors:Alain Komaty, Hatef Otroshi Shahreza, Anjith George, Sebastien Marcel
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model’s performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o’s promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
本研究重点探讨了ChatGPT(特别是GPT-4o)在人脸识别攻击检测(PAD)中的潜力,其在特定场景下对包括商业解决方案在内的多个PAD模型具有竞争优势。我们的结果表明,GPT-4o表现出高度的一致性,特别是在小样本上下文学习环境中,其性能会随着提供的示例数量增多而提高(参考数据)。我们还观察到,详细的提示使模型能够可靠地提供分数,这一行为在简洁提示下并未观察到。此外,寻求解释的提示略微提高了模型的性能,改善了其可解释性。值得注意的是,尽管没有明确要求分类攻击类型,该模型仍展现出涌现的推理能力,能够在小样本场景中准确预测攻击类型(打印或回放),且准确率极高。尽管有这些优点,GPT-4o在零样本任务中仍面临挑战,其性能与专业的PAD系统相比有限。实验是在SOTERIA数据集的一个子集上进行的,仅使用同意个人的数据,以确保符合数据隐私法规。这些发现强调了GPT-4o在PAD应用中的潜力,为未来研究解决更广泛的数据隐私问题和改进跨数据集泛化能力奠定了基础。相关代码可在此处找到:https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
论文及项目相关链接
PDF Accepted in WACV workshop 2025
Summary
本文研究了ChatGPT(特别是GPT-4o)在面部呈现攻击检测(PAD)中的潜力,并在特定场景下表现出超越多种PAD模型(包括商业解决方案)的性能。GPT-4o在少量样本的情况下展现出卓越的一致性,随着提供更多样本,其性能有所提升。详细的提示能使模型得分更可靠,而简洁的提示则未观察到这种行为。此外,寻求解释的提示略微提高了模型的解释性和性能。尽管GPT-4o未在零样本任务中表现出色,但它能正确预测攻击类型(打印或回放),展现出推理能力。实验在SOTERIA数据集的一个子集上进行,并严格遵守数据隐私法规,仅使用同意参与者的数据。这些发现突显了GPT-4o在PAD应用中的潜力。
Key Takeaways
- GPT-4o在面部呈现攻击检测(PAD)中表现出强大的竞争力,超越了多种PAD模型。
- GPT-4o在少量样本的情况下具有卓越的一致性和性能。
- 详细的提示能使GPT-4o的得分更可靠。
- 寻求解释的提示可以提高GPT-4o的解释性和性能。
- GPT-4o展现出正确的攻击类型预测能力,具有推理能力。
- 实验在符合数据隐私法规的SOTERIA数据集子集上进行。
- 研究为GPT-4o在PAD应用中的潜力奠定了基础,未来研究可关注数据隐私和跨数据集泛化能力。
点此查看论文截图



Few-Shot Learner Generalizes Across AI-Generated Image Detection
Authors:Shiyu Wu, Jing Liu, Jing Li, Yequan Wang
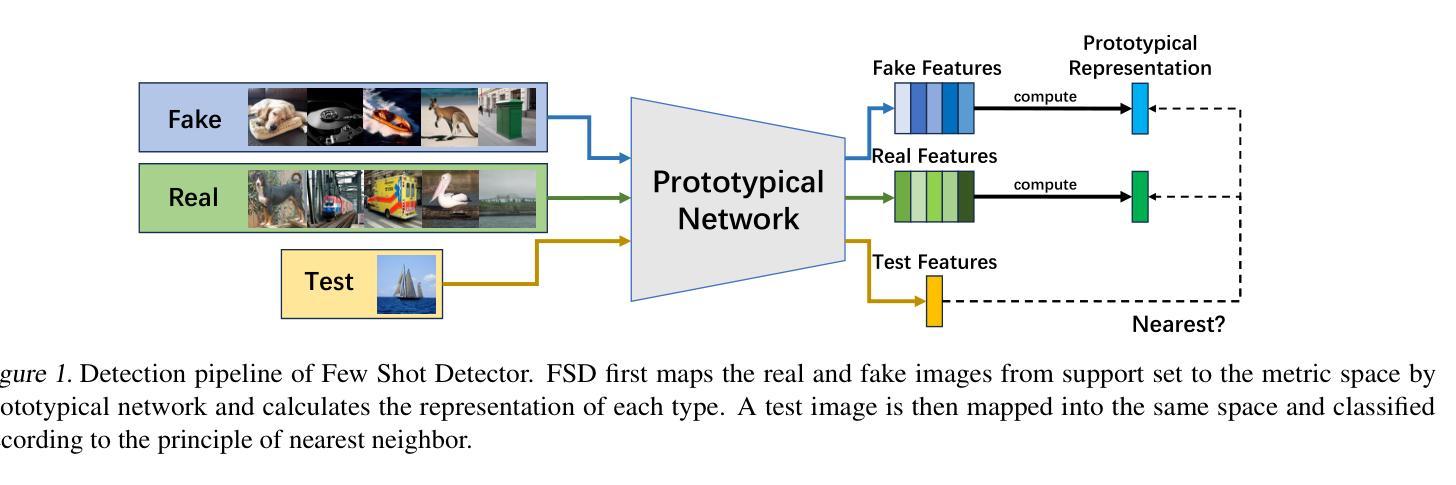
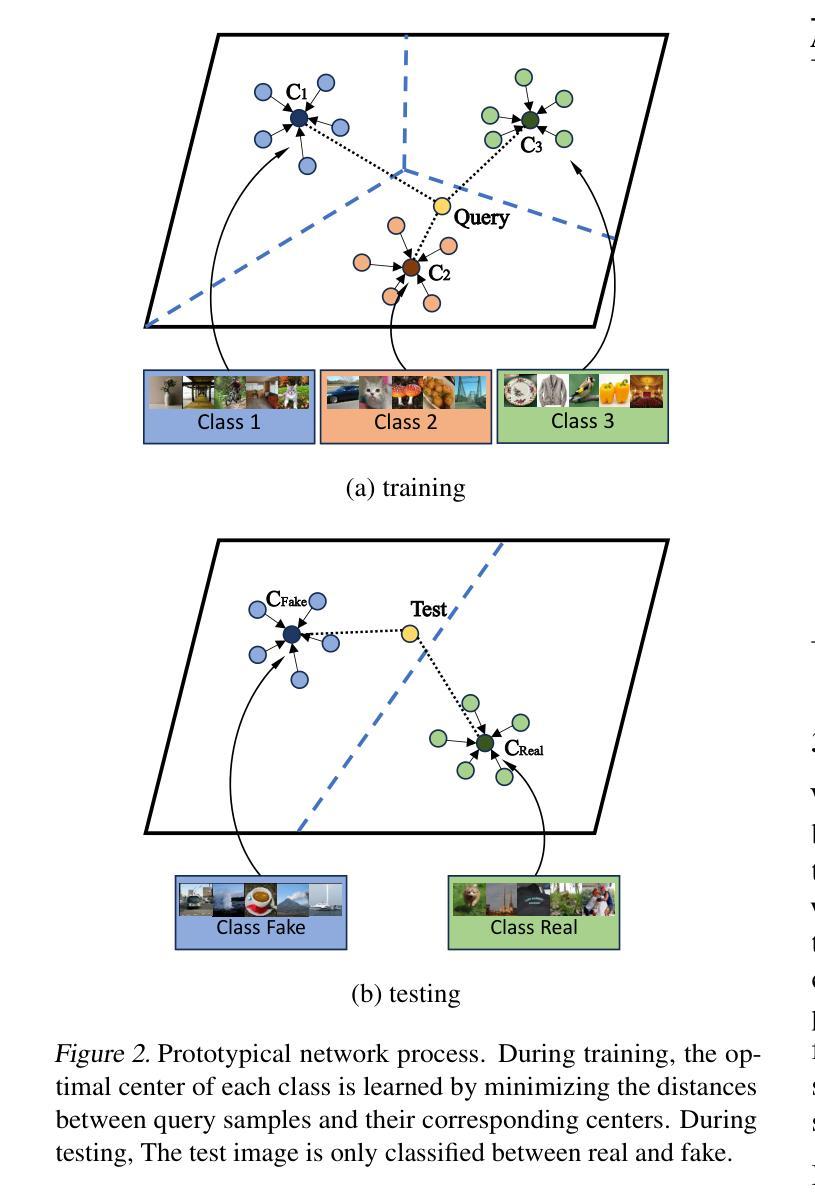
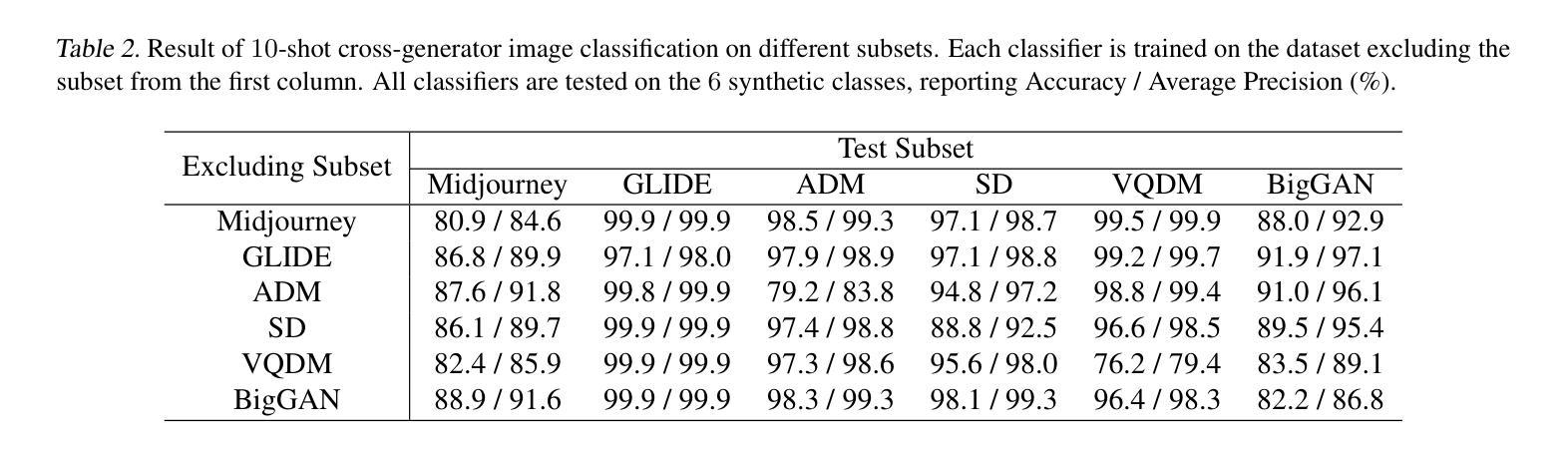
Current fake image detectors trained on large synthetic image datasets perform satisfactorily on limited studied generative models. However, they suffer a notable performance decline over unseen models. Besides, collecting adequate training data from online generative models is often expensive or infeasible. To overcome these issues, we propose Few-Shot Detector (FSD), a novel AI-generated image detector which learns a specialized metric space to effectively distinguish unseen fake images by utilizing very few samples. Experiments show FSD achieves state-of-the-art performance by $+7.4%$ average ACC on GenImage dataset. More importantly, our method is better capable of capturing the intra-category common features in unseen images without further training.
当前在大型合成图像数据集上训练的虚假图像检测器,在有限的生成模型上的表现尚可。然而,它们在未见模型上的性能会出现显著下降。此外,从在线生成模型中收集足够的训练数据通常成本高昂或不可行。为了克服这些问题,我们提出了小样检测器(FSD),这是一种新型的AI生成图像检测器。通过利用极少的样本,它学习专门的度量空间,以有效区分未见过的虚假图像。实验表明,FSD在GenImage数据集上的平均准确率提高了+7.4%,达到最新技术水平。更重要的是,我们的方法无需进一步训练,便能更好地捕捉未见图像中的类别内通用特征。
论文及项目相关链接
PDF 11 pages, 5 figures
Summary
本文介绍了一种新型的基于AI技术的图像检测器——Few-Shot Detector(FSD)。该检测器通过利用极少量样本学习专门的度量空间,有效区分未见过的虚假图像。实验表明,FSD在GenImage数据集上的平均准确率达到了领先水平,提高了7.4%。更重要的是,该方法能够更好地捕捉未见图像中的类别内通用特征,无需进一步训练。
Key Takeaways
- Few-Shot Detector(FSD)是一种新型的AI生成的图像检测器,旨在解决现有虚假图像检测器在面对未见模型时性能下降的问题。
- FSD通过学习专门的度量空间来区分虚假图像,仅利用少量样本即可实现有效检测。
- 实验表明,FSD在GenImage数据集上的平均准确率较之前的方法有所提高,达到了领先水平。
- FSD能够捕捉未见图像中的类别内通用特征,这是其与其他检测器的重要区别。
- FSD的优势在于其对于训练数据的获取需求较小,即使面临有限或昂贵的训练数据情况,也能表现出良好的性能。
- FSD的提出为虚假图像检测领域提供了新的思路和方法,有望在未来得到广泛应用。
点此查看论文截图


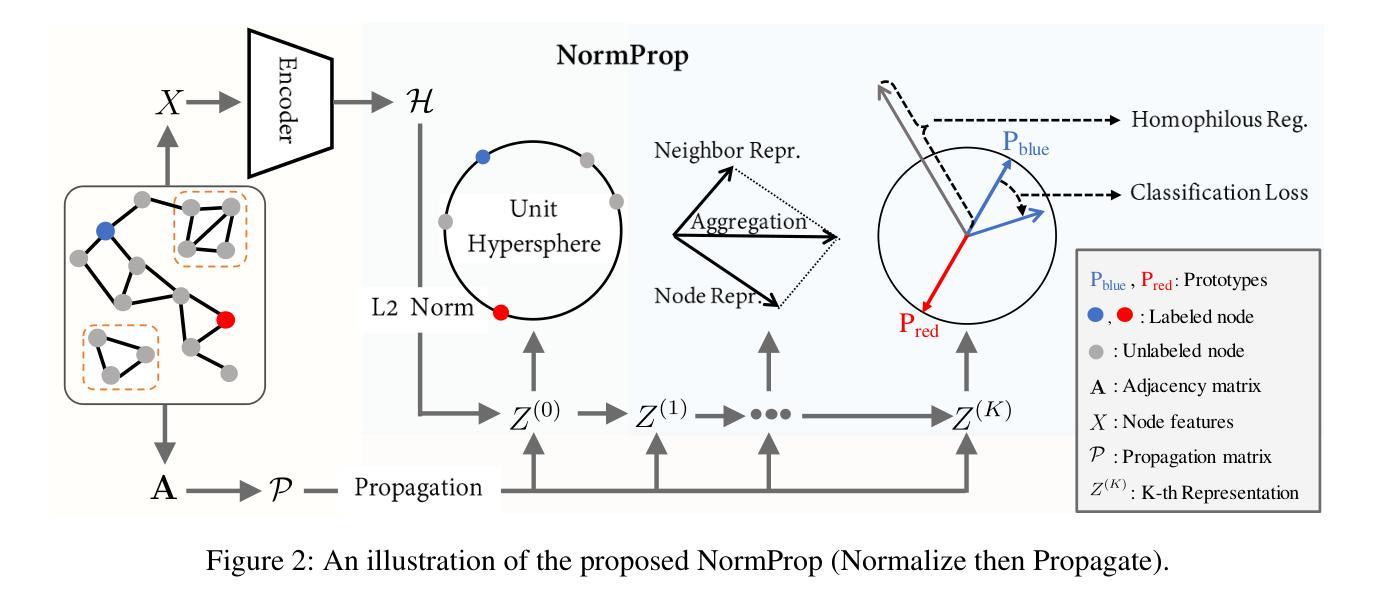
Normalize Then Propagate: Efficient Homophilous Regularization for Few-shot Semi-Supervised Node Classification
Authors:Baoming Zhang, MingCai Chen, Jianqing Song, Shuangjie Li, Jie Zhang, Chongjun Wang
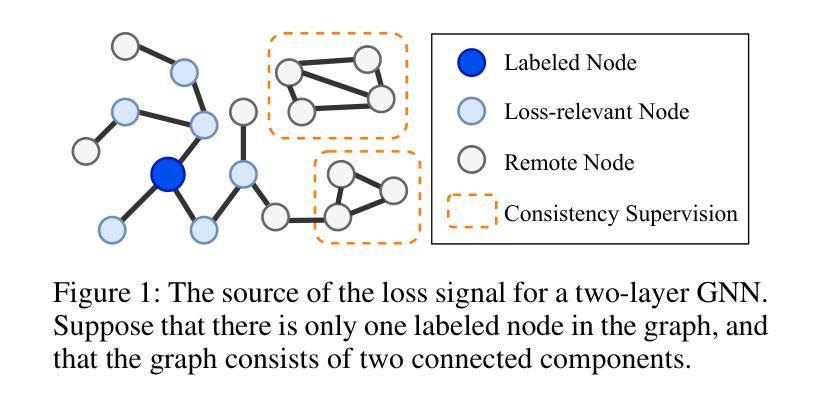
Graph Neural Networks (GNNs) have demonstrated remarkable ability in semi-supervised node classification. However, most existing GNNs rely heavily on a large amount of labeled data for training, which is labor-intensive and requires extensive domain knowledge. In this paper, we first analyze the restrictions of GNNs generalization from the perspective of supervision signals in the context of few-shot semi-supervised node classification. To address these challenges, we propose a novel algorithm named NormProp, which utilizes the homophily assumption of unlabeled nodes to generate additional supervision signals, thereby enhancing the generalization against label scarcity. The key idea is to efficiently capture both the class information and the consistency of aggregation during message passing, via decoupling the direction and Euclidean norm of node representations. Moreover, we conduct a theoretical analysis to determine the upper bound of Euclidean norm, and then propose homophilous regularization to constraint the consistency of unlabeled nodes. Extensive experiments demonstrate that NormProp achieve state-of-the-art performance under low-label rate scenarios with low computational complexity.
图神经网络(GNNs)在半监督节点分类中表现出了显著的能力。然而,大多数现有的GNNs严重依赖于大量的标注数据进行训练,这既耗费人力又需要广泛的专业知识。本文首先分析了少样本半监督节点分类背景下,监督信号对GNNs泛化的限制。为了解决这些挑战,我们提出了一种名为NormProp的新型算法,它利用未标记节点的同亲假设来生成额外的监督信号,从而提高对标签稀缺的泛化能力。关键思想是通过解耦节点表示的方向和欧几里得范数,有效地捕获类信息和聚合过程中的一致性。此外,我们还进行了理论分析,以确定欧几里得范数的上限,然后提出同亲正则化来约束未标记节点的一致性。大量实验表明,NormProp在低标签率场景下实现了最先进的性能,且计算复杂度低。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文分析了图神经网络(GNNs)在少样本半监督节点分类中的泛化限制,并提出了一种名为NormProp的新型算法。该算法利用未标记节点的同质性假设生成额外的监督信号,以提高对标签稀缺的泛化能力。其核心思想是通过解耦节点表示的方向和欧几里得范数,有效地捕获类信息和聚合过程中的一致性。同时,进行了理论分析和实验验证,表明NormProp在低标签率场景下实现了最佳性能,且计算复杂度低。
Key Takeaways
- GNNs在少样本半监督节点分类中面临挑战,需要大量标注数据训练,但标注数据获取困难且需要大量领域知识。
- NormProp算法利用未标记节点的同质性假设生成额外的监督信号,以提高模型泛化能力。
- NormProp通过解耦节点表示的方向和欧几里得范数,捕获类信息和聚合过程中的一致性。
- 进行了理论分析和实验验证,确定了欧几里得范数的上限。
- NormProp提出了同质性正则化来约束未标记节点的一致性。
- NormProp在低标签率场景下实现了最佳性能。
点此查看论文截图

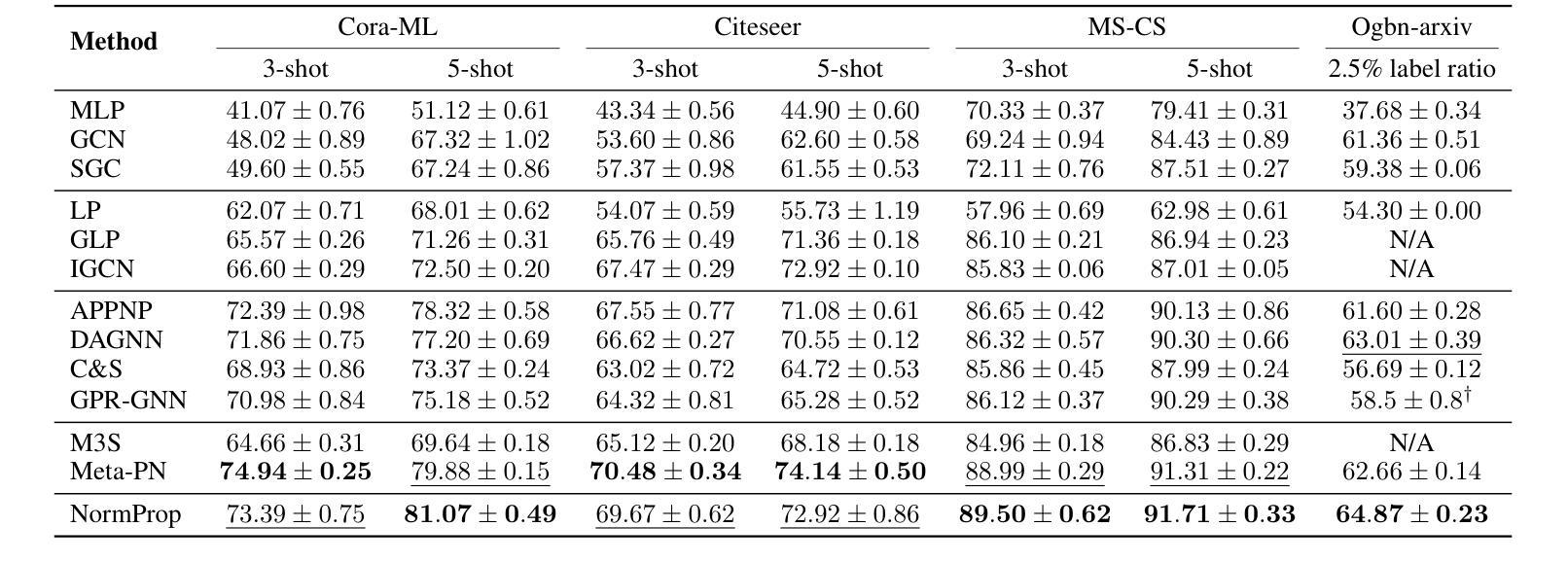

Get Rid of Isolation: A Continuous Multi-task Spatio-Temporal Learning Framework
Authors:Zhongchao Yi, Zhengyang Zhou, Qihe Huang, Yanjiang Chen, Liheng Yu, Xu Wang, Yang Wang
Spatiotemporal learning has become a pivotal technique to enable urban intelligence. Traditional spatiotemporal models mostly focus on a specific task by assuming a same distribution between training and testing sets. However, given that urban systems are usually dynamic, multi-sourced with imbalanced data distributions, current specific task-specific models fail to generalize to new urban conditions and adapt to new domains without explicitly modeling interdependencies across various dimensions and types of urban data. To this end, we argue that there is an essential to propose a Continuous Multi-task Spatio-Temporal learning framework (CMuST) to empower collective urban intelligence, which reforms the urban spatiotemporal learning from single-domain to cooperatively multi-dimensional and multi-task learning. Specifically, CMuST proposes a new multi-dimensional spatiotemporal interaction network (MSTI) to allow cross-interactions between context and main observations as well as self-interactions within spatial and temporal aspects to be exposed, which is also the core for capturing task-level commonality and personalization. To ensure continuous task learning, a novel Rolling Adaptation training scheme (RoAda) is devised, which not only preserves task uniqueness by constructing data summarization-driven task prompts, but also harnesses correlated patterns among tasks by iterative model behavior modeling. We further establish a benchmark of three cities for multi-task spatiotemporal learning, and empirically demonstrate the superiority of CMuST via extensive evaluations on these datasets. The impressive improvements on both few-shot streaming data and new domain tasks against existing SOAT methods are achieved. Code is available at https://github.com/DILab-USTCSZ/CMuST.
时空学习已成为实现城市智能化的关键技术。传统的时空模型大多是通过假设训练集和测试集之间的相同分布来专注于特定任务。然而,鉴于城市系统通常是动态的、多源头的且数据分布不均衡,当前针对特定任务的模型无法推广到新的城市条件,并且无法适应新的领域,而没有明确地对城市数据的各种维度和类型之间的依赖关系进行建模。为此,我们提出需要提出一种连续多任务时空学习框架(CMuST),以实现集体城市智能化,该框架将城市时空学习从单域改革为合作的多维度多任务学习。具体来说,CMuST提出了一种新的多维时空交互网络(MSTI),允许上下文和主要观察结果之间的交叉交互以及空间和时间内部的自我交互,这也是捕捉任务级共性和个性化的核心。为了确保连续任务学习,设计了一种新型的滚动适应训练方案(RoAda),它不仅通过构建数据摘要驱动的任务提示来保持任务的独特性,而且还通过迭代模型行为建模来利用任务之间的相关模式。我们进一步建立了三个城市的多任务时空学习基准,并通过在这些数据集上进行广泛评估,实证证明了CMuST的优越性。与现有的SOAT方法相比,在少量流式数据和新任务域上的表现令人印象深刻。代码可在https://github.com/DILab-USTCSZ/CMuST找到。
论文及项目相关链接
PDF Accepted by NeurIPS 2024
Summary
时空学习已成为实现城市智能化的关键技术。传统时空模型大多专注于特定任务,假设训练集和测试集之间具有相同的分布。然而,由于城市系统的动态性和多源性以及数据分布的不平衡性,当前针对特定任务的模型无法泛化到新的城市条件并适应新领域,没有显式地对城市数据的各种维度和类型之间的依赖关系进行建模。因此,提出一种连续多任务时空学习框架(CMuST)来推动集体城市智能化是必要的,它将城市时空学习从单域改革为合作的多维度多任务学习。特别是,CMuST提出一种新的多维度时空交互网络(MSTI),以允许上下文和主观测之间的交叉交互以及空间和时间的自我交互,这也是捕捉任务级别共性及个性化的核心所在。为了确保连续任务学习,设计了一种新型的滚动适应训练方案(RoAda),这不仅通过构建数据摘要驱动的任务提示来保持任务的独特性,而且还通过迭代模型行为建模来利用任务之间的相关模式。通过在城市多任务时空学习的基准测试中进行了实证演示,CMuST的优越性得到了广泛评估。对于少量流式数据和新的领域任务,相较于现有的顶尖方法,CMuST取得了令人印象深刻的改进。代码可通过https://github.com/DILab-USTCSZ/CMuST访问。
Key Takeaways
- 城市时空学习对于实现城市智能化至关重要。
- 传统时空模型难以适应城市系统的动态性和数据分布的不平衡性。
- 提出了一种新的连续多任务时空学习框架(CMuST),从单域改革为多维度多任务学习。
- CMuST通过多维度时空交互网络(MSTI)捕捉任务级别共性及个性化。
- 滚动适应训练方案(RoAda)能确保连续任务学习并利用任务间的相关模式。
- CMuST在基准测试中表现优越,特别是在处理少量流式数据和新的领域任务时。
点此查看论文截图

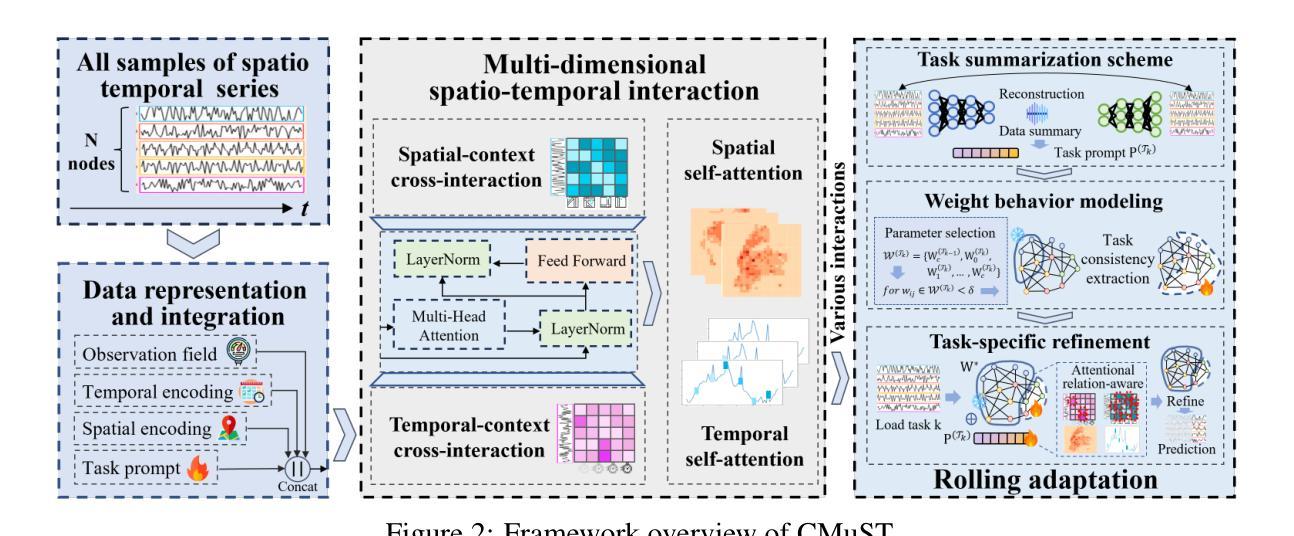
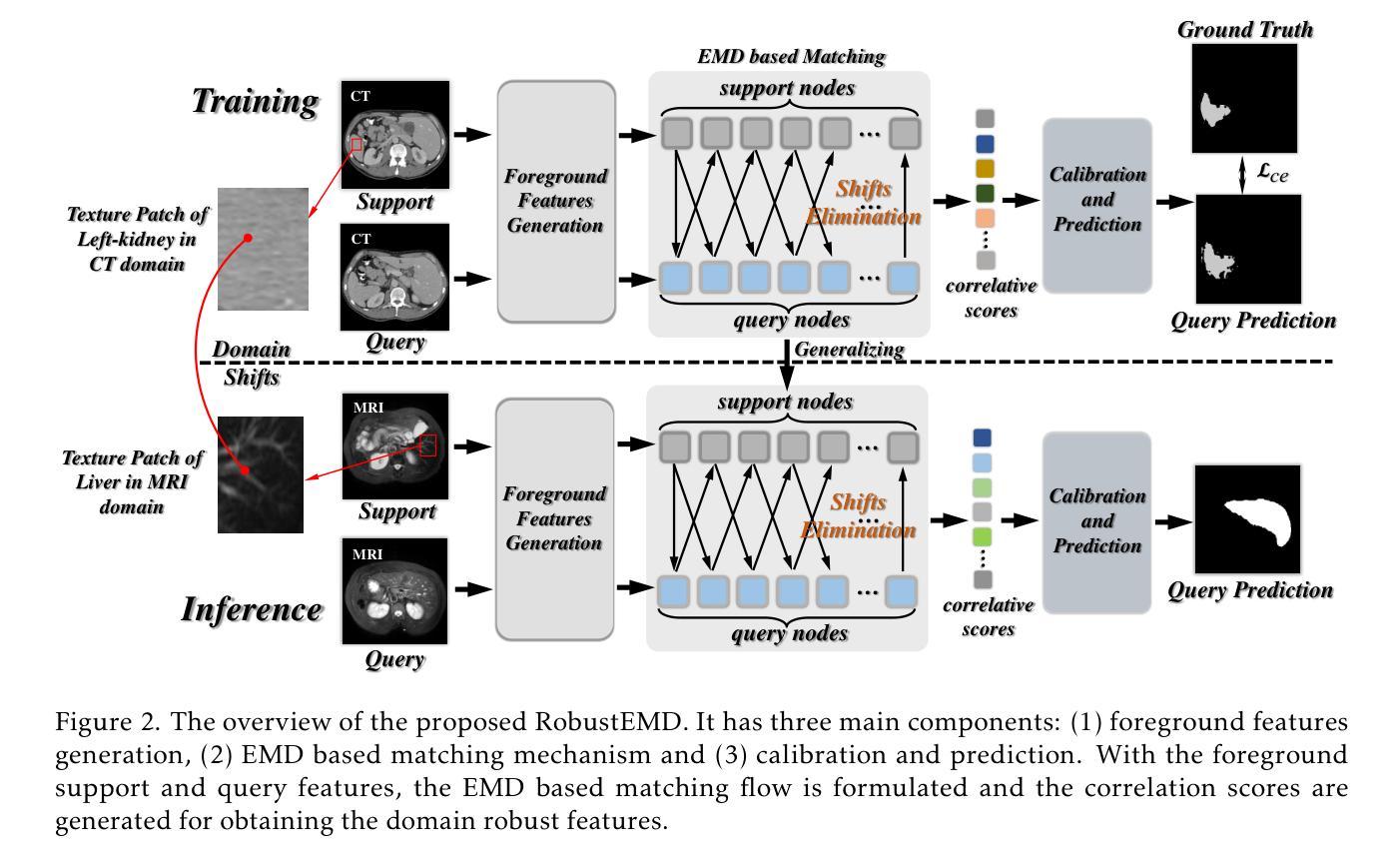
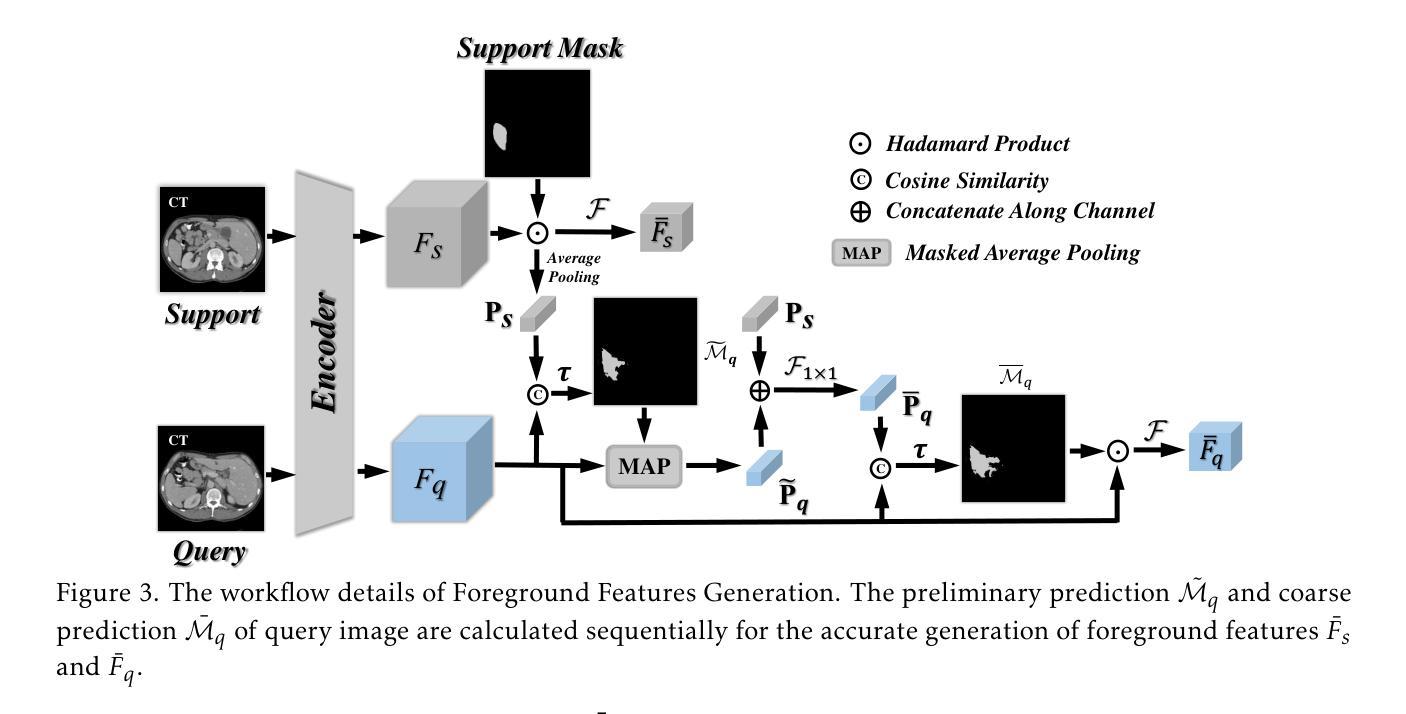
RobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Authors:Yazhou Zhu, Minxian Li, Qiaolin Ye, Shidong Wang, Tong Xin, Haofeng Zhang
Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover’s Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
少量标注数据的医疗图像分割(FSMIS)旨在实现医疗图像分析范围内的有限标注数据学习。尽管已经取得了一些进展,但目前的FSMIS模型都是在同一数据域中进行训练和部署的,这与医学成像数据总是跨不同数据域(例如成像模式、机构和设备序列)的临床现实不一致。如何增强FSMIS模型,使其在不同的特定医学成像域之间具有良好的通用性?在本文中,我们关注少量语义分割模型的匹配机制,并引入一种基于地球移动距离(EMD)计算的域稳健匹配机制,用于跨域场景。具体来说,我们制定了前景支持查询特征之间的EMD传输过程,并介绍了基于纹理结构感知的权重生成方法,该方法建议在节点上执行基于Sobel的图像梯度计算。在EMD匹配流中引入这种方法来约束与域相关的节点。此外,还引入了点集级距离测量指标,用于计算从支持集节点到查询集节点的运输成本。为了评估我们模型的性能,我们在三种场景(即跨模态、跨序列和跨机构)下进行了实验,包括八个医学数据集和三个身体区域,结果表明我们的模型与对比模型相比达到了最新性能水平。
论文及项目相关链接
Summary
基于地球移动距离(EMD)的跨域鲁棒匹配机制被引入到了少样本医学图像分割模型中,解决了模型在不同特定医学成像域中的泛化问题。该机制通过制定前景支持查询特征之间的EMD运输过程,并引入基于Sobel的图像梯度计算来约束域相关节点,同时在点集级别引入距离测量指标来计算运输成本。实验表明,该模型在跨模态、跨序列和跨机构等三种场景下均取得了最先进的性能表现。
Key Takeaways
- FSMIS旨在解决医学图像分析领域有限标注数据的学习问题。
- 当前FSMIS模型局限于同一数据域,但医学成像数据通常涉及不同的数据域。
- 引入基于地球移动距离(EMD)的跨域鲁棒匹配机制,以解决模型在不同医学成像域中的泛化问题。
- EMD匹配机制包括前景支持查询特征之间的EMD运输过程,以及基于Sobel的图像梯度计算来约束域相关节点。
- 点集级别的距离测量指标被用于计算运输成本。
- 模型在跨模态、跨序列和跨机构的三种场景下进行了实验验证。
点此查看论文截图

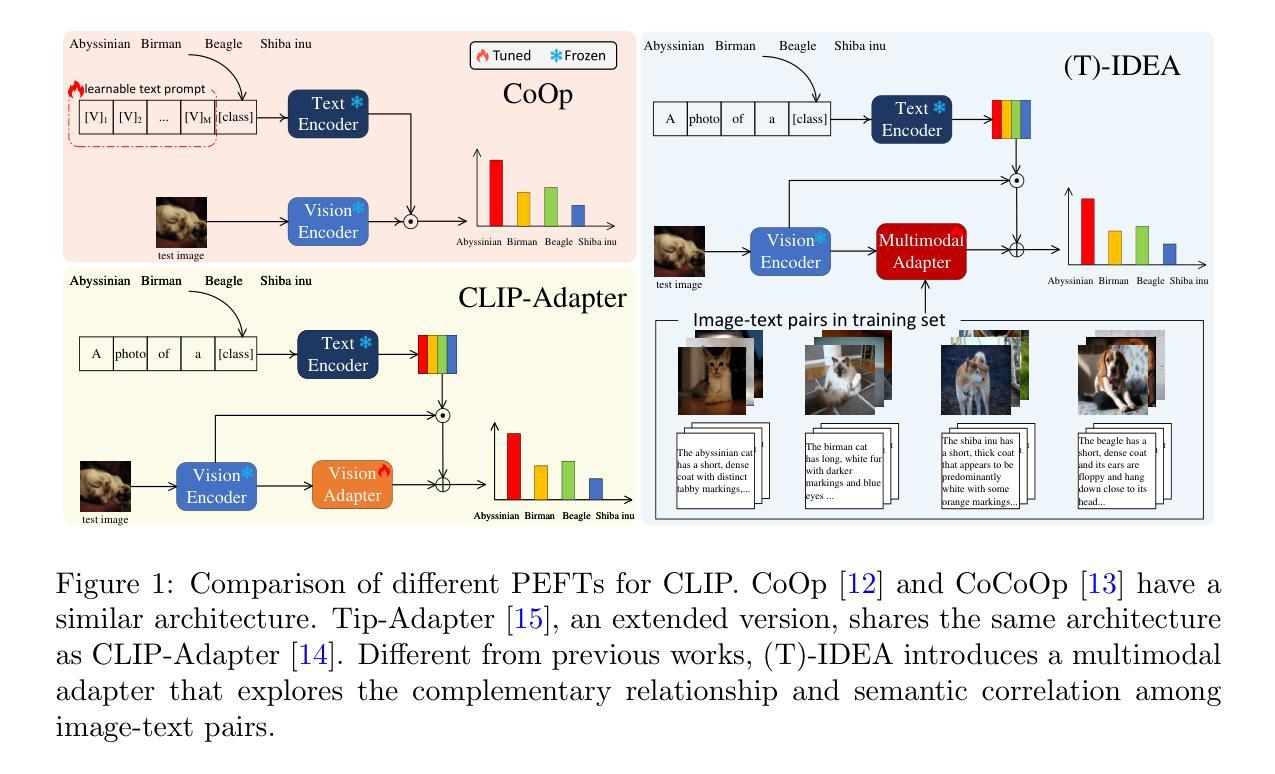
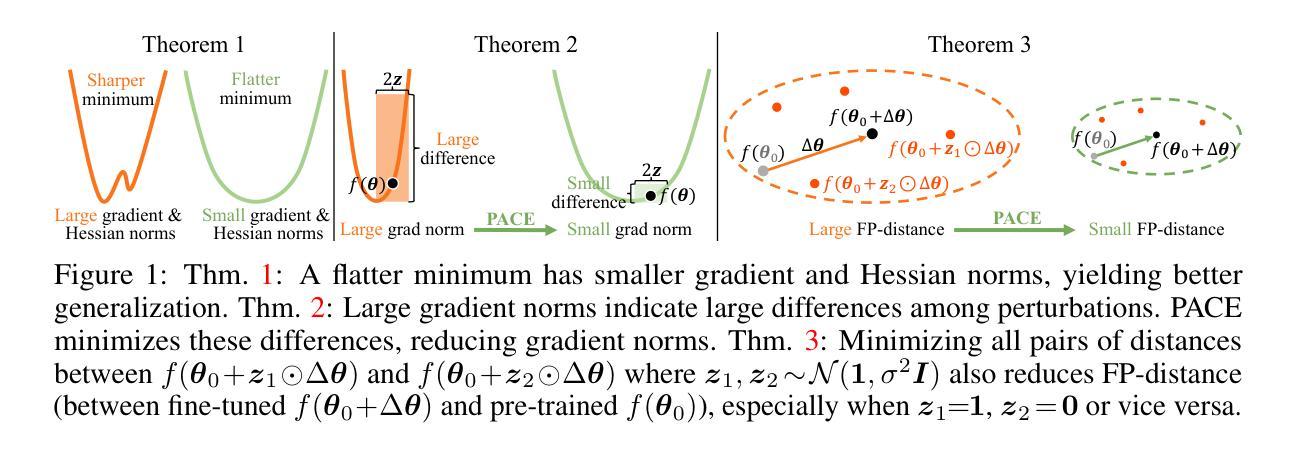
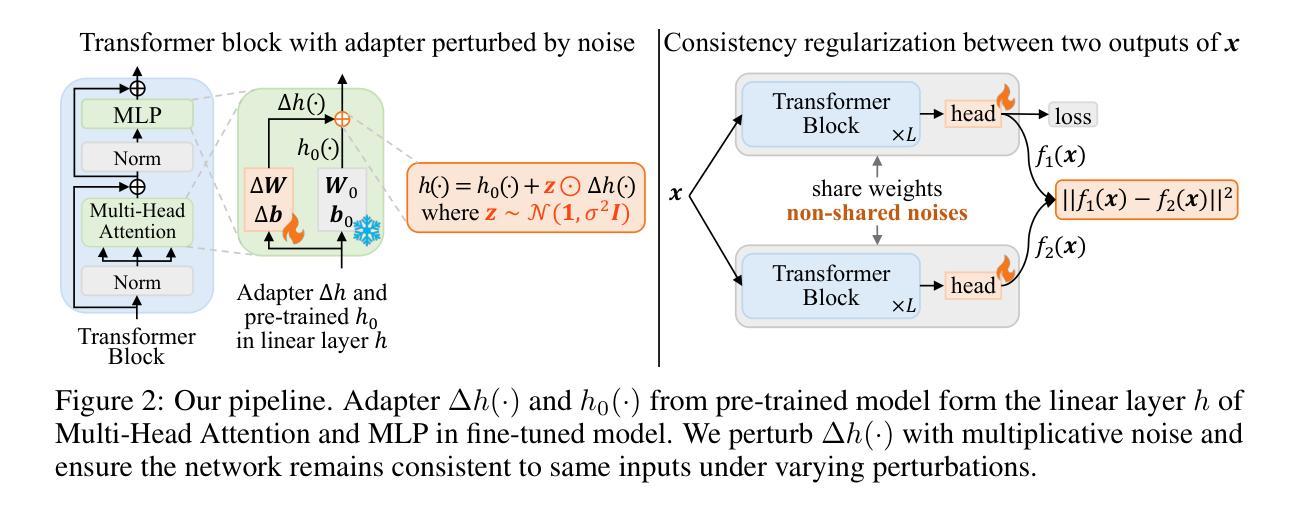
PACE: Marrying generalization in PArameter-efficient fine-tuning with Consistency rEgularization
Authors:Yao Ni, Shan Zhang, Piotr Koniusz
Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained transformers to downstream tasks. However, the optimization of tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improvements in model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such an issue, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE surpasses existing PEFT methods in visual adaptation tasks (VTAB-1k, FGVC, few-shot learning, domain adaptation) showcasing its potential for resource-efficient fine-tuning. It also improves LoRA in text classification (GLUE) and mathematical reasoning (GSM-8K). The code is available at https://github.com/MaxwellYaoNi/PACE
参数高效微调(PEFT)能够有效地使预训练转换器适应下游任务。然而,任务性能的优化往往以微调模型的泛化能力为代价。为了解决这一问题,我们从理论上将训练过程中较小的权重梯度范数和较大的数据集与模型泛化改进联系起来。受此联系的启发,我们提出通过减小梯度范数来提高泛化能力,并通过使微调模型与预训练模型对齐来保留大规模预训练数据中的知识。然而,简单的对齐并不能保证梯度的减小,并且可能导致梯度爆炸,使梯度的管理变得复杂。为了解决这一问题,我们提出了PACE,将参数高效的精细调整与一致性正则化相结合。我们通过乘性噪声扰动从适配器学习到的特征,并确保微调后的模型在不同扰动下对同一样本保持一致。理论分析表明,PACE不仅隐式地正则化梯度以提高泛化能力,而且隐式地对微调模型和预训练模型进行对齐以保留知识。实验证据支持我们的理论。PACE在视觉适应任务(VTAB-1k、FGVC、小样本学习和域适应)上超越了现有的PEFT方法,展示了其资源高效微调的优势。它在文本分类(GLUE)和数学推理(GSM-8K)方面的LoRA也有所改进。代码可在https://github.com/MaxwellYaoNi/PACE中找到。
论文及项目相关链接
PDF Accepted by NeurIPS 2024 as a spotlight
Summary
该文介绍了如何通过参数优化和一致性正则化技术改进预训练模型的微调过程。研究提出了一种新的方法PACE,该方法结合了参数高效微调(PEFT)和一致性正则化,以提高模型的泛化能力。通过理论分析和实验验证,PACE在视觉适应任务(VTAB-1k、FGVC、少样本学习和域适应)以及文本分类和数学推理任务中均表现出优越的性能。
Key Takeaways
- PEFT有助于适应预训练模型到下游任务,但可能牺牲模型的泛化能力。
- 较小权重梯度范数和大数据集与模型泛化改进之间存在理论联系。
- 为了提高泛化能力,提出了PACE方法,结合了参数高效微调与一致性正则化。
- PACE通过引入特征扰动来确保模型对同一样本在不同扰动下的一致性。
- PACE不仅隐式地正则化梯度以提高泛化能力,而且隐式地对微调模型和预训练模型进行对齐以保留知识。
- 实验证据表明,PACE在多种任务上超越了现有的PEFT方法,包括视觉适应、文本分类和数学推理。
- PACE方法的代码已公开可用。
点此查看论文截图

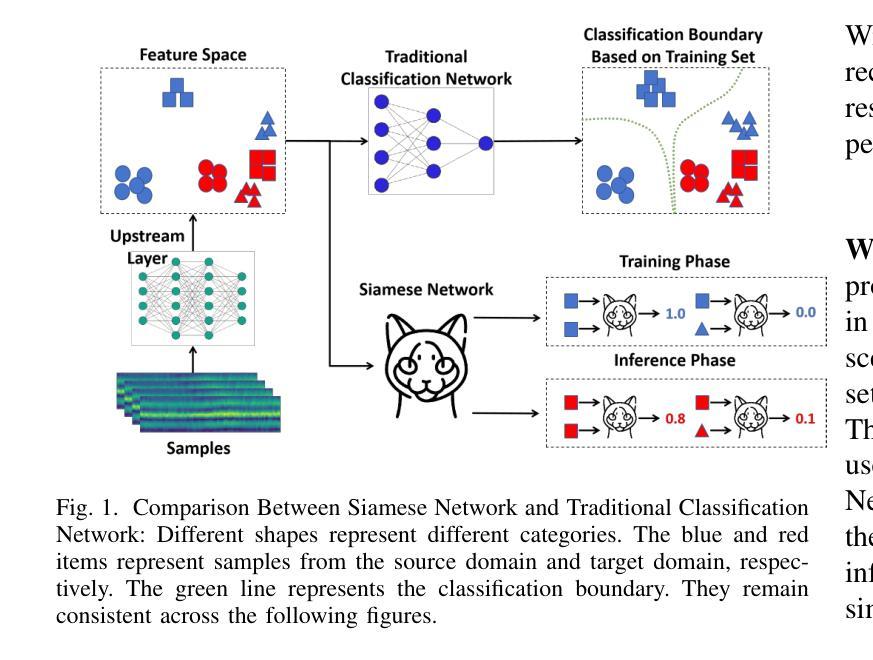
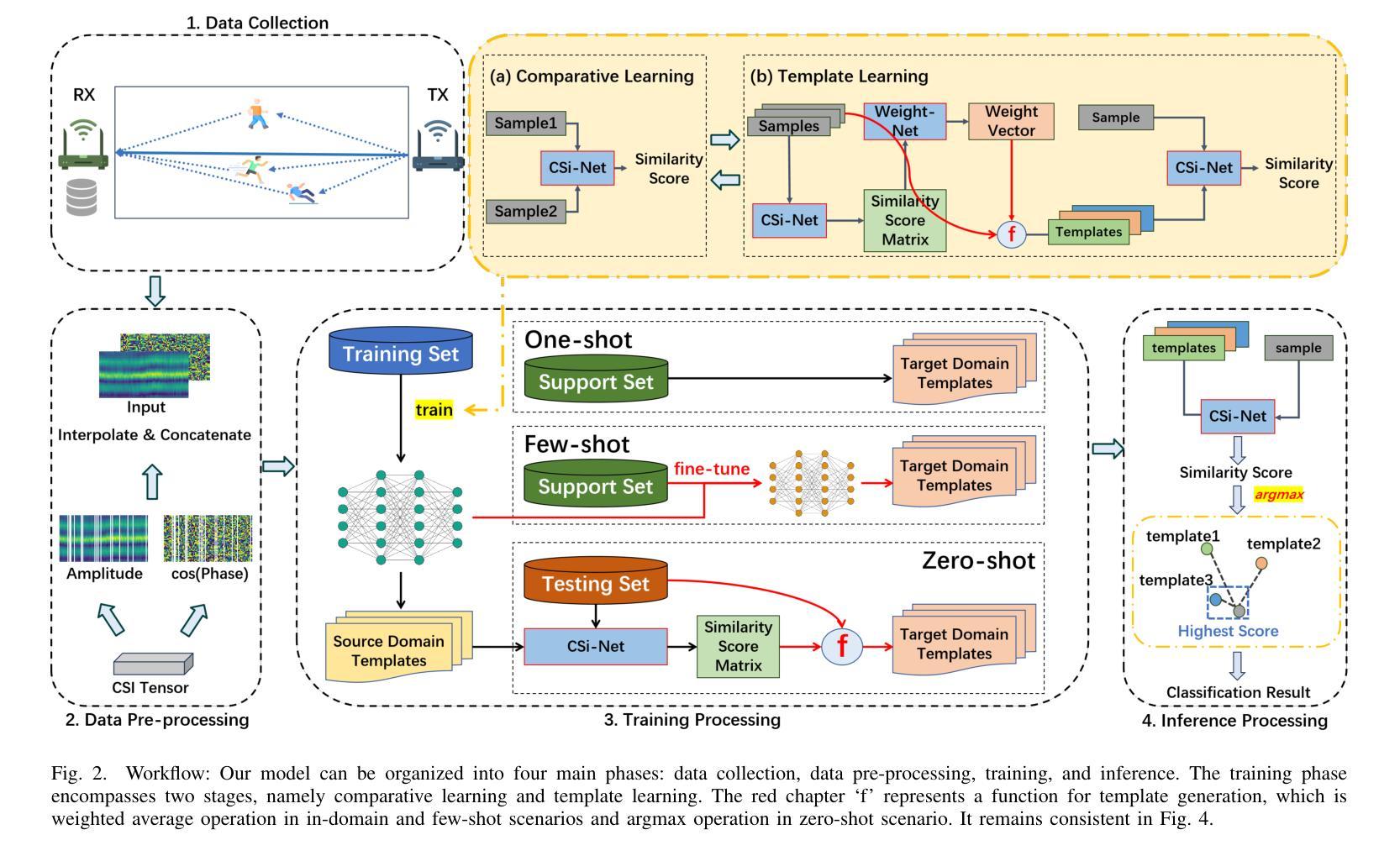
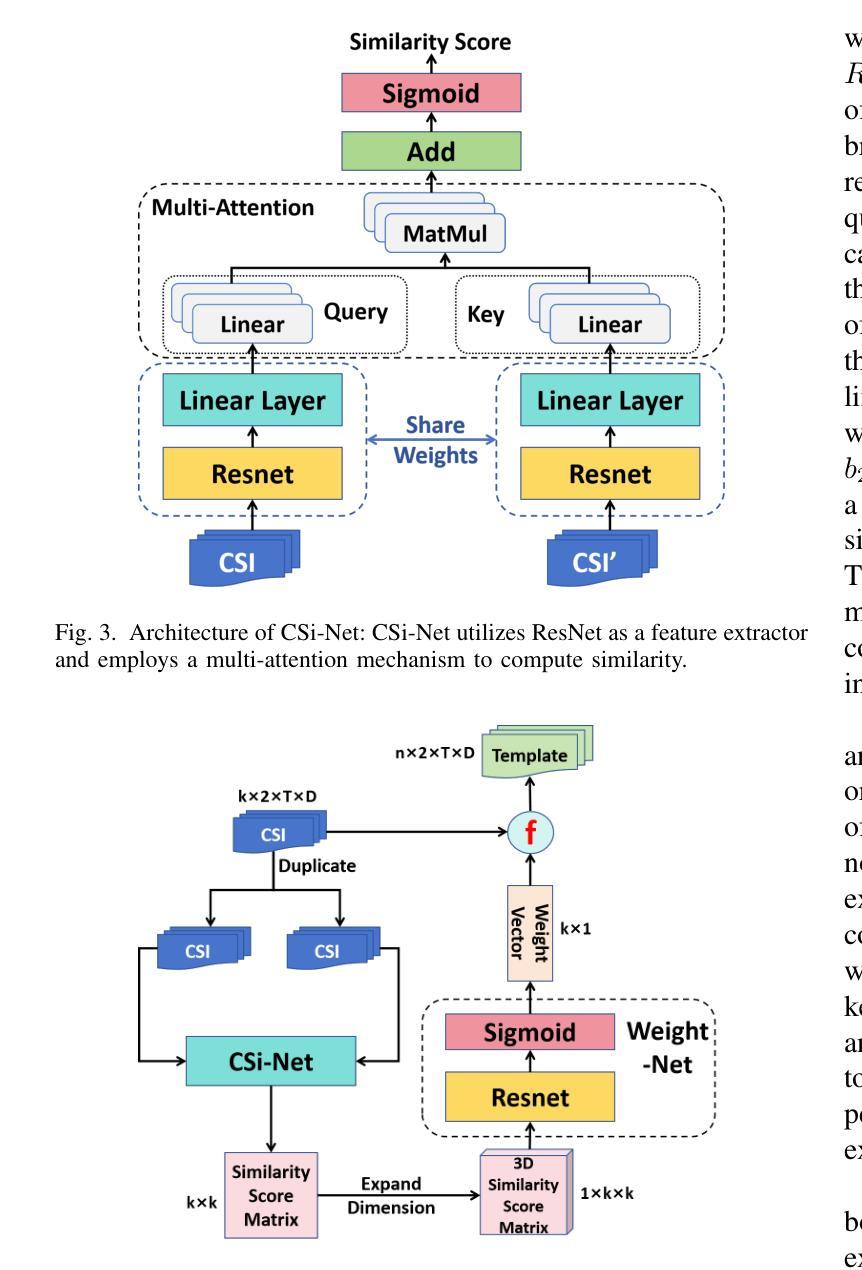
CrossFi: A Cross Domain Wi-Fi Sensing Framework Based on Siamese Network
Authors:Zijian Zhao, Tingwei Chen, Zhijie Cai, Xiaoyang Li, Hang Li, Qimei Chen, Guangxu Zhu
In recent years, Wi-Fi sensing has garnered significant attention due to its numerous benefits, such as privacy protection, low cost, and penetration ability. Extensive research has been conducted in this field, focusing on areas such as gesture recognition, people identification, and fall detection. However, many data-driven methods encounter challenges related to domain shift, where the model fails to perform well in environments different from the training data. One major factor contributing to this issue is the limited availability of Wi-Fi sensing datasets, which makes models learn excessive irrelevant information and over-fit to the training set. Unfortunately, collecting large-scale Wi-Fi sensing datasets across diverse scenarios is a challenging task. To address this problem, we propose CrossFi, a siamese network-based approach that excels in both in-domain scenario and cross-domain scenario, including few-shot, zero-shot scenarios, and even works in few-shot new-class scenario where testing set contains new categories. The core component of CrossFi is a sample-similarity calculation network called CSi-Net, which improves the structure of the siamese network by using an attention mechanism to capture similarity information, instead of simply calculating the distance or cosine similarity. Based on it, we develop an extra Weight-Net that can generate a template for each class, so that our CrossFi can work in different scenarios. Experimental results demonstrate that our CrossFi achieves state-of-the-art performance across various scenarios. In gesture recognition task, our CrossFi achieves an accuracy of 98.17% in in-domain scenario, 91.72% in one-shot cross-domain scenario, 64.81% in zero-shot cross-domain scenario, and 84.75% in one-shot new-class scenario. The code for our model is publicly available at https://github.com/RS2002/CrossFi.
近年来,Wi-Fi感知因其隐私保护、低成本和穿透能力等诸多优势而备受关注。在此领域,已经进行了大量研究,主要集中在手势识别、人员识别和跌倒检测等方面。然而,许多数据驱动的方法在面临领域偏移挑战时效果不佳,即在不同于训练数据的环境中模型表现不佳。导致此问题的一个主要因素是Wi-Fi感知数据集的可获取性有限,这使得模型学习了过多的无关信息并对训练集过度拟合。不幸的是,在多种场景下收集大规模的Wi-Fi感知数据集是一项具有挑战性的任务。为了解决这个问题,我们提出了CrossFi,这是一种基于孪生网络的方法,在域内场景和跨域场景中都表现出色,包括小样本次、零样本场景,甚至在新类别小样本次场景中也能工作,其中测试集包含新类别。CrossFi的核心组件是一个名为CSi-Net的样本相似性计算网络,它通过注意力机制改进了孪生网络的架构,以捕获相似性信息,而不是简单地计算距离或余弦相似性。基于此,我们开发了一个额外的Weight-Net,可以为每个类别生成一个模板,使我们的CrossFi能够在不同的场景中工作。实验结果表明,CrossFi在各种场景中实现了最先进的性能。在手势识别任务中,CrossFi在域内场景中的准确率为98.17%,在单样本跨域场景中的准确率为91.72%,在零样本跨域场景中的准确率为64.81%,在新类别单样本场景中的准确率为84.75%。我们的模型代码公开在https://github.com/RS2002/CrossFi。
论文及项目相关链接
Summary
Wi-Fi感知技术近年来备受关注,但数据驱动的方法面临域偏移问题。本文提出CrossFi方法,基于孪生网络和样本相似性计算网络CSi-Net,能在不同场景下实现优秀性能,包括少样本、零样本场景和新类别场景。实验结果表明,CrossFi在多种场景下达到最佳性能。
Key Takeaways
- Wi-Fi感知技术受到广泛关注,具有隐私保护、低成本和穿透能力等优点。
- 数据驱动的方法在Wi-Fi感知领域面临域偏移问题,模型在不同于训练数据的环境中表现不佳。
- CrossFi方法基于孪生网络和样本相似性计算网络CSi-Net,能有效解决域偏移问题。
- CrossFi在多种场景下表现优秀,包括少样本、零样本场景和新类别场景。
- 实验结果表明,CrossFi在姿态识别任务中达到98.17%的准确率。
- CrossFi模型的代码已公开可用。
点此查看论文截图

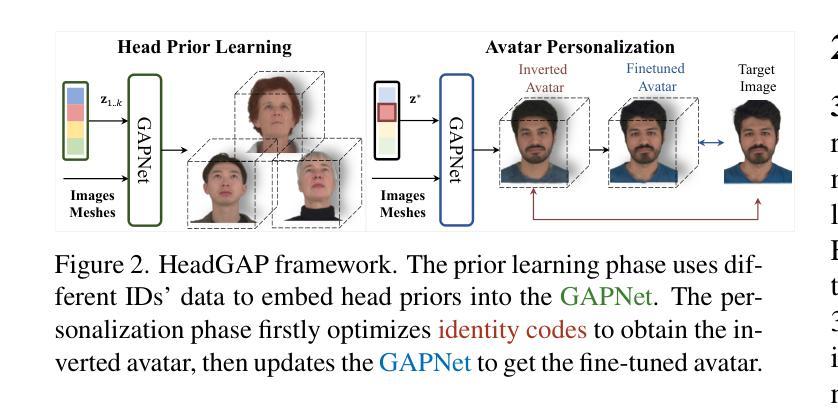
HeadGAP: Few-Shot 3D Head Avatar via Generalizable Gaussian Priors
Authors:Xiaozheng Zheng, Chao Wen, Zhaohu Li, Weiyi Zhang, Zhuo Su, Xu Chang, Yang Zhao, Zheng Lv, Xiaoyuan Zhang, Yongjie Zhang, Guidong Wang, Lan Xu
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
本文介绍了一种新型的三维头部化身创建方法,能够从少量野外数据中进行高度保真和可动画的稳健性概括。鉴于这个问题的约束性较小,融入先验知识至关重要。因此,我们提出了一个包含先验学习阶段和化身创建阶段的框架。先验学习阶段利用大规模多视角动态数据集衍生的三维头部先验知识,而化身创建阶段则应用这些先验知识来进行少量个性化设置。我们的方法有效地捕捉这些先验知识,采用基于高斯拼贴技术的自动解码器网络进行部分动态建模。我们的方法采用具有个性化潜在代码的身份共享编码来学习高斯基本元素的属性。在化身创建阶段,我们通过利用反转和微调策略实现了快速头部化身的个性化设置。大量实验表明,我们的模型有效地利用了头部先验知识,并成功将其推广到少量个性化设置上,实现了逼真的渲染质量、多视角一致性和稳定的动画效果。
论文及项目相关链接
PDF Accepted to 3DV 2025. Project page: https://headgap.github.io/
Summary
本文提出了一种新型的三维头部虚拟角色创建方法,该方法能够从小规模数据中进行泛化,并展现出高度保真和动画鲁棒性。方法包括两个阶段:先验学习阶段和角色创建阶段。先验学习阶段利用大规模多视角动态数据集提取的头部三维先验知识,角色创建阶段则应用这些先验进行个性化创建。该方法通过基于高斯拼贴技术的自动解码器网络和部分动态建模技术有效捕捉这些先验知识。方法采用共享身份编码和个性化潜在代码学习高斯基本属性的身份特征。在角色创建阶段,通过反转和微调策略实现快速头部角色个性化。实验证明,该模型有效地利用头部先验知识,成功泛化到小规模个性化数据,达到逼真的渲染质量、多视角一致性和稳定的动画效果。
Key Takeaways
- 提出了一种新型三维头部虚拟角色创建方法,能够从少量数据中泛化并表现出高度保真和动画鲁棒性。
- 方法包括先验学习阶段和角色创建阶段,前者利用大规模多视角动态数据集提取头部三维先验知识。
- 采用基于高斯拼贴技术的自动解码器网络和部分动态建模技术捕捉先验知识。
- 方法采用共享身份编码和个性化潜在代码来学习高斯基本属性的身份特征。
- 通过反转和微调策略实现快速头部角色个性化。
- 模型有效泛化到小规模个性化数据,达到逼真的渲染质量。
点此查看论文截图

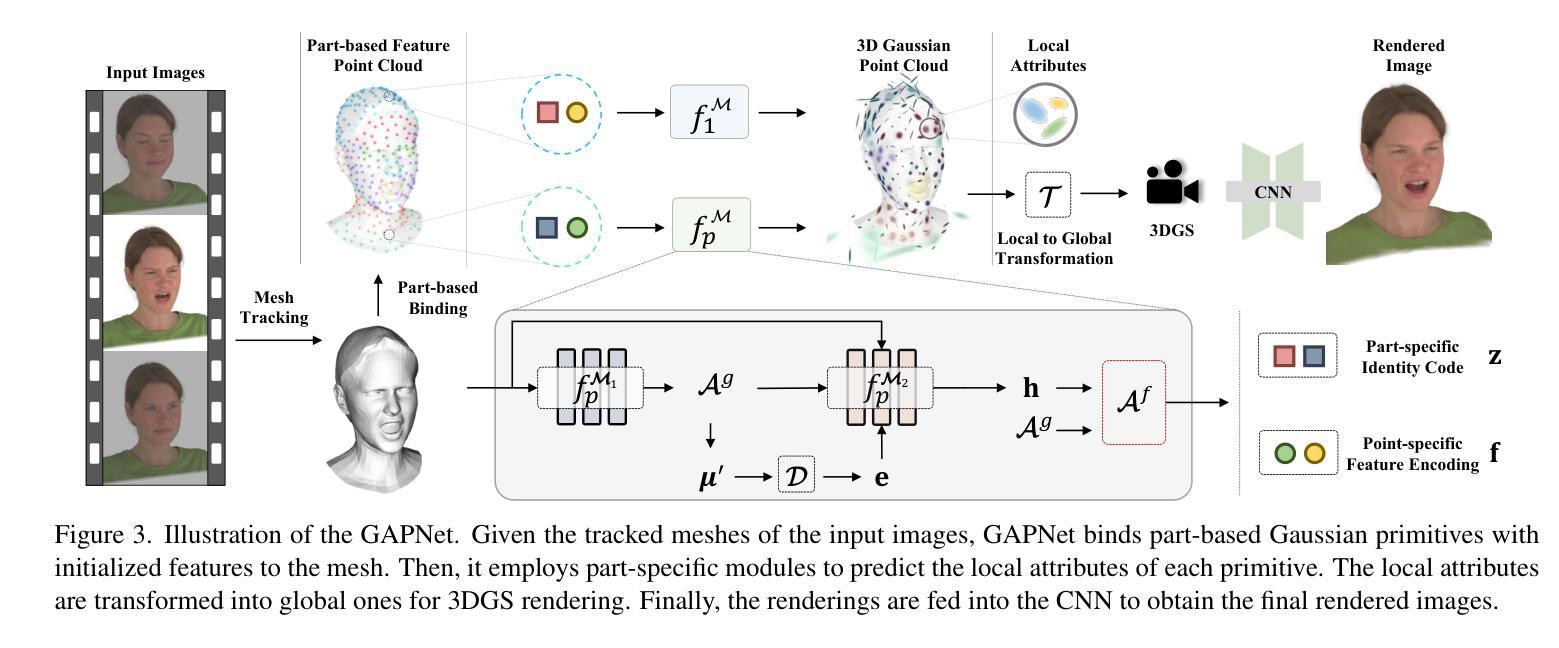
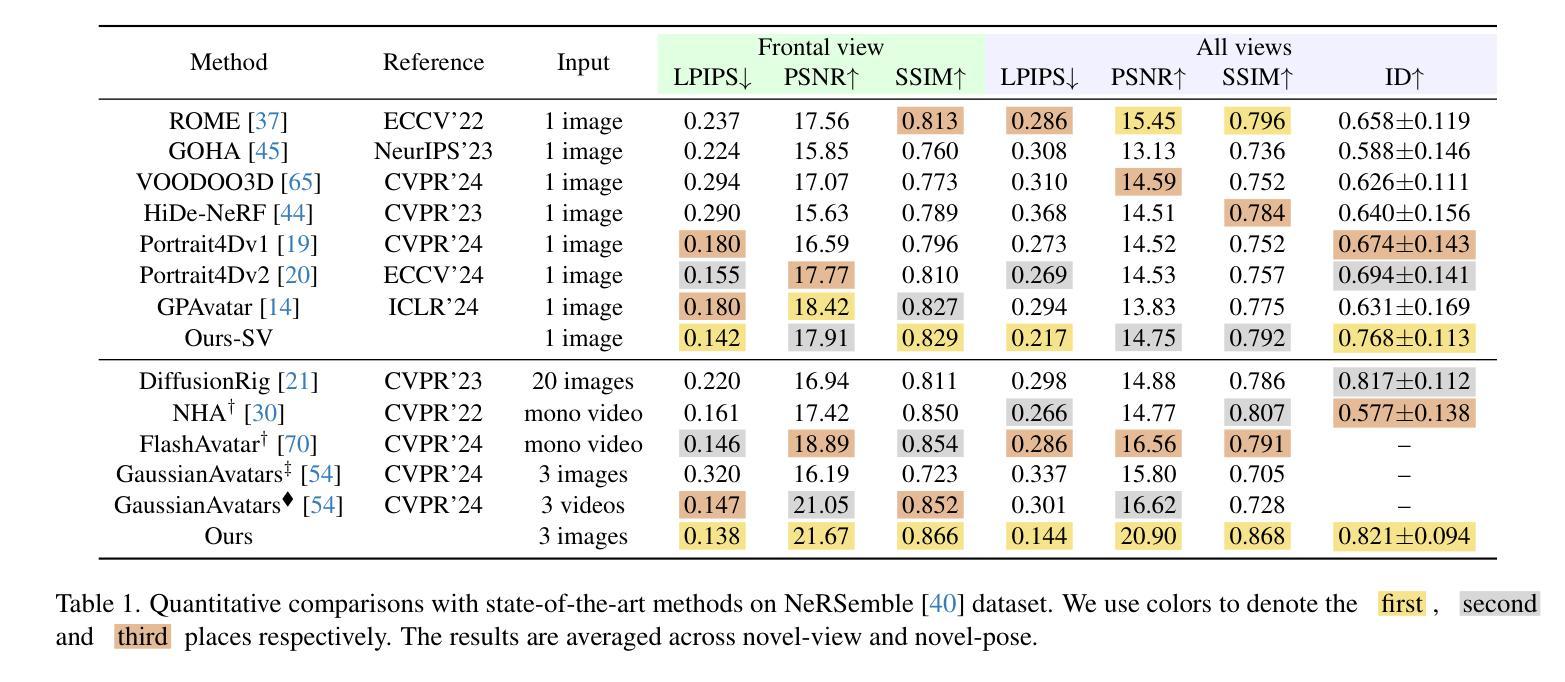

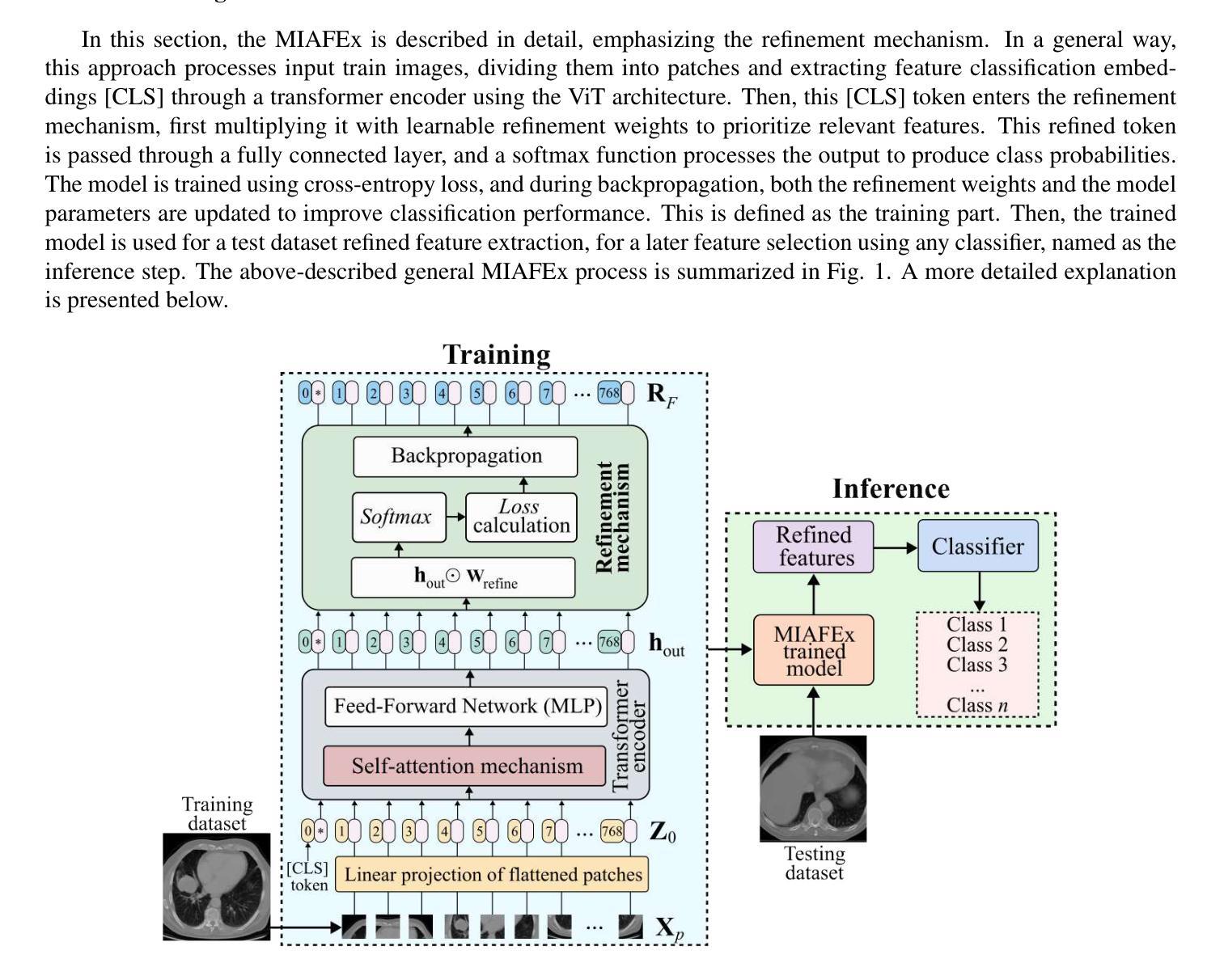
A Foundation Language-Image Model of the Retina (FLAIR): Encoding Expert Knowledge in Text Supervision
Authors:Julio Silva-Rodríguez, Hadi Chakor, Riadh Kobbi, Jose Dolz, Ismail Ben Ayed
Foundation vision-language models are currently transforming computer vision, and are on the rise in medical imaging fueled by their very promising generalization capabilities. However, the initial attempts to transfer this new paradigm to medical imaging have shown less impressive performances than those observed in other domains, due to the significant domain shift and the complex, expert domain knowledge inherent to medical-imaging tasks. Motivated by the need for domain-expert foundation models, we present FLAIR, a pre-trained vision-language model for universal retinal fundus image understanding. To this end, we compiled 38 open-access, mostly categorical fundus imaging datasets from various sources, with up to 101 different target conditions and 288,307 images. We integrate the expert’s domain knowledge in the form of descriptive textual prompts, during both pre-training and zero-shot inference, enhancing the less-informative categorical supervision of the data. Such a textual expert’s knowledge, which we compiled from the relevant clinical literature and community standards, describes the fine-grained features of the pathologies as well as the hierarchies and dependencies between them. We report comprehensive evaluations, which illustrate the benefit of integrating expert knowledge and the strong generalization capabilities of FLAIR under difficult scenarios with domain shifts or unseen categories. When adapted with a lightweight linear probe, FLAIR outperforms fully-trained, dataset-focused models, more so in the few-shot regimes. Interestingly, FLAIR outperforms by a wide margin larger-scale generalist image-language models and retina domain-specific self-supervised networks, which emphasizes the potential of embedding experts’ domain knowledge and the limitations of generalist models in medical imaging.
目前,基础视觉语言模型正在改变计算机视觉领域,并且在医疗成像领域呈现出上升趋势,这得益于其非常有前景的泛化能力。然而,将这一新范式应用于医疗成像的初步尝试,由于领域转移和医疗成像任务固有的复杂专家知识,其表现不如其他领域那么令人印象深刻。为了满足对领域专家基础模型的需求,我们提出了FLAIR,这是一个用于通用视网膜眼底图像理解的基础视觉语言模型。为此,我们从各种来源整合了38个开放访问的眼底成像数据集,涵盖多达101种不同目标疾病和288,307张图像。我们以描述性文本提示的形式整合专家的领域知识,这种知识是我们在相关临床文献和社区标准中编译的,描述了病理的细微特征以及它们之间的层次结构和依赖关系。我们在预训练和零样本推理中都融入了这种文本专家知识。我们进行了全面的评估,展示了融入专家知识的益处以及FLAIR在领域转移或未见类别等困难场景下的强大泛化能力。当使用轻量级线性探针进行适应时,FLAIR在少数类别中的表现优于专注于数据集的模型,特别是在视网膜疾病的识别方面。有趣的是,FLAIR大幅超越了大规模通用图像语言模型和视网膜领域的特定自监督网络,这强调了嵌入专家领域知识的潜力以及通用模型在医疗成像中的局限性。
论文及项目相关链接
PDF Accepted in Medical Image Analysis. The pre-trained model is available at: https://github.com/jusiro/FLAIR
摘要
基于跨领域迁移学习的视角,文章介绍了面向视网膜基金图像理解的预训练视觉语言模型FLAIR。为提高模型在医学成像领域的表现,研究团队整合了专业领域的知识,并以描述性的文本提示形式融入模型,强化了数据的类别监督信息。通过全面的评估,文章展示了整合专家知识的优势以及FLAIR在困难场景下的强大泛化能力。当使用轻量级线性探针进行适配时,FLAIR在少样本情况下表现优异,并大幅超越大规模的综合图像语言模型和视网膜领域的特定自监督网络,突显了嵌入专家领域知识的潜力以及通用模型在医学成像中的局限性。
关键见解
- 跨领域迁移学习对于将视觉语言模型应用于医学成像具有重要意义。
- 在开发面向视网膜基金图像理解的模型FLAIR时,结合了专家领域知识,并以文本提示的形式融入模型训练与零样本推理过程。
- 文本提示包含精细的病理特征描述以及病理层次和依赖关系的描述。
- 通过全面的评估证明了整合专家知识的优势以及FLAIR的泛化能力。
- 在少样本情况下,使用轻量级线性探针适配的FLAIR表现突出。
- 与大规模的综合图像语言模型和视网膜领域的特定自监督网络相比,FLAIR大幅领先,突显了嵌入专家领域知识的潜力。
点此查看论文截图

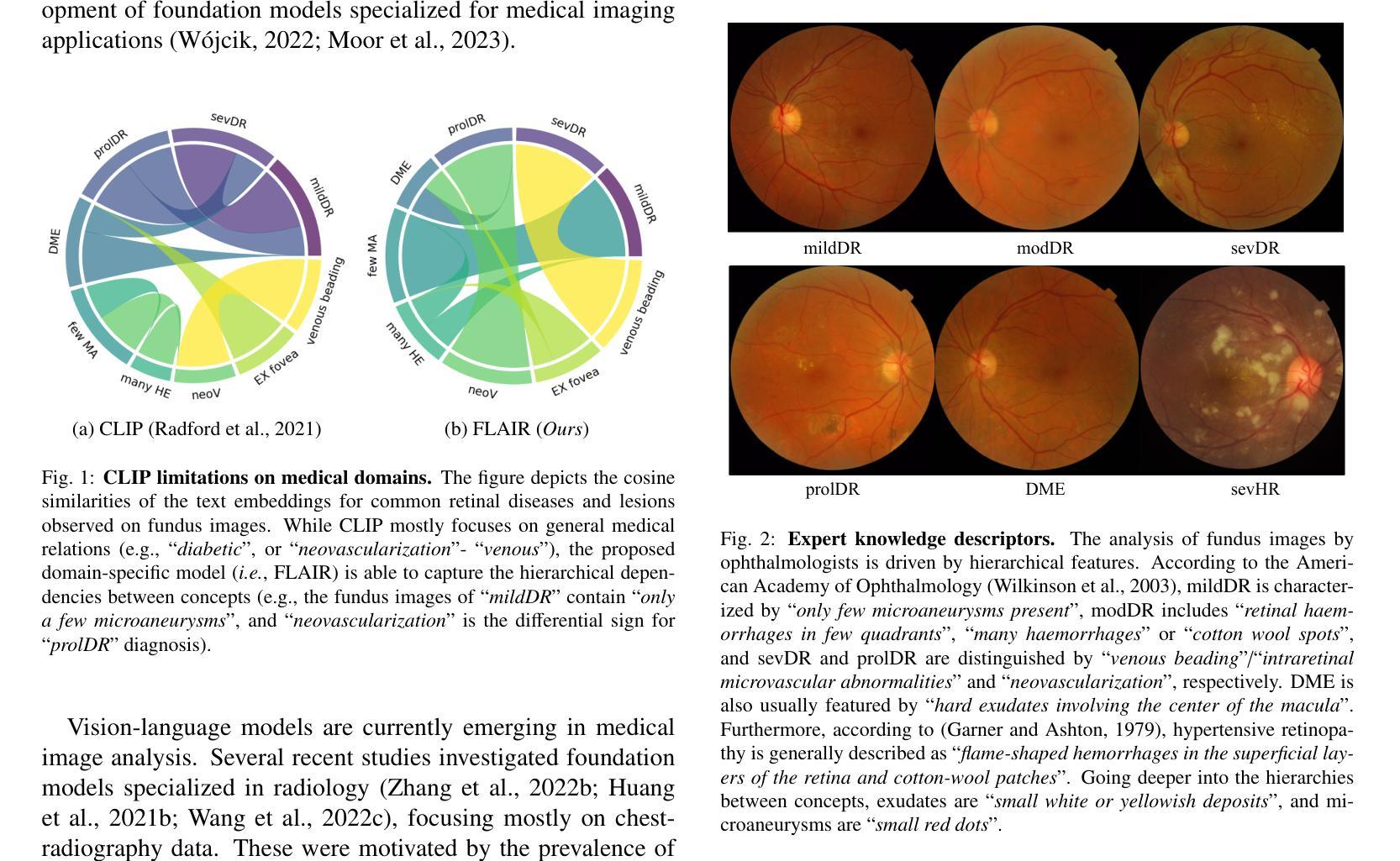
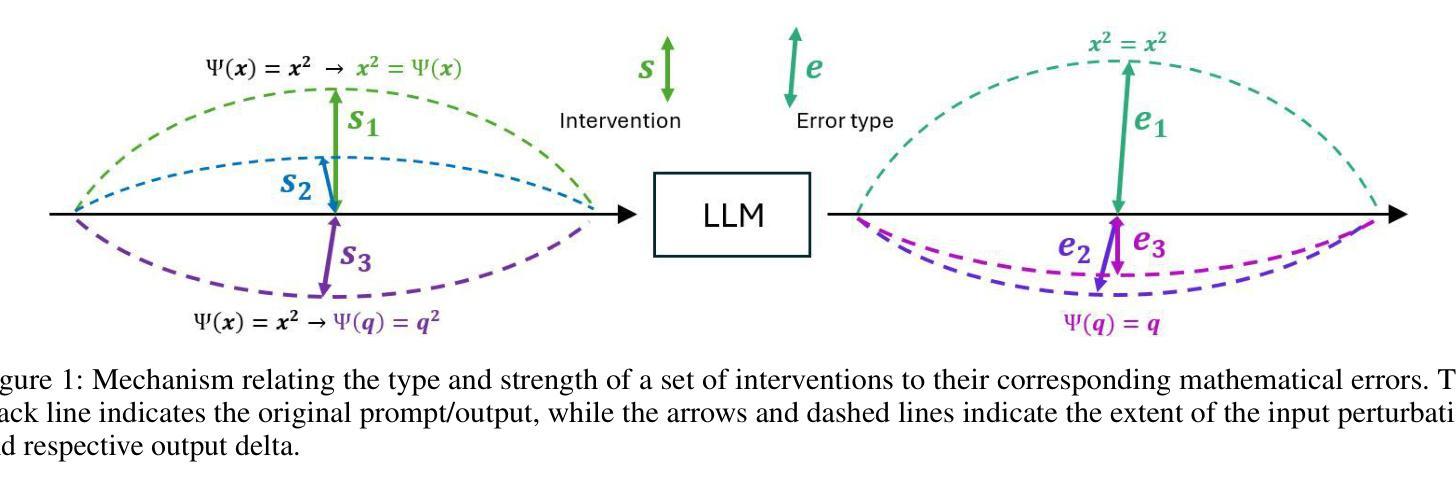
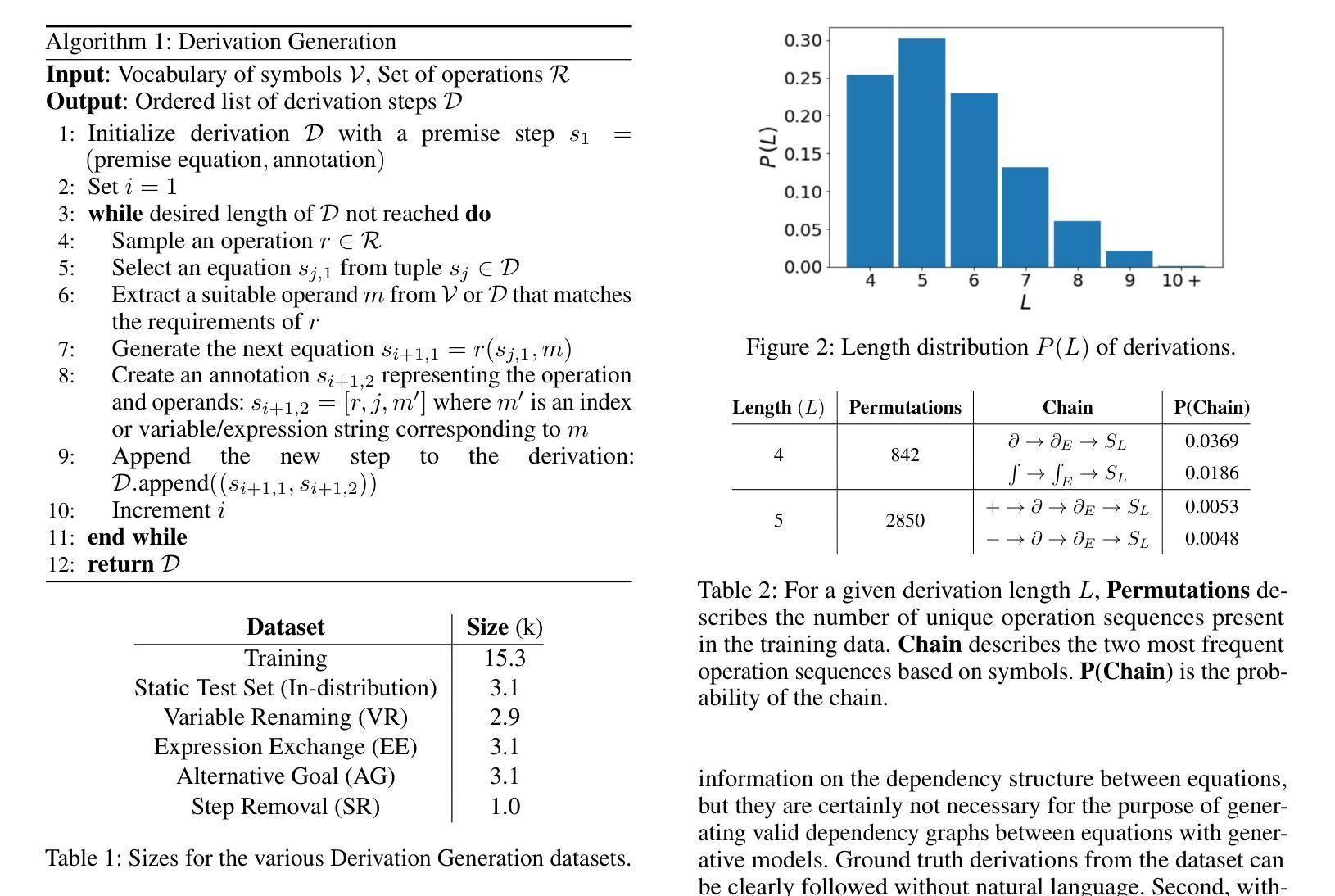
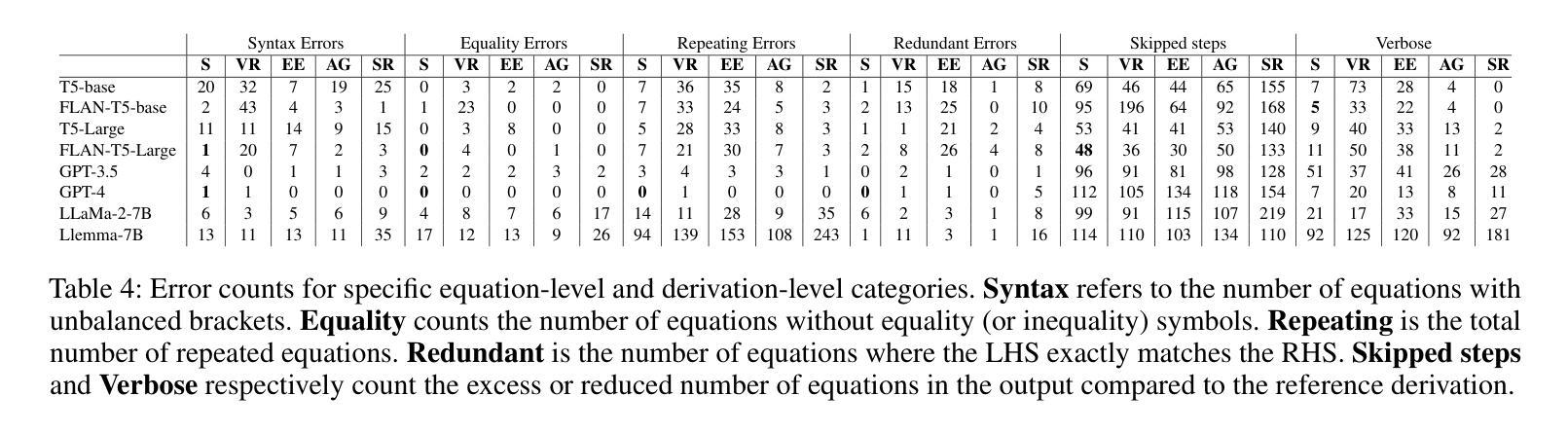
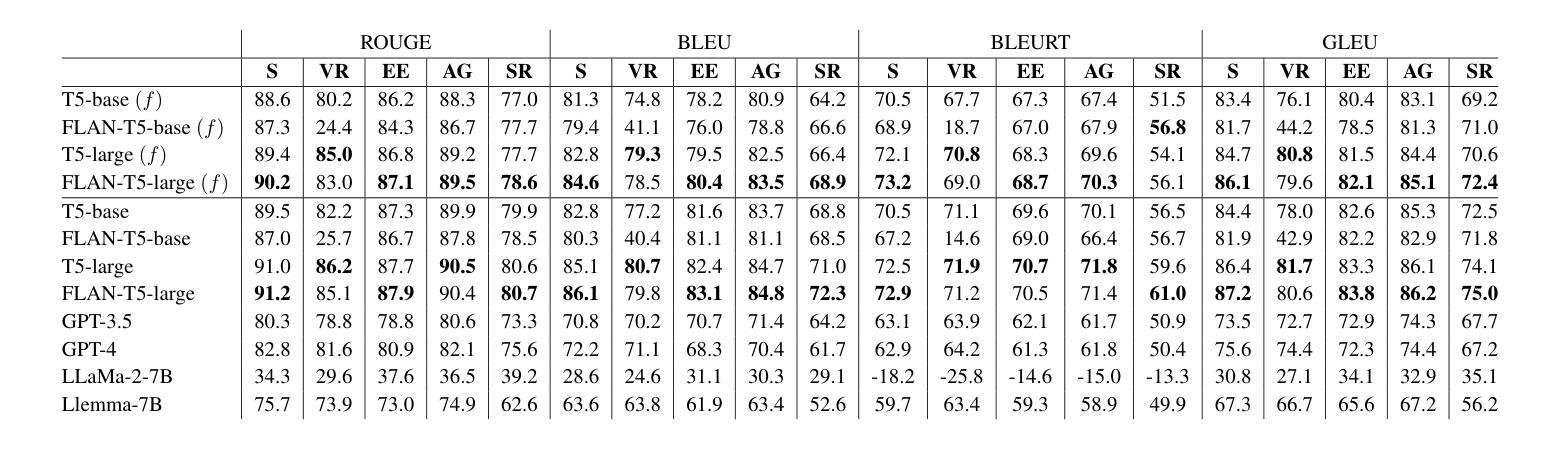
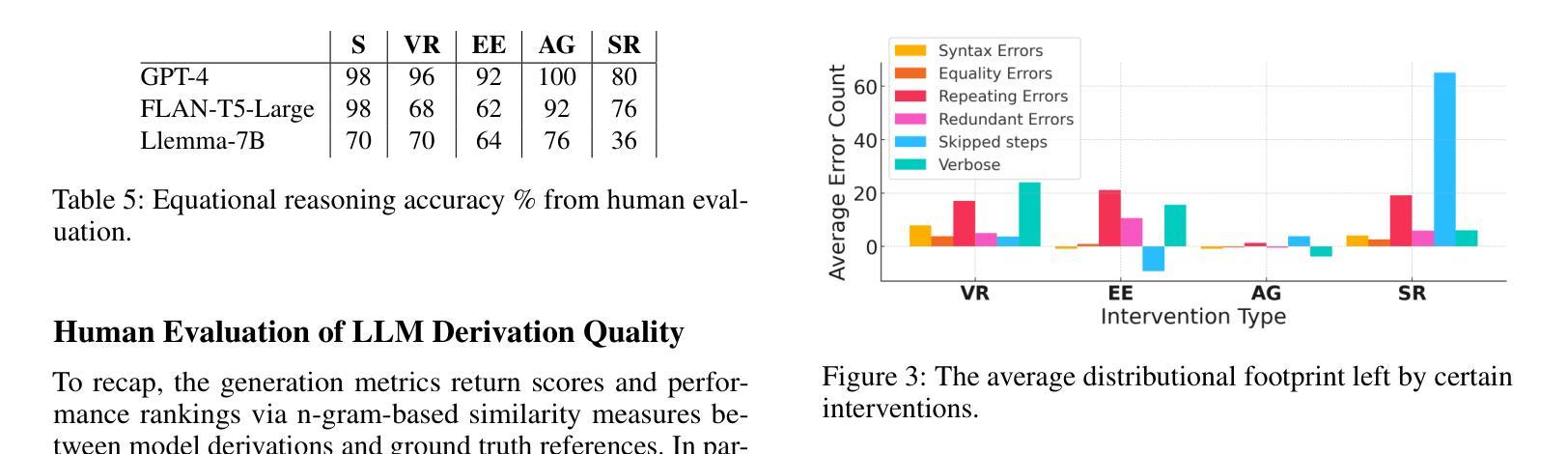
Controlling Equational Reasoning in Large Language Models with Prompt Interventions
Authors:Jordan Meadows, Marco Valentino, Andre Freitas
This paper investigates how hallucination rates in Large Language Models (LLMs) may be controlled via a symbolic data generation framework, exploring a fundamental relationship between the rate of certain mathematical errors and types of input intervention. Specifically, we systematically generate data for a derivation generation task using a symbolic engine, applying targeted interventions to prompts to perturb features of mathematical derivations such as the surface forms of symbols, equational tree structures, and mathematical context. We then evaluate the effect of prompt interventions across a range of LLMs including fine-tuned T5 models, GPT, and LLaMa-based models. Our experiments suggest that T5-Large can outperform the few-shot performance of GPT-4 on various evaluation sets generated via the framework. However, an extensive evaluation based on human analysis, template-based error detection, and text generation metrics reveals model weaknesses beyond what the reference-based metrics singularly describe. We use these results to tie characteristic distributional footprints of interventions to the human evaluation of LLM derivation quality, potentially leading to significant control over fine-grained mathematical capabilities of language models with respect to specific types of errors.
本文探讨如何通过符号数据生成框架控制大型语言模型(LLM)中的幻觉率,探索特定数学错误率与输入干预类型之间的基本关系。具体来说,我们使用符号引擎为推导生成任务系统地生成数据,对提示进行有针对性的干预,以扰动数学推导的特征,如符号的表面形式、方程式树结构和数学上下文。然后,我们在一系列LLM(包括微调T5模型、GPT和LLama基于的模型)中评估提示干预的效果。我们的实验表明,T5-Large可以在各种通过该框架生成的评估集上实现优于GPT-4的少样本表现。然而,基于人类分析、模板错误检测和文本生成指标的广泛评估揭示了模型在单一基准测试指标之外存在的弱点。我们使用这些结果将干预的分布特征与LLM推导质量的人类评估联系起来,这可能会为针对特定类型错误的控制语言模型的精细数学能力提供显著的控制力。
论文及项目相关链接
PDF AAAI 2025 (7 pages)
Summary
这篇论文探讨如何通过符号数据生成框架控制大型语言模型(LLM)中的幻觉率,研究数学错误率与输入干预类型之间的基本关系。论文通过符号引擎系统地生成数据,针对推导生成任务应用有针对性的干预措施,扰动数学推导的特征,如符号的表面形式、方程式树结构和数学上下文。评估了不同LLMs在提示干预下的表现,包括微调T5模型、GPT和LLaMa模型。实验表明,T5-Large在某些评估集上的表现优于GPT-4。然而,基于人类分析、模板化错误检测和文本生成指标的全面评估揭示了模型除了参考基准指标所描述的弱点之外的其他弱点。研究结果将干预的分布特征与LLM推导质量的人类评估联系起来,有望实现对语言模型精细数学能力的显著控制,并减少特定类型的错误。
Key Takeaways
- 论文探索了如何通过符号数据生成框架控制大型语言模型中的幻觉率。
- 研究了数学错误率与输入干预类型之间的基本关系。
- 通过符号引擎系统地生成数据,并应用有针对性的干预措施来扰动数学推导的特征。
- 评估了不同LLMs在提示干预下的表现。
- T5-Large在某些评估集上的表现优于GPT-4。
- 全面评估揭示了模型除了参考基准指标所描述的弱点之外的其他弱点。
点此查看论文截图