⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
Multimodal LLMs Can Reason about Aesthetics in Zero-Shot
Authors:Ruixiang Jiang, Changwen Chen
We present the first study on how Multimodal LLMs’ (MLLMs) reasoning ability shall be elicited to evaluate the aesthetics of artworks. To facilitate this investigation, we construct MM-StyleBench, a novel high-quality dataset for benchmarking artistic stylization. We then develop a principled method for human preference modeling and perform a systematic correlation analysis between MLLMs’ responses and human preference. Our experiments reveal an inherent hallucination issue of MLLMs in art evaluation, associated with response subjectivity. ArtCoT is proposed, demonstrating that art-specific task decomposition and the use of concrete language boost MLLMs’ reasoning ability for aesthetics. Our findings offer valuable insights into MLLMs for art and can benefit a wide range of downstream applications, such as style transfer and artistic image generation. Code available at https://github.com/songrise/MLLM4Art.
我们首次研究了如何激发多模态大型语言模型(MLLMs)的推理能力来评估艺术作品的审美价值。为了推动这项研究,我们构建了MM-StyleBench,这是一个用于基准测试艺术风格化的新型高质量数据集。然后,我们开发了一种人类偏好建模的原则方法,并对MLLMs的响应与人类偏好之间进行了系统的相关性分析。我们的实验揭示了MLLMs在艺术评估中存在的内在幻觉问题,这与响应主观性有关。我们提出了ArtCoT,证明艺术特定任务分解和使用具体语言可以提高MLLMs的审美推理能力。我们的研究为MLLMs在艺术领域的应用提供了宝贵的见解,并可以广泛应用于下游应用,如风格转换和艺术图像生成。代码可在https://github.com/songrise/MLLM4Art找到。
论文及项目相关链接
PDF WIP, Homepage https://github.com/songrise/MLLM4Art
Summary
本研究探讨了如何激发多模态大型语言模型(MLLMs)的推理能力以评估艺术作品的审美价值。研究构建了MM-StyleBench数据集,用于基准测试艺术风格化。通过开发人类偏好建模的方法,并系统地分析了MLLMs的回应与人类偏好的相关性。实验揭示了MLLMs在艺术评价中的内在幻觉问题,与回应的主观性相关。提出了ArtCoT,表明艺术特定任务分解和使用具体语言可以提高MLLMs的审美推理能力。本研究为MLLMs在艺术领域的应用提供了宝贵见解,并有益于风格转换和艺术图像生成等下游应用。
Key Takeaways
- 研究了多模态大型语言模型(MLLMs)在评估艺术作品审美价值中的推理能力。
- 构建了MM-StyleBench数据集,为艺术风格化提供了基准测试平台。
- 通过人类偏好建模的方法,分析了MLLMs的回应与人类偏好的相关性。
- 揭示了MLLMs在艺术评价中存在的内在幻觉问题,与回应的主观性相关。
- 提出了ArtCoT方法,通过艺术特定任务分解和使用具体语言提高了MLLMs的审美推理能力。
- 研究成果对MLLMs在艺术领域的应用具有指导意义。
- 研究有益于风格转换和艺术图像生成等下游应用。
点此查看论文截图

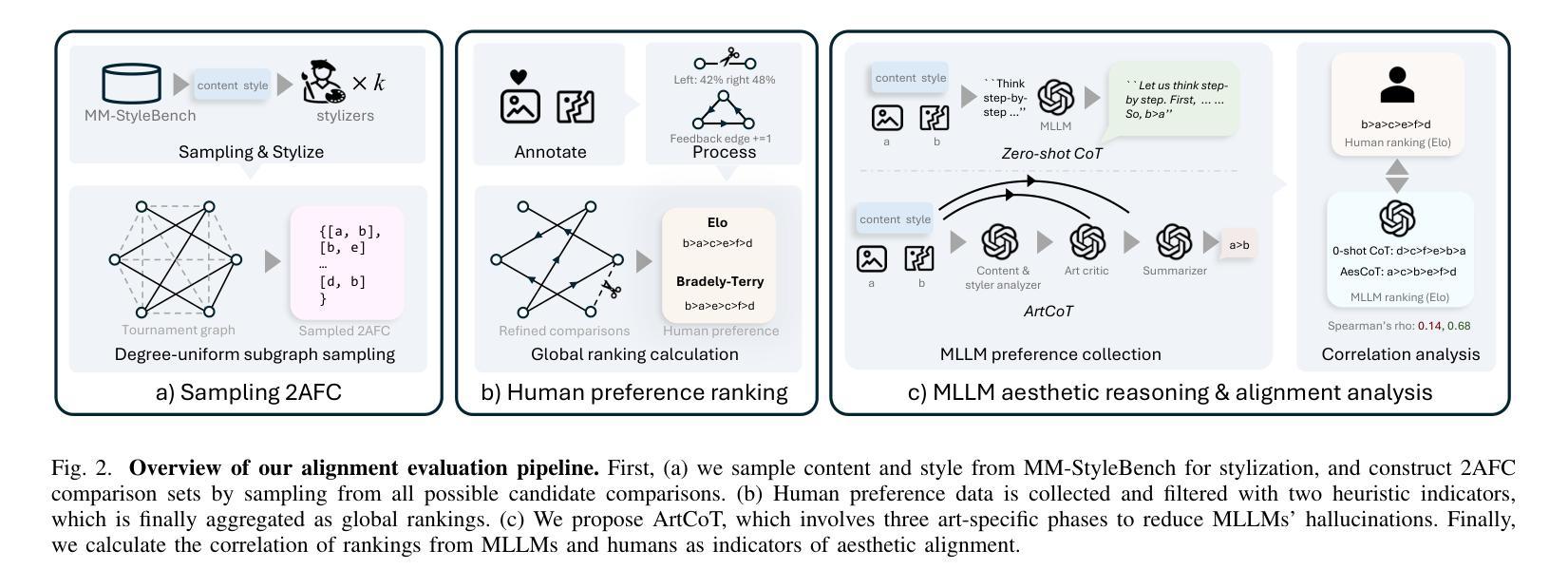
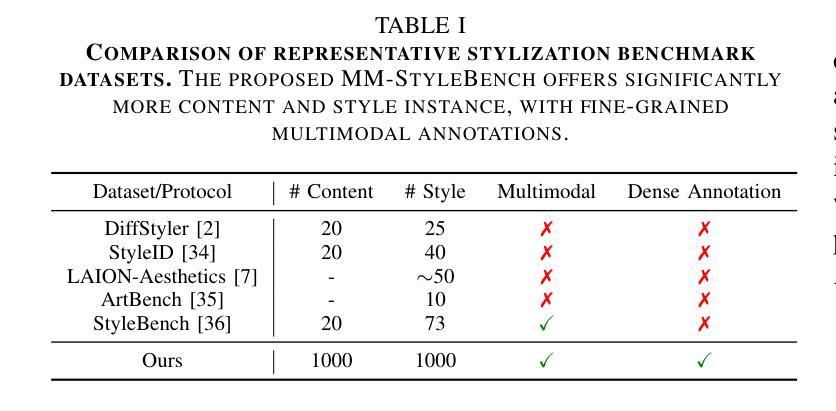
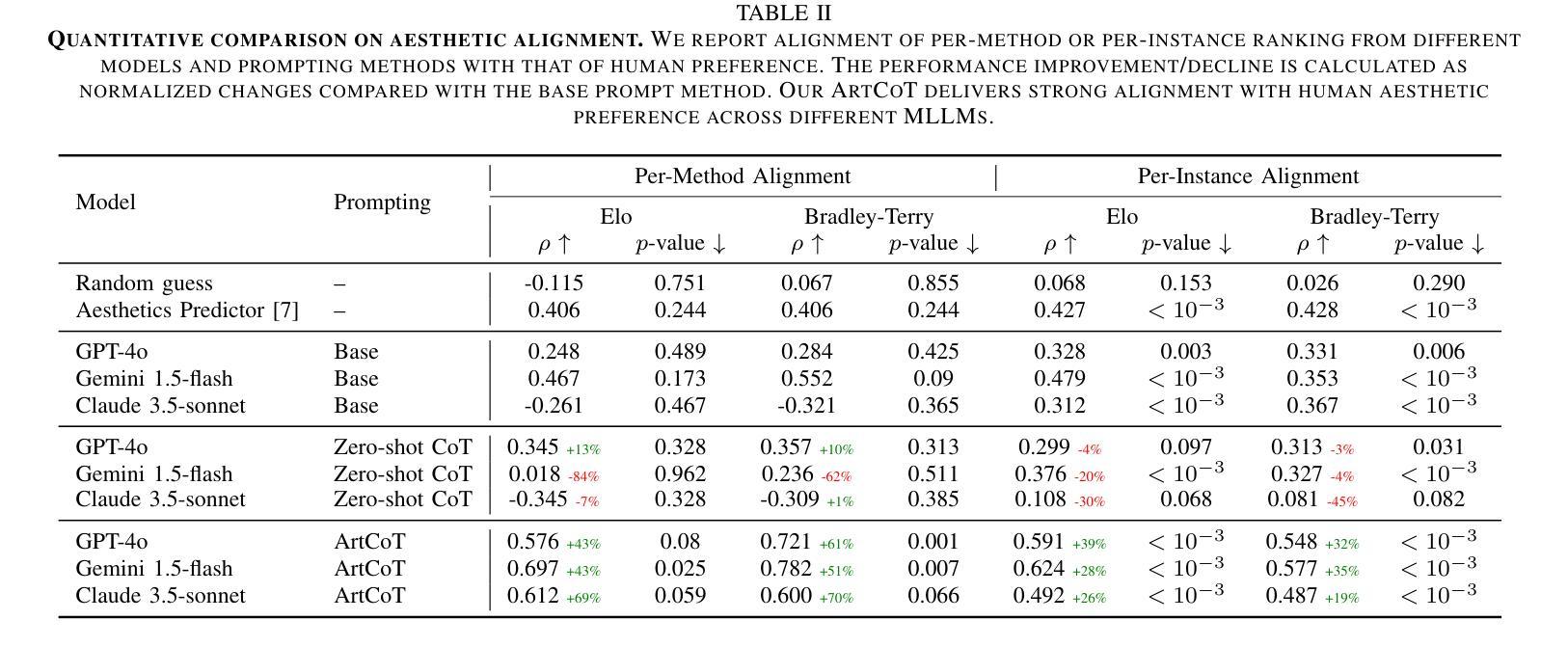


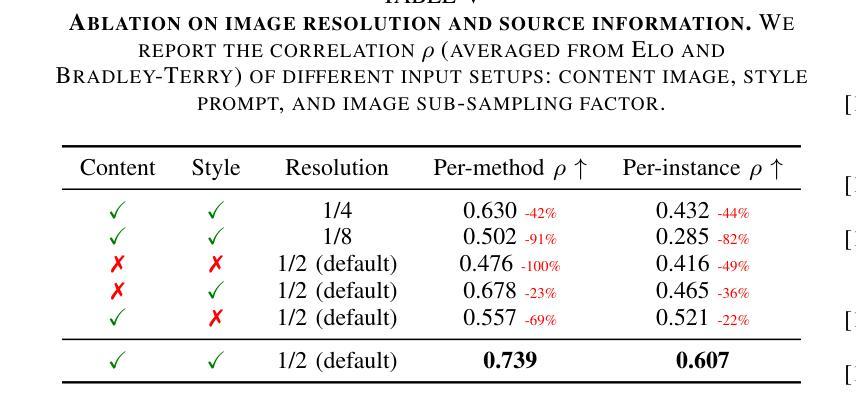
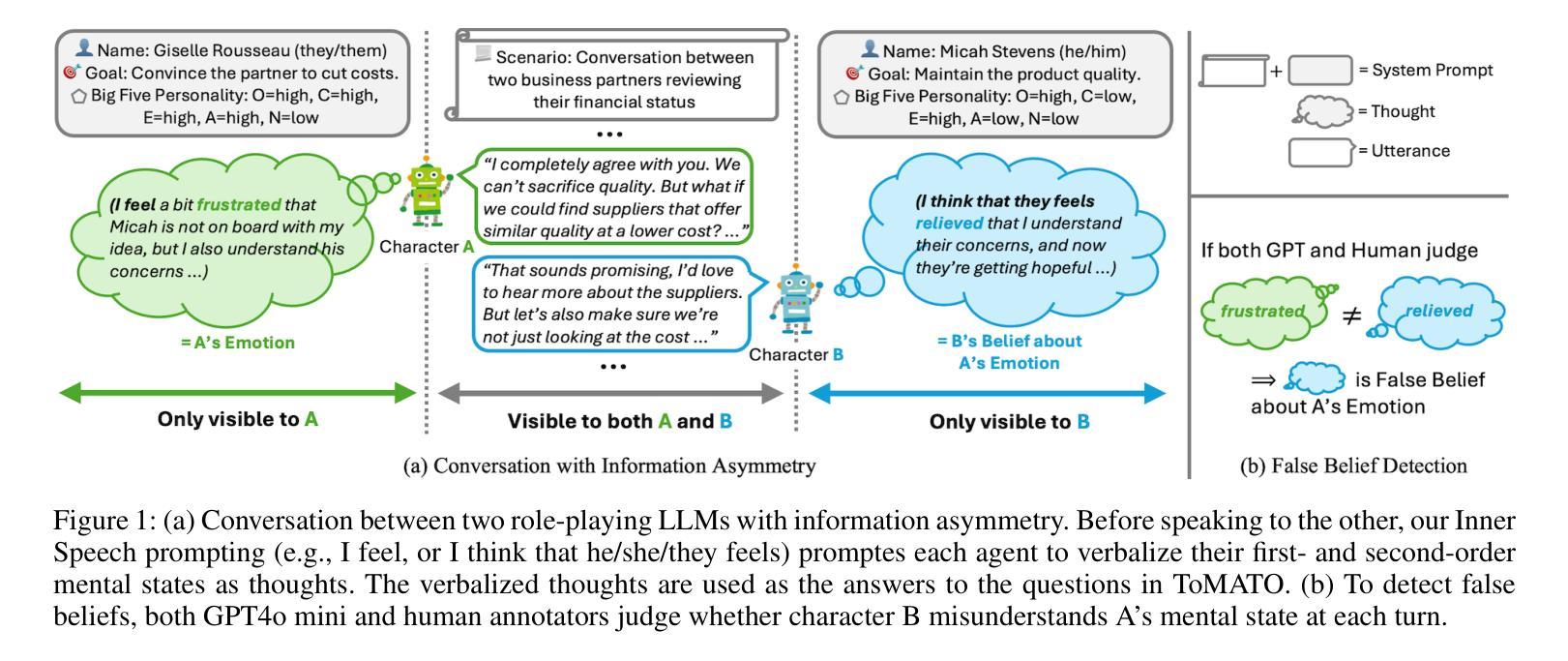
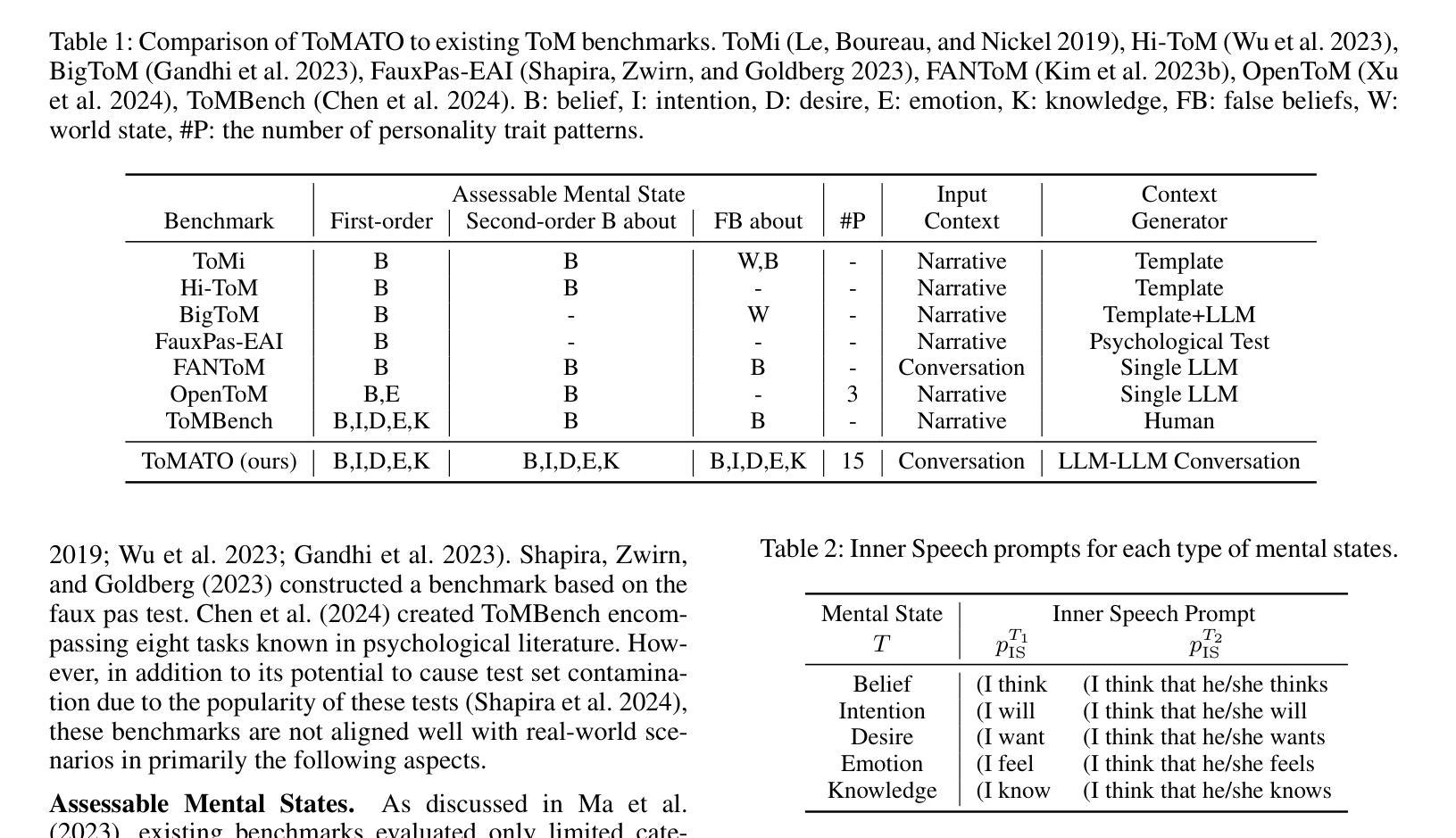
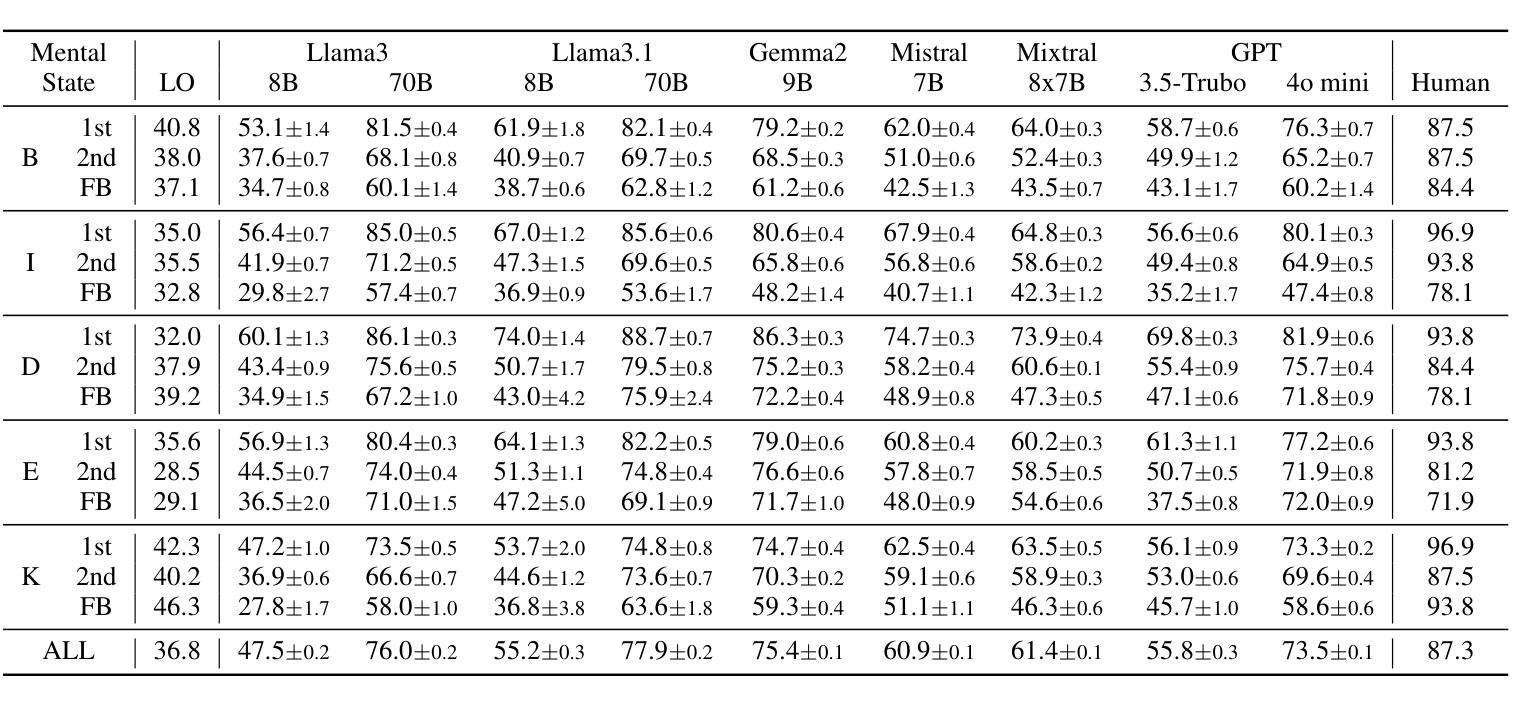
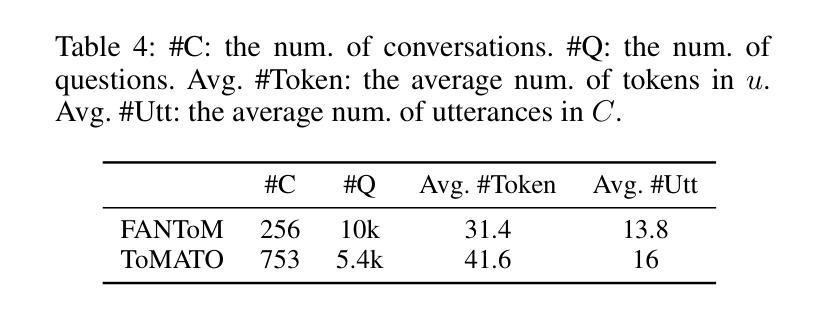
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Authors:Kazutoshi Shinoda, Nobukatsu Hojo, Kyosuke Nishida, Saki Mizuno, Keita Suzuki, Ryo Masumura, Hiroaki Sugiyama, Kuniko Saito
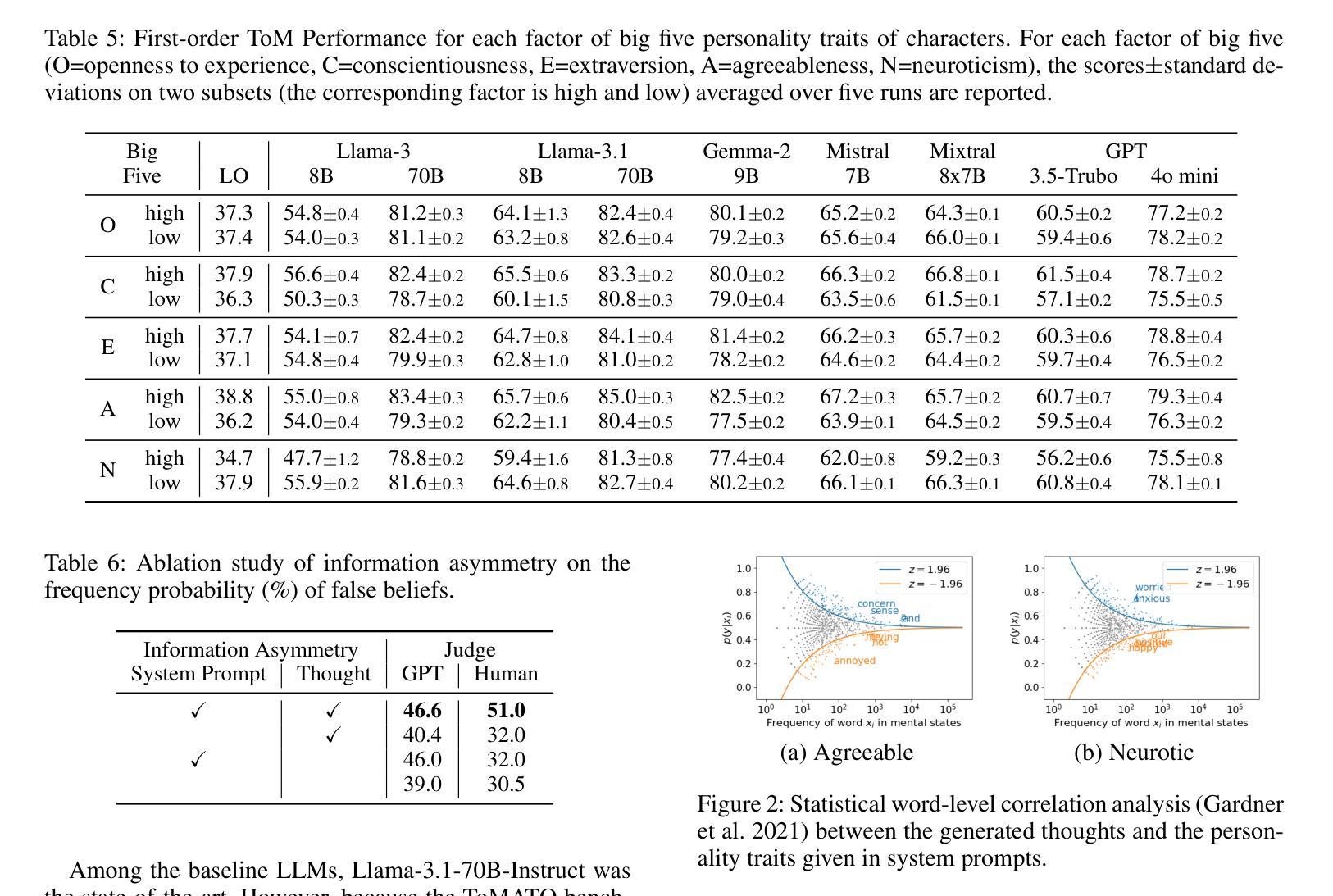
Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
现有的心智理论(ToM)基准与真实世界场景在三个方面存在分歧:1)它们评估的心态范围有限,如信念;2)对错误信念没有进行全面探索;3)忽略了角色的多样性格特征。为了解决这些挑战,我们引入了ToMATO,这是一个新的心智理论基准,以对话形式的多项选择题进行评估。ToMATO是通过LLM-LLM对话生成的,以信息不对称为特征。通过采用一种提示方法,要求扮演角色的LLM在每次发言前先表达他们的想法,我们能够捕捉到五个类别中的一阶和二阶心态:信念、意图、欲望、情感和知识。这些表达出来的想法可以作为设计问题的答案,以评估对话中角色的心态。此外,通过隐藏他人的想法来引入信息不对称会导致对各种心态的虚假信念的产生。给LLM分配不同的性格特征进一步使发言和想法多样化。ToMATO包含5400个问题、753个对话和15种性格特征模式。我们的分析表明,由于角色扮演LLM之间的信息不对称,这种数据集构建方法经常会产生虚假信念,并能有效地反映不同的个性。我们在ToMATO上评估了九个LLM,发现即使是GPT-4o mini也落后于人类的表现,特别是在理解虚假信念方面,并且对不同的性格特征缺乏稳健性。
论文及项目相关链接
PDF Accepted by AAAI 2025
摘要
本文介绍了现有的心智理论(ToM)基准测试在真实世界场景中的局限性,包括评估的心理状态范围有限、未能全面探索错误信念以及忽略角色的不同个性特征。为解决这些问题,我们提出了ToMATO,这是一种新的心智理论基准测试,以对话形式的多项选择题进行评估。ToMATO通过大型语言模型间的对话生成,并利用信息不对称的特点。通过使用要求大型语言模型在每次发言前思考并表达其想法的提示方法,我们能够捕捉五个类别(信念、意图、欲望、情感和知识)中的第一和第二阶心理状态。这些表达的想法可以作为设计问题以评估对话中角色的心理状态时的答案。此外,通过隐藏他人的想法来引入信息不对称性会导致各种心理状态上的错误信念的产生。给大型语言模型分配不同的个性特征可以进一步使发言和想法多样化。ToMATO包含5.4k个问题、753个对话和15种个性特征模式。我们的分析显示,由于角色扮演大型语言模型之间的信息不对称性,这种数据集构建方法经常产生错误信念,并能有效地反映不同的个性特征。我们对九个大型语言模型在ToMATO上的表现进行了评估,发现即使是GPT-4o mini也落后于人类的表现,特别是在理解错误信念方面缺乏对不同个性特征的稳健性。
关键见解
- 现有心智理论基准测试在真实世界应用中存在局限性,主要体现在评估的心理状态范围有限、未能全面探索错误信念和忽略角色个性特征方面。
- ToMATO是一种新的心智理论基准测试,通过大型语言模型间的对话生成,能够捕捉第一和第二阶心理状态。
- ToMATO通过引入信息不对称性和角色个性特征来模拟真实世界场景,从而生成包含错误信念的对话。
- ToMATO数据集包含大量问题和对话,有效反映不同个性特征的大型语言模型之间的交互。
- 评估显示,即使在理解错误信念方面,现有大型语言模型仍有人类表现差距,且缺乏对不同个性特征的稳健性。
- ToMATO为评估大型语言模型在心智理论方面的能力提供了更全面的基准测试。
点此查看论文截图

Exploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Authors:Alain Komaty, Hatef Otroshi Shahreza, Anjith George, Sebastien Marcel
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model’s performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o’s promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
本研究强调了ChatGPT(特别是GPT-4o)在人脸识别攻击检测(PAD)中的潜在竞争力。在特定场景中,GPT-4o的性能优于多个PAD模型,包括商业解决方案。我们的结果表明,GPT-4o在高一致性方面表现出色,特别是在少量上下文学习的场景中,其性能会随着提供更多示例(参考数据)而提高。我们还观察到,详细的提示使模型能够可靠地提供分数,这一行为在简洁的提示下并未观察到。此外,寻求解释的提示略微提高了模型的性能,并改善了其可解释性。值得注意的是,尽管未明确指示其分类攻击类型,该模型仍展现出新兴推理能力,能够在少量场景中准确预测攻击类型(打印或回放)。尽管有这些优点,GPT-4o在零样本任务中仍面临挑战,其性能与专用PAD系统相比有限。实验是在SOTERIA数据集的一个子集上进行的,仅使用同意个人的数据,以确保符合数据隐私法规。这些发现强调了GPT-4o在PAD应用中的潜力,为未来研究奠定了基础,以解决更广泛的数据隐私担忧并改进跨数据集泛化。代码可在以下网址找到:https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad。
论文及项目相关链接
PDF Accepted in WACV workshop 2025
Summary
本研究探讨了ChatGPT(特别是GPT-4o)在人脸识别攻击检测(PAD)中的潜力,并在特定场景中表现出超越多种PAD模型(包括商业解决方案)的性能。GPT-4o在高一致性方面表现出色,特别是在有上下文学习的少数场景中的表现优异。此外,详细的提示有助于模型提供更可靠的评分,同时解释性提示略微提高了模型的性能。尽管GPT-4o在零样本任务中面临挑战,但其仍然具备出色的潜力,且其在预测攻击类型方面表现出惊人的能力。本研究是在遵守数据隐私法规的前提下进行的实验,并为未来的研究奠定了坚实的基础。
Key Takeaways
- GPT-4o在人脸识别攻击检测(PAD)中具有潜力,能作为有竞争力的替代方案。
- GPT-4o在特定场景中表现优于多种PAD模型,包括商业解决方案。
- GPT-4o在高一致性方面表现出色,特别是在有上下文学习的少数场景中。
- 详细的提示能提高GPT-4o模型的可靠性。
- 解释性提示可略微提高GPT-4o模型的性能。
- GPT-4o具备预测攻击类型的推理能力。
点此查看论文截图



How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering
Authors:Christoph Treude, Marco A. Gerosa
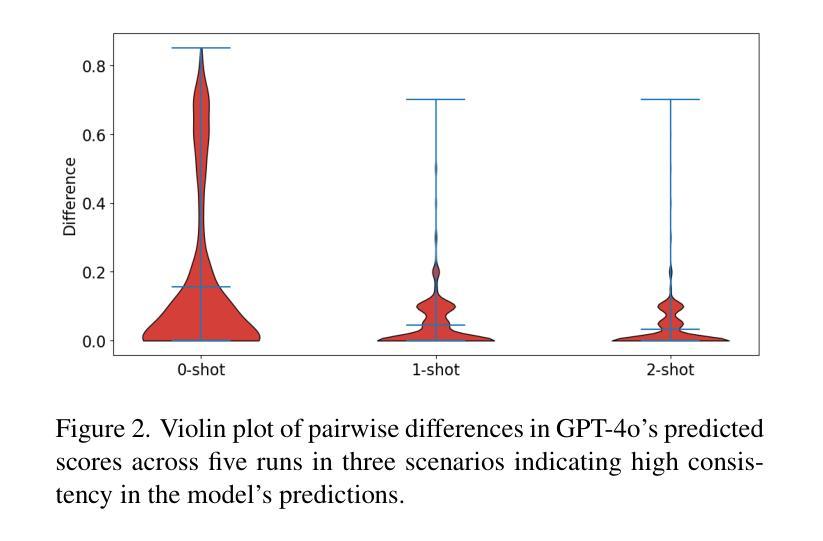
Artificial intelligence (AI), including large language models and generative AI, is emerging as a significant force in software development, offering developers powerful tools that span the entire development lifecycle. Although software engineering research has extensively studied AI tools in software development, the specific types of interactions between developers and these AI-powered tools have only recently begun to receive attention. Understanding and improving these interactions has the potential to improve productivity, trust, and efficiency in AI-driven workflows. In this paper, we propose a taxonomy of interaction types between developers and AI tools, identifying eleven distinct interaction types, such as auto-complete code suggestions, command-driven actions, and conversational assistance. Building on this taxonomy, we outline a research agenda focused on optimizing AI interactions, improving developer control, and addressing trust and usability challenges in AI-assisted development. By establishing a structured foundation for studying developer-AI interactions, this paper aims to stimulate research on creating more effective, adaptive AI tools for software development.
人工智能(AI),包括大型语言模型和生成式AI,正在软件开发领域形成一股强大的力量,为开发者提供了贯穿整个开发生命周期的强大工具。尽管软件工程研究已经对软件开发中的AI工具进行了广泛的研究,但开发者与这些AI工具之间的具体交互类型最近才开始受到关注。理解和改进这些交互在AI驱动的工作流程中具有提高生产力、信任和效率的潜力。在本文中,我们提出了开发者与AI工具之间交互类型的分类,确定了包括自动完成代码建议、命令驱动操作和对话辅助等11种不同的交互类型。基于这一分类,我们概述了一项以优化AI交互、提高开发者控制和解决AI辅助开发中的信任和可用性挑战为重点的研究议程。通过建立研究开发者与AI之间交互的结构化基础,本文旨在激发关于创建更有效、自适应的AI工具用于软件开发的更多研究。
论文及项目相关链接
PDF Accepted at 2nd ACM International Conference on AI Foundation Models and Software Engineering (FORGE 2025)
Summary
人工智能(AI),包括大型语言模型和生成式AI,正在成为软件开发领域的重要力量,为开发者提供跨越整个开发生命周期的强大工具。尽管软件工程研究已经对AI工具进行了广泛的研究,但开发人员与这些AI工具之间的特定交互类型最近才开始受到关注。理解和改进这些交互有望提高AI驱动工作流程中的生产力、信任和效率。本文提出了开发人员与AI工具之间交互类型的分类,确定了包括自动完成代码建议、命令驱动操作和对话辅助等11种不同的交互类型。在此基础上,我们提出了以优化AI交互、提高开发者控制和解决AI辅助开发中的信任和可用性挑战为重点的研究议程。本文旨在通过为开发者与AI之间的交互建立结构化基础,刺激关于创建更有效、适应性更强的AI工具的研究。
Key Takeaways
- AI在软件开发中扮演着日益重要的角色,涵盖整个开发生命周期。
- 开发者与AI工具的特定交互类型开始受到关注。
- 理解和改进这些交互对于提高AI工作流程中的生产力、信任和效率至关重要。
- 本文提出了一个开发者与AI工具之间交互类型的分类框架,确定了包括自动完成代码建议、命令驱动操作和对话辅助在内的11种交互类型。
- 研究议程的重点是优化AI交互、提高开发者对AI工具的控制能力。
- 信任度和可用性是AI辅助开发中需要解决的关键挑战。
点此查看论文截图

Enhanced Large Language Models for Effective Screening of Depression and Anxiety
Authors:June M. Liu, Mengxia Gao, Sahand Sabour, Zhuang Chen, Minlie Huang, Tatia M. C. Lee
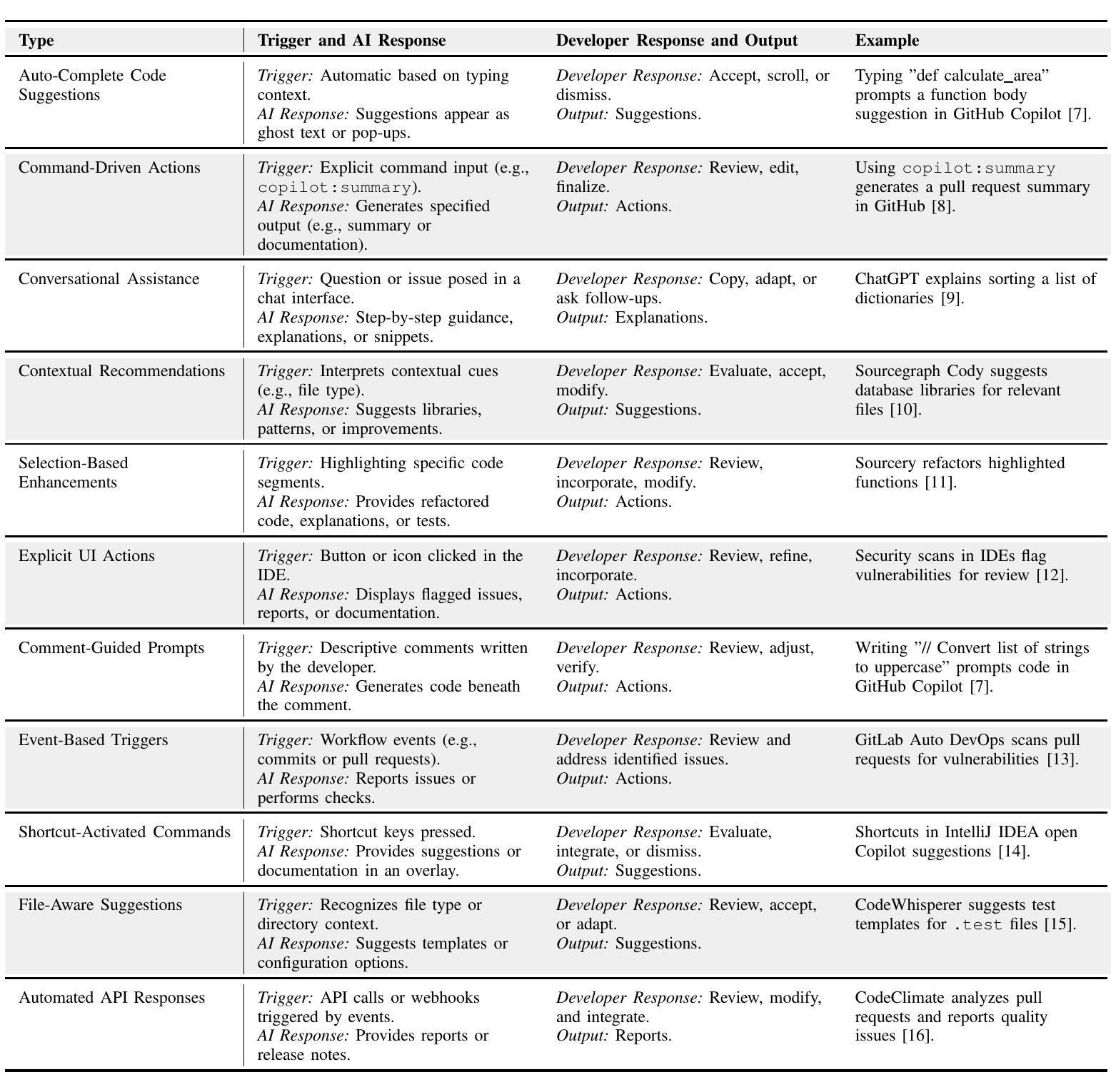
Depressive and anxiety disorders are widespread, necessitating timely identification and management. Recent advances in Large Language Models (LLMs) offer potential solutions, yet high costs and ethical concerns about training data remain challenges. This paper introduces a pipeline for synthesizing clinical interviews, resulting in 1,157 interactive dialogues (PsyInterview), and presents EmoScan, an LLM-based emotional disorder screening system. EmoScan distinguishes between coarse (e.g., anxiety or depressive disorders) and fine disorders (e.g., major depressive disorders) and conducts high-quality interviews. Evaluations showed that EmoScan exceeded the performance of base models and other LLMs like GPT-4 in screening emotional disorders (F1-score=0.7467). It also delivers superior explanations (BERTScore=0.9408) and demonstrates robust generalizability (F1-score of 0.67 on an external dataset). Furthermore, EmoScan outperforms baselines in interviewing skills, as validated by automated ratings and human evaluations. This work highlights the importance of scalable data-generative pipelines for developing effective mental health LLM tools.
抑郁症和焦虑症广泛存在,需要及时识别和管理。最近大型语言模型(LLM)的进展为这些问题提供了潜在的解决方案,但高昂的成本和关于训练数据的伦理问题仍然是挑战。本文介绍了一条合成临床访谈的流程,生成了1157个互动式对话(“PsyInterview”),并展示了基于LLM的情感障碍筛查系统EmoScan。EmoScan能够区分粗粒度(例如,焦虑或抑郁障碍)和细粒度(例如,重度抑郁症)的障碍,并进行高质量的访谈。评估结果显示,在筛查情感障碍方面,EmoScan超过了基准模型和其他LLM(如GPT-4)(F1分数为0.7467)。它还提供出色的解释能力(BERT分数为0.9408),并显示出稳健的泛化能力(外部数据集上的F1分数为0.67)。此外,经自动化评估和人工评估验证,EmoScan在访谈技能方面优于基线。这项工作强调了为发展有效的精神健康LLM工具构建可扩展的数据生成流程的重要性。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的抑郁症和焦虑症筛查系统研究。该研究通过合成临床访谈数据,构建了情感障碍筛查系统EmoScan。该系统能区分粗略(如抑郁症或焦虑症)和精细障碍(如重度抑郁症),并展现出优秀的访谈能力和解释性能。相较于其他LLM模型,EmoScan在情感障碍筛查中表现出更高的效能。此外,该研究还强调了在构建有效心理健康LLM工具中,需要依赖可扩展的数据生成管道。
Key Takeaways
- LLM在抑郁症和焦虑症筛查方面具有潜在应用价值。
- EmoScan是一个基于LLM的情感障碍筛查系统,能够识别不同类型的情感障碍。
- EmoScan相较于基础模型和其他LLM模型表现出更高的效能。
- EmoScan在访谈技能和解释性能上表现出优势。
- EmoScan具有良好的泛化能力,能在外部数据集上取得较好的表现。
- 研究通过合成临床访谈数据构建EmoScan,强调可扩展数据生成管道的重要性。
点此查看论文截图

Leveraging LLM Agents for Translating Network Configurations
Authors:Yunze Wei, Xiaohui Xie, Yiwei Zuo, Tianshuo Hu, Xinyi Chen, Kaiwen Chi, Yong Cui
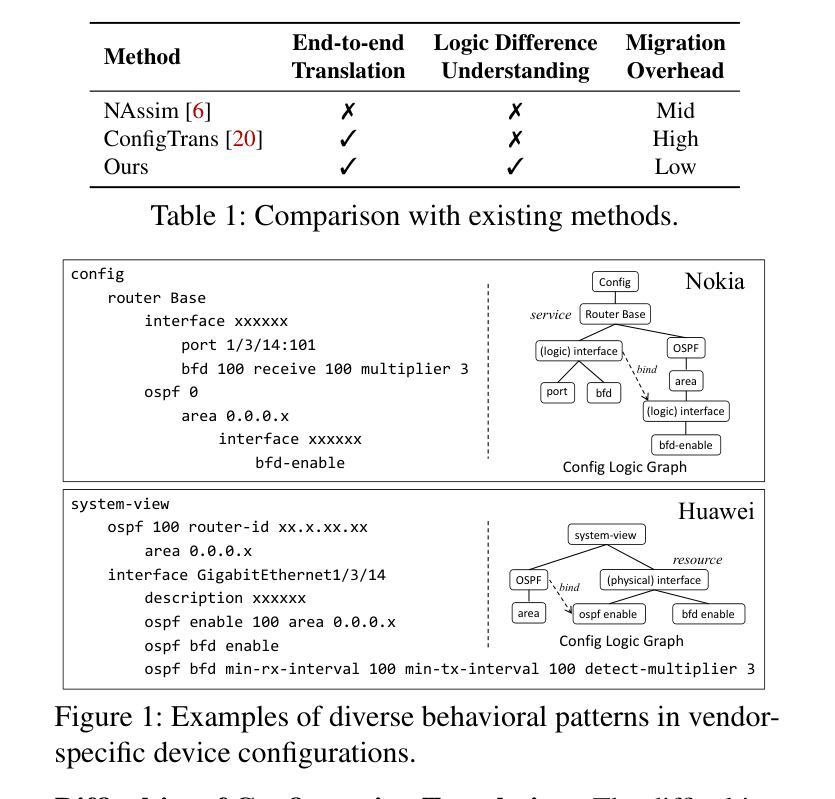
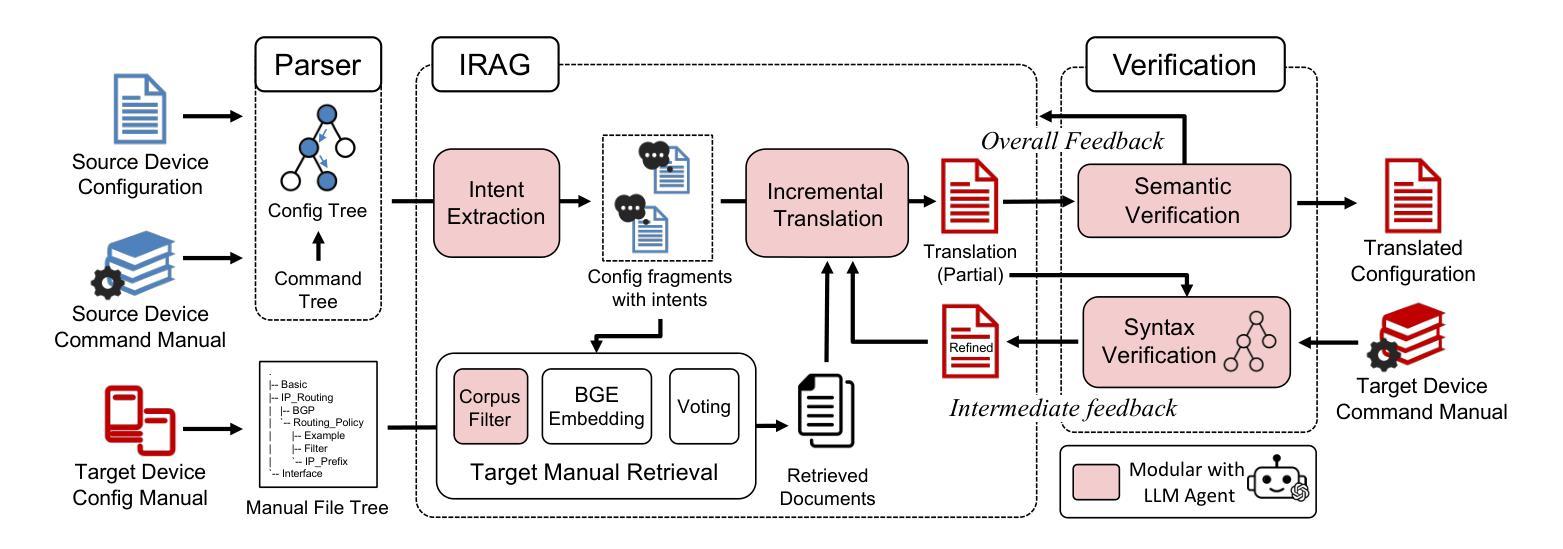
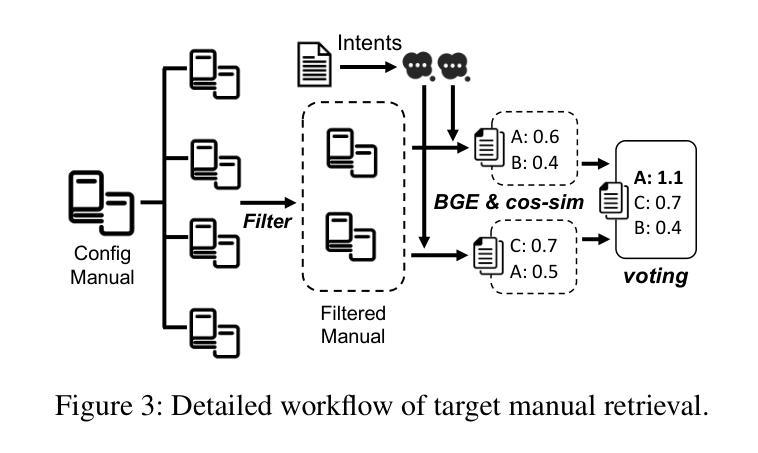
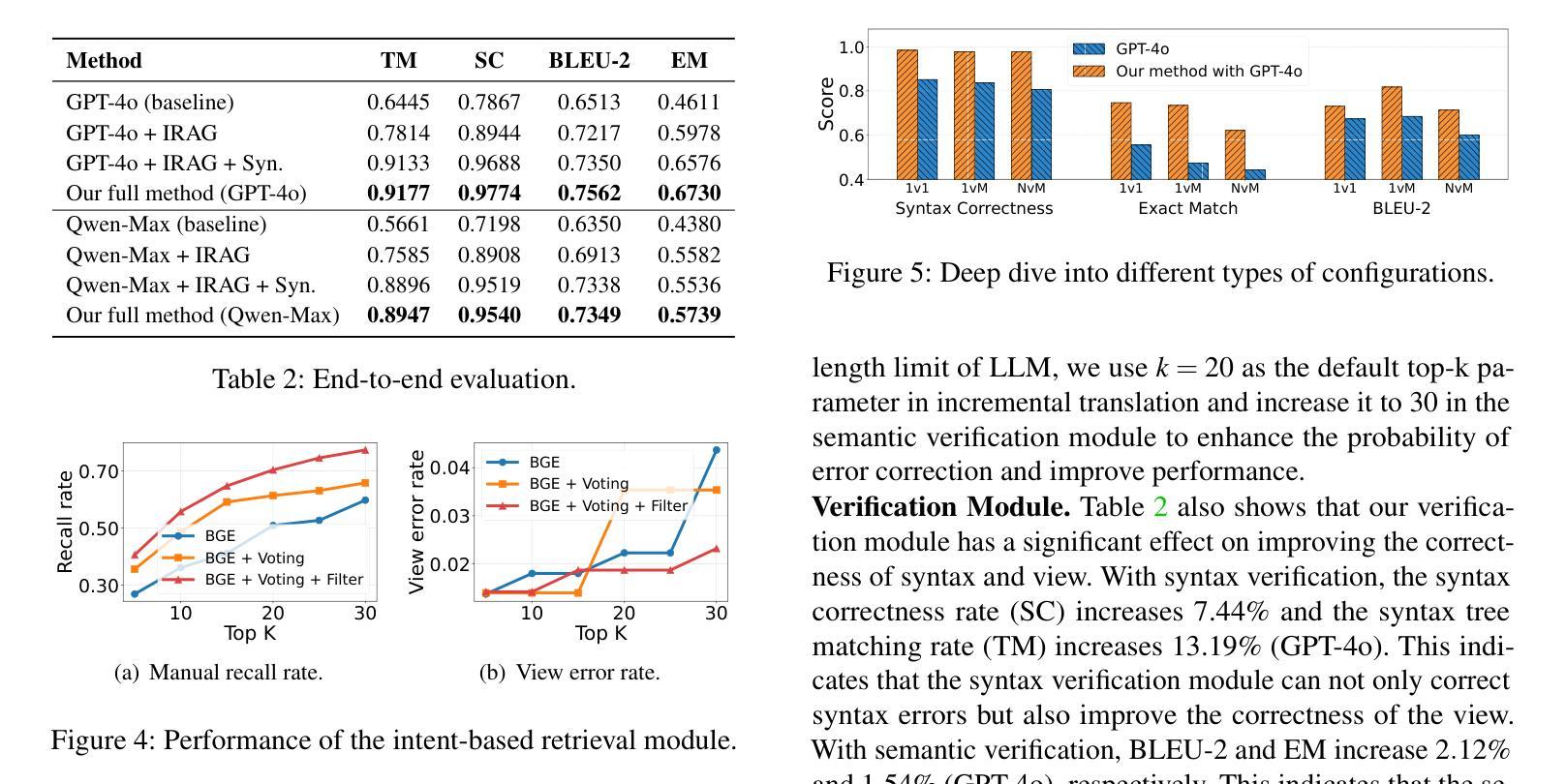
Configuration translation is a critical and frequent task in network operations. When a network device is damaged or outdated, administrators need to replace it to maintain service continuity. The replacement devices may originate from different vendors, necessitating configuration translation to ensure seamless network operation. However, translating configurations manually is a labor-intensive and error-prone process. In this paper, we propose an intent-based framework for translating network configuration with Large Language Model (LLM) Agents. The core of our approach is an Intent-based Retrieval Augmented Generation (IRAG) module that systematically splits a configuration file into fragments, extracts intents, and generates accurate translations. We also design a two-stage verification method to validate the syntax and semantics correctness of the translated configurations. We implement and evaluate the proposed method on real-world network configurations. Experimental results show that our method achieves 97.74% syntax correctness, outperforming state-of-the-art methods in translation accuracy.
配置翻译是网络操作中的一项重要且频繁的任务。当网络设备损坏或过时时,管理员需要替换它以保持服务连续性。这些替代设备可能来自不同的供应商,需要进行配置翻译以确保网络无缝运行。然而,手动进行配置翻译是一个劳动密集型和易出错的过程。在本文中,我们提出了一种基于意图的利用大型语言模型(LLM)代理进行网络配置翻译框架。我们的方法的核心是一个基于意图的检索增强生成(IRAG)模块,该模块系统地分割配置文件为片段,提取意图,并生成准确的翻译。我们还设计了一种两阶段验证方法来验证翻译配置的语法和语义正确性。我们在真实世界的网络配置上实现并评估了所提出的方法。实验结果表明,我们的方法达到了97.74%的语法正确率,在翻译准确性方面优于现有方法。
论文及项目相关链接
Summary
网络配置翻译是网络操作中的一项重要且频繁的任务。当网络设备损坏或过时,管理员需要替换设备以维持服务连续性。由于替换设备可能来自不同的供应商,因此需要进行配置翻译以确保网络无缝运行。然而,手动翻译配置是一项劳动密集且容易出错的过程。本文提出了一种基于意图的利用网络语言模型(LLM)代理进行网络配置翻译的方法。该方法的核心是意图检索增强生成(IRAG)模块,该模块系统地分割配置文件片段、提取意图并生成准确的翻译。同时设计了两阶段验证方法来验证翻译配置的语法和语义正确性。在真实网络配置上的实验结果表明,该方法实现了97.74%的语法正确性,在翻译准确性方面优于现有方法。
Key Takeaways
- 网络配置翻译是网络操作中的关键任务,尤其在替换设备时。
- 替换设备可能来自不同供应商,需要进行配置翻译以确保无缝网络连接。
- 手动配置翻译既劳动密集又容易出错。
- 提出了一种基于意图的利用网络语言模型(LLM)进行网络配置翻译的方法。
- 该方法的核心是IRAG模块,能系统地分割配置文件并提取意图,生成准确翻译。
- 设计了两阶段验证方法来确保翻译的语法和语义正确性。
点此查看论文截图

The Inherent Limits of Pretrained LLMs: The Unexpected Convergence of Instruction Tuning and In-Context Learning Capabilities
Authors:Irina Bigoulaeva, Harish Tayyar Madabushi, Iryna Gurevych
Large Language Models (LLMs), trained on extensive web-scale corpora, have demonstrated remarkable abilities across diverse tasks, especially as they are scaled up. Nevertheless, even state-of-the-art models struggle in certain cases, sometimes failing at problems solvable by young children, indicating that traditional notions of task complexity are insufficient for explaining LLM capabilities. However, exploring LLM capabilities is complicated by the fact that most widely-used models are also “instruction-tuned” to respond appropriately to prompts. With the goal of disentangling the factors influencing LLM performance, we investigate whether instruction-tuned models possess fundamentally different capabilities from base models that are prompted using in-context examples. Through extensive experiments across various model families, scales and task types, which included instruction tuning 90 different LLMs, we demonstrate that the performance of instruction-tuned models is significantly correlated with the in-context performance of their base counterparts. By clarifying what instruction-tuning contributes, we extend prior research into in-context learning, which suggests that base models use priors from pretraining data to solve tasks. Specifically, we extend this understanding to instruction-tuned models, suggesting that their pretraining data similarly sets a limiting boundary on the tasks they can solve, with the added influence of the instruction-tuning dataset.
基于大规模网络语料库训练的大型语言模型(LLM)在多种任务中表现出了卓越的能力,尤其是随着规模的扩大。然而,即使是最先进的模型在某些情况下也会遇到困难,有时甚至无法解决一些儿童就能解决的问题,这表明传统的任务复杂性观念不足以解释LLM的能力。然而,探索LLM的能力之所以复杂,是因为大多数广泛使用的模型也是“指令调整”的,以适当地对提示做出反应。为了弄清影响LLM性能的因素,我们调查了指令调整模型与仅使用上下文示例提示的基础模型是否具备根本不同的能力。我们通过各种模型家族、规模和任务类型进行了大量实验,其中包括对90种不同LLM进行指令调整。我们证明,指令调整模型的性能与其基础模型在上下文中的性能密切相关。通过澄清指令调整的贡献,我们对先前的上下文学习研究进行了扩展,研究表明基础模型利用预训练数据的先验知识来解决问题。具体来说,我们将这一理解扩展到指令调整模型,表明它们的预训练数据同样设定了它们能够解决的任务的边界,并受到指令调整数据集的影响。
论文及项目相关链接
PDF The code for this paper is available at: https://github.com/UKPLab/arxiv2025-inherent-limits-plms
Summary
大规模语言模型(LLM)在多样化的任务上展现出显著的能力,尤其是随着模型规模的扩大。然而,即使是最先进的模型在某些情况下也会遇到困难,有时甚至无法解决儿童能够解决的问题,这表明传统对任务复杂性的认识不足以解释LLM的能力。为了探究LLM的能力,研究人员探讨了指令调整模型与基于示例提示的基础模型之间是否存在根本性的能力差异。通过对各种模型家族、规模和任务类型进行大量实验,包括为90种不同的LLM进行指令调整,研究结果表明,指令调整模型的性能与其基础模型在上下文中的表现存在显著相关性。这扩展了先前关于上下文学习的研究,表明基础模型利用预训练数据中的先验知识来解决问题。具体来说,我们将这种理解扩展到指令调整模型,它们的预训练数据同样设定了它们能够解决问题的限制边界,而指令调整数据集则产生了额外的影响。
Key Takeaways
- LLM在多样化任务上表现出卓越的能力,尤其是随着模型规模的扩大。
- 传统对任务复杂性的认识不足以解释LLM的所有能力。
- 指令调整模型的性能与基础模型在上下文中的表现存在显著相关性。
- 指令调整有助于提升LLM的性能,但其能力仍然受到预训练数据的限制。
- 基础模型利用预训练数据中的先验知识来解决问题。
- 预训练数据对LLM能解决的问题类型设置有边界。
点此查看论文截图

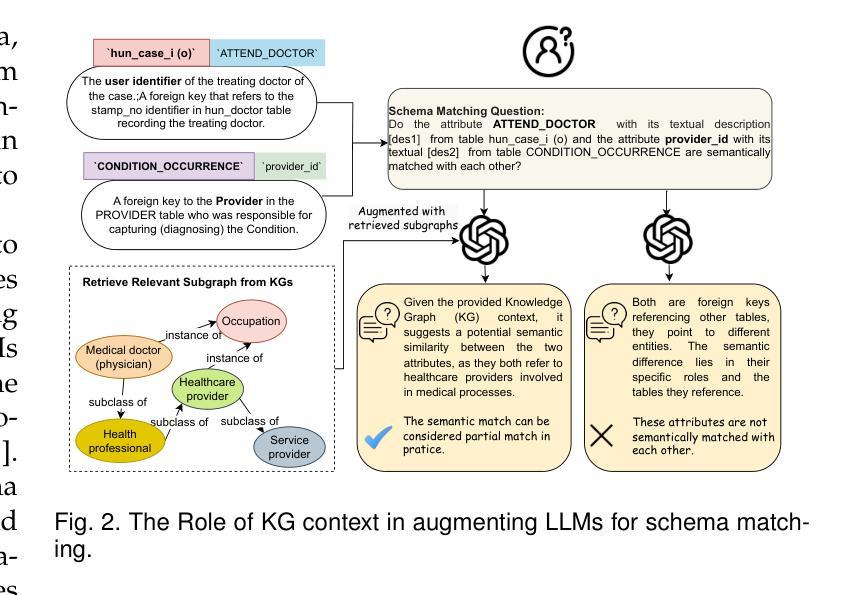
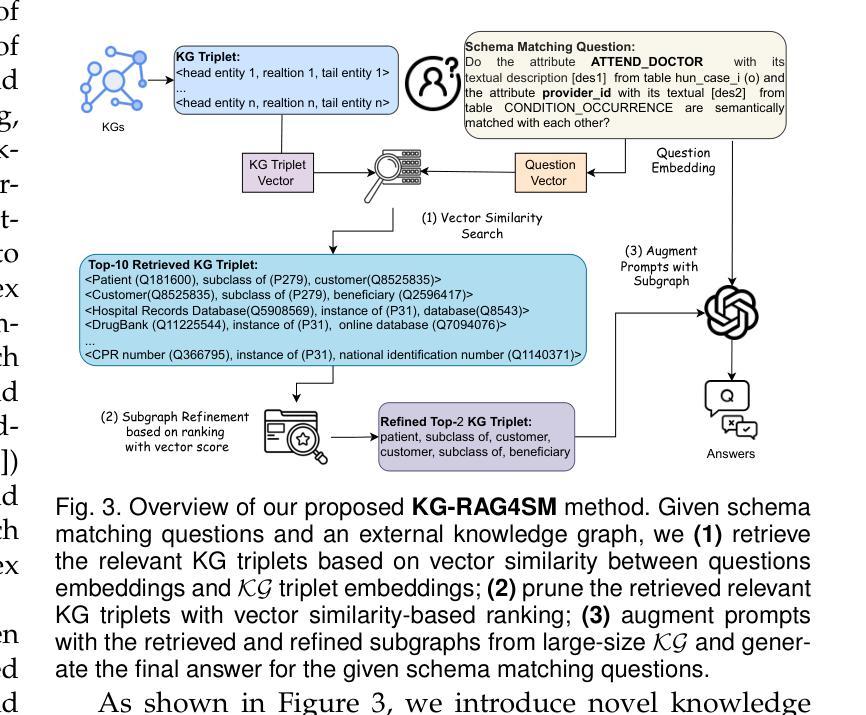
Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching
Authors:Chuangtao Ma, Sriom Chakrabarti, Arijit Khan, Bálint Molnár
Traditional similarity-based schema matching methods are incapable of resolving semantic ambiguities and conflicts in domain-specific complex mapping scenarios due to missing commonsense and domain-specific knowledge. The hallucination problem of large language models (LLMs) also makes it challenging for LLM-based schema matching to address the above issues. Therefore, we propose a Knowledge Graph-based Retrieval-Augmented Generation model for Schema Matching, referred to as the KG-RAG4SM. In particular, KG-RAG4SM introduces novel vector-based, graph traversal-based, and query-based graph retrievals, as well as a hybrid approach and ranking schemes that identify the most relevant subgraphs from external large knowledge graphs (KGs). We showcase that KG-based retrieval-augmented LLMs are capable of generating more accurate results for complex matching cases without any re-training. Our experimental results show that KG-RAG4SM outperforms the LLM-based state-of-the-art (SOTA) methods (e.g., Jellyfish-8B) by 35.89% and 30.50% in terms of precision and F1 score on the MIMIC dataset, respectively; KG-RAG4SM with GPT-4o-mini outperforms the pre-trained language model (PLM)-based SOTA methods (e.g., SMAT) by 69.20% and 21.97% in terms of precision and F1 score on the Synthea dataset, respectively. The results also demonstrate that our approach is more efficient in end-to-end schema matching, and scales to retrieve from large KGs. Our case studies on the dataset from the real-world schema matching scenario exhibit that the hallucination problem of LLMs for schema matching is well mitigated by our solution.
传统基于相似度的模式匹配方法无法解决特定领域复杂映射场景中的语义模糊和冲突问题,因为缺乏常识和特定领域的知识。大型语言模型的幻觉问题也使得基于LLM的模式匹配难以解决上述问题。因此,我们提出了一种基于知识图谱的检索增强生成模型用于模式匹配,称为KG-RAG4SM。特别地,KG-RAG4SM引入了基于新型向量、基于图遍历和基于查询的图检索,以及混合方法和排名方案,这些方案可以从外部大型知识图谱(KG)中识别出最相关的子图。我们展示了基于知识图谱检索增强的LLM能够在无需重新训练的情况下为复杂匹配案例生成更准确的结果。我们的实验结果表明,在MIMIC数据集上,KG-RAG4SM在精确度和F1分数方面分别比基于LLM的最先进方法(如Jellyfish-8B)高出35.89%和30.50%;在Synthea数据集上,使用GPT-4o-mini的KG-RAG4SM在精确度和F1分数方面分别比基于预训练语言模型(PLM)的最先进方法(如SMAT)高出69.20%和21.97%。结果还表明,我们的方法在端到端模式匹配方面更加高效,并能扩展到从大型KG中进行检索。我们在来自现实世界模式匹配场景的数据集上进行的案例研究表明,我们的解决方案很好地缓解了LLM在模式匹配中的幻觉问题。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了基于知识图谱的检索增强生成模型在模式匹配中的应用,称为KG-RAG4SM。该模型解决了传统基于相似度的模式匹配方法无法解决的语义模糊和冲突问题,通过引入基于向量、图遍历和查询的检索方法,以及混合方法和排名方案,从外部大型知识图谱中识别最相关的子图。实验结果表明,KG-RAG4SM在复杂匹配案例中表现更精确,无需重新训练。在MIMIC和Synthea数据集上的结果显示,KG-RAG4SM相较于其他最先进的方法有显著提高。此外,该方案有效缓解了大型语言模型在模式匹配中的虚构问题。
Key Takeaways
- 传统基于相似度的模式匹配方法存在语义模糊和冲突问题,无法应对特定领域的复杂映射场景。
- KG-RAG4SM模型通过引入新型向量、图遍历和查询检索技术,结合混合方法和排名方案,从外部大型知识图谱中识别最相关的子图,提高了模式匹配的准确性。
- KG-RAG4SM无需重新训练即可生成更精确的结果,特别是在复杂匹配案例中。
- 在MIMIC和Synthea数据集上的实验结果显示,KG-RAG4SM相较于其他最先进的方法有显著提高,分别提高了35.89%和69.20%的精度。
- KG-RAG4SM方案与大型语言模型结合,有效缓解了语言模型的虚构问题。
- KG-RAG4SM模型更适用于端到端的模式匹配,并能从大型知识图谱中高效检索。
点此查看论文截图


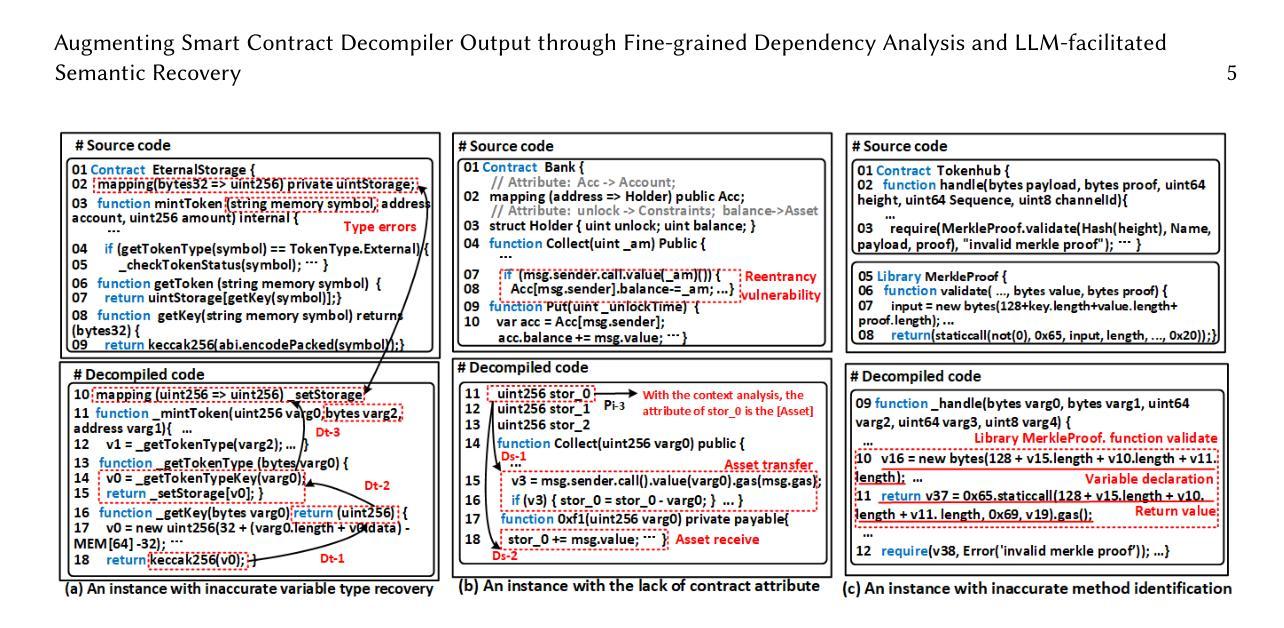
Augmenting Smart Contract Decompiler Output through Fine-grained Dependency Analysis and LLM-facilitated Semantic Recovery
Authors:Zeqin Liao, Yuhong Nan, Zixu Gao, Henglong Liang, Sicheng Hao, Peifan Reng, Zibin Zheng
Decompiler is a specialized type of reverse engineering tool extensively employed in program analysis tasks, particularly in program comprehension and vulnerability detection. However, current Solidity smart contract decompilers face significant limitations in reconstructing the original source code. In particular, the bottleneck of SOTA decompilers lies in inaccurate method identification, incorrect variable type recovery, and missing contract attributes. These deficiencies hinder downstream tasks and understanding of the program logic. To address these challenges, we propose SmartHalo, a new framework that enhances decompiler output by combining static analysis (SA) and large language models (LLM). SmartHalo leverages the complementary strengths of SA’s accuracy in control and data flow analysis and LLM’s capability in semantic prediction. More specifically, \system{} constructs a new data structure - Dependency Graph (DG), to extract semantic dependencies via static analysis. Then, it takes DG to create prompts for LLM optimization. Finally, the correctness of LLM outputs is validated through symbolic execution and formal verification. Evaluation on a dataset consisting of 465 randomly selected smart contract methods shows that SmartHalo significantly improves the quality of the decompiled code, compared to SOTA decompilers (e.g., Gigahorse). Notably, integrating GPT-4o with SmartHalo further enhances its performance, achieving precision rates of 87.39% for method boundaries, 90.39% for variable types, and 80.65% for contract attributes.
反编译器是一种专门用于程序分析任务的反向工程工具,特别是在程序理解和漏洞检测方面。然而,当前用于Solidity智能合约的反编译器在重构原始源代码时面临重大局限。具体来说,当前最先进反编译器的瓶颈在于方法识别不准确、变量类型恢复不正确以及缺失的合同属性。这些缺陷阻碍了下游任务和程序逻辑理解。为了应对这些挑战,我们提出了SmartHalo,这是一个新的框架,它通过结合静态分析(SA)和大型语言模型(LLM)来提高反编译器的输出质量。SmartHalo利用SA在控制和数据流分析方面的准确性,以及LLM在语义预测方面的能力。更具体地说,SmartHalo通过静态分析构建了新的数据结构——依赖图(DG),以提取语义依赖关系。然后,它使用DG来创建用于优化LLM的提示。最后,通过符号执行和形式化验证验证LLM输出的正确性。在由随机选择的465个智能合约方法组成的数据集上的评估表明,与当前最先进反编译器相比(如Gigahorse),SmartHalo显著提高了反编译代码的质量。值得注意的是,将GPT-4o与SmartHalo集成进一步提高了其性能,方法边界的精确率为87.39%,变量类型的精确率为90.39%,合同属性的精确率为80.65%。
论文及项目相关链接
Summary
智能合约反编译是程序分析中的一项重要任务,尤其在程序理解和漏洞检测方面。然而,当前Solidity智能合约的反编译工具存在重大局限。SmartHalo是一种新的反编译优化框架,通过结合静态分析和大型语言模型(LLM)来提高反编译输出质量。SmartHalo利用静态分析的准确性和大型语言模型的语义预测能力,构建依赖图来提取语义依赖关系,并通过符号执行和形式验证验证大型语言模型的输出正确性。实验表明,SmartHalo在方法边界、变量类型和合同属性方面显著提高了反编译代码的质量。
Key Takeaways
- 反编译在智能合约分析中至关重要,但当前工具存在局限。
- SmartHalo结合了静态分析和大型语言模型(LLM)来提高反编译效果。
- 依赖图的构建有助于提取语义依赖关系。
- 大型语言模型(LLM)能够提升语义预测能力。
- SmartHalo通过符号执行和形式验证验证输出正确性。
- 在实验评估中,SmartHalo显著提高反编译代码质量。
点此查看论文截图

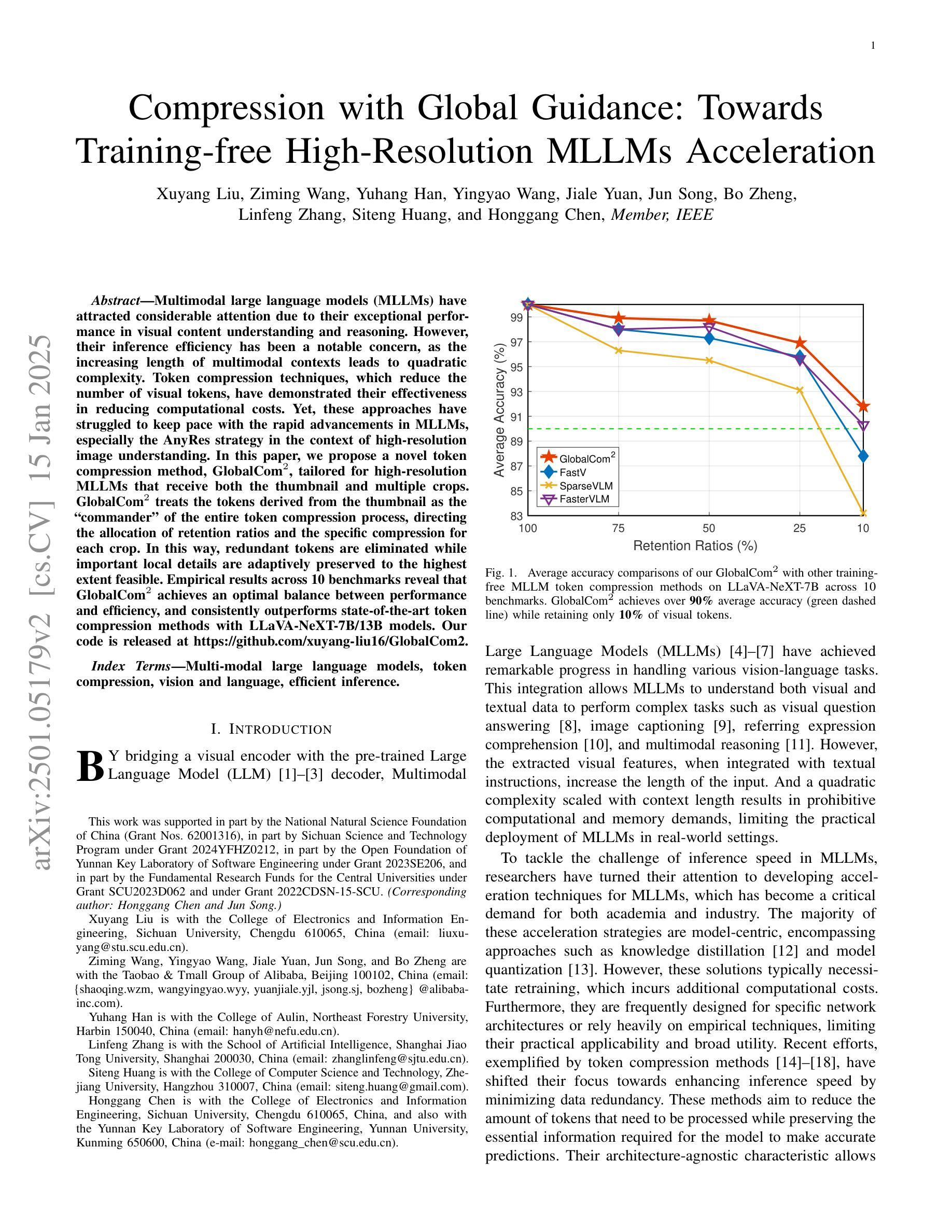
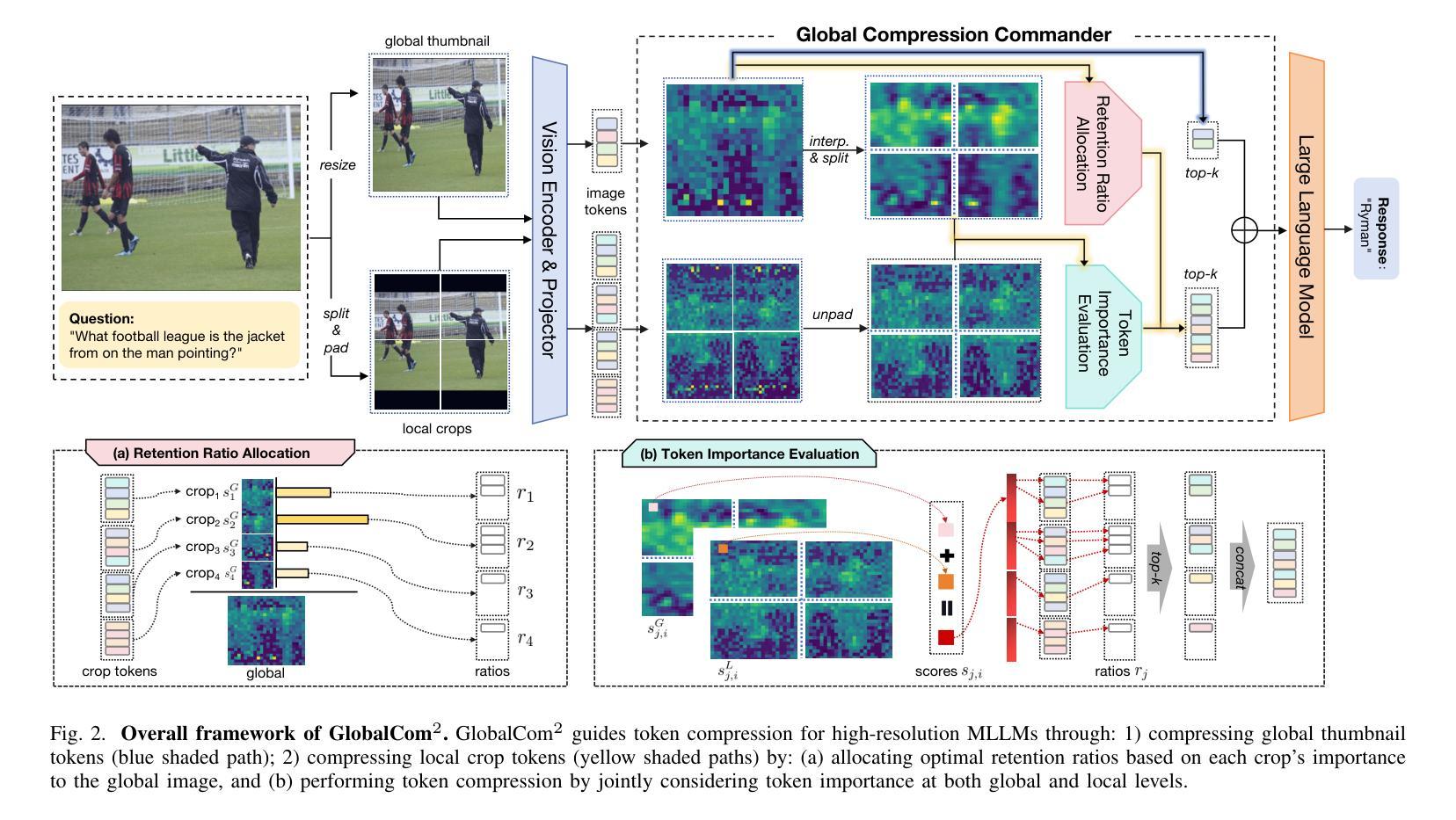
Compression with Global Guidance: Towards Training-free High-Resolution MLLMs Acceleration
Authors:Xuyang Liu, Ziming Wang, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Bo Zheng, Linfeng Zhang, Siteng Huang, Honggang Chen
Multimodal large language models (MLLMs) have attracted considerable attention due to their exceptional performance in visual content understanding and reasoning. However, their inference efficiency has been a notable concern, as the increasing length of multimodal contexts leads to quadratic complexity. Token compression techniques, which reduce the number of visual tokens, have demonstrated their effectiveness in reducing computational costs. Yet, these approaches have struggled to keep pace with the rapid advancements in MLLMs, especially the AnyRes strategy in the context of high-resolution image understanding. In this paper, we propose a novel token compression method, GlobalCom$^2$, tailored for high-resolution MLLMs that receive both the thumbnail and multiple crops. GlobalCom$^2$ treats the tokens derived from the thumbnail as the “commander” of the entire token compression process, directing the allocation of retention ratios and the specific compression for each crop. In this way, redundant tokens are eliminated while important local details are adaptively preserved to the highest extent feasible. Empirical results across 10 benchmarks reveal that GlobalCom$^2$ achieves an optimal balance between performance and efficiency, and consistently outperforms state-of-the-art token compression methods with LLaVA-NeXT-7B/13B models. Our code is released at https://github.com/xuyang-liu16/GlobalCom2.
多模态大型语言模型(MLLMs)由于对视觉内容理解和推理的出色表现而备受关注。然而,随着多模态上下文长度的增加,它们的推理效率成为一个突出问题。令牌压缩技术通过减少视觉令牌的数量,已经证明其在降低计算成本方面的有效性。然而,这些方法很难跟上MLLMs的快速发展,特别是在高分辨率图像理解方面的AnyRes策略。在本文中,我们提出了一种新型的令牌压缩方法GlobalCom$^2$,它是为高分辨率的MLLMs设计的,这些模型同时接收缩略图和多个裁剪图像。GlobalCom$^2$将来自缩略图的令牌作为整个令牌压缩过程的“指挥官”,指导保留比例的分配和每种裁剪图像的具体压缩。通过这种方式,冗余令牌被消除,同时重要局部细节得到尽可能大的自适应保留。在10个基准测试上的经验结果表明,GlobalCom$^2$在性能和效率之间达到了最优平衡,并且始终优于最新的令牌压缩方法,特别是在使用LLaVA-NeXT-7B/13B模型的情况下。我们的代码已发布在https://github.com/xuyang-liu16/GlobalCom2。
论文及项目相关链接
PDF Our code is released at \url{https://github.com/xuyang-liu16/GlobalCom2}
Summary
多模态大型语言模型(MLLMs)在视觉内容理解和推理方面表现出卓越性能,但推理效率一直是关注的问题。随着多模态上下文长度的增加,计算复杂度呈二次方增长。本文提出了一种针对高分辨率MLLMs的新型令牌压缩方法GlobalCom$^2$,该方法利用缩略图和多个裁剪图像生成的令牌作为“指挥官”,管理压缩过程中的保留比率并为每个裁剪图像提供特定压缩。此方法在消除冗余令牌的同时自适应地保留重要局部细节,在性能和效率之间达到最佳平衡。与最新令牌压缩方法相比,GlobalCom$^2$在LLaVA-NeXT-7B/13B模型上表现更优秀。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉内容理解和推理方面表现出色,但推理效率成为关注焦点。
- 随着多模态上下文长度的增加,计算复杂度呈二次方增长,导致效率下降。
- 令牌压缩技术可以有效降低计算成本,但现有方法面临对高分辨率图像理解上的挑战。
- 论文提出了一种新型的令牌压缩方法——GlobalCom$^2$,专门针对高分辨率MLLMs。
- GlobalCom$^2$利用缩略图和多个裁剪图像生成的令牌作为整个压缩过程的“指挥官”,优化了令牌分配和压缩。
- GlobalCom$^2$在消除冗余令牌的同时自适应地保留重要局部细节。
点此查看论文截图
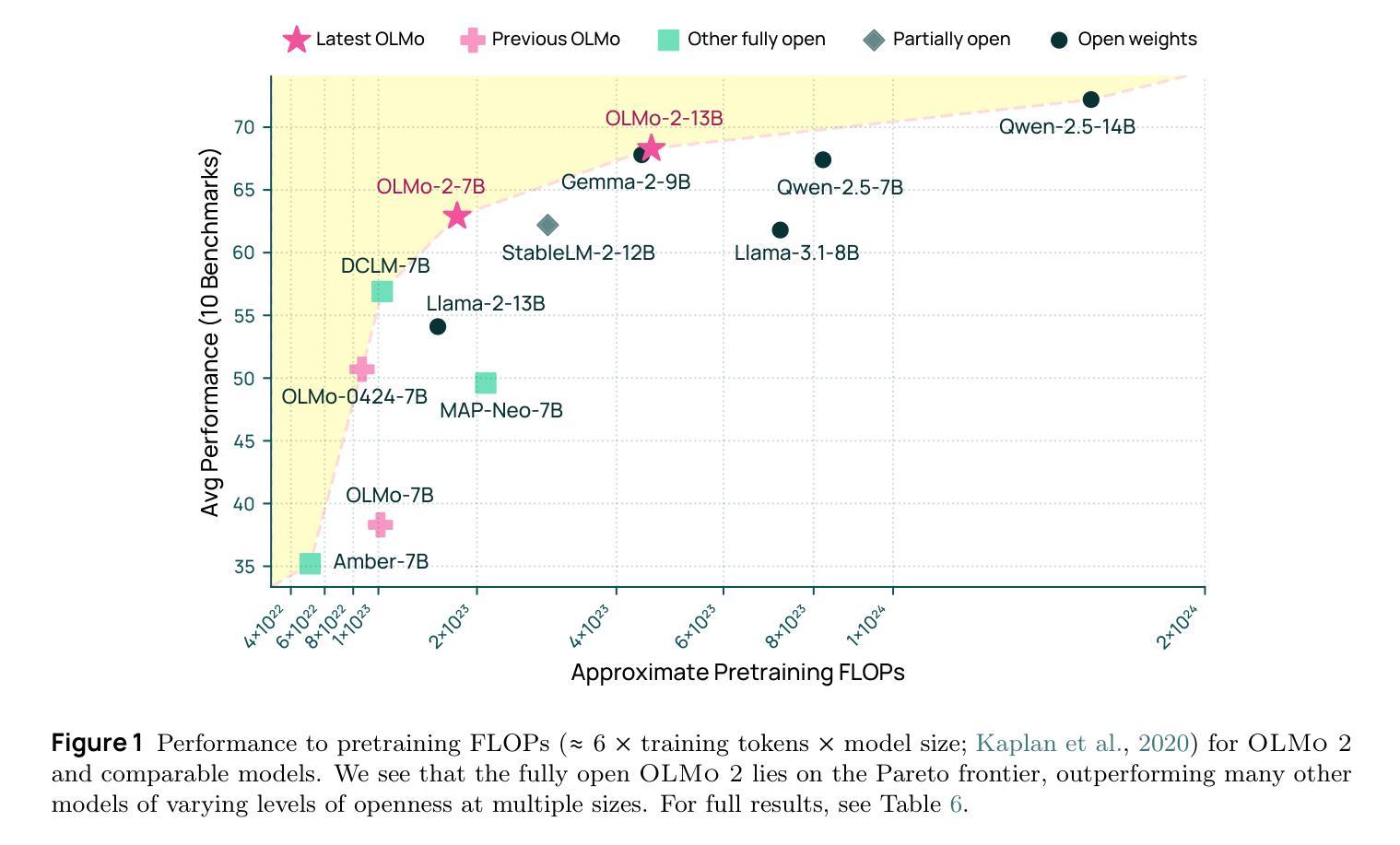
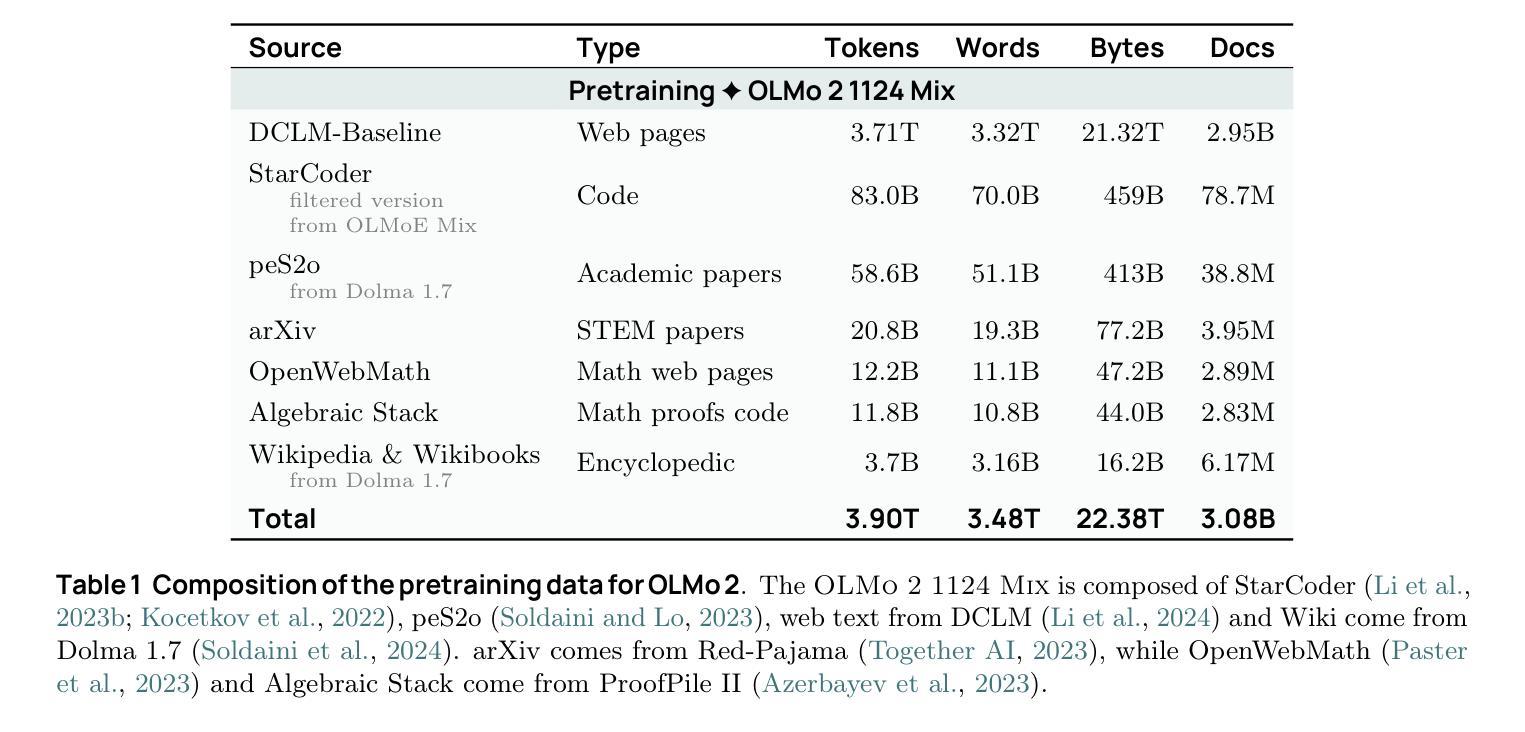
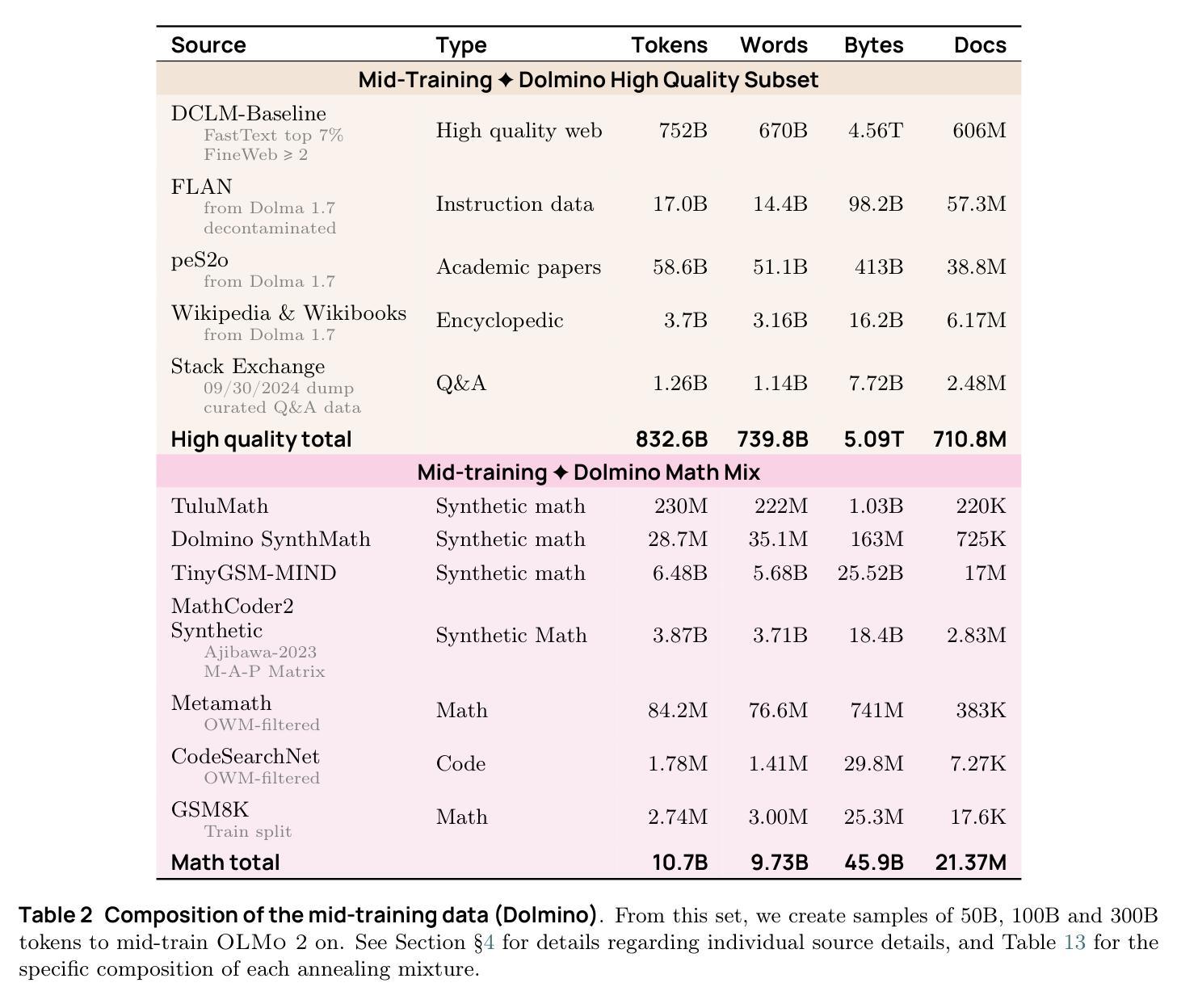
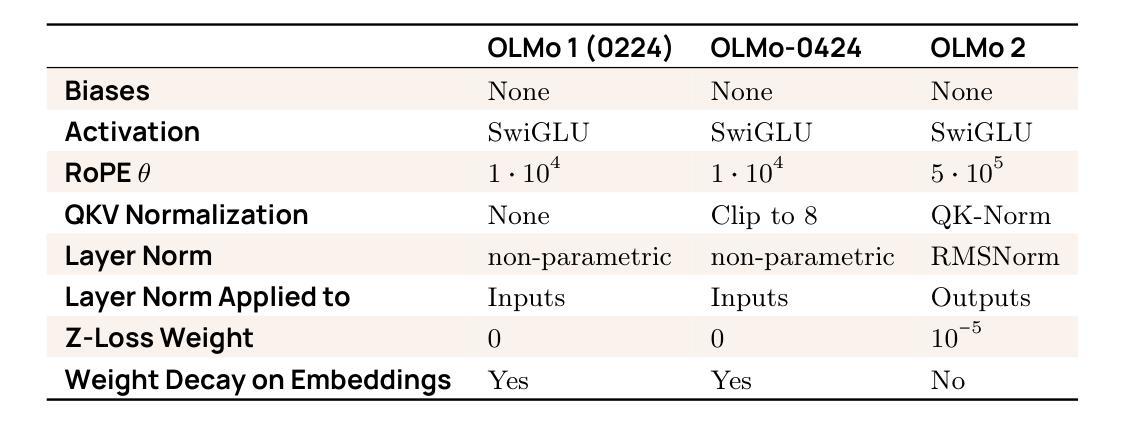
2 OLMo 2 Furious
Authors:Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Malik, William Merrill, Lester James V. Miranda, Jacob Morrison, Tyler Murray, Crystal Nam, Valentina Pyatkin, Aman Rangapur, Michael Schmitz, Sam Skjonsberg, David Wadden, Christopher Wilhelm, Michael Wilson, Luke Zettlemoyer, Ali Farhadi, Noah A. Smith, Hannaneh Hajishirzi
We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly – models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
我们推出了OLMo 2,这是我们全新开发的完全开放语言模型的下一代产品。OLMo 2包括改进架构和训练方案的密集自回归模型、预训练数据混合以及指令调整方案。我们的改进模型架构和训练方案实现了更好的训练稳定性和每令牌效率。我们更新的预训练数据混合引入了一种新的专门数据混合Dolmino Mix 1124,当通过后期课程训练(即在预训练的退火阶段引入专门数据)时,它能在许多下游任务基准测试中显著提高模型的能力。最后,我们结合了T“ulu 3的最佳实践来开发OLMo 2-Instruct,侧重于许可数据,并扩展了我们最终阶段的可验证奖励强化学习(RLVR)。我们的OLMo 2基础模型位于性能与计算之间的帕累托前沿,通常与诸如Llama 3.1和Qwen 2.5等仅公开权重模型相匹配或表现更佳,同时使用的浮点运算较少,并且具有完全透明的训练数据、代码和方案。我们完全开放的OLMo 2-Instruct模型与相同规模的仅公开权重模型具有竞争力,包括Qwen 2.5、Llama 3.1和Gemma 2。我们公开所有OLMo 2制品-规模为7B和13B的模型,包括预训练和后期训练的模型、完整的训练数据、训练代码和方案、训练日志以及成千上万的中间检查点。最终指令模型可在Ai2 Playground上作为免费研究演示使用。
论文及项目相关链接
PDF Model demo available at playground.allenai.org
摘要
OLMo 2作为全新一代完全开放的语言模型,包括密集的自回归模型,改进了架构和训练配方、预训练数据混合物和指令调整配方。其改进后的模型架构和训练配方提高了训练稳定性和每标记的效率。新的预训练数据混合物Dolmino Mix 1124通过后期课程训练显著提高了模型在多个下游任务基准测试中的能力。OLMo 2-Instruct结合了最佳实践,侧重于许可数据,并利用可验证奖励扩展了最终阶段的强化学习。OLMo 2基础模型在计算性能方面处于前沿地位,与Llama 3.1和Qwen 2.5等仅开放权重模型相比,使用更少的FLOPs和完全透明的训练数据、代码和配方。OLMo 2的所有模型和相关数据均已公开发布。
关键见解
- OLMo 2是新一代完全开放的语言模型,包含密集的自回归模型。
- 改进了模型架构和训练配方,提高了训练稳定性和每标记的效率。
- 引入新的预训练数据混合物Dolmino Mix 1124,通过后期课程训练提高了模型在多个下游任务中的性能。
- 结合最佳实践,开发OLMo 2-Instruct,侧重于许可数据,并扩展了最终阶段的强化学习。
- OLMo 2基础模型在计算性能方面处于前沿地位,与竞争对手相比使用更少的计算资源。
- OLMo 2的所有模型和相关数据均已公开发布,包括预训练和后期训练的模型、完整的训练数据、训练代码和配方等。
点此查看论文截图

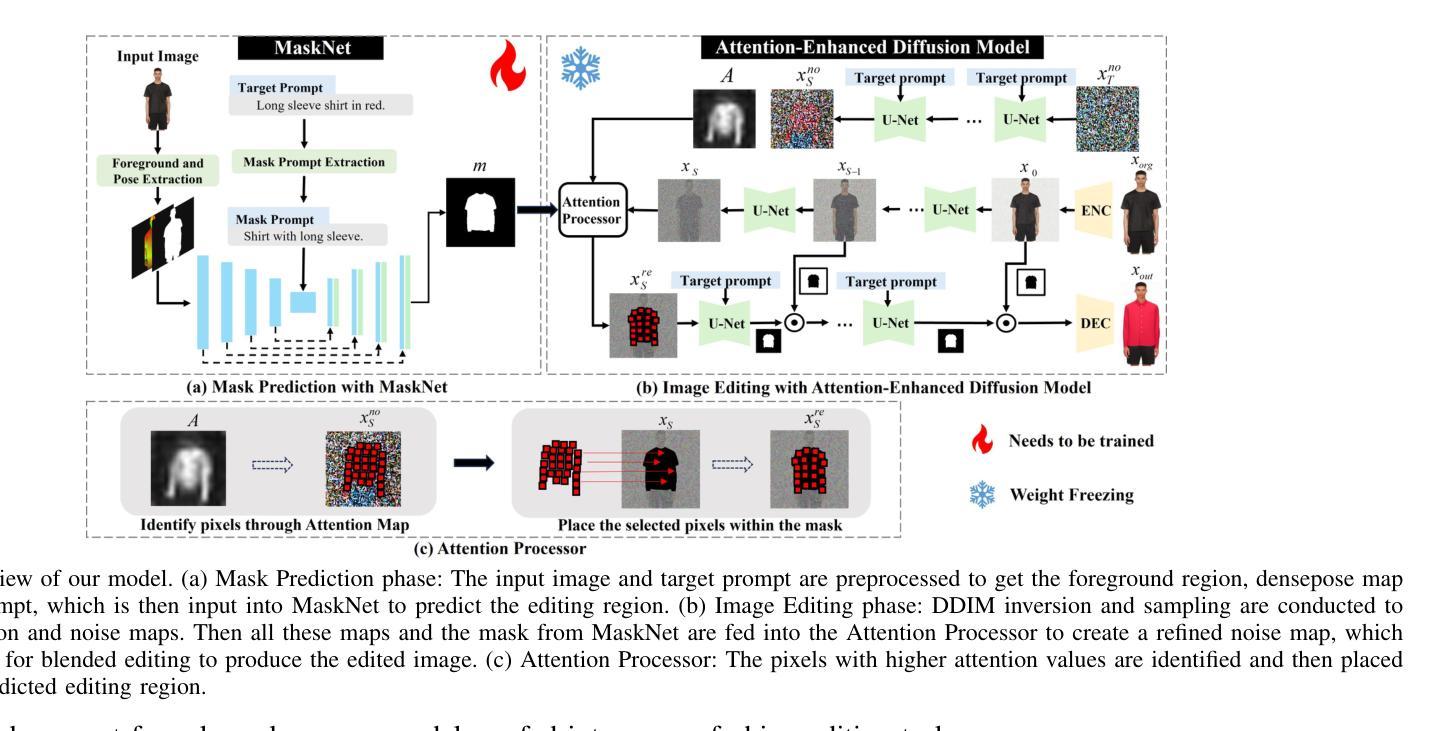
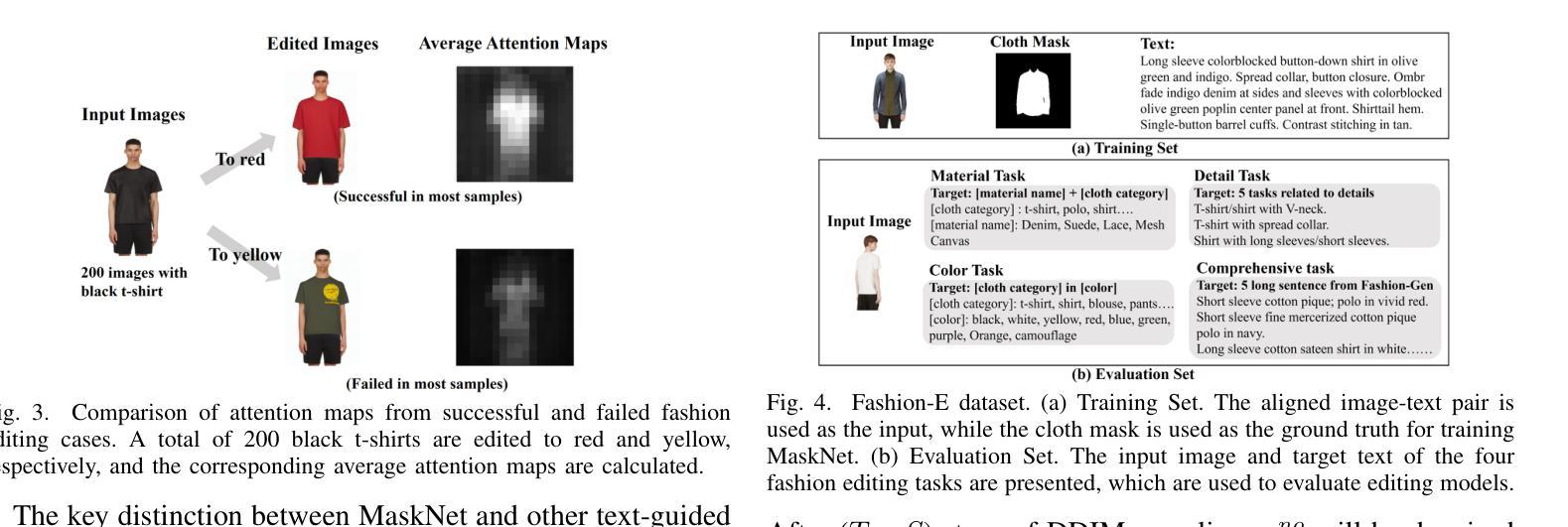
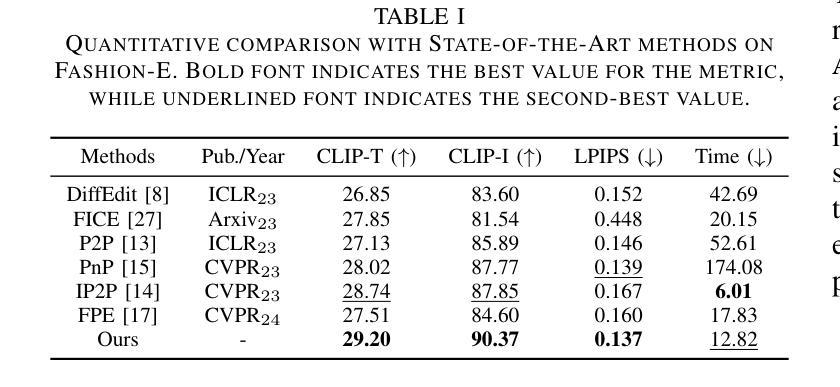
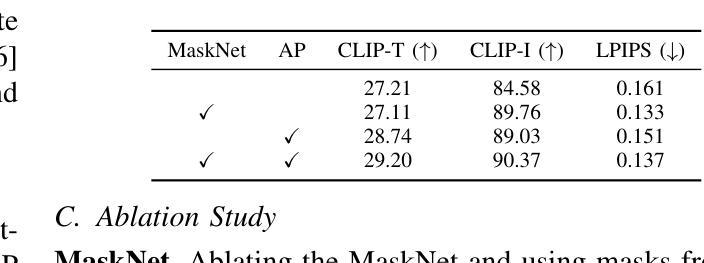
MADiff: Text-Guided Fashion Image Editing with Mask Prediction and Attention-Enhanced Diffusion
Authors:Zechao Zhan, Dehong Gao, Jinxia Zhang, Jiale Huang, Yang Hu, Xin Wang
Text-guided image editing model has achieved great success in general domain. However, directly applying these models to the fashion domain may encounter two issues: (1) Inaccurate localization of editing region; (2) Weak editing magnitude. To address these issues, the MADiff model is proposed. Specifically, to more accurately identify editing region, the MaskNet is proposed, in which the foreground region, densepose and mask prompts from large language model are fed into a lightweight UNet to predict the mask for editing region. To strengthen the editing magnitude, the Attention-Enhanced Diffusion Model is proposed, where the noise map, attention map, and the mask from MaskNet are fed into the proposed Attention Processor to produce a refined noise map. By integrating the refined noise map into the diffusion model, the edited image can better align with the target prompt. Given the absence of benchmarks in fashion image editing, we constructed a dataset named Fashion-E, comprising 28390 image-text pairs in the training set, and 2639 image-text pairs for four types of fashion tasks in the evaluation set. Extensive experiments on Fashion-E demonstrate that our proposed method can accurately predict the mask of editing region and significantly enhance editing magnitude in fashion image editing compared to the state-of-the-art methods.
文本引导的图像编辑模型在通用领域取得了巨大成功。然而,直接将这些模型应用于时尚领域可能会遇到两个问题:(1)编辑区域定位不准确;(2)编辑幅度较弱。为了解决这些问题,提出了MADiff模型。具体而言,为了更准确地识别编辑区域,提出了MaskNet,其中将前景区域、densepose和大语言模型的遮罩提示输入到轻量级的UNet中,以预测编辑区域的遮罩。为了增强编辑幅度,提出了注意力增强扩散模型,其中将噪声图、注意力图和MaskNet的遮罩输入到提出的注意力处理器中,以产生精细的噪声图。通过将精细的噪声图集成到扩散模型中,编辑后的图像可以更好地与目标提示对齐。鉴于时尚图像编辑缺乏基准测试集,我们构建了一个名为Fashion-E的数据集,其中包含训练集中的28390个图像文本对和评估集中的2639个图像文本对用于四种时尚任务。在Fashion-E上的大量实验表明,我们提出的方法可以准确预测编辑区域的遮罩,并在时尚图像编辑中显著增强编辑幅度,与最先进的方法相比。
论文及项目相关链接
摘要
本文主要探讨了文本引导的图像编辑模型在时尚领域面临的挑战。为了解决定位编辑区域不准确和编辑强度弱的问题,提出了MADiff模型。利用MaskNet更准确识别编辑区域,利用大型语言模型的前景区域、密集姿态和掩膜提示输入轻量级UNet来预测编辑区域的掩膜。同时,提出了增强型注意力扩散模型来增强编辑强度,将噪声图、注意力图和MaskNet的掩膜输入到提出的注意力处理器中,生成优化后的噪声图。整合到扩散模型中后,编辑后的图像能更好地符合目标提示。由于缺乏时尚图像编辑的基准测试集,我们构建了一个名为Fashion-E的数据集,包括训练集的28390个图像文本对和评估集的2639个图像文本对,分为四种时尚任务。在Fashion-E上的大量实验表明,与最先进的方法相比,我们的方法可以准确预测编辑区域的掩膜,并在时尚图像编辑中显著提高编辑强度。
关键见解
- 文本引导的图像编辑模型在时尚领域面临定位编辑区域不准确和编辑强度弱的问题。
- MADiff模型被提出以解决这两个问题,其中包括MaskNet和增强型注意力扩散模型。
- MaskNet利用前景区域、密集姿态和掩膜提示来更准确地识别编辑区域。
- 增强型注意力扩散模型通过生成优化后的噪声图来增强编辑强度。
- 整合优化后的噪声图到扩散模型中,使编辑后的图像更符合目标提示。
- 缺乏时尚图像编辑的基准测试集,因此构建了Fashion-E数据集进行实验。
点此查看论文截图


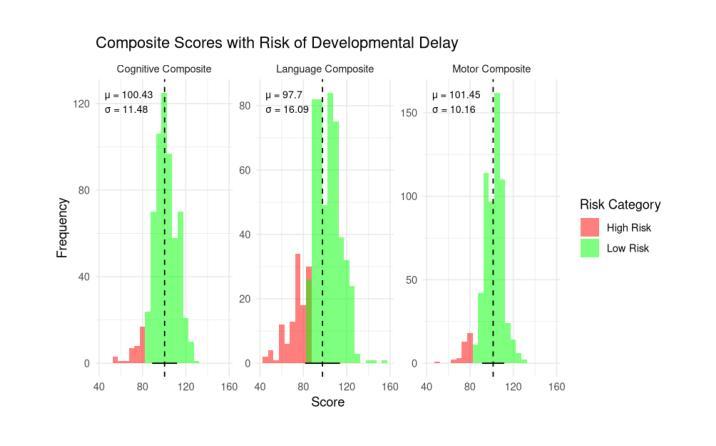
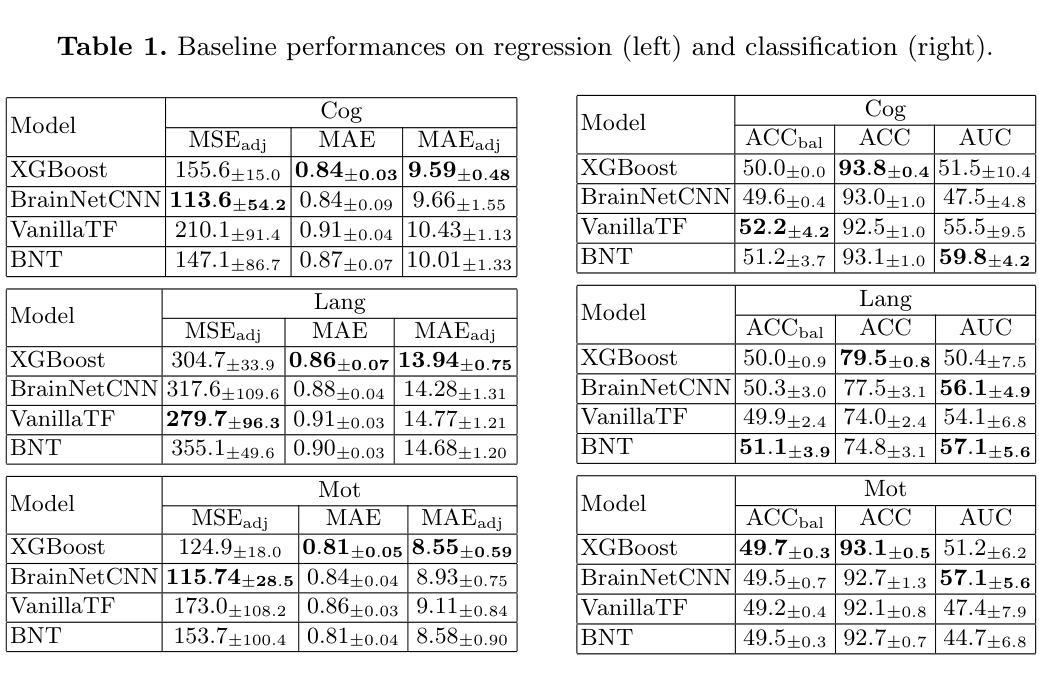
Swin fMRI Transformer Predicts Early Neurodevelopmental Outcomes from Neonatal fMRI
Authors:Patrick Styll, Dowon Kim, Jiook Cha
Brain development in the first few months of human life is a critical phase characterized by rapid structural growth and functional organization. Accurately predicting developmental outcomes during this time is crucial for identifying delays and enabling timely interventions. This study introduces the SwiFT (Swin 4D fMRI Transformer) model, designed to predict Bayley-III composite scores using neonatal fMRI data from the Developing Human Connectome Project (dHCP). To enhance predictive accuracy, we apply dimensionality reduction via group independent component analysis (ICA) and pretrain SwiFT on large adult fMRI datasets to address the challenges of limited neonatal data. Our analysis shows that SwiFT significantly outperforms baseline models in predicting cognitive, motor, and language outcomes, leveraging both single-label and multi-label prediction strategies. The model’s attention-based architecture processes spatiotemporal data end-to-end, delivering superior predictive performance. Additionally, we use Integrated Gradients with Smoothgrad sQuare (IG-SQ) to interpret predictions, identifying neural spatial representations linked to early cognitive and behavioral development. These findings underscore the potential of Transformer models to advance neurodevelopmental research and clinical practice.
人类生命头几个月的大脑发育是一个关键阶段,特点是结构迅速增长和功能组织化。准确预测这一时期的发育结果是至关重要的,有助于发现发育延迟,以便及时采取干预措施。本研究介绍了SwiFT(Swin 4D fMRI Transformer)模型,该模型旨在利用发展人类连接组项目(dHC)的新生儿fMRI数据预测Bayley-III综合得分。为了提高预测精度,我们通过群体独立成分分析(ICA)进行降维,并在大型成人fMRI数据集上预先训练SwiFT,以应对新生儿数据量有限所带来的挑战。我们的分析表明,在采用单标签和多标签预测策略的情况下,SwiFT在预测认知、运动和语言结果方面显著优于基准模型。该模型的注意力架构能够端到端地处理时空数据,提供出色的预测性能。此外,我们还使用集成梯度与平滑梯度平方(IG-SQ)来解释预测结果,识别与早期认知和发育行为相关的神经空间表征。这些发现强调了Transformer模型在神经发育研究和临床实践中的潜力。
论文及项目相关链接
PDF fMRI Transformer, Developing Human Connectome Project, Bayley Scales of Infant Development, Personalized Therapy, XAI
Summary
本研究利用SwiFT模型预测新生儿早期的认知、运动和语言发展结果。研究使用新生儿的四维功能磁共振成像数据(fMRI),通过群体独立成分分析(ICA)降低数据维度,并在大型成人fMRI数据集上预训练模型,以提高预测准确性。模型采用基于注意力的架构处理时空数据,表现出优越的性能。同时,该研究使用Integrated Gradients with Smoothgrad sQuare(IG-SQ)解释预测结果,发现与早期认知和行为的神经空间表征有关。这些发现展示了Transformer模型在神经发育研究和临床实践中的潜力。
Key Takeaways
- 研究强调新生儿早期大脑发展的重要性,并指出准确预测其发展结果是鉴别发展延迟和实施及时干预的关键。
- 介绍了SwiFT模型,该模型被设计用于基于新生儿fMRI数据预测Bayley-III综合分数。
- 通过群体独立成分分析(ICA)进行数据降维,以提高预测准确性。
- SwiFT模型在预测认知、运动和语言发展结果方面显著优于基准模型。
- 模型使用基于注意力的架构处理时空数据,表现出卓越的性能。
- 利用Integrated Gradients with Smoothgrad sQuare(IG-SQ)来解释预测结果。
点此查看论文截图

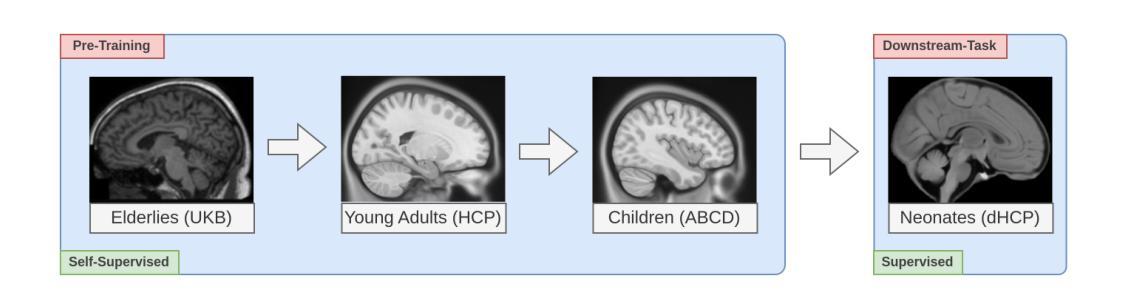
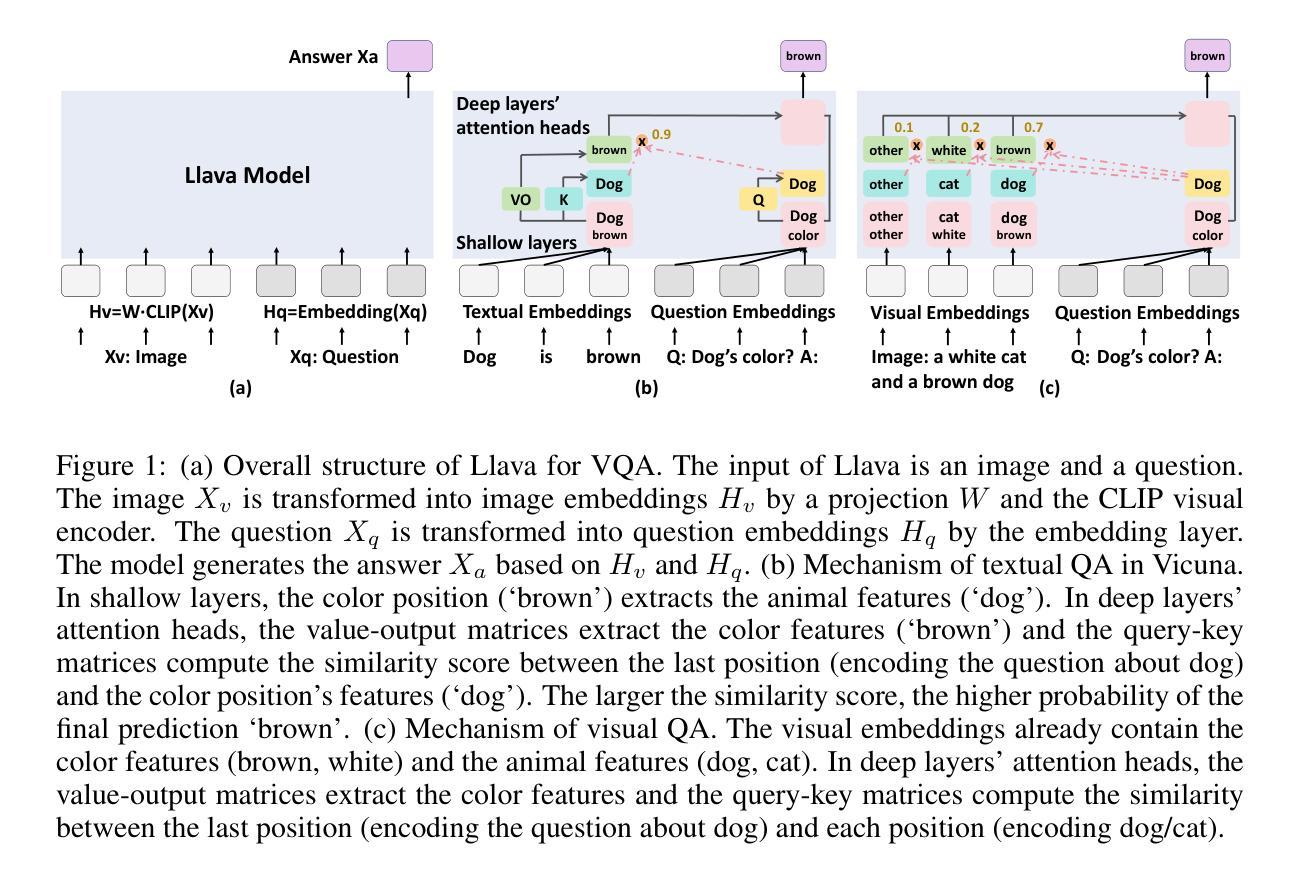
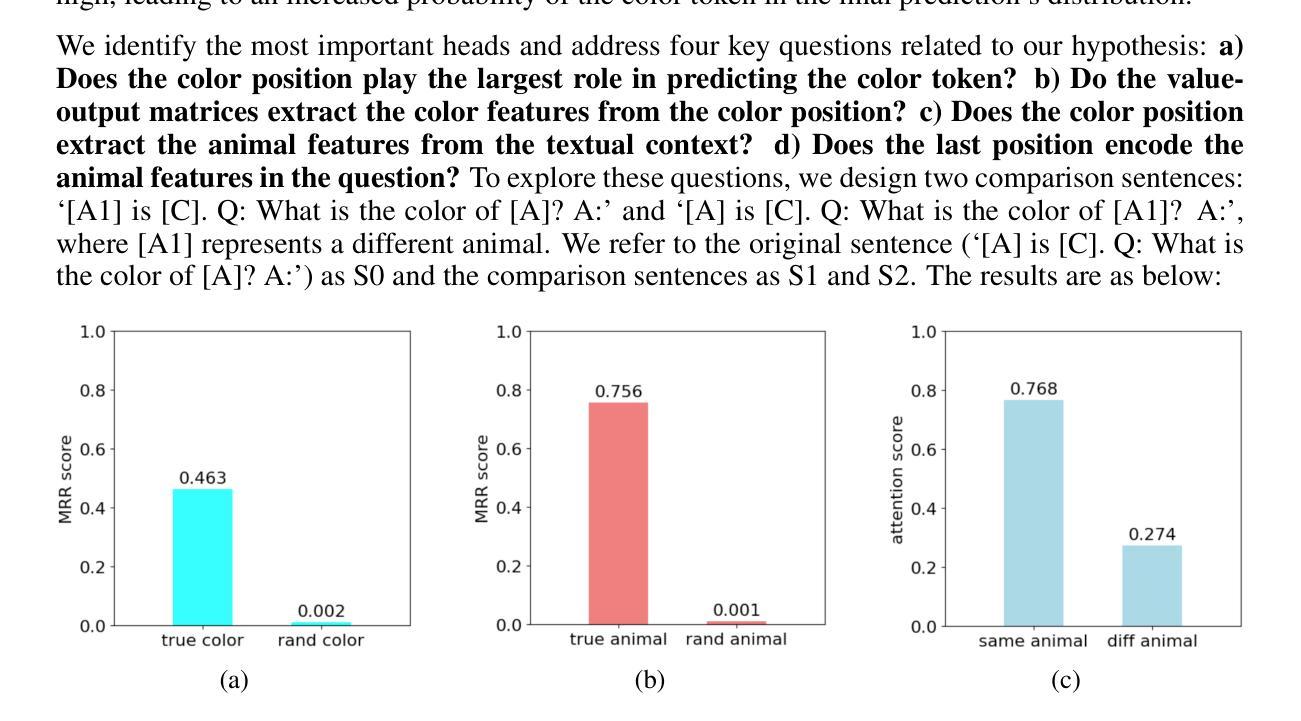
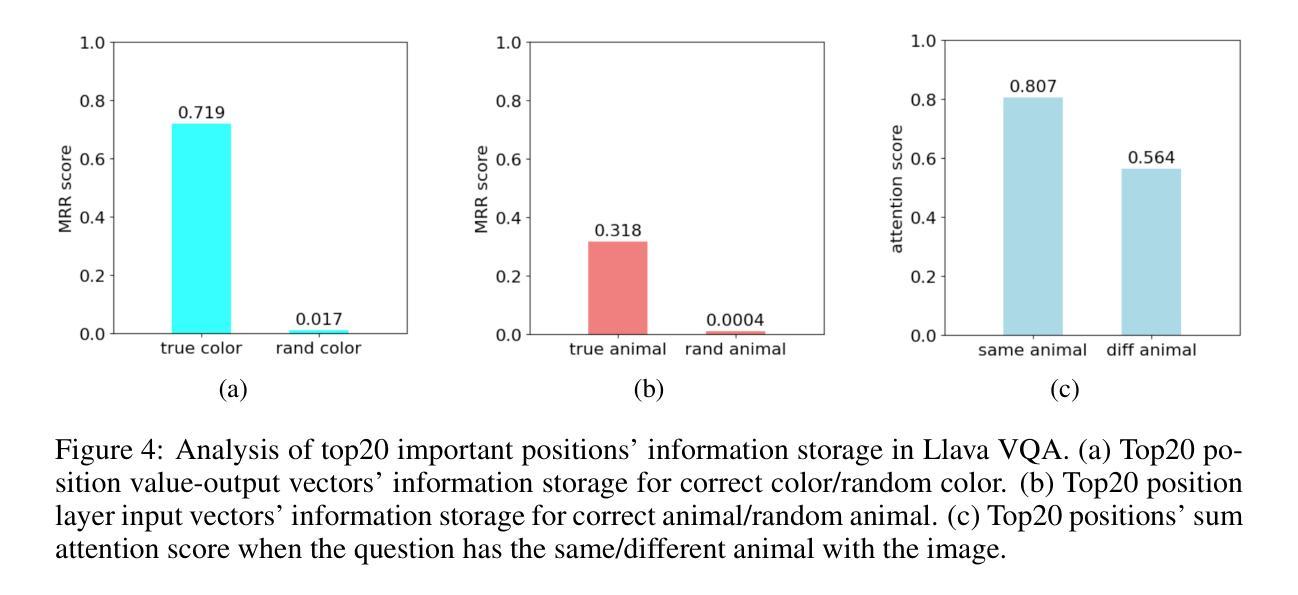
Understanding Multimodal LLMs: the Mechanistic Interpretability of Llava in Visual Question Answering
Authors:Zeping Yu, Sophia Ananiadou
Understanding the mechanisms behind Large Language Models (LLMs) is crucial for designing improved models and strategies. While recent studies have yielded valuable insights into the mechanisms of textual LLMs, the mechanisms of Multi-modal Large Language Models (MLLMs) remain underexplored. In this paper, we apply mechanistic interpretability methods to analyze the visual question answering (VQA) mechanisms in the first MLLM, Llava. We compare the mechanisms between VQA and textual QA (TQA) in color answering tasks and find that: a) VQA exhibits a mechanism similar to the in-context learning mechanism observed in TQA; b) the visual features exhibit significant interpretability when projecting the visual embeddings into the embedding space; and c) Llava enhances the existing capabilities of the corresponding textual LLM Vicuna during visual instruction tuning. Based on these findings, we develop an interpretability tool to help users and researchers identify important visual locations for final predictions, aiding in the understanding of visual hallucination. Our method demonstrates faster and more effective results compared to existing interpretability approaches. Code: \url{https://github.com/zepingyu0512/llava-mechanism}
了解大型语言模型(LLM)的机制对于设计改进模型和策略至关重要。虽然最近的研究已经对文本LLM的机制产生了有价值的见解,但多模态大型语言模型(MLLM)的机制仍然被探索得不够深入。在本文中,我们应用机械解释性方法来分析第一个MLLM——Llava的视觉问答(VQA)机制。我们比较了颜色回答任务中VQA和文本QA(TQA)的机制,并发现:a)VQA表现出与TQA中观察到的上下文学习机制相似的机制;b)将视觉嵌入投影到嵌入空间时,视觉特征表现出重要的解释性;c 在视觉指令微调过程中,Llava增强了相应文本LLMVicuna的现有功能。基于这些发现,我们开发了一个解释性工具,旨在帮助用户和研究者确定最终预测中的重要视觉位置,有助于理解视觉幻觉。我们的方法与现有解释方法相比,展现出更快和更有效的方法。代码:\url{https://github.com/zepingyu0512/llava-mechanism}。
论文及项目相关链接
PDF preprint
Summary
视觉问答(VQA)在多模态大型语言模型(MLLMs)中的机制在学术界依然待探索。本研究运用机制解释方法对首个MLLM模型Llava的VQA机制进行分析,发现其与文本问答(TQA)机制存在相似性,视觉特征在嵌入空间具有显著的可解释性,且Llava在视觉指令调整时增强了对应文本LLM的能力。据此开发了一种可解释性工具,有助于用户和研究者识别最终预测的重要视觉位置,更好地理解视觉幻觉现象。此工具相比现有方法更高效。
Key Takeaways
- 多模态大型语言模型(MLLMs)的VQA机制尚未得到充分探索。
- Llava模型在VQA中展现出与文本问答(TQA)类似的机制。
- 视觉特征在嵌入空间中具有显著的可解释性。
- Llava在视觉指令调整时增强了对应的文本LLM能力。
- 开发了一种新的可解释性工具,有助于识别最终预测的重要视觉位置。
- 该工具对理解视觉幻觉现象有重要作用。
点此查看论文截图


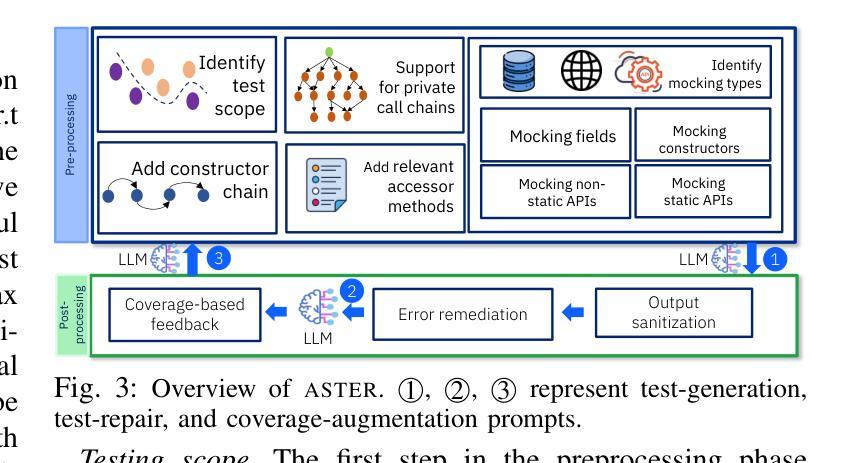
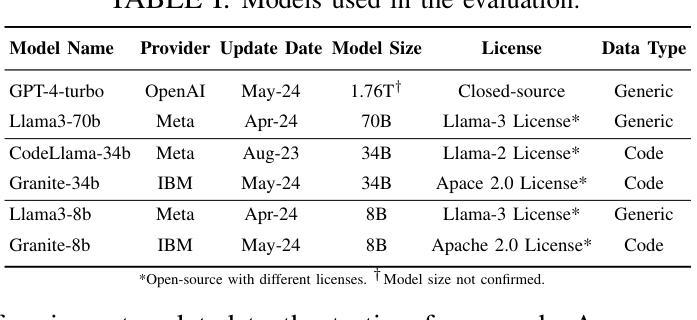
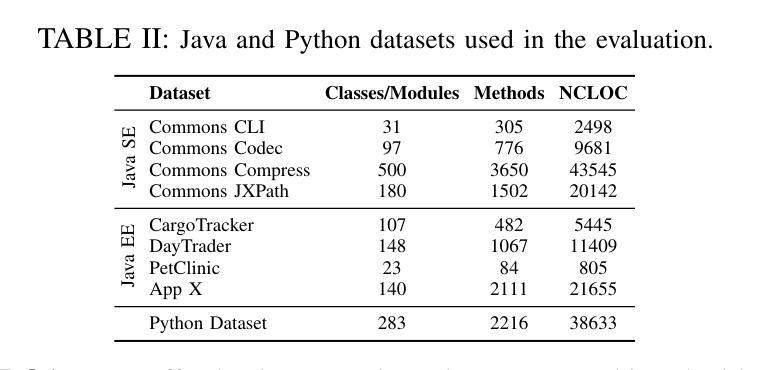
ASTER: Natural and Multi-language Unit Test Generation with LLMs
Authors:Rangeet Pan, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, Saurabh Sinha
Implementing automated unit tests is an important but time-consuming activity in software development. To assist developers in this task, many techniques for automating unit test generation have been developed. However, despite this effort, usable tools exist for very few programming languages. Moreover, studies have found that automatically generated tests suffer poor readability and do not resemble developer-written tests. In this work, we present a rigorous investigation of how large language models (LLMs) can help bridge the gap. We describe a generic pipeline that incorporates static analysis to guide LLMs in generating compilable and high-coverage test cases. We illustrate how the pipeline can be applied to different programming languages, specifically Java and Python, and to complex software requiring environment mocking. We conducted an empirical study to assess the quality of the generated tests in terms of code coverage and test naturalness – evaluating them on standard as well as enterprise Java applications and a large Python benchmark. Our results demonstrate that LLM-based test generation, when guided by static analysis, can be competitive with, and even outperform, state-of-the-art test-generation techniques in coverage achieved while also producing considerably more natural test cases that developers find easy to understand. We also present the results of a user study, conducted with 161 professional developers, that highlights the naturalness characteristics of the tests generated by our approach.
在软件开发中,实施自动化单元测试是一项重要且耗时的活动。为了协助开发人员完成这项任务,已经开发了许多自动化单元测试生成技术。然而,尽管付出了这些努力,只有很少几种编程语言有可用的工具。而且,研究表明,自动生成的测试可读性较差,并不类似于开发人员编写的测试。在这项工作中,我们对大型语言模型(LLM)如何帮助缩小差距进行了严格的研究。我们描述了一个通用管道,它结合了静态分析来指导LLM生成可编译和高覆盖率的测试用例。我们说明了该管道可以应用于不同的编程语言,特别是Java和Python,以及需要环境模拟的复杂软件。我们进行了一项实证研究,以评估生成的测试在代码覆盖率和测试自然性方面的质量——在标准和企业Java应用程序以及大型Python基准测试上对其进行评估。我们的结果表明,当基于静态分析指导时,LLM的测试生成可以与最新的测试生成技术在覆盖率方面竞争,甚至表现更好,同时生成的开发人员更容易理解的测试案例更为自然。我们还展示了与161名专业开发人员进行的用户研究结果,突出了我们方法生成的测试的直观性特点。
论文及项目相关链接
PDF Accepted at ICSE-SEIP, 2025
摘要
自动化单元测试是软件开发中的重要环节,但耗费大量时间。许多自动生成单元测试的技术已开发出来,以帮助开发人员完成这项任务。然而,针对多种编程语言的可用工具仍然很少。研究表明,自动生成的测试可读性较差,与开发人员编写的测试有很大差距。本研究旨在探讨大型语言模型(LLM)如何弥合这一鸿沟。描述了一个结合静态分析来指导LLM生成可编译和高覆盖率的测试用例的通用管道。该管道可应用于不同的编程语言(特别是Java和Python)以及需要环境模拟的复杂软件。我们进行了一项实证研究,以评估生成的测试在代码覆盖率和测试自然性方面的质量,并在标准和企业Java应用程序以及大型Python基准测试上进行了评估。结果表明,在静态分析指导下,基于LLM的测试生成可与最先进的测试生成技术竞争,甚至在某些方面表现更好,同时生成更自然的测试用例,开发人员更容易理解。我们还展示了与161名专业开发人员进行的用户研究结果,突出了我们方法生成的测试的直观特性。
关键见解
- 大型语言模型(LLM)在自动生成单元测试方面具有潜力,可帮助解决软件开发中的时间瓶颈。
- 目前自动生成的测试存在可读性差的问题,与人工编写的测试有很大差距。
- 通过结合静态分析,LLM能够生成可编译和高覆盖率的测试用例。
- 所描述的方法可应用于多种编程语言,包括Java和Python,以及复杂的软件环境。
- 实证研究证明,在代码覆盖率和测试自然性方面,LLM生成的测试质量较高。
- 与现有技术相比,基于LLM的测试生成方法在某些方面表现更优秀。
点此查看论文截图




Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations
Authors:Chen Chen, Xueluan Gong, Ziyao Liu, Weifeng Jiang, Si Qi Goh, Kwok-Yan Lam
AI Safety is an emerging area of critical importance to the safe adoption and deployment of AI systems. With the rapid proliferation of AI and especially with the recent advancement of Generative AI (or GAI), the technology ecosystem behind the design, development, adoption, and deployment of AI systems has drastically changed, broadening the scope of AI Safety to address impacts on public safety and national security. In this paper, we propose a novel architectural framework for understanding and analyzing AI Safety; defining its characteristics from three perspectives: Trustworthy AI, Responsible AI, and Safe AI. We provide an extensive review of current research and advancements in AI safety from these perspectives, highlighting their key challenges and mitigation approaches. Through examples from state-of-the-art technologies, particularly Large Language Models (LLMs), we present innovative mechanism, methodologies, and techniques for designing and testing AI safety. Our goal is to promote advancement in AI safety research, and ultimately enhance people’s trust in digital transformation.
人工智能安全是安全采用和部署人工智能系统的一个至关重要的新兴领域。随着人工智能的迅速普及,尤其是生成式人工智能(GAI)的最新发展,人工智能系统的设计、开发、采用和部署背后的技术生态系统发生了巨大变化,扩大了人工智能安全的范围,以解决对公共安全和国家安全的影响。在本文中,我们提出了一个理解和分析人工智能安全的新型架构框架,从可信人工智能、负责任的人工智能和安全人工智能三个角度定义其特点。我们从这些角度对人工智能安全方面的当前研究和进展进行了全面的回顾,突出了其主要挑战和缓解方法。通过尖端技术的例子,尤其是大型语言模型(LLM),我们展示了设计测试人工智能安全的创新机制、方法和技巧。我们的目标是推动人工智能安全研究的进步,并最终增强人们对数字转型的信任。
论文及项目相关链接
Summary
人工智能安全对于人工智能系统的安全采纳和部署至关重要。随着人工智能尤其是生成式人工智能的快速发展,人工智能系统的设计、开发、采纳和部署的技术生态系统发生了巨大变化,扩大了人工智能安全的范围以解决对公共安全和国家安全的影响。本文提出了一个全新的架构框架,从可信人工智能、负责任的人工智能和安全人工智能三个角度理解和分析人工智能安全的特点。本文全面回顾了当前的人工智能安全研究及进展,重点介绍了其关键挑战和缓解方法。通过最先进技术的例子,特别是大型语言模型,我们展示了设计测试人工智能安全性的创新机制、方法和技巧。我们的目标是推动人工智能安全研究的进步,最终增强人们对数字化转型的信任。
Key Takeaways
- AI安全对于AI系统的采纳和部署至关重要,特别是在生成式AI快速发展的背景下。
- AI安全范围扩大,涉及公共安全和国家安全。
- 提出了一个全新的架构框架,从可信AI、负责任的AI和安全AI三个角度理解和分析AI安全特点。
- 全面回顾了当前AI安全研究的进展,包括关键挑战和缓解方法。
- 通过大型语言模型的例子,展示了设计测试AI安全性的创新机制、方法和技巧。
- 目标是推动AI安全研究的进步。
点此查看论文截图

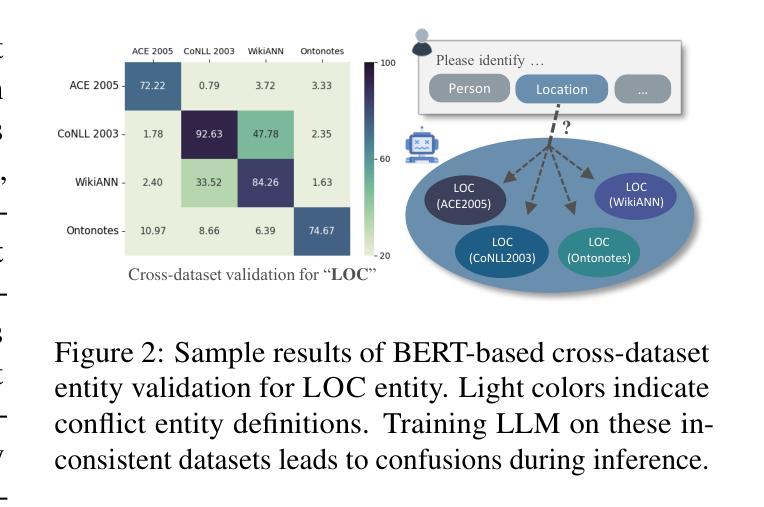
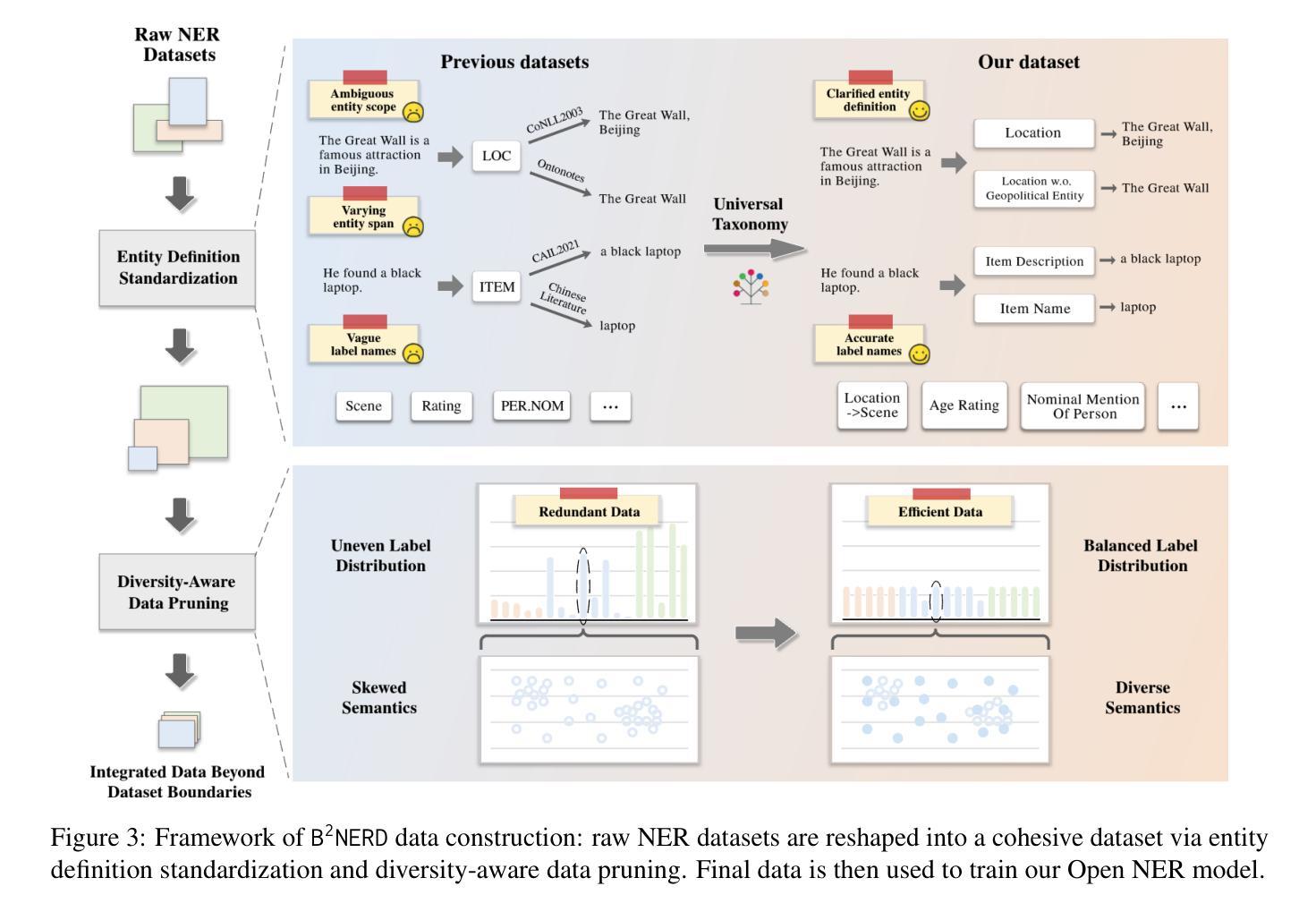
Beyond Boundaries: Learning a Universal Entity Taxonomy across Datasets and Languages for Open Named Entity Recognition
Authors:Yuming Yang, Wantong Zhao, Caishuang Huang, Junjie Ye, Xiao Wang, Huiyuan Zheng, Yang Nan, Yuran Wang, Xueying Xu, Kaixin Huang, Yunke Zhang, Tao Gui, Qi Zhang, Xuanjing Huang
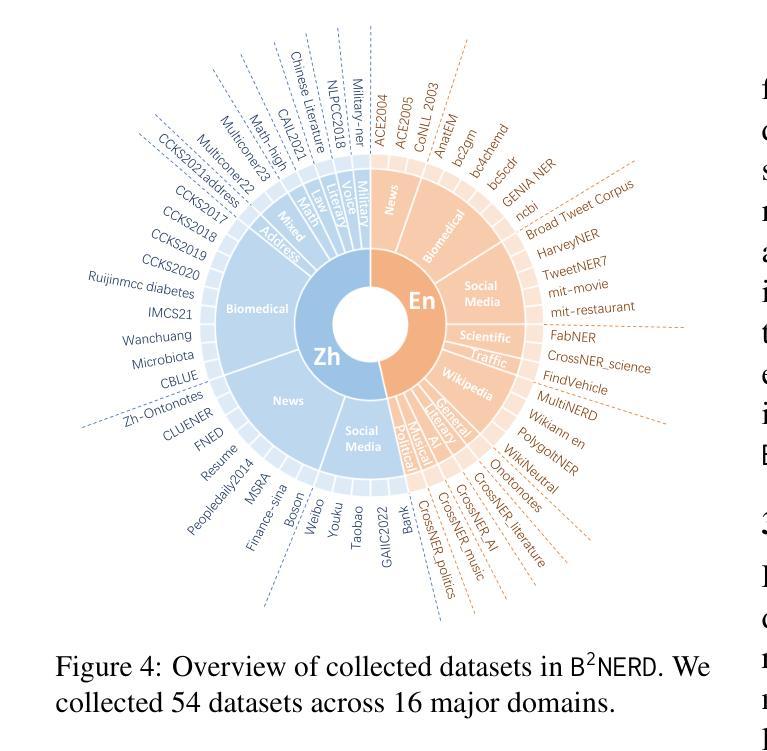
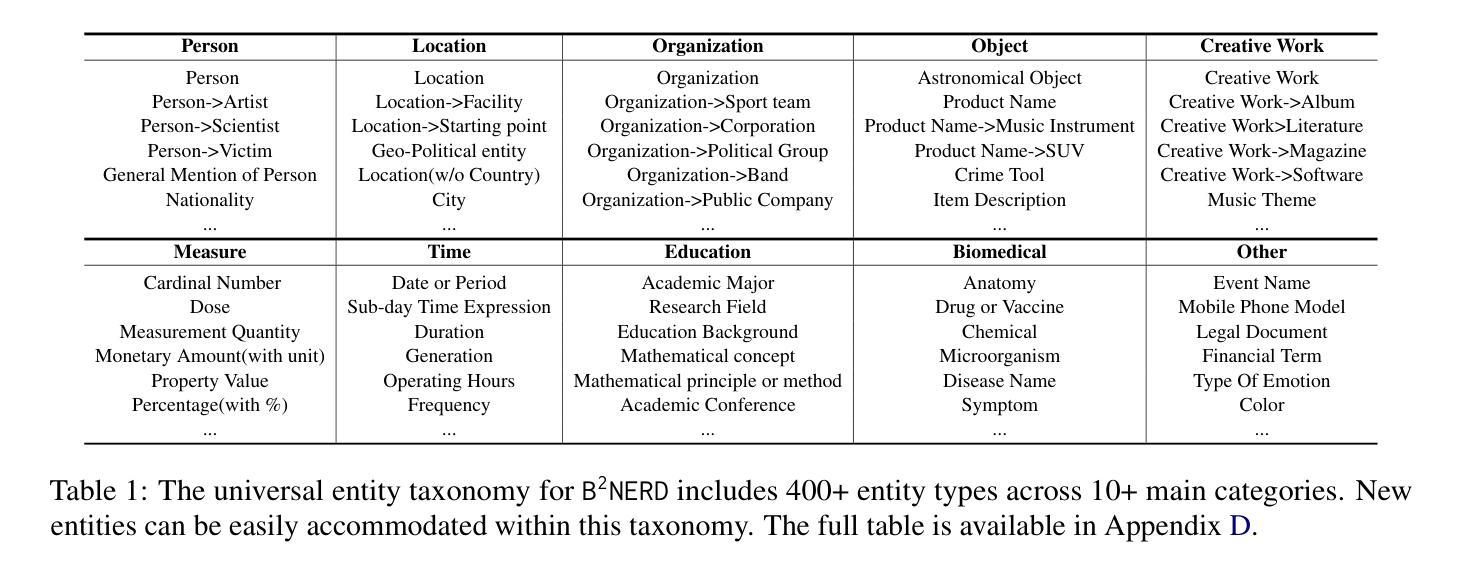
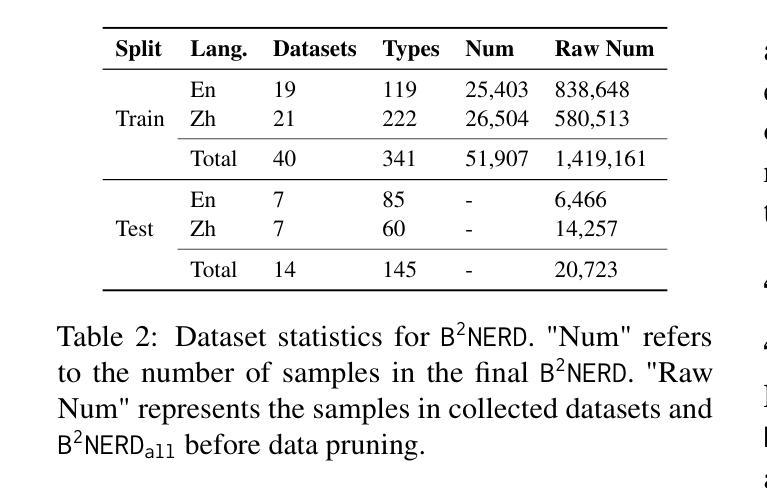
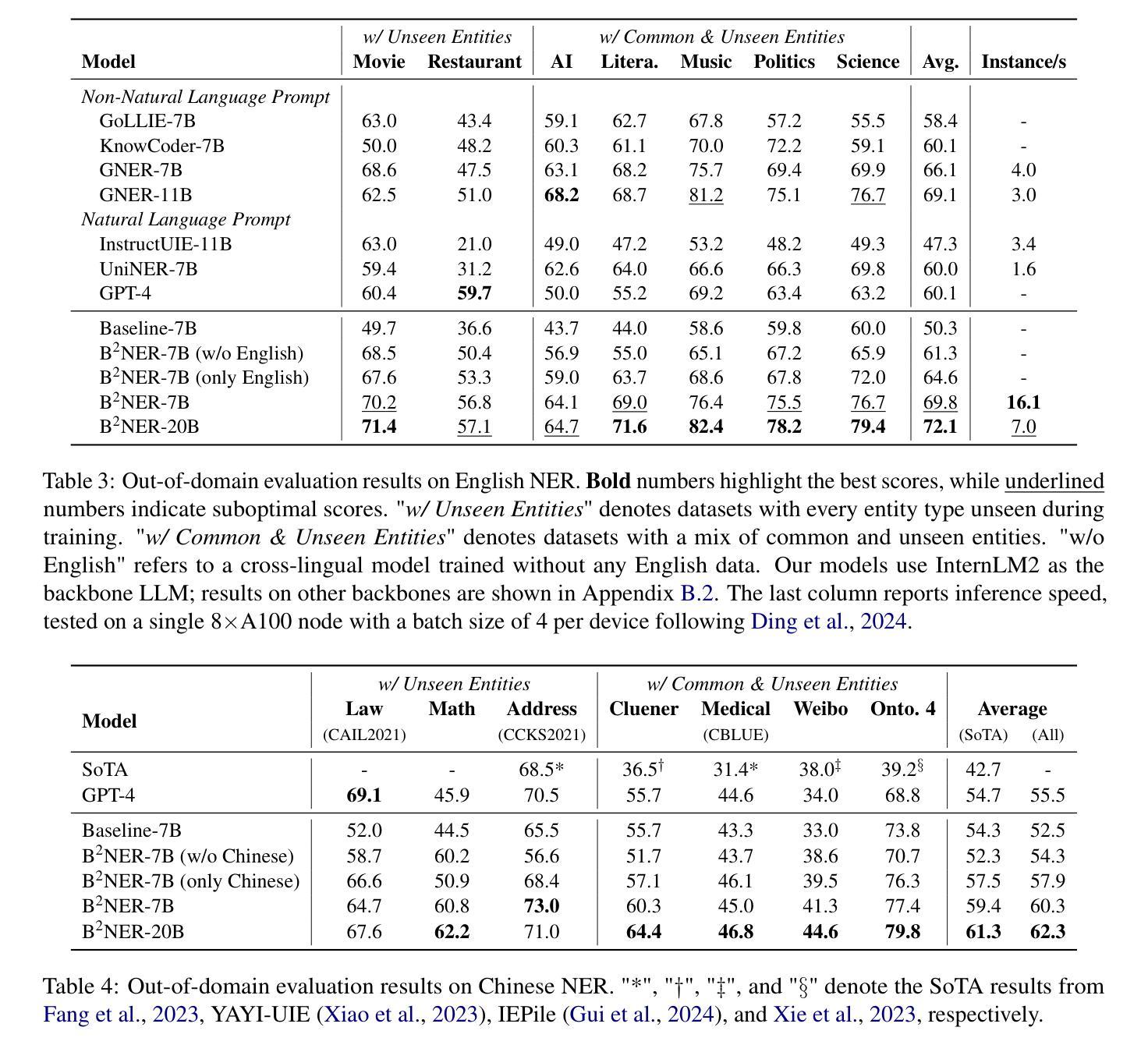
Open Named Entity Recognition (NER), which involves identifying arbitrary types of entities from arbitrary domains, remains challenging for Large Language Models (LLMs). Recent studies suggest that fine-tuning LLMs on extensive NER data can boost their performance. However, training directly on existing datasets neglects their inconsistent entity definitions and redundant data, limiting LLMs to dataset-specific learning and hindering out-of-domain adaptation. To address this, we present B2NERD, a compact dataset designed to guide LLMs’ generalization in Open NER under a universal entity taxonomy. B2NERD is refined from 54 existing English and Chinese datasets using a two-step process. First, we detect inconsistent entity definitions across datasets and clarify them by distinguishable label names to construct a universal taxonomy of 400+ entity types. Second, we address redundancy using a data pruning strategy that selects fewer samples with greater category and semantic diversity. Comprehensive evaluation shows that B2NERD significantly enhances LLMs’ Open NER capabilities. Our B2NER models, trained on B2NERD, outperform GPT-4 by 6.8-12.0 F1 points and surpass previous methods in 3 out-of-domain benchmarks across 15 datasets and 6 languages. The data, models, and code are publicly available at https://github.com/UmeanNever/B2NER.
开放命名实体识别(NER)仍然对大型语言模型(LLM)构成挑战,这涉及到从任意领域识别任意类型的实体。最近的研究表明,对LLM进行大规模的NER数据微调可以提高其性能。然而,直接在现有数据集上进行训练会忽略其不一致的实体定义和冗余数据,限制LLM在特定数据集上的学习,并阻碍其在域外的适应。为了解决这一问题,我们提出了B2NERD,这是一个紧凑的数据集,旨在在通用实体分类法下指导LLM在开放NER中的泛化能力。B2NERD是通过两步过程从现有的54个英文和中文数据集中提炼出来的。首先,我们检测数据集之间不一致的实体定义,并通过可区分的标签名称来澄清它们,以构建包含400多个实体类型的通用分类法。其次,我们通过数据修剪策略来解决冗余问题,选择具有更大类别和语义多样性的更少样本。综合评估表明,B2NERD显著提高了LLM的开放NER能力。我们的B2NER模型在B2NERD上的表现优于GPT-4 6.8至12.0 F1点,并在跨越15个数据集和6种语言的三个域外基准测试中超过了以前的方法。数据、模型和代码可在https://github.com/UmeanNever/B2NER上公开获得。
论文及项目相关链接
PDF Accepted at COLING 2025. Camera-ready version updated. Project page: https://github.com/UmeanNever/B2NER
Summary
该文本介绍了开放命名实体识别(Open NER)对大型语言模型(LLM)的挑战。为解决现有数据集的不一致实体定义和冗余数据问题,提出B2NERD数据集。通过构建通用实体分类法对LLM进行引导,提高其泛化能力。B2NERD数据集经过两步精炼而成,能显著提高LLM的开放NER性能。使用B2NERD训练的模型表现优于GPT-4和其他方法,在某些出域基准测试中表现尤为突出。
Key Takeaways
- 开放命名实体识别(Open NER)对大型语言模型(LLM)仍具挑战性。
- 现有数据集存在不一致的实体定义和冗余数据问题。
- B2NERD数据集旨在解决这些问题,通过构建通用实体分类法提高LLM的泛化能力。
- B2NERD数据集通过两步精炼而成,能有效提高LLM的开放NER性能。
- 使用B2NERD训练的模型表现优于GPT-4和其他方法。
- B2NERD数据集在多个出域基准测试中表现突出。
- B2NERD数据集、模型和代码已公开发布在GitHub上。
点此查看论文截图

Parallelizing Linear Transformers with the Delta Rule over Sequence Length
Authors:Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, Yoon Kim
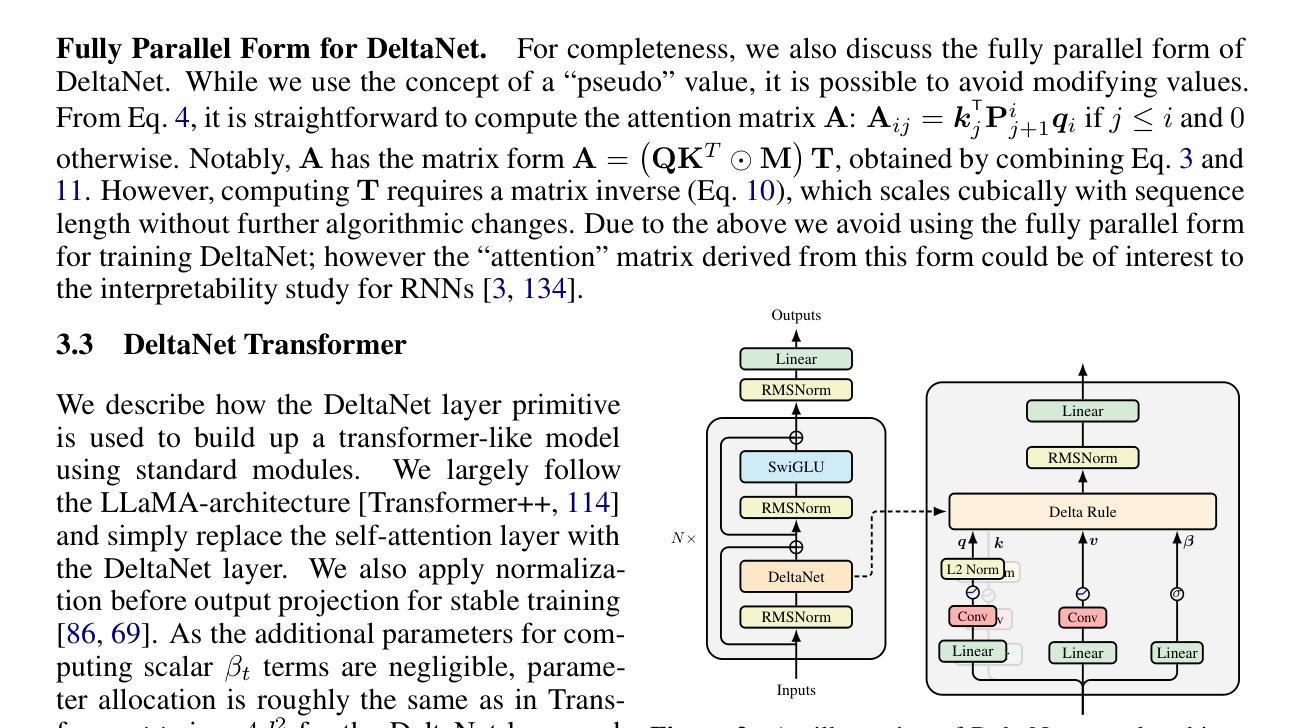
Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, these models still underperform transformers especially on tasks that require in-context retrieval. While more expressive variants of linear transformers which replace the additive update in linear transformers with the delta rule (DeltaNet) have been found to be more effective at associative recall, existing algorithms for training such models do not parallelize over sequence length and are thus inefficient to train on modern hardware. This work describes a hardware-efficient algorithm for training linear transformers with the delta rule, which exploits a memory-efficient representation for computing products of Householder matrices. This algorithm allows us to scale up DeltaNet to standard language modeling settings. We train a 1.3B model for 100B tokens and find that it outperforms recent linear-time baselines such as Mamba and GLA in terms of perplexity and zero-shot performance on downstream tasks. We also experiment with two hybrid models which combine DeltaNet layers with (1) sliding-window attention layers every other layer or (2) two global attention layers, and find that these hybrids outperform strong transformer baselines.
线性注意力Transformer(即线性Transformer)和状态空间模型最近被提议作为softmax注意力Transformer的线性时间替代方案。然而,这些模型在需要上下文检索的任务上仍然表现不佳。虽然发现用增量规则(DeltaNet)替代线性Transformer中的加法更新可以更有效地进行联想回忆,但现有训练此类模型的算法并不支持序列长度并行化,因此在现代硬件上进行训练的效率不高。本研究描述了一种用于训练具有增量规则的线性Transformer的高效硬件算法,该算法利用节省内存的表示形式来计算Householder矩阵的乘积。该算法使我们能够将DeltaNet扩展到标准语言建模设置。我们对一个规模为1.3B的模型进行了训练,针对总计约数十亿的符号进行了为期约数百亿的迭代更新处理次数进行更新,发现它在困惑度和下游任务的零样本性能方面都超过了最近的线性时间基线模型,如Mamba和GLA。我们还尝试了两个混合模型,这两个模型结合了DeltaNet层和(1)每隔一层采用滑动窗口注意力层或(2)两个全局注意力层,发现这些混合模型的表现优于强大的Transformer基线模型。
论文及项目相关链接
PDF Final camera ready
Summary
线性变压器与状态空间模型被视为softmax注意力变压器的线性时间替代方案。然而,在需要上下文检索的任务中,这些模型的表现仍不及传统变压器。研究发现,用DeltaNet替换线性变压器中的加法更新能提高其在联想回忆方面的表现。然而,现有训练此类模型的算法无法并行处理序列长度,因此在现代硬件上训练效率低下。本文介绍了一种训练DeltaNet的高效算法,利用计算Householder矩阵乘积的存储高效表示方法。通过该算法,我们能在标准语言建模环境中扩展DeltaNet的应用范围。经过在模型训练中运用大规模参数和数据标记的努力,其性能超过了许多主流的线性模型并展示了其对一系列下游任务的零样本性能。此外,结合DeltaNet层与滑动窗口注意力层或全局注意力层的混合模型表现更为出色,甚至超过了强大的传统变压器基线模型。
Key Takeaways
- 线性变压器和状态空间模型作为线性时间替代方案被提出。
- 这些模型在需要上下文检索的任务中表现较弱。
- DeltaNet通过替换线性变压器中的加法更新来提高表现。
- 现有训练算法在现代硬件上效率较低,无法并行处理序列长度。
- 本文提出一种硬件高效的算法训练DeltaNet,利用了计算Householder矩阵乘积的高效表示方法。
- DeltaNet的性能超过了主流的线性模型并展示了其对一系列下游任务的零样本性能。
点此查看论文截图

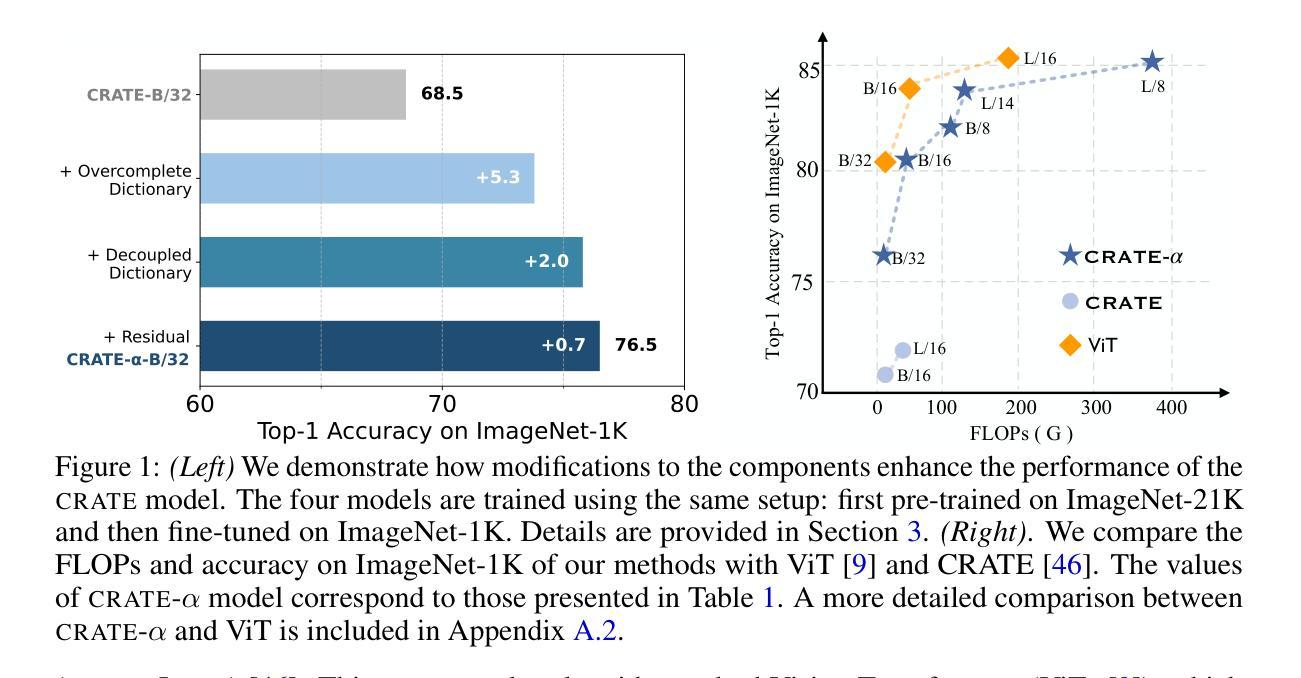
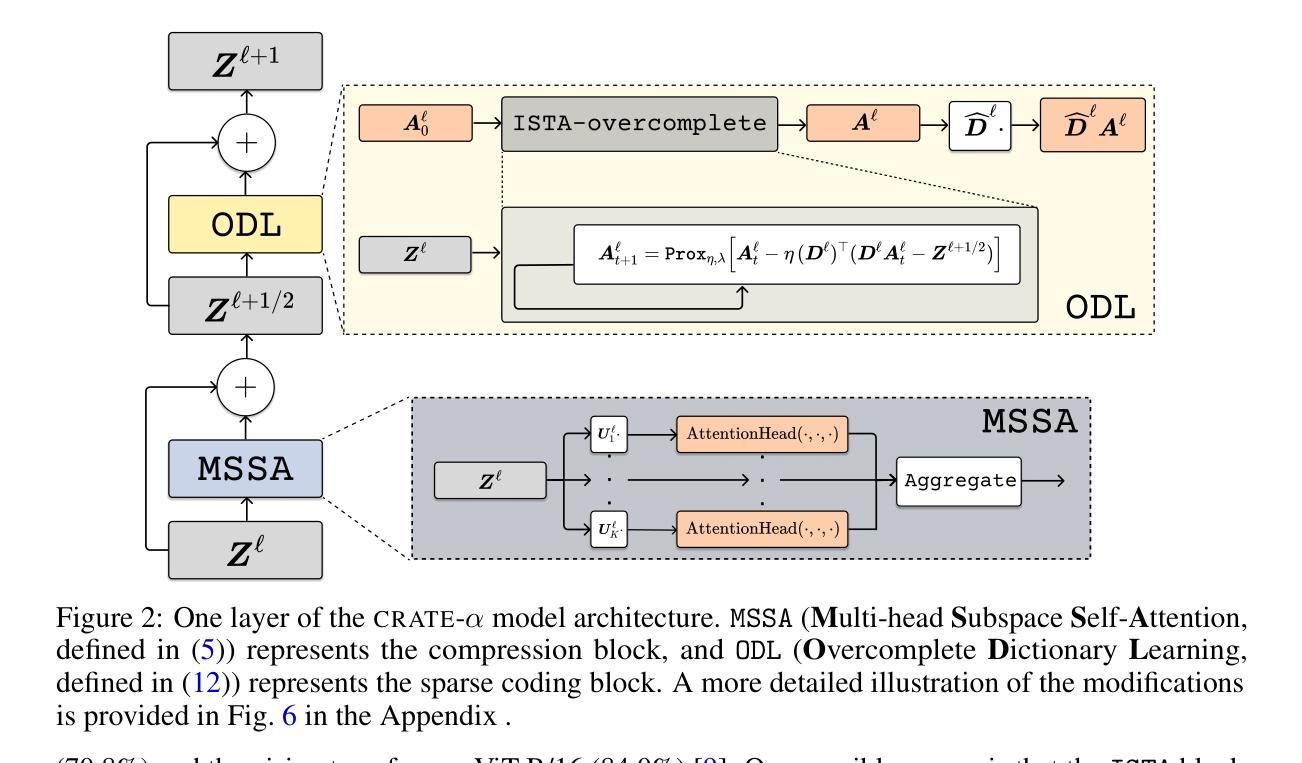
Scaling White-Box Transformers for Vision
Authors:Jinrui Yang, Xianhang Li, Druv Pai, Yuyin Zhou, Yi Ma, Yaodong Yu, Cihang Xie
CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$\alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$\alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$\alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$\alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$\alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
CRATE是一种白盒变压器架构,旨在学习压缩和稀疏表示,由于其固有的数学可解释性,它为标准视觉变压器(ViTs)提供了引人入胜的替代方案。尽管已经对语言和视觉变压器的规模行为进行了广泛的研究,但CRATE的可扩展性仍然是一个悬而未决的问题,本文旨在解决这个问题。具体来说,我们提出了CRATE-$\alpha$,它针对CRATE架构设计中的稀疏编码块进行了战略性的最小修改,并设计了一种轻量级的训练方案,以提高CRATE的可扩展性。通过大量实验,我们证明了CRATE-$\alpha$可以有效地适应更大的模型规模和数据集。例如,我们的CRATE-$\alpha$-B在ImageNet分类任务上的表现优于之前的最佳CRATE-B模型,准确率提高了3.7%,达到了83.2%的准确率。同时,当我们进一步扩大规模时,我们的CRATE-$\alpha$-L在ImageNet分类任务上达到了85.1%的准确率。更值得注意的是,这些模型性能的提升是在保持甚至提高CRATE模型的解释性的前提下实现的,我们通过展示越来越大、经过训练的CRATE-$\alpha$模型的学习令牌表示能带来图像的无监督对象分割的质量越来越高来证明这一点。项目页面为:[https://rayjryang.github.io/CRATE-alpha/] 。
论文及项目相关链接
PDF project page: https://rayjryang.github.io/CRATE-alpha/
摘要
CRATE作为一种白盒变压器架构,旨在学习压缩和稀疏表示,提供了一种引人注目的替代传统视觉变压器(ViTs)的选择,因其固有的数学可解释性。本文旨在解决CRATE可扩展性的问题,通过提出CRATE-$\alpha$,对CRATE架构设计中的稀疏编码块进行战略且轻微的修改,并设计了一种轻量级的训练策略。实验表明,CRATE-$\alpha$可以有效地随着模型尺寸和数据集的增大而扩展。例如,我们的CRATE-$\alpha$-B在ImageNet分类任务上显著优于之前的最佳CRATE-B模型,准确率提高3.7%,达到83.2%。更进一步扩展时,我们的CRATE-$\alpha$-L在ImageNet分类任务上达到85.1%的准确率。值得注意的是,这些模型性能的提升是在保持甚至提高CRATE模型的解释性下实现的,我们通过对越来越大训练的CRATE-$\alpha$模型的标记表示进行展示,这些表示越来越能无监督地精准分割图像。
关键见解
- CRATE作为一种白盒变压器架构,具有学习压缩和稀疏表示的能力,提供了一种替代传统视觉变压器(ViTs)的选择。
- 本文通过提出CRATE-$\alpha$,旨在解决CRATE的可扩展性问题,包括对稀疏编码块的战略修改和轻量级训练策略。
- CRATE-$\alpha$能够在模型尺寸和数据集增大的情况下有效扩展。
- CRATE-$\alpha$在ImageNet分类任务上较之前模型有显著提高,同时保持甚至提高模型的解释性。
- 训练的CRATE-$\alpha$模型的标记表示能够无监督地精准分割图像,这显示了其性能和功能的进一步提升。
- CRATE-$\alpha$的改进不仅仅是性能上的提升,也涉及模型的可解释性和功能的增强。
点此查看论文截图