⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
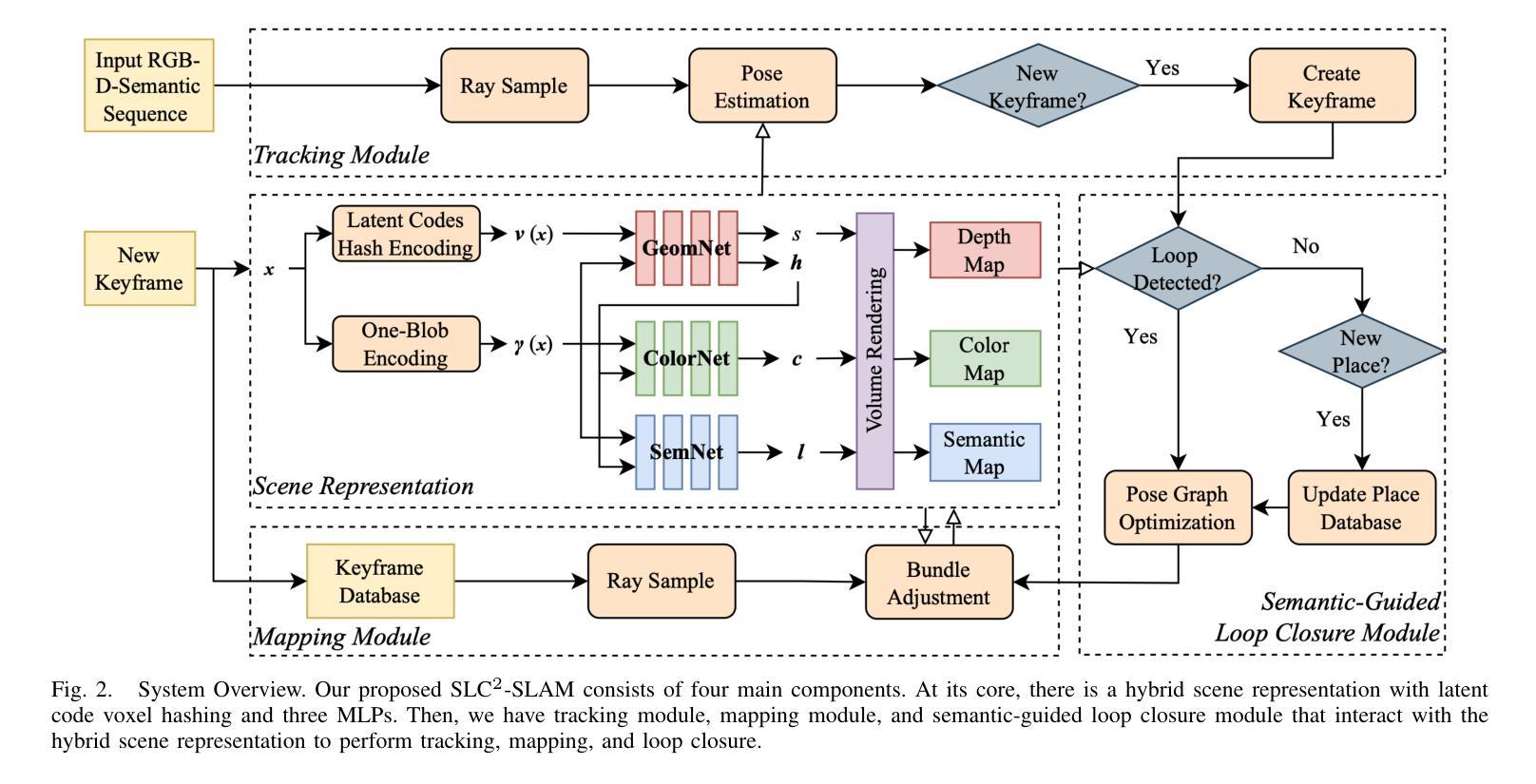
SLC$^2$-SLAM: Semantic-guided Loop Closure with Shared Latent Code for NeRF SLAM
Authors:Yuhang Ming, Di Ma, Weichen Dai, Han Yang, Rui Fan, Guofeng Zhang, Wanzeng Kong
Targeting the notorious cumulative drift errors in NeRF SLAM, we propose a Semantic-guided Loop Closure with Shared Latent Code, dubbed SLC$^2$-SLAM. Especially, we argue that latent codes stored in many NeRF SLAM systems are not fully exploited, as they are only used for better reconstruction. In this paper, we propose a simple yet effective way to detect potential loops using the same latent codes as local features. To further improve the loop detection performance, we use the semantic information, which are also decoded from the same latent codes to guide the aggregation of local features. Finally, with the potential loops detected, we close them with a graph optimization followed by bundle adjustment to refine both the estimated poses and the reconstructed scene. To evaluate the performance of our SLC$^2$-SLAM, we conduct extensive experiments on Replica and ScanNet datasets. Our proposed semantic-guided loop closure significantly outperforms the pre-trained NetVLAD and ORB combined with Bag-of-Words, which are used in all the other NeRF SLAM with loop closure. As a result, our SLC$^2$-SLAM also demonstrated better tracking and reconstruction performance, especially in larger scenes with more loops, like ScanNet.
针对NeRF SLAM中恶名昭彰的累积漂移误差,我们提出了一种语义引导的回环闭合方法,使用共享潜在代码,称为SLC$^2$-SLAM。尤其是,我们认为许多NeRF SLAM系统中存储的潜在代码尚未得到充分利用,因为它们仅用于更好的重建。在本文中,我们提出了一种简单而有效的方法,使用相同的局部特征潜在代码来检测潜在的回环。为了进一步提高回环检测性能,我们使用语义信息,这些信息也是从相同的潜在代码中解码出来的,用于引导局部特征的聚合。最后,通过检测到潜在的回环,我们使用图优化和后续捆绑调整来关闭它们,以优化估计的姿态和重建的场景。为了评估我们的SLC$^2$-SLAM的性能,我们在Replica和ScanNet数据集上进行了大量实验。我们提出的语义引导回环闭合方法显著优于其他NeRF SLAM中所使用的预训练NetVLAD和ORB与词袋组合的方法。因此,我们的SLC$^2$-SLAM还表现出了更好的跟踪和重建性能,特别是在具有更多回环的大型场景(例如ScanNet)中。
论文及项目相关链接
PDF 8 pages, 5 figures, 4 tables
摘要
针对NeRF SLAM中累积的漂移误差,我们提出了一种语义引导环路闭合算法,称为SLC$^2$-SLAM。我们认为现有NeRF SLAM系统中的潜在代码并未得到充分利用,仅限于用于重建。本文通过一种简单而有效的方法利用这些潜在代码作为局部特征来检测潜在环路。为了进一步提高环路检测性能,我们引入了语义信息,通过解码同一潜在代码来指导局部特征的聚合。最后,通过检测到的潜在环路进行图优化和捆绑调整,以优化估计姿态和重建场景。在Replica和ScanNet数据集上进行的实验表明,我们的SLC$^2$-SLAM语义引导环路闭合显著优于其他NeRF SLAM中的环路闭合方法(如预训练的NetVLAD和ORB结合Bag-of-Words)。因此,SLC$^2$-SLAM在大型场景中的跟踪和重建性能更佳,特别是在ScanNet等场景中有更多环路。
关键见解
- 针对NeRF SLAM中的累积漂移误差问题,提出了语义引导环路闭合算法SLC$^2$-SLAM。
- 利用NeRF SLAM系统中的潜在代码进行环路检测,该方法简单有效。
- 通过解码同一潜在代码引入语义信息,以指导局部特征的聚合,提高了环路检测性能。
- 通过图优化和捆绑调整来优化估计姿态和重建场景。
- 在多个数据集上进行了广泛实验验证,证明SLC$^2$-SLAM显著优于其他NeRF SLAM中的环路闭合方法。
- 在大型场景中表现更好,特别是在有更多环路的场景中表现更佳。
点此查看论文截图

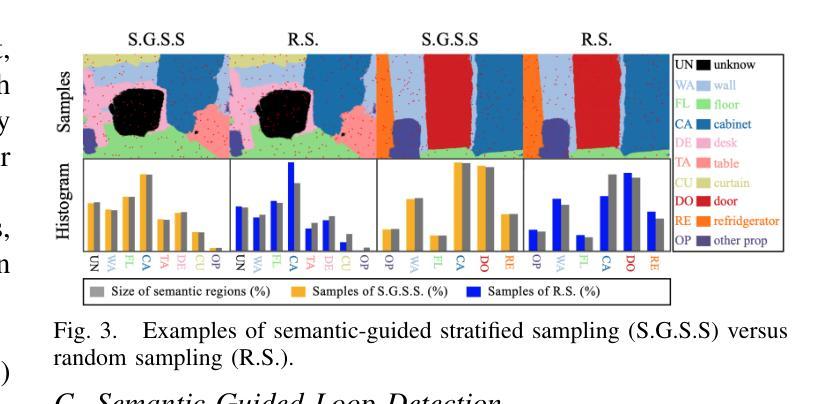
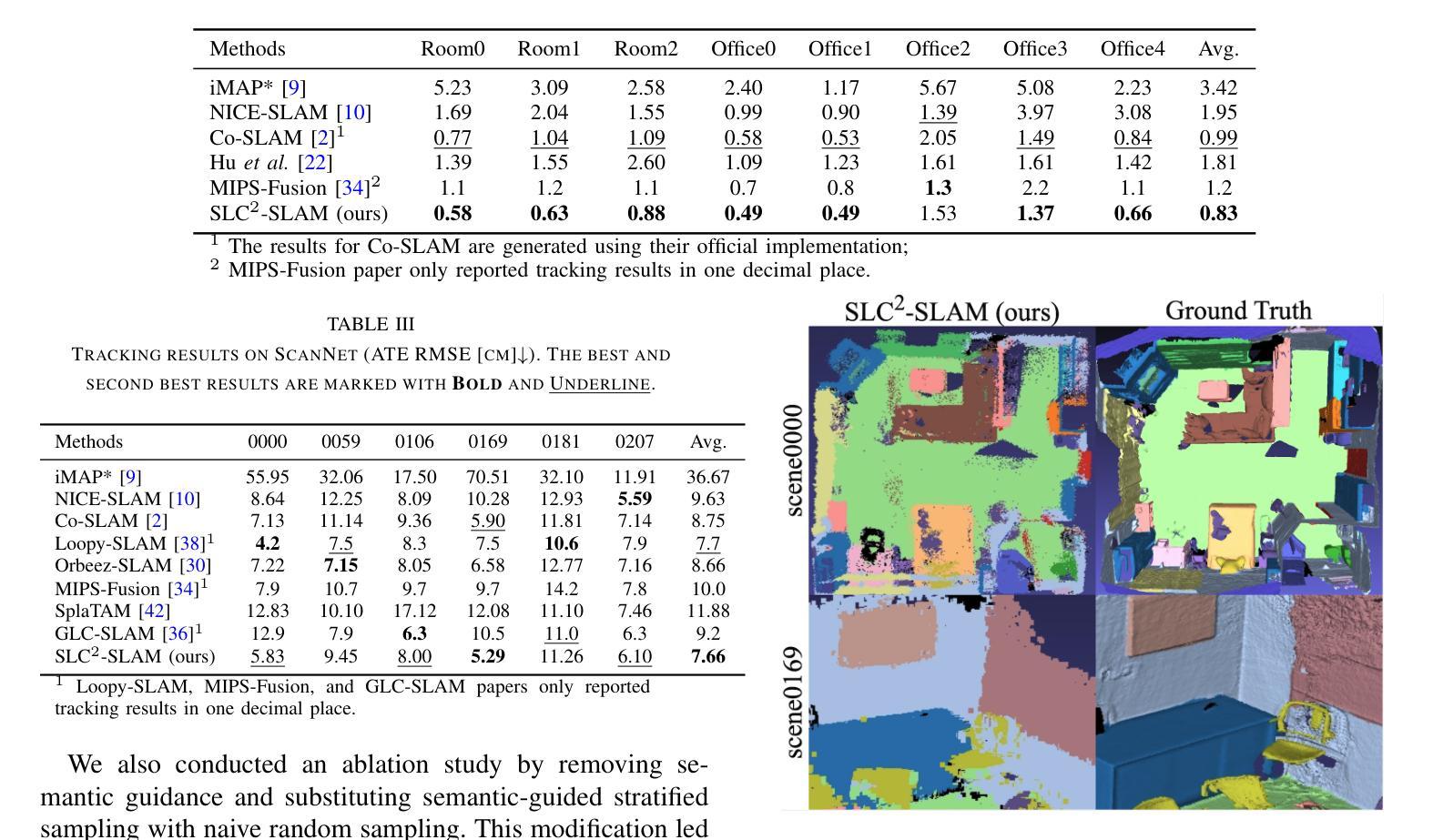
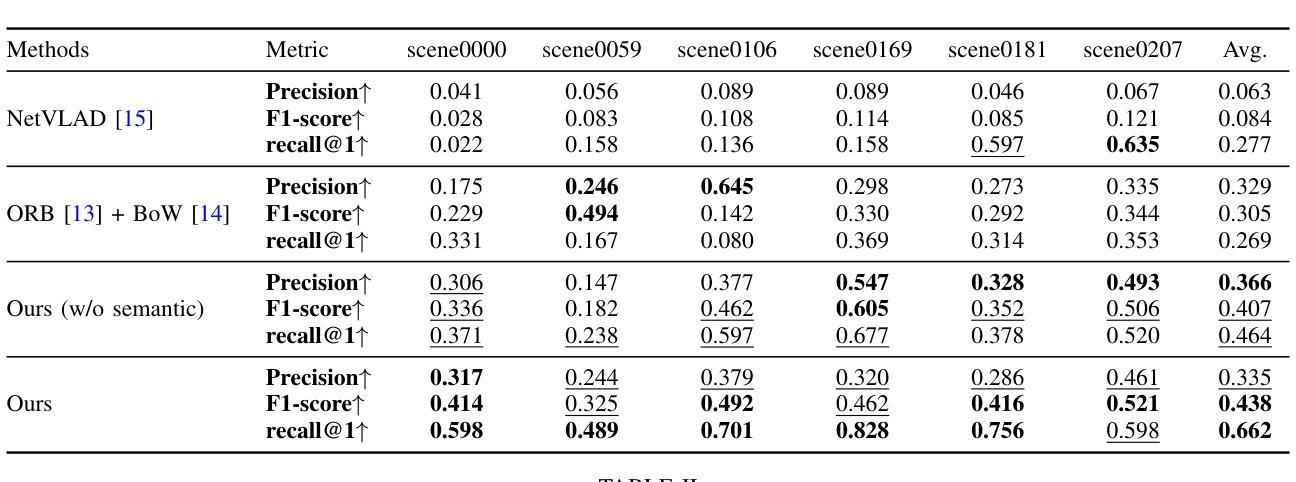
SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Authors:Yue Hu, Rong Liu, Meida Chen, Peter Beerel, Andrew Feng
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM’s dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
从单目视频中实现高保真3D重建仍然是一个挑战,这主要是由于传统方法(如结构从运动(SfM)和单目SLAM)在准确捕捉场景细节方面的固有局限性。虽然神经辐射场(NeRF)等可微分渲染技术解决了其中的一些挑战,但它们的高计算成本使它们不适合实时应用。此外,现有的3D高斯平铺(3DGS)方法通常侧重于光度一致性,忽视了几何精度,并且未能利用SLAM的动态深度和姿态更新来进行场景细化。我们提出了一种结合密集SLAM和3DGS的实时高保真密集重建框架。我们的方法引入了SLAM信息自适应细化,通过利用SLAM的密集点云来动态更新和细化高斯模型。此外,我们结合了几何引导优化,它结合了边缘感知几何约束和光度一致性,以联合优化3DGS场景表示的外观和几何形状,从而实现详细而准确的SLAM映射重建。在Replica和TUM-RGBD数据集上的实验证明了我们的方法的有效性,在单目系统中实现了最先进的成果。具体来说,我们的方法在Replica上实现了PSNR为36.864,SSIM为0.985,LPIPS为0.040的成绩,分别比之前的最佳成绩提高了10.7%、6.4%和49.4%。在TUM-RGBD上,我们的方法在相同的指标上比最接近的基线高出10.2%、6.6%和34.7%。这些结果突显了我们的框架在桥接光度学和几何学密集3D场景表示之间的鸿沟方面的潜力,为实用和高效的单目密集重建铺平了道路。
论文及项目相关链接
摘要
针对从单目视频中实现高保真3D重建的问题,传统方法如结构从运动(SfM)和单目SLAM在捕捉场景细节方面存在局限性。虽然神经辐射场(NeRF)等可微分渲染技术解决了部分挑战,但其高计算成本使其不适合实时应用。现有3D高斯贴图(3DGS)方法常注重光度一致性,忽视几何精度,未能利用SLAM的动态深度和姿态更新进行场景优化。为此,我们提出了一种整合密集SLAM与3DGS的实时高保真密集重建框架。该方法引入SLAM信息自适应细化,利用SLAM的密集点云动态更新和优化高斯模型。同时,结合几何引导优化,通过边缘感知几何约束和光度一致性联合优化3DGS场景表示的外观和几何,实现详细准确的SLAM映射重建。在Replica和TUM-RGBD数据集上的实验表明,该方法在单目系统中取得了最新效果。具体而言,我们的方法在Replica上的PSNR达到36.864,SSIM为0.985,LPIPS为0.040,相较于之前的最优方案分别提高了10.7%、6.4%和49.4%。在TUM-RGBD上,我们的方法在同一指标上比最接近的基线高出10.2%、6.6%和34.7%。结果证明,我们的框架在桥接光度与几何密集3D场景表示方面的潜力,为实用高效的单目密集重建铺平了道路。
关键见解
- 传统方法如SfM和单目SLAM在捕捉场景细节方面存在局限。
- NeRF等可微分渲染技术虽能解决部分挑战,但计算成本高,不适合实时应用。
- 现有3DGS方法注重光度一致性,忽视几何精度和SLAM的动态深度及姿态更新。
- 提出的框架整合密集SLAM与3DGS,实现实时高保真密集重建。
- 引入SLAM信息自适应细化,利用SLAM的密集点云优化高斯模型。
- 结合几何引导优化,通过边缘感知几何约束和光度一致性联合优化场景表示。
点此查看论文截图



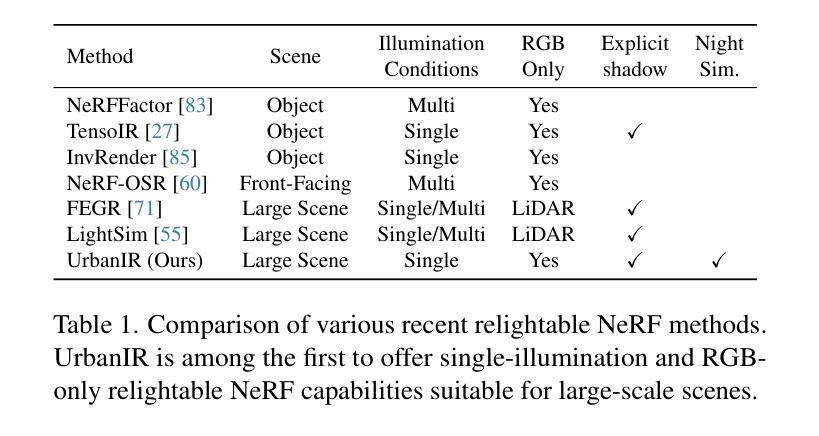
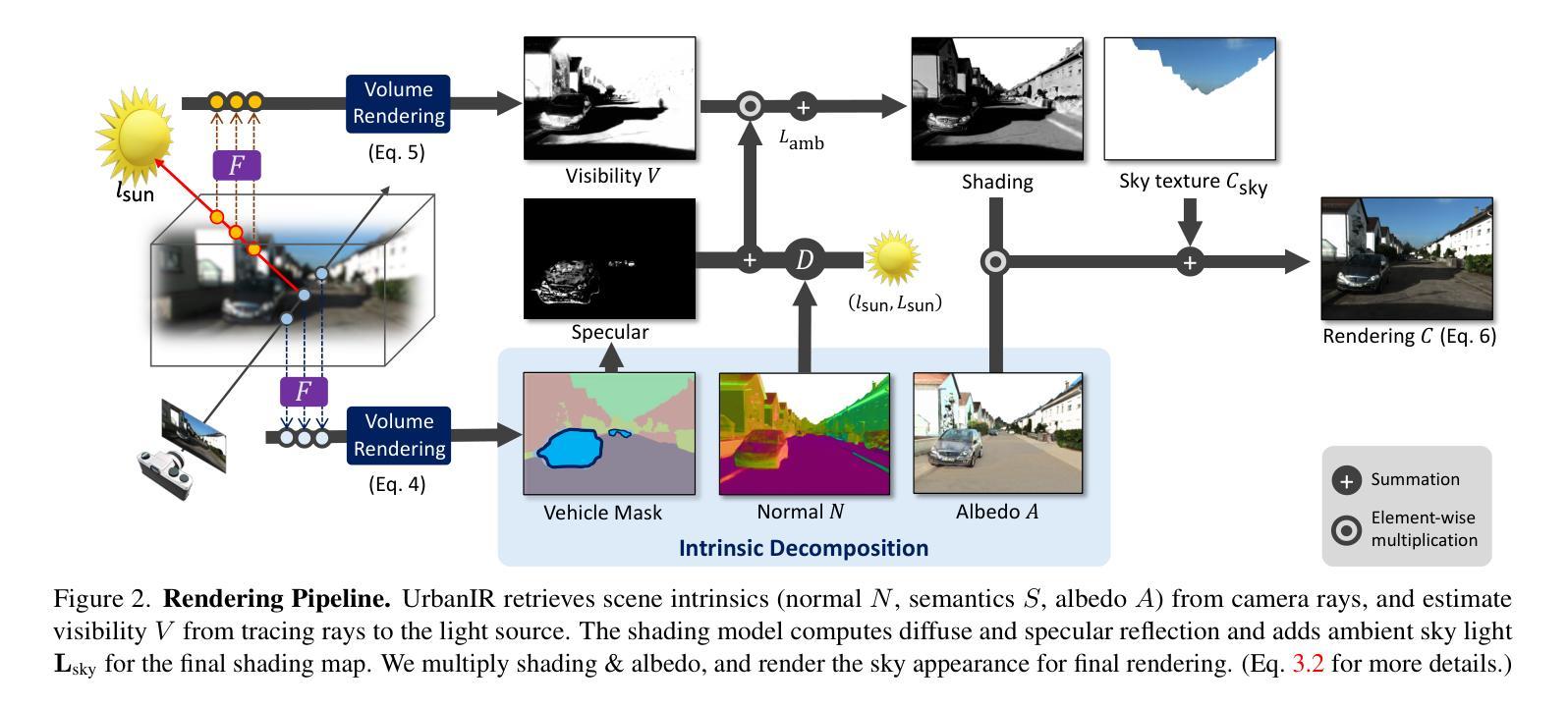
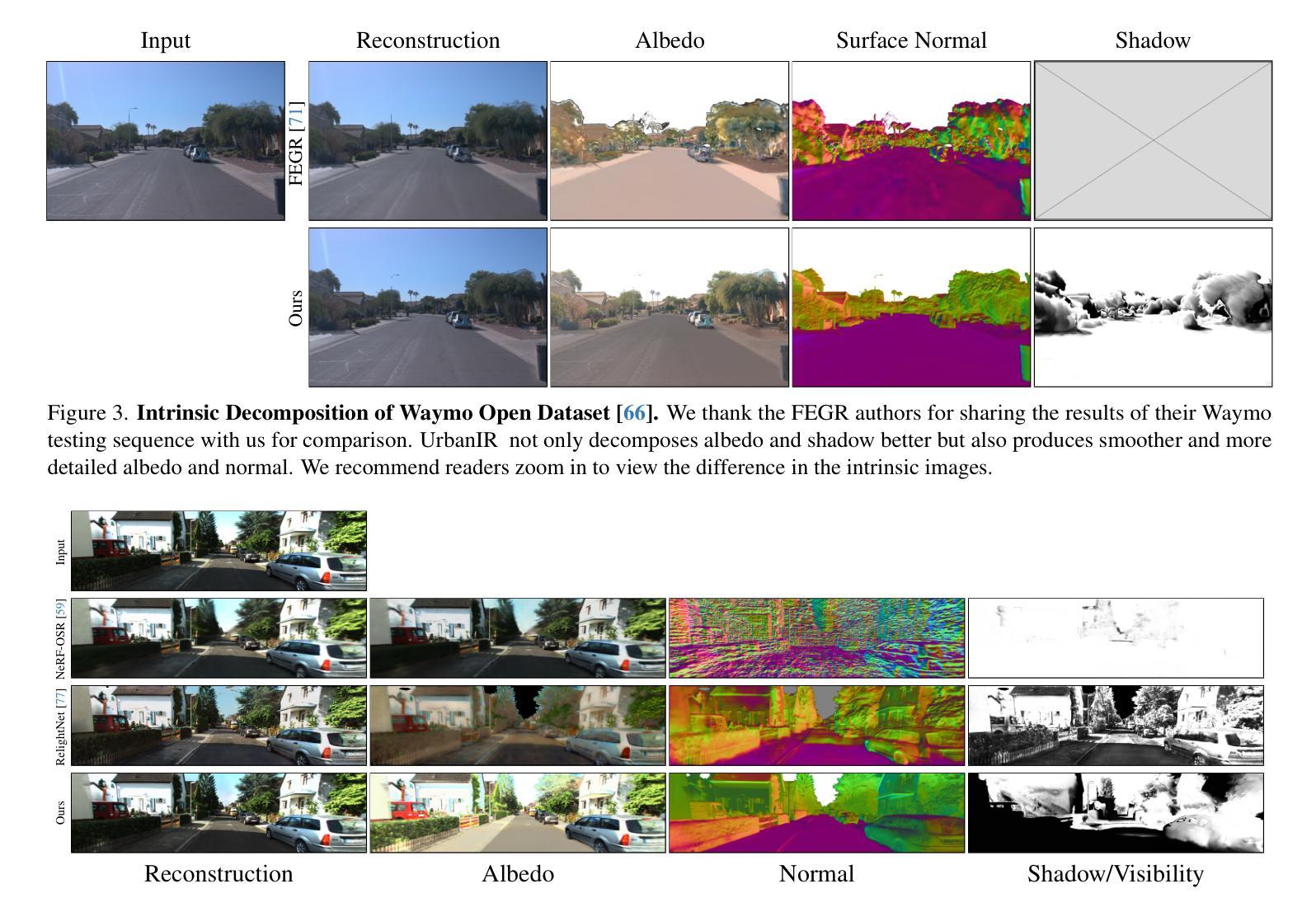
UrbanIR: Large-Scale Urban Scene Inverse Rendering from a Single Video
Authors:Chih-Hao Lin, Bohan Liu, Yi-Ting Chen, Kuan-Sheng Chen, David Forsyth, Jia-Bin Huang, Anand Bhattad, Shenlong Wang
We present UrbanIR (Urban Scene Inverse Rendering), a new inverse graphics model that enables realistic, free-viewpoint renderings of scenes under various lighting conditions with a single video. It accurately infers shape, albedo, visibility, and sun and sky illumination from wide-baseline videos, such as those from car-mounted cameras, differing from NeRF’s dense view settings. In this context, standard methods often yield subpar geometry and material estimates, such as inaccurate roof representations and numerous ‘floaters’. UrbanIR addresses these issues with novel losses that reduce errors in inverse graphics inference and rendering artifacts. Its techniques allow for precise shadow volume estimation in the original scene. The model’s outputs support controllable editing, enabling photorealistic free-viewpoint renderings of night simulations, relit scenes, and inserted objects, marking a significant improvement over existing state-of-the-art methods.
我们提出了UrbanIR(城市场景逆向渲染),这是一种新的逆向图形模型,它可以通过单个视频实现在各种光照条件下的真实、自由视角的场景渲染。它可以从宽基线视频(如车载摄像头拍摄的视频)准确推断出形状、材质反射率、可见性以及太阳和天空的照明情况,这与NeRF的密集视图设置不同。在这种情况下,标准方法通常会产生较差的几何和材料估算,例如不准确屋顶表示和许多“浮动”物体。UrbanIR通过新颖的损耗函数来解决这些问题,减少了逆向图形推理和渲染中的误差。其技术允许对原始场景进行精确的阴影体积估算。该模型的输出支持可控编辑,能够实现真实感的夜间模拟、重新照明的场景和插入物体的自由视角渲染,标志着对现有最先进的方法的重大改进。
论文及项目相关链接
PDF https://urbaninverserendering.github.io/
Summary
UrbanIR(城市场景逆向渲染)是一种新型逆向图形模型,通过单个视频实现各种光照条件下的真实感自由视角渲染。它从广角基线视频准确推断场景的形状、材质、可见性以及日光和天空照明,不同于NeRF的密集视图设置。UrbanIR采用新型损失函数,减少逆向图形推断和渲染误差,能精确估计原始场景的阴影体积。该模型支持可控编辑,可生成夜模拟、重新照明场景和插入物体的真实感自由视角渲染,标志着对现有前沿技术的显著改进。
Key Takeaways
- UrbanIR是一种逆向渲染模型,适用于城市场景。
- 它能够从单个广角基线视频推断场景信息。
- UrbanIR与NeRF不同,不需要密集视图设置。
- 通过新型损失函数,UrbanIR提高了逆向图形推断和渲染的准确性。
- 该模型能精确估计原始场景的阴影体积。
- 支持可控编辑,可生成夜模拟、重新照明场景和插入物体的真实感渲染。
点此查看论文截图