⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
Subject Disentanglement Neural Network for Speech Envelope Reconstruction from EEG
Authors:Li Zhang, Jiyao Liu
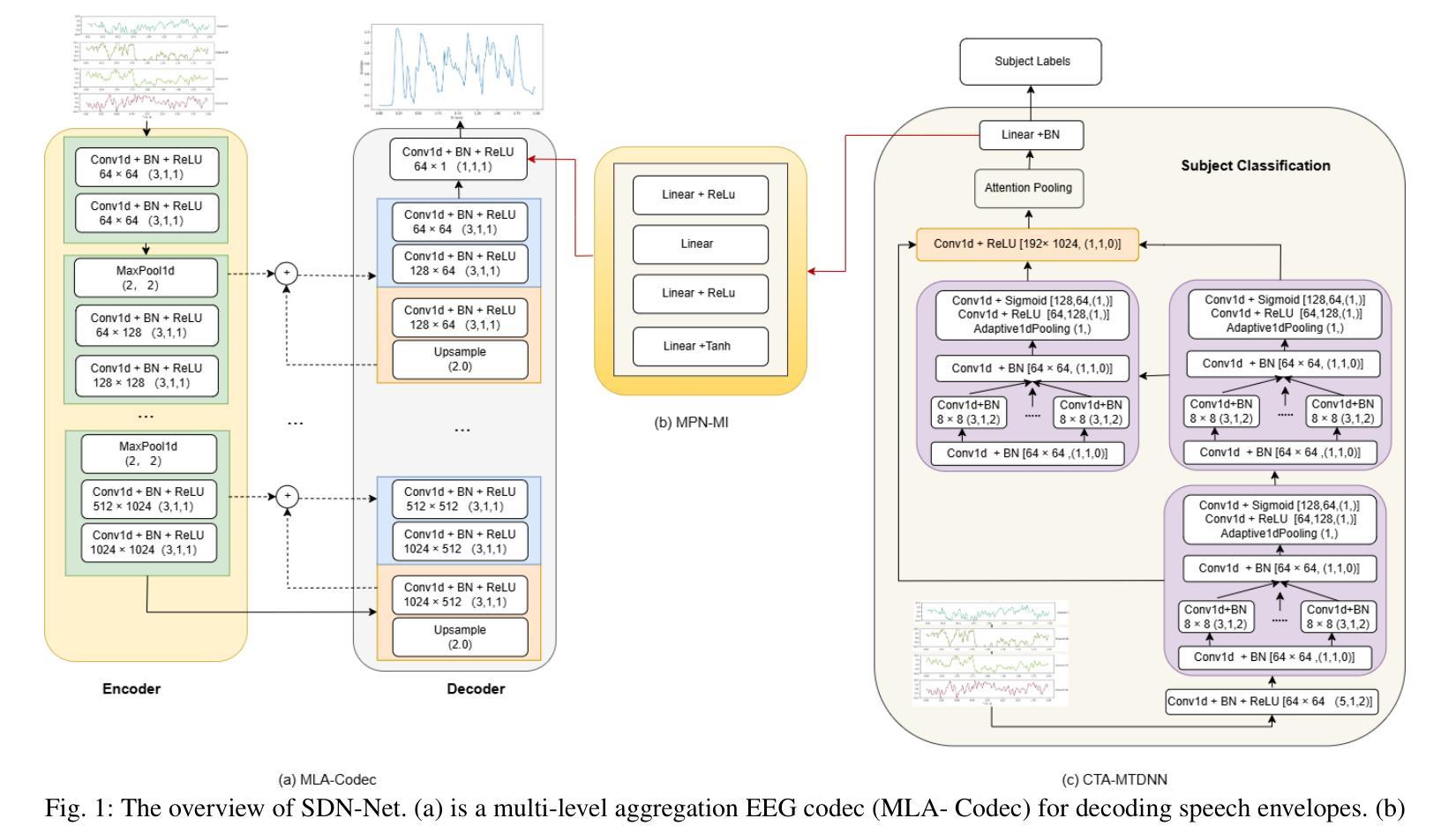
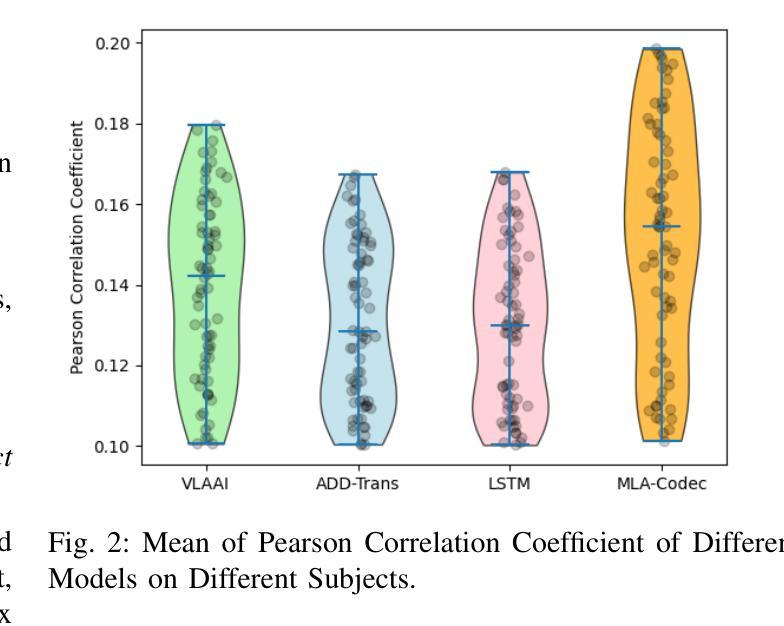
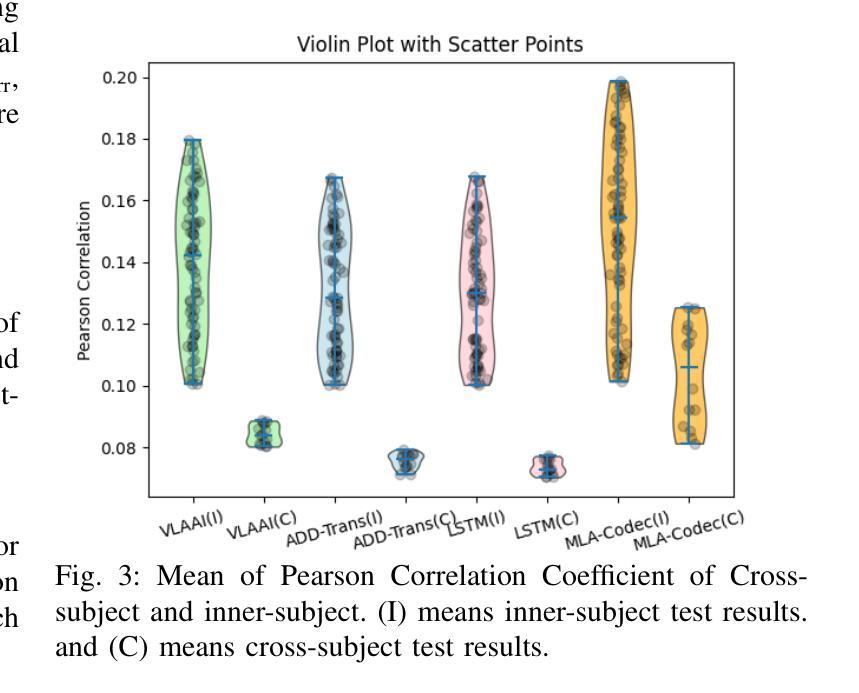
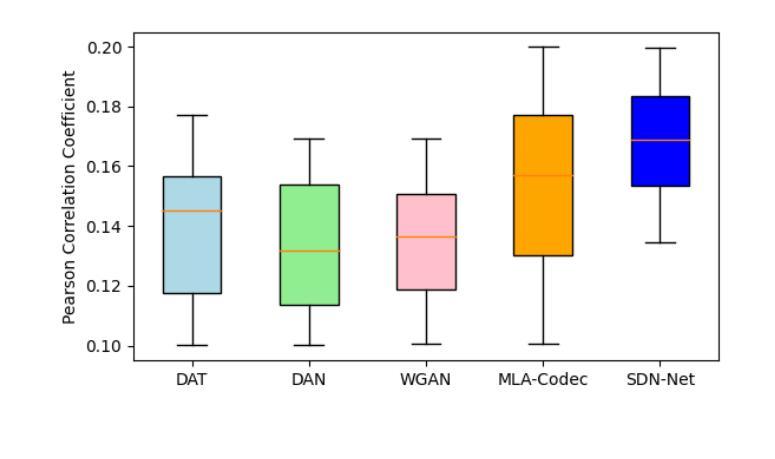
Reconstructing speech envelopes from EEG signals is essential for exploring neural mechanisms underlying speech perception. Yet, EEG variability across subjects and physiological artifacts complicate accurate reconstruction. To address this problem, we introduce Subject Disentangling Neural Network (SDN-Net), which disentangles subject identity information from reconstructed speech envelopes to enhance cross-subject reconstruction accuracy. SDN-Net integrates three key components: MLA-Codec, MPN-MI, and CTA-MTDNN. The MLA-Codec, a fully convolutional neural network, decodes EEG signals into speech envelopes. The CTA-MTDNN module, a multi-scale time-delay neural network with channel and temporal attention, extracts subject identity features from EEG signals. Lastly, the MPN-MI module, a mutual information estimator with a multi-layer perceptron, supervises the removal of subject identity information from the reconstructed speech envelope. Experiments on the Auditory EEG Decoding Dataset demonstrate that SDN-Net achieves superior performance in inner- and cross-subject speech envelope reconstruction compared to recent state-of-the-art methods.
从脑电图信号重建语音包络对于探索语音感知的神经网络机制至关重要。然而,受试者之间的脑电图变异和生理伪迹使准确重建变得复杂。为了解决这个问题,我们引入了主体分离神经网络(SDN-Net),该网络可以从重建的语音包络中分离出主体身份信息,以提高跨主体重建的准确性。SDN-Net集成了三个关键组件:MLA-Codec、MPN-MI和CTA-MTDNN。MLA-Codec是一个全卷积神经网络,可将脑电图信号解码为语音包络。CTA-MTDNN模块是一个具有通道和时间注意力的多尺度时延神经网络,从脑电图信号中提取主体身份特征。最后,MPN-MI模块是一个多层感知机的互信息估计器,负责监督从重建的语音包络中去除主体身份信息。在听觉脑电图解码数据集上的实验表明,与最新的先进方法相比,SDN-Net在内部和跨主体语音包络重建方面实现了卓越的性能。
论文及项目相关链接
Summary
基于脑电图信号重构语音包络对于探索语音感知的神经网络机制至关重要。为解决受试者间脑电图信号的差异和生理噪声对准确重构的影响,我们引入了主体分离神经网络(SDN-Net)。它通过从重构的语音包络中分离出主体身份信息,提高了跨主体重构的准确性。SDN-Net集成了MLA-Codec、MPN-MI和CTA-MTDNN三个关键组件。实验证明,在听觉脑电图解码数据集上,SDN-Net相较于最新的先进方法,在个体内和跨个体的语音包络重构性能上实现了优越的表现。
Key Takeaways
- 语音包络重构对探索语音感知的神经网络机制至关重要。
- EEG信号的个体差异和生理噪声会影响语音包络重构的准确性。
- 引入主体分离神经网络(SDN-Net)以提高跨主体重构的准确性。
- SDN-Net集成了MLA-Codec、MPN-MI和CTA-MTDNN三个关键组件。
- MLA-Codec是一个全卷积神经网络,能将EEG信号解码为语音包络。
- CTA-MTDNN模块从EEG信号中提取主体特征。
- MPN-MI模块通过多层感知器估计互信息,监督从重构的语音包络中移除主体身份信息。
点此查看论文截图


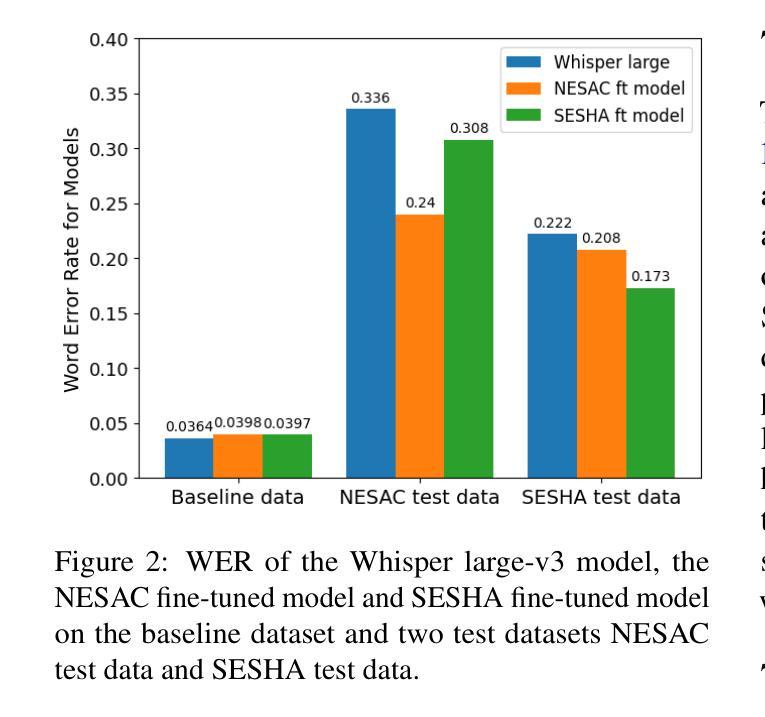
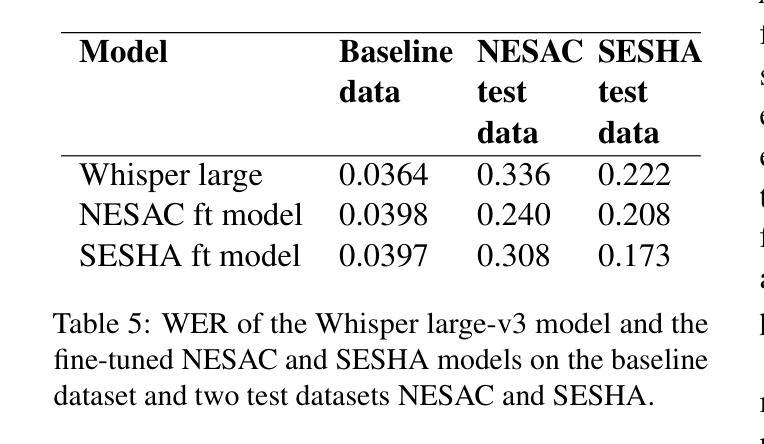
Adapting Whisper for Regional Dialects: Enhancing Public Services for Vulnerable Populations in the United Kingdom
Authors:Melissa Torgbi, Andrew Clayman, Jordan J. Speight, Harish Tayyar Madabushi
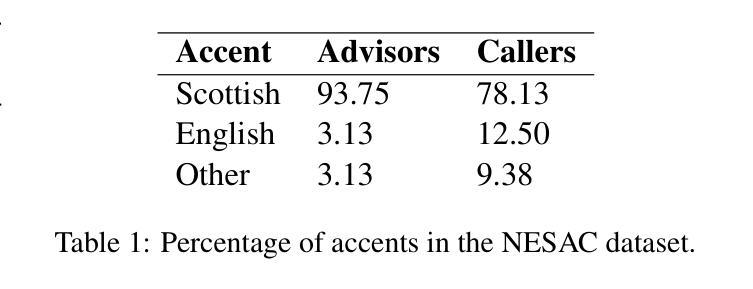
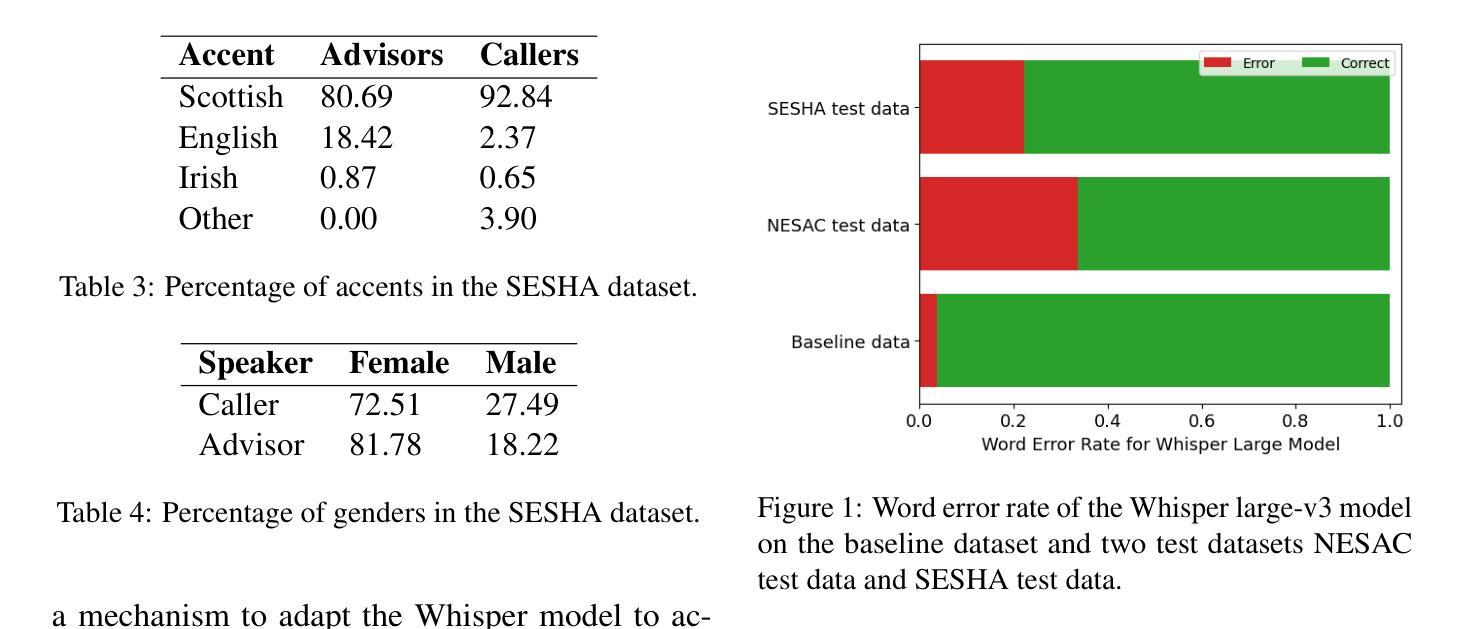
We collect novel data in the public service domain to evaluate the capability of the state-of-the-art automatic speech recognition (ASR) models in capturing regional differences in accents in the United Kingdom (UK), specifically focusing on two accents from Scotland with distinct dialects. This study addresses real-world problems where biased ASR models can lead to miscommunication in public services, disadvantaging individuals with regional accents particularly those in vulnerable populations. We first examine the out-of-the-box performance of the Whisper large-v3 model on a baseline dataset and our data. We then explore the impact of fine-tuning Whisper on the performance in the two UK regions and investigate the effectiveness of existing model evaluation techniques for our real-world application through manual inspection of model errors. We observe that the Whisper model has a higher word error rate (WER) on our test datasets compared to the baseline data and fine-tuning on a given data improves performance on the test dataset with the same domain and accent. The fine-tuned models also appear to show improved performance when applied to the test data outside of the region it was trained on suggesting that fine-tuned models may be transferable within parts of the UK. Our manual analysis of model outputs reveals the benefits and drawbacks of using WER as an evaluation metric and fine-tuning to adapt to regional dialects.
我们收集公共服务领域的新数据,以评估最新自动语音识别(ASR)模型捕捉英国区域口音差异的能力,特别是重点关注苏格兰两种带有明显方言的口音。本研究解决现实世界中的问题,即存在偏见的ASR模型可能导致公共服务中的沟通障碍,尤其对具有区域口音的个人以及弱势群体不利。我们首先检查Whisper large-v3模型在基准数据集和我们数据上的开箱性能。然后,我们探索对Whisper进行微调对这两个英国地区性能的影响,并通过手动检查模型错误,调查现有模型评估技术在我们现实应用中的有效性。我们发现,与基准数据相比,Whisper模型在我们的测试数据集上的单词错误率(WER)更高,针对给定数据的微调可以改善具有相同领域和口音的测试数据集的性能。经过微调的模型在应用于训练区域外的测试数据时似乎也表现出更好的性能,这表明经过微调的模型可能在英国的某些地区具有可转移性。我们对模型输出的手动分析揭示了使用WER作为评估指标的利弊,以及微调以适应区域方言的适应性。
论文及项目相关链接
Summary:
本研究收集公共服务领域的新数据,评估当前自动语音识别(ASR)模型捕捉英国区域口音差异的能力,重点关注苏格兰两种具有明显方言特点的口音。研究解决现实问题,即带有偏见的ASR模型可能导致公共服务中的沟通障碍,对具有区域口音的个人尤其是弱势群体造成不利影响。研究发现,在未进行微调的情况下,Whisper大型V3模型在基准数据集和本研究数据集上的表现欠佳,对特定口音的识别存在较高词错误率(WER)。通过对模型进行微调并手动检查模型错误,发现微调后的模型在同一领域和口音的测试数据集上的表现有所提升,并且在非训练区域的测试数据上也有较好的表现,这表明微调后的模型在英国内部具有一定的可迁移性。此外,本研究还对使用WER作为评估指标和通过微调适应方言的利弊进行了分析。
Key Takeaways:
- 本研究关注ASR模型在捕捉英国区域口音差异方面的能力,特别是苏格兰的两种方言。
- 发现未调校的Whisper大型V3模型在特定口音识别上存在较高词错误率(WER)。
- 通过对模型进行微调,可提高模型在特定领域和口音测试数据集上的表现。
- 微调后的模型在非训练区域的测试数据上也有较好的表现,具有一定的可迁移性。
- 手动分析揭示了使用WER作为评估指标的利弊。
- 研究强调了解决ASR模型偏见问题的必要性,以避免公共服务中的沟通障碍。
点此查看论文截图



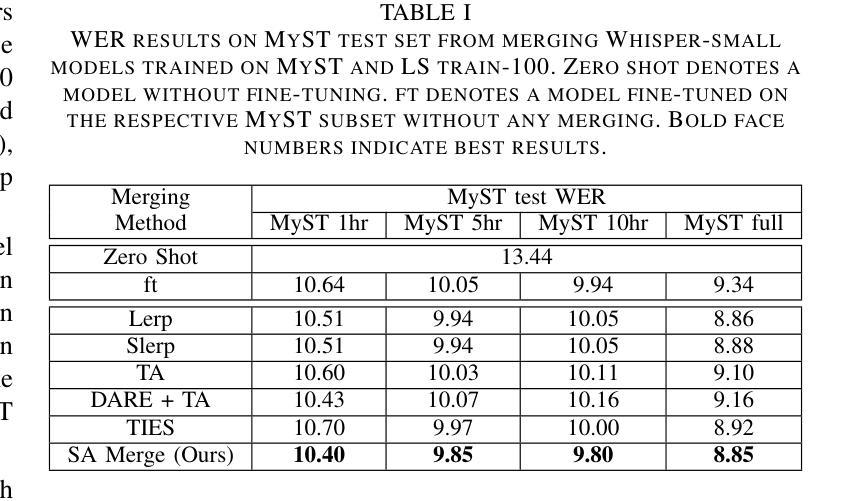
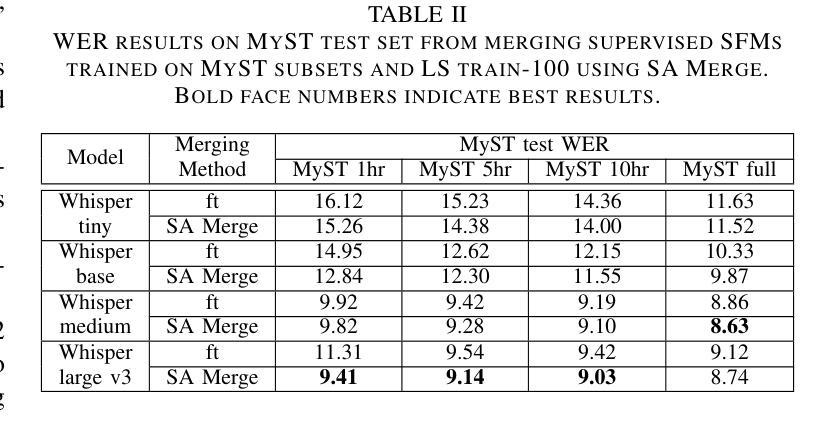
Selective Attention Merging for low resource tasks: A case study of Child ASR
Authors:Natarajan Balaji Shankar, Zilai Wang, Eray Eren, Abeer Alwan
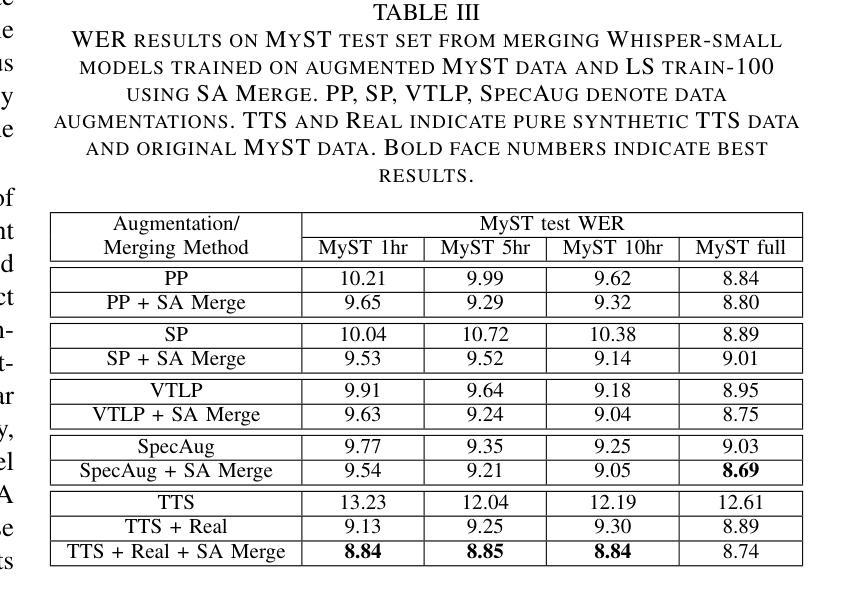
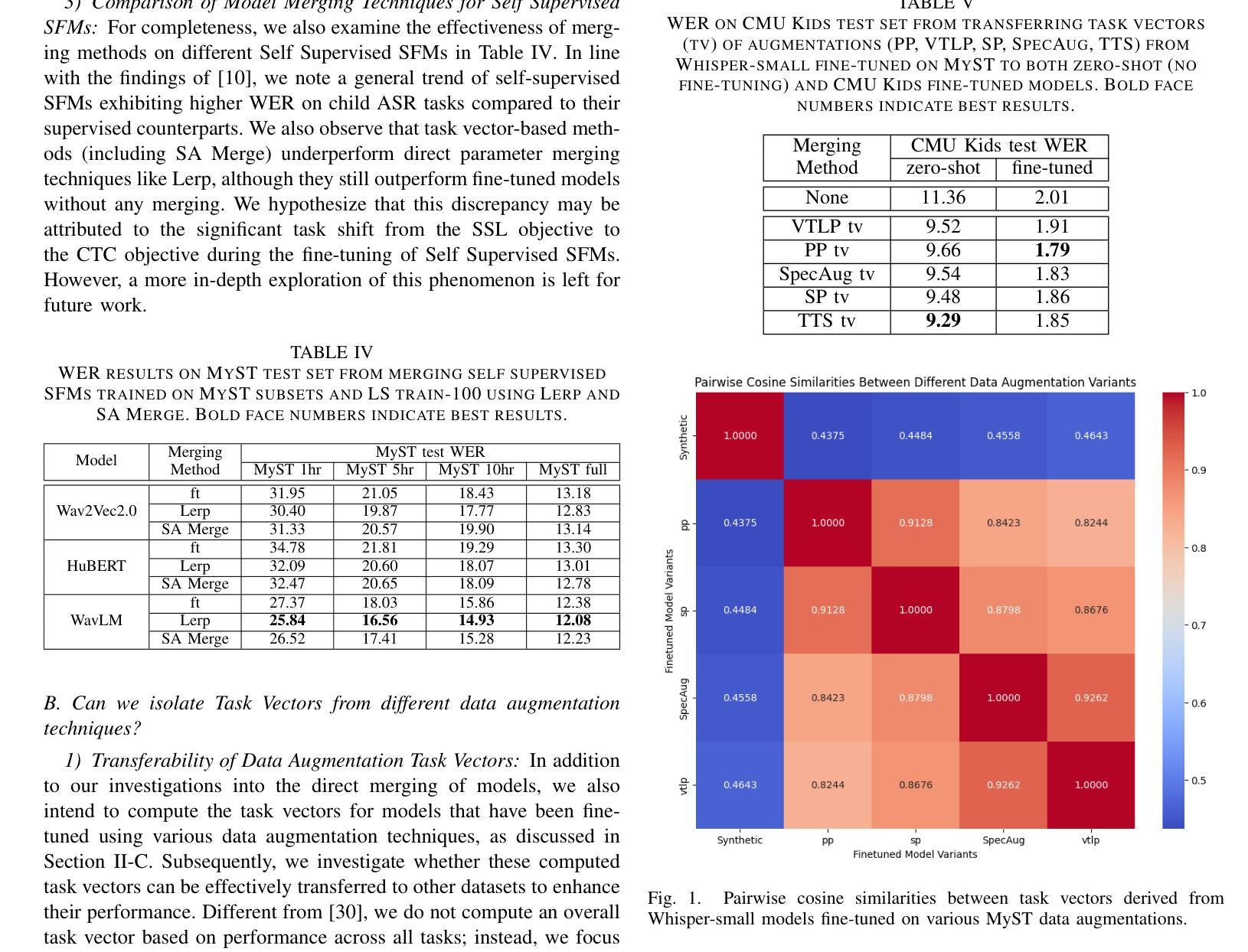
While Speech Foundation Models (SFMs) excel in various speech tasks, their performance for low-resource tasks such as child Automatic Speech Recognition (ASR) is hampered by limited pretraining data. To address this, we explore different model merging techniques to leverage knowledge from models trained on larger, more diverse speech corpora. This paper also introduces Selective Attention (SA) Merge, a novel method that selectively merges task vectors from attention matrices to enhance SFM performance on low-resource tasks. Experiments on the MyST database show significant reductions in relative word error rate of up to 14%, outperforming existing model merging and data augmentation techniques. By combining data augmentation techniques with SA Merge, we achieve a new state-of-the-art WER of 8.69 on the MyST database for the Whisper-small model, highlighting the potential of SA Merge for improving low-resource ASR.
语音基础模型(SFMs)在各种语音任务中表现出色,但在儿童自动语音识别(ASR)等低资源任务的性能受到有限预训练数据的限制。为了解决这一问题,我们探索了不同的模型合并技术,以利用在更大、更多样化的语音语料库上训练的模型的知识。本文还介绍了选择性注意(SA)合并,这是一种新的方法,它选择性地合并来自注意力矩阵的任务向量,以提高SFM在低资源任务上的性能。在MyST数据库上的实验表明,相对词错误率最高降低了14%,超过了现有的模型合并和数据增强技术。通过将数据增强技术与SA Merge相结合,我们在MyST数据库上为Whisper-small模型达到了新的最先进的词错误率(WER)8.69%,这突显了SA Merge在提高低资源ASR方面的潜力。
论文及项目相关链接
PDF To appear in ICASSP 2025
Summary
本文探讨了如何利用模型合并技术来提升低资源任务(如儿童自动语音识别ASR)的语音基础模型性能问题。研究介绍了选择性注意力合并技术(Selective Attention Merge),它通过选择性合并注意力矩阵中的任务向量,提高在低资源任务上的表现。实验显示,该方法在MyST数据库上的相对词错误率降低幅度达14%,与其他模型合并和数据增强技术相比表现更优越。通过与数据增强技术结合,利用选择性注意力合并技术实现的whisper小型模型在MyST数据库上的词错误率降至8.69%,展示了其提升低资源ASR性能的潜力。
Key Takeaways
- 研究针对低资源任务的语音基础模型性能问题,尤其是儿童自动语音识别ASR领域,性能受到限制,需要进行模型合并来优化利用大型和多样的预训练数据知识。
- 研究提出了一种新的模型合并方法——选择性注意力合并技术(Selective Attention Merge),通过选择性合并注意力矩阵中的任务向量,提高低资源任务的性能。
- 实验表明选择性注意力合并技术显著降低了相对词错误率(WER),在某些场景下提升效果显著,相对于现有模型合并和数据增强技术有更好的表现。
- 在MyST数据库上进行的实验表明,当选择性注意力合并技术与数据增强技术结合使用时,可以进一步降低词错误率至8.69%,展现出该技术在改善低资源ASR任务中的巨大潜力。
- 该研究为低资源环境下的语音任务提供了一个有效的解决方案,特别是针对缺乏大规模预训练数据的场景。
- 研究结果具有广泛的应用前景,特别是在儿童语音识别、辅助通讯技术以及多语言语音识别等领域。
点此查看论文截图

SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
Authors:Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Ziqiang Dang, Jianqiang Ren, Liefeng Bo, Zhigang Tu
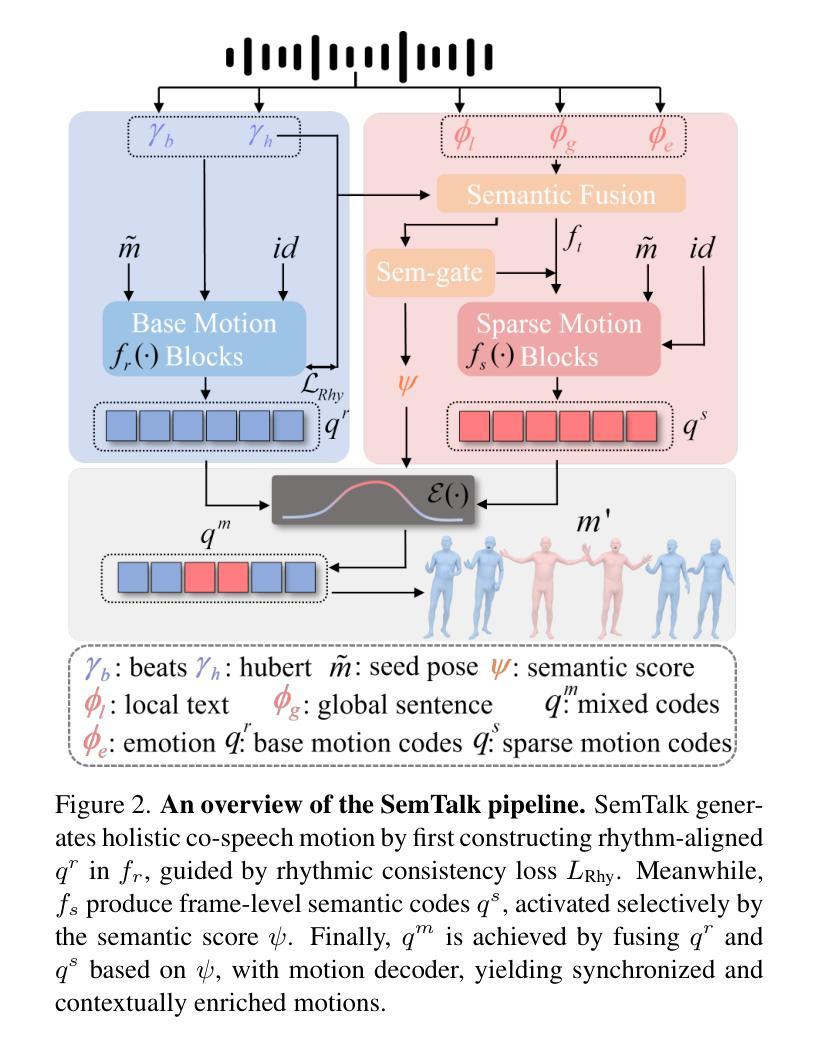
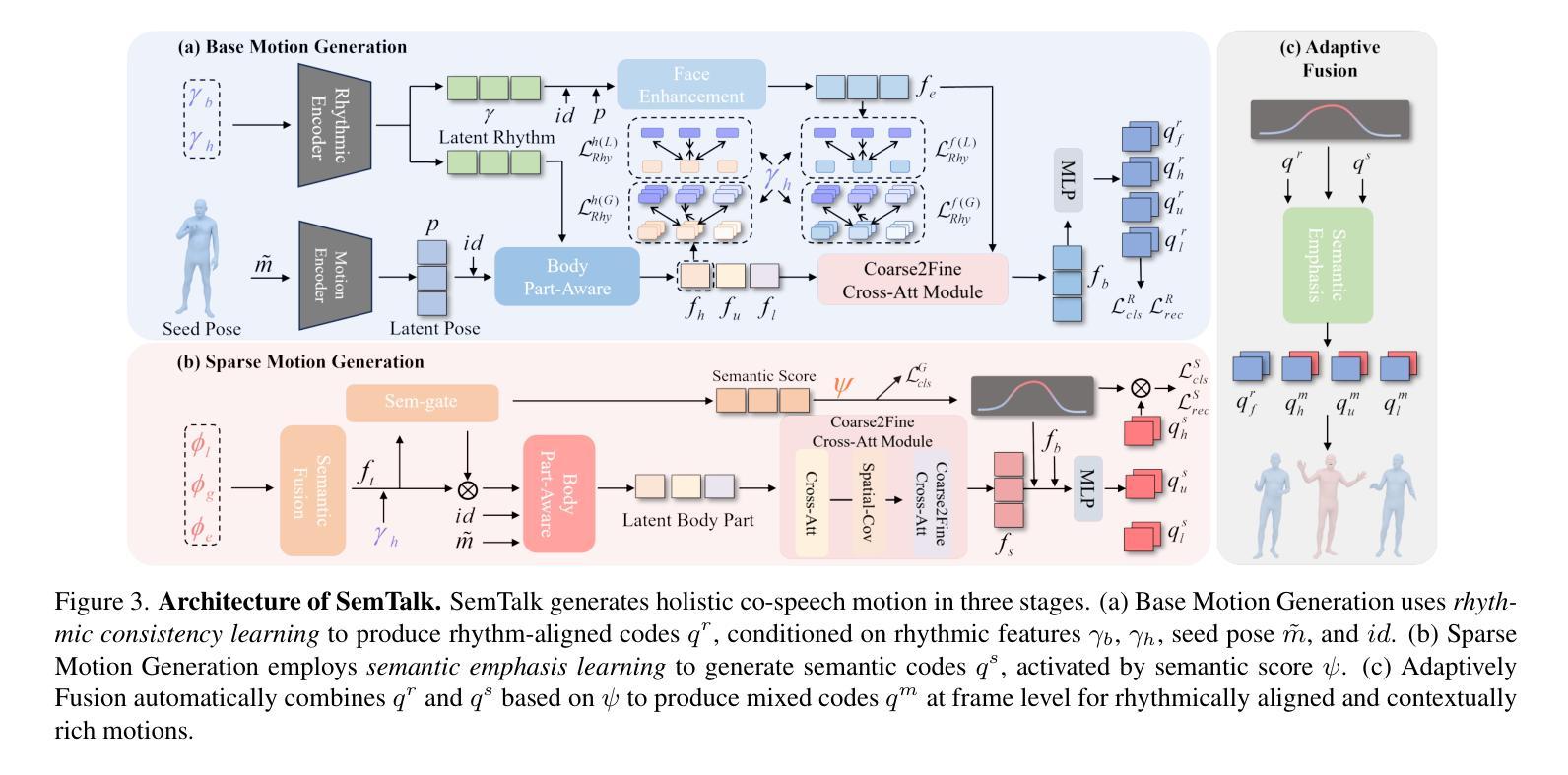
A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, textit{semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.
良好的协同语音动作生成离不开常见的节奏动作和罕见但必要的语义动作的仔细融合。在这项工作中,我们提出了用于整体协同语音动作生成的SemTalk方法,具有帧级语义强调。我们的关键见解是分别学习一般运动和稀疏运动,然后自适应地融合它们。特别是,探索了节奏一致性学习来建立与节奏相关的基本运动,确保与语音节奏同步的手势连贯基础。随后,设计语义重点学习来生成具有语义感知的稀疏运动,侧重于帧级语义线索。最后,为了将稀疏动作融入基本动作并生成具有语义强调的协同语音手势,我们进一步利用学习到的语义分数进行自适应合成。在两项公共数据集上的定性和定量比较表明,我们的方法优于最新技术,在稳定的基本动作上提供高质量的协同语音动作,增强了语义丰富性。
论文及项目相关链接
PDF 11 pages, 8 figures
摘要
共同语音运动生成需要综合考虑常见的节奏运动和罕见但重要的语义运动。本研究提出SemTalk方法,用于整体共同语音运动生成,具有帧级语义重点。我们的关键见解是分别学习一般运动和稀疏运动,然后自适应融合它们。特别探索了节奏一致性学习,以建立与节奏相关的基本运动,确保姿势与语音节奏的同步性。此外,设计语义重点学习以生成具有语义意识的稀疏运动,侧重于帧级语义线索。最后,为了将稀疏运动融入基本运动并生成具有语义强调的共同语音姿势,我们进一步利用学习到的语义分数进行自适应合成。在公共数据集上的定性和定量比较表明,我们的方法优于现有技术,生成高质量的共同语音运动,具有稳定的基本运动和增强的语义丰富性。
要点
- 共同语音运动生成需要整合节奏运动和语义运动。
- 提出SemTalk方法,整体进行共同语音运动生成,引入帧级语义重点。
- 分别学习一般运动和稀疏运动,然后自适应融合。
- 通过节奏一致性学习建立与语音节奏同步的基本运动。
- 语义重点学习用于生成具有帧级语义线索的语义感知稀疏运动。
- 利用学习到的语义分数将稀疏运动融入基本运动。
- 在公共数据集上的表现优于现有技术,生成高质量共同语音运动,增强语义丰富性并保持稳定的基本运动。
点此查看论文截图

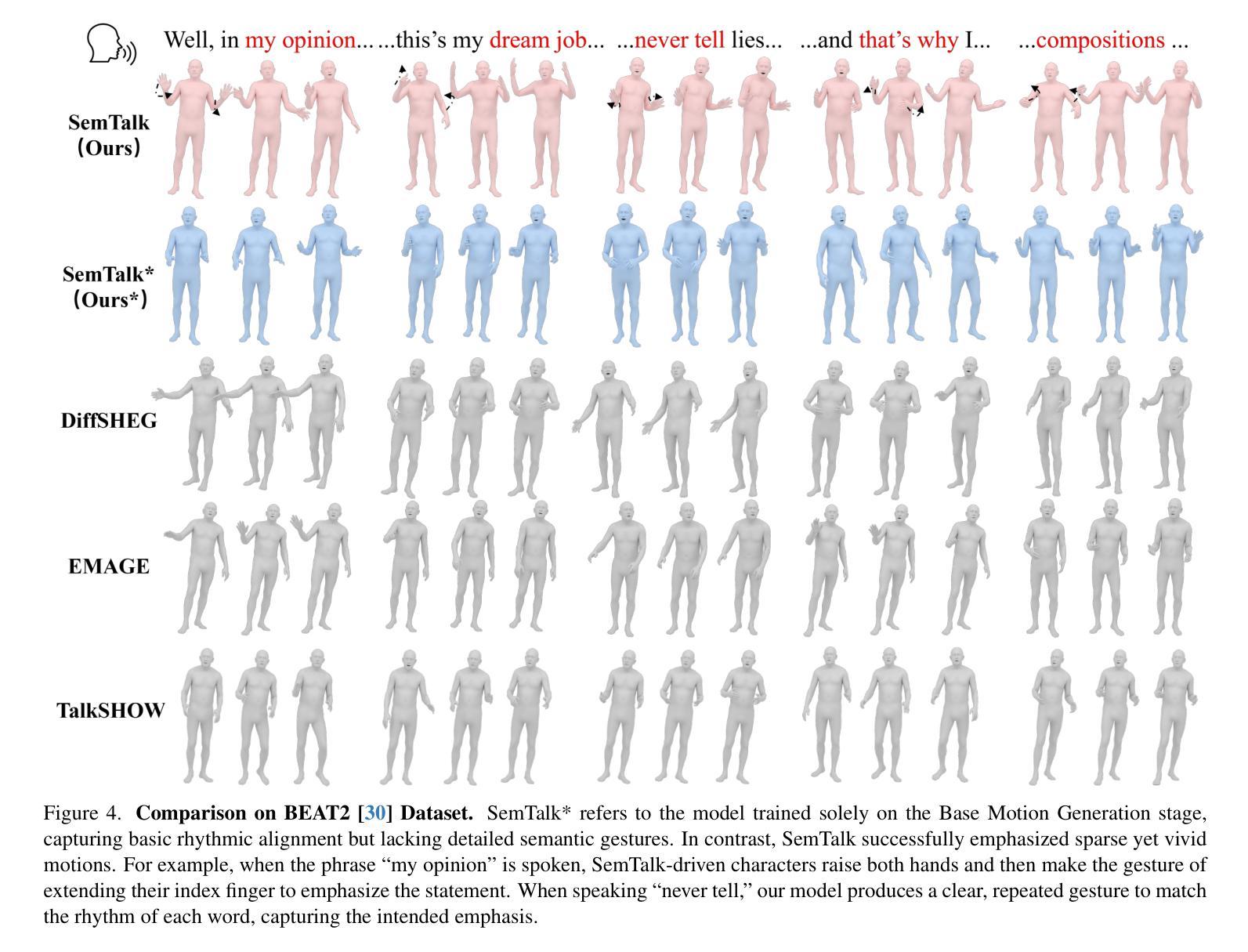
CSL-L2M: Controllable Song-Level Lyric-to-Melody Generation Based on Conditional Transformer with Fine-Grained Lyric and Musical Controls
Authors:Li Chai, Donglin Wang
Lyric-to-melody generation is a highly challenging task in the field of AI music generation. Due to the difficulty of learning strict yet weak correlations between lyrics and melodies, previous methods have suffered from weak controllability, low-quality and poorly structured generation. To address these challenges, we propose CSL-L2M, a controllable song-level lyric-to-melody generation method based on an in-attention Transformer decoder with fine-grained lyric and musical controls, which is able to generate full-song melodies matched with the given lyrics and user-specified musical attributes. Specifically, we first introduce REMI-Aligned, a novel music representation that incorporates strict syllable- and sentence-level alignments between lyrics and melodies, facilitating precise alignment modeling. Subsequently, sentence-level semantic lyric embeddings independently extracted from a sentence-wise Transformer encoder are combined with word-level part-of-speech embeddings and syllable-level tone embeddings as fine-grained controls to enhance the controllability of lyrics over melody generation. Then we introduce human-labeled musical tags, sentence-level statistical musical attributes, and learned musical features extracted from a pre-trained VQ-VAE as coarse-grained, fine-grained and high-fidelity controls, respectively, to the generation process, thereby enabling user control over melody generation. Finally, an in-attention Transformer decoder technique is leveraged to exert fine-grained control over the full-song melody generation with the aforementioned lyric and musical conditions. Experimental results demonstrate that our proposed CSL-L2M outperforms the state-of-the-art models, generating melodies with higher quality, better controllability and enhanced structure. Demos and source code are available at https://lichaiustc.github.io/CSL-L2M/.
歌词到旋律的生成是人工智能音乐生成领域中的一个极具挑战性的任务。由于学习歌词和旋律之间严格但微弱的关联存在困难,以前的方法在可控性、质量和结构方面存在生成质量不高的问题。为了解决这些挑战,我们提出了基于注意力缺失的Transformer解码器的可控歌曲级别的歌词到旋律生成方法CSL-L2M。它能够根据给定的歌词和用户指定的音乐属性生成全曲的旋律。具体来说,我们首先引入了REMI-Aligned这一新型音乐表示方法,它结合了歌词和旋律之间的音节和句子级别的严格对齐,便于精确对齐建模。接着,从句子级的Transformer编码器中独立提取的语义歌词嵌入与词级的词性嵌入和音节级的音调嵌入相结合,作为精细控制来增强歌词对旋律生成的操控性。然后,我们将人类标注的音乐标签、句子级的统计音乐属性以及从预训练的VQ-VAE中提取的学习到的音乐特征分别引入为粗粒度、细粒度和高保真控制,以用于生成过程,从而使用户能够控制旋律的生成。最后,利用注意力缺失的Transformer解码器技术,根据前述的歌词和音乐条件对全曲的旋律生成进行精细控制。实验结果表明,我们提出的CSL-L2M优于现有模型,生成的旋律质量更高、可控性更好、结构更加增强。Demo和源代码可在[https://lichaiustc.github.io/CSL-L2M/]访问。
论文及项目相关链接
PDF Accepted at AAAI-25
Summary
基于AI音乐生成领域中的歌词到旋律生成任务的高度挑战性,前人方法存在可控性弱、生成质量低和结构不佳等问题。为此,我们提出了基于注意力缺失Transformer解码器的可控歌词级别歌词到旋律生成方法CSL-L2M。它通过精细的歌词和音乐控制,能够生成与给定歌词和用户指定的音乐属性相匹配的完整歌曲旋律。
Key Takeaways
- AI音乐生成中的歌词到旋律生成具有挑战性,因歌词与旋律间的严格但弱关联难以学习,前人方法存在可控性、质量及结构问题。
- CSL-L2M方法基于注意力缺失的Transformer解码器,实现了歌曲级别的歌词到旋律生成。
- REMI-Aligned音乐表示方法融入了歌词和旋律之间的音节和句子级别严格对齐,便于精准对齐建模。
- CSL-L2M使用了细粒度的控制,包括句子级别的语义歌词嵌入、词级别的词性嵌入和音节级别的音调嵌入,增强了旋律生成的可控性。
- 引入了人类标注的音乐标签、句子级别的统计音乐属性和从预训练VQ-VAE中提取的学习音乐特征,分别为粗粒度、细粒度和高保真控制,使用户能够控制旋律生成。
- 实验结果证明,CSL-L2M相较于现有最先进的模型,生成的旋律质量更高、可控性更强、结构更佳。
点此查看论文截图



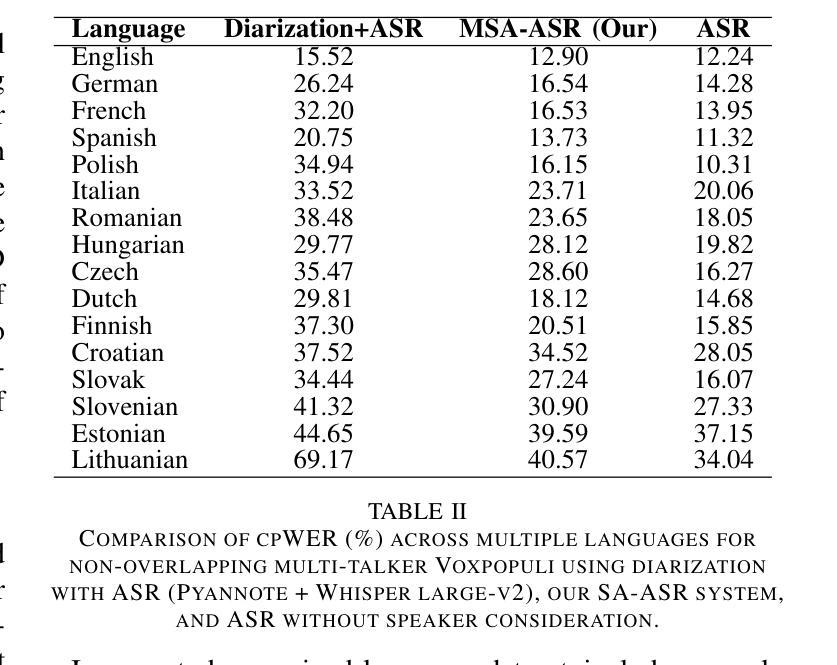
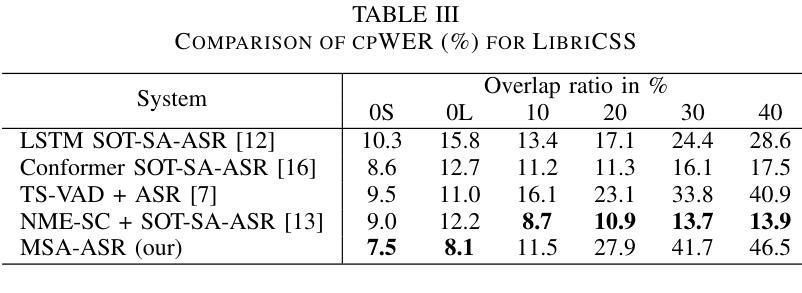
MSA-ASR: Efficient Multilingual Speaker Attribution with frozen ASR Models
Authors:Thai-Binh Nguyen, Alexander Waibel
Speaker-attributed automatic speech recognition (SA-ASR) aims to transcribe speech while assigning transcripts to the corresponding speakers accurately. Existing methods often rely on complex modular systems or require extensive fine-tuning of joint modules, limiting their adaptability and general efficiency. This paper introduces a novel approach, leveraging a frozen multilingual ASR model to incorporate speaker attribution into the transcriptions, using only standard monolingual ASR datasets. Our method involves training a speaker module to predict speaker embeddings based on weak labels without requiring additional ASR model modifications. Despite being trained exclusively with non-overlapping monolingual data, our approach effectively extracts speaker attributes across diverse multilingual datasets, including those with overlapping speech. Experimental results demonstrate competitive performance compared to strong baselines, highlighting the model’s robustness and potential for practical applications.
说话人属性自动语音识别(SA-ASR)旨在准确地将语音转录并分配给相应的说话人。现有方法通常依赖于复杂的模块化系统,或者需要对联合模块进行大量的微调,这限制了它们的适应性和总体效率。本文介绍了一种新方法,利用冻结的多语言ASR模型来结合说话人属性进行转录,仅使用标准单语言ASR数据集。我们的方法是通过训练说话人模块来预测基于弱标签的说话人嵌入,而无需额外的ASR模型修改。尽管只使用非重叠的单语言数据进行训练,但我们的方法可以有效地提取跨多种多语言数据集的说话人属性,包括具有重叠语音的情况。实验结果与强基线相比具有竞争力,突显了模型的稳健性和实际应用潜力。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary:
本文介绍了自动语音识别(ASR)中的说话人属性识别技术。传统方法依赖于复杂的模块化系统,需要大量精细调整联合模块,限制了其适应性和效率。本文提出了一种新方法,利用冻结的多语言ASR模型将说话人属性纳入转录中,仅使用标准单语言ASR数据集。该方法通过训练说话人模块预测基于弱标签的说话人嵌入,无需修改额外的ASR模型。尽管仅在非重叠单语言数据上进行训练,但该方法在多种多语言数据集上有效地提取了说话人属性,包括重叠语音数据集。实验结果表明,与强基线相比具有竞争力,突显了模型的稳健性和实际应用潜力。
Key Takeaways:
- SA-ASR技术旨在准确地将语音转录并分配给相应的说话人。
- 传统方法依赖于复杂的模块化系统,需要精细调整,限制了适应性和效率。
- 本文提出一种利用冻结的多语言ASR模型的方法,通过结合说话人模块和预测说话人嵌入技术实现说话人属性识别。
- 方法仅使用标准单语言ASR数据集进行训练。
- 通过弱标签预测说话人嵌入,无需额外修改ASR模型。
- 即使在非重叠单语言数据上训练,该方法也能在多种多语言数据集上有效提取说话人属性,包括处理重叠语音的情况。
点此查看论文截图


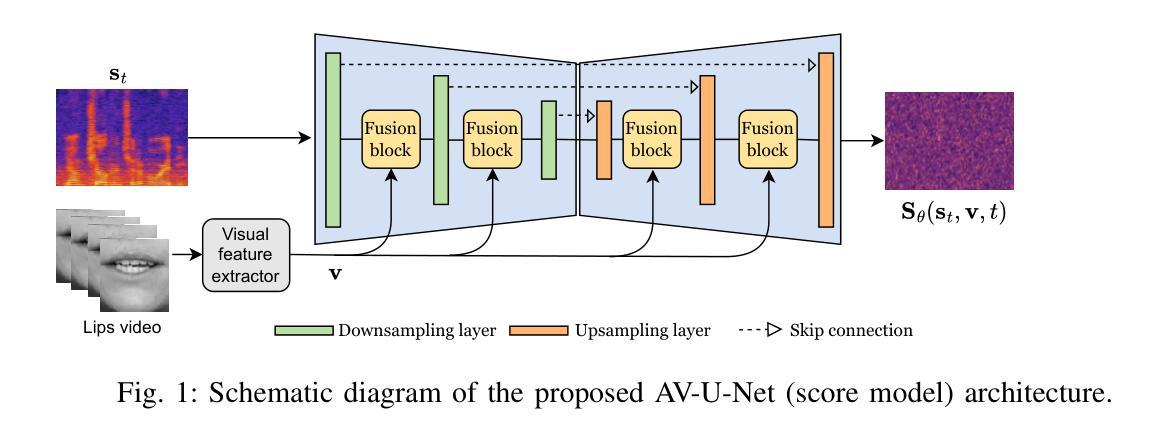
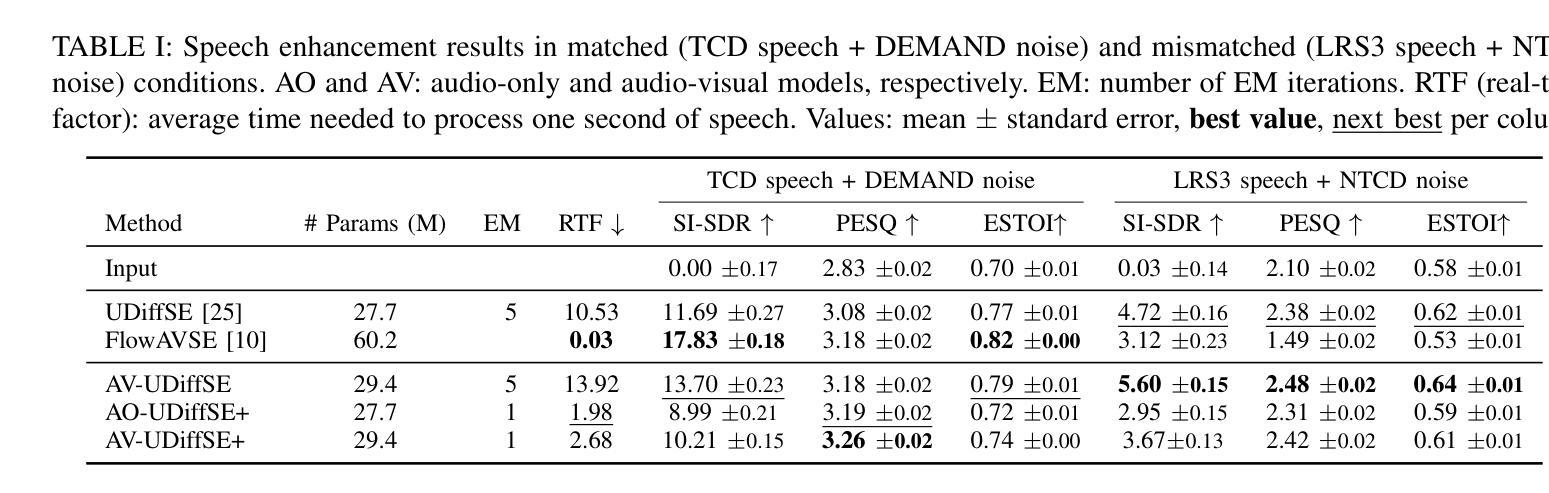
Diffusion-based Unsupervised Audio-visual Speech Enhancement
Authors:Jean-Eudes Ayilo, Mostafa Sadeghi, Romain Serizel, Xavier Alameda-Pineda
This paper proposes a new unsupervised audio-visual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to estimate clean speech iteratively. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervised-generative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method. Code and demo available at: https://jeaneudesayilo.github.io/fast_UdiffSE
本文提出了一种新的无监督音视频语音增强(AVSE)方法,该方法结合了基于扩散的音视频语音生成模型和非负矩阵分解(NMF)噪声模型。首先,扩散模型在对应的视频数据条件下对干净语音进行预训练,以模拟语音生成分布。然后,将此预训练模型与基于NMF的噪声模型配对,以迭代方式估计干净语音。具体来说,在反向扩散过程中实现了基于扩散的后验采样方法,每次迭代后,都会获得一个语音估计值,并用于更新噪声参数。实验结果表明,所提出的AVSE方法不仅优于仅使用音频的对应方法,而且相较于最新的有监督生成AVSE方法具有更好的泛化能力。此外,与之前的基于扩散的方法相比,新的推理算法在推理速度和性能之间提供了更好的平衡。相关代码和演示可在:[https://jeaneudesayilo.github.io/fast_UdiffSE](https://jeaneudesayilo.github.io/fast_UdiffSE)上找到。
论文及项目相关链接
摘要
本文提出了一种新的无监督音频视觉语音增强(AVSE)方法,该方法结合了基于扩散的音频视觉语音生成模型与非负矩阵分解(NMF)噪声模型。首先,扩散模型在对应的视频数据上进行预训练清洁语音,以模拟语音生成分布。然后,将此预训练模型与基于NMF的噪声模型结合,以迭代方式估计清洁语音。具体实现了一种基于扩散的后验采样方法,在反向扩散过程中,每次迭代后都会获得语音估计并用于更新噪声参数。实验结果表明,所提出的AVSE方法不仅优于仅使用音频的对应方法,而且比一般监督生成AVSE方法的泛化能力更强。此外,新的推理算法在推理速度与性能之间达到了更好的平衡,相较于之前的扩散方法有所改进。相关代码与演示见:链接。
关键见解
- 本文提出了一种新的无监督音频视觉语音增强(AVSE)方法,融合了扩散模型和NMF噪声模型。
- 扩散模型通过模拟语音生成分布进行预训练,以提高性能。
- 结合预训练扩散模型和NMF噪声模型,通过迭代方式估计清洁语音。
- 采用基于扩散的后验采样方法,在反向扩散过程中更新噪声参数。
- 实验结果显示,该方法优于仅使用音频的对应方法,且泛化能力更强。
- 新推理算法在推理速度与性能之间达到了平衡,改进了之前的扩散方法。
- 相关代码与演示可在指定链接中找到。
点此查看论文截图


Joint Beam Search Integrating CTC, Attention, and Transducer Decoders
Authors:Yui Sudo, Muhammad Shakeel, Yosuke Fukumoto, Brian Yan, Jiatong Shi, Yifan Peng, Shinji Watanabe
End-to-end automatic speech recognition (E2E-ASR) can be classified by its decoder architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and Mask-CTC models. Each decoder architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and Mask-CTC) share the same encoder – we refer to this as 4D modeling. The 4D model is trained jointly, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes the joint training. In addition, we propose three novel joint beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed joint beam search algorithm outperforms the previously proposed CTC/attention decoding.
端到端自动语音识别(E2E-ASR)可按照其解码器架构进行分类,如连接时序分类(CTC)、循环神经网络转换器(RNN-T)、基于注意力的编码器解码器以及Mask-CTC模型等。每种解码器架构都有其优缺点,实际应用中需要根据应用需求在这些不同模型之间进行切换。我们提出了一种联合建模方案,四种解码器(CTC、RNN-T、注意力以及Mask-CTC)共享同一个编码器,我们称之为4D建模。4D模型进行联合训练,这带来了模型正则化,并因它们的互补性质而最大化模型的稳健性。为了有效训练4D模型,我们引入了一种两阶段训练策略,使联合训练更加稳定。此外,我们通过结合三种解码器(CTC、RNN-T和注意力)提出了三种新型联合束搜索算法,以进一步提高性能。这三种束搜索算法的区别在于所使用的主要解码器不同。我们仔细评估了每种算法的性能和计算折衷。实验结果表明,联合训练的4D模型优于仅使用单个解码器训练的E2E-ASR模型。此外,我们证明所提出的联合束搜索算法优于先前提出的CTC/注意力解码。
论文及项目相关链接
PDF accepted to IEEE/ACM Transactions on Audio Speech and Language Processing
Summary
本文介绍了端对端语音识别(E2E-ASR)的四种解码器架构(CTC、RNN-T、注意力编码器解码器和Mask-CTC)的联合建模方案。该4D模型通过共享同一编码器实现四种解码器的联合训练,从而提高模型的正则化和鲁棒性。文章还提出了两阶段训练策略和三种联合束搜索算法以优化模型性能和计算效率。实验结果表明,联合训练的4D模型优于仅使用单个解码器的E2E-ASR模型,而提出的联合束搜索算法也优于先前的CTC/注意力解码。
Key Takeaways
- 端对端语音识别(E2E-ASR)的解码器架构包括CTC、RNN-T、注意力编码器解码器和Mask-CTC。
- 4D模型实现了四种解码器的联合建模,通过共享同一编码器提高模型的正则化和鲁棒性。
- 提出了两阶段训练策略以稳定联合训练。
- 提出了三种联合束搜索算法,通过结合不同解码器进一步优化性能。
- 实验结果表明,联合训练的4D模型在性能上优于单一解码器的E2E-ASR模型。
- 联合束搜索算法在性能上优于传统的CTC/注意力解码。
点此查看论文截图

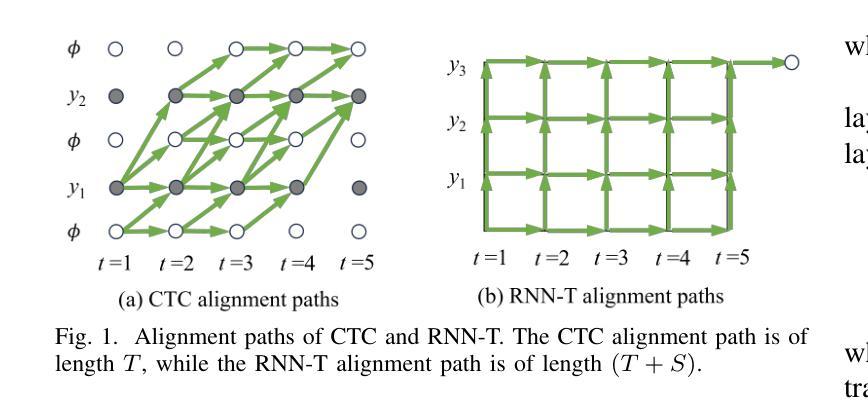

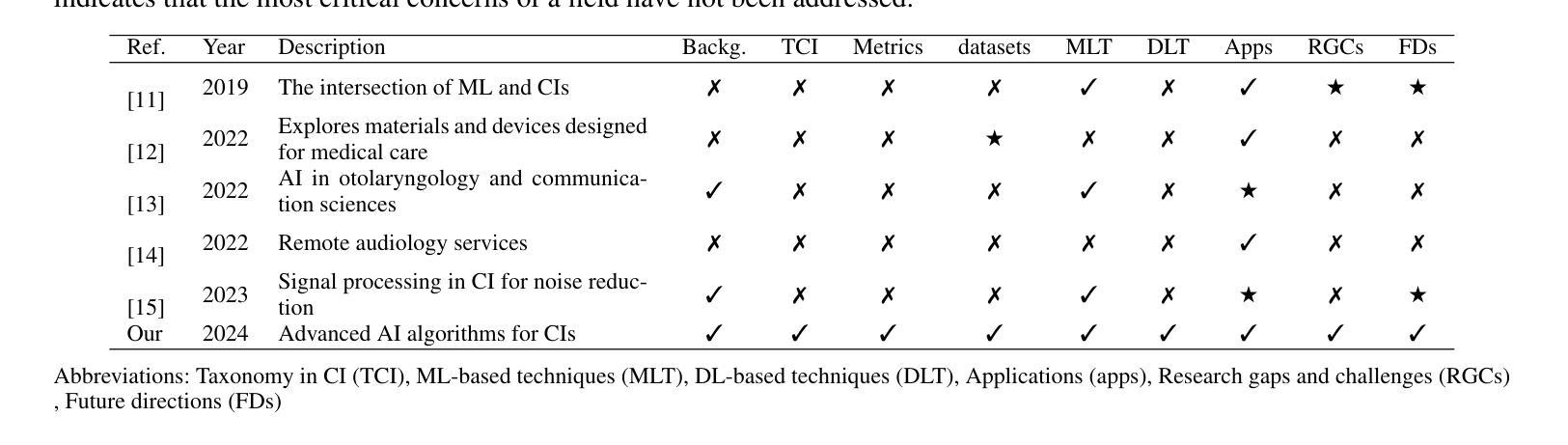
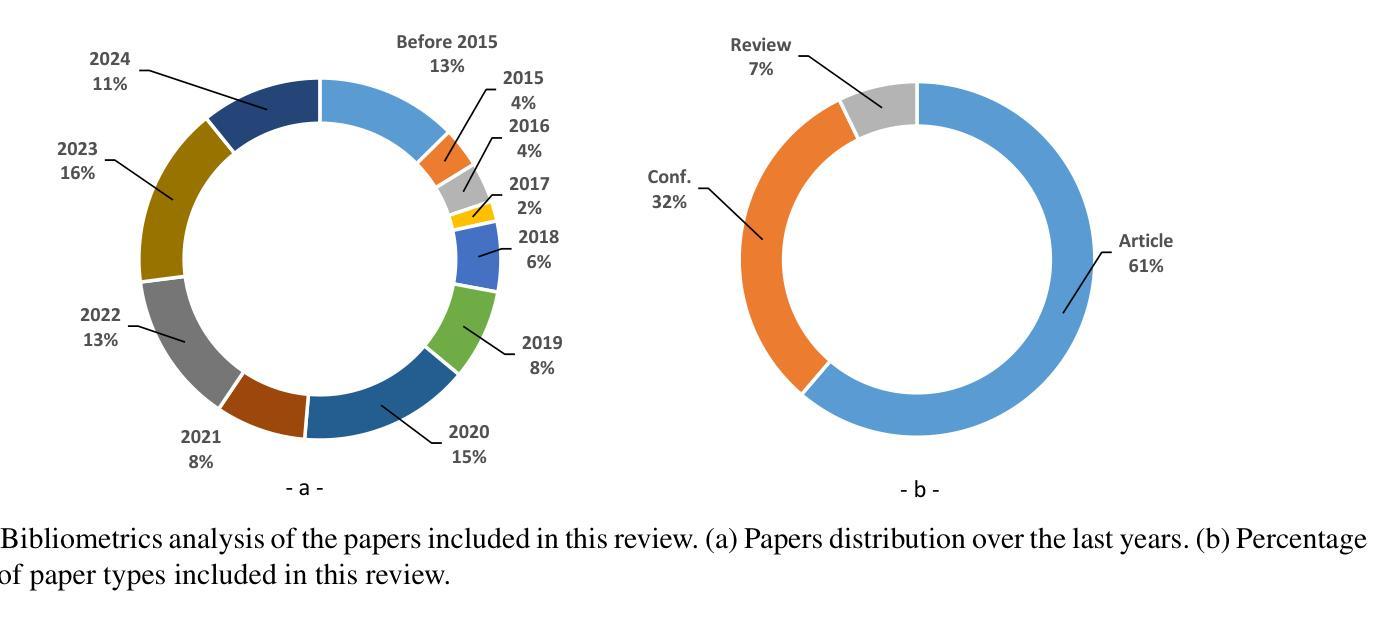
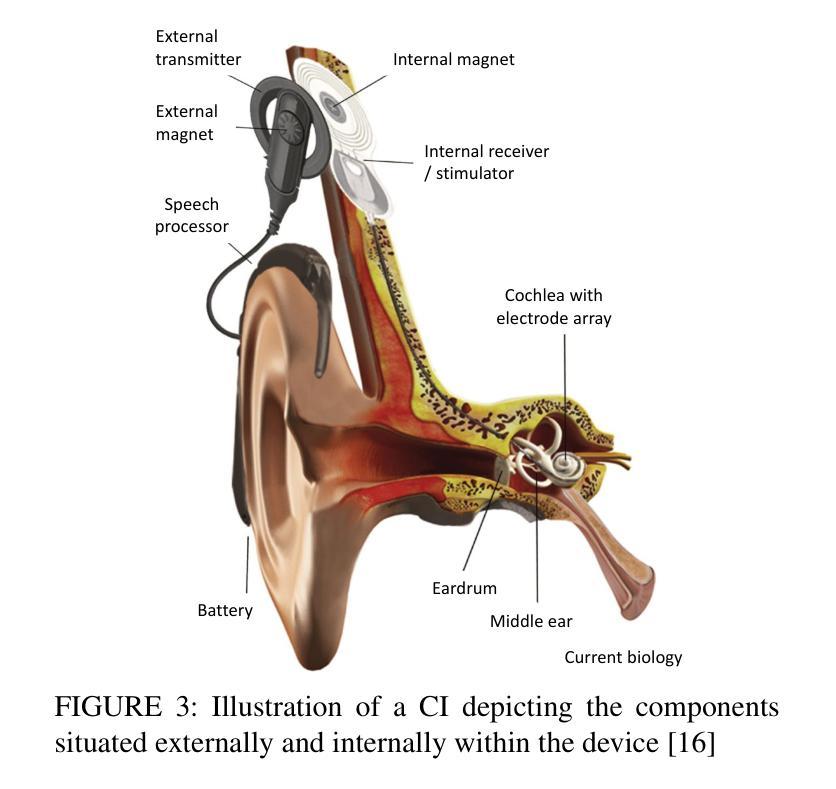
Artificial Intelligence for Cochlear Implants: Review of Strategies, Challenges, and Perspectives
Authors:Billel Essaid, Hamza Kheddar, Noureddine Batel, Muhammad E. H. Chowdhury, Abderrahmane Lakas
Automatic speech recognition (ASR) plays a pivotal role in our daily lives, offering utility not only for interacting with machines but also for facilitating communication for individuals with partial or profound hearing impairments. The process involves receiving the speech signal in analog form, followed by various signal processing algorithms to make it compatible with devices of limited capacities, such as cochlear implants (CIs). Unfortunately, these implants, equipped with a finite number of electrodes, often result in speech distortion during synthesis. Despite efforts by researchers to enhance received speech quality using various state-of-the-art (SOTA) signal processing techniques, challenges persist, especially in scenarios involving multiple sources of speech, environmental noise, and other adverse conditions. The advent of new artificial intelligence (AI) methods has ushered in cutting-edge strategies to address the limitations and difficulties associated with traditional signal processing techniques dedicated to CIs. This review aims to comprehensively cover advancements in CI-based ASR and speech enhancement, among other related aspects. The primary objective is to provide a thorough overview of metrics and datasets, exploring the capabilities of AI algorithms in this biomedical field, and summarizing and commenting on the best results obtained. Additionally, the review will delve into potential applications and suggest future directions to bridge existing research gaps in this domain.
自动语音识别(ASR)在我们的日常生活中扮演着至关重要的角色,它不仅用于与机器交互,还帮助部分或重度听力受损人士进行日常沟通。这一过程包括接收模拟形式的语音信号,然后通过各种信号处理算法使其与有限容量的设备(如耳蜗植入装置)兼容。然而,这些植入物电极数量有限,经常在合成过程中导致语音失真。尽管研究人员尝试使用各种最先进的信号处理技术和人工智能(AI)方法提升接收到的语音质量,但仍存在挑战,特别是在涉及多语音源、环境噪声和其他不利条件的情况下。基于人工智能的新方法的出现为传统信号处理技术带来的局限性带来了前沿解决方案,特别是在耳蜗植入物方面。本综述旨在全面涵盖耳蜗植入物相关的ASR和语音增强的进展以及其他相关方面。主要目的是提供关于该生物医学领域中AI算法能力的指标和数据集的全面概述,并总结评论最佳结果。此外,本综述还将深入探讨潜在应用,并针对当前领域内的研究空白提出未来研究方向。
论文及项目相关链接
Summary
随着语音识别技术在日常生活中的普及,助听器植入物(CI)在改善听障人士的听力方面发挥着重要作用。然而,由于电极数量的限制,CI在合成过程中常常导致语音失真。近年来,人工智能方法的发展为解决这个问题提供了新的策略。本文旨在全面回顾CI相关的语音识别和语音增强技术的进展,探讨AI算法在这一生物医学领域的能力,并对最佳结果进行总结和评论,同时探讨潜在的应用和未来研究方向。
Key Takeaways
- 自动语音识别(ASR)在日常生活中扮演着重要角色,不仅用于与机器交互,还为听障人士提供沟通便利。
- 语音信号接收后需经过一系列算法处理以适配有限容量的设备,如助听器植入物(CI)。
- CI面临的主要挑战之一是电极数量有限导致的语音失真问题。
- 人工智能方法为解决传统信号处理技术面临的挑战提供了新的策略。
- 本文全面回顾了CI在ASR和语音增强方面的进展,包括评估指标和数据集。
- AI算法在CI领域的应用能力得到了深入探讨。
点此查看论文截图


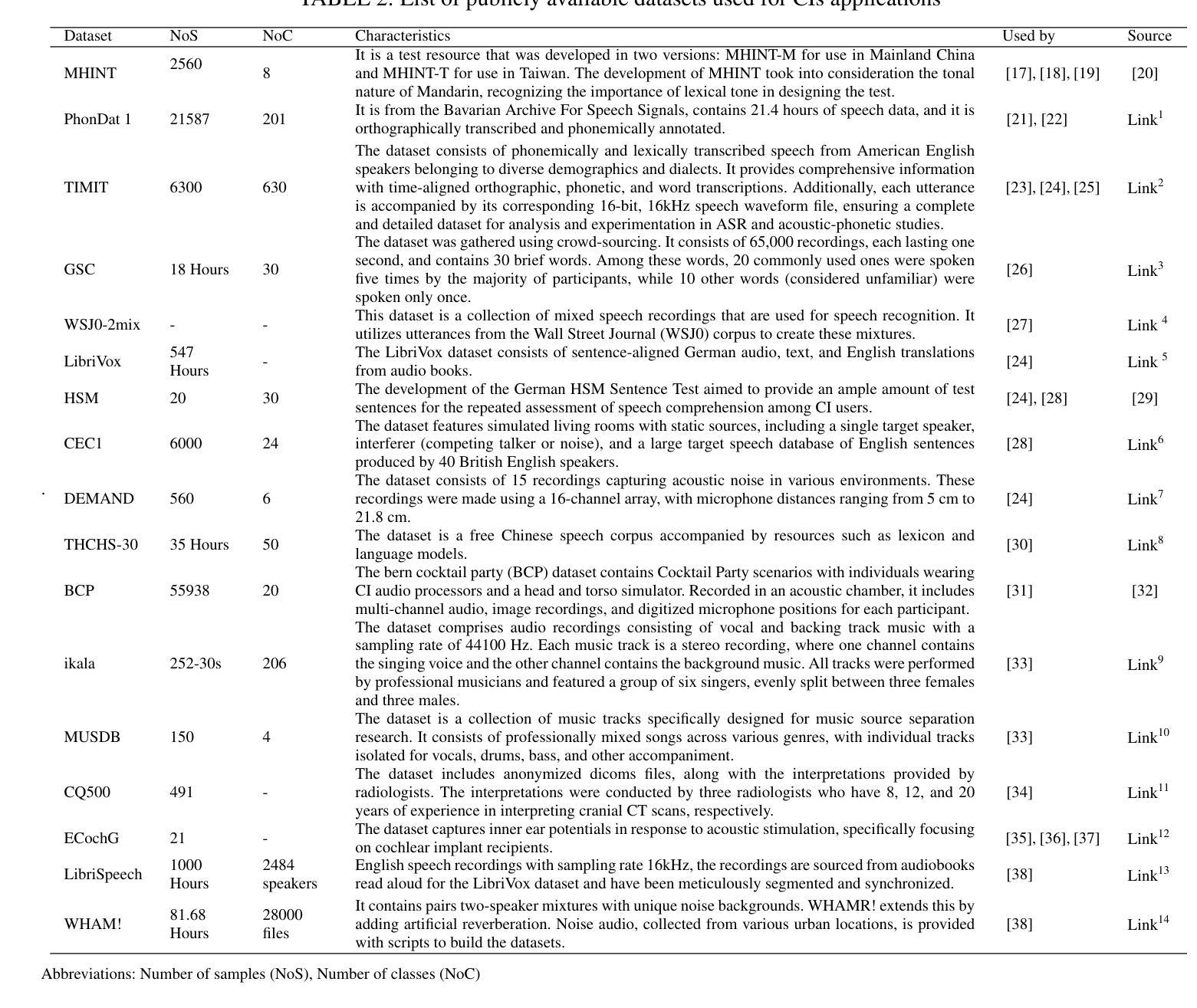
On the Effectiveness of ASR Representations in Real-world Noisy Speech Emotion Recognition
Authors:Xiaohan Shi, Jiajun He, Xingfeng Li, Tomoki Toda
This paper proposes an efficient attempt to noisy speech emotion recognition (NSER). Conventional NSER approaches have proven effective in mitigating the impact of artificial noise sources, such as white Gaussian noise, but are limited to non-stationary noises in real-world environments due to their complexity and uncertainty. To overcome this limitation, we introduce a new method for NSER by adopting the automatic speech recognition (ASR) model as a noise-robust feature extractor to eliminate non-vocal information in noisy speech. We first obtain intermediate layer information from the ASR model as a feature representation for emotional speech and then apply this representation for the downstream NSER task. Our experimental results show that 1) the proposed method achieves better NSER performance compared with the conventional noise reduction method, 2) outperforms self-supervised learning approaches, and 3) even outperforms text-based approaches using ASR transcription or the ground truth transcription of noisy speech.
本文提出了一种有效的针对带噪语音情感识别(NSER)的尝试。传统的NSER方法已经证明在减少人工噪声源(如白高斯噪声)的影响方面是有效的,但由于其复杂性和不确定性,它们在现实环境中的非平稳噪声方面存在局限性。为了克服这一局限性,我们采用了一种新的NSER方法,通过采用自动语音识别(ASR)模型作为噪声鲁棒性特征提取器,消除带噪语音中的非语音信息。我们首先获取ASR模型的中间层信息作为情感语音的特征表示,然后将其应用于下游NSER任务。实验结果表明,1)所提出的方法在NSER性能上优于传统的降噪方法;2)表现优于自监督学习方法;3)甚至优于基于文本的ASR转录或有噪语音的地面真实转录方法。
论文及项目相关链接
PDF Submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing
摘要
基于自动语音识别(ASR)模型的噪声鲁棒特征提取器方法,提出一种针对含噪语音情感识别的有效尝试。传统的含噪语音情感识别方法虽然能有效减轻人工噪声源(如白高斯噪声)的影响,但在现实环境中的非稳态噪声下表现受限。新方法采用ASR模型作为噪声鲁棒特征提取器,消除含噪语音中的非语音信息。首先,从ASR模型中获取中间层信息作为情感语音的特征表示,然后将其应用于下游含噪语音情感识别任务。实验结果表明,该方法相较于传统降噪方法和自监督学习方法有更好的性能表现,甚至超越了基于ASR转录或含噪语音的地面真实转录的文本方法。
要点
- 该方法引入ASR模型作为噪声鲁棒特征提取器,用于消除含噪语音中的非语音信息。
- 通过获取ASR模型的中间层信息作为情感语音的特征表示,进而应用于下游含噪语音情感识别任务。
- 实验结果显示,该方法在含噪语音情感识别方面表现优异,相较于传统降噪方法和自监督学习方法有更好的性能。
- 该方法超越了基于文本的方法,如使用ASR转录或含噪语音的地面真实转录。
- 采用ASR模型可有效处理非稳态噪声下的含噪语音情感识别问题。
- 该方法提供了一种新的视角来解决现实环境中非稳态噪声对语音情感识别的影响。
- 采用自动语音识别技术提升了含噪语音情感识别的准确度和鲁棒性。
点此查看论文截图


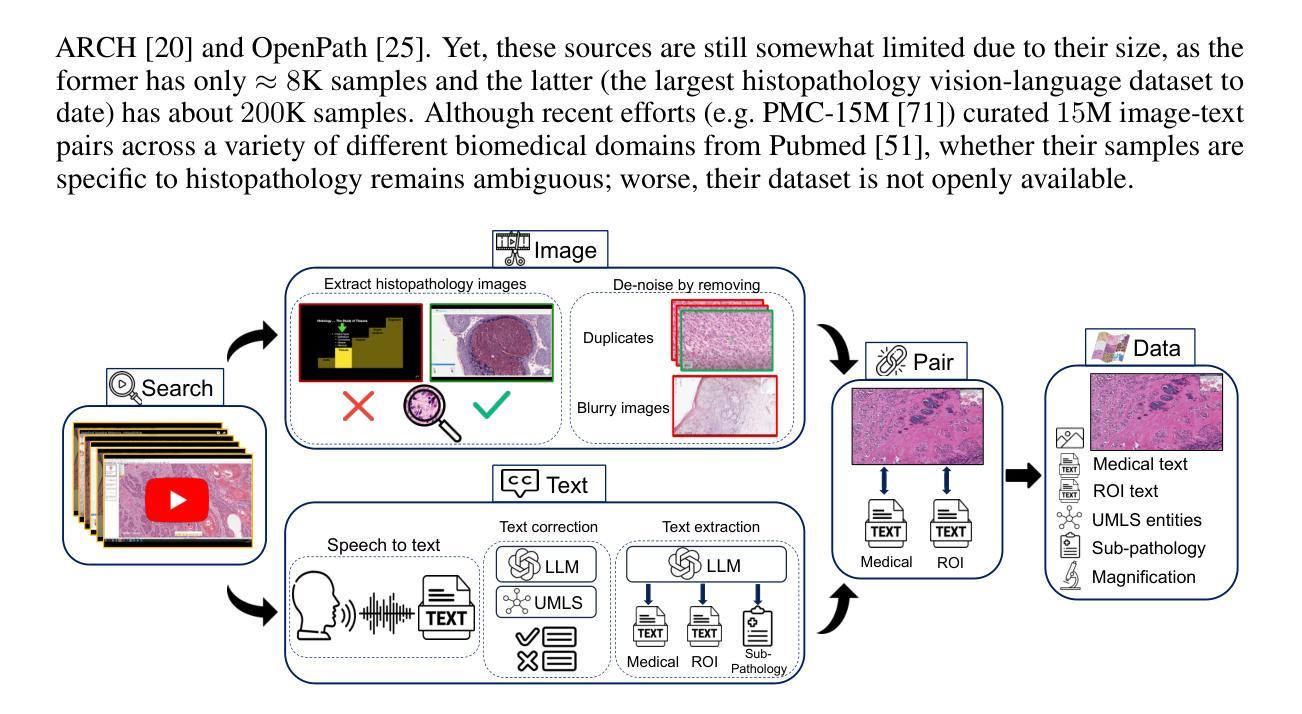
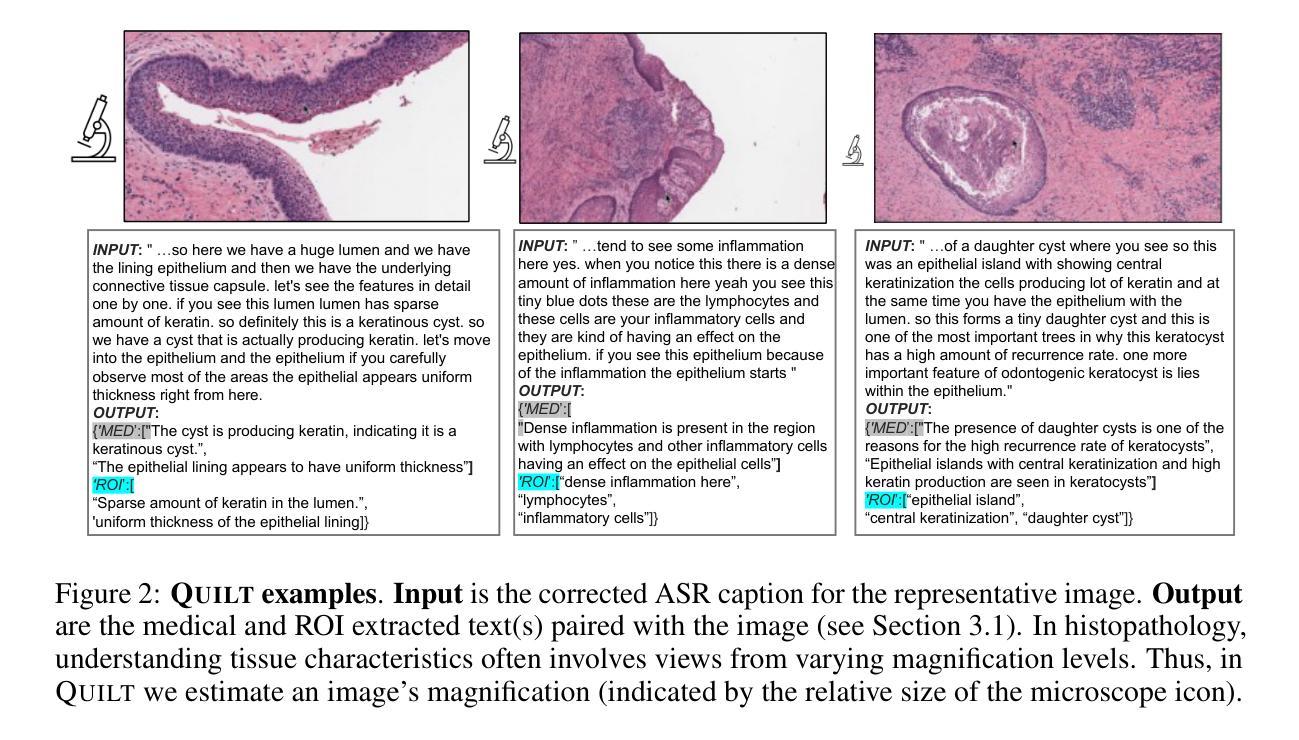
Quilt-1M: One Million Image-Text Pairs for Histopathology
Authors:Wisdom Oluchi Ikezogwo, Mehmet Saygin Seyfioglu, Fatemeh Ghezloo, Dylan Stefan Chan Geva, Fatwir Sheikh Mohammed, Pavan Kumar Anand, Ranjay Krishna, Linda Shapiro
Recent accelerations in multi-modal applications have been made possible with the plethora of image and text data available online. However, the scarcity of analogous data in the medical field, specifically in histopathology, has slowed comparable progress. To enable similar representation learning for histopathology, we turn to YouTube, an untapped resource of videos, offering $1,087$ hours of valuable educational histopathology videos from expert clinicians. From YouTube, we curate QUILT: a large-scale vision-language dataset consisting of $802, 144$ image and text pairs. QUILT was automatically curated using a mixture of models, including large language models, handcrafted algorithms, human knowledge databases, and automatic speech recognition. In comparison, the most comprehensive datasets curated for histopathology amass only around $200$K samples. We combine QUILT with datasets from other sources, including Twitter, research papers, and the internet in general, to create an even larger dataset: QUILT-1M, with $1$M paired image-text samples, marking it as the largest vision-language histopathology dataset to date. We demonstrate the value of QUILT-1M by fine-tuning a pre-trained CLIP model. Our model outperforms state-of-the-art models on both zero-shot and linear probing tasks for classifying new histopathology images across $13$ diverse patch-level datasets of $8$ different sub-pathologies and cross-modal retrieval tasks.
近期多模态应用的加速发展得益于网络上大量图像和文本数据的可用性。然而,医学领域,特别是在组织病理学方面,类似数据的稀缺性减缓了相应的进展。为了在组织病理学中实现类似的表示学习,我们转向YouTube这一未被开发的视频资源宝库,从中获取了来自专家医生的1087小时宝贵的教育组织病理学视频。从YouTube上,我们精心策划了QUILT:一个大规模视觉语言数据集,包含802,144个图像和文本对。QUILT是使用多种模型自动策划的,包括大型语言模型、手工算法、人类知识数据库和自动语音识别。相比之下,为组织病理学策划的最全面的数据集仅积累了大约20万样本。我们将QUILT与其他来源的数据集相结合,包括Twitter、研究论文和互联网上的一般来源,创建了一个更大的数据集:QUILT-1M,包含100万个配对图像文本样本,成为迄今为止最大的视觉语言组织病理学数据集。我们通过微调预训练的CLIP模型展示了QUILT-1M的价值。我们的模型在零样本和线性探测任务上超越了最新模型,在跨越13个不同补丁级别的数据集中对新的组织病理学图像进行分类任务跨越八种不同的子病理,并且在实际操作中的跨模态检索任务中也表现优异。
论文及项目相关链接
Summary
该文本介绍了由于在线图像和文本数据的丰富性,多模态应用领域的最新加速进展。然而,医疗领域尤其是组织病理学中类似数据的稀缺性限制了相应的进展。为实现在组织病理学中的类似表示学习,该文本利用YouTube这一未开发资源,从中获取了1,087小时专家医生的珍贵教育组织病理学视频。基于此,构建了QUILT大规模视觉语言数据集,包含802,144个图像和文本对。该数据集是通过大型语言模型、手工算法、人类知识数据库和自动语音识别等多种模型自动构建的。与迄今为止为组织病理学整理的最全面的数据集相比,QUILT的样本量高出数倍。通过将QUILT与其他来源的数据集(包括Twitter、研究论文和互联网上的数据集)相结合,创建了更大的QUILT-1M数据集,包含1百万配对图像文本样本,成为迄今为止最大的视觉语言组织病理学数据集。通过对预训练的CLIP模型进行微调,证明了QUILT-1M的价值,在零样本和线性探测任务中对新组织病理学图像进行分类时表现出卓越性能,跨越了13个不同的补丁级别数据集,涉及8种不同的子病理学,并在跨模态检索任务中也表现出色。
Key Takeaways
- 多模态应用领域因在线图像和文本数据的丰富性而加速发展,但医疗领域尤其是组织病理学中类似数据的稀缺性限制了进展。
- 利用YouTube等未开发资源,获取教育组织病理学视频,构建QUILT视觉语言数据集。
- QUILT数据集包含大量的图像和文本对,是通过多种模型自动构建的。
- QUILT数据集与其他来源的数据集相结合,创建了更大的QUILT-1M数据集,成为最大的视觉语言组织病理学数据集。
- 通过微调预训练的CLIP模型,QUILT-1M在分类新组织病理学图像和跨模态检索任务中表现出卓越性能。
- QUILT-1M的价值在于其能够跨越多个不同的病理学领域,包括对各种子病理学的分类。
点此查看论文截图