⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
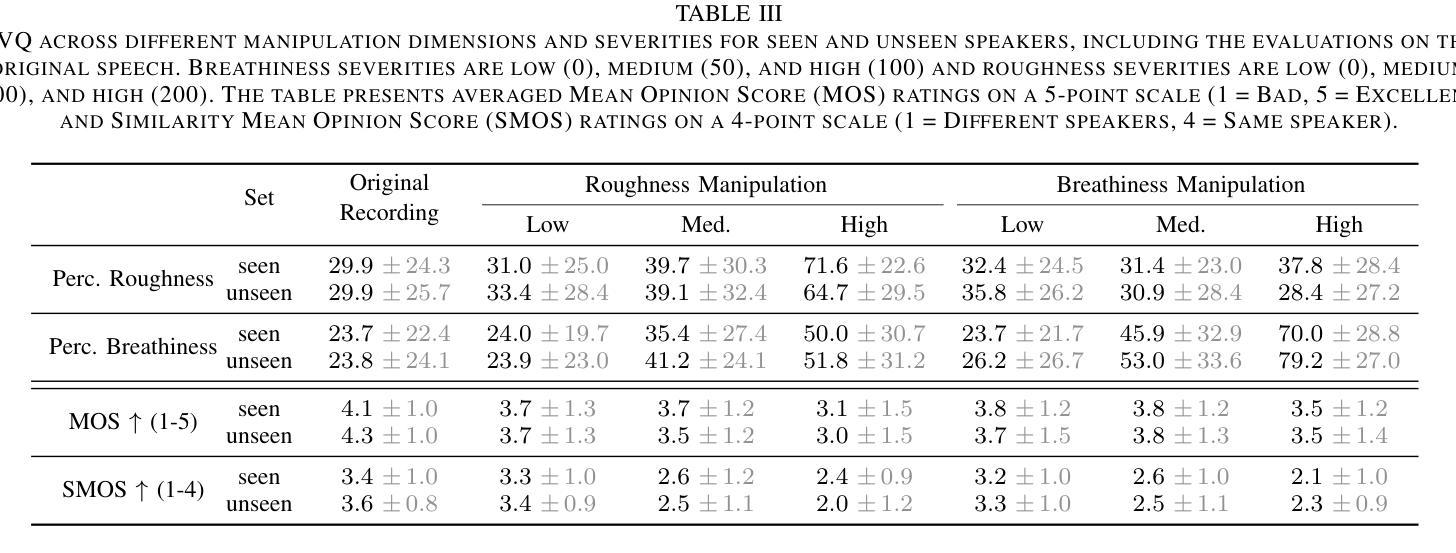
Speech Synthesis along Perceptual Voice Quality Dimensions
Authors:Frederik Rautenberg, Michael Kuhlmann, Fritz Seebauer, Jana Wiechmann, Petra Wagner, Reinhold Haeb-Umbach
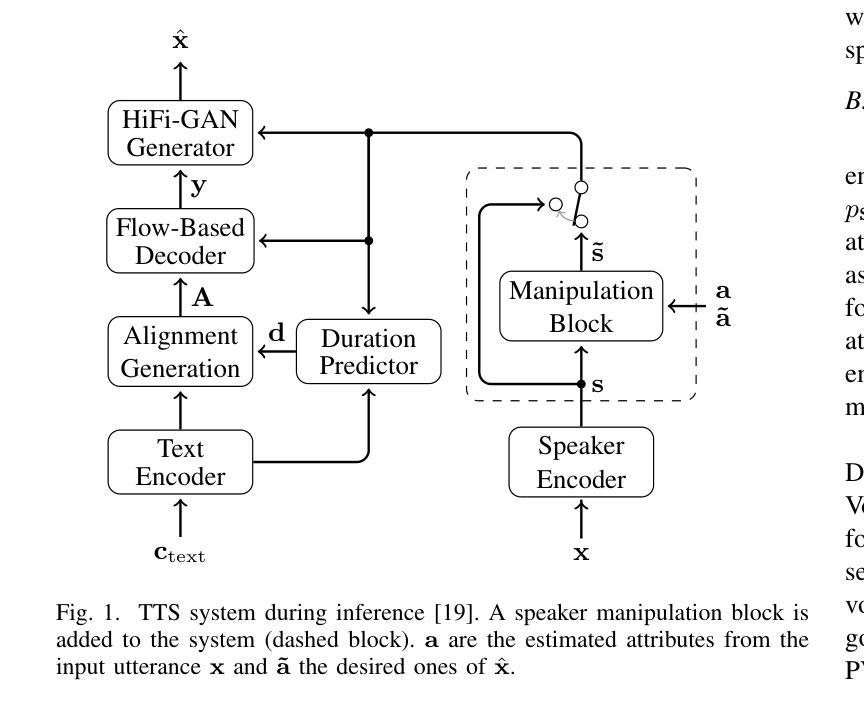
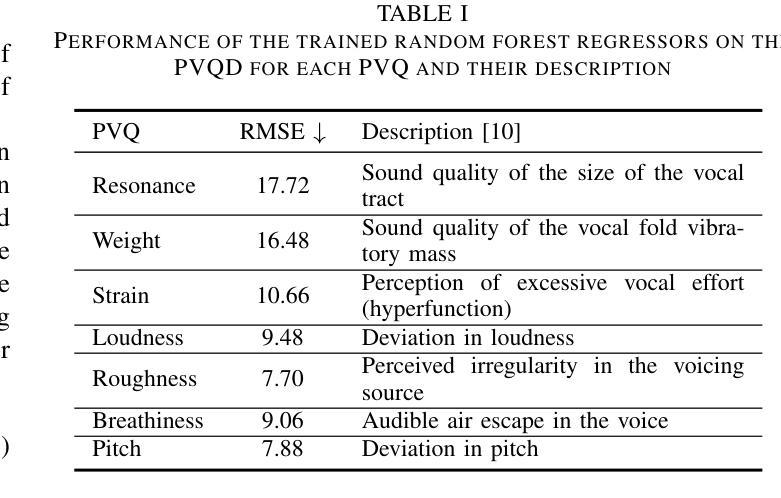
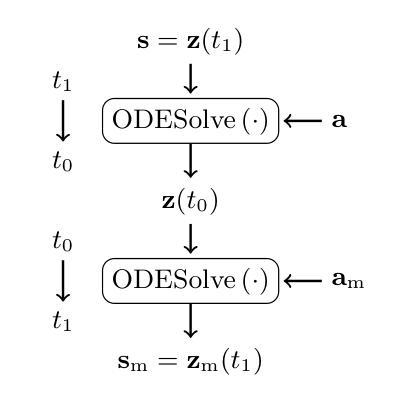
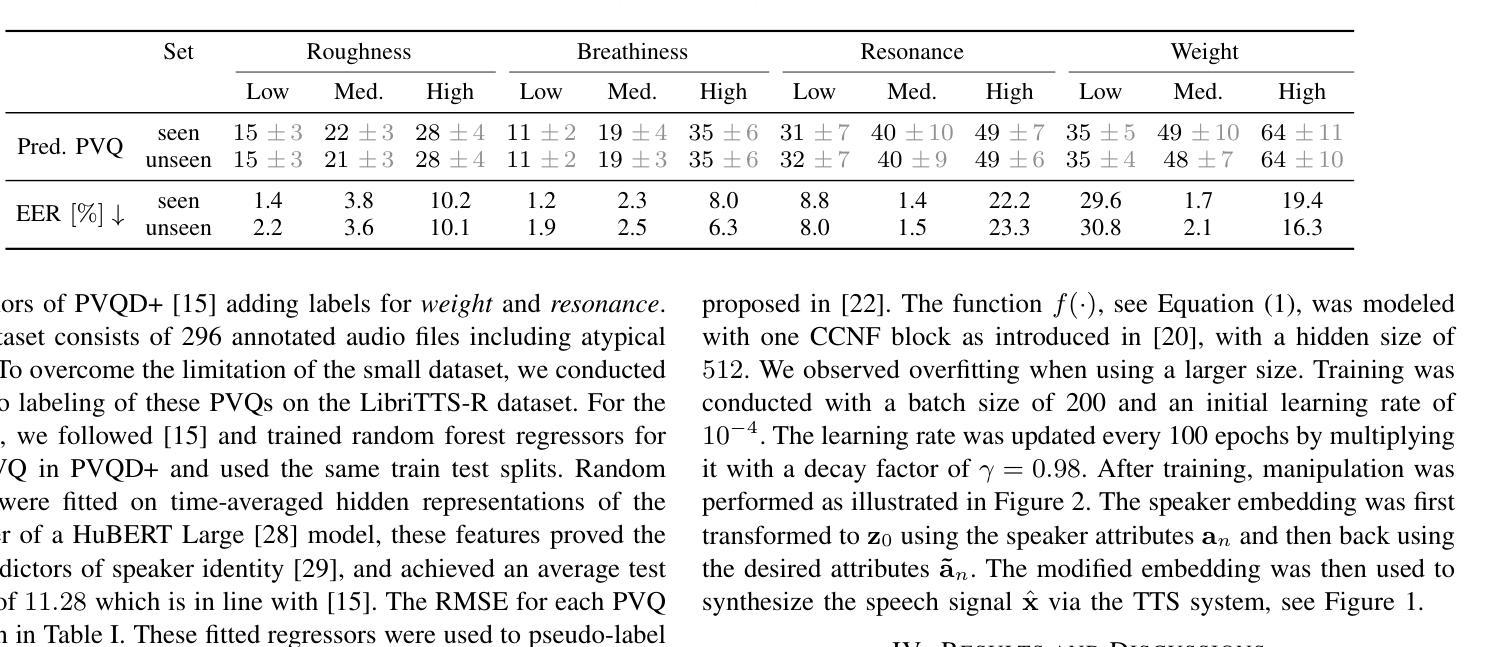
While expressive speech synthesis or voice conversion systems mainly focus on controlling or manipulating abstract prosodic characteristics of speech, such as emotion or accent, we here address the control of perceptual voice qualities (PVQs) recognized by phonetic experts, which are speech properties at a lower level of abstraction. The ability to manipulate PVQs can be a valuable tool for teaching speech pathologists in training or voice actors. In this paper, we integrate a Conditional Continuous-Normalizing-Flow-based method into a Text-to-Speech system to modify perceptual voice attributes on a continuous scale. Unlike previous approaches, our system avoids direct manipulation of acoustic correlates and instead learns from examples. We demonstrate the system’s capability by manipulating four voice qualities: Roughness, breathiness, resonance and weight. Phonetic experts evaluated these modifications, both for seen and unseen speaker conditions. The results highlight both the system’s strengths and areas for improvement.
在表达性语音合成或语音转换系统中,主要关注的是控制或操作抽象语音的韵律特征,如情感或口音。而在这里,我们关注的是语音专家所识别的感知语音质量(PVQs)的控制,这是抽象层次较低的语音特征。对感知语音质量的操作能力对于训练语音病理学家或配音演员来说可能是一个有价值的工具。在本文中,我们将基于条件连续归一化流的方法集成到文本到语音系统中,以在连续尺度上改变感知语音属性。不同于以前的方法,我们的系统避免了直接操作声学相关因素,而是从样本中学习。我们通过调整粗糙度、气息感、共鸣和重量四种语音质量来展示系统的能力。语音专家对已知和未知说话人的条件进行了评价。结果突出了系统的优点和改进的空间。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
文本聚焦于在文本转语音系统中控制感知语音质量(PVQs),这是一种被语音学家识别的语音属性,属于较低层次的抽象。文章介绍了集成条件连续归一化流方法到文本转语音系统中,以连续尺度修改感知语音特征。该系统避免直接操作声学关联,而是从例子中学习。通过操作粗糙度、气息感、共鸣和重量四种语音质量,展示了系统的能力,并得到了语音学家的评估结果。
Key Takeaways
- 文本主要关注在文本转语音系统中控制感知语音质量(PVQs)。
- 集成条件连续归一化流方法到TTS系统中,以修改感知语音特征。
- 系统避免直接操作声学关联,而是从例子中学习。
- 系统能够操作四种语音质量:粗糙度、气息感、共鸣和重量。
- 通过语音学家的评估,展示了系统的能力和改进空间。
- 此技术对于训练语音病理学家或声优具有潜在价值。
点此查看论文截图

Adaptive Data Augmentation with NaturalSpeech3 for Far-field Speaker Verification
Authors:Li Zhang, Jiyao Liu, Lei Xie
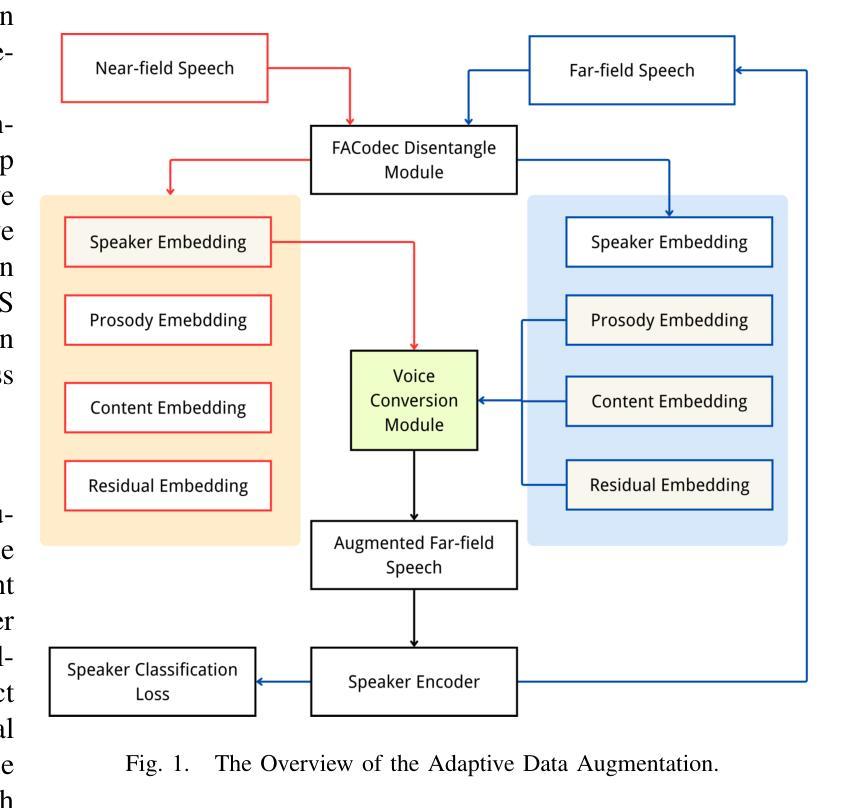
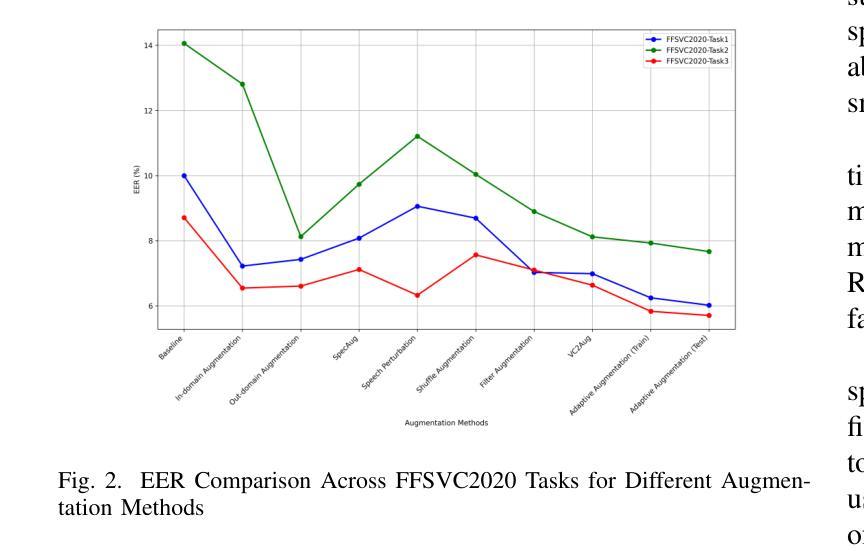
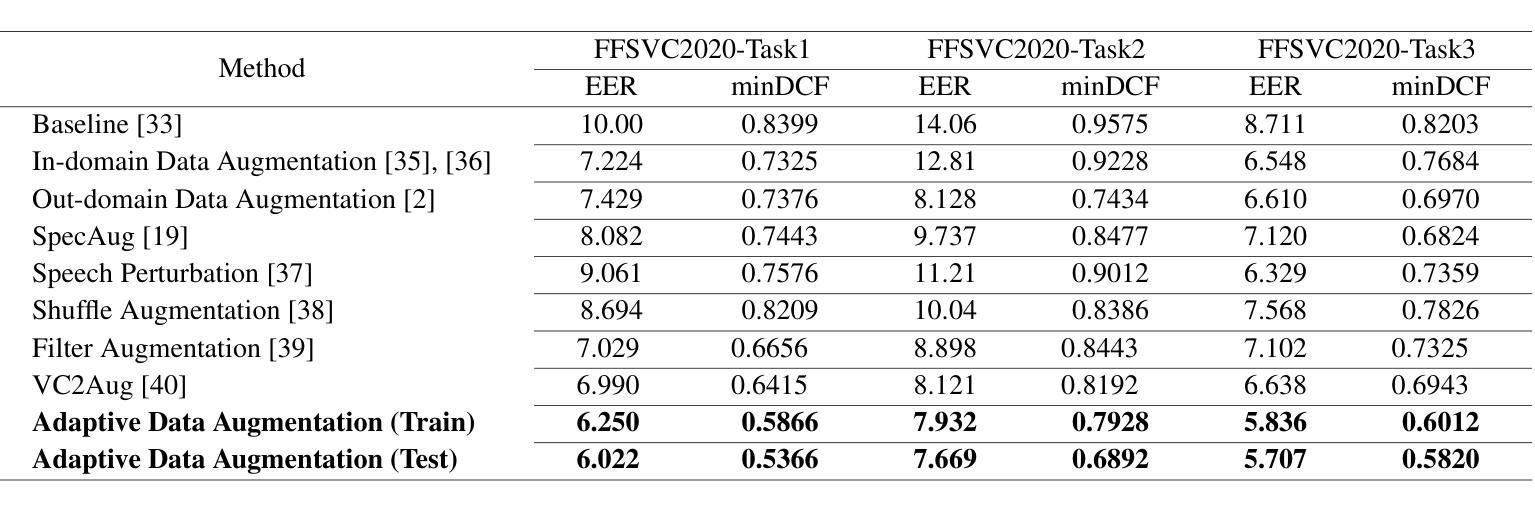
The scarcity of speaker-annotated far-field speech presents a significant challenge in developing high-performance far-field speaker verification (SV) systems. While data augmentation using large-scale near-field speech has been a common strategy to address this limitation, the mismatch in acoustic environments between near-field and far-field speech significantly hinders the improvement of far-field SV effectiveness. In this paper, we propose an adaptive speech augmentation approach leveraging NaturalSpeech3, a pre-trained foundation text-to-speech (TTS) model, to convert near-field speech into far-field speech by incorporating far-field acoustic ambient noise for data augmentation. Specifically, we utilize FACodec from NaturalSpeech3 to decompose the speech waveform into distinct embedding subspaces-content, prosody, speaker, and residual (acoustic details) embeddings-and reconstruct the speech waveform from these disentangled representations. In our method, the prosody, content, and residual embeddings of far-field speech are combined with speaker embeddings from near-field speech to generate augmented pseudo far-field speech that maintains the speaker identity from the out-domain near-field speech while preserving the acoustic environment of the in-domain far-field speech. This approach not only serves as an effective strategy for augmenting training data for far-field speaker verification but also extends to cross-data augmentation for enrollment and test speech in evaluation trials.Experimental results on FFSVC demonstrate that the adaptive data augmentation method significantly outperforms traditional approaches, such as random noise addition and reverberation, as well as other competitive data augmentation strategies.
在高性能远场语音识别(SV)系统的开发过程中,语音标注的稀缺性成为一大挑战。虽然使用大规模近场语音进行数据增强是一种常见的策略来解决这一局限性,但近场和远场语音声学环境的不匹配严重阻碍了远场SV效果的改进。在本文中,我们提出了一种自适应语音增强方法,利用预训练的文本到语音(TTS)模型NaturalSpeech3,通过融入远场声学环境噪声,将近场语音转换为远场语音来进行数据增强。具体来说,我们利用NaturalSpeech3中的FACodec将语音波形分解成不同的嵌入子空间——内容、韵律、说话者和残余(声学细节)嵌入,并从这些解耦的表示中重建语音波形。在我们的方法中,远场语音的韵律、内容和残余嵌入与近场语音的说话者嵌入相结合,生成了保留近域说话人身份但保留目标域远场语音声学环境的增强的伪远场语音。这种方法不仅可作为远场语音识别训练数据增强的有效策略,还可扩展到评估试验中的跨数据增强报名和测试语音。在FFSVC上的实验结果表明,自适应数据增强方法显著优于传统的随机噪声添加和混响方法以及其他竞争性的数据增强策略。
论文及项目相关链接
Summary
本文介绍了在自然说话场景下远场语音识别(SV)系统的挑战,尤其是数据匮乏的问题。为了解决这一挑战,提出了利用自适应语音增强技术结合预训练文本转语音(TTS)模型NaturalSpeech3来转化近场语音为远场语音的策略。通过FACodec分解语音波形,并结合近场语音的说话者嵌入与远场语音的声学细节嵌入,生成具有说话者身份且保留远场声学环境的伪远场语音数据。实验结果表明,该方法在远场说话者验证上的表现优于传统数据增强策略。
Key Takeaways
- 远场语音识别系统面临缺乏说话者标注数据的挑战。
- 数据增强是解决此问题的一种常见策略,但近场与远场语音声学环境的差异限制了其效果。
- 提出了一种自适应语音增强方法,结合预训练的TTS模型NaturalSpeech3进行近转远场语音转化。
- 使用FACodec分解语音波形为内容、语调、说话者和残余声学细节嵌入。
- 结合近场语音的说话者嵌入和远场语音的声学细节嵌入生成伪远场语音数据。
- 该方法不仅有效增强了训练数据,还适用于评估试验中的跨数据增强。
点此查看论文截图