⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
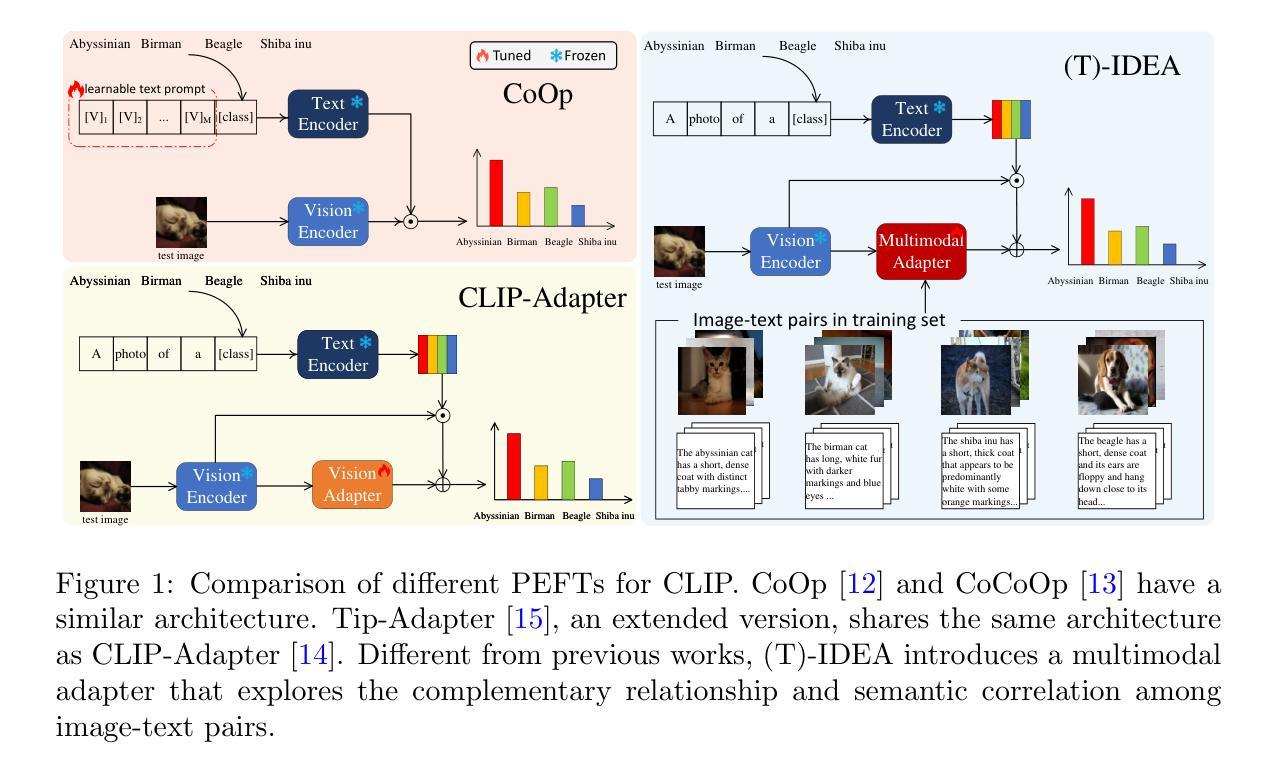
IDEA: Image Description Enhanced CLIP-Adapter
Authors:Zhipeng Ye, Feng Jiang, Qiufeng Wang, Kaizhu Huang, Jiaqi Huang
CLIP (Contrastive Language-Image Pre-training) has attained great success in pattern recognition and computer vision. Transferring CLIP to downstream tasks (e.g. zero- or few-shot classification) is a hot topic in multimodal learning. However, current studies primarily focus on either prompt learning for text or adapter tuning for vision, without fully exploiting the complementary information and correlations among image-text pairs. In this paper, we propose an Image Description Enhanced CLIP-Adapter (IDEA) method to adapt CLIP to few-shot image classification tasks. This method captures fine-grained features by leveraging both visual features and textual descriptions of images. IDEA is a training-free method for CLIP, and it can be comparable to or even exceeds state-of-the-art models on multiple tasks. Furthermore, we introduce Trainable-IDEA (T-IDEA), which extends IDEA by adding two lightweight learnable components (i.e., a projector and a learnable latent space), further enhancing the model’s performance and achieving SOTA results on 11 datasets. As one important contribution, we employ the Llama model and design a comprehensive pipeline to generate textual descriptions for images of 11 datasets, resulting in a total of 1,637,795 image-text pairs, named “IMD-11”. Our code and data are released at https://github.com/FourierAI/IDEA.
CLIP(对比语言图像预训练)在模式识别和计算机视觉领域取得了巨大的成功。将CLIP应用于下游任务(例如零样本或小样本分类)是多模态学习的热门话题。然而,当前的研究主要关注文本提示学习或视觉适配器调整,而没有充分利用图像文本对之间的互补信息和关联。在本文中,我们提出了一种图像描述增强CLIP适配器(IDEA)方法,将CLIP适应于小样本图像分类任务。该方法通过利用图像的视觉特征和文本描述来捕获精细特征。IDEA是一种不需要训练的CLIP方法,它在多个任务上的表现可与最新模型相当甚至超过。此外,我们引入了可训练的IDEA(T-IDEA),它通过添加两个轻量级的学习组件(即投影器和可学习的潜在空间)来扩展IDEA,进一步提高了模型的性能,并在11个数据集上达到了最新结果。作为重要贡献之一,我们采用了Llama模型,并设计了一个综合流程来生成11个数据集的图像文本描述,共生成了1,637,795个图像文本对,命名为“IMD-11”。我们的代码和数据已发布在https://github.com/FourierAI/IDEA。
论文及项目相关链接
Summary
CLIP模型在多模态学习中备受关注,尤其在图像分类任务中的应用。当前研究主要集中在文本提示学习或视觉适配器调整上,但未充分利用图像文本对之间的互补信息和关联。本文提出了一种基于图像描述增强的CLIP适配器(IDEA)方法,用于适应少样本图像分类任务。该方法利用视觉特征和图像文本描述来捕捉细粒度特征。IDEA是CLIP的一种无训练方法,可在多个任务上与最新模型相比,甚至超越它们。此外,本文还介绍了通过添加两个轻量级可学习组件(即投影器和可学习潜在空间)的Trainable-IDEA(T-IDEA),进一步提高了模型性能,并在11个数据集上实现了最新结果。本文还使用Llama模型设计了一个全面的流程来生成图像文本描述,并发布了代码和数据集。
Key Takeaways
- CLIP模型在多模态学习中的研究主要集中在图像分类任务上。
- 当前研究在CLIP模型的迁移应用中,主要关注文本提示学习或视觉适配器调整,未能充分利用图像与文本之间的互补信息和关联。
- IDEA方法通过结合视觉特征和图像文本描述,用于适应少样本图像分类任务,实现了良好的性能。
- IDEA是一种无训练方法,可在多个任务上与最新模型相比或超越它们。
- Trainable-IDEA(T-IDEA)通过添加两个轻量级可学习组件来进一步增强模型性能。
- 该研究使用Llama模型生成了全面的图像文本描述流程和数据集,名为“IMD-11”。
点此查看论文截图

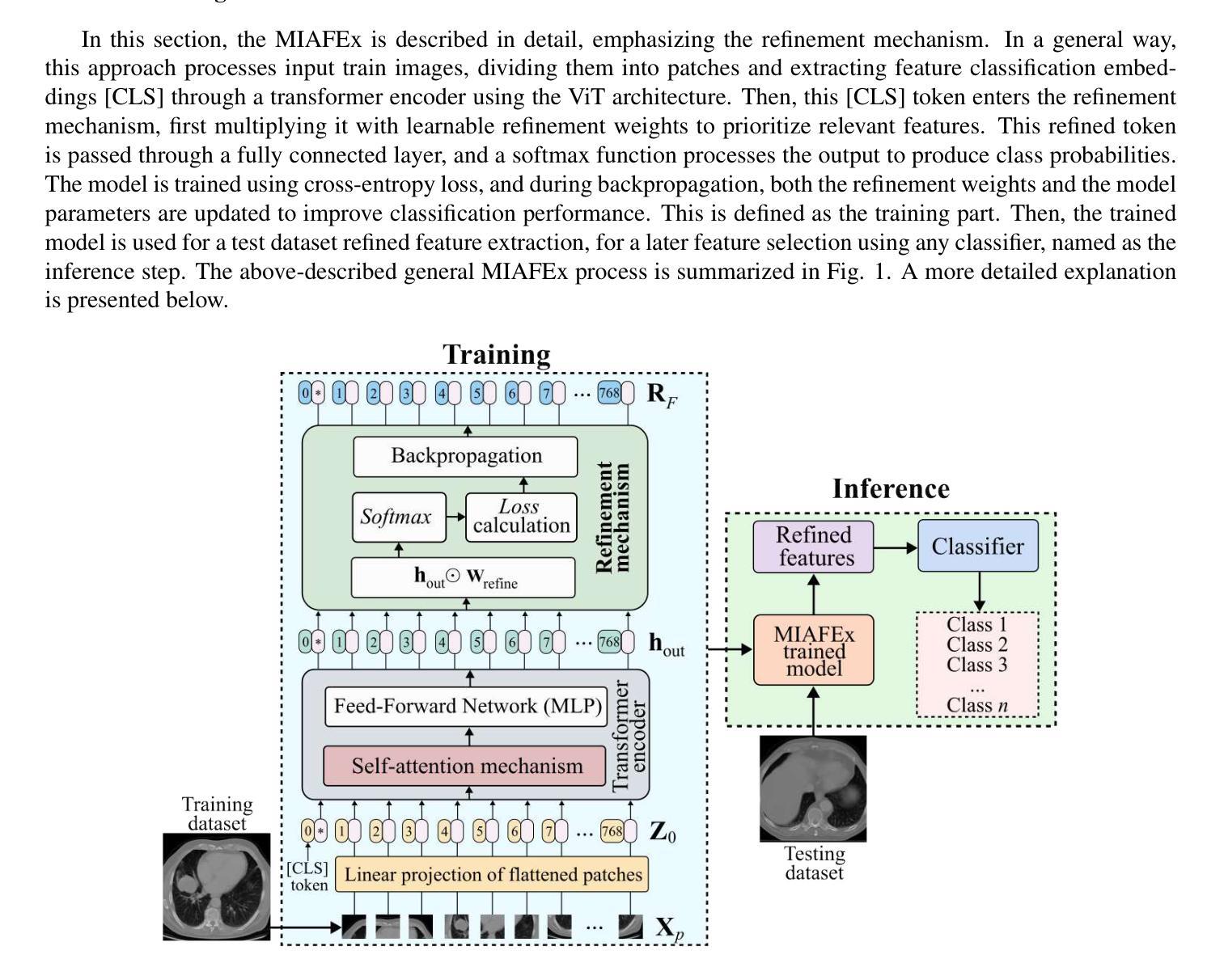
MIAFEx: An Attention-based Feature Extraction Method for Medical Image Classification
Authors:Oscar Ramos-Soto, Jorge Ramos-Frutos, Ezequiel Perez-Zarate, Diego Oliva, Sandra E. Balderas-Mata
Feature extraction techniques are crucial in medical image classification; however, classical feature extractors in addition to traditional machine learning classifiers often exhibit significant limitations in providing sufficient discriminative information for complex image sets. While Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) have shown promise in feature extraction, they are prone to overfitting due to the inherent characteristics of medical imaging data, including small sample sizes or high intra-class variance. In this work, the Medical Image Attention-based Feature Extractor (MIAFEx) is proposed, a novel method that employs a learnable refinement mechanism to enhance the classification token within the Transformer encoder architecture. This mechanism adjusts the token based on learned weights, improving the extraction of salient features and enhancing the model’s adaptability to the challenges presented by medical imaging data. The MIAFEx output features quality is compared against classical feature extractors using traditional and hybrid classifiers. Also, the performance of these features is compared against modern CNN and ViT models in classification tasks, demonstrating its superiority in accuracy and robustness across multiple complex classification medical imaging datasets. This advantage is particularly pronounced in scenarios with limited training data, where traditional and modern models often struggle to generalize effectively. The source code of this proposal can be found at https://github.com/Oscar-RamosS/Medical-Image-Attention-based-Feature-Extractor-MIAFEx
特征提取技术在医学图像分类中至关重要;然而,除了传统的机器学习分类器外,经典的特征提取器在为复杂的图像集提供足够的判别信息方面通常存在显著局限性。虽然卷积神经网络(CNN)和视觉转换器(ViT)在特征提取方面显示出潜力,但由于医学成像数据固有的特性,包括样本量小或类内方差高,它们容易发生过拟合。在本研究中,提出了医学图像注意力特征提取器(MIAFEx),这是一种采用可学习细化机制的新方法,旨在增强Transformer编码器架构中的分类令牌。该机制根据学习到的权重调整令牌,提高了显著特征的提取,并增强了模型对医学成像数据挑战的适应性。MIAFEx输出的特征质量使用传统和混合分类器与经典特征提取器进行了比较。此外,这些特征在分类任务中的性能与现代CNN和ViT模型进行了比较,在多个复杂的医学图像分类数据集上证明了其在准确性和稳健性方面的优越性。在训练数据有限的情况下,这种优势尤为突出,传统和现代模型往往难以有效地推广。该提案的源代码可在https://github.com/Oscar-RamosS/Medical-Image-Attention-based-Feature-Extractor-MIAFEx找到。
论文及项目相关链接
PDF In preparation for Journal Submission
Summary
医疗图像分类中特征提取技术至关重要。传统特征提取器及机器学习分类器在处理复杂图像集时提供的判别信息不足。卷积神经网络(CNN)和视觉转换器(ViT)虽具潜力,但医疗图像数据的小样本量或高类内差异等内在特性导致其容易过拟合。为此,提出了医疗图像注意力特征提取器(MIAFEx),采用可学习的细化机制,调整基于学习权重的令牌,提高显著特征的提取能力,增强模型对医疗图像数据的适应性。与经典特征提取器和现代CNN及ViT模型相比,MIAFEx在多个复杂的医疗图像分类数据集上表现出更高的准确性和稳健性,特别是在训练数据有限的情况下,传统和现代模型的泛化能力往往较弱。
Key Takeaways
- 医疗图像分类中特征提取的重要性及其对传统特征提取器和机器学习分类器的挑战。
- CNN和ViT在医疗图像数据上的潜力,但存在过拟合问题。
- 新提出的MIAEx模型采用注意力机制,通过可学习的细化机制增强特征提取能力。
- MIAEx模型在多个医疗图像分类数据集上表现出优异的性能和准确性。
5.MIAEx模型尤其适用于训练数据有限的情况,传统和现代模型的泛化能力在此场景下相对较弱。
6.MIAEx模型的源代码可公开获取,便于进一步研究和应用。 - 该方法通过结合注意力机制和现代深度学习技术,为医疗图像分析领域提供了新的解决方案。
点此查看论文截图