⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
SRE-Conv: Symmetric Rotation Equivariant Convolution for Biomedical Image Classification
Authors:Yuexi Du, Jiazhen Zhang, Tal Zeevi, Nicha C. Dvornek, John A. Onofrey
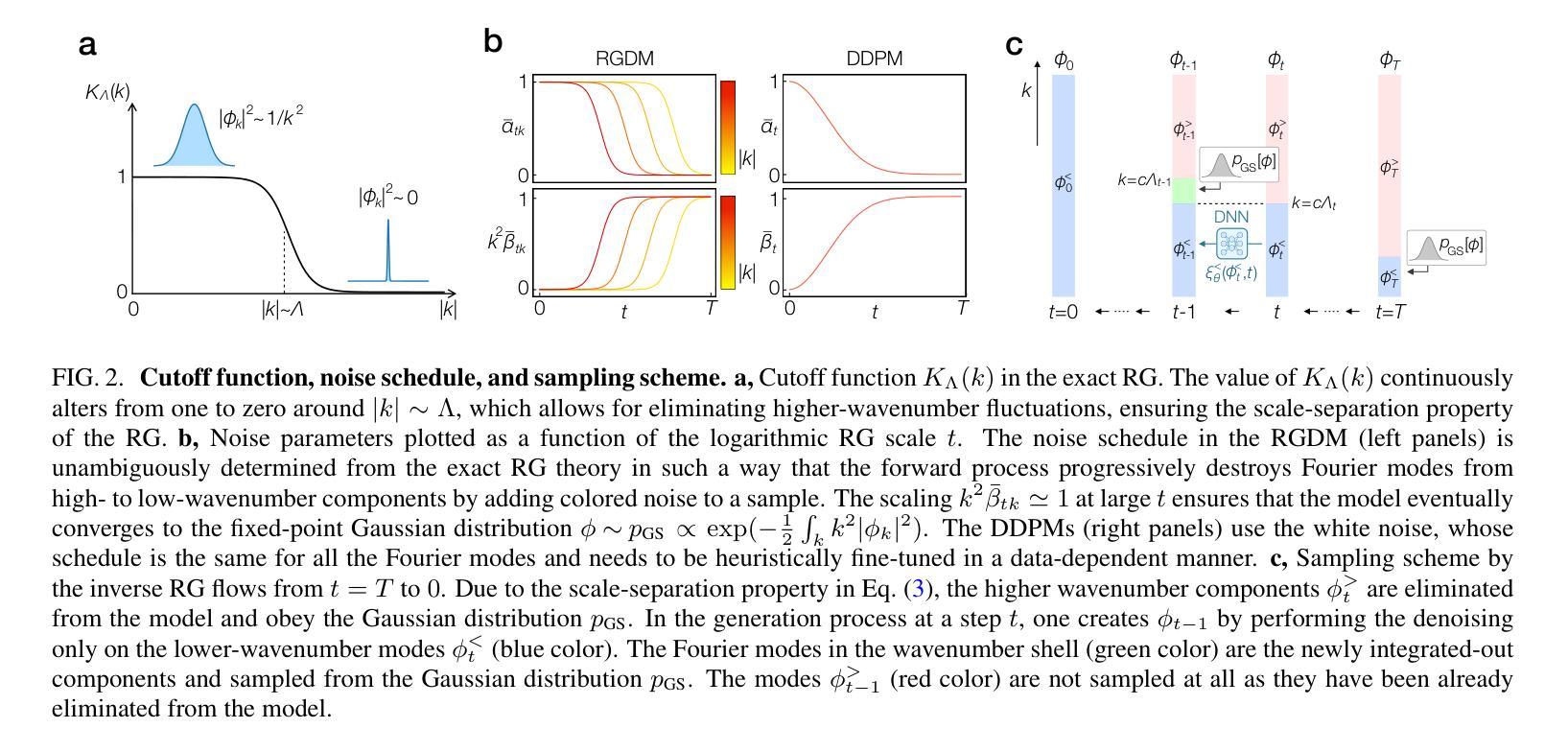
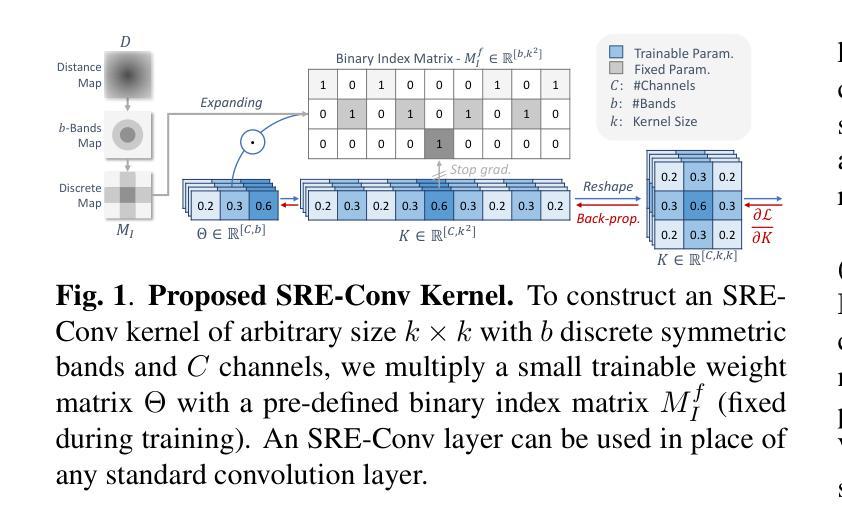
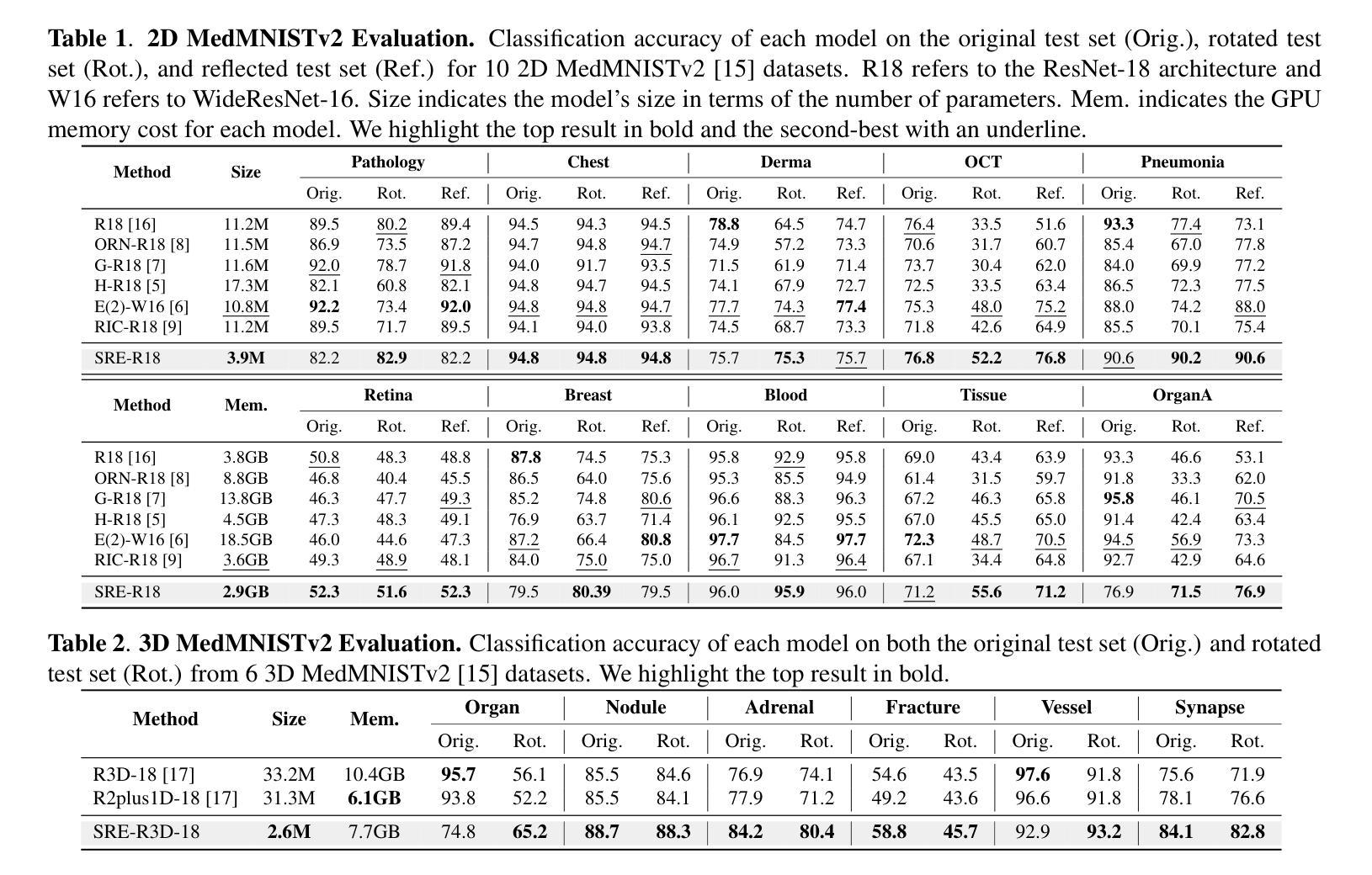
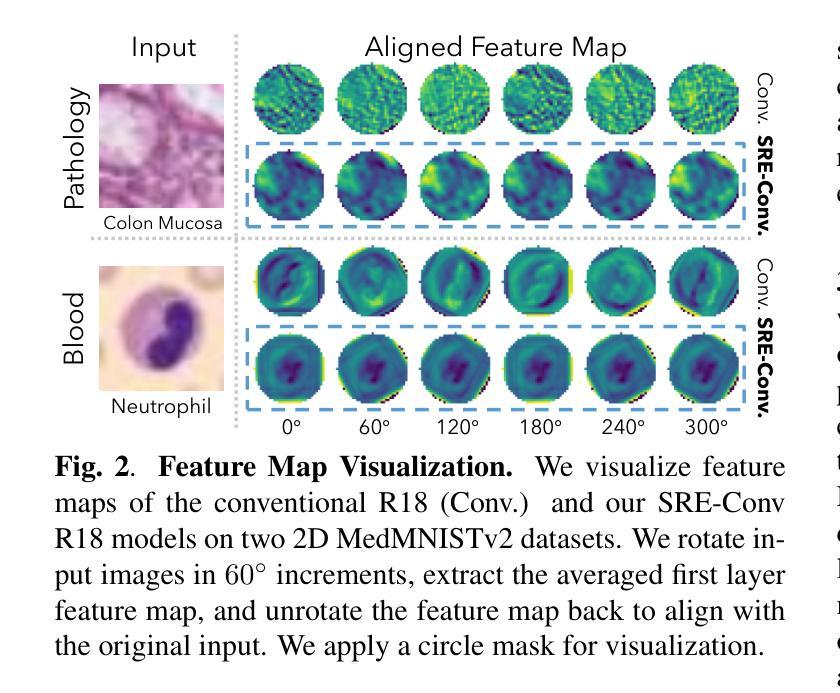
Convolutional neural networks (CNNs) are essential tools for computer vision tasks, but they lack traditionally desired properties of extracted features that could further improve model performance, e.g., rotational equivariance. Such properties are ubiquitous in biomedical images, which often lack explicit orientation. While current work largely relies on data augmentation or explicit modules to capture orientation information, this comes at the expense of increased training costs or ineffective approximations of the desired equivariance. To overcome these challenges, we propose a novel and efficient implementation of the Symmetric Rotation-Equivariant (SRE) Convolution (SRE-Conv) kernel, designed to learn rotation-invariant features while simultaneously compressing the model size. The SRE-Conv kernel can easily be incorporated into any CNN backbone. We validate the ability of a deep SRE-CNN to capture equivariance to rotation using the public MedMNISTv2 dataset (16 total tasks). SRE-Conv-CNN demonstrated improved rotated image classification performance accuracy on all 16 test datasets in both 2D and 3D images, all while increasing efficiency with fewer parameters and reduced memory footprint. The code is available at https://github.com/XYPB/SRE-Conv.
卷积神经网络(CNN)是计算机视觉任务的重要工具,但它们缺乏能够进一步提高模型性能的所提取特征的传统所需属性,例如旋转等变性。这种属性在生物医学图像中普遍存在,而生物医学图像往往缺乏明确的方位。尽管当前的工作大多依赖于数据增强或显式模块来捕获方位信息,但这会增加训练成本或对所需的等变性的近似无效。为了克服这些挑战,我们提出了一种新型高效的对称旋转等变(SRE)卷积(SRE-Conv)内核的实现方式,旨在学习旋转不变特征的同时压缩模型大小。SRE-Conv内核可以轻松集成到任何CNN主干中。我们使用公共MedMNISTv2数据集(共16项任务)验证了深度SRE-CNN捕获旋转等变性的能力。在16个测试数据集的二维和三维旋转图像分类中,SRE-Conv-CNN均表现出更高的分类性能准确性,同时提高了效率,减少了参数和内存占用。代码可在https://github.com/XYPB/SRE-Conv找到。
论文及项目相关链接
PDF Accepted by IEEE ISBI 2025 4-page paper
Summary
本文提出了一种新型的对称旋转等变卷积(SRE-Conv)核,该核可轻松融入任何CNN骨干网络,用于学习旋转不变特征并压缩模型大小。在公共MedMNISTv2数据集上进行的实验表明,SRE-Conv-CNN在旋转图像分类任务上表现优异,同时减少了参数和内存占用。
Key Takeaways
- 本文介绍了卷积神经网络(CNN)在医学图像处理中的局限性,特别是在处理旋转等变性问题时面临的挑战。
- 提出了一种新型的对称旋转等变卷积(SRE-Conv)核,旨在解决这些问题并提升模型性能。
- SRE-Conv核具有学习旋转不变特征的能力,同时可压缩模型大小。
- 实验结果显示,SRE-Conv-CNN在旋转图像分类任务上表现优于传统CNN。
- 该方法在所有测试的16个数据集上均表现出较好的性能提升,适用于二维和三维图像。
- 该方法通过减少参数和内存占用提高了效率。
点此查看论文截图

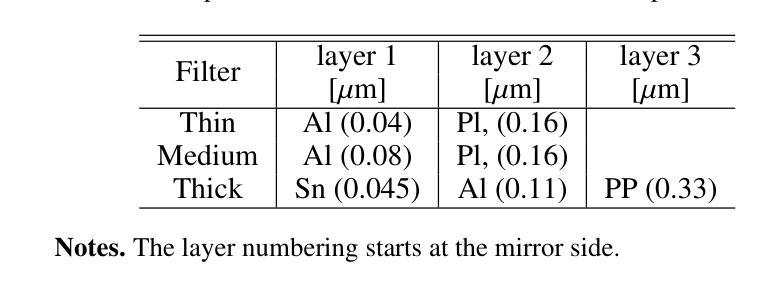
Unveiling the origin of XMM-Newton soft proton flares: I. Design and validation of a response matrix for proton spectral analysis
Authors:Valentina Fioretti, Teresa Mineo, Simone Lotti, Silvano Molendi, Giorgio Lanzuisi, Roberta Amato, Claudio Macculi, Massimo Cappi, Mauro Dadina, Stefano Ettori, Fabio Gastaldello
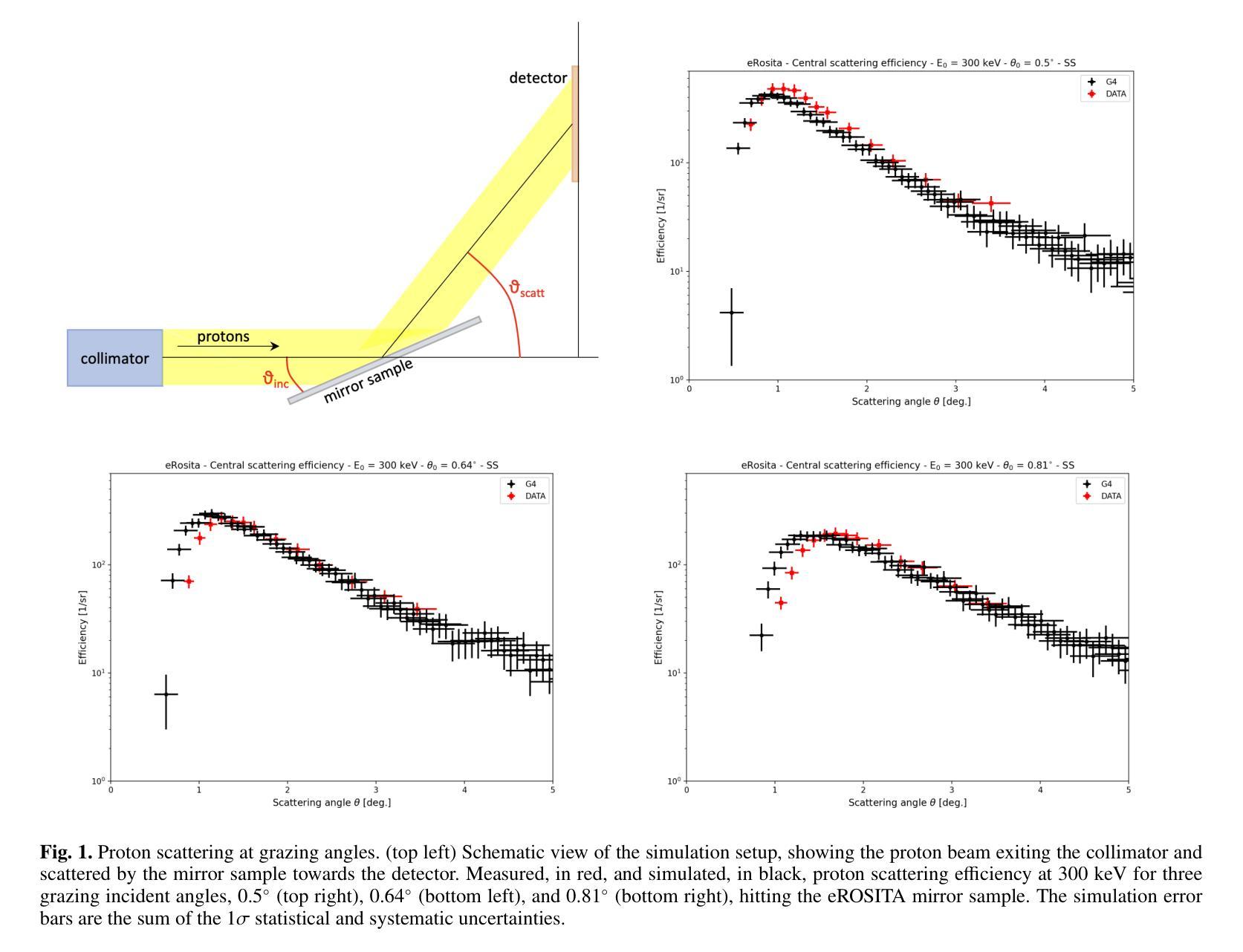
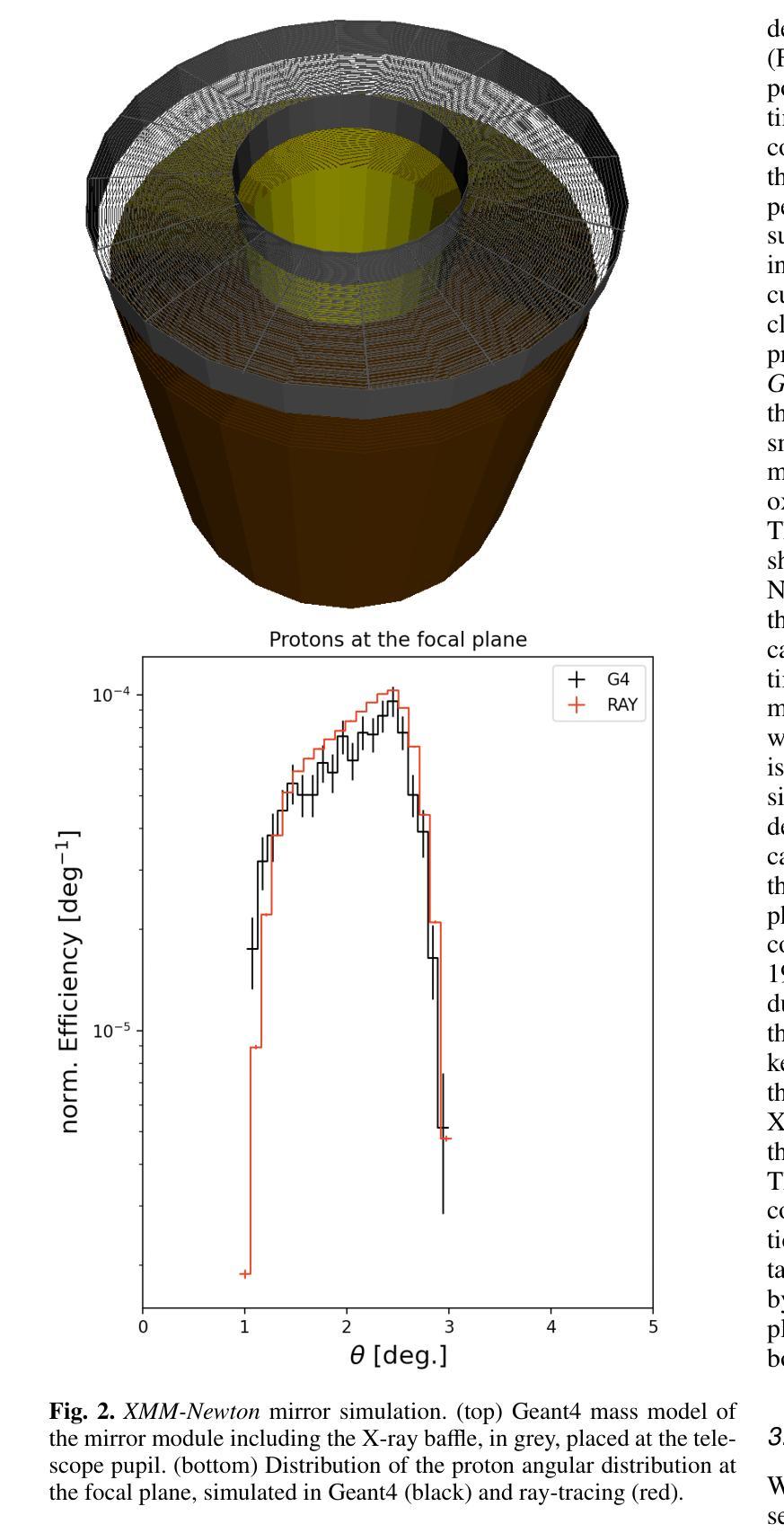
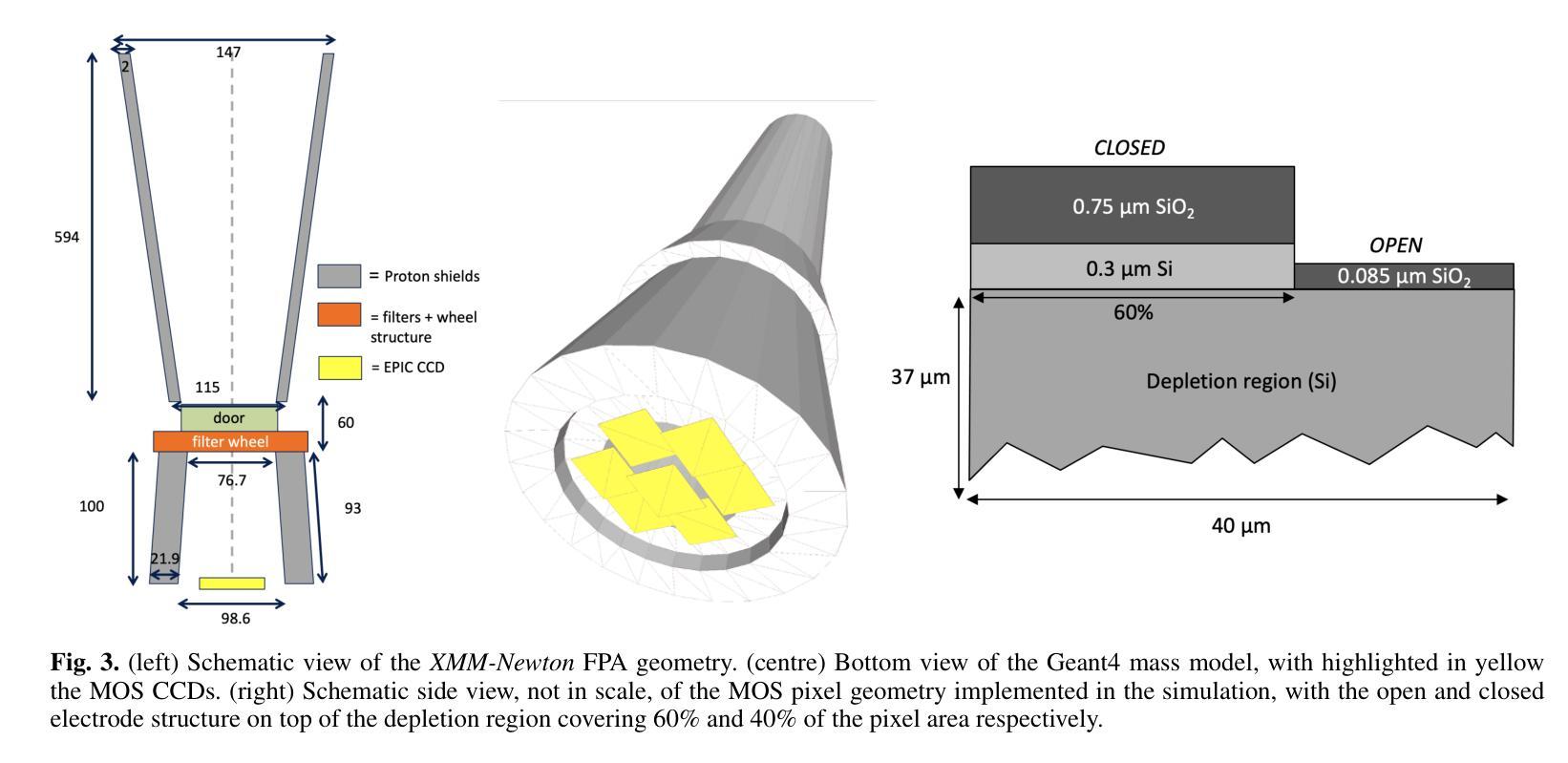
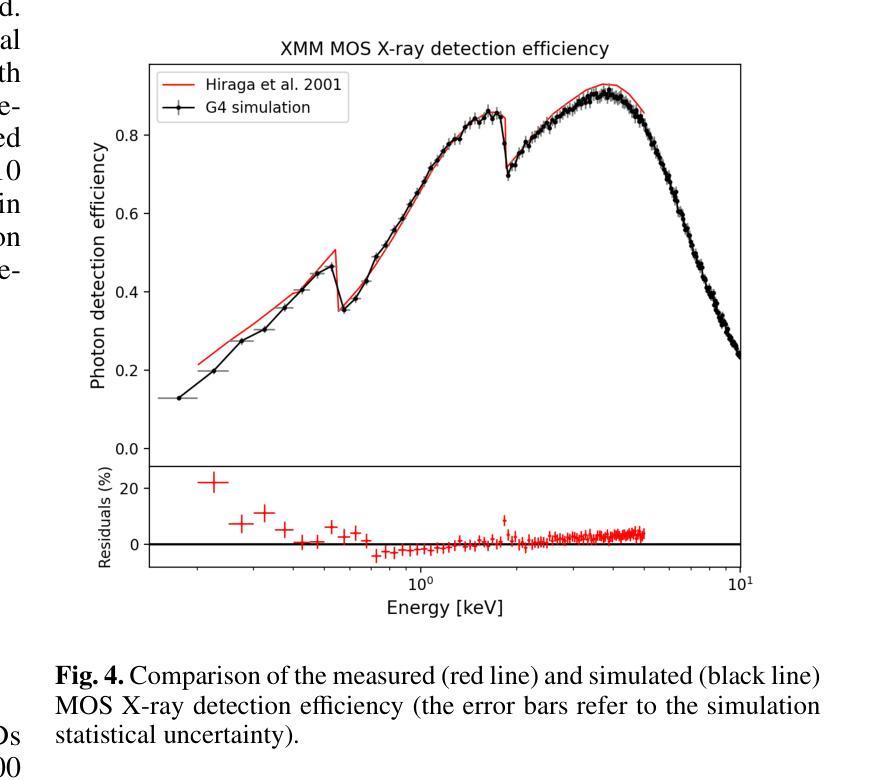
Low-energy (<300 keV) protons entering the field of view of XMM-Newton are observed in the form of a sudden increase in the background level, the so-called soft proton flares, affecting up to 40% of the mission observing time. In-flight XMM-Newton’s observations of soft protons represent a unique laboratory to validate and improve our understanding of their interaction with the mirror, optical filters, and X-ray instruments. At the same time, such models would link the observed background flares to the primary proton population encountered by the telescope, converting XMM-Newton into a monitor for soft protons. We built a Geant4 simulation of XMM-Newton, including a verified mass model of the X-ray mirror, the focal plane assembly, and the EPIC MOS and pn-CCDs. We encoded the energy redistribution and proton transmission efficiency into a redistribution matrix file (RMF) and an auxiliary response file (ARF). For the validation, three averaged soft proton spectra, one for each filter configuration, were extracted from a collection of 13 years of MOS observations of the focused non X-ray background and analysed with Xspec. The best-fit model is in agreement with the power-law distribution predicted from independent measurements for the XMM-Newton orbit, spent mostly in the magnetosheath and nearby regions. For the first time we are able to link detected soft proton flares with the proton radiation environment in the Earth’s magnetosphere, while proving the validity of the simulation chain in predicting the background of future missions. Benefiting from this work and contributions from the Athena instrument consortia, we also present the response files for the Athena mission and updated estimates for its focused charged background.
低能量(<300 keV)质子进入XMM-Newton的视野时,以背景水平的突然增加的形式被观察到,这就是所谓的软质子耀斑,影响高达40%的任务观测时间。飞行中的XMM-Newton对软质子的观测为我们提供了一个独特的实验室,以验证和改进我们对它们与镜子、光学过滤器以及X射线仪器相互作用的了解。同时,这样的模型将观察到的背景耀斑与望远镜遇到的主要质子群体联系起来,将XMM-Newton转化为软质子监测器。我们建立了Geant4模拟的XMM-Newton,包括经过验证的X射线镜子的质量模型、焦平面组件以及EPIC MOS和pn-CCD。我们将能量再分配和质子传输效率编码为再分配矩阵文件(RMF)和辅助响应文件(ARF)。为了验证,我们从13年的MOS观测中抽取了三种平均软质子光谱(每种过滤器配置一种),并对其进行了分析。最佳拟合模型与XMM-Newton轨道的独立测量所预测出的幂律分布一致,其大部分时间都在磁鞘和附近区域度过。我们首次能够将检测到的软质子耀斑与地球磁层中的质子辐射环境联系起来,同时证明了模拟链在预测未来任务背景方面的有效性。得益于这项工作以及雅典娜仪器联合会的贡献,我们还为雅典娜任务提供了响应文件,并更新了其聚焦带电背景的估计。
论文及项目相关链接
摘要
低能质子进入XMM-牛顿望远镜视场时,会观察到背景水平突然增加,即所谓的软质子耀斑,影响高达40%的任务观测时间。在飞行过程中,XMM-牛顿对软质子的观测为我们验证和改进对镜子、光学过滤器以及X射线仪器与质子的相互作用的理解提供了独特的实验室。同时,该模型将观测到的背景耀斑与望远镜遇到的主要质子人口联系起来,使XMM-牛顿成为软质子的监测器。我们建立了Geant4模拟的XMM-牛顿模型,包括经验证的X射线镜、焦平面组件以及EPIC MOS和pn-CCD的质量模型。我们将能量再分配和质子传输效率编码为再分配矩阵文件(RMF)和辅助响应文件(ARF)。为了验证,我们从13年的MOS观测中抽取了三种平均软质子光谱,每种过滤器配置一种,并用Xspec进行了分析。最佳拟合模型与XMM-牛顿轨道的独立测量所预测出的幂律分布一致,其大部分时间都在磁鞘和附近区域度过。我们首次能够将检测到的软质子耀斑与地球磁层中的质子辐射环境联系起来,同时证明了模拟链在预测未来任务背景方面的有效性。得益于这项工作以及雅典娜仪器联合会的贡献,我们还为雅典娜任务提供了响应文件,并更新了其聚焦带电背景的估计。
关键见解
- 低能质子进入XMM-牛顿望远镜会引起背景水平突然增加,即软质子耀斑,影响约40%的观测时间。
- 在轨XMM-牛顿对软质子的观测提供了一个验证和改进质子与仪器相互作用理解的平台。
- 构建了包括X射线镜、焦平面组件等的Geant4模拟XMM-牛顿模型。
- 通过编码能量再分配和质子传输效率,创建了RMF和ARF文件。
- 通过Xspec分析,最佳拟合模型与独立测量预测的幂律分布一致。
- 首次将软质子耀斑与地球磁层中的质子辐射环境联系起来。
点此查看论文截图

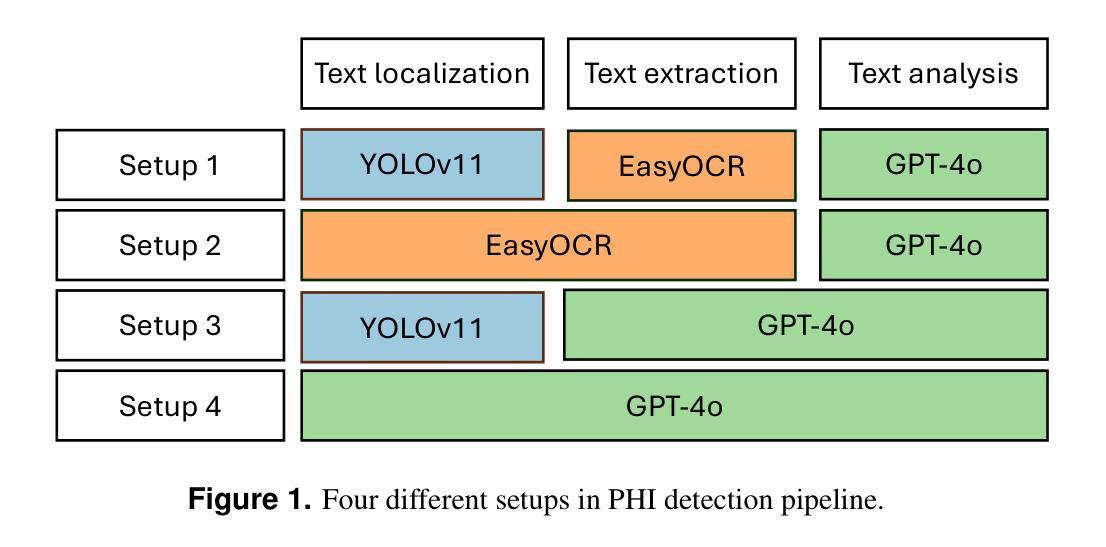
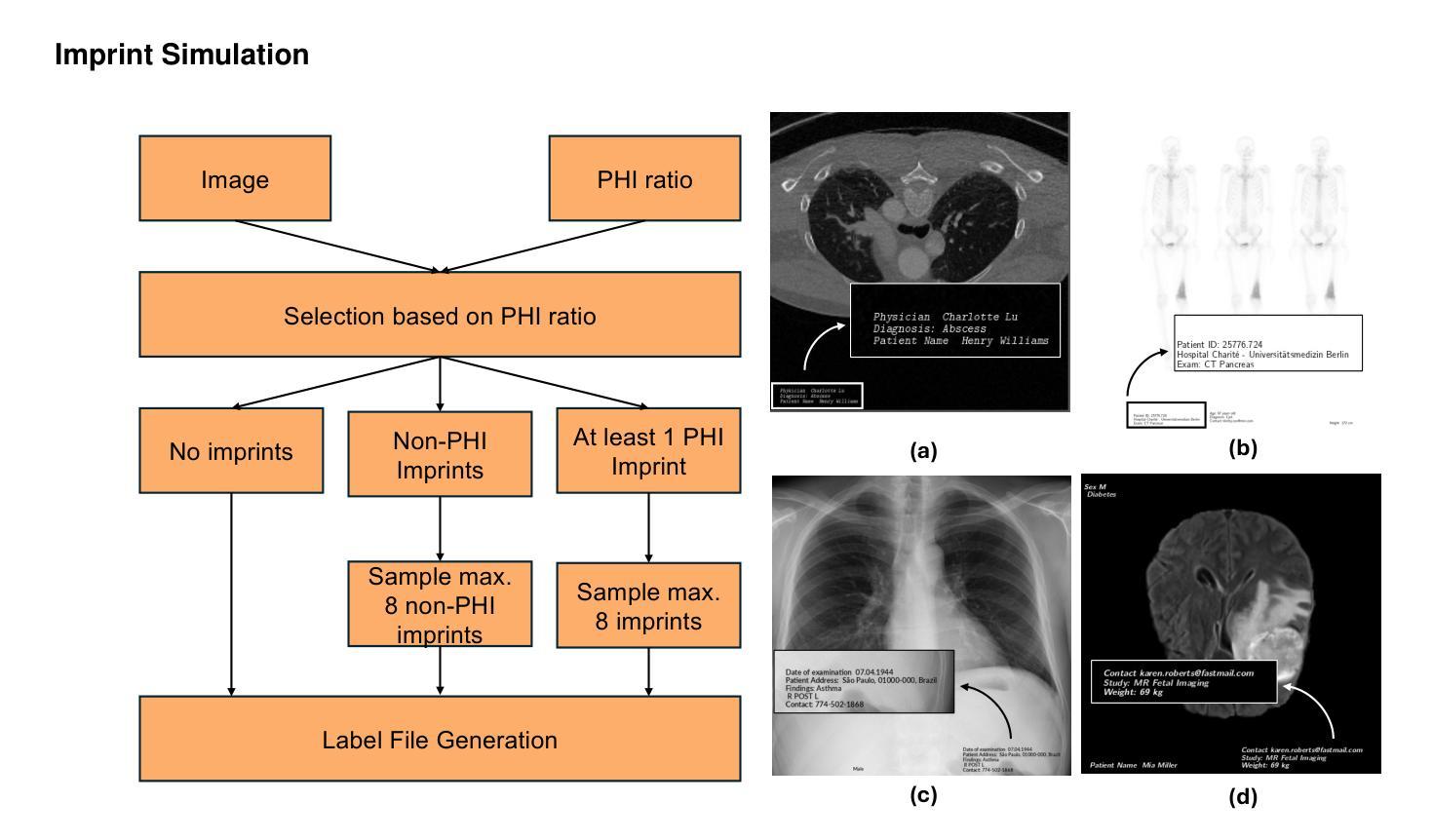
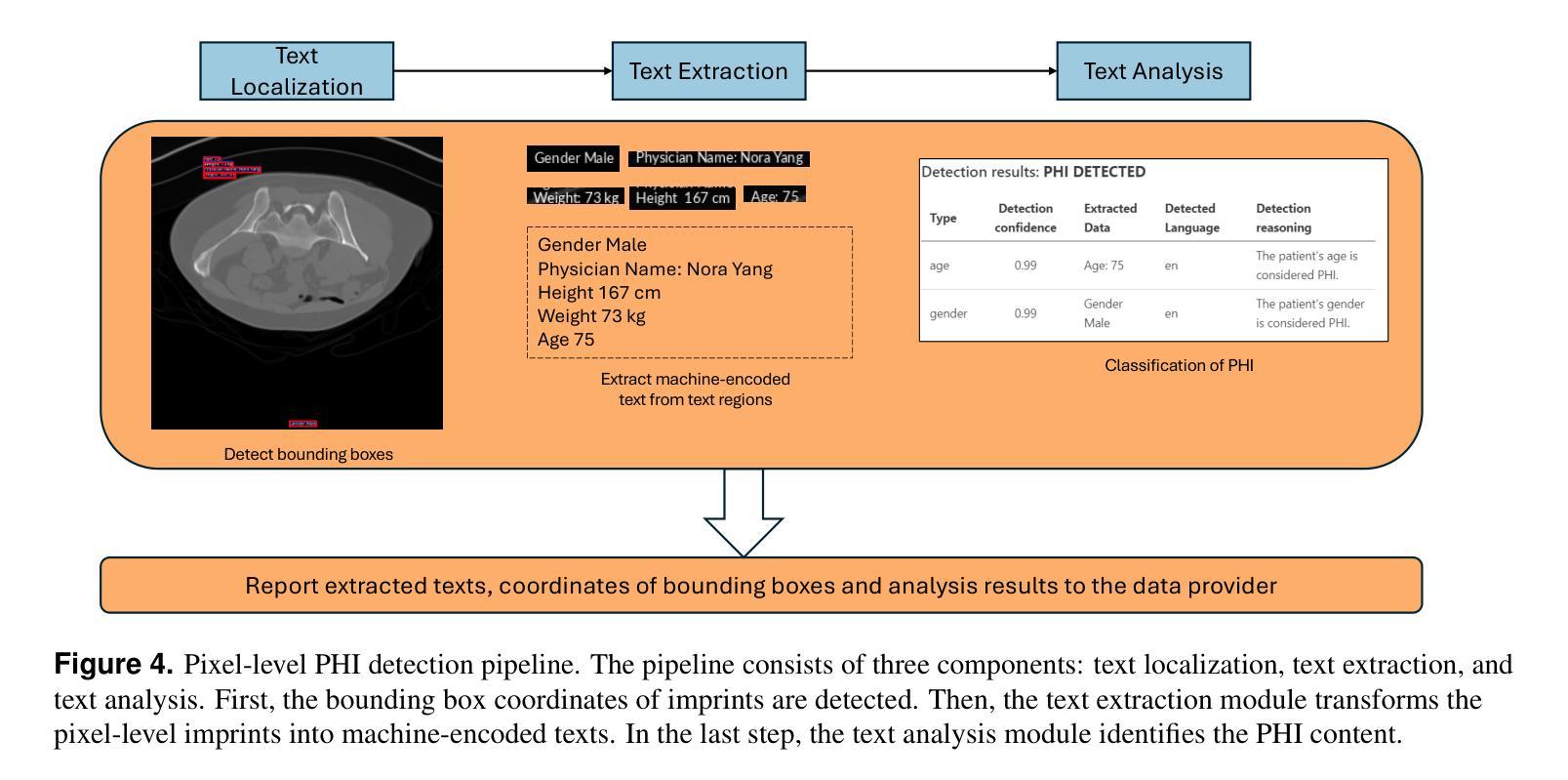
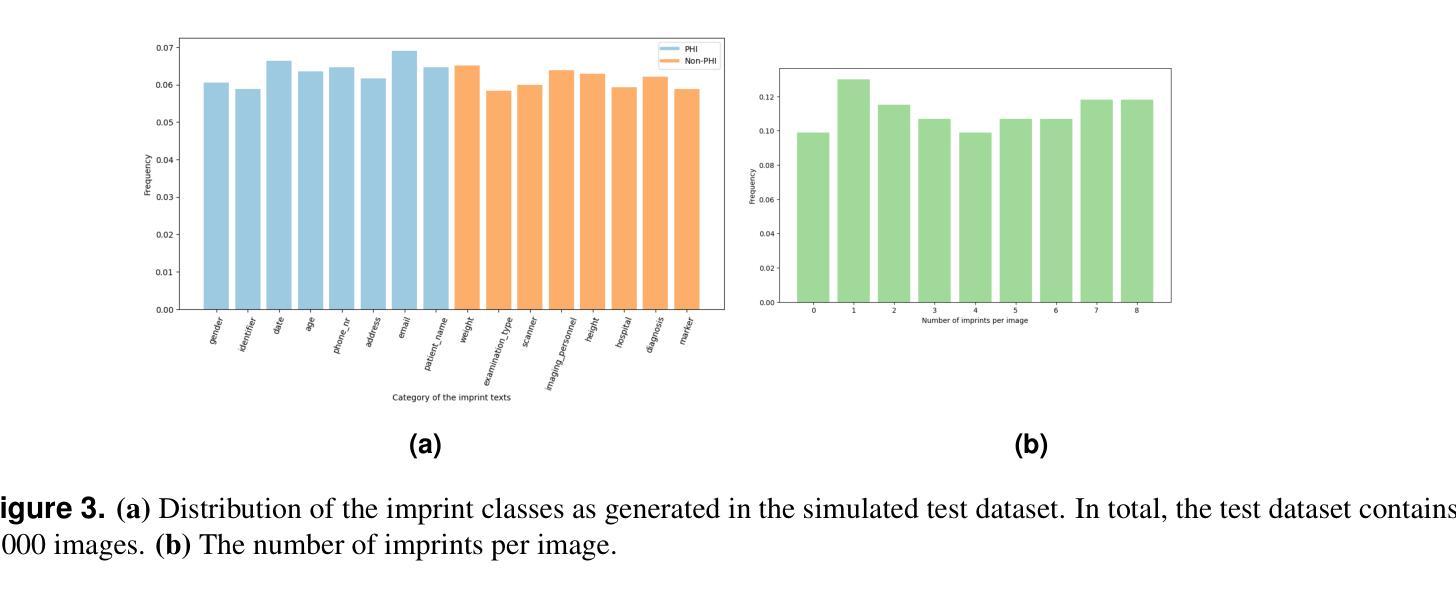
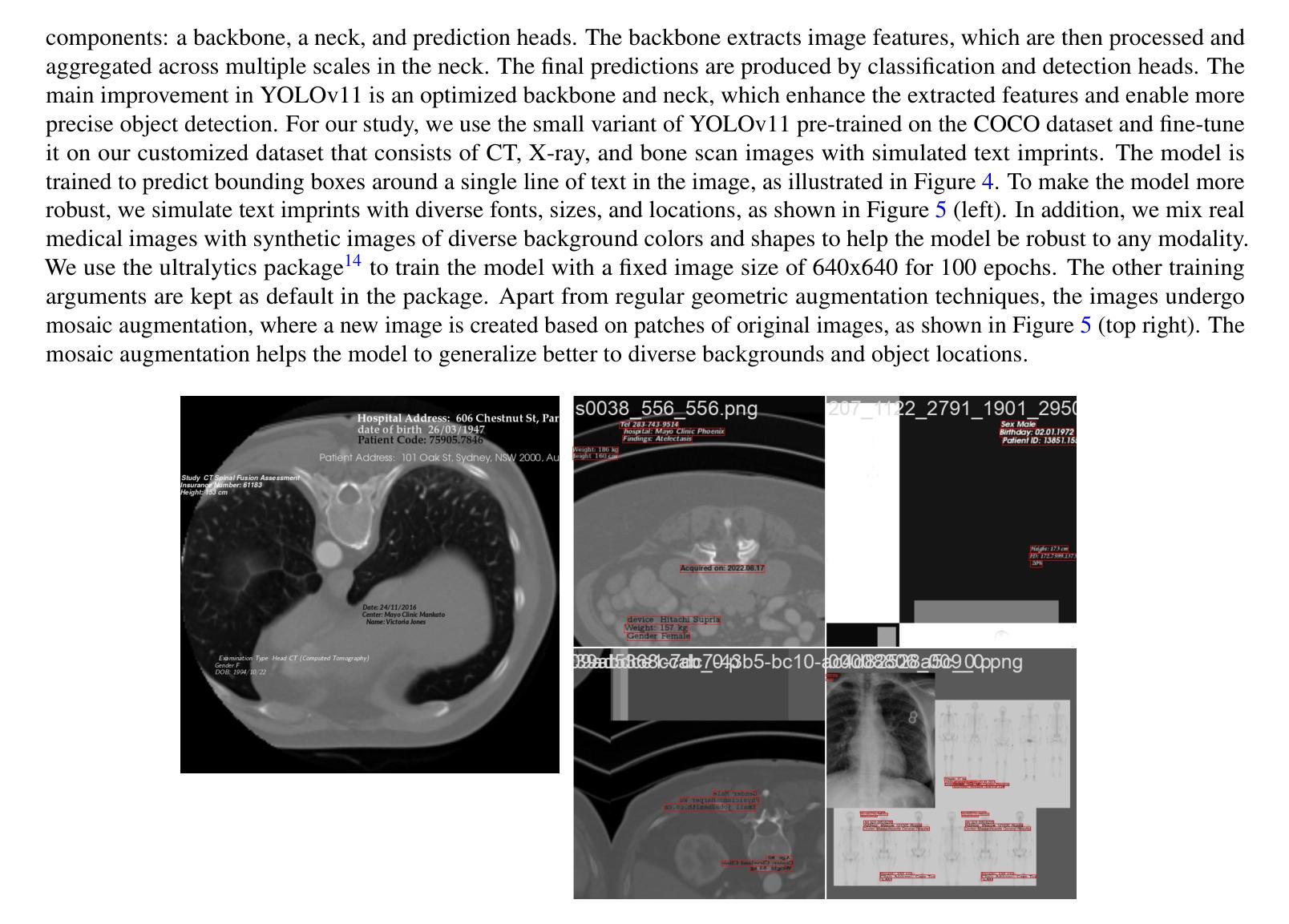
Exploring AI-based System Design for Pixel-level Protected Health Information Detection in Medical Images
Authors:Tuan Truong, Ivo M. Baltruschat, Mark Klemens, Grit Werner, Matthias Lenga
De-identification of medical images is a critical step to ensure privacy during data sharing in research and clinical settings. The initial step in this process involves detecting Protected Health Information (PHI), which can be found in image metadata or imprinted within image pixels. Despite the importance of such systems, there has been limited evaluation of existing AI-based solutions, creating barriers to the development of reliable and robust tools. In this study, we present an AI-based pipeline for PHI detection, comprising three key components: text detection, text extraction, and analysis of PHI content in medical images. By experimenting with exchanging roles of vision and language models within the pipeline, we evaluate the performance and recommend the best setup for the PHI detection task.
医疗图像的匿名化是在研究和临床环境中进行数据共享时确保隐私的关键步骤。该过程的初步步骤是检测受保护的卫生信息(PHI),这些信息可能存在于图像元数据或印在图像像素中。尽管这些系统很重要,但对现有的基于人工智能的解决方案的评估仍然有限,这阻碍了可靠和稳健工具的开发。在这项研究中,我们提出了一种基于人工智能的PHI检测流水线,包含三个关键组件:文本检测、文本提取和医疗图像中PHI内容的分析。通过尝试在流水线中交换视觉和语言模型的角色,我们评估了性能并推荐了最适合PHI检测任务的最佳设置。
论文及项目相关链接
PDF In progress
Summary
医学图像去标识化是确保研究和临床环境中数据共享时隐私安全的关键步骤。其首要步骤是检测图像中的受保护健康信息(PHI),这些信息可能隐藏在图像元数据或像素中。尽管这些系统至关重要,但对现有基于人工智能的解决方案的评估仍有限,阻碍了可靠且稳健工具的开发。本研究提出了一种基于人工智能的PHI检测流程,包括文本检测、文本提取和医学图像中的PHI内容分析三个关键部分。我们通过实验验证了在流程中交换视觉和语言模型角色的效果,评估了性能,并推荐了最适合PHI检测任务的最佳配置。
Key Takeaways
- 医学图像去标识化是保护隐私的关键步骤,特别是在研究和临床环境中的数据共享中。
- 受保护健康信息(PHI)可隐藏在图像元数据或像素中。
- 当前对基于人工智能的PHI检测解决方案的评估有限,阻碍了可靠工具的开发。
- 本研究提出了一种基于人工智能的PHI检测流程,包括文本检测、文本提取和PHI内容分析。
- 通过实验验证了不同模型角色交换对PHI检测性能的影响。
- 评估了各流程配置的性能。
点此查看论文截图

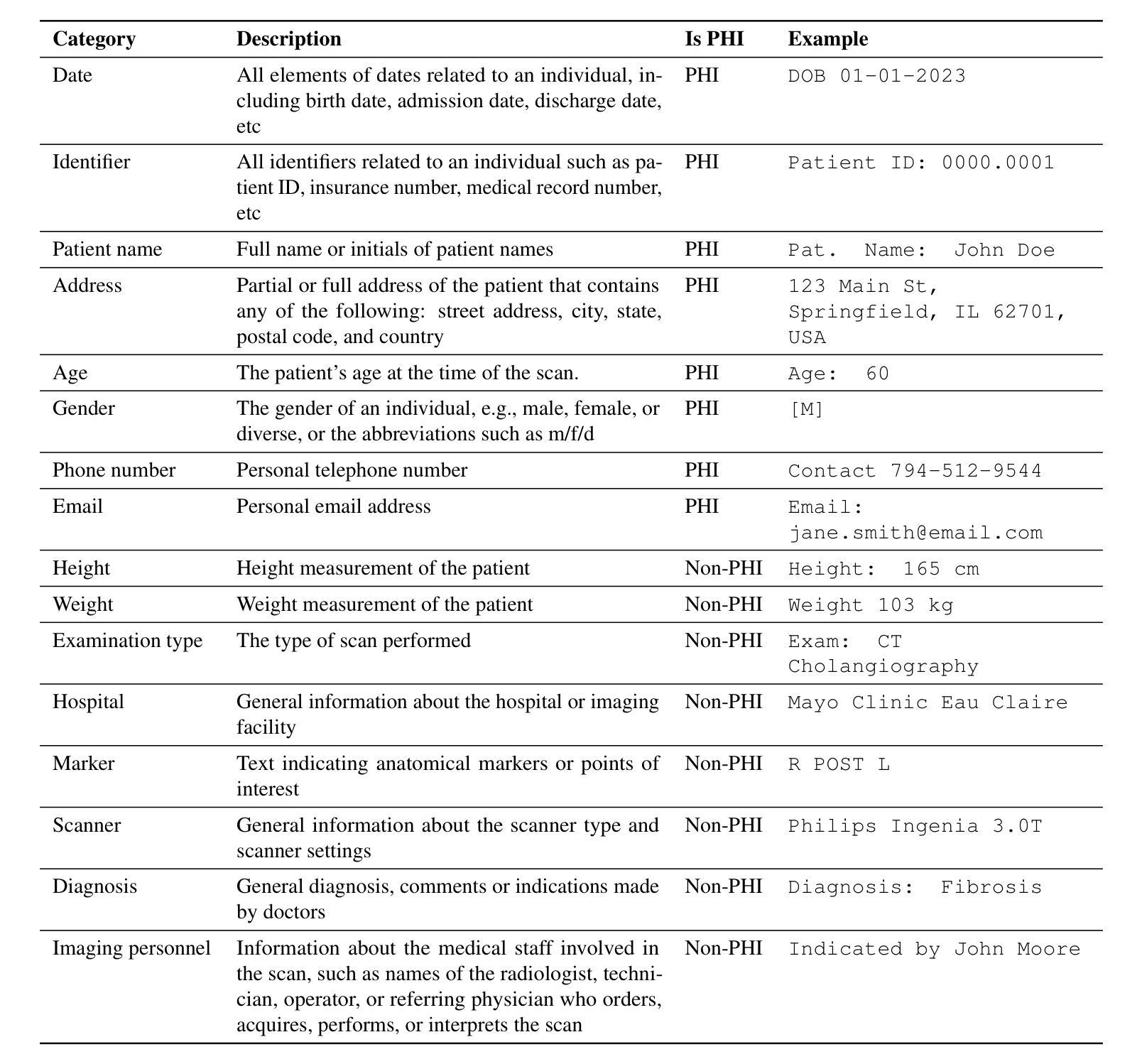
PISCO: Self-Supervised k-Space Regularization for Improved Neural Implicit k-Space Representations of Dynamic MRI
Authors:Veronika Spieker, Hannah Eichhorn, Wenqi Huang, Jonathan K. Stelter, Tabita Catalan, Rickmer F. Braren, Daniel Rueckert, Francisco Sahli Costabal, Kerstin Hammernik, Dimitrios C. Karampinos, Claudia Prieto, Julia A. Schnabel
Neural implicit k-space representations (NIK) have shown promising results for dynamic magnetic resonance imaging (MRI) at high temporal resolutions. Yet, reducing acquisition time, and thereby available training data, results in severe performance drops due to overfitting. To address this, we introduce a novel self-supervised k-space loss function $\mathcal{L}_\mathrm{PISCO}$, applicable for regularization of NIK-based reconstructions. The proposed loss function is based on the concept of parallel imaging-inspired self-consistency (PISCO), enforcing a consistent global k-space neighborhood relationship without requiring additional data. Quantitative and qualitative evaluations on static and dynamic MR reconstructions show that integrating PISCO significantly improves NIK representations. Particularly for high acceleration factors (R$\geq$54), NIK with PISCO achieves superior spatio-temporal reconstruction quality compared to state-of-the-art methods. Furthermore, an extensive analysis of the loss assumptions and stability shows PISCO’s potential as versatile self-supervised k-space loss function for further applications and architectures. Code is available at: https://github.com/compai-lab/2025-pisco-spieker
神经隐式k空间表示(NIK)在动态磁共振成像(MRI)的高时间分辨率方面展现出有前景的结果。然而,减少采集时间以及可用的训练数据导致性能大幅度下降,出现过度拟合的问题。为了解决这一问题,我们引入了一种新型自监督k空间损失函数$\mathcal{L}_\mathrm{PISCO}$,可用于NIK重建的正则化。所提出的损失函数基于并行成像启发式的自一致性(PISCO)概念,在不要求额外数据的情况下强制实施一致的全球k空间邻域关系。对静态和动态MR重建的定量和定性评估表明,整合PISCO能显著改善NIK表示。特别是在高加速因子(R≥54)的情况下,使用PISCO的NIK在时空重建质量方面达到了优于最新技术的方法。此外,对损失假设和稳定性的深入分析表明,PISCO作为一种通用的自监督k空间损失函数具有进一步的用途和架构应用的潜力。代码可从以下网站获取:https://github.com/compai-lab/2025-pisco-spieker。
论文及项目相关链接
Summary
基于神经隐式k空间表示(NIK)在动态磁共振成像(MRI)的高时间分辨率上展现出良好效果,但由于训练数据不足导致的过拟合问题限制了其性能。为解决这一问题,引入了一种新型自监督k空间损失函数$\mathcal{L}_\mathrm{PISCO}$,用于NIK重建的正则化。该损失函数基于并行成像的自一致性(PISCO)概念,无需额外数据即可强制实施一致的k空间全局邻域关系。定量和定性评估表明,集成PISCO可显著改善NIK表示,特别是在高加速因子下,NIK与PISCO结合使用可实现优于现有方法的时空重建质量。此外,对损失假设和稳定性的深入分析表明,PISCO作为通用的自监督k空间损失函数在其他应用和架构中具有潜力。
Key Takeaways
- NIK在动态MRI高时间分辨率上表现良好,但训练数据不足会导致性能下降。
- 引入自监督k空间损失函数$\mathcal{L}_\mathrm{PISCO}$以改善NIK的性能。
- PISCO基于并行成像的自一致性概念,强制实施k空间全局邻域关系的一致性。
- 集成PISCO可以显著提高NIK的重建质量,特别是在高加速因子下。
- 与现有方法相比,NIK结合PISCO可以实现更好的时空重建质量。
- PISCO作为通用的自监督k空间损失函数在其他应用和架构中具有潜力。
点此查看论文截图

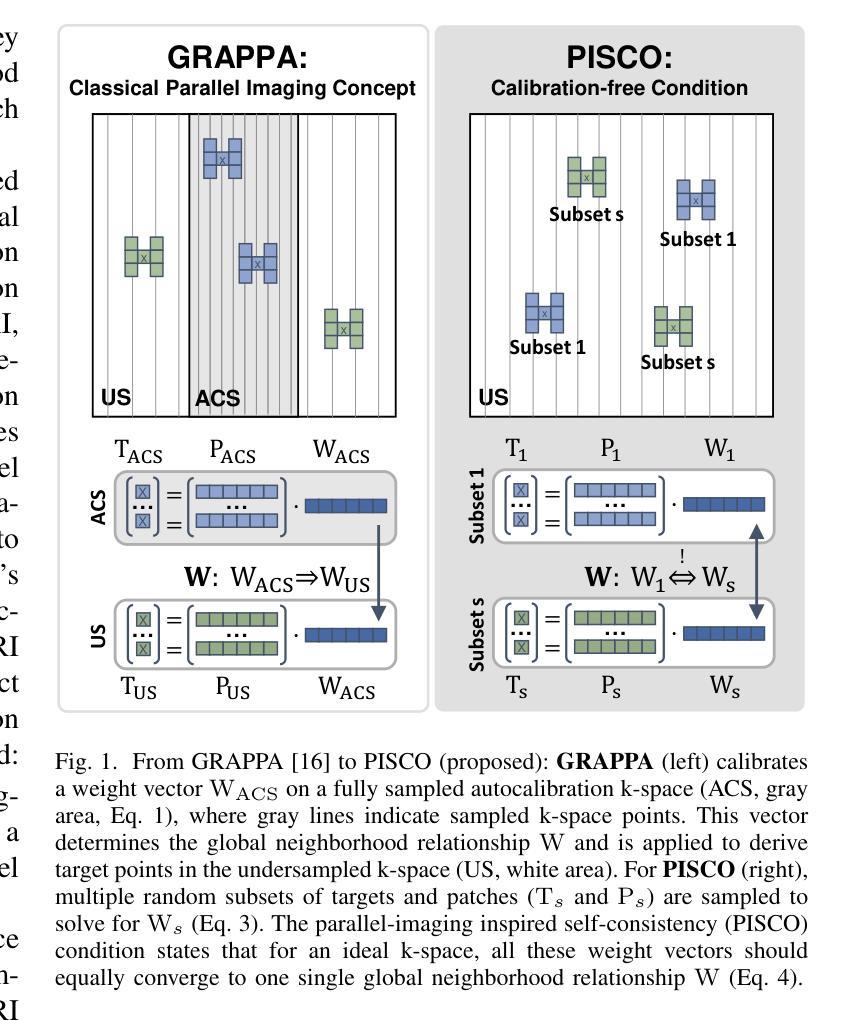

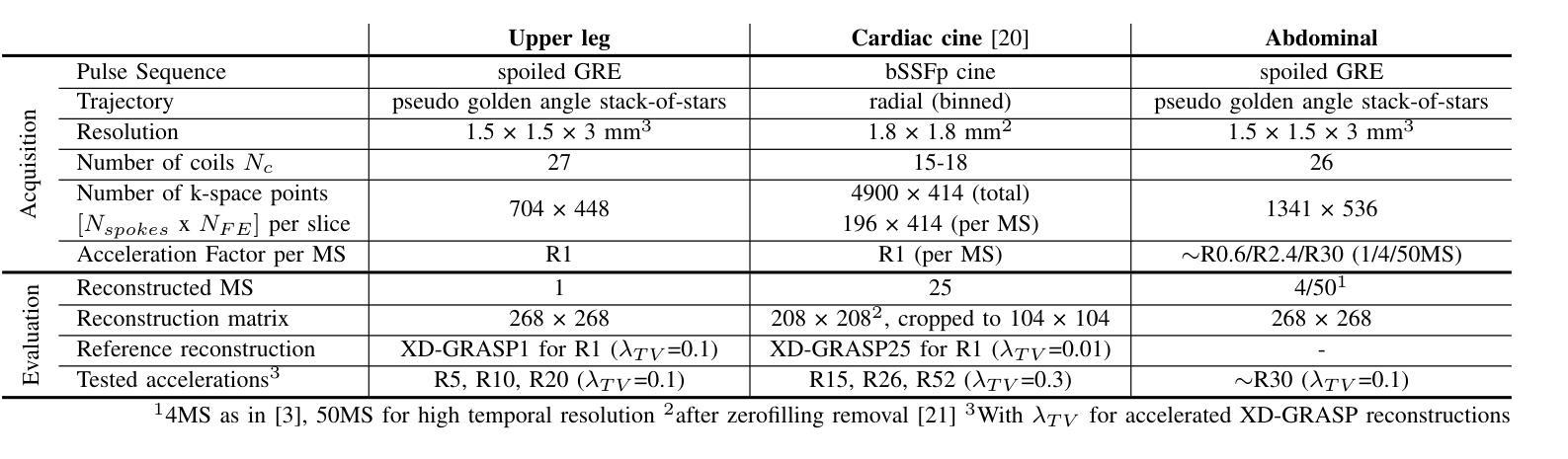
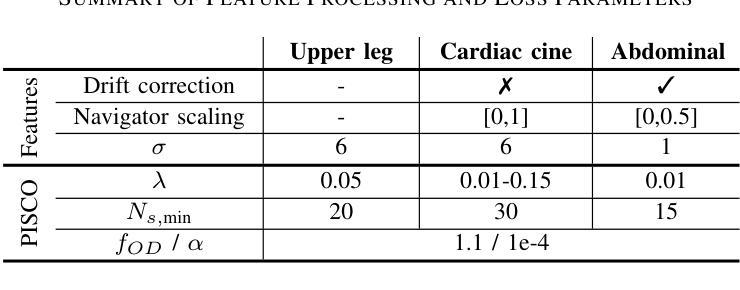
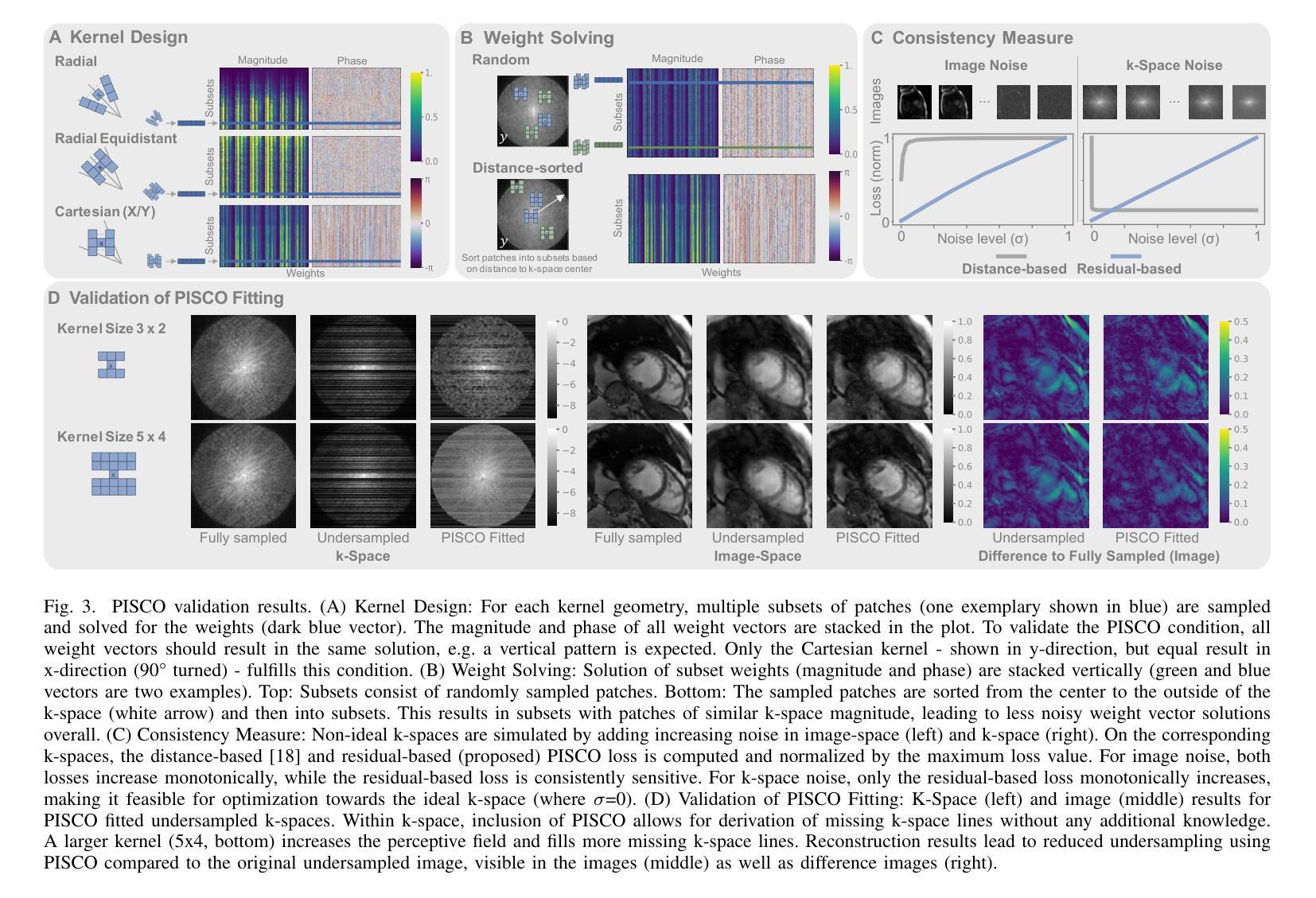
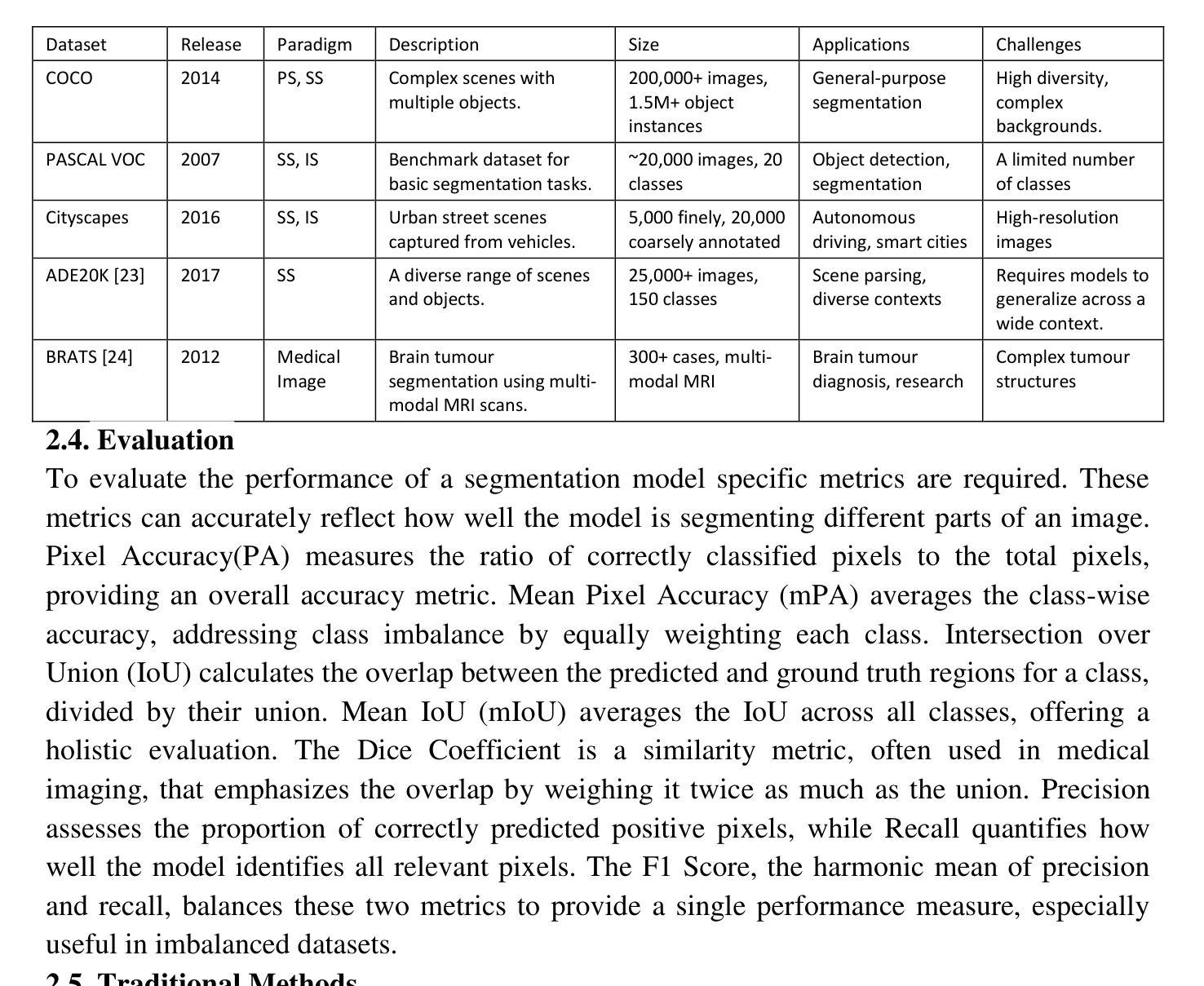
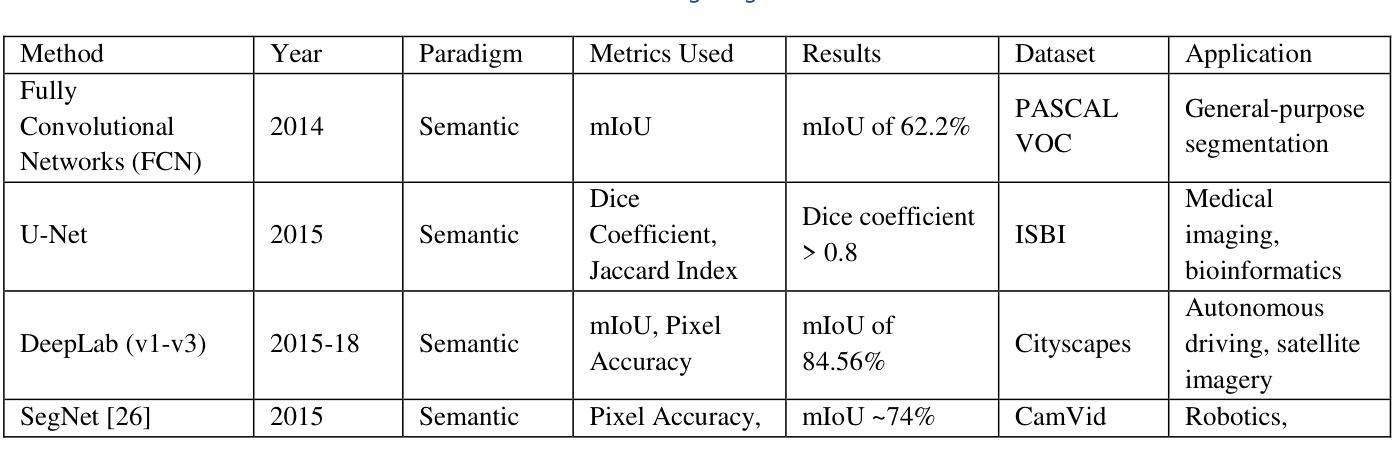
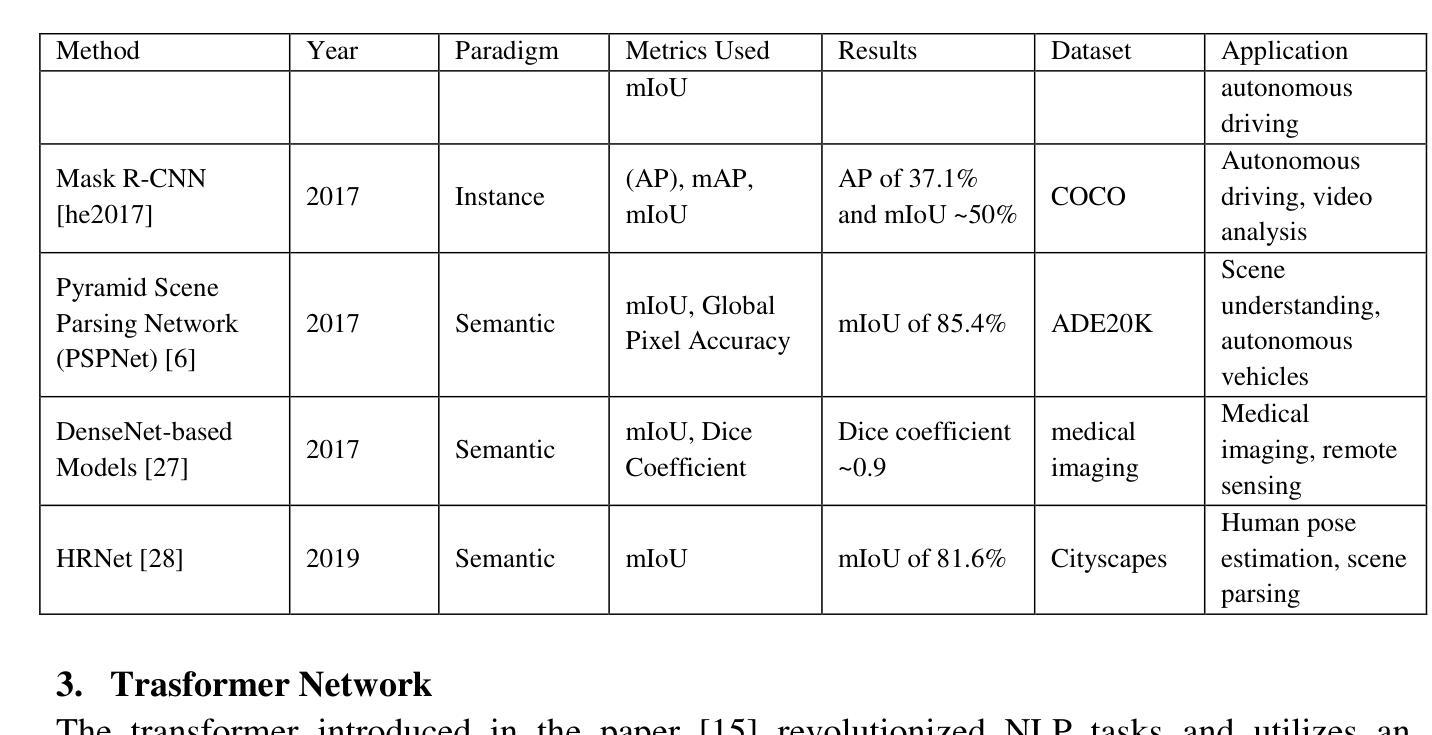
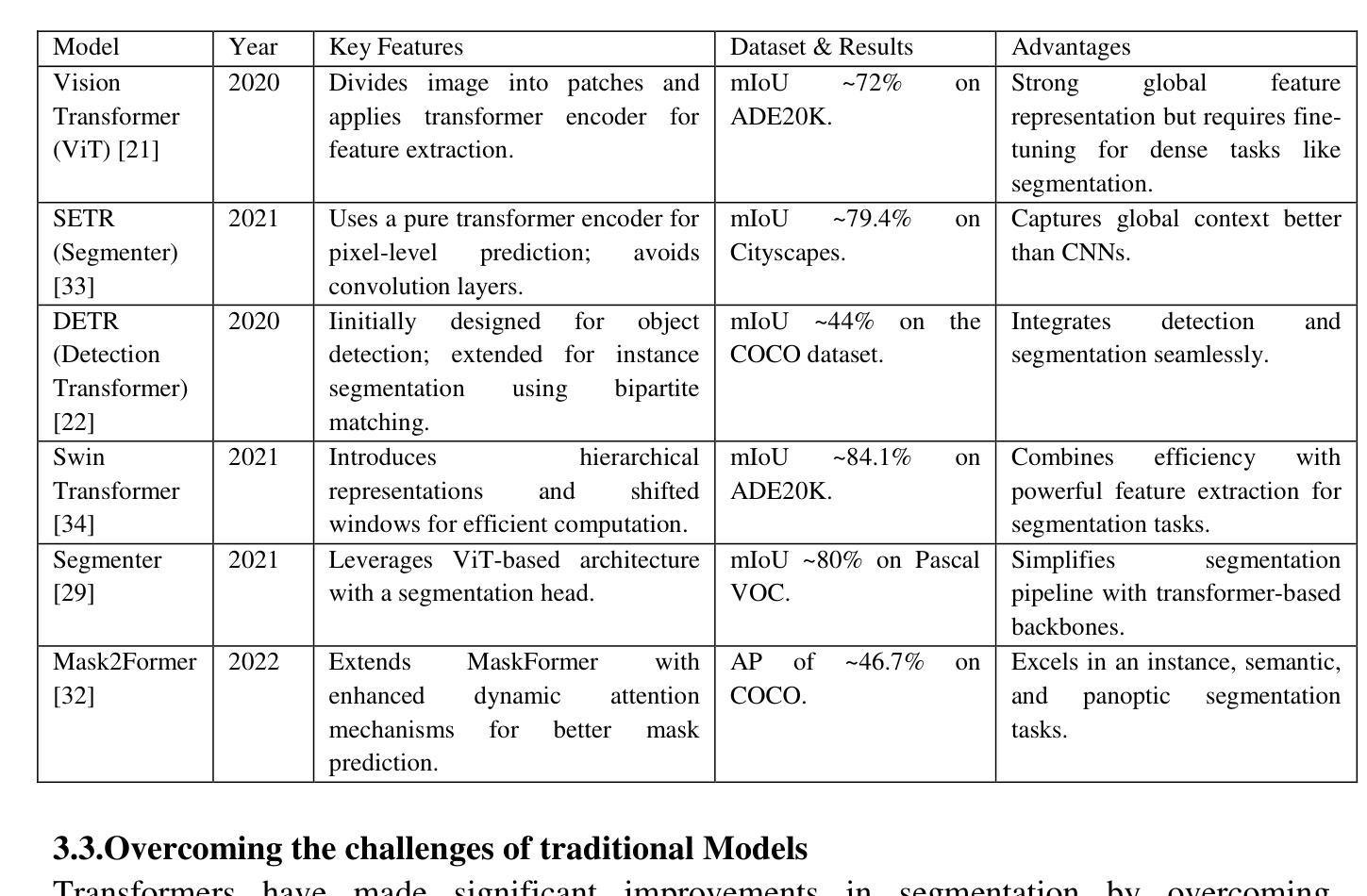
Image Segmentation with transformers: An Overview, Challenges and Future
Authors:Deepjyoti Chetia, Debasish Dutta, Sanjib Kr Kalita
Image segmentation, a key task in computer vision, has traditionally relied on convolutional neural networks (CNNs), yet these models struggle with capturing complex spatial dependencies, objects with varying scales, need for manually crafted architecture components and contextual information. This paper explores the shortcomings of CNN-based models and the shift towards transformer architectures -to overcome those limitations. This work reviews state-of-the-art transformer-based segmentation models, addressing segmentation-specific challenges and their solutions. The paper discusses current challenges in transformer-based segmentation and outlines promising future trends, such as lightweight architectures and enhanced data efficiency. This survey serves as a guide for understanding the impact of transformers in advancing segmentation capabilities and overcoming the limitations of traditional models.
图像分割是计算机视觉中的一项关键任务,传统上依赖于卷积神经网络(CNN)。然而,这些模型在捕捉复杂的空间依赖性、处理不同尺度的物体、需要手动构建架构组件和上下文信息方面存在困难。本文探讨了基于CNN的模型的不足,以及转向transformer架构以克服这些限制的趋势。本文回顾了最先进的基于transformer的分割模型,解决特定的分割挑战及其解决方案。论文讨论了基于transformer的分割的当前挑战,并概述了有前途的未来趋势,例如轻量级架构和增强的数据效率。这篇综述有助于了解transformer在提高分割能力和克服传统模型局限性方面的影响。
论文及项目相关链接
Summary
本文探讨了计算机视觉中图像分割任务的传统方法依赖的卷积神经网络(CNNs)的局限性,包括难以捕捉复杂的空间依赖性、处理不同尺度的对象、需要手动构建架构组件和上下文信息等问题。本文转向探索基于transformer的架构来克服这些限制,评述了最新的基于transformer的分割模型,并针对分割特定挑战及其解决方案进行了讨论。本文还讨论了当前基于transformer的分割所面临的挑战,并概述了未来有前景的趋势,如轻量化架构和数据效率的提高。本文旨在了解transformer在提升分割能力方面的影响和克服传统模型的局限性。
Key Takeaways
- 图像分割是计算机视觉中的关键任务,传统上依赖于卷积神经网络(CNNs)。
- CNNs在处理复杂空间依赖性、不同尺度对象和上下文信息方面存在局限性。
- 基于transformer的架构被探索以克服CNN的局限性。
- 论文评述了最新的基于transformer的分割模型,并讨论了它们如何解决分割特定的挑战。
- 当前基于transformer的分割仍面临一些挑战。
- 论文概述了基于transformer的未来趋势,包括轻量化架构和数据效率的提高。
点此查看论文截图

Shape-Based Single Object Classification Using Ensemble Method Classifiers
Authors:Nur Shazwani Kamarudin, Mokhairi Makhtar, Syadiah Nor Wan Shamsuddin, Syed Abdullah Fadzli
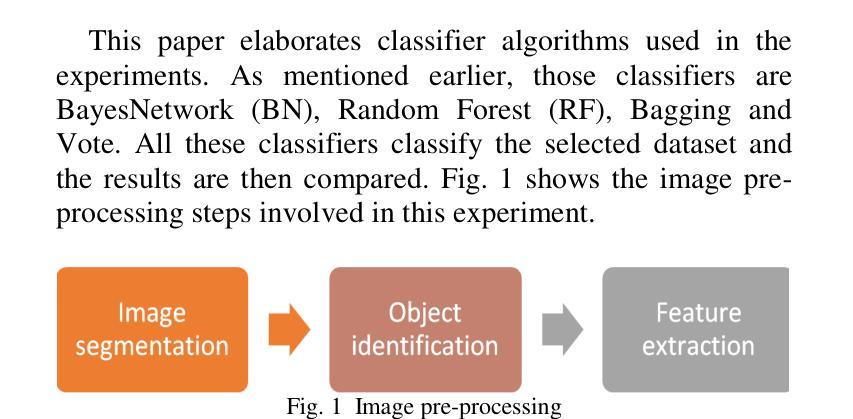
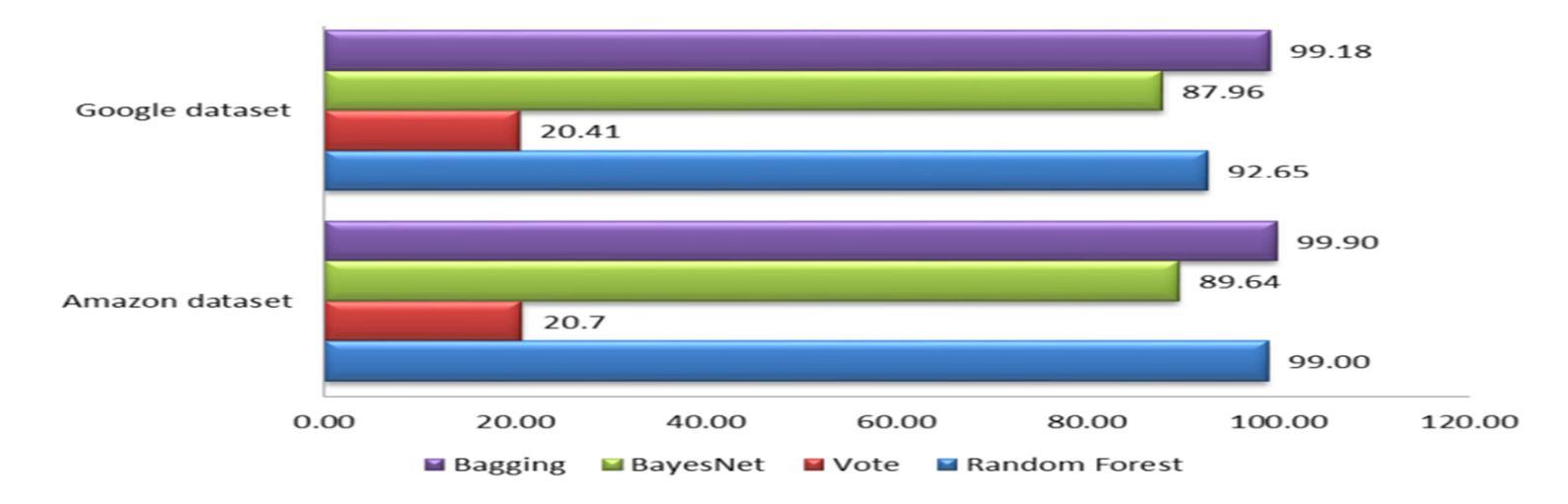
Nowadays, more and more images are available. Annotation and retrieval of the images pose classification problems, where each class is defined as the group of database images labelled with a common semantic label. Various systems have been proposed for content-based retrieval, as well as for image classification and indexing. In this paper, a hierarchical classification framework has been proposed for bridging the semantic gap effectively and achieving multi-category image classification. A well known pre-processing and post-processing method was used and applied to three problems; image segmentation, object identification and image classification. The method was applied to classify single object images from Amazon and Google datasets. The classification was tested for four different classifiers; BayesNetwork (BN), Random Forest (RF), Bagging and Vote. The estimated classification accuracies ranged from 20% to 99% (using 10-fold cross validation). The Bagging classifier presents the best performance, followed by the Random Forest classifier.
如今,越来越多的图像可供使用。图像的标注和检索构成了分类问题,其中每个类别被定义为数据库中具有共同语义标签的图像组。针对基于内容的检索以及图像分类和索引,已经提出了各种系统。本文提出了一个层次分类框架,以有效地弥合语义差距并实现多类别图像分类。使用了一种众所周知的预处理和后处理方法,并应用于三个问题:图像分割、对象识别和图像分类。该方法应用于对亚马逊和谷歌数据集的单目标图像进行分类。对四种不同的分类器进行了测试:BayesNetwork(BN)、Random Forest(RF)、Bagging和投票。估计的分类准确率在20%到99%之间(使用10倍交叉验证)。Bagging分类器表现最佳,其次是随机森林分类器。
论文及项目相关链接
Summary
本文提出一种层次分类框架,用于有效地弥合语义差距并实现多类别图像分类。该方法应用于图像分割、对象识别和图像分类三个问题,并应用于亚马逊和谷歌数据集的单对象图像分类。测试了四种不同的分类器,包括BayesNetwork、Random Forest、Bagging和Vote。其中Bagging分类器表现最佳,其次是Random Forest分类器。
Key Takeaways
- 层次分类框架用于多类别图像分类,有效缩小语义差距。
- 该方法应用于图像分割、对象识别和图像分类。
- Bagging分类器在测试中表现最佳。
- Random Forest分类器紧随其后。
- 使用了预处理和后处理方法。
- 分类测试是在亚马逊和谷歌数据集的单对象图像上进行的。
点此查看论文截图





Efficient Few-Shot Medical Image Analysis via Hierarchical Contrastive Vision-Language Learning
Authors:Harrison Fuller, Fernando Gabriela Garcia, Victor Flores
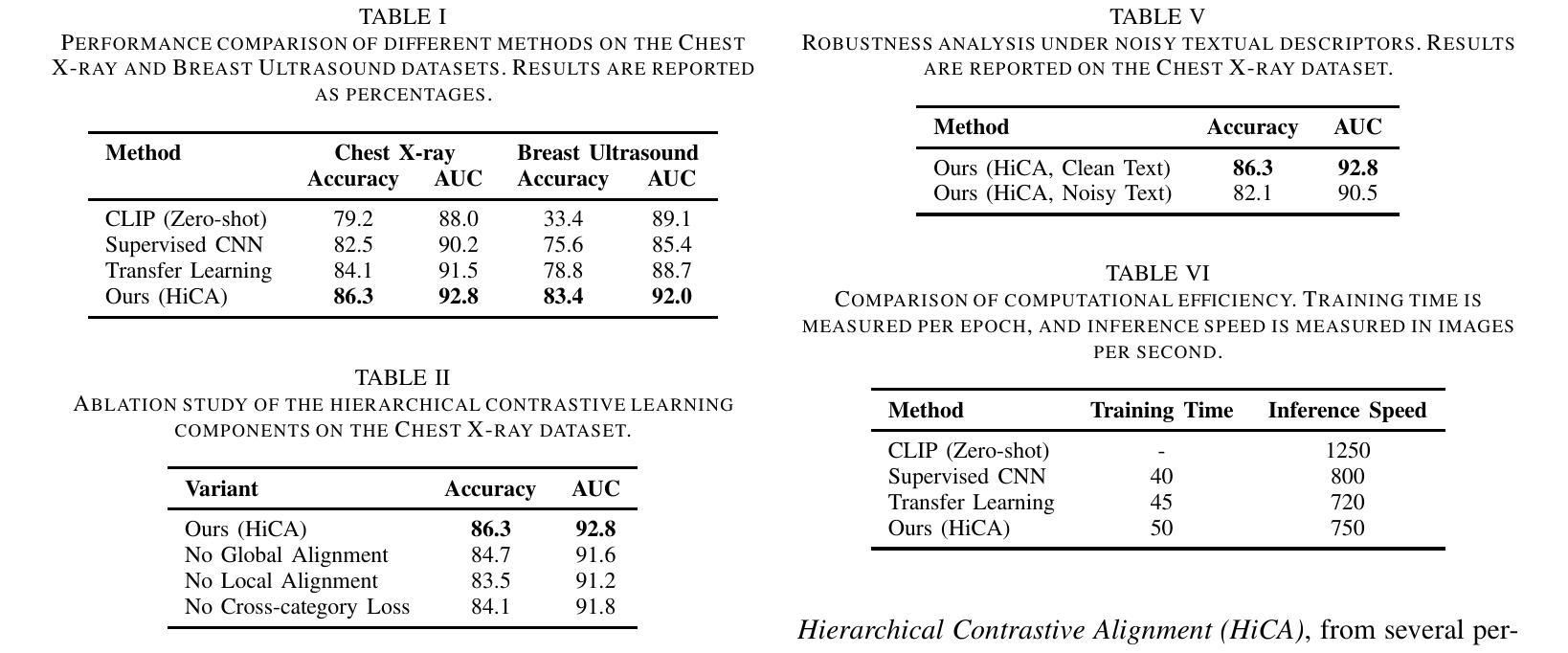
Few-shot learning in medical image classification presents a significant challenge due to the limited availability of annotated data and the complex nature of medical imagery. In this work, we propose Adaptive Vision-Language Fine-tuning with Hierarchical Contrastive Alignment (HiCA), a novel framework that leverages the capabilities of Large Vision-Language Models (LVLMs) for medical image analysis. HiCA introduces a two-stage fine-tuning strategy, combining domain-specific pretraining and hierarchical contrastive learning to align visual and textual representations at multiple levels. We evaluate our approach on two benchmark datasets, Chest X-ray and Breast Ultrasound, achieving state-of-the-art performance in both few-shot and zero-shot settings. Further analyses demonstrate the robustness, generalizability, and interpretability of our method, with substantial improvements in performance compared to existing baselines. Our work highlights the potential of hierarchical contrastive strategies in adapting LVLMs to the unique challenges of medical imaging tasks.
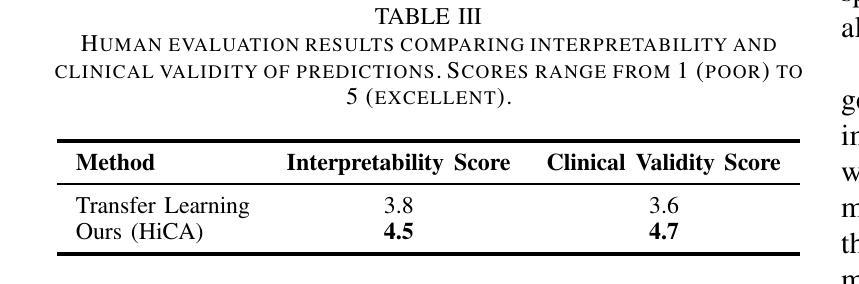
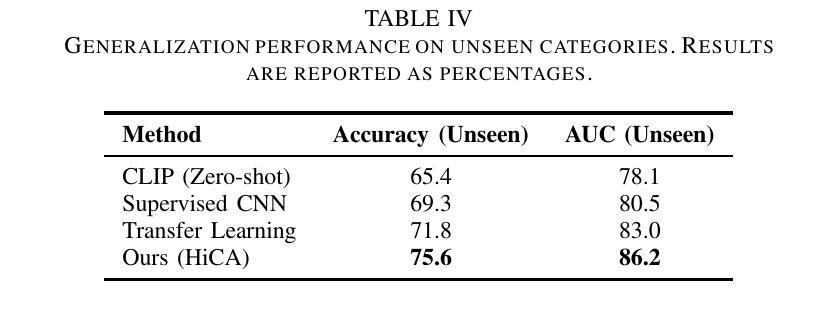
在医学图像分类中,小样本学习面临重大挑战,因为标注数据有限,且医学图像具有复杂性。在这项工作中,我们提出了基于层次对比对齐的适应性视觉语言微调(HiCA)新型框架,它利用大型视觉语言模型(LVLMs)进行医学图像分析。HiCA引入了两阶段的微调策略,结合领域特定预训练和层次对比学习,在多级别对齐视觉和文本表示。我们在Chest X光片和乳腺超声两个基准数据集上评估了我们的方法,在少量样本和零样本设置中都达到了最先进的性能。进一步的分析表明,我们的方法在稳健性、通用性和可解释性方面具有优势,与现有基线相比在性能上有显著改进。我们的研究突出了层次对比策略在适应医学成像任务的独特挑战中大型视觉语言模型的潜力。
论文及项目相关链接
Summary
本文提出了基于大型视觉语言模型(LVLMs)的医学图像分析新框架——自适应视觉语言微调与层次对比对齐(HiCA)。该框架采用两阶段微调策略,结合领域特定预训练和层次对比学习,实现视觉和文字的多层次对齐。在Chest X-ray和Breast Ultrasound两个基准数据集上的评估显示,该框架在少样本和无样本场景下均达到最先进的性能水平。进一步的分析证明了该方法的稳健性、通用性和可解释性,相较于现有基线方法有明显的性能提升。本研究突显了层次对比策略在适应医学成像任务的独特挑战方面的潜力。
Key Takeaways
- 医学图像分类中的小样本学习因标注数据有限和医学图像复杂性而面临挑战。
- 提出了自适应视觉语言微调与层次对比对齐(HiCA)的新框架。
- HiCA利用大型视觉语言模型(LVLMs)进行医学图像分析。
- HiCA采用两阶段微调策略,结合领域特定预训练和层次对比学习。
- 在Chest X-ray和Breast Ultrasound数据集上实现了先进性能。
- 该方法具有稳健性、通用性和可解释性。
点此查看论文截图

Knowledge Distillation for Image Restoration : Simultaneous Learning from Degraded and Clean Images
Authors:Yongheng Zhang, Danfeng Yan
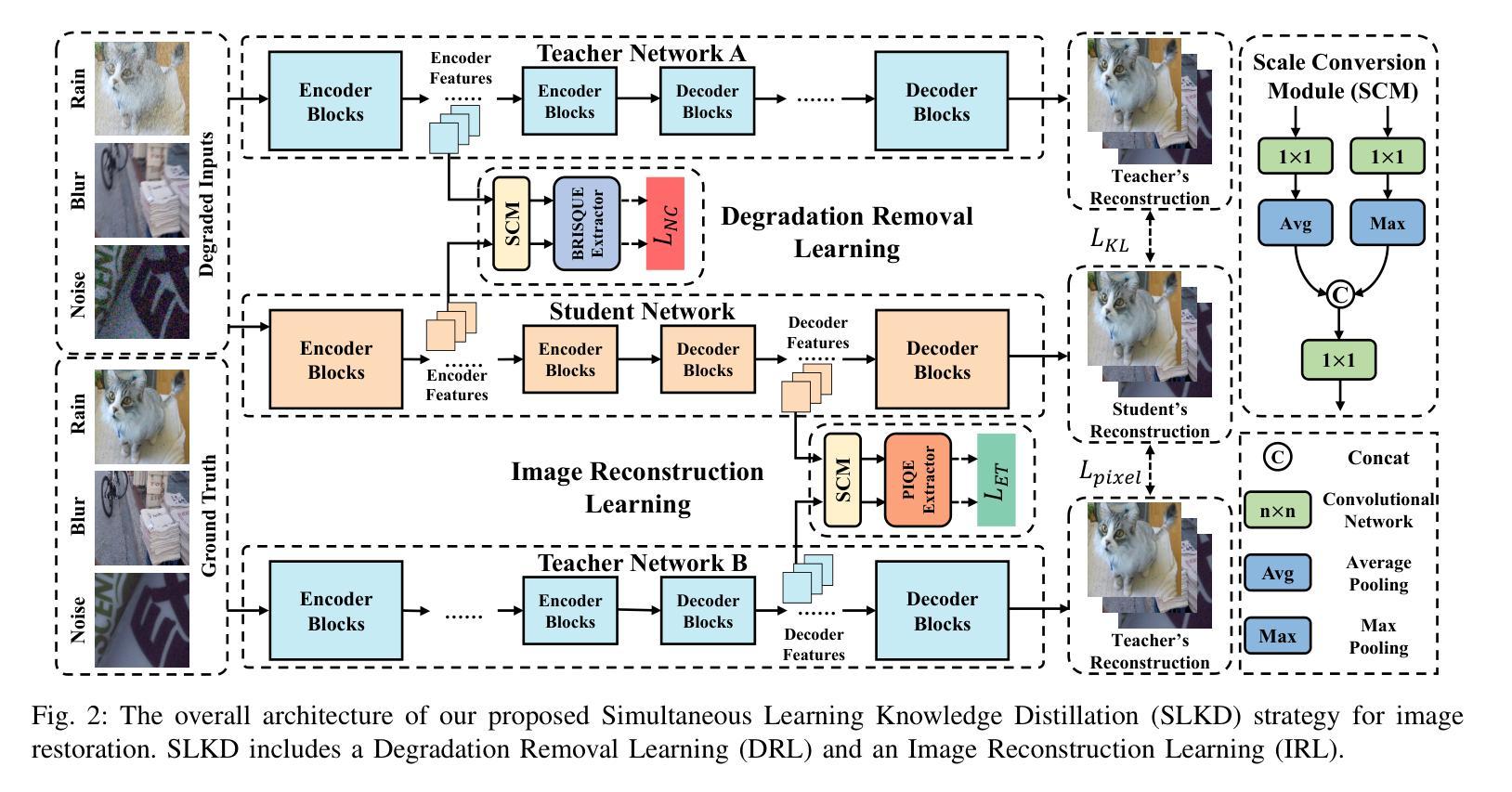
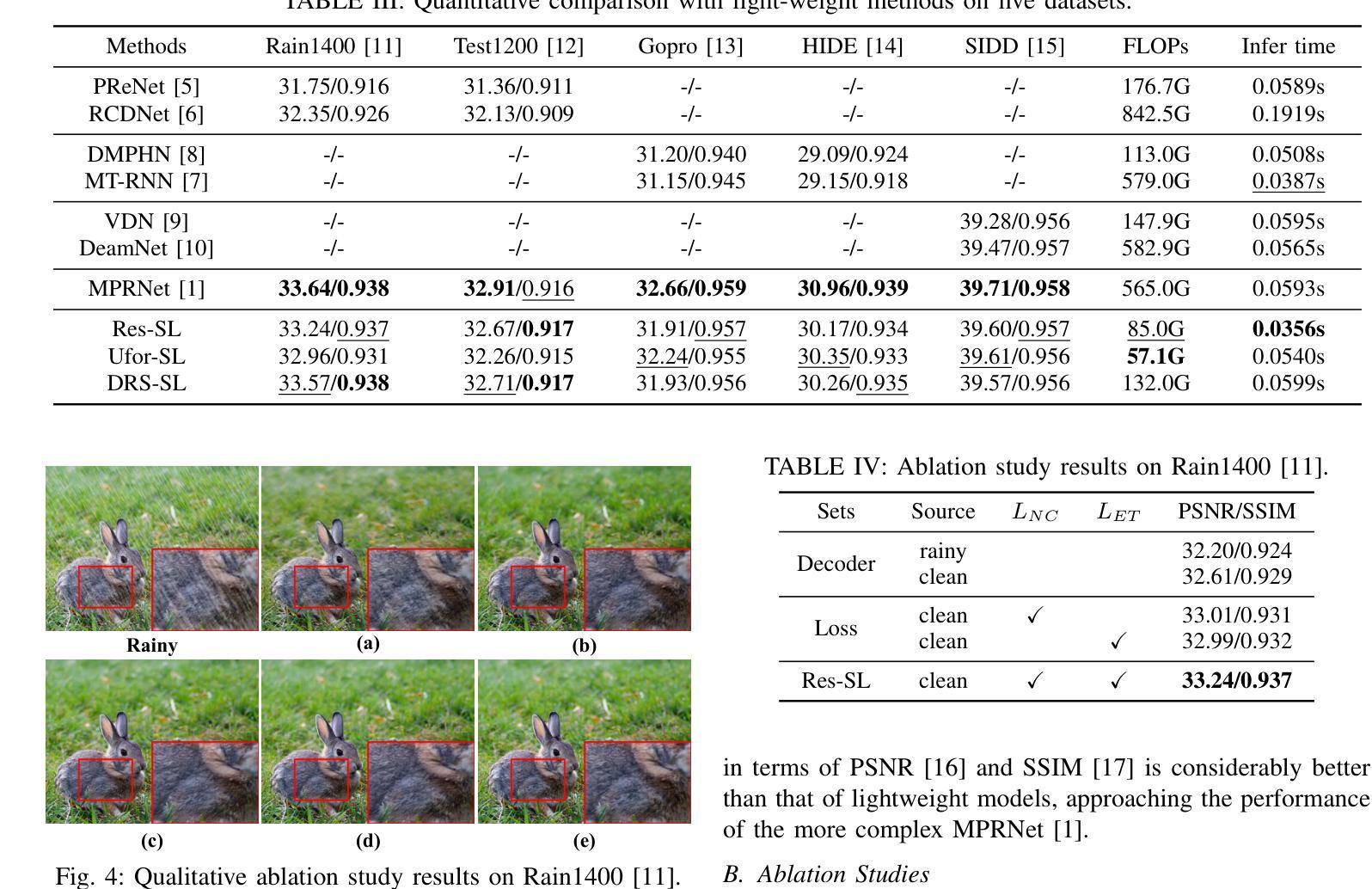
Model compression through knowledge distillation has seen extensive application in classification and segmentation tasks. However, its potential in image-to-image translation, particularly in image restoration, remains underexplored. To address this gap, we propose a Simultaneous Learning Knowledge Distillation (SLKD) framework tailored for model compression in image restoration tasks. SLKD employs a dual-teacher, single-student architecture with two distinct learning strategies: Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL), simultaneously. In DRL, the student encoder learns from Teacher A to focus on removing degradation factors, guided by a novel BRISQUE extractor. In IRL, the student decoder learns from Teacher B to reconstruct clean images, with the assistance of a proposed PIQE extractor. These strategies enable the student to learn from degraded and clean images simultaneously, ensuring high-quality compression of image restoration models. Experimental results across five datasets and three tasks demonstrate that SLKD achieves substantial reductions in FLOPs and parameters, exceeding 80%, while maintaining strong image restoration performance.
通过知识蒸馏进行模型压缩在分类和分割任务中已得到广泛应用。然而,其在图像到图像的翻译,特别是在图像恢复中的潜力尚未得到充分探索。为了弥补这一空白,我们提出了一种针对图像恢复任务模型压缩的同步学习知识蒸馏(SLKD)框架。SLKD采用双教师、单学生的架构,同时采用两种独特的学习策略:退化去除学习(DRL)和图像重建学习(IRL)。在DRL中,学生编码器从教师A身上学习,专注于去除退化因素,由新型BRISQUE提取器引导。在IRL中,学生解码器从教师B身上学习重建清晰图像,辅以提出的PIQE提取器。这些策略使学生能够从退化和清晰的图像中同时学习,确保图像恢复模型的高质量压缩。在五个数据集和三个任务上的实验结果表明,SLKD在FLOPs和参数方面实现了超过80%的大幅减少,同时保持了强大的图像恢复性能。
论文及项目相关链接
PDF Accepted by ICASSP2025
Summary
模型压缩知识蒸馏在分类和分割任务中广泛应用,但在图像翻译,特别是图像恢复方面的潜力尚未得到充分探索。为解决此问题,本文提出一种针对图像恢复任务的模型压缩知识蒸馏框架——同步学习知识蒸馏(SLKD)。SLKD采用双教师、单学生的架构,并融合两种独特学习策略:去噪学习(DRL)和图像重建学习(IRL)。DRL使学生编码器从教师A中学习去除退化因素,由新型BRISQUE提取器引导;而IRL使学生解码器从教师B中学习重建清晰图像,辅以新提出的PIQE提取器。此策略使学生模型可从退化及清晰图像中学习,确保图像恢复模型的高质量压缩。实验结果显示,SLKD在五个数据集、三项任务中实现了超过80%的FLOPs和参数大幅减少,同时保持出色的图像恢复性能。
Key Takeaways
- 知识蒸馏在图像恢复领域的模型压缩具有较大潜力,尚未被充分探索。
- 提出的SLKD框架融合双教师、单学生架构,专为图像恢复任务设计。
- SLKD包含两种学习策略:去噪学习(DRL)和图像重建学习(IRL)。
- DRL策略使学生编码器从教师A学习去除退化因素,借助BRISQUE提取器。
- IRL策略使学生解码器从教师B学习重建清晰图像,辅以PIQE提取器。
- 学生模型可从退化及清晰图像中学习,确保高质量压缩图像恢复模型。
点此查看论文截图


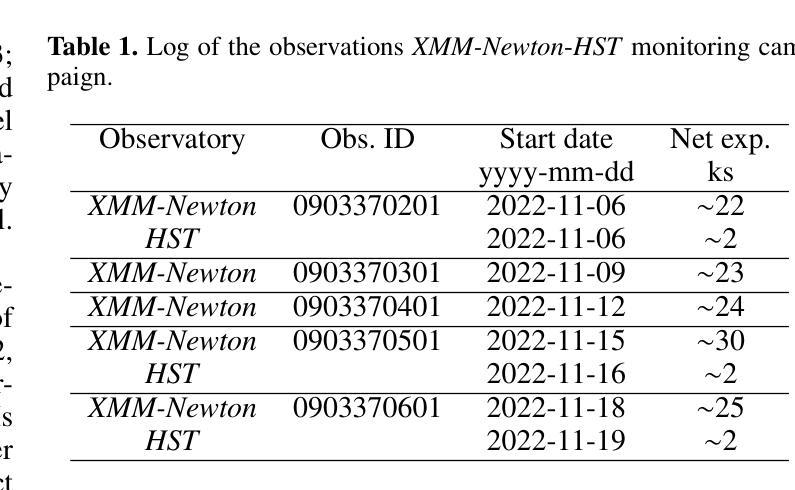
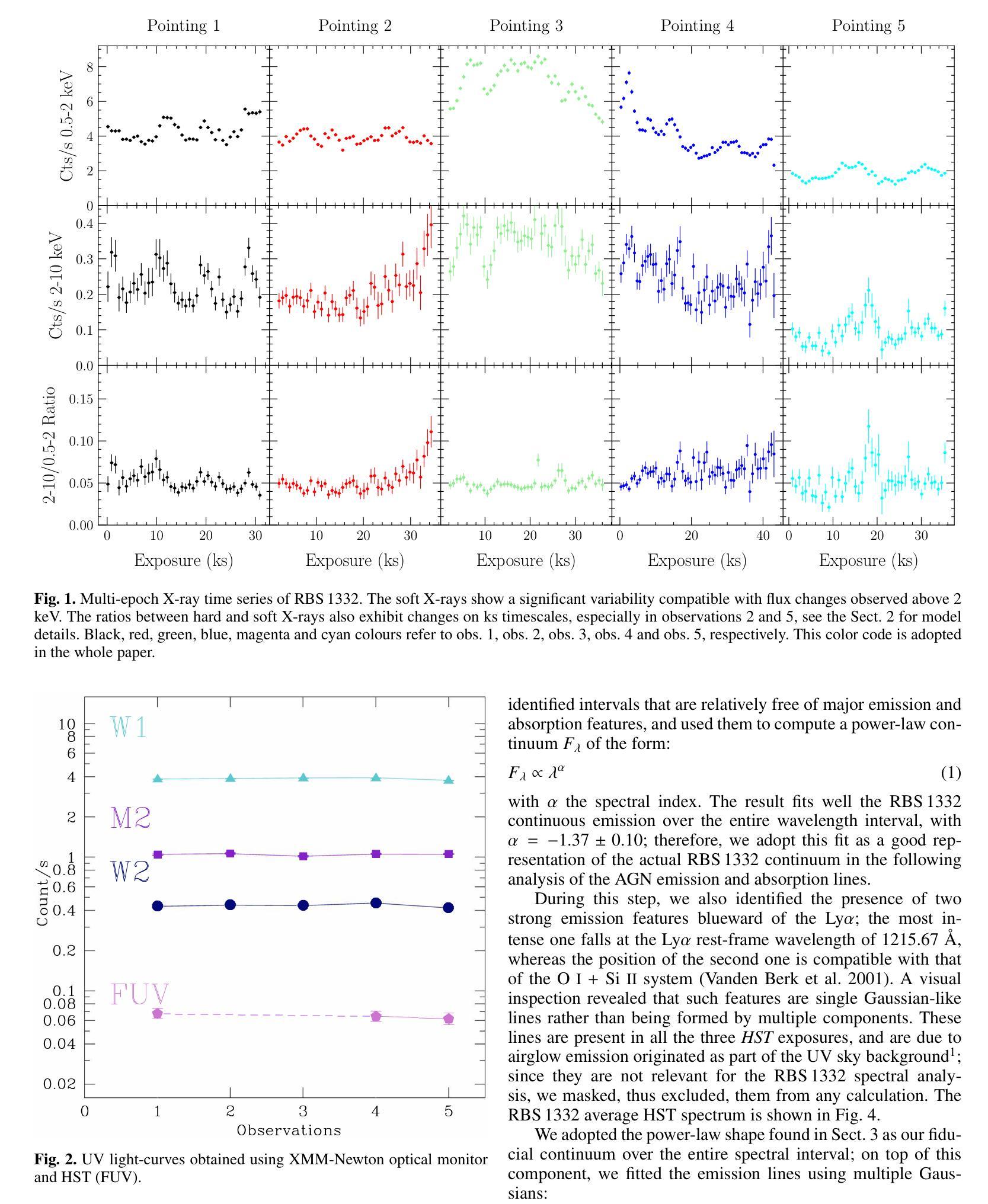
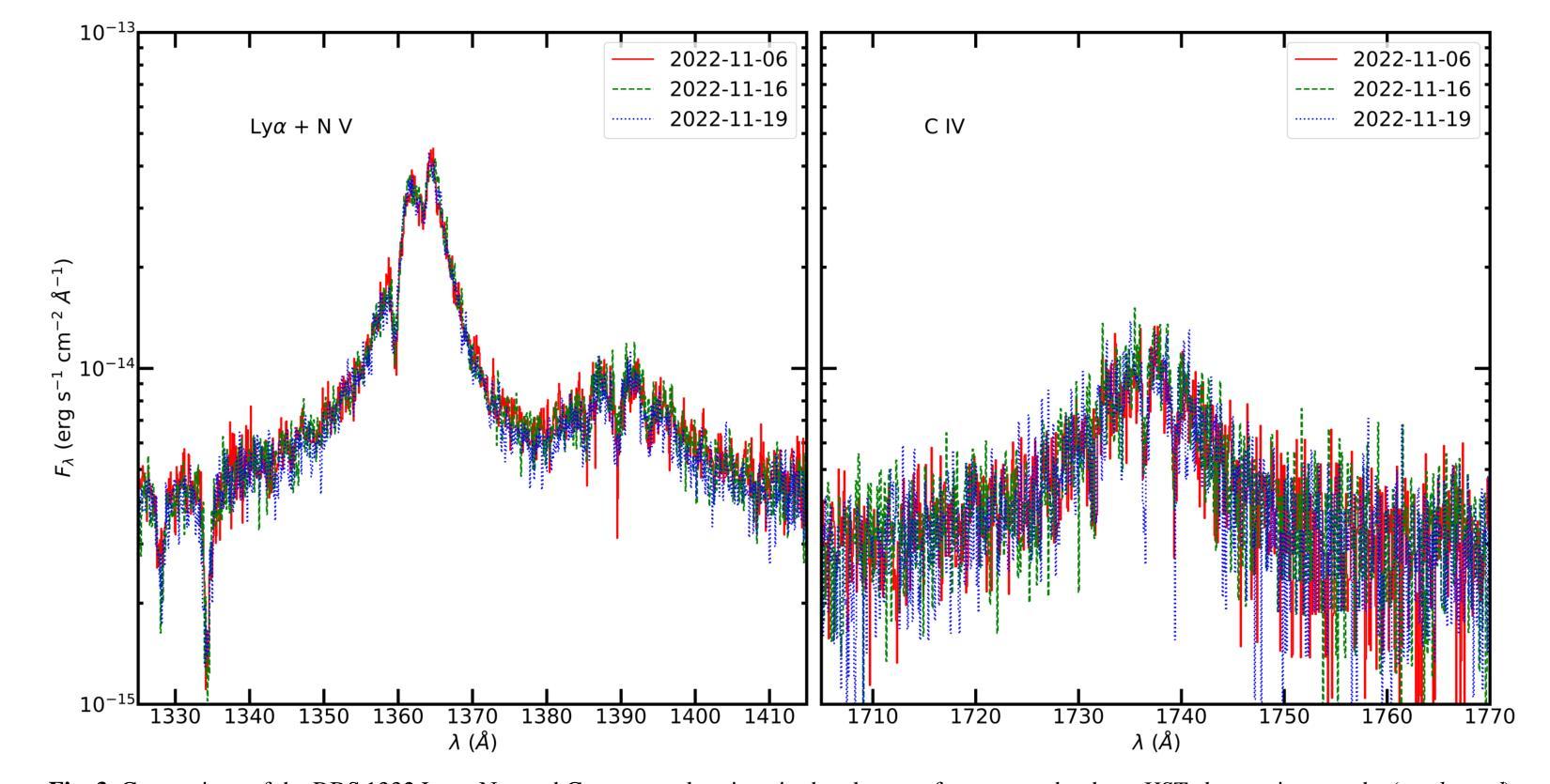
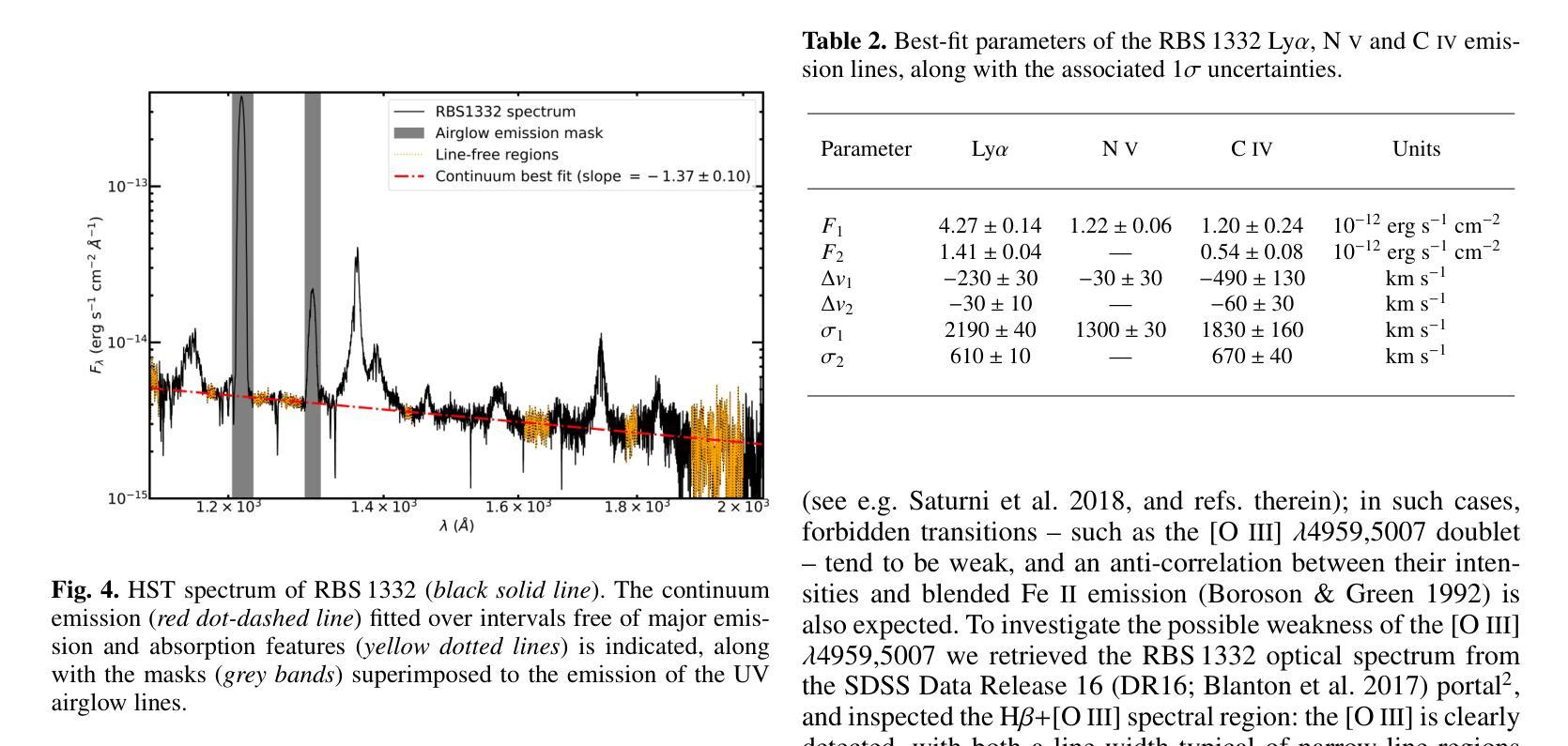
XMM/HST monitoring of the ultra-soft highly accreting Narrow Line Seyfert 1 RBS 1332
Authors:R. Middei, S. Barnier, F. G. Saturni, F. Ursini, P. -O. Petrucci, S. Bianchi, M. Cappi, M. Clavel, B. De Marco, A. De Rosa, G. Matt, G. A. Matzeu, M. Perri
Ultra-soft narrow line Seyfert 1 (US-NLSy) are a poorly observed class of active galactic nuclei characterized by significant flux changes and an extreme soft X-ray excess. This peculiar spectral shape represents a golden opportunity to test whether the standard framework commonly adopted for modelling local AGN is still valid. We thus present the results on the joint XMM-Newton and HST monitoring campaign of the highly accreting US-NLSy RBS 1332. The optical-to-UV spectrum of RBS 1332 exhibits evidence of both a stratified narrow-line region and an ionized outflow, that produces absorption troughs over a wide range of velocities (from ~1500 km s-1 to ~1700 km s-1) in several high-ionization transitions (Lyalpha, N V, C IV). From a spectroscopic point of view, the optical/UV/FUV/X-rays emission of this source is due to the superposition of three distinct components which are best modelled in the context of the two-coronae framework in which the radiation of RBS 1332 can be ascribed to a standard outer disk, a warm Comptonization region and a soft coronal continuum. The present dataset is not compatible with a pure relativistic reflection scenario. Finally, the adoption of the novel model reXcor allowed us to determine that the soft X-ray excess in RBS 1332 is dominated by the emission of the optically thick and warm Comptonizing medium, and only marginal contribution is expected from relativistic reflection from a lamppost-like corona.
超软窄线塞弗特1型(US-NLSy)是一类活动星系核,其特征为显著的流量变化和极端的软X射线过剩,这一特殊光谱形状为测试本地AGN建模的标准框架是否仍然有效提供了黄金机会。因此,我们对高度吸收的US-NLSy RBS 1332进行了联合XMM-牛顿和HST监测活动的研究结果进行了介绍。RBS 1332的光学至紫外线光谱显示分层窄线区域和电离流出的证据,这在多种高电离过渡中产生了一系列速度范围的吸收谷(从约1500公里每秒至约1700公里每秒)(Lyalpha,NV,CIV)。从光谱学的角度来看,该源的光学/紫外线/远紫外线/X射线发射是由于三个不同成分的叠加而产生的,最好在两层冠状物的背景下进行建模,其中RBS 1332的辐射可归因于外部磁盘的标准部分、温暖的康普顿化区域和软冠状连续体。当前数据集与纯粹的相对论反射场景不兼容。最后,采用新型模型ReXcor,我们确定了RBS 1332中的软X射线过剩主要由光学厚且温暖的康普顿化介质的发射引起,仅预期来自类似灯柱的冠状物的相对论反射有轻微贡献。
论文及项目相关链接
PDF 13 pages, 9 figures, accepted in A&A
Summary
研究结果表明RBS 1332的光谱由三部分组成,包括外层盘、暖康普顿化区域和软冕连续谱的贡献。此外,数据排除了纯相对论反射模型的可能性,并采用新模型确定软X射线过剩主要由厚热且暖化的康普顿化介质发射引起。
Key Takeaways
- RBS 1332是一种高度吸积的US-NLSy星系核,其光谱表现出显著的变化和极端的软X射线过剩。
- RBS 1332的光谱由三部分组成:外层盘、暖康普顿化区域和软冕连续谱,这在光学至紫外波段都有体现。
- 该源表现出分层窄线区和离子化流出物的证据,吸收槽在宽范围速度(从约1500公里每秒到约1700公里每秒)内出现多个高电离过渡(如Lyalpha、NV、CIV)。
- 数据排除了纯相对论反射模型的可能性。
点此查看论文截图

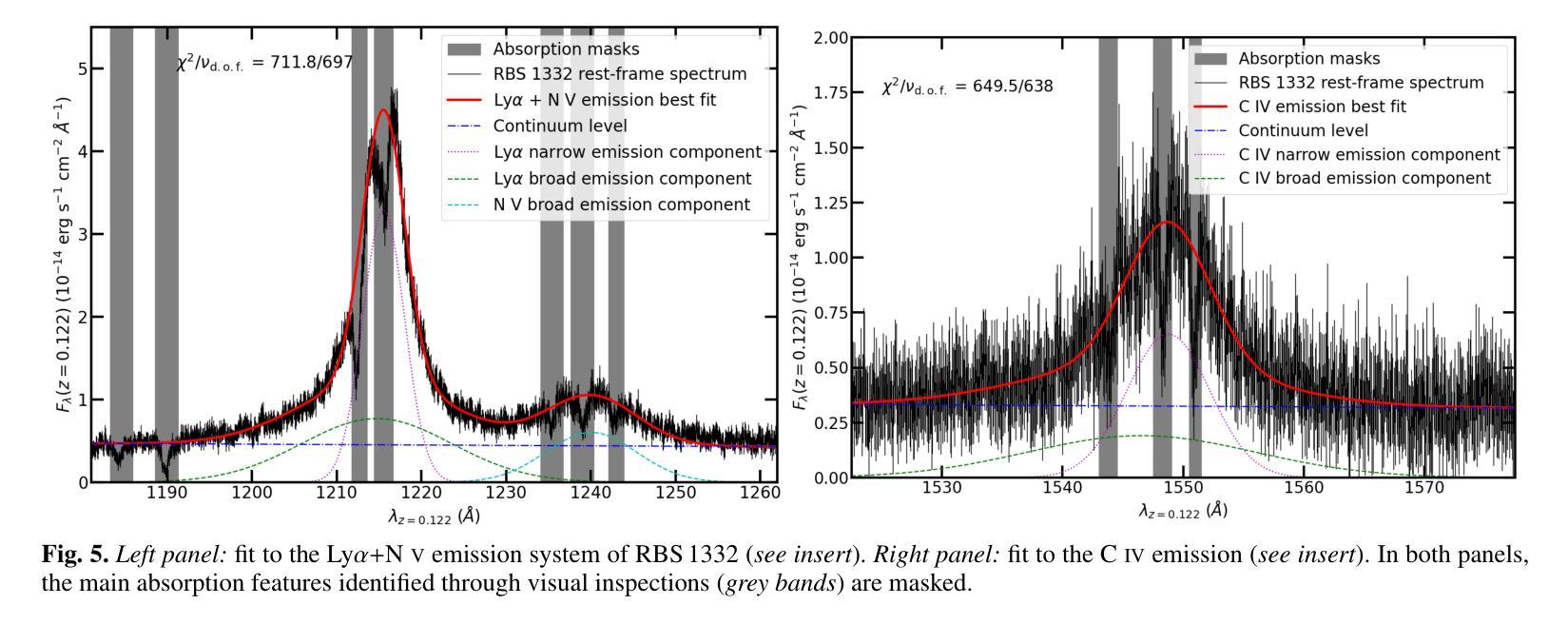
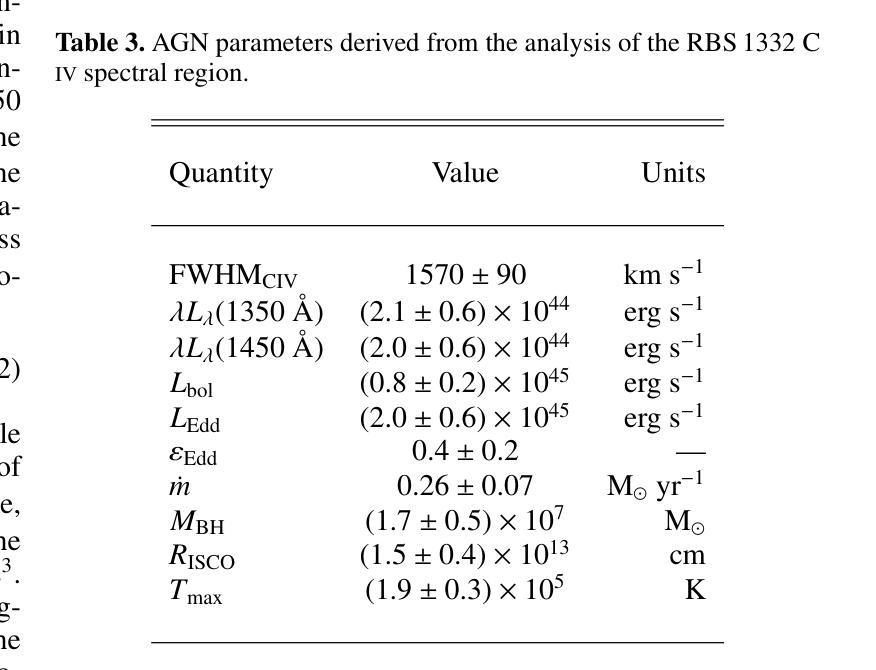
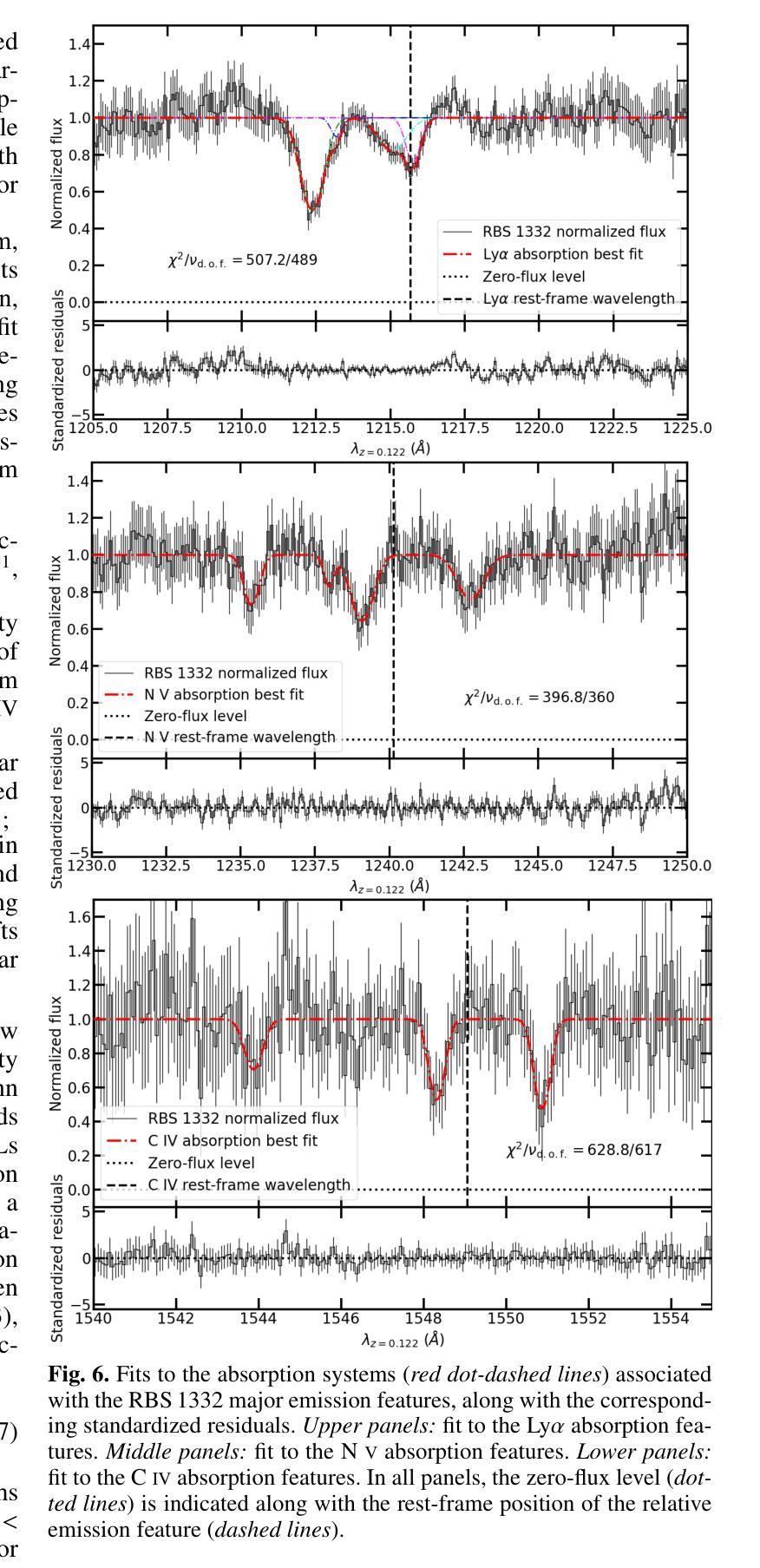
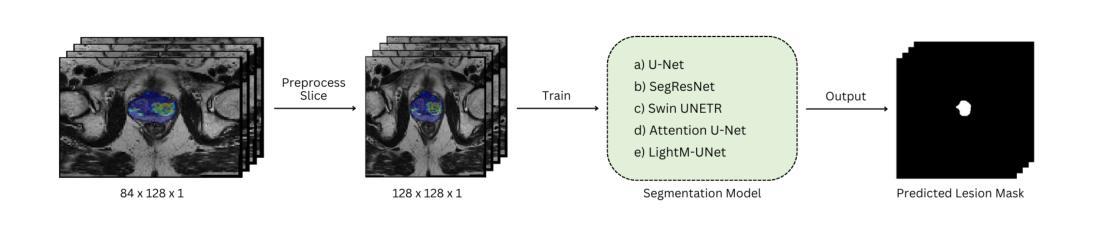
Cancer-Net PCa-Seg: Benchmarking Deep Learning Models for Prostate Cancer Segmentation Using Synthetic Correlated Diffusion Imaging
Authors:Jarett Dewbury, Chi-en Amy Tai, Alexander Wong
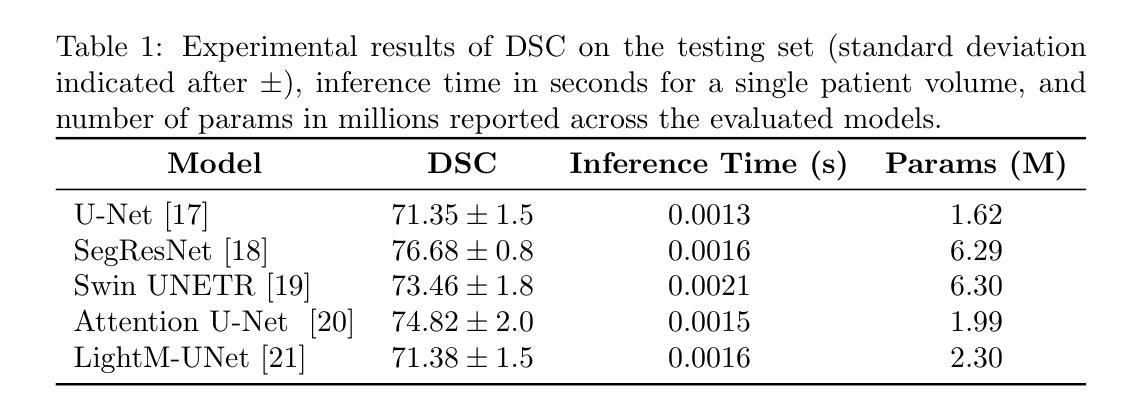
Prostate cancer (PCa) is the most prevalent cancer among men in the United States, accounting for nearly 300,000 cases, 29% of all diagnoses and 35,000 total deaths in 2024. Traditional screening methods such as prostate-specific antigen (PSA) testing and magnetic resonance imaging (MRI) have been pivotal in diagnosis, but have faced limitations in specificity and generalizability. In this paper, we explore the potential of enhancing PCa lesion segmentation using a novel MRI modality called synthetic correlated diffusion imaging (CDI$^s$). We employ several state-of-the-art deep learning models, including U-Net, SegResNet, Swin UNETR, Attention U-Net, and LightM-UNet, to segment PCa lesions from a 200 CDI$^s$ patient cohort. We find that SegResNet achieved superior segmentation performance with a Dice-Sorensen coefficient (DSC) of $76.68 \pm 0.8$. Notably, the Attention U-Net, while slightly less accurate (DSC $74.82 \pm 2.0$), offered a favorable balance between accuracy and computational efficiency. Our findings demonstrate the potential of deep learning models in improving PCa lesion segmentation using CDI$^s$ to enhance PCa management and clinical support.
前列腺癌(PCa)是美国男性中最常见的癌症,2024年将近有30万例病例,占所有诊断的29%,以及3.5万例死亡病例。传统的筛查方法,如前列腺特异性抗原(PSA)检测和磁共振成像(MRI),在诊断中发挥了关键作用,但在特异性和普遍性方面存在局限性。在本文中,我们探索了使用一种称为合成相关扩散成像(CDI$^s$)的新型MRI模态提高前列腺癌病变分割的潜力。我们采用了最先进的深度学习模型,包括U-Net、SegResNet、Swin UNETR、Attention U-Net和LightM-UNet,对200例CDI$^s$患者的前列腺癌病变进行分割。我们发现SegResNet的分割性能较优,Dice-Sorensen系数(DSC)为$76.68 \pm 0.8$。值得注意的是,虽然Attention U-Net的准确度稍低(DSC $74.82 \pm 2.0$),但在准确性和计算效率之间达到了有利的平衡。我们的研究结果表明,深度学习模型在利用CDI$^s$提高前列腺癌病变分割方面具有潜力,可改善前列腺癌管理和临床支持。
论文及项目相关链接
PDF 8 pages, 2 figures, to be published in Studies in Computational Intelligence. This paper introduces Cancer-Net PCa-Seg, a comprehensive evaluation of deep learning models for prostate cancer segmentation using synthetic correlated diffusion imaging (CDI$^s$). We benchmark five state-of-the-art architectures: U-Net, SegResNet, Swin UNETR, Attention U-Net, and LightM-UNet
Summary
前列腺癌(PCa)是美国男性最常见的癌症之一,预计到2024年将导致近30万例病例和约3万五千人死亡。传统筛查方法如前列腺特异性抗原(PSA)检测和磁共振成像(MRI)对诊断至关重要,但在特异性和通用性方面存在局限性。本文探讨了使用合成相关扩散成像(CDI$^s$)这一新型MRI模态提高PCa病灶分割的潜力。利用多种先进的深度学习模型,包括U-Net、SegResNet、Swin UNETR、Attention U-Net和LightM-UNet,从一组包含200个CDI$^s$患者的队列中分割PCa病灶。研究发现,SegResNet的分割性能最佳,Dice-Sørensen系数(DSC)为$76.68 \pm 0.8$。尽管Attention U-Net的准确度稍低(DSC $74.82 \pm 2.0$),但其准确性和计算效率之间的平衡较为理想。研究结果表明深度学习模型在利用CDI$^s$提高PCa病灶分割方面具有潜力,有望改善PCa管理和临床支持。
Key Takeaways
- 前列腺癌是美国男性最常见的癌症之一,预计到2024年将导致大量新增病例和死亡。
- 传统筛查方法如PSA检测和MRI在前列腺癌诊断中具有重要意义,但存在特异性和通用性方面的局限性。
- 合成相关扩散成像(CDI$^s$)是一种新型MRI模态,在前列腺癌病灶分割方面具有潜在应用价值。
- 深度学习模型如SegResNet和Attention U-Net在CDI$^s$图像上表现出较好的前列腺癌病灶分割性能。
- SegResNet在分割性能上达到较高的Dice-Sørensen系数(DSC $76.68 \pm 0.8$)。
- Attention U-Net在准确性和计算效率之间达到平衡,虽然其DSC略低但仍具有实际应用价值。
点此查看论文截图

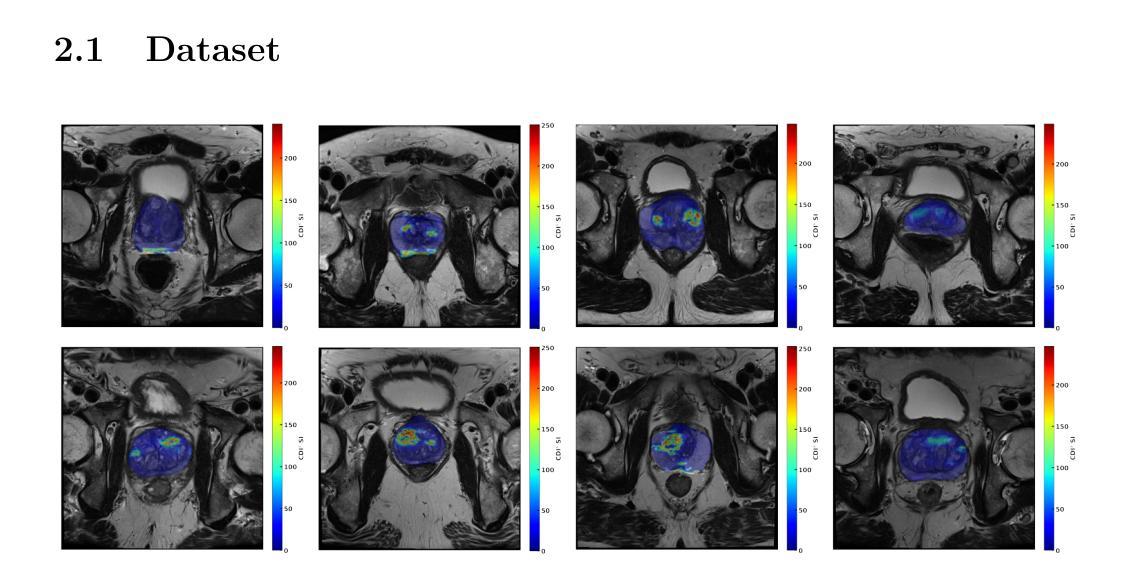
A Vessel Bifurcation Landmark Pair Dataset for Abdominal CT Deformable Image Registration (DIR) Validation
Authors:Edward R Criscuolo, Yao Hao, Zhendong Zhang, Trevor McKeown, Deshan Yang
Deformable image registration (DIR) is an enabling technology in many diagnostic and therapeutic tasks. Despite this, DIR algorithms have limited clinical use, largely due to a lack of benchmark datasets for quality assurance during development. To support future algorithm development, here we introduce our first-of-its-kind abdominal CT DIR benchmark dataset, comprising large numbers of highly accurate landmark pairs on matching blood vessel bifurcations. Abdominal CT image pairs of 30 patients were acquired from several public repositories as well as the authors’ institution with IRB approval. The two CTs of each pair were originally acquired for the same patient on different days. An image processing workflow was developed and applied to each image pair: 1) Abdominal organs were segmented with a deep learning model, and image intensity within organ masks was overwritten. 2) Matching image patches were manually identified between two CTs of each image pair 3) Vessel bifurcation landmarks were labeled on one image of each image patch pair. 4) Image patches were deformably registered, and landmarks were projected onto the second image. 5) Landmark pair locations were refined manually or with an automated process. This workflow resulted in 1895 total landmark pairs, or 63 per case on average. Estimates of the landmark pair accuracy using digital phantoms were 0.7+/-1.2mm. The data is published in Zenodo at https://doi.org/10.5281/zenodo.14362785. Instructions for use can be found at https://github.com/deshanyang/Abdominal-DIR-QA. This dataset is a first-of-its-kind for abdominal DIR validation. The number, accuracy, and distribution of landmark pairs will allow for robust validation of DIR algorithms with precision beyond what is currently available.
可变形图像配准(DIR)是许多诊断和治疗任务中的关键技术。尽管如此,DIR算法在临床应用中的使用仍然有限,这主要是因为开发过程中缺乏用于质量保证的基准数据集。为了支持未来的算法开发,我们在此介绍了我们首创的腹部CT DIR基准数据集,其中包含大量关于匹配血管分叉的准确地标对。30名患者的腹部CT图像对是从一些公共仓库以及作者机构获得,并且获得了IRB批准。每对中的两个CT最初是在不同的日子为同一患者获取的。针对每对图像开发并应用了一个图像处理工作流程:1) 使用深度学习模型分割腹部器官,并覆盖器官掩膜内的图像强度。2)在两个CT之间手动识别匹配图像块。3)在每个图像块对上的一幅图像上标注血管分叉地标。4)可变形地配准图像块,并将地标投影到第二幅图像上。5)通过手动或自动化过程对地标对位置进行微调。这一工作流程产生了总共1895个地标对,平均每个病例有63个。使用数字幻影估计地标对的精度为0.7±1.2毫米。数据已在Zenodo上发表,可通过https://doi.org/10.5281/zenodo.14362785访问。使用说明可在https://github.com/deshanyang/Abdominal-DIR-QA找到。该数据集是腹部DIR验证的首创,地标对的数量、准确性和分布将允许对DIR算法进行稳健验证,其精确度超越了当前可用的水平。
论文及项目相关链接
PDF 19 pages, 3 figures
Summary
本文介绍了一个用于评估腹部可变形图像配准(DIR)算法的新颖基准数据集。该数据集包含了大量患者的高精度地标配对,这些地标位于匹配的血管分叉处。数据集的创建过程包括图像分割、图像强度处理、手动标识匹配图像块、标注血管分叉地标、可变形图像配准以及地标投影等步骤。该数据集为腹部DIR验证提供了独特的资源,其地标对的数量、准确性和分布为DIR算法的稳健验证提供了超越现有水平的新工具。
Key Takeaways
- 介绍了用于开发腹部CT可变形图像配准(DIR)基准数据集的研究。
- 数据集包含高度准确的血管分叉地标配对。
- 数据集创建过程包括图像分割、匹配图像块标识、地标标注、图像配准和地标投影等步骤。
- 该数据集是首个用于腹部DIR验证的数据集。
- 地标对的数量、准确性和分布允许对DIR算法进行稳健验证。
- 数据集已在Zenodo上发布,并提供使用说明。
点此查看论文截图

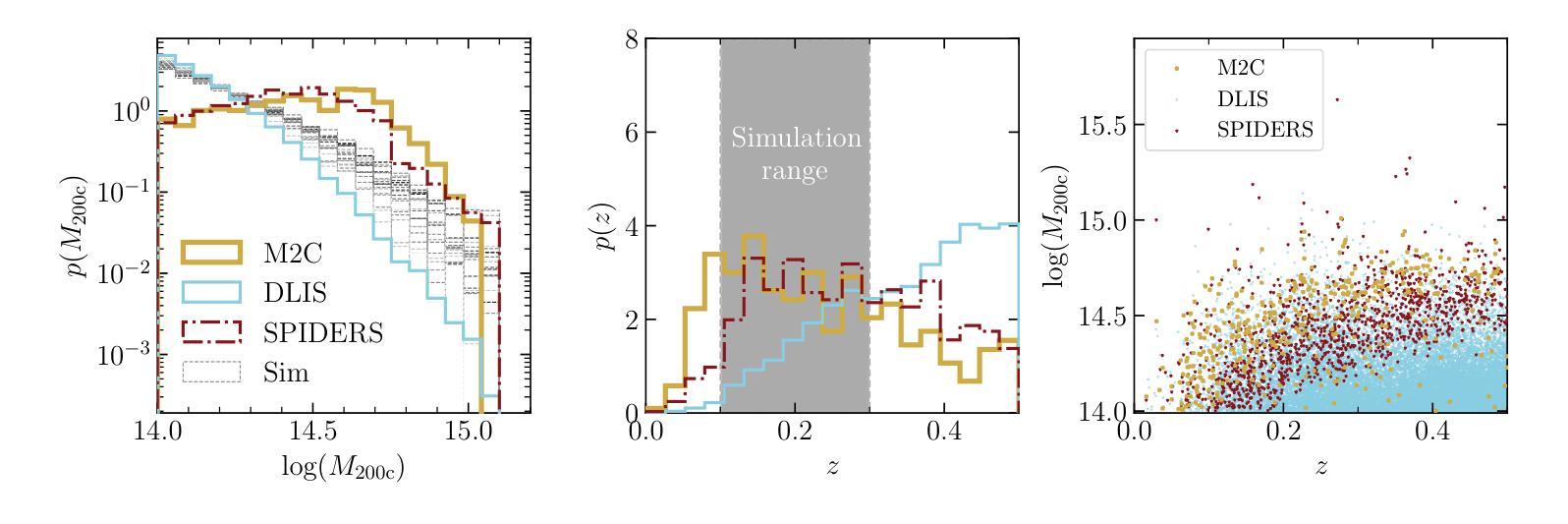
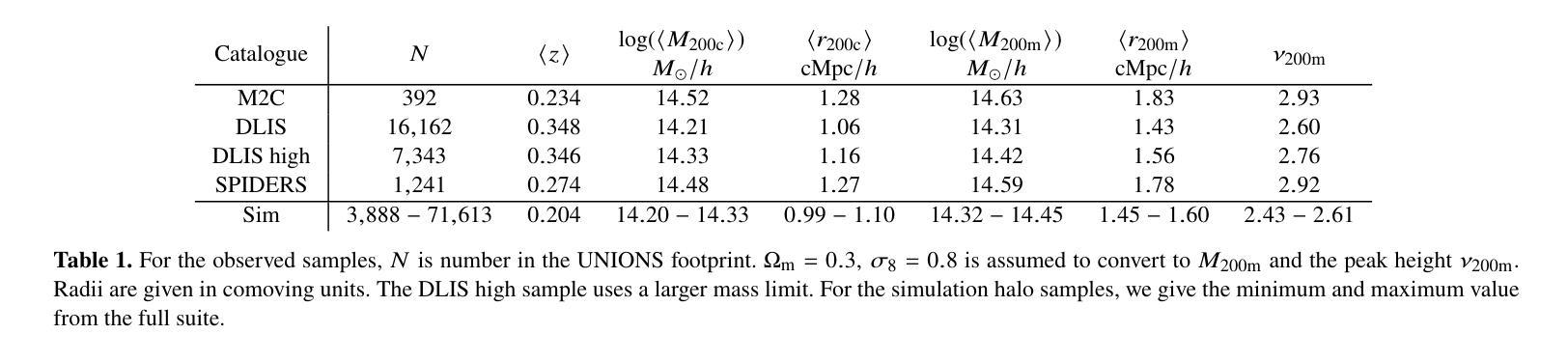
Cosmology from UNIONS weak lensing profiles of galaxy clusters
Authors:Charlie T. Mpetha, James E. Taylor, Yuba Amoura, Roan Haggar, Thomas de Boer, Sacha Guerrini, Axel Guinot, Fabian Hervas Peters, Hendrik Hildebrandt, Michael J. Hudson, Martin Kilbinger, Tobias Liaudat, Alan McConnachie, Ludovic Van Waerbeke, Anna Wittje
Cosmological information is encoded in the structure of galaxy clusters. In Universes with less matter and larger initial density perturbations, clusters form earlier and have more time to accrete material, leading to a more extended infall region. Thus, measuring the mean mass distribution in the infall region provides a novel cosmological test. The infall region is largely insensitive to baryonic physics, and provides a cleaner structural test than other measures of cluster assembly time such as concentration. We consider cluster samples from three publicly available galaxy cluster catalogues: the Spectrsopic Identification of eROSITA Sources (SPIDERS) catalogue, the X-ray and Sunyaev-Zeldovich effect selected clusters in the meta-catalogue M2C, and clusters identified in the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Survey. Using a preliminary shape catalogue from the Ultraviolet Near Infrared Optical Northern Survey (UNIONS), we derive excess surface mass density profiles for each sample. We then compare the mean profile for the DESI Legacy sample, which is the most complete, to predictions from a suite of simulations covering a range of $\Omega_{\rm m}$ and $\sigma_8$, obtaining constraints of $\Omega_{\rm m}=0.29\pm 0.05$ and $\sigma_8=0.80 \pm 0.04$. We also measure mean (comoving) splashback radii for SPIDERS, M2C and DESI Legacy Imaging Survey clusters of $1.59^{+0.16}{-0.13} {\rm cMpc}/h$, $1.30^{+0.25}{-0.13} {\rm cMpc}/h$ and $1.45\pm0.11 {\rm cMpc}/h$ respectively. Performing this analysis with the final UNIONS shape catalogue and the full sample of spectroscopically observed clusters in DESI, we can expect to improve on the best current constraints from cluster abundance studies by a factor of 2 or more.
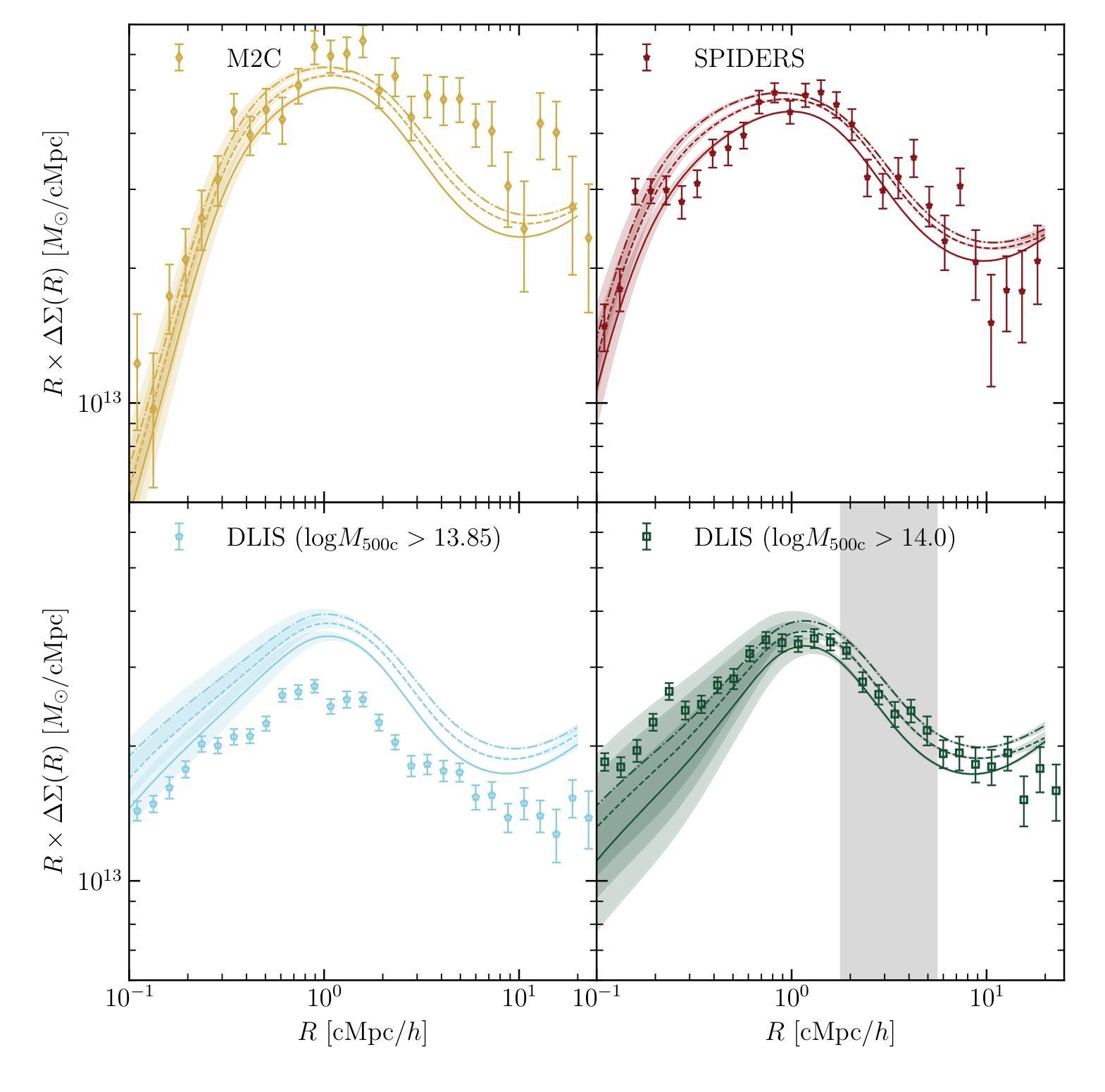
宇宙学信息被编码在星系团的结构中。在物质较少、初始密度扰动较大的宇宙中,星系团形成较早,有更多的时间累积物质,从而导致坠落区域更加广阔。因此,测量坠落区域的平均质量分布提供了一种新的宇宙学测试方法。坠落区域对重子物理基本不受影响,相较于其他衡量星系团组装时间的指标(如浓度),它提供了一个更清洁的结构测试。我们考虑了三个公开可用的星系团目录中的星系团样本:光谱识别eROSITA源的SPIDERS目录、元目录M2C中的X射线和Sunyaev-Zeldovich效应选择的集群以及在暗能量光谱仪(DESI)遗产成像调查中识别的集群。我们使用紫外线近红外光学北部调查(UNIONS)的初步形态目录,为每个样本推导出多余表面质量密度分布曲线。然后,我们将最完整的DESI遗产样本的平均分布曲线与一系列模拟预测值进行比较,这些模拟覆盖了Ωm和σ8的范围,得到约束Ωm=0.29±0.05和σ8=0.80±0.04。我们还测量了SPIDERS、M2C和DESI遗产成像调查集群的平均(移动)溅射半径分别为$1.59^{+0.16}{-0.13} {\rm cMpc}/h$、$1.30^{+0.25}{-0.13} {\rm cMpc}/h$和$1.45\pm0.11 {\rm cMpc}/h$。使用最终的UNIONS形态目录和DESI中光谱观测的完整样本进行此分析,我们有望将目前基于集群丰度的研究的最佳约束提高一倍或更多。
论文及项目相关链接
PDF 16 pages, 10 figures. Submitted to MNRAS
Summary
宇宙学信息被编码在星系团的结构中。在物质较少、初始密度扰动较大的宇宙中,星系团形成较早,有更多的时间积累物质,导致坠落区域更为广阔。因此,测量坠落区域的平均质量分布提供了一项新的宇宙学测试。本研究利用三个公开的星系团目录,即SPIDERS目录、M2C元目录以及DESI成像调查中的星系团,通过UNIONS初步形态目录推导出各样本的过量表面质量密度分布。然后,我们将DESI遗产样本的平均分布与一系列模拟预测进行比较,得出物质密度参数Ωm和σ8的限制值。此外,我们还测量了SPIDERS、M2C和DESI成像调查星系团的平均(移动)溅射半径。随着UNIONS形态目录和DESI光谱观测星系团样本的完善,我们有望将当前基于集群丰度的最佳约束提高一倍以上。
Key Takeaways
- 宇宙学信息被编码在星系团的结构中。
- 星系团形成的时间和方式影响坠落区域的大小和结构。
- 测量坠落区域的平均质量分布是一种新的宇宙学测试方法。
- 此方法主要关注坠落区域,较少受到重子物理的影响。
- 研究使用了三个公开的星系团目录中的样本数据进行分析。
- 通过对比模拟预测和实测数据,得出了物质密度参数Ωm和σ8的限制值。
点此查看论文截图

Benchmarking Robustness of Contrastive Learning Models for Medical Image-Report Retrieval
Authors:Demetrio Deanda, Yuktha Priya Masupalli, Jeong Yang, Young Lee, Zechun Cao, Gongbo Liang
Medical images and reports offer invaluable insights into patient health. The heterogeneity and complexity of these data hinder effective analysis. To bridge this gap, we investigate contrastive learning models for cross-domain retrieval, which associates medical images with their corresponding clinical reports. This study benchmarks the robustness of four state-of-the-art contrastive learning models: CLIP, CXR-RePaiR, MedCLIP, and CXR-CLIP. We introduce an occlusion retrieval task to evaluate model performance under varying levels of image corruption. Our findings reveal that all evaluated models are highly sensitive to out-of-distribution data, as evidenced by the proportional decrease in performance with increasing occlusion levels. While MedCLIP exhibits slightly more robustness, its overall performance remains significantly behind CXR-CLIP and CXR-RePaiR. CLIP, trained on a general-purpose dataset, struggles with medical image-report retrieval, highlighting the importance of domain-specific training data. The evaluation of this work suggests that more effort needs to be spent on improving the robustness of these models. By addressing these limitations, we can develop more reliable cross-domain retrieval models for medical applications.
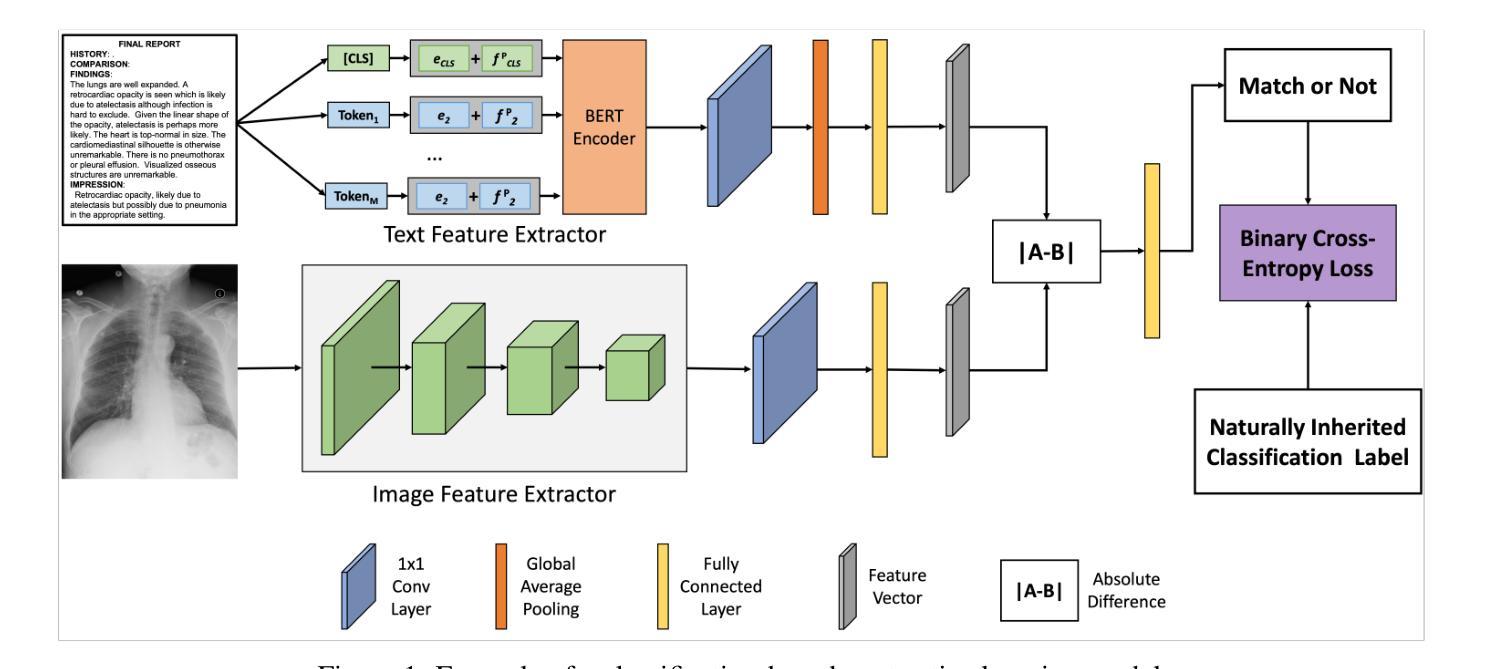
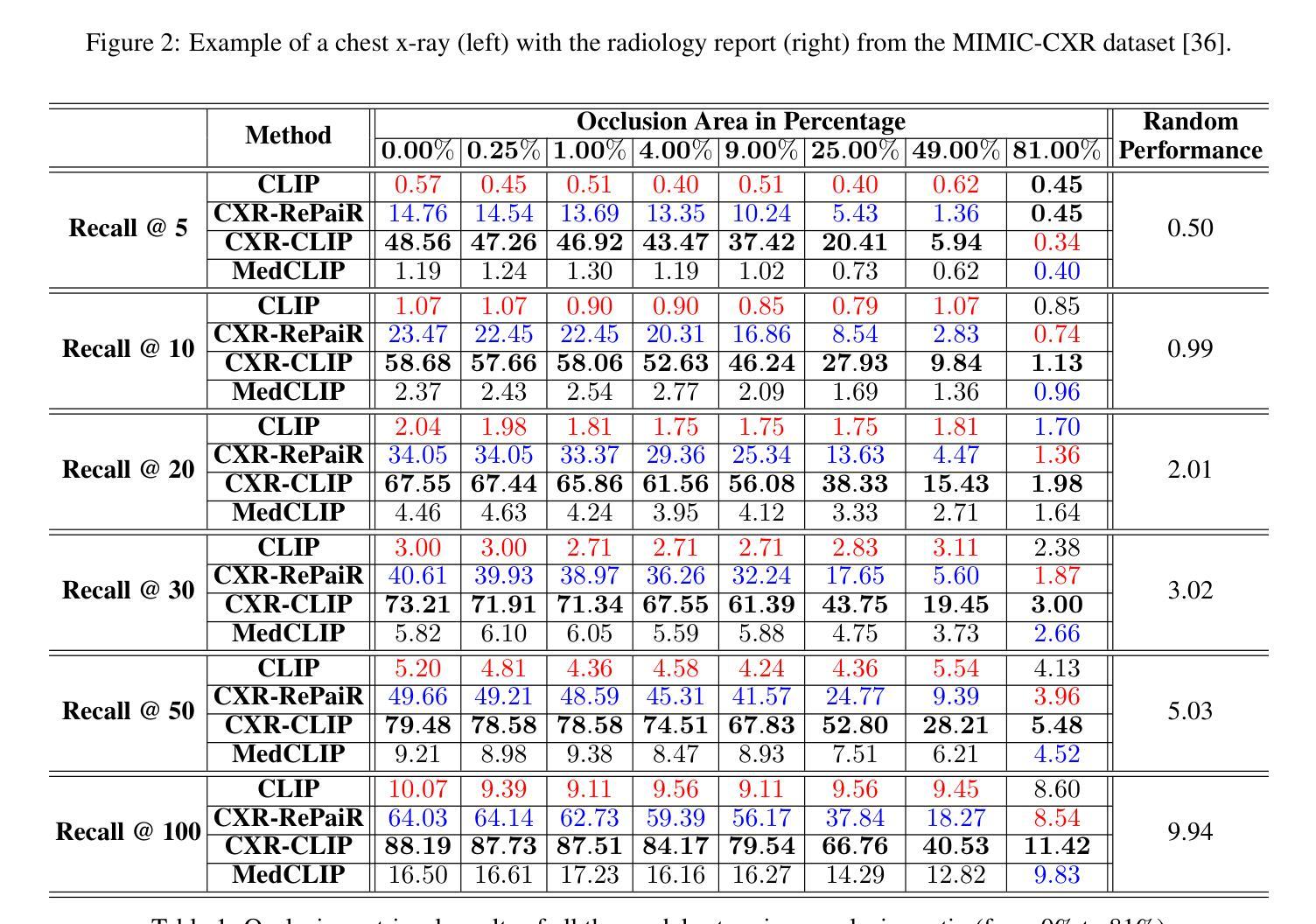
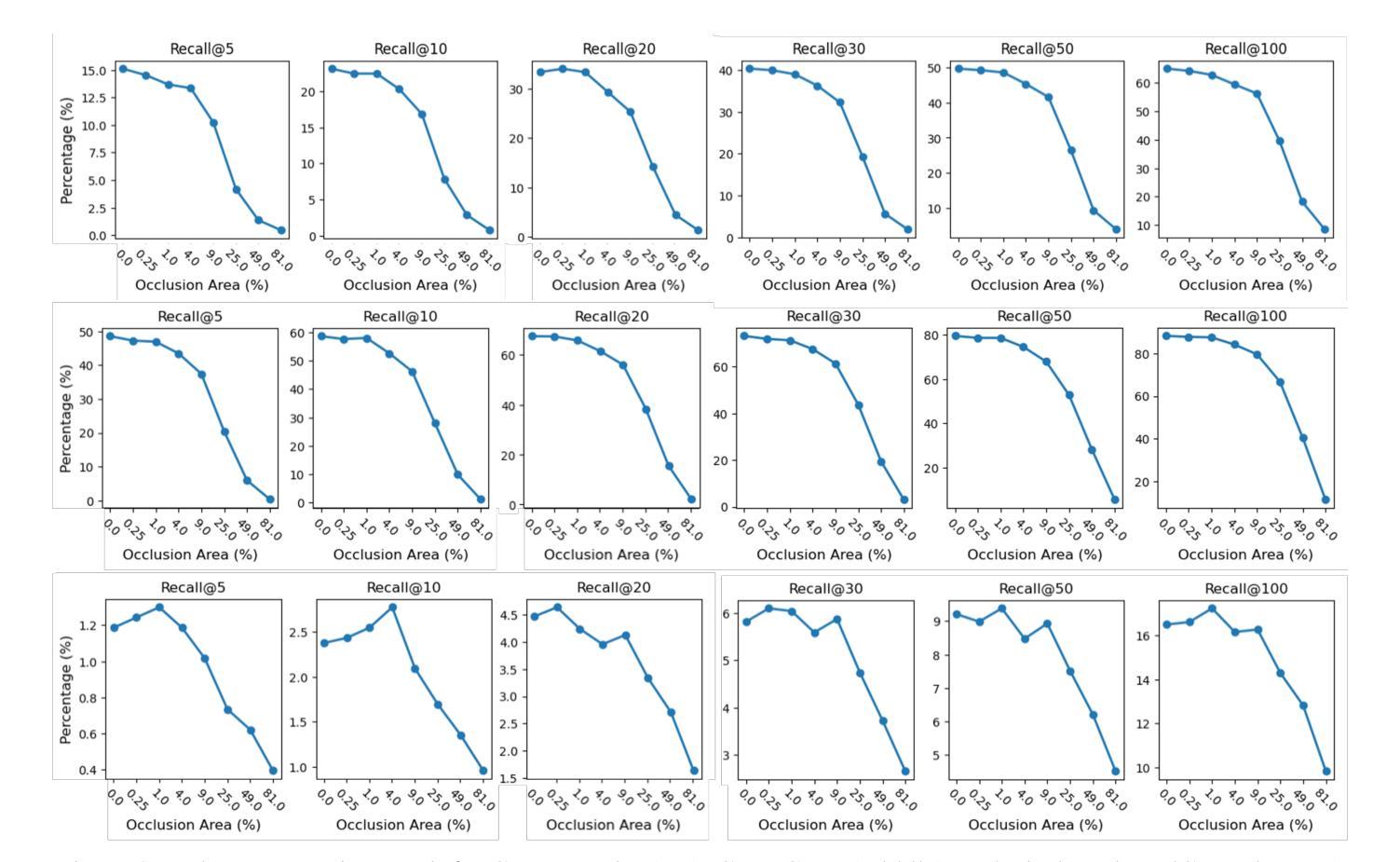
医疗图像和报告为患者健康提供了宝贵的见解。这些数据的异质性和复杂性阻碍了有效的分析。为了弥差距,我们研究了跨域检索的对比学习模型,该模型将医学图像与其相应的临床报告相关联。本研究对四种最先进的对比学习模型进行了稳健性评估:CLIP、CXR-RePaiR、MedCLIP和CXR-CLIP。我们引入了一个遮挡检索任务来评估模型在不同程度的图像损坏下的性能。我们的研究结果表明,所有评估模型对异常数据的敏感性都很高,随着遮挡程度的增加,性能有所下降。虽然MedCLIP显示出轻微的更多稳健性,但其总体性能仍然远远落后于CXR-CLIP和CXR-RePaiR。CLIP在通用数据集上进行训练,因此在医学图像报告检索方面表现挣扎,这突出了特定领域训练数据的重要性。对此工作的评估表明,还需要更多努力来提高这些模型的稳健性。通过解决这些局限性,我们可以开发更可靠的医学应用跨域检索模型。
论文及项目相关链接
PDF This work is accepted to AAAI 2025 Workshop – the 9th International Workshop on Health Intelligence
Summary
本文探讨了医学图像与临床报告之间的跨域检索问题,引入对比学习模型来解决医学图像数据的异质性和复杂性。通过对四种先进的对比学习模型(CLIP、CXR-RePaiR、MedCLIP和CXR-CLIP)的评估和比较,发现这些模型对遮挡等异常数据敏感,且性能下降幅度较大。MedCLIP虽稍具稳健性,但总体性能仍落后于CXR-CLIP和CXR-RePaiR。研究强调需要更多努力改进模型的稳健性,以开发更可靠的医学应用跨域检索模型。
Key Takeaways
- 对比学习模型被用于解决医学图像与临床报告的跨域检索问题。
- 引入遮挡检索任务来评估模型性能,以应对不同遮挡程度的挑战。
- 研究的模型对异常数据敏感,性能随遮挡程度增加而下降。
- MedCLIP模型虽稳健性稍强,但总体性能落后于特定领域训练的模型如CXR-CLIP和CXR-RePaiR。
- CLIP模型在医学图像报告检索方面的表现较弱,突显出领域特定训练数据的重要性。
- 研究表明需要改进模型的稳健性,以提高其在医学应用中的可靠性。
点此查看论文截图


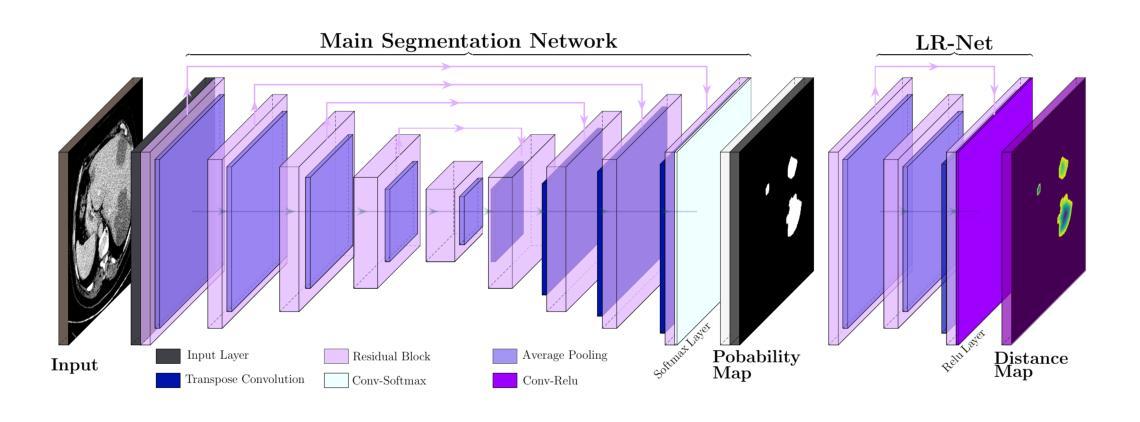
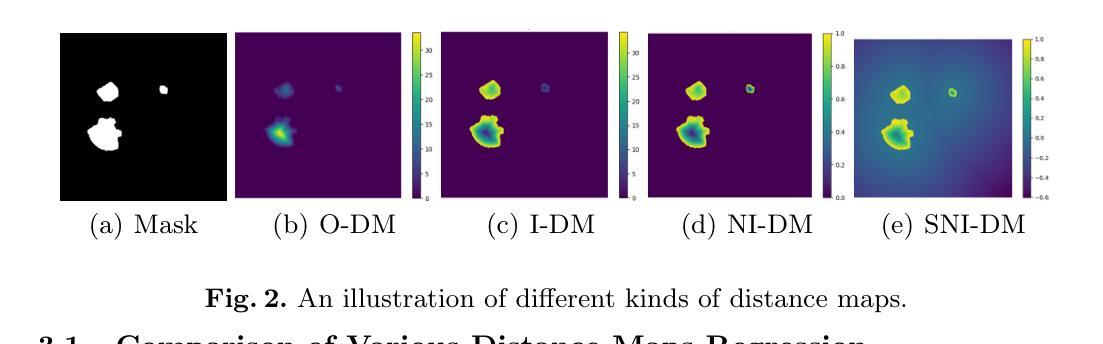
Deep Distance Map Regression Network with Shape-aware Loss for Imbalanced Medical Image Segmentation
Authors:Huiyu Li, Xiabi Liu, Said Boumaraf, Xiaopeng Gong, Donghai Liao, Xiaohong Ma
Small object segmentation, like tumor segmentation, is a difficult and critical task in the field of medical image analysis. Although deep learning based methods have achieved promising performance, they are restricted to the use of binary segmentation mask. Inspired by the rigorous mapping between binary segmentation mask and distance map, we adopt distance map as a novel ground truth and employ a network to fulfill the computation of distance map. Specially, we propose a new segmentation framework that incorporates the existing binary segmentation network and a light weight regression network (dubbed as LR-Net). Thus, the LR-Net can convert the distance map computation into a regression task and leverage the rich information of distance maps. Additionally, we derive a shape-aware loss by employing distance maps as penalty map to infer the complete shape of an object. We evaluated our approach on MICCAI 2017 Liver Tumor Segmentation (LiTS) Challenge dataset and a clinical dataset. Experimental results show that our approach outperforms the classification-based methods as well as other existing state-of-the-arts.
医学图像分析中,小物体分割(如肿瘤分割)是一项既困难又关键的任务。尽管基于深度学习的方法已经取得了有前景的效果,但它们受限于使用二元分割掩膜。受二元分割掩膜与距离映射之间严格映射关系的启发,我们采用距离映射作为新的基准真实值,并使用网络完成距离映射的计算。特别是,我们提出了一种新的分割框架,该框架结合了现有的二元分割网络和轻量级回归网络(称为LR-Net)。因此,LR-Net可以将距离映射计算转换为回归任务,并利用距离映射的丰富信息。此外,我们通过使用距离映射作为惩罚映射,推导了一种形状感知损失来推断对象的完整形状。我们在MICCAI 2017肝脏肿瘤分割挑战赛数据集和临床数据集上评估了我们的方法。实验结果表明,我们的方法优于基于分类的方法以及其他现有最新技术。
论文及项目相关链接
PDF Conference
Summary
基于深度学习的医学图像小目标分割,如肿瘤分割,是医学图像分析中的关键任务。本研究采用距离图作为新的真实标签,并提出一个结合二元分割网络和轻量级回归网络(称为LR-Net)的分割框架。LR-Net将距离图计算转化为回归任务,并利用距离图的丰富信息。此外,通过距离图作为惩罚图,我们推导出形状感知损失来推断对象的完整形状。在MICCAI 2017年肝脏肿瘤分割挑战赛数据集和临床数据集上的实验结果表明,我们的方法优于基于分类的方法和其他现有先进技术。
Key Takeaways
- 医学图像中的小目标分割,如肿瘤分割,是深度学习方法的重要应用领域。
- 研究采用距离图作为新的真实标签,以更精确地描述目标物体的边界信息。
- 提出结合二元分割网络和轻量级回归网络(LR-Net)的新分割框架。
- LR-Net能将距离图的计算转化为回归任务,利用距离图中丰富的信息。
- 通过距离图推导出的形状感知损失,有助于更准确地推断目标的完整形状。
- 在多个数据集上的实验结果表明,该方法在性能上超越了基于分类的方法和其他先进技术。
- 该研究为医学图像分割任务提供了新的思路和方向。
点此查看论文截图

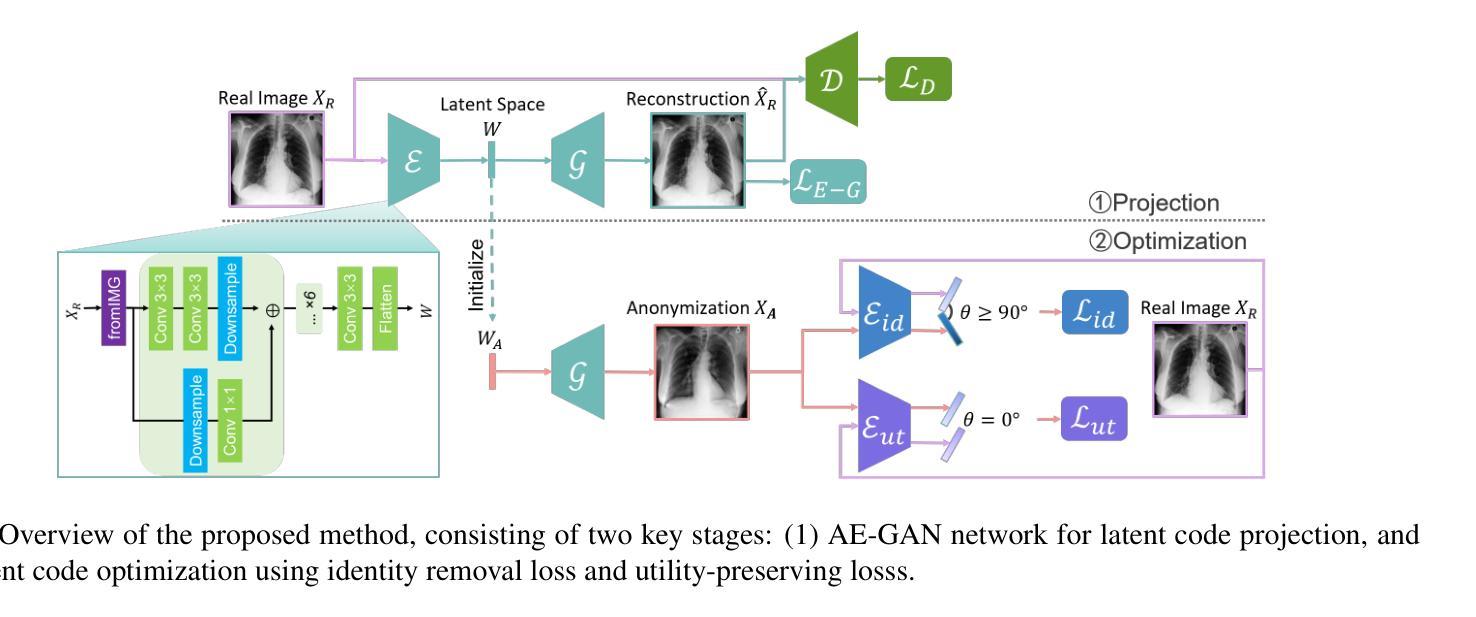
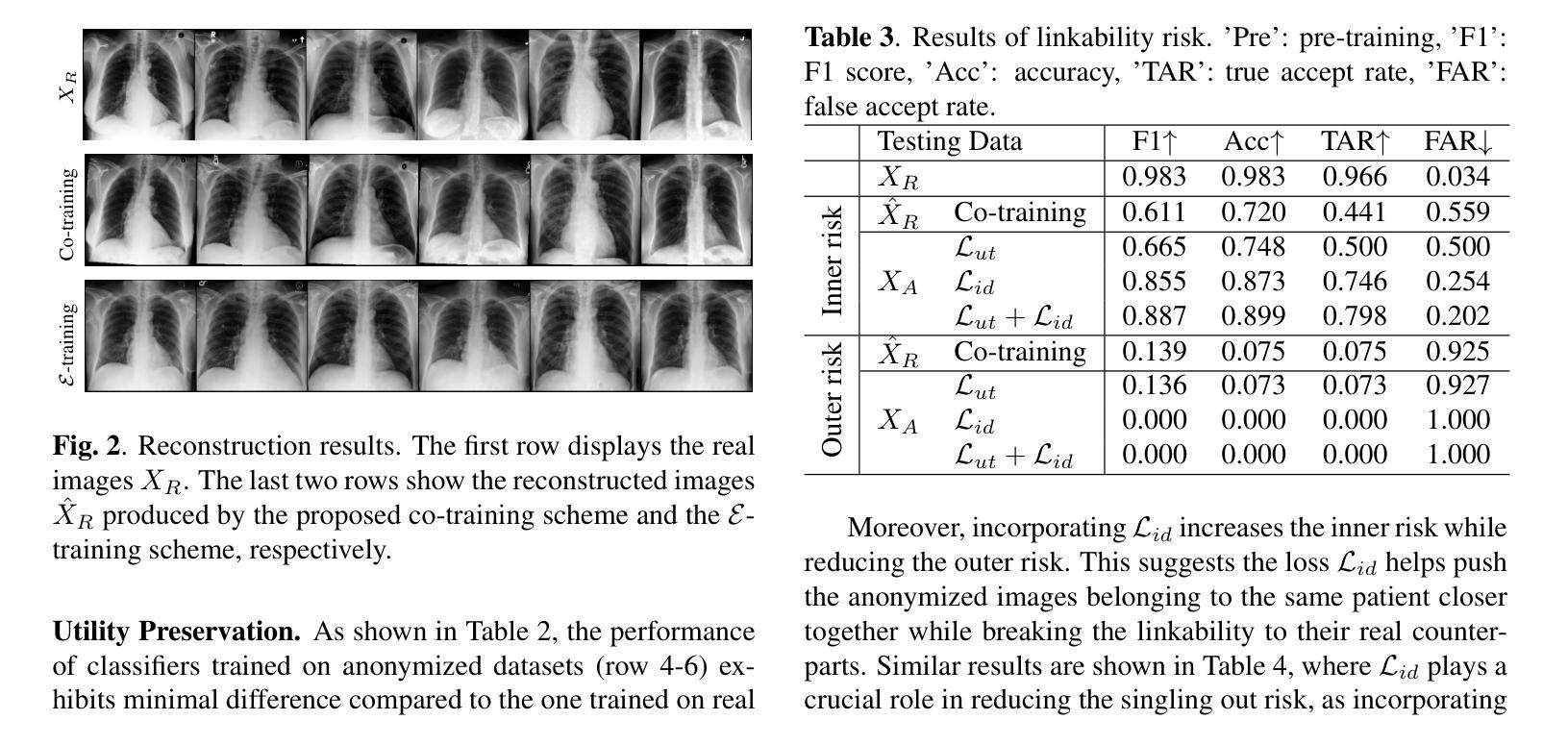
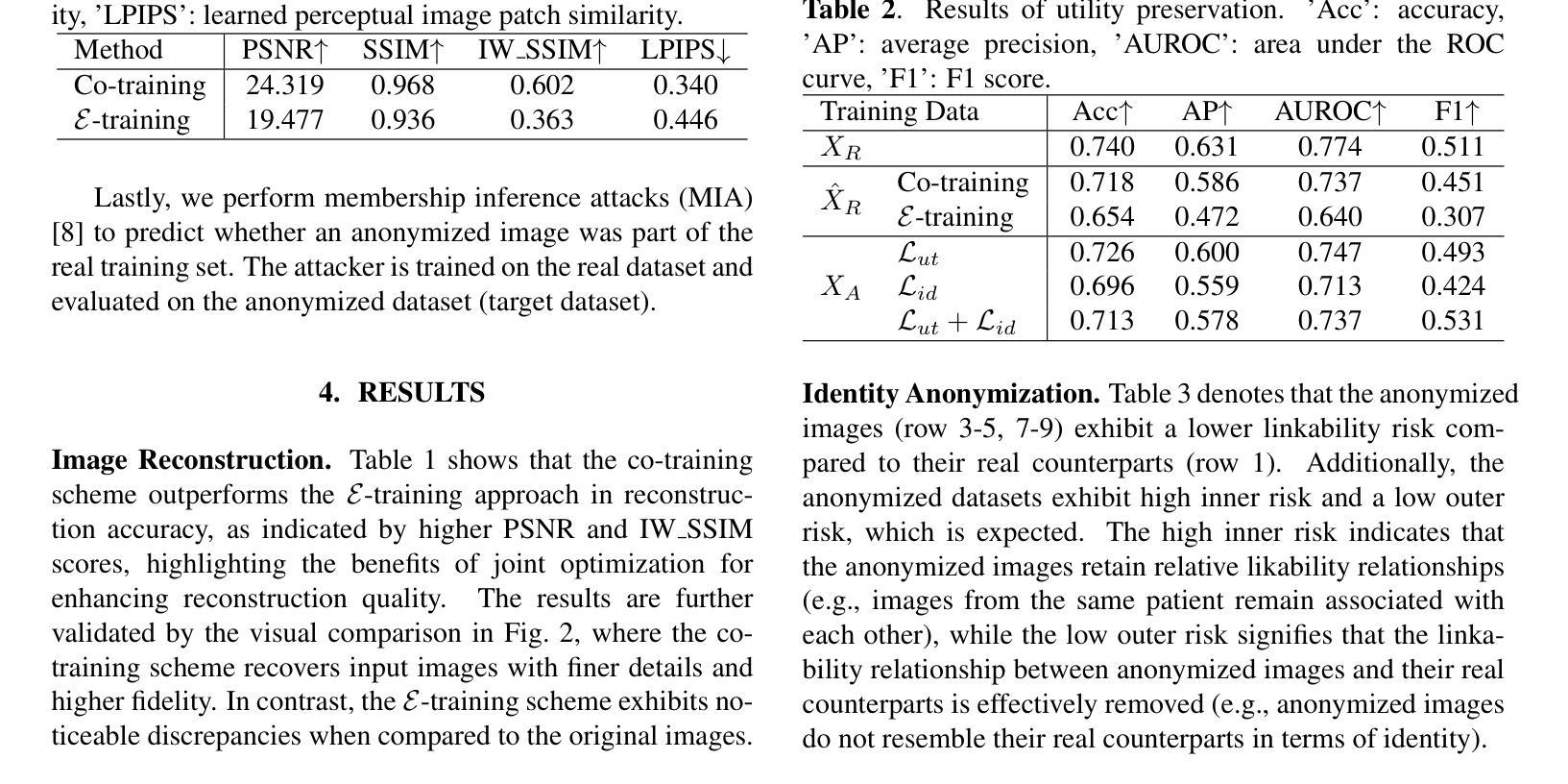
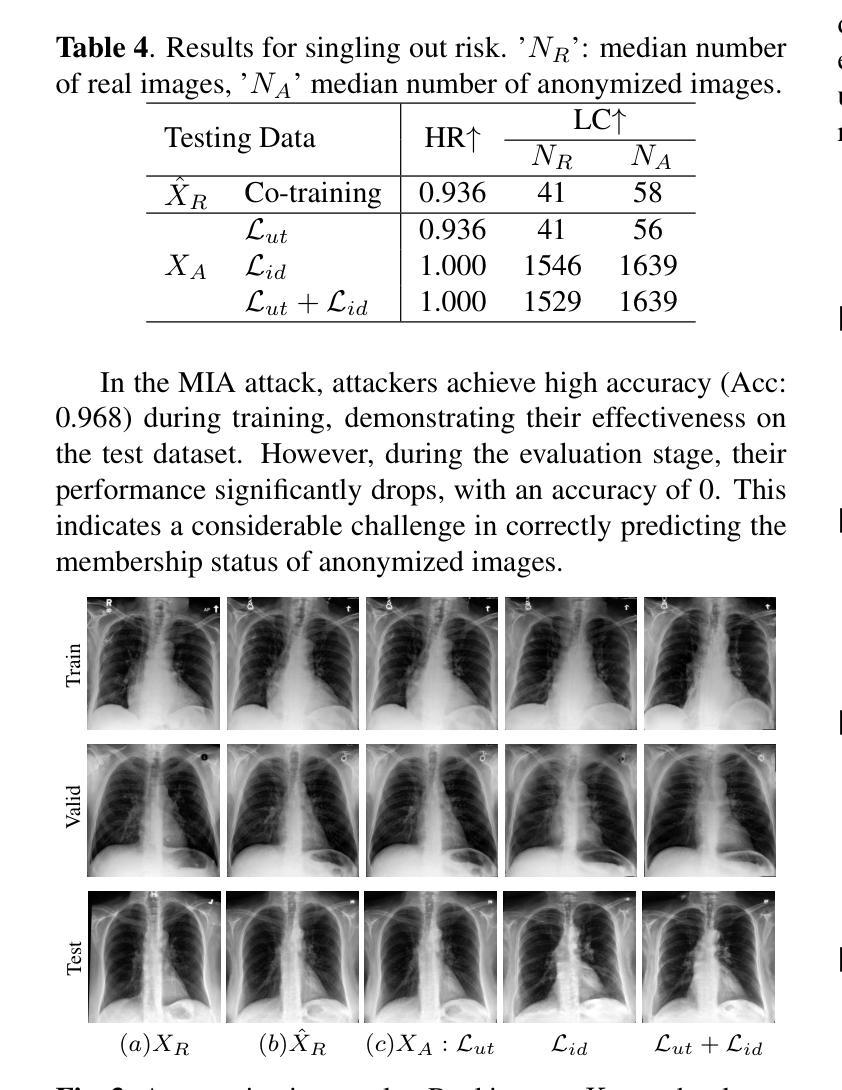
Generative Medical Image Anonymization Based on Latent Code Projection and Optimization
Authors:Huiyu Li, Nicholas Ayache, Hervé Delingette
Medical image anonymization aims to protect patient privacy by removing identifying information, while preserving the data utility to solve downstream tasks. In this paper, we address the medical image anonymization problem with a two-stage solution: latent code projection and optimization. In the projection stage, we design a streamlined encoder to project input images into a latent space and propose a co-training scheme to enhance the projection process. In the optimization stage, we refine the latent code using two deep loss functions designed to address the trade-off between identity protection and data utility dedicated to medical images. Through a comprehensive set of qualitative and quantitative experiments, we showcase the effectiveness of our approach on the MIMIC-CXR chest X-ray dataset by generating anonymized synthetic images that can serve as training set for detecting lung pathologies. Source codes are available at https://github.com/Huiyu-Li/GMIA.
医学图像匿名化的目的是通过移除识别信息来保护患者隐私,同时保留数据效用以解决下游任务。在本文中,我们采用两阶段解决方案来解决医学图像匿名化问题:潜在代码投影和优化。在投影阶段,我们设计了一个简化的编码器,将输入图像投影到潜在空间,并提出一种联合训练方案来增强投影过程。在优化阶段,我们利用两种深度损失函数来优化潜在代码,这些函数旨在解决身份保护与数据效用之间的权衡,专门用于医学图像。通过一系列综合的定性和定量实验,我们在MIMIC-CXR胸部X射线数据集上展示了我们的方法的有效性,通过生成匿名合成图像作为训练集,可用于检测肺部病理。相关源代码可在https://github.com/Huiyu-Li/GMIA中找到。
论文及项目相关链接
PDF Conference
Summary
医学图像匿名化旨在去除患者身份识别信息以保护患者隐私,同时保留数据用于解决下游任务。本文提出一个两阶段的医学图像匿名化解决方案:潜在代码投影和优化。投影阶段设计简洁的编码器将输入图像投影到潜在空间,并提出协同训练方案以增强投影过程。优化阶段使用两个针对医学图像身份保护和数据效用权衡的深度损失函数来优化潜在代码。通过一系列定性和定量实验,在MIMIC-CXR胸部X射线数据集上展示了该方法的有效性,生成匿名合成图像可作为检测肺部疾病的训练集。
Key Takeaways
- 医学图像匿名化的目标是去除患者身份识别信息,同时保留数据用于解决下游任务。
- 本文提出一个两阶段的医学图像匿名化解决方案:潜在代码投影和优化。
- 投影阶段利用简洁的编码器和协同训练方案进行图像投影。
- 优化阶段使用深度损失函数来平衡身份保护和数据效用。
- 实验表明,该方法在MIMIC-CXR数据集上生成了有效的匿名合成图像。
- 这些合成图像可以作为医学图像分析中检测肺部疾病的训练集。
点此查看论文截图

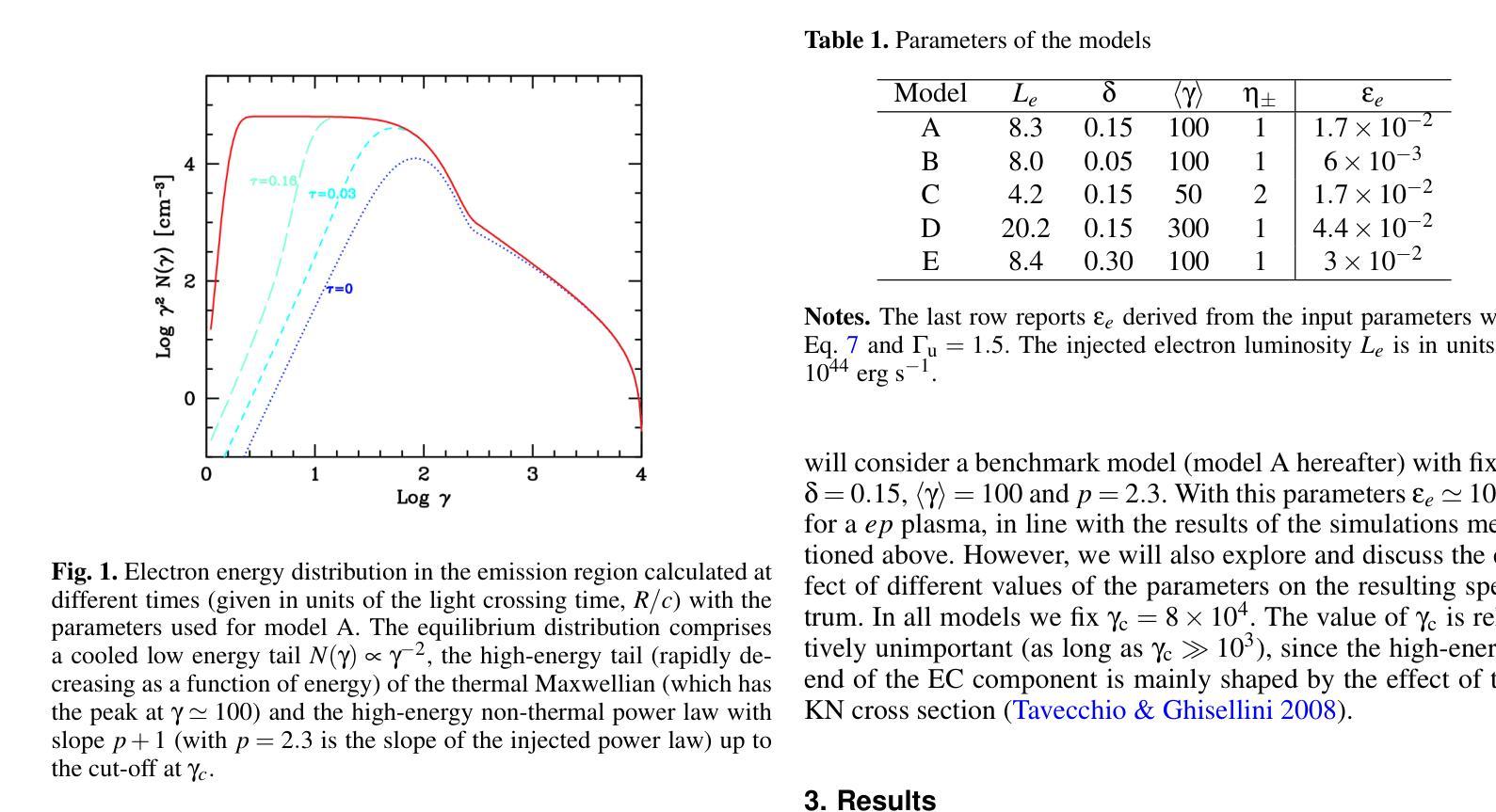
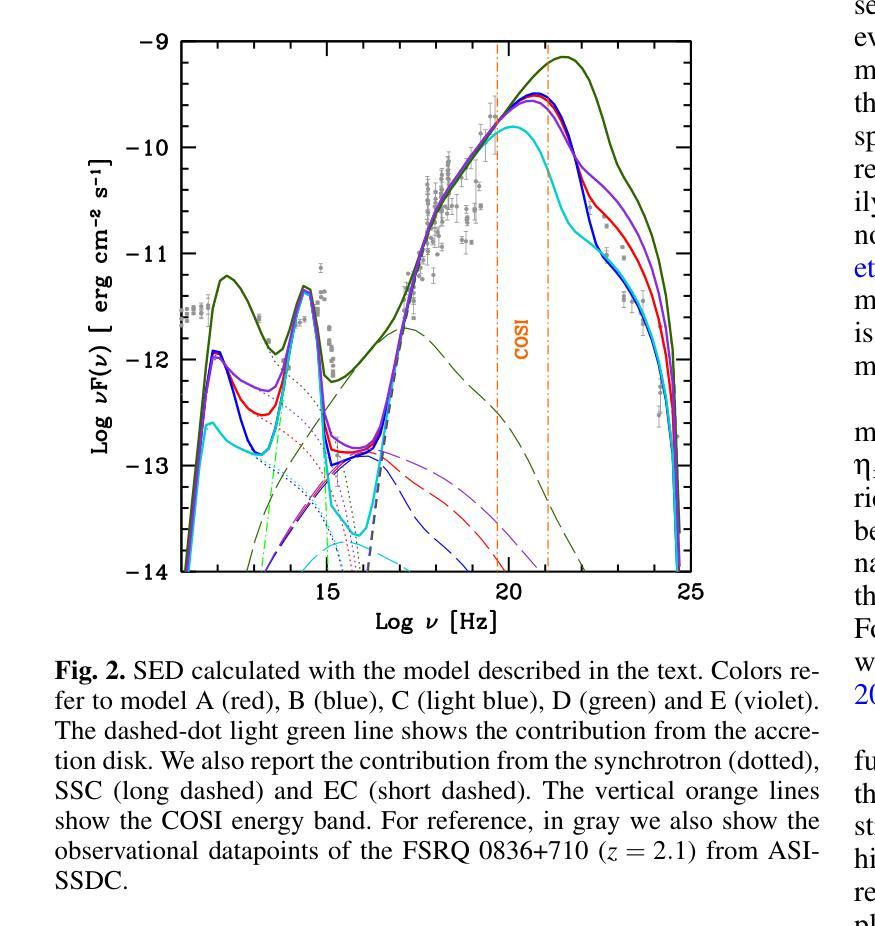
Probing the low-energy particle content of blazar jets through MeV observations
Authors:F. Tavecchio, L. Nava, A. Sciaccaluga, P. Coppi
Many of the blazars observed by Fermi actually have the peak of their time-averaged gamma-ray emission outside the $\sim$ GeV Fermi energy range, at $\sim$ MeV energies. The detailed shape of the emission spectrum around the $\sim$ MeV peak places important constraints on acceleration and radiation mechanisms in the blazar jet and may not be the simple broken power law obtained by extrapolating from the observed X-ray and GeV gamma-ray spectra. In particular, state-of-the-art simulations of particle acceleration by shocks show that a significant fraction (possibly up to $\approx 90%$) of the available energy may go into bulk, quasi-thermal heating of the plasma crossing the shock rather than producing a non-thermal power law tail. Other gentler" but possibly more pervasive acceleration mechanisms such as shear acceleration at the jet boundary may result in a further build-up of the low-energy ($\gamma \lesssim 10^{2}$) electron/positron population in the jet. As already discussed for the case of gamma-ray bursts, the presence of a low-energy, Maxwellian-like bump’’ in the jet particle energy distribution can strongly affect the spectrum of the emitted radiation, e.g., producing an excess over the emission expected from a power-law extrapolation of a blazar’s GeV-TeV spectrum. We explore the potential detectability of the spectral component ascribable to a hot, quasi-thermal population of electrons in the high-energy emission of flat-spectrum radio quasars (FSRQ). We show that for typical FSRQ physical parameters, the expected spectral signature is located at $\sim$ MeV energies. For the brightest Fermi FSRQ sources, the presence of such a component will be constrained by the upcoming MeV Compton Spectrometer and Imager (COSI) satellite.
由费米观测到的许多耀斑实际上其时间平均的伽马射线发射峰值位于约MeV能量,而非费米能量范围的GeV内。MeV峰值周围的发射光谱的详细形状对耀斑喷流中的加速和辐射机制施加了重要的约束,可能并非通过观测到的X射线和GeV伽马射线光谱推断出的简单分段幂律。特别是,关于冲击波粒子加速的最新模拟显示,相当一部分(可能高达约90%)的可用能量可能用于通过冲击区域的等离子体的大规模准热加热,而非产生非热幂律尾巴。其他较为温和的但可能更为普遍的加速机制,如在喷流边界处的剪切加速,可能导致喷流中低能(γ≤10²)的电子/正电子种群进一步增加。如已针对伽马射线爆发的情况进行讨论,喷流粒子能量分布中存在类似于麦克斯韦分布的低能“凸起”会强烈影响发射的辐射光谱,例如,在耀斑的GeV-TeV光谱的幂律外推预期之上产生过量辐射。我们探讨了高温、准热电子种群所产生的高能发射在平谱射电类星(FSRQ)中的潜在可探测性。我们表明,对于典型的FSRQ物理参数,预期的谱特征位于约MeV能量。对于费米最明亮的FSRQ源,这种成分的存在将受到即将到来的MeV康普顿光谱仪和成像仪(COSI)卫星的约束。
论文及项目相关链接
PDF 5 pages, 2 figures, accepted for publication in A&A Letters
摘要
本文指出,许多费米观测到的耀变体在平均γ射线发射峰值时,其能量并非在费米的$\sim$gev能量范围内,而是在$\sim$MeV能量范围内。耀变体发射光谱的详细形状在$\sim$MeV峰值处对喷流中的加速和辐射机制有重要的限制,可能并不只是通过观测到的X射线和gevγ射线光谱推断出的简单分段幂律。先进的粒子加速模拟显示,可用能量的很大一部分(可能高达90%)可能用于穿过冲击波的等离子体整体、准热加热,而不是产生非热幂律尾。其他较为温和但可能更普遍的加速机制,如喷射边界处的剪切加速,可能导致喷射中能量较低(γ≤10²)的电子/正电子群体进一步增加。对于伽马射线暴的情况已经进行了讨论,喷射粒子能量分布中存在低能、类似麦克斯韦的“凸起”会强烈影响发射的辐射光谱,例如,在耀变体的gev-tev光谱的幂律外推中预期会出现过多的发射。我们探讨了可归因于热、准热电子群体的光谱成分在高能发射中的潜在可探测性。对于典型的平谱射电类星物理参数,预期的光谱特征位于MeV能量范围内。对于最亮的费米平谱射电类星源,该成分的存在将受到即将发射的MeV康普顿光谱仪和成像器(COSI)卫星的限制。
关键见解
- 许多耀变体的平均γ射线发射峰值在MeV能量范围内,不在费米的GEV能量范围内。
- 耀变体发射光谱的详细形状对喷流中的加速和辐射机制有重要的限制,可能不同于简单的分段幂律。
- 先进的模拟显示,大部分能量可能用于等离子体整体加热而非产生非热幂律尾。
- 存在温和但普遍的加速机制如剪切加速可能导致喷射中低能电子/正电子群体增加。
- 低能Maxwellian型粒子能量分布可能影响发射的辐射光谱,导致与预期的幂律外推不符的发射结果。
- 对于平谱射电类星源的高能发射中,可能存在一个归因于热、准热电子群体的光谱成分。这一成分位于MeV能量范围内且对物理参数敏感。
点此查看论文截图

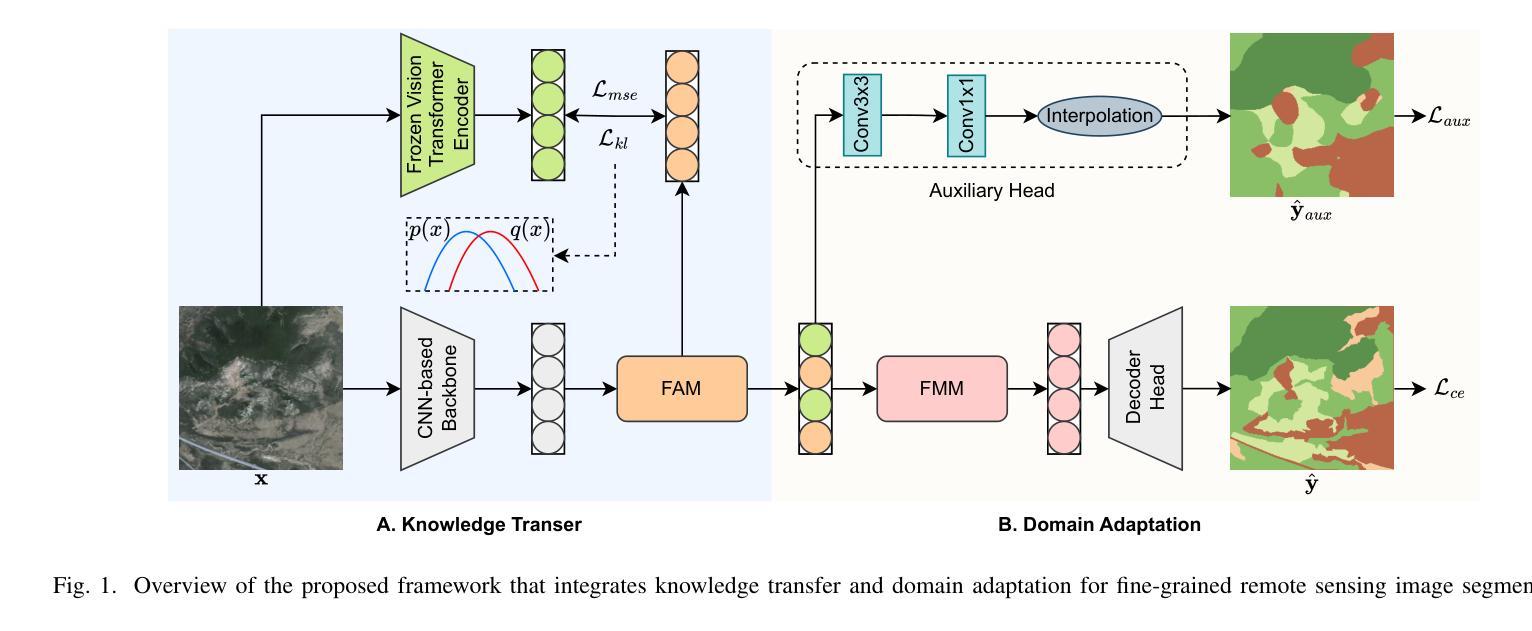
Knowledge Transfer and Domain Adaptation for Fine-Grained Remote Sensing Image Segmentation
Authors:Shun Zhang, Xuechao Zou, Kai Li, Congyan Lang, Shiying Wang, Pin Tao, Tengfei Cao
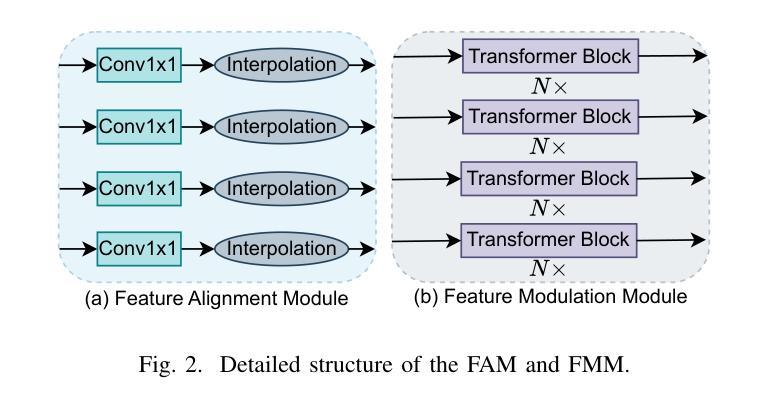
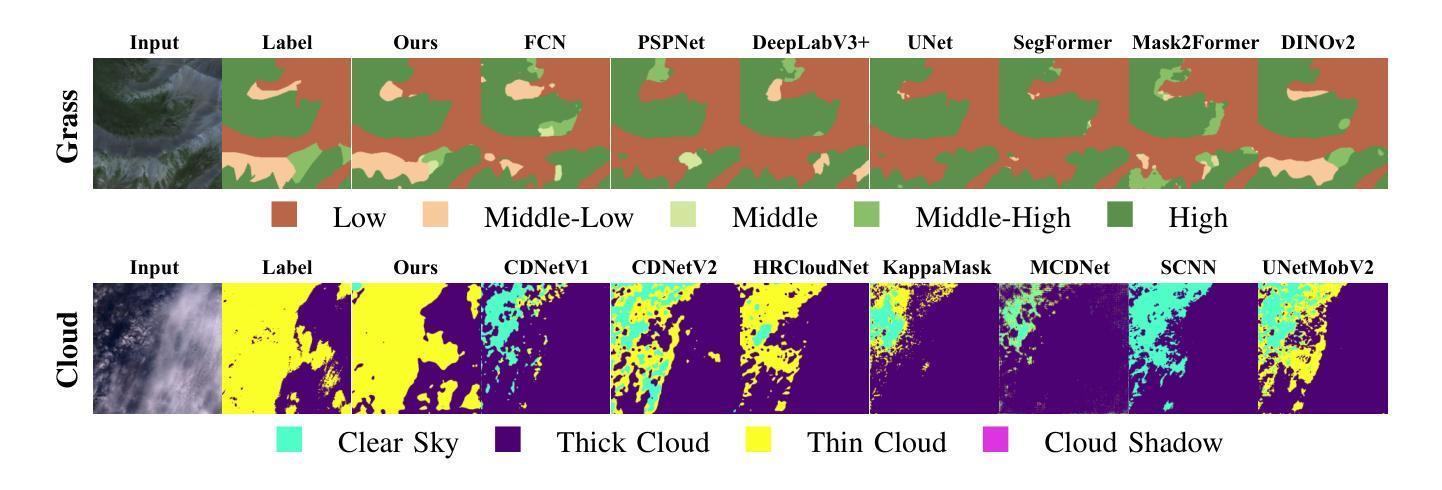
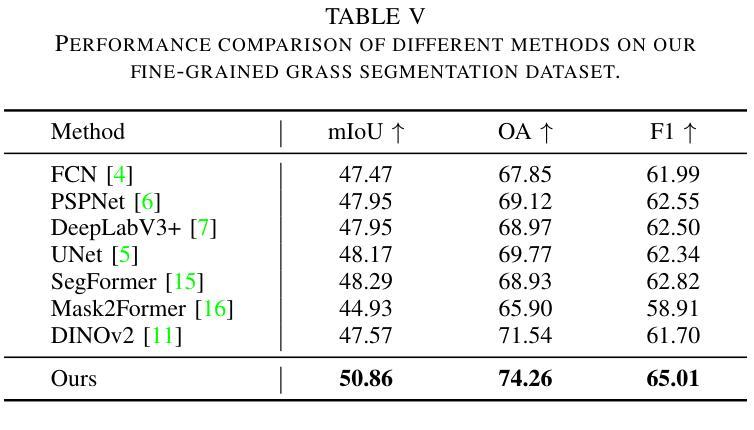
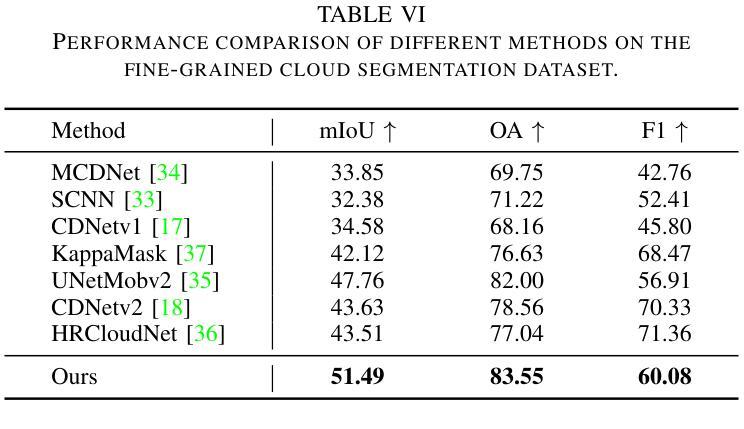
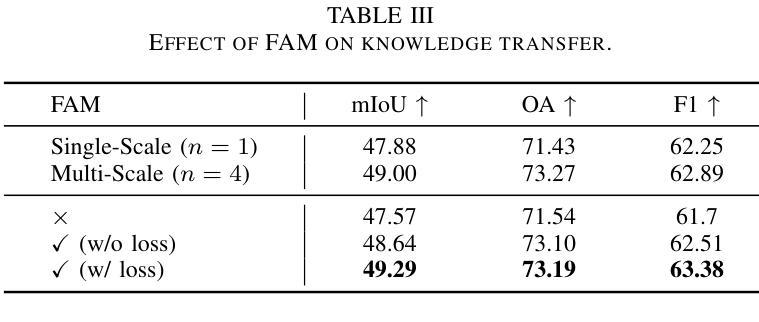
Fine-grained remote sensing image segmentation is essential for accurately identifying detailed objects in remote sensing images. Recently, vision transformer models (VTMs) pre-trained on large-scale datasets have demonstrated strong zero-shot generalization. However, directly applying them to specific tasks may lead to domain shift. We introduce a novel end-to-end learning paradigm combining knowledge guidance with domain refinement to enhance performance. We present two key components: the Feature Alignment Module (FAM) and the Feature Modulation Module (FMM). FAM aligns features from a CNN-based backbone with those from the pretrained VTM’s encoder using channel transformation and spatial interpolation, and transfers knowledge via KL divergence and L2 normalization constraint. FMM further adapts the knowledge to the specific domain to address domain shift. We also introduce a fine-grained grass segmentation dataset and demonstrate, through experiments on two datasets, that our method achieves a significant improvement of 2.57 mIoU on the grass dataset and 3.73 mIoU on the cloud dataset. The results highlight the potential of combining knowledge transfer and domain adaptation to overcome domain-related challenges and data limitations. The project page is available at https://xavierjiezou.github.io/KTDA/.
精细遥感图像分割对于准确识别遥感图像中的详细对象至关重要。最近,在大型数据集上预训练的视觉转换器模型(VTM)表现出了强大的零样本泛化能力。然而,直接将其应用于特定任务可能会导致领域偏移。我们引入了一种结合知识引导和领域精炼的新型端到端学习范式,以提高性能。我们提出了两个关键组件:特征对齐模块(FAM)和特征调制模块(FMM)。FAM通过对通道变换和空间插值,将对来自基于CNN的骨干网的特征与预训练VTM编码器的特征进行对齐,并通过KL散度和L2归一化约束进行知识转移。FMM进一步将知识适应到特定领域,以解决领域偏移问题。我们还介绍了一个精细的草分割数据集,并通过两个数据集的实验证明,我们的方法在草数据集上实现了2.57 mIoU的显著改进,在云数据集上实现了3.73 mIoU的改进。结果突出了结合知识转移和领域适应的潜力,可以克服与领域相关的挑战和数据限制。项目页面可在[https://xavierjiezou.github.io/KTDA/]访问。
论文及项目相关链接
PDF 6 pages, 3 figures, 6 tables
Summary
基于遥感图像的特点和需求,本研究提出了一种结合知识指导和领域精炼的端到端学习范式,用于精细遥感图像分割。研究创新性地设计了特征对齐模块(FAM)和特征调制模块(FMM),并通过实验验证了在特定数据集上的显著性能提升。此研究为遥感图像分析提供了新思路。
Key Takeaways
- 介绍了精细遥感图像分割的重要性以及视觉转换器模型(VTMs)在零样本迁移学习中的优势。
- 提出了一种结合知识指导和领域精炼的端到端学习范式,旨在解决直接应用VTMs于特定任务时可能出现的领域偏移问题。
- 介绍了两个关键组件:特征对齐模块(FAM)和特征调制模块(FMM)。FAM通过对齐来自CNN基础架构和预训练VTM编码器的特征来实现知识转移。FMM进一步调整知识以适应特定领域,以解决领域偏移问题。
- 引入了一个精细的草地分割数据集,并通过在两个数据集上的实验验证了该方法的有效性。
- 实验结果显示,该方法在草地数据集上的mIoU提高了2.57,在云数据集上提高了3.73,证明了该方法的潜力。
- 研究强调了结合知识转移和领域适应以克服与领域相关的挑战和数据限制的重要性。
点此查看论文截图



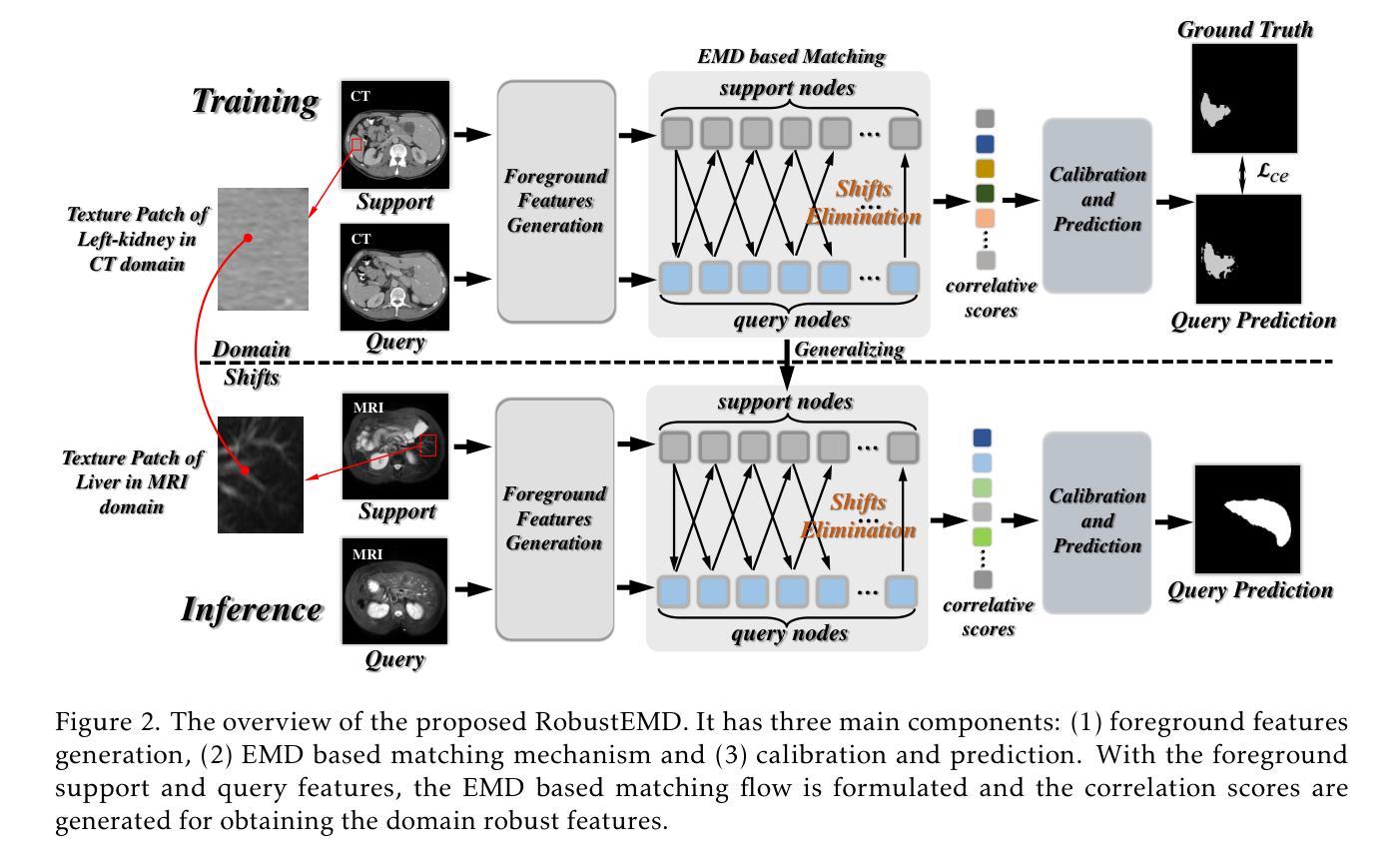
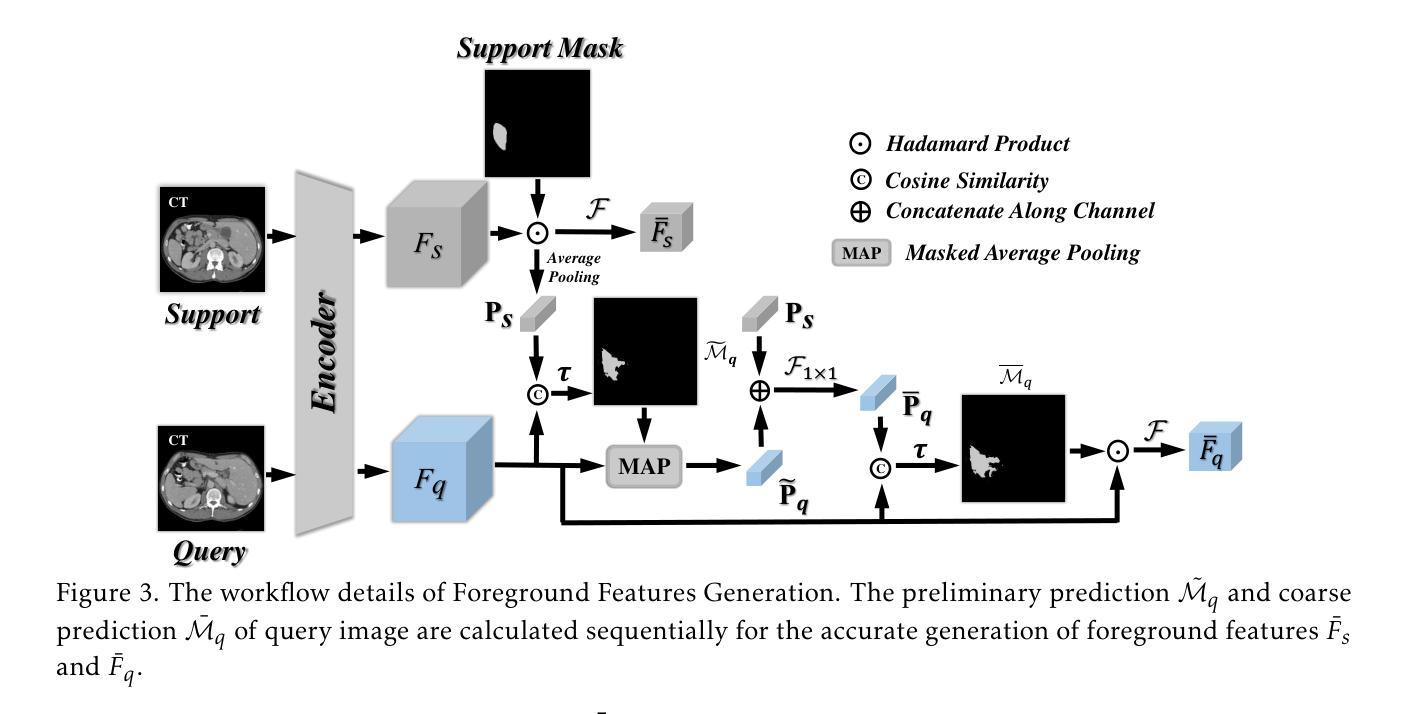
RobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Authors:Yazhou Zhu, Minxian Li, Qiaolin Ye, Shidong Wang, Tong Xin, Haofeng Zhang
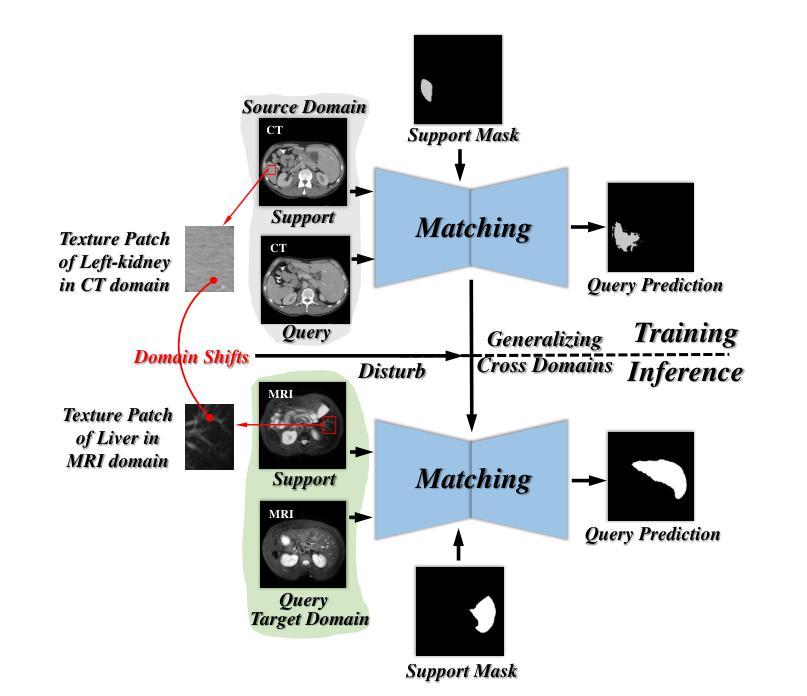
Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover’s Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
少数样本医学图像分割(FSMIS)旨在实现医学图像分析范围内的有限标注数据学习。尽管已经取得了一些进展,但当前的FSMIS模型都在同一数据域中进行训练和部署,这与医学成像数据在临床现实中跨不同数据域(例如成像模式、机构和设备序列)的情况不一致。如何增强FSMIS模型在不同特定医学成像域之间的泛化能力?在本文中,我们关注少数样本语义分割模型的匹配机制,并引入一种基于地球移动距离(EMD)计算的域稳健匹配机制,用于跨域场景。具体来说,我们制定了前景支持查询特征之间的EMD传输过程,并引入了纹理结构感知权重生成方法,该方法建议在节点上进行基于Sobel的图像梯度计算,被引入到EMD匹配流中以约束域相关节点。此外,还引入了点集级距离测量指标,以计算从支持集节点到查询集节点的传输成本。为了评估我们模型的性能,我们在三种场景(即跨模态、跨序列和跨机构)进行了实验,包括八个医学数据集和三个身体区域,结果表明我们的模型在对比模型中达到了最先进的性能。
论文及项目相关链接
Summary
本文研究了小样本医学图像分割(FSMIS)技术在跨不同医学成像领域中的通用化问题。针对现有FSMIS模型无法适应临床实际中跨领域医学图像数据的情况,提出了一种基于地球移动距离(EMD)计算的新型稳健匹配机制。该机制通过前景支持查询特征之间的EMD运输过程进行形式化,引入纹理结构感知权重生成方法,并提出在EMD匹配流中进行基于Sobel的图像梯度计算,以限制与领域相关的节点。此外,还引入了点集级别距离测量指标来计算支持集节点到查询集节点的运输成本。实验在三种场景(跨模态、跨序列和跨机构)下进行,涉及八个医学数据集和三个身体区域,结果表明该模型相较于其他模型达到了最新性能水平。
Key Takeaways
- 小样本医学图像分割(FSMIS)面临跨领域数据挑战。
- 现有FSMIS模型无法适应临床实际中的跨领域医学图像数据。
- 引入基于地球移动距离(EMD)计算的稳健匹配机制,以改进FSMIS模型的通用性。
- 该机制通过EMD运输过程形式化前景支持查询特征的匹配。
- 引入纹理结构感知权重生成方法和基于Sobel的图像梯度计算,以限制与领域相关的节点。
- 实验在多种跨领域场景下进行,涉及多个医学数据集和身体区域。
点此查看论文截图

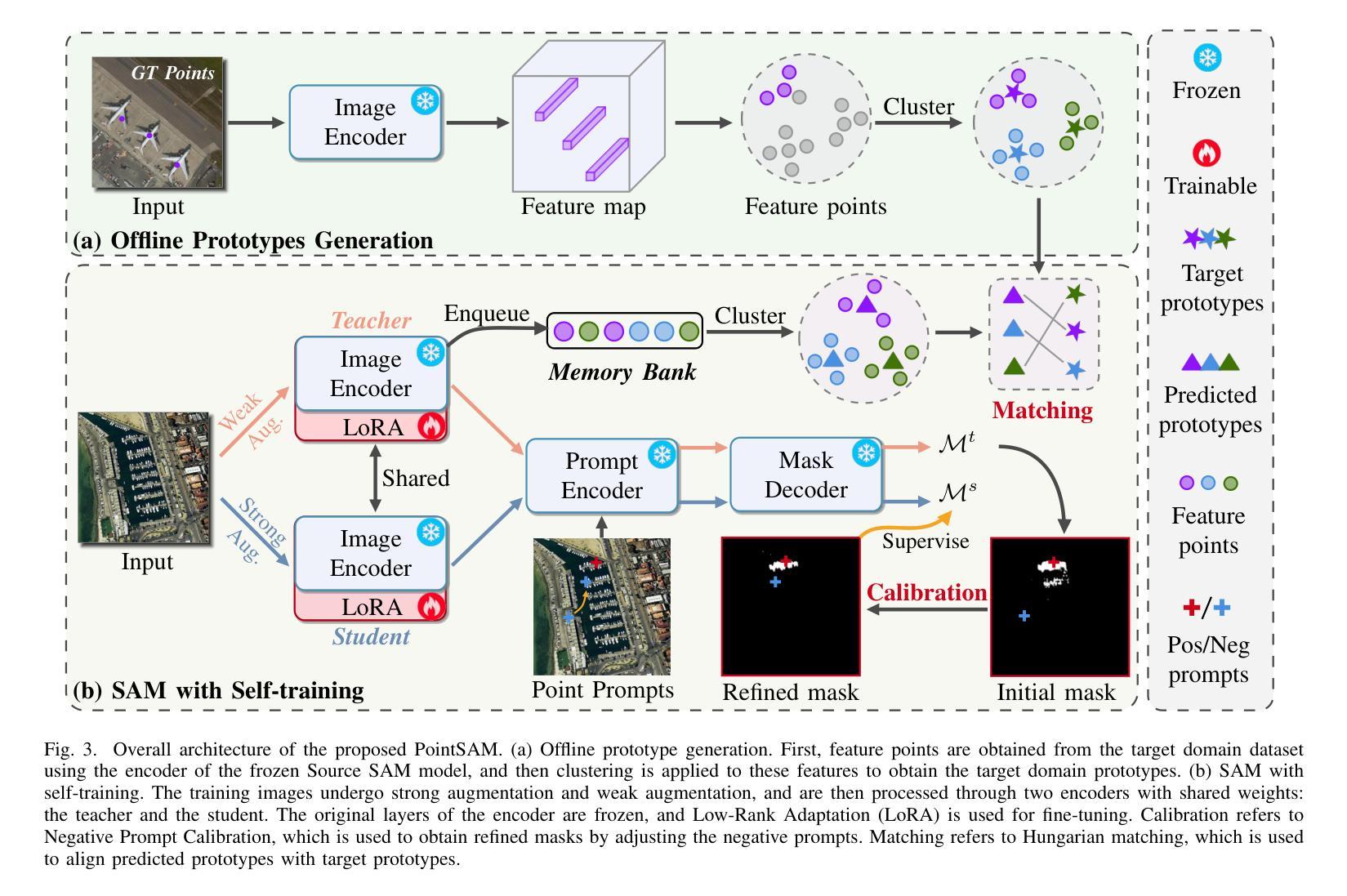
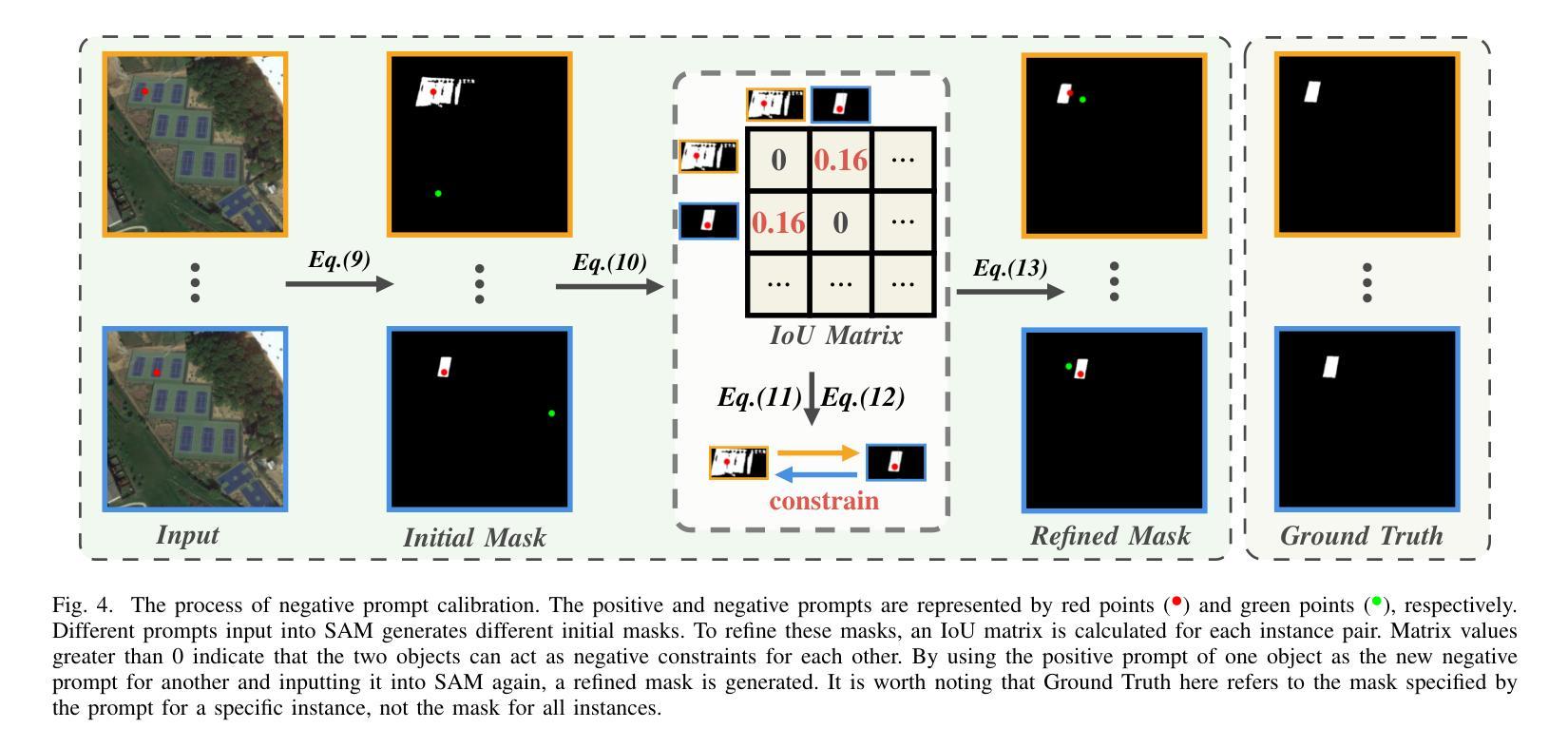
PointSAM: Pointly-Supervised Segment Anything Model for Remote Sensing Images
Authors:Nanqing Liu, Xun Xu, Yongyi Su, Haojie Zhang, Heng-Chao Li
Segment Anything Model (SAM) is an advanced foundational model for image segmentation, which is gradually being applied to remote sensing images (RSIs). Due to the domain gap between RSIs and natural images, traditional methods typically use SAM as a source pre-trained model and fine-tune it with fully supervised masks. Unlike these methods, our work focuses on fine-tuning SAM using more convenient and challenging point annotations. Leveraging SAM’s zero-shot capabilities, we adopt a self-training framework that iteratively generates pseudo-labels for training. However, if the pseudo-labels contain noisy labels, there is a risk of error accumulation. To address this issue, we extract target prototypes from the target dataset and use the Hungarian algorithm to match them with prediction prototypes, preventing the model from learning in the wrong direction. Additionally, due to the complex backgrounds and dense distribution of objects in RSI, using point prompts may result in multiple objects being recognized as one. To solve this problem, we propose a negative prompt calibration method based on the non-overlapping nature of instance masks. In brief, we use the prompts of overlapping masks as corresponding negative signals, resulting in refined masks. Combining the above methods, we propose a novel Pointly-supervised Segment Anything Model named PointSAM. We conduct experiments on RSI datasets, including WHU, HRSID, and NWPU VHR-10, and the results show that our method significantly outperforms direct testing with SAM, SAM2, and other comparison methods. Furthermore, we introduce PointSAM as a point-to-box converter and achieve encouraging results, suggesting that this method can be extended to other point-supervised tasks. The code is available at https://github.com/Lans1ng/PointSAM.
分段任何事模型(SAM)是一个先进的图像分割基础模型,正逐渐应用于遥感图像(RSI)。由于遥感图像与自然图像领域之间的差距,传统方法通常将SAM用作源预训练模型,并使用全监督掩膜对其进行微调。不同于这些方法,我们的工作专注于使用更方便且具有挑战性的点注释来微调SAM。我们利用SAM的零样本能力,采用自训练框架迭代生成伪标签用于训练。然而,如果伪标签包含噪声标签,则存在误差累积的风险。为解决此问题,我们从目标数据集中提取目标原型,并使用匈牙利算法将它们与预测原型匹配,防止模型向错误方向学习。此外,由于遥感图像的复杂背景和目标对象的密集分布,使用点提示可能会导致多个对象被识别为一个对象。针对这一问题,我们提出了一种基于实例掩膜非重叠特性的负提示校准方法。简而言之,我们使用重叠掩膜的提示作为相应的负信号,从而获得更精细的掩膜。结合上述方法,我们提出了名为PointSAM的新型点监督分段任何事模型。我们在WHU、HRSID和NWPU VHR-10等RSI数据集上进行了实验,结果表明我们的方法明显优于直接使用SAM、SAM2和其他对比方法。此外,我们将PointSAM作为点到框的转换器,并获得了令人鼓舞的结果,这表明该方法可扩展到其他点监督任务。代码可在[https://github.com/Lans1ng/PointSAM找到。]
论文及项目相关链接
PDF Accepted by IEEE TGRS
摘要
本文介绍了PointSAM模型,这是一种先进的图像分割基础模型,并应用于遥感图像。研究采用自我训练框架,利用SAM的零样本能力进行微调,解决遥感图像与自然图像领域间的差距问题。为解决伪标签中的噪声标签问题,研究采用目标原型与预测原型匹配的方法。同时,针对遥感图像复杂背景和物体密集分布的问题,研究提出了基于非重叠实例掩膜的负提示校准方法。实验结果表明,PointSAM在遥感图像数据集上显著优于其他方法。此外,PointSAM作为点至盒的转换器,在点监督任务中取得了令人鼓舞的结果。
关键见解
- PointSAM是一个基于图像分割的先进模型,特别适用于遥感图像。
- 研究采用自我训练框架,利用SAM的零样本能力进行微调,以缩小遥感图像与自然图像之间的差距。
- 通过采用目标原型与预测原型匹配的方法,解决了伪标签中的噪声标签问题。
- 针对遥感图像复杂背景和物体密集分布的问题,提出了基于非重叠实例掩膜的负提示校准方法。
- PointSAM在多个遥感图像数据集上的实验结果显著优于其他方法。
- PointSAM被引入作为点至盒的转换器,为点监督任务提供了新的视角。
点此查看论文截图


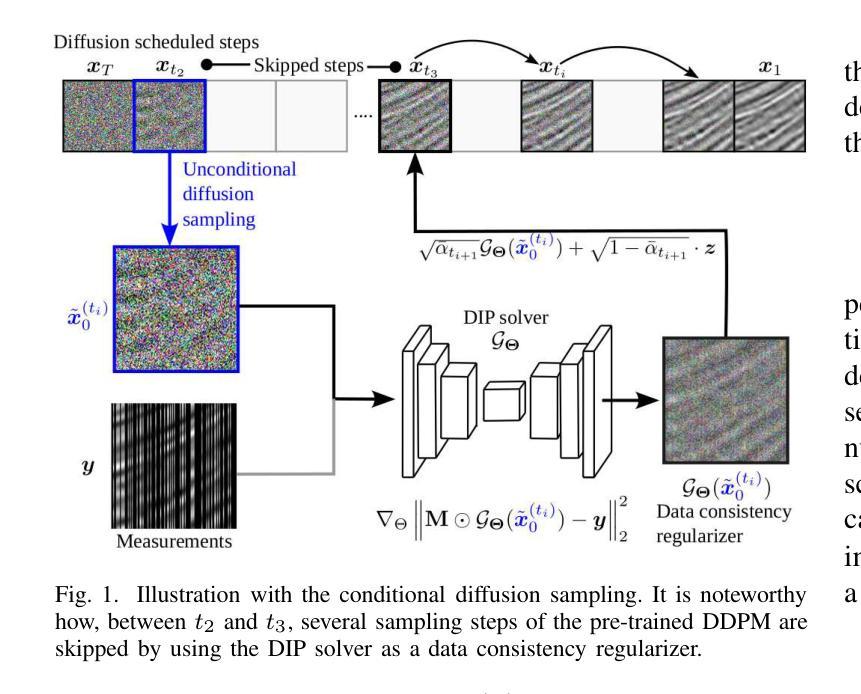
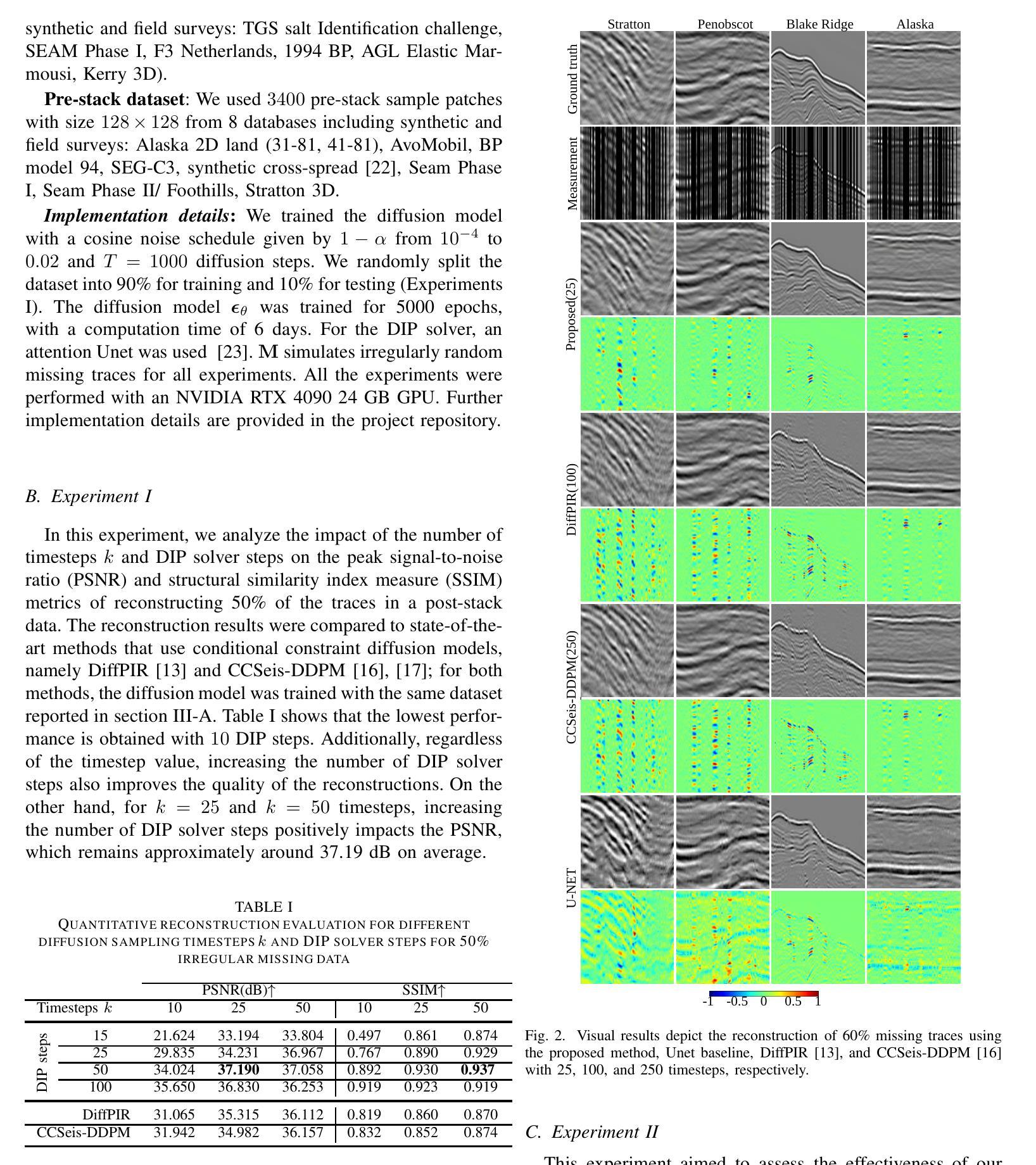
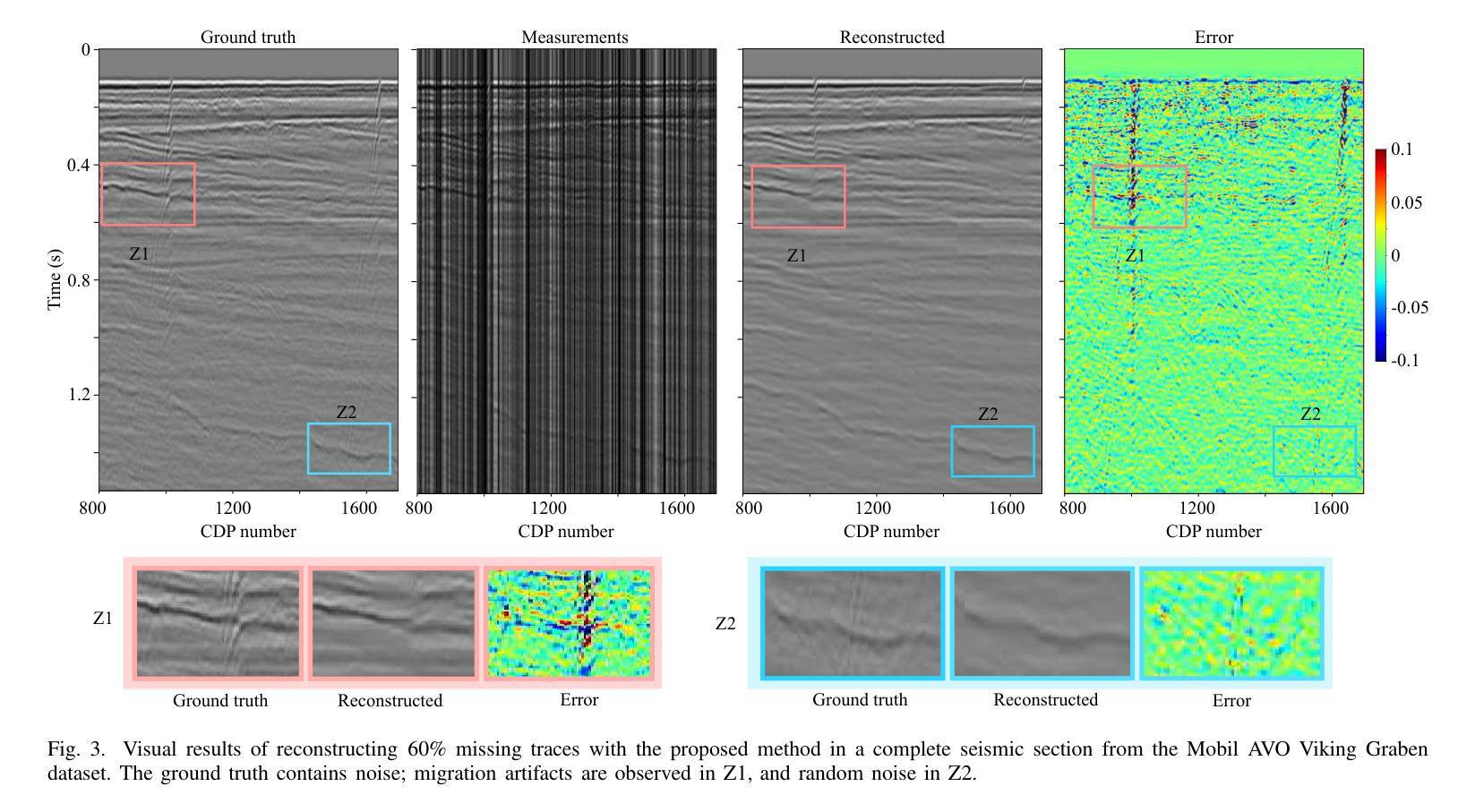
CDDIP: Constrained Diffusion-Driven Deep Image Prior for Seismic Image Reconstruction
Authors:Paul Goyes-Peñafiel, Ulugbek Kamilov, Henry Arguello
Seismic data frequently exhibits missing traces, substantially affecting subsequent seismic processing and interpretation. Deep learning-based approaches have demonstrated significant advancements in reconstructing irregularly missing seismic data through supervised and unsupervised methods. Nonetheless, substantial challenges remain, such as generalization capacity and computation time cost during the inference. Our work introduces a reconstruction method that uses a pre-trained generative diffusion model for image synthesis and incorporates Deep Image Prior to enforce data consistency when reconstructing missing traces in seismic data. The proposed method has demonstrated strong robustness and high reconstruction capability of post-stack and pre-stack data with different levels of structural complexity, even in field and synthetic scenarios where test data were outside the training domain. This indicates that our method can handle the high geological variability of different exploration targets. Additionally, compared to other state-of-the-art seismic reconstruction methods using diffusion models. During inference, our approach reduces the number of sampling timesteps by up to 4x.
地震数据经常存在缺失道集,对后续的地震处理和解释产生很大影响。基于深度学习的方法在通过有监督和无监督方法重建不规则缺失的地震数据方面取得了显著的进步。然而,仍存在诸多挑战,如推理过程中的泛化能力和计算时间成本。我们的工作引入了一种重建方法,该方法使用预训练的生成扩散模型进行图像合成,并结合深度图像先验在重建地震数据中缺失道集时强制数据一致性。所提出的方法表现出强大的稳健性和高重建能力,能够处理不同结构复杂性的叠加和未叠加数据,即使在测试数据超出训练领域的实际和合成场景中亦是如此。这表明我们的方法可以应对不同勘探目标的高地质变化性。此外,与其他使用扩散模型的先进地震重建方法相比,我们的方法在推理过程中减少了高达4倍的采样时间步数。
论文及项目相关链接
PDF 5 pages, 4 figures, 3 tables. Submitted to geoscience and remote sensing letters
Summary
本文介绍了一种利用预训练生成扩散模型进行地震数据重建的方法,该方法结合了深度图像先验来强制数据一致性。该方法在不同结构复杂度的后叠前叠数据中表现出强大的鲁棒性和高重建能力,即使测试数据超出训练域,也能处理不同勘探目标的高地质变化性。与其他使用扩散模型的地震重建方法相比,该方法在推理过程中减少了高达4倍的采样时间步数。
Key Takeaways
- 地震数据经常缺失痕迹,影响后续的地震处理和解释。
- 深度学习已在重建不规则缺失的地震数据方面取得显著进展,包括监督和无监督方法。
- 本文引入了一种利用预训练生成扩散模型进行图像合成的方法,并结合深度图像先验来重建地震数据中缺失的痕迹。
- 该方法在结构复杂的后叠前叠数据中表现出强大的鲁棒性和高重建能力。
- 该方法能够处理不同勘探目标的高地质变化性,即使在测试数据超出训练域的情况下。
- 与其他使用扩散模型的地震重建方法相比,该方法在推理过程中减少了采样时间步数。
点此查看论文截图