⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
Pseudolabel guided pixels contrast for domain adaptive semantic segmentation
Authors:Jianzi Xiang, Cailu Wan, Zhu Cao
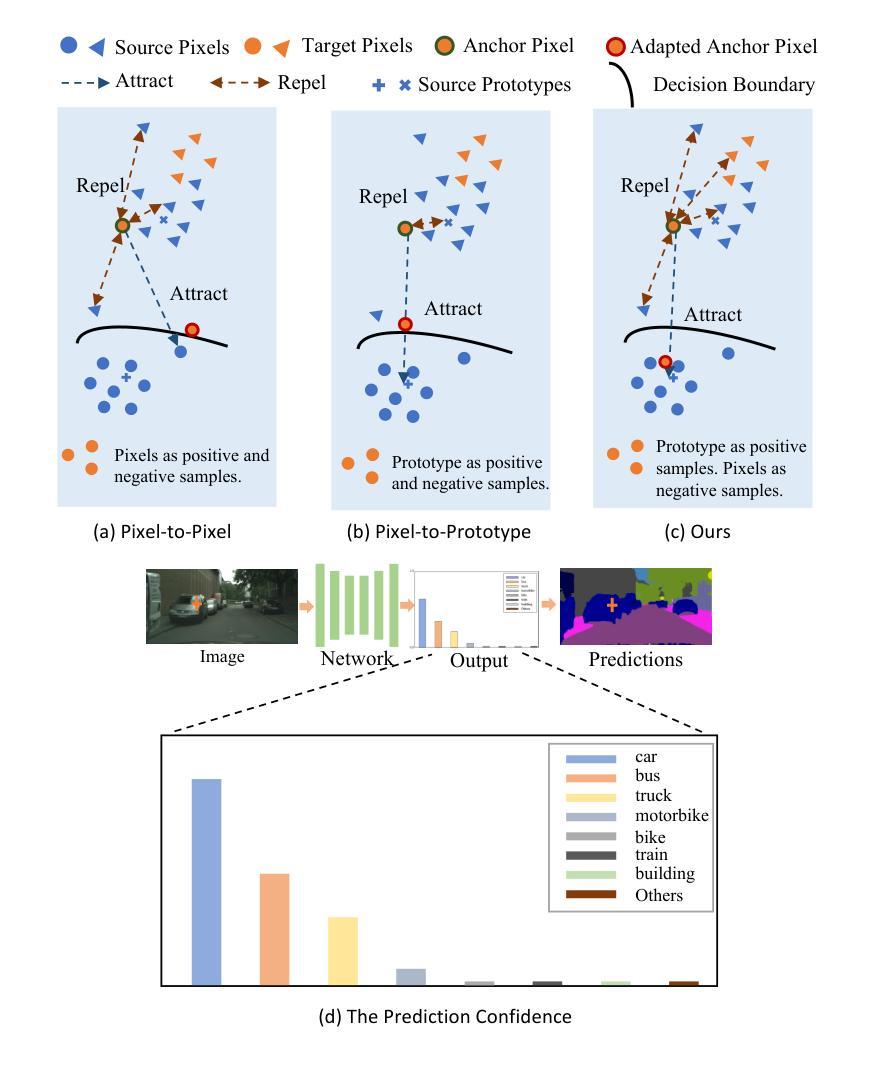
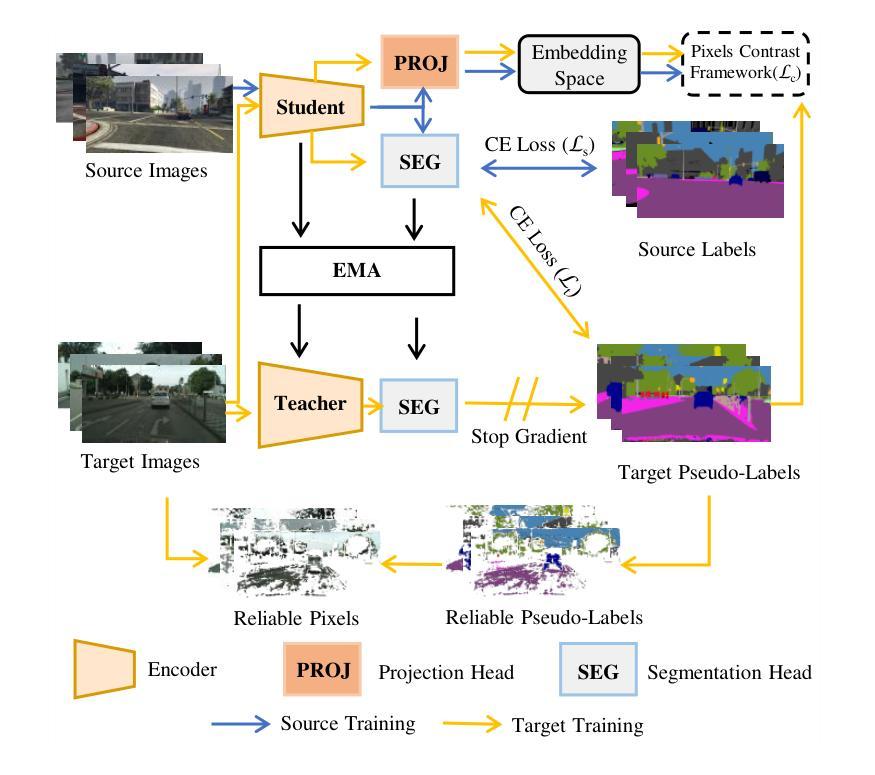
Semantic segmentation is essential for comprehending images, but the process necessitates a substantial amount of detailed annotations at the pixel level. Acquiring such annotations can be costly in the real-world. Unsupervised domain adaptation (UDA) for semantic segmentation is a technique that uses virtual data with labels to train a model and adapts it to real data without labels. Some recent works use contrastive learning, which is a powerful method for self-supervised learning, to help with this technique. However, these works do not take into account the diversity of features within each class when using contrastive learning, which leads to errors in class prediction. We analyze the limitations of these works and propose a novel framework called Pseudo-label Guided Pixel Contrast (PGPC), which overcomes the disadvantages of previous methods. We also investigate how to use more information from target images without adding noise from pseudo-labels. We test our method on two standard UDA benchmarks and show that it outperforms existing methods. Specifically, we achieve relative improvements of 5.1% mIoU and 4.6% mIoU on the Grand Theft Auto V (GTA5) to Cityscapes and SYNTHIA to Cityscapes tasks based on DAFormer, respectively. Furthermore, our approach can enhance the performance of other UDA approaches without increasing model complexity. Code is available at https://github.com/embar111/pgpc
语义分割对于图像理解至关重要,但这一过程需要在像素级别进行大量详细的标注。在现实世界中,获取这样的标注可能成本高昂。无监督域自适应(UDA)语义分割是一种使用带有标签的虚拟数据来训练模型,并将其适应无标签的真实数据的技术。最近的一些作品采用对比学习这一强大的自监督学习方法来辅助该技术。然而,这些作品在使用对比学习时,没有考虑到每个类别内特征多样性的重要性,从而导致类别预测错误。我们分析了这些作品的局限性,并提出了一种名为伪标签引导像素对比(PGPC)的新型框架,克服了以往方法的缺点。我们还探讨了如何从目标图像中利用更多信息,而不增加伪标签产生的噪声。我们在两个标准的UDA基准测试集上测试了我们的方法,并展示了其超越现有方法的性能。具体来说,基于DAFormer,我们在Grand Theft Auto V(GTA5)到Cityscapes和SYNTHIA到Cityscapes的任务上分别实现了5.1%和4.6%的相对mIoU改进。此外,我们的方法还可以增强其他UDA方法的性能,且不增加模型复杂度。代码可在https://github.com/embar111/pgpc找到。
论文及项目相关链接
PDF 24 pages, 5 figures. Code: https://github.com/embar111/pgpc
Summary
语义分割在图像理解中扮演着至关重要的角色,但它需要大量像素级别的详细标注。现实世界中获取这些标注成本高昂。针对这一问题,研究人员采用无监督域自适应(UDA)技术,利用虚拟数据进行模型训练并适应无标签的真实数据。最新的研究尝试结合对比学习这一强大的自监督学习方法来提升UDA的效果。然而,这些方法忽略了同一类别内特征的多样性,导致类别预测错误。本文分析了这些方法的局限性,并提出了一种新的框架——伪标签引导像素对比(PGPC),克服了之前方法的缺点。此外,本文还探讨了如何利用目标图像中的更多信息,同时避免伪标签带来的噪声干扰。实验结果表明,该方法在两种标准的UDA基准测试中均表现出色,相较于现有方法有明显的提升。具体地,在基于DAFormer的Grand Theft Auto V(GTA5)到Cityscapes和SYNTHIA到Cityscapes的任务中,分别实现了5.1%和4.6%的相对提升。此外,该方法还能增强其他UDA方法的性能,且不增加模型复杂度。
Key Takeaways
- 语义分割需要大量像素级别的标注,但获取这些标注成本高昂。
- 无监督域自适应(UDA)技术利用虚拟数据进行模型训练并适应真实数据。
- 对比学习在UDA中受到关注,但忽略同一类别内特征的多样性导致预测错误。
- 提出新的框架——伪标签引导像素对比(PGPC),克服之前方法的缺点。
- 利用目标图像中的更多信息,同时避免伪标签带来的噪声干扰。
- 在标准UDA基准测试中表现优异,相较于现有方法有明显提升。
点此查看论文截图

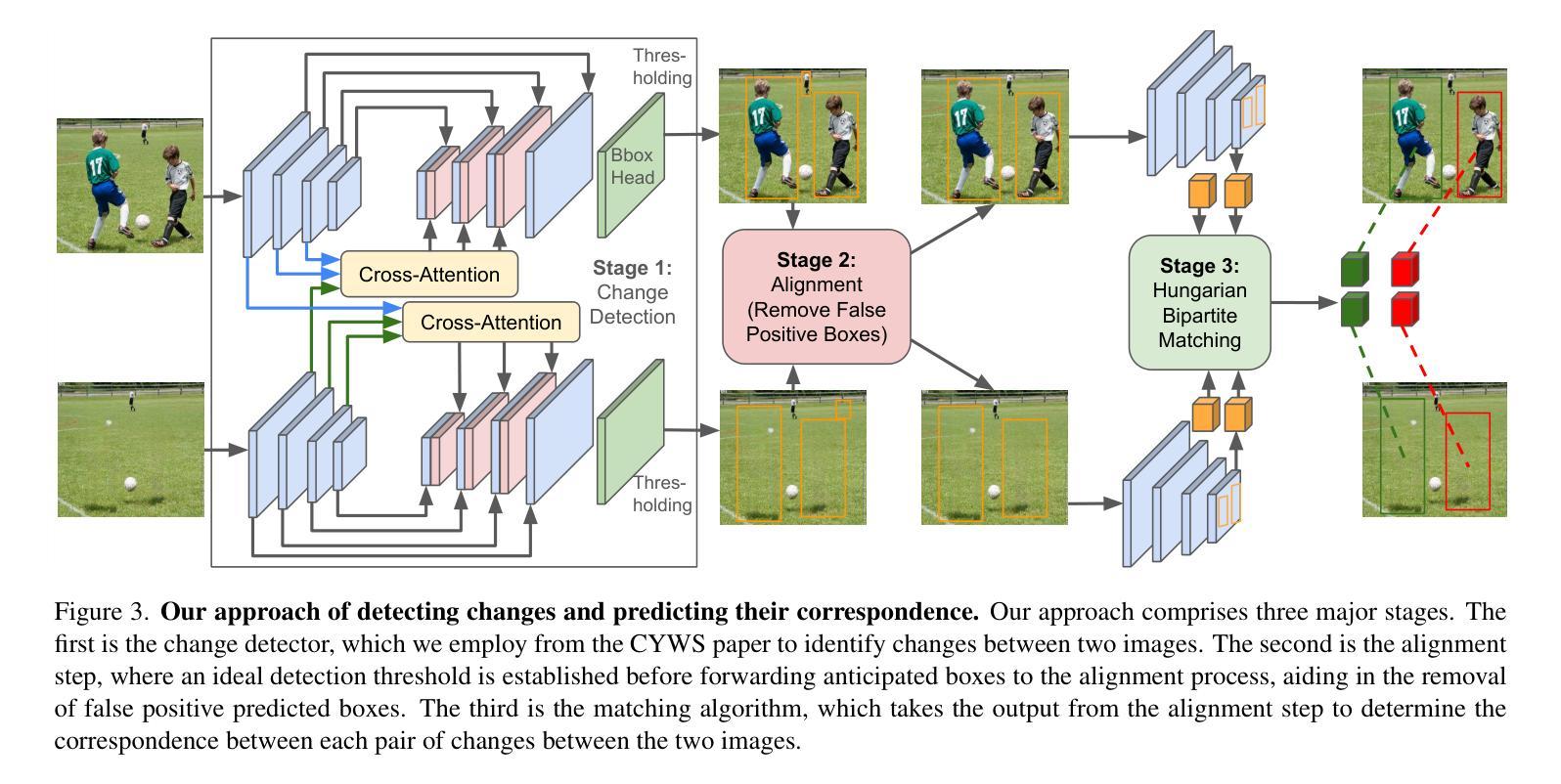
Improving Zero-Shot Object-Level Change Detection by Incorporating Visual Correspondence
Authors:Hung Huy Nguyen, Pooyan Rahmanzadehgervi, Long Mai, Anh Totti Nguyen
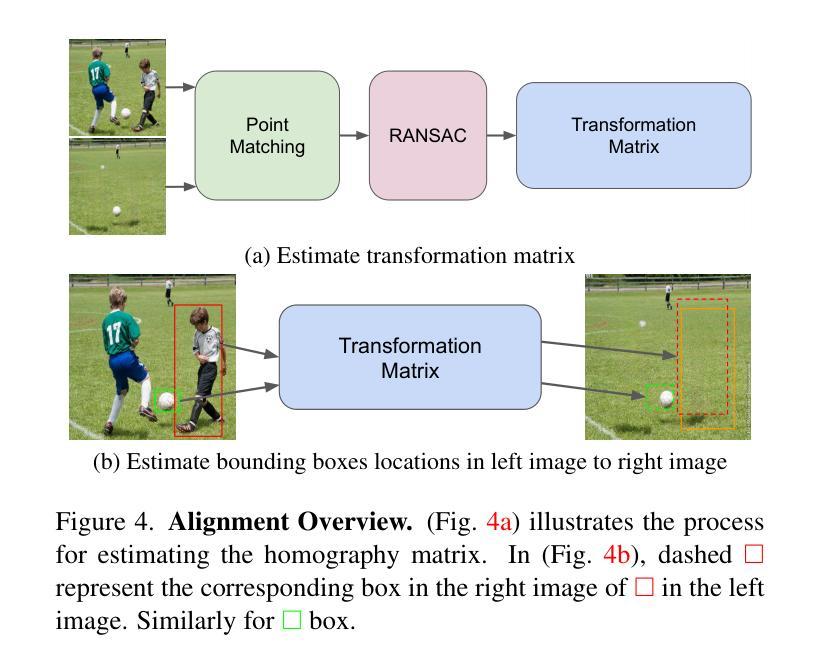
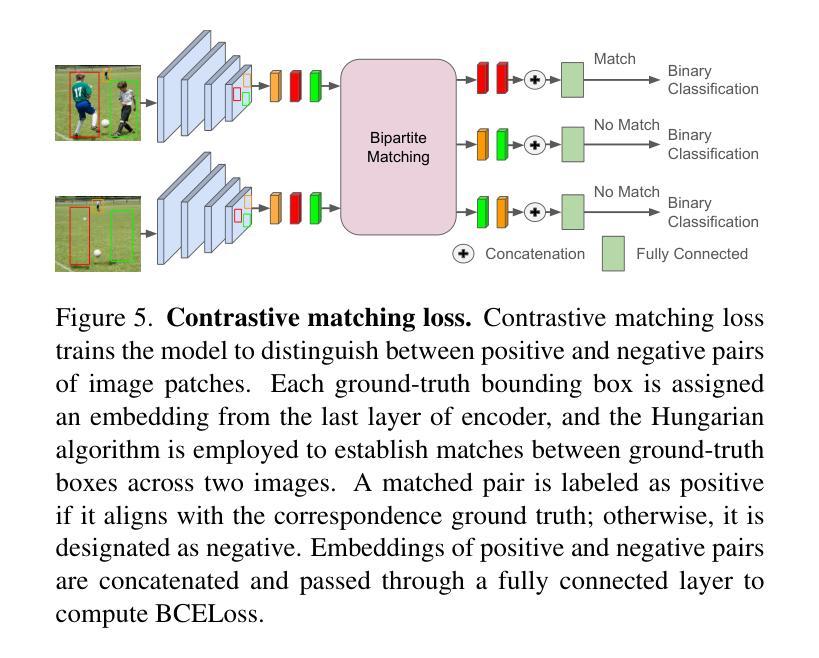
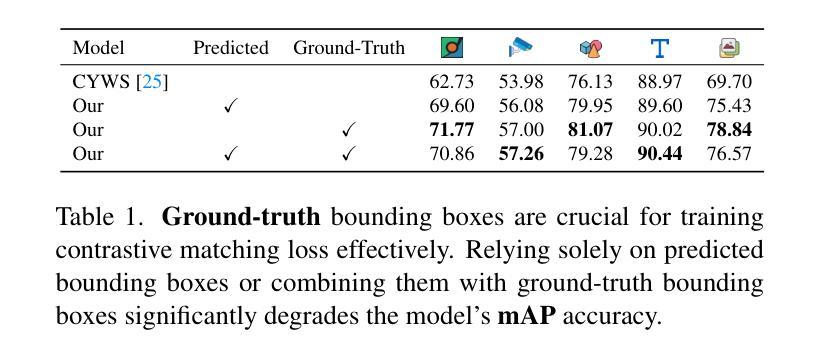
Detecting object-level changes between two images across possibly different views is a core task in many applications that involve visual inspection or camera surveillance. Existing change-detection approaches suffer from three major limitations: (1) lack of evaluation on image pairs that contain no changes, leading to unreported false positive rates; (2) lack of correspondences (i.e., localizing the regions before and after a change); and (3) poor zero-shot generalization across different domains. To address these issues, we introduce a novel method that leverages change correspondences (a) during training to improve change detection accuracy, and (b) at test time, to minimize false positives. That is, we harness the supervision labels of where an object is added or removed to supervise change detectors, improving their accuracy over previous work by a large margin. Our work is also the first to predict correspondences between pairs of detected changes using estimated homography and the Hungarian algorithm. Our model demonstrates superior performance over existing methods, achieving state-of-the-art results in change detection and change correspondence accuracy across both in-distribution and zero-shot benchmarks.
检测两张可能从不同视角拍摄的图像之间对象级别的变化是许多涉及视觉检查或相机监控应用中的核心任务。现有的变化检测方法存在三大局限:(1)对于不包含变化的图像对缺乏评估,导致未报告的误报率;(2)缺乏对应关系(即定位变化前后的区域);以及(3)在不同领域的零样本泛化能力较差。为了解决这些问题,我们引入了一种新方法,该方法利用变化对应关系(a)在训练过程中提高变化检测的准确性,以及(b)在测试时最小化误报。也就是说,我们利用一个对象添加或删除的位置的监督标签来监督变化检测器,大大提高了其准确性,超过了之前的工作。我们的工作还是首次利用估计的透视变换和匈牙利算法来预测配对检测变化之间的对应关系。我们的模型在变化检测和变化对应准确性方面都表现出卓越的性能,在内部和外部基准测试中都达到了最新水平。
论文及项目相关链接
Summary
本文介绍了一种新的变化检测方法来识别两个图像之间的对象级变化。该方法利用变化对应信息进行训练,提高变化检测的准确性,并在测试时用于减少误报。利用对象的添加或移除的监督标签来监督变化检测器,并首次预测检测到变化的对应性,通过使用估计的同构映射和匈牙利算法达到这一点。该模型在变化检测和变化对应准确性方面均表现出卓越的性能,无论是在常规分布还是零样本基准测试中均达到最佳水平。
Key Takeaways
- 介绍了一种新的变化检测方法,能够识别两个图像之间的对象级变化。
- 该方法利用变化对应信息来提高变化检测的准确性,并减少误报。
- 利用对象的添加或移除的监督标签来监督变化检测器。
- 该模型首次预测检测到变化的对应性,通过使用估计的同构映射和匈牙利算法实现。
- 该模型在变化检测和变化对应准确性方面表现出卓越的性能。
- 该方法在常规分布和零样本基准测试中均达到最佳水平。
点此查看论文截图