⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
Crafting Customisable Characters with LLMs: Introducing SimsChat, a Persona-Driven Role-Playing Agent Framework
Authors:Bohao Yang, Dong Liu, Chenghao Xiao, Kun Zhao, Chen Tang, Chao Li, Lin Yuan, Guang Yang, Lanxiao Huang, Chenghua Lin
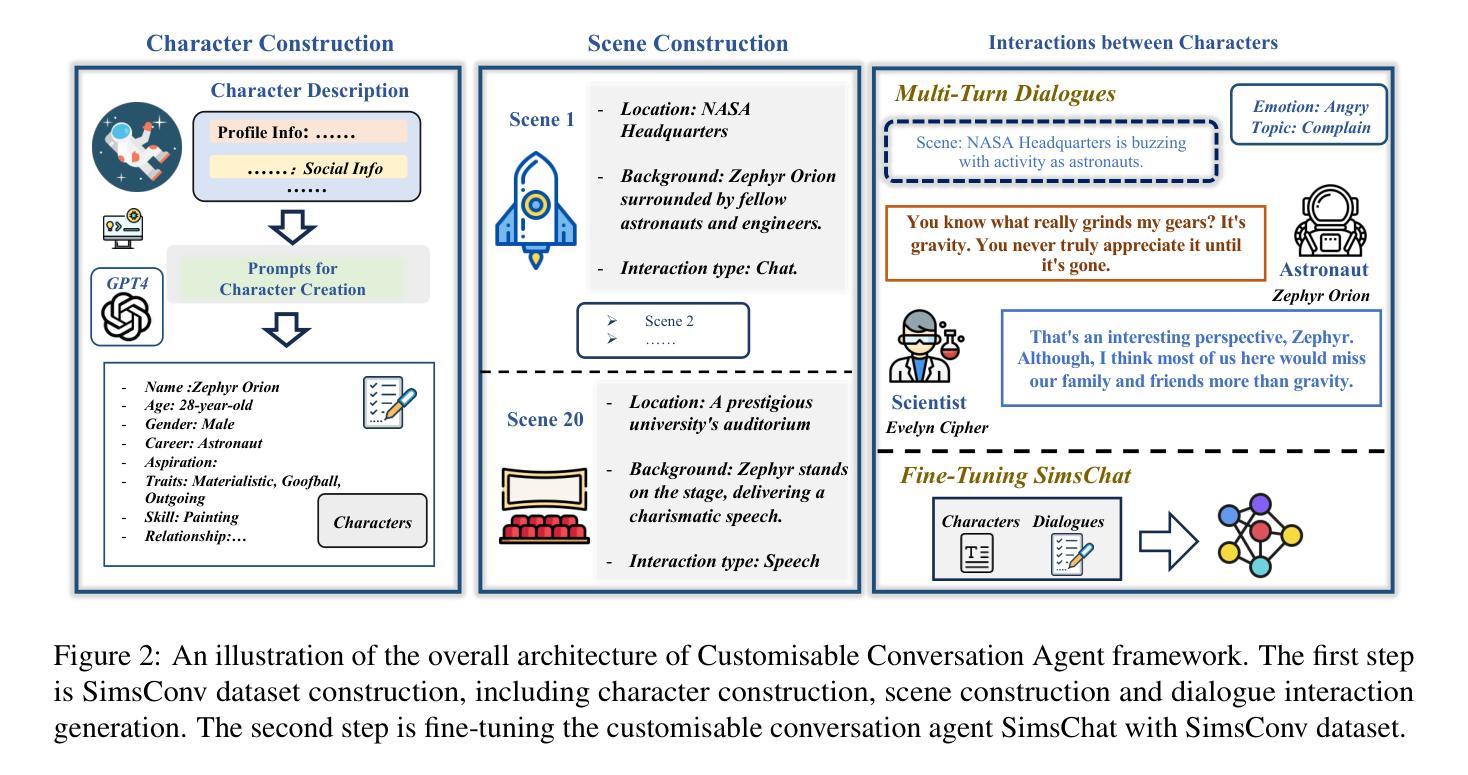
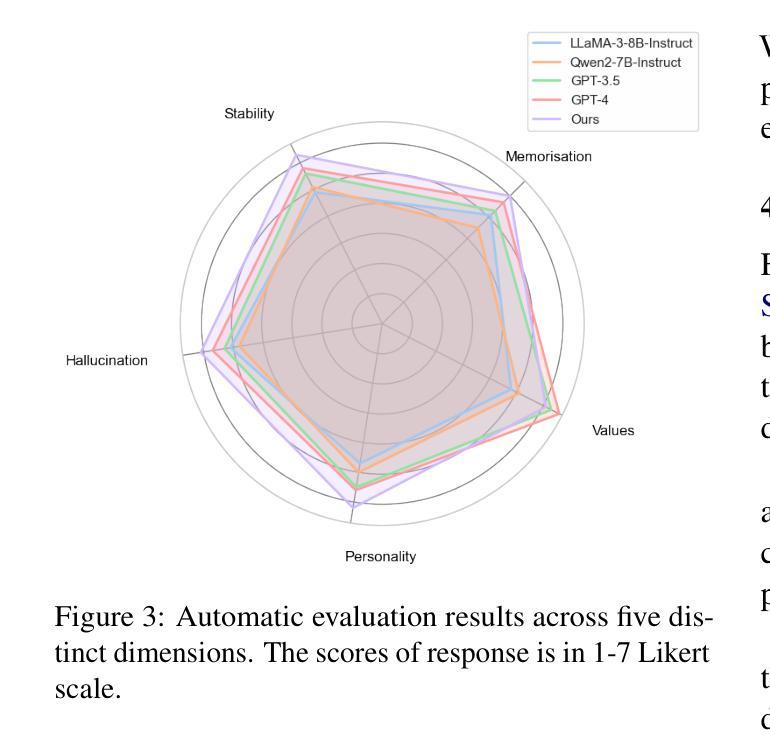
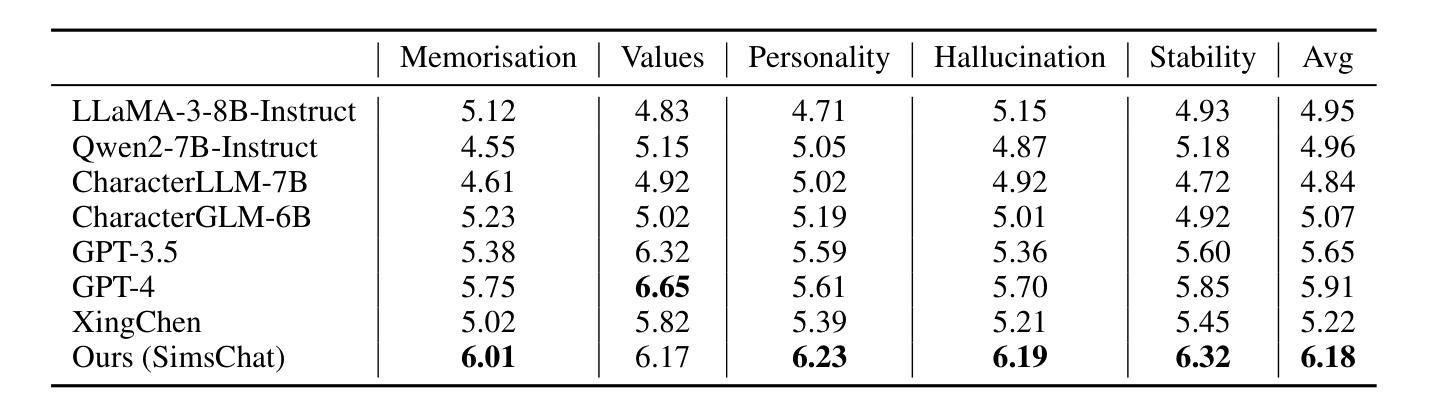
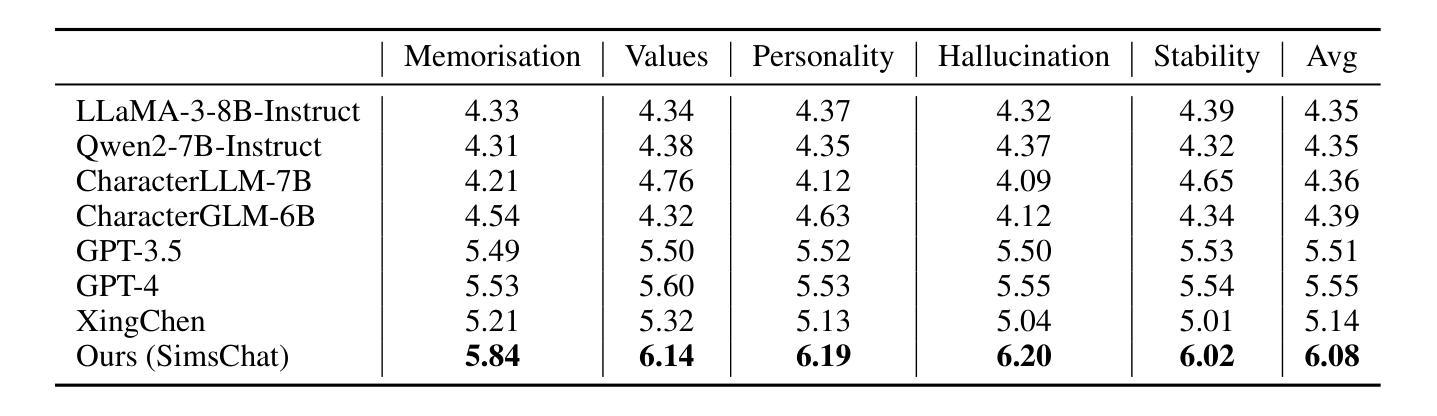
Large Language Models (LLMs) demonstrate remarkable ability to comprehend instructions and generate human-like text, enabling sophisticated agent simulation beyond basic behavior replication. However, the potential for creating freely customisable characters remains underexplored. We introduce the Customisable Conversation Agent Framework, which employs LLMs to simulate real-world characters through personalised characteristic feature injection, enabling diverse character creation according to user preferences. We propose the SimsConv dataset, comprising 68 customised characters and 13,971 multi-turn role-playing dialogues across 1,360 real-world scenes. Characters are initially customised using pre-defined elements (career, aspiration, traits, skills), then expanded through personal and social profiles. Building on this, we present SimsChat, a freely customisable role-playing agent incorporating various realistic settings and topic-specified character interactions. Experimental results on both SimsConv and WikiRoleEval datasets demonstrate SimsChat’s superior performance in maintaining character consistency, knowledge accuracy, and appropriate question rejection compared to existing models. Our framework provides valuable insights for developing more accurate and customisable human simulacra. Our data and code are publicly available at https://github.com/Bernard-Yang/SimsChat.
大型语言模型(LLM)表现出令人瞩目的理解和执行指令的能力,以及生成类似人类的文本的能力,从而实现了超越基本行为复制的复杂代理模拟。然而,创建可自由定制角色的潜力仍未得到充分探索。我们引入了可定制对话代理框架,该框架使用LLM通过个性化特征注入模拟现实世界角色,并根据用户偏好实现多样化的角色创建。我们提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个现实场景的多轮角色扮演对话。角色最初使用预定义元素(职业、志向、特质、技能)进行定制,然后通过个人和社会概况进行扩展。在此基础上,我们推出了SimsChat,这是一个可自由定制的角色扮演代理,包含各种现实设置和特定话题的角色互动。在SimsConv和WikiRoleEval数据集上的实验结果证明了SimsChat在保持角色一致性、知识准确性和适当问题拒绝方面的优越性能。我们的框架为开发更准确和可定制的人类模拟物提供了有价值的见解。我们的数据和代码可在https://github.com/Bernard-Yang/SimsChat公开访问。
论文及项目相关链接
Summary
大型语言模型(LLMs)在理解和执行指令以及生成人类文本方面表现出卓越的能力,能够进行超越基本行为复制的复杂代理模拟。然而,创建可自由定制角色的潜力尚未得到充分探索。我们引入了可定制对话代理框架,该框架利用LLMs模拟现实世界角色,通过个性化特征注入实现根据用户偏好创建多样化角色。我们提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个现实场景的多轮角色扮演对话。角色最初使用预定义元素(职业、抱负、特质、技能)进行定制,然后通过个人和社会概况进行扩展。在此基础上,我们推出了SimsChat,一个可自由定制的角色扮演代理,包含各种现实场景和主题特定的角色交互。在SimsConv和WikiRoleEval数据集上的实验结果表明,SimsChat在保持角色一致性、知识准确性和适当的问题拒绝方面优于现有模型。我们的框架为开发更准确、可定制的人类模拟体提供了宝贵见解。
Key Takeaways
- 大型语言模型(LLMs)能模拟复杂代理,具备理解和执行指令以及生成人类文本的能力。
- 自定义角色模拟的潜力尚未充分探索。
- 引入了可定制对话代理框架,利用LLMs模拟现实世界角色,实现用户定制的角色创建。
- 提出了SimsConv数据集,包含自定义角色和跨现实场景的多轮角色扮演对话。
- 角色通过预定义元素(职业、抱负等)和个人社会概况进行定制和扩展。
- SimsChat具备自由定制的角色扮演能力,能处理各种现实场景和主题特定的角色交互。
点此查看论文截图



Dynamics of Moral Behavior in Heterogeneous Populations of Learning Agents
Authors:Elizaveta Tennant, Stephen Hailes, Mirco Musolesi
Growing concerns about safety and alignment of AI systems highlight the importance of embedding moral capabilities in artificial agents: a promising solution is the use of learning from experience, i.e., Reinforcement Learning. In multi-agent (social) environments, complex population-level phenomena may emerge from interactions between individual learning agents. Many of the existing studies rely on simulated social dilemma environments to study the interactions of independent learning agents; however, they tend to ignore the moral heterogeneity that is likely to be present in societies of agents in practice. For example, at different points in time a single learning agent may face opponents who are consequentialist (i.e., focused on maximizing outcomes over time), norm-based (i.e., conforming to specific norms), or virtue-based (i.e., considering a combination of different virtues). The extent to which agents’ co-development may be impacted by such moral heterogeneity in populations is not well understood. In this paper, we present a study of the learning dynamics of morally heterogeneous populations interacting in a social dilemma setting. Using an Iterated Prisoner’s Dilemma environment with a partner selection mechanism, we investigate the extent to which the prevalence of diverse moral agents in populations affects individual agents’ learning behaviors and emergent population-level outcomes. We observe several types of non-trivial interactions between pro-social and anti-social agents, and find that certain types of moral agents are able to steer selfish agents towards more cooperative behavior.
随着对人工智能系统安全和对齐性的日益关注,将道德能力嵌入人工智能代理中的重要性变得凸显。一种前景广阔的解决方案是利用经验学习,即强化学习。在多代理(社会)环境中,个体学习代理之间的交互可能会产生复杂的人口层面现象。许多现有研究依赖于模拟的社会困境环境来研究独立学习代理之间的交互;然而,它们往往忽略了实践中代理社会可能存在的道德异质性。例如,在时间的不同点,单个学习代理可能会面临以结果为导向(即专注于长期最大化结果)、基于规范(即符合特定规范)或基于美德(即考虑不同美德的组合)的对手。代理共同发展中受到此类人口中道德异质性影响的程度尚不清楚。在本文中,我们研究了道德异质性人口在社会困境设置中互动的学习动态。我们利用带有伙伴选择机制的迭代囚徒困境环境,调查人口中多样化的道德代理普遍存在对个体代理学习行为和新兴的人口层面结果的影响程度。我们观察到亲社会和反社会代理之间几种非平凡类型的交互,并发现某些类型的道德代理能够将自私的代理引导向更合作的行为。
论文及项目相关链接
PDF Presented at AIES 2024 (7th AAAI/ACM Conference on AI, Ethics, and Society - San Jose, CA, USA) - see https://ojs.aaai.org/index.php/AIES/article/view/31736
Summary
本文关注人工智能系统的安全性和对齐性问题,提出在人工智能系统中嵌入道德能力的重要性。通过利用强化学习等经验学习方法,研究多智能体社交环境中个体学习智能体间的复杂群体现象。现有研究倾向于忽略实践中智能体社会中存在的道德异质性。本文在一个社会困境的迭代囚徒困境环境中,研究道德异质性对个体学习行为和群体层面结果的影响,并发现某些类型的道德智能体能够引导自私的智能体表现出更合作的行为。
Key Takeaways
- 人工智能系统的安全性和对齐性引发对嵌入道德能力的关注。
- 强化学习是处理多智能体社交环境中复杂群体现象的一种有效方法。
- 现有研究忽视了实践中智能体社会中的道德异质性。
- 在社会困境的迭代囚徒困境环境中研究道德异质性对智能体学习的影响是一个新的研究方向。
- 道德异质性影响个体学习行为和群体结果。
- 不同类型的道德智能体能引发不同类型的交互行为,进而影响群体动态。
点此查看论文截图







