⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
SynthLight: Portrait Relighting with Diffusion Model by Learning to Re-render Synthetic Faces
Authors:Sumit Chaturvedi, Mengwei Ren, Yannick Hold-Geoffroy, Jingyuan Liu, Julie Dorsey, Zhixin Shu
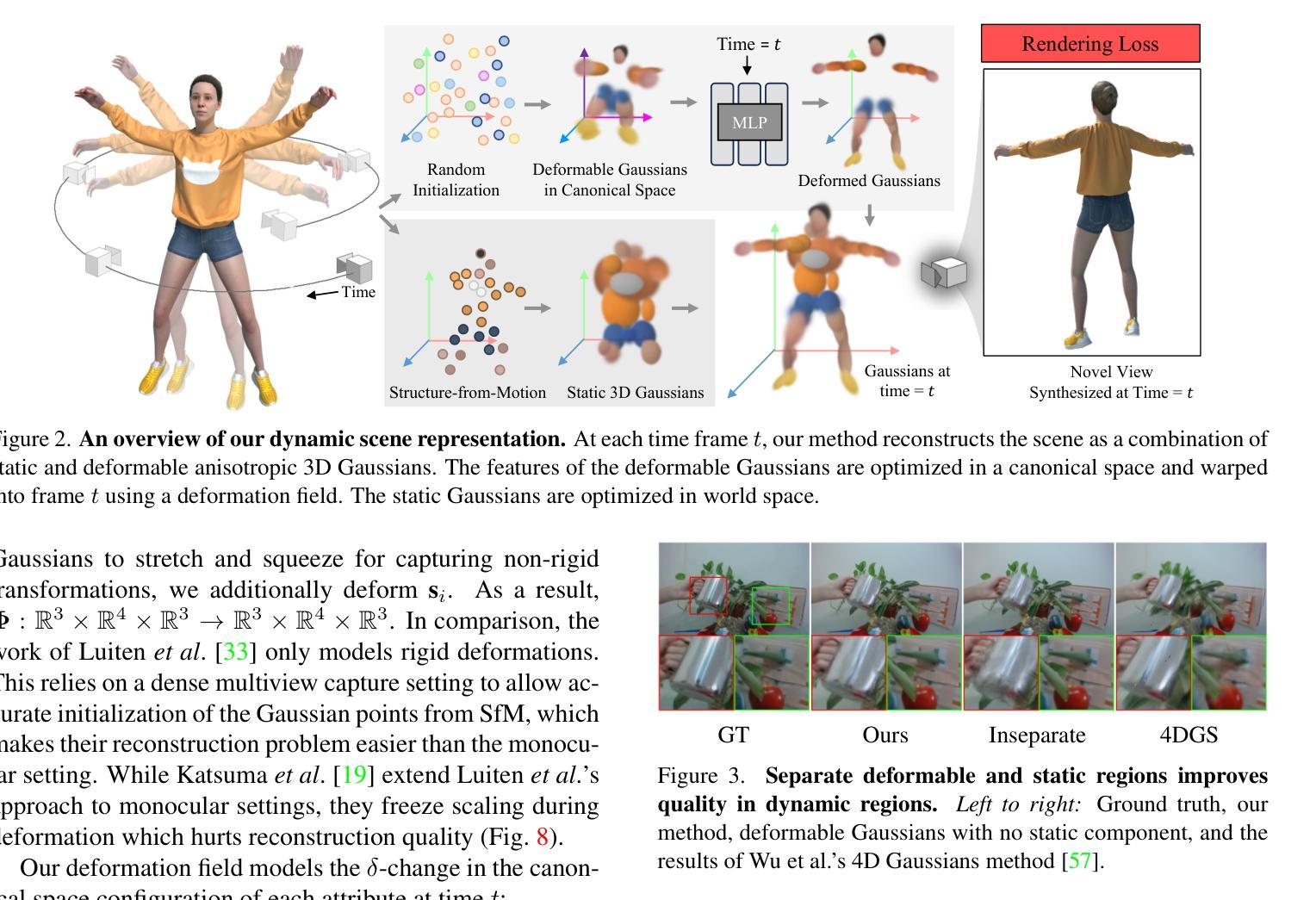
We introduce SynthLight, a diffusion model for portrait relighting. Our approach frames image relighting as a re-rendering problem, where pixels are transformed in response to changes in environmental lighting conditions. Using a physically-based rendering engine, we synthesize a dataset to simulate this lighting-conditioned transformation with 3D head assets under varying lighting. We propose two training and inference strategies to bridge the gap between the synthetic and real image domains: (1) multi-task training that takes advantage of real human portraits without lighting labels; (2) an inference time diffusion sampling procedure based on classifier-free guidance that leverages the input portrait to better preserve details. Our method generalizes to diverse real photographs and produces realistic illumination effects, including specular highlights and cast shadows, while preserving the subject’s identity. Our quantitative experiments on Light Stage data demonstrate results comparable to state-of-the-art relighting methods. Our qualitative results on in-the-wild images showcase rich and unprecedented illumination effects. Project Page: \url{https://vrroom.github.io/synthlight/}
我们介绍了SynthLight,这是一个用于肖像重新打光的扩散模型。我们的方法将图像重新打光视为重新渲染问题,像素会随环境照明条件的改变而发生变化。我们使用基于物理的渲染引擎,合成了一个数据集,以模拟在不同照明条件下使用3D头部资产进行这种光照调整转换。我们提出了两种训练和推理策略,以缩小合成图像和真实图像领域之间的差距:(1)多任务训练,利用没有光照标签的真实人像;(2)基于分类器引导的自由采样过程的推理时间扩散,利用输入的人像来更好地保留细节。我们的方法适用于各种真实照片,产生逼真的照明效果,包括高光和阴影,同时保持主体的身份。我们在Light Stage数据上的定量实验表明,我们的结果与最先进的重新打光方法相当。我们在野外图像上的定性结果展示了丰富且前所未有的照明效果。项目页面:https://vrroom.github.io/synthlight/
论文及项目相关链接
PDF 27 pages, 25 figures, Project Page https://vrroom.github.io/synthlight/
Summary
介绍了一种名为SynthLight的肖像重照明扩散模型。该方法将图像重照明视为重渲染问题,通过物理渲染引擎合成数据集,模拟不同光照条件下的像素变化。提出两种训练和推理策略,以缩小合成图像和真实图像之间的差距:一是利用无光照标签的真实人像进行多任务训练;二是在推理时间采用基于无分类器引导扩散采样程序,利用输入肖像更好地保留细节。该方法可广泛应用于各种真实照片,产生逼真的照明效果,包括高光和阴影,同时保持主体身份。
Key Takeaways
- SynthLight是一种用于肖像重光的扩散模型。
- 该方法将图像重照明视为重渲染问题,并模拟光照条件下的像素变化。
- 使用物理渲染引擎合成数据集。
- 提出两种训练和推理策略来缩小合成图像和真实图像之间的差距。
- 多任务训练利用无光照标签的真实人像。
- 推理时间采用基于无分类器引导扩散采样程序,利用输入肖像保留细节。
- 该方法能广泛应用于各种真实照片,产生逼真的照明效果,并保持主体身份。
点此查看论文截图




PATCHEDSERVE: A Patch Management Framework for SLO-Optimized Hybrid Resolution Diffusion Serving
Authors:Desen Sun, Zepeng Zhao, Yuke Wang
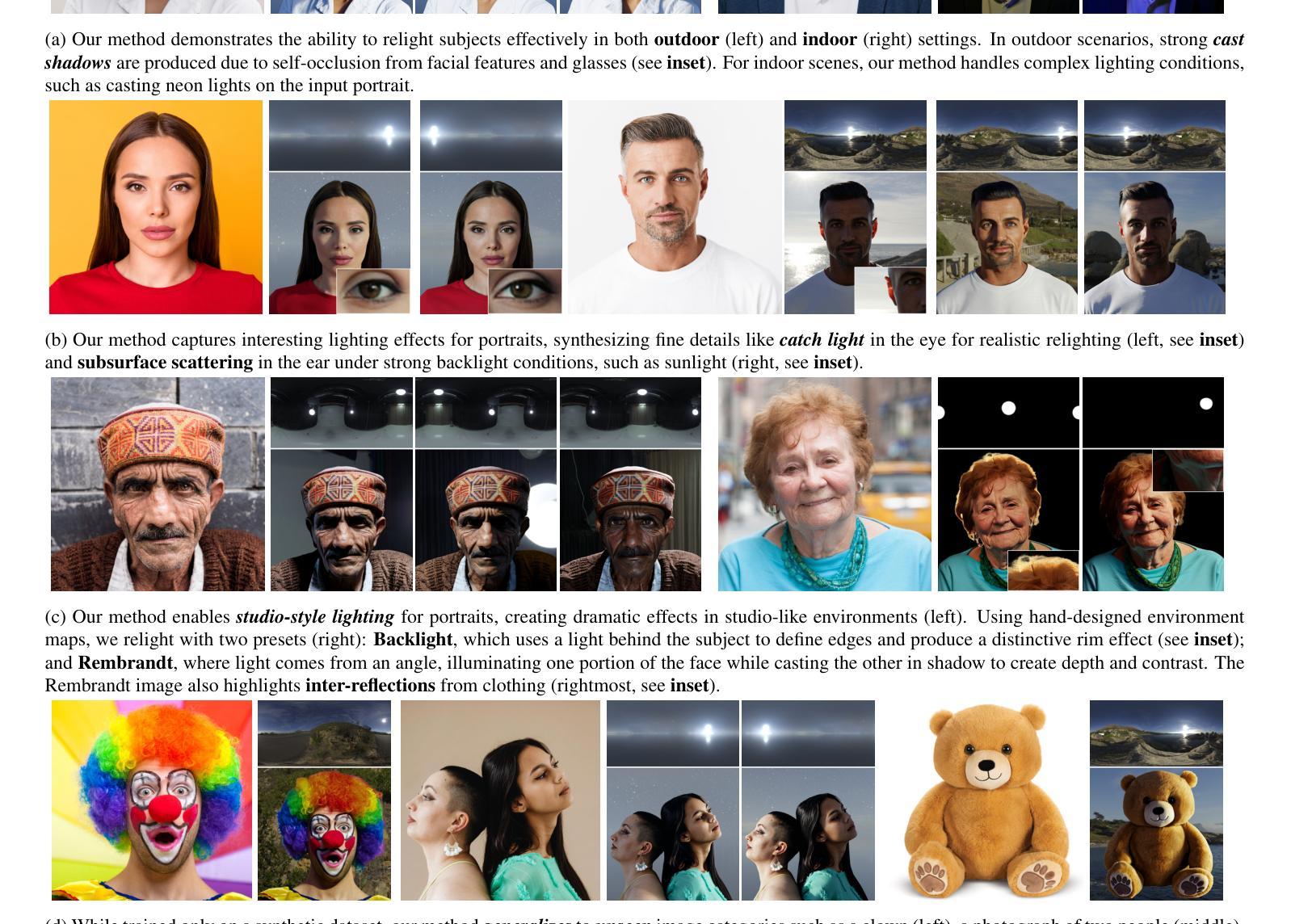
The Text-to-Image (T2I) diffusion model is one of the most popular models in the world. However, serving diffusion models at the entire image level faces several problems, especially when there are multiple candidate resolutions. First, image based serving system prevents requests with different resolutions from batching together. On the other hand, requests with hybrid resolutions also indicate diverse locality features, which makes it hard to apply the same cache policy to all of them. To this end, we propose PATCHEDSERVE, A Patch Management Framework for SLO-Optimized Hybrid Resolution Diffusion Serving that provides a patch-level management strategy to gather hybrid resolution requests into batches. Specifically, PATCHEDSERVE incorporates a novel patch-based processing workflow, significantly enhancing throughput for hybrid resolution inputs. Furthermore, PATCHEDSERVE designs a patch-level cache reuse policy to fully exploit the redundancy in diffusion. In addition, PATCHEDSERVE features an SLO-aware scheduling algorithm with lightweight online latency prediction, achieving higher SLO satisfaction rates. We show that PATCHEDSERVE can achieve 30.1 % higher SLO satisfaction compared to SOTA diffusion serving system while not hurt the image quality.
文本到图像(T2I)扩散模型是世界上最受欢迎模型之一。然而,在整个图像层面服务扩散模型面临几个问题,尤其是当存在多个候选分辨率时。首先,基于图像的服务系统阻止具有不同分辨率的请求进行批处理。另一方面,混合分辨率的请求也表现出不同的局部特征,这使得难以对所有请求应用相同的缓存策略。为此,我们提出PATCHEDSERVE,一个面向SLO优化的混合分辨率扩散服务的补丁管理框架,它提供了一种补丁级的管理策略,将混合分辨率的请求聚集到批次中。具体来说,PATCHEDSERVE引入了一种新颖的基于补丁的处理工作流程,显著提高了混合分辨率输入的吞吐量。此外,PATCHEDSERVE设计了一种补丁级的缓存重用策略,以充分利用扩散中的冗余信息。而且,PATCHEDSERVE还采用了具有轻量级在线延迟预测功能的SLO感知调度算法,以实现更高的SLO满意度。我们展示,相较于最先进(SOTA)的扩散服务系统,PATCHEDSERVE可以实现高出30.1%的SLO满意度,同时不损害图像质量。
论文及项目相关链接
摘要
文本转图像(T2I)扩散模型面临多种分辨率服务的问题。为解决此问题,提出PATCHDESERVE框架,采用补丁级管理策略,聚集混合分辨率请求进行批量处理,增强混合分辨率输入的吞吐量,并设计补丁级缓存重用策略,充分利用扩散中的冗余信息。此外,PATCHEDSERVE还具备SLO感知调度算法和轻量级在线延迟预测功能,以提高SLO满意度。相比现有扩散服务系统,PATCHEDSERVE能提高30.1%的SLO满意度,同时不影响图像质量。
关键见解
- 文本转图像(T2I)扩散模型在服务多个候选分辨率时面临挑战。
- 现有图像服务系统无法有效处理混合分辨率请求。
- PATCHEDSERVE框架采用补丁级管理策略,聚集混合分辨率请求进行批量处理。
- PATCHEDSERVE通过补丁级缓存策略,充分利用扩散中的冗余信息。
- PATCHEDSERVE具备SLO感知调度算法,以提高服务等级协议(SLO)的满意度。
- PATCHEDSERVE通过轻量级在线延迟预测功能优化性能。
- 与现有系统相比,PATCHEDSERVE在不影响图像质量的情况下,提高了SLO满意度。
点此查看论文截图


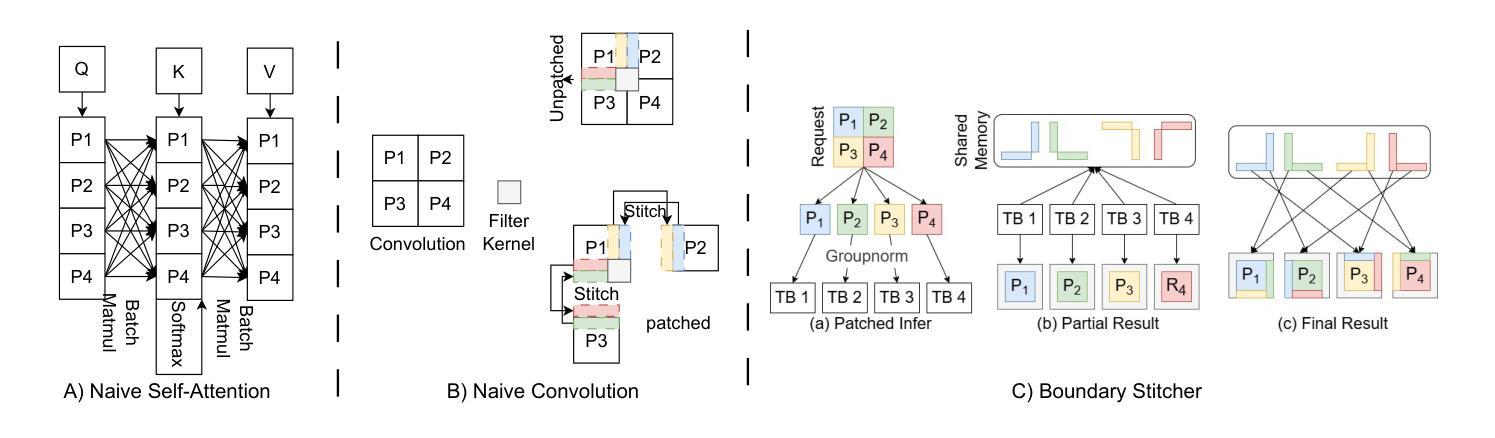
Grounding Text-To-Image Diffusion Models For Controlled High-Quality Image Generation
Authors:Ahmad Süleyman, Göksel Biricik
Large-scale text-to-image (T2I) diffusion models have demonstrated an outstanding performance in synthesizing diverse high-quality visuals from natural language text captions. Multiple layout-to-image models have been developed to control the generation process by utilizing a broad array of layouts such as segmentation maps, edges, and human keypoints. In this work, we present ObjectDiffusion, a model that takes inspirations from the top cutting-edge image generative frameworks to seamlessly condition T2I models with new bounding boxes capabilities. Specifically, we make substantial modifications to the network architecture introduced in ContorlNet to integrate it with the condition processing and injection techniques proposed in GLIGEN. ObjectDiffusion is initialized with pretraining parameters to leverage the generation knowledge obtained from training on large-scale datasets. We fine-tune ObjectDiffusion on the COCO2017 training dataset and evaluate it on the COCO2017 validation dataset. Our model achieves an AP$_{50}$ of 46.6, an AR of 44.5, and a FID of 19.8 outperforming the current SOTA model trained on open-source datasets in all of the three metrics. ObjectDiffusion demonstrates a distinctive capability in synthesizing diverse, high-quality, high-fidelity images that seamlessly conform to the semantic and spatial control layout. Evaluated in qualitative and quantitative tests, ObjectDiffusion exhibits remarkable grounding abilities on closed-set and open-set settings across a wide variety of contexts. The qualitative assessment verifies the ability of ObjectDiffusion to generate multiple objects of different sizes and locations.
大规模文本到图像(T2I)扩散模型已经显示出从自然语言文本描述中合成多样高质量图像的出色性能。已经开发出了多种布局到图像模型,通过利用广泛的布局(如分割图、边缘和人体关键点)来控制生成过程。在这项工作中,我们提出了ObjectDiffusion模型,该模型受到最新图像生成框架的启发,能够无缝地将T2I模型与新的边界框功能相结合。具体来说,我们对ControlNet中引入的网络架构进行了重大修改,将其与GLIGEN中提出的条件处理技术和注入技术相结合。ObjectDiffusion使用预训练参数进行初始化,以利用在大规模数据集上训练得到的生成知识。我们在COCO2017训练数据集上对ObjectDiffusion进行了微调,并在COCO2017验证数据集上对其进行了评估。我们的模型在AP50、AR和FID三个指标上分别达到了46.6、44.5和19.8,优于当前在开源数据集上训练的最新模型。ObjectDiffusion在合成多样、高质量、高保真图像方面表现出独特的能力,这些图像无缝地符合语义和空间控制布局。在定性和定量测试中,ObjectDiffusion在封闭集和开放集设置下,在各种上下文中表现出卓越的接地能力。定性评估验证了ObjectDiffusion生成不同大小和位置多个对象的能力。
论文及项目相关链接
Summary
本文介绍了一种名为ObjectDiffusion的大型文本转图像扩散模型。该模型融合了顶级图像生成框架的灵感,为文本转图像模型增加了新的边界框功能。ObjectDiffusion在COCO2017数据集上进行微调并评估,实现了出色的性能,优于在开放源代码数据集上训练的当前最佳模型。
Key Takeaways
- ObjectDiffusion是一个大型文本转图像扩散模型,能够从自然语言文本生成多样化的高质量图像。
- 该模型通过引入边界框功能,实现了对生成过程的精细控制。
- ObjectDiffusion采用预训练参数进行初始化,利用大规模数据集上的生成知识。
- 在COCO2017数据集上进行微调后,ObjectDiffusion实现了高性能指标,包括AP50为46.6,AR为44.5,FID为19.8。
- ObjectDiffusion在合成与语义和空间控制布局相匹配的多样化、高质量、高保真图像方面表现出独特的能力。
- 在定性测试和定量测试中,ObjectDiffusion在封闭集和开放集设置下表现出卓越的接地能力,适用于各种上下文。
点此查看论文截图

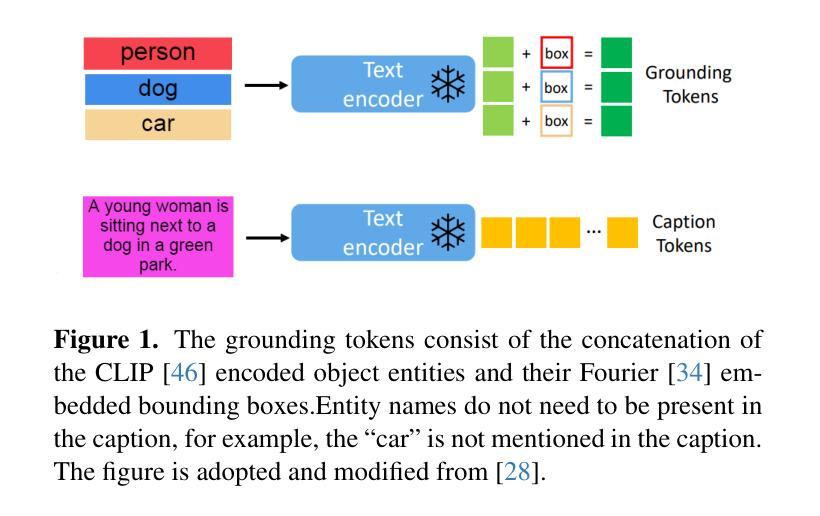

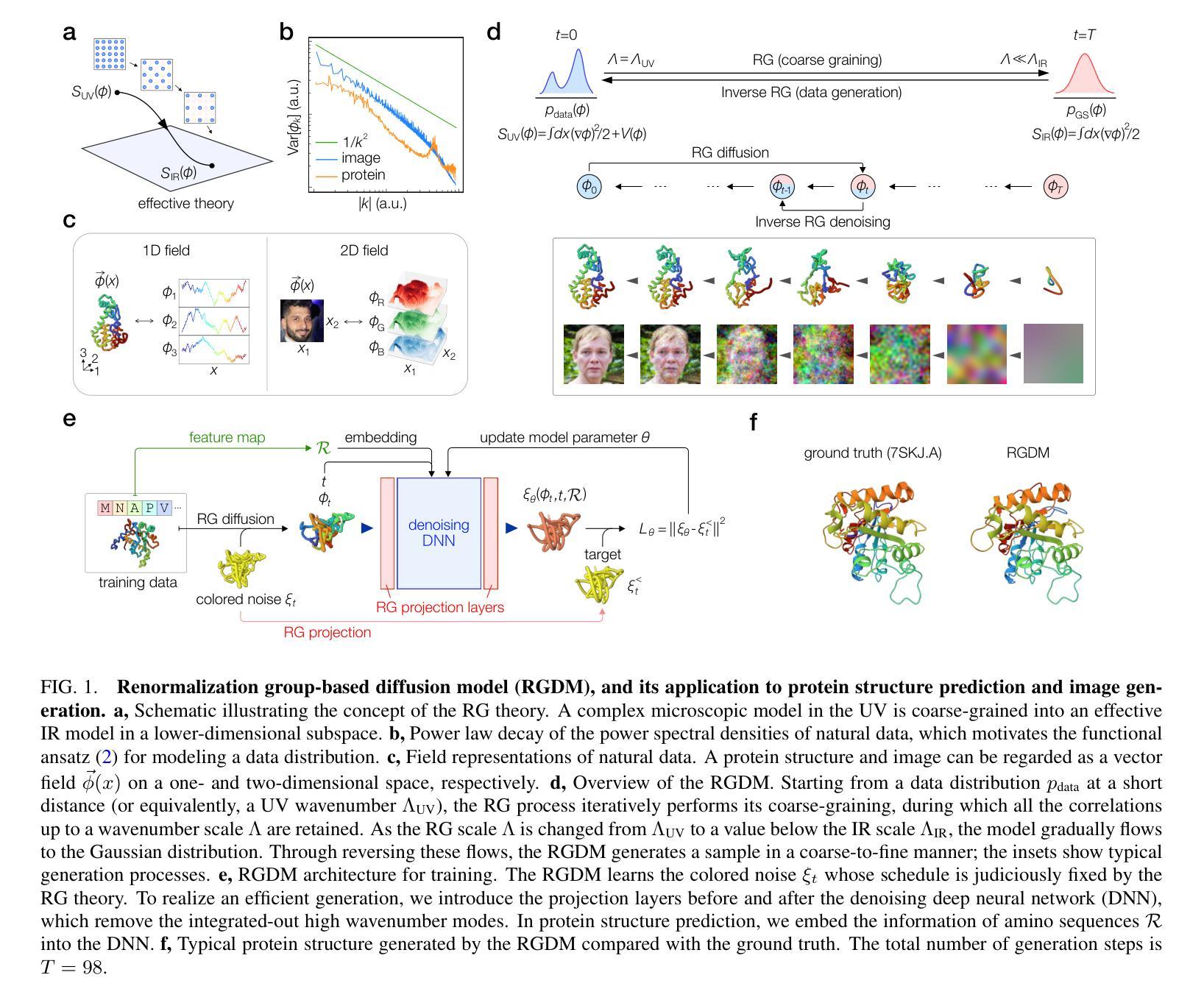
Generative diffusion model with inverse renormalization group flows
Authors:Kanta Masuki, Yuto Ashida
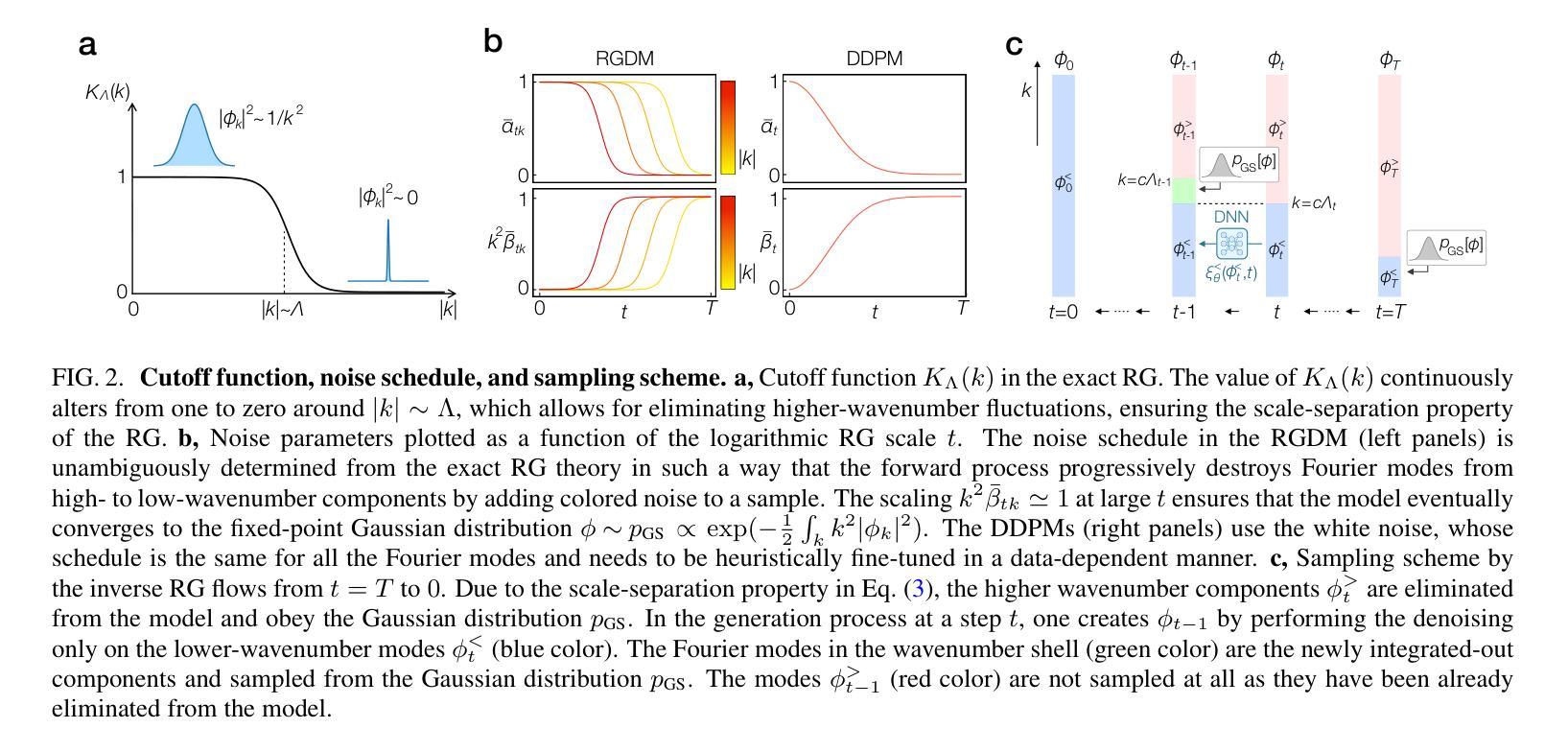
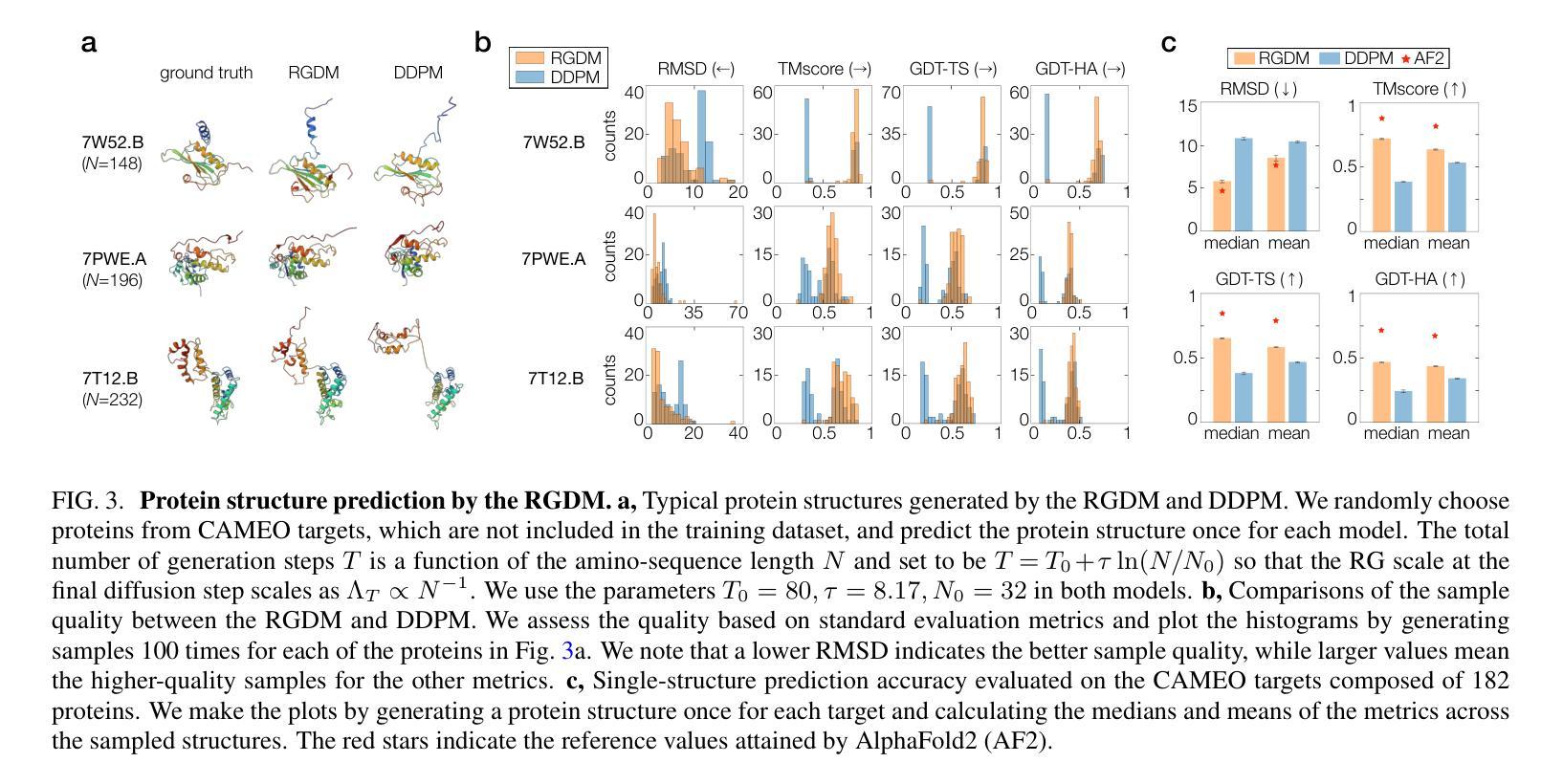
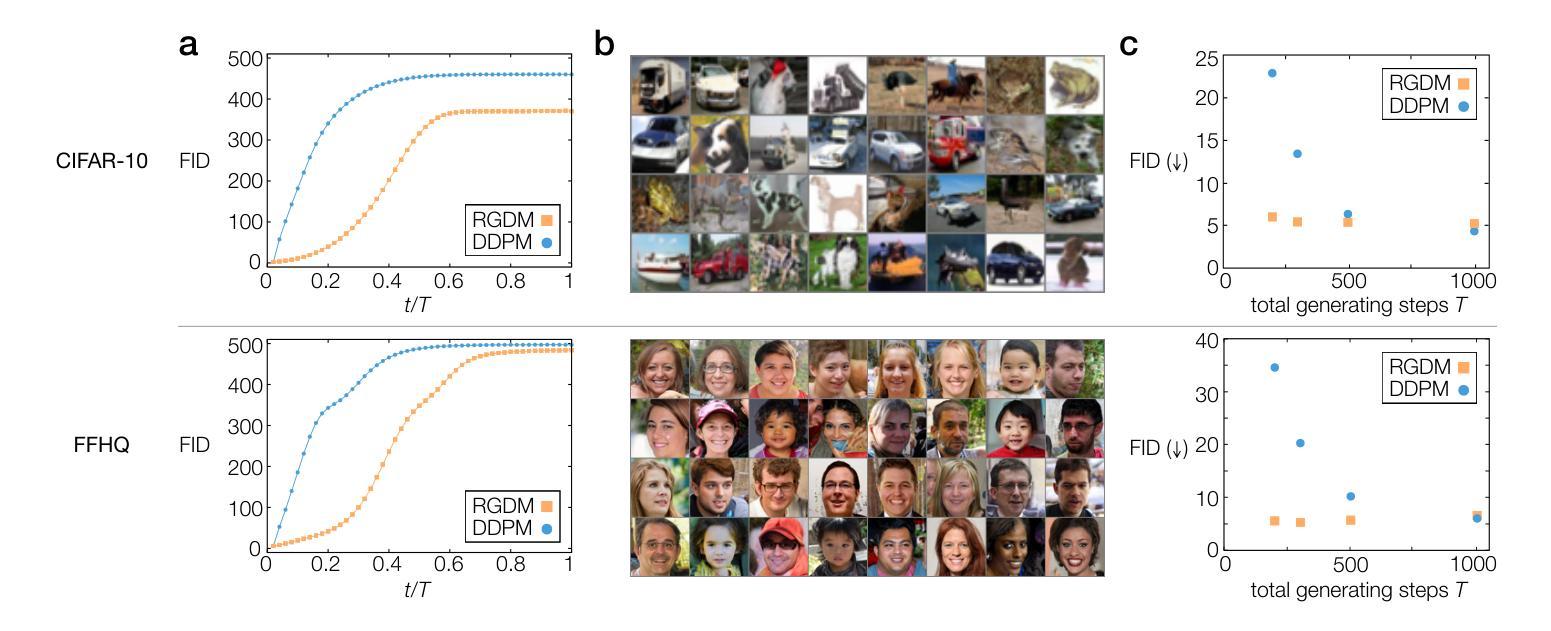
Diffusion models represent a class of generative models that produce data by denoising a sample corrupted by white noise. Despite the success of diffusion models in computer vision, audio synthesis, and point cloud generation, so far they overlook inherent multiscale structures in data and have a slow generation process due to many iteration steps. In physics, the renormalization group offers a fundamental framework for linking different scales and giving an accurate coarse-grained model. Here we introduce a renormalization group-based diffusion model that leverages multiscale nature of data distributions for realizing a high-quality data generation. In the spirit of renormalization group procedures, we define a flow equation that progressively erases data information from fine-scale details to coarse-grained structures. Through reversing the renormalization group flows, our model is able to generate high-quality samples in a coarse-to-fine manner. We validate the versatility of the model through applications to protein structure prediction and image generation. Our model consistently outperforms conventional diffusion models across standard evaluation metrics, enhancing sample quality and/or accelerating sampling speed by an order of magnitude. The proposed method alleviates the need for data-dependent tuning of hyperparameters in the generative diffusion models, showing promise for systematically increasing sample efficiency based on the concept of the renormalization group.
扩散模型是一类生成模型,通过消除由白噪声破坏的样本中的噪声来产生数据。尽管扩散模型在计算机视觉、音频合成和点云生成方面取得了成功,但它们忽视了数据中的内在多尺度结构,并且由于许多迭代步骤,生成过程缓慢。在物理学中,重整化组提供了一个联系不同尺度并给出精确粗粒度模型的基本框架。在这里,我们介绍了一种基于重整化组的扩散模型,该模型利用数据分布的多尺度特性来实现高质量的数据生成。秉承重整化组程序的精神,我们定义了一个流方程,该方程从精细尺度细节到粗粒度结构逐步消除数据信息。通过反转重整化组流,我们的模型能够以粗到细的方式生成高质量样本。我们通过将模型应用于蛋白质结构预测和图像生成来验证其通用性。我们的模型在标准评估指标上一致地优于传统扩散模型,通过提高样本质量或加速采样速度来提高一个数量级的性能。所提出的方法减轻了生成扩散模型中数据依赖的超参数调整需求,显示出根据重整化组的理念系统地提高样本效率的潜力。
论文及项目相关链接
PDF 9+21 pages, 4+11 figures. The code and trained models are available at https://github.com/kantamasuki/RGDM
Summary
扩散模型通过去噪被白噪声破坏的样本产生数据。虽然扩散模型在计算机视觉、音频合成和点云生成方面取得了成功,但它们忽略了数据内在的多尺度结构,并且由于许多迭代步骤而导致生成过程缓慢。结合物理中的重整化组理论,我们提出了一种基于重整化组的扩散模型,该模型利用数据分布的多尺度特性实现高质量的数据生成。通过逆转重整化组流程,该模型能够以从粗到细的方式生成高质量样本。在蛋白质结构预测和图像生成方面的应用验证了该模型的通用性。该模型在标准评估指标上一致地优于传统扩散模型,提高了样本质量,并将采样速度提高了数倍。所提出的方法减轻了生成扩散模型中数据相关超参数调整的需求,显示出基于重整化组概念的系统提高样本效率的潜力。
Key Takeaways
- 扩散模型通过去噪被噪声破坏的样本产生数据。
- 传统的扩散模型忽略了数据的多尺度结构,并且生成过程较慢。
- 本文提出了基于重整化组的扩散模型,该模型能利用数据分布的多尺度特性。
- 通过逆转重整化组流程,该模型能以从粗到细的方式生成高质量样本。
- 模型在蛋白质结构预测和图像生成方面有着广泛的应用。
- 与传统扩散模型相比,该模型在评估指标上表现更优秀,提高了样本质量并加速了采样速度。
点此查看论文截图

NeurOp-Diff:Continuous Remote Sensing Image Super-Resolution via Neural Operator Diffusion
Authors:Zihao Xu, Yuzhi Tang, Bowen Xu, Qingquan Li
Most publicly accessible remote sensing data suffer from low resolution, limiting their practical applications. To address this, we propose a diffusion model guided by neural operators for continuous remote sensing image super-resolution (NeurOp-Diff). Neural operators are used to learn resolution representations at arbitrary scales, encoding low-resolution (LR) images into high-dimensional features, which are then used as prior conditions to guide the diffusion model for denoising. This effectively addresses the artifacts and excessive smoothing issues present in existing super-resolution (SR) methods, enabling the generation of high-quality, continuous super-resolution images. Specifically, we adjust the super-resolution scale by a scaling factor s, allowing the model to adapt to different super-resolution magnifications. Furthermore, experiments on multiple datasets demonstrate the effectiveness of NeurOp-Diff. Our code is available at https://github.com/zerono000/NeurOp-Diff.
大部分公开可访问的遥感数据存在分辨率低的问题,这限制了它们的实际应用。为解决这一问题,我们提出了一种由神经算子引导的扩散模型,用于连续遥感图像超分辨率(NeurOp-Diff)。神经算子用于学习任意尺度的分辨率表示,将低分辨率(LR)图像编码为高维特征,然后用作先验条件,引导扩散模型进行去噪。这有效地解决了现有超分辨率(SR)方法中出现的伪影和过度平滑问题,能够生成高质量、连续的超高分辨率图像。具体来说,我们通过缩放因子s调整超分辨率尺度,使模型能够适应不同的超分辨率放大倍数。此外,对多个数据集的实验证明了NeurOp-Diff的有效性。我们的代码可在[https://github.com/zerono000/NeurOp-Diff找到。]
论文及项目相关链接
摘要
针对大多数公开可用的遥感数据分辨率低的问题,提出了一种基于神经算子和扩散模型的连续遥感图像超分辨率方法(NeurOp-Diff)。神经算子用于学习任意尺度的分辨率表示,将低分辨率(LR)图像编码为高维特征,作为先验条件引导扩散模型进行去噪。这有效解决了一倍的超分辨率方法中存在的伪影和过度平滑问题,能够生成高质量、连续的超高分辨率图像。通过缩放因子s调整超分辨率尺度,使模型能够适应不同的超分辨率放大倍数。在多个数据集上的实验验证了NeurOp-Diff的有效性。
要点
- 神经算子用于学习任意尺度的分辨率表示。
- 低分辨率图像被编码为高维特征作为先验条件。
- 扩散模型在超分辨率过程中用于去噪。
- 方法解决了现有超分辨率方法的伪影和过度平滑问题。
- 通过缩放因子调整超分辨率尺度,适应不同的放大需求。
- 在多个数据集上的实验验证了NeurOp-Diff的有效性。
点此查看论文截图



FlexiClip: Locality-Preserving Free-Form Character Animation
Authors:Anant Khandelwal
Animating clipart images with seamless motion while maintaining visual fidelity and temporal coherence presents significant challenges. Existing methods, such as AniClipart, effectively model spatial deformations but often fail to ensure smooth temporal transitions, resulting in artifacts like abrupt motions and geometric distortions. Similarly, text-to-video (T2V) and image-to-video (I2V) models struggle to handle clipart due to the mismatch in statistical properties between natural video and clipart styles. This paper introduces FlexiClip, a novel approach designed to overcome these limitations by addressing the intertwined challenges of temporal consistency and geometric integrity. FlexiClip extends traditional B'ezier curve-based trajectory modeling with key innovations: temporal Jacobians to correct motion dynamics incrementally, continuous-time modeling via probability flow ODEs (pfODEs) to mitigate temporal noise, and a flow matching loss inspired by GFlowNet principles to optimize smooth motion transitions. These enhancements ensure coherent animations across complex scenarios involving rapid movements and non-rigid deformations. Extensive experiments validate the effectiveness of FlexiClip in generating animations that are not only smooth and natural but also structurally consistent across diverse clipart types, including humans and animals. By integrating spatial and temporal modeling with pre-trained video diffusion models, FlexiClip sets a new standard for high-quality clipart animation, offering robust performance across a wide range of visual content. Project Page: https://creative-gen.github.io/flexiclip.github.io/
将剪贴画图像以无缝运动进行动画处理,同时保持视觉保真度和时间连贯性,这带来了相当大的挑战。现有方法,如AniClipart,能够有效地模拟空间变形,但往往不能保证平滑的时间过渡,导致运动突兀和几何失真等伪影。同样,文本到视频(T2V)和图像到视频(I2V)的模型在处理剪贴画时也遇到了困难,因为自然视频和剪贴画风格之间的统计属性不匹配。本文介绍了FlexiClip,这是一种旨在克服这些限制的新方法,通过解决时间一致性和几何完整性的交织挑战来应对。FlexiClip对传统基于Bézier曲线的轨迹建模进行了关键创新:使用时间雅可比矩阵逐步纠正运动动力学,通过概率流ODE(pfODEs)进行连续时间建模以减轻时间噪声,并受到GFlowNet原理启发的流匹配损失以优化平滑运动过渡。这些增强功能确保了涉及快速运动和非刚性变形的复杂场景中的连贯动画。大量实验验证了FlexiClip在生成动画方面的有效性,这些动画不仅平滑自然,而且在不同类型剪贴画(包括人物和动物)之间结构一致。通过结合预训练的视频扩散模型进行空间和时间建模,FlexiClip为高质量剪贴动画设定了新标准,在广泛的视觉内容中表现出稳健的性能。项目页面:https://creative-gen.github.io/flexiclip.github.io/
论文及项目相关链接
PDF 13 pages, 4 figures, 7 tables
Summary
FlexiClip是一种针对clipart图像动画的新方法,旨在实现平滑流畅的运动,同时保持视觉保真度和时间连贯性。它结合了创新的轨迹建模技术,包括使用临时雅可比矩阵进行增量运动校正、概率流ODEs进行连续时间建模以及基于GFlowNet原理的流匹配损失来优化平滑运动过渡。FlexiClip通过整合空间和时间建模与预训练的视频扩散模型,为高质量的clipart动画设定了新的标准,能在各种视觉内容中表现稳健。
Key Takeaways
- FlexiClip解决了clipart图像动画中的显著挑战,如保持视觉保真度和时间连贯性。
- 方法结合了创新的轨迹建模技术,确保运动平滑且自然。
- 通过使用临时雅可比矩阵和概率流ODEs等技术,FlexiClip实现了复杂场景下的连贯动画。
- FlexiClip集成了空间和时间建模,与预训练的视频扩散模型相结合,为高质量clipart动画树立了新标准。
- 该方法在各种视觉内容中表现稳健,包括人类和动物等多种clipart类型。
- FlexiClip能有效处理快速运动和非刚性变形等挑战。
点此查看论文截图




TimeFlow: Longitudinal Brain Image Registration and Aging Progression Analysis
Authors:Bailiang Jian, Jiazhen Pan, Yitong Li, Fabian Bongratz, Ruochen Li, Daniel Rueckert, Benedikt Wiestler, Christian Wachinger
Predicting future brain states is crucial for understanding healthy aging and neurodegenerative diseases. Longitudinal brain MRI registration, a cornerstone for such analyses, has long been limited by its inability to forecast future developments, reliance on extensive, dense longitudinal data, and the need to balance registration accuracy with temporal smoothness. In this work, we present \emph{TimeFlow}, a novel framework for longitudinal brain MRI registration that overcomes all these challenges. Leveraging a U-Net architecture with temporal conditioning inspired by diffusion models, TimeFlow enables accurate longitudinal registration and facilitates prospective analyses through future image prediction. Unlike traditional methods that depend on explicit smoothness regularizers and dense sequential data, TimeFlow achieves temporal consistency and continuity without these constraints. Experimental results highlight its superior performance in both future timepoint prediction and registration accuracy compared to state-of-the-art methods. Additionally, TimeFlow supports novel biological brain aging analyses, effectively differentiating neurodegenerative conditions from healthy aging. It eliminates the need for segmentation, thereby avoiding the challenges of non-trivial annotation and inconsistent segmentation errors. TimeFlow paves the way for accurate, data-efficient, and annotation-free prospective analyses of brain aging and chronic diseases.
预测未来的大脑状态对于理解健康老龄化和神经退行性疾病至关重要。纵向脑MRI注册是此类分析的核心,长期以来一直受到无法预测未来发展、依赖广泛而密集的纵向数据以及需要在注册精度和时间平滑之间取得平衡的限制。在这项工作中,我们提出了\emph{TimeFlow},这是一种新型的纵向脑MRI注册框架,克服了所有这些挑战。TimeFlow利用受扩散模型启发的具有时间条件的U-Net架构,实现了准确的纵向注册,并通过未来图像预测促进了前瞻性分析。与传统方法不同,这些方法依赖于明确的平滑正则器和密集序列数据,TimeFlow在不使用这些约束的情况下实现了时间一致性和连续性。实验结果表明,与最先进的方法相比,它在未来时间点的预测和注册精度方面表现出卓越的性能。此外,TimeFlow支持新型生物脑衰老分析,可有效区分神经退行性疾病和健康衰老。它消除了对分割的需求,从而避免了非平凡注释和不一致的分割错误带来的挑战。TimeFlow为准确、高效且无需注释的前瞻性分析脑衰老和慢性疾病开辟了道路。
论文及项目相关链接
Summary
基于扩散模型的时间流框架,能有效解决长期大脑MRI注册的挑战。它使用U型网络架构,通过扩散模型启发的时间条件,实现准确的长周期注册和未来图像预测。与传统方法相比,时间流在无需显式平滑正则化和密集序列数据的情况下,实现了时间一致性和连续性。其性能优于现有方法,并支持新型脑衰老分析,有效区分神经退行性疾病与健康衰老。时间流消除了对分割的需求,避免了非平凡标注和分割错误的不一致性。它为准确、高效且无标注的脑衰老和慢性病前瞻性分析铺平了道路。
Key Takeaways
- 时间流框架解决了长期大脑MRI注册的多个挑战。
- 利用U型网络架构和扩散模型的启发,实现了准确的长周期注册和未来图像预测。
- 时间流在不依赖显式平滑正则化和密集序列数据的情况下实现了时间一致性和连续性。
- 与现有方法相比,时间流在未来时间点预测和注册准确性方面表现出卓越性能。
- 时间流支持新型脑衰老分析,并能有效区分神经退行性疾病与健康衰老。
- 时间流消除了对分割的需求,避免了标注和分割错误的问题。
点此查看论文截图



DynamicFace: High-Quality and Consistent Video Face Swapping using Composable 3D Facial Priors
Authors:Runqi Wang, Sijie Xu, Tianyao He, Yang Chen, Wei Zhu, Dejia Song, Nemo Chen, Xu Tang, Yao Hu
Face swapping transfers the identity of a source face to a target face while retaining the attributes like expression, pose, hair, and background of the target face. Advanced face swapping methods have achieved attractive results. However, these methods often inadvertently transfer identity information from the target face, compromising expression-related details and accurate identity. We propose a novel method DynamicFace that leverages the power of diffusion model and plug-and-play temporal layers for video face swapping. First, we introduce four fine-grained face conditions using 3D facial priors. All conditions are designed to be disentangled from each other for precise and unique control. Then, we adopt Face Former and ReferenceNet for high-level and detailed identity injection. Through experiments on the FF++ dataset, we demonstrate that our method achieves state-of-the-art results in face swapping, showcasing superior image quality, identity preservation, and expression accuracy. Besides, our method could be easily transferred to video domain with temporal attention layer. Our code and results will be available on the project page: https://dynamic-face.github.io/
面部替换技术能够将源面部的身份转移到目标面部,同时保留目标面部的表情、姿态、发型和背景等属性。先进的面部替换方法已经取得了吸引人的成果。然而,这些方法常常会在不经意间从目标面部转移身份信息,从而影响到表情相关的细节和准确的身份表达。我们提出了一种新型方法DynamicFace,它利用扩散模型的强大功能和即插即用的时间层来实现视频面部替换。首先,我们引入四个精细的面部条件,使用3D面部先验。所有条件都被设计为相互独立,以实现精确和独特的控制。然后,我们采用Face Former和ReferenceNet进行高级和详细的身份注入。在FF++数据集上的实验表明,我们的方法在面部替换方面达到了最新水平,展现了卓越的图片质量、身份保留和表情准确性。此外,我们的方法能够轻松地通过时间注意力层转移到视频领域。我们的代码和结果将在项目页面公布:https://dynamic-face.github.io/
论文及项目相关链接
Summary
本文介绍了一种基于扩散模型的新型动态面部替换方法,该方法利用四维精细面部条件和Face Former与ReferenceNet进行高级和详细身份注入,实现视频面部替换。实验结果表明,该方法在面部替换方面达到最新水平,具有出色的图像质量、身份保留和表情准确性。
Key Takeaways
- 面部替换技术能够将源面部的身份转移到目标面部,同时保留目标面部的表情、姿态、发型和背景等属性。
- 当前先进的面部替换方法面临在转移身份信息时损失表情细节和准确身份的问题。
- 提出了一种新型动态面部替换方法DynamicFace,利用扩散模型的强大功能以及即插即用的时间层,实现视频面部替换。
- DynamicFace通过引入四个精细面部条件,利用三维面部先验进行精确而独特的控制。
- 采用Face Former和ReferenceNet进行高级和详细的身份注入,以提高面部替换的效果。
- 实验结果表明,DynamicFace方法在面部替换方面达到最新水平,具有优秀的图像质量、身份保留和表情准确性。
点此查看论文截图





A General Framework for Inference-time Scaling and Steering of Diffusion Models
Authors:Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, Rajesh Ranganath
Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
扩散模型在图像、视频、蛋白质设计和文本等多种模态中取得了令人印象深刻的效果。然而,生成具有用户指定属性的样本仍然是一个挑战。最近的研究提出对模型进行微调,以最大化捕捉所需属性的奖励,但这些方法需要昂贵的训练且容易出现模式崩溃。在这项工作中,我们提出了费曼·卡克(FK)转向,这是一种在推理时间框架中使用奖励函数引导扩散模型的框架。FK转向通过采样多个相互作用的扩散过程系统(称为粒子)进行工作,并在中间步骤基于使用称为潜力的函数计算得分进行粒子重采样。潜力是通过中间状态的奖励定义的,并选择使得高值表示粒子将产生高奖励样本。我们探讨了各种潜力的选择、中间奖励和采样器。我们对文本到图像和文本扩散模型评估了FK转向。对于使用人类偏好奖励引导文本到图像模型,我们发现FK转向一个0.8B参数模型的提示保真度超过了2.6B参数微调模型,具有更快的采样速度和无需训练。对于使用文本质量和特定文本属性的奖励引导文本扩散模型,我们发现FK转向产生了更低的困惑度,更在语言上可接受的输出,并实现了对诸如毒性等属性的无梯度控制。我们的结果证明了即使在离线奖励的情况下,推理时间尺度和引导扩散模型也可以提供显著的样本质量提升和可控性优势。相关代码可在https://github.com/zacharyhorvitz/Fk-Diffusion-Steering中找到。
论文及项目相关链接
摘要
扩散模型广泛应用于图像、视频、蛋白质设计和文本等多个领域,生成具有用户指定属性的样本仍是一个挑战。现有方法通过微调模型以最大化奖励来捕捉所需属性,但这种方法训练成本高昂且容易出现模式崩溃。本研究提出Feynman Kac(FK)转向,这是一种在推理时间框架内使用奖励函数控制扩散模型的框架。FK转向通过采样多个相互作用的扩散过程(粒子)的系统,并在中间步骤基于使用势能计算的分数重新采样粒子。势能利用中间状态的奖励定义,选择高值的粒子将产生高奖励样本。本研究探讨了不同的势能、中间奖励和采样器选择。在文本到图像和文本扩散模型上评估FK转向效果。对于利用人类偏好奖励控制文本到图像模型,发现FK转向的0.8B参数模型在提示保真度上优于2.6B参数微调模型,采样速度更快且无需训练。对于控制文本质量和特定文本属性的文本扩散模型,FK转向生成了更低困惑度、更符合语言学的输出,并实现了无毒性的梯度控制。结果表明,即使在离线奖励下,扩散模型的推理时间尺度和转向也能显著提高样本质量和可控性。相关代码可访问:https://github.com/zacharyhorvitz/Fk-Diffusion-Steering。
关键见解
- 扩散模型广泛应用于多个领域,生成具有用户指定属性的样本是当前的挑战。
- 现有方法微调模型以最大化奖励,但这种方法成本高昂且易陷入模式崩溃。
- 提出Feynman Kac(FK)转向,一种在推理时间使用奖励函数控制扩散模型的框架。
- FK转向通过采样多个相互作用的扩散过程(粒子)并在中间步骤重新采样来实现控制。
- 利用不同的势能和奖励函数选择进行试验,以优化生成样本的质量。
- 在文本到图像和文本扩散模型上评估FK转向,效果显著。
点此查看论文截图




CDDIP: Constrained Diffusion-Driven Deep Image Prior for Seismic Image Reconstruction
Authors:Paul Goyes-Peñafiel, Ulugbek Kamilov, Henry Arguello
Seismic data frequently exhibits missing traces, substantially affecting subsequent seismic processing and interpretation. Deep learning-based approaches have demonstrated significant advancements in reconstructing irregularly missing seismic data through supervised and unsupervised methods. Nonetheless, substantial challenges remain, such as generalization capacity and computation time cost during the inference. Our work introduces a reconstruction method that uses a pre-trained generative diffusion model for image synthesis and incorporates Deep Image Prior to enforce data consistency when reconstructing missing traces in seismic data. The proposed method has demonstrated strong robustness and high reconstruction capability of post-stack and pre-stack data with different levels of structural complexity, even in field and synthetic scenarios where test data were outside the training domain. This indicates that our method can handle the high geological variability of different exploration targets. Additionally, compared to other state-of-the-art seismic reconstruction methods using diffusion models. During inference, our approach reduces the number of sampling timesteps by up to 4x.
地震数据经常存在缺失的轨迹,这会对后续的地震处理和解释产生重大影响。基于深度学习的方法在通过有监督和无监督方法重建不规则缺失的地震数据方面取得了显著的进步。然而,仍然存在重大挑战,例如在推理过程中的泛化能力和计算时间成本。我们的工作引入了一种重建方法,该方法使用预训练的生成扩散模型进行图像合成,并结合深度图像先验在重建地震数据中缺失轨迹时强制数据一致性。所提出的方法表现出强大的稳健性和对不同结构复杂性级别的叠加后数据和叠加前数据的高重建能力,即使在测试数据超出训练领域的现场和合成场景中亦是如此。这表明我们的方法可以处理不同勘探目标的高地质变异性。此外,与其他使用扩散模型的最新地震重建方法相比,我们的方法在推理过程中减少了高达4倍的采样时间步数。
论文及项目相关链接
PDF 5 pages, 4 figures, 3 tables. Submitted to geoscience and remote sensing letters
Summary
本文介绍了一种基于预训练生成扩散模型的重建方法,用于合成图像并重建地震数据中缺失的轨迹。该方法结合了深度图像先验技术,以确保在重建过程中数据的一致性。实验表明,该方法在应对不同结构复杂度的后堆栈和预堆栈数据时表现出强大的稳健性和高重建能力,即使在超出训练域的场景下也能处理各种勘探目标的高地质变异性。相较于其他使用扩散模型的先进地震重建方法,此方法在推理阶段减少了高达4倍的采样时间步数。
Key Takeaways
- 地震数据中的缺失轨迹对后续的地震处理和解释产生了影响。
- 深度学习在重建不规则缺失的地震数据方面已显示出显著进展。
- 本文引入了一种基于预训练生成扩散模型的重建方法,用于合成图像。
- 结合深度图像先验技术,该方法在重建缺失轨迹时保证了数据的一致性。
- 该方法在应对不同结构复杂度的地震数据以及不同地质环境下表现出强大的稳健性和高重建能力。
- 与其他使用扩散模型的先进地震重建方法相比,该方法在推理阶段的采样时间步数减少了高达4倍。
点此查看论文截图






Zero-shot Video Restoration and Enhancement Using Pre-Trained Image Diffusion Model
Authors:Cong Cao, Huanjing Yue, Xin Liu, Jingyu Yang
Diffusion-based zero-shot image restoration and enhancement models have achieved great success in various tasks of image restoration and enhancement. However, directly applying them to video restoration and enhancement results in severe temporal flickering artifacts. In this paper, we propose the first framework for zero-shot video restoration and enhancement based on the pre-trained image diffusion model. By replacing the spatial self-attention layer with the proposed short-long-range (SLR) temporal attention layer, the pre-trained image diffusion model can take advantage of the temporal correlation between frames. We further propose temporal consistency guidance, spatial-temporal noise sharing, and an early stopping sampling strategy to improve temporally consistent sampling. Our method is a plug-and-play module that can be inserted into any diffusion-based image restoration or enhancement methods to further improve their performance. Experimental results demonstrate the superiority of our proposed method. Our code is available at https://github.com/cao-cong/ZVRD.
基于扩散的零样本图像修复和增强模型在图像修复和增强的各种任务中取得了巨大的成功。然而,将其直接应用于视频修复和增强会导致严重的时空闪烁伪影。在本文中,我们提出了基于预训练图像扩散模型的零样本视频修复和增强的第一个框架。通过用所提出的短长程(SLR)时间注意力层替换空间自注意力层,预训练的图像扩散模型可以利用帧之间的时间相关性。我们还提出了时间一致性指导、时空噪声共享和早期停止采样策略,以改善时间一致性的采样。我们的方法是一个即插即用的模块,可以插入到任何基于扩散的图像修复或增强方法中,以进一步提高其性能。实验结果证明了我们的方法优越性。我们的代码可在https://github.com/cao-cong/ZVRD找到。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
扩散模型在零样本图像修复和增强任务中取得了巨大成功,但直接应用于视频修复和增强会导致严重的时序闪烁伪影。本文首次提出基于预训练图像扩散模型的零样本视频修复和增强框架。通过用所提出的长短程时序注意力层替换空间自注意力层,利用帧间的时序相关性,预训练的图像扩散模型能够改善视频修复和增强的效果。此外,本文还提出了时序一致性引导、时空噪声共享和早期停止采样策略来提高时序一致性采样效果。本文方法是一个即插即用模块,可插入任何扩散式图像修复或增强方法中,进一步提高其性能。实验结果表明,本文提出的方法具有优越性。
Key Takeaways
- 扩散模型在零样本图像修复和增强任务中表现优异,但应用于视频修复和增强时存在时序闪烁问题。
- 本文首次提出了基于预训练图像扩散模型的零样本视频修复和增强框架。
- 通过用长短程时序注意力层替换空间自注意力层,利用帧间时序相关性。
- 提出了时序一致性引导、时空噪声共享和早期停止采样策略来提高时序一致性采样。
- 本文方法是一个通用的模块,可以方便地集成到现有的扩散模型中,提高图像修复和增强的性能。
- 实验结果证明了该方法在视频修复和增强任务上的优越性。
点此查看论文截图





Simplified and Generalized Masked Diffusion for Discrete Data
Authors:Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, Michalis K. Titsias
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.75 (CIFAR-10) and 3.40 (ImageNet 64x64) bits per dimension that are better than autoregressive models of similar sizes. Our code is available at https://github.com/google-deepmind/md4.
遮蔽(或吸收)扩散作为一种离散数据生成模型的自回归模型的替代方案,正在得到积极的研究。然而,该领域现有的工作受到了模型公式不必要地复杂和不同观点之间关系不明确的影响,导致了参数化、训练目标和临时调整效果不佳。在这项工作中,我们的目标是提供一个简单且通用的框架,以充分发挥遮蔽扩散模型的潜力。我们证明了遮蔽扩散模型的连续时间变分目标是交叉熵损失的简单加权积分。我们的框架还允许使用状态依赖的遮蔽时间表来训练广义遮蔽扩散模型。以困惑度评估时,我们在OpenWebText上训练的模型超越了GPT-2规模的先前扩散语言模型,并在五项零镜头语言建模任务中的四项上表现出卓越性能。此外,我们的模型在像素级图像建模上大大优于先前的离散扩散模型,在CIFAR-10和ImageNet 64x64上实现了每维度分别为2.75比特和3.40比特的结果,优于类似规模的自回归模型。我们的代码位于https://github.com/google-deepmind/md4。
论文及项目相关链接
PDF NeurIPS 2024. Code is available at: https://github.com/google-deepmind/md4
Summary
本文探索了掩膜扩散模型作为生成离散数据的替代方案。文章提出了一种简单通用的掩膜扩散模型框架,解决了现有研究中模型公式复杂、不同视角关系不明确的问题,实现了参数化、训练目标的最优化。此外,本文展示了掩膜扩散模型的连续时间变分目标与交叉熵损失的加权积分关系。模型能在OpenWebText数据集上达到GPT-2规模的最低困惑度,并在零样本语言建模任务中表现出卓越性能。同时,在像素级图像建模方面,模型表现优于先前的离散扩散模型,实现了CIFAR-10的2.75比特和ImageNet 64x64的3.4比特每维度的高性能表现。代码已公开于GitHub。
Key Takeaways
- 掩膜扩散模型作为一种生成离散数据的替代方案正受到关注。
- 提出了一种简单通用的掩膜扩散模型框架,解决了现有研究中模型复杂和关系不明确的问题。
- 揭示了掩膜扩散模型的连续时间变分目标与交叉熵损失的加权积分关系。
- 模型在GPT-2规模的OpenWebText数据集上实现了最低的困惑度。
- 模型在零样本语言建模任务中表现出卓越性能,特别是在某些特定任务上表现优于其他模型。
- 模型在像素级图像建模方面显著优于先前的离散扩散模型。
点此查看论文截图



Learning Discrete Concepts in Latent Hierarchical Models
Authors:Lingjing Kong, Guangyi Chen, Biwei Huang, Eric P. Xing, Yuejie Chi, Kun Zhang
Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory’s implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.
从自然的高维数据(例如图像)中学习概念,在构建与人类对齐和可解释的机器学习模型方面具潜力。尽管其前景鼓舞人心,但关于这一关键任务的形式化和理论洞察仍然缺乏。在这项工作中,我们将概念形式化为离散的潜在因果变量,这些变量通过层次化因果模型相关联,该模型对高维数据中嵌入概念的不同抽象层次进行编码(例如,自然图像中的犬种及其眼睛形状)。我们制定条件,以促进所提出因果模型的识别,揭示从非监督数据中学习此类概念的可能性。我们的条件允许超出先前工作中的潜在树和多级有向无环图的复杂因果层次结构,并能够处理高维、连续的观测变量,这非常适合图像等无结构的数据模式。我们通过合成数据实验来证实我们的理论主张。此外,我们讨论了我们的理论对理解潜在扩散模型的内在机制的影响,并为我们的理论见解提供相应的实证证据。
论文及项目相关链接
PDF NeurIPS 2024
Summary
本文探讨从自然高维数据(如图像)中学习概念在构建人类对齐和可解释的机器学习模型中的潜力。文章将概念形式化为离散潜在因果变量,并通过层次因果模型关联,该模型编码嵌入在高维数据中的不同抽象层次的概念。文章制定了条件以促进所提出的因果模型的识别,揭示从非监督数据中学习此类概念的可能性。该条件能够处理超越先前工作中潜在树和多级有向无环图的复杂因果层次结构,以及适合图像等非结构化数据的高维连续观测变量。文章通过合成数据实验证实了理论主张,并探讨了理论对潜在扩散模型的内在机制的影响,为理论见解提供了相应的实证证据。
Key Takeaways
- 文章将概念形式化为离散潜在因果变量,并提出了一个层次化的因果模型来表示高维数据中的不同概念间的关系。
- 文章制定了条件以促进因果模型的识别,并揭示了从非监督数据中学习概念的可能性。
- 该理论框架能够处理复杂的因果层次结构,包括高维连续观测变量,适用于非结构化数据,如图像。
- 文章通过合成数据实验证实了理论主张。
- 文章讨论了理论对理解潜在扩散模型的内在机制的影响,并为理论见解提供了实证证据。
- 学习从自然高维数据中提取概念对于构建与人类对齐和可解释的机器学习模型具有潜力。
点此查看论文截图



DiffMesh: A Motion-aware Diffusion Framework for Human Mesh Recovery from Videos
Authors:Ce Zheng, Xianpeng Liu, Qucheng Peng, Tianfu Wu, Pu Wang, Chen Chen
Human mesh recovery (HMR) provides rich human body information for various real-world applications. While image-based HMR methods have achieved impressive results, they often struggle to recover humans in dynamic scenarios, leading to temporal inconsistencies and non-smooth 3D motion predictions due to the absence of human motion. In contrast, video-based approaches leverage temporal information to mitigate this issue. In this paper, we present DiffMesh, an innovative motion-aware Diffusion-like framework for video-based HMR. DiffMesh establishes a bridge between diffusion models and human motion, efficiently generating accurate and smooth output mesh sequences by incorporating human motion within the forward process and reverse process in the diffusion model. Extensive experiments are conducted on the widely used datasets (Human3.6M \cite{h36m_pami} and 3DPW \cite{pw3d2018}), which demonstrate the effectiveness and efficiency of our DiffMesh. Visual comparisons in real-world scenarios further highlight DiffMesh’s suitability for practical applications.
人体网格恢复(HMR)为各种现实世界应用提供了丰富的人体信息。虽然基于图像的HMR方法已经取得了令人印象深刻的结果,但在动态场景中恢复人体时常常遇到困难,由于缺乏人体运动导致时间不一致和非平滑的3D运动预测。相比之下,基于视频的方法利用时间信息来缓解这个问题。在本文中,我们提出了DiffMesh,这是一个创新的运动感知扩散式框架,用于基于视频的HMR。DiffMesh在扩散模型和人体运动之间建立了桥梁,通过将在扩散模型的前向过程和反向过程中融入人体运动,有效地生成准确和平滑的输出网格序列。在广泛使用的数据集(Human3.6M \cite{h36m_pami}和3DPW \cite{pw3d2018})上进行了大量实验,证明了我们的DiffMesh的有效性和效率。在真实场景中的视觉对比进一步突出了DiffMesh在实际应用中的适用性。
论文及项目相关链接
PDF WACV 2025
Summary
人类网格恢复(HMR)为各种实际应用提供了丰富的人体信息。尽管基于图像的方法已取得了令人印象深刻的结果,但它们通常在动态场景中难以恢复人体信息,导致时间不一致和非平滑的3D运动预测。相反,基于视频的方法利用时间信息来缓解这个问题。本文提出了一种创新的运动感知扩散框架DiffMesh,用于基于视频的HMR。DiffMesh在扩散模型中建立了扩散模型与人类运动的桥梁,通过在前向过程和反向过程中融入人类运动,有效地生成准确和平滑的输出网格序列。在广泛使用数据集上的大量实验证明了DiffMesh的有效性和效率。在真实场景中的视觉对比进一步突出了DiffMesh在实际应用中的适用性。
Key Takeaways
- HMR为多种实际应用提供了丰富的人体信息。
- 基于图像的方法在动态场景中恢复人体信息存在挑战,导致时间不一致和非平滑的3D运动预测。
- 基于视频的方法利用时间信息缓解上述问题。
- DiffMesh是创新的运动感知扩散框架,用于基于视频的HMR。
- DiffMesh在扩散模型中融入人类运动,生成准确、平滑的输出网格序列。
- 在广泛使用数据集上的实验证明了DiffMesh的有效性和效率。
点此查看论文截图