⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
Text-driven Adaptation of Foundation Models for Few-shot Surgical Workflow Analysis
Authors:Tingxuan Chen, Kun Yuan, Vinkle Srivastav, Nassir Navab, Nicolas Padoy
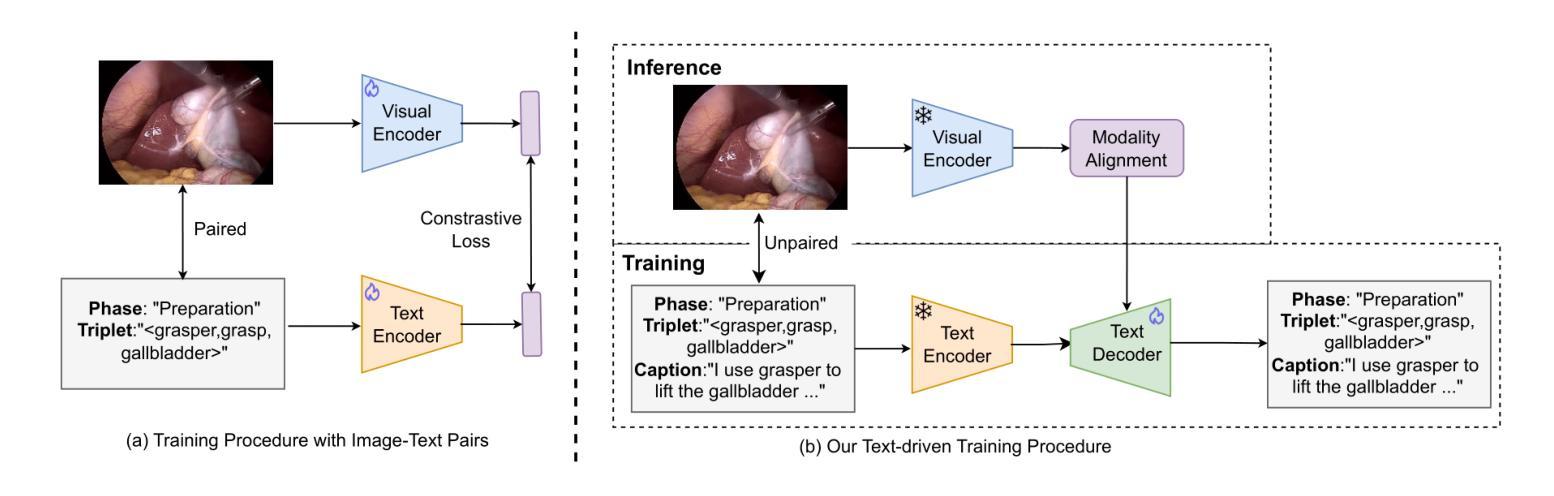
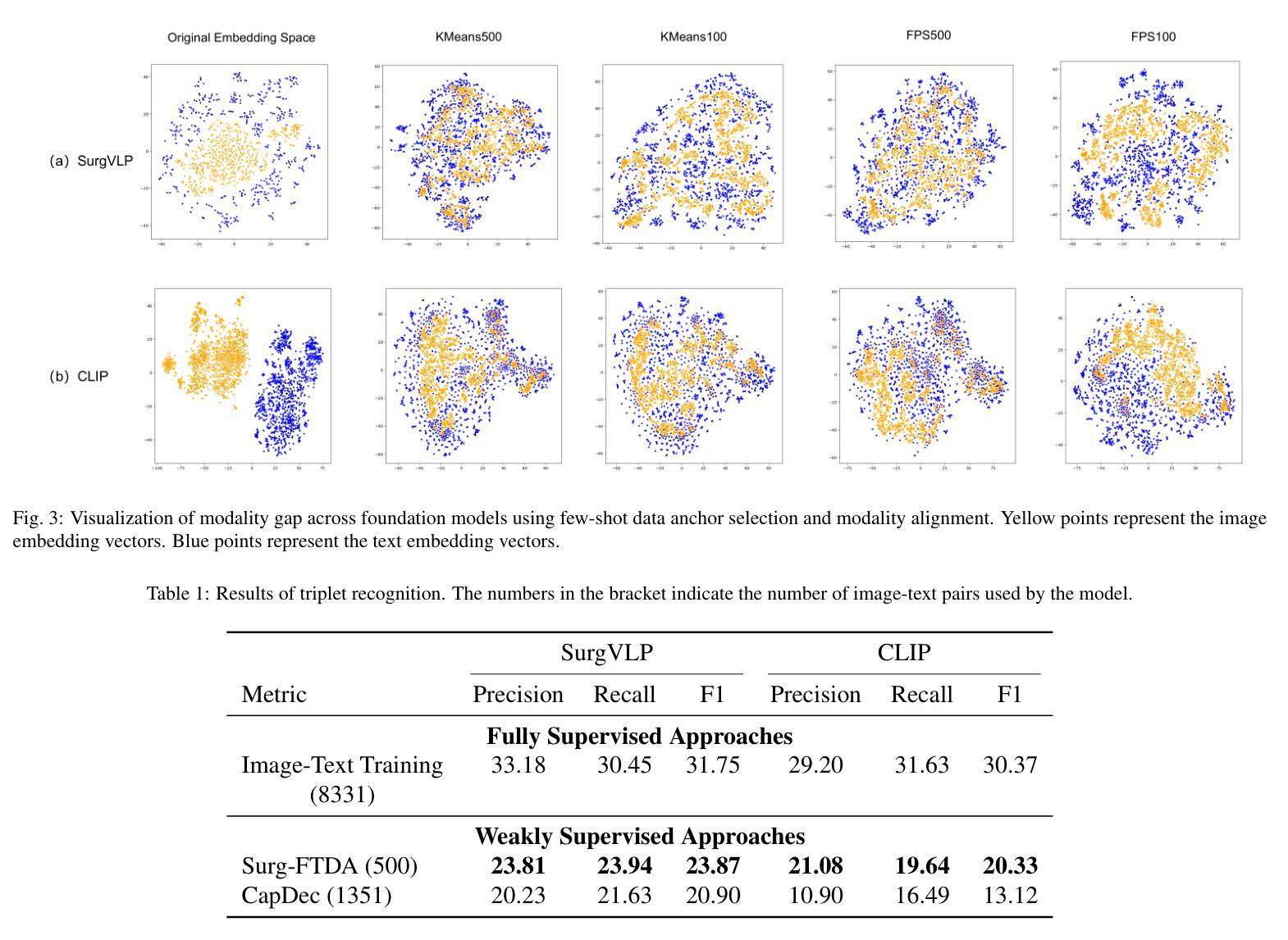
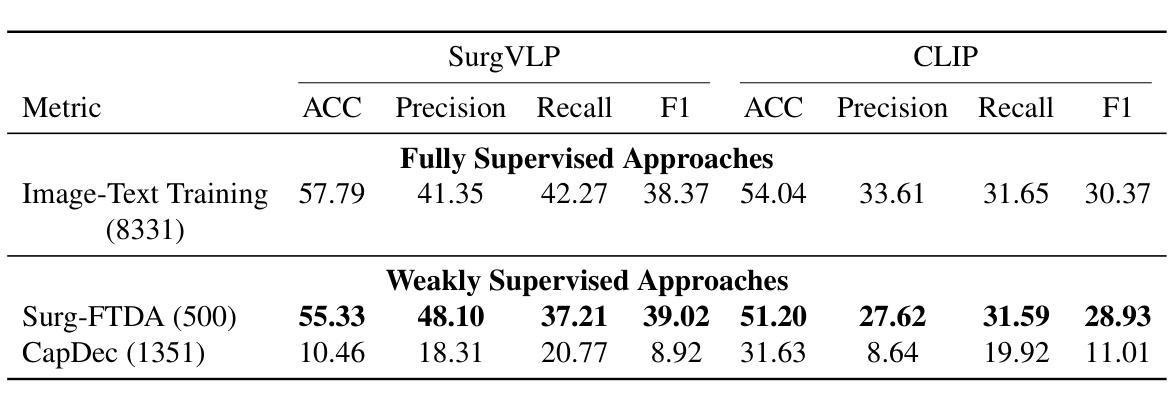
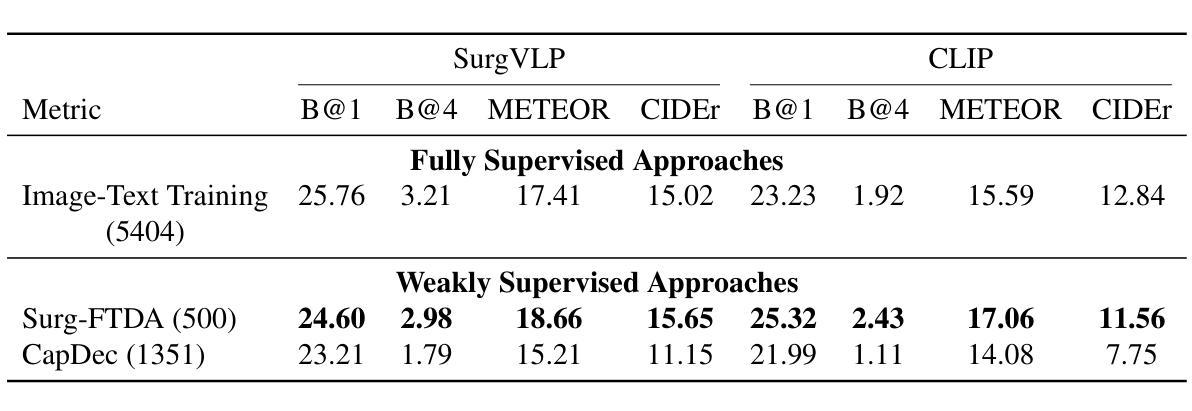
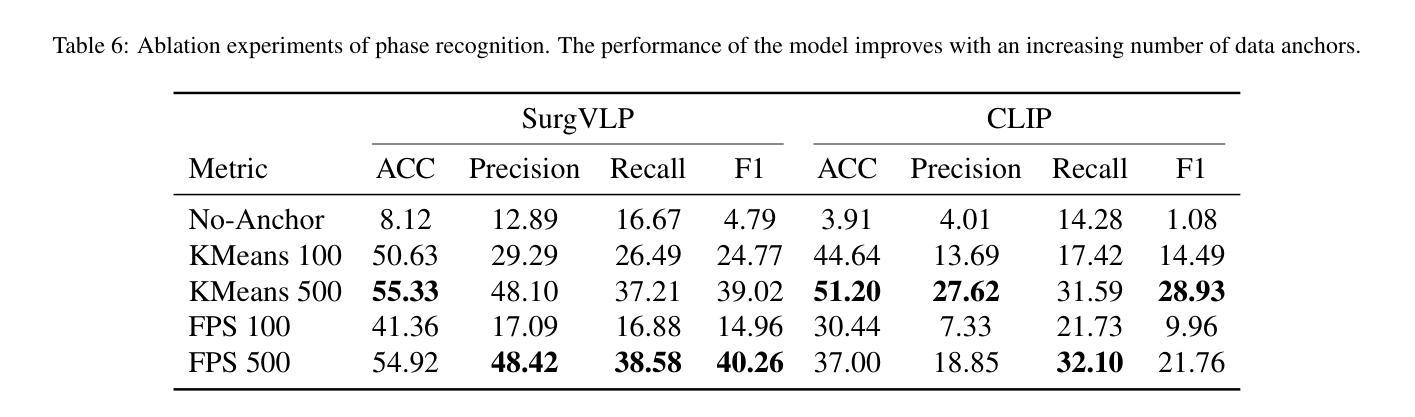
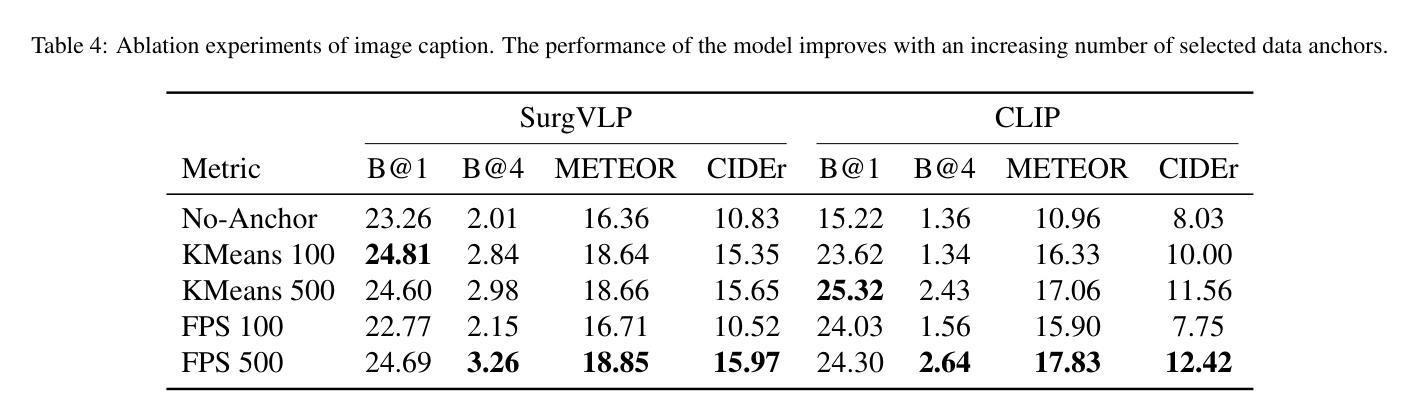
Purpose: Surgical workflow analysis is crucial for improving surgical efficiency and safety. However, previous studies rely heavily on large-scale annotated datasets, posing challenges in cost, scalability, and reliance on expert annotations. To address this, we propose Surg-FTDA (Few-shot Text-driven Adaptation), designed to handle various surgical workflow analysis tasks with minimal paired image-label data. Methods: Our approach has two key components. First, Few-shot selection-based modality alignment selects a small subset of images and aligns their embeddings with text embeddings from the downstream task, bridging the modality gap. Second, Text-driven adaptation leverages only text data to train a decoder, eliminating the need for paired image-text data. This decoder is then applied to aligned image embeddings, enabling image-related tasks without explicit image-text pairs. Results: We evaluate our approach to generative tasks (image captioning) and discriminative tasks (triplet recognition and phase recognition). Results show that Surg-FTDA outperforms baselines and generalizes well across downstream tasks. Conclusion: We propose a text-driven adaptation approach that mitigates the modality gap and handles multiple downstream tasks in surgical workflow analysis, with minimal reliance on large annotated datasets. The code and dataset will be released in https://github.com/TingxuanSix/Surg-FTDA.
目的:手术流程分析对于提高手术效率和安全性至关重要。然而,以往的研究严重依赖于大规模标注数据集,这带来了成本、可扩展性和对专家标注的依赖等方面的挑战。为了解决这一问题,我们提出了Surg-FTDA(小样本文本驱动适应)方法,旨在在极少量配对图像标签数据的情况下,处理各种手术流程分析任务。
方法:我们的方法有两个关键组成部分。首先,基于小样本选择的模态对齐方法选择一小部分图像,并将其嵌入与下游任务的文本嵌入进行对齐,从而弥合了模态间的差距。其次,文本驱动适应仅利用文本数据来训练解码器,从而消除了对配对图像文本数据的需求。然后,将此解码器应用于已对齐的图像嵌入,从而可以在没有明确的图像文本对的情况下执行图像相关任务。
结果:我们通过对生成任务(图像字幕)和判别任务(三元组识别和阶段识别)来评估我们的方法。结果表明,Surg-FTDA在基线之上表现出更高的性能,并在下游任务之间具有良好的泛化能力。
论文及项目相关链接
Summary
本文提出一种名为Surg-FTDA(Few-shot文本驱动适应)的方法,用于改善手术流程分析中的效率与安全性。通过运用少量的配对图像标签数据来处理多样的手术工作流程分析任务。该方法包含两个关键部分:一是基于少数选择的模态对齐,二是文本驱动的适应。最终,该方法在生成任务(图像描述)和判别任务(三元组识别和阶段识别)中展现出卓越性能,且在跨下游任务中具有良好的泛化能力。本文研究降低了对传统大规模标注数据集的依赖。相关代码和数据集将发布在:https://github.com/TingxuanSix/Surg-FTDA。
Key Takeaways
- Surg-FTDA旨在提高手术效率与安全性,处理多种手术工作流程分析任务,减少大规模标注数据集的依赖。
- 方法包含两大核心部分:基于少数选择的模态对齐,用于选择与任务相关的图像并对齐其嵌入向量;文本驱动的适应策略利用纯文本数据进行解码器训练,无需配对图像文本数据。
- 该方法实现了图像相关任务执行,即使在没有明确的图像文本配对情况下也能进行。
- 在生成任务和判别任务中均取得了出色的性能表现。
- 代码和数据集将在特定网站发布以供公开访问和使用。
- 此方法对于解决手术工作流程分析中的挑战具有实际应用价值。
点此查看论文截图



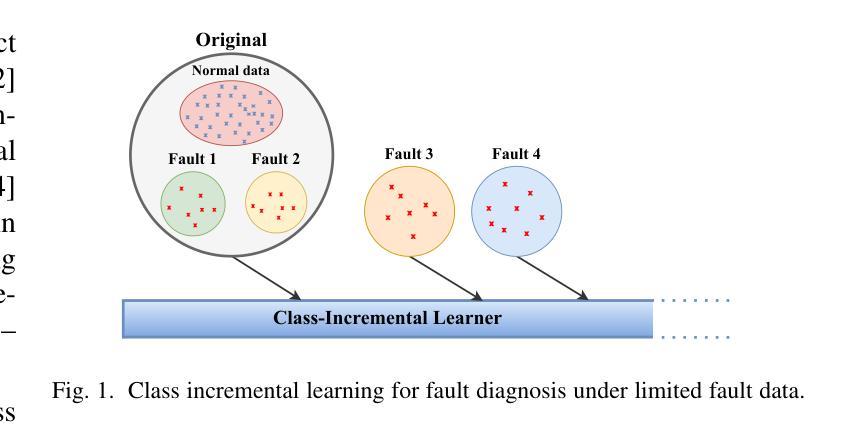
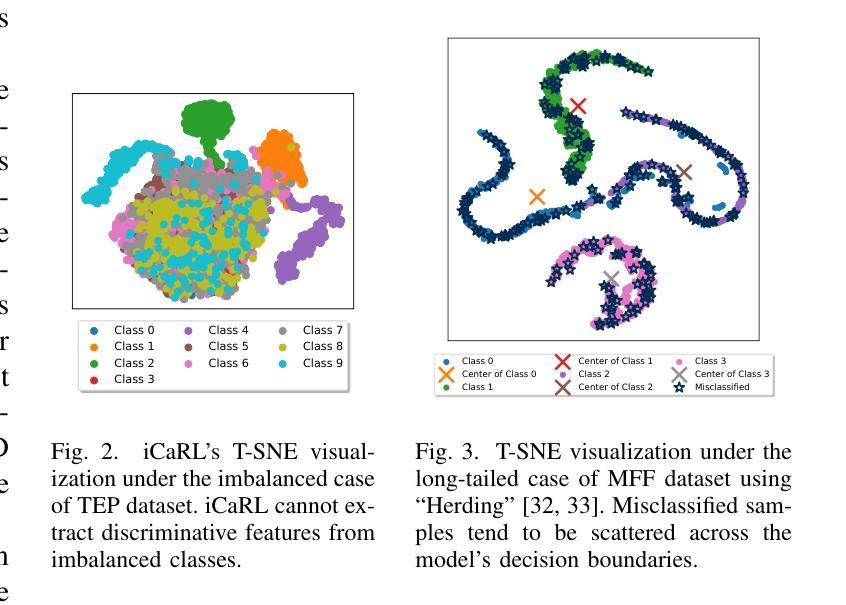
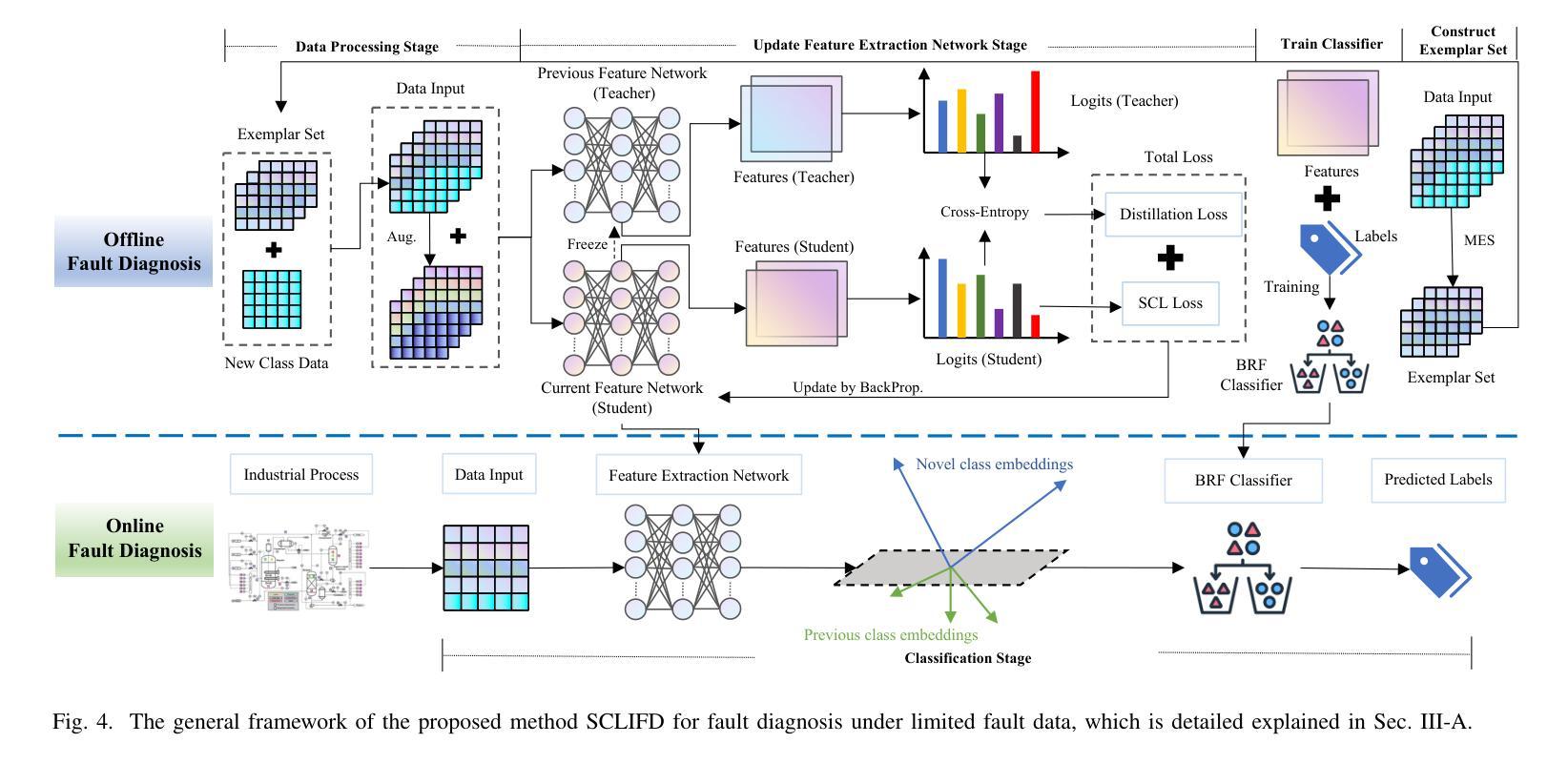
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Authors:Hanrong Zhang, Yifei Yao, Zixuan Wang, Jiayuan Su, Mengxuan Li, Peng Peng, Hongwei Wang
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model’s decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
类增量故障诊断需要模型在适应新故障类的同时保留先前知识。然而,对于不平衡和长尾数据的研究有限。从少量故障数据中提取判别特征是困难的,添加新故障类通常需要昂贵的模型重新训练。此外,现有方法的增量训练存在灾难性遗忘的风险,严重的类别不平衡可能使模型决策偏向正常类别。为了解决这些问题,我们引入了用于类增量故障诊断的监督对比知识蒸馏(SCLIFD)框架,该框架提出监督对比知识蒸馏以提高表示学习能力并减少遗忘,一种新的优先示例选择方法进行样本回放以缓解灾难性遗忘,以及随机森林分类器来解决类别不平衡问题。在模拟和真实工业数据集上的各种不平衡比率的大量实验表明,SCLIFD优于现有方法。我们的代码位于https://github.com/Zhang-Henry/SCLIFD_TII。
论文及项目相关链接
Summary
本文介绍了针对类增量故障诊断中面临的新问题所提出的解决方案。考虑到有限的样本和不平衡的数据分布,文章提出了SCLIFD框架,包括监督对比知识蒸馏、改进的表示学习能力以减少遗忘,以及针对样本重播的优先示例选择方法以缓解灾难性遗忘问题。此外,文章还采用随机森林分类器来解决类别不平衡问题。通过广泛的实验验证,该框架在模拟和真实工业数据集上表现优越。
Key Takeaways
- 类增量故障诊断需要在适应新故障类别时保留先前知识。
- 在处理不平衡和长尾分布数据时,从少量故障数据中提取判别特征具有挑战性。
- 模型再训练的成本较高,并且现有增量训练方法存在灾难性遗忘的风险。
- SCLIFD框架引入监督对比知识蒸馏来改善表示学习能力并减少遗忘。
- 采用优先示例选择方法进行样本重播,以缓解灾难性遗忘问题。
- 使用随机森林分类器解决类别不平衡问题。
点此查看论文截图





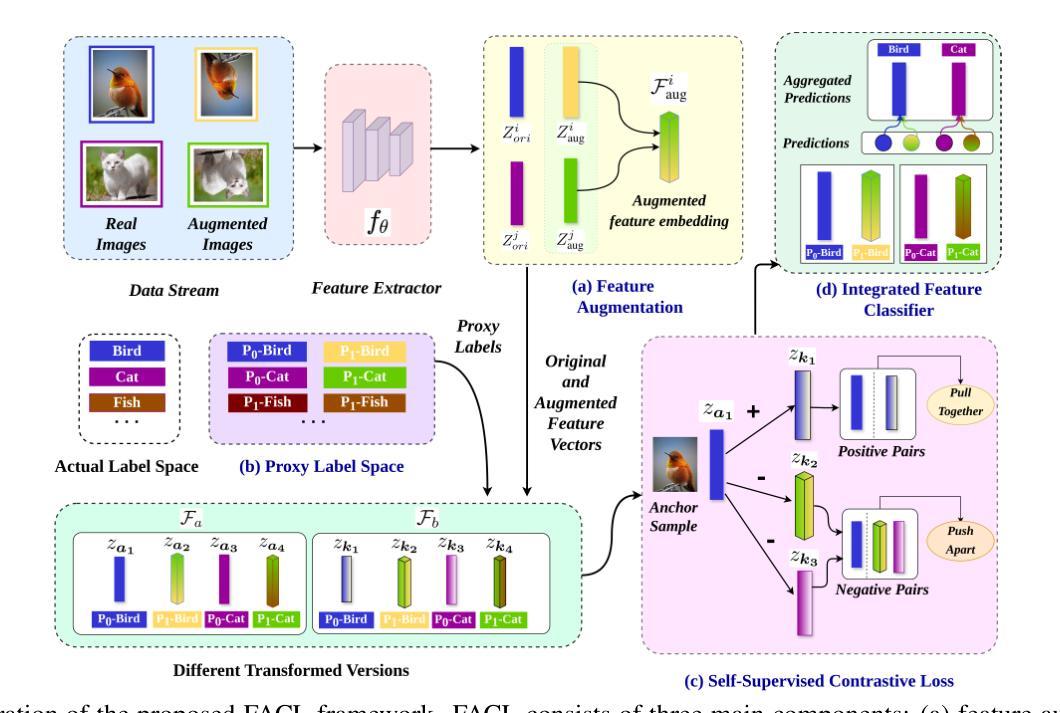
Strategic Base Representation Learning via Feature Augmentations for Few-Shot Class Incremental Learning
Authors:Parinita Nema, Vinod K Kurmi
Few-shot class incremental learning implies the model to learn new classes while retaining knowledge of previously learned classes with a small number of training instances. Existing frameworks typically freeze the parameters of the previously learned classes during the incorporation of new classes. However, this approach often results in suboptimal class separation of previously learned classes, leading to overlap between old and new classes. Consequently, the performance of old classes degrades on new classes. To address these challenges, we propose a novel feature augmentation driven contrastive learning framework designed to enhance the separation of previously learned classes to accommodate new classes. Our approach involves augmenting feature vectors and assigning proxy labels to these vectors. This strategy expands the feature space, ensuring seamless integration of new classes within the expanded space. Additionally, we employ a self-supervised contrastive loss to improve the separation between previous classes. We validate our framework through experiments on three FSCIL benchmark datasets: CIFAR100, miniImageNet, and CUB200. The results demonstrate that our Feature Augmentation driven Contrastive Learning framework significantly outperforms other approaches, achieving state-of-the-art performance.
少量样本类别增量学习意味着模型能够在少量训练样本的情况下学习新类别,同时保留对先前学习类别的知识。现有的框架通常在纳入新类别时冻结先前学习类别的参数。然而,这种方法往往导致先前学习类别的类别分离不佳,从而导致新旧类别之间的重叠。因此,新类别对旧类别的性能产生影响。为了应对这些挑战,我们提出了一种新的特征增强对比学习框架,旨在增强先前学习类别的分离以适应新类别。我们的方法包括增强特征向量并为这些向量分配代理标签。这一策略扩大了特征空间,确保新类别在扩展空间内的无缝集成。此外,我们采用自监督对比损失来改善旧类别之间的分离。我们通过CIFAR100、miniImageNet和CUB200三个FSCIL基准数据集上的实验验证了我们的框架。结果表明,我们的特征增强对比学习框架在性能上大大超过了其他方法,达到了最新技术水平。
论文及项目相关链接
PDF Accepted at WACV 2025
Summary
本文介绍了基于特征增强的对比学习框架,用于解决小样本类增量学习中的挑战。框架旨在增强已学类的分类边界以适应新类的加入,通过特征向量扩充和代理标签分配策略实现。采用自监督对比损失提高类间分离度。在三个FSCIL基准数据集上的实验结果表明,该框架显著优于其他方法,达到最新性能水平。
Key Takeaways
- 基于特征增强的对比学习框架用于解决小样本类增量学习中的知识保留问题。
- 通过扩充特征空间和分配代理标签的策略,确保新类无缝集成在扩展的空间中。
- 采用自监督对比损失提高已学类与新类之间的分离度。
- 现有框架在引入新类时通常会冻结已学类的参数,导致性能下降。
- 提出的方法通过在特征空间进行增强和改进类间分离,解决了现有方法的不足。
- 在三个FSCIL基准数据集上的实验验证了所提框架的有效性和优越性。
点此查看论文截图


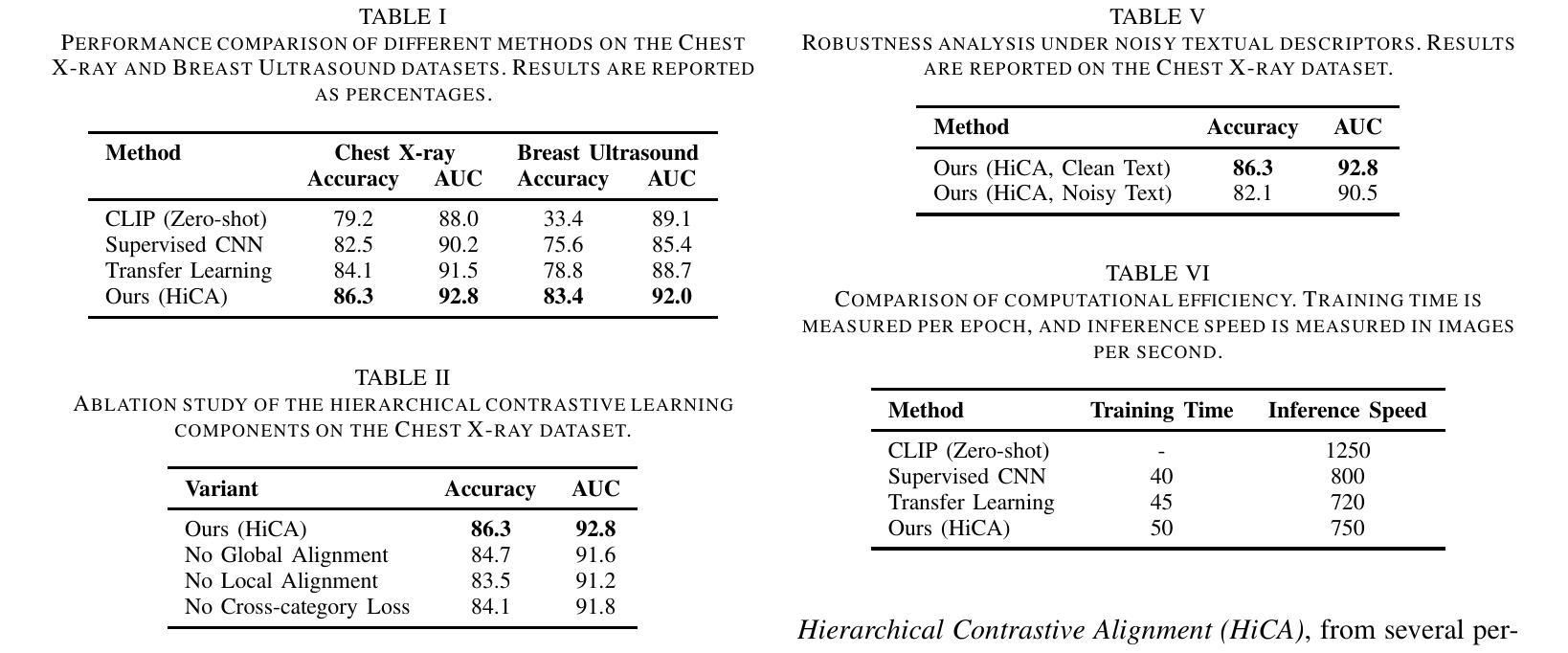
Efficient Few-Shot Medical Image Analysis via Hierarchical Contrastive Vision-Language Learning
Authors:Harrison Fuller, Fernando Gabriela Garcia, Victor Flores
Few-shot learning in medical image classification presents a significant challenge due to the limited availability of annotated data and the complex nature of medical imagery. In this work, we propose Adaptive Vision-Language Fine-tuning with Hierarchical Contrastive Alignment (HiCA), a novel framework that leverages the capabilities of Large Vision-Language Models (LVLMs) for medical image analysis. HiCA introduces a two-stage fine-tuning strategy, combining domain-specific pretraining and hierarchical contrastive learning to align visual and textual representations at multiple levels. We evaluate our approach on two benchmark datasets, Chest X-ray and Breast Ultrasound, achieving state-of-the-art performance in both few-shot and zero-shot settings. Further analyses demonstrate the robustness, generalizability, and interpretability of our method, with substantial improvements in performance compared to existing baselines. Our work highlights the potential of hierarchical contrastive strategies in adapting LVLMs to the unique challenges of medical imaging tasks.
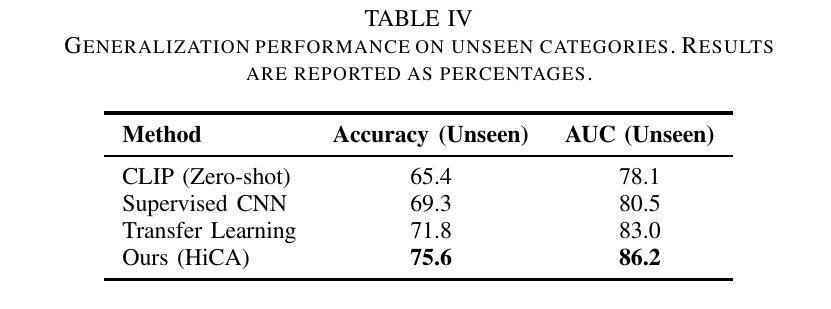
医疗图像分类中的小样本学习由于标注数据的有限性和医疗图像本身的复杂性而面临巨大挑战。在这项工作中,我们提出了基于自适应视觉语言微调与层次对比对齐(HiCA)的新型框架,该框架利用大型视觉语言模型(LVLMs)进行医学图像分析。HiCA引入了两阶段微调策略,结合领域特定预训练和层次对比学习,在多个层次上对齐视觉和文本表示。我们在两个基准数据集Chest X射线和乳腺超声上评估了我们的方法,在少量样本和零样本设置下均达到了最先进的性能。进一步的分析表明了我们方法的稳健性、通用性和可解释性,与现有基线相比,性能有实质性提高。我们的研究突出了层次对比策略在适应医疗成像任务的独特挑战中大型视觉语言模型的潜力。
论文及项目相关链接
Summary
本文介绍了针对医学图像分类中的小样例学习问题,提出了一种新型的框架——自适应视觉语言精细调整与层次对比对齐(HiCA)。该框架利用大型视觉语言模型(LVLMs)进行医学图像分析。HiCA采用两阶段精细调整策略,结合领域特定预训练和层次对比学习,在多个级别对齐视觉和文本表示。在Chest X-ray和Breast Ultrasound两个基准数据集上的评估结果表明,该框架在小样例和零样例设置下均达到了最新技术水平。进一步的分析证明了我们方法的稳健性、泛化能力和可解释性,与现有基线相比,性能得到了显著提高。本研究突显了层次对比策略在适应医学成像任务的独特挑战中的潜力。
Key Takeaways
- 医学图像分类中的小样例学习面临挑战,因为标注数据有限且医学图像复杂。
- 提出了自适应视觉语言精细调整与层次对比对齐(HiCA)框架,利用大型视觉语言模型(LVLMs)进行医学图像分析。
- HiCA采用两阶段精细调整策略,结合领域特定预训练和层次对比学习。
- 在Chest X-ray和Breast Ultrasound数据集上的评估结果表明,该框架在小样例和零样例设置下均达到最新技术水平。
- 该方法具有稳健性、泛化能力和可解释性。
- 与现有方法相比,该框架在性能上有了显著提高。
点此查看论文截图


Unified Few-shot Crack Segmentation and its Precise 3D Automatic Measurement in Concrete Structures
Authors:Pengru Deng, Jiapeng Yao, Chun Li, Su Wang, Xinrun Li, Varun Ojha, Xuhui He, Takashi Matsumoto
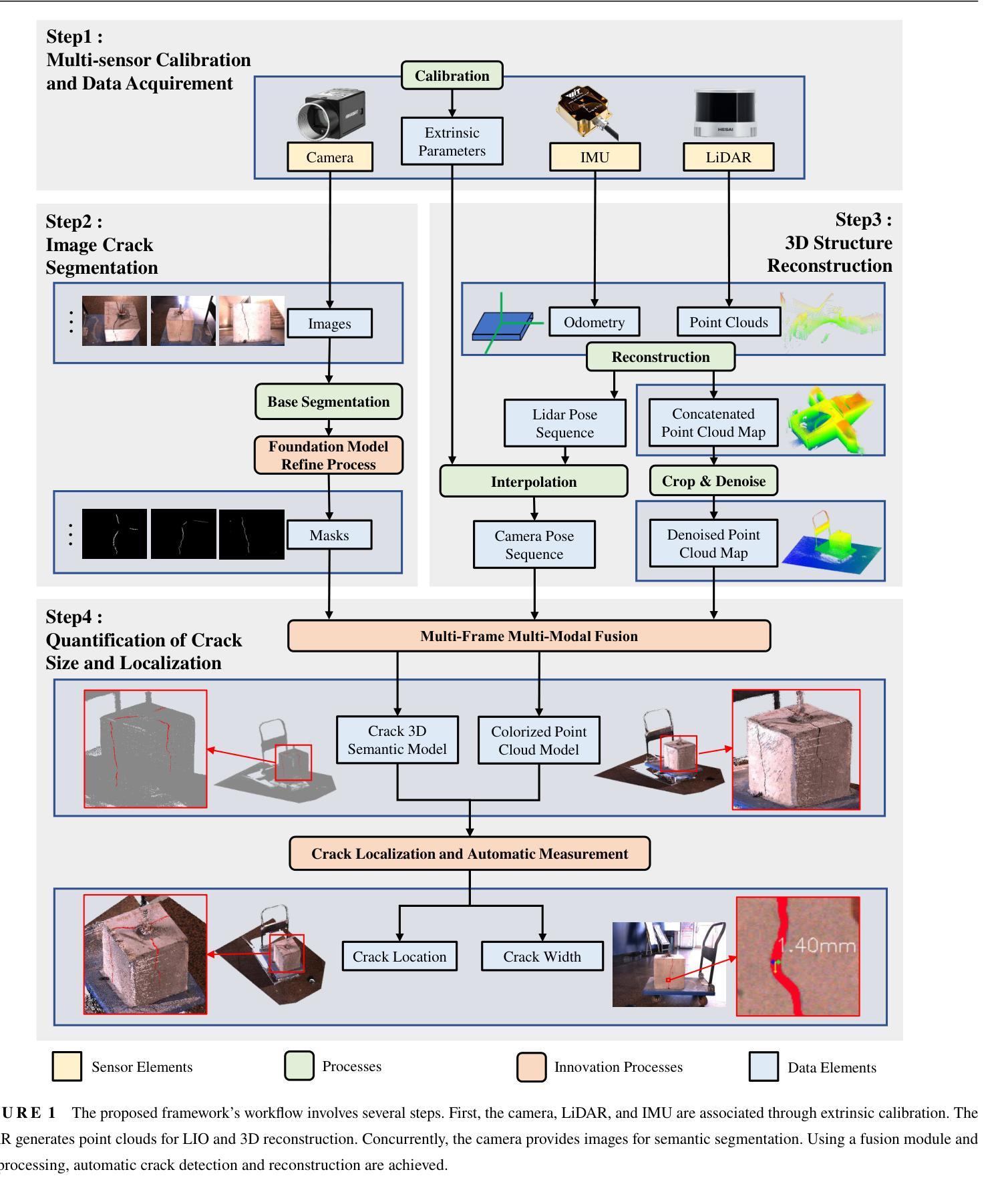
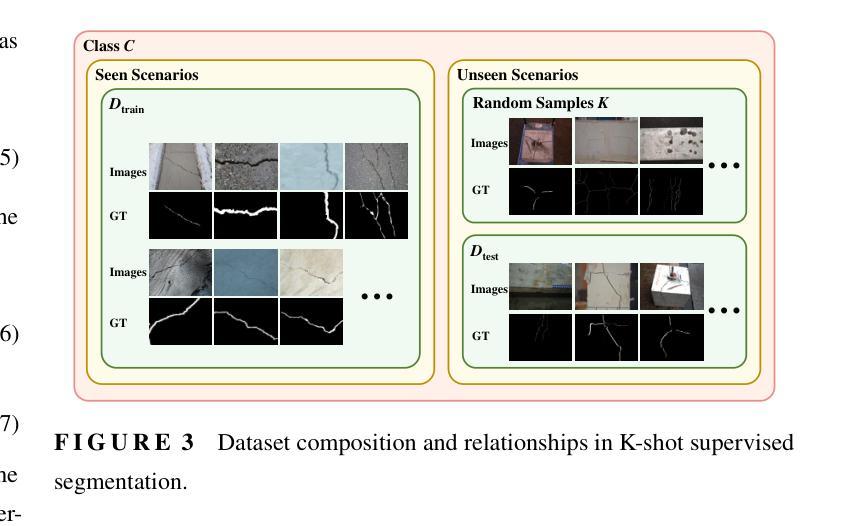
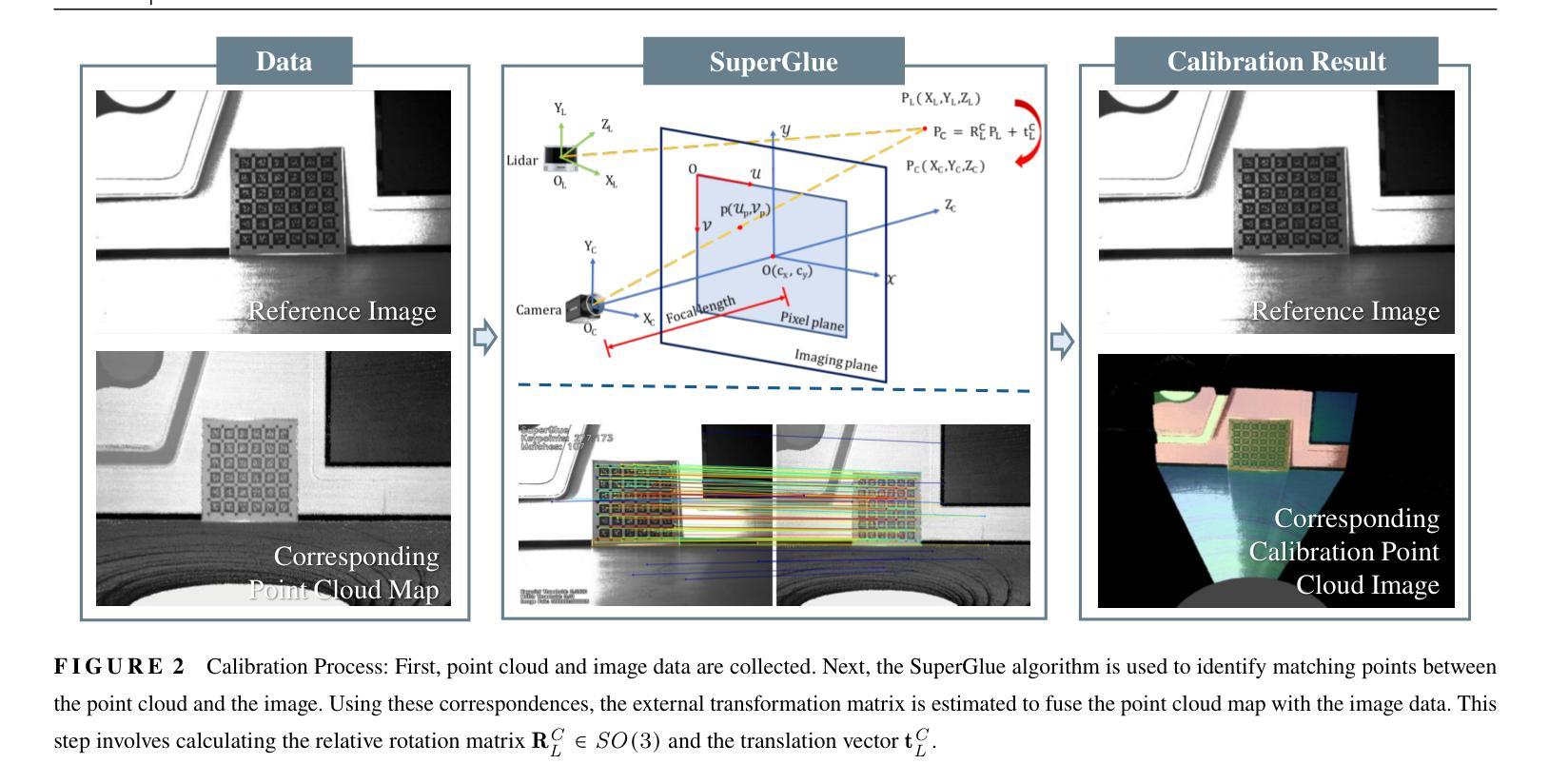
Visual-Spatial Systems has become increasingly essential in concrete crack inspection. However, existing methods often lacks adaptability to diverse scenarios, exhibits limited robustness in image-based approaches, and struggles with curved or complex geometries. To address these limitations, an innovative framework for two-dimensional (2D) crack detection, three-dimensional (3D) reconstruction, and 3D automatic crack measurement was proposed by integrating computer vision technologies and multi-modal Simultaneous localization and mapping (SLAM) in this study. Firstly, building on a base DeepLabv3+ segmentation model, and incorporating specific refinements utilizing foundation model Segment Anything Model (SAM), we developed a crack segmentation method with strong generalization across unfamiliar scenarios, enabling the generation of precise 2D crack masks. To enhance the accuracy and robustness of 3D reconstruction, Light Detection and Ranging (LiDAR) point clouds were utilized together with image data and segmentation masks. By leveraging both image- and LiDAR-SLAM, we developed a multi-frame and multi-modal fusion framework that produces dense, colorized point clouds, effectively capturing crack semantics at a 3D real-world scale. Furthermore, the crack geometric attributions were measured automatically and directly within 3D dense point cloud space, surpassing the limitations of conventional 2D image-based measurements. This advancement makes the method suitable for structural components with curved and complex 3D geometries. Experimental results across various concrete structures highlight the significant improvements and unique advantages of the proposed method, demonstrating its effectiveness, accuracy, and robustness in real-world applications.
视觉空间系统在混凝土裂缝检测中变得越来越重要。然而,现有方法往往缺乏对多种场景的适应性,在基于图像的方法中表现出有限的稳健性,并且在处理弯曲或复杂几何结构时遇到困难。为了解决这些局限性,本研究提出了一种创新的二维(2D)裂缝检测、三维(3D)重建和自动三维裂缝测量的框架,该框架集成了计算机视觉技术和多模态同步定位和映射(SLAM)。首先,在基础DeepLabv3+分割模型上,结合使用基础模型“任何内容分割模型”(SAM)的特定优化,我们开发了一种裂缝分割方法,该方法在陌生场景中具有强大的泛化能力,能够生成精确的二维裂缝掩膜。为了提高三维重建的准确性和稳健性,我们结合了激光雷达(LiDAR)点云和图像数据以及分割掩膜。通过利用图像和激光雷达SLAM技术,我们开发了一个多帧和多模态融合框架,生成密集彩色点云,有效捕获三维真实世界规模的裂缝语义。此外,裂缝的几何属性可在三维密集点云空间内自动直接测量,突破了传统二维图像测量的局限性。这一进展使该方法适用于具有弯曲和复杂三维几何结构的结构部件。在各种混凝土结构上的实验结果突出了该方法的显著改进和独特优势,证明了其在真实世界应用中的有效性、准确性和稳健性。
论文及项目相关链接
摘要
视觉空间系统在混凝土裂缝检测中变得越来越重要。然而,现有方法缺乏适应不同场景的能力,图像方法稳健性有限,且难以处理弯曲或复杂的几何形状。本研究提出了一种创新的二维(2D)裂缝检测、三维(3D)重建和自动三维裂缝测量框架,融合了计算机视觉技术和多模态同步定位与地图构建(SLAM)。首先,在基础DeepLabv3+分割模型上,结合使用基础模型SAM的特定改进,我们开发了一种裂缝分割方法,具有很强的跨未知场景的泛化能力,能够生成精确的二维裂缝掩膜。为提高三维重建的准确性和稳健性,结合了激光雷达(LiDAR)点云和图像数据以及分割掩膜。通过利用图像和LiDAR-SLAM,我们开发了一个多帧和多模态融合框架,生成密集彩色点云,有效捕获三维现实世界尺度的裂缝语义。此外,裂缝几何属性可在三维密集点云空间内自动直接测量,克服了传统二维图像测量的局限性。这一进展使得该方法适用于具有曲线和复杂三维几何形状的结构部件。在各种混凝土结构上的实验结果突出了该方法的显著改进和独特优势,证明了其在现实世界应用中的有效性、准确性和稳健性。
关键见解
- 视觉空间系统在混凝土裂缝检测中至关重要,但现有方法存在局限。
- 研究提出了一种创新的二维裂缝检测、三维重建和自动裂缝测量框架。
- 结合计算机视觉技术和多模态SLAM,提高了方法的泛化能力和准确性。
- 利用DeepLabv3+和SAM模型开发裂缝分割方法,生成精确二维裂缝掩膜。
- 结合LiDAR点云和图像数据,提高三维重建的准确性和稳健性。
- 提出的多帧和多模态融合框架能生成密集彩色点云,有效捕获裂缝语义。
点此查看论文截图

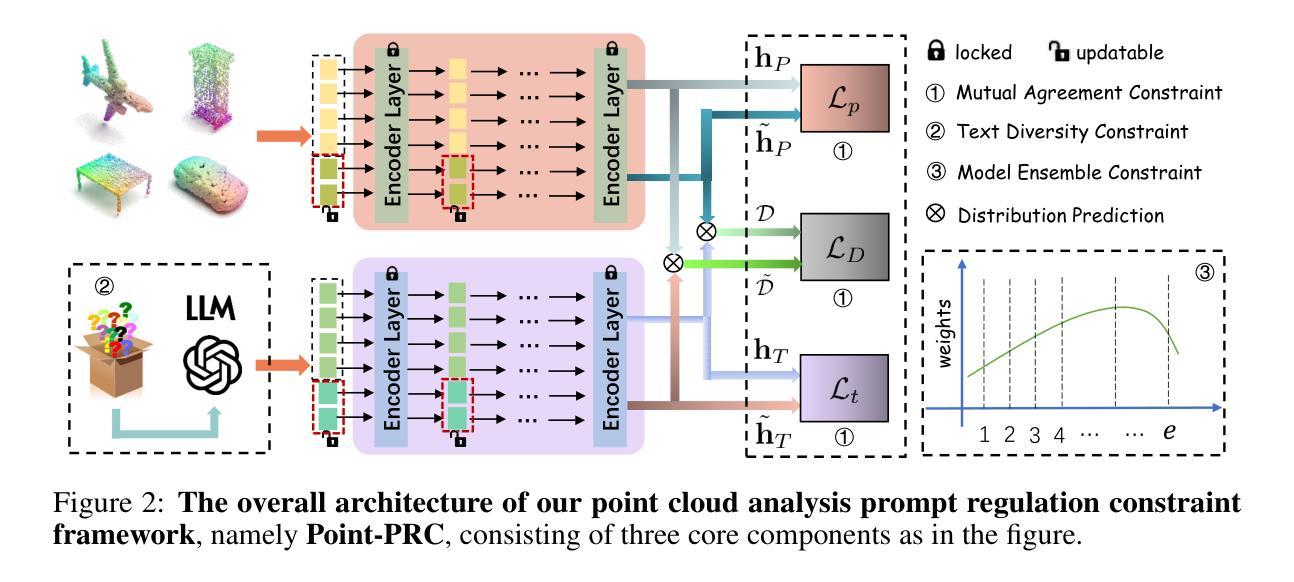
Point-PRC: A Prompt Learning Based Regulation Framework for Generalizable Point Cloud Analysis
Authors:Hongyu Sun, Qiuhong Ke, Yongcai Wang, Wang Chen, Kang Yang, Deying Li, Jianfei Cai
This paper investigates the 3D domain generalization (3DDG) ability of large 3D models based on prevalent prompt learning. Recent works demonstrate the performances of 3D point cloud recognition can be boosted remarkably by parameter-efficient prompt tuning. However, we observe that the improvement on downstream tasks comes at the expense of a severe drop in 3D domain generalization. To resolve this challenge, we present a comprehensive regulation framework that allows the learnable prompts to actively interact with the well-learned general knowledge in large 3D models to maintain good generalization. Specifically, the proposed framework imposes multiple explicit constraints on the prompt learning trajectory by maximizing the mutual agreement between task-specific predictions and task-agnostic knowledge. We design the regulation framework as a plug-and-play module to embed into existing representative large 3D models. Surprisingly, our method not only realizes consistently increasing generalization ability but also enhances task-specific 3D recognition performances across various 3DDG benchmarks by a clear margin. Considering the lack of study and evaluation on 3DDG, we also create three new benchmarks, namely base-to-new, cross-dataset and few-shot generalization benchmarks, to enrich the field and inspire future research. Code and benchmarks are available at \url{https://github.com/auniquesun/Point-PRC}.
本文研究了基于流行提示学习的大型3D模型的3D域泛化(3DDG)能力。近期的研究表明,通过参数有效的提示调整,可以显著提高3D点云识别的性能。然而,我们发现下游任务的改进是以3D域泛化的严重下降为代价的。为了解决这一挑战,我们提出了一个综合的规范框架,允许可学习的提示与大型3D模型中的良好学习的通用知识积极进行交互,以保持良好的泛化能力。具体来说,所提出的框架通过最大化任务特定预测和任务无关知识之间的相互一致性,对提示学习轨迹施加多个显式约束。我们将监管框架设计为一个即插即用的模块,可以嵌入到现有的代表性大型3D模型中。令人惊讶的是,我们的方法不仅实现了持续的泛化能力增强,而且在各种3DDG基准测试中提高了任务特定的3D识别性能,具有明显优势。考虑到对3DDG的研究和评估不足,我们还创建了三个新的基准测试,即base-to-new、跨数据集和少样本泛化基准测试,以丰富该领域并激发未来的研究。代码和基准测试可在\url{https://github.com/auniquesun/Point-PRC}找到。
论文及项目相关链接
PDF 5 figures, 14 tables; accepted by NeurIPS 2024
Summary
本文探讨基于流行提示学习的大型3D模型的3D域泛化(3DDG)能力。研究发现,虽然参数有效的提示调整可以显著提高3D点云识别的性能,但下游任务的改进往往伴随着严重的3D域泛化能力下降。为解决这一挑战,本文提出了一种全面的调节框架,使可学习提示能够与大型3D模型中的通用知识积极互动,以保持良好的泛化能力。该框架通过最大化任务特定预测和任务无关知识之间的相互一致性,对提示学习轨迹施加多个显式约束。此外,本文创建了三个新的基准测试,即基础到新测试、跨数据集测试和少样本泛化基准测试,以丰富该领域并激发未来的研究。
Key Takeaways
- 大型3D模型的3D域泛化(3DDG)能力研究重要性。
- 参数有效的提示调整显著提升3D点云识别性能,但会影响3DDG。
- 提出一个调节框架,结合提示学习与大型3D模型中的通用知识,改善3DDG。
- 框架通过最大化任务特定预测与任务无关知识间的相互一致性,对提示学习施加约束。
- 调节框架设计为即插即用模块,可嵌入现有代表性大型3D模型。
- 方法不仅提高了泛化能力,而且增强了各种3DDG基准测试的任务特定3D识别性能。
- 创建了三个新的基准测试(base-to-new、cross-dataset和few-shot)以丰富领域并激发未来研究。
点此查看论文截图



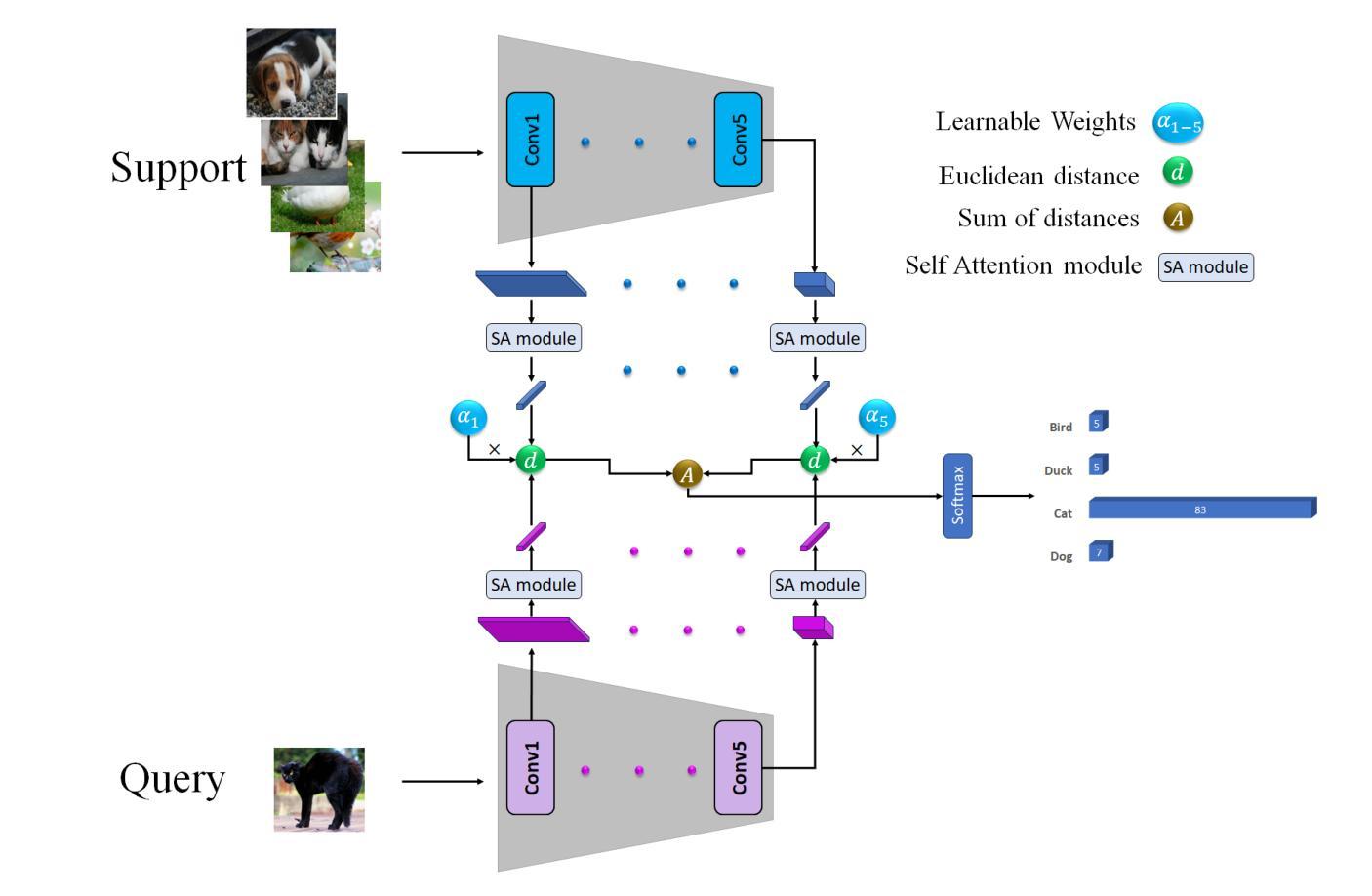
Enhancing Few-Shot Image Classification through Learnable Multi-Scale Embedding and Attention Mechanisms
Authors:Fatemeh Askari, Amirreza Fateh, Mohammad Reza Mohammadi
In the context of few-shot classification, the goal is to train a classifier using a limited number of samples while maintaining satisfactory performance. However, traditional metric-based methods exhibit certain limitations in achieving this objective. These methods typically rely on a single distance value between the query feature and support feature, thereby overlooking the contribution of shallow features. To overcome this challenge, we propose a novel approach in this paper. Our approach involves utilizing a multi-output embedding network that maps samples into distinct feature spaces. The proposed method extracts feature vectors at different stages, enabling the model to capture both global and abstract features. By utilizing these diverse feature spaces, our model enhances its performance. Moreover, employing a self-attention mechanism improves the refinement of features at each stage, leading to even more robust representations and improved overall performance. Furthermore, assigning learnable weights to each stage significantly improved performance and results. We conducted comprehensive evaluations on the MiniImageNet and FC100 datasets, specifically in the 5-way 1-shot and 5-way 5-shot scenarios. Additionally, we performed cross-domain tasks across eight benchmark datasets, achieving high accuracy in the testing domains. These evaluations demonstrate the efficacy of our proposed method in comparison to state-of-the-art approaches. https://github.com/FatemehAskari/MSENet
在少样本分类的情境中,目标是使用有限数量的样本训练一个分类器,同时保持令人满意的性能。然而,传统的基于指标的方法在实现这一目标时表现出一定的局限性。这些方法通常依赖于查询特征和支撑特征之间的单个距离值,从而忽略了浅层特征的贡献。为了克服这一挑战,我们在本文中提出了一种新方法。我们的方法利用多输出嵌入网络将样本映射到不同的特征空间。所提出的方法在不同的阶段提取特征向量,使模型能够捕获全局和抽象特征。通过利用这些多样化的特征空间,我们的模型提高了其性能。此外,采用自注意力机制改进了每个阶段的特征细化,产生了更稳健的表示和整体性能的提升。进一步地,对每阶段分配可学习的权重显著提高了性能和结果。我们在MiniImageNet和FC100数据集上进行了全面的评估,特别是在5路1射和5路5射场景下。此外,我们在八个基准数据集上执行了跨域任务,在测试域中实现了高准确率。这些评估结果证明了我们的方法与最新技术相比的有效性。想了解更多信息,请访问:https://github.com/FatemehAskari/MSENet。
论文及项目相关链接
Summary
针对小样分类任务,本文提出一种新型的多输出嵌入网络方法,该方法通过在不同阶段提取特征向量,映射样本到不同的特征空间,能捕捉全局和抽象特征以提高模型性能。采用自注意力机制和可学习权重进一步提升了特征的精细程度和模型的性能。在MiniImageNet和FC100数据集上的5-way 1-shot和5-way 5-shot场景评估表现优异,且跨域任务在八个基准数据集上实现高准确率。
Key Takeaways
- 本文针对小样分类任务,提出了多输出嵌入网络方法。
- 该方法通过映射样本到不同特征空间,能捕捉全局和抽象特征。
- 采用自注意力机制提升了特征的精细程度。
- 通过赋予模型不同阶段可学习权重,显著提高了模型性能。
- 在MiniImageNet和FC100数据集上的评估表现优于现有方法。
- 跨域任务在多个数据集上实现高准确率。
- 论文实现了代码公开,便于研究和应用。
点此查看论文截图