⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Authors:Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, Zhizheng Wu
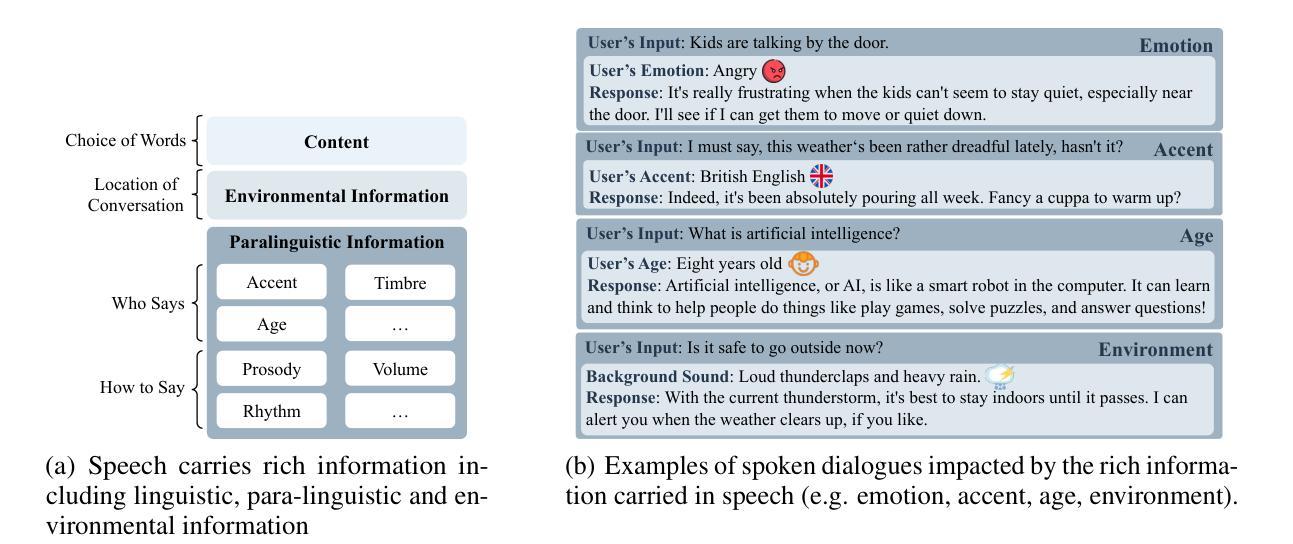
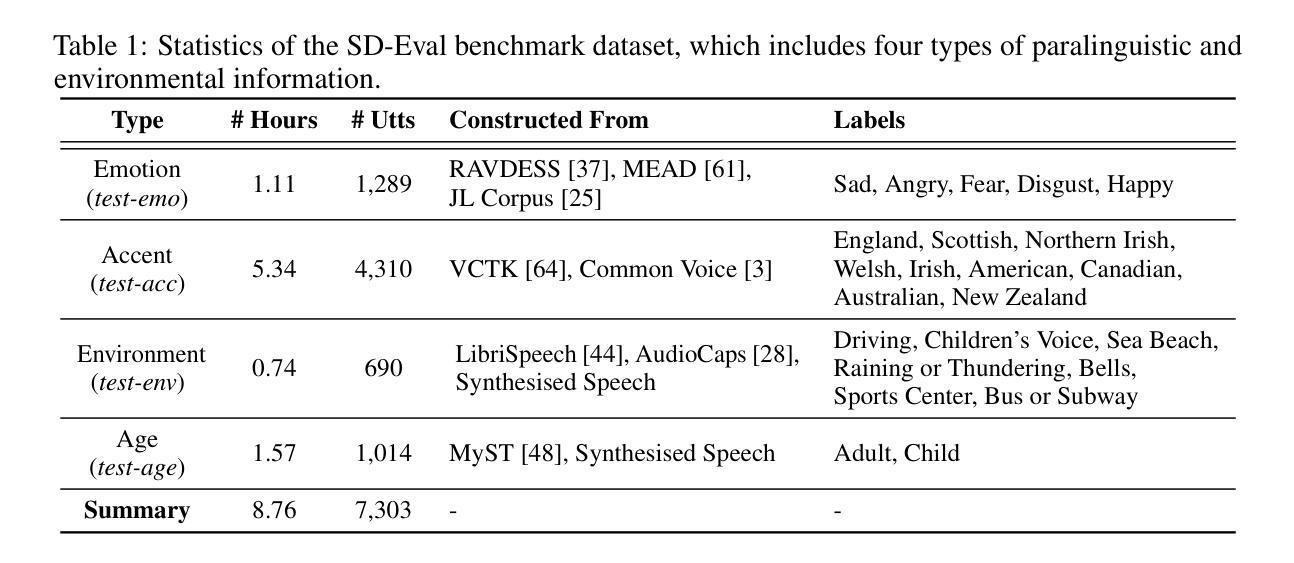
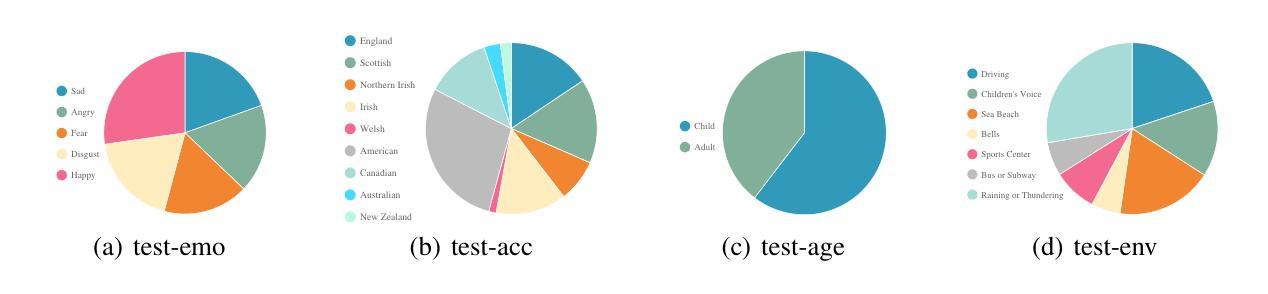
Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a process similar to that of SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate that LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
语音包含大量信息,包括但不仅限于内容、副语言和环境信息。语音的这种综合性对通信产生重大影响,对于人机交互也至关重要。面向聊天的大型语言模型(LLM)以通用辅助能力而著称,已发展到能够处理包括语音在内的多模式输入。尽管这些模型在识别和分析语音方面很擅长,但在生成适当响应方面往往表现不足。我们认为这是由于任务定义和模型开发的原则缺失所导致的,这需要适合模型评估的开源数据集和指标。为了弥补这一差距,我们推出了SD-Eval,一个旨在多维度评估口语对话理解和生成的基准数据集。SD-Eval侧重于副语言和环境信息,包含7,303个话语,相当于8.76小时的语音数据。数据来自八个公共数据集,代表情感、口音、年龄和背景声音四个维度。为了评估SD-Eval基准数据集,我们实施了三种不同的模型,并按照与SD-Eval类似的流程构建了一个训练集。训练集包含1,052.72小时的语音数据和724.4k个话语。我们还使用客观评估方法(如BLEU和ROUGE)、主观评估以及基于LLM的指标对生成的响应进行了全面评估。在客观和主观措施方面,以副语言和环境信息为条件的模型都优于同类产品。此外,实验表明,与传统指标相比,基于LLM的指标与人类评估的相关性更高。我们在https://github.com/amphionspace/SD-Eval上公开了SD-Eval。
论文及项目相关链接
PDF Accepted to NeurIPS 2024
Summary
本文介绍了语音在沟通中的重要性,特别是在人机交互领域。针对大型语言模型在语音识别和分析方面的不足,提出了一种名为SD-Eval的基准数据集,用于多维评估口语对话理解和生成能力。SD-Eval数据集聚焦于超语言学和环境信息,包括情感、口音、年龄和背景声音四个方面。同时,实验验证了结合超语言学和环境信息的模型在客观和主观评价方面的优势。最后公开分享了SD-Eval数据集,用于相关研究与应用。
Key Takeaways
- 语音包含内容、超语言学和环境信息,对于沟通和人机交互至关重要。
- 大型语言模型在处理多模态输入时,包括语音识别的能力有所不足。
- 提出SD-Eval基准数据集,用于口语对话理解和生成的多维评估。
- SD-Eval数据集涵盖情感、口音、年龄和背景声音四个方面的超语言学和环境信息。
- 结合超语言学和环境信息的模型在客观和主观评价中表现更佳。
- 采用客观评价法(如BLEU和ROUGE)、主观评价和大型语言模型度量法对生成响应进行评估。
- LLM度量法与人工评价有较高的相关性。
点此查看论文截图