⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
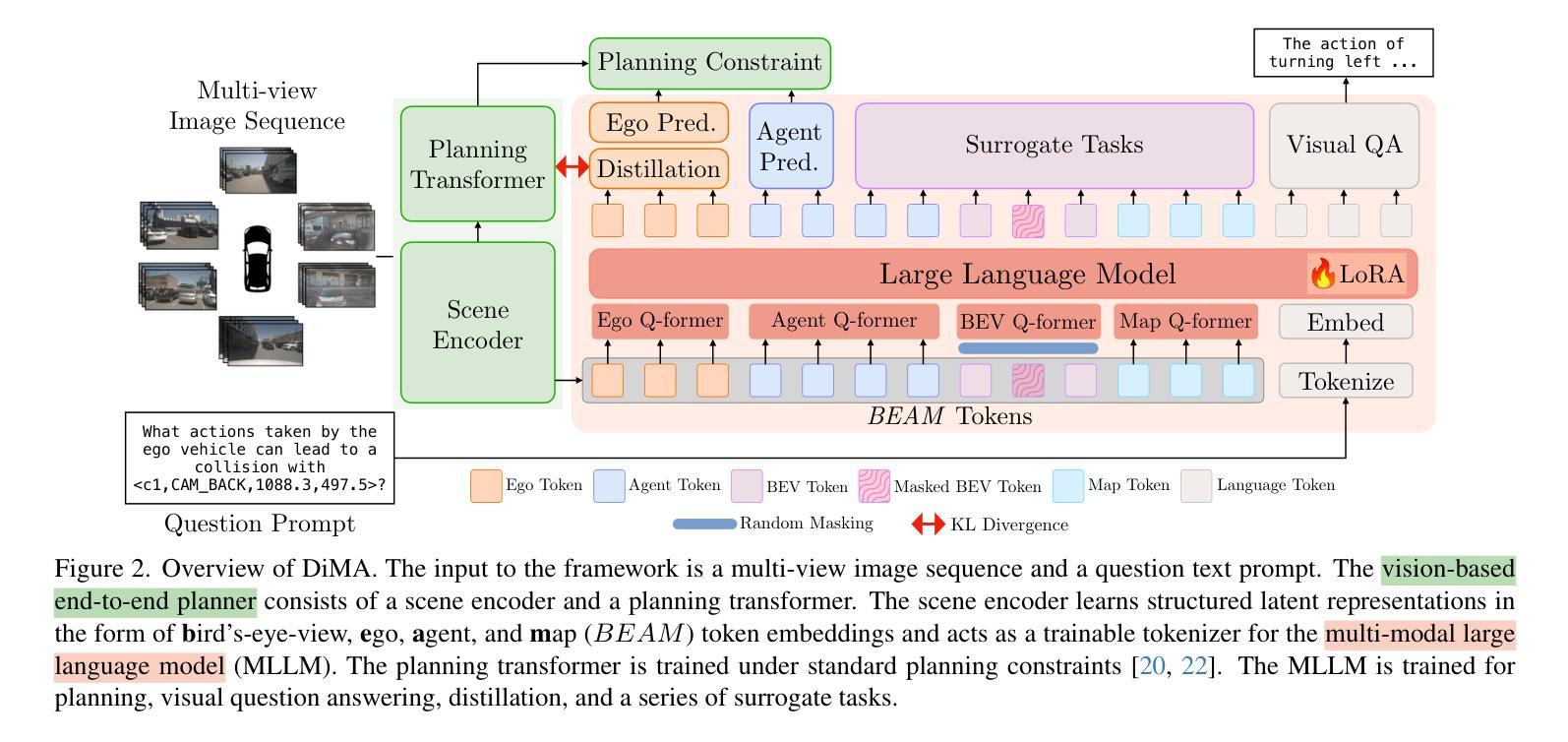
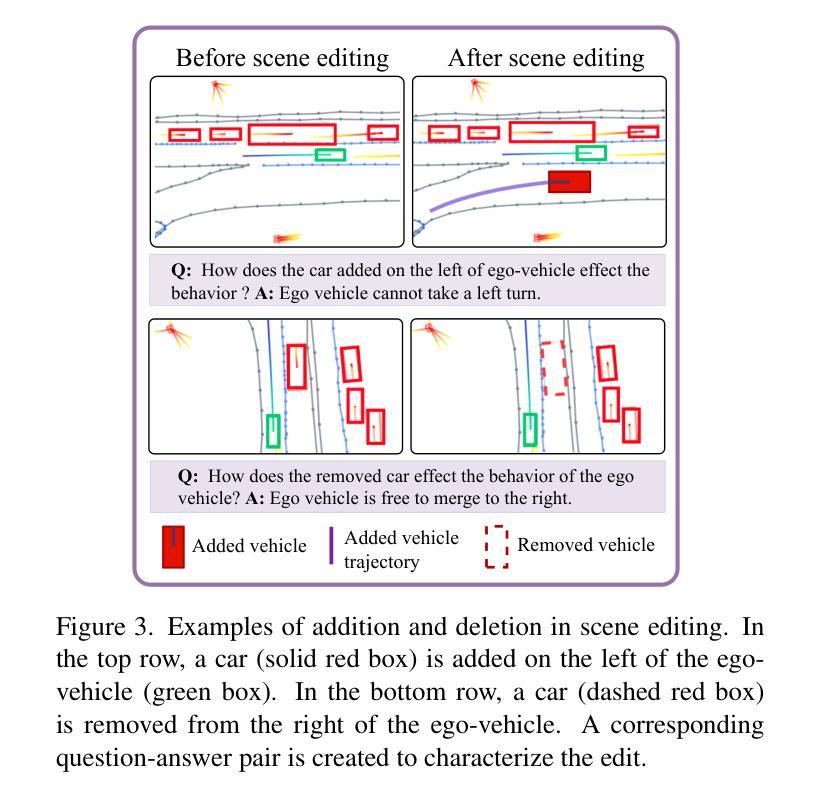
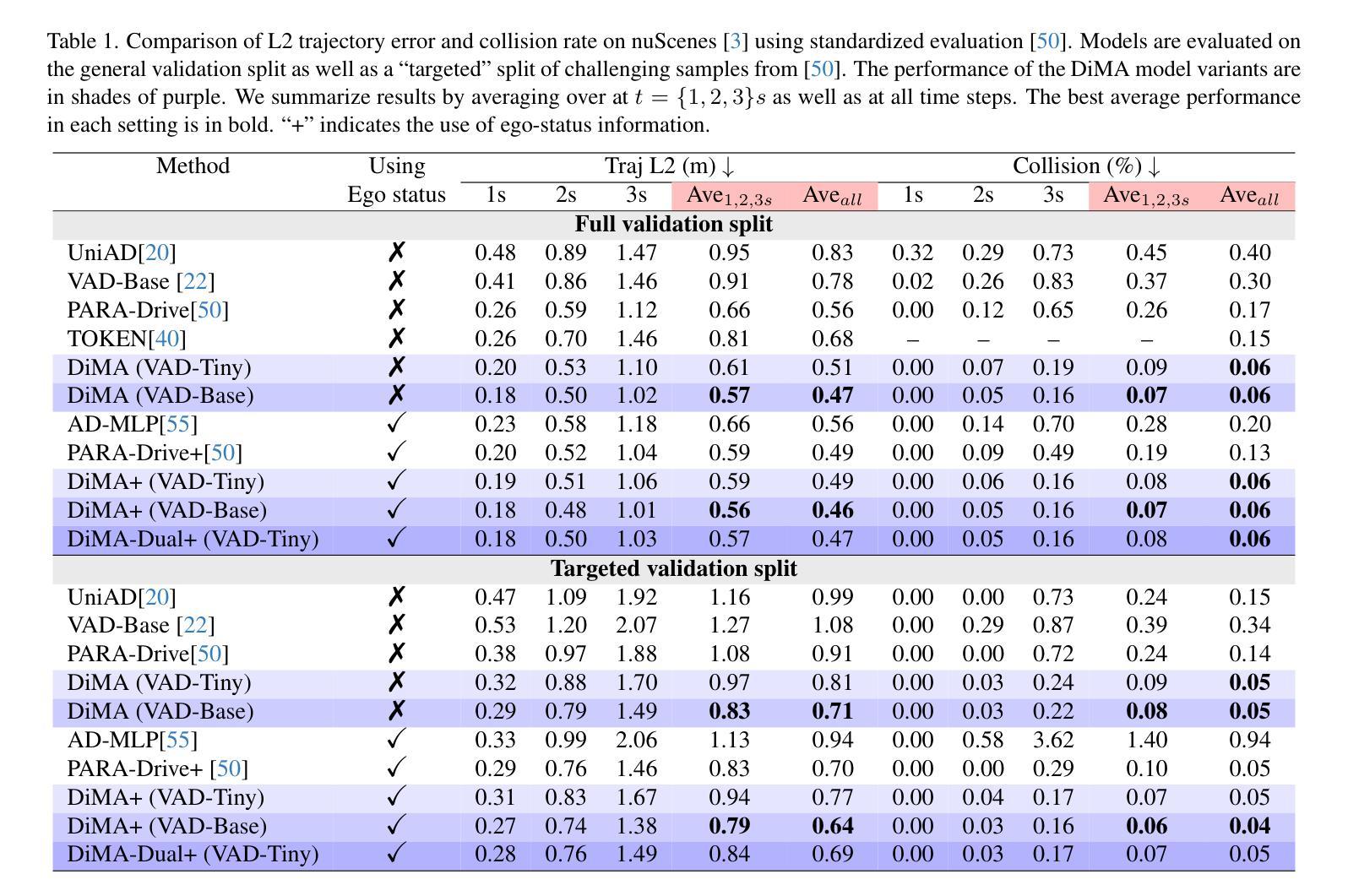
Distilling Multi-modal Large Language Models for Autonomous Driving
Authors:Deepti Hegde, Rajeev Yasarla, Hong Cai, Shizhong Han, Apratim Bhattacharyya, Shweta Mahajan, Litian Liu, Risheek Garrepalli, Vishal M. Patel, Fatih Porikli
Autonomous driving demands safe motion planning, especially in critical “long-tail” scenarios. Recent end-to-end autonomous driving systems leverage large language models (LLMs) as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.
自动驾驶需要安全的运动规划,特别是在关键的“长尾”场景中。最近的端到端自动驾驶系统利用大型语言模型(LLM)作为规划器,以提高对罕见事件的通用性。然而,在测试时使用LLM会引入较高的计算成本。为了解决这一问题,我们提出了DiMA,这是一个端到端的自动驾驶系统,它能在不依赖LLM(或基于视觉)的规划器的情况下保持效率,同时利用LLM的世界知识。DiMA通过一系列专门设计的替代任务,将从多模态LLM中提取的信息蒸馏到基于视觉的端到端规划器中。在联合训练策略下,两个网络共用的场景编码器产生结构化表示,这些表示在语义上是固定的,并与最终的规划目标对齐。值得注意的是,推理过程中LLM是可选的,能够在不损害效率的情况下实现稳健的规划。通过DiMA进行训练,实现了基于视觉的规划器的L2轨迹误差降低37%,碰撞率降低80%,以及在长尾场景中的轨迹误差降低44%。DiMA还在nuScenes规划基准测试上达到了最先进的性能。
论文及项目相关链接
Summary:
自主驾驶需要安全运动规划,特别是在关键的“长尾”场景中。近期端到端的自主驾驶系统利用大型语言模型(LLM)作为规划器,以提高对罕见事件的泛化能力。然而,使用LLM进行测试时会产生高计算成本。为解决这一问题,我们提出了DiMA系统,它是一个端到端的自主驾驶系统,在保持无LLM(或基于视觉)规划器的效率的同时,利用LLM的世界知识。DiMA通过一系列专门设计的替代任务,从多模态LLM中提炼信息到基于视觉的端到端规划器。在联合训练策略下,一个用于两者的场景编码器产生结构化的表示形式,这些表示既语义上地根植于知识又符合最终的规划目标。值得注意的是,LLM在推断中是可选的,能够实现高效而稳健的规划。经过DiMA训练后,基于视觉的规划器的L2轨迹误差降低了37%,碰撞率降低了80%,长尾场景中的轨迹误差降低了44%。DiMA还在nuScenes规划基准测试中达到了业界领先水平。
Key Takeaways:
- 自主驾驶需要安全运动规划,特别是在长尾场景中。
- 端到端的自主驾驶系统利用大型语言模型(LLM)提高泛化能力。
- 使用LLM进行测试会导致高计算成本。
- DiMA系统能够在无LLM的情况下保持规划效率并引入LLM的世界知识。
- DiMA通过专门设计的替代任务将LLM信息提炼并应用到基于视觉的规划器中。
- DiMA训练后显著提高基于视觉的规划器性能,包括减少轨迹误差和碰撞率。
点此查看论文截图

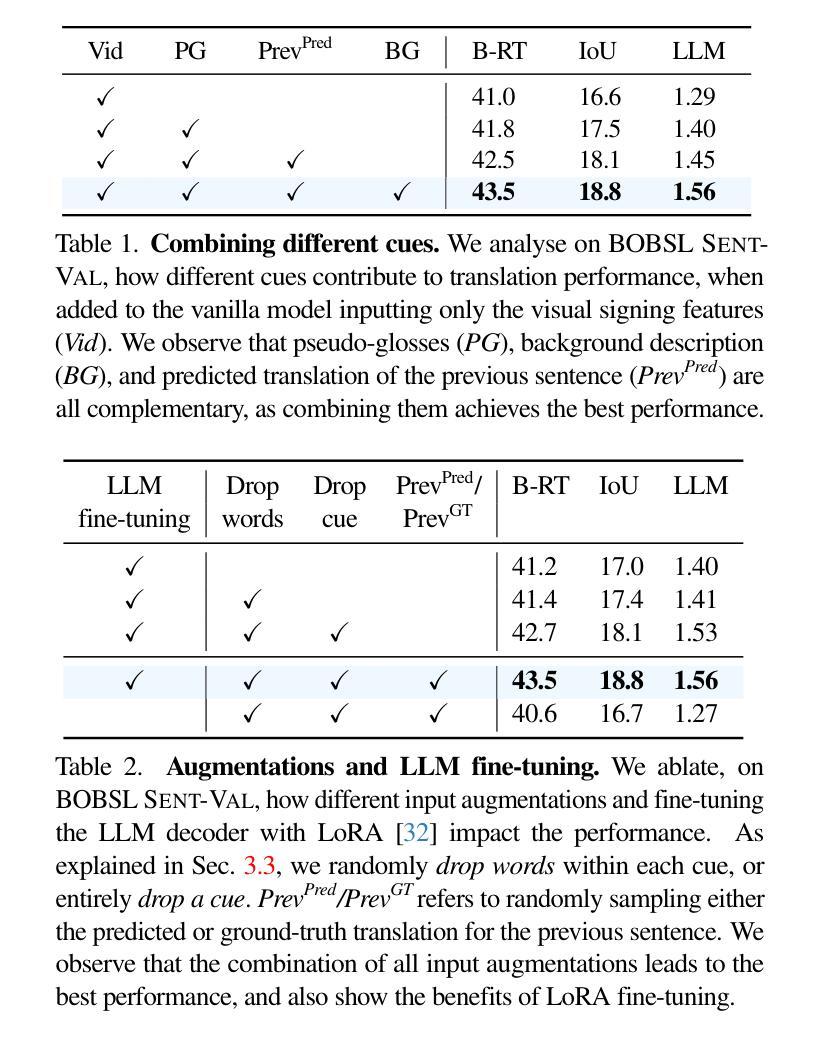
Lost in Translation, Found in Context: Sign Language Translation with Contextual Cues
Authors:Youngjoon Jang, Haran Raajesh, Liliane Momeni, Gül Varol, Andrew Zisserman
Our objective is to translate continuous sign language into spoken language text. Inspired by the way human interpreters rely on context for accurate translation, we incorporate additional contextual cues together with the signing video, into a new translation framework. Specifically, besides visual sign recognition features that encode the input video, we integrate complementary textual information from (i) captions describing the background show, (ii) translation of previous sentences, as well as (iii) pseudo-glosses transcribing the signing. These are automatically extracted and inputted along with the visual features to a pre-trained large language model (LLM), which we fine-tune to generate spoken language translations in text form. Through extensive ablation studies, we show the positive contribution of each input cue to the translation performance. We train and evaluate our approach on BOBSL – the largest British Sign Language dataset currently available. We show that our contextual approach significantly enhances the quality of the translations compared to previously reported results on BOBSL, and also to state-of-the-art methods that we implement as baselines. Furthermore, we demonstrate the generality of our approach by applying it also to How2Sign, an American Sign Language dataset, and achieve competitive results.
我们的目标是将连续的手语翻译成口语文本。受人类翻译者依赖上下文进行准确翻译的启发,我们将额外的上下文线索与手语视频结合,融入新的翻译框架。具体来说,除了编码输入视频的视觉手语识别特征外,我们还整合了(i)描述背景显示的字幕、(ii)之前句子的翻译以及(iii)手语转录的伪语音等补充文本信息。这些自动提取并与视觉特征一起输入到预训练的大型语言模型(LLM)中,我们对模型进行微调以生成口语形式的文本翻译。通过广泛的消融研究,我们证明了每个输入线索对翻译性能的积极贡献。我们在BOBSL(当前可用的最大英国手语数据集)上对我们的方法进行了训练和评估。我们证明了我们的上下文方法在BOBSL上的翻译质量相比以前报告的结果以及我们实现的最新方法作为基准线有显著提升。此外,我们将该方法应用于How2Sign(美国手语数据集),并获得了具有竞争力的结果,展示了其通用性。
论文及项目相关链接
Summary
本文主要介绍了一种将连续手语实时翻译成文字的新方法。该方法借鉴了人类翻译依赖语境进行准确翻译的方式,结合手语视频中的额外语境线索,构建了一个新的翻译框架。通过整合手语识别特征、背景描述字幕、先前句子的翻译以及手语转录的伪术语等文本信息,输入到预训练的大型语言模型中,生成口语形式的翻译。在BOBSL数据集上的实验表明,该方法显著提高了翻译质量,并在How2Sign数据集上取得了具有竞争力的结果。
Key Takeaways
- 研究目标是将连续手语实时翻译成文字。
- 借鉴人类翻译依赖语境的方式,结合手语视频的额外语境线索构建新的翻译框架。
- 通过整合多种文本信息(手语识别特征、背景描述字幕等)来提高翻译准确性。
- 使用预训练的大型语言模型(LLM),并进行微调以生成口语形式的翻译。
- 在BOBSL数据集上的实验证明了该方法的有效性,提高了翻译质量。
- 将该方法应用于How2Sign数据集,取得了具有竞争力的结果。
点此查看论文截图


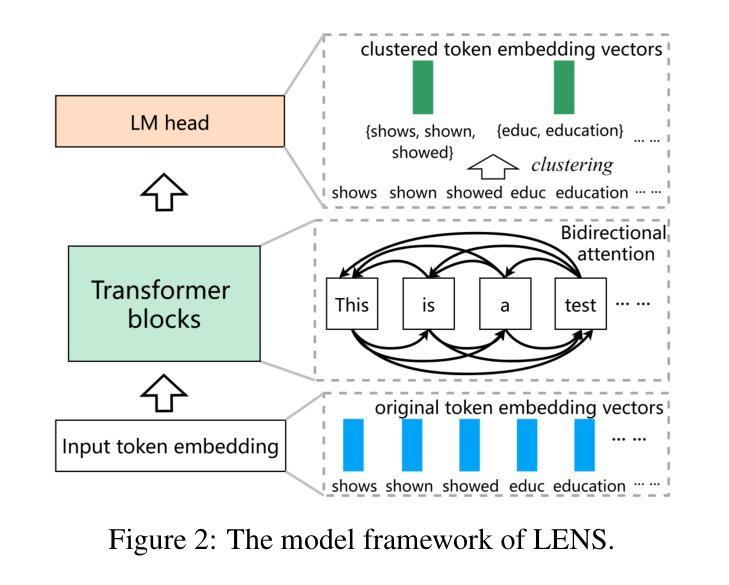
Enhancing Lexicon-Based Text Embeddings with Large Language Models
Authors:Yibin Lei, Tao Shen, Yu Cao, Andrew Yates
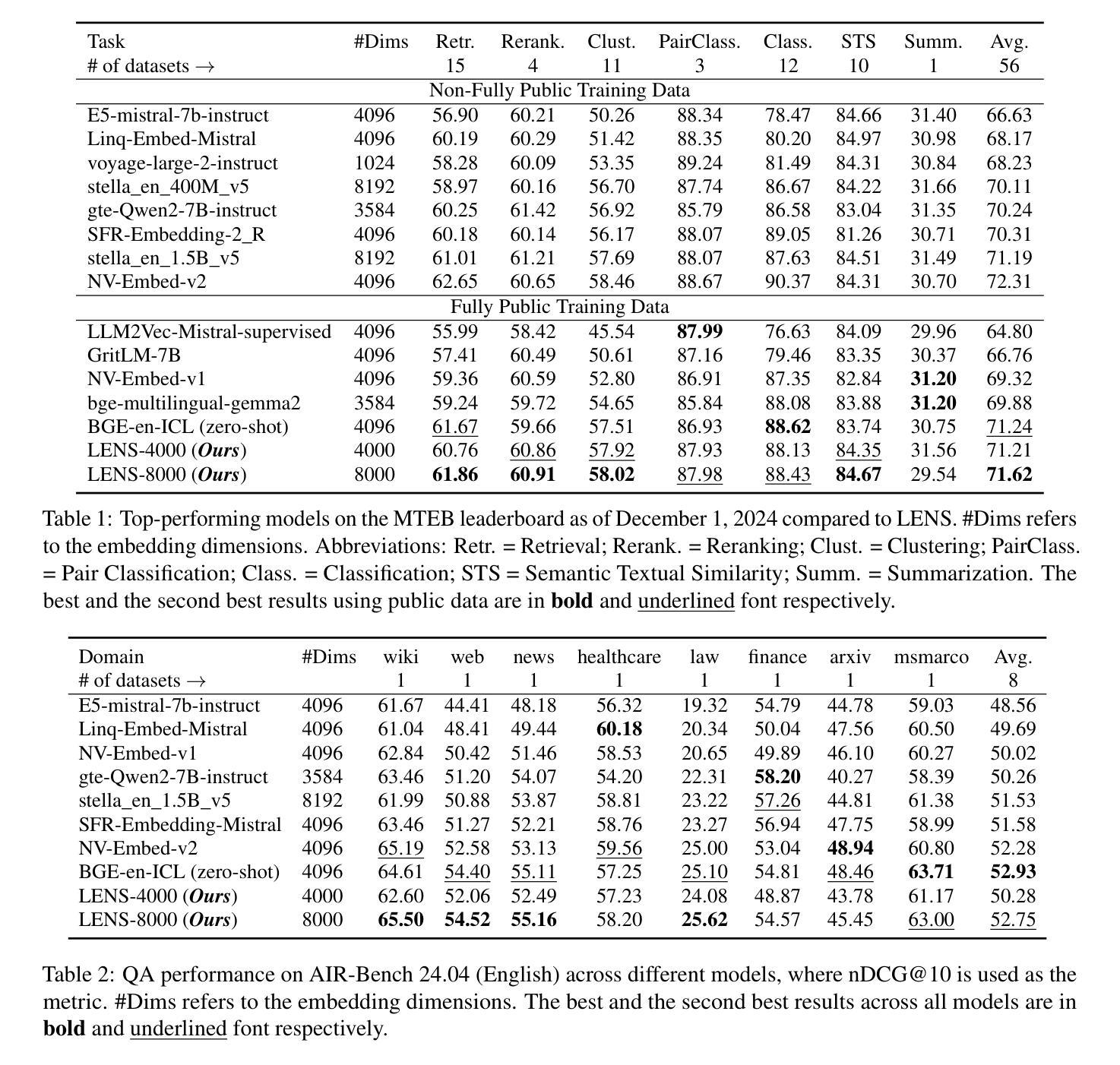
Recent large language models (LLMs) have demonstrated exceptional performance on general-purpose text embedding tasks. While dense embeddings have dominated related research, we introduce the first Lexicon-based EmbeddiNgS (LENS) leveraging LLMs that achieve competitive performance on these tasks. Regarding the inherent tokenization redundancy issue and unidirectional attention limitations in traditional causal LLMs, LENS consolidates the vocabulary space through token embedding clustering, and investigates bidirectional attention and various pooling strategies. Specifically, LENS simplifies lexicon matching by assigning each dimension to a specific token cluster, where semantically similar tokens are grouped together, and unlocking the full potential of LLMs through bidirectional attention. Extensive experiments demonstrate that LENS outperforms dense embeddings on the Massive Text Embedding Benchmark (MTEB), delivering compact feature representations that match the sizes of dense counterparts. Notably, combining LENSE with dense embeddings achieves state-of-the-art performance on the retrieval subset of MTEB (i.e. BEIR).
最近的大型语言模型(LLM)在通用文本嵌入任务上表现出了卓越的性能。虽然密集嵌入在相关研究中长期占据主导地位,但我们引入了首款基于词典的嵌入(LENS),利用LLM在这些任务上实现了竞争性的性能。针对传统因果LLM中的固有分词冗余问题和单向注意力限制,LENS通过令牌嵌入聚类整合词汇空间,并研究双向注意力和各种池策略。具体来说,LENS通过为每个维度分配特定的令牌集群来简化词典匹配,其中语义相似的令牌被组合在一起,并通过双向注意力释放LLM的全部潜力。大量实验表明,LENS在大型文本嵌入基准测试(MTEB)上的性能优于密集嵌入,提供紧凑的特征表示,与密集对应的规模相匹配。值得注意的是,将LENS与密集嵌入相结合,在MTEB的检索子集上达到了最先进的性能(即BEIR)。
论文及项目相关链接
Summary
近期的大型语言模型(LLM)在通用文本嵌入任务上表现出卓越性能。尽管密集嵌入相关研究占据主导,我们首次引入利用LLM的Lexicon-based EmbeddiNgS(LENS),在这些任务上实现具有竞争力的表现。针对传统因果LLM中的内在令牌化冗余问题和单向注意力限制,LENS通过令牌嵌入聚类整合词汇空间,并研究双向注意力以及各种池策略。具体来说,LENS简化了词汇匹配过程,将每个维度分配给特定的令牌簇,其中语义相似的令牌会被组合在一起,从而解锁LLM的潜力通过双向注意力。大量实验表明,LENS在大型文本嵌入基准测试(MTEB)上的性能优于密集嵌入,产生紧凑的特征表示,可与密集对应的规模相匹配。值得注意的是,将LENS与密集嵌入相结合在MTEB检索子集上达到了最先进的性能(即BEIR)。
Key Takeaways
- LLMs在通用文本嵌入任务上表现卓越。
- 引入了一种新的基于LLM的文本嵌入方法——Lexicon-based EmbeddiNgS(LENS)。
- LENS解决了传统LLM中的令牌化冗余和单向注意力限制问题。
- LENS通过令牌嵌入聚类整合词汇空间,并采用双向注意力和池策略。
- LENS简化了词汇匹配过程,将语义相似的令牌组合在一起。
- LENS在大型文本嵌入基准测试(MTEB)上的性能优于密集嵌入。
点此查看论文截图

Generating particle physics Lagrangians with transformers
Authors:Yong Sheng Koay, Rikard Enberg, Stefano Moretti, Eliel Camargo-Molina
In physics, Lagrangians provide a systematic way to describe laws governing physical systems. In the context of particle physics, they encode the interactions and behavior of the fundamental building blocks of our universe. By treating Lagrangians as complex, rule-based constructs similar to linguistic expressions, we trained a transformer model – proven to be effective in natural language tasks – to predict the Lagrangian corresponding to a given list of particles. We report on the transformer’s performance in constructing Lagrangians respecting the Standard Model $\mathrm{SU}(3)\times \mathrm{SU}(2)\times \mathrm{U}(1)$ gauge symmetries. The resulting model is shown to achieve high accuracies (over 90%) with Lagrangians up to six matter fields, with the capacity to generalize beyond the training distribution, albeit within architectural constraints. We show through an analysis of input embeddings that the model has internalized concepts such as group representations and conjugation operations as it learned to generate Lagrangians. We make the model and training datasets available to the community. An interactive demonstration can be found at: \url{https://huggingface.co/spaces/JoseEliel/generate-lagrangians}.
在物理学中,拉格朗日量为描述物理系统的规律提供了一种系统的方法。在粒子物理学的背景下,它们编码了我们宇宙基本构成要素的相互作用和行为。通过把拉格朗日量视为复杂的、基于规则的结构,类似于语言表达,我们训练了一种变压器模型——在自然语言任务中被证明是有效的——来预测对应于给定粒子列表的拉格朗日量。我们报告了变压器在构建尊重标准模型$\mathrm{SU}(3)\times \mathrm{SU}(2)\times \mathrm{U}(1)$规范对称性的拉格朗日量时的性能。结果模型显示,在拉格朗日量达到六个物质场的情况下,其准确率高达90%以上,虽然在架构约束内,但其能力可以推广到训练分布之外。通过对输入嵌入的分析,我们表明该模型已经内化了诸如群表示和共轭运算等概念,因为它学会了生成拉格朗日量。我们向社区提供模型和训练数据集。一个交互式演示可以在以下网址找到:https://huggingface.co/spaces/JoseEliel/generate-lagrangians。
论文及项目相关链接
PDF 32 pages, 11 figues, 18 tables
Summary
物理学中,拉格朗日函数提供了一种描述物理系统规律的系统方法。在粒子物理学背景下,它们编码了宇宙基本构建块的相互作用和行为。本文提出将拉格朗日函数视为复杂的规则结构,类似于语言表达式,并训练了一种已在自然语言任务中表现优异的变压器模型来预测给定粒子列表对应的拉格朗日函数。本文报道了该模型在遵循标准模型SU(3)×SU(2)×U(1)规范对称性的前提下构建拉格朗日的性能。结果表明,该模型在生成涉及多达六个物质场的拉格朗日函数时,准确率超过90%,并在建筑约束内具有超越训练分布的概括能力。通过对输入嵌入的分析,我们展示了该模型已经掌握了诸如群表示和共轭运算等概念。我们向公众提供了模型和训练数据集。一个交互式演示可以在链接中找到:https://huggingface.co/spaces/JoseEliel/generate-lagrangians。
Key Takeaways
- 拉格朗日函数在物理学中用于描述物理系统的规律,尤其是在粒子物理学中描述基本粒子的相互作用和行为。
- 通过将拉格朗日函数视为语言表达式并应用变压器模型,可以实现给定粒子列表的拉格朗日预测。
- 模型在遵循标准模型SU(3)×SU(2)×U(1)规范对称性的条件下表现出高性能。
- 模型在生成涉及多达六个物质场的拉格朗日函数时准确率超过90%。
- 模型具有概括能力,能够在建筑约束内超越训练分布。
- 输入嵌入分析显示模型掌握了群表示和共轭运算等概念。
点此查看论文截图

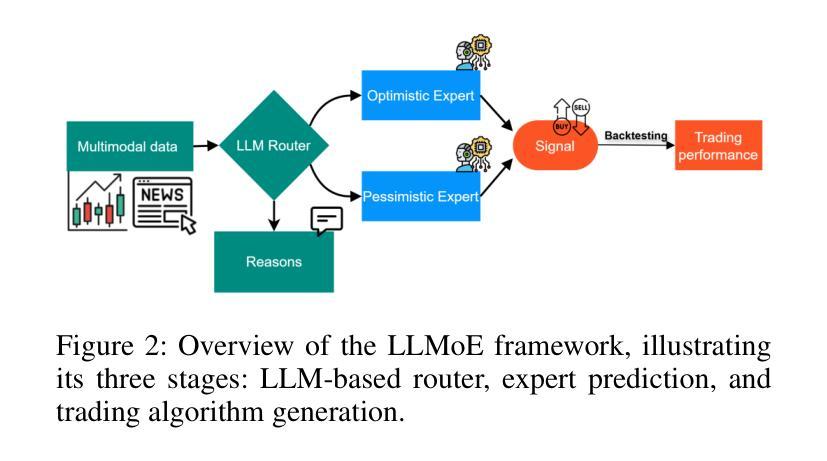
LLM-Based Routing in Mixture of Experts: A Novel Framework for Trading
Authors:Kuan-Ming Liu, Ming-Chih Lo
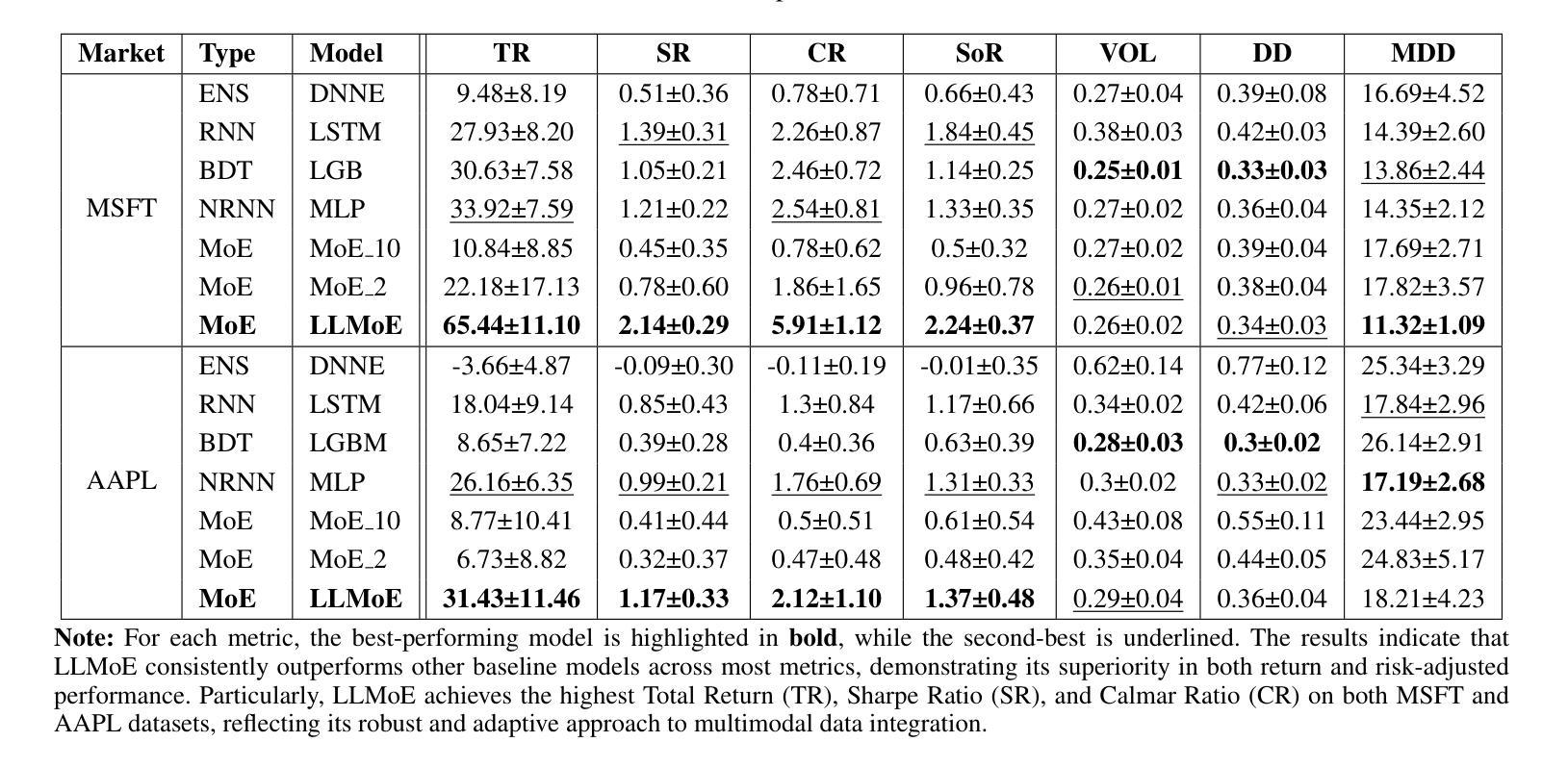
Recent advances in deep learning and large language models (LLMs) have facilitated the deployment of the mixture-of-experts (MoE) mechanism in the stock investment domain. While these models have demonstrated promising trading performance, they are often unimodal, neglecting the wealth of information available in other modalities, such as textual data. Moreover, the traditional neural network-based router selection mechanism fails to consider contextual and real-world nuances, resulting in suboptimal expert selection. To address these limitations, we propose LLMoE, a novel framework that employs LLMs as the router within the MoE architecture. Specifically, we replace the conventional neural network-based router with LLMs, leveraging their extensive world knowledge and reasoning capabilities to select experts based on historical price data and stock news. This approach provides a more effective and interpretable selection mechanism. Our experiments on multimodal real-world stock datasets demonstrate that LLMoE outperforms state-of-the-art MoE models and other deep neural network approaches. Additionally, the flexible architecture of LLMoE allows for easy adaptation to various downstream tasks.
最近深度学习和大语言模型(LLM)的进步促进了专家混合(MoE)机制在股票投资领域的应用。虽然这些模型已经表现出了有前景的交易性能,但它们通常是单模态的,忽略了其他模态(如文本数据)中丰富的信息。此外,基于传统神经网络的路由器选择机制没有考虑到上下文和现实世界中的细微差别,导致专家选择不佳。为了解决这些局限性,我们提出了LLMoE这一新型框架,它采用LLM作为MoE架构中的路由器。具体来说,我们用LLM替代了基于常规神经网络的路由器,利用其丰富的世界知识和推理能力,根据历史价格数据和股票新闻选择专家。这种方法提供了一个更有效和可解释的选择机制。我们在多模态现实世界股票数据集上的实验表明,LLMoE优于最新的MoE模型和其他深度神经网络方法。此外,LLMoE的灵活架构可轻松适应各种下游任务。
论文及项目相关链接
PDF Accepted by AAAI 2025 Workshop on AI for Social Impact - Bridging Innovations in Finance, Social Media, and Crime Prevention
Summary
深度学习与大型语言模型(LLM)的最新进展促进了混合专家(MoE)机制在股票投资领域的应用。传统神经网络路由选择机制缺乏上下文与现实世界的细微差别,导致专家选择不尽人意。为此,我们提出LLMoE框架,采用LLM作为MoE架构中的路由器,基于历史价格数据与股票新闻选择专家。实验证明,LLMoE在模态现实股票数据集上的表现优于最先进MoE模型和其他深度神经网络方法。
Key Takeaways
- 深度学习及大型语言模型(LLM)的进展推动了混合专家(MoE)机制在股票投资中的应用。
- 传统神经网络路由选择机制存在局限性,无法充分考虑上下文与现实世界的细微差别。
- LLMoE框架采用LLM作为路由器,基于历史价格数据与股票新闻选择专家。
- LLMoE框架在模态现实股票数据集上的表现优于其他方法。
- LLMoE框架具有灵活性和易适应性,可轻松适应各种下游任务。
- LLMs的丰富知识和推理能力在股票投资领域具有应用价值。
点此查看论文截图


From Scarcity to Capability: Empowering Fake News Detection in Low-Resource Languages with LLMs
Authors:Hrithik Majumdar Shibu, Shrestha Datta, Md. Sumon Miah, Nasrullah Sami, Mahruba Sharmin Chowdhury, Md. Saiful Islam
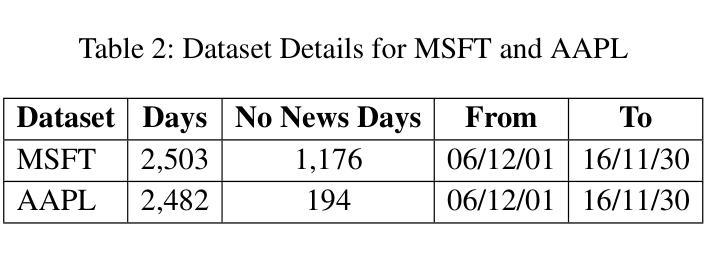
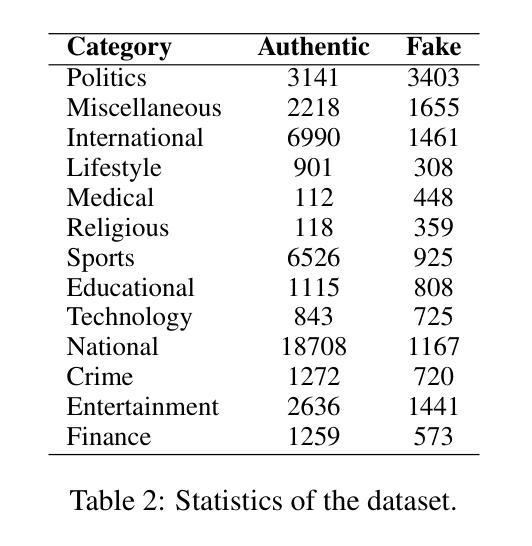
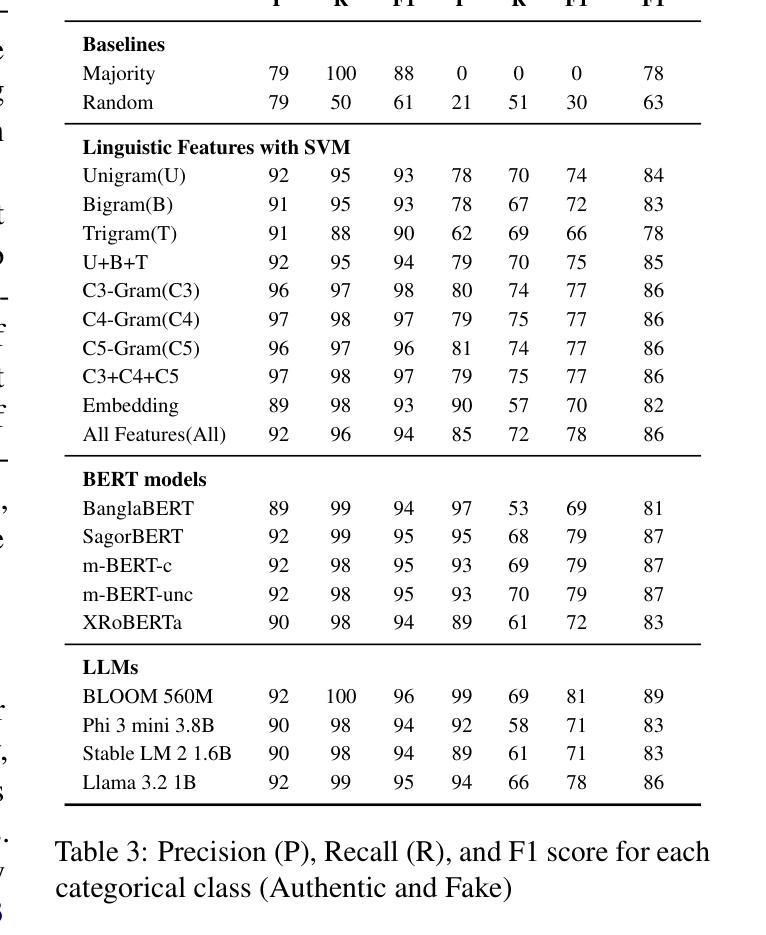
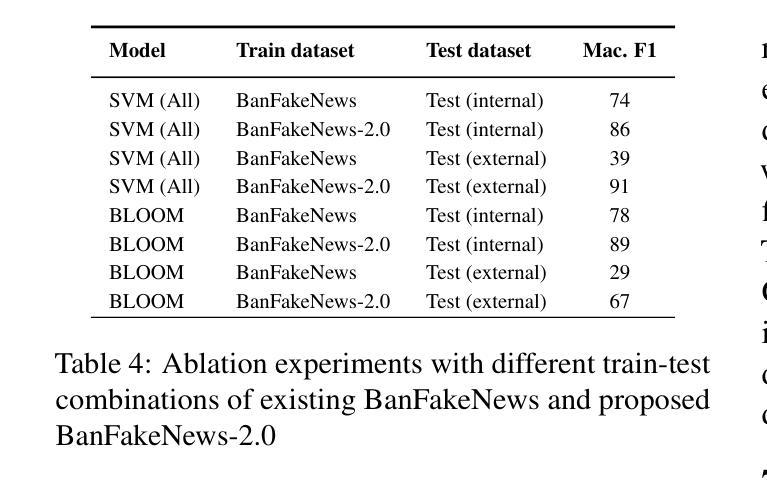
The rapid spread of fake news presents a significant global challenge, particularly in low-resource languages like Bangla, which lack adequate datasets and detection tools. Although manual fact-checking is accurate, it is expensive and slow to prevent the dissemination of fake news. Addressing this gap, we introduce BanFakeNews-2.0, a robust dataset to enhance Bangla fake news detection. This version includes 11,700 additional, meticulously curated fake news articles validated from credible sources, creating a proportional dataset of 47,000 authentic and 13,000 fake news items across 13 categories. In addition, we created a manually curated independent test set of 460 fake and 540 authentic news items for rigorous evaluation. We invest efforts in collecting fake news from credible sources and manually verified while preserving the linguistic richness. We develop a benchmark system utilizing transformer-based architectures, including fine-tuned Bidirectional Encoder Representations from Transformers variants (F1-87%) and Large Language Models with Quantized Low-Rank Approximation (F1-89%), that significantly outperforms traditional methods. BanFakeNews-2.0 offers a valuable resource to advance research and application in fake news detection for low-resourced languages. We publicly release our dataset and model on Github to foster research in this direction.
虚假新闻的迅速传播给全球带来了重大挑战,特别是在像孟加拉语这样的资源匮乏的语言中,缺乏足够的数据集和检测工具。虽然手动事实核查是准确的,但其在阻止虚假新闻的传播方面是昂贵且缓慢的。为了解决这一差距,我们推出了BanFakeNews-2.0,这是一个增强孟加拉语虚假新闻检测能力的稳健数据集。此版本新增了11,700篇精心策划的虚假新闻文章,这些文章来自可靠来源并经过了验证,创建了包含47,000篇真实和13,000篇虚假新闻文章的均衡数据集,涵盖13个类别。此外,我们还创建了包含460篇虚假新闻和540篇真实新闻的独立测试集,以便进行严格评估。我们努力从可靠来源收集虚假新闻,并进行手动验证,同时保留语言的丰富性。我们开发了一个基于Transformer架构的基准系统,包括微调后的双向编码器表示(F1-87%)和具有量化低秩逼近的大型语言模型(F1-89%),该系统显著优于传统方法。BanFakeNews-2.0为推进虚假新闻检测研究与应用提供了宝贵资源,特别是对于资源匮乏的语言。我们在GitHub上公开发布了我们的数据集和模型,以促进这一方向的研究。
论文及项目相关链接
摘要
Bangla语由于缺乏足够的语料库和检测工具,假新闻的快速传播成为一个重大挑战。尽管手动事实核查很准确,但其高昂的成本和缓慢的进度无法阻止假新闻的散布。为解决这一问题,推出BanFakeNews-2.0数据集,旨在增强Bangla假新闻的检测能力。此版本新增了来自可靠来源的11700篇精心策划的假新闻文章,创建了包含比例适当的语料库,涵盖真实新闻47000篇和假新闻13000篇,共涉及13个类别。同时创建了一个独立的手动验证测试集,包括460篇假新闻和540篇真实新闻,用于严格的评估。我们致力于收集来自可靠来源的假新闻并进行手动验证,同时保留语言的丰富性。我们开发了一个基于Transformer架构的基准系统,包括微调后的双向编码器表示(F1-87%)和低秩近似量化的大型语言模型(F1-89%),显著优于传统方法。BanFakeNews-2.0对于推动低资源语言假新闻检测的研究和应用具有重要意义。我们在GitHub上公开发布数据集和模型,以促进这一方向的研究发展。
关键见解
- 假新闻在全球范围内的传播构成重大挑战,特别是在缺乏数据和检测工具的Bangla等低资源语言中尤为明显。
- 手动事实核查虽然准确但成本高昂且进度缓慢,难以满足阻止假新闻传播的需求。
- 推出BanFakeNews-2.0数据集,包含真实新闻和假新闻文章数量得到显著扩充,便于构建更为完善的检测模型。
- 采用基于Transformer架构开发基准系统,包括微调双向编码器表示和低秩近似量化的语言模型等先进技术,显著提高假新闻检测准确率。
- 手动验证确保数据集和模型的有效性和准确性,强调语言学上的丰富性对模型训练的重要性。
- 数据集及模型的公开提供有利于低资源语言假新闻检测研究的进步与应用开发。此举可通过共享平台和资源加强该领域的协作与创新。
点此查看论文截图

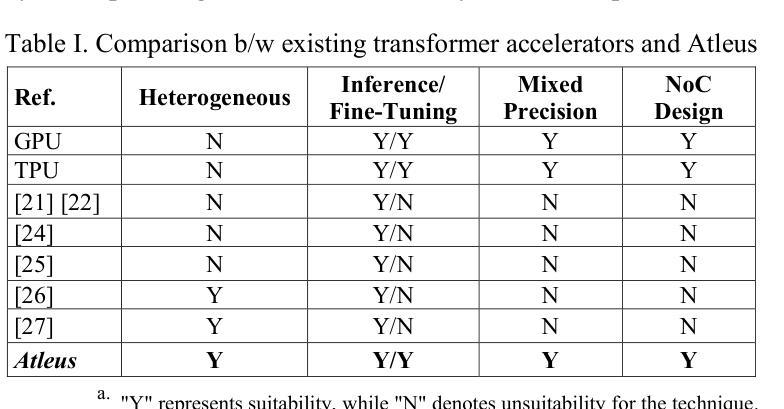
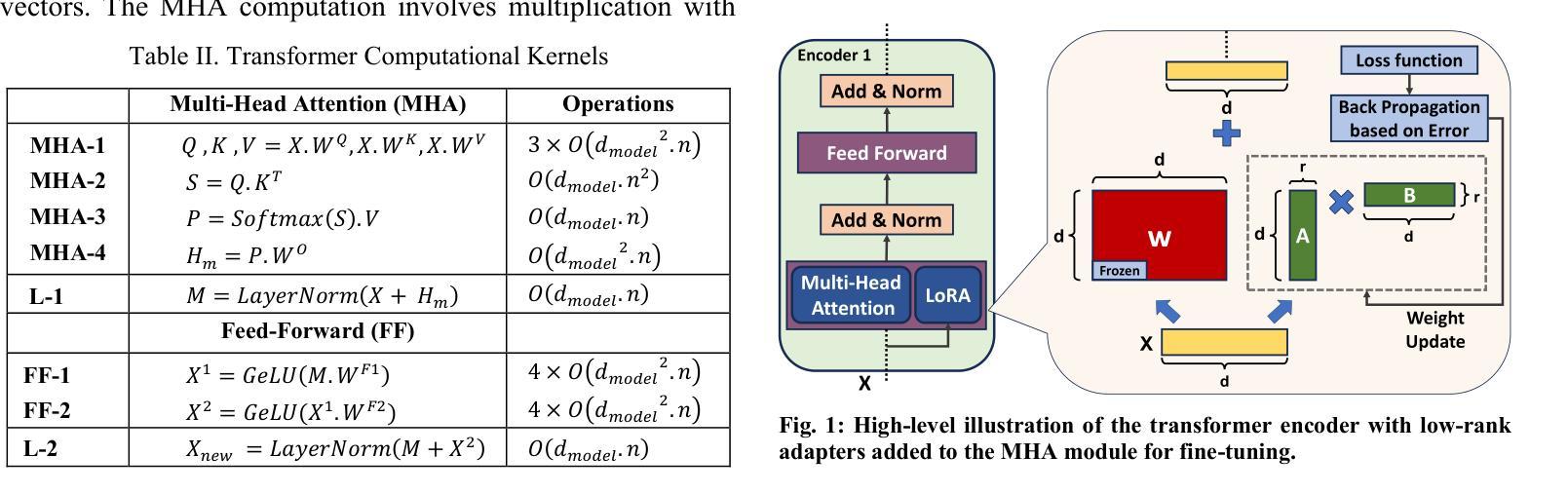
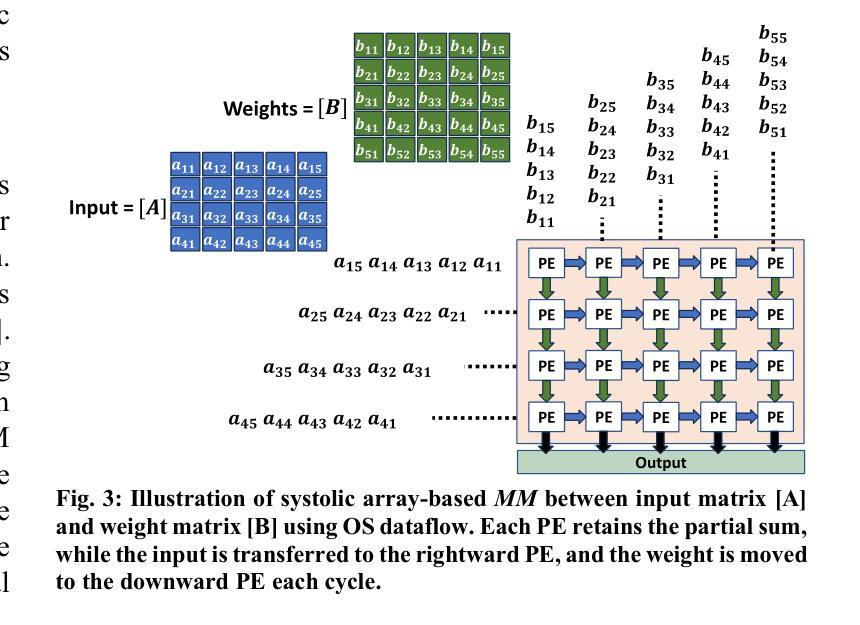
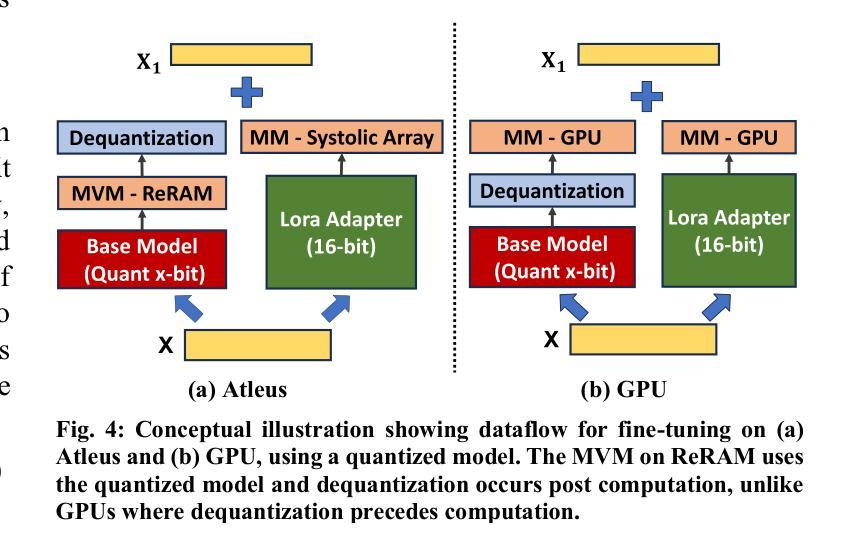
Atleus: Accelerating Transformers on the Edge Enabled by 3D Heterogeneous Manycore Architectures
Authors:Pratyush Dhingra, Janardhan Rao Doppa, Partha Pratim Pande
Transformer architectures have become the standard neural network model for various machine learning applications including natural language processing and computer vision. However, the compute and memory requirements introduced by transformer models make them challenging to adopt for edge applications. Furthermore, fine-tuning pre-trained transformers (e.g., foundation models) is a common task to enhance the model’s predictive performance on specific tasks/applications. Existing transformer accelerators are oblivious to complexities introduced by fine-tuning. In this paper, we propose the design of a three-dimensional (3D) heterogeneous architecture referred to as Atleus that incorporates heterogeneous computing resources specifically optimized to accelerate transformer models for the dual purposes of fine-tuning and inference. Specifically, Atleus utilizes non-volatile memory and systolic array for accelerating transformer computational kernels using an integrated 3D platform. Moreover, we design a suitable NoC to achieve high performance and energy efficiency. Finally, Atleus adopts an effective quantization scheme to support model compression. Experimental results demonstrate that Atleus outperforms existing state-of-the-art by up to 56x and 64.5x in terms of performance and energy efficiency respectively
Transformer架构已成为各种机器学习应用的标准神经网络模型,包括自然语言处理和计算机视觉。然而,Transformer模型带来的计算和内存要求,使得其在边缘应用的采用面临挑战。此外,微调预训练的Transformer(例如基础模型)是一个常见任务,旨在提高模型在特定任务/应用上的预测性能。现有的Transformer加速器对微调引入的复杂性缺乏认识。在本文中,我们提出了一种名为Atleus的三维异构架构设计,该架构结合了异构计算资源,专门用于加速Transformer模型的微调与推理。具体来说,Atleus利用非易失性内存和脉动阵列,通过集成三维平台来加速Transformer计算内核。此外,我们设计了一种合适的网络芯片互联技术(NoC),以实现高性能和能效。最后,Atleus采用有效的量化方案来支持模型压缩。实验结果表明,在性能和能效方面,Atleus分别达到了最高56倍和最高至64.5倍的最佳状态
论文及项目相关链接
PDF Accepted for Publication in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)
Summary
本文提出了一种名为Atleus的三维异构架构,该架构专门优化了用于加速转换器模型的微调与推断任务。通过利用非易失性内存和脉动阵列,Atleus在一个集成化的三维平台上加速转换器计算内核。此外,设计了一种高效的NoC,以实现高性能和能源效率。Atleus还采用有效的量化方案以支持模型压缩,并且实验结果表明其性能优于现有技术,性能提升最高达56倍,能效提升最高达64.5倍。
Key Takeaways
- Transformer架构已成为各种机器学习应用的标准神经网络模型,包括自然语言处理和计算机视觉。
- 转换器模型对计算和内存的需求使其难以在边缘应用中使用。
- 对预训练的转换器进行微调是增强模型对特定任务/应用预测性能的一种常见任务。现有的转换器加速器忽略了微调带来的复杂性。
- 本文提出了一种名为Atleus的三维异构架构,旨在加速转换器模型的微调与推断。
- Atleus利用非易失性内存和脉动阵列来加速转换器计算内核。
- Atleus设计了一种高效的NoC,以实现高性能和能源效率。
点此查看论文截图


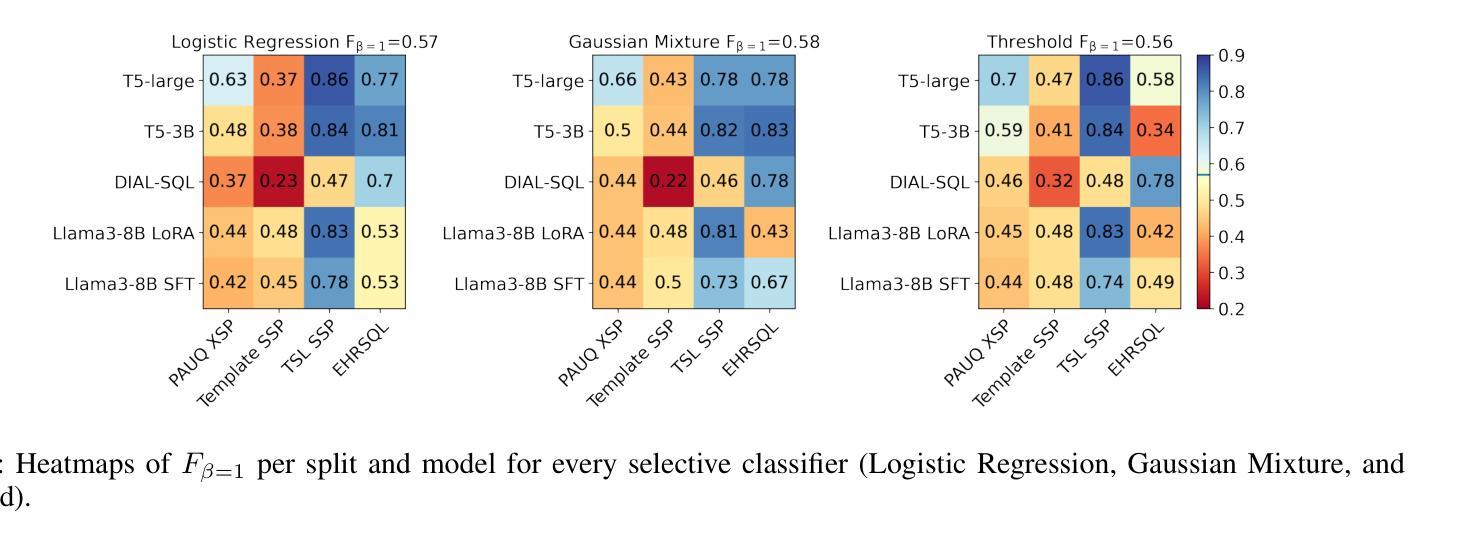
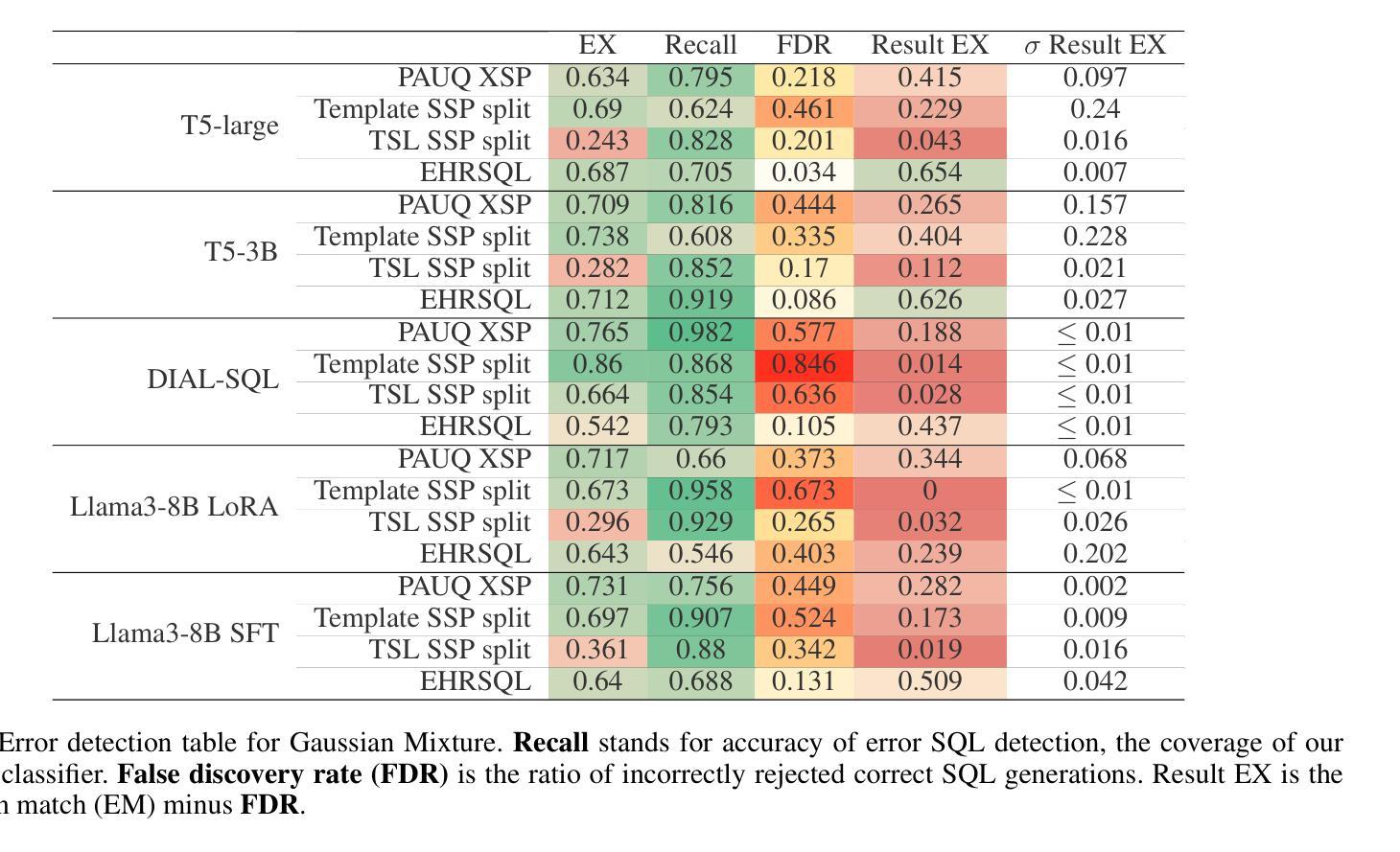
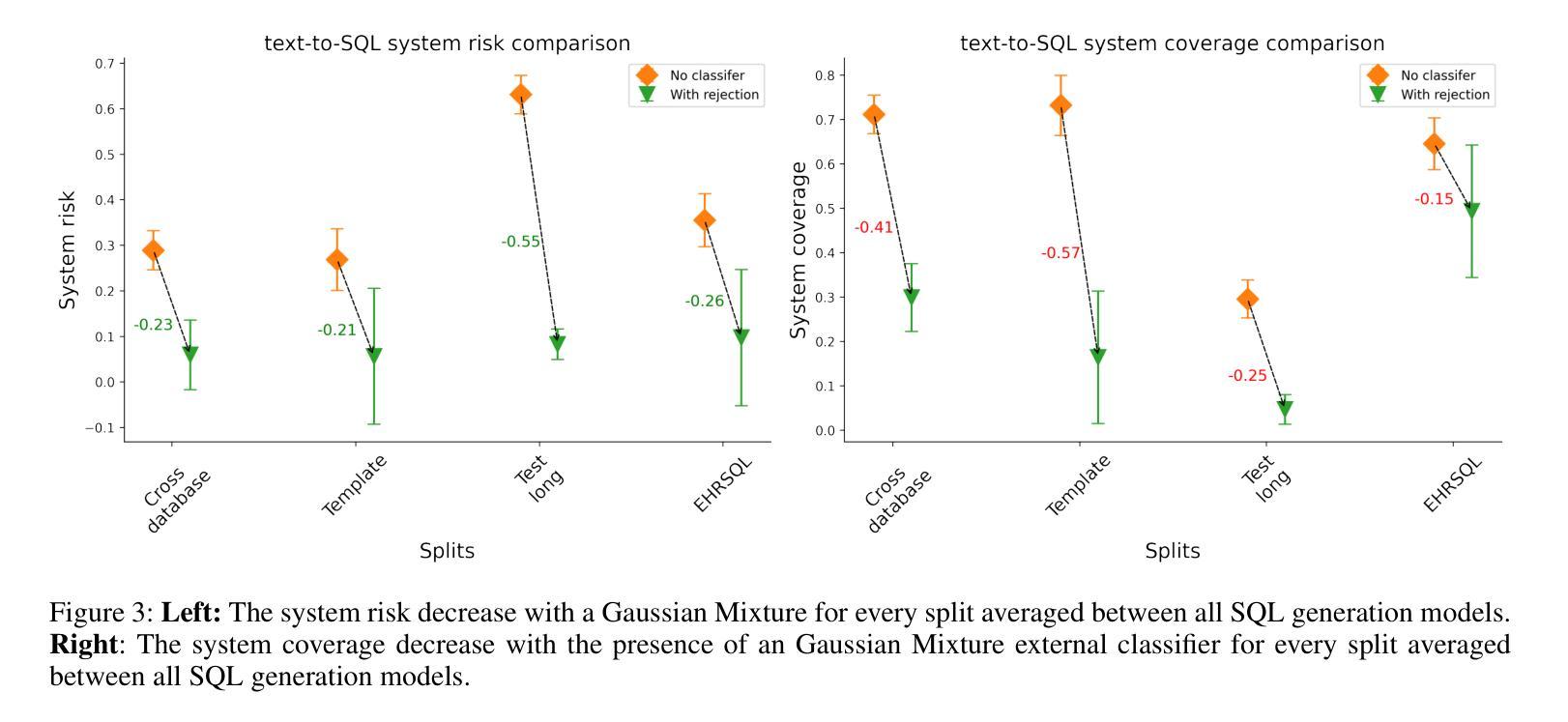
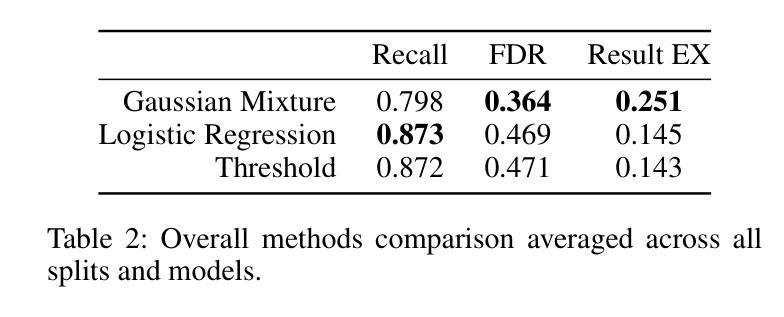
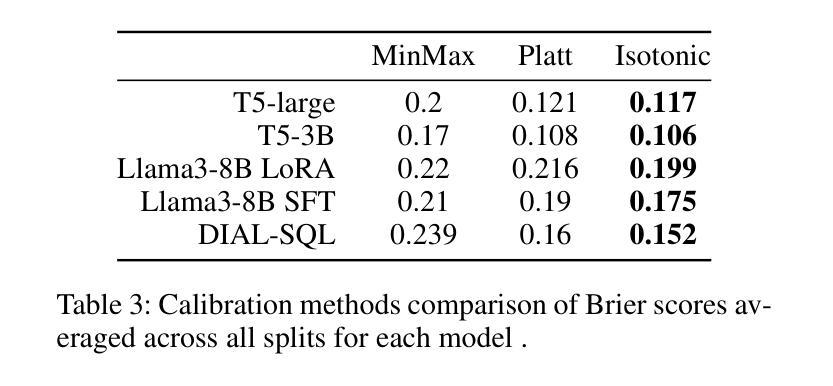
Confidence Estimation for Error Detection in Text-to-SQL Systems
Authors:Oleg Somov, Elena Tutubalina
Text-to-SQL enables users to interact with databases through natural language, simplifying the retrieval and synthesis of information. Despite the success of large language models (LLMs) in converting natural language questions into SQL queries, their broader adoption is limited by two main challenges: achieving robust generalization across diverse queries and ensuring interpretative confidence in their predictions. To tackle these issues, our research investigates the integration of selective classifiers into Text-to-SQL systems. We analyse the trade-off between coverage and risk using entropy based confidence estimation with selective classifiers and assess its impact on the overall performance of Text-to-SQL models. Additionally, we explore the models’ initial calibration and improve it with calibration techniques for better model alignment between confidence and accuracy. Our experimental results show that encoder-decoder T5 is better calibrated than in-context-learning GPT 4 and decoder-only Llama 3, thus the designated external entropy-based selective classifier has better performance. The study also reveal that, in terms of error detection, selective classifier with a higher probability detects errors associated with irrelevant questions rather than incorrect query generations.
文本到SQL使用户能够通过自然语言与数据库进行交互,简化了信息的检索和合成。尽管大型语言模型(LLM)在将自然语言问题转换为SQL查询方面取得了成功,但它们更广泛的采用受到两个主要挑战的限制:实现跨不同查询的稳健泛化,以及确保对其预测的解释信心。为了应对这些问题,我们的研究探讨了选择性分类器在文本到SQL系统中的集成。我们使用基于熵的置信估计来分析覆盖率和风险之间的权衡,并评估其对文本到SQL模型整体性能的影响。此外,我们探索了模型的初始校准,并通过校准技术对其进行改进,以更好地实现置信和准确性之间的模型对齐。实验结果表明,编码器-解码器T5的校准效果优于上下文学习GPT 4和仅解码器Llama 3,因此指定的外部基于熵的选择性分类器具有更好的性能。该研究还表明,就错误检测而言,具有较高概率的选择性分类器更擅长检测与无关问题相关的错误,而不是不正确的查询生成。
论文及项目相关链接
PDF 15 pages, 11 figures, to be published in AAAI 2025 Proceedings
Summary
文本介绍了如何通过集成选择性分类器来解决文本到SQL转换系统中的两个主要挑战:实现跨不同查询的稳健泛化和确保预测的可解释性信心。研究探讨了基于熵的置信估计的权衡,并评估了其对文本到SQL模型整体性能的影响。此外,该研究还探索了模型的初始校准问题,并使用校准技术提高其性能。实验结果表明,编码器-解码器T5相较于上下文学习GPT 4和仅解码器Llama 3具有更好的校准性能,所设计的外置基于熵的选择性分类器表现更佳。同时发现,选择性分类器在检测到与问题不相关错误方面的概率更高,而非错误的查询生成。
Key Takeaways
- 文本到SQL技术简化了数据库的信息检索与合成,让用户通过自然语言与数据库进行交互。
- 大型语言模型(LLM)在将自然语言问题转换为SQL查询方面取得了成功,但仍面临两个主要挑战:泛化能力和预测的可解释性。
- 研究通过集成选择性分类器来解决上述挑战,以提高模型的泛化能力和预测的准确性及可解释性。
- 基于熵的置信估计被用于分析覆盖面与风险之间的权衡,以评估对模型整体性能的影响。
- 研究发现编码器-解码器T5相较于其他模型具有更好的校准性能。
- 外部基于熵的选择性分类器表现更佳,特别是在检测与问题不相关的错误方面。
- 错误更多地与问题不相关性相关,而非错误的查询生成。
点此查看论文截图

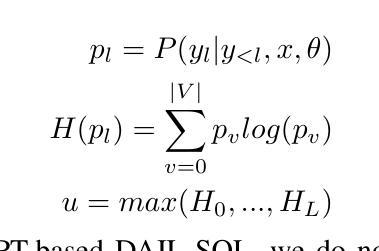
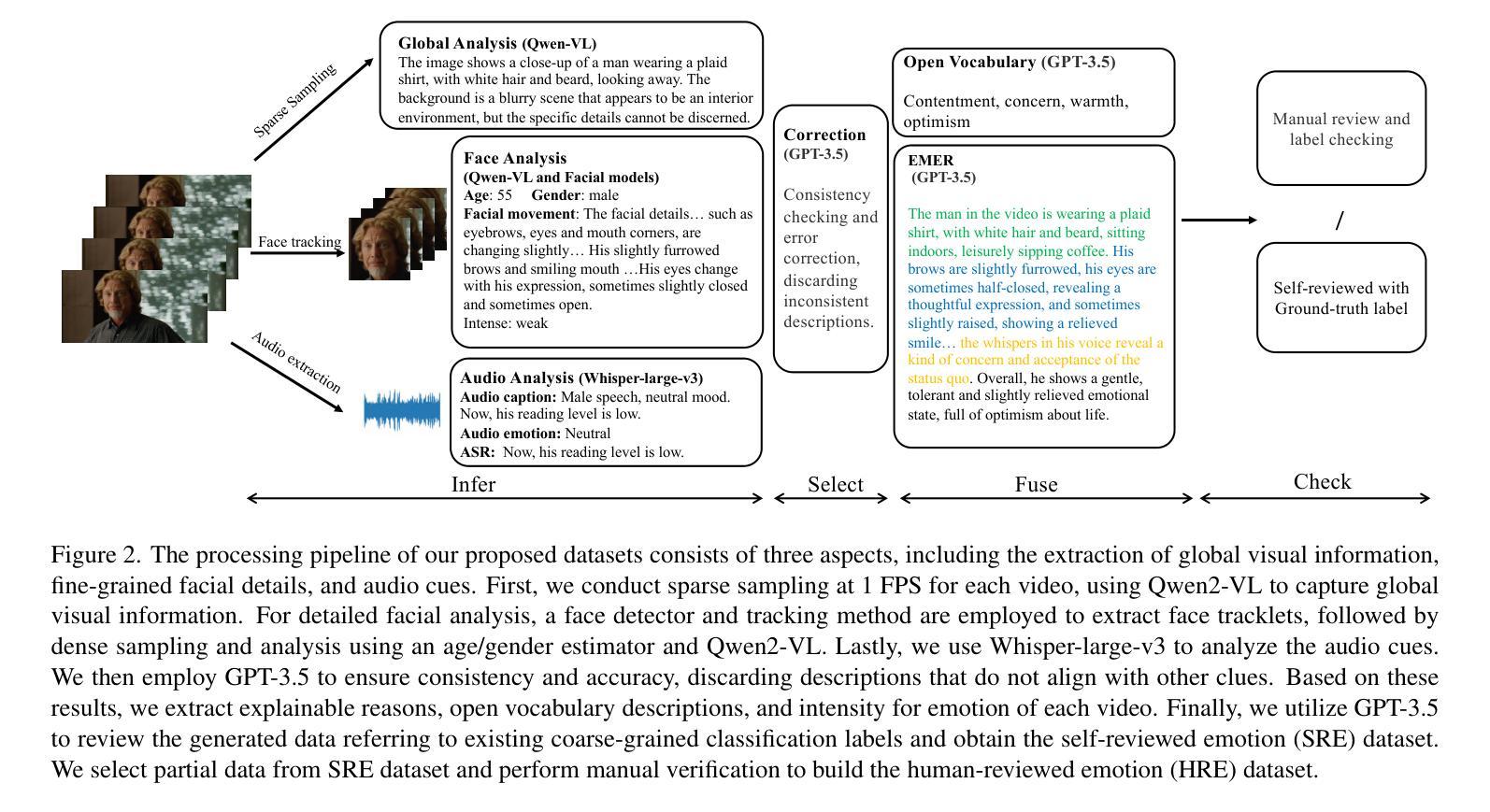
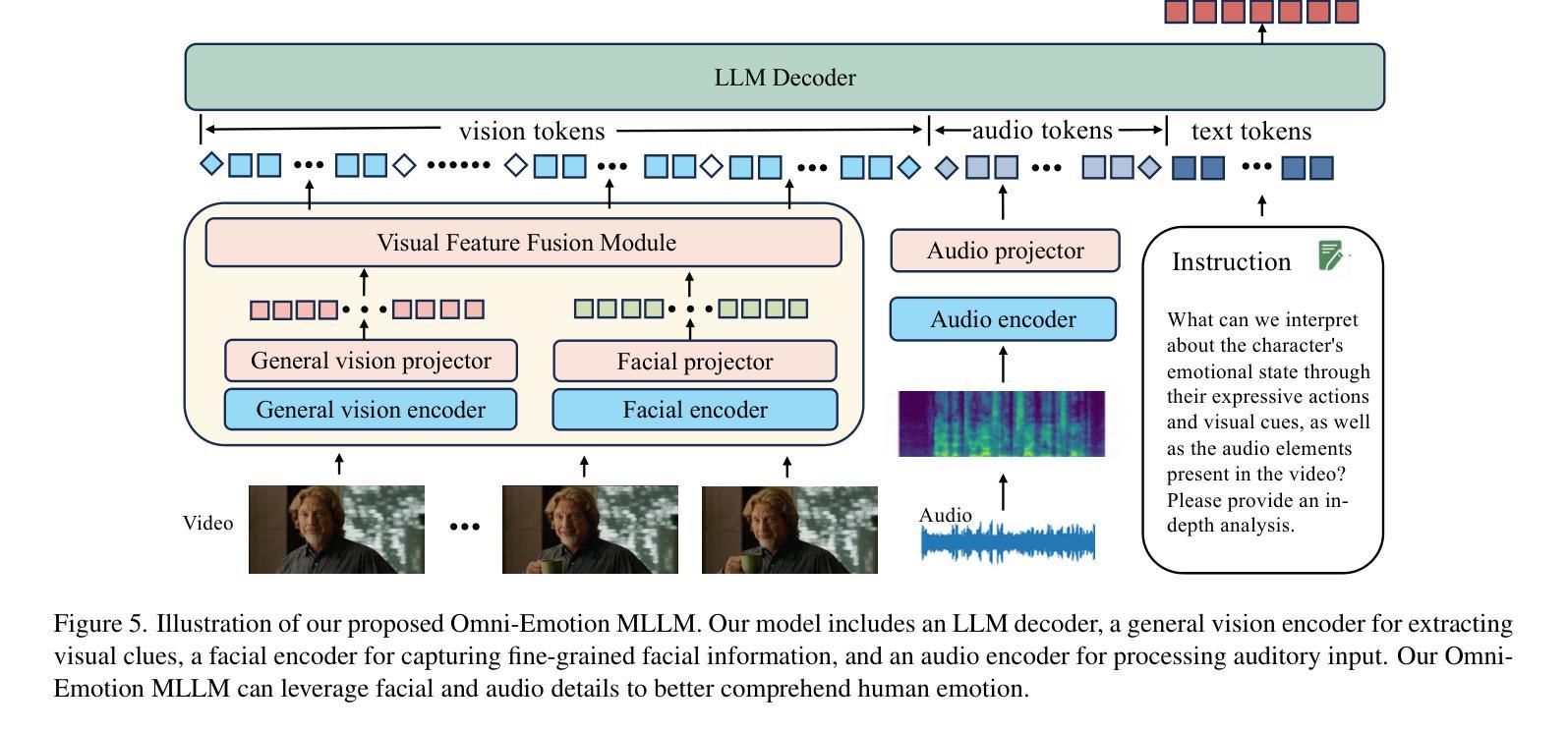
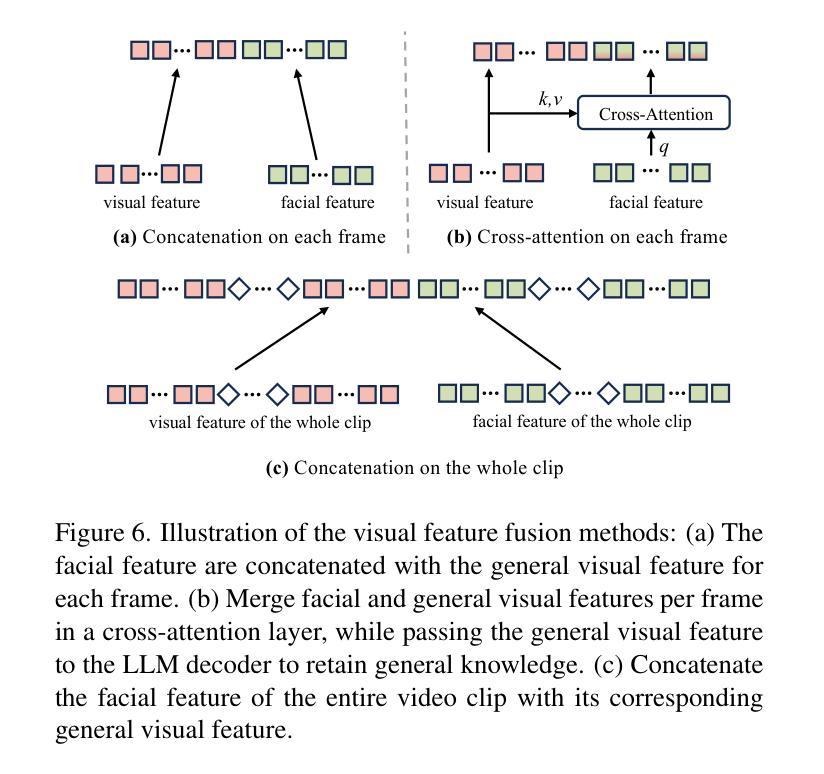
Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
Authors:Qize Yang, Detao Bai, Yi-Xing Peng, Xihan Wei
Understanding emotions accurately is essential for fields like human-computer interaction. Due to the complexity of emotions and their multi-modal nature (e.g., emotions are influenced by facial expressions and audio), researchers have turned to using multi-modal models to understand human emotions rather than single-modality. However, current video multi-modal large language models (MLLMs) encounter difficulties in effectively integrating audio and identifying subtle facial micro-expressions. Furthermore, the lack of detailed emotion analysis datasets also limits the development of multimodal emotion analysis. To address these issues, we introduce a self-reviewed dataset and a human-reviewed dataset, comprising 24,137 coarse-grained samples and 3,500 manually annotated samples with detailed emotion annotations, respectively. These datasets allow models to learn from diverse scenarios and better generalize to real-world applications. Moreover, in addition to the audio modeling, we propose to explicitly integrate facial encoding models into the existing advanced Video MLLM, enabling the MLLM to effectively unify audio and the subtle facial cues for emotion understanding. By aligning these features within a unified space and employing instruction tuning in our proposed datasets, our Omni-Emotion achieves state-of-the-art performance in both emotion recognition and reasoning tasks.
准确地理解情绪对于人机交互等领域至关重要。由于情绪的复杂性和其多模态性质(例如,情绪受到面部表情和音频的影响),研究人员已经转向使用多模态模型来理解人类情绪,而不是单模态模型。然而,当前的视频多模态大型语言模型(MLLM)在有效整合音频和识别微妙的面部表情微动作方面遇到困难。此外,缺乏详细的情感分析数据集也限制了多模态情感分析的发展。为了解决这些问题,我们引入了一个自我审查的数据集和一个人工审查的数据集,分别包含24,137个粗粒度样本和3,500个带有详细情感注释的手动注释样本。这些数据集使模型能够学习各种场景,并更好地推广现实世界的实际应用。除了音频建模之外,我们还提议将面部编码模型显式地集成到现有的先进视频MLLM中,使MLLM能够有效地统一音频和微妙的面部线索来进行情感理解。通过在一个统一的空间内对齐这些特征,并在我们提出的数据集中进行指令调整,我们的Omni-Emotion在情感识别和推理任务上均达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了多模态情感分析的重要性,特别是在处理人类与计算机交互时。当前视频多模态大语言模型在处理音频和识别微妙的面部表情时面临挑战。为解决这些问题,文章引入了一个自我审查的数据集和一个经过人工审查的数据集,并建议将面部编码模型显式地集成到现有的高级视频多模态语言模型中,以提高情感理解的准确性。通过在这些数据集中采用指令微调的方法,Omni-Emotion模型在情感识别和推理任务上达到了最佳性能。
Key Takeaways
- 多模态情感分析对于人类与计算机交互至关重要。
- 当前视频多模态大语言模型在处理音频和识别微妙的面部表情方面存在挑战。
- 引入自我审查的数据集和经过人工审查的数据集,以提供更详细的情感注释。
- 建议将面部编码模型集成到现有的高级视频多模态语言模型中。
- 通过在数据集中采用指令微调的方法,Omni-Emotion模型可以提高情感理解的准确性。
- Omni-Emotion模型在情感识别和推理任务上达到了最佳性能。
点此查看论文截图

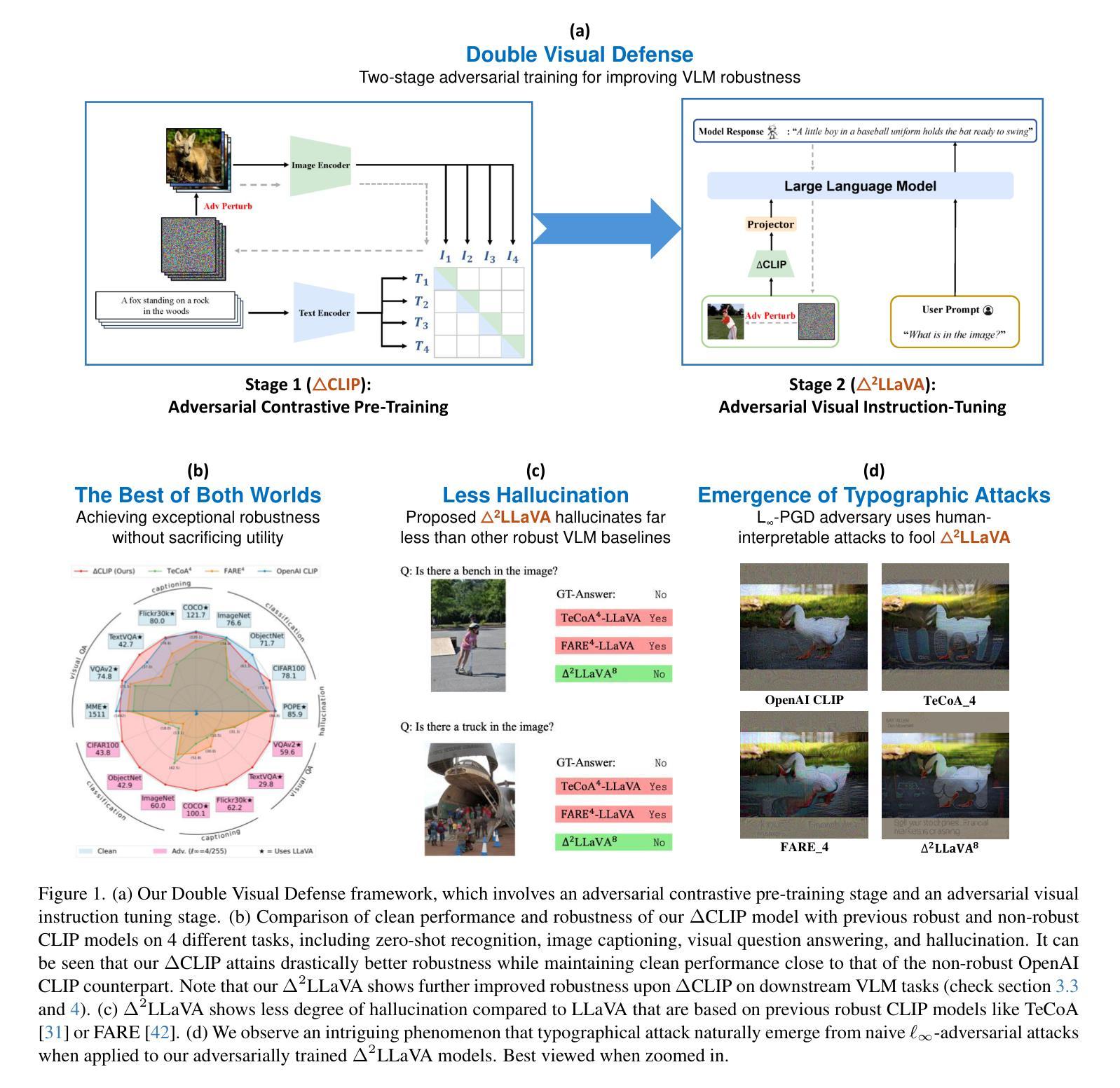
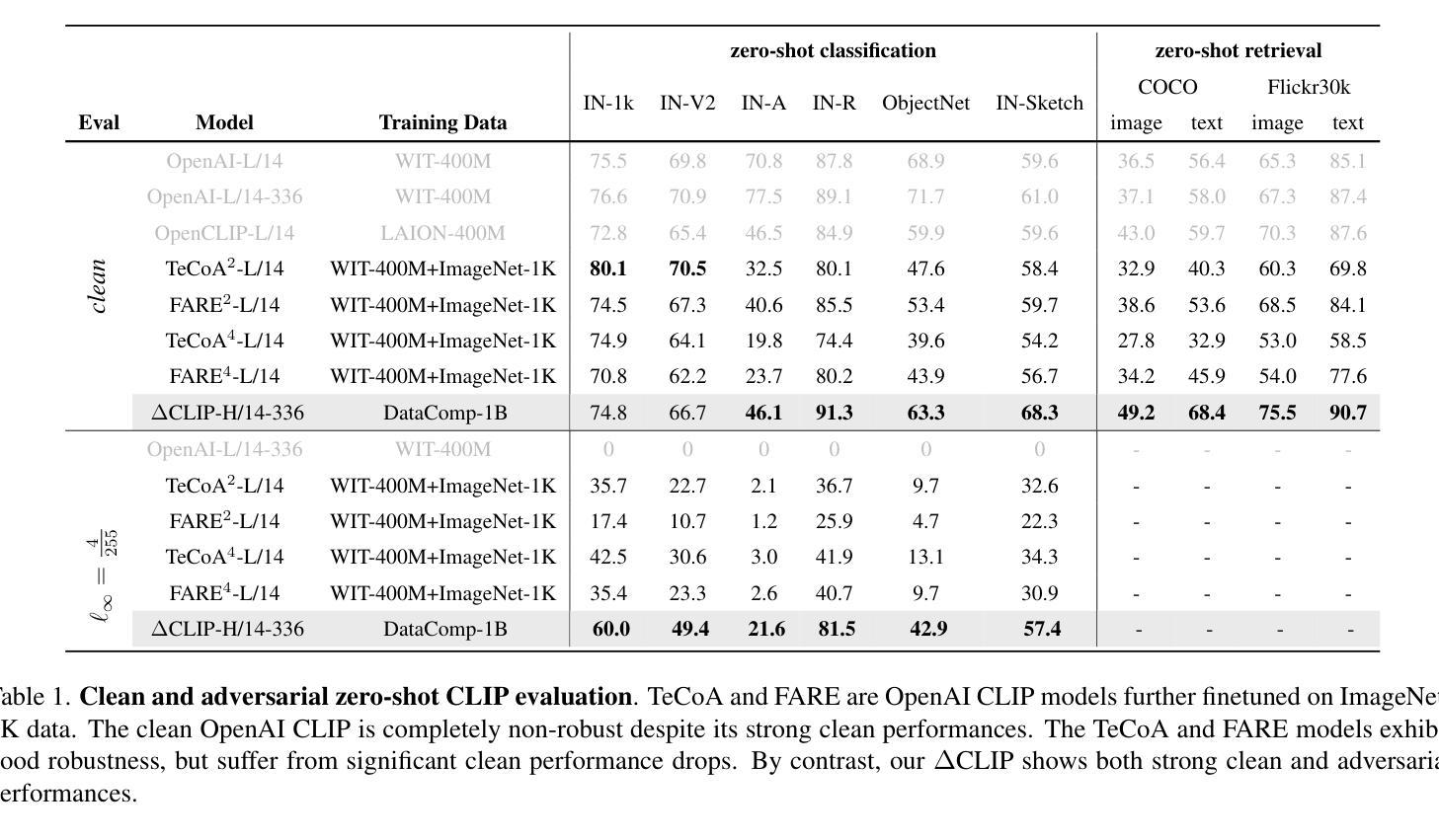
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Authors:Zeyu Wang, Cihang Xie, Brian Bartoldson, Bhavya Kailkhura
This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense” to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.
本文研究了视觉语言模型对抗对视觉干扰的鲁棒性,并引入了一种新型的“双重视觉防御”方法来提高这种鲁棒性。与其他方法不同,我们没有使用预训练的CLIP模型进行轻量级的对抗微调,而是使用大规模网络数据从头开始进行大规模的对抗性视觉语言预训练。然后我们通过融入对抗视觉指令微调来加强防御。各阶段得出的模型,包括ΔCLIP和Δ²LLaVA,表现出大幅增强的零样本鲁棒性,并在视觉语言模型的对抗防御方面创造了新的技术记录。例如,ΔCLIP在ImageNet-1k上的对抗鲁棒性超过了以前最优秀的模型约20%。与现有技术相比,Δ²LLaVA为图像描述任务带来了约30%的鲁棒性提升,并为视觉问答任务带来了约20%的鲁棒性提升。此外,我们的模型还表现出更强的零样本识别能力、更少的幻觉和优于基准线的推理性能。我们的项目页面是:[https://doublevisualdefense.github.io/] 。
论文及项目相关链接
Summary
本文研究了视觉语言模型对抗视觉扰动攻击的鲁棒性,并提出了一种新的“双重视觉防御”方法来增强模型的鲁棒性。不同于之前的方法,我们采用大规模的对抗性视觉语言预训练,从原始数据开始使用网络规模数据进行训练。随后,通过引入对抗性视觉指令调整来加强防御。由此产生的模型,如$\Delta$CLIP和$\Delta^2$LLaVA,在零样本鲁棒性上有显著增强,并在视觉语言模型的对抗性防御方面创造了新的最佳状态。例如,$\Delta$CLIP在ImageNet-1k上的对抗性鲁棒性超过了以前的最佳模型约20%。我们的项目页面是https://doublevisualdefense.github.io/。
Key Takeaways
- 该论文研究了视觉语言模型面对对抗性视觉扰动的鲁棒性。
- 论文提出了“双重视觉防御”策略以增强模型的鲁棒性。
- 与之前的方法不同,该研究采用大规模的对抗性视觉语言预训练。
- 通过引入对抗性视觉指令调整,进一步加强了模型的防御能力。
- $\Delta$CLIP和$\Delta^2$LLaVA模型显著提高了零样本鲁棒性,并在对抗性防御方面达到新的最佳水平。
- $\Delta$CLIP在ImageNet-1k上的对抗性鲁棒性优于之前的最佳模型约20%。
点此查看论文截图

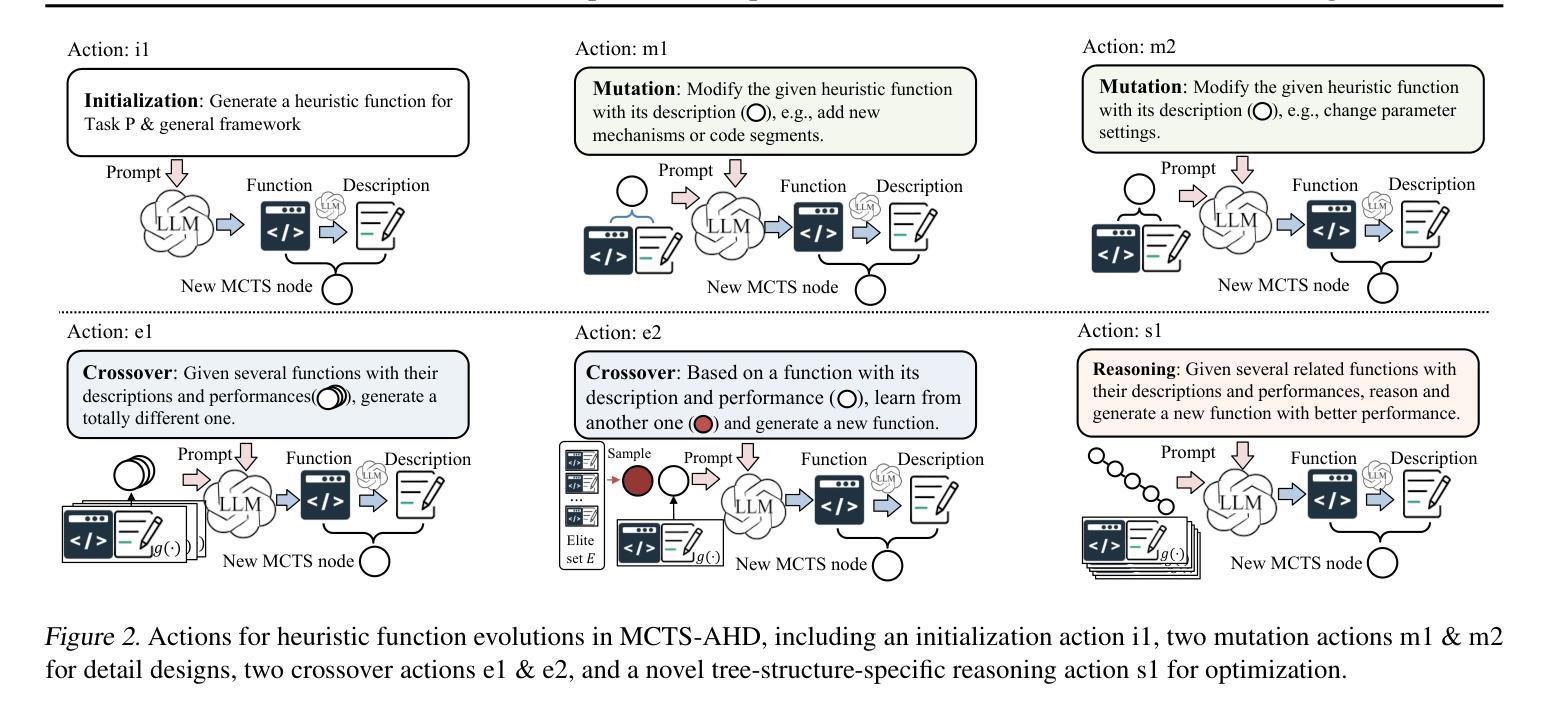
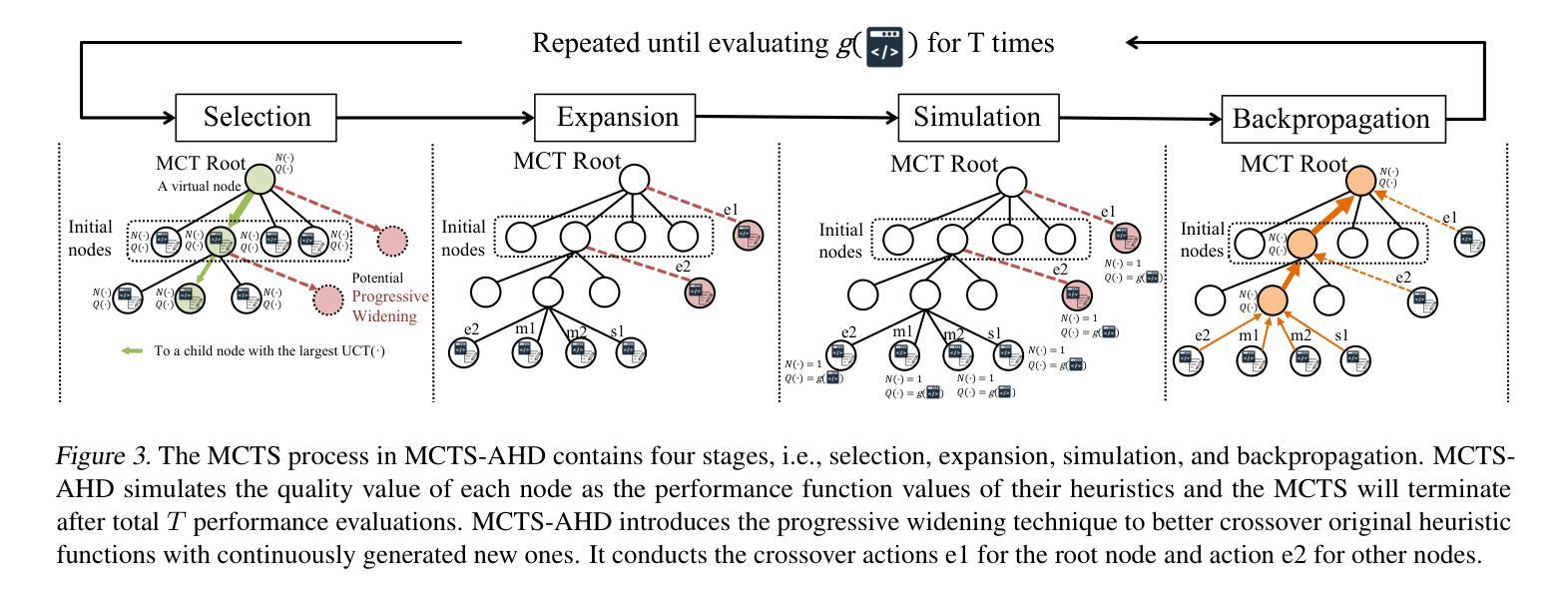
Monte Carlo Tree Search for Comprehensive Exploration in LLM-Based Automatic Heuristic Design
Authors:Zhi Zheng, Zhuoliang Xie, Zhenkun Wang, Bryan Hooi
Handcrafting heuristics for solving complex planning tasks (e.g., NP-hard combinatorial optimization (CO) problems) is a common practice but requires extensive domain knowledge. Recently, Large Language Model (LLM)-based automatic heuristics design (AHD) methods have shown promise in generating high-quality heuristics without manual intervention. Existing LLM-based AHD methods employ a population to maintain a fixed number of top-performing LLM-generated heuristics and introduce evolutionary computation (EC) to enhance the population iteratively. However, the population-based procedure brings greedy properties, often resulting in convergence to local optima. Instead, to more comprehensively explore the space of heuristics, we propose using Monte Carlo Tree Search (MCTS) for LLM-based heuristic evolution while preserving all LLM-generated heuristics in a tree structure. With a novel thought-alignment process and an exploration-decay technique, the proposed MCTS-AHD method delivers significantly higher-quality heuristics on various complex tasks. Our code is available at https://github.com/zz1358m/MCTS-AHD-master.
手动设计启发式方法来解决复杂的规划任务(例如NP难的组合优化问题)是一种常见的做法,但需要广泛的领域知识。最近,基于大型语言模型(LLM)的自动启发式设计(AHD)方法在生成高质量启发式方面显示出巨大潜力,无需人工干预。现有的基于LLM的AHD方法采用种群方式维持性能最佳的LLM生成启发式方法的数量,并引入进化计算(EC)来逐步增强种群。然而,基于种群的方法具有贪婪性,往往会导致收敛到局部最优解。相反,为了更全面地探索启发式方法的空间,我们提出使用蒙特卡洛树搜索(MCTS)来进行基于LLM的启发式方法演化,同时将所有由LLM生成的启发式方法保存在树结构中。通过一种新的思想对齐过程和探索衰减技术,所提出的MCTS-AHD方法在多种复杂任务上提供了更高质量的启发式方法。我们的代码可在https://github.com/zz1358m/MCTS-AHD-master找到。
论文及项目相关链接
Summary
大规模语言模型(LLM)自动启发式设计(AHD)是解决复杂规划任务的有效方法。虽然传统方法采用种群来维护最佳启发式,但存在局限性。本文提出使用蒙特卡洛树搜索(MCTS)进行LLM启发式进化,并将所有生成的启发式保存在树结构中。新方法提高了启发式质量,适用于多种复杂任务。相关代码已公开分享。
Key Takeaways
- LLM在启发式设计(AHD)领域展现出潜力,能够生成高质量启发式而无需人工干预。
- 传统LLM-based AHD方法使用种群维护最佳启发式,但可能陷入局部最优解。
- 提出使用蒙特卡洛树搜索(MCTS)进行LLM-based启发式进化,以更全面地探索启发式空间。
- 新方法通过思想对齐过程和探索衰减技术提高了启发式质量。
- MCTS-AHD方法在多种复杂任务中表现优异。
- 相关研究代码已公开分享,便于进一步研究和应用。
点此查看论文截图

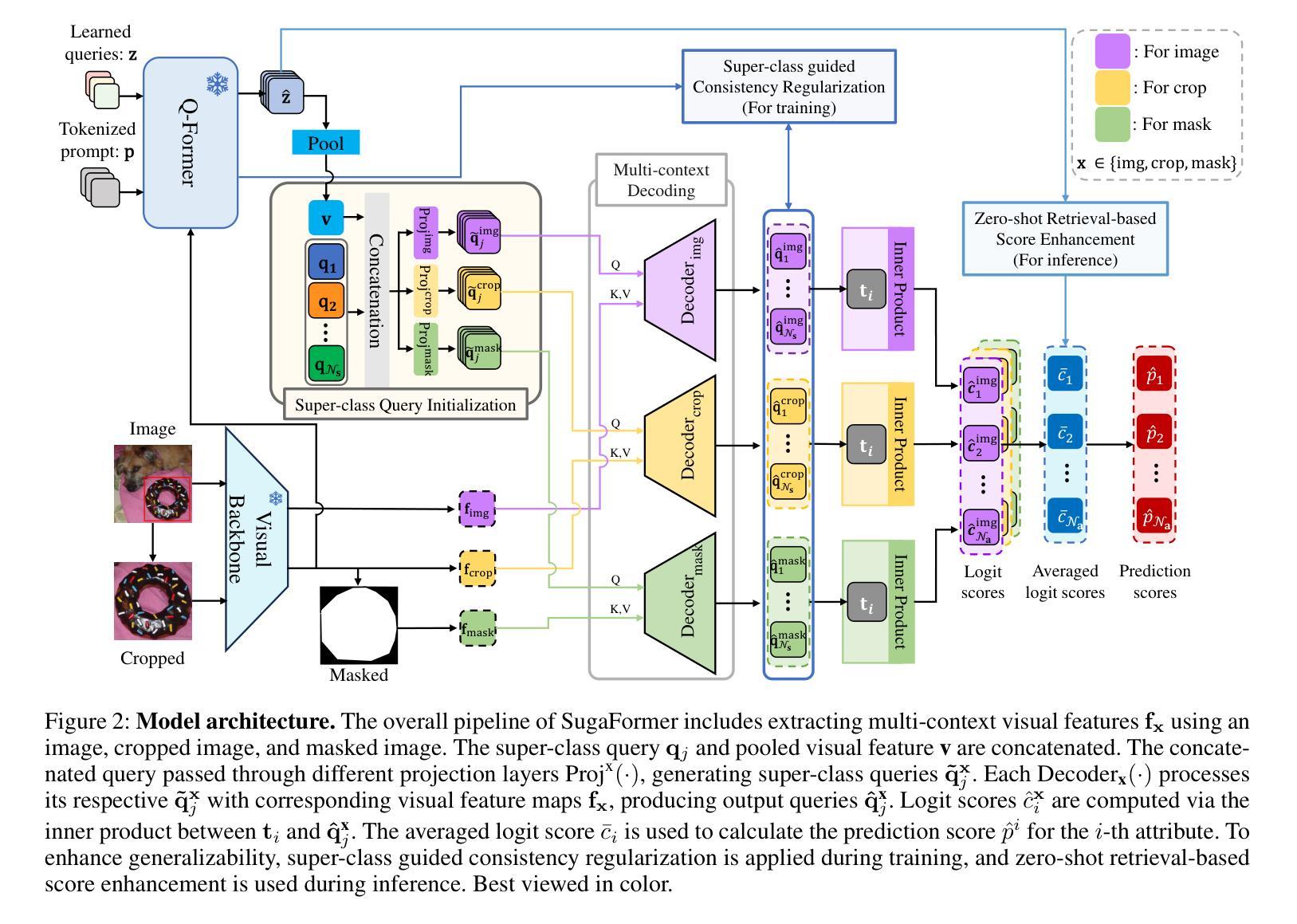
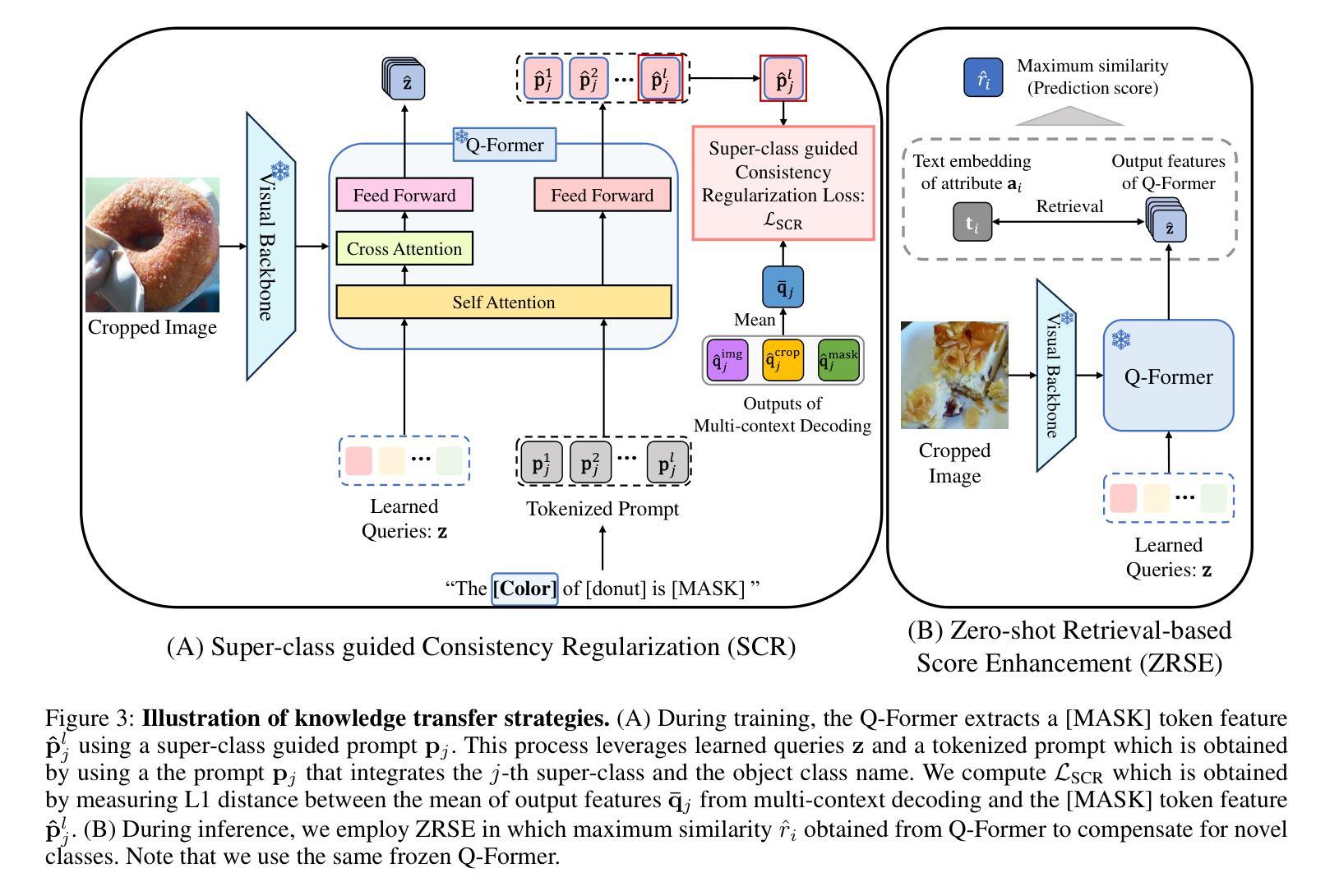
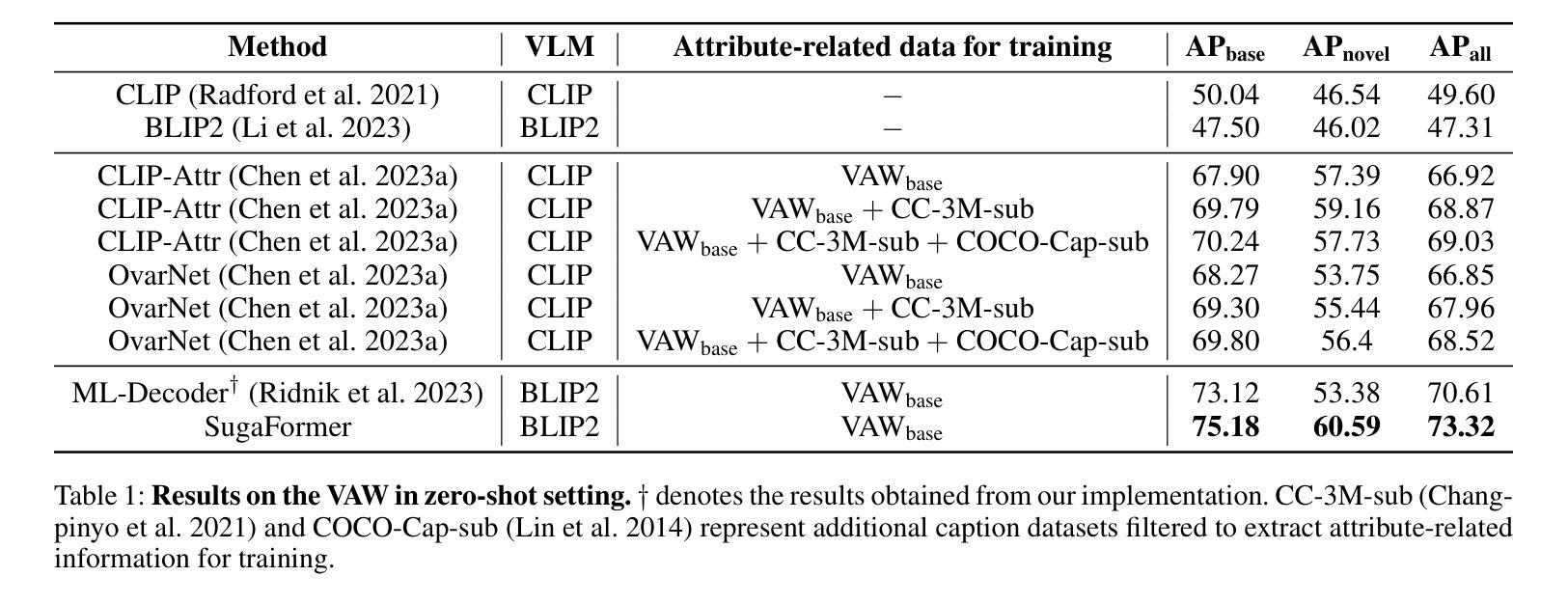
Super-class guided Transformer for Zero-Shot Attribute Classification
Authors:Sehyung Kim, Chanhyeong Yang, Jihwan Park, Taehoon Song, Hyunwoo J. Kim
Attribute classification is crucial for identifying specific characteristics within image regions. Vision-Language Models (VLMs) have been effective in zero-shot tasks by leveraging their general knowledge from large-scale datasets. Recent studies demonstrate that transformer-based models with class-wise queries can effectively address zero-shot multi-label classification. However, poor utilization of the relationship between seen and unseen attributes makes the model lack generalizability. Additionally, attribute classification generally involves many attributes, making maintaining the model’s scalability difficult. To address these issues, we propose Super-class guided transFormer (SugaFormer), a novel framework that leverages super-classes to enhance scalability and generalizability for zero-shot attribute classification. SugaFormer employs Super-class Query Initialization (SQI) to reduce the number of queries, utilizing common semantic information from super-classes, and incorporates Multi-context Decoding (MD) to handle diverse visual cues. To strengthen generalizability, we introduce two knowledge transfer strategies that utilize VLMs. During training, Super-class guided Consistency Regularization (SCR) aligns model’s features with VLMs using super-class guided prompts, and during inference, Zero-shot Retrieval-based Score Enhancement (ZRSE) refines predictions for unseen attributes. Extensive experiments demonstrate that SugaFormer achieves state-of-the-art performance across three widely-used attribute classification benchmarks under zero-shot, and cross-dataset transfer settings. Our code is available at https://github.com/mlvlab/SugaFormer.
属性分类对于识别图像区域内的特定特征至关重要。视觉语言模型(VLMs)通过利用大规模数据集的一般知识,在零样本任务中表现出色。最近的研究表明,基于transformer的具有类别查询的模型可以有效地解决零样本多标签分类问题。然而,可见和不可见属性之间关系利用不足使得模型缺乏泛化能力。此外,属性分类通常涉及许多属性,使得保持模型的可扩展性变得困难。为了解决这些问题,我们提出了Super-class guided transFormer(SugaFormer)这一新颖框架,利用超类增强零样本属性分类的可扩展性和泛化能力。SugaFormer采用Super-class Query Initialization(SQI)减少查询数量,利用超类的通用语义信息,并结合Multi-context Decoding(MD)处理多样的视觉线索。为了加强泛化能力,我们引入了两种利用VLMs的知识转移策略。在训练过程中,Super-class guided Consistency Regularization(SCR)通过超类引导提示将模型特征与VLMs对齐,而在推理过程中,Zero-shot Retrieval-based Score Enhancement(ZRSE)对未见过的属性预测进行细化。大量实验表明,SugaFormer在三个广泛使用的属性分类基准测试下实现了零样本和跨数据集迁移设置的最新性能。我们的代码可在https://github.com/mlvlab/SugaFormer找到。
论文及项目相关链接
PDF AAAI25
Summary
本文介绍了属性分类在识别图像区域特定特征中的重要性。尽管视觉语言模型(VLMs)在零样本任务中表现出色,但现有研究在解决零样本多标签分类时,未能充分利用已见和未见属性之间的关系,导致模型泛化性不足。为解决这些问题,提出了Super-class guided transFormer(SugaFormer)框架,通过利用超类增强零样本属性分类的扩展性和泛化性。该框架采用超级类查询初始化(SQI)减少查询数量,利用超级类的通用语义信息,并结合多上下文解码(MD)处理多样的视觉线索。此外,还引入两种利用VLMs的知识转移策略以增强泛化能力。在三个广泛使用的属性分类基准测试下,SugaFormer在零样本和跨数据集转移设置中实现了最佳性能。
Key Takeaways
- 属性分类是识别图像区域特定特征的关键。
- 视觉语言模型(VLMs)在零样本任务中表现良好,但在多标签分类中泛化性不足。
- SugaFormer框架通过利用超类增强零样本属性分类的泛化性和扩展性。
- SugaFormer采用超级类查询初始化和多上下文解码处理视觉信息。
- SugaFormer引入两种知识转移策略,利用VLMs增强泛化能力。
- SugaFormer在多个属性分类基准测试中实现最佳性能。
点此查看论文截图

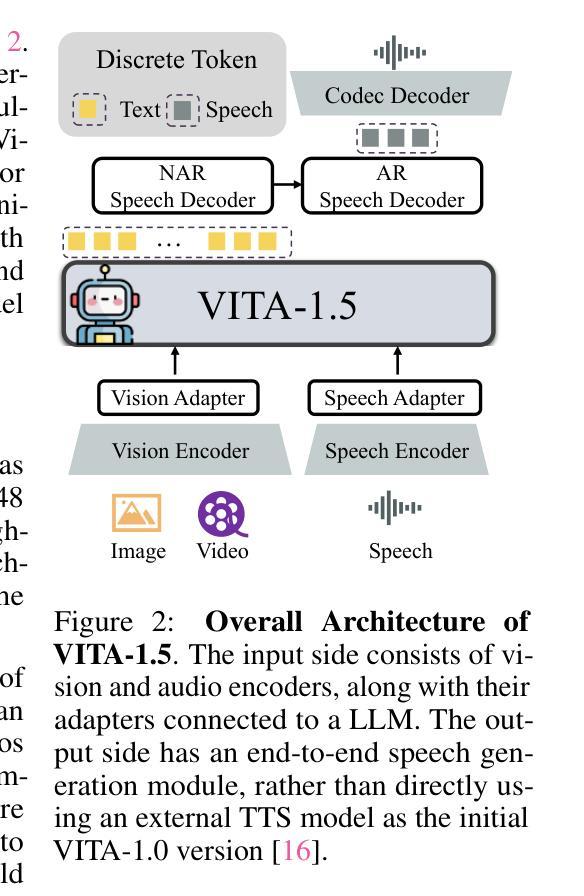
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Authors:Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, Ran He
Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
最近的跨模态大型语言模型(MLLM)主要集中于整合视觉和文本模态,对语音在增强交互中的作用重视不够。然而,语音在多模态对话系统中起着至关重要的作用,由于基本模态差异,在视觉和语音任务中实现高性能仍然是一个巨大的挑战。在本文中,我们提出了一种精心设计的多阶段训练方法论,逐步训练大型语言模型以理解视觉和语音信息,最终实现流畅的视觉和语音交互。我们的方法不仅保留了强大的视觉语言功能,还实现了高效的语音对话功能,无需使用单独的自动语音识别(ASR)和文本转语音(TTS)模块,从而显著加快了多模态端到端的响应速度。通过与图像、视频和语音任务的最新基准进行比较,我们证明了我们的模型拥有强大的视觉和语音功能,能够实现接近实时的视觉和语音交互。
论文及项目相关链接
PDF https://github.com/VITA-MLLM/VITA
Summary:
近期多模态大型语言模型(MLLMs)主要聚焦于整合视觉和文本模态,较少关注语音在增强交互中的作用。然而,语音在多模态对话系统中扮演关键角色,实现在视觉和语音任务中的高性能仍然是一个重大挑战,因为存在基本的模态差异。本文提出了一种精心设计的多阶段训练方法论,逐步训练大型语言模型以理解视觉和语音信息,最终实现流畅的视觉和语音交互。该方法不仅保留了强大的视觉语言功能,还能实现高效的语音对话能力,无需额外的自动语音识别和文本转语音模块,显著加快多模态端到端的响应速度。通过与图像、视频和语音任务的最新前沿模型进行对比,本文证明了该模型具备强大的视觉和语音功能,可实现近乎实时的视觉和语音交互。
Key Takeaways:
- MLLMs 在整合视觉和文本模态时较少关注语音的重要性。
- 实现视觉和语音任务的高性能是一个重大挑战,因为存在基本的模态差异。
- 提出了一种多阶段训练方法论来训练大型语言模型,以理解视觉和语音信息。
- 该方法实现了流畅的视觉和语音交互。
- 模型不仅具备强大的视觉语言功能,还能实现高效的语音对话能力。
- 模型无需额外的ASR和TTS模块即可实现语音交互,加快响应速度。
点此查看论文截图

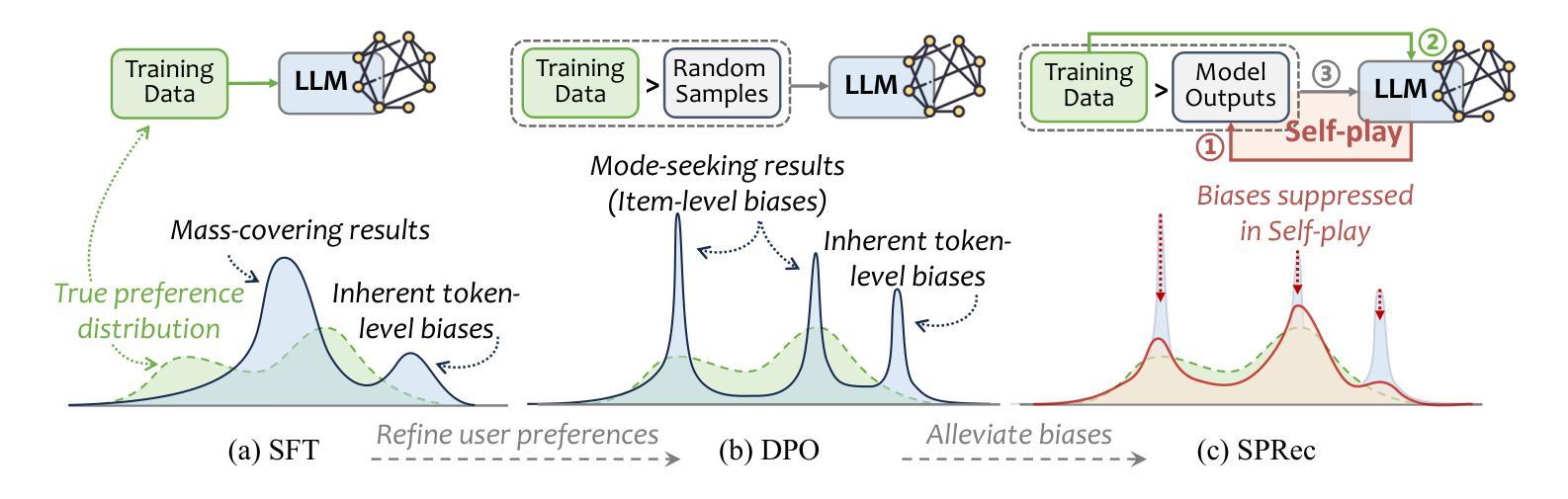
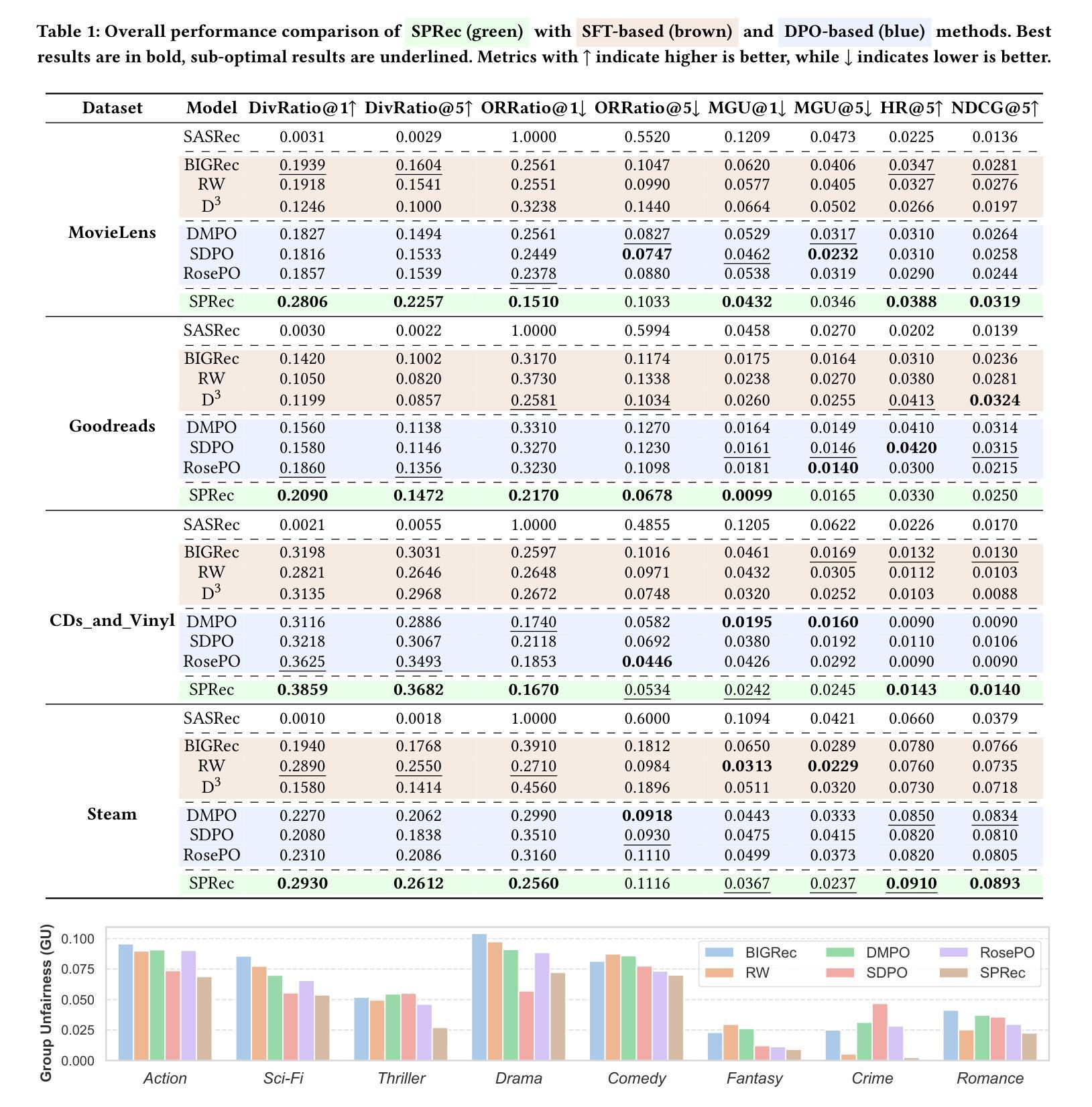
SPRec: Leveraging Self-Play to Debias Preference Alignment for Large Language Model-based Recommendations
Authors:Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, Xiangnan He
Large language models (LLMs) have attracted significant attention in recommendation systems. Current LLM-based recommender systems primarily rely on supervised fine-tuning (SFT) to train the model for recommendation tasks. However, relying solely on positive samples limits the model’s ability to align with user satisfaction and expectations. To address this, researchers have introduced Direct Preference Optimization (DPO), which explicitly aligns recommendations with user preferences using offline preference ranking data. Despite its advantages, our theoretical analysis reveals that DPO inherently biases the model towards a few items, exacerbating the filter bubble issue and ultimately degrading user experience. In this paper, we propose SPRec, a novel self-play recommendation framework designed to mitigate over-recommendation and improve fairness without requiring additional data or manual intervention. In each self-play iteration, the model undergoes an SFT step followed by a DPO step, treating offline interaction data as positive samples and the predicted outputs from the previous iteration as negative samples. This effectively re-weights the DPO loss function using the model’s logits, adaptively suppressing biased items. Extensive experiments on multiple real-world datasets demonstrate SPRec’s effectiveness in enhancing recommendation accuracy and addressing fairness concerns. The implementation is available via https://github.com/RegionCh/SPRec
大型语言模型(LLM)在推荐系统中引起了广泛关注。当前的基于LLM的推荐系统主要依赖于监督微调(SFT)来训练推荐任务模型。然而,仅依赖正面样本限制了模型与用户满意度和期望对齐的能力。为了解决这一问题,研究人员引入了直接偏好优化(DPO),它利用离线偏好排名数据显式地将推荐与用户偏好对齐。尽管DPO有其优势,但我们的理论分析表明,它天生会使模型偏向于少数物品,加剧了过滤泡沫问题,最终降低了用户体验。在本文中,我们提出了SPRec,这是一种新型的自玩推荐框架,旨在缓解过度推荐问题,提高公平性,而无需额外数据或人工干预。在每次自玩迭代中,模型会经历一个SFT步骤,然后是一个DPO步骤,将离线交互数据视为正面样本,而上一轮的预测输出视为负面样本。这有效地使用模型的逻辑重新加权DPO损失函数,自适应地抑制偏见物品。在多个真实世界数据集上的广泛实验证明了SPRec在提高推荐准确性和解决公平性问题方面的有效性。实现可通过https://github.com/RegionCh/SPRec获得。
论文及项目相关链接
Summary:LLM在推荐系统中的应用引起广泛关注。现有LLM推荐系统主要依赖监督微调(SFT)进行训练,但仅依赖正样本限制了模型与用户满意度和期望的契合度。研究者引入直接偏好优化(DPO)以利用离线偏好排名数据显式匹配用户偏好。然而,理论分析表明DPO会导致模型偏向少数物品,加剧滤镜泡沫问题并降低用户体验。本文提出SPRec,一种新型自我博弈推荐框架,旨在缓解过度推荐并改善公平性,无需额外数据或人工干预。SPRec通过迭代使用离线交互数据作为正样本,以及前一次迭代的预测输出作为负样本,自适应调整DPO损失函数权重。实验证明SPRec在提高推荐准确性和解决公平性问题方面有效。
Key Takeaways:
- LLM在推荐系统中的应用受到关注,但依赖监督微调(SFT)存在局限性。
- 直接偏好优化(DPO)能够利用用户偏好数据提高推荐效果。
- DPO可能导致模型偏向少数物品,加剧滤镜泡沫问题。
- SPRec框架旨在通过自我博弈方式缓解过度推荐问题并改善公平性。
- SPRec利用离线交互数据迭代更新模型,使用前一次迭代的预测输出作为负样本。
- SPRec通过自适应调整DPO损失函数权重,提高推荐准确性并解决公平性问题。
点此查看论文截图

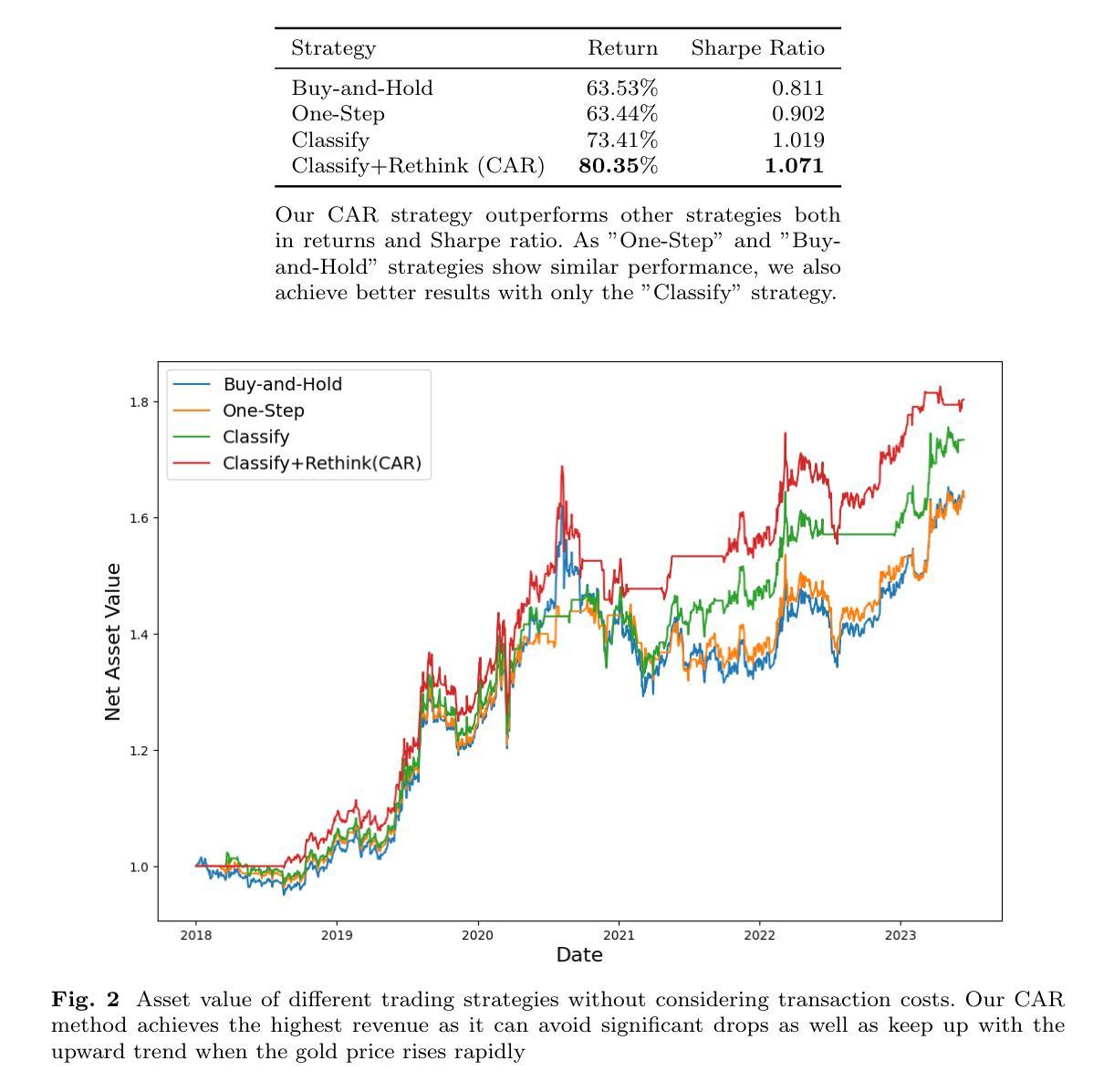
Can ChatGPT Overcome Behavioral Biases in the Financial Sector? Classify-and-Rethink: Multi-Step Zero-Shot Reasoning in the Gold Investment
Authors:Shuoling Liu, Gaoguo Jia, Yuhang Jiang, Liyuan Chen, Qiang Yang
Large Language Models (LLMs) have achieved remarkable success recently, displaying exceptional capabilities in creating understandable and organized text. These LLMs have been utilized in diverse fields, such as clinical research, where domain-specific models like Med-Palm have achieved human-level performance. Recently, researchers have employed advanced prompt engineering to enhance the general reasoning ability of LLMs. Despite the remarkable success of zero-shot Chain-of-Thoughts (CoT) in solving general reasoning tasks, the potential of these methods still remains paid limited attention in the financial reasoning task.To address this issue, we explore multiple prompt strategies and incorporated semantic news information to improve LLMs’ performance on financial reasoning tasks.To the best of our knowledge, we are the first to explore this important issue by applying ChatGPT to the gold investment.In this work, our aim is to investigate the financial reasoning capabilities of LLMs and their capacity to generate logical and persuasive investment opinions. We will use ChatGPT, one of the most powerful LLMs recently, and prompt engineering to achieve this goal. Our research will focus on understanding the ability of LLMs in sophisticated analysis and reasoning within the context of investment decision-making. Our study finds that ChatGPT with CoT prompt can provide more explainable predictions and overcome behavioral biases, which is crucial in finance-related tasks and can achieve higher investment returns.
大型语言模型(LLM)最近取得了显著的成就,展现出在创建可理解和有组织的文本方面的卓越能力。这些LLM已被应用于多个领域,如临床研究,其中特定领域的模型(如Med-Palm)已达到了人类水平的性能。最近,研究人员采用先进的提示工程来增强LLM的一般推理能力。尽管零镜头链思维(CoT)在解决一般推理任务方面取得了显著成功,但这些方法在财务推理任务中的潜力仍然受到的关注有限。
为了解决这一问题,我们探索了多种提示策略并融入了语义新闻信息,以提高LLM在财务推理任务上的性能。据我们所知,我们是第一个将ChatGPT应用于黄金投资来探索这一重要问题。
论文及项目相关链接
Summary
大型语言模型(LLM)在创建可理解和组织化的文本方面取得了显著的成功,并在临床研域等领域得到应用。最近,研究人员通过先进的提示工程技术增强了LLM的一般推理能力。尽管零样本链思维(CoT)在解决一般推理任务中表现出色,但其在金融推理任务中的潜力仍未得到充分关注。本研究旨在探索将ChatGPT等LLM应用于金融推理的能力,并关注其在投资决策中的复杂分析和推理能力。研究发现,带有CoT提示的ChatGPT可以提供更可解释的预测,并克服行为偏见,实现更高的投资回报。
Key Takeaways
- LLMs已在多个领域取得显著成功,包括临床研究和金融领域。
- 通过先进的提示工程技术,LLM的推理能力得到了增强。
- 零样本链思维(CoT)在一般推理任务中表现出良好的性能,但在金融推理任务中的潜力尚未得到充分研究。
- 本研究首次将ChatGPT应用于金融投资领域,探索其在金融推理方面的能力。
- 使用ChatGPT和CoT提示可以提供更可解释的预测,这在金融任务中至关重要。
- LLMs能够克服人类行为偏见,实现更高的投资回报。
点此查看论文截图


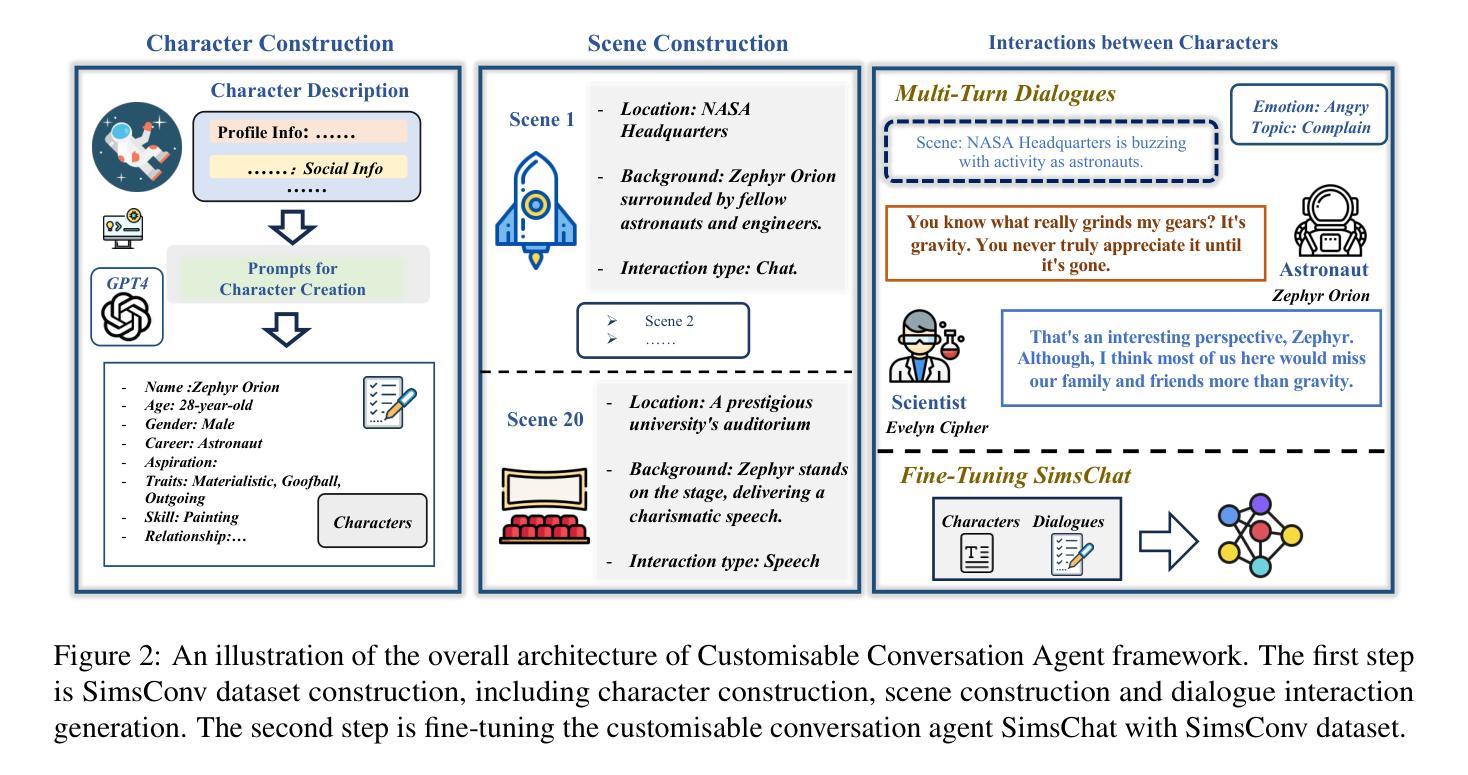
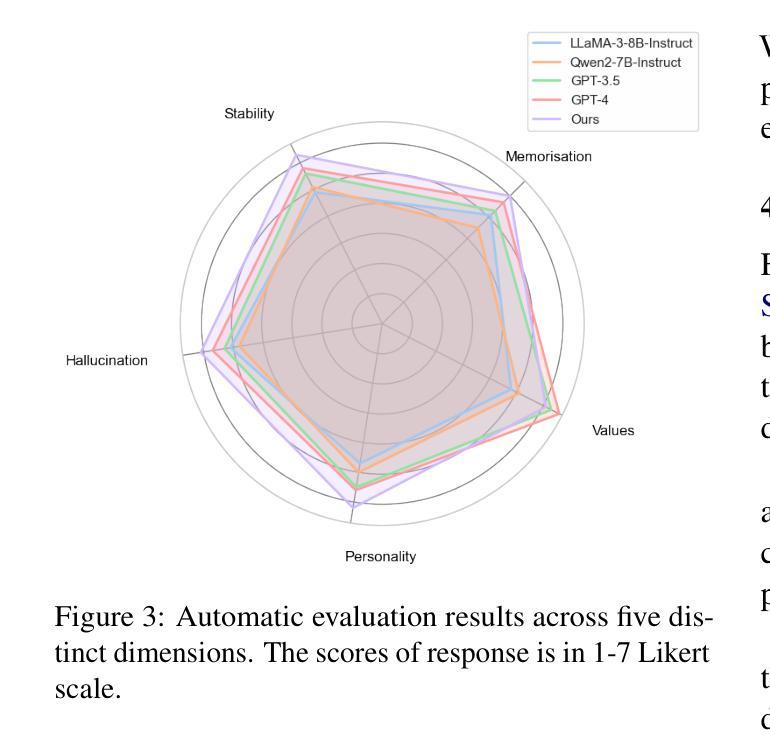
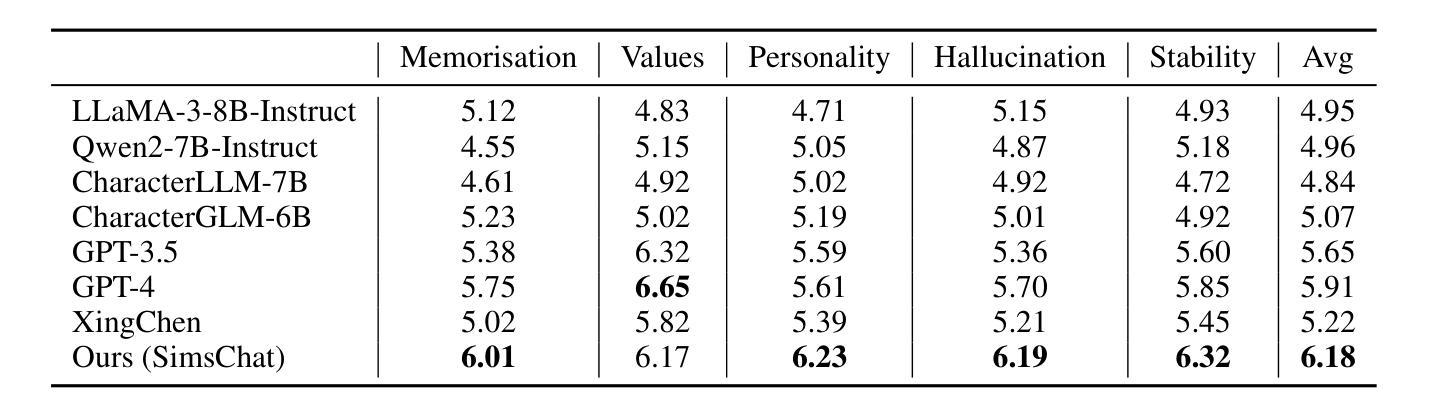
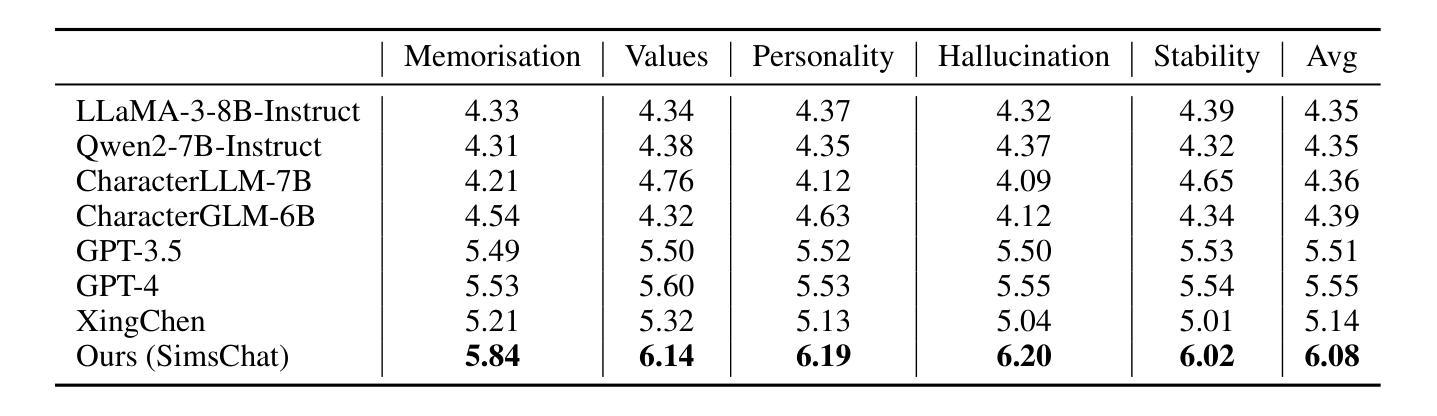
Crafting Customisable Characters with LLMs: Introducing SimsChat, a Persona-Driven Role-Playing Agent Framework
Authors:Bohao Yang, Dong Liu, Chenghao Xiao, Kun Zhao, Chen Tang, Chao Li, Lin Yuan, Guang Yang, Lanxiao Huang, Chenghua Lin
Large Language Models (LLMs) demonstrate remarkable ability to comprehend instructions and generate human-like text, enabling sophisticated agent simulation beyond basic behavior replication. However, the potential for creating freely customisable characters remains underexplored. We introduce the Customisable Conversation Agent Framework, which employs LLMs to simulate real-world characters through personalised characteristic feature injection, enabling diverse character creation according to user preferences. We propose the SimsConv dataset, comprising 68 customised characters and 13,971 multi-turn role-playing dialogues across 1,360 real-world scenes. Characters are initially customised using pre-defined elements (career, aspiration, traits, skills), then expanded through personal and social profiles. Building on this, we present SimsChat, a freely customisable role-playing agent incorporating various realistic settings and topic-specified character interactions. Experimental results on both SimsConv and WikiRoleEval datasets demonstrate SimsChat’s superior performance in maintaining character consistency, knowledge accuracy, and appropriate question rejection compared to existing models. Our framework provides valuable insights for developing more accurate and customisable human simulacra. Our data and code are publicly available at https://github.com/Bernard-Yang/SimsChat.
大型语言模型(LLM)表现出令人瞩目的理解和执行指令的能力,以及生成类似人类的文本,能够实现超越基本行为复制的复杂代理模拟。然而,创建可自由定制角色的潜力尚未得到充分探索。我们引入了可定制对话代理框架,该框架采用LLM通过个性化特征注入模拟现实世界角色,并根据用户偏好实现多样化角色创建。我们提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个现实场景的多轮角色扮演对话。角色最初使用预定义元素(职业、志向、特质、技能)进行定制,然后通过个人和社会概况进行扩展。在此基础上,我们推出了SimsChat,一个可自由定制的角色扮演代理,包含各种现实设置和主题特定的角色交互。在SimsConv和WikiRoleEval数据集上的实验结果证明了SimsChat在保持角色一致性、知识准确性和适当问题拒绝方面的性能优于现有模型。我们的框架为开发更准确、可定制的人类模拟物提供了宝贵的见解。我们的数据和代码可在https://github.com/Bernard-Yang/SimsChat公开访问。
论文及项目相关链接
Summary
大型语言模型(LLM)具备理解指令和生成类似人类文本的能力,可以实现超越基本行为复制的复杂代理模拟。然而,创建可自由定制角色的潜力尚未得到充分探索。本文介绍了可定制对话代理框架,该框架利用LLM模拟真实世界角色,通过个性化特征注入实现根据用户偏好创建多样化角色。本文还提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个真实场景的多轮角色扮演对话。通过SimsChat这一可自由定制的角色扮演代理,结合各种现实场景和主题特定的角色交互,实验结果表明SimsChat在保持角色一致性、知识准确性和适当的问题拒绝方面优于现有模型。该框架为开发更准确和可定制的人类模拟体提供了有价值的见解。
Key Takeaways
- LLM具备理解和生成类似人类文本的能力,可实现复杂代理模拟。
- 创建可自由定制角色的潜力尚未充分探索。
- 介绍了可定制对话代理框架,利用LLM模拟真实世界角色,实现角色个性化定制。
- 提出了SimsConv数据集,包含自定义角色和跨真实场景的多轮角色扮演对话。
- SimsChat是自由可定制的角色扮演代理,结合现实场景和主题特定的角色交互。
- 实验结果表明SimsChat在角色一致性、知识准确性和问题拒绝方面优于现有模型。
点此查看论文截图



Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Authors:Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Rühle, Saravan Rajmohan
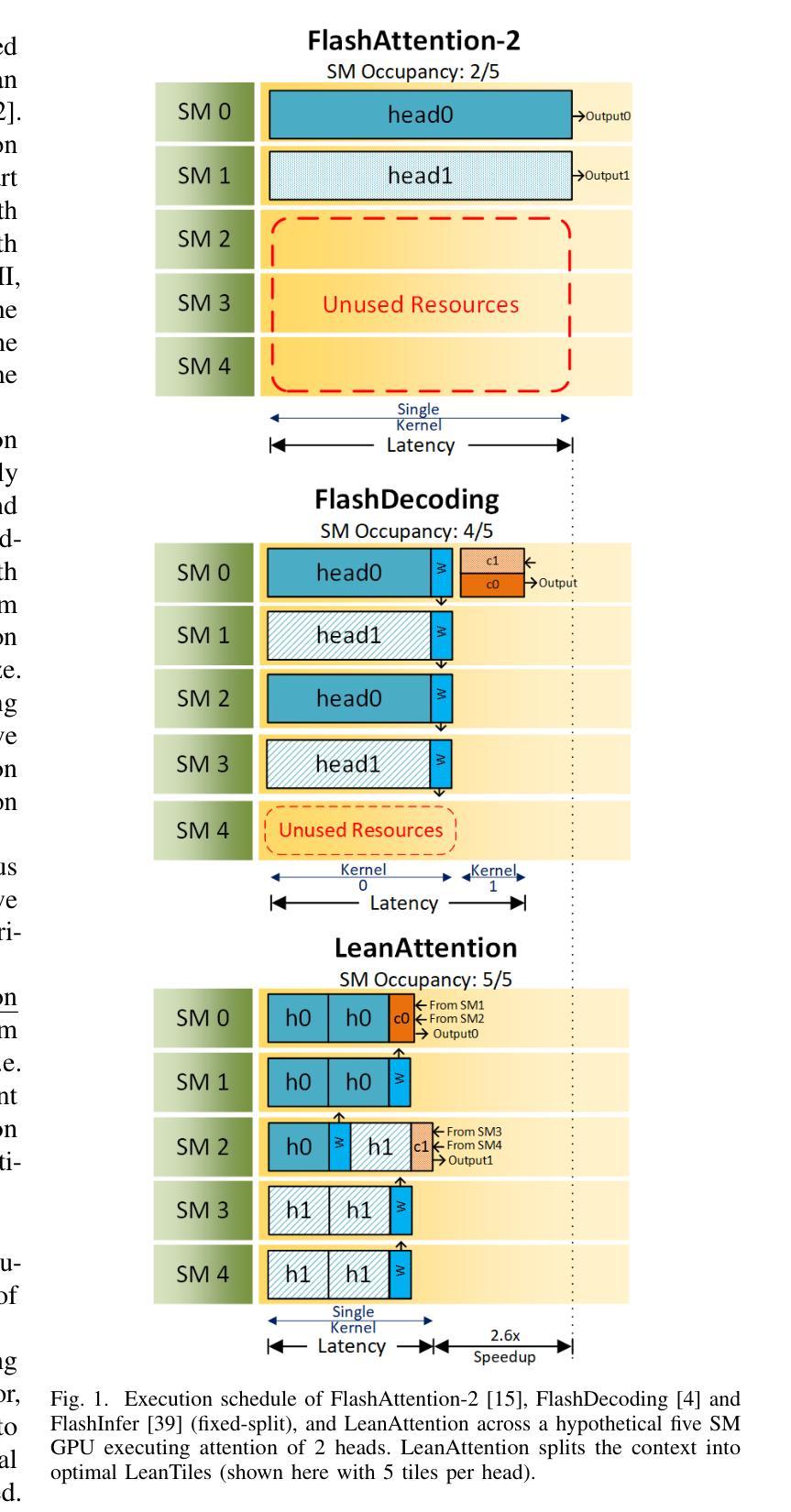
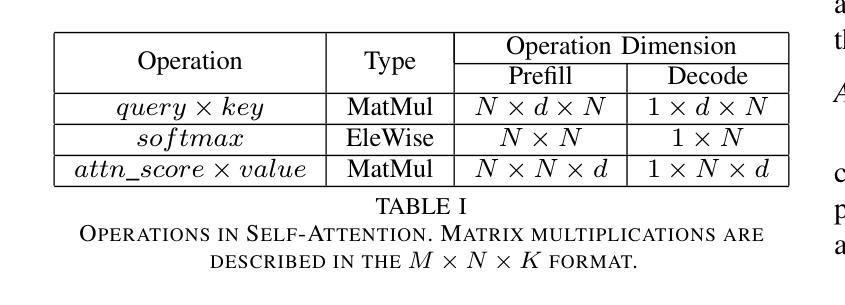
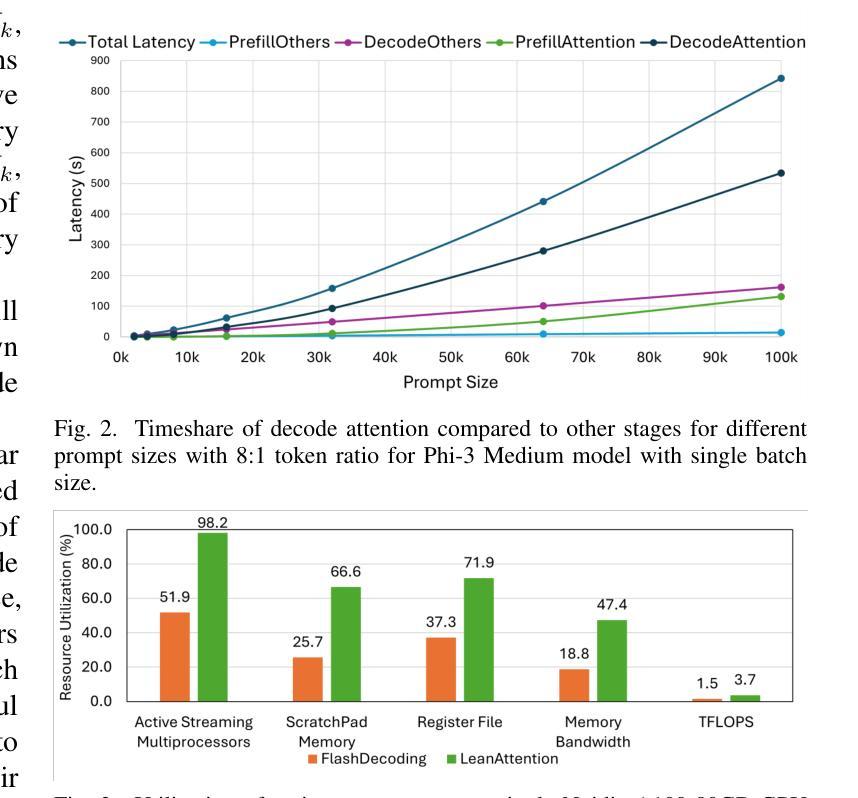
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the “stream-K” style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
基于Transformer的模型已成为自然语言处理、自然语言生成和图像生成领域最广泛使用的架构之一。最先进的模型规模持续增大,已达到数十亿参数。这些大型模型需要大量内存,即使在先进的AI加速器(如GPU)上也会产生显著的推理延迟。具体来说,注意力操作的时间和内存复杂度与总上下文长度成二次方关系,即提示和输出令牌。因此,已经提出了键值张量缓存和FlashAttention计算等优化措施,以满足依赖这些大型模型的应用程序的低延迟需求。然而,这些技术并不适应推理过程中不同阶段的计算特性。为此,我们提出了LeanAttention,这是一种用于解码器仅解码器transformer模型的令牌生成阶段(解码阶段)的自注意力计算的可扩展技术。LeanAttention通过重新设计解码阶段的执行流程,实现了对长上下文情况下注意力机制的缩放。我们发现在线softmax的关联属性可以视为归约操作,从而允许我们在这些长上下文上并行计算注意力。我们将“流K”风格的平铺计算归约扩展到自注意力,以实现并行计算,相对于FlashAttention-2实现平均2.6倍的注意力执行速度提升,对于512k的上下文长度甚至达到8.33倍的速度提升。
论文及项目相关链接
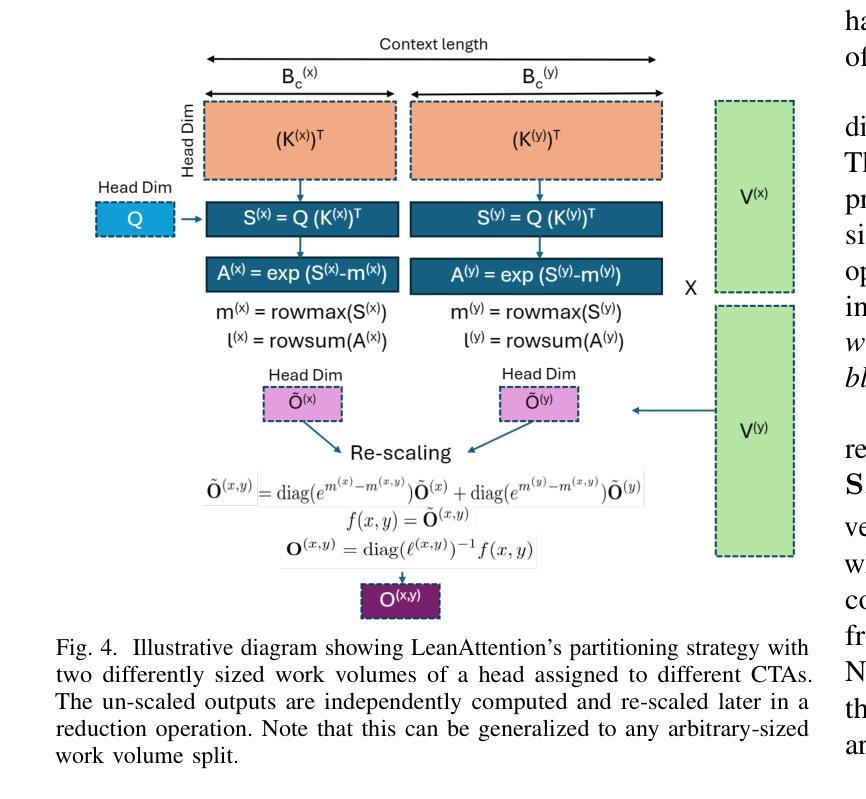
PDF 13 pages, 10 figures
Summary
本文介绍了Transformer模型在自然语言处理、自然语言生成和图像生成等领域中的广泛应用。针对大型Transformer模型在推理过程中面临的内存消耗大、延迟高的问题,提出了一种名为LeanAttention的可扩展自注意力计算方法。该方法针对解码阶段的token生成阶段进行优化,通过重新设计执行流程,实现对长上下文情况下注意力机制的扩展。利用在线softmax的关联属性,将其视为归约操作,从而允许在大上下文长度上并行计算注意力。实验结果表明,LeanAttention在大型上下文长度下实现了显著的速度提升。
Key Takeaways
- Transformer模型在自然语言处理和图像生成领域广泛应用,但大型模型面临内存消耗大、延迟高的问题。
- 现有优化技术如键值张量缓存和FlashAttention计算不能满足推理过程中不同阶段的计算特点。
- LeanAttention提出了一种可扩展的自注意力计算方法,针对解码阶段的token生成进行优化。
- LeanAttention通过重新设计执行流程,实现对长上下文情况下注意力机制的扩展。
- 利用在线softmax的关联属性,将其视为归约操作,允许在大上下文长度上并行计算注意力。
- LeanAttention相比FlashAttention-2实现了平均2.6倍的速度提升,对于512k的上下文长度实现了最高8.33倍的速度提升。
点此查看论文截图

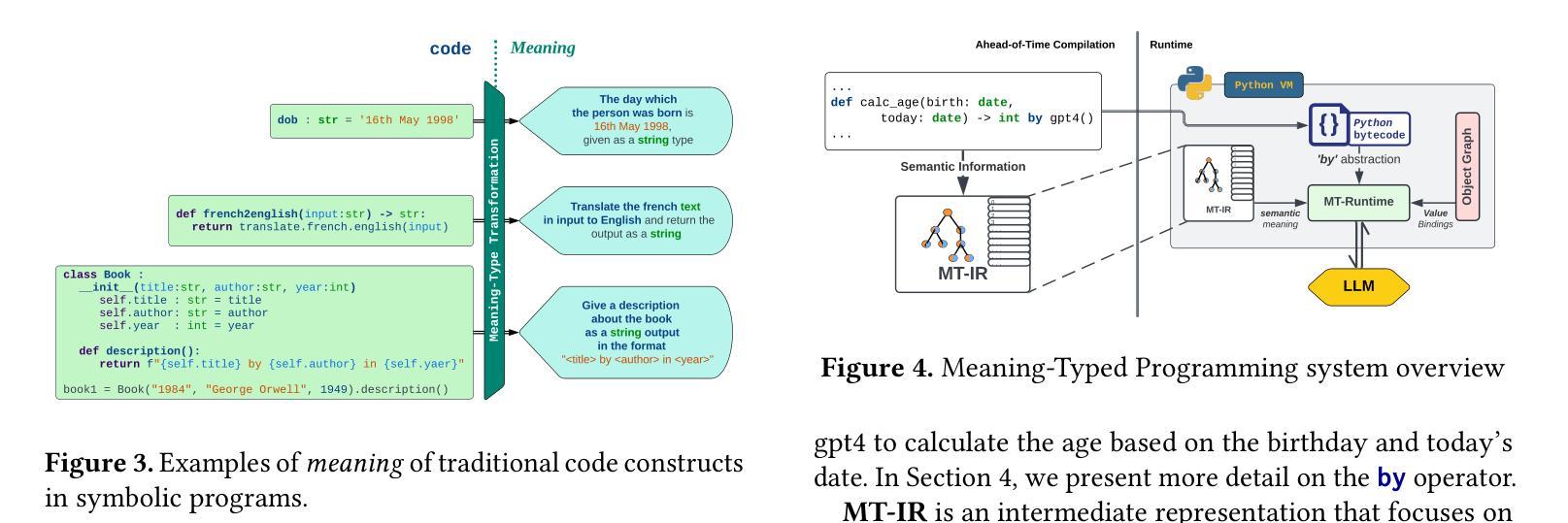
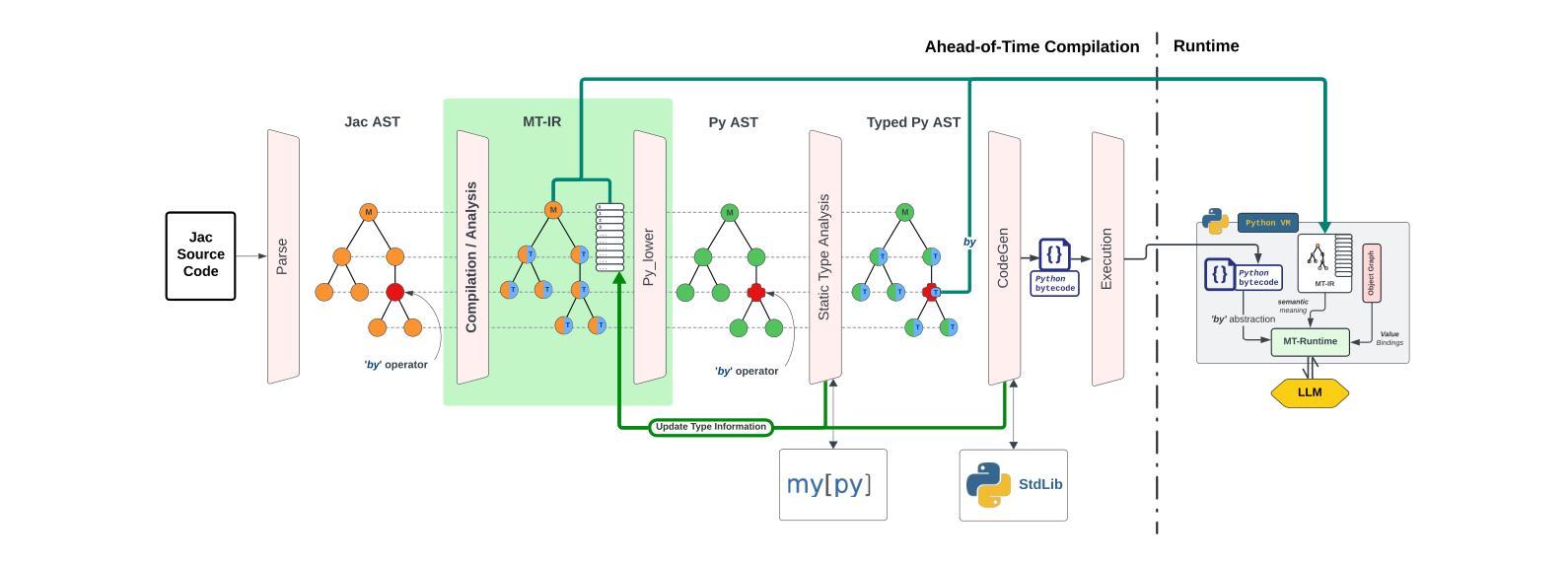
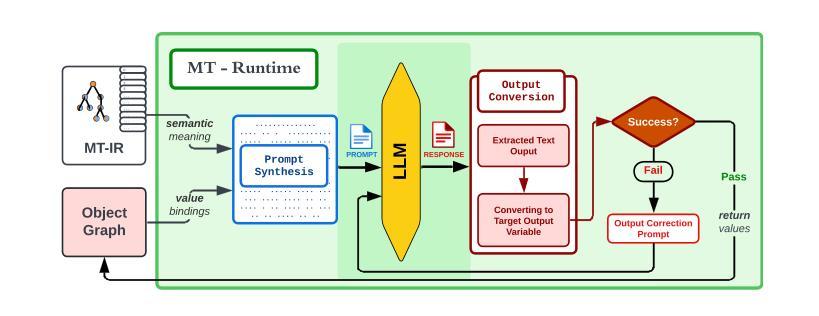
Meaning-Typed Programming: Language-level Abstractions and Runtime for GenAI Applications
Authors:Jason Mars, Yiping Kang, Jayanaka L. Dantanarayana, Kugesan Sivasothynathan, Christopher Clarke, Baichuan Li, Krisztian Flautner, Lingjia Tang
Software is rapidly evolving from being programmed with traditional logical code, to neuro-integrated applications that leverage generative AI and large language models (LLMs) for application functionality. This shift increases the complexity of building applications, as developers now must reasoning about, program, and prompt LLMs. Despite efforts to create tools to assist with prompt engineering, these solutions often introduce additional layers of complexity to the development of neuro-integrated applications. This paper proposes meaning-typed programming (MTP), a novel approach to simplify the creation of neuro-integrated applications by introducing new language-level abstractions that hide the complexities of LLM integration. Our key insight is that typical conventional code already possesses a high level of semantic richness that can be automatically reasoned about, as it is designed to be readable and maintainable by humans. Leveraging this insight, we conceptualize LLMs as meaning-typed code constructs and introduce a by abstraction at the language level, MT-IR, a new meaning-based intermediate representation at the compiler level, and MT Runtime, an automated run-time engine for LLM integration and operations. We implement MTP in a production-grade Python super-set language called Jac and perform an extensive evaluation. Our results demonstrate that MTP not only simplifies the development process but also meets or exceeds the efficacy of state-of-the-art manual and tool-assisted prompt engineering techniques in terms of accuracy and usability.
软件正从使用传统逻辑代码编程迅速演变为利用生成式人工智能和大型语言模型(LLM)的神经集成应用程序。这一转变增加了构建应用程序的复杂性,因为开发者现在必须理解、编程和提示LLM。尽管有创建辅助提示工程的工具的努力,但这些解决方案往往为神经集成应用程序的开发增加了额外的复杂层。
论文及项目相关链接
Summary
在现代软件开发中,逻辑编程正逐渐转向以生成式人工智能和大语言模型(LLM)为核心的神经集成应用。然而,这增加了开发复杂性。本文提出意义类型编程(MTP),通过引入新的语言级抽象来简化神经集成应用的创建,隐藏LLM集成的复杂性。研究的关键见解在于利用传统代码的高语义丰富性,将LLM视为意义类型代码构造。通过编译器级别的意义基础中间表示(MT-IR)和自动化运行时引擎(MT Runtime),实现了MTP。在Python超集语言Jac中的实现并进行评估表明,MTP不仅简化了开发过程,而且在准确性和可用性方面达到或超过了最新手动和工具辅助提示工程技术的效果。
Key Takeaways
- 软件正在从逻辑编程向利用生成式人工智能和大语言模型(LLM)的神经集成应用转变。
- 这种转变增加了开发复杂性,需要开发者理解和操作LLM。
- 当前工具在辅助提示工程时,可能引入额外的复杂性。
- 提出意义类型编程(MTP)来简化神经集成应用的开发。
- MTP利用传统代码的高语义丰富性,将LLM视为意义类型代码构造。
- 通过引入新的语言级抽象(如MT-IR和MT Runtime),实现了MTP。
点此查看论文截图




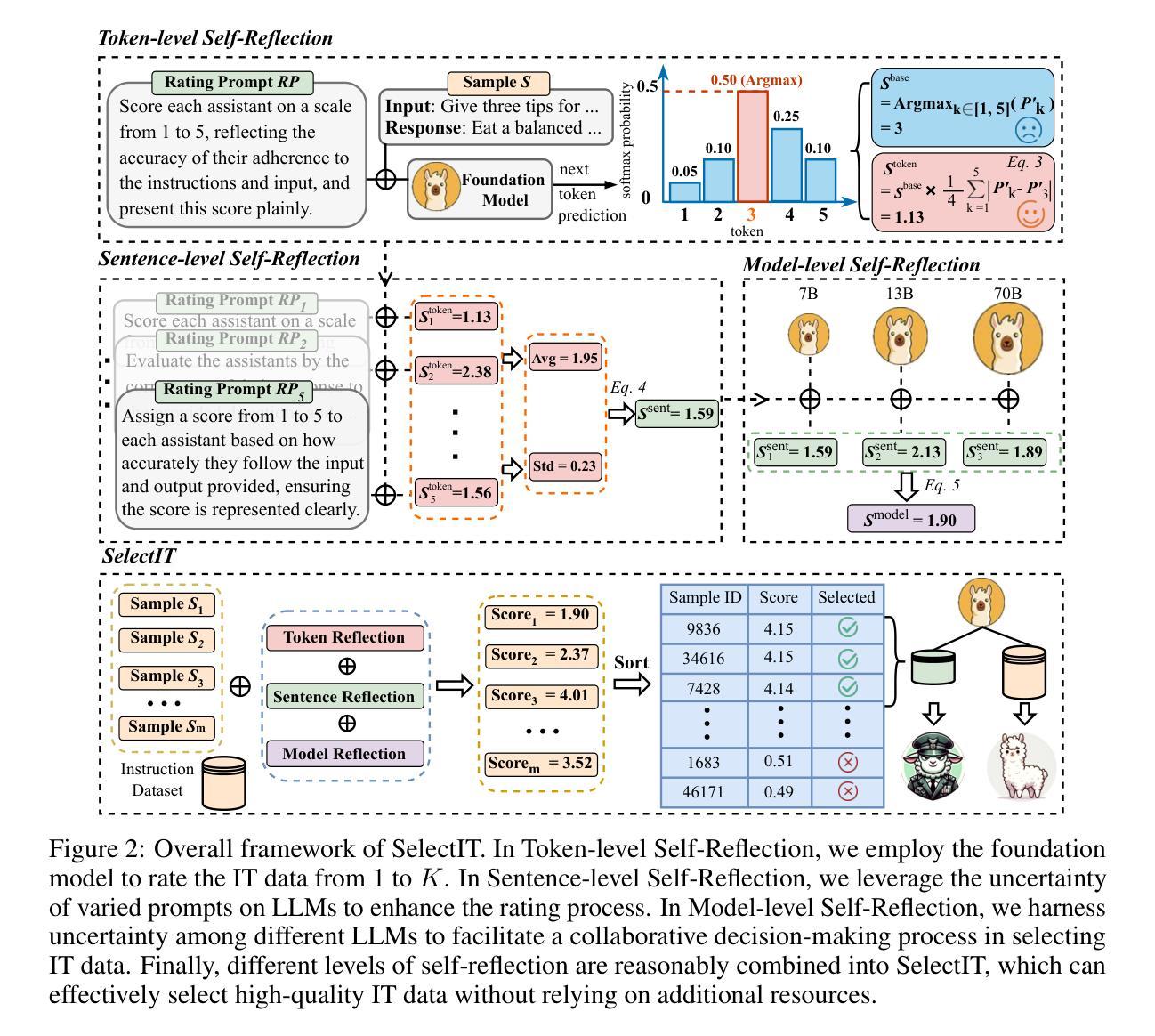
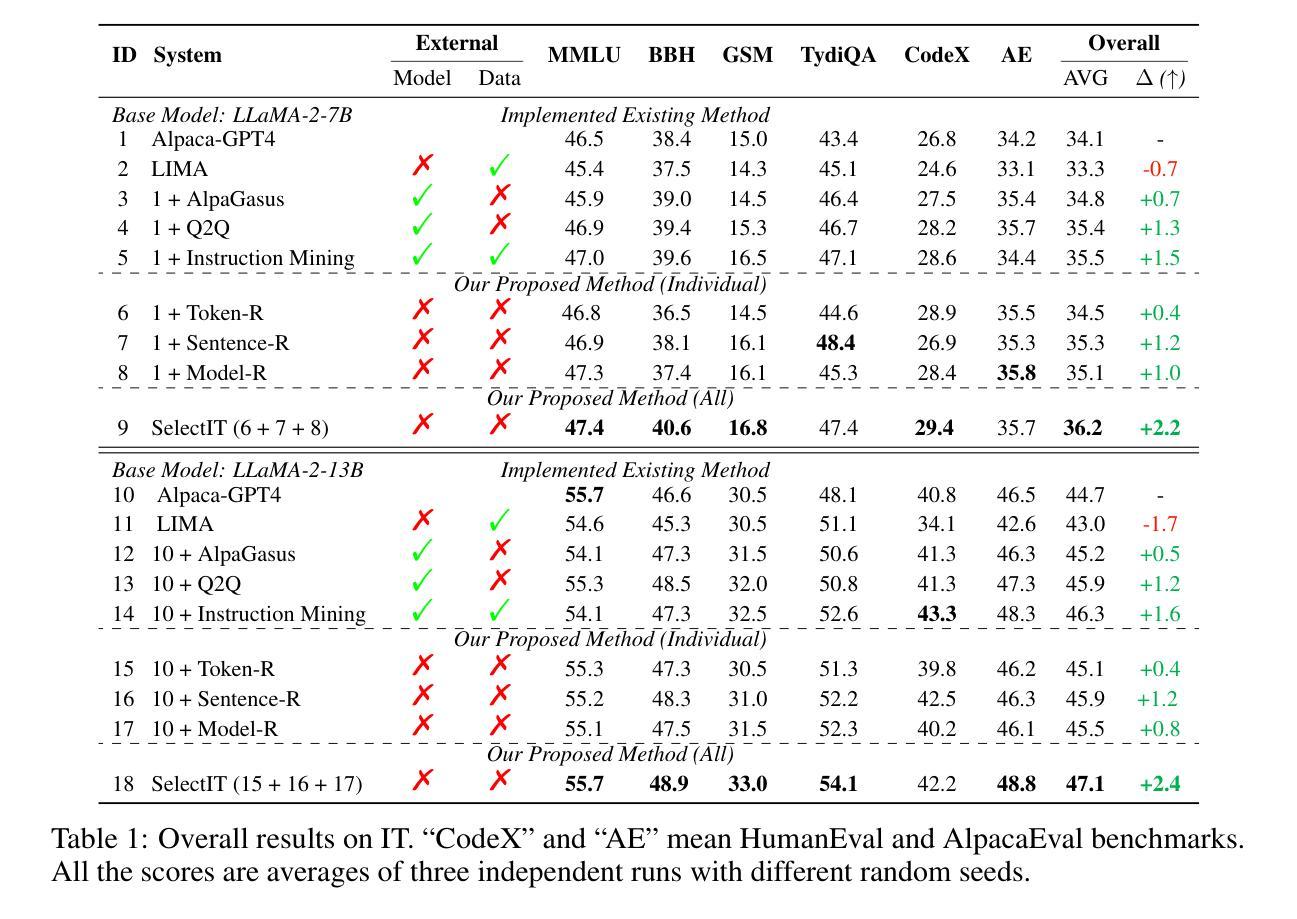
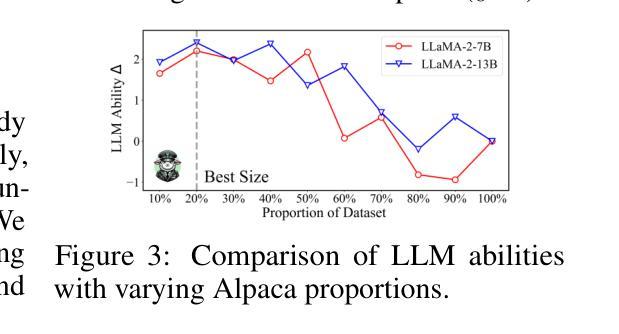
SelectIT: Selective Instruction Tuning for LLMs via Uncertainty-Aware Self-Reflection
Authors:Liangxin Liu, Xuebo Liu, Derek F. Wong, Dongfang Li, Ziyi Wang, Baotian Hu, Min Zhang
Instruction tuning (IT) is crucial to tailoring large language models (LLMs) towards human-centric interactions. Recent advancements have shown that the careful selection of a small, high-quality subset of IT data can significantly enhance the performance of LLMs. Despite this, common approaches often rely on additional models or data, which increases costs and limits widespread adoption. In this work, we propose a novel approach, termed SelectIT, that capitalizes on the foundational capabilities of the LLM itself. Specifically, we exploit the intrinsic uncertainty present in LLMs to more effectively select high-quality IT data, without the need for extra resources. Furthermore, we introduce a curated IT dataset, the Selective Alpaca, created by applying SelectIT to the Alpaca-GPT4 dataset. Empirical results demonstrate that IT using Selective Alpaca leads to substantial model ability enhancement. The robustness of SelectIT has also been corroborated in various foundation models and domain-specific tasks. Our findings suggest that longer and more computationally intensive IT data may serve as superior sources of IT, offering valuable insights for future research in this area. Data, code, and scripts are freely available at https://github.com/Blue-Raincoat/SelectIT.
指令微调(IT)对于针对人类中心交互的大型语言模型(LLM)定制至关重要。最近的进展表明,仔细选择一小部分高质量的IT数据可以显著提高LLM的性能。尽管如此,常见的方法往往依赖于额外的模型或数据,这增加了成本并限制了广泛应用。在这项工作中,我们提出了一种新方法,称为SelectIT,它利用LLM本身的基础能力。具体来说,我们利用LLM中存在的内在不确定性来更有效地选择高质量的IT数据,无需额外的资源。此外,我们通过将SelectIT应用于Alpaca-GPT4数据集,引入了一个精选的IT数据集Selective Alpaca。经验结果表明,使用Selective Alpaca的IT大大提高了模型的能力。SelectIT在各种基础模型和特定领域任务中的稳健性也得到了证实。我们的研究结果表明,更长和计算上更密集的IT数据可能作为IT的优质来源,为这一领域的未来研究提供了宝贵的见解。数据、代码和脚本可在https://github.com/Blue-Raincoat/SelectIT免费获取。
论文及项目相关链接
PDF Accepted to NeurIPS 2024
Summary
大型语言模型(LLM)在指令微调(IT)下能更好地进行人类交互。研究表明,选择高质量的小型IT数据集能有效提升LLM性能。但现有方法常依赖额外模型或数据,导致成本增加并限制了普及。本研究提出了一种新方法SelectIT,利用LLM的基础能力来选择高质量的IT数据,无需额外资源。我们还通过SelectIT方法创建了Selective Alpaca数据集,并证明其能显著提升模型能力。SelectIT在多种基础模型和领域特定任务中表现出稳健性。研究指出,长且计算密集的IT数据可能是更优的IT来源,为未来的研究提供了宝贵启示。
Key Takeaways
- 指令微调(IT)对大型语言模型(LLM)进行人类交互至关重要。
- 选择高质量的小型IT数据集能显著提升LLM性能。
- 现有方法常依赖额外资源,SelectIT方法利用LLM的基础能力选择IT数据,无需额外资源。
- 通过SelectIT方法创建了Selective Alpaca数据集,表现优异。
- SelectIT在多种模型和任务中表现出稳健性。
- 更长、计算密集的IT数据可能是更优的IT来源。
点此查看论文截图