⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
PIER: A Novel Metric for Evaluating What Matters in Code-Switching
Authors:Enes Yavuz Ugan, Ngoc-Quan Pham, Leonard Bärmann, Alex Waibel
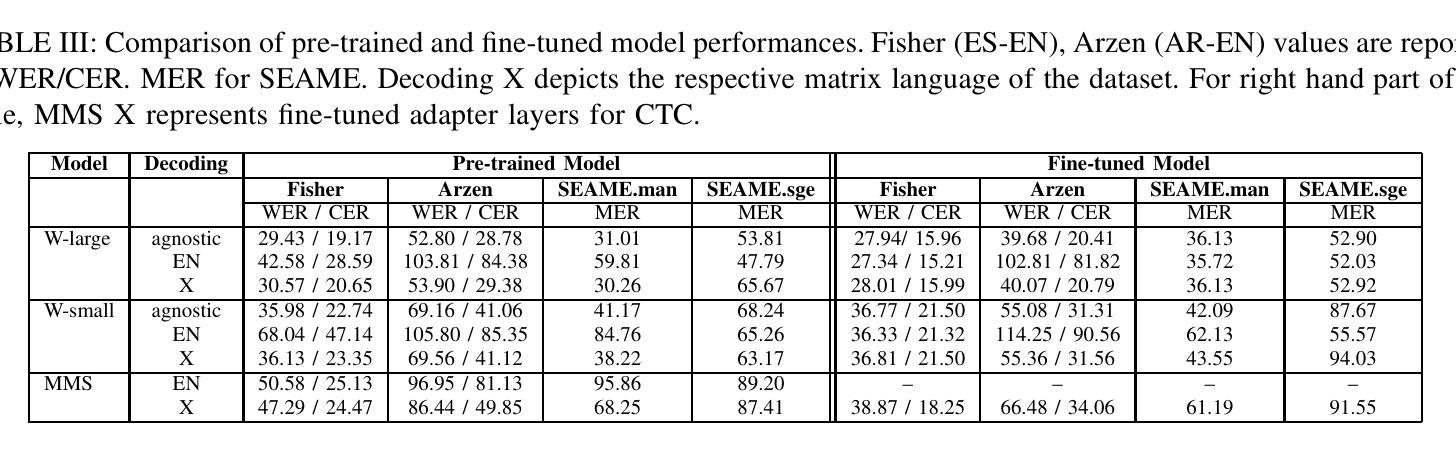
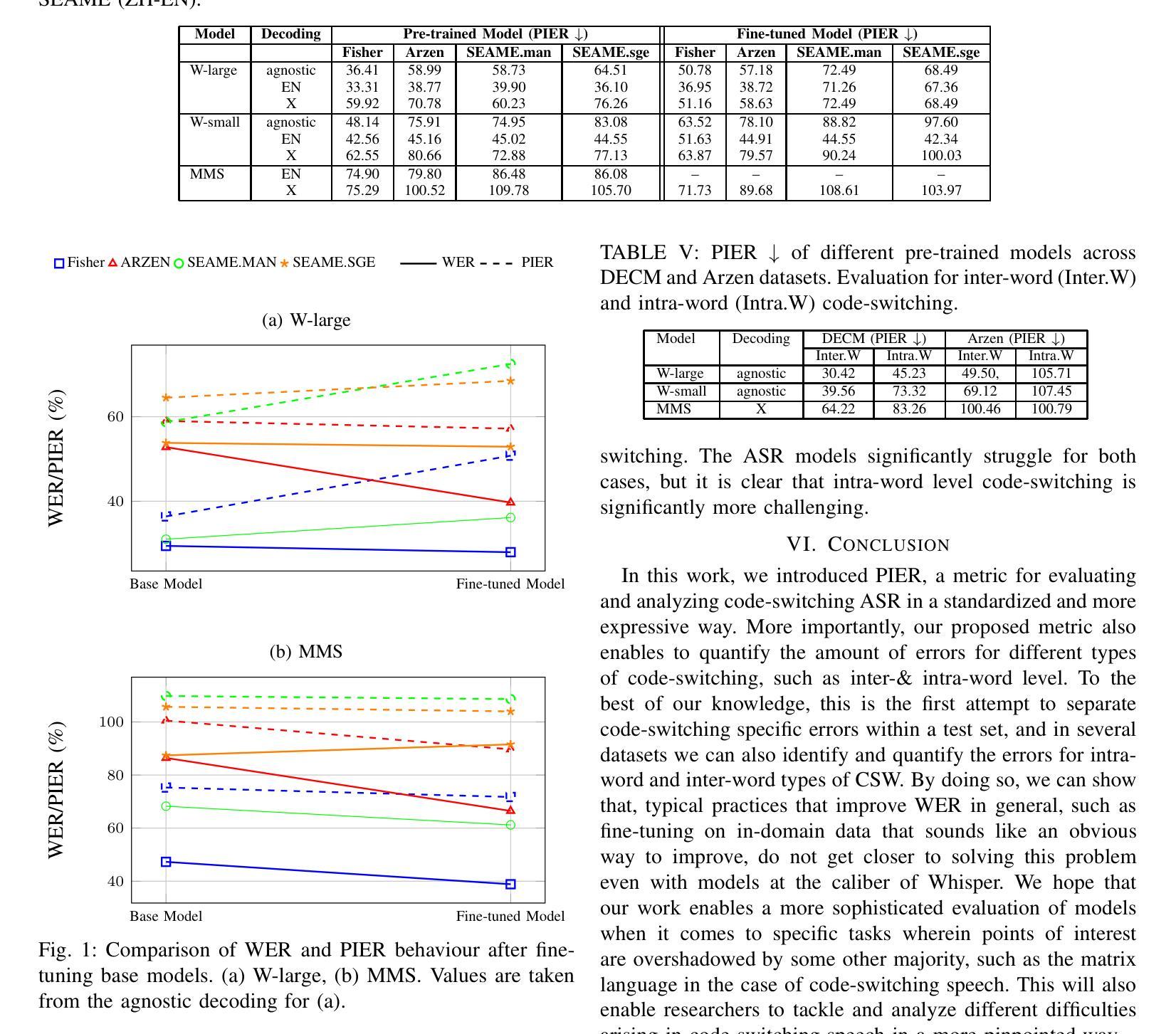
Code-switching, the alternation of languages within a single discourse, presents a significant challenge for Automatic Speech Recognition. Despite the unique nature of the task, performance is commonly measured with established metrics such as Word-Error-Rate (WER). However, in this paper, we question whether these general metrics accurately assess performance on code-switching. Specifically, using both Connectionist-Temporal-Classification and Encoder-Decoder models, we show fine-tuning on non-code-switched data from both matrix and embedded language improves classical metrics on code-switching test sets, although actual code-switched words worsen (as expected). Therefore, we propose Point-of-Interest Error Rate (PIER), a variant of WER that focuses only on specific words of interest. We instantiate PIER on code-switched utterances and show that this more accurately describes the code-switching performance, showing huge room for improvement in future work. This focused evaluation allows for a more precise assessment of model performance, particularly in challenging aspects such as inter-word and intra-word code-switching.
语言转换(code-switching)指的是在同一语境中交替使用不同的语言,这给自动语音识别(ASR)带来了很大的挑战。尽管该任务具有独特性,但通常使用标准的度量方法(如单词错误率(WER))来评估性能。然而,本文对此提出质疑,认为这些通用指标是否能准确评估语言转换情况下的性能。具体来说,我们利用连接时序分类和编码器-解码器模型,展示了对来自矩阵和嵌入式语言的非语言转换数据的微调能提高语言转换测试集上的经典指标,尽管实际的转换词有所恶化(符合预期)。因此,我们提出了兴趣点错误率(PIER),这是WER的一个变体,只关注特定的兴趣词。我们在语言转换的片段上实现了PIER,并证明它能更准确地描述语言转换的性能,显示出未来工作中有很大的改进空间。这种有针对性的评估允许对模型性能进行更精确的判断,特别是在词语间和词语内的语言转换等具有挑战性的方面。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
本文主要探讨了自动语音识别中的语言代码转换问题。研究指出传统评估指标如词错误率(WER)无法准确评估代码切换场景下的性能。通过使用CTC和Encoder-Decoder模型,研究发现在非代码切换数据上进行微调会提高在代码切换测试集上的经典指标得分,但对实际代码切换单词的性能依然有待提高。为此,提出了一种新的评估方法——关键词错误率(PIER),它能更准确地描述代码切换的性能,显示出未来研究存在巨大改进空间。该评估方法有助于更精确地评估模型性能,特别是在跨词和词内代码切换等挑战方面。
Key Takeaways
- 代码转换在自动语音识别中是一项重要挑战。
- 传统评估指标如词错误率(WER)无法准确评估代码切换场景下的模型性能。
- 使用CTC和Encoder-Decoder模型的微调能提高在非代码切换数据上的性能,但在实际代码切换单词上的性能仍然有待提高。
- 提出了一种新的评估方法——关键词错误率(PIER),能更准确地反映模型在代码切换场景下的性能。
- PIER评估方法特别关注特定单词的错误,适用于评估跨词和词内代码切换等挑战方面的性能。
- PIER评估方法的提出显示出在自动语音识别中的代码转换问题上仍存在巨大的改进空间。
- 精确评估模型性能对于解决自动语音识别中的代码转换问题至关重要。
点此查看论文截图

Multimodal Marvels of Deep Learning in Medical Diagnosis: A Comprehensive Review of COVID-19 Detection
Authors:Md Shofiqul Islama, Khondokar Fida Hasanc, Hasibul Hossain Shajeebd, Humayan Kabir Ranae, Md Saifur Rahmand, Md Munirul Hasanb, AKM Azadf, Ibrahim Abdullahg, Mohammad Ali Moni
This study presents a comprehensive review of the potential of multimodal deep learning (DL) in medical diagnosis, using COVID-19 as a case example. Motivated by the success of artificial intelligence applications during the COVID-19 pandemic, this research aims to uncover the capabilities of DL in disease screening, prediction, and classification, and to derive insights that enhance the resilience, sustainability, and inclusiveness of science, technology, and innovation systems. Adopting a systematic approach, we investigate the fundamental methodologies, data sources, preprocessing steps, and challenges encountered in various studies and implementations. We explore the architecture of deep learning models, emphasising their data-specific structures and underlying algorithms. Subsequently, we compare different deep learning strategies utilised in COVID-19 analysis, evaluating them based on methodology, data, performance, and prerequisites for future research. By examining diverse data types and diagnostic modalities, this research contributes to scientific understanding and knowledge of the multimodal application of DL and its effectiveness in diagnosis. We have implemented and analysed 11 deep learning models using COVID-19 image, text, and speech (ie, cough) data. Our analysis revealed that the MobileNet model achieved the highest accuracy of 99.97% for COVID-19 image data and 93.73% for speech data (i.e., cough). However, the BiGRU model demonstrated superior performance in COVID-19 text classification with an accuracy of 99.89%. The broader implications of this research suggest potential benefits for other domains and disciplines that could leverage deep learning techniques for image, text, and speech analysis.
本研究全面回顾了多模态深度学习(DL)在医学诊断中的潜力,并以COVID-19作为案例进行研究。本研究受COVID-19疫情期间人工智能应用成功的启发,旨在揭示深度学习在疾病筛查、预测和分类方面的能力,并借此获得能够增强科学、技术和创新系统韧性、可持续性和包容性的见解。我们采用系统的方法,研究了各种研究和实践中的基本方法、数据来源、预处理步骤和所面临的挑战。我们探讨了深度学习模型的架构,重点介绍了它们针对数据的特定结构和基础算法。随后,我们对COVID-19分析中使用的不同深度学习策略进行了比较,根据方法、数据、性能和未来研究的前提要求进行了评估。本研究通过检查多种数据类型和诊断方式,探讨了深度学习多模态应用在诊断中的科学理解和有效性方面的贡献。我们使用COVID-19图像、文本和语音(即咳嗽声)数据实现了11个深度学习模型,并对其进行了分析。分析结果显示,MobileNet模型在COVID-19图像数据上达到了99.97%的准确率,在语音数据(即咳嗽声)上达到了93.73%的准确率。然而,BiGRU模型在COVID-19文本分类方面表现出卓越的性能,准确率为99.89%。这项研究的更广泛意义表明,其他领域和学科也有可能受益于深度学习技术在图像、文本和语音分析方面的应用。
论文及项目相关链接
PDF 43 pages
摘要
本文全面综述了多模态深度学习在医学诊断中的潜力,以COVID-19为例。该研究旨在揭示深度学习在疾病筛查、预测和分类方面的能力,并借此增强科学、技术和创新系统的复原力、可持续性和包容性。研究采用系统方法,探讨了根本的方法论、数据来源、预处理步骤以及在不同研究和实践中的挑战。本文探讨了深度学习模型的架构,重点介绍了其数据特定结构和基础算法。通过考察不同类型的数据和诊断方式,本研究有助于理解多模态深度学习在诊断中的有效性。研究发现,MobileNet模型在COVID-19图像和语音数据上的准确率最高,分别为99.97%和93.73%,而BiGRU模型在COVID-19文本分类中表现最佳,准确率为99.89%。此研究对其他领域和学科具有潜在应用价值。
关键见解
- 研究全面回顾了多模态深度学习在医学诊断中的潜力,以COVID-19为案例进行详细分析。
- 深度学习在疾病筛查、预测和分类方面展现出强大能力,有助于增强科学系统的复原力、可持续性和包容性。
- 研究深入探讨了深度学习模型的基础架构和数据特定结构,强调了其在处理不同数据类型(如图像、文本和语音)时的优势。
- MobileNet模型在COVID-19图像和语音数据准确率高,而BiGRU模型在文本分类中表现最佳。
- 研究通过系统方法,探讨了深度学习在实践中的应用挑战和未来发展所需的前提条件。
- 此研究不仅局限于COVID-19的医学诊断,对其他领域和学科的深度学习应用也提供了有价值的参考。
- 研究成果有助于提升对多模态深度学习应用的理解和知识贡献。
点此查看论文截图



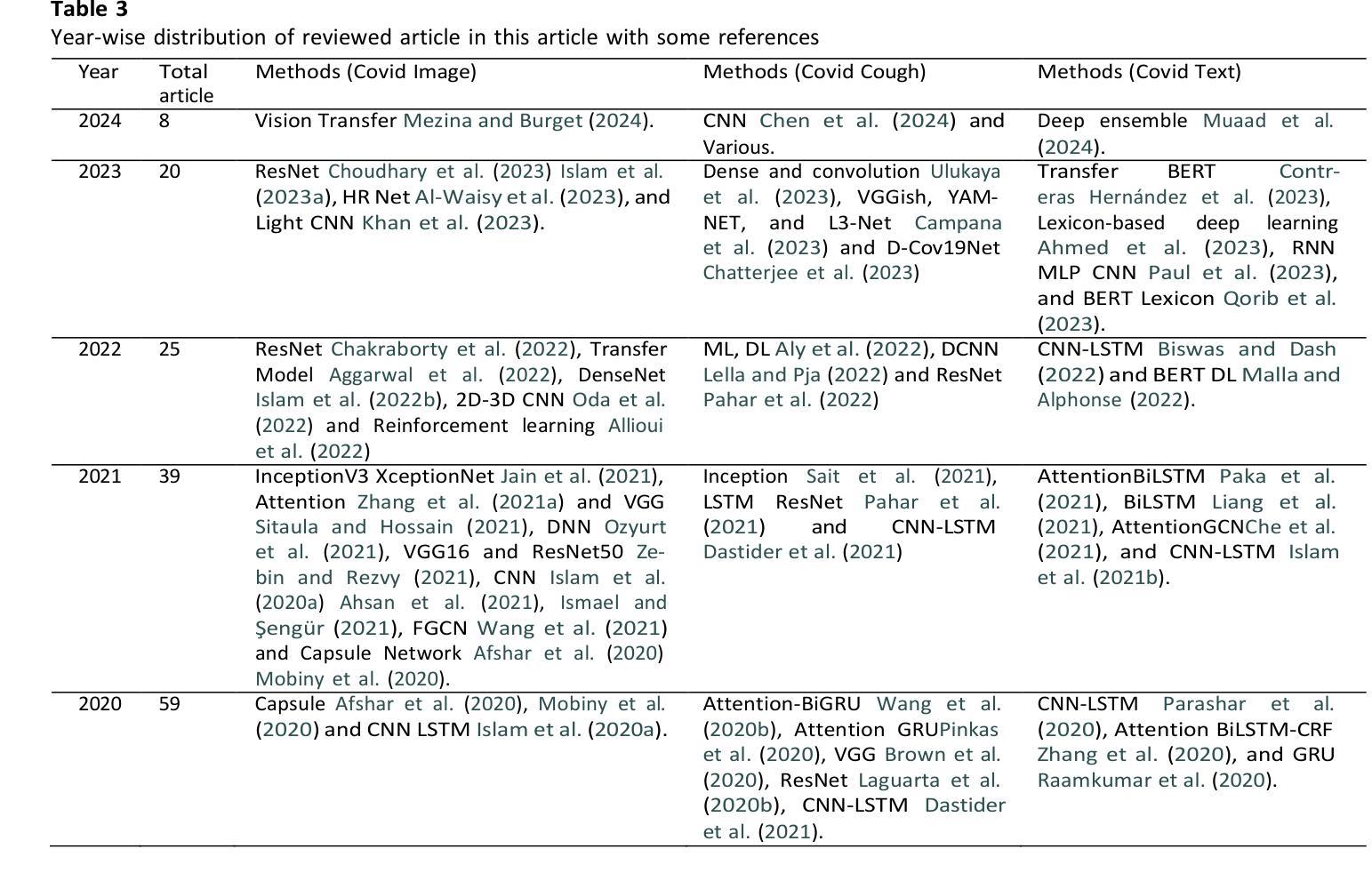
Teaching Wav2Vec2 the Language of the Brain
Authors:Tobias Fiedler, Leon Hermann, Florian Müller, Sarel Cohen, Peter Chin, Tobias Friedrich, Eilon Vaadia
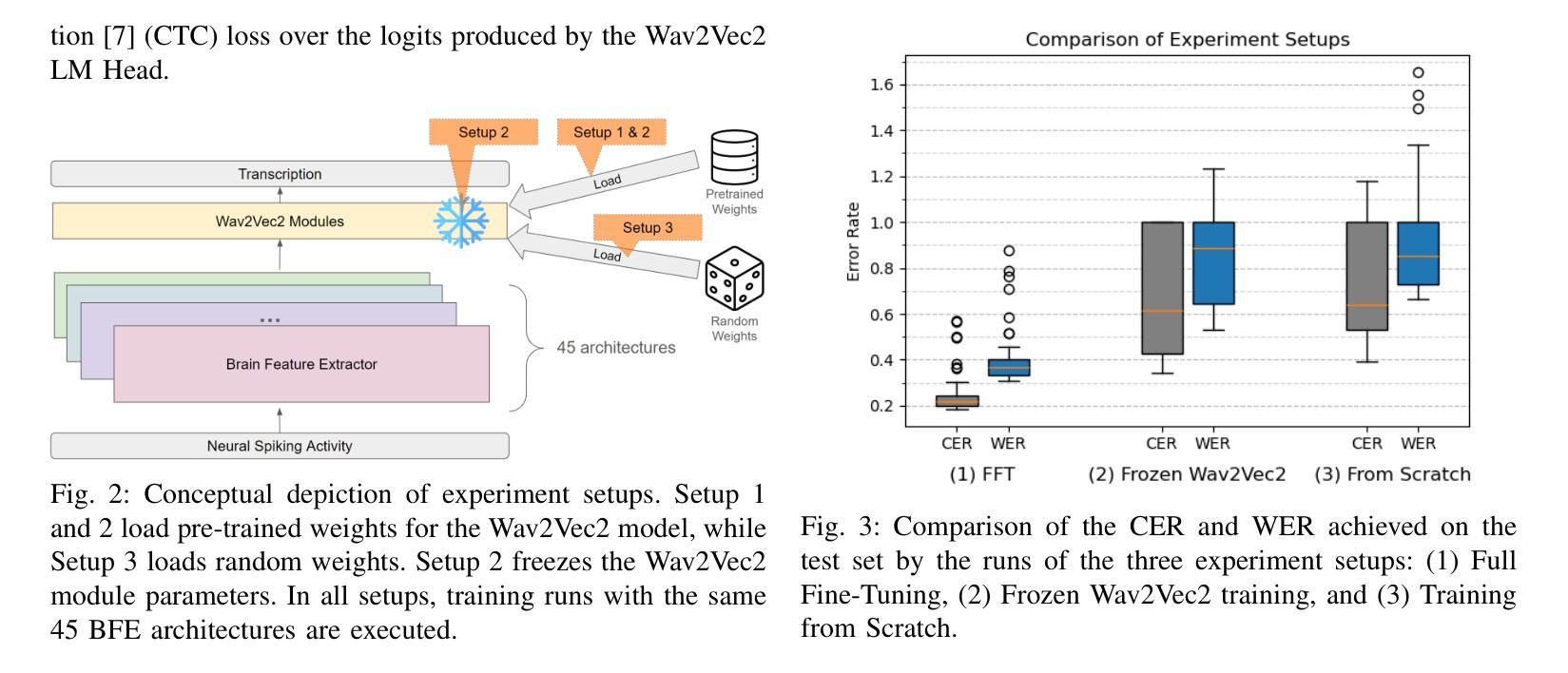
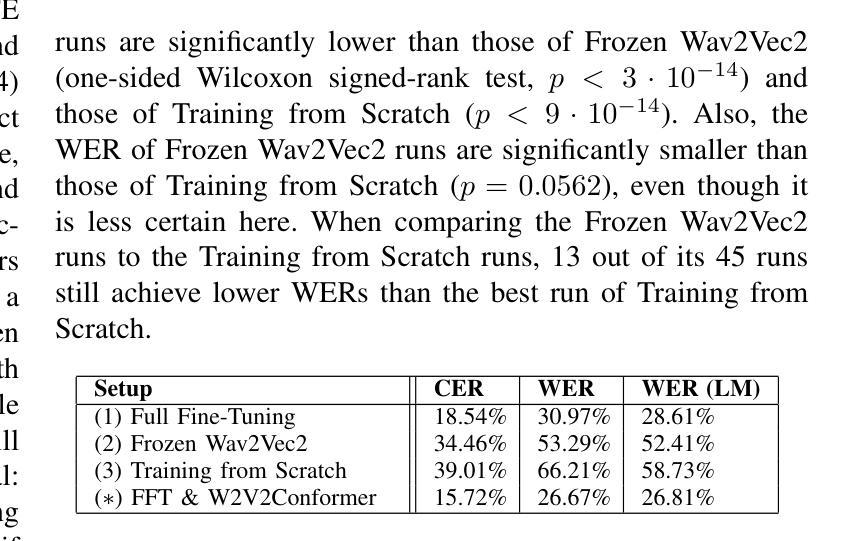
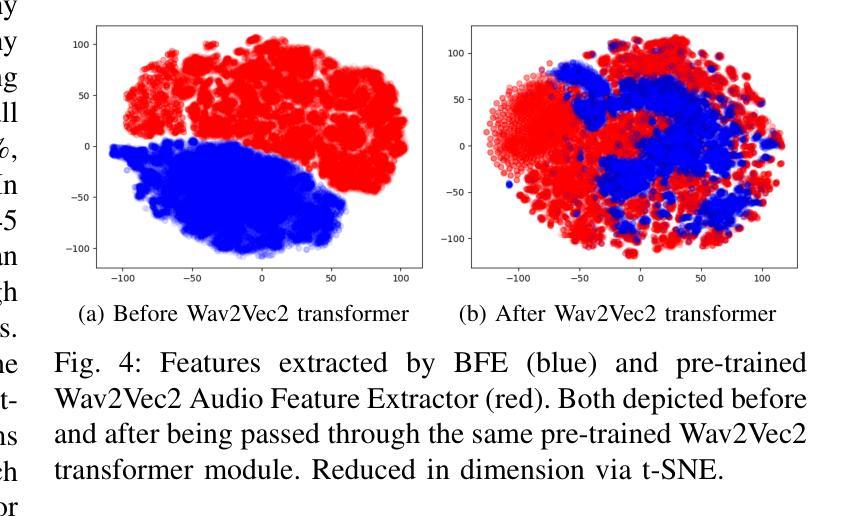
The decoding of continuously spoken speech from neuronal activity has the potential to become an important clinical solution for paralyzed patients. Deep Learning Brain Computer Interfaces (BCIs) have recently successfully mapped neuronal activity to text contents in subjects who attempted to formulate speech. However, only small BCI datasets are available. In contrast, labeled data and pre-trained models for the closely related task of speech recognition from audio are widely available. One such model is Wav2Vec2 which has been trained in a self-supervised fashion to create meaningful representations of speech audio data. In this study, we show that patterns learned by Wav2Vec2 are transferable to brain data. Specifically, we replace its audio feature extractor with an untrained Brain Feature Extractor (BFE) model. We then execute full fine-tuning with pre-trained weights for Wav2Vec2, training ‘’from scratch’’ without pre-trained weights as well as freezing a pre-trained Wav2Vec2 and training only the BFE each for 45 different BFE architectures. Across these experiments, the best run is from full fine-tuning with pre-trained weights, achieving a Character Error Rate (CER) of 18.54%, outperforming the best training from scratch run by 20.46% and that of frozen Wav2Vec2 training by 15.92% percentage points. These results indicate that knowledge transfer from audio speech recognition to brain decoding is possible and significantly improves brain decoding performance for the same architectures. Related source code is available at https://github.com/tfiedlerdev/Wav2Vec2ForBrain.
从神经元活动解码连续语音具有成为瘫痪患者重要临床解决方案的潜力。深度学习脑机接口(BCIs)最近成功地将神经元活动映射到尝试进行语音的主体文本内容中。然而,可用的BCI数据集很小。相比之下,与从音频进行语音识别这一紧密相关的任务相关的标记数据和预训练模型却随处可见。其中一种模型是Wav2Vec2,它采用自我监督的方式进行训练,能够创建语音音频数据的有意义表示。在这项研究中,我们展示了Wav2Vec2所学习到的模式可以转移到脑数据。具体来说,我们用未经训练的脑特征提取器(BFE)模型替换了其音频特征提取器。然后我们对Wav2Vec2进行预训练权重的全面微调,同时训练“从头开始”的模型,以及冻结预训练的Wav2Vec2并仅对BFE进行训练,共尝试了45种不同的BFE架构。在这些实验中,最好的结果是使用预训练权重进行的全微调,字符错误率(CER)达到18.54%,比从头开始训练的最好成绩高出20.46%,比冻结的Wav2Vec2训练高出15.92个百分点。这些结果表明,从语音识别到大脑解码的知识转移是可能的,并显著提高了相同架构的大脑解码性能。相关源代码可在https://github.com/tfiedlerdev/Wav2Vec2ForBrain找到。
论文及项目相关链接
PDF Paper was submitted to ICASSP 2025 but marginally rejected
摘要
基于深度学习的大脑计算机接口(BCIs)可从神经元活动中解码连续口语,为瘫痪患者带来重要的临床解决方案。本研究利用Wav2Vec2模型,一种经过自我监督训练的语音音频数据表示方法,展示其从音频到大脑的知识的可迁移性。通过将Wav2Vec2的音频特征提取器替换为未训练的大脑特征提取器(BFE)模型,并进行全面微调,实验结果显示,使用预训练权重的全微调方式表现最佳,字符错误率(CER)达到18.54%,相较于从头开始训练和冻结Wav2Vec2仅训练BFE的方式,分别提高了20.46%和15.92%。这表明语音识别的知识可以迁移到大脑解码中,并显著提高解码性能。相关源代码已公开。
关键见解
- 研究探索了将深度学习与大脑计算机接口(BCIs)结合的方法,使从神经元活动中解码连续口语成为可能。
- 利用Wav2Vec2模型,一个经过自我监督训练的语音音频数据表示方法,在大脑解码任务中展示了其有效性。
- 研究通过替换Wav2Vec2的音频特征提取器为大脑特征提取器(BFE)模型,实现了知识的迁移学习。
- 实验结果显示全微调方式表现最佳,字符错误率(CER)达到18.54%。
- 与从头开始训练和冻结Wav2Vec2仅训练BFE的方式相比,使用预训练权重的全微调方式显著提高了解码性能。
- 知识从语音识别迁移到大脑解码是可能的,这有助于为瘫痪患者提供临床解决方案。
点此查看论文截图


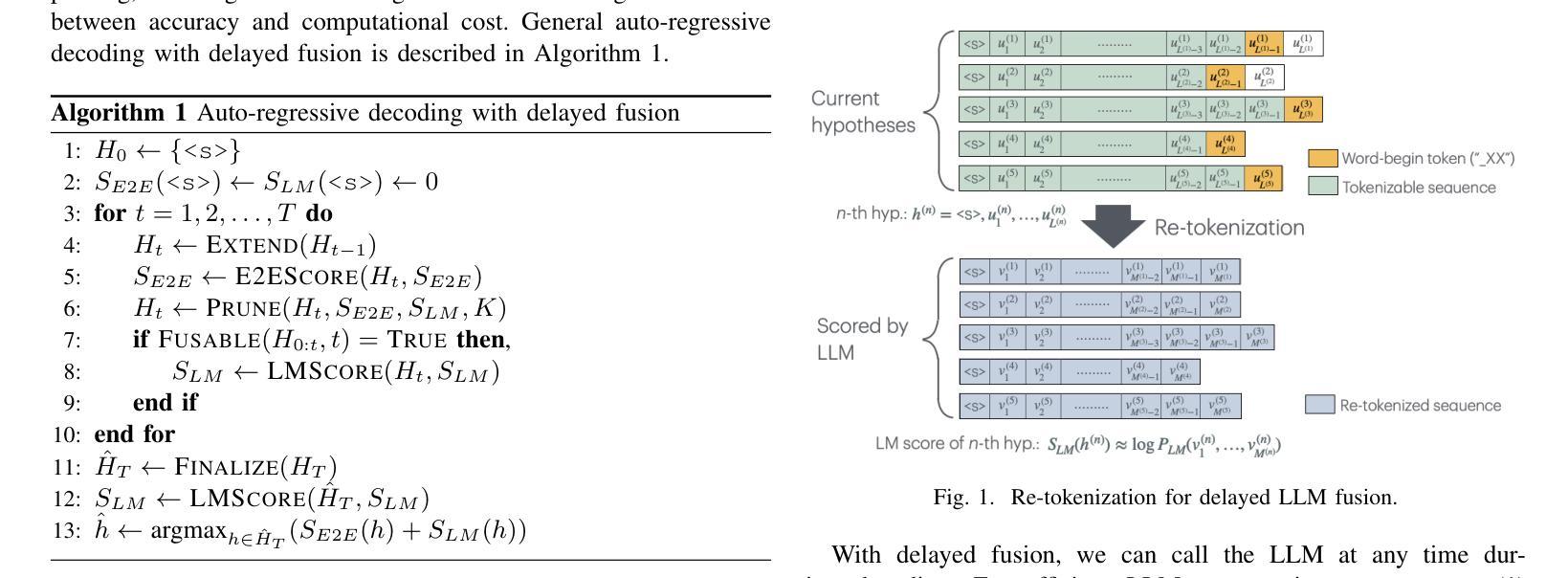
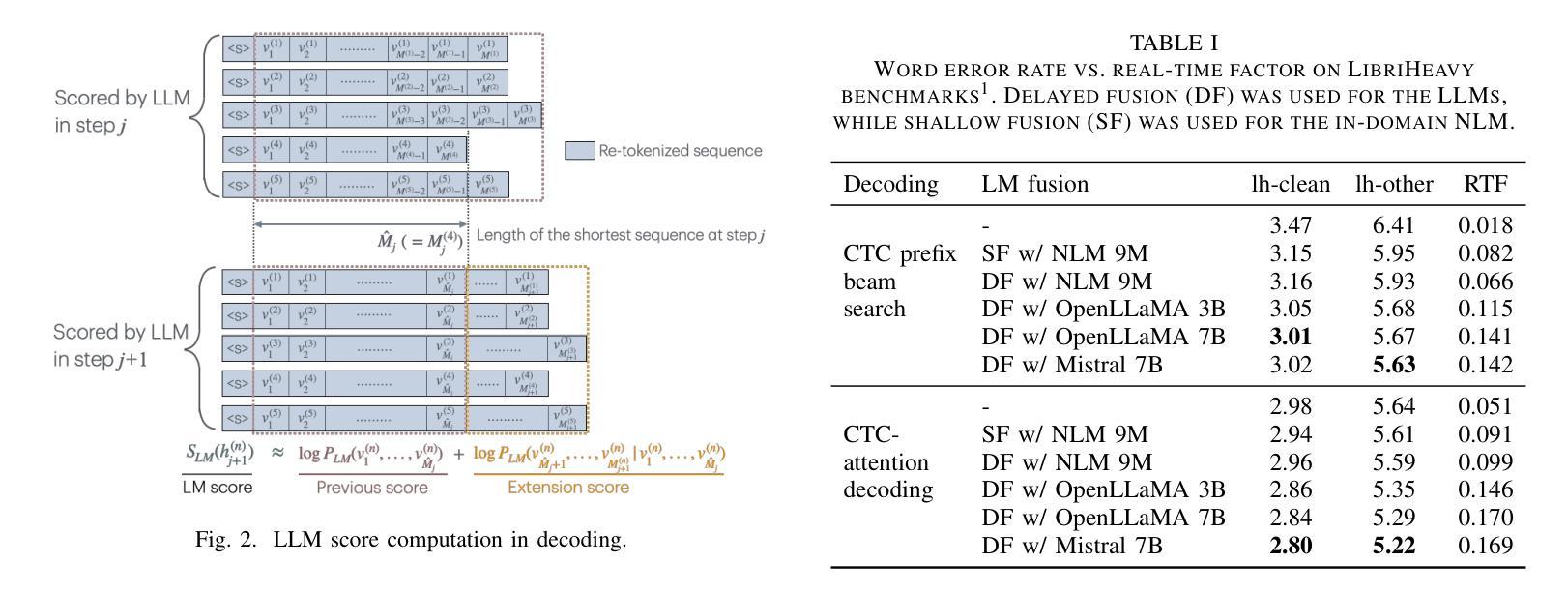
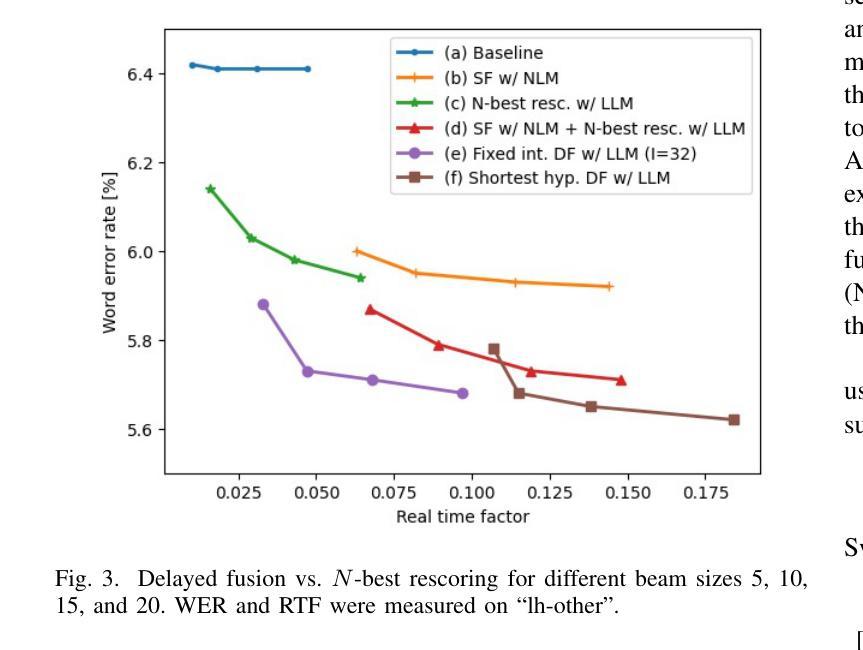
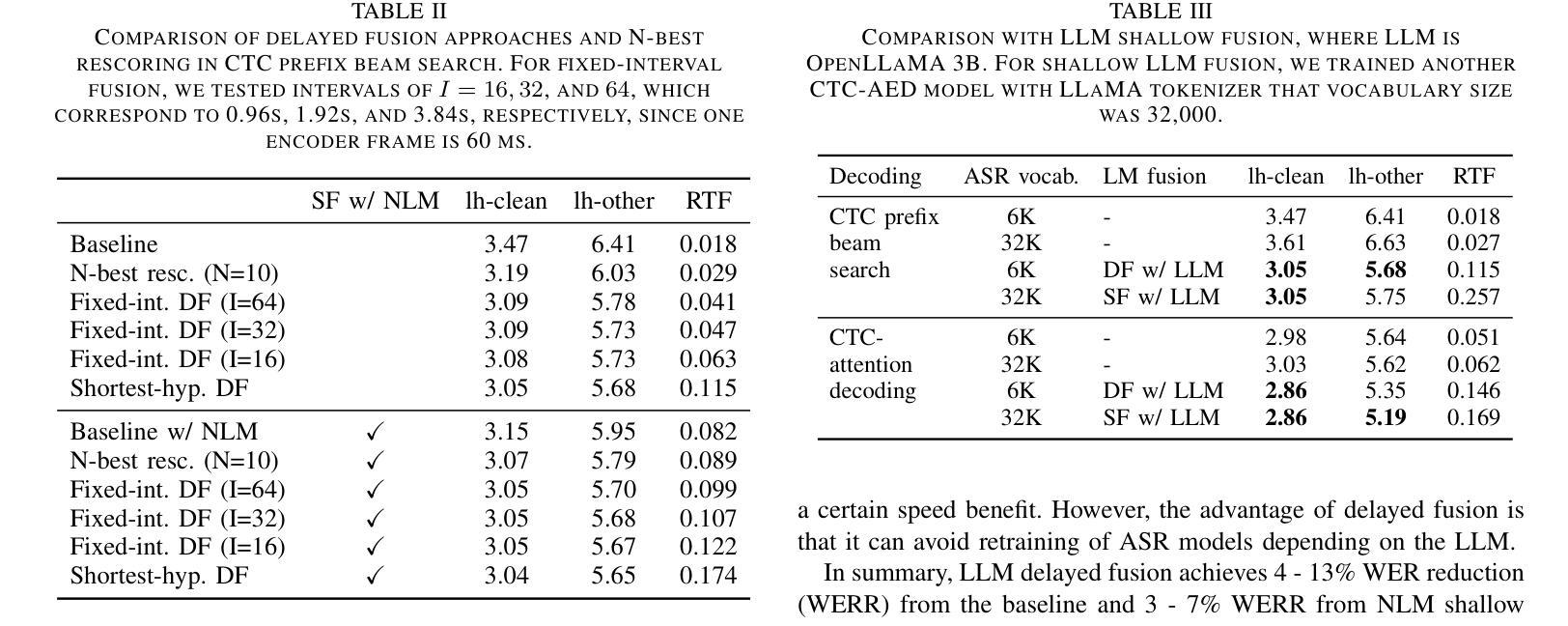
Delayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Authors:Takaaki Hori, Martin Kocour, Adnan Haider, Erik McDermott, Xiaodan Zhuang
This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose “delayed fusion,” which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
本文提出了一种利用大型语言模型(LLM)进行端到端自动语音识别(E2E-ASR)的高效解码方法。尽管浅融合是将语言模型融入E2E-ASR解码的最常见方法,但在使用LLMs时,我们面临两个实际问题。(1) LLM推理计算成本高昂。(2) ASR模型和LLM之间可能存在词汇不匹配的问题。为解决这一不匹配问题,我们需要重新训练ASR模型或LLM,这至少很耗时,并且在许多情况下并不可行。我们提出了“延迟融合”的方法,该方法在解码过程中延迟将LLM分数应用于ASR假设,使得在ASR任务中更容易使用预训练的LLM。这种方法不仅可以减少LLM评分的假设数量,还可以减少LLM推理调用次数。如果ASR和LLM采用不同的标记化方式,它还可以在解码过程中重新标记ASR假设。我们在LibriHeavy ASR语料库和三个公共LLM(OpenLLaMA 3B & 7B和Mistral 7B)上演示了延迟融合相比浅融合和N-best重评分提供了更高的解码速度和准确性。
论文及项目相关链接
PDF Accepted to ICASSP2025
Summary
本文提出一种高效的解码方法,用于结合大型语言模型(LLMs)进行端到端自动语音识别(E2E-ASR)。传统的浅融合方法面临计算成本高和词汇不匹配的问题。为解决这一问题,本文提出了延迟融合策略,在解码过程中延迟应用LLM评分,减少了LLM评分假设数量和推理调用次数,并允许在解码过程中进行ASR假设的重标记化。实验表明,延迟融合相较于浅融合和N-best重评分方法,能提高解码速度和准确性。
Key Takeaways
- 论文提出了一种新的解码方法,用于将大型语言模型(LLMs)与端到端自动语音识别(E2E-ASR)系统结合。
- 传统浅融合方法存在计算成本高和词汇不匹配的问题。
- 延迟融合策略能够减少LLM评分的假设数量和推理调用次数。
- 延迟融合允许在解码过程中进行ASR假设的重标记化,以适应不同的词汇表或标记化方式。
- 实验结果表明,延迟融合策略相较于传统的浅融合和N-best重评分方法,具有更高的解码速度和准确性。
- 论文使用了LibriHeavy ASR语料库和三个公开的大型语言模型(OpenLLaMA 3B & 7B以及Mistral 7B)进行验证。
点此查看论文截图

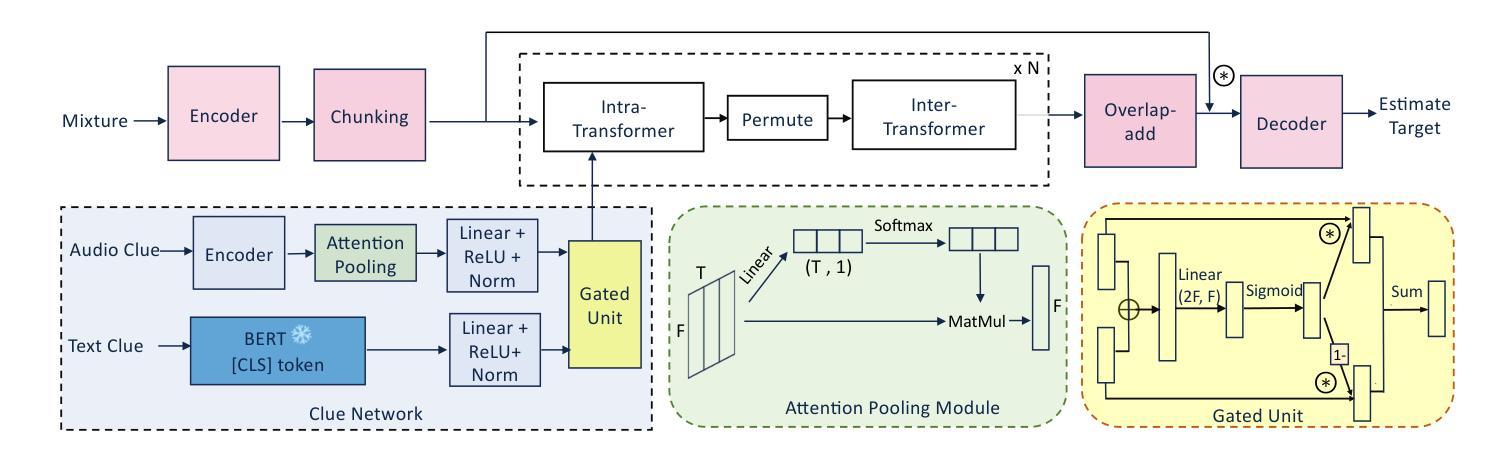
Beyond Speaker Identity: Text Guided Target Speech Extraction
Authors:Mingyue Huo, Abhinav Jain, Cong Phuoc Huynh, Fanjie Kong, Pichao Wang, Zhu Liu, Vimal Bhat
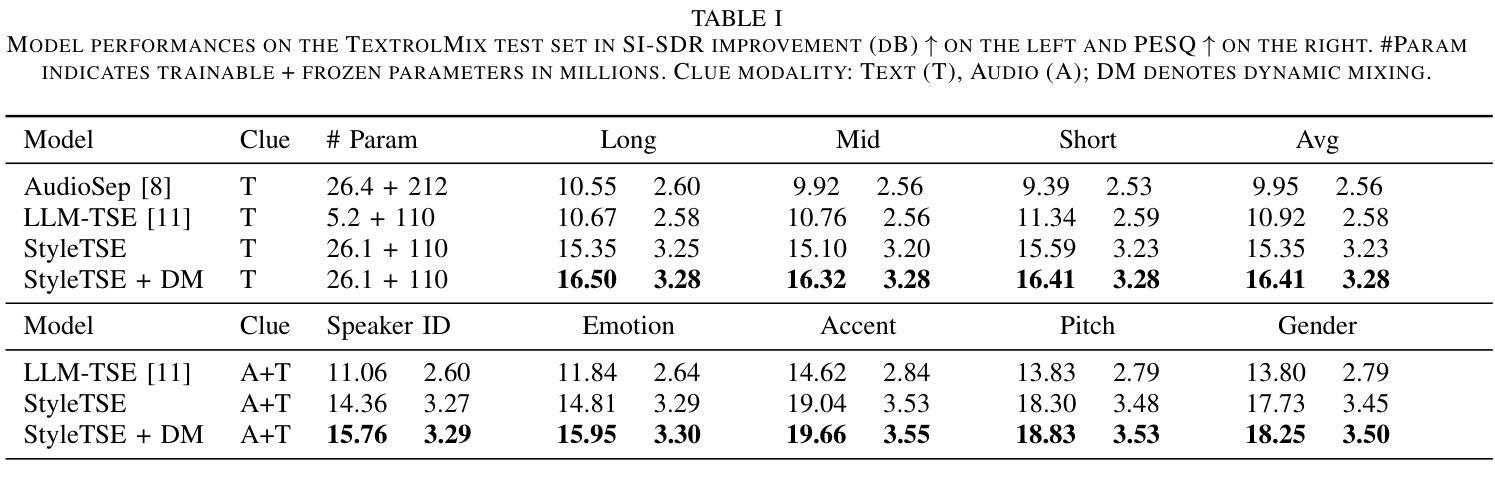
Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker’s identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
传统目标语音提取(TSE)依赖于关于说话人身份的明确线索,如注册音频、面部图像或视频,但这些可能并不总是可用。在本文中,我们提出了一种文本引导的TSE模型StyleTSE,该模型使用对说话风格的自然语言描述以及音频线索,从给定的混合语音中提取所需的语音。我们的模型将基于SepFormer的语音分离网络与双模态线索网络相结合,该网络可以灵活处理音频和文本线索。为了训练和评估我们的模型,我们引入了一个新的数据集TextrolMix,该数据集包含混合语音和自然语言描述。实验结果表明,我们的方法不仅有效地根据“谁在说话”进行语音分离,还根据“他们如何说话”进行语音分离,增强了在缺少传统音频线索的场景下的TSE。相关演示请访问:[https://mingyue66.github.io/TextrolMix/demo/]
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
目标语音提取(TSE)通常依赖于说话人身份的明确线索,如注册音频、面部图像或视频,但这些信息并非总是可用。本文提出了一种文本引导的目标语音提取模型StyleTSE,它使用音频线索之外的文本描述的说话风格来从给定的混合声音中提取所需的语音。模型结合了SepFormer改进的自适应语音分离网络和双模态线索网络,可以灵活处理音频和文本线索。为了训练和评估模型,引入了新数据集TextrolMix包含混合语音和文本描述。实验结果表明,该方法不仅基于说话人身份,还基于说话方式有效地分离语音,提高了在没有传统音频线索的场景下的TSE性能。
Key Takeaways
- StyleTSE模型结合了语音分离网络和双模态线索网络,以处理音频和文本描述的说话风格。
- 模型使用自然语言的说话风格描述作为提取目标语音的额外线索。
- 引入新数据集TextrolMix用于训练和评估模型。
- 实验结果表明,StyleTSE能够在无传统音频线索的场景下有效分离语音。
- 该方法不仅能根据说话人身份分离语音,还能根据说话方式分离语音。
点此查看论文截图

persoDA: Personalized Data Augmentation forPersonalized ASR
Authors:Pablo Peso Parada, Spyros Fontalis, Md Asif Jalal, Karthikeyan Saravanan, Anastasios Drosou, Mete Ozay, Gil Ho Lee, Jungin Lee, Seokyeong Jung
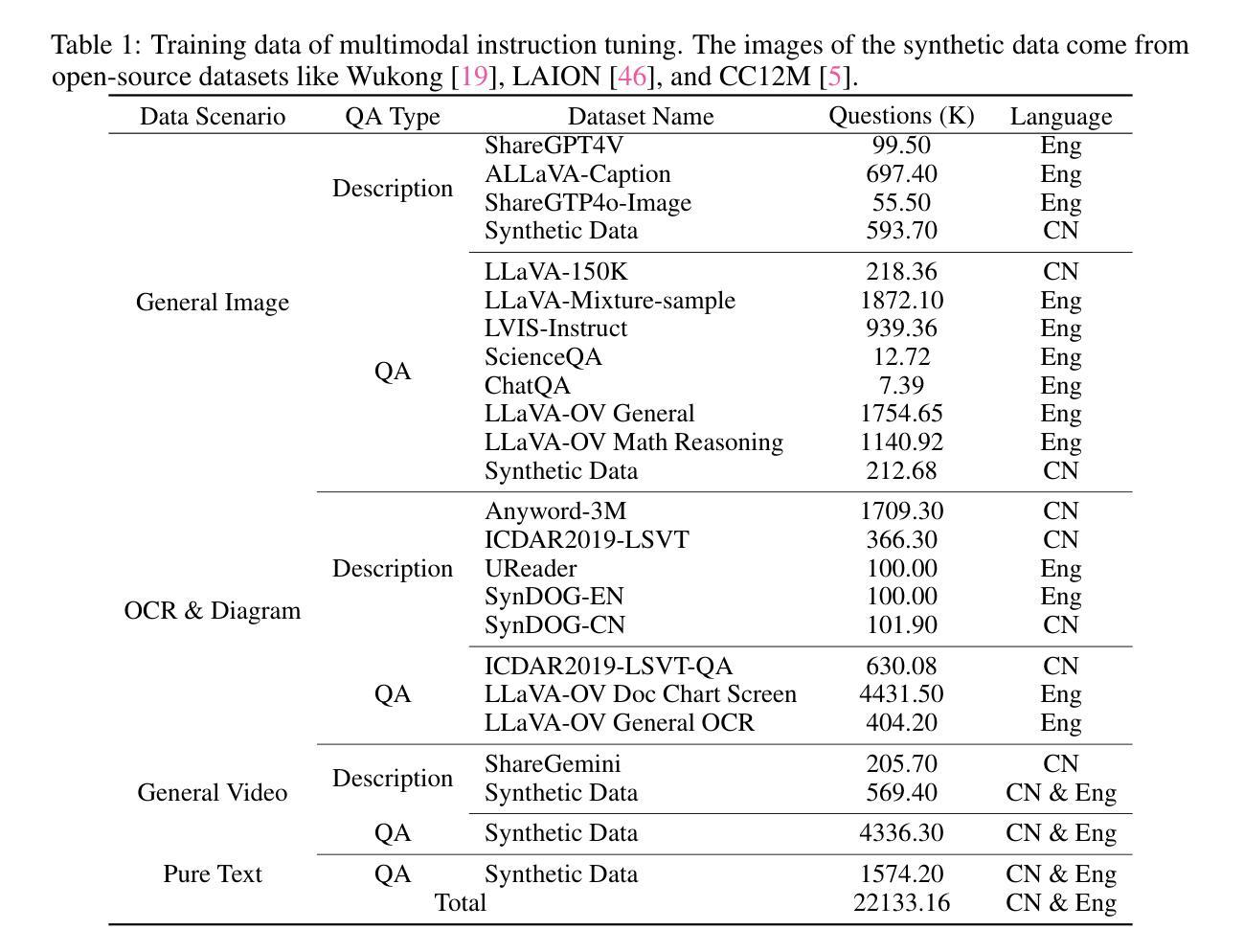
Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user’s data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
数据增强(DA)在自动语音识别(ASR)模型的训练中得到了广泛应用。DA提供了增加数据变化、稳健性和对不同声学失真的泛化能力。最近,在移动设备上进行ASR模型的个性化已被证明可以降低词错误率(WER)。本文在此背景下评估数据增强,并提出persoDA;一种利用用户数据驱动的DA方法,用于个性化ASR。persoDA旨在利用针对最终用户声学特性调整的数据来增强训练,而不是基于多条件训练(MCT)的标准增强,后者应用随机混响和噪声。我们在Librispeech上训练的基于语音识别的确认者基线进行了评估,并对人声进行了个性化处理,结果表明,与标准数据增强(使用随机噪声和混响)相比,persoDA实现了相对降低13.9%的WER。此外,与MCT相比,persoDA显示出更快的收敛速度,提高了16%至20%。
论文及项目相关链接
PDF Accepted at ICASSP 2025; “\c{opyright} 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of …”
Summary:
数据增强(DA)广泛应用于语音识别(ASR)模型的训练,能够增加数据多样性、提高模型的稳健性和泛化能力。本文评估了个性化ASR模型中数据增强的效果,并提出一种基于用户数据驱动的数据增强方法——persoDA。该方法旨在通过针对最终用户的声学特性调整数据来增强训练,而不是基于多条件训练(MCT)应用随机混响和噪声。评估结果显示,与标准数据增强相比,persoDA在语音识别的词错误率(WER)上降低了13.9%,并且收敛速度提高了16%至20%。
Key Takeaways:
- 数据增强(DA)广泛应用于语音识别(ASR)模型的训练,可增加数据多样性和模型稳健性。
- 本文提出了基于用户数据驱动的数据增强方法——persoDA,旨在针对最终用户的声学特性调整数据。
- persoDA相对于标准的多条件训练(MCT),更侧重于应用用户的个性化数据。
- persoDA在词错误率(WER)上取得了显著的改进,相较于标准数据增强降低了13.9%。
- persoDA还显示出比MCT更快的收敛速度,提高了16%至20%。
- 此方法对于个性化ASR模型的应用具有潜力,可以提高模型在特定用户声学特性上的性能。
点此查看论文截图

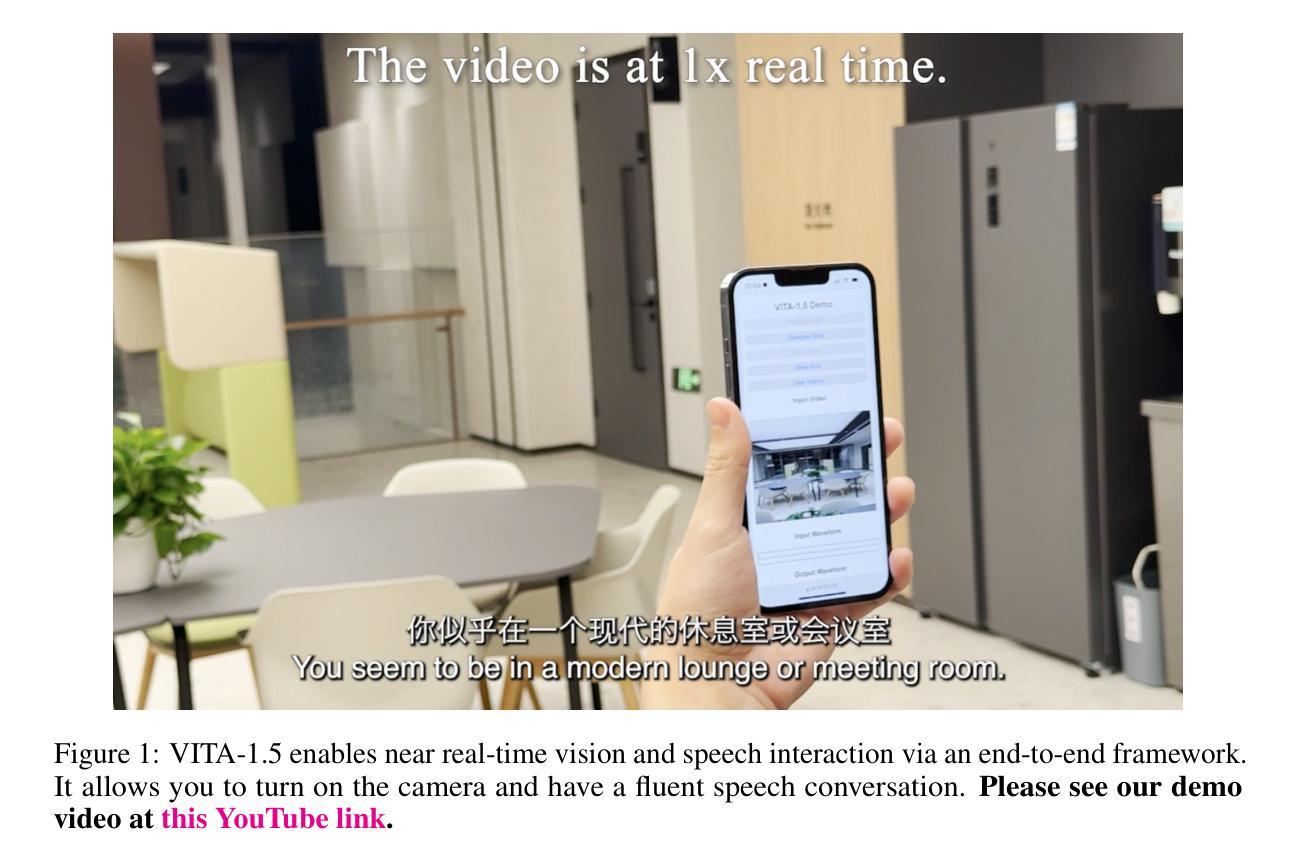
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Authors:Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, Ran He
Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
最近的多模态大型语言模型(MLLMs)主要聚焦于整合视觉和文本模态,较少强调语音在增强交互中的作用。然而,语音在多模态对话系统中扮演关键角色,由于在基础模态上的差异,在视觉和语音任务中都实现高性能仍然是一个重大挑战。在本文中,我们提出了一种精心设计的多阶段训练方法论,逐步训练大型语言模型以理解视觉和语音信息,最终使流畅的视觉和语音交互成为可能。我们的方法不仅保留了强大的视觉语言功能,还实现了高效的语音对话能力,无需单独的自动语音识别(ASR)和文本到语音(TTS)模块,从而显著加快了多模态端到端的响应速度。通过与图像、视频和语音任务的最新前沿技术进行对比评估,我们证明了我们的模型具备强大的视觉和语音功能,可实现近乎实时的视觉和语音交互。
论文及项目相关链接
PDF https://github.com/VITA-MLLM/VITA
Summary
近期多模态大型语言模型(MLLMs)在集成视觉和文本模态方面取得了进展,但对语音在增强交互中的作用重视不足。本文提出了一种精心设计的多阶段训练方法,逐步训练LLM理解视觉和语音信息,实现流畅的视听交互。该方法不仅保留了强大的视觉语言能力,还能实现高效的语音对话能力,无需额外的语音识别和文本转语音模块,显著加快多模态端到端的响应速度。对比现有先进技术,本文模型在图像、视频和语音任务基准测试中均表现出强大的视觉和语音能力,实现近乎实时的视听交互。
Key Takeaways
- 近期多模态语言模型倾向于融合视觉和文本模态,但对语音在交互中的重要性关注不足。
- 语音在多媒体对话系统中起关键作用,实现视觉和语音任务的高性能是一个重大挑战。
- 提出了一种多阶段训练方法,使LLM能够理解视觉和语音信息,实现流畅的视听交互。
- 该方法保留了强大的视觉语言能力,并具备高效的语音对话能力,无需额外的ASR和TTS模块。
- 模型在图像、视频和语音任务基准测试中表现优异,具备强大的视觉和语音能力。
- 该模型加速了多模态端到端的响应速度,实现了近乎实时的视听交互。
点此查看论文截图

Target Speaker ASR with Whisper
Authors:Alexander Polok, Dominik Klement, Matthew Wiesner, Sanjeev Khudanpur, Jan Černocký, Lukáš Burget
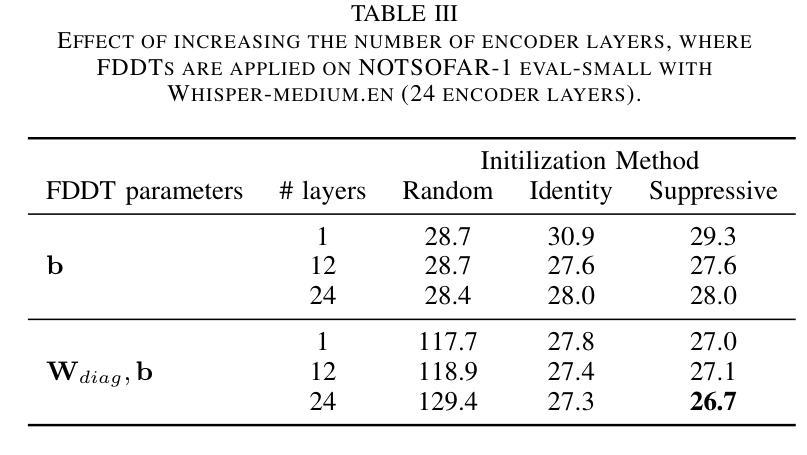
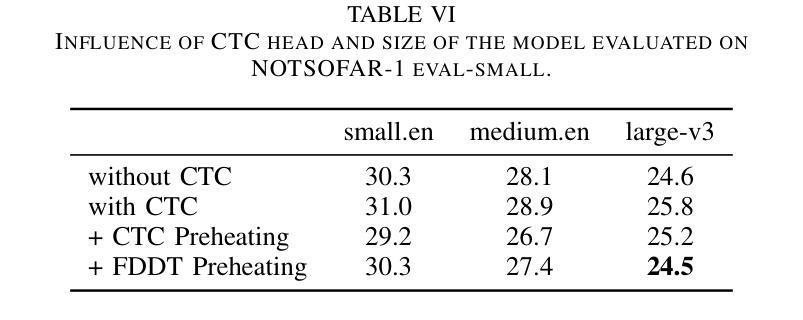
We propose a novel approach to enable the use of large, single-speaker ASR models, such as Whisper, for target speaker ASR. The key claim of this method is that it is much easier to model relative differences among speakers by learning to condition on frame-level diarization outputs than to learn the space of all speaker embeddings. We find that adding even a single bias term per diarization output type before the first transformer block can transform single-speaker ASR models into target-speaker ASR models. Our approach also supports speaker-attributed ASR by sequentially generating transcripts for each speaker in a diarization output. This simplified method outperforms baseline speech separation and diarization cascade by 12.9 % absolute ORC-WER on the NOTSOFAR-1 dataset.
我们提出了一种新型方法,旨在将大型单说话人语音识别模型(如Whisper)应用于目标说话人语音识别。该方法的关键主张是,通过学习以帧级聚类输出为条件,对说话人之间的相对差异进行建模,比学习所有说话人嵌入的空间更容易。我们发现,在第一个transformer块之前为每种聚类输出类型添加一个偏差项,就可以将单说话人语音识别模型转变为目标说话人语音识别模型。我们的方法还支持通过顺序生成每个说话人的字幕来进行属性化语音识别。在NOTSOFAR-1数据集上,该方法相对于基线语音分离和聚类串联方法,绝对ORC-WER提高了12.9%。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文提出一种新方法,通过基于帧级别的分栏输出条件训练,使大型单一说话人自动语音识别模型(如Whisper)能够用于目标说话人自动语音识别。该方法的关键在于,通过建模不同说话人之间的相对差异来改进模型性能,而非学习所有说话人的嵌入空间。添加单一偏置项,在分栏输出类型之前进行预处理即可将单一说话人自动语音识别模型转化为目标说话人自动语音识别模型。此方法还具备生成每位说话人对应转写的功能。在NOTSOFAR-1数据集上,相较于基准语音分离和对齐级联方法,此方法在绝对误差率上提高了12.9%。
Key Takeaways
- 提出一种新方法使大型单一说话人ASR模型(如Whisper)可用于目标说话人ASR。
- 建模相对差异优于学习所有说话人的嵌入空间。
- 添加偏置项可简化模型转换过程。
- 方法支持基于分栏输出的说话人属性ASR。
- 该方法生成每位说话人的转写内容。
- 方法在NOTSOFAR-1数据集上性能显著提升,绝对误差率降低12.9%。
点此查看论文截图



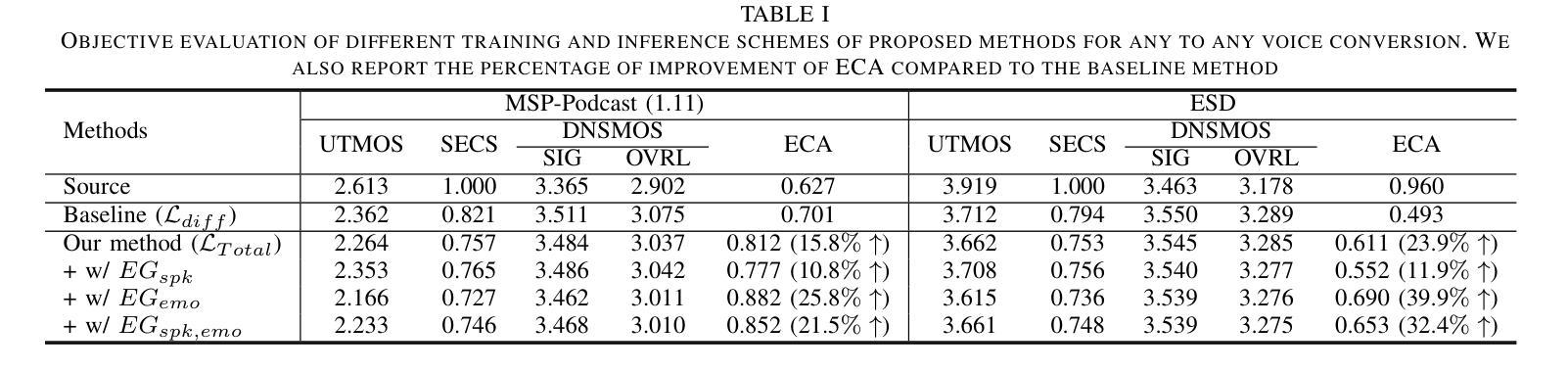
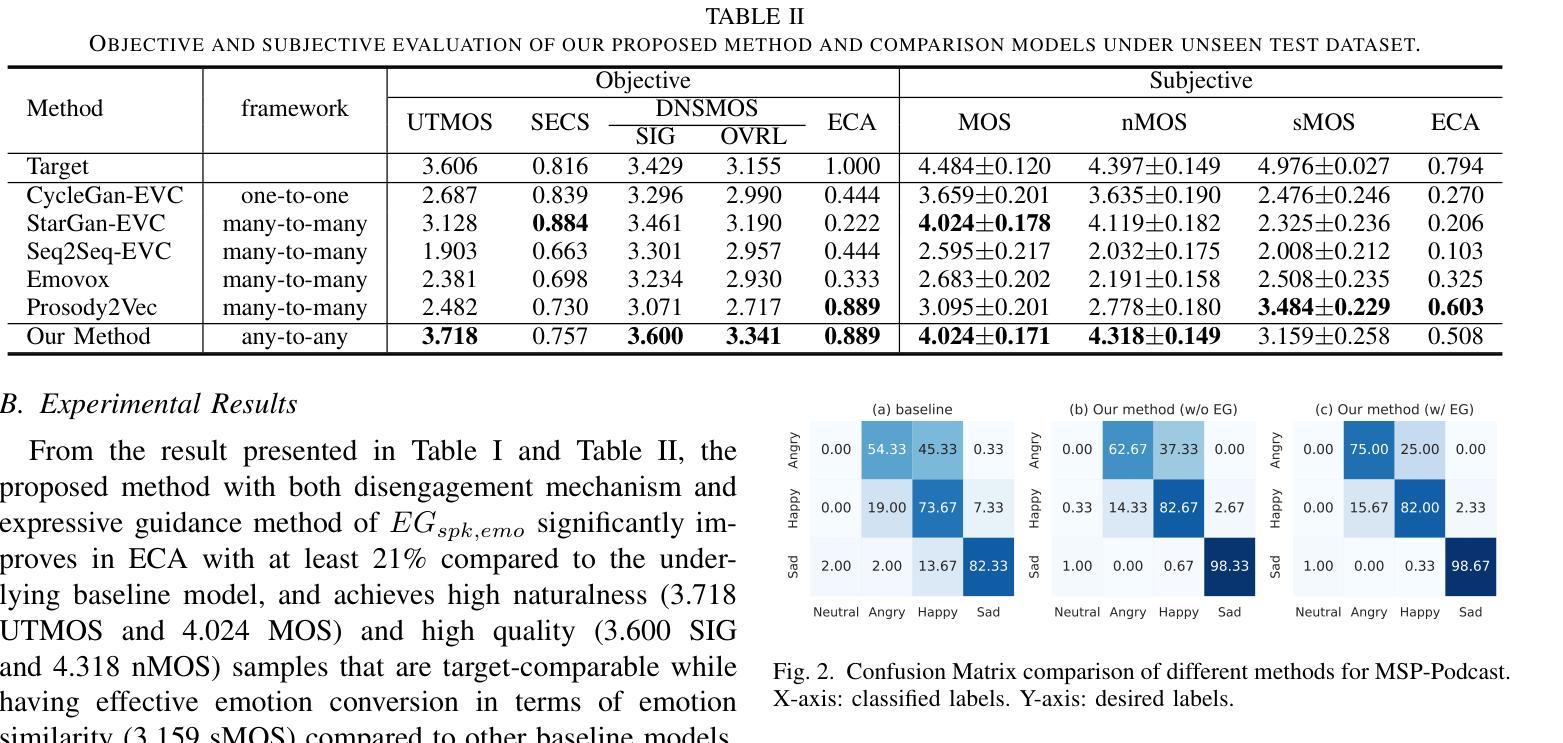
Toward Any-to-Any Emotion Voice Conversion using Disentangled Diffusion Framework
Authors:Hsing-Hang Chou, Yun-Shao Lin, Ching-Chin Sung, Yu Tsao, Chi-Chun Lee
Emotional Voice Conversion (EVC) aims to modify the emotional expression of speech for various applications, such as human-machine interaction. Previous deep learning-based approaches using generative adversarial networks and autoencoder models have shown promise but suffer from quality degradation and limited emotion control. To address these issues, a novel diffusion-based EVC framework with disentangled loss and expressive guidance is proposed. Our method separates speaker and emotional features to maintain speech quality while improving emotional expressiveness. Tested on real-world and acted-out datasets, the approach achieved significant improvements in emotion classification accuracy for both in-the-wild and act-out datasets and showed reduced distortion compared to state-of-the-art models.
情感语音转换(EVC)旨在修改语音的情感表达,以应用于人机交互等各种场景。虽然基于深度学习的对抗生成网络和自编码器模型的方法已经展现出一定的潜力,但它们仍面临质量下降和情感控制有限的问题。为了解决这些问题,提出了一种新型的基于扩散的EVC框架,该框架具有分离损失和表达指导的特点。我们的方法能够分离说话者和情感特征,从而保持语音质量,同时提高情感表现力。在真实世界和演绎数据集上进行测试,该方法在野生和演绎数据集的情感分类精度上取得了显著的提高,与最先进的模型相比,失真度也有所降低。
论文及项目相关链接
PDF 5 pages; revised arguments, typos and references corrected
Summary:情感语音转换(EVC)旨在修改语音的情感表达,以应用于人机交互等各种场景。针对以往基于深度学习的对抗生成网络和自编码器模型在情感控制上的不足和语音质量下降的问题,提出了新型扩散模型基础的EVC框架,具有分离损失和表现性指导的特性,可保持语音质量的同时提升情感表达力。在真实世界和模拟数据集上的测试显示,该方法在野外和模拟数据集的情感分类准确率上实现了显著提升,与当前主流模型相比失真度降低。
Key Takeaways:
- 情感语音转换(EVC)旨在修改语音的情感表达,应用于人机交互等场景。
- 以往的深度学习方法存在语音质量下降和有限情感控制的问题。
- 新提出的扩散模型基础的EVC框架旨在解决上述问题。
- 新框架通过分离损失和表现性指导来保持语音质量并提升情感表达力。
- 在真实世界和模拟数据集上的测试显示新框架的情感分类准确率显著提升。
- 与现有主流模型相比,新框架的语音失真度较低。
点此查看论文截图