⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
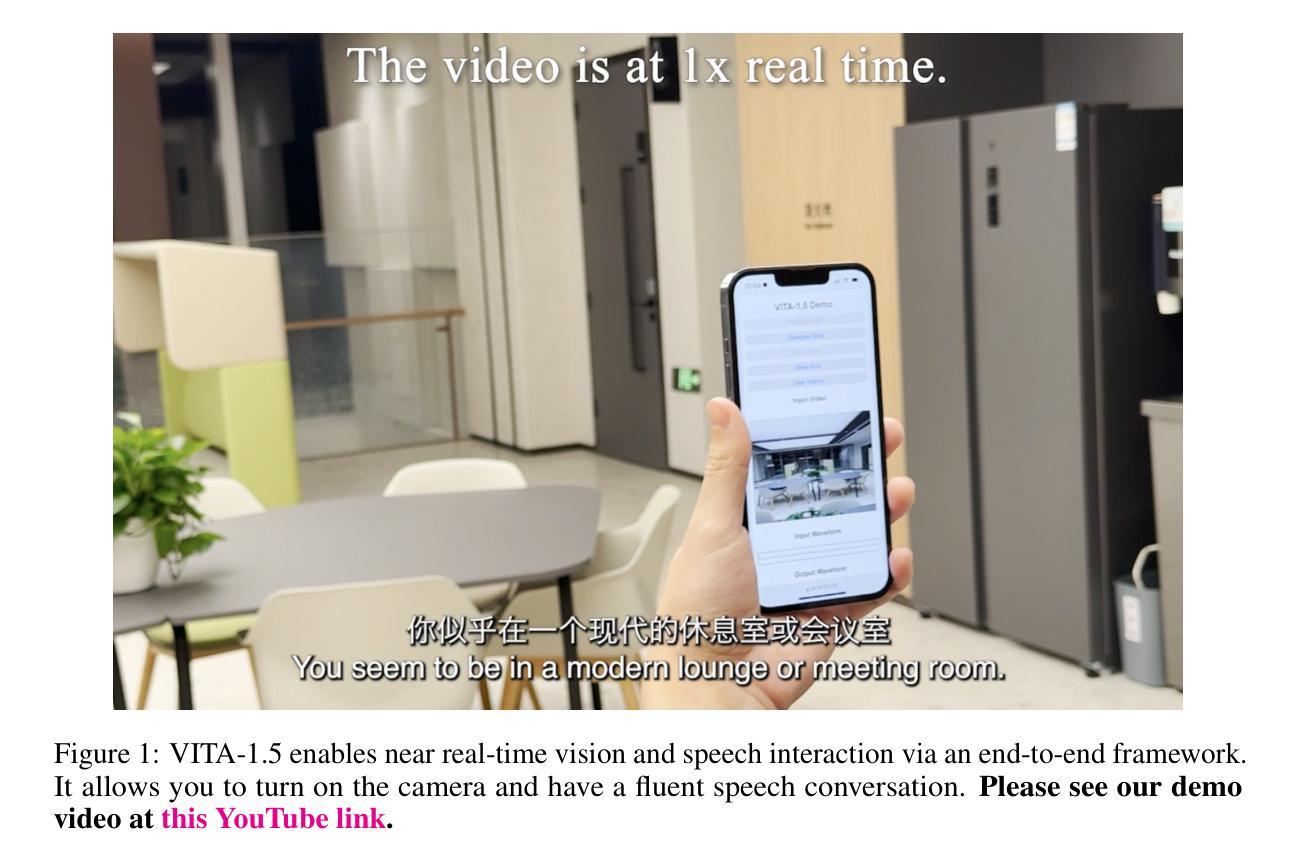
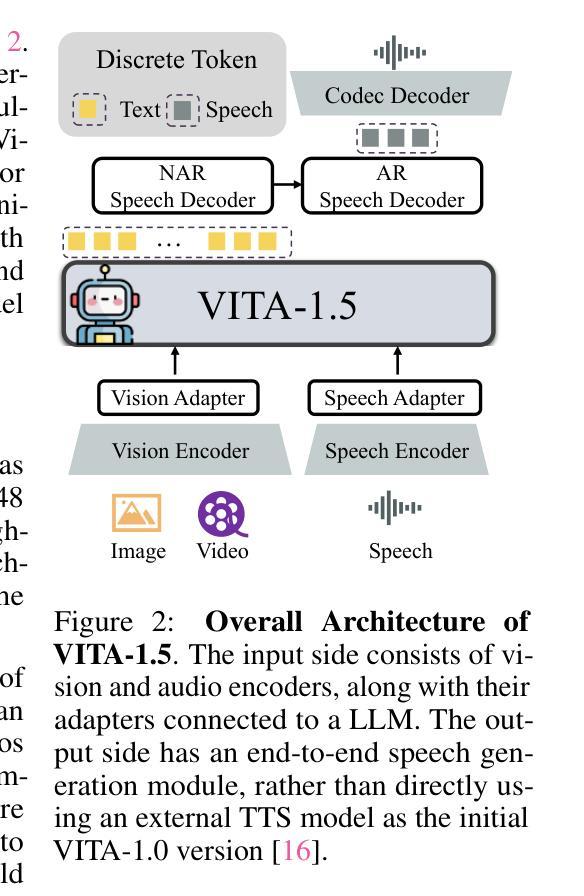
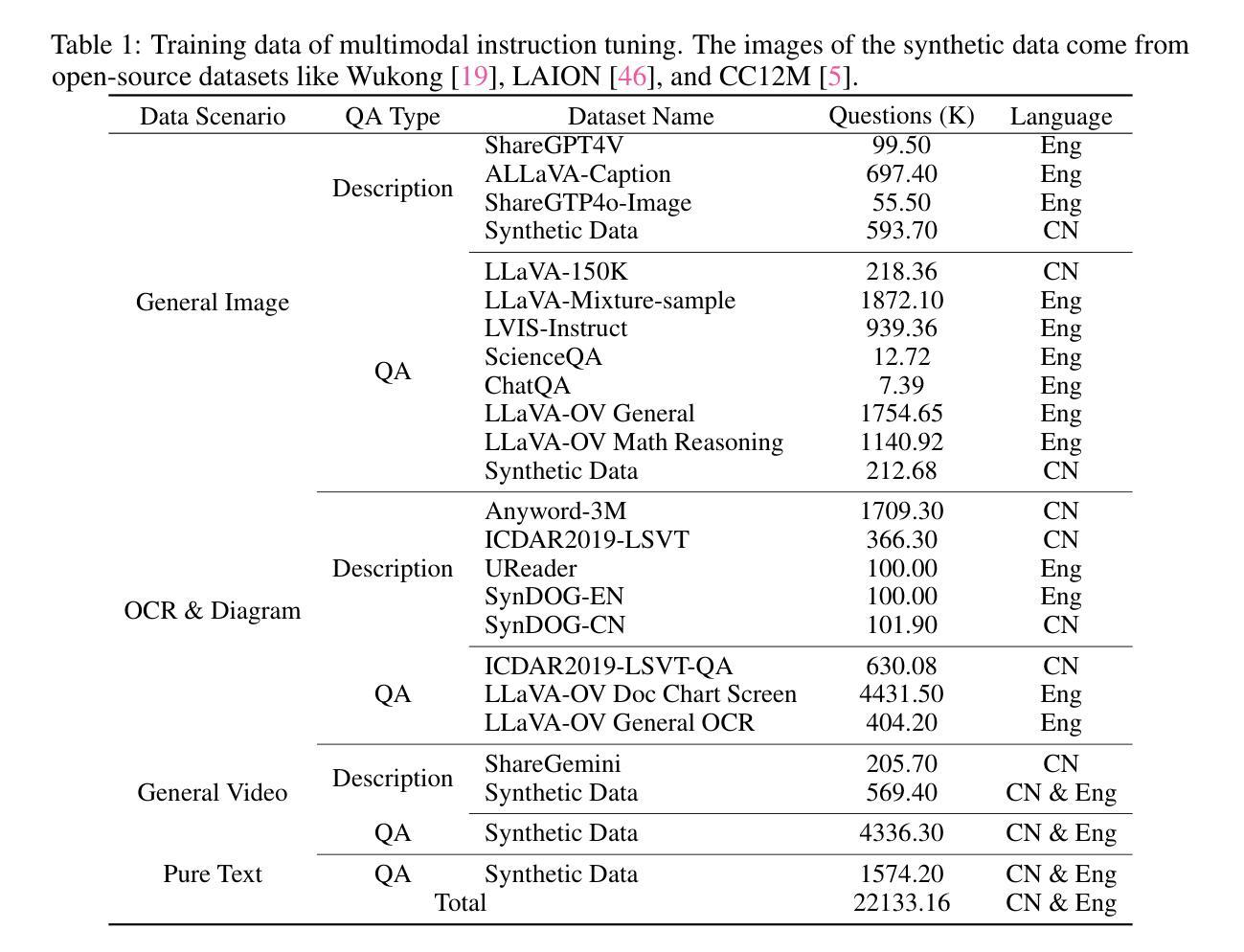
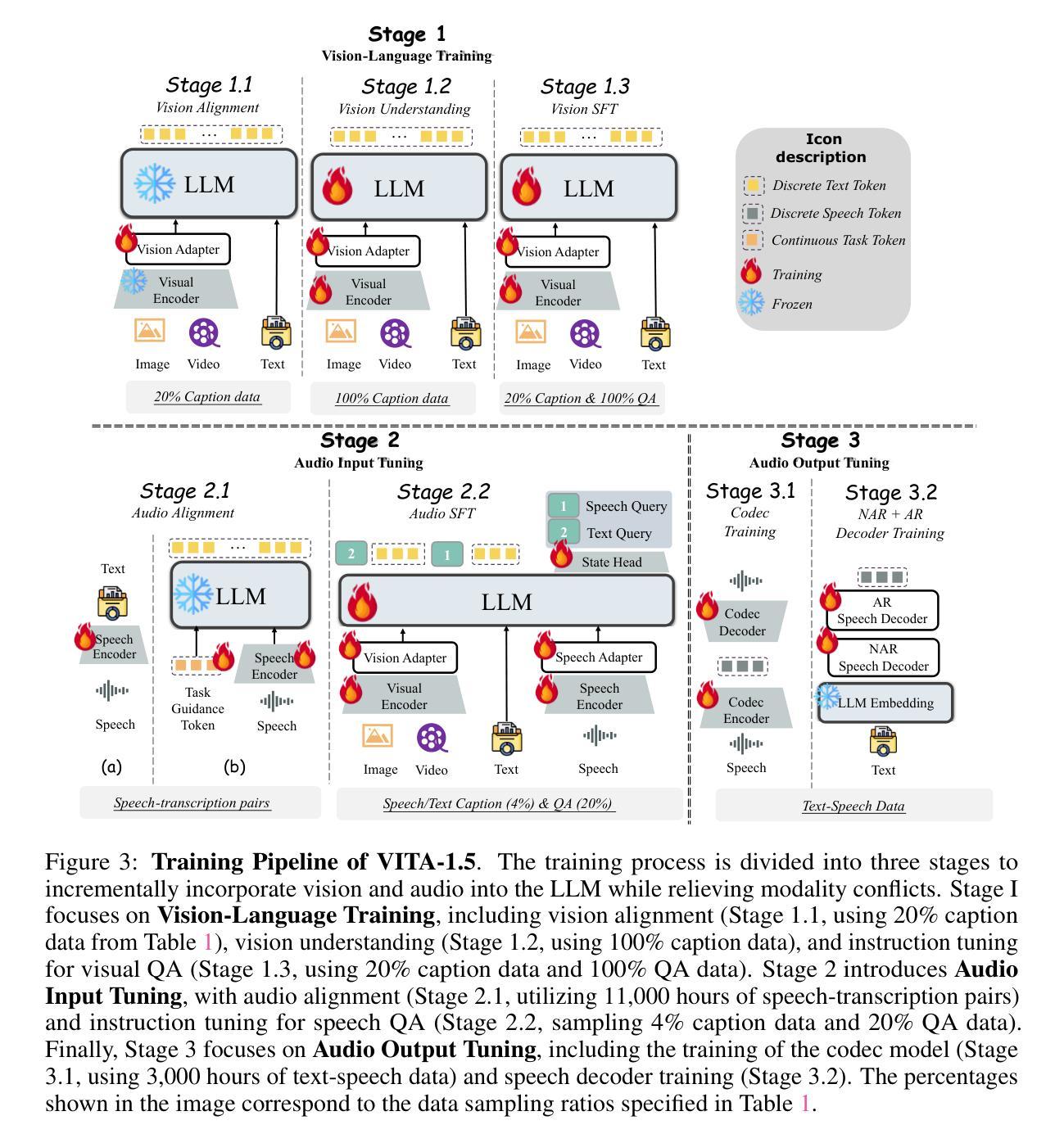
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Authors:Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, Ran He
Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
近期多模态大型语言模型(MLLMs)主要集中于整合视觉和文本模态,较少关注语音在增强交互中的作用。然而,语音在多模态对话系统中起着至关重要的作用,由于在根本模态上的差异,在视觉和语音任务中实现高性能仍然是一个重大挑战。在本文中,我们提出了一种精心设计的多阶段训练方法论,逐步训练大型语言模型以理解视觉和语音信息,最终使流畅的视觉和语音交互成为可能。我们的方法不仅保留了强大的视觉语言功能,还实现了高效的语音对话功能,无需单独的语音识别和文本转语音模块,从而大大加快了多模态端到端的响应速度。通过与图像、视频和语音任务的最新先进模型进行比较,我们证明了我们的模型具有强大的视觉和语音功能,可实现近乎实时的视觉和语音交互。
论文及项目相关链接
PDF https://github.com/VITA-MLLM/VITA
Summary
近期多模态大型语言模型(MLLMs)主要关注视觉和文本模态的融合,较少关注语音在增强交互中的作用。然而,语音在多模态对话系统中扮演关键角色,由于基本模态差异,在视觉和语音任务中实现高性能仍是一大挑战。本文提出精心设计的多阶段训练法,逐步训练LLM理解视觉和语音信息,最终实现流畅的视觉和语音交互。该方法不仅保留了强大的视觉语言能力,还能实现高效的语音对话能力,无需单独的ASR和TTS模块,显著加速多模态端到端响应速度。对比先进方法在图像、视频和语音任务上的基准测试显示,该模型具备强大的视觉和语音能力,可实现近乎实时的视觉和语音交互。
Key Takeaways
- 多模态大型语言模型(MLLMs)开始融合视觉和文本模态,但忽略了语音的重要性。
- 语音在多模态对话系统中起到关键作用。
- 实现视觉和语音任务的高性能是一大挑战,因为存在基本模态差异。
- 论文提出了一种多阶段训练法,旨在让LLM理解视觉和语音信息。
- 该方法提高了LLM的流畅视觉和语音交互能力。
- 该方法不仅保持了强大的视觉语言能力,还允许高效的语音对话能力。
点此查看论文截图

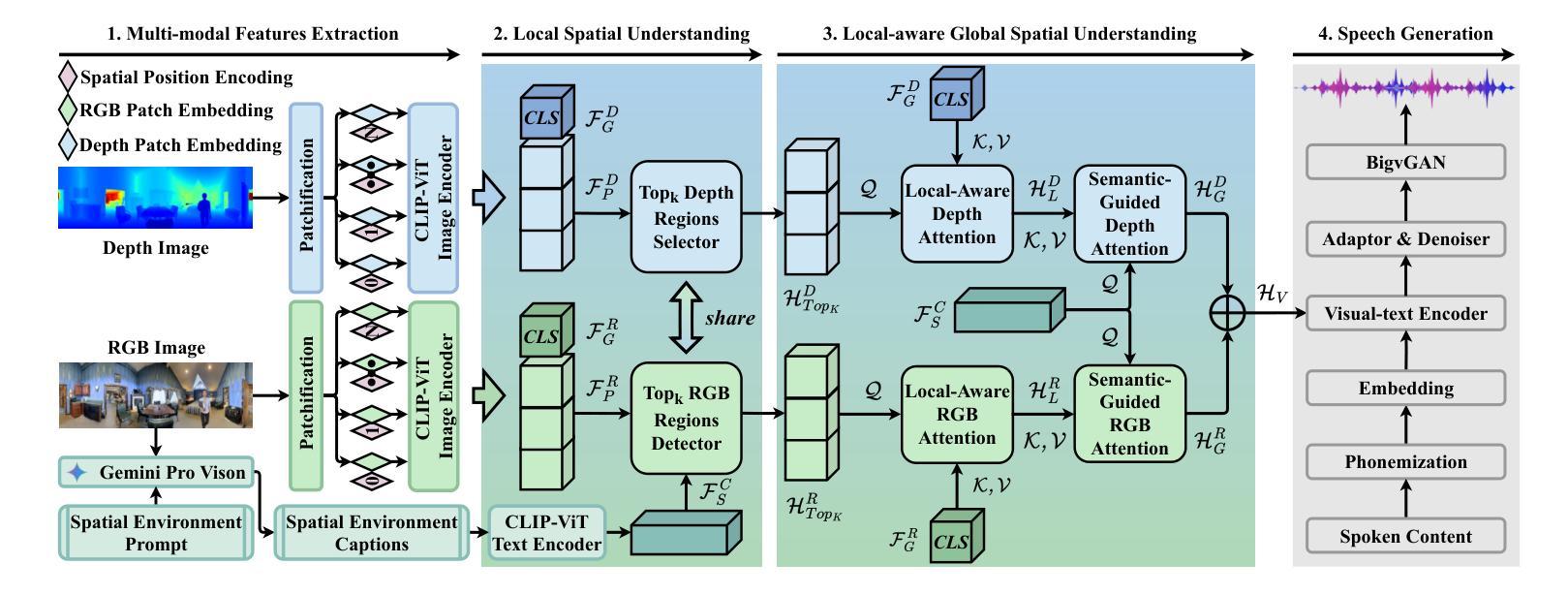
Multi-modal and Multi-scale Spatial Environment Understanding for Immersive Visual Text-to-Speech
Authors:Rui Liu, Shuwei He, Yifan Hu, Haizhou Li
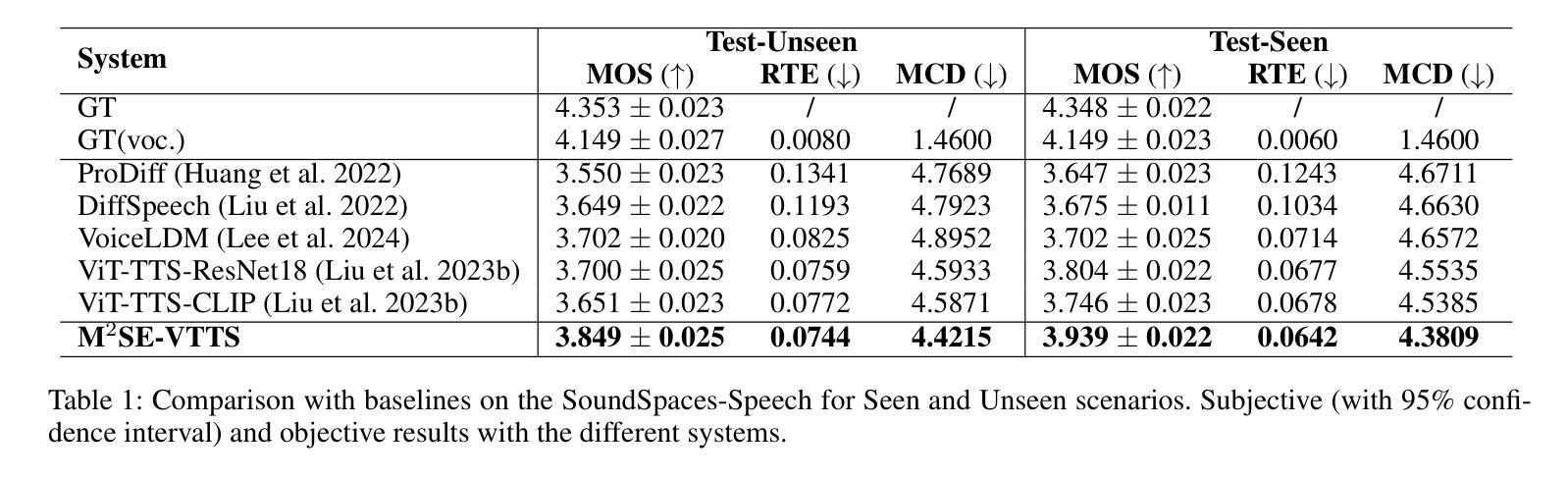
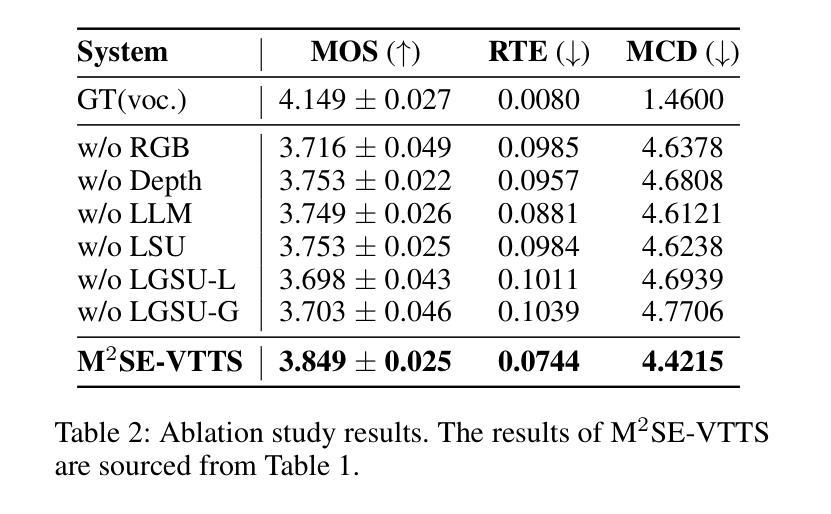
Visual Text-to-Speech (VTTS) aims to take the environmental image as the prompt to synthesize the reverberant speech for the spoken content. The challenge of this task lies in understanding the spatial environment from the image. Many attempts have been made to extract global spatial visual information from the RGB space of an spatial image. However, local and depth image information are crucial for understanding the spatial environment, which previous works have ignored. To address the issues, we propose a novel multi-modal and multi-scale spatial environment understanding scheme to achieve immersive VTTS, termed M2SE-VTTS. The multi-modal aims to take both the RGB and Depth spaces of the spatial image to learn more comprehensive spatial information, and the multi-scale seeks to model the local and global spatial knowledge simultaneously. Specifically, we first split the RGB and Depth images into patches and adopt the Gemini-generated environment captions to guide the local spatial understanding. After that, the multi-modal and multi-scale features are integrated by the local-aware global spatial understanding. In this way, M2SE-VTTS effectively models the interactions between local and global spatial contexts in the multi-modal spatial environment. Objective and subjective evaluations suggest that our model outperforms the advanced baselines in environmental speech generation. The code and audio samples are available at: https://github.com/AI-S2-Lab/M2SE-VTTS.
视觉文本到语音(VTTS)旨在以环境图像为提示,合成相应的语音内容。该任务面临的挑战在于从图像中理解空间环境。许多尝试已从空间图像的RGB空间中提取全局空间视觉信息。然而,局部和深度图像信息对于理解空间环境至关重要,而以前的工作忽略了这一点。为了解决这些问题,我们提出了一种名为M2SE-VTTS的全新多模式、多尺度空间环境理解方案,以实现沉浸式VTTS。多模式旨在利用空间图像的RGB和深度空间来学习更全面的空间信息,多尺度则旨在同时建模局部和全局空间知识。具体来说,我们首先将RGB和深度图像分割成斑块,并采用Gemini生成的环境字幕来指导局部空间理解。之后,通过具有局部意识的全局空间理解,将多模式和多尺度特征相结合。通过这种方式,M2SE-VTTS有效地对多模式空间环境中局部和全局空间上下文之间的交互进行建模。客观和主观评估表明,我们的模型在环境语音生成方面优于先进的基线模型。代码和音频样本可在:https://github.com/AI-S2-Lab/M2SE-VTTS找到。
论文及项目相关链接
PDF 9 pages,2 figures, Accepted by AAAI’2025
Summary
视觉文本到语音(VTTS)以环境图像为提示合成语音内容。其挑战在于从图像理解空间环境。为理解空间环境,提出一种新型的多模式多尺度空间环境理解方案,实现沉浸式VTTS,称为M2SE-VTTS。多模式旨在结合空间图像的RGB和深度空间学习更全面的空间信息,多尺度则旨在同时建模局部和全局空间知识。该方案在环境语音生成中超越了先进的基线模型。
Key Takeaways
- VTTS的目标是根据环境图像合成语音内容。
- 理解空间环境是VTTS的主要挑战。
- 以往的VTTS研究主要关注从RGB空间提取全局空间视觉信息,但忽略了局部和深度图像信息的重要性。
- M2SE-VTTS是一种多模式多尺度的空间环境理解方案,旨在实现沉浸式VTTS。
- 多模式结合RGB和深度空间学习全面的空间信息,而多尺度则同时建模局部和全局空间知识。
- M2SE-VTTS通过分割RGB和深度图像成小块并采用Gemini生成的环境描述来指导局部空间理解。
- 客观和主观评估表明,M2SE-VTTS在环境语音生成方面超越了先进的基线模型。
点此查看论文截图