⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-18 更新
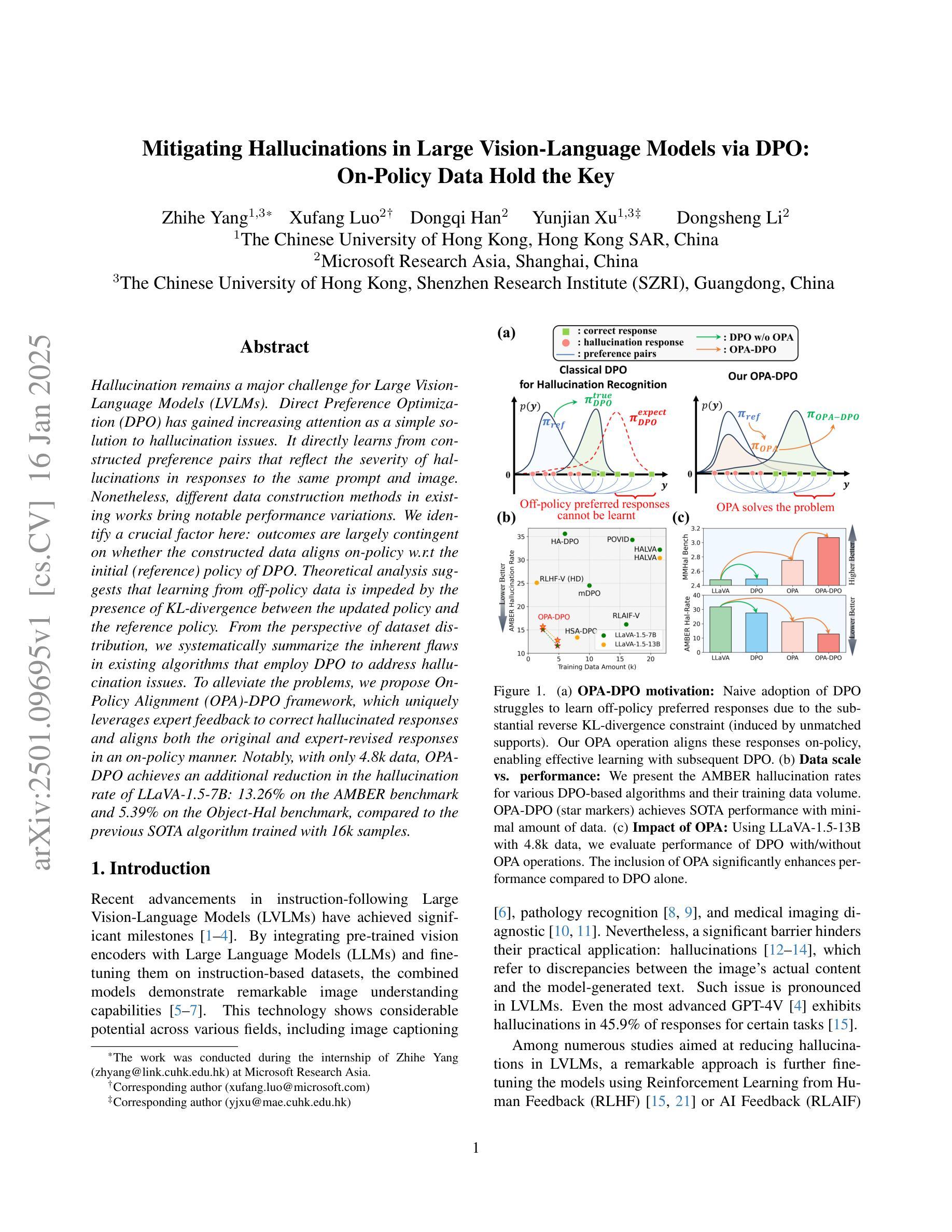
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key
Authors:Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, Dongsheng Li
Hallucination remains a major challenge for Large Vision-Language Models (LVLMs). Direct Preference Optimization (DPO) has gained increasing attention as a simple solution to hallucination issues. It directly learns from constructed preference pairs that reflect the severity of hallucinations in responses to the same prompt and image. Nonetheless, different data construction methods in existing works bring notable performance variations. We identify a crucial factor here: outcomes are largely contingent on whether the constructed data aligns on-policy w.r.t the initial (reference) policy of DPO. Theoretical analysis suggests that learning from off-policy data is impeded by the presence of KL-divergence between the updated policy and the reference policy. From the perspective of dataset distribution, we systematically summarize the inherent flaws in existing algorithms that employ DPO to address hallucination issues. To alleviate the problems, we propose On-Policy Alignment (OPA)-DPO framework, which uniquely leverages expert feedback to correct hallucinated responses and aligns both the original and expert-revised responses in an on-policy manner. Notably, with only 4.8k data, OPA-DPO achieves an additional reduction in the hallucination rate of LLaVA-1.5-7B: 13.26% on the AMBER benchmark and 5.39% on the Object-Hal benchmark, compared to the previous SOTA algorithm trained with 16k samples.
幻觉仍然是大型视觉语言模型(LVLMs)的主要挑战。直接偏好优化(DPO)作为解决幻觉问题的简单解决方案,已越来越受到关注。它直接从构建的偏好对中学习,这些偏好对反映了相同提示和图像下的响应中幻觉的严重程度。然而,现有工作中的不同数据构建方法带来了显著的性能差异。我们在这里确定了一个关键因素:结果在很大程度上取决于构建的数据是否与DPO的初始(参考)政策保持一致。理论分析表明,从非策略数据中学习会受到更新后的策略与参考策略之间KL散度存在的影响。从数据集分布的角度来看,我们系统地总结了现有算法在采用DPO解决幻觉问题方面的固有缺陷。为了缓解这些问题,我们提出了On-Policy Alignment(OPA)-DPO框架,该框架独特地利用专家反馈来纠正幻觉响应,并以策略一致的方式对齐原始和专家修订的响应。值得注意的是,仅使用4.8k数据,OPA-DPO在AMBER基准测试上实现了LLaVA-1.5-7B幻觉率的额外降低:13.26%,在Object-Hal基准测试上降低了5.39%,与之前使用16k样本训练的SOTA算法相比。
论文及项目相关链接
PDF 18 pages, 15 figures
Summary
本文探讨了大型视觉语言模型(LVLMs)中的幻象问题,并指出直接偏好优化(DPO)作为一种解决幻象问题的简单方法受到了广泛关注。文章强调了数据构建方法对DPO性能的影响,并指出关键问题在于构建的数据是否与初始政策对齐。为解决这一问题,文章提出了OPA-DPO框架,利用专家反馈纠正幻象响应,并对原始和专家修订的响应进行政策对齐。实验结果表明,OPA-DPO在减少幻象方面取得了显著成效。
Key Takeaways
- 大型视觉语言模型(LVLMs)面临幻象挑战。
- 直接偏好优化(DPO)是解决幻象问题的一种简单有效方法。
- 数据构建方法对DPO性能有重要影响,关键在于是否与初始政策对齐。
- 现有算法在运用DPO解决幻象问题时存在内在缺陷。
- 提出了OPA-DPO框架,利用专家反馈纠正幻象响应并进行政策对齐。
- OPA-DPO在减少幻象方面取得了显著成效,例如LLaVA-1.5-7B模型的幻象率降低了13.26%。
点此查看论文截图
TCMM: Token Constraint and Multi-Scale Memory Bank of Contrastive Learning for Unsupervised Person Re-identification
Authors:Zheng-An Zhu, Hsin-Che Chien, Chen-Kuo Chiang
This paper proposes the ViT Token Constraint and Multi-scale Memory bank (TCMM) method to address the patch noises and feature inconsistency in unsupervised person re-identification works. Many excellent methods use ViT features to obtain pseudo labels and clustering prototypes, then train the model with contrastive learning. However, ViT processes images by performing patch embedding, which inevitably introduces noise in patches and may compromise the performance of the re-identification model. On the other hand, previous memory bank based contrastive methods may lead data inconsistency due to the limitation of batch size. Furthermore, existing pseudo label methods often discard outlier samples that are difficult to cluster. It sacrifices the potential value of outlier samples, leading to limited model diversity and robustness. This paper introduces the ViT Token Constraint to mitigate the damage caused by patch noises to the ViT architecture. The proposed Multi-scale Memory enhances the exploration of outlier samples and maintains feature consistency. Experimental results demonstrate that our system achieves state-of-the-art performance on common benchmarks. The project is available at \href{https://github.com/andy412510/TCMM}{https://github.com/andy412510/TCMM}.
本文提出了ViT令牌约束和多尺度记忆库(TCMM)方法,以解决无监督行人再识别工作中的补丁噪声和特征不一致问题。许多优秀的方法使用ViT特征来获得伪标签和聚类原型,然后使用对比学习训练模型。然而,ViT通过执行补丁嵌入来处理图像,这不可避免地会在补丁中引入噪声,并可能损害再识别模型的性能。另一方面,基于先前记忆库的对比方法可能会由于批次大小的限制而导致数据不一致。此外,现有的伪标签方法通常会丢弃难以聚类的异常值样本。这牺牲了异常值样本的潜在价值,导致模型多样性和稳健性有限。本文引入了ViT令牌约束,以减轻补丁噪声对ViT架构造成的损害。所提出的多尺度记忆库增强了异常值样本的探索并保持特征一致性。实验结果表明,我们的系统在常用基准测试上达到了最先进的性能。该项目可在[https://github.com/andy412510/TCMM]上找到。
论文及项目相关链接
Summary
本论文针对无监督行人再识别任务中的补丁噪声和特征不一致问题,提出了ViT令牌约束和多尺度内存银行(TCMM)方法。论文引入ViT令牌约束减轻补丁噪声对ViT架构的损害,同时多尺度内存增强对异常样本的探索并保持特征一致性。实验结果表明,该系统在常用基准测试中达到领先水平。
Key Takeaways
- 论文针对无监督行人再识别中的补丁噪声和特征不一致问题提出解决方案。
- 引入ViT令牌约束减轻补丁噪声对ViT架构的影响。
- 多尺度内存银行方法增强对异常样本的探索,并保持特征一致性。
- 现有伪标签方法会丢弃难以聚类的异常样本,影响模型多样性和稳健性。
- TCMM方法通过改进伪标签处理来提升模型性能。
- 实验结果表明,该系统在常用基准测试中表现优异。
点此查看论文截图

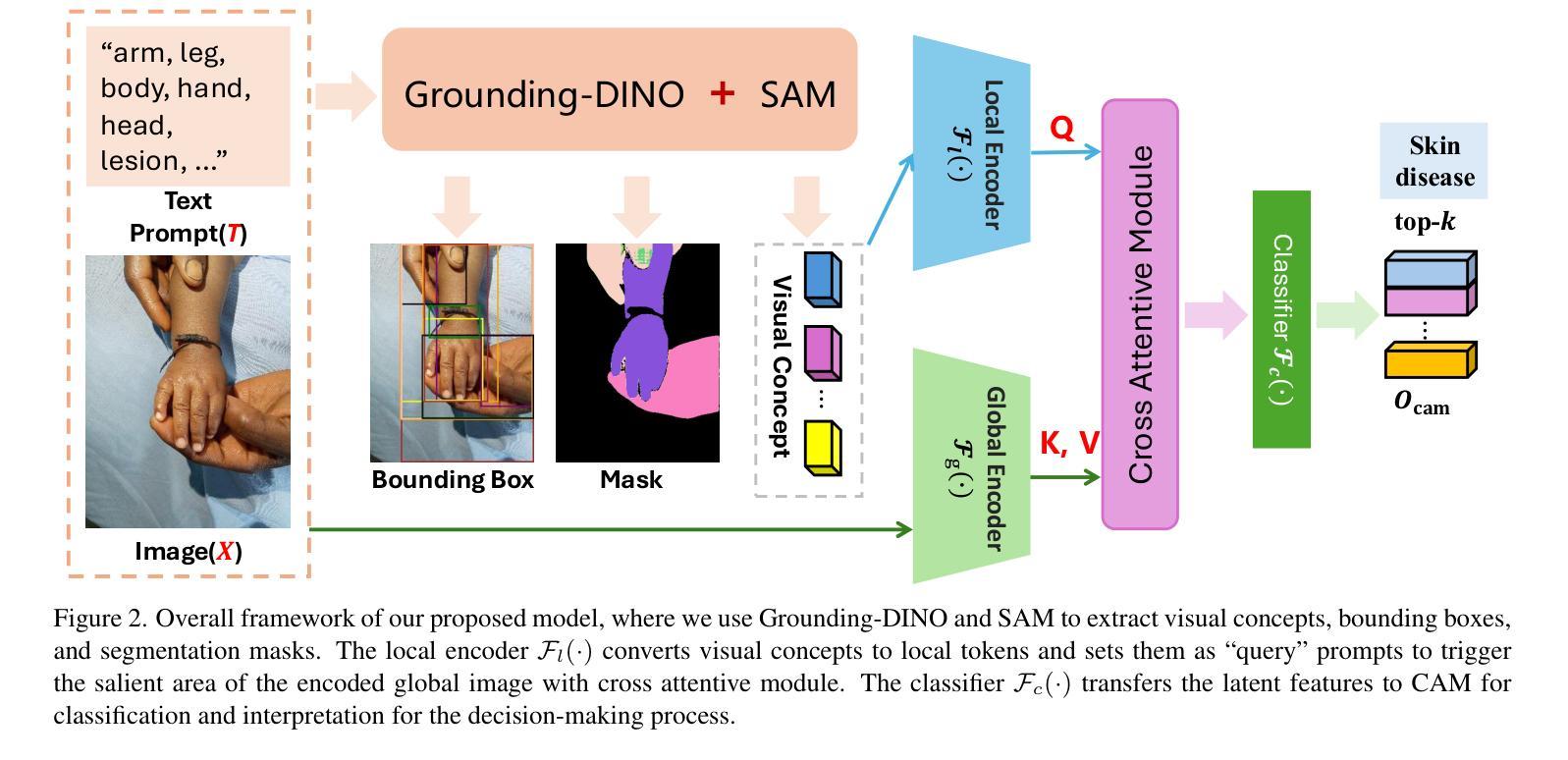
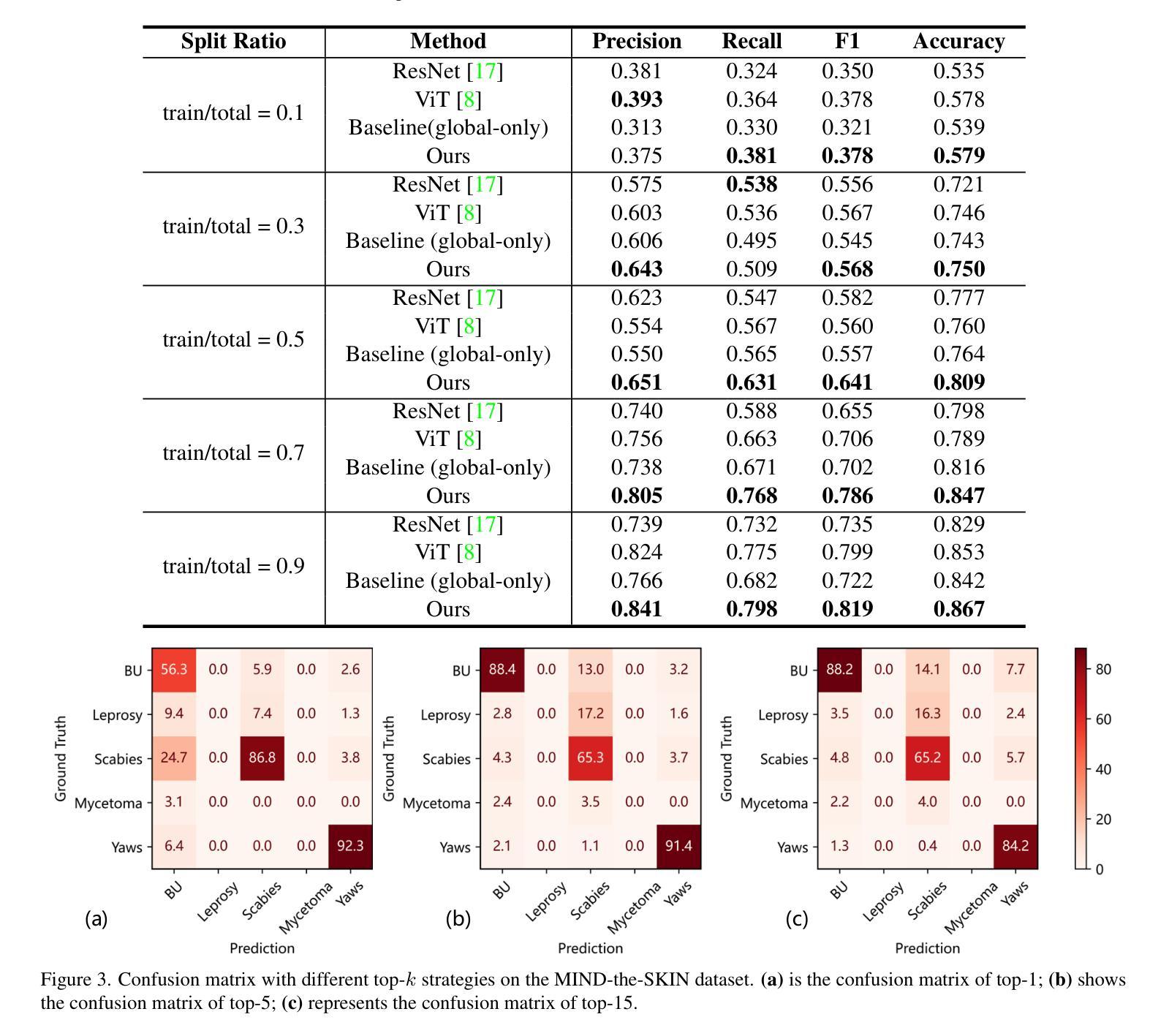
Enhancing Skin Disease Diagnosis: Interpretable Visual Concept Discovery with SAM
Authors:Xin Hu, Janet Wang, Jihun Hamm, Rie R Yotsu, Zhengming Ding
Current AI-assisted skin image diagnosis has achieved dermatologist-level performance in classifying skin cancer, driven by rapid advancements in deep learning architectures. However, unlike traditional vision tasks, skin images in general present unique challenges due to the limited availability of well-annotated datasets, complex variations in conditions, and the necessity for detailed interpretations to ensure patient safety. Previous segmentation methods have sought to reduce image noise and enhance diagnostic performance, but these techniques require fine-grained, pixel-level ground truth masks for training. In contrast, with the rise of foundation models, the Segment Anything Model (SAM) has been introduced to facilitate promptable segmentation, enabling the automation of the segmentation process with simple yet effective prompts. Efforts applying SAM predominantly focus on dermatoscopy images, which present more easily identifiable lesion boundaries than clinical photos taken with smartphones. This limitation constrains the practicality of these approaches to real-world applications. To overcome the challenges posed by noisy clinical photos acquired via non-standardized protocols and to improve diagnostic accessibility, we propose a novel Cross-Attentive Fusion framework for interpretable skin lesion diagnosis. Our method leverages SAM to generate visual concepts for skin diseases using prompts, integrating local visual concepts with global image features to enhance model performance. Extensive evaluation on two skin disease datasets demonstrates our proposed method’s effectiveness on lesion diagnosis and interpretability.
当前,人工智能辅助的皮肤图像诊断在分类皮肤癌方面已达到皮肤科医生的水平,这得益于深度学习架构的快速发展。然而,与传统的视觉任务不同,皮肤图像通常面临着独特的挑战,包括标注良好的数据集有限、条件复杂多变以及需要详细的解释以确保患者安全。之前的分割方法试图减少图像噪声并增强诊断性能,但这些技术需要精细的、像素级的真实掩膜来进行训练。相比之下,随着基础模型的兴起,推出了“任何内容分割模型”(SAM),以实现可提示的分割,使分割过程的自动化成为可能,使用简单而有效的提示。应用SAM的主要努力集中在皮肤科镜检图像上,这些图像比智能手机拍摄的临床照片更容易识别病灶边界。这一局限性限制了这些方法在现实世界应用中的实用性。为了克服由非标准化协议采集的嘈杂临床照片所带来的挑战,并提高诊断的普及性,我们提出了一种用于可解释性皮肤病灶诊断的新型跨注意力融合框架。我们的方法利用SAM生成皮肤疾病的视觉概念提示,将局部视觉概念与全局图像特征相结合,以提高模型性能。在两个皮肤病数据集上的广泛评估证明了我们所提出方法在病灶诊断和可解释性方面的有效性。
论文及项目相关链接
PDF This paper is accepted by WACV 2025
Summary
本文介绍了当前人工智能辅助皮肤图像诊断已达到皮肤科医生水平的性能,但在处理皮肤图像时仍面临独特挑战,如数据集标注有限、条件复杂多变以及需要详细解释以确保患者安全。为应对这些挑战,提出了一种新型的Cross-Attentive Fusion框架,用于可解释的皮肤病变诊断。该方法利用SAM生成皮肤疾病的视觉概念提示,并将局部视觉概念与全局图像特征相结合,以提高模型性能。在两个皮肤病数据集上的广泛评估证明了该方法在病变诊断和可解释性方面的有效性。
Key Takeaways
- 当前AI辅助皮肤图像诊断已达到皮肤科医生水平,但仍面临数据集标注有限、条件复杂等挑战。
- Segment Anything Model (SAM)的引入推动了可提示的分割方法的发展,为自动化分割过程提供了简单而有效的方法。
- 皮肤科镜头图像较智能手机拍摄的临床照片更容易识别病变边界,限制了现有方法在实际应用中的实用性。
- 为应对非标准化协议下采集的嘈杂临床照片带来的挑战,提高诊断的可及性,提出了一种新型的Cross-Attentive Fusion框架。
- 该框架利用SAM生成皮肤疾病的视觉概念提示,并将局部和全局特征相结合,以提高模型性能。
- 在两个皮肤病数据集上的评估证明了该方法在病变诊断方面的有效性。
点此查看论文截图