⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-19 更新
On the optimal prediction of extreme events in heavy-tailed time series with applications to solar flare forecasting
Authors:Victor Verma, Stilian Stoev, Yang Chen
The prediction of extreme events in time series is a fundamental problem arising in many financial, scientific, engineering, and other applications. We begin by establishing a general Neyman-Pearson-type characterization of optimal extreme event predictors in terms of density ratios. This yields new insights and several closed-form optimal extreme event predictors for additive models. These results naturally extend to time series, where we study optimal extreme event prediction for both light- and heavy-tailed autoregressive and moving average models. Using a uniform law of large numbers for ergodic time series, we establish the asymptotic optimality of an empirical version of the optimal predictor for autoregressive models. Using multivariate regular variation, we obtain an expression for the optimal extremal precision in heavy-tailed infinite moving averages, which provides theoretical bounds on the ability to predict extremes in this general class of models. We address the important problem of predicting solar flares by applying our theory and methodology to a state-of-the-art time series consisting of solar soft X-ray flux measurements. Our results demonstrate the success and limitations in solar flare forecasting of long-memory autoregressive models and long-range-dependent, heavy-tailed FARIMA models.
极端事件时间序列预测是金融、科学、工程等许多应用领域中一个基本的问题。我们首先针对密度比建立了一种一般性的奈曼-皮尔逊型极端事件最优预测器的表征。这为加法模型提供了新的见解和几个封闭形式的最佳极端事件预测器。这些结果自然地扩展到时间序列,我们研究了轻尾和重尾自回归和移动平均模型的最佳极端事件预测。利用遍历时间序列的大数定律,我们建立了自回归模型最优预测器经验版本的渐近最优性。利用多元正则变化,我们得到了重尾无限移动平均中的最优极值精度的表达式,这为预测此类一般模型中极端事件的能力提供了理论界限。我们通过将理论和方法论应用于最先进的太阳软X射线流量测量时间序列来解决预测太阳耀斑这一重要问题。我们的结果展示了长记忆自回归模型和长程依赖重尾FARIMA模型在太阳耀斑预报中的成功和局限性。
论文及项目相关链接
PDF 62 pages, 6 figures. Revised version accepted for publication in the Journal of Time Series Analysis
Summary
本文研究了时间序列中极端事件的预测问题,在多个领域有广泛应用。文章建立了最优极端事件预测器的Neyman-Pearson类型表征,为加法模型提供了封闭形式的最优极端事件预测器。此外,文章研究了自回归和移动平均模型的轻重尾极端事件预测,并建立了自回归模型预测器的经验版本渐近最优性。对于重尾无限移动平均模型,文章获得了最优极端精度表达式,为预测极端事件提供了理论界限。最后,文章将理论和方法应用于太阳软X射线流量测量时间序列,展示了长期记忆自回归模型和长期依赖重尾FARIMA模型在太阳耀斑预测中的成功和局限性。
Key Takeaways
- 建立了最优极端事件预测器的Neyman-Pearson类型表征。
- 为加法模型提供了封闭形式的最优极端事件预测器。
- 研究了自回归和移动平均模型的轻重尾极端事件预测。
- 建立了自回归模型预测器的经验版本渐近最优性。
- 对于重尾无限移动平均模型,获得了最优极端精度表达式。
- 将理论和方法应用于太阳软X射线流量测量时间序列。
点此查看论文截图


Enhanced Masked Image Modeling to Avoid Model Collapse on Multi-modal MRI Datasets
Authors:Linxuan Han, Sa Xiao, Zimeng Li, Haidong Li, Xiuchao Zhao, Yeqing Han, Fumin Guo, Xin Zhou
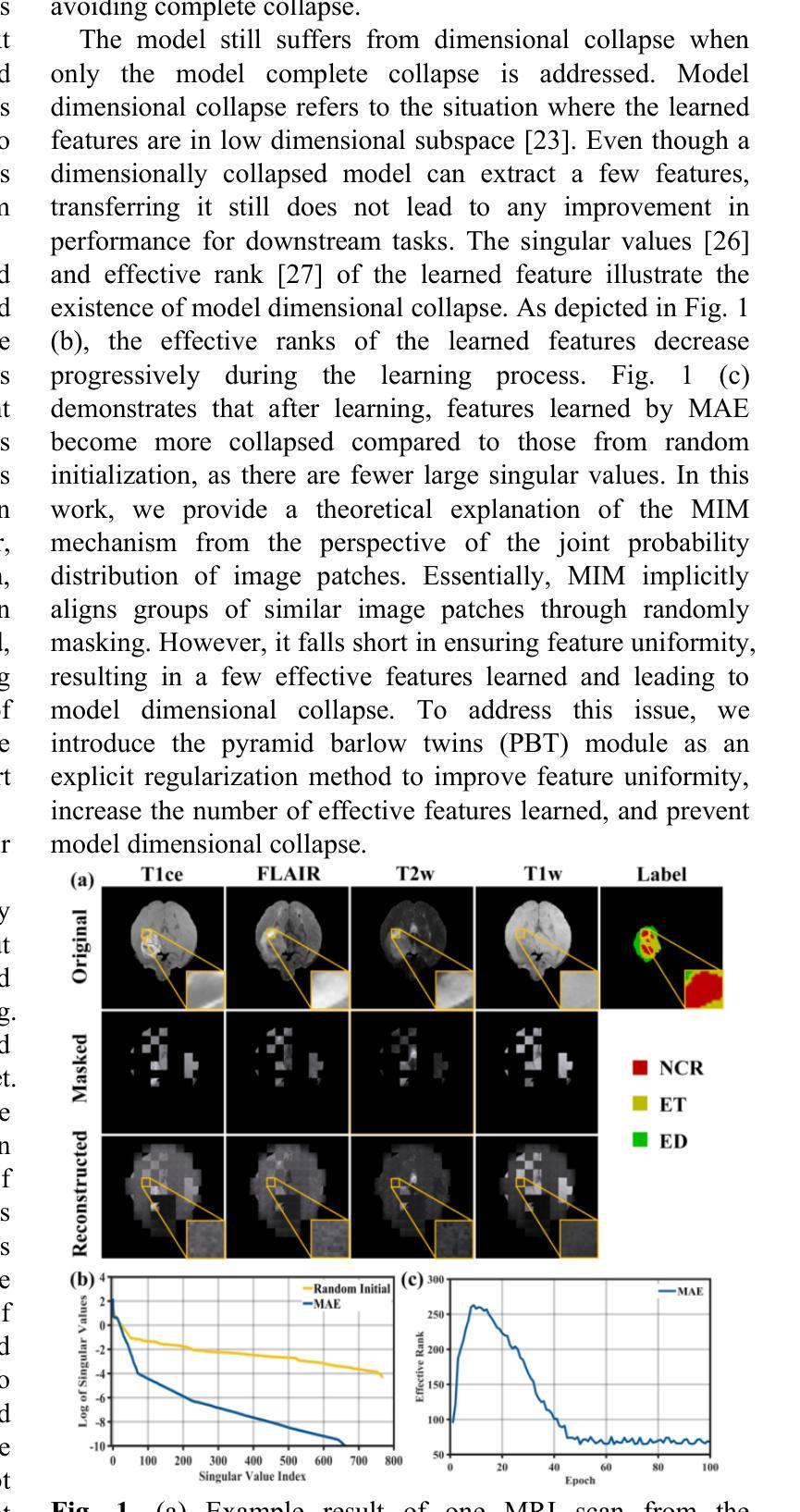
Multi-modal magnetic resonance imaging (MRI) provides information of lesions for computer-aided diagnosis from different views. Deep learning algorithms are suitable for identifying specific anatomical structures, segmenting lesions, and classifying diseases. Manual labels are limited due to the high expense, which hinders further improvement of accuracy. Self-supervised learning, particularly masked image modeling (MIM), has shown promise in utilizing unlabeled data. However, we spot model collapse when applying MIM to multi-modal MRI datasets. The performance of downstream tasks does not see any improvement following the collapsed model. To solve model collapse, we analyze and address it in two types: complete collapse and dimensional collapse. We find complete collapse occurs because the collapsed loss value in multi-modal MRI datasets falls below the normally converged loss value. Based on this, the hybrid mask pattern (HMP) masking strategy is introduced to elevate the collapsed loss above the normally converged loss value and avoid complete collapse. Additionally, we reveal that dimensional collapse stems from insufficient feature uniformity in MIM. We mitigate dimensional collapse by introducing the pyramid barlow twins (PBT) module as an explicit regularization method. Overall, we construct the enhanced MIM (E-MIM) with HMP and PBT module to avoid model collapse multi-modal MRI. Experiments are conducted on three multi-modal MRI datasets to validate the effectiveness of our approach in preventing both types of model collapse. By preventing model collapse, the training of the model becomes more stable, resulting in a decent improvement in performance for segmentation and classification tasks. The code is available at https://github.com/LinxuanHan/E-MIM.
多模态磁共振成像(MRI)从不同视角为计算机辅助诊断提供病变信息。深度学习算法适用于识别特定解剖结构、分割病变和分类疾病。由于高昂的费用,手动标签受到限制,这阻碍了准确性的进一步提高。自监督学习,尤其是掩膜图像建模(MIM)在利用无标签数据方面显示出潜力。然而,我们在将MIM应用于多模态MRI数据集时发现了模型崩溃的情况。崩溃的模型并未改善下游任务的表现。为了解决模型崩溃问题,我们分析和解决了两种类型的崩溃:完全崩溃和维度崩溃。我们发现完全崩溃是由于多模态MRI数据集中的损失值崩溃低于正常收敛的损失值。基于此,我们引入了混合掩膜模式(HMP)掩膜策略,将崩溃的损失值提升到正常收敛的损失值之上,避免完全崩溃。此外,我们揭示了维度崩溃源于MIM中特征均匀性不足。我们通过引入金字塔巴洛孪生(PBT)模块作为显式正则化方法来缓解维度崩溃。总体而言,我们结合了HMP和PBT模块构建了增强型MIM(E-MIM)来避免多模态MRI的模型崩溃。我们在三个多模态MRI数据集上进行了实验,以验证我们的方法在防止两种模型崩溃方面的有效性。通过防止模型崩溃,模型的训练变得更加稳定,分割和分类任务的性能也得到了显著提高。代码可在https://github.com/LinxuanHan/E-MIM找到。
论文及项目相关链接
PDF This work has been submitted to the lEEE for possible publication. copyright may be transferred without notice, after which this version may no longer be accessible
Summary
多模态磁共振成像结合深度学习算法,通过不同视角为计算机辅助诊断提供病变信息。自监督学习中的掩膜图像建模在利用未标注数据方面展现出潜力,但应用于多模态MRI数据集时会出现模型崩溃问题。为解决此问题,本文提出了混合掩膜策略和金字塔Barlow双生模块,增强了掩膜图像建模(E-MIM),有效避免了模型崩溃,提高了分割和分类任务的性能。
Key Takeaways
- 多模态磁共振成像从不同视角为计算机辅助诊断提供病变信息。
- 深度学习算法在识别特定解剖结构、分割病变和疾病分类方面表现出优势。
- 自监督学习中的掩膜图像建模在利用未标注数据方面展现出潜力。
- 掩膜图像建模应用于多模态MRI数据集时可能出现模型崩溃问题。
- 模型崩溃分为完全崩溃和维度崩溃两种类型,需分别应对。
- 引入混合掩膜策略和金字塔Barlow双生模块增强掩膜图像建模,解决模型崩溃问题。
点此查看论文截图


reBEN: Refined BigEarthNet Dataset for Remote Sensing Image Analysis
Authors:Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Begüm Demir, Volker Markl
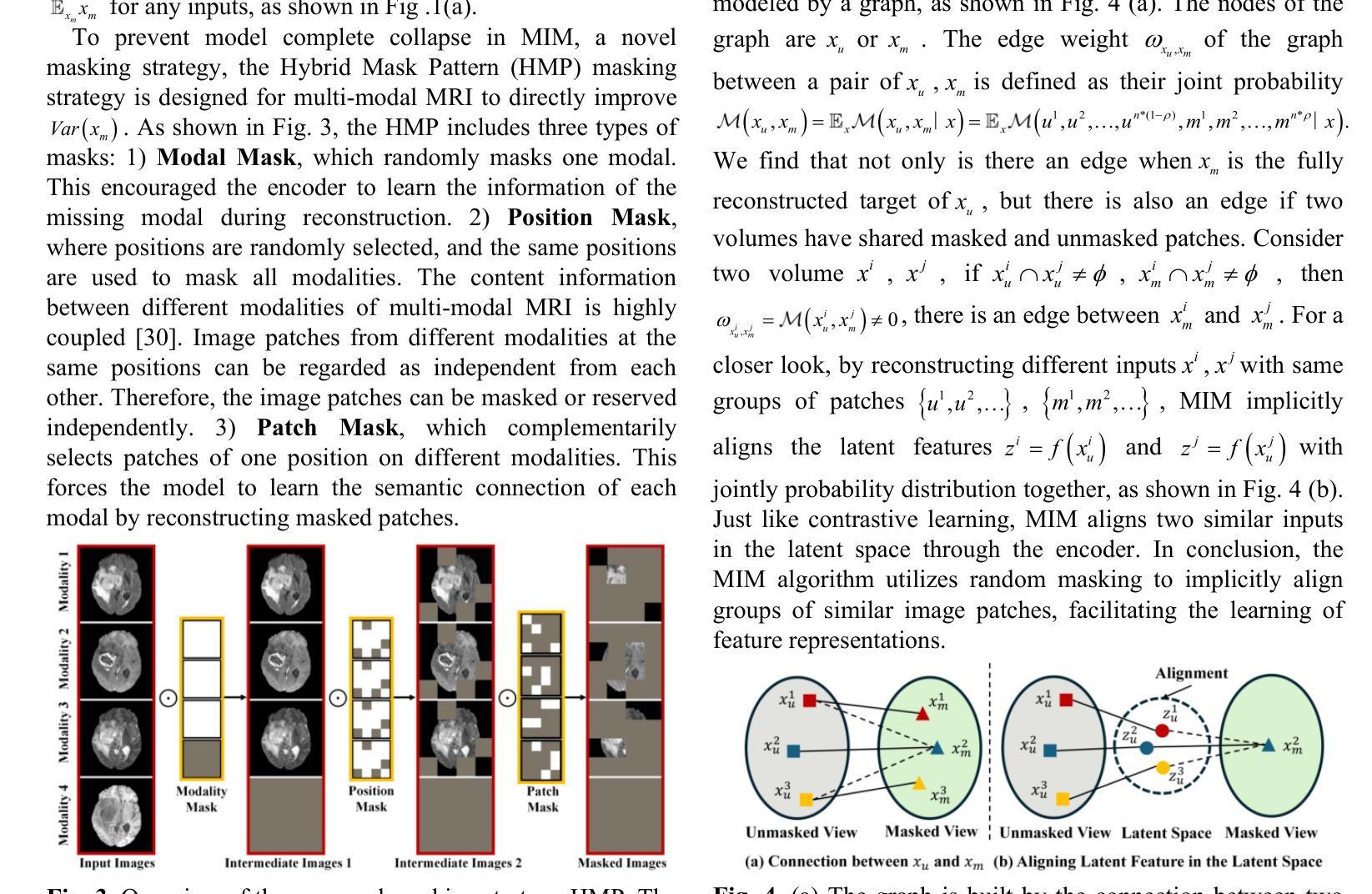
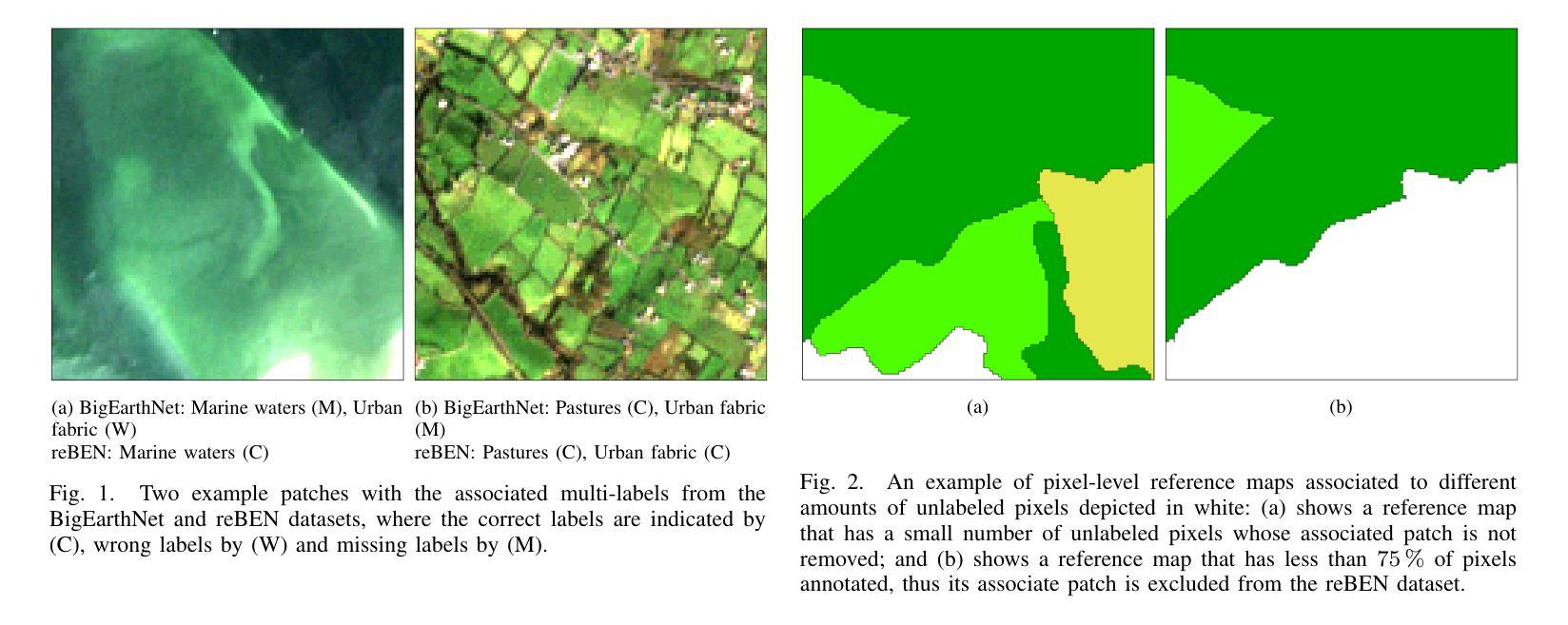
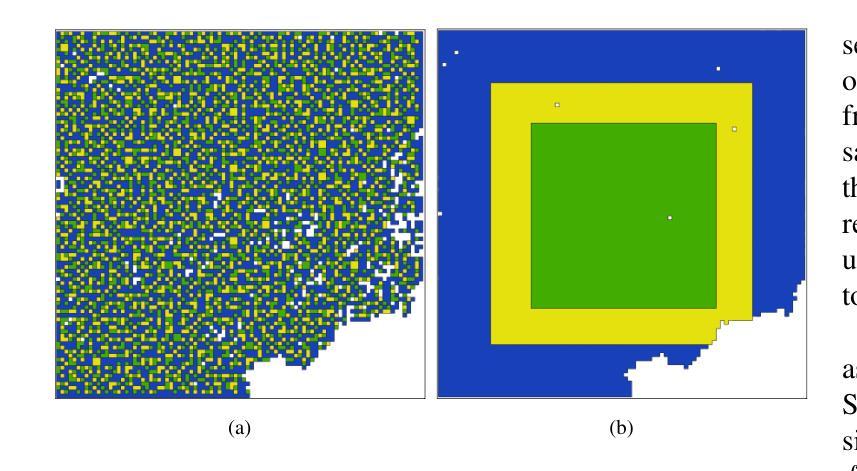
This paper presents refined BigEarthNet (reBEN) that is a large-scale, multi-modal remote sensing dataset constructed to support deep learning (DL) studies for remote sensing image analysis. The reBEN dataset consists of 549,488 pairs of Sentinel-1 and Sentinel-2 image patches. To construct reBEN, we initially consider the Sentinel-1 and Sentinel-2 tiles used to construct the BigEarthNet dataset and then divide them into patches of size 1200 m x 1200 m. We apply atmospheric correction to the Sentinel-2 patches using the latest version of the sen2cor tool, resulting in higher-quality patches compared to those present in BigEarthNet. Each patch is then associated with a pixel-level reference map and scene-level multi-labels. This makes reBEN suitable for pixel- and scene-based learning tasks. The labels are derived from the most recent CORINE Land Cover (CLC) map of 2018 by utilizing the 19-class nomenclature as in BigEarthNet. The use of the most recent CLC map results in overcoming the label noise present in BigEarthNet. Furthermore, we introduce a new geographical-based split assignment algorithm that significantly reduces the spatial correlation among the train, validation, and test sets with respect to those present in BigEarthNet. This increases the reliability of the evaluation of DL models. To minimize the DL model training time, we introduce software tools that convert the reBEN dataset into a DL-optimized data format. In our experiments, we show the potential of reBEN for multi-modal multi-label image classification problems by considering several state-of-the-art DL models. The pre-trained model weights, associated code, and complete dataset are available at https://bigearth.net.
本文介绍了精细化的BigEarthNet(reBEN),这是一个为支持遥感图像分析的深度学习(DL)研究而构建的大规模、多模态遥感数据集。reBEN数据集包含549,488对Sentinel-1和Sentinel-2图像补丁。为了构建reBEN,我们首先考虑了用于构建BigEarthNet数据集的Sentinel-1和Sentinel-2瓦片,然后将其划分为大小为1200米x 1200米的补丁。我们对Sentinel-2补丁应用了使用sen2cor工具最新版本的大气校正,结果产生了与BigEarthNet中现有的补丁相比质量更高的补丁。然后,每个补丁都与像素级参考地图和场景级多标签相关联。这使得reBEN适合用于像素和场景基础的学习任务。标签是通过利用BigEarthNet中的19类命名法,从最新的2018年CORINE土地覆盖(CLC)地图中得出的。使用最新的CLC地图克服了BigEarthNet中存在的标签噪声。此外,我们引入了一种新的基于地理的分割分配算法,该算法显著减少了训练集、验证集和测试集之间的空间相关性,与BigEarthNet中的相关集相比。这增加了深度学习模型评估的可靠性。为了最小化深度学习模型训练时间,我们引入了将reBEN数据集转换为深度学习优化数据格式的软件工具。在我们的实验中,我们通过考虑一些最先进的深度学习模型,展示了reBEN在多模态多标签图像分类问题上的潜力。预训练模型权重、相关代码和完整数据集可在https://bigearth.net上找到。
论文及项目相关链接
摘要
本论文推出精细化的BigEarthNet(reBEN),这是一套大型、多模式遥感数据集,专为支持遥感图像分析的深度学习(DL)研究而构建。reBEN数据集包含549,488对Sentinel-1和Sentinel-2图像补丁。相较于BigEarthNet,通过对Sentinel-2补丁应用大气校正及采用最新sen2cor工具版本,reBEN的图像质量更高。每个补丁都与像素级参考地图和场景级多标签相关联,使其适合像素和场景基础的学习任务。标签由最新的2018年CORINE土地覆盖(CLC)地图派生而来,克服了BigEarthNet中的标签噪声问题。此外,我们引入新的基于地理的分割分配算法,显著减少了训练、验证和测试集之间的空间相关性,提高了深度学习模型评估的可靠性。为减少深度学习模型训练时间,我们提供软件工具将reBEN数据集转换为深度学习优化格式。实验表明,reBEN在多模式多标签图像分类问题上具有潜力,可通过考虑若干最先进的深度学习模型进行验证。预训练模型权重、相关代码和完整数据集可在https://bigearth.net访问。
关键见解
- reBEN是一个大型、多模式遥感数据集,用于支持深度学习研究。
- reBEN包含高质量图像补丁,通过应用大气校正和采用最新sen2cor工具版本改进了图像质量。
- 数据集中的每个补丁都与像素级参考地图和场景级多标签关联,适合多种学习任务。
- 使用最新的CORINE土地覆盖(CLC)地图,减少了标签噪声问题。
- 新的基于地理的分割分配算法降低了训练、验证和测试集之间的空间相关性,提高了模型评估的可靠性。
- 提供软件工具将数据集转换为深度学习优化格式,以缩短模型训练时间。
点此查看论文截图

CMRxRecon2024: A Multi-Modality, Multi-View K-Space Dataset Boosting Universal Machine Learning for Accelerated Cardiac MRI
Authors:Zi Wang, Fanwen Wang, Chen Qin, Jun Lyu, Cheng Ouyang, Shuo Wang, Yan Li, Mengyao Yu, Haoyu Zhang, Kunyuan Guo, Zhang Shi, Qirong Li, Ziqiang Xu, Yajing Zhang, Hao Li, Sha Hua, Binghua Chen, Longyu Sun, Mengting Sun, Qin Li, Ying-Hua Chu, Wenjia Bai, Jing Qin, Xiahai Zhuang, Claudia Prieto, Alistair Young, Michael Markl, He Wang, Lianming Wu, Guang Yang, Xiaobo Qu, Chengyan Wang
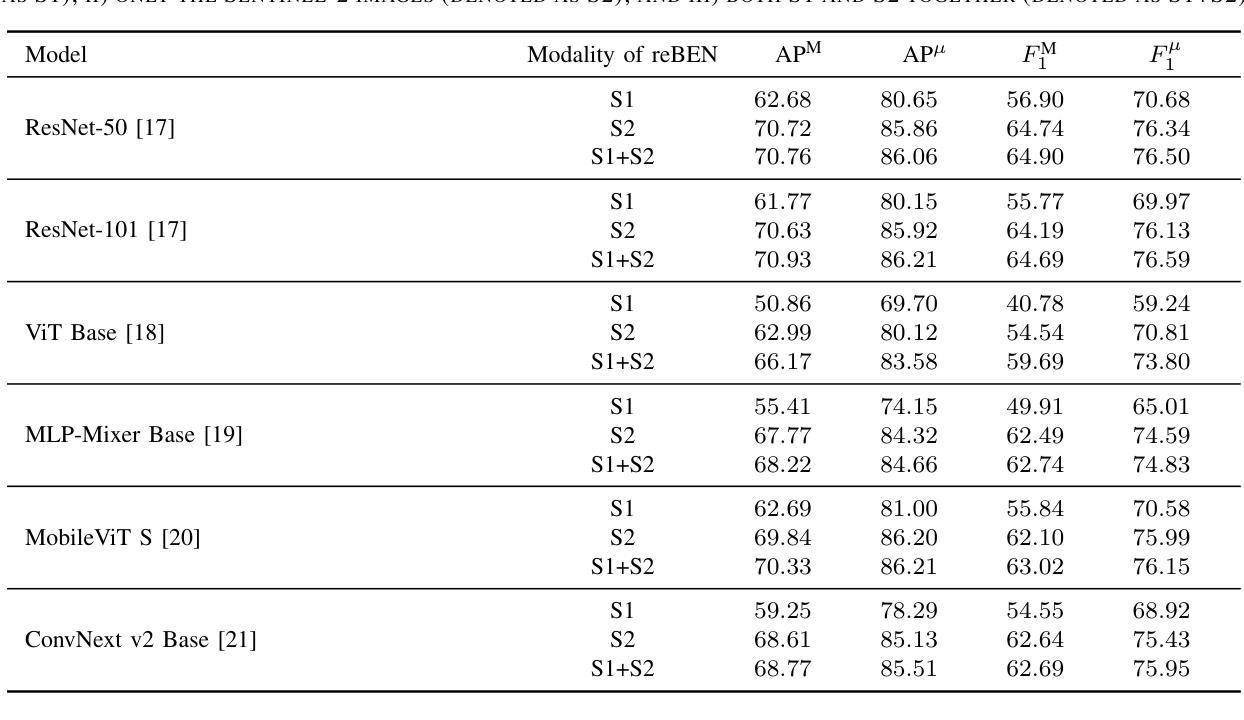
Cardiac magnetic resonance imaging (MRI) has emerged as a clinically gold-standard technique for diagnosing cardiac diseases, thanks to its ability to provide diverse information with multiple modalities and anatomical views. Accelerated cardiac MRI is highly expected to achieve time-efficient and patient-friendly imaging, and then advanced image reconstruction approaches are required to recover high-quality, clinically interpretable images from undersampled measurements. However, the lack of publicly available cardiac MRI k-space dataset in terms of both quantity and diversity has severely hindered substantial technological progress, particularly for data-driven artificial intelligence. Here, we provide a standardized, diverse, and high-quality CMRxRecon2024 dataset to facilitate the technical development, fair evaluation, and clinical transfer of cardiac MRI reconstruction approaches, towards promoting the universal frameworks that enable fast and robust reconstructions across different cardiac MRI protocols in clinical practice. To the best of our knowledge, the CMRxRecon2024 dataset is the largest and most protocal-diverse publicly available cardiac k-space dataset. It is acquired from 330 healthy volunteers, covering commonly used modalities, anatomical views, and acquisition trajectories in clinical cardiac MRI workflows. Besides, an open platform with tutorials, benchmarks, and data processing tools is provided to facilitate data usage, advanced method development, and fair performance evaluation.
心脏磁共振成像(MRI)已成为临床诊断心脏疾病的金标准技术,它能够提供多种模态和解剖视角的多样化信息。加速心脏MRI被寄予厚望,以实现高效且患者友好的成像,因此需要先进的图像重建方法从欠采样的测量中恢复高质量、可临床解读的图像。然而,缺乏公开可用的心脏MRI k-space数据集,无论是在数量还是多样性方面,都严重阻碍了实质性的技术进步,特别是对于数据驱动的人工智能。在此,我们提供了标准化、多样化、高质量的CMRxRecon2024数据集,以促进心脏MRI重建方法的技术发展、公平评估以及临床转化,推动在临床实践中不同心脏MRI协议都能快速稳健重建的通用框架。据我们所知,CMRxRecon2024数据集是最大且协议最多样化的公开可用的心脏k-space数据集。它来自330名健康志愿者的数据,涵盖了临床心脏MRI工作流程中常用的模态、解剖视角和采集轨迹。此外,我们还提供了一个开放平台,提供教程、基准测试和数据处理工具,以促进数据使用、先进方法开发和公平性能评估。
论文及项目相关链接
PDF 23 pages, 3 figures, 2 tables
Summary
这篇文本介绍了心脏磁共振成像(MRI)作为诊断心脏疾病的临床金标准技术,其能够提供多种模态和解剖视图的信息。为了从欠采样的测量中恢复高质量、可临床解读的图像,需要先进的图像重建方法。由于缺乏公开可用的心脏MRI k-space数据集,在数量和多样性方面存在严重缺陷,特别是在数据驱动的人工智能方面,阻碍了重大技术进步。为此,提供了标准化、多样化和高质量的CMRxRecon2024数据集,以促进心脏MRI重建方法的技术发展、公平评估和临床转化,推动在临床实践中不同心脏MRI协议实现快速稳健重建的通用框架。据我们所知,CMRxRecon2024数据集是最大且协议最多元的心脏k-space公开数据集。
Key Takeaways
- 心脏MRI是诊断心脏疾病的金标准技术,具有提供多种模态和解剖视图信息的能力。
- 加速心脏MRI需要先进的图像重建方法来恢复高质量的临床图像。
- 缺乏公开可用的心脏MRI k-space数据集在数量和多样性方面限制了技术进步,特别是在数据驱动的AI方面。
- CMRxRecon2024数据集是最大且协议最多元的心脏k-space公开数据集。
- 数据集涵盖了临床心脏MRI工作流程中常用的模态、解剖视图和采集轨迹。
- 数据集从330名健康志愿者中获取。
点此查看论文截图

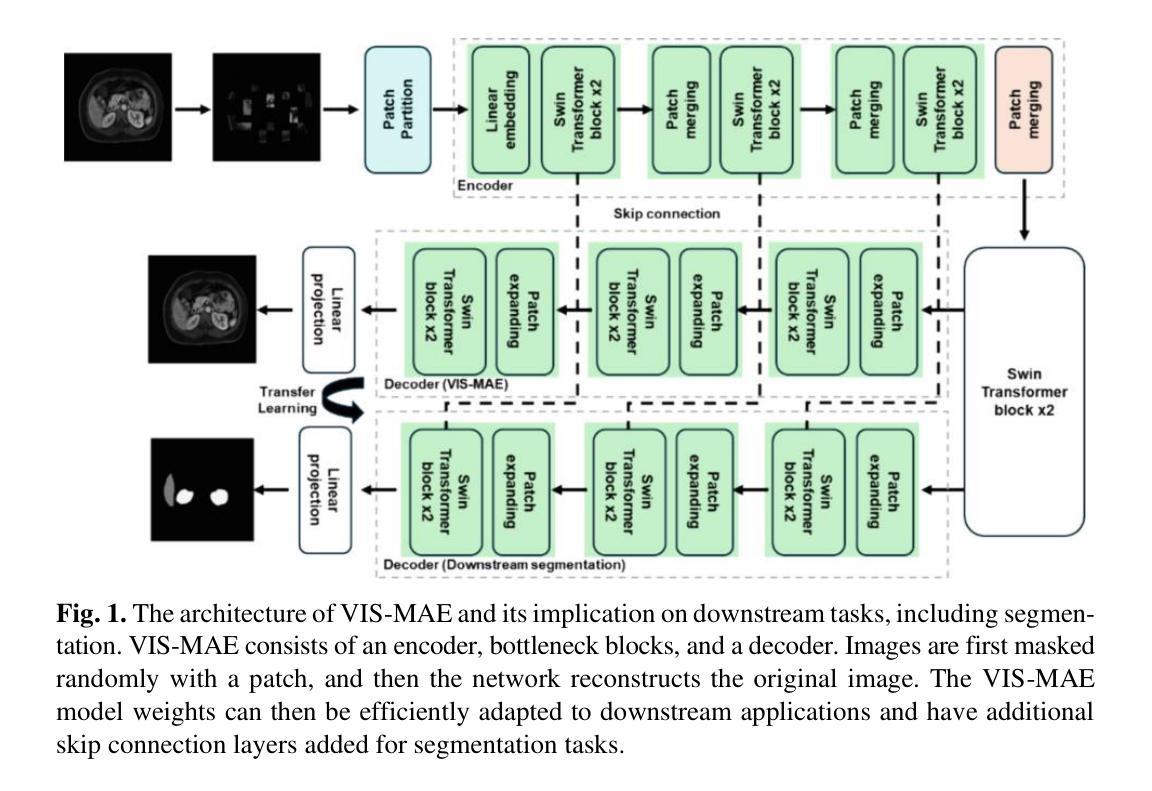
VIS-MAE: An Efficient Self-supervised Learning Approach on Medical Image Segmentation and Classification
Authors:Zelong Liu, Andrew Tieu, Nikhil Patel, Georgios Soultanidis, Louisa Deyer, Ying Wang, Sean Huver, Alexander Zhou, Yunhao Mei, Zahi A. Fayad, Timothy Deyer, Xueyan Mei
Artificial Intelligence (AI) has the potential to revolutionize diagnosis and segmentation in medical imaging. However, development and clinical implementation face multiple challenges including limited data availability, lack of generalizability, and the necessity to incorporate multi-modal data effectively. A foundation model, which is a large-scale pre-trained AI model, offers a versatile base that can be adapted to a variety of specific tasks and contexts. Here, we present VIsualization and Segmentation Masked AutoEncoder (VIS-MAE), novel model weights specifically designed for medical imaging. Specifically, VIS-MAE is trained on a dataset of 2.5 million unlabeled images from various modalities (CT, MR, PET,X-rays, and ultrasound), using self-supervised learning techniques. It is then adapted to classification and segmentation tasks using explicit labels. VIS-MAE has high label efficiency, outperforming several benchmark models in both in-domain and out-of-domain applications. In addition, VIS-MAE has improved label efficiency as it can achieve similar performance to other models with a reduced amount of labeled training data (50% or 80%) compared to other pre-trained weights. VIS-MAE represents a significant advancement in medical imaging AI, offering a generalizable and robust solution for improving segmentation and classification tasks while reducing the data annotation workload. The source code of this work is available at https://github.com/lzl199704/VIS-MAE.
人工智能(AI)有潜力在医学成像领域实现诊断和分割的革命性变革。然而,其在开发和临床应用过程中面临多重挑战,包括数据有限、缺乏通用性以及必须有效地整合多模态数据等。基础模型是一个大规模预训练的AI模型,提供了一个通用的基础,可以适应各种特定任务和上下文。在这里,我们推出VIsualization and Segmentation Masked AutoEncoder(VIS-MAE),这是一款专门针对医学成像设计的全新模型权重。具体来说,VIS-MAE在包含来自各种模态(CT、MR、PET、X射线和超声波)的250万张无标签图像的数据集上进行训练,采用自监督学习技术。然后,它适应于使用明确标签的分类和分割任务。VIS-MAE具有很高的标签效率,在领域内外应用中均优于多个基准模型。此外,VIS-MAE改进了标签效率,与其他预训练权重相比,它可以使用较少的标记训练数据(50%或80%)实现与其他模型相当的性能。VIS-MAE在医学成像AI中代表了重大进展,为改善分割和分类任务同时减少数据注释工作量提供了通用且稳健的解决方案。该工作的源代码可在https://github.com/lzl199704/VIS-MAE获取。
论文及项目相关链接
Summary
人工智能在医学成像领域具有潜力,可推动诊断和分割的革新。面临有限数据可用性、缺乏通用性和多模态数据的有效融合等挑战。VIS-MAE是一种针对医学成像的新型基础模型权重,通过自监督学习技术在大量未标记图像上进行训练,适应分类和分割任务。该模型标签效率高,具有改善领域内外应用表现的能力。通过使用较少的标记训练数据即可达到与其他预训练权重相似的性能水平。VIS-MAE在医学成像人工智能领域代表了重要进展,为解决分割和分类任务提供了通用性和稳健的解决方案,并降低了数据注释工作量。更多信息可访问相关代码仓库链接:https://github.com/lzl199704/VIS-MAE。
Key Takeaways
- 人工智能在医学成像中有潜力推动诊断和分割的进步。
- VIS-MAE是一种针对医学成像的新型基础模型权重,通过自监督学习技术训练。
- VIS-MAE可适应多种分类和分割任务,具有高标签效率。
- VIS-MAE在减少标记训练数据量的情况下即可达到与其他预训练权重相似的性能水平。
- VIS-MAE提升了模型在领域内外应用的性能表现。
- VIS-MAE为医学成像领域提供了通用性和稳健的解决方案。
点此查看论文截图

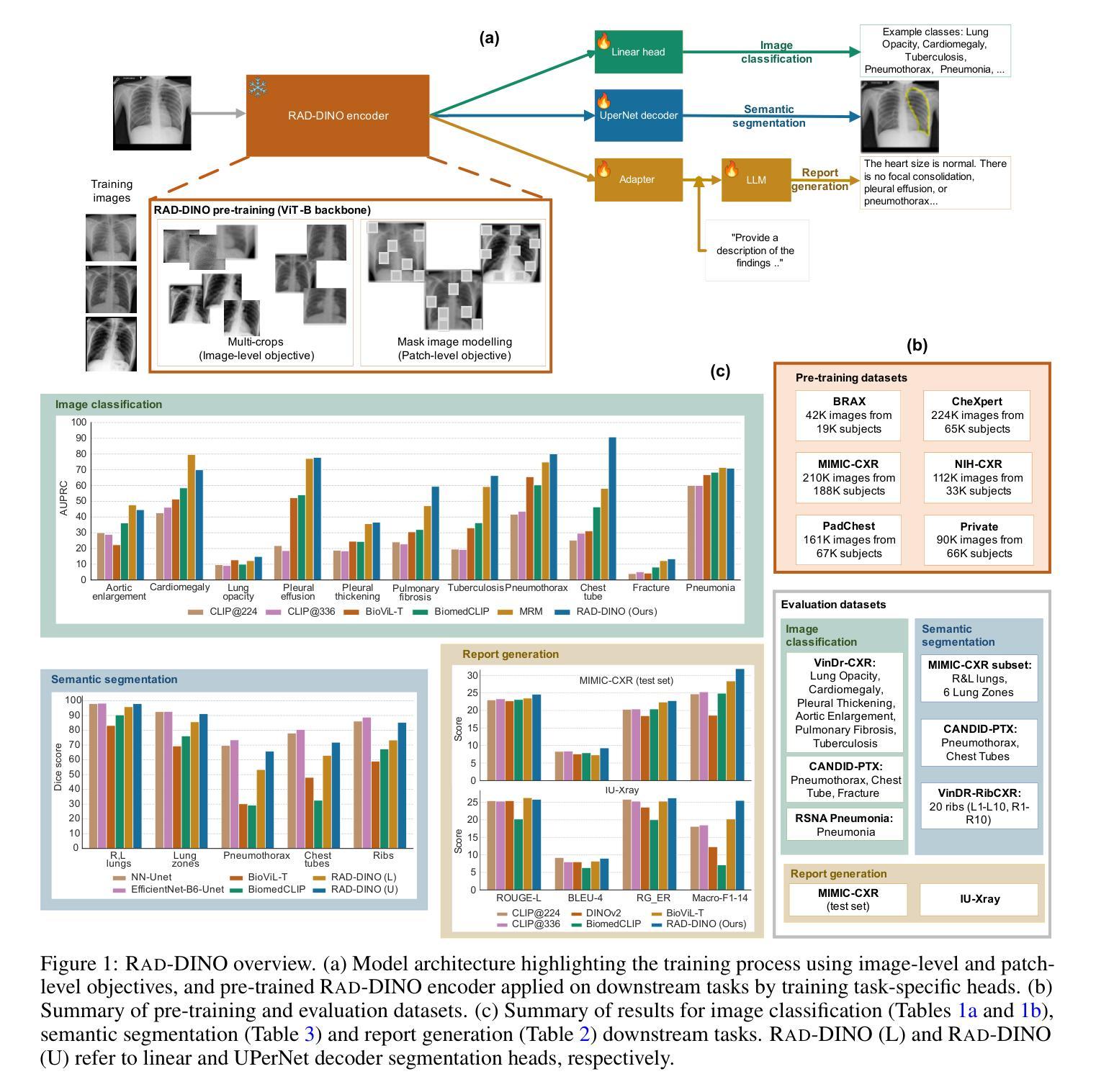
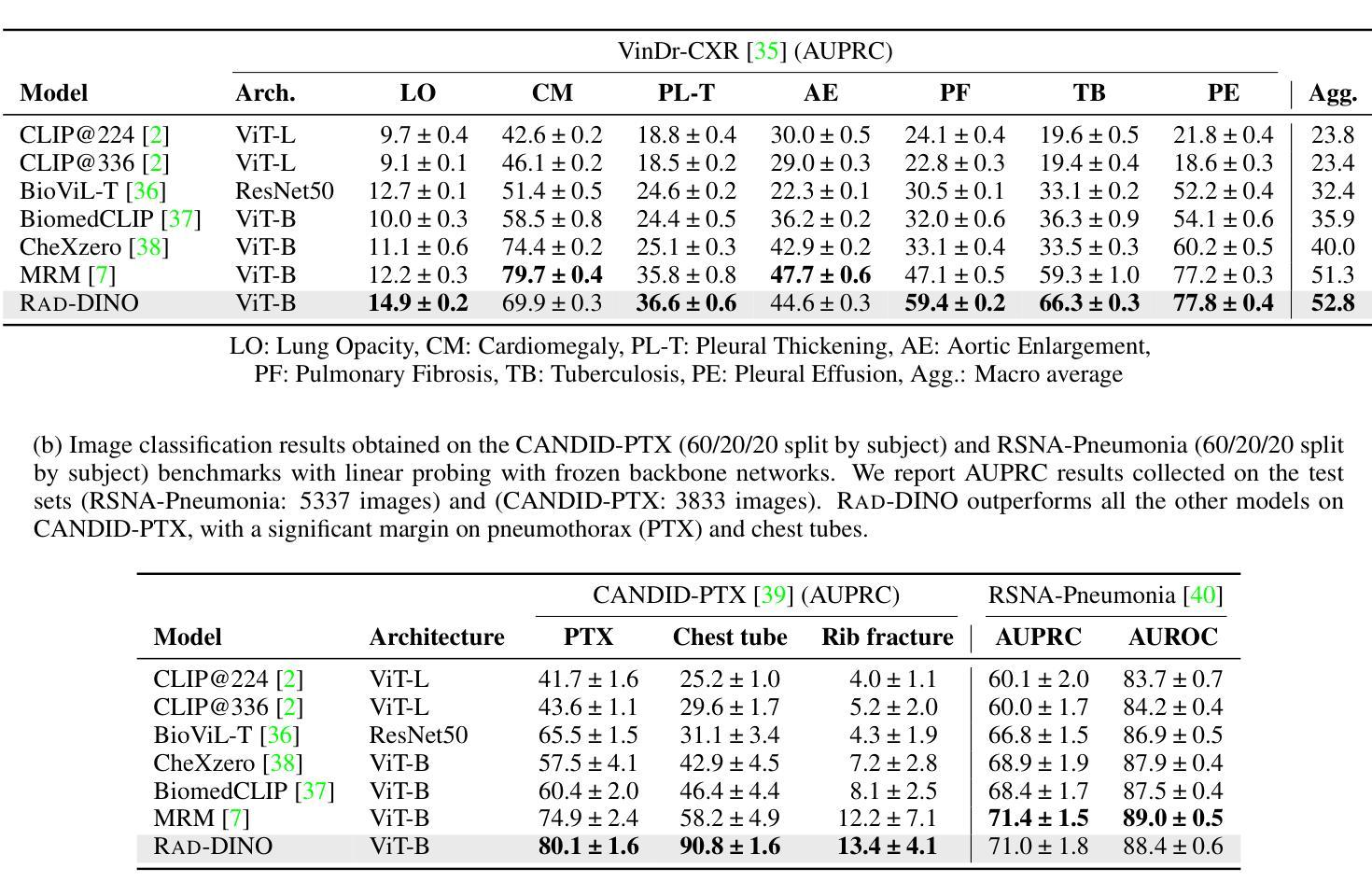
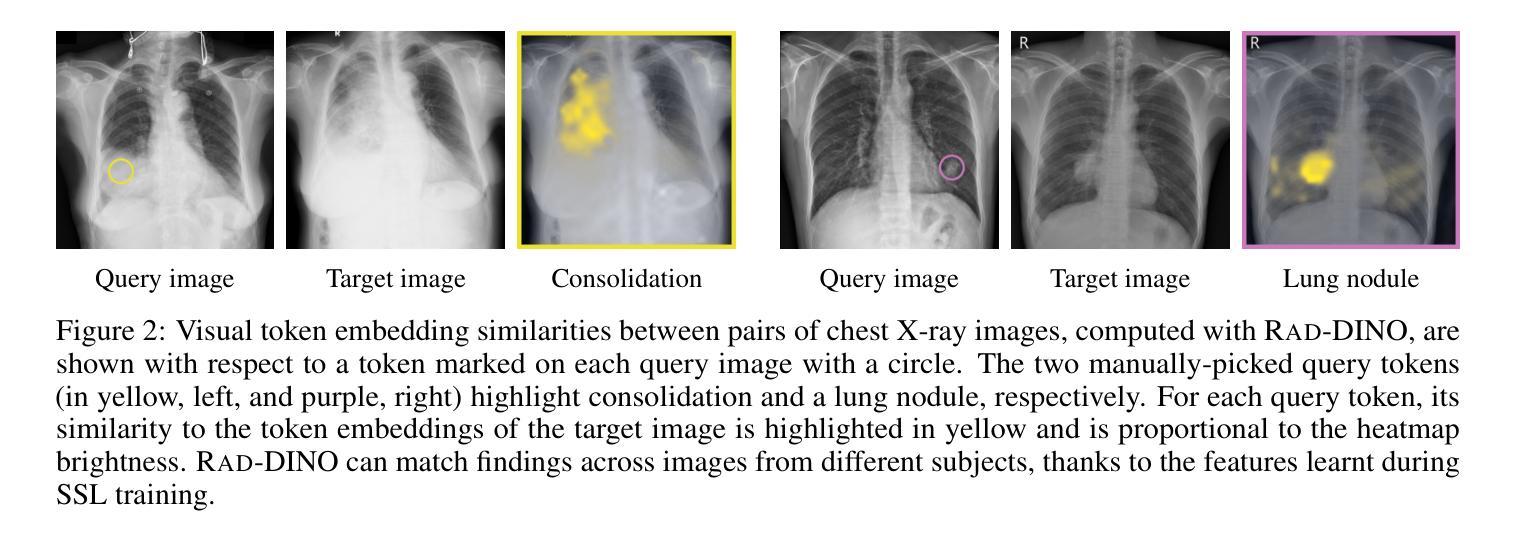
RAD-DINO: Exploring Scalable Medical Image Encoders Beyond Text Supervision
Authors:Fernando Pérez-García, Harshita Sharma, Sam Bond-Taylor, Kenza Bouzid, Valentina Salvatelli, Maximilian Ilse, Shruthi Bannur, Daniel C. Castro, Anton Schwaighofer, Matthew P. Lungren, Maria Wetscherek, Noel Codella, Stephanie L. Hyland, Javier Alvarez-Valle, Ozan Oktay
Language-supervised pre-training has proven to be a valuable method for extracting semantically meaningful features from images, serving as a foundational element in multimodal systems within the computer vision and medical imaging domains. However, the computed features are limited by the information contained in the text, which is particularly problematic in medical imaging, where the findings described by radiologists focus on specific observations. This challenge is compounded by the scarcity of paired imaging-text data due to concerns over leakage of personal health information. In this work, we fundamentally challenge the prevailing reliance on language supervision for learning general-purpose biomedical imaging encoders. We introduce RAD-DINO, a biomedical image encoder pre-trained solely on unimodal biomedical imaging data that obtains similar or greater performance than state-of-the-art biomedical language-supervised models on a diverse range of benchmarks. Specifically, the quality of learned representations is evaluated on standard imaging tasks (classification and semantic segmentation), and a vision-language alignment task (text report generation from images). To further demonstrate the drawback of language supervision, we show that features from RAD-DINO correlate with other medical records (e.g., sex or age) better than language-supervised models, which are generally not mentioned in radiology reports. Finally, we conduct a series of ablations determining the factors in RAD-DINO’s performance; notably, we observe that RAD-DINO’s downstream performance scales well with the quantity and diversity of training data, demonstrating that image-only supervision is a scalable approach for training a foundational biomedical image encoder. Model weights of RAD-DINO trained on publicly available datasets are available at https://huggingface.co/microsoft/rad-dino.
语言监督的预训练已被证明是从图像中提取语义特征的一种有价值的方法,它作为计算机视觉和医学成像领域中的多模态系统的基础元素。然而,计算出的特征受限于文本中所包含的信息,这在医学成像中尤其成问题,因为放射科医生所描述的发现重点关注特定的观察结果。这一挑战还因配对成像-文本数据的稀缺而加剧,这是出于对泄露个人健康信息的担忧。在这项工作中,我们从根本上质疑对语言监督学习通用生物医学成像编码器的依赖。我们引入了RAD-DINO,这是一种仅在一模态生物医学成像数据上进行预训练的生物医学图像编码器,在多种基准测试中,它获得与最新语言监督模型相当或更好的性能。具体来说,通过标准成像任务(分类和语义分割)以及视觉语言对齐任务(从图像生成文本报告)来评估所学习表示的质量。为了进一步证明语言监督的局限性,我们展示了RAD-DINO的特征与其他医疗记录(如性别或年龄)的相关性优于语言监督模型,这些通常在放射学报告中并未提及。最后,我们进行了一系列测试以确定RAD-DINO性能的因素;值得注意的是,我们观察到RAD-DINO的下游性能随着训练数据数量和多样性的增加而提高,这表明仅使用图像监督是一种可扩展的方法来训练基础生物医学图像编码器。RAD-DINO在公开数据集上训练的模型权重可在[https://huggingface.co/microsoft/rad-dino获取。]
论文及项目相关链接
Summary
本文主要介绍了RAD-DINO模型,这是一种仅依赖生物医学影像数据进行预训练的生物医学影像编码器。该模型在多种基准测试上取得了与先进的语言监督模型相似或更好的性能,且更适用于图像生成报告等跨模态任务。RAD-DINO的特征与医疗记录关联更强,尤其在性别和年龄预测等任务中。其表现良好且可扩展,随着训练数据量和多样性的增加,性能会进一步提升。模型权重已公开提供。
Key Takeaways
- RAD-DINO是一个生物医学影像编码器,仅依赖生物医学影像数据进行预训练。
- 在多种基准测试中,RAD-DINO性能与先进的语言监督模型相当或更好。
- RAD-DINO适用于跨模态任务,如图像生成报告。
- RAD-DINO学到的特征与医疗记录关联更强,尤其在性别和年龄预测任务中表现突出。
- RAD-DINO模型表现良好且可扩展,随着训练数据量和多样性的增加,其性能会进一步提升。
点此查看论文截图

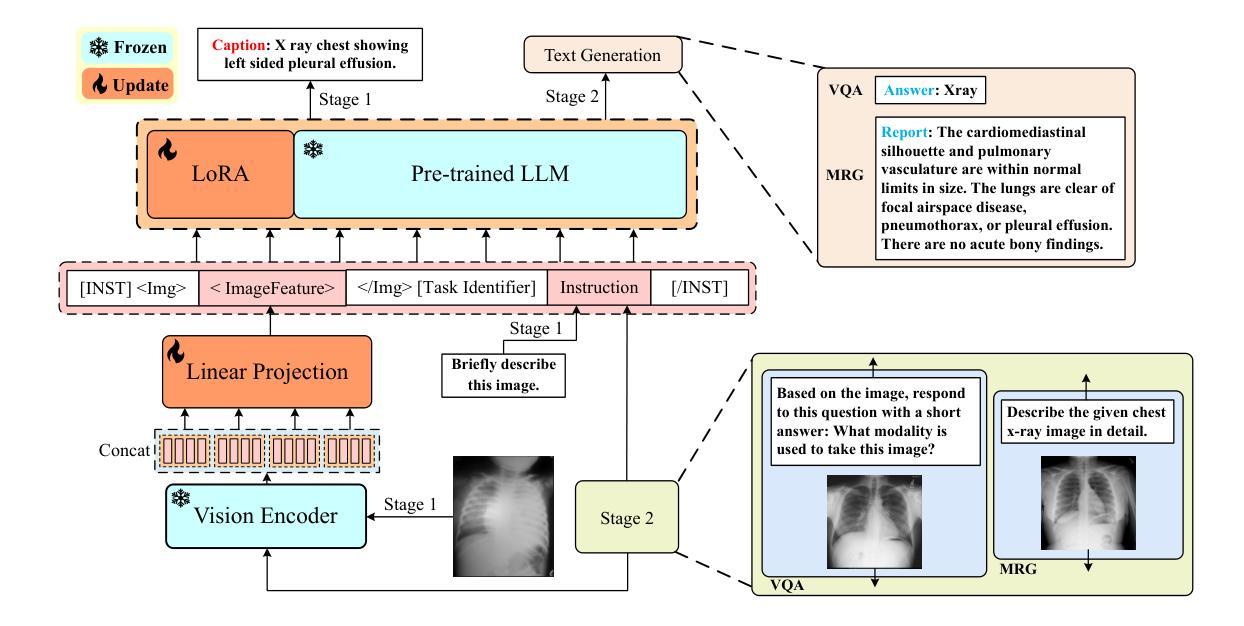
PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
Authors:Jinlong He, Pengfei Li, Gang Liu, Genrong He, Zhaolin Chen, Shenjun Zhong
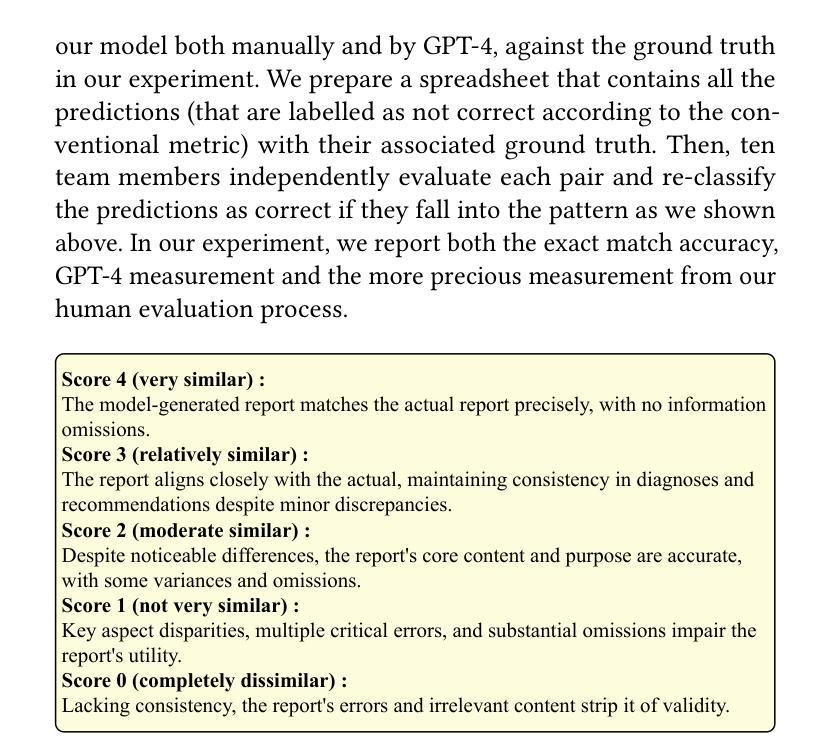
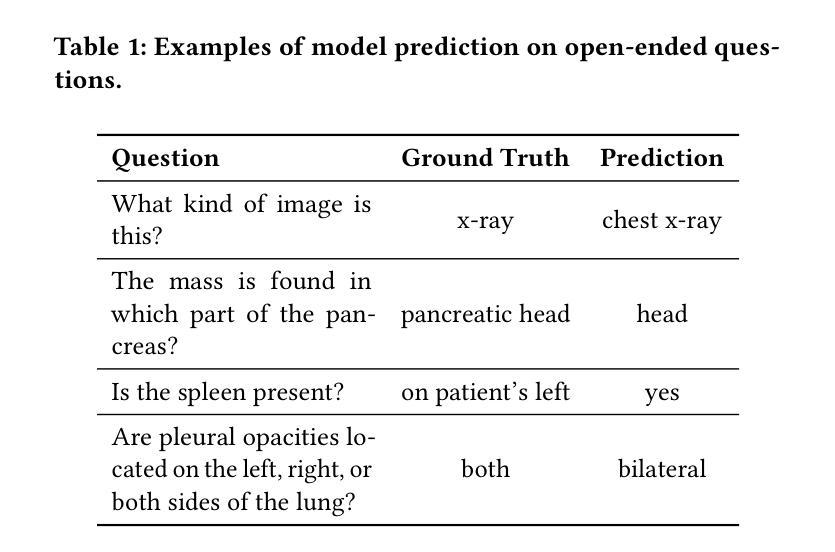
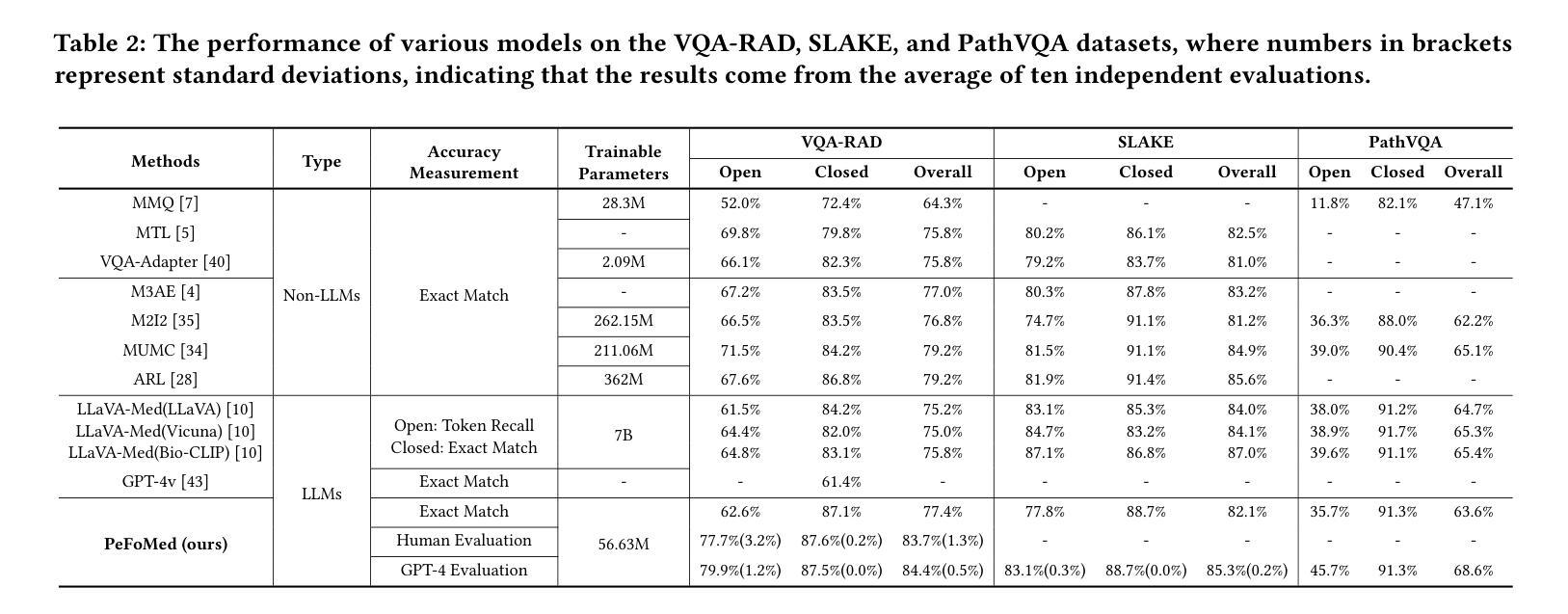
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
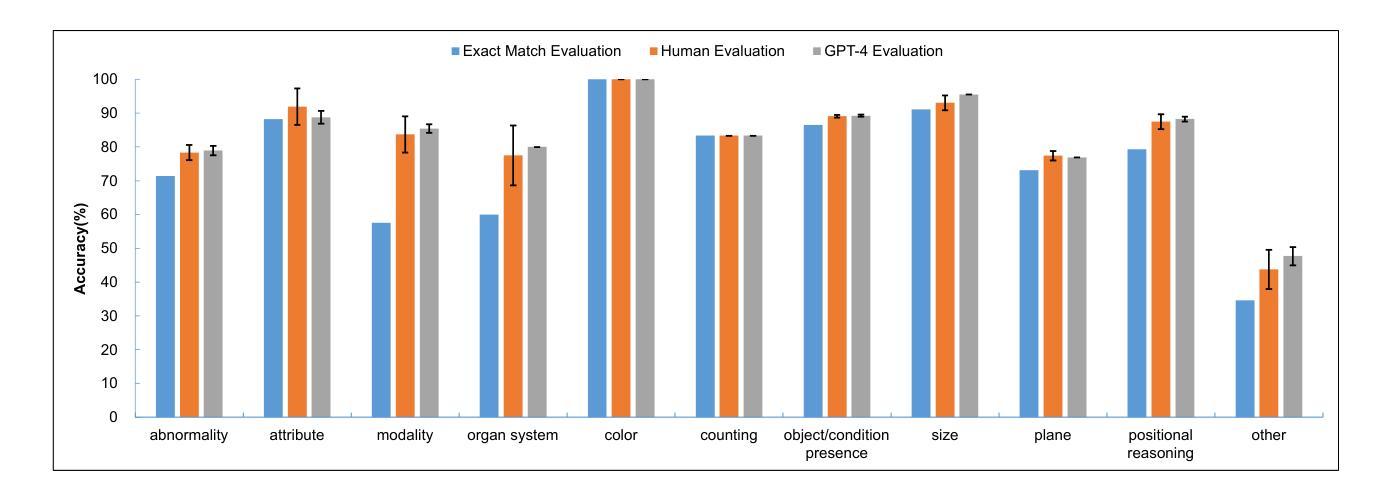
多模态大型语言模型(MLLMs)代表了传统大型语言模型能力上的进化扩展,使它们能够应对超越纯文本应用程序范围的挑战。它利用这些语言模型内部先前编码的知识,从而增强其在多模态上下文中的适用性和功能。近期的研究探讨了将MLLMs作为解决医学多模态问题的通用解决方案的生成任务。在本文中,我们提出了一个参数高效的框架,用于微调MLLMs,该框架在医疗视觉问答(Med-VQA)和医疗报告生成(MRG)任务上进行了验证,使用的是公共基准数据集。我们还介绍了一种使用5点利克特量表及其加权平均值作为评估生成的报告质量的评价指标,用于测量MRG任务的报告质量,量表评分由人工和GPT-4模型标记。我们进一步评估了传统度量标准、GPT-4和人类评分在VQA和MRG任务上的性能指标的一致性。结果表明,使用GPT-4的语义相似性评估与人类注释者紧密对齐,并提供更大的稳定性,然而,与传统的词汇相似性度量相比,它们显示出差异。这质疑了词汇相似性指标在评估Med-VQA和报告生成任务的生成模型性能方面的可靠性。此外,我们微调的模型显著优于GPT-4v。这表明未经额外微调的多模态模型如GPT-4v在医学成像任务上的表现并不有效。代码将在此处提供:https://github.com/jinlHe/PeFoMed。
论文及项目相关链接
PDF 12 pages, 8 figures, 12 tables
摘要
多模态大型语言模型(MLLMs)是传统大型语言模型的扩展,能够应对单纯文本应用程序无法应对的挑战。它利用已编码在语言模型中的知识,增强其在多模态上下文中的适用性和功能。最近的研究探讨了将MLLMs作为解决医学多模态问题的通用解决方案的生成任务。本文提出了一种参数高效的微调MLLMs框架,并在医学视觉问答(Med-VQA)和医学报告生成(MRG)任务上进行验证。我们还介绍了一种使用五点李克特量表及其加权平均值作为评价生成报告质量的评估指标。该量表的评分由人工和GPT-4模型标注。我们进一步评估了传统度量标准、GPT-4和人类评分在VQA和MRG任务上的性能指标的一致性。结果表明,使用GPT-4进行的语义相似性评估与人类注释者密切相关,并提供更大的稳定性,但与传统的词汇相似性度量相比,它们显示出差异。这质疑了词汇相似性度量在评估Med-VQA和报告生成任务的生成模型性能方面的可靠性。此外,我们的微调模型显著优于GPT-4v。这表明未经额外微调的多模态模型,如GPT-4v,在医学成像任务上的表现并不有效。代码将在此处提供:https://github.com/jinlHe/PeFoMed。
关键见解
- 多模态大型语言模型(MLLMs)能够应对传统语言模型无法处理的挑战,特别是在处理多模态上下文时。
- 论文提出了一种参数高效的微调MLLMs框架,适用于医学视觉问答(Med-VQA)和医学报告生成(MRG)任务。
- 论文介绍了一种新的评估指标,结合五点李克特量表及其加权平均值来评价生成的报告质量,其中评分由人工和GPT-4模型共同完成。
- GPT-4在语义相似性评估方面与人类注释者密切相关,但与传统词汇相似性度量相比存在差异。
- 论文质疑了词汇相似性度量在评估生成模型在Med-VQA和报告生成任务中的性能时的可靠性。
- 论文的微调模型在医学报告生成任务上显著优于GPT-4v,表明未经额外调参的多模态模型在医学成像任务上的性能有限。
- 论文提供的代码将公开,供其他研究者使用和改进。
点此查看论文截图