⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-19 更新
Quilt-LLaVA: Visual Instruction Tuning by Extracting Localized Narratives from Open-Source Histopathology Videos
Authors:Mehmet Saygin Seyfioglu, Wisdom O. Ikezogwo, Fatemeh Ghezloo, Ranjay Krishna, Linda Shapiro
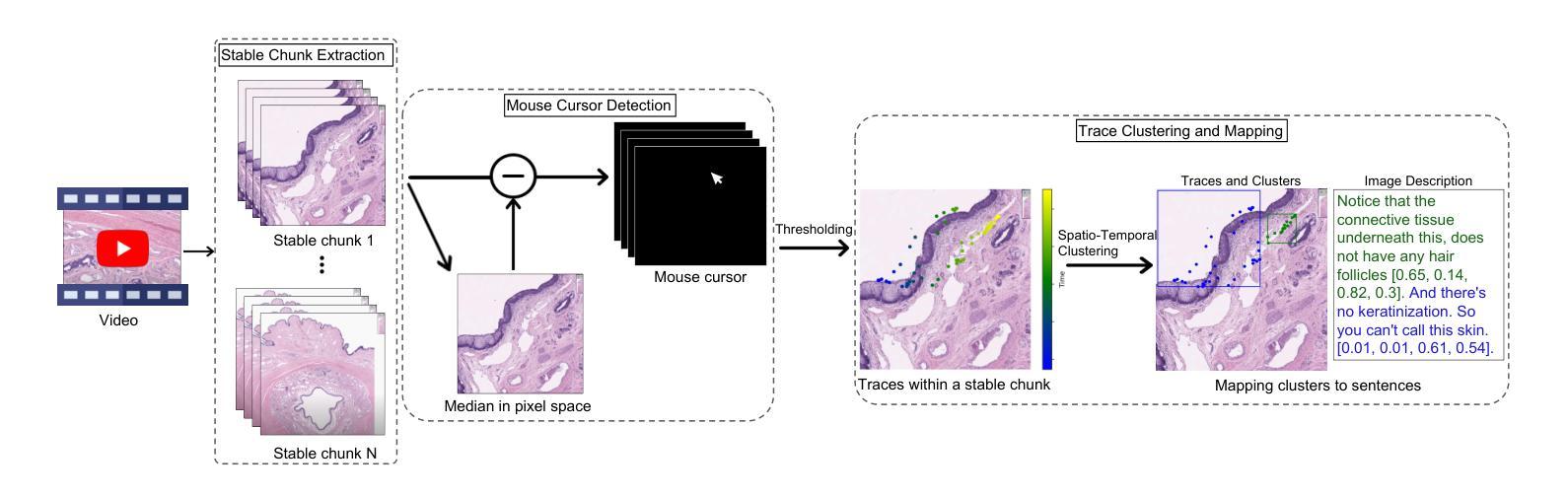
Diagnosis in histopathology requires a global whole slide images (WSIs) analysis, requiring pathologists to compound evidence from different WSI patches. The gigapixel scale of WSIs poses a challenge for histopathology multi-modal models. Training multi-model models for histopathology requires instruction tuning datasets, which currently contain information for individual image patches, without a spatial grounding of the concepts within each patch and without a wider view of the WSI. Therefore, they lack sufficient diagnostic capacity for histopathology. To bridge this gap, we introduce Quilt-Instruct, a large-scale dataset of 107,131 histopathology-specific instruction question/answer pairs, grounded within diagnostically relevant image patches that make up the WSI. Our dataset is collected by leveraging educational histopathology videos from YouTube, which provides spatial localization of narrations by automatically extracting the narrators’ cursor positions. Quilt-Instruct supports contextual reasoning by extracting diagnosis and supporting facts from the entire WSI. Using Quilt-Instruct, we train Quilt-LLaVA, which can reason beyond the given single image patch, enabling diagnostic reasoning across patches. To evaluate Quilt-LLaVA, we propose a comprehensive evaluation dataset created from 985 images and 1283 human-generated question-answers. We also thoroughly evaluate Quilt-LLaVA using public histopathology datasets, where Quilt-LLaVA significantly outperforms SOTA by over 10% on relative GPT-4 score and 4% and 9% on open and closed set VQA. Our code, data, and model are publicly accessible at quilt-llava.github.io.
组织病理学诊断需要对全组织切片图像(Whole Slide Images,WSIs)进行全局分析,这需要病理学家将来自不同WSI斑块(patches)的证据进行合并。WSIs的千兆像素规模对组织病理学多模态模型提出了挑战。训练组织病理学的多模态模型需要指令调整数据集,这些数据集目前包含单个图像斑块的信息,但没有每个斑块内概念的空间定位以及缺乏对整个WSI的更广泛视图。因此,它们对于组织病理学的诊断能力有所不足。为了弥补这一差距,我们引入了Quilt-Instruct数据集,这是一组包含107,131个组织病理学特定指令问答对的大规模数据集,这些问答对基于构成WSI的诊断相关图像斑块。我们的数据集是通过利用YouTube上的教育组织病理学视频收集的,这些视频通过自动提取叙述者的光标位置,为叙述提供了空间定位。Quilt-Instruct支持上下文推理,通过从整个WSI中提取诊断和事实来支持推理。使用Quilt-Instruct,我们训练了Quilt-LLaVA模型,它能够超越给定的单个图像斑块进行推理,从而实现跨斑块的诊断推理。为了评估Quilt-LLaVA的性能,我们创建了一个综合评估数据集,该数据集由985张图像和1283个人类生成的问答组成。我们还使用公共组织病理学数据集全面评估了Quilt-LLaVA的性能。相较于其他顶尖模型,Quilt-LLaVA的相对GPT-4得分高出超过10%,且在开放和封闭式视觉问答(VQA)中的表现均显著提高了约4%和约9%。我们的代码、数据和模型可在quilt-llava.github.io上公开访问。
论文及项目相关链接
Summary
为提高病理诊断能力,该研究引入了Quilt-Instruct数据集和Quilt-LLaVA模型。Quilt-Instruct包含基于YouTube教育视频的诊断相关图像补丁的问答对,有助于对全切片图像进行上下文推理。Quilt-LLaVA能够在不同补丁之间进行诊断推理,并在评估中表现出显著优势。
Key Takeaways
- 诊断在病理学中需要全局全切片图像分析,要求病理学家从不同WSI补丁中综合证据。
- WSIs的gigapixel规模对病理多模态模型构成挑战。
- 训练多模态模型需要指导调整数据集,但当前数据集缺乏补丁内的概念空间定位及对整个WSI的宏观视角,导致诊断能力不足。
- 为弥补这一差距,引入了Quilt-Instruct数据集,包含基于诊断相关图像补丁的问答对。
- Quilt-Instruct通过利用YouTube教育视频自动提取叙述者的光标位置,提供空间定位信息。
- Quilt-LLaVA模型使用Quilt-Instruct训练,能够进行跨补丁的上下文推理。
点此查看论文截图