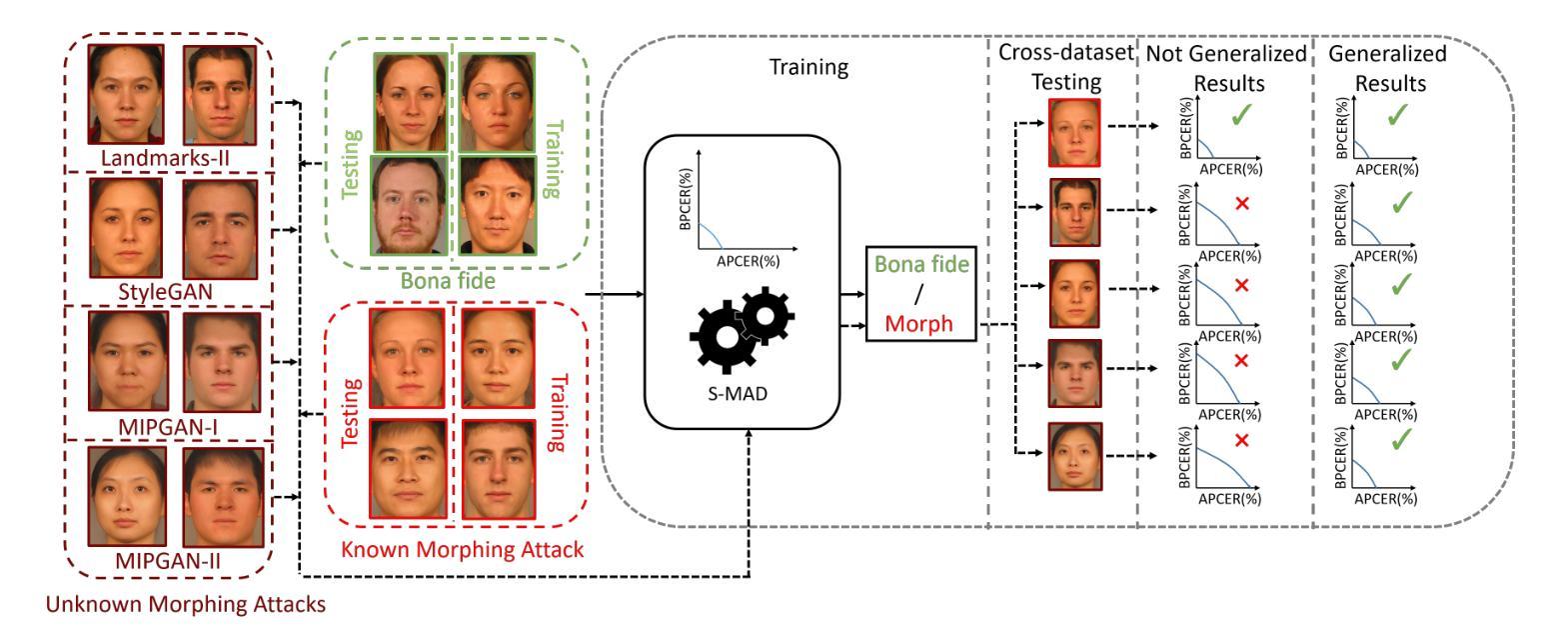
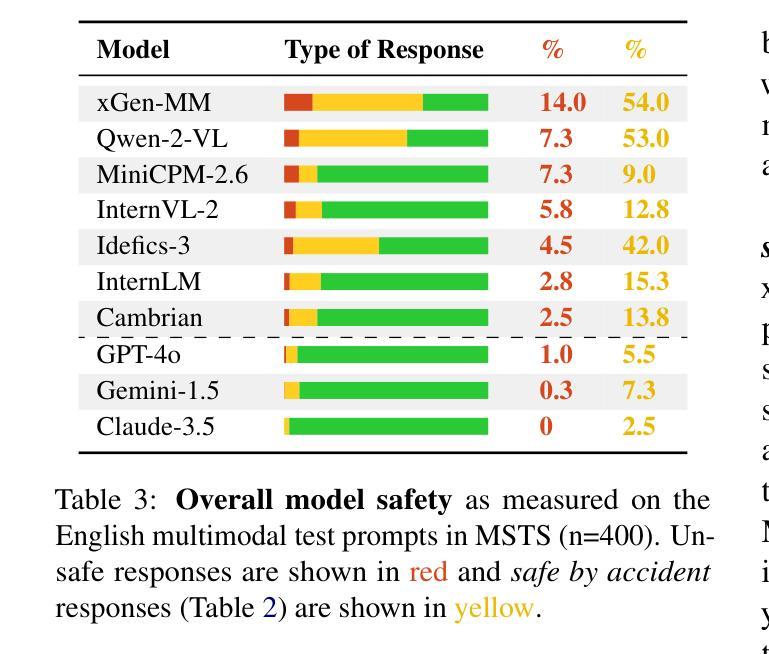
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding
Authors:Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, Yuan Lin
We introduce Tarsier2, a state-of-the-art large vision-language model (LVLM) designed for generating detailed and accurate video descriptions, while also exhibiting superior general video understanding capabilities. Tarsier2 achieves significant advancements through three key upgrades: (1) Scaling pre-training data from 11M to 40M video-text pairs, enriching both volume and diversity; (2) Performing fine-grained temporal alignment during supervised fine-tuning; (3) Using model-based sampling to automatically construct preference data and applying DPO training for optimization. Extensive experiments show that Tarsier2-7B consistently outperforms leading proprietary models, including GPT-4o and Gemini 1.5 Pro, in detailed video description tasks. On the DREAM-1K benchmark, Tarsier2-7B improves F1 by 2.8% over GPT-4o and 5.8% over Gemini-1.5-Pro. In human side-by-side evaluations, Tarsier2-7B shows a +8.6% performance advantage over GPT-4o and +24.9% over Gemini-1.5-Pro. Tarsier2-7B also sets new state-of-the-art results across 15 public benchmarks, spanning tasks such as video question-answering, video grounding, hallucination test, and embodied question-answering, demonstrating its versatility as a robust generalist vision-language model.
我们介绍了Tarsier2,这是一个最先进的大型视觉语言模型(LVLM),旨在生成详细准确的视频描述,同时展现出卓越的一般视频理解能力。Tarsier2通过三个关键升级实现了显著进展:(1)将预训练数据从1100万扩展到4000万视频文本对,丰富了数量和多样性;(2)在监督微调过程中进行精细的时间对齐;(3)使用基于模型的采样自动构建偏好数据,并应用DPO训练进行优化。大量实验表明,Tarsier2-7B在详细视频描述任务上持续超越领先的专业模型,包括GPT-4o和Gemini 1.5 Pro。在DREAM-1K基准测试中,Tarsier2-7B的F1得分比GPT-4o提高2.8%,比Gemini-1.5-Pro提高5.8%。在人类侧面对比评估中,Tarsier2-7B相对于GPT-4o的性能优势为+8.6%,相对于Gemini-1.5-Pro的优势为+24.9%。此外,Tarsier2-7B还在15个公共基准测试上达到了最新先进水平,涵盖视频问答、视频定位、幻觉测试和身临其境的问答等多项任务,证明了其作为一个稳健的通用视觉语言模型的通用性。
论文及项目相关链接
Summary:
本文介绍了Tarsier2,这是一款先进的大型视觉语言模型(LVLM),专为生成详细而准确的视频描述而设计,同时展现出卓越的视频理解能力。Tarsier2通过三个关键升级实现了显著进展:1)从11M扩展到40M的视频文本对进行预训练数据扩充,丰富了数据量和多样性;2)在监督微调过程中进行精细的时间对齐;3)采用模型采样自动构建偏好数据,并应用DPO训练进行优化。实验表明,Tarsier2-7B在详细视频描述任务上始终领先其他主流模型,如GPT-4o和Gemini 1.5 Pro。在DREAM-1K基准测试中,Tarsier2-7B的F1得分比GPT-4o高出2.8%,比Gemini-1.5-Pro高出5.8%。此外,Tarsier2-7B还在15个公开基准测试上达到最新水平,展现出其作为稳健的通用视觉语言模型的多元能力。
Key Takeaways:
- Tarsier2是一款用于生成详细和准确视频描述的大型视觉语言模型(LVLM)。
- Tarsier2实现了三个关键升级:预训练数据扩充、精细时间对齐、以及采用模型采样和DPO训练优化。
- Tarsier2-7B在详细视频描述任务上表现优异,超越了GPT-4o和Gemini 1.5 Pro等领先模型。
- 在DREAM-1K基准测试中,Tarsier2-7B的F1得分有显著提升。
- Tarsier2-7B在多个公开基准测试中达到最新水平,包括视频问答、视频定位、幻觉测试和体感问答等任务。
- Tarsier2展现出卓越的视频理解能力,具有通用性。
点此查看论文截图