⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Authors:Weibo Gao, Qi Liu, Linan Yue, Fangzhou Yao, Rui Lv, Zheng Zhang, Hao Wang, Zhenya Huang
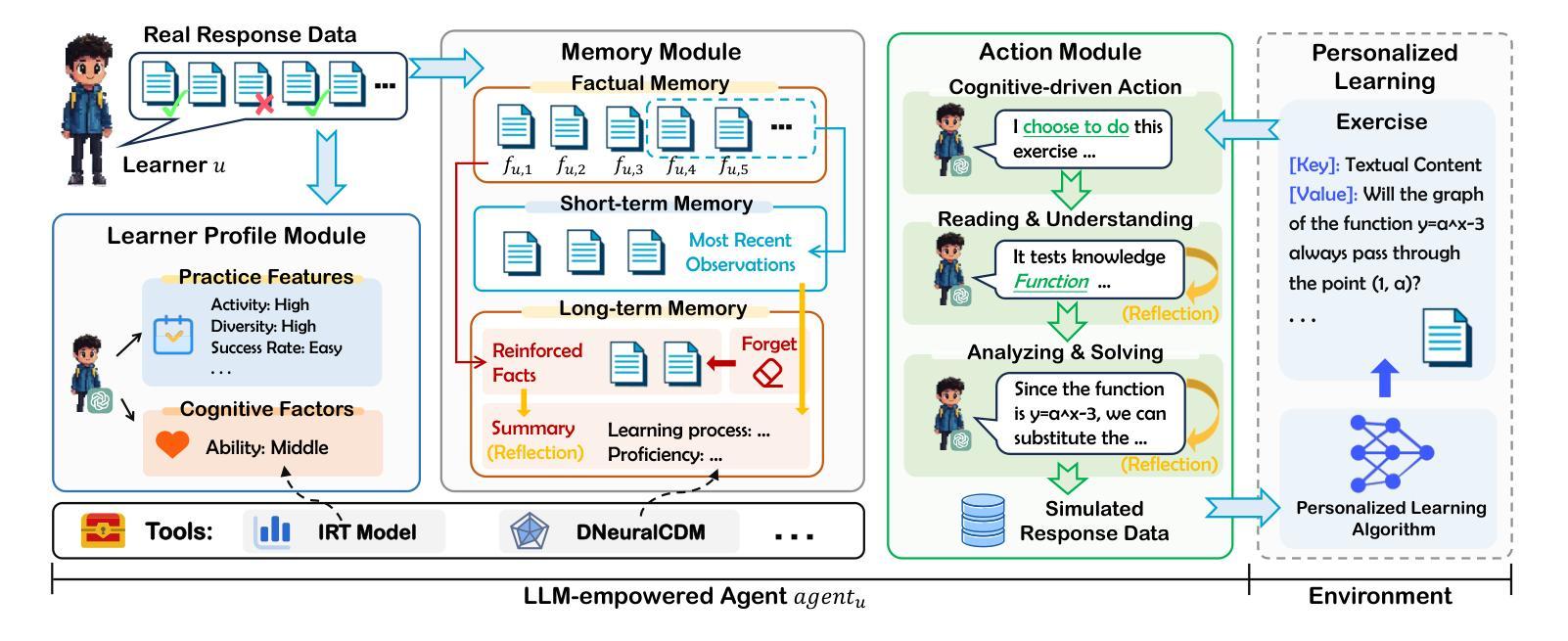
Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners’ practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.
个性化学习在智能教育系统中代表着一种有前景的教育策略,旨在提高学习者的实践效率。然而,离线指标与在线表现之间的差异显著阻碍了他们的进步。为了应对这一挑战,我们引入了Agent4Edu,这是一种利用大型语言模型(LLM)的最新进展的新型个性化学习模拟器。Agent4Edu以大型语言模型为动力,具备生成式智能体,配备学习者个性化学习算法所需的个性化学习算法的学习者概况、记忆和行动模块。学习者概况使用现实世界响应数据进行初始化,捕捉实践风格和认知因素。受人类心理学理论的启发,记忆模块记录实践事实和高层次摘要,集成反思机制。行动模块支持各种行为,包括理解练习、分析和生成响应。每个智能体都能与个性化学习算法互动,如计算机化自适应测试,实现对定制服务的多元化评估和提升。通过全面评估,我们探讨了Agent4Edu的优势和劣势,重点强调了智能体与人类学习者在响应之间的一致性和差异。代码、数据和附录可在https://github.com/bigdata-ustc/Agent4Edu上公开查阅。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
个性化学习是智能教育系统中一种有前景的教育策略,旨在提高学习者的实践效率。然而,离线指标与在线表现之间的差异阻碍了学习者的进步。为解决这一挑战,我们推出了Agent4Edu,一种利用最新的人工智能技术——大型语言模型(LLMs)驱动的新型个性化学习模拟器。Agent4Edu的生成代理具有学习者个性化配置、记忆和行动模块,可针对个性化学习算法进行定制。学习者个性化配置通过现实世界反馈数据进行初始化,捕捉学习风格和认知因素。基于心理学理论,记忆模块记录实践事实和高级摘要,整合反思机制。行动模块支持多种行为,包括理解练习、分析和生成反馈。每个代理都能与个性化学习算法互动,如计算机化适应性测试,实现对个性化服务的多维度评估和提升。我们对Agent4Edu进行了全面评估,重点探讨了其在响应一致性方面的优势和不足,以及与人类学习者的差异。
Key Takeaways
- 个性化学习是智能教育系统中一种提升实践效率的策略。
- Agent4Edu是一种新型个性化学习模拟器,利用大型语言模型(LLMs)技术。
- Agent4Edu具有学习者个性化配置、记忆和行动等模块。
- 学习者个性化配置基于现实世界反馈数据,包括学习风格和认知因素。
- Agent4Edu的记忆模块记录实践事实和高级摘要,并整合反思机制。
- Agent4Edu的行动模块支持多种行为,包括理解练习、分析和生成反馈。
- Agent4Edu能与个性化学习算法互动,如计算机适应性测试。
点此查看论文截图

PaSa: An LLM Agent for Comprehensive Academic Paper Search
Authors:Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, Weinan E
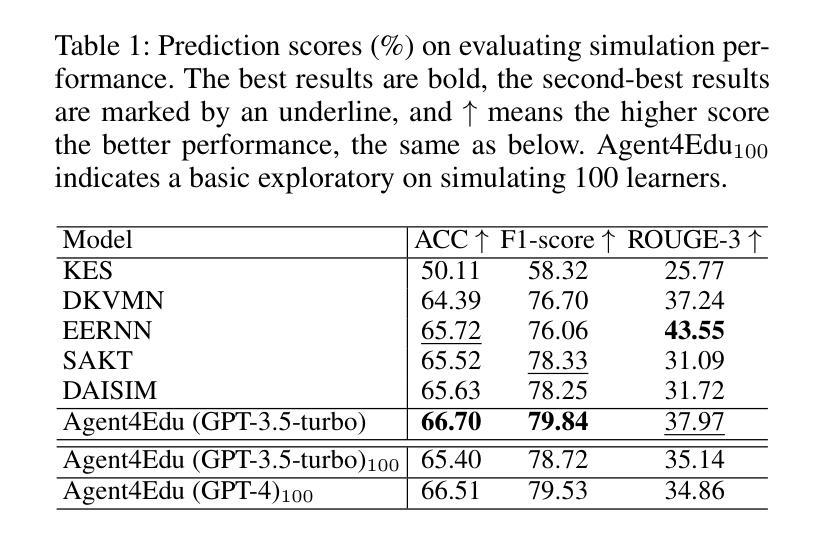
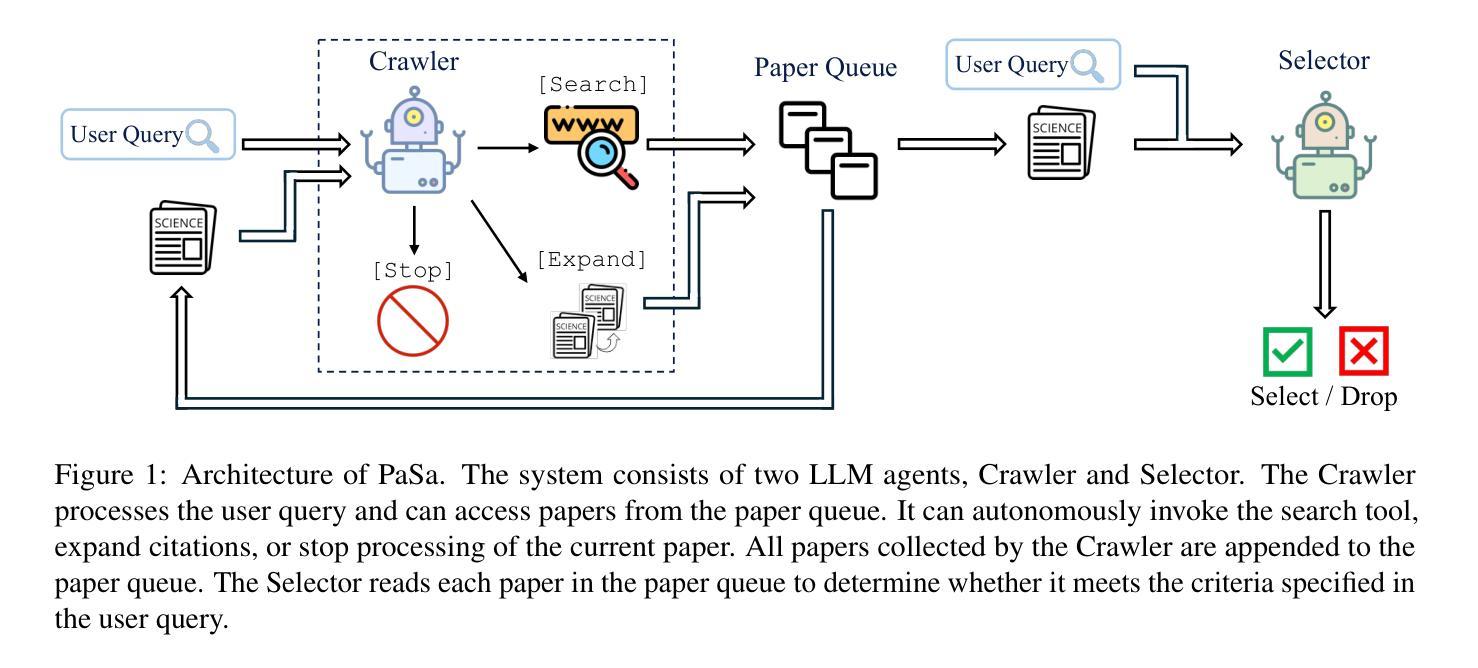
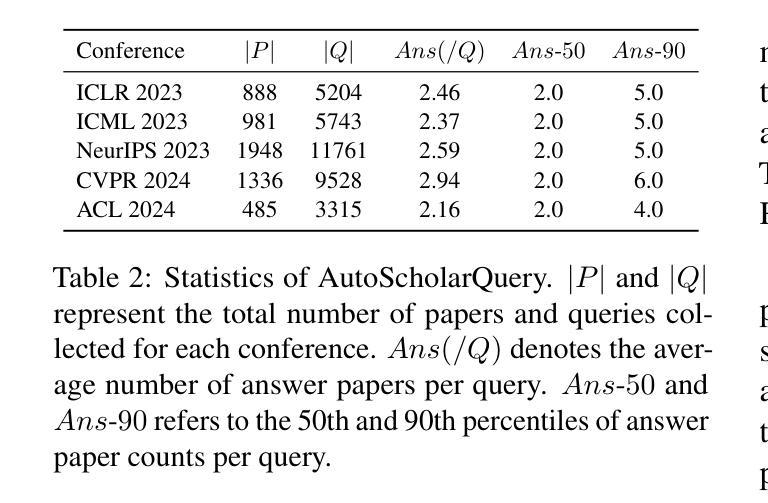
We introduce PaSa, an advanced Paper Search agent powered by large language models. PaSa can autonomously make a series of decisions, including invoking search tools, reading papers, and selecting relevant references, to ultimately obtain comprehensive and accurate results for complex scholarly queries. We optimize PaSa using reinforcement learning with a synthetic dataset, AutoScholarQuery, which includes 35k fine-grained academic queries and corresponding papers sourced from top-tier AI conference publications. Additionally, we develop RealScholarQuery, a benchmark collecting real-world academic queries to assess PaSa performance in more realistic scenarios. Despite being trained on synthetic data, PaSa significantly outperforms existing baselines on RealScholarQuery, including Google, Google Scholar, Google with GPT-4 for paraphrased queries, chatGPT (search-enabled GPT-4o), GPT-o1, and PaSa-GPT-4o (PaSa implemented by prompting GPT-4o). Notably, PaSa-7B surpasses the best Google-based baseline, Google with GPT-4o, by 37.78% in recall@20 and 39.90% in recall@50. It also exceeds PaSa-GPT-4o by 30.36% in recall and 4.25% in precision. Model, datasets, and code are available at https://github.com/bytedance/pasa.
我们推出PaSa,一个由大型语言模型驱动的高级论文搜索代理。PaSa可以自主地做出一系列决策,包括调用搜索工具、阅读论文和选择相关参考文献,以获取针对复杂学术查询的全面和准确结果。我们使用强化学习和合成数据集来优化PaSa,其中包括3.5万条精细的学术查询和相应论文,这些论文来源于顶级AI会议出版物。此外,我们还开发了RealScholarQuery基准测试,收集现实世界的学术查询以评估PaSa在更现实场景中的性能。尽管是在合成数据上进行训练的,但PaSa在RealScholarQuery上的表现显著优于现有基线,包括Google、Google Scholar、针对改述查询的Google与GPT-4结合、chatGPT(具备搜索功能的GPT-4o)、GPT-o1以及通过提示GPT-4o实现的PaSa-GPT-4o。值得注意的是,PaSa-7B在召回率@20和召回率@50方面分别超越了最佳的Google基线——Google与GPT-4的结合达37.78%和39.90%。它也以30.36%的召回率和4.25%的精确度超过了PaSa-GPT-4o。模型、数据集和代码均可在https://github.com/bytedance/pasa找到。
论文及项目相关链接
Summary
引入基于大型语言模型的先进论文搜索代理PaSa。PaSa可自主做出一系列决策,包括调用搜索工具、阅读论文和选择相关参考文献,以获取针对复杂学术查询的全面和准确结果。使用合成数据集AutoScholarQuery通过强化学习优化PaSa,并在现实场景中评估其性能。尽管在合成数据上进行训练,PaSa在RealScholarQuery上的表现优于现有基线,包括Google、Google Scholar等。特别地,PaSa-7B在召回率方面超过了最佳Google基线Google with GPT-4o,并且表现优于PaSa-GPT-4o。模型和代码已发布在GitHub上。
Key Takeaways
- PaSa是一个先进的论文搜索代理,基于大型语言模型。
- PaSa能自主做出决策,包括调用搜索工具、阅读论文和选择相关文献。
- PaSa通过强化学习进行优化,使用合成数据集AutoScholarQuery进行训练。
- PaSa在现实场景的学术查询评估中表现优异,优于Google、Google Scholar等现有工具。
- PaSa-7B在召回率方面显著超过Google with GPT-4o和PaSa-GPT-4o。
- PaSa模型和代码已发布在GitHub上供公众访问和使用。
点此查看论文截图



GAWM: Global-Aware World Model for Multi-Agent Reinforcement Learning
Authors:Zifeng Shi, Meiqin Liu, Senlin Zhang, Ronghao Zheng, Shanling Dong, Ping Wei
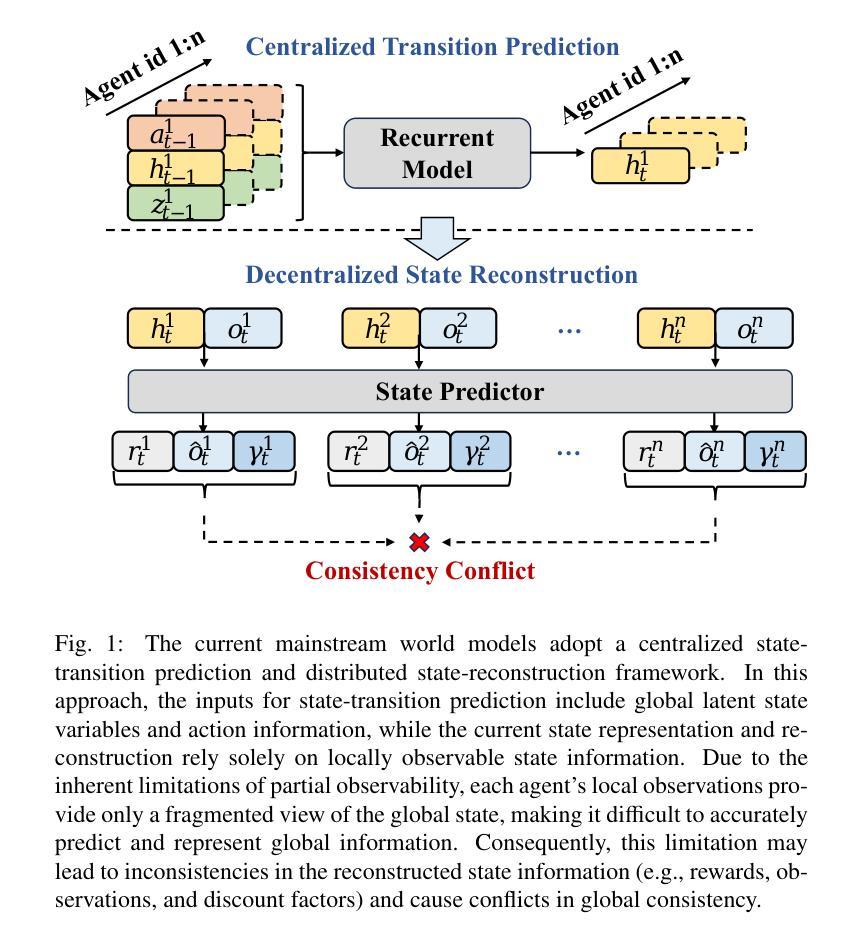
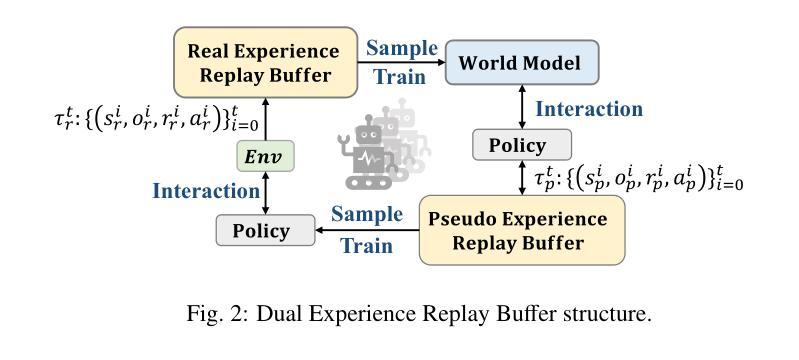
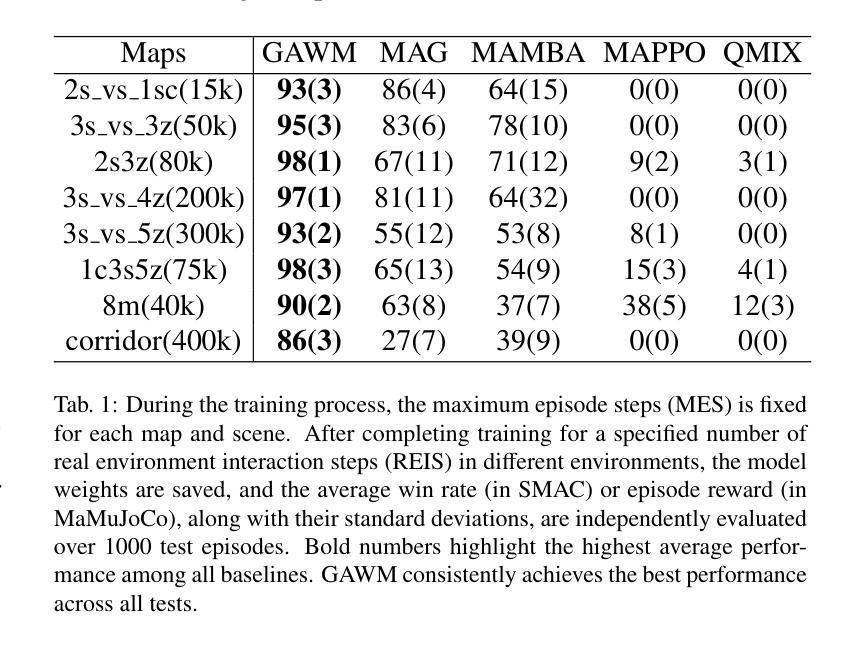
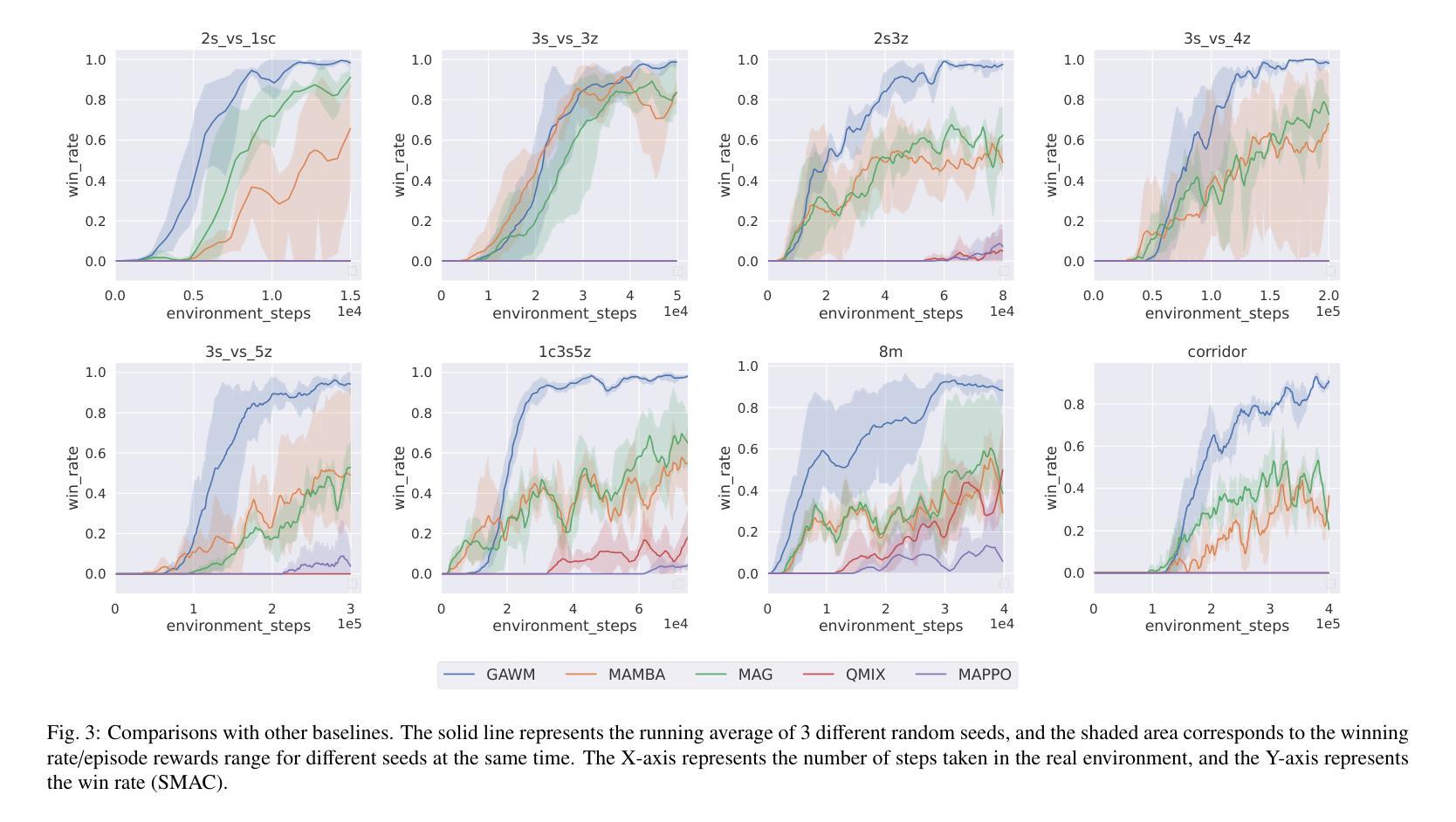
In recent years, Model-based Multi-Agent Reinforcement Learning (MARL) has demonstrated significant advantages over model-free methods in terms of sample efficiency by using independent environment dynamics world models for data sample augmentation. However, without considering the limited sample size, these methods still lag behind model-free methods in terms of final convergence performance and stability. This is primarily due to the world model’s insufficient and unstable representation of global states in partially observable environments. This limitation hampers the ability to ensure global consistency in the data samples and results in a time-varying and unstable distribution mismatch between the pseudo data samples generated by the world model and the real samples. This issue becomes particularly pronounced in more complex multi-agent environments. To address this challenge, we propose a model-based MARL method called GAWM, which enhances the centralized world model’s ability to achieve globally unified and accurate representation of state information while adhering to the CTDE paradigm. GAWM uniquely leverages an additional Transformer architecture to fuse local observation information from different agents, thereby improving its ability to extract and represent global state information. This enhancement not only improves sample efficiency but also enhances training stability, leading to superior convergence performance, particularly in complex and challenging multi-agent environments. This advancement enables model-based methods to be effectively applied to more complex multi-agent environments. Experimental results demonstrate that GAWM outperforms various model-free and model-based approaches, achieving exceptional performance in the challenging domains of SMAC.
近年来,基于模型的多智能体强化学习(MARL)通过使用独立的环境动态世界模型进行数据样本增强,在样本效率方面显示出对无模型方法的显著优势。然而,在不考虑有限样本大小的情况下,这些方法在最终收敛性能稳定性方面仍落后于无模型方法。这主要是因为世界模型对部分可观察环境中全局状态的表示不足且不稳定。这种局限性阻碍了确保数据样本全局一致性的能力,并导致由世界模型生成的伪数据样本与真实样本之间存在时变且不稳定的分布不匹配。在更复杂的多智能体环境中,这个问题变得尤为突出。为了解决这一挑战,我们提出了一种基于模型的MARL方法,称为GAWM。GAWM增强了集中式世界模型在遵循CTDE范式的同时实现全局统一和准确的状态信息表示的能力。GAWM独特地利用额外的Transformer架构来融合来自不同智能体的局部观测信息,从而提高了其提取和表示全局状态信息的能力。这种增强不仅提高了样本效率,还提高了训练稳定性,导致了卓越的收敛性能,特别是在复杂和具有挑战性的多智能体环境中。这一进展使得基于模型的方法能够有效地应用于更复杂的多智能体环境。实验结果表明,GAWM在各种模型和模型基础方法中都表现出卓越性能,在SMAC等具有挑战性的领域中取得了出色表现。
论文及项目相关链接
PDF 9 pages, 5 figures
摘要
强化学习中的基于模型的Multi-Agent强化学习(MARL)通过利用独立的环境动态世界模型进行数据样本扩充,近年来在样本效率方面显示出显著优势。然而,在不考虑有限样本量的情况下,这些方法在最终收敛性能与稳定性方面仍落后于无模型方法,这主要是因为世界模型对部分可观察环境中全局状态的表示不足且不稳定。这种局限性阻碍了确保数据样本全局一致性的能力,并导致由世界模型生成的伪数据样本与真实样本之间存在时变和不稳定分布不匹配的问题。在更复杂的多智能体环境中,这个问题变得尤为突出。为解决这一挑战,我们提出了一种基于模型的MARL方法GAWM,它通过改进集中式世界模型,提高全局统一和准确的状态信息表示能力,同时遵循CTDE范式。GAWM独特地利用额外的Transformer架构来融合来自不同智能体的局部观测信息,从而提高其提取和表示全局状态信息的能力。这种增强不仅提高了样本效率,还提高了训练稳定性,导致收敛性能优越,特别是在复杂且具有挑战性的多智能体环境中。实验结果表明,GAWM在各种无模型和基于模型的方法中表现出色,在SMAC等挑战领域取得了卓越的性能。
关键见解
- 基于模型的MARL方法在样本效率上优于模型无关方法,通过独立环境动态世界模型进行数据样本扩充。
- 在考虑有限样本量时,这些方法在最终收敛性能和稳定性方面存在不足。
- 主要挑战在于世界模型对部分可观察环境中全局状态的表示不足和不稳定。
- 世界模型生成的伪数据样本与真实样本之间存在时变和不稳定分布不匹配的问题。
- 在复杂和多智能体环境中,这些问题变得尤为突出。
- GAWM通过改进集中式世界模型并提高全局状态信息表示能力来解决这些挑战。
点此查看论文截图



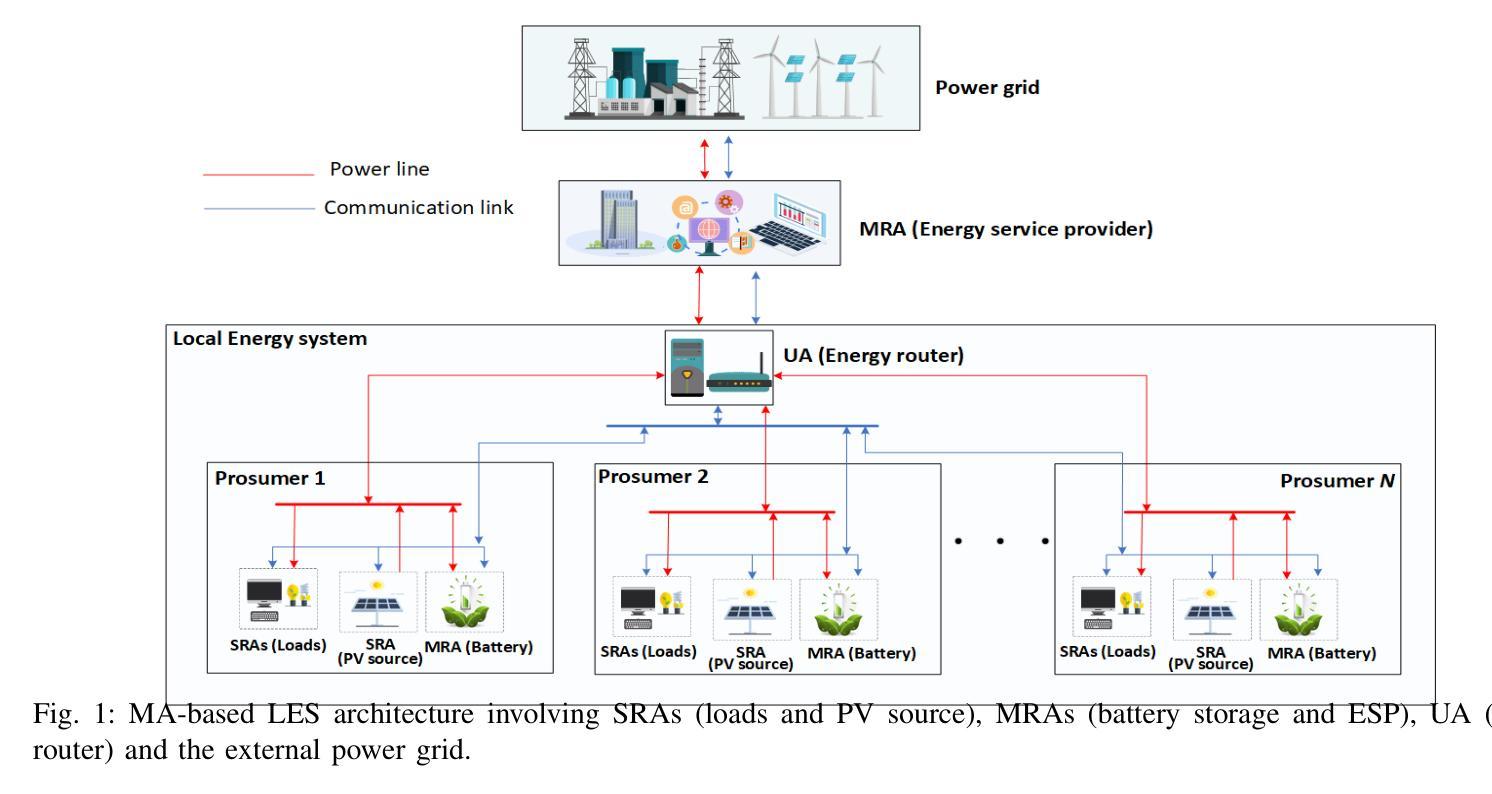
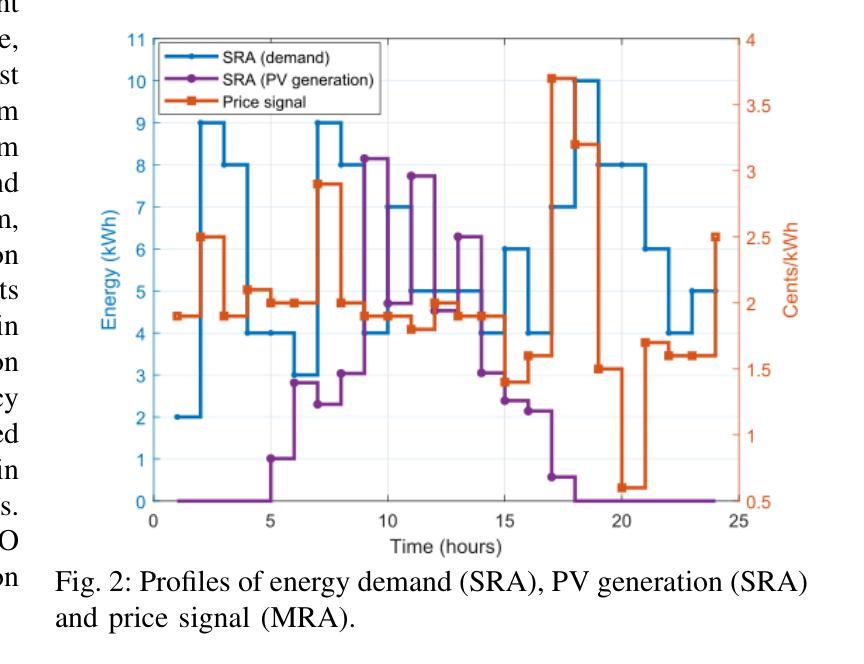
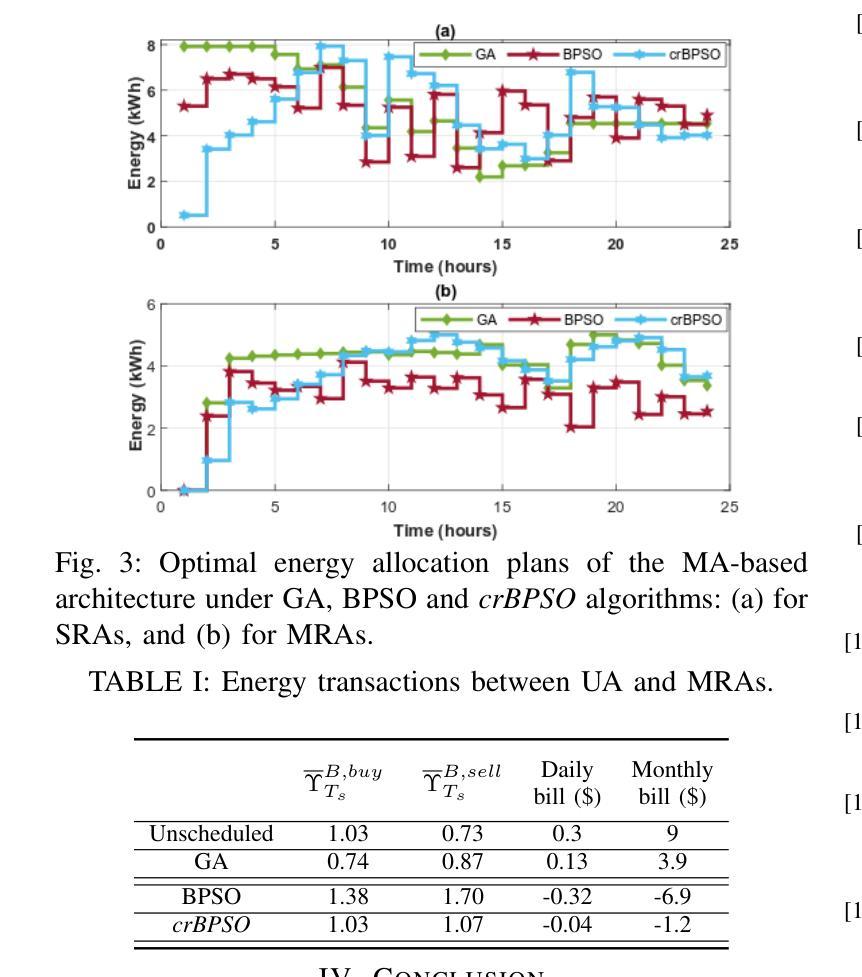
Crossover-BPSO Driven Multi-Agent Technology for Managing Local Energy Systems
Authors:Hafiz Majid Hussain, Ashfaq Ahmad. Pedro H. J. Nardelli
This article presents a new hybrid algorithm, crossover binary particle swarm optimization (crBPSO), for allocating resources in local energy systems via multi-agent (MA) technology. Initially, a hierarchical MA-based architecture in a grid-connected local energy setup is presented. In this architecture, task specific agents operate in a master-slave manner. Where, the master runs a well-formulated optimization routine aiming at minimizing costs of energy procurement, battery degradation, and load scheduling delay. The slaves update the master on their current status and receive optimal action plans accordingly. Simulation results demonstrate that the proposed algorithm outperforms selected existing ones by 21% in terms average energy system costs while satisfying customers’ energy demand and maintaining the required quality of service.
本文提出了一种新的混合算法——交叉二进制粒子群优化(crBPSO),通过多智能体(MA)技术在地方能源系统中进行资源配置。首先,介绍了一种在并网地方能源设置中基于层次结构的MA架构。在此架构中,特定任务的智能体以主从方式运行。其中,主智能体运行一个经过良好制定的优化流程,旨在最小化能源采购、电池退化和调度延迟的成本。从智能体会向主智能体更新其当前状态并据此接收最佳行动计划。仿真结果表明,所提出的算法在平均能源系统成本方面比某些现有算法高出21%,同时满足了客户的能源需求并保持所需的服务质量。
论文及项目相关链接
Summary
该文章介绍了一种新的混合算法——交叉二进制粒子群优化(crBPSO),通过多智能体技术为本地能源系统分配资源。文章首先提出了一种基于分层多智能体的本地能源系统架构,在该架构中,任务特定的智能体以主-从方式运行。模拟结果表明,所提出的算法在平均能源系统成本方面比一些现有算法提高了21%,同时满足了客户的能源需求并保持了所需的服务质量。
Key Takeaways
- 介绍了一种新的混合算法——交叉二进制粒子群优化(crBPSO)。
- 该算法应用于本地能源系统的资源分配,并采用了多智能体技术。
- 提出了一种基于分层多智能体的本地能源系统架构。
- 在此架构中,任务特定的智能体以主-从方式运行。
- 主智能体执行优化程序以最小化能源采购、电池退化和负载调度延迟的成本。
- 模拟结果表明,新算法在平均能源系统成本方面表现优异,优于一些现有算法。
点此查看论文截图

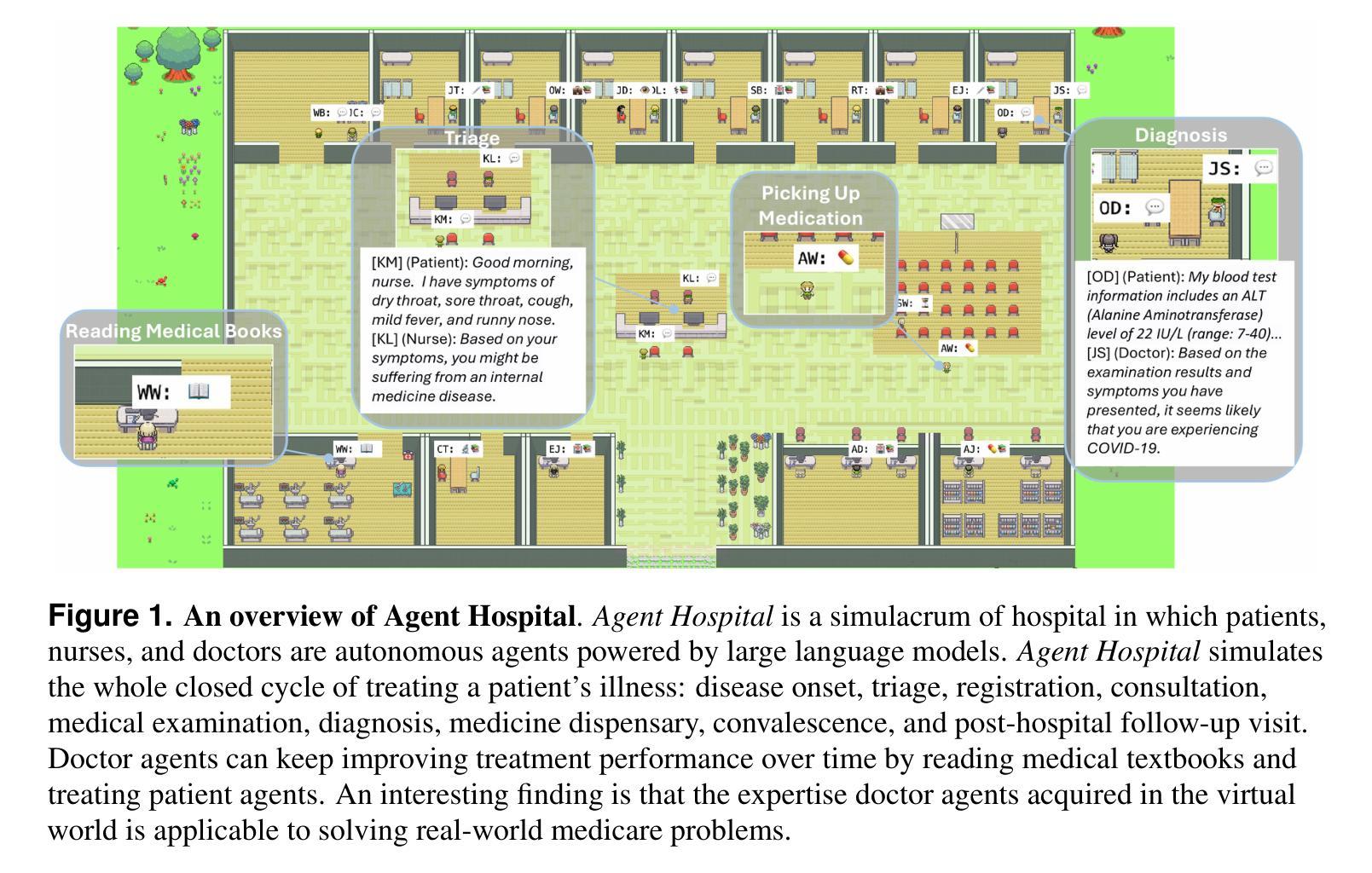
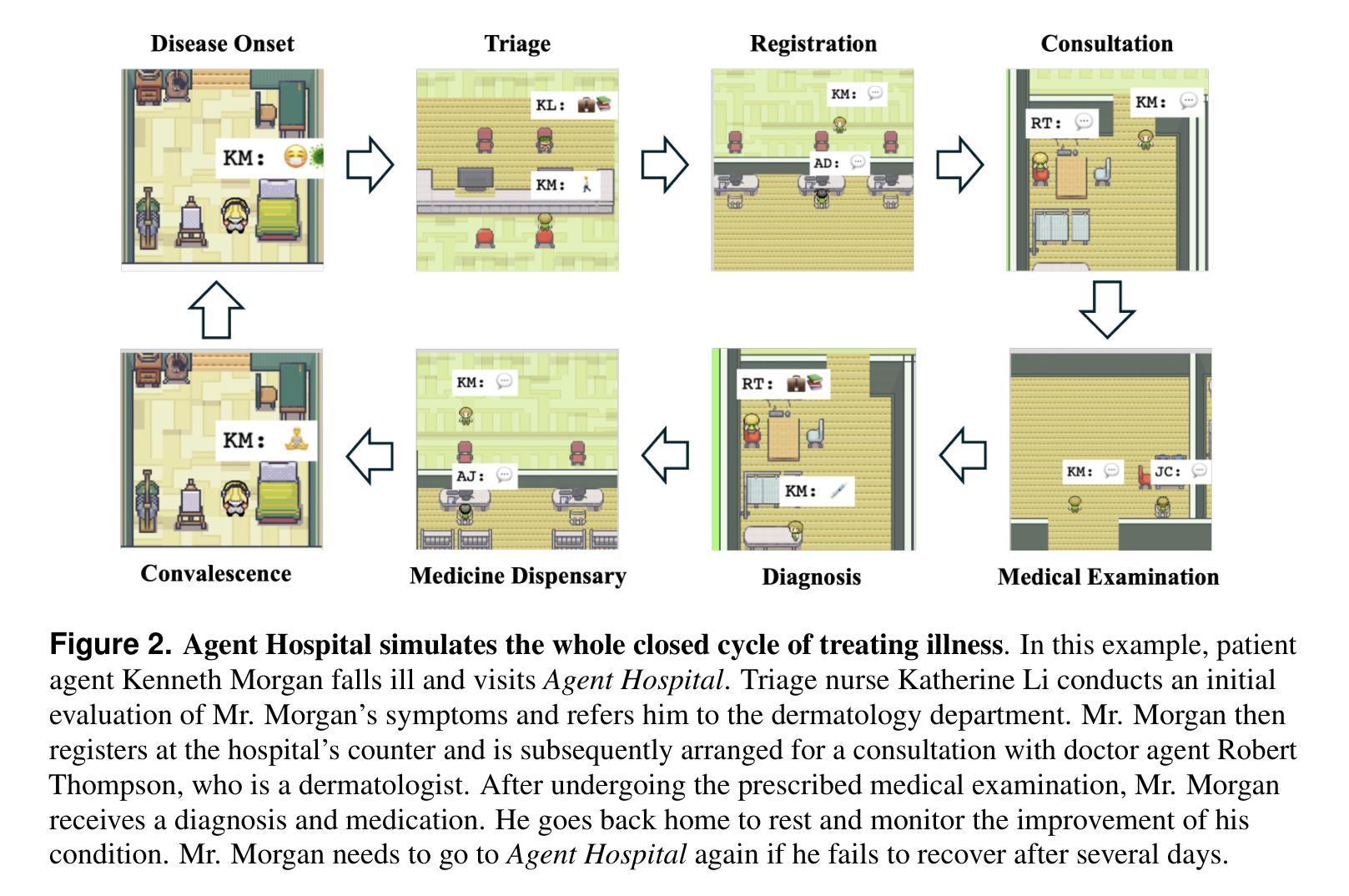
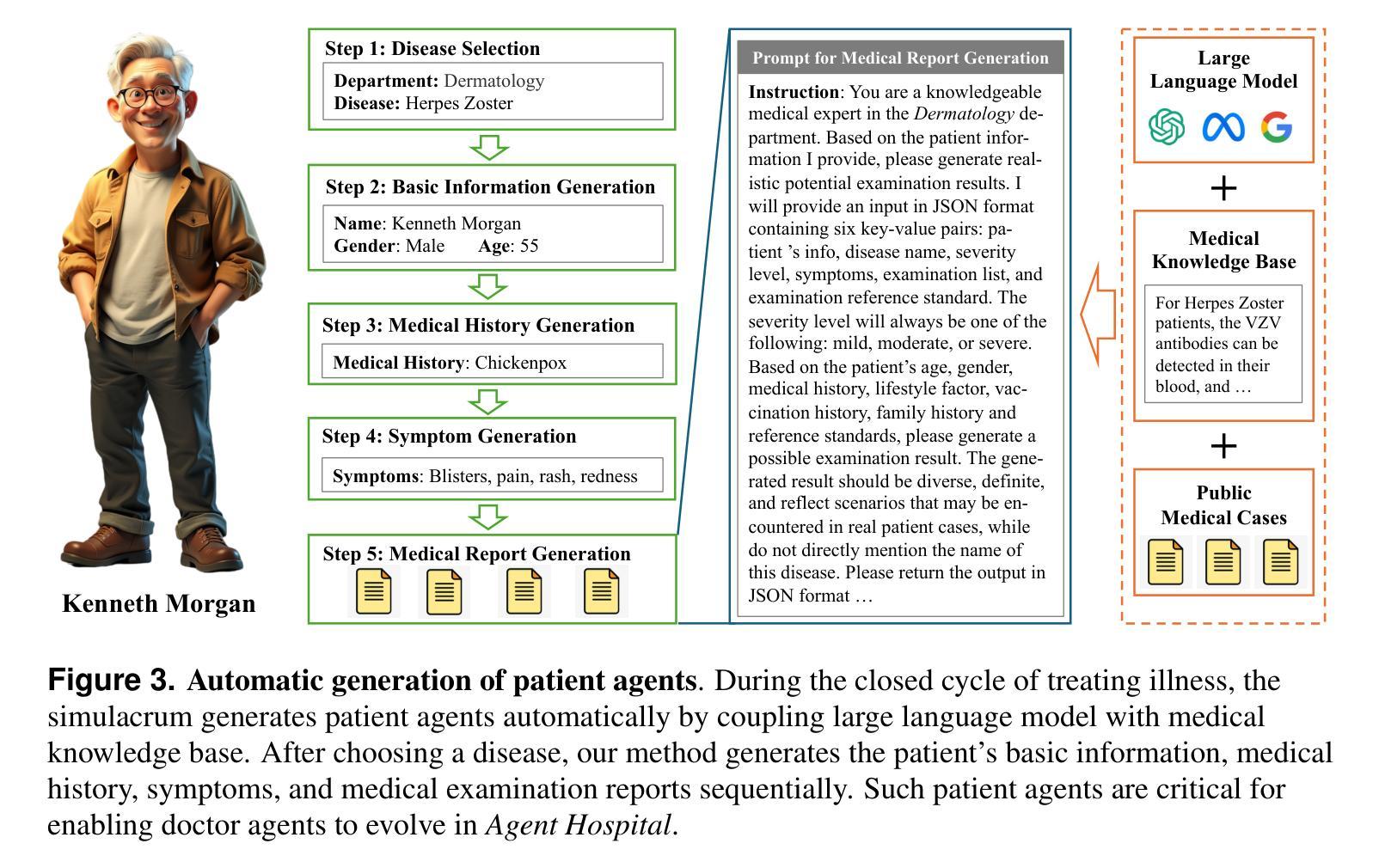
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
Authors:Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma, Yang Liu
The recent rapid development of large language models (LLMs) has sparked a new wave of technological revolution in medical artificial intelligence (AI). While LLMs are designed to understand and generate text like a human, autonomous agents that utilize LLMs as their “brain” have exhibited capabilities beyond text processing such as planning, reflection, and using tools by enabling their “bodies” to interact with the environment. We introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness, in which all patients, nurses, and doctors are LLM-powered autonomous agents. Within the simulacrum, doctor agents are able to evolve by treating a large number of patient agents without the need to label training data manually. After treating tens of thousands of patient agents in the simulacrum (human doctors may take several years in the real world), the evolved doctor agents outperform state-of-the-art medical agent methods on the MedQA benchmark comprising US Medical Licensing Examination (USMLE) test questions. Our methods of simulacrum construction and agent evolution have the potential in benefiting a broad range of applications beyond medical AI.
最近大型语言模型(LLM)的快速发展,在医疗人工智能(AI)领域掀起了一场新的技术革命。虽然大型语言模型被设计用来像人类一样理解和生成文本,但利用大型语言模型作为“大脑”的自主智能体已经展现出超越文本处理的能力,如规划、反思和使用工具,使其“身体”能与环境进行交互。我们介绍了一个名为Agent Hospital的模拟医院,它模拟了整个疾病治疗过程,其中所有病人、护士和医生都是基于大型语言模型驱动的智能体。在这个模拟环境中,医生智能体能够通过治疗大量病人智能体来不断进化,而无需手动标注训练数据。在模拟环境中治疗了成千上万病人智能体(在现实世界中可能需要人类医生数年时间)后,进化后的医生智能体在包含美国医学执照考试(USMLE)试题的MedQA基准测试上超越了最先进的医疗智能体方法。我们的模拟构建方法和智能体进化方法有可能在医疗人工智能以外的广泛应用领域中受益。
论文及项目相关链接
Summary
大型语言模型(LLM)的快速发展引发了医疗人工智能(AI)的新技术革命。通过模拟人类理解和生成文本的方式,LLM被用作自主代理的“大脑”,表现出文本处理之外的规划、反思和使用工具的能力,促使代理能够与环境中互动。提出了一种名为Agent Hospital的模拟医院,其中所有病人、护士和医生都是LLM驱动的自主代理。在该模拟中,医生代理能够通过治疗大量病人代理而进化,无需手动标注训练数据。经过在模拟中治疗数万名病人代理(在现实世界中可能需要数年时间),进化后的医生代理在包含美国医学执照考试(USMLE)问题的MedQA基准测试上表现优于最先进的医疗代理方法。我们的模拟构建和代理进化方法具有在医疗AI之外广泛应用潜力。
Key Takeaways
- 大型语言模型(LLM)的发展推动了医疗人工智能的新技术革命。
- LLM被应用于自主代理的“大脑”,展现出超越文本处理的能力,如规划、反思和使用工具。
- 提出了名为Agent Hospital的模拟医院,其中所有医疗角色均为LLM驱动的自主代理。
- 在模拟环境中,医生代理可以通过治疗大量病人代理而进化,无需手动标注训练数据。
- 进化后的医生代理在MedQA基准测试上的表现优于现有医疗代理方法。
- Agent Hospital的模拟构建和代理进化方法具有广泛的应用潜力,不仅限于医疗AI领域。
点此查看论文截图