⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
ACE: Anatomically Consistent Embeddings in Composition and Decomposition
Authors:Ziyu Zhou, Haozhe Luo, Mohammad Reza Hosseinzadeh Taher, Jiaxuan Pang, Xiaowei Ding, Michael Gotway, Jianming Liang
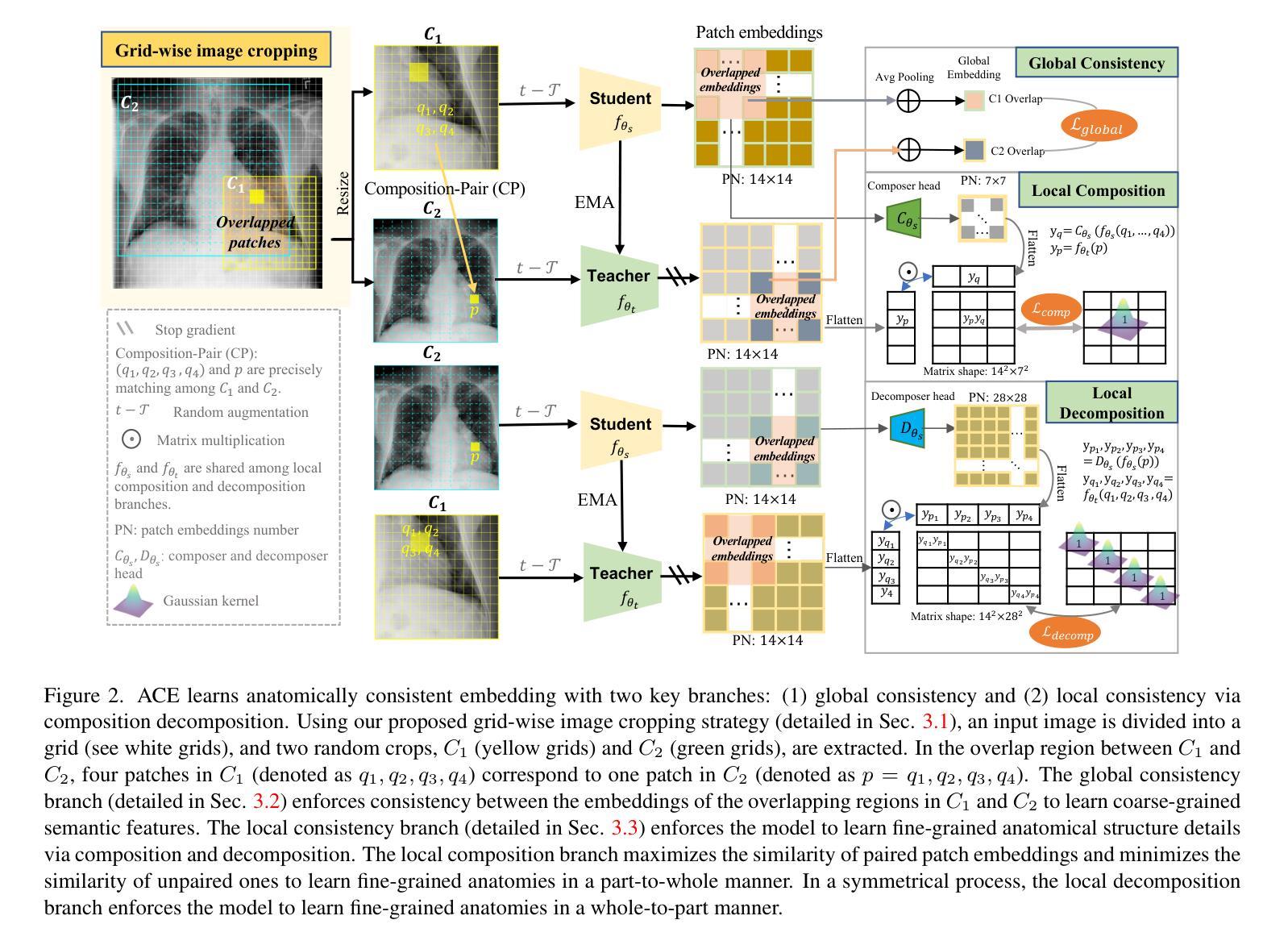
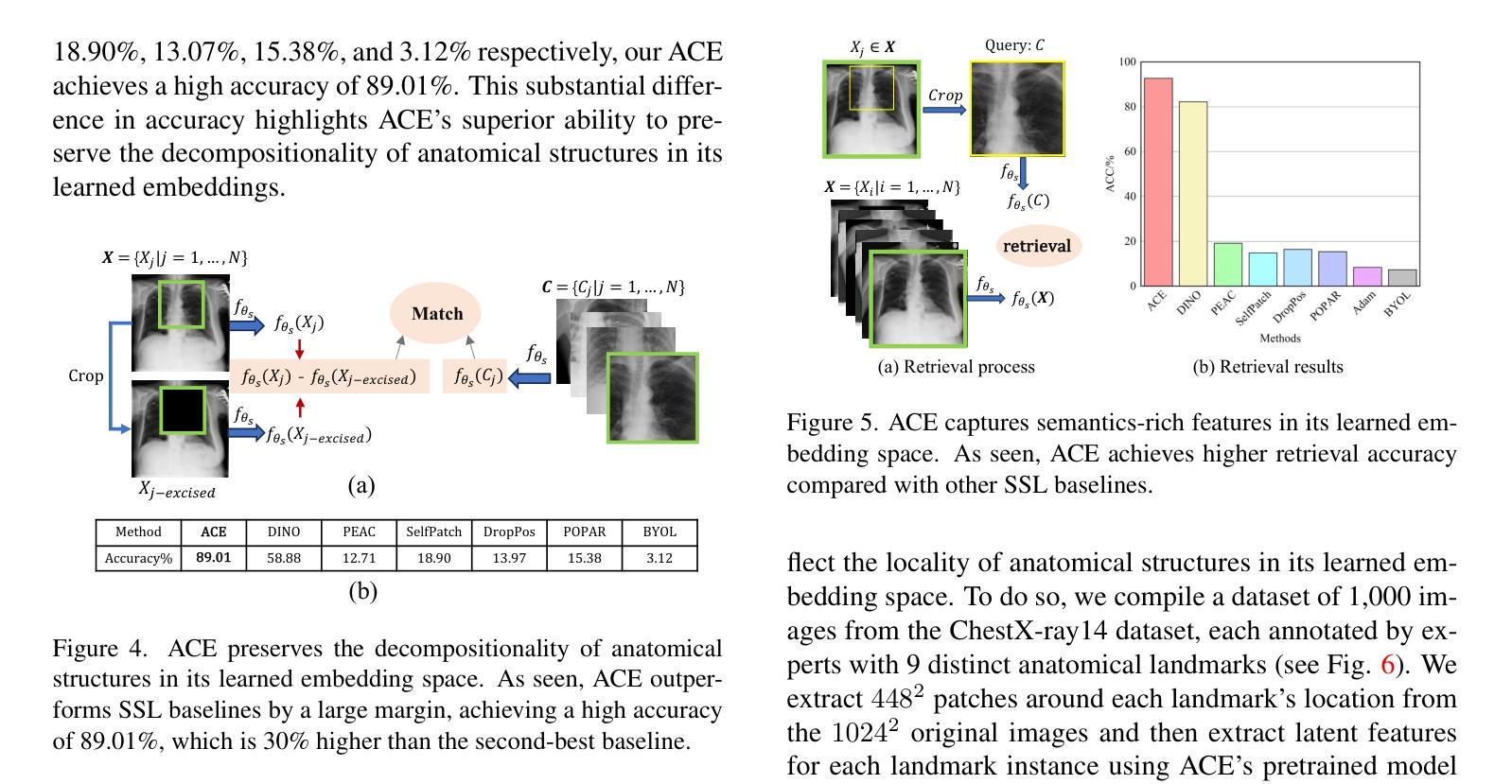
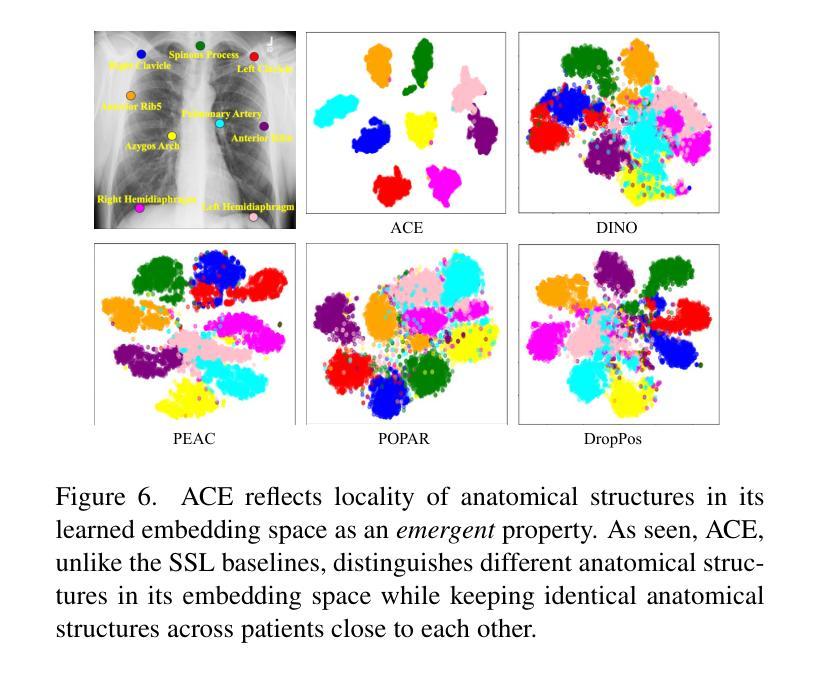
Medical images acquired from standardized protocols show consistent macroscopic or microscopic anatomical structures, and these structures consist of composable/decomposable organs and tissues, but existing self-supervised learning (SSL) methods do not appreciate such composable/decomposable structure attributes inherent to medical images. To overcome this limitation, this paper introduces a novel SSL approach called ACE to learn anatomically consistent embedding via composition and decomposition with two key branches: (1) global consistency, capturing discriminative macro-structures via extracting global features; (2) local consistency, learning fine-grained anatomical details from composable/decomposable patch features via corresponding matrix matching. Experimental results across 6 datasets 2 backbones, evaluated in few-shot learning, fine-tuning, and property analysis, show ACE’s superior robustness, transferability, and clinical potential. The innovations of our ACE lie in grid-wise image cropping, leveraging the intrinsic properties of compositionality and decompositionality of medical images, bridging the semantic gap from high-level pathologies to low-level tissue anomalies, and providing a new SSL method for medical imaging.
根据标准化协议获取的医学图像显示出一致的宏观或微观解剖结构,这些结构由可组合/可分解的器官和组织组成。然而,现有的自监督学习方法(SSL)并没有重视医学图像中固有的这种可组合/可分解的结构属性。为了克服这一局限性,本文介绍了一种新型SSL方法,称为ACE(解剖结构一致性嵌入学习法),通过组合和分解进行解剖结构一致性嵌入学习,分为两个主要分支:(1)全局一致性,通过提取全局特征来捕捉鉴别性宏观结构;(2)局部一致性,通过对应的矩阵匹配学习来自可组合/可分解的补丁特征的精细解剖细节。在涵盖六个数据集和两个主干网络的实验中,通过小样学习、微调以及属性分析评估表明,ACE具有卓越的稳健性、迁移能力和临床潜力。我们ACE的创新之处在于网格图像裁剪方式,利用医学图像组合性和分解性的内在属性,缩小了从高级病理到低级组织异常的语义差距,并为医学影像提供了新的SSL方法。
论文及项目相关链接
PDF Accepted by WACV 2025
Summary
本文提出一种名为ACE的新型自监督学习方法,用于通过组合和分解学习解剖结构一致的嵌入。该方法包括两个关键分支:全局一致性,通过提取全局特征捕获具有鉴别力的宏观结构;局部一致性,通过相应的矩阵匹配从可组合/可分解的补丁特征中学习精细的解剖细节。在六种数据集和两种骨干网的研究结果上进行的少数学习、微调属性分析表明,ACE具有卓越的稳健性、可迁移性和临床潜力。ACE的创新之处在于网格图像裁剪,利用医学图像的组合性和分解性内在属性,缩短高级病理与低级组织异常的语义差距,并为医学影像提供了新的自监督学习方法。
Key Takeaways
- ACE是一种新型自监督学习方法,旨在通过组合和分解学习解剖结构一致的嵌入。
- ACE包含两个关键分支:全局一致性和局部一致性,分别关注宏观结构和精细解剖细节的学习。
- ACE通过网格图像裁剪来利用医学图像的组合性和分解性内在属性。
- ACE能够缩短高级病理与低级组织异常的语义差距。
点此查看论文截图


Few-shot Structure-Informed Machinery Part Segmentation with Foundation Models and Graph Neural Networks
Authors:Michael Schwingshackl, Fabio Francisco Oberweger, Markus Murschitz
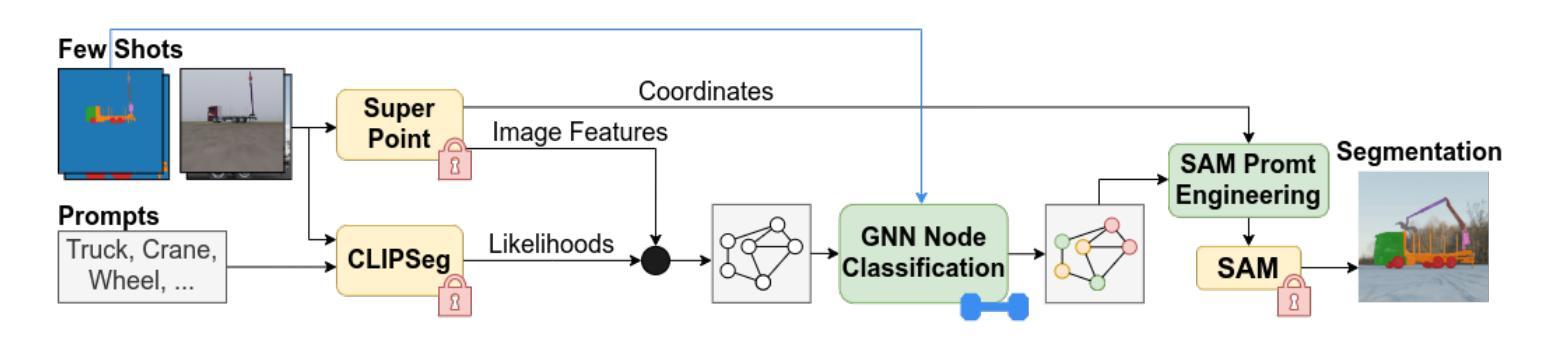
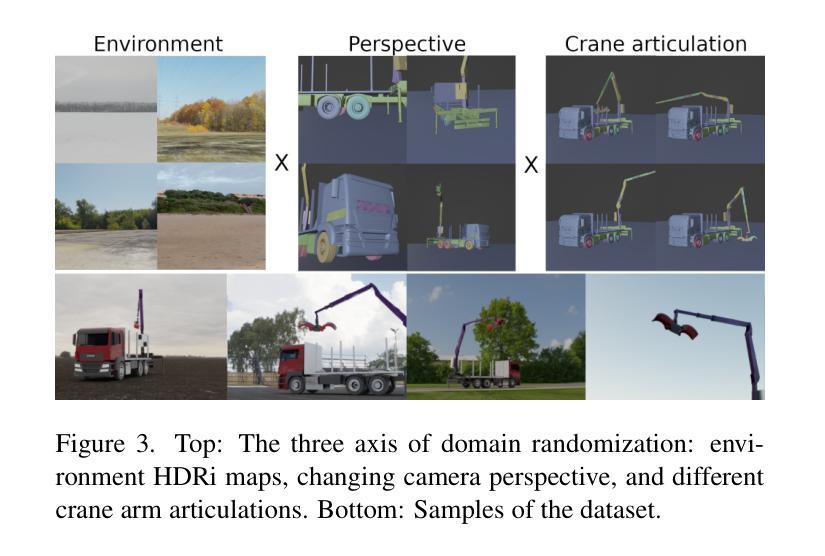
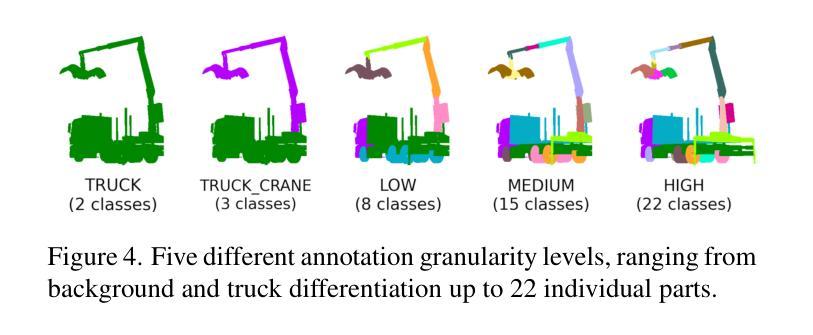
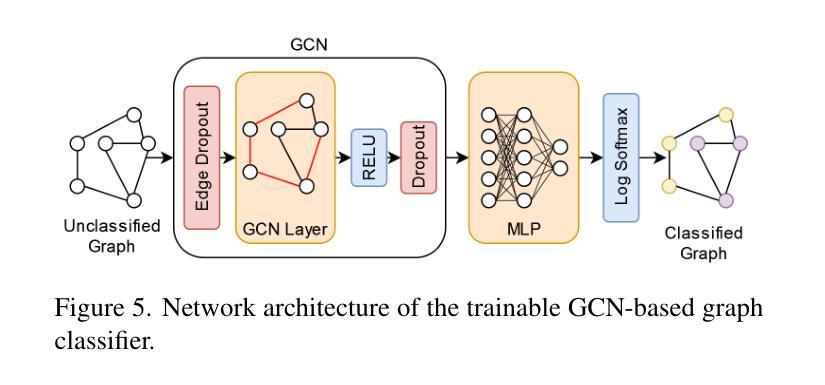
This paper proposes a novel approach to few-shot semantic segmentation for machinery with multiple parts that exhibit spatial and hierarchical relationships. Our method integrates the foundation models CLIPSeg and Segment Anything Model (SAM) with the interest point detector SuperPoint and a graph convolutional network (GCN) to accurately segment machinery parts. By providing 1 to 25 annotated samples, our model, evaluated on a purely synthetic dataset depicting a truck-mounted loading crane, achieves effective segmentation across various levels of detail. Training times are kept under five minutes on consumer GPUs. The model demonstrates robust generalization to real data, achieving a qualitative synthetic-to-real generalization with a $J&F$ score of 92.2 on real data using 10 synthetic support samples. When benchmarked on the DAVIS 2017 dataset, it achieves a $J&F$ score of 71.5 in semi-supervised video segmentation with three support samples. This method’s fast training times and effective generalization to real data make it a valuable tool for autonomous systems interacting with machinery and infrastructure, and illustrate the potential of combined and orchestrated foundation models for few-shot segmentation tasks.
本文提出了一种针对具有展示空间分层关系多个部件的机器进行少样本语义分割的新方法。我们的方法融合了CLIPSeg和Segment Anything Model(SAM)基础模型,结合兴趣点检测器SuperPoint和图卷积网络(GCN)来准确分割机器部件。通过提供1至25个标注样本,我们的模型在纯粹合成数据集上评估,该数据集描绘了一辆装载着起重机的卡车,能够在不同层次的细节上实现有效的分割。在消费者GPU上,训练时间保持在五分钟以内。该模型在真实数据上展示了强大的泛化能力,使用10个合成支持样本在真实数据上实现了定性合成到真实的泛化,JF得分为92.2。在DAVIS 2017数据集上进行基准测试时,使用三个支持样本进行半监督视频分割时,其JF得分为71.5。该方法的快速训练时间和对真实数据的有效泛化使其成为自主系统与机械和基础设施交互的有价值的工具,并展示了组合和协同基础模型在少样本分割任务中的潜力。
论文及项目相关链接
PDF Accepted at Winter Conference on Applications of Computer Vision (WACV) 2025. Code and available at https://github.com/AIT-Assistive-Autonomous-Systems/Hopomop
Summary
基于本文,提出一种新颖的用于处理机械设备少样本语义分割的方法。该方法结合了CLIPSeg和Segment Anything Model(SAM)基础模型,利用兴趣点检测器SuperPoint和图卷积网络(GCN)准确分割机械设备部件。在仅提供1至25个标注样本的情况下,该模型在模拟的卡车装载起重机数据集上实现了有效的分割,并且在消费者GPU上训练时间不到五分钟。模型展示了对真实数据的稳健泛化能力,使用仅10个合成支持样本在真实数据上的JF分数达到92.2。在DAVIS 2017数据集上,使用三个支持样本进行半监督视频分割时,其JF分数达到71.5。此方法快速训练时间和对真实数据的有效泛化使其成为自主系统与机械设备交互的有力工具,并展示了联合编排基础模型在少样本分割任务中的潜力。
Key Takeaways
- 提出了一个用于少样本语义分割的新方法,专注于机械设备,并处理了其空间层次关系。
- 结合了CLIPSeg、Segment Anything Model (SAM)、SuperPoint检测器和图卷积网络(GCN)。
- 在模拟的卡车装载起重机数据集上,使用少量标注样本实现了有效的分割。
- 训练时间非常短,仅在消费者GPU上不到五分钟。
- 模型在真实数据上展示了强大的泛化能力,使用少量合成支持样本即达到较高的JF分数。
- 在DAVIS 2017数据集上,使用三个支持样本进行半监督视频分割时表现出良好的性能。
点此查看论文截图



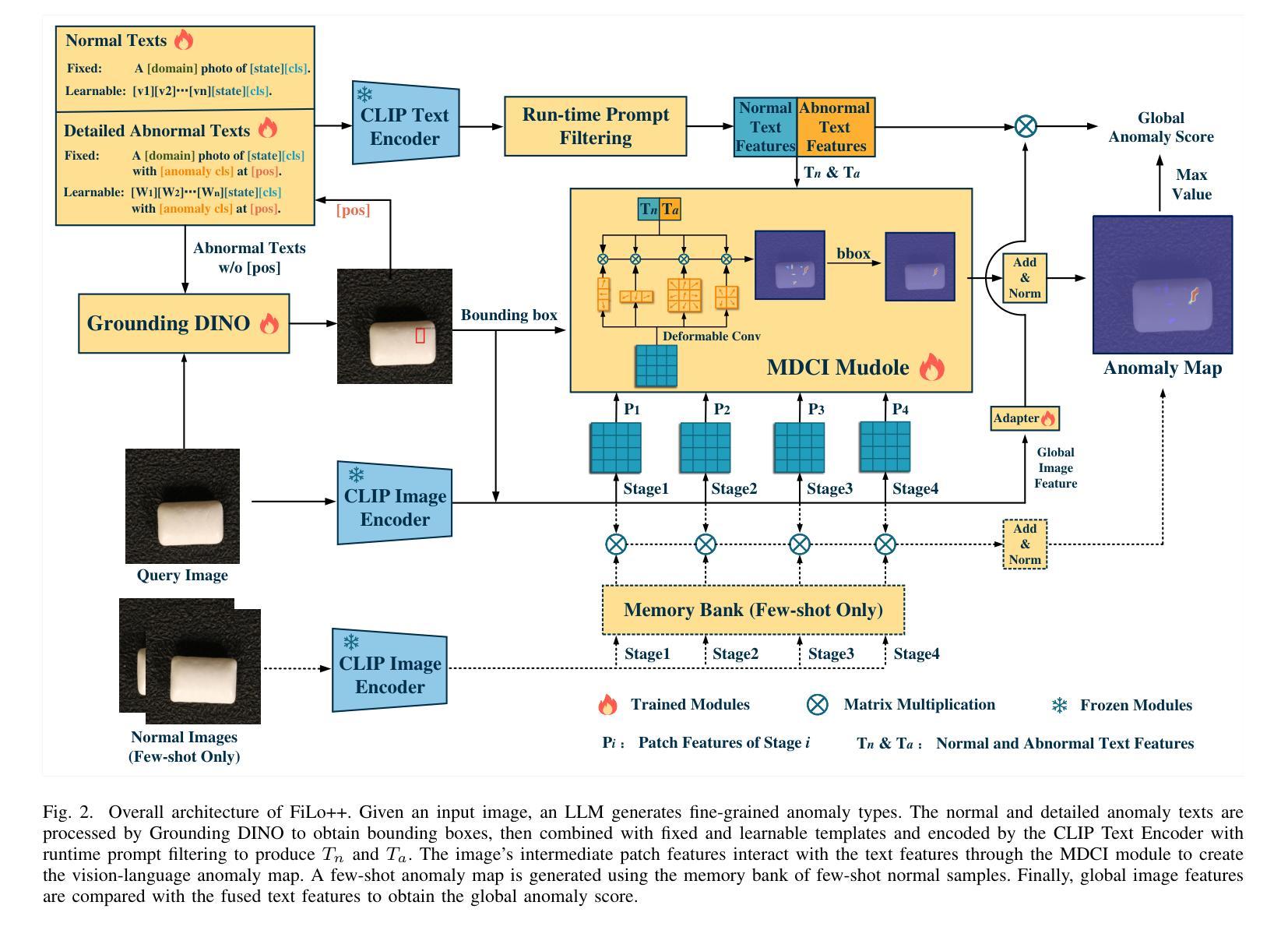
FiLo++: Zero-/Few-Shot Anomaly Detection by Fused Fine-Grained Descriptions and Deformable Localization
Authors:Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, Jinqiao Wang
Anomaly detection methods typically require extensive normal samples from the target class for training, limiting their applicability in scenarios that require rapid adaptation, such as cold start. Zero-shot and few-shot anomaly detection do not require labeled samples from the target class in advance, making them a promising research direction. Existing zero-shot and few-shot approaches often leverage powerful multimodal models to detect and localize anomalies by comparing image-text similarity. However, their handcrafted generic descriptions fail to capture the diverse range of anomalies that may emerge in different objects, and simple patch-level image-text matching often struggles to localize anomalous regions of varying shapes and sizes. To address these issues, this paper proposes the FiLo++ method, which consists of two key components. The first component, Fused Fine-Grained Descriptions (FusDes), utilizes large language models to generate anomaly descriptions for each object category, combines both fixed and learnable prompt templates and applies a runtime prompt filtering method, producing more accurate and task-specific textual descriptions. The second component, Deformable Localization (DefLoc), integrates the vision foundation model Grounding DINO with position-enhanced text descriptions and a Multi-scale Deformable Cross-modal Interaction (MDCI) module, enabling accurate localization of anomalies with various shapes and sizes. In addition, we design a position-enhanced patch matching approach to improve few-shot anomaly detection performance. Experiments on multiple datasets demonstrate that FiLo++ achieves significant performance improvements compared with existing methods. Code will be available at https://github.com/CASIA-IVA-Lab/FiLo.
异常检测方法通常需要目标类别的大量正常样本进行训练,这在需要快速适应的场景(如冷启动)中限制了其适用性。零样本和少样本异常检测不需要提前获得目标类别的标记样本,因此成为了一个有前景的研究方向。现有的零样本和少样本方法经常利用强大的多模态模型,通过比较图像文本相似性来检测和定位异常。然而,他们手工制作的通用描述无法捕捉不同对象中可能出现的各种异常,而简单的补丁级别的图像文本匹配往往难以定位形状和大小各异的异常区域。为了解决这些问题,本文提出了FiLo++方法,该方法由两个关键组件组成。第一个组件Fused Fine-Grained Descriptions(FusDes)利用大型语言模型为每个对象类别生成异常描述,结合了固定和可学习的提示模板,并应用了运行时提示过滤方法,从而产生更准确和任务特定的文本描述。第二个组件Deformable Localization(DefLoc)将视觉基础模型Grounding DINO与位置增强的文本描述和多尺度可变形跨模态交互(MDCI)模块集成,能够实现各种形状和大小的异常准确定位。此外,我们设计了一种位置增强的补丁匹配方法,以提高少样本异常检测的性能。在多个数据集上的实验表明,FiLo++与现有方法相比实现了显著的性能改进。代码将在https://github.com/CASIA-IVA-Lab/FiLo上提供。
论文及项目相关链接
Summary
本文提出一种名为FiLo++的方法,用于解决零样本和少样本异常检测中的两个问题:一是通用描述无法捕捉不同对象的多种异常,二是简单图像文本匹配难以定位形状和大小各异的异常区域。FiLo++包括两个关键组件:Fused Fine-Grained Descriptions(FusDes)和Deformable Localization(DefLoc)。前者利用大型语言模型为每个对象类别生成异常描述,提高文本描述的准确性。后者结合了视觉基础模型和位置增强的文本描述,以及多尺度可变形跨模态交互模块,实现了对形状和大小各异的异常区域的准确定位。实验证明,FiLo++相较于现有方法具有显著的性能提升。
Key Takeaways
- 零样本和少样本异常检测不需要提前获取目标类别的标签样本,具有快速适应新场景的优势。
- 现有方法使用通用描述难以捕捉不同对象的多种异常。
- FiLo++通过Fused Fine-Grained Descriptions(FusDes)组件利用大型语言模型生成更准确的异常描述。
- FiLo++的Deformable Localization(DefLoc)组件结合了视觉基础模型和位置增强的文本描述,实现了对形状和大小各异的异常区域的准确定位。
- FiLo++设计了一种位置增强的补丁匹配方法,提高了少样本异常检测的性能。
- 在多个数据集上的实验证明,FiLo++相较于现有方法具有显著性能提升。
点此查看论文截图

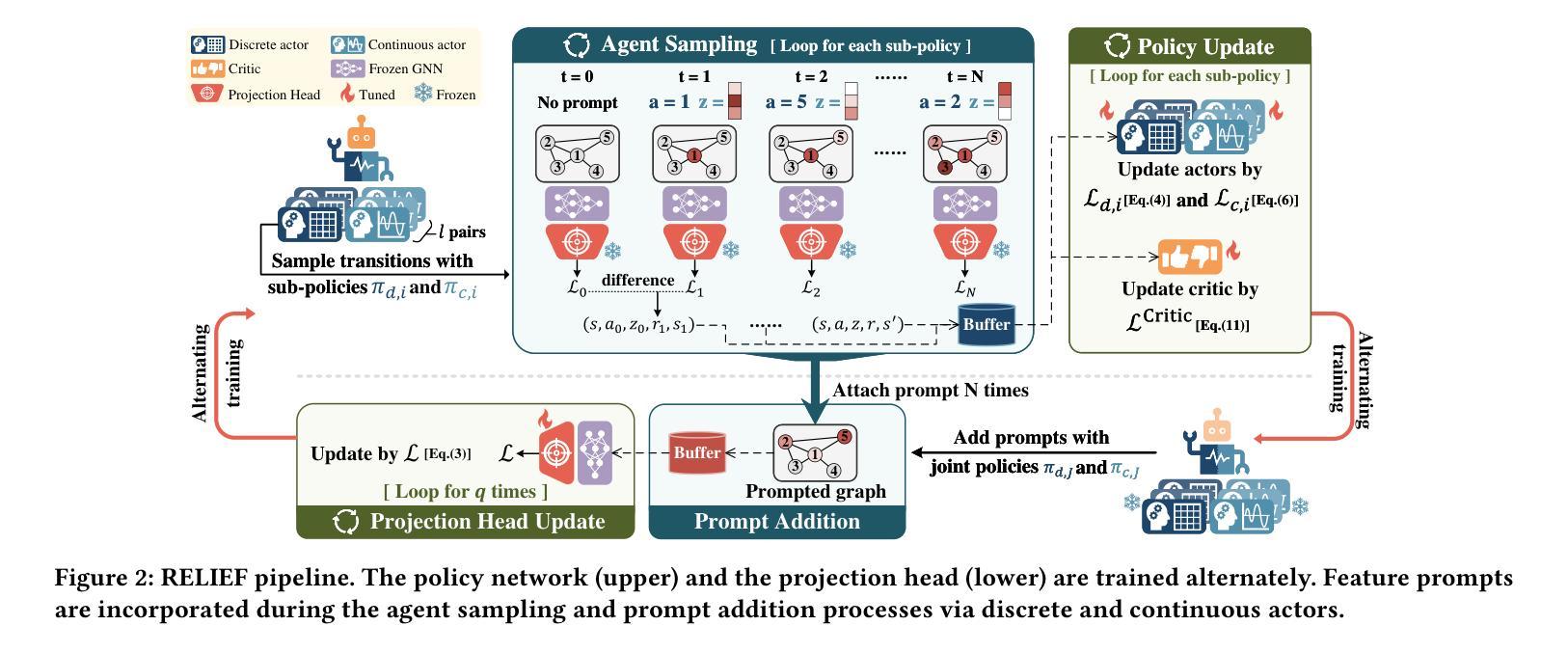
RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning
Authors:Jiapeng Zhu, Zichen Ding, Jianxiang Yu, Jiaqi Tan, Xiang Li, Weining Qian
The advent of the “pre-train, prompt” paradigm has recently extended its generalization ability and data efficiency to graph representation learning, following its achievements in Natural Language Processing (NLP). Initial graph prompt tuning approaches tailored specialized prompting functions for Graph Neural Network (GNN) models pre-trained with specific strategies, such as edge prediction, thus limiting their applicability. In contrast, another pioneering line of research has explored universal prompting via adding prompts to the input graph’s feature space, thereby removing the reliance on specific pre-training strategies. However, the necessity to add feature prompts to all nodes remains an open question. Motivated by findings from prompt tuning research in the NLP domain, which suggest that highly capable pre-trained models need less conditioning signal to achieve desired behaviors, we advocate for strategically incorporating necessary and lightweight feature prompts to certain graph nodes to enhance downstream task performance. This introduces a combinatorial optimization problem, requiring a policy to decide 1) which nodes to prompt and 2) what specific feature prompts to attach. We then address the problem by framing the prompt incorporation process as a sequential decision-making problem and propose our method, RELIEF, which employs Reinforcement Learning (RL) to optimize it. At each step, the RL agent selects a node (discrete action) and determines the prompt content (continuous action), aiming to maximize cumulative performance gain. Extensive experiments on graph and node-level tasks with various pre-training strategies in few-shot scenarios demonstrate that our RELIEF outperforms fine-tuning and other prompt-based approaches in classification performance and data efficiency. The code is available at https://github.com/JasonZhujp/RELIEF.
“预训练提示”范式的出现,最近将其泛化能力和数据效率扩展到了图表示学习,继其在自然语言处理(NLP)领域的成就之后。最初的图提示调整方法为使用特定策略(如边缘预测)进行预训练的图神经网络(GNN)模型量身定制了专门的提示功能,从而限制了其适用性。相比之下,另一条开创性的研究线路通过向输入图的特征空间添加提示来探索通用提示,从而消除了对特定预训练策略的依赖。然而,是否需要向所有节点添加特征提示仍然是一个悬而未决的问题。
论文及项目相关链接
PDF Accepted by SIGKDD 2025 (camera-ready version). Due to the space limitation, please refer to the V2 version for more details
Summary
随着“预训练,提示”模式在自然语言处理领域的成功,该模式已经扩展到图表示学习中。本文提出了一种基于强化学习的策略,通过添加特征提示来优化图神经网络模型的性能。该方法在多种预训练策略下的少样本场景中进行实验验证,并表现出在分类性能和数据效率方面的优越性。
Key Takeaways
- “预训练,提示”模式已扩展到图表示学习领域。
- 初始的图提示调整方法针对具有特定预训练策略(如边缘预测)的图神经网络模型使用专门的提示功能,这限制了其适用性。
- 研究人员正在探索通过向输入图的特征空间添加通用提示来消除对特定预训练策略的依赖。
- NLP领域的提示调整研究表明,高度预训练的模型需要较少的条件信号来实现所需的行为,这启发研究人员在图中某些节点上加入必要且轻量级的特征提示以增强下游任务性能。
- 引入了一种组合优化问题,需要决定哪些节点需要提示以及应附加哪些特定特征提示。
- 通过将提示融入过程构建为序列决策问题来解决该问题,并提出了一种使用强化学习优化的方法RELIEF。
点此查看论文截图


News Without Borders: Domain Adaptation of Multilingual Sentence Embeddings for Cross-lingual News Recommendation
Authors:Andreea Iana, Fabian David Schmidt, Goran Glavaš, Heiko Paulheim
Rapidly growing numbers of multilingual news consumers pose an increasing challenge to news recommender systems in terms of providing customized recommendations. First, existing neural news recommenders, even when powered by multilingual language models (LMs), suffer substantial performance losses in zero-shot cross-lingual transfer (ZS-XLT). Second, the current paradigm of fine-tuning the backbone LM of a neural recommender on task-specific data is computationally expensive and infeasible in few-shot recommendation and cold-start setups, where data is scarce or completely unavailable. In this work, we propose a news-adapted sentence encoder (NaSE), domain-specialized from a pretrained massively multilingual sentence encoder (SE). To this end, we construct and leverage PolyNews and PolyNewsParallel, two multilingual news-specific corpora. With the news-adapted multilingual SE in place, we test the effectiveness of (i.e., question the need for) supervised fine-tuning for news recommendation, and propose a simple and strong baseline based on (i) frozen NaSE embeddings and (ii) late click-behavior fusion. We show that NaSE achieves state-of-the-art performance in ZS-XLT in true cold-start and few-shot news recommendation.
随着多语言新闻消费者的数量迅速增长,为新闻推荐系统提供个性化推荐带来了越来越大的挑战。首先,现有的神经新闻推荐器,即使在多语言模型的驱动下,在零样本跨语言迁移(ZS-XLT)中也面临着显著的性能损失。其次,当前神经推荐器的骨干语言模型在特定任务数据上进行微调的模式,在计算资源方面成本高昂,在样本量较少的推荐和冷启动环境中并不可行,在这些环境中数据稀缺或完全不可用。在这项工作中,我们提出了一种新闻适配的句子编码器(NaSE),它是基于预训练的大规模多语言句子编码器(SE)进行领域专业化的。为此,我们构建并使用了PolyNews和PolyNewsParallel两个多语言新闻专用语料库。通过新闻适配的多语言SE,我们测试了(即质疑了)监督微调对新闻推荐的必要性,并提出了一个简单而强大的基线模型,该模型基于(i)冻结的NaSE嵌入和(ii)后期点击行为融合。我们证明了NaSE在零样本跨语言迁移、真正的冷启动和少量样本的新闻推荐中达到了最先进的性能。
论文及项目相关链接
PDF Accepted at the 47th European Conference on Information Retrieval (ECIR 2025) Appendix A is provided only in the arXiv version
Summary
该文本介绍了随着多语言新闻消费者的数量迅速增长,新闻推荐系统面临的挑战日益加剧。现有的神经新闻推荐器在多语言场景下表现出显著的性能损失,且需要大量任务特定数据进行微调,这在数据量稀少或完全不可用的情况下变得不切实际。为此,该研究提出了一种新闻适配的句子编码器(NaSE),它基于预训练的巨大规模多语言句子编码器(SE)进行领域专业化。通过构建并使用PolyNews和PolyNewsParallel两个多语言新闻特定语料库,该研究质疑了监督微调在新闻推荐中的必要性,并提出了一种基于冻结的NaSE嵌入和晚期点击行为融合的简单而强大的基线方法。实验表明,NaSE在零样本跨语言迁移和真正的冷启动及小样本新闻推荐中达到了最新的技术水平。
Key Takeaways
- 多语言新闻消费者的增长对新闻推荐系统提出了挑战。
- 现有神经新闻推荐器在多语言场景下存在性能损失。
- NaSE是一种新闻适配的句子编码器,基于预训练的多语言句子编码器进行领域专业化。
- PolyNews和PolyNewsParallel语料库被构建并用于训练NaSE。
- 研究质疑了监督微调在新闻推荐中的必要性。
- NaSE通过冻结嵌入和晚期点击行为融合取得了先进性能。
点此查看论文截图

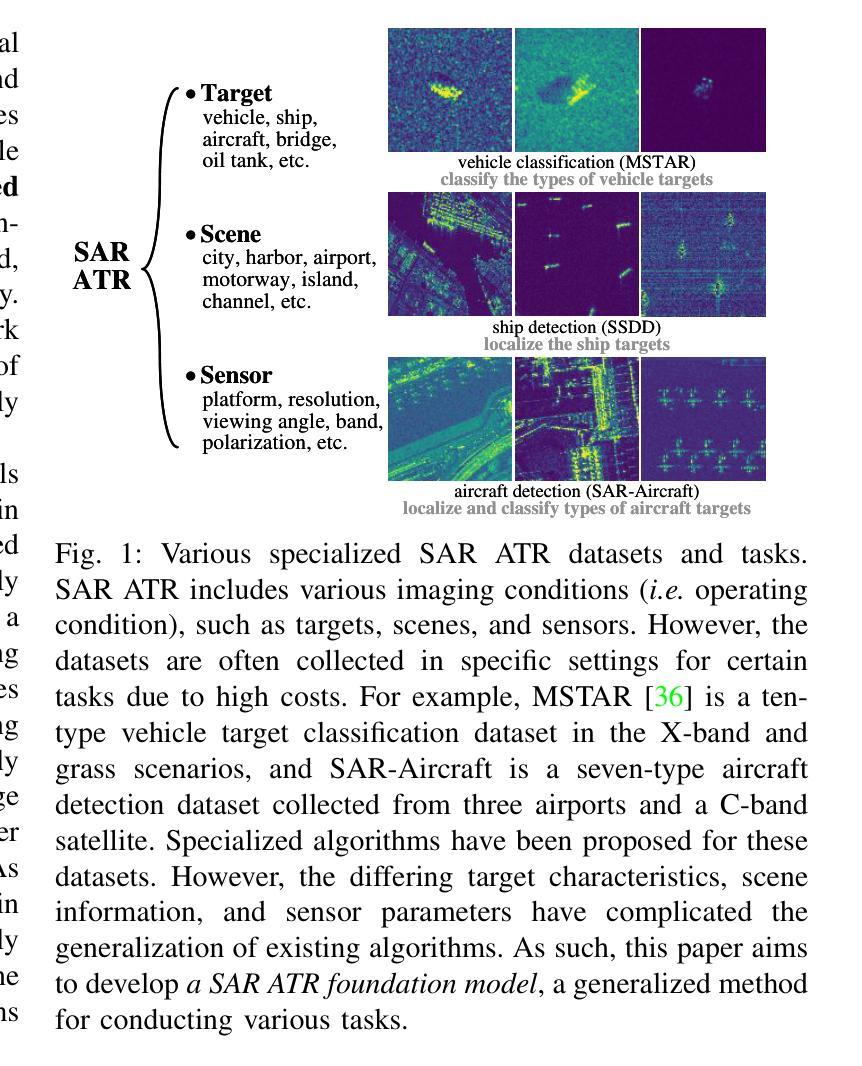
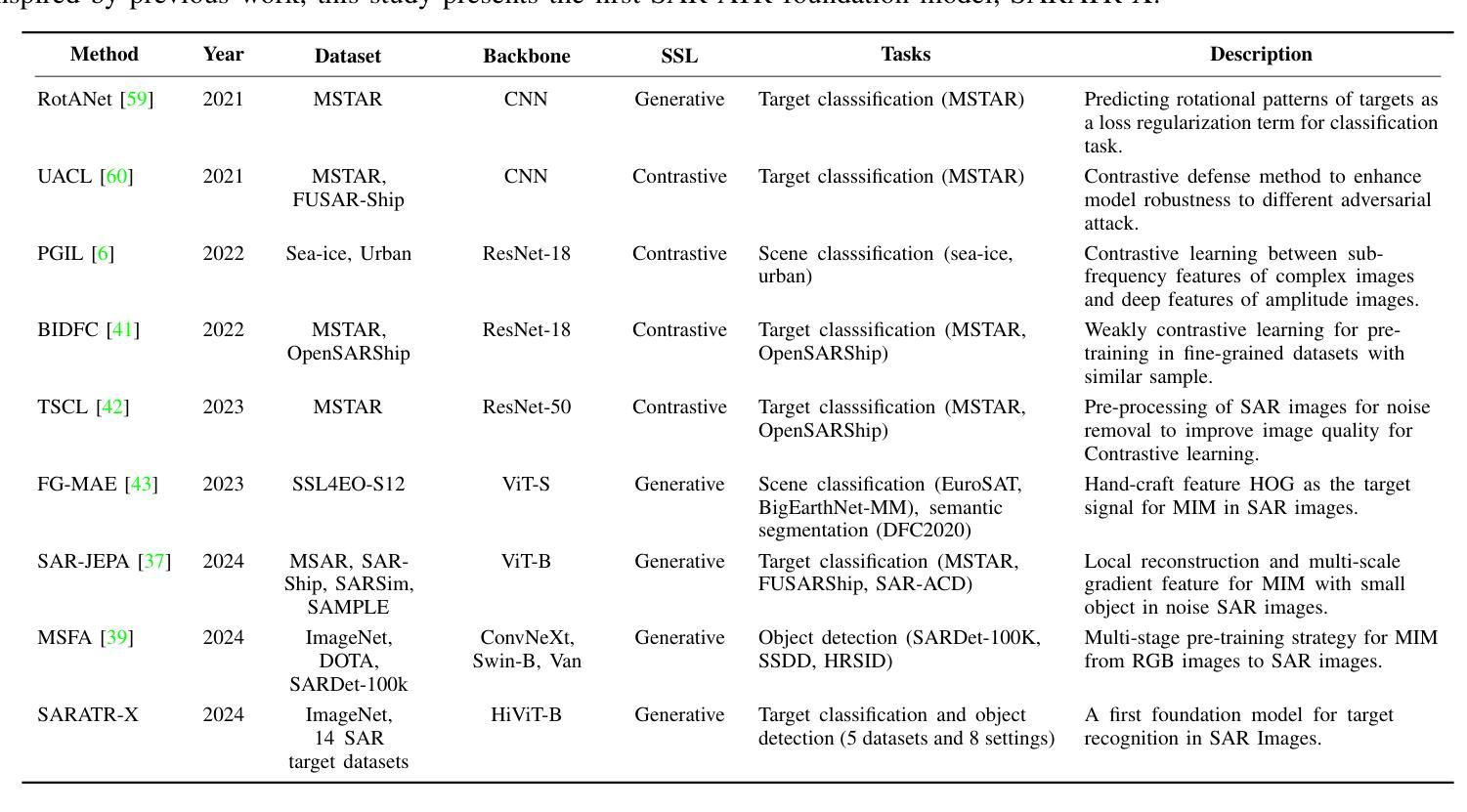
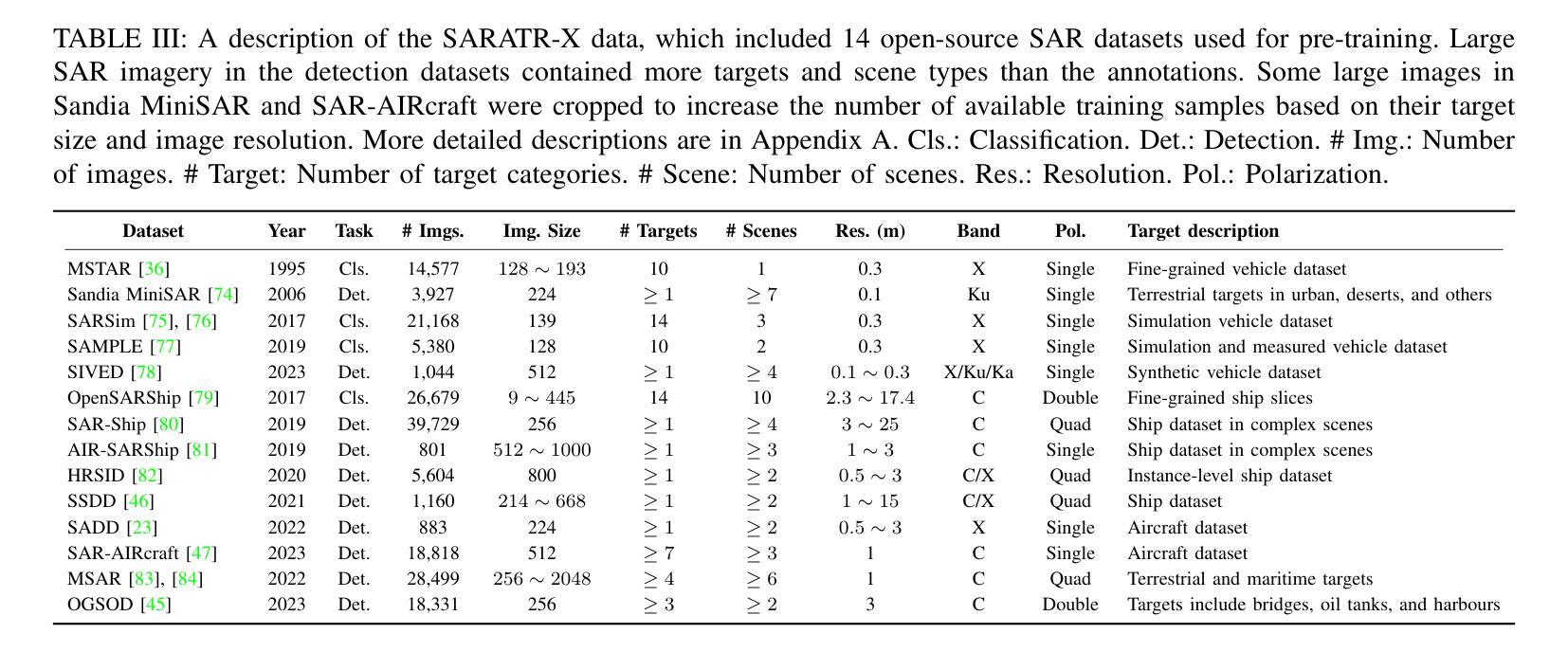
SARATR-X: Towards Building A Foundation Model for SAR Target Recognition
Authors:Weijie Li, Wei Yang, Yuenan Hou, Li Liu, Yongxiang Liu, Xiang Li
Despite the remarkable progress in synthetic aperture radar automatic target recognition (SAR ATR), recent efforts have concentrated on detecting and classifying a specific category, e.g., vehicles, ships, airplanes, or buildings. One of the fundamental limitations of the top-performing SAR ATR methods is that the learning paradigm is supervised, task-specific, limited-category, closed-world learning, which depends on massive amounts of accurately annotated samples that are expensively labeled by expert SAR analysts and have limited generalization capability and scalability. In this work, we make the first attempt towards building a foundation model for SAR ATR, termed SARATR-X. SARATR-X learns generalizable representations via self-supervised learning (SSL) and provides a cornerstone for label-efficient model adaptation to generic SAR target detection and classification tasks. Specifically, SARATR-X is trained on 0.18 M unlabelled SAR target samples, which are curated by combining contemporary benchmarks and constitute the largest publicly available dataset till now. Considering the characteristics of SAR images, a backbone tailored for SAR ATR is carefully designed, and a two-step SSL method endowed with multi-scale gradient features was applied to ensure the feature diversity and model scalability of SARATR-X. The capabilities of SARATR-X are evaluated on classification under few-shot and robustness settings and detection across various categories and scenes, and impressive performance is achieved, often competitive with or even superior to prior fully supervised, semi-supervised, or self-supervised algorithms. Our SARATR-X and the curated dataset are released at https://github.com/waterdisappear/SARATR-X to foster research into foundation models for SAR image interpretation.
尽管合成孔径雷达自动目标识别(SAR ATR)取得了显著的进步,但最近的努力主要集中在检测和分类特定类别,如车辆、船只、飞机或建筑物。高性能SAR ATR方法的基本局限之一是,其学习模式属于有监督的、针对特定任务的、有限类别的、封闭世界学习模式,这依赖于大量由专家SAR分析师准确标注的样本,其通用能力和可扩展性有限。在这项工作中,我们首次尝试构建SAR ATR的基础模型,称为SARATR-X。SARATR-X通过自监督学习(SSL)学习可推广的表示,并为标签有效的模型适应通用SAR目标检测和分类任务提供了基石。具体来说,SARATR-X是在0.18M无标签SAR目标样本上进行训练的,这些样本是通过结合当代基准测试集精心挑选的,构成了迄今为止最大的公开可用数据集。考虑到SAR图像的特点,我们仔细设计了针对SAR ATR的骨干网,并应用了具有多尺度梯度特征的两步SSL方法,以确保SARATR-X的特征多样性和模型可扩展性。SARATR-X在少镜头和稳健性设置下的分类能力,以及各类和场景中的检测能力得到了评估,其性能令人印象深刻,往往与之前的完全监督、半监督或自监督算法相当甚至更胜一筹。我们的SARATR-X和精选数据集已在https://github.com/waterdisappear/SARATR-X发布,以促进对SAR图像解释基础模型的研究。
论文及项目相关链接
PDF 20 pages, 9 figures
Summary
该文章介绍了合成孔径雷达自动目标识别(SAR ATR)的最新进展。针对当前SAR ATR方法面临的有监督学习、特定任务特定类别、封闭世界学习的局限性,提出了一种名为SARATR-X的基础模型。SARATR-X通过自监督学习(SSL)学习通用表示,为标签效率模型适应通用SAR目标检测和分类任务提供了基石。该模型在少量样本和鲁棒性设置下的分类以及各类别和场景的检测中表现出令人印象深刻的效果,且与先前的全监督、半监督或自监督算法相比具有竞争力或甚至更优越。SARATR-X和精选数据集已公开发布,以推动SAR图像解释的基础模型研究。
Key Takeaways
- SAR ATR领域虽有显著进展,但仍集中在特定类别的检测与分类,如车辆、船只、飞机或建筑。
- 当前顶尖SAR ATR方法基于大量精确标注样本的监督学习,存在成本高、泛化能力和可扩展性有限的问题。
- 提出了一种名为SARATR-X的基础模型,采用自监督学习(SSL)以实现更通用的表示学习。
- SARATR-X训练使用了迄今为止最大的公开可用数据集,包含0.18M未标记SAR目标样本。
- 针对SAR图像特性,设计了专门的backbone,并应用了两步SSL方法和多尺度梯度特征,确保SARATR-X的特征多样性和模型可扩展性。
- SARATR-X在少样本、鲁棒性分类和各类别场景检测方面表现出卓越性能,与现有算法相比具有竞争力。
点此查看论文截图