⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
BoK: Introducing Bag-of-Keywords Loss for Interpretable Dialogue Response Generation
Authors:Suvodip Dey, Maunendra Sankar Desarkar
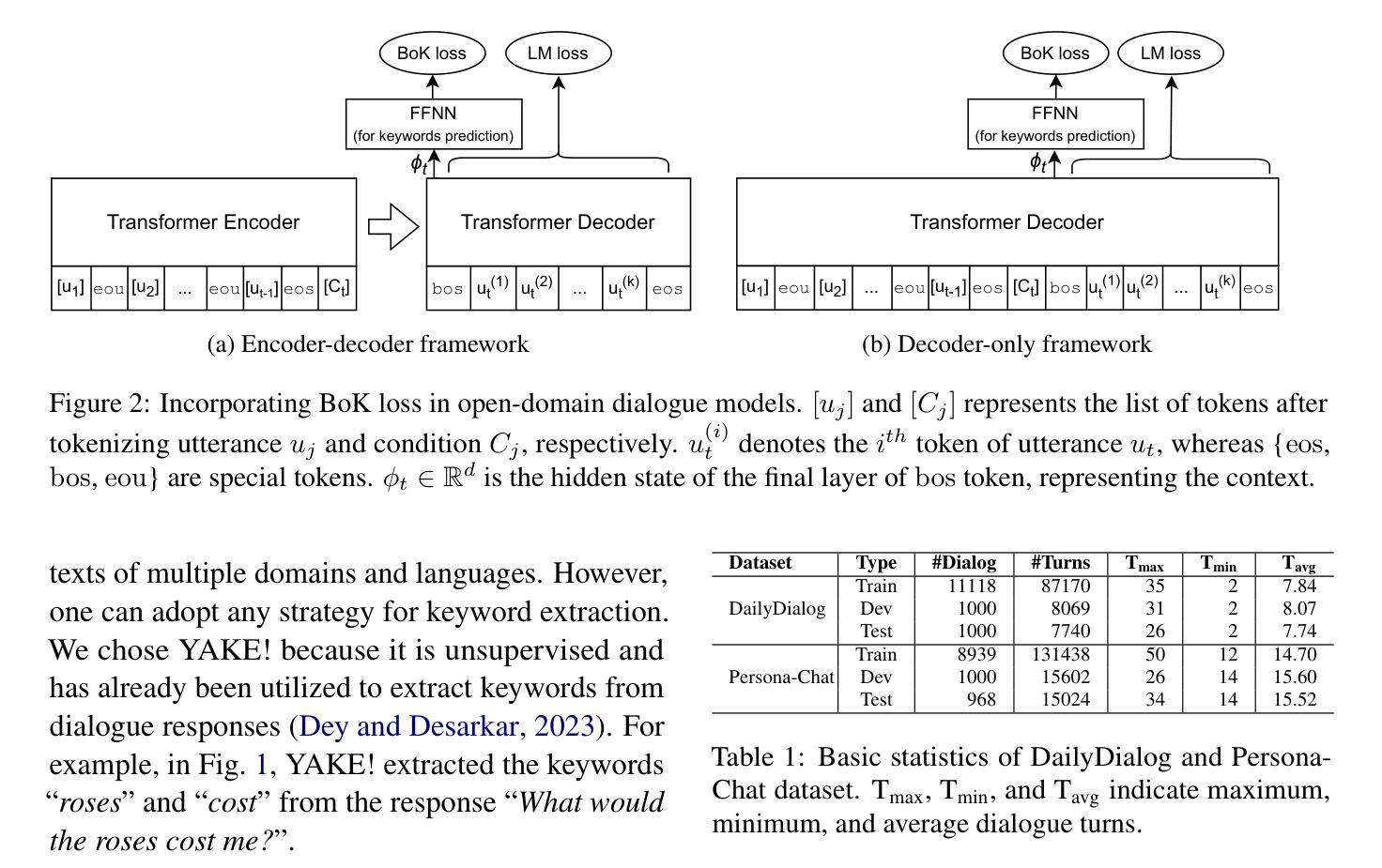
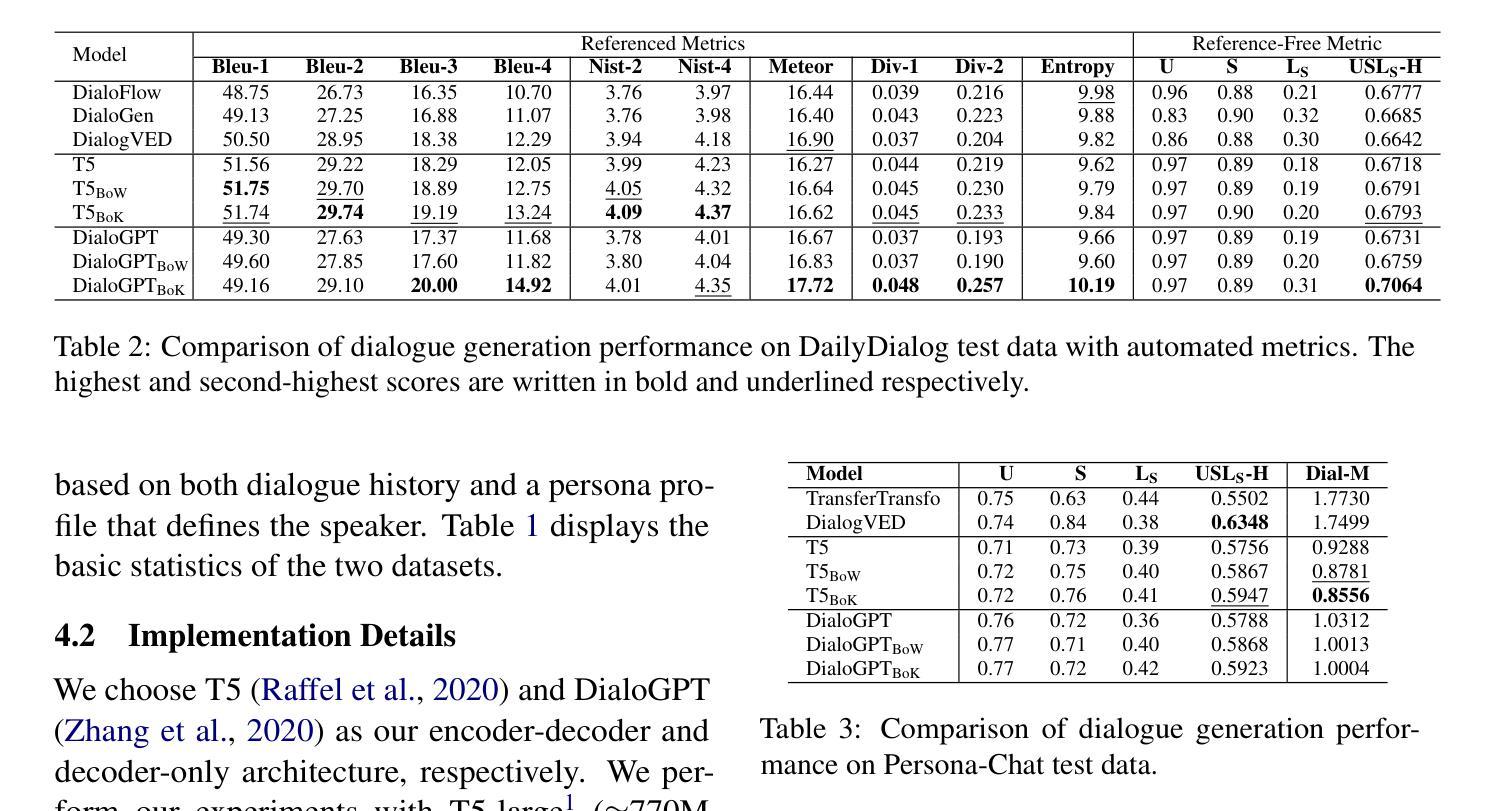
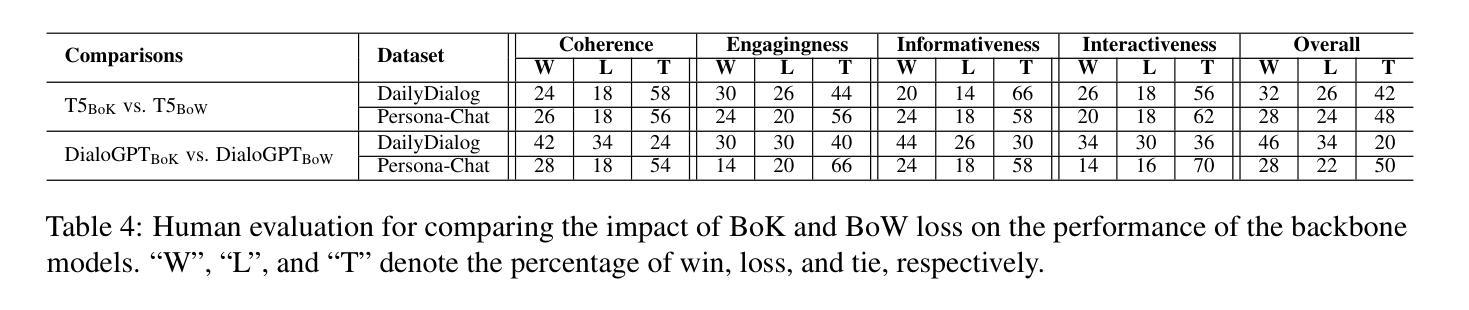
The standard language modeling (LM) loss by itself has been shown to be inadequate for effective dialogue modeling. As a result, various training approaches, such as auxiliary loss functions and leveraging human feedback, are being adopted to enrich open-domain dialogue systems. One such auxiliary loss function is Bag-of-Words (BoW) loss, defined as the cross-entropy loss for predicting all the words/tokens of the next utterance. In this work, we propose a novel auxiliary loss named Bag-of-Keywords (BoK) loss to capture the central thought of the response through keyword prediction and leverage it to enhance the generation of meaningful and interpretable responses in open-domain dialogue systems. BoK loss upgrades the BoW loss by predicting only the keywords or critical words/tokens of the next utterance, intending to estimate the core idea rather than the entire response. We incorporate BoK loss in both encoder-decoder (T5) and decoder-only (DialoGPT) architecture and train the models to minimize the weighted sum of BoK and LM (BoK-LM) loss. We perform our experiments on two popular open-domain dialogue datasets, DailyDialog and Persona-Chat. We show that the inclusion of BoK loss improves the dialogue generation of backbone models while also enabling post-hoc interpretability. We also study the effectiveness of BoK-LM loss as a reference-free metric and observe comparable performance to the state-of-the-art metrics on various dialogue evaluation datasets.
标准语言建模(LM)损失本身已被证明对于有效的对话建模是不足的。因此,正在采用各种训练方法来丰富开放域对话系统,如辅助损失函数和利用人类反馈。其中一种辅助损失函数是词袋(BoW)损失,定义为预测下一个语论的所有单词/代词的交叉熵损失。在这项工作中,我们提出了一种新的辅助损失,称为关键词袋(BoK)损失,通过关键词预测来捕捉答复的中心思想,并以此来增强开放域对话系统中生成有意义和可解释的回答。BoK损失通过预测下一个语论的关键词或关键单词/令牌来升级BoW损失,意图估计核心思想而不是整个答复。我们将BoK损失纳入编码器解码器(T5)和仅解码器(DialoGPT)架构中,并训练模型以最小化BoK和LM(BoK-LM)损失的加权和。我们在两个流行的开放域对话数据集DailyDialog和Persona-Chat上进行了实验。我们表明,包含BoK损失改进了主干模型的对话生成,同时实现了事后可解释性。我们还研究了BoK-LM损失作为无参考度量的有效性,并在各种对话评估数据集上观察到与最新指标相当的性能。
论文及项目相关链接
PDF Accepted at SIGDIAL 2024
Summary
针对标准语言模型(LM)损失在对话建模中的不足,本文提出一种新型的辅助损失函数——关键词袋(BoK)损失。该函数通过预测下一个回复中的关键词来捕捉回应的核心思想,旨在提高开放领域对话系统中生成的有意义和可解释性回复的质量。将BoK损失与编码解码器(T5)和仅解码器(DialoGPT)架构相结合,训练模型以最小化BoK与LM(BoK-LM)损失的加权和。实验证明,引入BoK损失可改善基础模型的对话生成能力,同时提供事后解释性。此外,BoK-LM损失作为一种无参考指标也表现出有效性和竞争力。
Key Takeaways
- 标准语言建模(LM)损失在对话建模中显示不足,需要更丰富的训练方法。
- 提出了关键词袋(BoK)损失作为新的辅助损失函数,旨在通过预测关键词捕捉回应的核心思想。
- BoK损失在开放领域对话系统中能提高生成回复的质量和可解释性。
- BoK损失被成功应用于编码解码器和仅解码器架构中。
- 在两个流行的开放领域对话数据集上进行实验验证,证明了BoK损失的有效性。
点此查看论文截图

Dialogue Benchmark Generation from Knowledge Graphs with Cost-Effective Retrieval-Augmented LLMs
Authors:Reham Omar, Omij Mangukiya, Essam Mansour
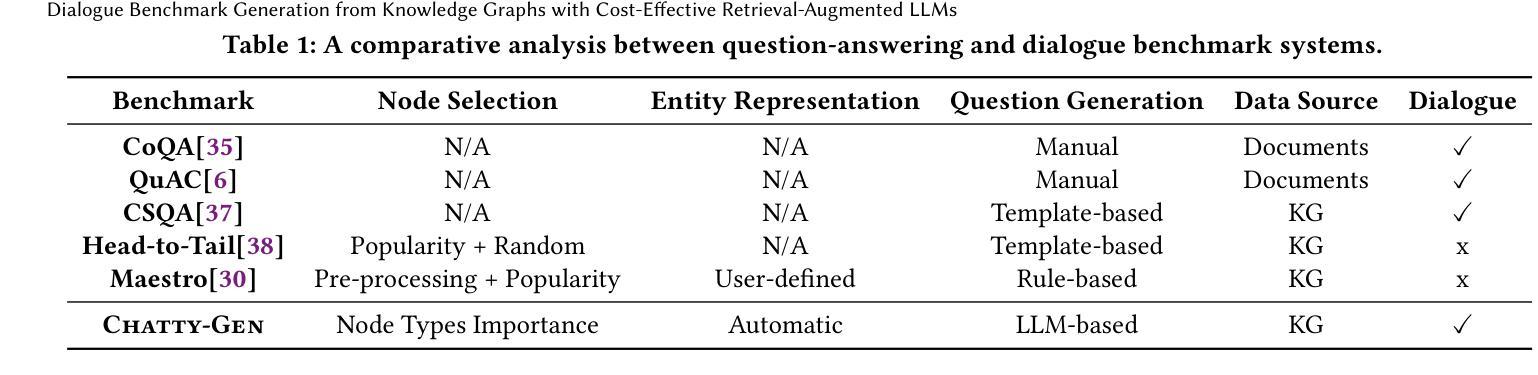
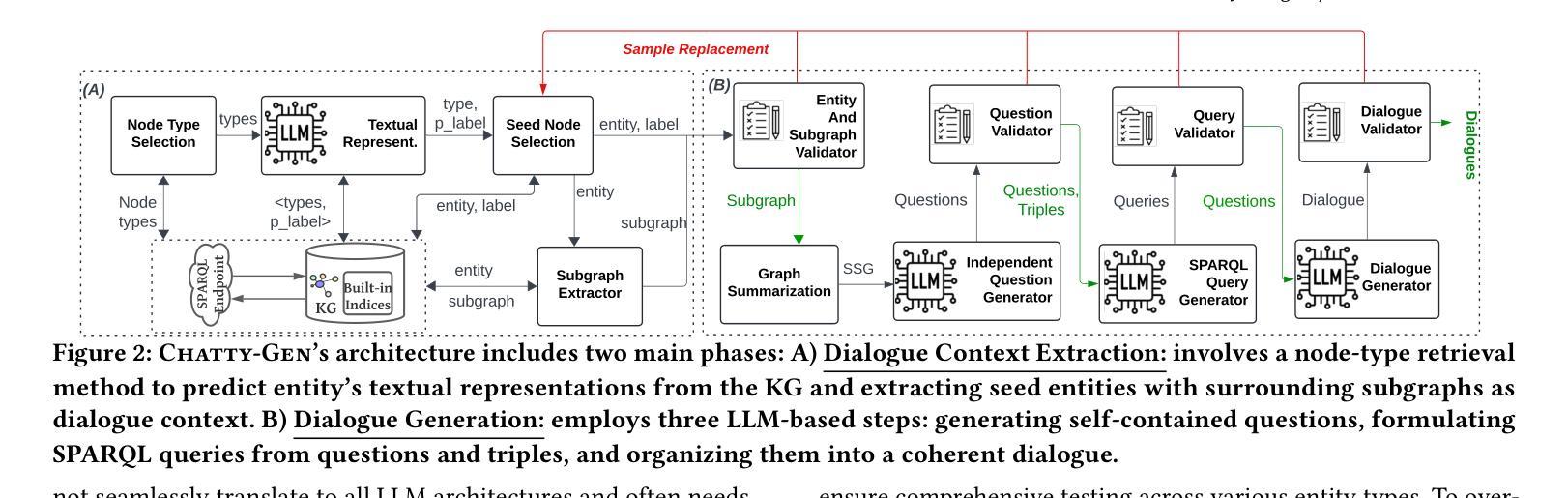
Dialogue benchmarks are crucial in training and evaluating chatbots engaging in domain-specific conversations. Knowledge graphs (KGs) represent semantically rich and well-organized data spanning various domains, such as DBLP, DBpedia, and YAGO. Traditionally, dialogue benchmarks have been manually created from documents, neglecting the potential of KGs in automating this process. Some question-answering benchmarks are automatically generated using extensive preprocessing from KGs, but they do not support dialogue generation. This paper introduces Chatty-Gen, a novel multi-stage retrieval-augmented generation platform for automatically generating high-quality dialogue benchmarks tailored to a specific domain using a KG. Chatty-Gen decomposes the generation process into manageable stages and uses assertion rules for automatic validation between stages. Our approach enables control over intermediate results to prevent time-consuming restarts due to hallucinations. It also reduces reliance on costly and more powerful commercial LLMs. Chatty-Gen eliminates upfront processing of the entire KG using efficient query-based retrieval to find representative subgraphs based on the dialogue context. Our experiments with several real and large KGs demonstrate that Chatty-Gen significantly outperforms state-of-the-art systems and ensures consistent model and system performance across multiple LLMs of diverse capabilities, such as GPT-4o, Gemini 1.5, Llama 3, and Mistral.
对话基准测试对于训练和评价参与特定领域对话的聊天机器人至关重要。知识图谱(KGs)代表了跨越多个领域的丰富语义和有序组织的数据,如DBLP、DBpedia和YAGO。传统上,对话基准测试是通过文档手动创建的,忽视了知识图谱在自动化这一过程中的潜力。虽然一些问答基准测试是使用知识图谱的广泛预处理自动生成的,但它们不支持对话生成。本文介绍了Chatty-Gen,这是一种新型的多阶段检索增强生成平台,利用知识图谱自动生成针对特定领域的高质量对话基准测试。Chatty-Gen将生成过程分解为可管理阶段,并利用断言规则进行阶段间的自动验证。我们的方法能够对中间结果进行控制,以防止因幻觉而耗时的重新启动。它还减少了对于昂贵且功能更强大的商业大型语言模型(LLMs)的依赖。Chatty-Gen通过高效的基于查询的检索来消除对整个知识图谱的前期处理,根据对话上下文找到有代表性的子图。我们在多个真实且大型知识图谱上的实验表明,Chatty-Gen显著优于现有系统,并确保了跨不同能力和类型的大型语言模型的模型和系统性能的一致性,如GPT-4o、Gemini 1.5、Llama 3和Mistral。
论文及项目相关链接
PDF The paper is publsihed in SIGMOD 2025
Summary
基于知识图谱(KGs)自动创建对话基准测试的重要性及其挑战。本文介绍了一种新型的多阶段检索增强生成平台Chatty-Gen,该平台能够利用KGs针对特定领域自动生成高质量的对话基准测试。Chatty-Gen通过分解生成过程、使用断言规则进行自动验证以及采用高效查询检索策略,提高了测试生成的效率和质量。实验证明,Chatty-Gen显著优于现有系统,并且能够在不同能力的LLMs之间保持一致的模型和系统性能。
Key Takeaways
- 对话基准在训练和评价聊天机器人进行特定领域对话时至关重要。
- 知识图谱(KGs)代表语义丰富、组织良好的跨域数据,但在对话基准测试中未被充分利用。
- Chatty-Gen是一种新型的多阶段检索增强生成平台,能利用KGs自动创建针对特定领域的对话基准。
- Chatty-Gen通过分解生成过程、使用断言规则验证和采用高效查询检索策略,提高了效率和性能。
- Chatty-Gen减少了对话生成中的幻觉错误,避免了耗时重启。
- Chatty-Gen降低了对昂贵且强大的商业大型语言模型(LLMs)的依赖。
点此查看论文截图