⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
On Ambisonic Source Separation with Spatially Informed Non-negative Tensor Factorization
Authors:Mateusz Guzik, Konrad Kowalczyk
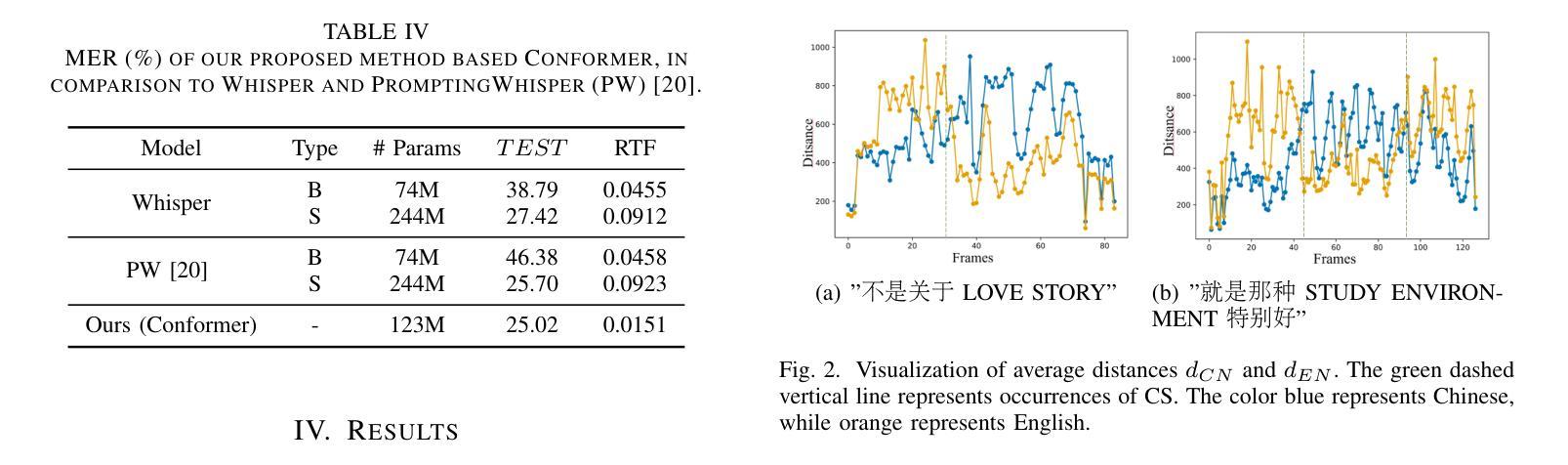
This article presents a Non-negative Tensor Factorization based method for sound source separation from Ambisonic microphone signals. The proposed method enables the use of prior knowledge about the Directions-of-Arrival (DOAs) of the sources, incorporated through a constraint on the Spatial Covariance Matrix (SCM) within a Maximum a Posteriori (MAP) framework. Specifically, this article presents a detailed derivation of four algorithms that are based on two types of cost functions, namely the squared Euclidean distance and the Itakura-Saito divergence, which are then combined with two prior probability distributions on the SCM, that is the Wishart and the Inverse Wishart. The experimental evaluation of the baseline Maximum Likelihood (ML) and the proposed MAP methods is primarily based on first-order Ambisonic recordings, using four different source signal datasets, three with musical pieces and one containing speech utterances. We consider under-determined, determined, as well as over-determined scenarios by separating two, four and six sound sources, respectively. Furthermore, we evaluate the proposed algorithms for different spherical harmonic orders and at different reverberation time levels, as well as in non-ideal prior knowledge conditions, for increasingly more corrupted DOAs. Overall, in comparison with beamforming and a state-of-the-art separation technique, as well as the baseline ML methods, the proposed MAP approach offers superior separation performance in a variety of scenarios, as shown by the analysis of the experimental evaluation results, in terms of the standard objective separation measures, such as the SDR, ISR, SIR and SAR.
本文提出了一种基于非负张量分解的方法,用于从Ambisonic麦克风信号中分离声源。该方法可以利用关于源到达方向(DOA)的先验知识,通过最大后验(MAP)框架中的空间协方差矩阵(SCM)约束将其结合。具体来说,本文详细推导了四种基于两种成本函数的算法,即平方欧几里得距离和Itakura-Saito发散,然后与SCM上的两个先验概率分布即Wishart和Inverse Wishart相结合。基线最大似然(ML)和所提出的MAP方法的实验评估主要基于第一阶Ambisonic录音,使用四个不同的源信号数据集,其中三个是音乐作品,一个是包含语音语句的。我们通过分离两个、四个和六个声源,分别考虑欠定、确定以及过度确定的情况。此外,我们还对不同的球面谐波阶数和不同的混响时间水平以及非理想的先验知识条件下,越来越受干扰的DOA进行了算法评估。总体而言,与波束形成和最新的分离技术以及基线ML方法相比,根据实验评估结果的分析,如在标准客观分离措施(如SDR、ISR、SIR和SAR)方面,所提出的MAP方法在各种场景下均表现出优越的分离性能。
论文及项目相关链接
摘要
本文介绍了一种基于非负张量分解的方法,用于从Ambisonic麦克风信号中分离声源。该方法能够利用有关声源到达方向(DOA)的先验知识,通过最大后验(MAP)框架中的空间协方差矩阵(SCM)约束将其融入。文章详细推导了四种算法,这些算法基于两种成本函数,即欧几里得距离的平方和Itakura-Saito散度,并结合SCM上的两个先验概率分布,即Wishart和Inverse Wishart。实验评估了基线最大似然(ML)和提出的MAP方法,主要基于一阶Ambisonic录音,使用四个不同的源信号数据集,其中三个是音乐片段,一个包含语音片段。我们考虑了欠定、确定以及过度定的情况,分别分离两个、四个和六个声源。此外,我们还对不同球面谐波阶数和不同混响时间水平以及非理想先验知识条件下的算法进行了评估,针对越来越受腐蚀的DOA。总体而言,与波束形成法和一种最新的分离技术相比,以及基线ML方法相比,所提出的MAP方法在各种场景下表现出优越的分离性能。
关键见解
- 文章提出了一种基于非负张量分解的方法,用于从Ambisonic麦克风信号中分离声源。
- 该方法结合了声源的到达方向(DOA)的先验知识,通过最大后验(MAP)框架中的空间协方差矩阵(SCM)约束来实现。
- 文章详细推导了四种算法,这些算法基于两种不同的成本函数和两种先验概率分布。
- 实验评估使用了多种源信号数据集,包括音乐片段和语音片段,并考虑了不同数量的声源分离情况。
- 算法在不同条件下进行了评估,包括不同的球面谐波阶数、混响时间水平以及非理想的先验知识条件。
- 与其他方法和基线ML方法相比,提出的MAP方法在各种场景下表现出更好的声源分离性能。
点此查看论文截图

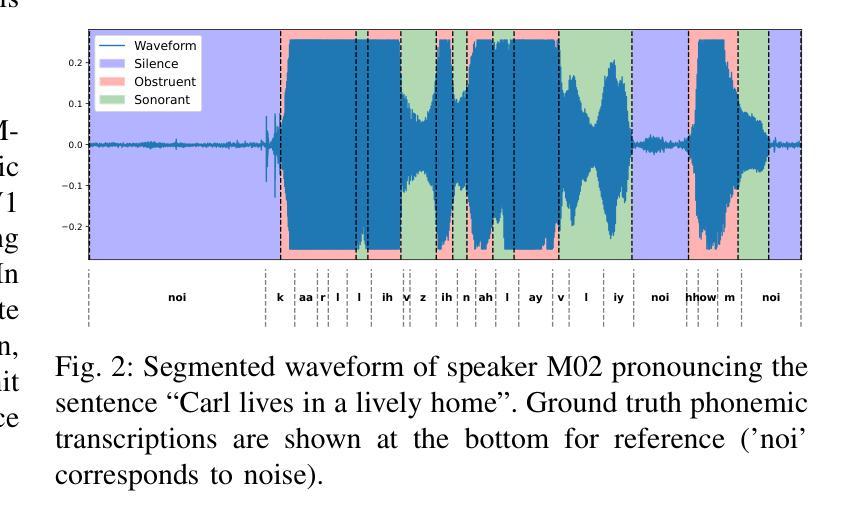
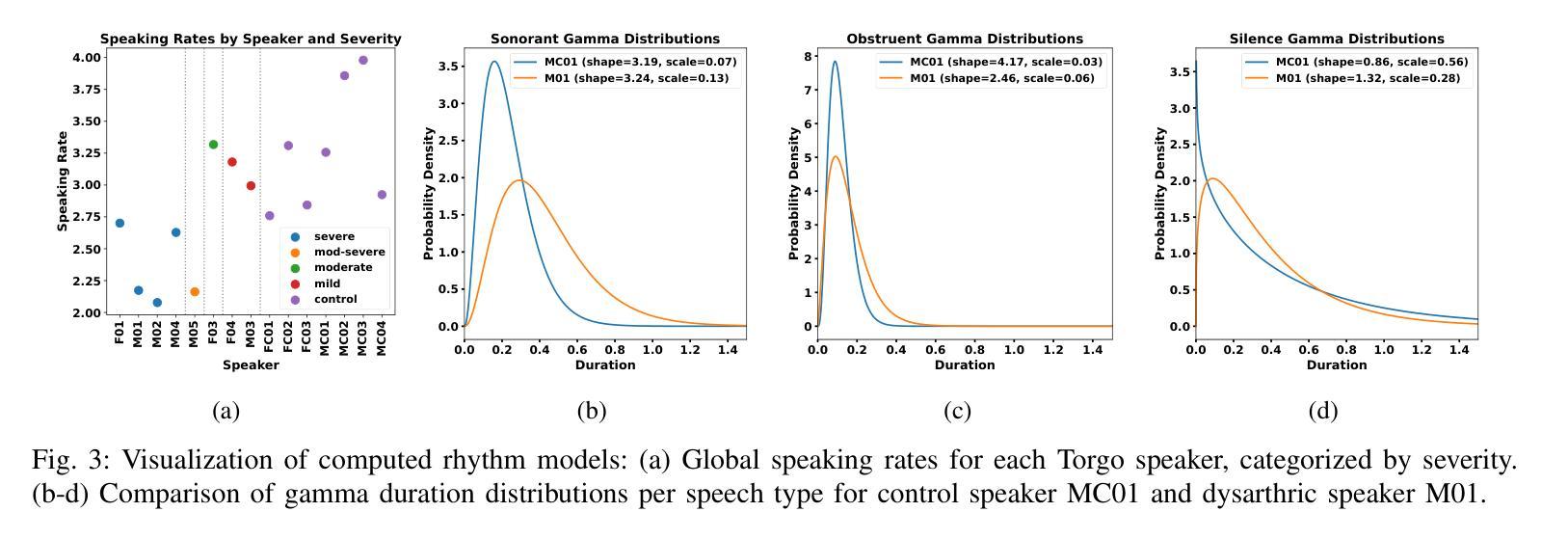
Unsupervised Rhythm and Voice Conversion of Dysarthric to Healthy Speech for ASR
Authors:Karl El Hajal, Enno Hermann, Ajinkya Kulkarni, Mathew Magimai. -Doss
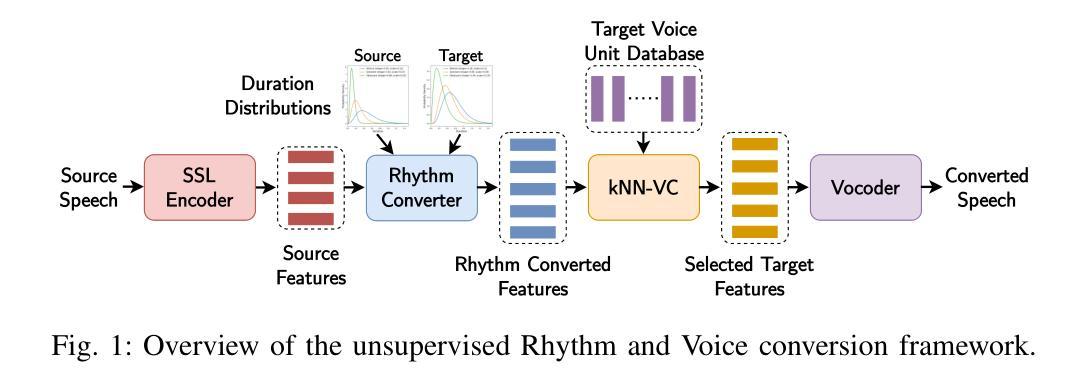
Automatic speech recognition (ASR) systems are well known to perform poorly on dysarthric speech. Previous works have addressed this by speaking rate modification to reduce the mismatch with typical speech. Unfortunately, these approaches rely on transcribed speech data to estimate speaking rates and phoneme durations, which might not be available for unseen speakers. Therefore, we combine unsupervised rhythm and voice conversion methods based on self-supervised speech representations to map dysarthric to typical speech. We evaluate the outputs with a large ASR model pre-trained on healthy speech without further fine-tuning and find that the proposed rhythm conversion especially improves performance for speakers of the Torgo corpus with more severe cases of dysarthria. Code and audio samples are available at https://idiap.github.io/RnV .
自动语音识别(ASR)系统在构音不全的语音上的表现普遍不佳。以前的研究通过调整语速来减少与正常语音的不匹配来解决这个问题。然而,这些方法依赖于转录语音数据来估计语速和音素持续时间,对于未见过的说话者可能无法获得这些数据。因此,我们结合了基于自监督语音表示的无人监督节奏和声音转换方法,将构音不全的语音映射到正常语音。我们使用在健康语音上预训练的大的ASR模型对输出进行评估,无需进一步微调。我们发现,所提出的节奏转换特别提高了Torgo语料库中构音不全更为严重的说话者的性能。代码和音频样本可在https://idiap.github.io/RnV上找到。
论文及项目相关链接
PDF Accepted at ICASSP 2025 Satellite Workshop: Workshop on Speech Pathology Analysis and DEtection (SPADE)
Summary:针对患有语言障碍(如口齿不清)的人自动语音识别(ASR)系统表现不佳的问题,研究者提出了一种结合无监督节奏和语音转换方法的方法。该方法基于自我监督的语音表征,可将口齿不清的语音映射为正常语音。在不进行微调的情况下,使用大型ASR模型对输出进行评估发现,对于患有严重语言障碍的Torgo语料库中的说话者,所提出的节奏转换方法尤其能提高性能。相关代码和音频样本可在https://idiap.github.io/RnV找到。
Key Takeaways:
- ASR系统在处理口齿不清的语音时表现不佳。
- 之前的研究通过调整语速来解决这一问题,但这种方法依赖于转录语音数据来估计语速和音素持续时间,这可能不适用于未见过的说话者。
- 研究者提出了一种结合无监督节奏和语音转换方法的新方法,基于自我监督的语音表征,将口齿不清的语音转换为正常语音。
- 该方法在不进行额外微调的情况下,使用大型ASR模型进行评估。
- 对于患有严重语言障碍的说话者,尤其是Torgo语料库中的说话者,新方法的性能显著提高。
- 相关的代码和音频样本可以在特定网站找到。
点此查看论文截图


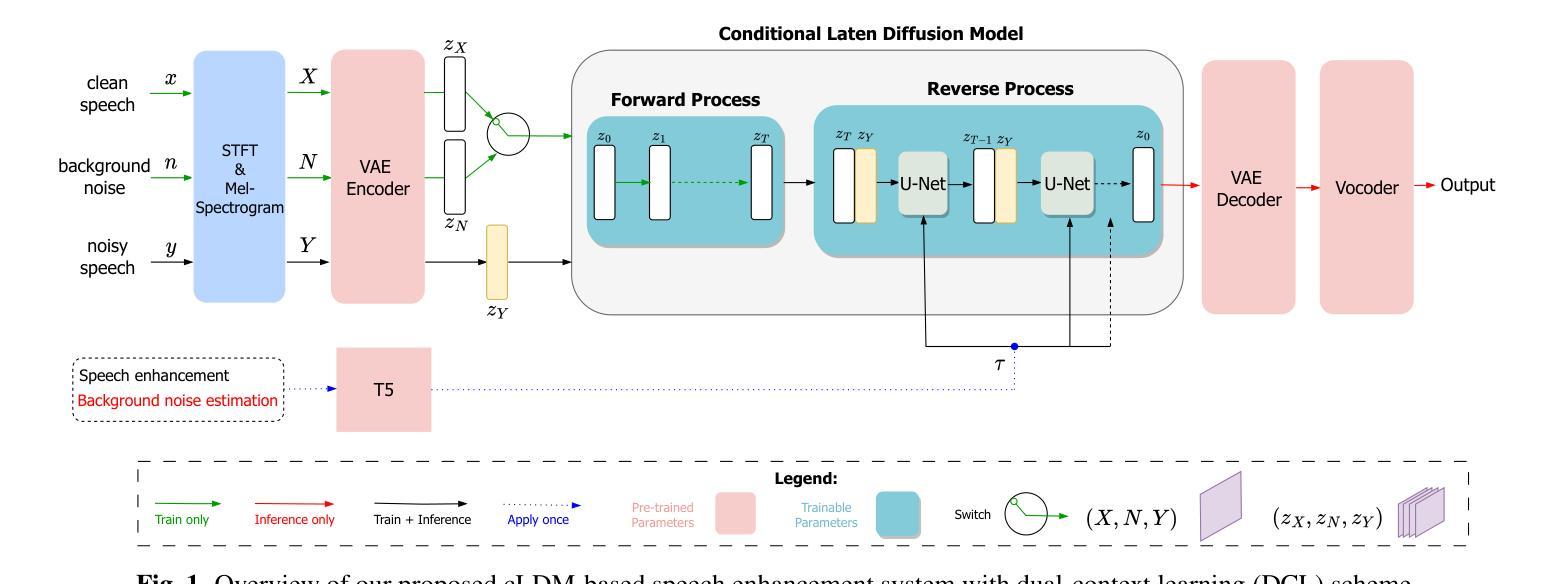
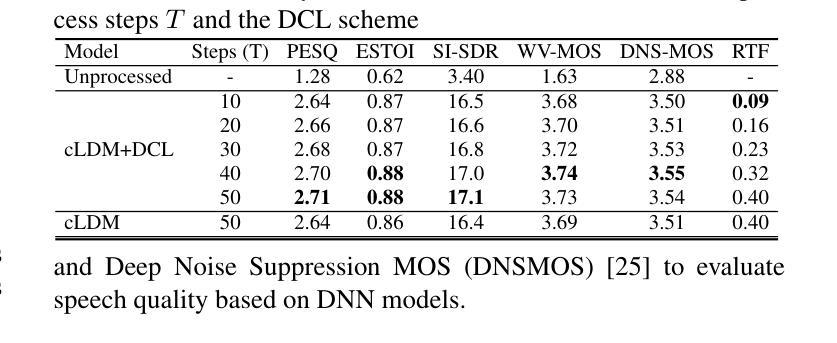
Conditional Latent Diffusion-Based Speech Enhancement Via Dual Context Learning
Authors:Shengkui Zhao, Zexu Pan, Kun Zhou, Yukun Ma, Chong Zhang, Bin Ma
Recently, the application of diffusion probabilistic models has advanced speech enhancement through generative approaches. However, existing diffusion-based methods have focused on the generation process in high-dimensional waveform or spectral domains, leading to increased generation complexity and slower inference speeds. Additionally, these methods have primarily modelled clean speech distributions, with limited exploration of noise distributions, thereby constraining the discriminative capability of diffusion models for speech enhancement. To address these issues, we propose a novel approach that integrates a conditional latent diffusion model (cLDM) with dual-context learning (DCL). Our method utilizes a variational autoencoder (VAE) to compress mel-spectrograms into a low-dimensional latent space. We then apply cLDM to transform the latent representations of both clean speech and background noise into Gaussian noise by the DCL process, and a parameterized model is trained to reverse this process, conditioned on noisy latent representations and text embeddings. By operating in a lower-dimensional space, the latent representations reduce the complexity of the generation process, while the DCL process enhances the model’s ability to handle diverse and unseen noise environments. Our experiments demonstrate the strong performance of the proposed approach compared to existing diffusion-based methods, even with fewer iterative steps, and highlight the superior generalization capability of our models to out-of-domain noise datasets (https://github.com/modelscope/ClearerVoice-Studio).
近期,扩散概率模型在生成方法方面推动了语音增强的应用发展。然而,现有的基于扩散的方法主要关注高维波形或频谱域的生成过程,导致生成复杂度增加和推理速度较慢。此外,这些方法主要对干净语音分布进行建模,对噪声分布的探索有限,从而限制了扩散模型在语音增强方面的判别能力。为了解决这些问题,我们提出了一种将条件潜在扩散模型(cLDM)与双重上下文学习(DCL)相结合的新方法。我们的方法利用变分自编码器(VAE)将梅尔频谱图压缩到低维潜在空间。然后,我们应用cLDM通过DCL过程将干净语音和背景噪声的潜在表示转换为高斯噪声,并训练参数化模型以在给定带有噪声的潜在表示和文本嵌入的情况下反转这一过程。通过在低维空间中进行操作,潜在表示降低了生成过程的复杂性,而DCL过程提高了模型处理多样化和未见过的噪声环境的能力。我们的实验表明,与现有的基于扩散的方法相比,所提出的方法表现出强大的性能,即使在较少的迭代步骤中也是如此,并突出了我们模型对域外噪声数据集的出色泛化能力(https://github.com/modelscope/ClearerVoice-Studio)。
论文及项目相关链接
PDF 5 pages, 1 figure, accepted by ICASSP 2025
Summary
本文提出一种结合条件潜在扩散模型(cLDM)和双语境学习(DCL)的语音增强新方法。该方法利用变分自编码器(VAE)将梅尔频谱图压缩到低维潜在空间,应用cLDM将干净语音和背景噪声的潜在表示转化为高斯噪声,再通过训练反向过程模型恢复语音,以处理带有噪声的潜在表示和文本嵌入。该方法在低维空间操作,简化生成过程,提高模型处理不同和未见噪声环境的能力。
Key Takeaways
- 扩散概率模型在语音增强中的生成方法得到了新的应用。
- 当前扩散方法主要处理高维波形或谱域生成过程,导致生成复杂度增加和推理速度较慢。
- 现有方法主要建模干净语音分布,对噪声分布探索有限,限制了扩散模型在语音增强中的判别能力。
- 提出了一种新的结合条件潜在扩散模型(cLDM)和双语境学习(DCL)的方法。
- 利用变分自编码器(VAE)将梅尔频谱图压缩到低维潜在空间以降低生成复杂度。
- cLDM用于将干净语音和背景噪声的潜在表示转化为高斯噪声。
点此查看论文截图


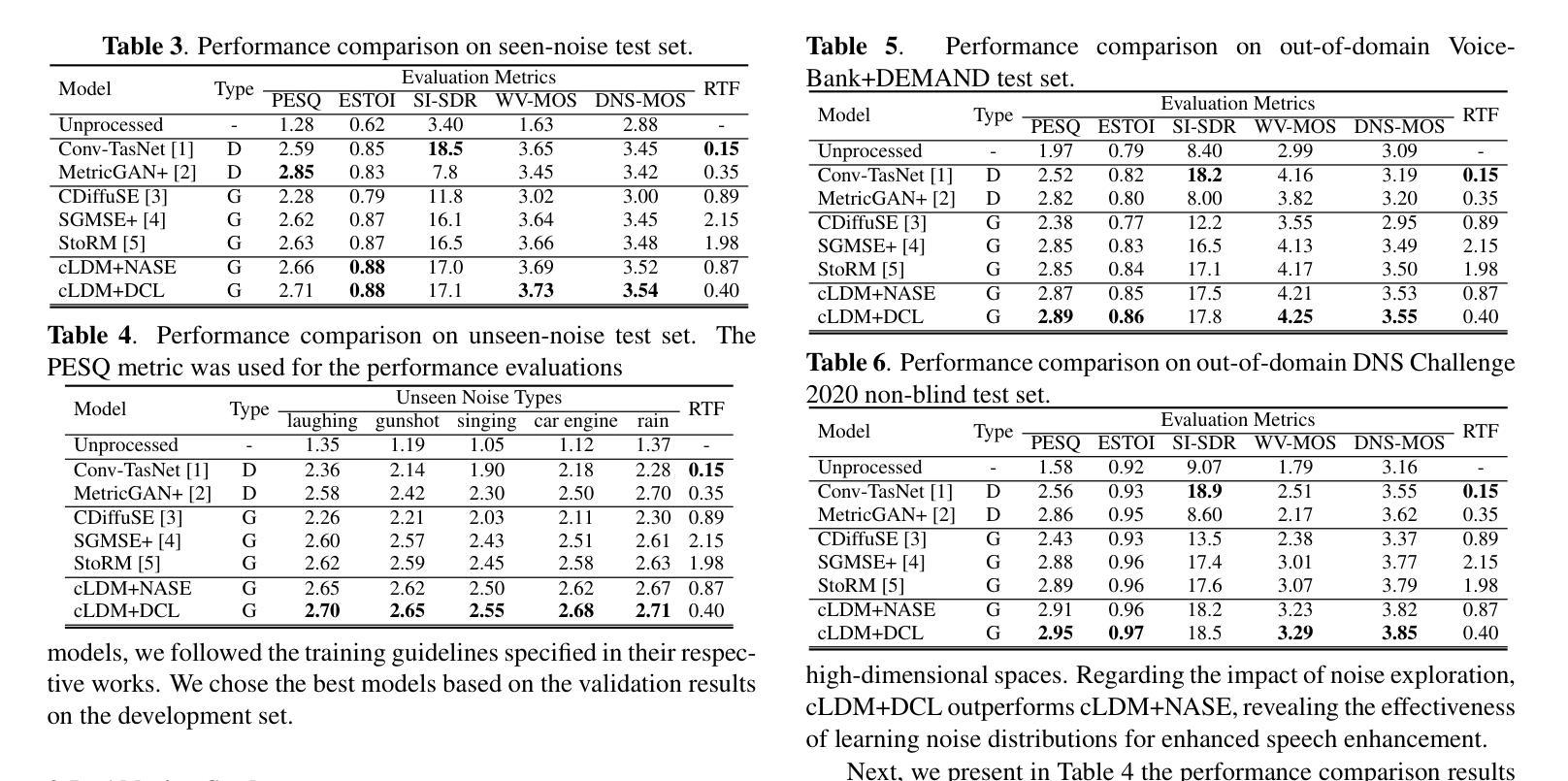
HiFi-SR: A Unified Generative Transformer-Convolutional Adversarial Network for High-Fidelity Speech Super-Resolution
Authors:Shengkui Zhao, Kun Zhou, Zexu Pan, Yukun Ma, Chong Zhang, Bin Ma
The application of generative adversarial networks (GANs) has recently advanced speech super-resolution (SR) based on intermediate representations like mel-spectrograms. However, existing SR methods that typically rely on independently trained and concatenated networks may lead to inconsistent representations and poor speech quality, especially in out-of-domain scenarios. In this work, we propose HiFi-SR, a unified network that leverages end-to-end adversarial training to achieve high-fidelity speech super-resolution. Our model features a unified transformer-convolutional generator designed to seamlessly handle both the prediction of latent representations and their conversion into time-domain waveforms. The transformer network serves as a powerful encoder, converting low-resolution mel-spectrograms into latent space representations, while the convolutional network upscales these representations into high-resolution waveforms. To enhance high-frequency fidelity, we incorporate a multi-band, multi-scale time-frequency discriminator, along with a multi-scale mel-reconstruction loss in the adversarial training process. HiFi-SR is versatile, capable of upscaling any input speech signal between 4 kHz and 32 kHz to a 48 kHz sampling rate. Experimental results demonstrate that HiFi-SR significantly outperforms existing speech SR methods across both objective metrics and ABX preference tests, for both in-domain and out-of-domain scenarios (https://github.com/modelscope/ClearerVoice-Studio).
近期,生成对抗网络(GANs)的应用已基于如梅尔频谱图等中间表示推动了语音超分辨率(SR)的发展。然而,现有的SR方法通常依赖于独立训练并连接的网络,这可能导致表示不一致和语音质量差,特别是在域外场景中。在这项工作中,我们提出了HiFi-SR,这是一个利用端到端对抗训练实现高保真语音超分辨率的统一网络。我们的模型特点是一个统一的transformer-卷积生成器,旨在无缝处理潜在表示的预测及其转换为时间域波形。Transformer网络作为一个强大的编码器,将低分辨率梅尔频谱图转换为潜在空间表示,而卷积网络将这些表示放大为高分辨率波形。为了提高高频保真度,我们在对抗训练过程中融入了多频带、多尺度的时间-频率鉴别器,以及多尺度梅尔重建损失。HiFi-SR通用性很强,能够将4kHz至32kHz之间的任何输入语音信号放大到48kHz的采样率。实验结果表明,无论是在域内还是域外场景中,HiFi-SR在客观指标和ABX偏好测试上均显著优于现有语音SR方法。(https://github.com/modelscope/ClearerVoice-Studio)
论文及项目相关链接
PDF 5 pages, 5 figures, accepted by ICASSP 2025
Summary
本文提出一种基于生成对抗网络(GANs)的高保真语音超分辨率技术(HiFi-SR)。HiFi-SR采用端到端的对抗训练,实现高保真语音超分辨率。模型采用统一的全卷积生成器,处理潜在表示的预测及其转换为时间域波形。通过强大的转换器网络将低分辨率梅尔频谱图转换为潜在空间表示,而卷积网络则将这些表示扩展到高分辨率波形。同时引入多频带、多尺度的时间频率判别器和多尺度梅尔重建损失,以提高高频保真度。HiFi-SR具有通用性,能将输入语音信号的采样率从任意4kHz至32kHz提升到48kHz。实验结果显示,HiFi-SR在客观指标和ABX偏好测试中均显著优于现有语音超分辨率方法,适用于不同领域和跨领域场景。
Key Takeaways
- 提出了一种新的基于生成对抗网络(GANs)的语音超分辨率技术HiFi-SR。
- HiFi-SR利用端到端的对抗训练来实现高保真语音超分辨率。
- 模型包含统一的全卷积生成器,用于处理潜在表示的预测和转换为时间域波形。
- 转换器网络将低分辨率梅尔频谱图转换为潜在空间表示。
- 多频带、多尺度的时间频率判别器和多尺度梅尔重建损失被用于提高高频保真度。
- HiFi-SR具有通用性,可将输入语音信号的采样率提升到更高的标准(如从任意范围内的低频到高频)。
点此查看论文截图


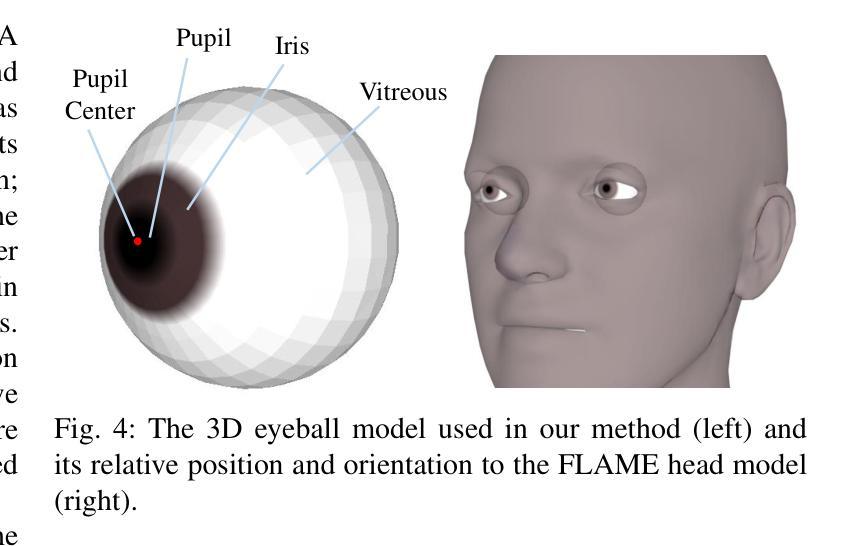
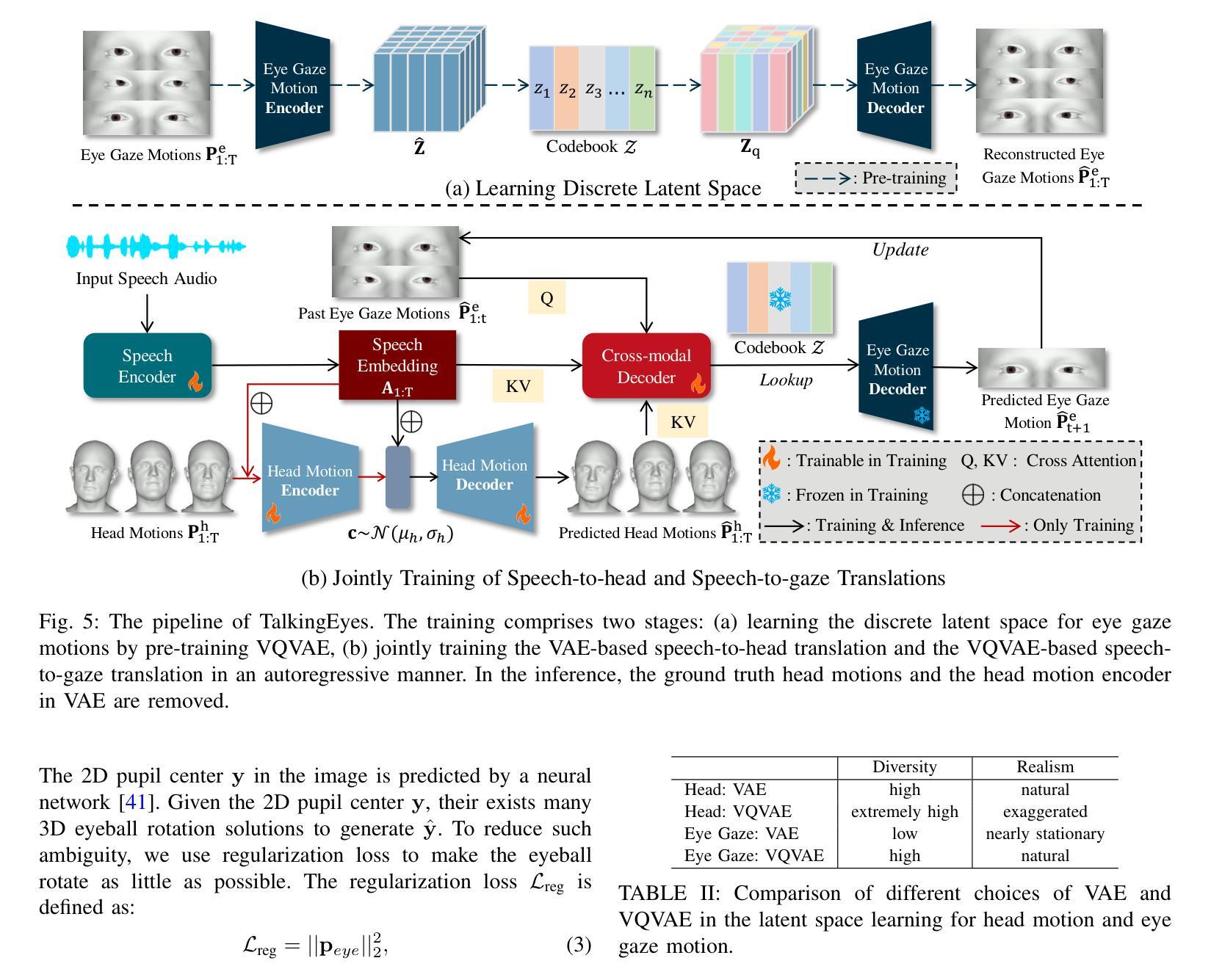
TalkingEyes: Pluralistic Speech-Driven 3D Eye Gaze Animation
Authors:Yixiang Zhuang, Chunshan Ma, Yao Cheng, Xuan Cheng, Jing Liao, Juncong Lin
Although significant progress has been made in the field of speech-driven 3D facial animation recently, the speech-driven animation of an indispensable facial component, eye gaze, has been overlooked by recent research. This is primarily due to the weak correlation between speech and eye gaze, as well as the scarcity of audio-gaze data, making it very challenging to generate 3D eye gaze motion from speech alone. In this paper, we propose a novel data-driven method which can generate diverse 3D eye gaze motions in harmony with the speech. To achieve this, we firstly construct an audio-gaze dataset that contains about 14 hours of audio-mesh sequences featuring high-quality eye gaze motion, head motion and facial motion simultaneously. The motion data is acquired by performing lightweight eye gaze fitting and face reconstruction on videos from existing audio-visual datasets. We then tailor a novel speech-to-motion translation framework in which the head motions and eye gaze motions are jointly generated from speech but are modeled in two separate latent spaces. This design stems from the physiological knowledge that the rotation range of eyeballs is less than that of head. Through mapping the speech embedding into the two latent spaces, the difficulty in modeling the weak correlation between speech and non-verbal motion is thus attenuated. Finally, our TalkingEyes, integrated with a speech-driven 3D facial motion generator, can synthesize eye gaze motion, eye blinks, head motion and facial motion collectively from speech. Extensive quantitative and qualitative evaluations demonstrate the superiority of the proposed method in generating diverse and natural 3D eye gaze motions from speech. The project page of this paper is: https://lkjkjoiuiu.github.io/TalkingEyes_Home/
尽管最近在语音驱动的三维面部动画领域取得了重大进展,但最近的研究忽略了不可或缺的面部组成部分——眼神的语音驱动动画。这主要是因为语音和眼神之间的弱相关性,以及音频注视数据的稀缺,使得仅从语音生成三维眼神运动非常具有挑战性。在本文中,我们提出了一种新颖的数据驱动方法,可以生成与语音协调的多样化的三维眼神运动。为实现这一点,我们首先构建了一个音频注视数据集,其中包含约14小时的音频网格序列,同时呈现高质量的眼神运动、头部运动和面部运动。运动数据是通过对来自现有视听数据集的视频执行轻量级眼神注视拟合和面部重建而获得的。然后,我们定制了一个新颖的语音到运动翻译框架,其中头部运动和眼神运动是从语音中联合生成的,但在两个单独的潜在空间中建模。这种设计源于生理知识,即眼球的旋转范围小于头部。通过将语音嵌入映射到这两个潜在空间,可以减轻对语音和非语言运动之间弱相关性的建模难度。最后,我们的TalkingEyes结合语音驱动的三维面部运动生成器,可以从语音中综合生成眼神运动、眨眼、头部运动和面部运动。大量的定量和定性评估证明,该方法在通过语音生成多样化和自然的三维眼神运动方面具有优越性。该论文的项目页面为:https://lkjkjoiuiu.github.io/TalkingEyes_Home/
论文及项目相关链接
摘要
近期虽然语音驱动3D面部动画领域取得了显著进展,但关于面部重要组成部分——眼动的语音驱动动画研究却被忽视。本文提出一种数据驱动的方法,能生成与语音相协调的多样化的3D眼动。首先构建了一个包含约14小时音频网格序列的视听数据集,同时进行眼动、头部运动和面部运动的高质量采集。然后设计了一个新颖的语音到动作转换框架,头部运动和眼动从语音中产生,但分别在两个独立潜空间建模。最后,通过集成语音驱动的3D面部动画生成器,我们的TalkingEyes能从语音中合成眼动、眨眼、头部和面部运动。广泛定量和定性评估表明,该方法在生成多样且自然的3D眼动方面表现卓越。
关键见解
- 近期研究忽视了语音驱动3D面部动画中的眼动部分。
- 提出了一个数据驱动的方法,生成多样化的与语音协调的3D眼动。
- 构建了一个包含高质量视听数据的音频网格数据集。
- 设计了一个新颖的语音到动作转换框架,将头部和眼动分开建模。
- 集成语音驱动的3D面部动画生成器,能合成多种动作。
- 方法在生成自然且多样的3D眼动方面表现优越。
点此查看论文截图




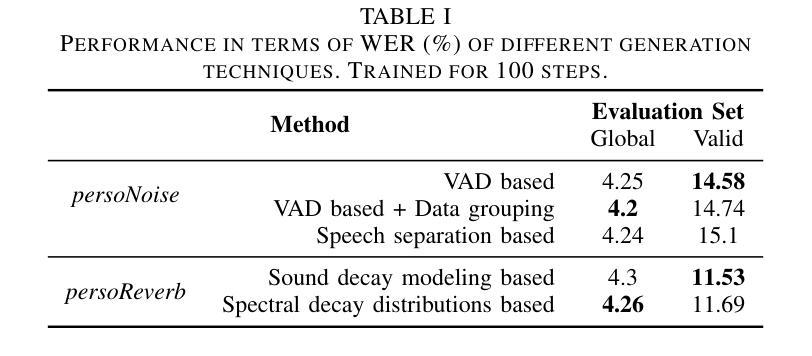
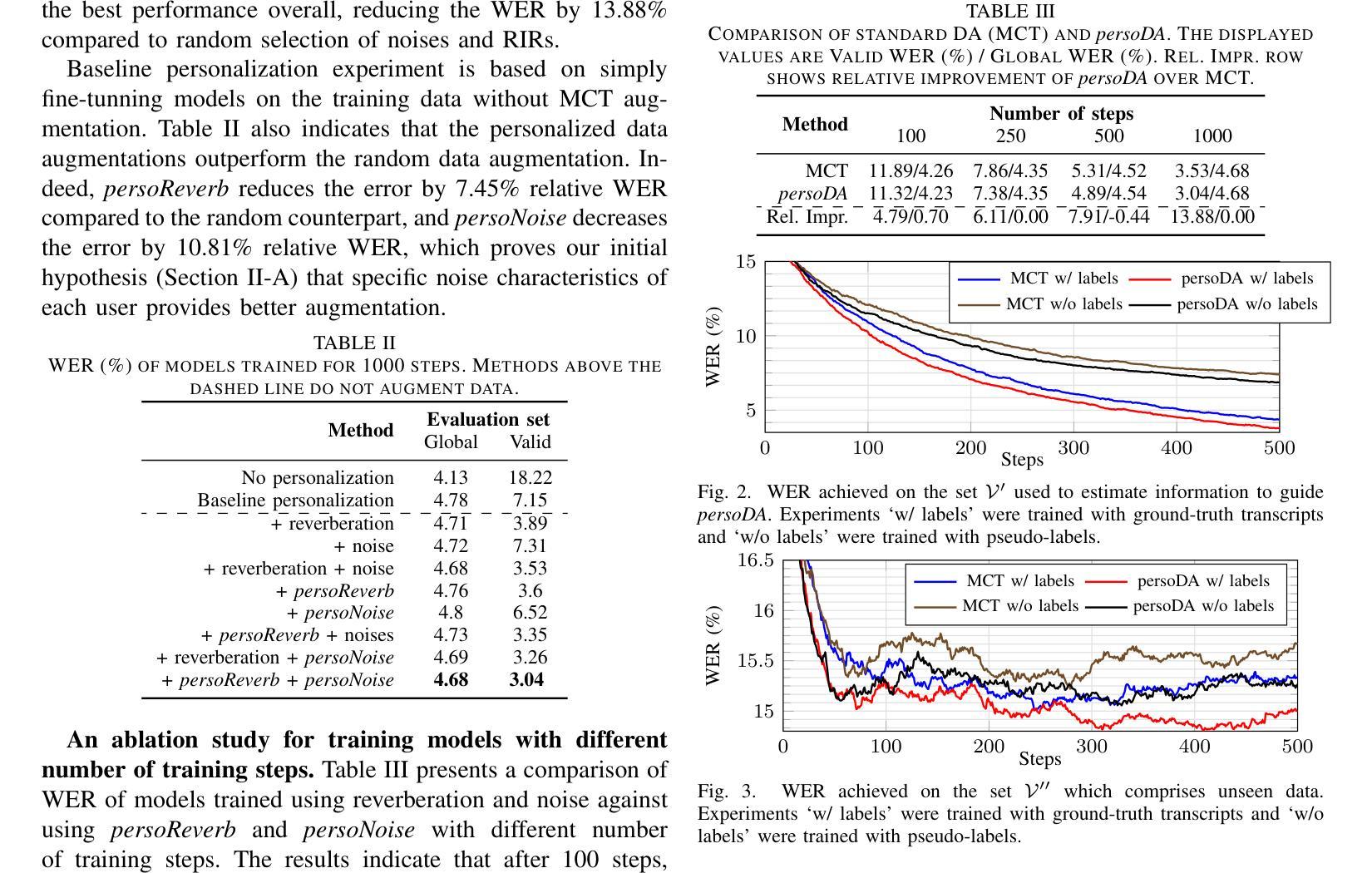
persoDA: Personalized Data Augmentation for Personalized ASR
Authors:Pablo Peso Parada, Spyros Fontalis, Md Asif Jalal, Karthikeyan Saravanan, Anastasios Drosou, Mete Ozay, Gil Ho Lee, Jungin Lee, Seokyeong Jung
Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user’s data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
数据增强(DA)在自动语音识别(ASR)模型的训练中无处不在。DA提供了增加数据变化、稳健性和对不同声学失真的泛化能力。最近,在移动设备上对ASR模型进行个性化展示,能够改善单词错误率(WER)。本文在此背景下评估数据增强,并提出persoDA;一种利用用户数据进行驱动的DA方法,用于个性化ASR。persoDA旨在使用专门针对最终用户声学特征调整的数据来增强训练,而不是基于多条件训练(MCT)的标准增强,后者应用随机混响和噪声。我们在Librispeech上训练的基于ASR conformer的基线并进行个性化处理用于语音评估,发现与标准数据增强相比(使用随机噪声和混响),persoDA相对减少了WER的百分比为百分之十三点九。此外,相较于MCT来说,persoDA的收敛速度提高了百分之十六到百分之二十。
论文及项目相关链接
PDF ICASSP’25-Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Summary
数据增强(DA)在自动语音识别(ASR)模型的训练中应用广泛。本文评估了个人化ASR模型中数据增强的效果,并提出一种名为persoDA的数据增强方法。该方法利用用户数据驱动,旨在针对最终用户的声学特性进行个性化训练,不同于基于多条件训练(MCT)的标准数据增强方法。实验结果显示,persoDA相对于使用随机噪声和回声的标准数据增强方法,实现了相对词错误率(WER)降低13.9%,并且收敛速度提高了16%至20%。
Key Takeaways
- 数据增强在自动语音识别模型训练中起着重要作用,能提高数据多变性和模型的稳健性。
- 针对移动设备上的语音识别模型进行个性化可以提高词错误率(WER)。
- 本论文提出一种名为persoDA的数据增强方法,根据用户的声学特性进行个性化训练。
- persoDA相对于标准的多条件训练(MCT),实现了更低的词错误率(WER)。
- persoDA在收敛速度上较MCT有显著提升。
- 实验结果显示,persoDA在基于Librispeech的语音识别人体工学模型上取得了良好效果。
点此查看论文截图

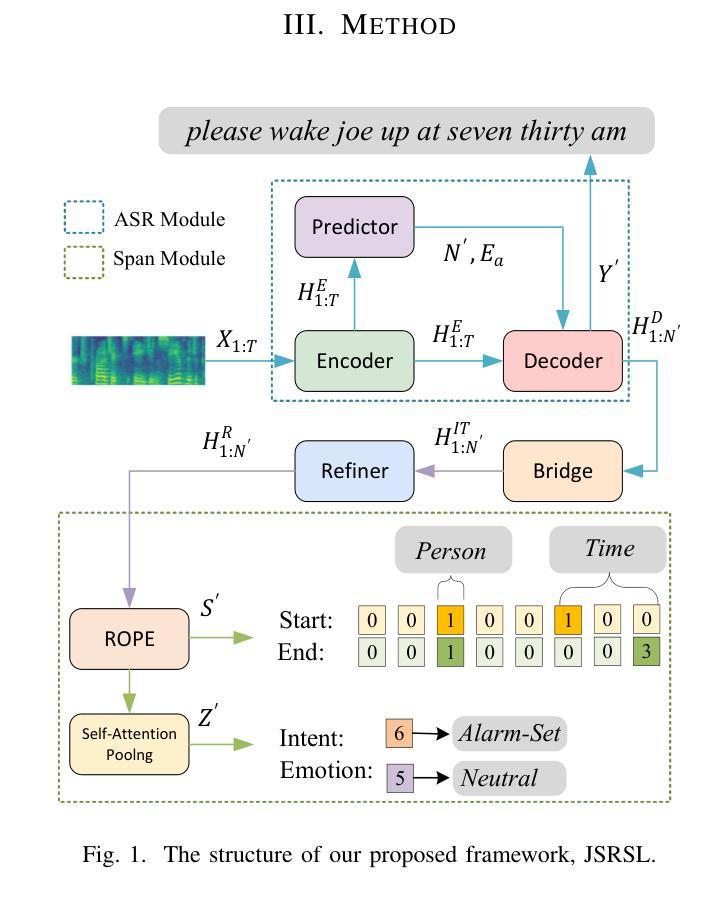
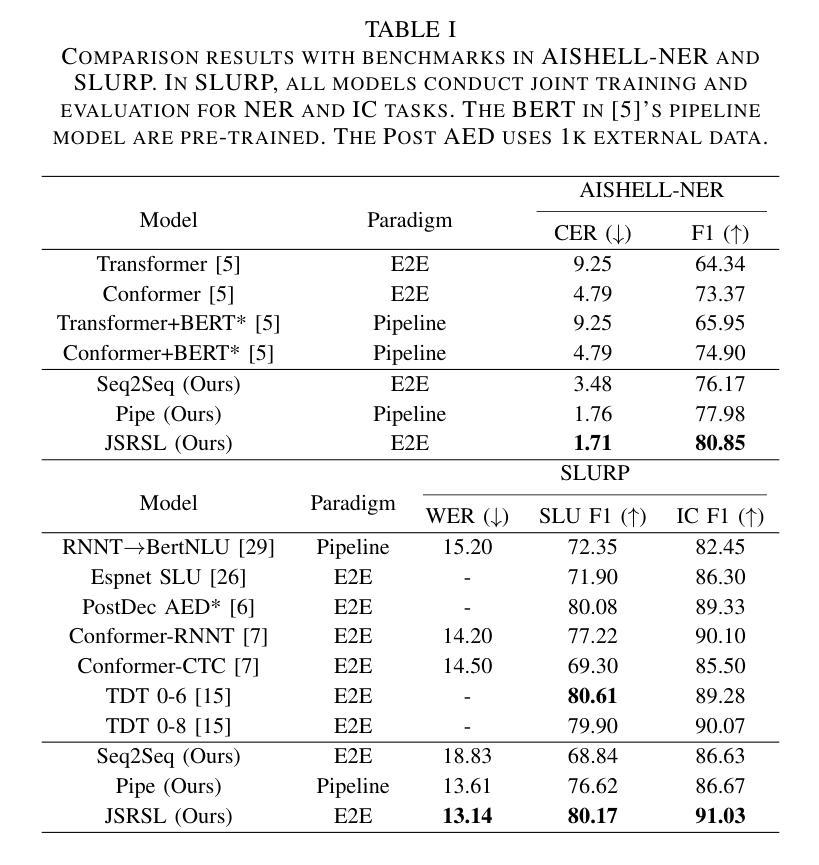
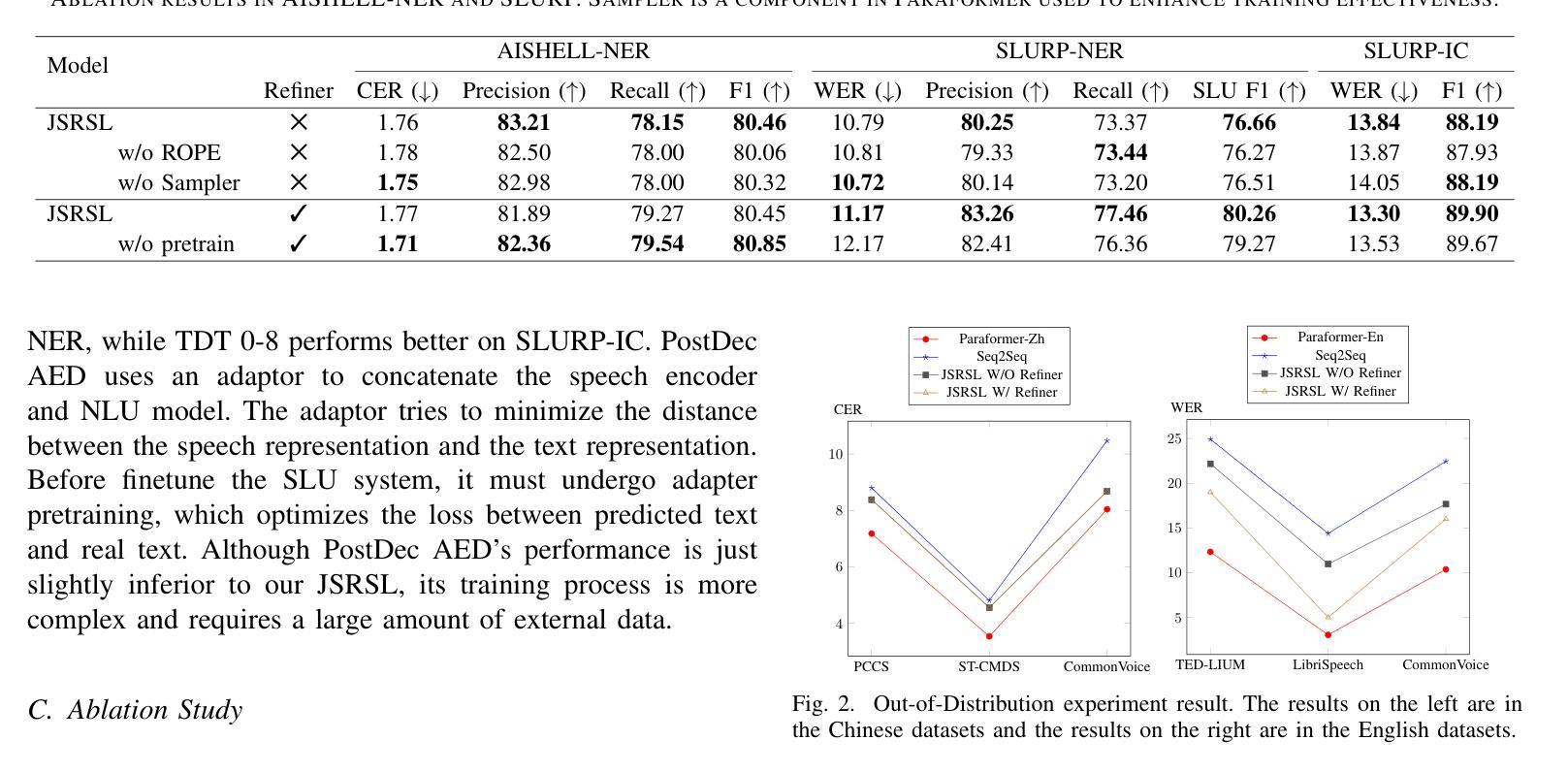
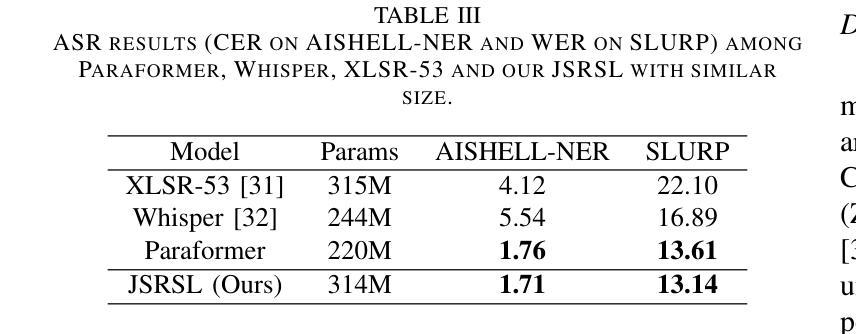
Joint Automatic Speech Recognition And Structure Learning For Better Speech Understanding
Authors:Jiliang Hu, Zuchao Li, Mengjia Shen, Haojun Ai, Sheng Li, Jun Zhang
Spoken language understanding (SLU) is a structure prediction task in the field of speech. Recently, many works on SLU that treat it as a sequence-to-sequence task have achieved great success. However, This method is not suitable for simultaneous speech recognition and understanding. In this paper, we propose a joint speech recognition and structure learning framework (JSRSL), an end-to-end SLU model based on span, which can accurately transcribe speech and extract structured content simultaneously. We conduct experiments on name entity recognition and intent classification using the Chinese dataset AISHELL-NER and the English dataset SLURP. The results show that our proposed method not only outperforms the traditional sequence-to-sequence method in both transcription and extraction capabilities but also achieves state-of-the-art performance on the two datasets.
语音语言理解(SLU)是语音领域的一种结构预测任务。最近,将SLU视为序列到序列任务的许多工作都取得了巨大的成功。然而,这种方法不适用于同步语音识别和理解。在本文中,我们提出了一种联合语音识别和结构学习框架(JSRSL),这是一种基于范围的端到端SLU模型,可以同时准确转录语音并提取结构内容。我们使用中国AISHELL-NER数据集和英语SLURP数据集进行命名实体识别和意图分类实验。结果表明,我们提出的方法不仅在转录和提取能力上优于传统的序列到序列方法,而且在两个数据集上达到了最新的性能水平。
论文及项目相关链接
PDF 5 pages, 2 figures, accepted by ICASSP 2025
Summary
该论文提出了一种基于区段的联合语音识别和结构学习框架(JSRSL),可同时准确转录语音并提取结构化内容。实验表明,该方法在中文数据集AISHELL-NER和英文数据集SLURP上的表现优于传统的序列到序列方法,并在两个数据集上均达到了最新的技术水平。它不仅改善了语音识别和理解的同步性,而且提高了转录和提取能力。
Key Takeaways
- Spoken language understanding (SLU)是语音领域的一个结构预测任务。序列到序列的SLU方法在多个研究工作中取得显著成果,但不支持语音的实时识别和语义理解。
- 为解决上述问题,提出了一种新的联合语音识别和结构学习框架(JSRSL),它结合了实时的语音识别和结构化内容提取。
- JSRSL是一个基于区段的端到端模型,能够同时准确转录语音并提取结构化的内容。这为解决语言理解的难题提供了一种有效的途径。
- 该方法使用了两个数据集进行测试:中文数据集AISHELL-NER和英文数据集SLURP。实验结果证明了其优越性。
- JSRSL不仅在转录能力上超越了传统的序列到序列方法,而且在两个数据集上都实现了前沿性能。这说明它能够准确地识别和解释复杂的语音信号和含义丰富的句子结构。
- JSRSL框架对于未来的语言处理任务具有广泛的应用前景,特别是在语音识别、机器翻译等领域。其强大的性能使其成为解决复杂语言任务的有效工具。
点此查看论文截图

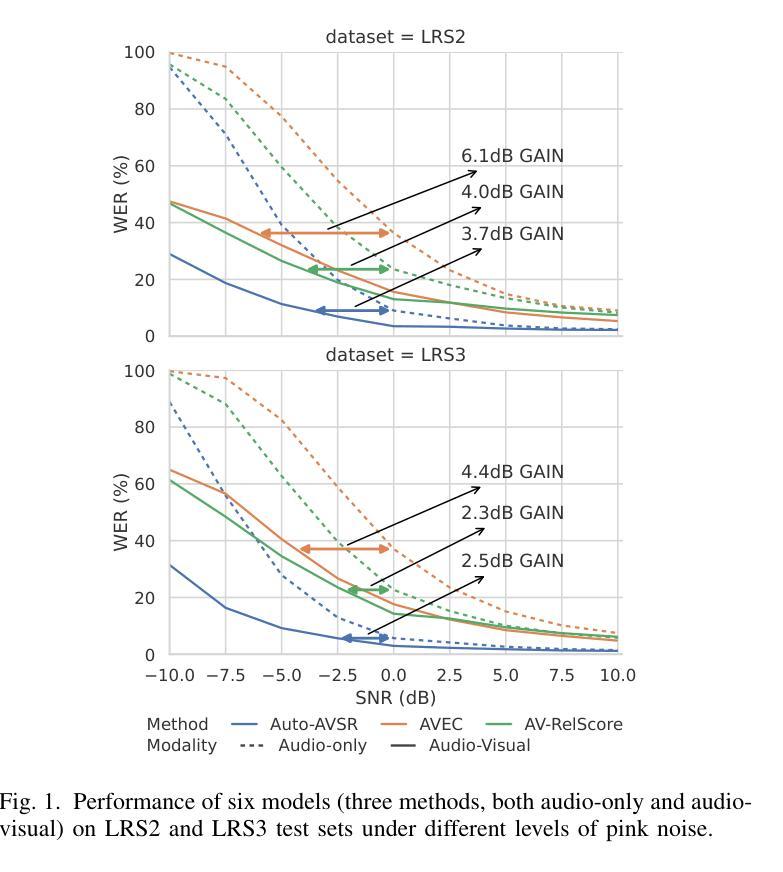
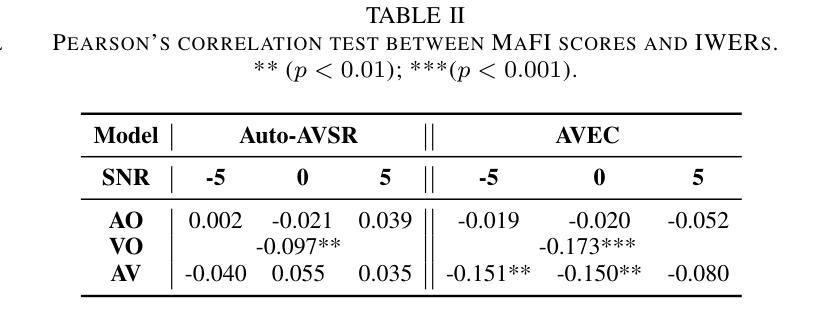
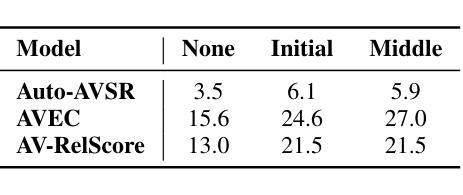
Uncovering the Visual Contribution in Audio-Visual Speech Recognition
Authors:Zhaofeng Lin, Naomi Harte
Audio-Visual Speech Recognition (AVSR) combines auditory and visual speech cues to enhance the accuracy and robustness of speech recognition systems. Recent advancements in AVSR have improved performance in noisy environments compared to audio-only counterparts. However, the true extent of the visual contribution, and whether AVSR systems fully exploit the available cues in the visual domain, remains unclear. This paper assesses AVSR systems from a different perspective, by considering human speech perception. We use three systems: Auto-AVSR, AVEC and AV-RelScore. We first quantify the visual contribution using effective SNR gains at 0 dB and then investigate the use of visual information in terms of its temporal distribution and word-level informativeness. We show that low WER does not guarantee high SNR gains. Our results suggest that current methods do not fully exploit visual information, and we recommend future research to report effective SNR gains alongside WERs.
视听语音识别(AVSR)结合了听觉和视觉语音线索,以提高语音识别系统的准确性和稳健性。与仅使用音频的同类系统相比,AVSR的最新进展在嘈杂环境中的性能有所提高。然而,视觉贡献的真正程度,以及AVSR系统是否充分利用视觉领域中的可用线索,仍然不清楚。本文通过考虑人类语音感知,从另一个角度评估AVSR系统。我们使用三种系统:Auto-AVSR、AVEC和AV-RelScore。我们首先使用有效信噪比增益(在0分贝处)量化视觉贡献,然后研究视觉信息的使用与其时间分布和词汇级别信息量有关。我们表明,低词错误率并不保证高信噪比增益。我们的结果表明,当前的方法并没有充分利用视觉信息,我们建议未来的研究在报告词错误率的同时,也要报告有效的信噪比增益。
论文及项目相关链接
PDF 5 pages, 2 figures. Accepted to ICASSP 2025
Summary
音频视觉语音识别(AVSR)结合听觉和视觉语音线索,提高了语音识别系统的准确性和稳健性。最新研究表明,相较于只使用音频的识别系统,AVSR在噪声环境中的表现有所提升。然而,视觉贡献的真实程度以及AVSR系统是否完全利用视觉领域的可用线索尚不清楚。本文通过借鉴人类语音感知来评估AVSR系统,使用Auto-AVSR、AVEC和AV-RelScore三种系统进行研究。我们量化视觉贡献并研究视觉信息的时序分布和词汇级别的信息量。研究发现,低词错误率并不保证信噪比增益高。我们的结果暗示当前的方法并未完全利用视觉信息,建议未来的研究在报告词错误率的同时也要报告有效的信噪比增益。
Key Takeaways
- AVSR结合了听觉和视觉语音线索,提高了语音识别系统的准确性及稳健性。
- 相较于音频识别系统,AVSR在噪声环境中的表现有所提升。
- 视觉贡献的真实程度尚不清楚,需要进一步研究。
- 通过借鉴人类语音感知来评估AVSR系统。
- 研究中使用了三种系统:Auto-AVSR、AVEC和AV-RelScore。
- 视觉信息的贡献被量化,同时研究了其在时序分布和词汇级别的信息量。
点此查看论文截图


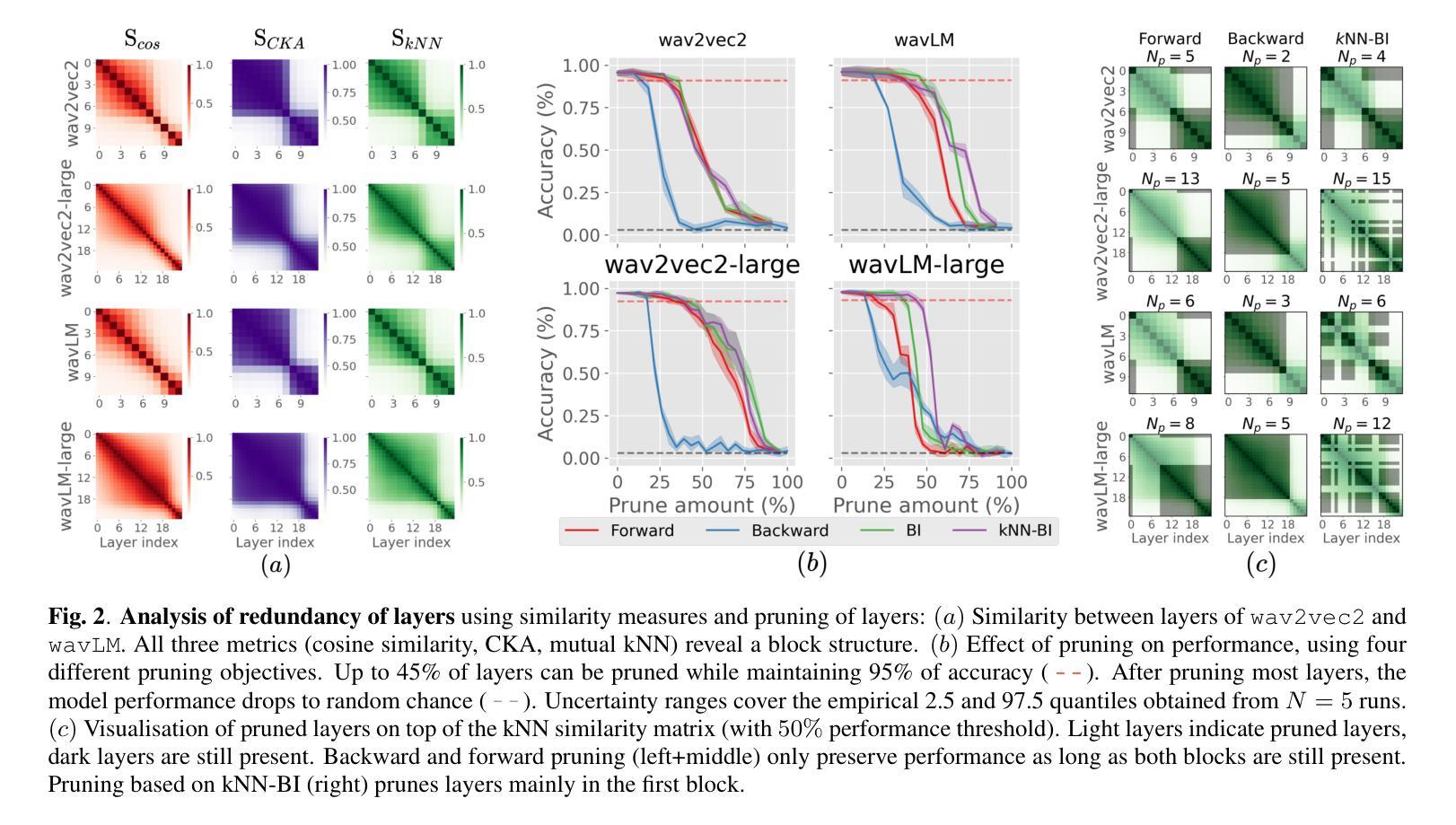
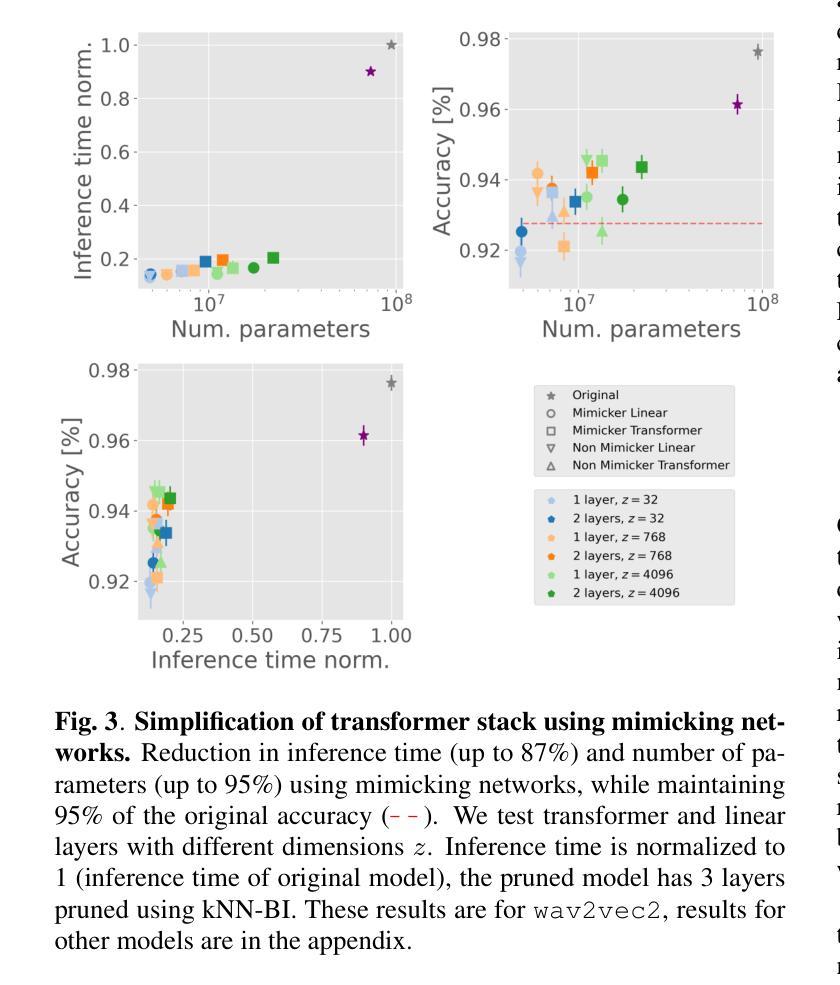
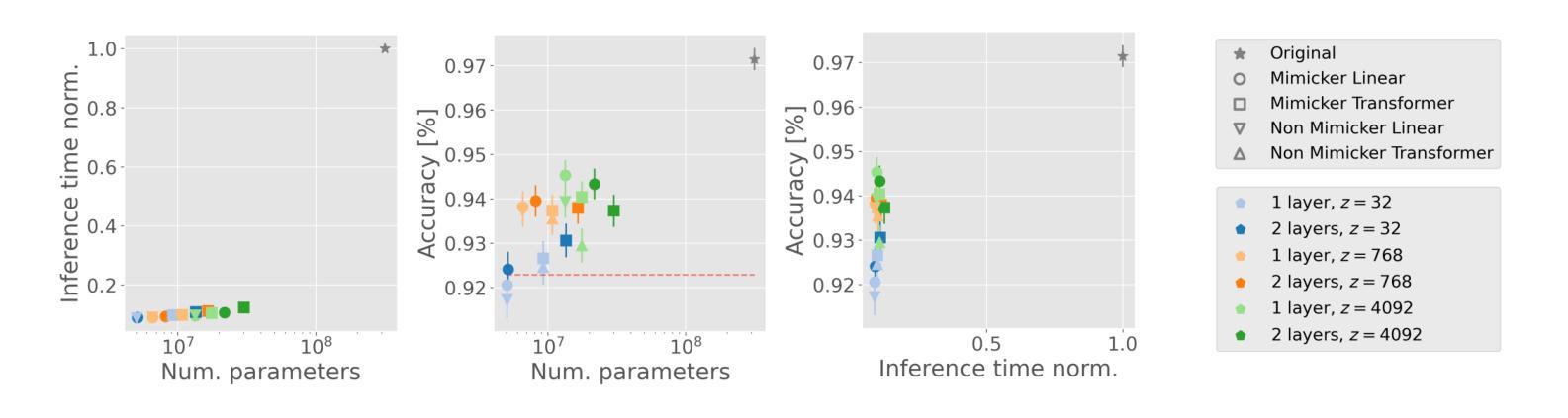
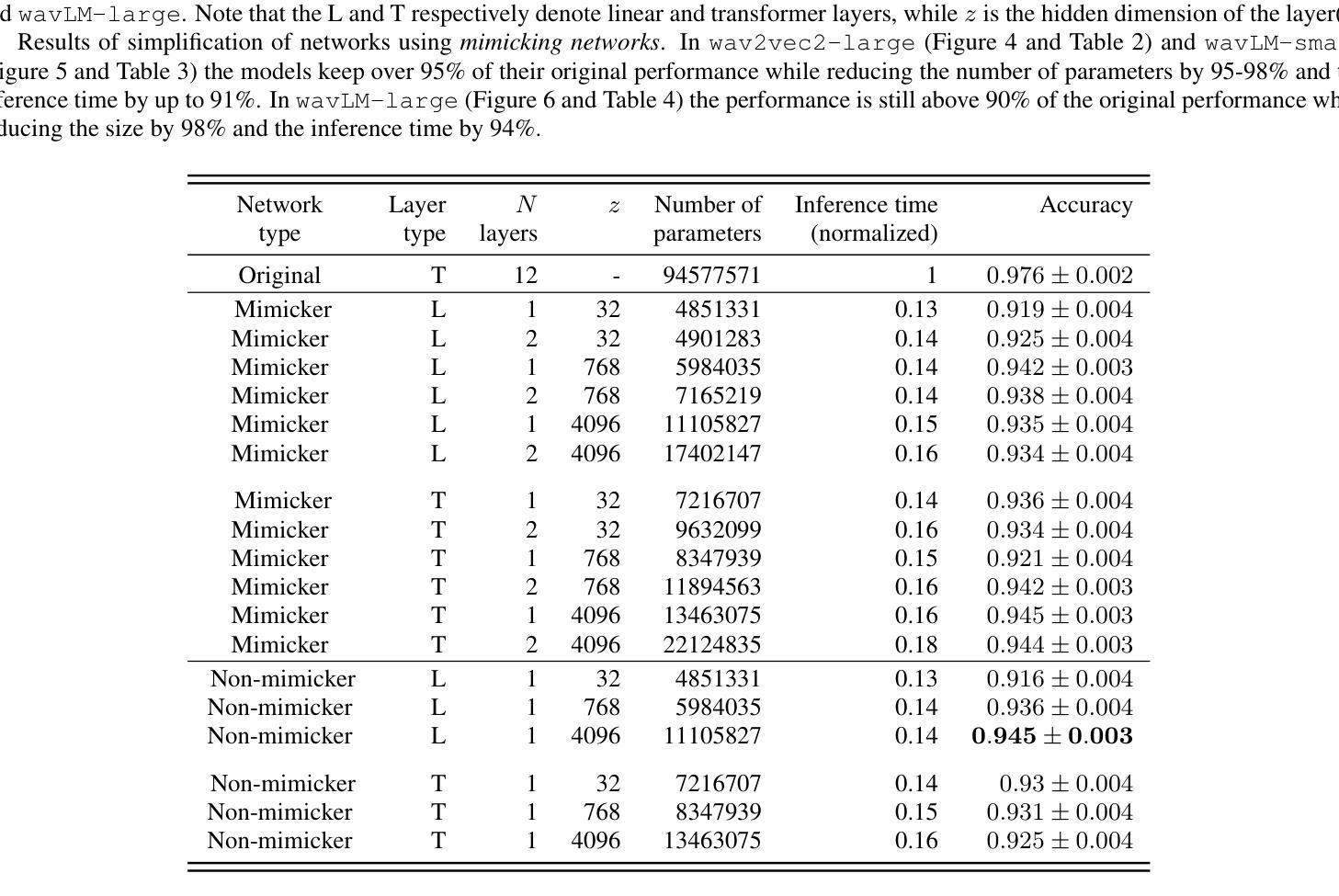
How Redundant Is the Transformer Stack in Speech Representation Models?
Authors:Teresa Dorszewski, Albert Kjøller Jacobsen, Lenka Tětková, Lars Kai Hansen
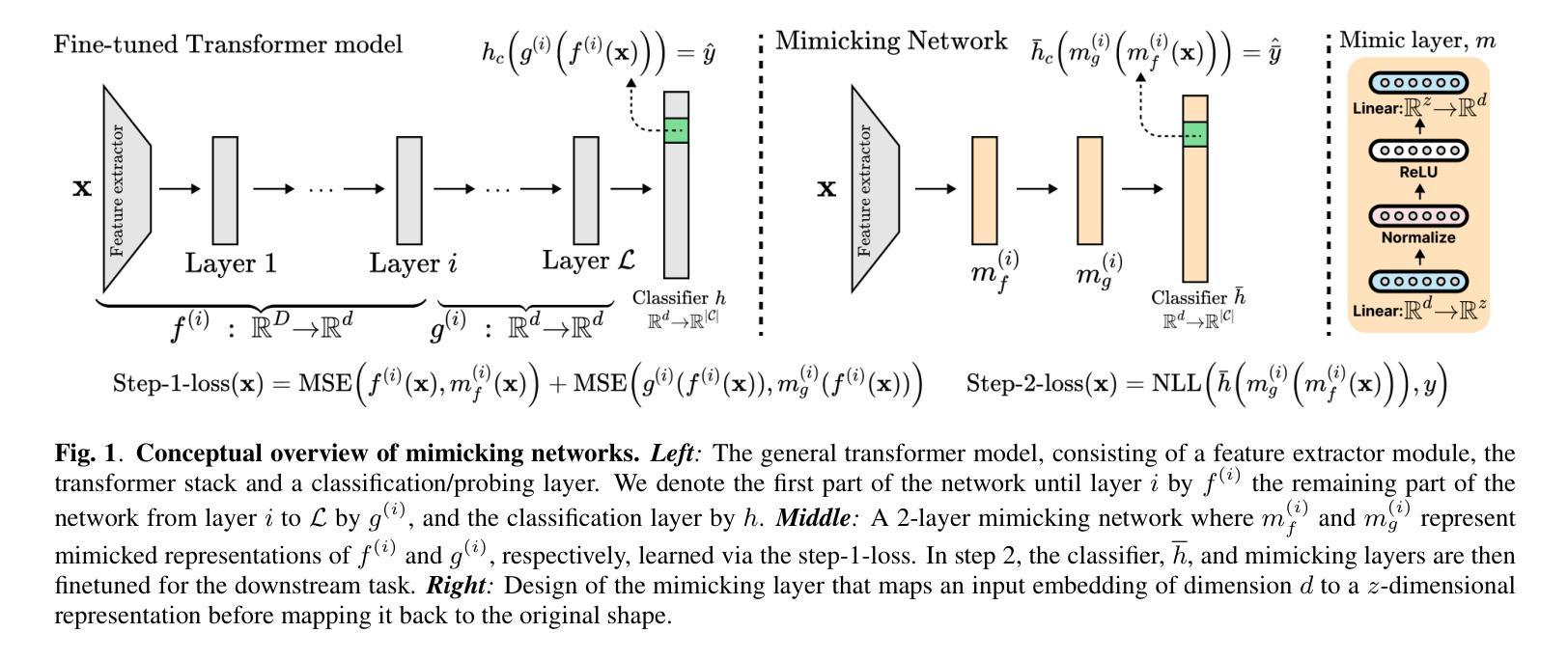
Self-supervised speech representation models, particularly those leveraging transformer architectures, have demonstrated remarkable performance across various tasks such as speech recognition, speaker identification, and emotion detection. Recent studies on transformer models revealed a high redundancy between layers and the potential for significant pruning, which we will investigate here for transformer-based speech representation models. We perform a detailed analysis of layer similarity in speech representation models using three similarity metrics: cosine similarity, centered kernel alignment, and mutual nearest-neighbor alignment. Our findings reveal a block-like structure of high similarity, suggesting two main processing steps and significant redundancy of layers. We demonstrate the effectiveness of pruning transformer-based speech representation models without the need for post-training, achieving up to 40% reduction in transformer layers while maintaining over 95% of the model’s predictive capacity. Furthermore, we employ a knowledge distillation method to substitute the entire transformer stack with mimicking layers, reducing the network size 95-98% and the inference time by up to 94%. This substantial decrease in computational load occurs without considerable performance loss, suggesting that the transformer stack is almost completely redundant for downstream applications of speech representation models.
自监督语音表示模型,尤其是利用转换器架构的模型,在语音识别、说话人识别和情感检测等任务中表现出了卓越的性能。关于转换器模型的研究揭示了层之间的高度冗余和潜在的大量剪枝可能性,我们将在这里基于转换器结构的语音表示模型进行研究。我们采用三种相似性度量方法(余弦相似性、中心化内核对齐和相互最近邻对齐)对语音表示模型中的层相似性进行了详细分析。我们的研究结果表明了一种高相似性的块状结构,这表明了主要的两个处理步骤和显著的层冗余性。我们展示了无需进行二次训练即可有效地修剪基于转换器的语音表示模型,在减少高达40%的转换器层的同时,保持模型预测能力的95%以上。此外,我们还采用了一种知识蒸馏方法,用模仿层替代了整个转换器堆栈,将网络规模减少了95-98%,推理时间减少了高达94%。这种计算负载的实质性下降发生在没有明显的性能损失的情况下,这表明转换器堆栈对于语音表示模型的下游应用几乎是完全冗余的。
论文及项目相关链接
PDF To appear at ICASSP 2025 (excluding appendix)
Summary
基于转换器架构的语音自监督表示模型在多个任务中表现出卓越性能,如语音识别、说话人识别和情感检测。研究发现转换器模型层之间存在高冗余性,通过层相似性分析揭示了其块状结构特点,并展示了显著的处理冗余性。在不进行训练后处理的情况下,通过修剪层实现模型效率提升,减少高达40%的转换器层同时保持模型预测能力的95%以上。此外,采用知识蒸馏法以模仿层代替整个转换器堆栈,降低网络规模高达98%,并可将推理时间缩短高达94%,且在计算负荷显著降低的情况下几乎没有性能损失。这显示出对于语音表示模型的下游应用而言,转换器堆栈几乎完全冗余。
Key Takeaways
- 自监督语音表示模型,特别是基于转换器架构的模型,在多种任务中表现卓越。
- 转换器模型层之间存在高冗余性。
- 通过层相似性分析揭示了模型块状结构特点。
- 通过修剪层可以提升模型效率,显著减少计算负荷并保持较高预测性能。
- 知识蒸馏法可用于以模仿层代替转换器堆栈的大部分部分。
- 网络规模可大幅缩减,同时推理时间显著减少。
点此查看论文截图

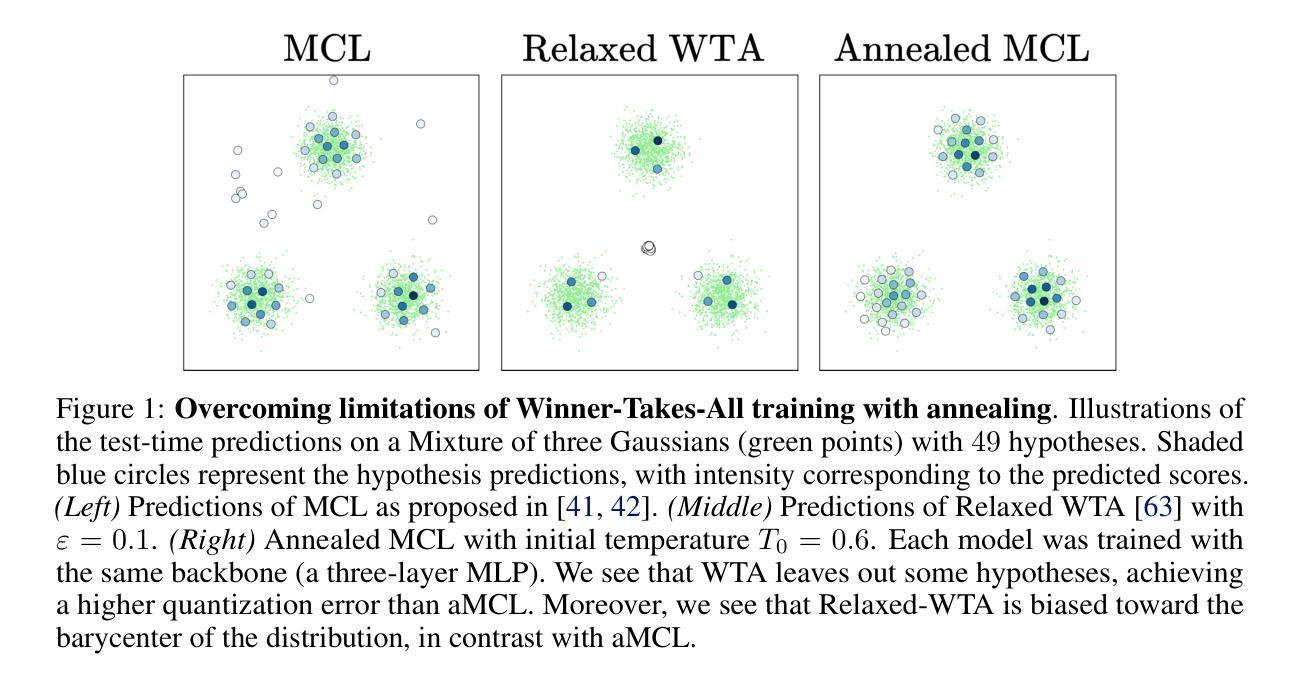
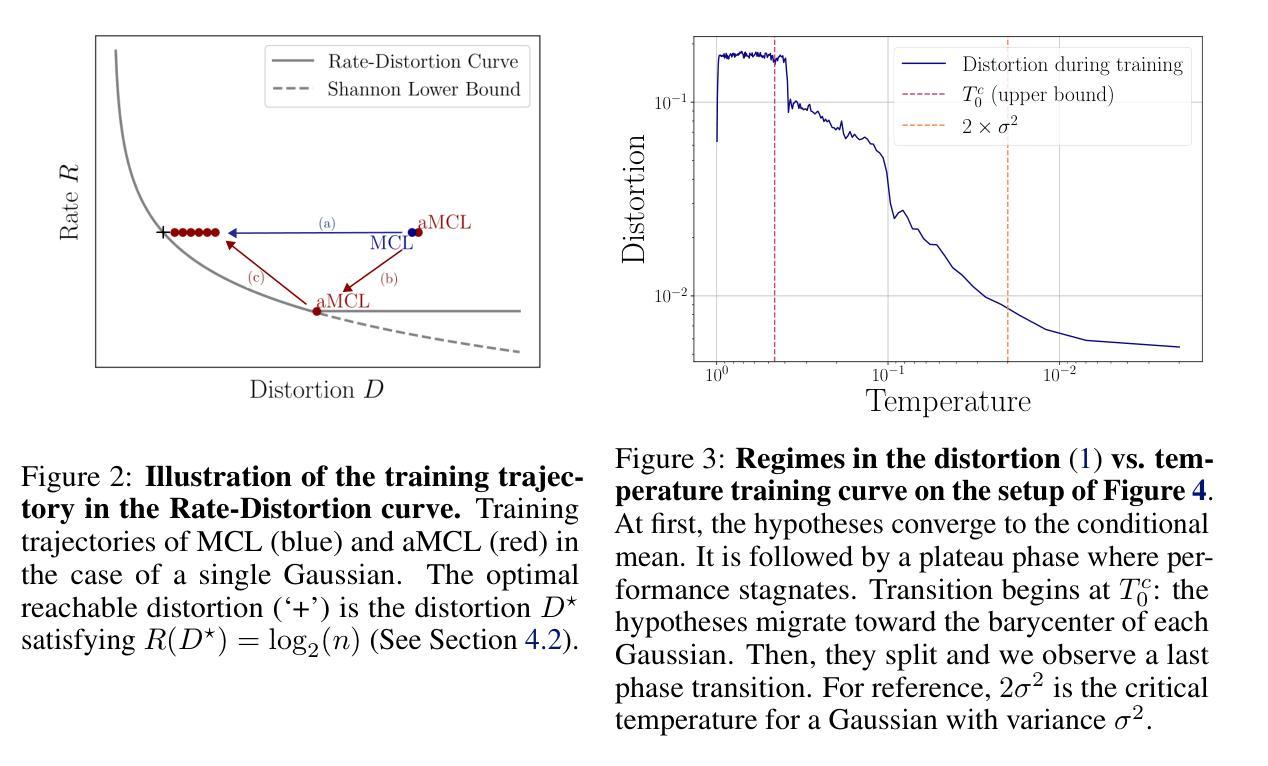
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Authors:David Perera, Victor Letzelter, Théo Mariotte, Adrien Cortés, Mickael Chen, Slim Essid, Gaël Richard
We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
我们介绍了退火多选项学习(aMCL),它将模拟退火与MCL相结合。MCL是一个学习框架,通过预测一小部分合理的假设来处理模糊任务。这些假设是使用胜者全取(WTA)方案进行训练的,该方案促进了预测的多样性。然而,由于WTA的贪婪性质,该方案可能会任意收敛到次优的局部最小值。我们通过使用退火来克服这一局限性,退火增强了训练过程中假设空间的探索。我们从统计物理学和信息理论中汲取灵感,为模型训练轨迹提供了详细描述。此外,我们通过合成数据集、标准UCI基准测试以及语音分离等方面的广泛实验验证了我们的算法。
论文及项目相关链接
PDF NeurIPS 2024
Summary:结合模拟退火算法和MCL学习框架,提出退火多重选择学习(aMCL)方法。该方法解决了MCL在处理具有不确定性的任务时可能出现的问题,利用模拟退火提高预测的多样性和质量。通过统计物理学和信息理论,描述了模型训练轨迹。实验验证了在合成数据集、UCI标准基准和语音分离上的有效性。
Key Takeaways:
- 提出新的学习算法aMCL,结合了模拟退火和MCL框架。
- MCL在处理具有不确定性的任务时,通过预测一系列可能假设来处理歧义性。
- 使用Winner-takes-all(WTA)方案进行训练预测,但可能导致预测结果收敛于任意局部最小值。
- 模拟退火用于克服WTA方案的局限性,提高预测空间的探索能力。
- 利用统计物理学和信息理论为模型训练轨迹提供详细描述。
- 通过合成数据集、UCI标准基准和语音分离实验验证了算法的有效性。
点此查看论文截图

Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Authors:Jiaming Zhou, Shiwan Zhao, Hui Wang, Tian-Hao Zhang, Haoqin Sun, Xuechen Wang, Yong Qin
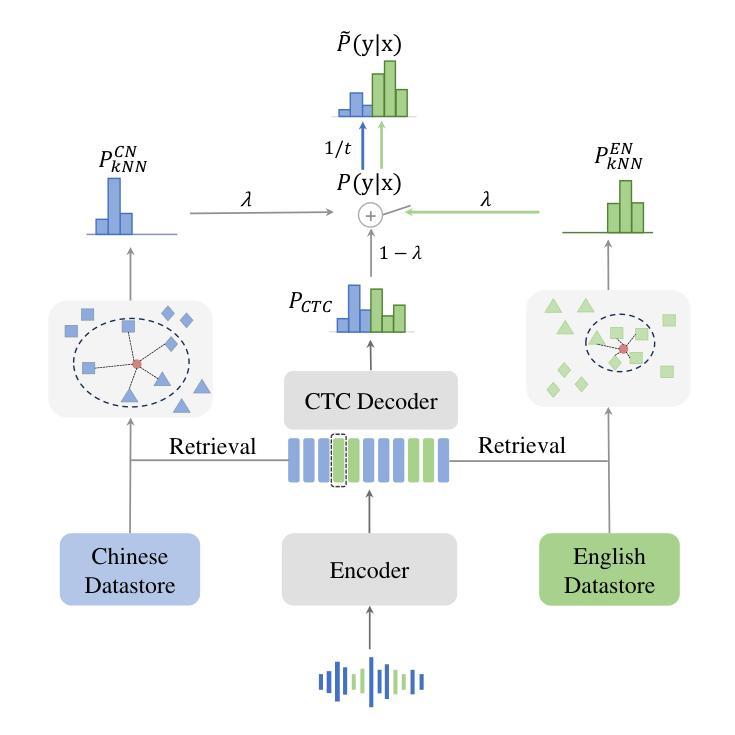
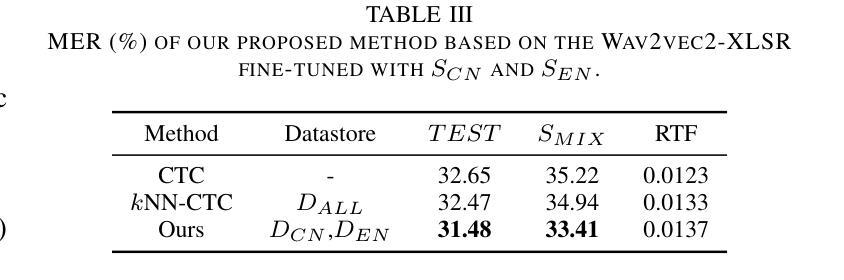
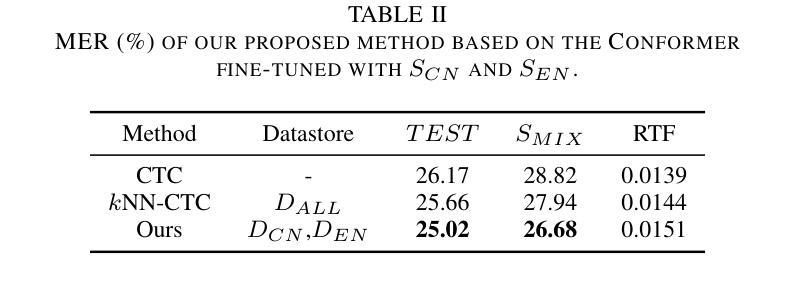
The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
kNN-CTC模型在单语种自动语音识别(ASR)中已被证明是有效的。然而,将其直接应用于多语种场景,如代码切换,还存在挑战。尽管有提高性能的潜力,但使用单一双语数据存储的kNN-CTC模型可能会无意中引入来自另一种语言的不希望有的噪声。为了解决这一问题,我们提出了一种基于kNN-CTC的代码切换ASR(CS-ASR)新框架,该框架采用双单语种数据存储和受控数据存储选择机制来减少噪声干扰。我们的方法选择适当的存储库来解码每一帧,确保语言特定信息的注入到ASR过程中。我们将该框架应用于最新的CTC模型,开发了一个先进的CS-ASR系统。大量实验表明,我们的受控数据存储机制在增强零中文-英文切换CS-ASR的性能方面具有显著效果。
论文及项目相关链接
PDF Accepted by ICASSP 2025
总结
kNN-CTC模型在单语言自动语音识别(ASR)中表现良好,但在应用于多语言场景如代码切换时面临挑战。使用单一双语数据存储库的kNN-CTC模型可能会引入来自另一种语言的不必要噪声。为解决这一问题,我们提出了一种基于kNN-CTC的代码切换ASR(CS-ASR)框架,采用双单语言数据存储和门控数据存储选择机制以减少噪声干扰。该方法能选择适合每帧解码的数据存储,确保语言特定信息注入ASR过程。我们将此框架应用于前沿的CTC模型,开发出先进的CS-ASR系统。大量实验证明,我们的门控数据存储机制在提升零中文-英文代码切换ASR的性能方面具有显著效果。
关键见解
- kNN-CTC模型在单语言自动语音识别(ASR)中表现有效。
- 在多语言场景如代码切换中,直接使用kNN-CTC模型会面临挑战。
- 使用单一双语数据存储库可能会在kNN-CTC模型中引入来自另一种语言的不必要噪声。
- 提出了基于kNN-CTC的代码切换ASR(CS-ASR)框架。
- CS-ASR框架采用双单语言数据存储和门控数据存储选择机制以减少噪声干扰。
- 门控数据存储选择机制能根据每帧解码选择合适的数据存储。
点此查看论文截图