⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-21 更新
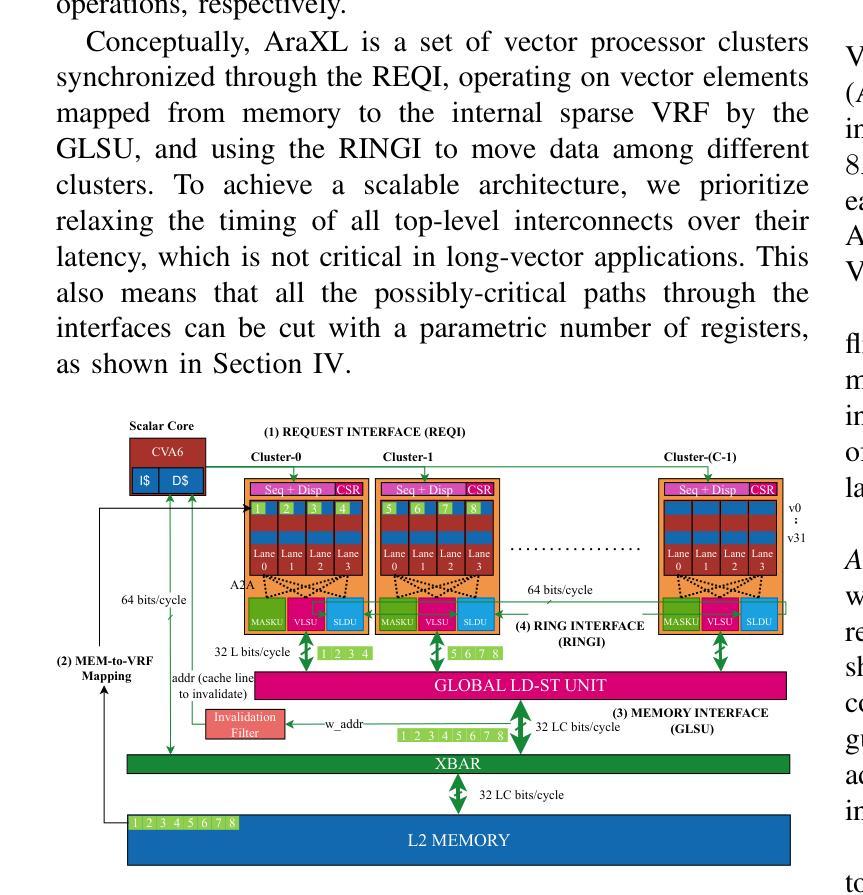
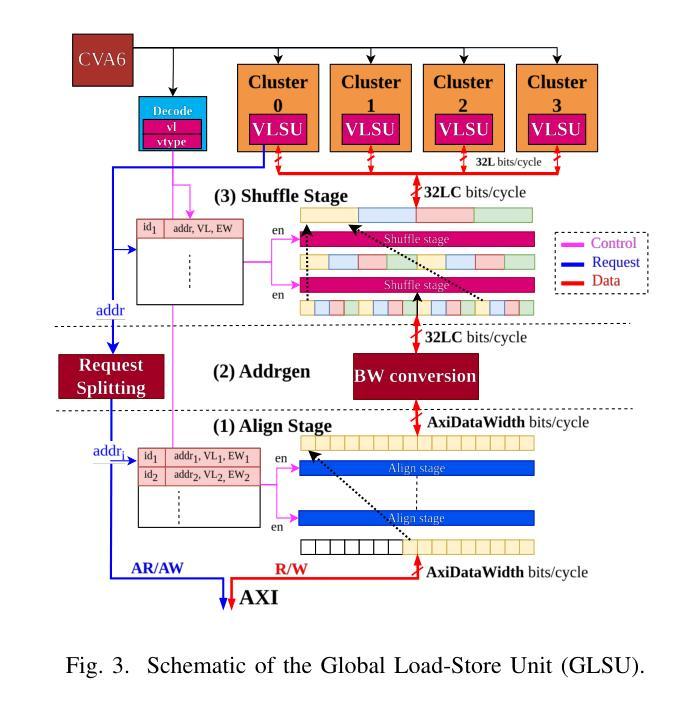
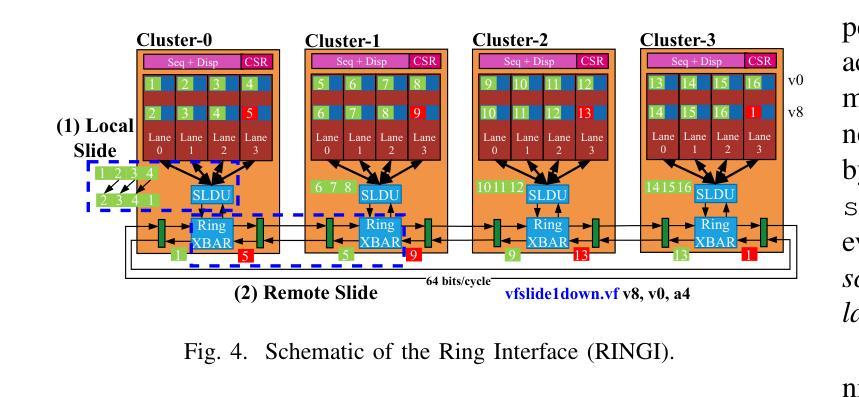
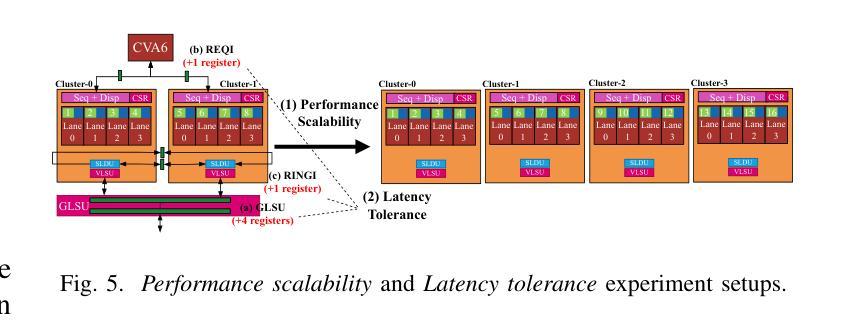
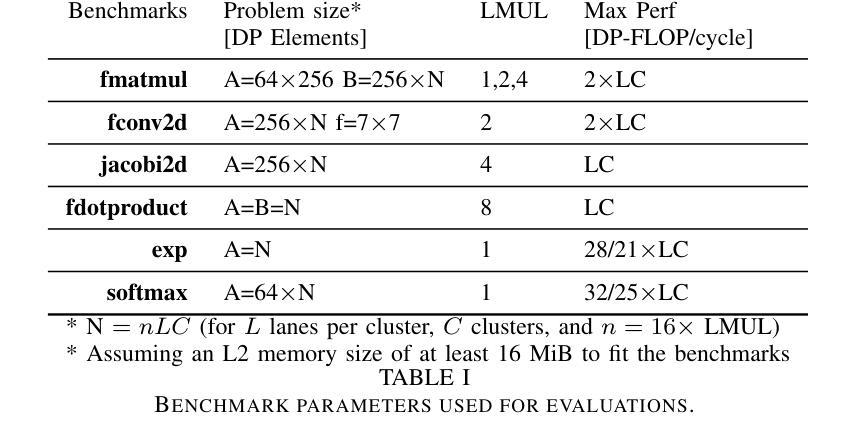
AraXL: A Physically Scalable, Ultra-Wide RISC-V Vector Processor Design for Fast and Efficient Computation on Long Vectors
Authors:Navaneeth Kunhi Purayil, Matteo Perotti, Tim Fischer, Luca Benini
The ever-growing scale of data parallelism in today’s HPC and ML applications presents a big challenge for computing architectures’ energy efficiency and performance. Vector processors address the scale-up challenge by decoupling Vector Register File (VRF) and datapath widths, allowing the VRF to host long vectors and increase register-stored data reuse while reducing the relative cost of instruction fetch and decode. However, even the largest vector processor designs today struggle to scale to more than 8 vector lanes with double-precision Floating Point Units (FPUs) and 256 64-bit elements per vector register. This limitation is induced by difficulties in the physical implementation, which becomes wire-dominated and inefficient. In this work, we present AraXL, a modular and scalable 64-bit RISC-V V vector architecture targeting long-vector applications for HPC and ML. AraXL addresses the physical scalability challenges of state-of-the-art vector processors with a distributed and hierarchical interconnect, supporting up to 64 parallel vector lanes and reaching the maximum Vector Register File size of 64 Kibit/vreg permitted by the RISC-V V 1.0 ISA specification. Implemented in a 22-nm technology node, our 64-lane AraXL achieves a performance peak of 146 GFLOPs on computation-intensive HPC/ML kernels (>99% FPU utilization) and energy efficiency of 40.1 GFLOPs/W (1.15 GHz, TT, 0.8V), with only 3.8x the area of a 16-lane instance.
当前的高性能计算和机器学习应用中的并行数据规模不断扩大,对计算架构的能效和性能提出了巨大挑战。向量处理器通过解耦向量寄存器文件(VRF)和数据路径宽度来应对规模扩展的挑战,允许VRF托管长向量,增加寄存器中数据的重用,同时降低指令获取和解码的相对成本。然而,即使是目前最大的向量处理器设计,在配备双精度浮点单元(FPU)和每个向量寄存器包含256个64位元素的情况下,也很难扩展到超过8个向量通道。这一限制是由物理实现的困难所导致的,随着物理实现的复杂性增加,其主导因素逐渐变为线路,导致效率低下。在这项工作中,我们提出了AraXL,这是一种面向高性能计算和机器学习长向量应用的模块化可伸缩64位RISC-V向量架构。AraXL采用分布式分层互连,解决最先进的向量处理器的物理可扩展性挑战,支持高达64个并行向量通道,并达到RISC-V V 1.0 ISA规范所允许的最大向量寄存器文件大小64Kibit/vreg。在22纳米技术节点上实现,我们的64通道AraXL在计算密集型高性能计算/机器学习内核上达到了146GFLOPs的性能峰值(FPU利用率> 99%),能量效率为40.1 GFLOPs/W(1.15 GHz,TT,0.8V),面积仅为16通道实例的3.8倍。
论文及项目相关链接
PDF To be published in Design, Automation and Test in Europe Conference (DATE) 2025
Summary
本文介绍了数据并行性在高性能计算和机器学习应用中的挑战,以及向量处理器如何通过解耦向量寄存器文件和数据处理路径宽度来应对这一挑战。然而,当前向量处理器设计在物理实现上存在的困难限制了其扩展性,特别是在长向量应用中。为解决这一问题,本文提出了一种名为AraXL的模块化、可扩展的RISC-V向量架构,该架构针对高性能计算和机器学习应用的长向量需求进行了优化。通过分布式和分层互联技术,AraXL支持多达64个并行向量通道,并达到了RISC-V V 1.0 ISA规范所允许的最大向量寄存器文件大小。实验结果表明,在高性能计算和机器学习内核上,其性能峰值达到了惊人的水平,能效也相当出色。
Key Takeaways
- 数据并行性对高性能计算和机器学习应用的挑战在于计算架构的能效和性能。
- 向量处理器通过解耦向量寄存器文件和数据处理路径宽度来应对这一挑战。
- 当前向量处理器设计在物理实现上存在困难,限制了其扩展性,特别是在长向量应用中。
- AraXL是一种针对高性能计算和机器学习应用的长向量需求的模块化、可扩展的RISC-V向量架构。
- AraXL采用分布式和分层互联技术,支持多达64个并行向量通道。
- AraXL达到了RISC-V V 1.0 ISA规范所允许的最大向量寄存器文件大小。
点此查看论文截图



MRI2Speech: Speech Synthesis from Articulatory Movements Recorded by Real-time MRI
Authors:Neil Shah, Ayan Kashyap, Shirish Karande, Vineet Gandhi
Previous real-time MRI (rtMRI)-based speech synthesis models depend heavily on noisy ground-truth speech. Applying loss directly over ground truth mel-spectrograms entangles speech content with MRI noise, resulting in poor intelligibility. We introduce a novel approach that adapts the multi-modal self-supervised AV-HuBERT model for text prediction from rtMRI and incorporates a new flow-based duration predictor for speaker-specific alignment. The predicted text and durations are then used by a speech decoder to synthesize aligned speech in any novel voice. We conduct thorough experiments on two datasets and demonstrate our method’s generalization ability to unseen speakers. We assess our framework’s performance by masking parts of the rtMRI video to evaluate the impact of different articulators on text prediction. Our method achieves a $15.18%$ Word Error Rate (WER) on the USC-TIMIT MRI corpus, marking a huge improvement over the current state-of-the-art. Speech samples are available at https://mri2speech.github.io/MRI2Speech/
先前基于实时磁共振成像(rtMRI)的语音合成模型在很大程度上依赖于嘈杂的真实语音。直接在真实梅尔频谱图上应用损失会使语音内容与磁共振成像噪声混淆,导致语音清晰度降低。我们引入了一种新方法,该方法适应多模态自监督AV-HuBERT模型,用于从rtMRI进行文本预测,并引入新的基于流的持续时间预测器,以实现针对特定说话人的对齐。预测的文本和持续时间然后被语音解码器用于合成任何新颖声音的对齐语音。我们在两个数据集上进行了全面的实验,证明了我们的方法对于未见过的说话人的泛化能力。我们通过遮挡rtMRI视频的部分内容来评估我们的框架的性能,以评估不同发音器官对文本预测的影响。我们的方法在USC-TIMIT MRI语料库上实现了15.18%的词错误率(WER),标志着与当前最新技术相比的巨大改进。语音样本可在https://mri2speech.github.io/MRI2Speech/上找到。
论文及项目相关链接
PDF Accepted at IEEE ICASSP 2025
摘要
基于实时MRI(rtMRI)的语音合成模型过去严重依赖于带有噪声的真实语音。直接在真实梅尔频谱图上应用损失会导致语音内容与MRI噪声混淆,从而降低语音清晰度。我们引入了一种新方法,该方法自适应多模态自监督AV-HuBERT模型,用于从rtMRI进行文本预测,并引入新的基于流的持续时间预测器以实现针对特定说话者的对齐。预测的文本和持续时间随后被语音解码器用于合成任何新颖声音的语音。我们在两个数据集上进行了全面的实验,证明了我们的方法在未见过的新说话者上的泛化能力。我们通过遮挡rtMRI视频的部分内容来评估我们的框架在文本预测方面的性能影响。我们的方法在USC-TIMIT MRI语料库上实现了15.18%的词错误率(WER),相较于当前最佳水平有了巨大的提升。语音样本可在链接找到。
关键见解
- 实时MRI语音合成模型对带有噪声的真实语音有较大依赖。
- 直接在真实梅尔频谱图上应用损失导致语音内容和MRI噪声混淆,降低语音清晰度。
- 引入AV-HuBERT模型用于从rtMRI进行文本预测,提高预测准确性。
- 采用新的基于流的持续时间预测器,实现特定说话者的对齐。
- 预测的文本和持续时间用于合成新颖的语音。
- 在两个数据集上的实验证明了方法对于未见过的说话者具有良好的泛化能力。
- 通过评估不同发音器对文本预测的影响,方法实现了较低的词错误率(WER)。
点此查看论文截图