⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
Authors:Linrui Tian, Siqi Hu, Qi Wang, Bang Zhang, Liefeng Bo
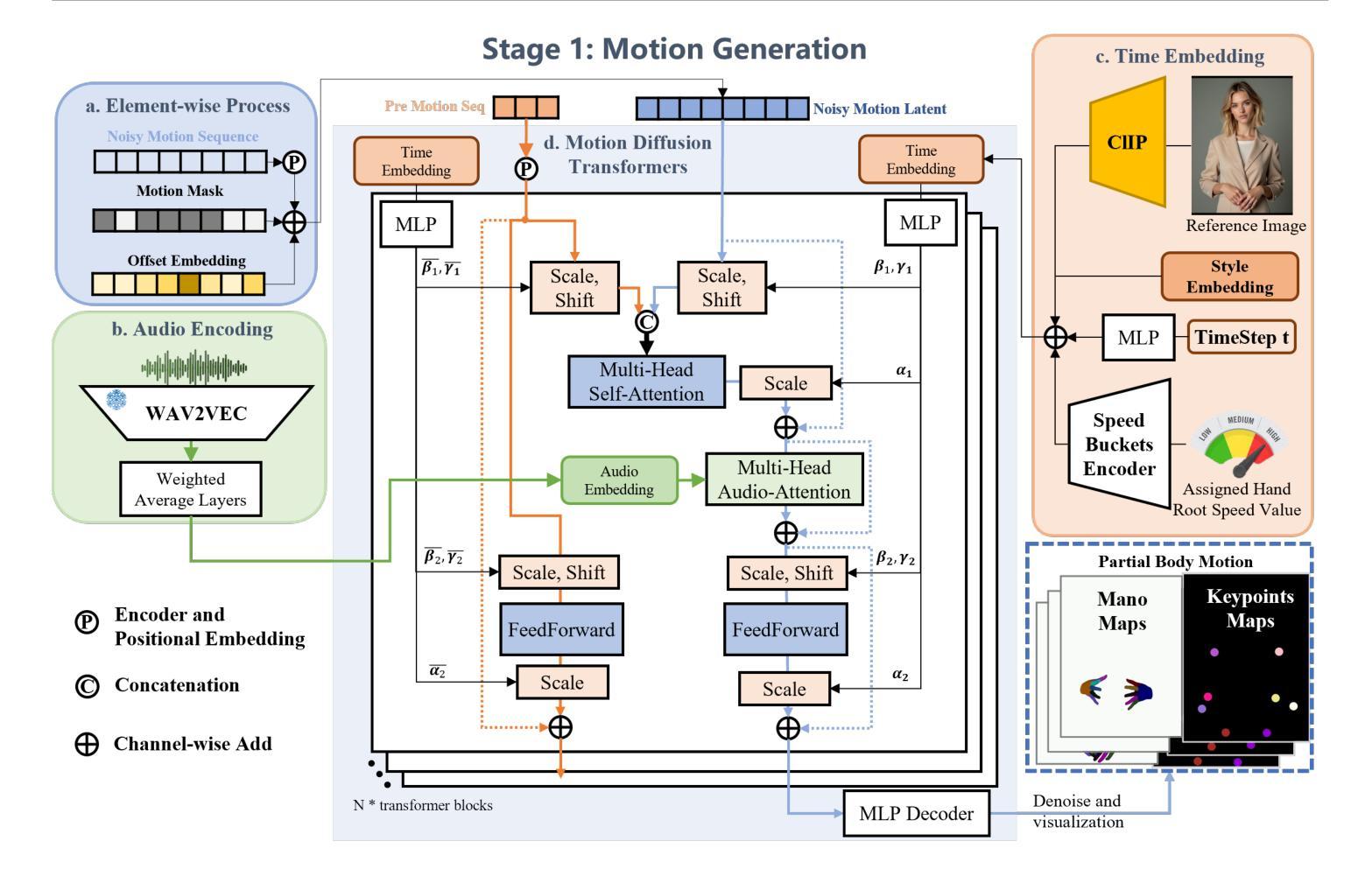
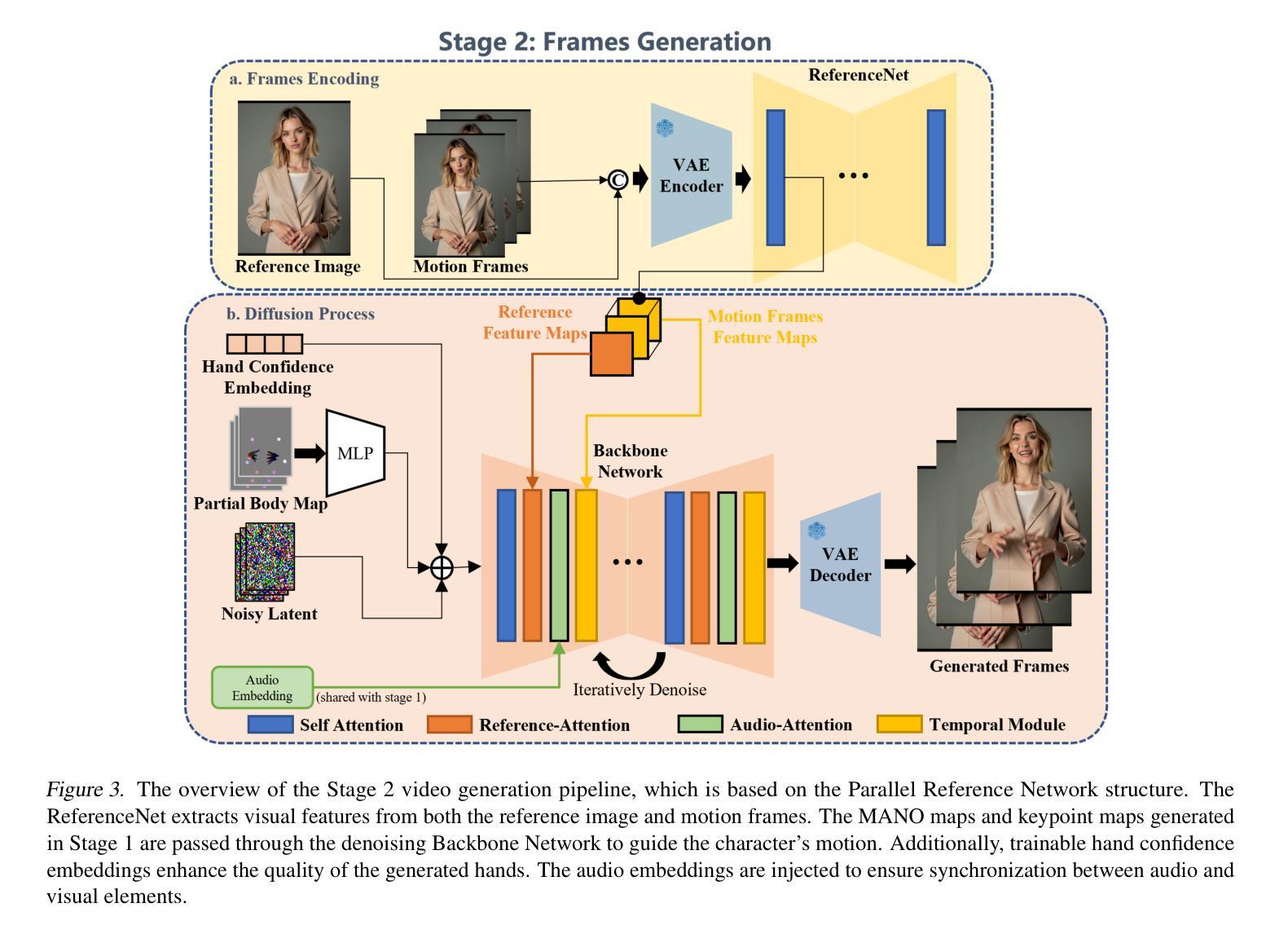
In this paper, we propose a novel audio-driven talking head method capable of simultaneously generating highly expressive facial expressions and hand gestures. Unlike existing methods that focus on generating full-body or half-body poses, we investigate the challenges of co-speech gesture generation and identify the weak correspondence between audio features and full-body gestures as a key limitation. To address this, we redefine the task as a two-stage process. In the first stage, we generate hand poses directly from audio input, leveraging the strong correlation between audio signals and hand movements. In the second stage, we employ a diffusion model to synthesize video frames, incorporating the hand poses generated in the first stage to produce realistic facial expressions and body movements. Our experimental results demonstrate that the proposed method outperforms state-of-the-art approaches, such as CyberHost and Vlogger, in terms of both visual quality and synchronization accuracy. This work provides a new perspective on audio-driven gesture generation and a robust framework for creating expressive and natural talking head animations.
本文提出了一种新型音频驱动的头部分离式方法,可同时生成高度表达的面部表情和手势。不同于现有主要生成全身或半身姿态的方法,我们研究了语音手势生成的挑战,并识别出音频特征与全身手势之间的弱对应性为主要限制。为解决此问题,我们将任务重新定义为两阶段过程。在第一阶段,我们直接从音频输入生成手部姿态,利用音频信号与手部动作之间的强相关性。在第二阶段,我们采用扩散模型合成视频帧,结合第一阶段生成的手部姿态,以产生逼真的面部表情和躯体动作。我们的实验结果表明,所提出的方法在视觉质量和同步准确性方面优于如CyberHost和Vlogger等最新技术方法。这项工作为音频驱动的手势生成提供了新的视角,并为创建表情丰富、自然的头部动画提供了稳健的框架。
论文及项目相关链接
摘要
该文提出了一种新型音频驱动说话人头方法,可同时生成高度表达的面部表情和手势。不同于现有方法主要关注全身或半身姿势的生成,该研究探讨了音频驱动手势生成的挑战,并识别出音频特征与全身手势之间弱对应关系的关键问题。为解决这一问题,研究将任务重新定义为两阶段过程。第一阶段直接从音频输入生成手势,利用音频信号与手部动作之间的强相关性。第二阶段采用扩散模型合成视频帧,结合第一阶段生成的手势,产生逼真的面部表情和身体动作。实验结果表明,该方法在视觉质量和同步准确性方面优于如CyberHost和Vlogger等前沿方法。该研究为音频驱动的手势生成提供了新的视角和稳健的框架,可创建出表达丰富且自然的说话人头动画。
关键见解
- 提出了一种新颖的音频驱动说话人头方法,能同时生成面部表情和手势。
- 识别了现有方法主要关注全身或半身姿势生成的问题,并强调音频驱动手势生成的挑战。
- 发现了音频特征与全身手势之间弱对应关系的关键问题,并重新定义了任务为两阶段过程。
- 第一阶段直接从音频生成手势,利用音频与手部动作的强相关性。
- 第二阶段使用扩散模型合成视频帧,融入手势以产生更逼真的动画效果。
- 实验结果显示该方法在视觉质量和同步准确性上超越现有技术。
点此查看论文截图