⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
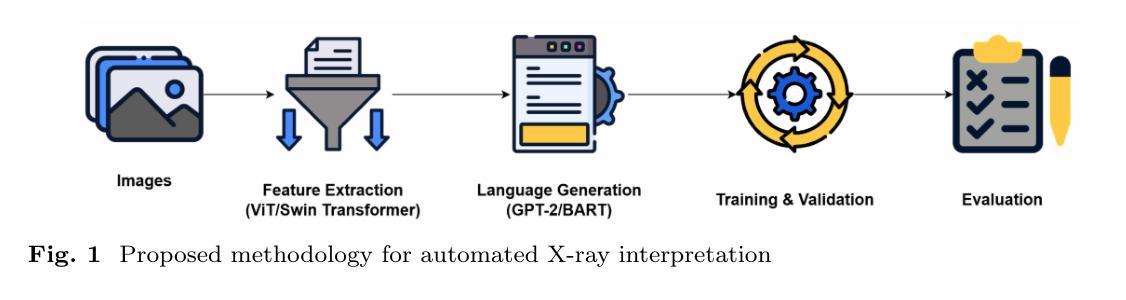
Vision-Language Models for Automated Chest X-ray Interpretation: Leveraging ViT and GPT-2
Authors:Md. Rakibul Islam, Md. Zahid Hossain, Mustofa Ahmed, Most. Sharmin Sultana Samu
Radiology plays a pivotal role in modern medicine due to its non-invasive diagnostic capabilities. However, the manual generation of unstructured medical reports is time consuming and prone to errors. It creates a significant bottleneck in clinical workflows. Despite advancements in AI-generated radiology reports, challenges remain in achieving detailed and accurate report generation. In this study we have evaluated different combinations of multimodal models that integrate Computer Vision and Natural Language Processing to generate comprehensive radiology reports. We employed a pretrained Vision Transformer (ViT-B16) and a SWIN Transformer as the image encoders. The BART and GPT-2 models serve as the textual decoders. We used Chest X-ray images and reports from the IU-Xray dataset to evaluate the usability of the SWIN Transformer-BART, SWIN Transformer-GPT-2, ViT-B16-BART and ViT-B16-GPT-2 models for report generation. We aimed at finding the best combination among the models. The SWIN-BART model performs as the best-performing model among the four models achieving remarkable results in almost all the evaluation metrics like ROUGE, BLEU and BERTScore.
放射学在现代医学中扮演着至关重要的角色,因其具有无创诊断能力。然而,手动生成非结构化医疗报告既耗时又容易出错,这成为了临床工作流程中的重大瓶颈。尽管人工智能生成的放射学报告有所发展,但在实现详细和准确的报告生成方面仍存在挑战。在本研究中,我们评估了结合计算机视觉和自然语言处理的多模态模型的不同组合,以生成全面的放射学报告。我们采用了预训练的Vision Transformer(ViT-B16)和SWIN Transformer作为图像编码器。BART和GPT-2模型则作为文本解码器。我们使用IU-Xray数据集中的胸部X射线图像和报告来评估SWIN Transformer-BART、SWIN Transformer-GPT-2、ViT-B16-BART和ViT-B16-GPT-2模型在报告生成方面的实用性。我们的目标是找到模型之间的最佳组合。在四项模型中,SWIN-BART模型表现最佳,在几乎所有评估指标(如ROUGE、BLEU和BERTScore)上都取得了显著的成绩。
论文及项目相关链接
PDF Preprint, manuscript under-review
Summary
本文研究了利用计算机视觉和自然语言处理的多模态模型生成综合医学影像报告的方法。通过对比使用不同模型的组合,发现SWIN Transformer与BART模型结合表现最佳,在多种评估指标上均表现优异。
Key Takeaways
- 医学影像在现代医学中发挥着重要作用,但手动生成非结构化医学报告耗时且易出错,成为临床工作流程中的瓶颈。
- AI在生成医学影像报告方面虽有进展,但仍面临详细准确报告生成方面的挑战。
- 研究者评估了不同多模态模型组合生成医学影像报告的效果。
- 使用的模型包括预训练的Vision Transformer(ViT-B16)和SWIN Transformer作为图像编码器,以及BART和GPT-2作为文本解码器。
- 研究使用了IU-Xray数据集中的Chest X-ray图像和报告来评估各模型的使用效果。
- SWIN Transformer与BART模型结合表现最佳,在所有评估指标上均表现出最佳性能。
点此查看论文截图

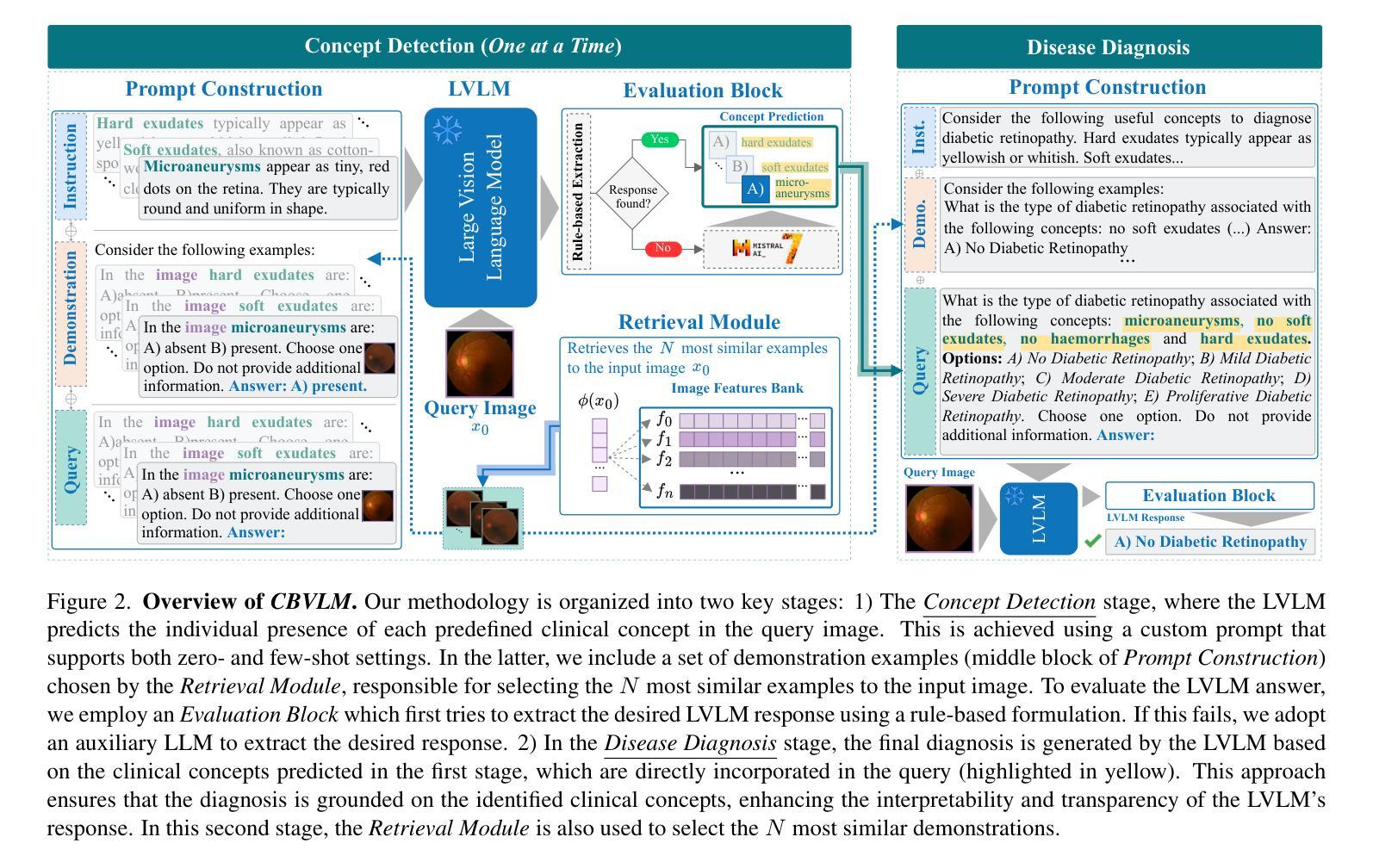
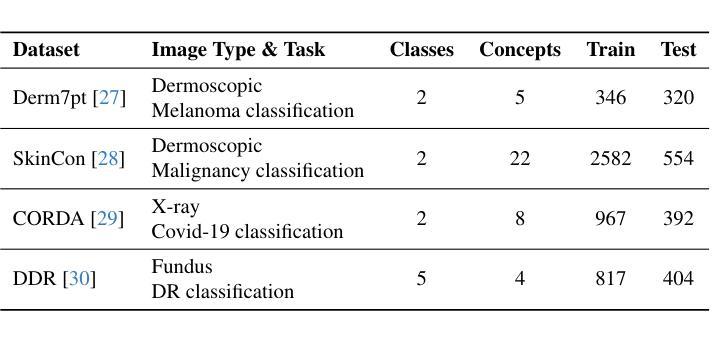
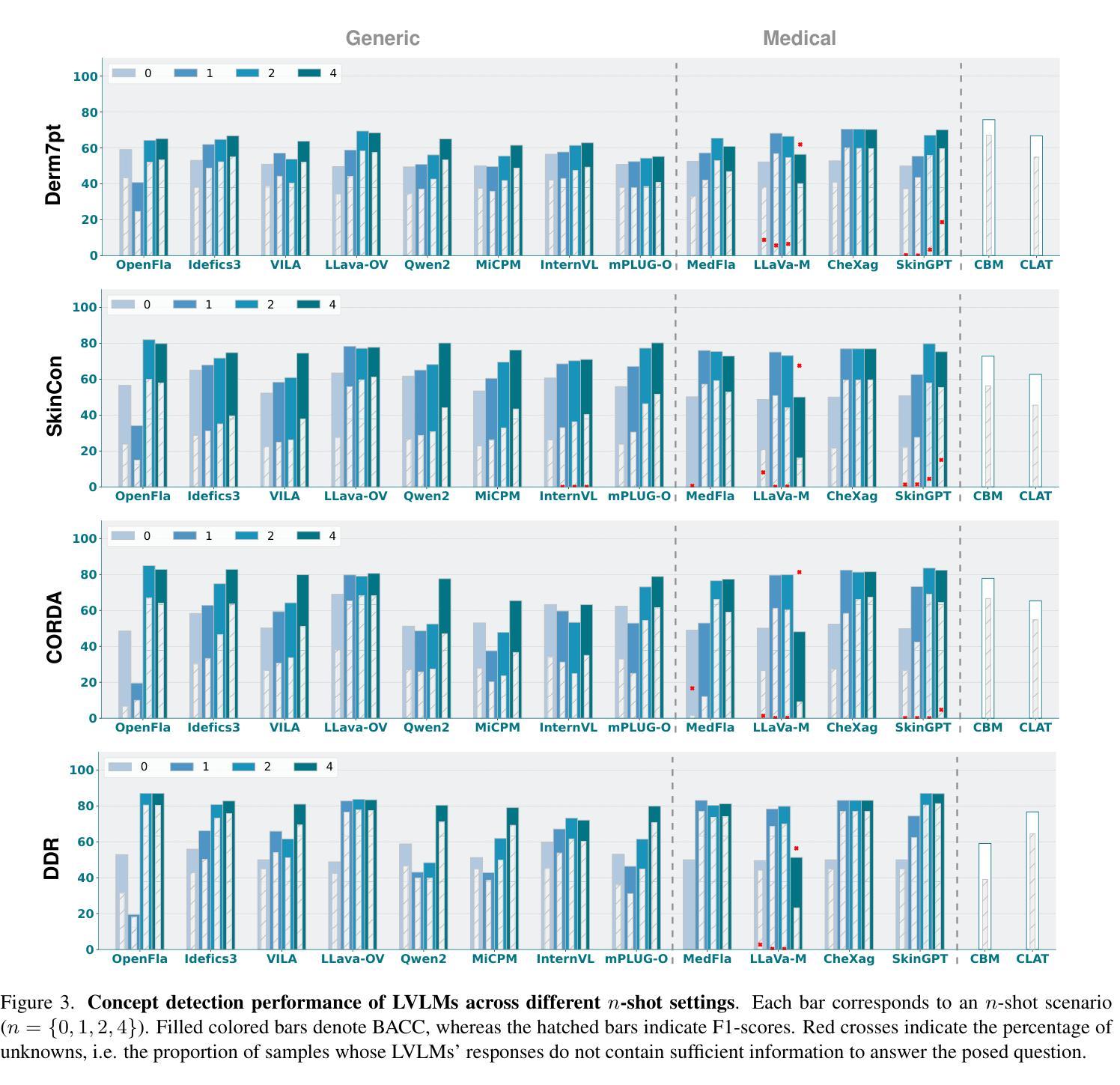
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Authors:Cristiano Patrício, Isabel Rio-Torto, Jaime S. Cardoso, Luís F. Teixeira, João C. Neves
The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
在医疗工作流中采用基于深度学习的解决方案的主要挑战在于标注数据的可用性和系统解释性的缺乏。概念瓶颈模型(CBM)通过约束最终疾病预测在一组预定义和人类可解释的概念上解决后者问题。然而,通过基于概念的解释实现的增加的解释性意味着更高的标注负担。而且,如果需要添加新概念,整个系统需要重新训练。受大型视觉语言模型(LVLM)在少量样本设置中的卓越性能的启发,我们提出了一种简单而有效的方法,即CBVLM,它解决了上述两个挑战。首先,对于每个概念,我们提示LVLM回答概念是否出现在输入图像中。然后,我们让LVLM基于先前的概念预测对图像进行分类。而且,在两个阶段中,我们引入了负责选择最佳上下文学习例子的检索模块。通过将最终诊断建立在预测的概念上,我们确保了可解释性,并通过利用LVLM的少量样本能力,我们大大降低了标注成本。我们通过四个医疗数据集和十二个(通用和医疗)LVLM的广泛实验验证了我们的方法,并表明CBVLM始终优于CBM和特定任务监督方法,且无需任何训练,只需使用少量标注例子。更多信息请参见我们的项目页面:https://cristianopatricio.github.io/CBVLM/。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
Summary
本文提出了一个名为CBVLM的方法,旨在解决深度学习在医学工作流中的两大挑战:标注数据的可用性和系统解释性的缺乏。通过利用大型视觉语言模型(LVLMs)的少样本学习能力,CBVLM不仅提高了系统的解释性,而且降低了标注成本。在四个医学数据集上的实验表明,CBVLM在不需要任何训练和只需少量标注样本的情况下,始终优于概念瓶颈模型(CBMs)和任务特定的监督方法。
Key Takeaways
- CBVLM方法解决了深度学习在医学领域面临的标注数据可用性和系统解释性挑战。
- CBVLM利用大型视觉语言模型(LVLMs)的少样本学习能力。
- CBVLM通过概念预测和图像分类,提高了系统的解释性。
- CBVLM通过检索模块选择最佳上下文学习样本。
- CBVLM方法在四个医学数据集上的实验表现优异,优于概念瓶颈模型(CBMs)和任务特定的监督方法。
- CBVLM方法不需要任何训练,且使用少量标注样本即可实现高性能。
点此查看论文截图

Early Detection and Classification of Breast Cancer Using Deep Learning Techniques
Authors:Mst. Mumtahina Labonno, D. M. Asadujjaman, Md. Mahfujur Rahman, Abdullah Tamim, Mst. Jannatul Ferdous, Rafi Muttaki Mahi
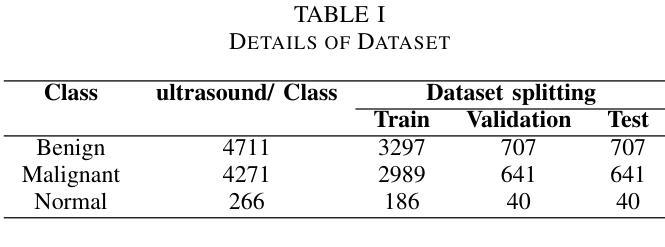
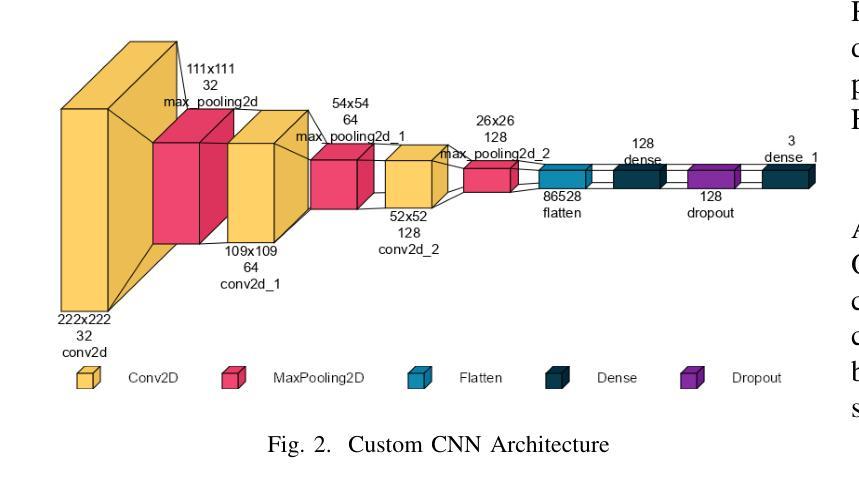
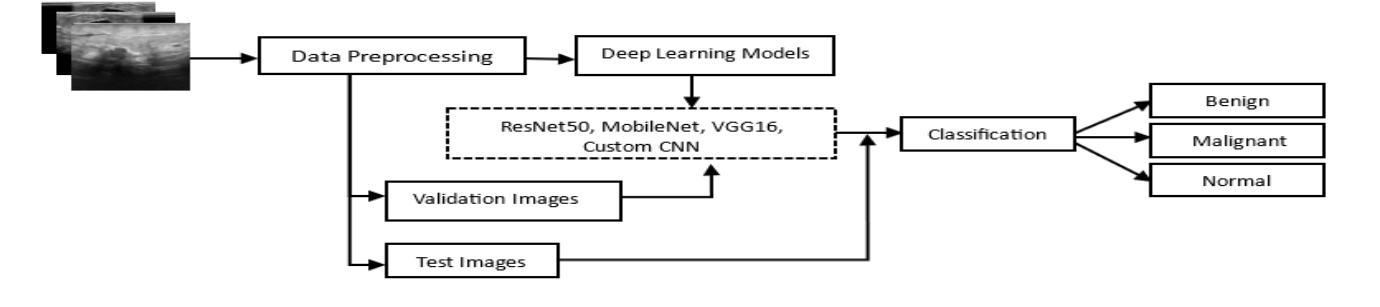
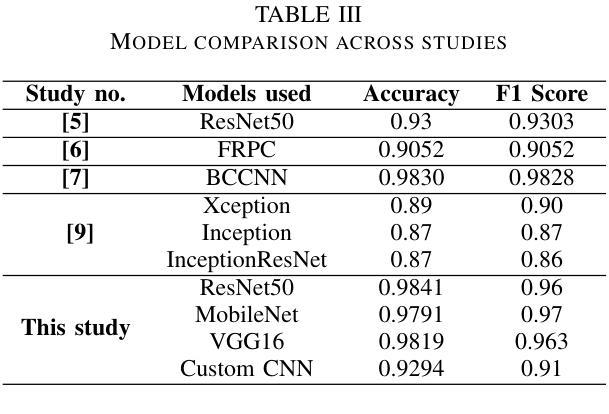
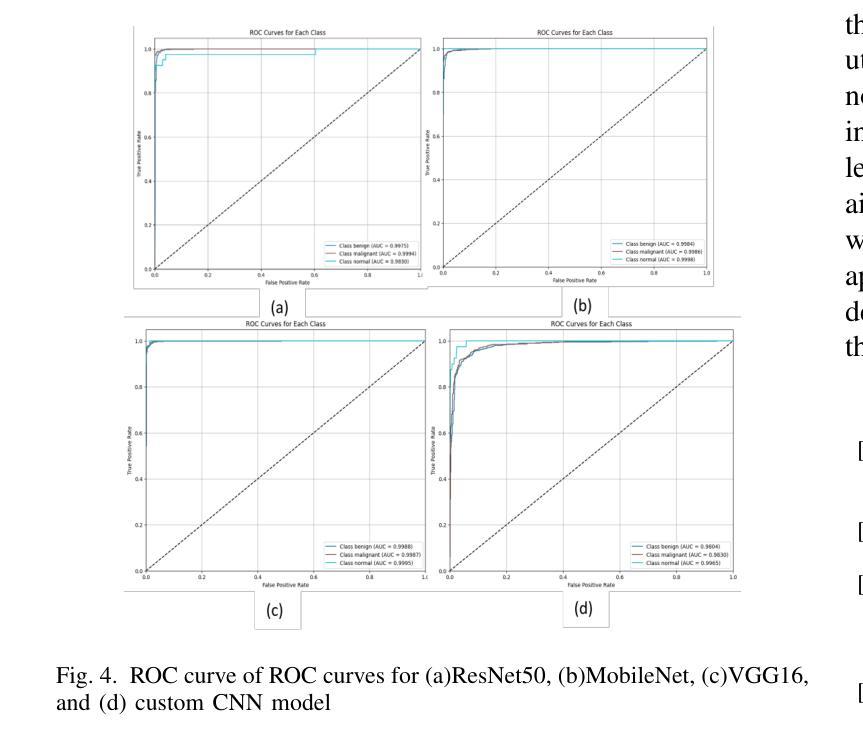
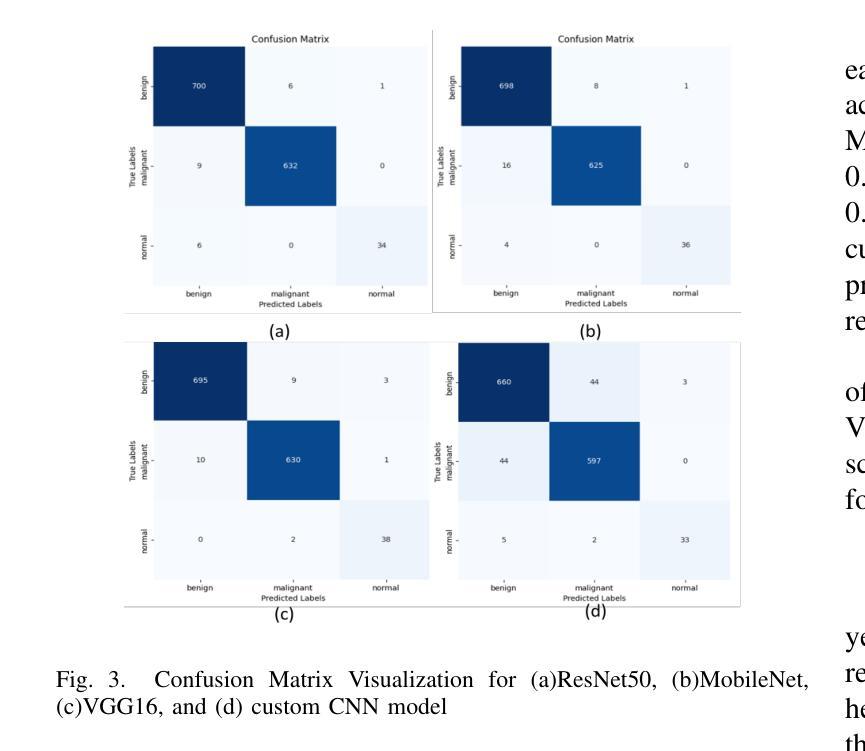
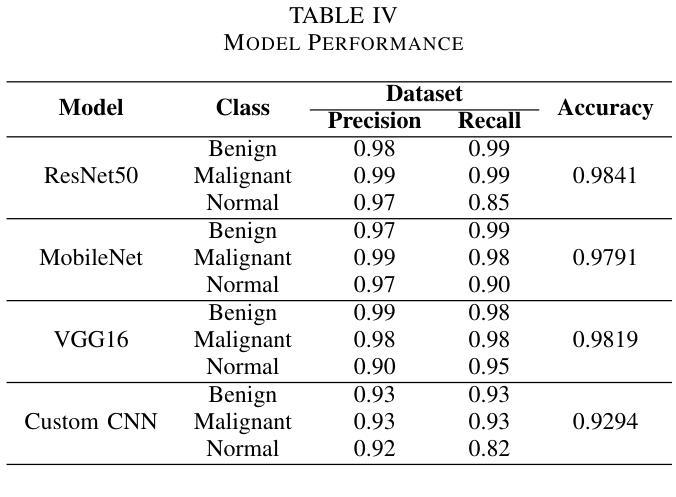
Breast cancer is one of the deadliest cancers causing about massive number of patients to die annually all over the world according to the WHO. It is a kind of cancer that develops when the tissues of the breast grow rapidly and unboundly. This fatality rate can be prevented if the cancer is detected before it gets malignant. Using automation for early-age detection of breast cancer, Artificial Intelligence and Machine Learning technologies can be implemented for the best outcome. In this study, we are using the Breast Cancer Image Classification dataset collected from the Kaggle depository, which comprises 9248 Breast Ultrasound Images and is classified into three categories: Benign, Malignant, and Normal which refers to non-cancerous, cancerous, and normal images.This research introduces three pretrained model featuring custom classifiers that includes ResNet50, MobileNet, and VGG16, along with a custom CNN model utilizing the ReLU activation function.The models ResNet50, MobileNet, VGG16, and a custom CNN recorded accuracies of 98.41%, 97.91%, 98.19%, and 92.94% on the dataset, correspondingly, with ResNet50 achieving the highest accuracy of 98.41%.This model, with its deep and powerful architecture, is particularly successful in detecting aberrant cells as well as cancerous or non-cancerous tumors. These accuracies show that the Machine Learning methods are more compatible for the classification and early detection of breast cancer.
乳腺癌是致死率较高的癌症之一,世界卫生组织报告称其每年导致大量患者死亡。它是一种乳房组织快速且无限制增长形成的癌症。如果在癌症恶化之前检测到,可以避免这种高死亡率。使用自动化技术进行乳腺癌的早期检测,应用人工智能和机器学习技术可以获得最佳效果。在这项研究中,我们使用从Kaggle存储库中收集的乳腺癌图像分类数据集,该数据集包含9248张乳腺超声图像,分为三类:良性、恶性和正常(指非癌性、癌性和正常图像)。本研究介绍了三个预训练模型,包括带有自定义分类器的ResNet50、MobileNet和VGG16,以及使用ReLU激活函数的自定义CNN模型。ResNet50、MobileNet、VGG16和自定义CNN在数据集上的准确率分别为98.41%、97.91%、98.19%和92.94%,其中ResNet50的准确率最高,达到98.41%。该模型具有深度和强大的架构,特别擅长检测异常细胞以及癌性或非癌性肿瘤。这些准确率表明,机器学习方法在乳腺癌分类和早期检测方面更具兼容性。
论文及项目相关链接
Summary
乳腺癌是一种致死率较高的癌症,世界卫生组织数据显示其每年导致大量患者死亡。为尽早发现乳腺癌,可使用自动化检测手段,借助人工智能和机器学习技术达到最佳效果。本研究采用乳腺癌图像分类数据集,包含良性、恶性及正常三类乳腺超声图像共9248张,通过运用ResNet50、MobileNet、VGG16三种预训练模型和自定义分类器,以及使用ReLU激活函数的自定义CNN模型进行分类,准确率分别为98.41%、97.91%、98.19%和92.94%,其中ResNet50模型准确率最高,达到98.41%,可成功检测异常细胞及癌性或非癌性肿瘤。这些准确率表明机器学习方法在乳腺癌分类和早期检测方面更具优势。
Key Takeaways
1. 乳腺癌是一种致死率较高的癌症,每年导致大量患者死亡。
2. 人工智能和机器学习技术可用于早期发现乳腺癌,有助于提高治愈率。
3. 本研究采用了包含良性、恶性及正常乳腺超声图像的数据集进行分类研究。
4. ResNet50、MobileNet、VGG16预训练模型和自定义CNN模型用于分类研究。
5. ResNet50模型在乳腺癌图像分类中准确率最高,达到98.41%。
6. 机器学习方法在乳腺癌分类和早期检测方面表现出更高的准确性。
点此查看论文截图

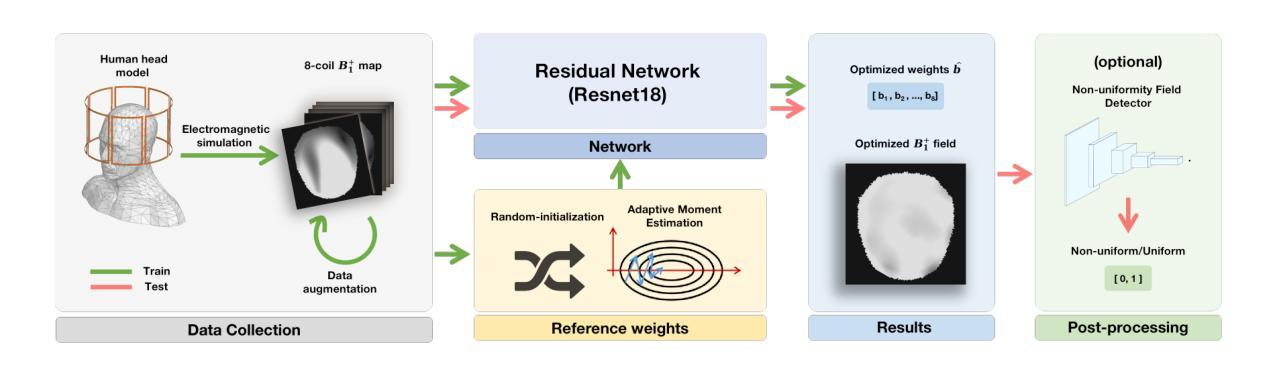
Fast-RF-Shimming: Accelerate RF Shimming in 7T MRI using Deep Learning
Authors:Zhengyi Lu, Hao Liang, Ming Lu, Xiao Wang, Xinqiang Yan, Yuankai Huo
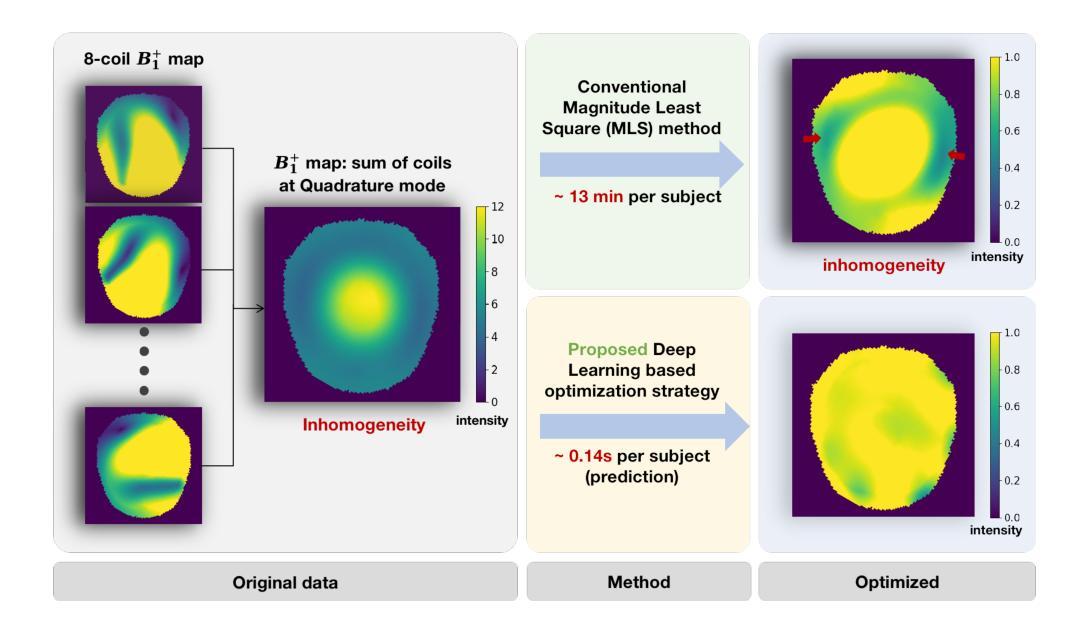
Ultrahigh field (UHF) Magnetic Resonance Imaging (MRI) provides a high signal-to-noise ratio (SNR), enabling exceptional spatial resolution for clinical diagnostics and research. However, higher fields introduce challenges such as transmit radiofrequency (RF) field inhomogeneities, which result in uneven flip angles and image intensity artifacts. These artifacts degrade image quality and limit clinical adoption. Traditional RF shimming methods, including Magnitude Least Squares (MLS) optimization, mitigate RF field inhomogeneity but are time-intensive and often require the presence of the patient. Recent machine learning methods, such as RF Shim Prediction by Iteratively Projected Ridge Regression and other deep learning architectures, offer alternative approaches but face challenges such as extensive training requirements, limited complexity, and practical data constraints. This paper introduces a holistic learning-based framework called Fast RF Shimming, which achieves a 5000-fold speedup compared to MLS methods. First, random-initialized Adaptive Moment Estimation (Adam) derives reference shimming weights from multichannel RF fields. Next, a Residual Network (ResNet) maps RF fields to shimming outputs while incorporating a confidence parameter into the loss function. Finally, a Non-uniformity Field Detector (NFD) identifies extreme non-uniform outcomes. Comparative evaluations demonstrate significant improvements in both speed and predictive accuracy. The proposed pipeline also supports potential extensions, such as the integration of anatomical priors or multi-echo data, to enhance the robustness of RF field correction. This approach offers a faster and more efficient solution to RF shimming challenges in UHF MRI.
超高场(UHF)磁共振成像(MRI)具有高信噪比(SNR),为临床诊断和治疗提供了卓越的空间分辨率。然而,更高的磁场引入了传输射频(RF)场不均匀性的挑战,这会导致翻转角度不均匀和图像强度伪影。这些伪影会降低图像质量并限制其临床采用。传统的射频补偿方法,包括幅度最小二乘法(MLS)优化,可以缓解射频场的不均匀性,但耗时且需要患者参与。最近的机器学习方法,如通过迭代投影岭回归进行射频补偿预测和其他深度学习架构,提供了替代方法,但面临训练需求大、复杂性有限和实际数据约束等挑战。本文介绍了一种基于学习的全面框架,称为快速射频补偿(Fast RF Shimming),与MLS方法相比,实现了5000倍的速度提升。首先,使用随机初始化的自适应矩估计(Adam)从多通道射频场导出参考补偿权重。接下来,残差网络(ResNet)将射频场映射到补偿输出,同时将置信参数纳入损失函数。最后,非均匀场检测器(NFD)识别出极端的非均匀结果。比较评估表明,在速度和预测精度方面都有显著提高。该管道还支持潜在的扩展,如整合先验解剖信息或多回声数据,以增强射频场校正的稳健性。该方法为解决超高场MRI中射频补偿的挑战提供了更快、更高效的解决方案。
论文及项目相关链接
Summary
超高频磁共振成像(UHF MRI)具有高的信噪比,为临床诊断和治疗提供了卓越的空间分辨率。然而,高场引入的射频场不均匀性等问题会导致图像质量下降。本文提出了一种基于学习的快速射频匀场框架,实现了与传统MLS方法相比高达5000倍的速度提升。该框架利用Adam算法推导参考匀场权重,结合ResNet进行射频场到匀场输出的映射,并引入置信参数到损失函数中。同时,采用非均匀场检测器识别极端非均匀结果。该方法在速度和预测精度上都有显著提升,并支持潜在扩展,如结合解剖学先验或多回声数据,提高射频场校正的稳健性。
Key Takeaways
- UHF MRI提供了高的信噪比和卓越的空间分辨率,但高场带来的射频场不均匀性降低了图像质量。
- 传统RF shimming方法(如MLS优化)虽然有效,但耗时且需要患者参与。
- 机器学习方法为RF shim预测提供了新的途径,但仍面临训练要求高、模型复杂度和实际数据约束等挑战。
- 本文提出的Fast RF Shimming框架实现了快速匀场,相比MLS方法有显著的速度提升。
- 该框架利用Adam算法和ResNet模型进行匀场权重推导和射频场到匀场输出的映射。
- 置信参数被引入损失函数中,同时采用非均匀场检测器识别极端非均匀结果。
点此查看论文截图

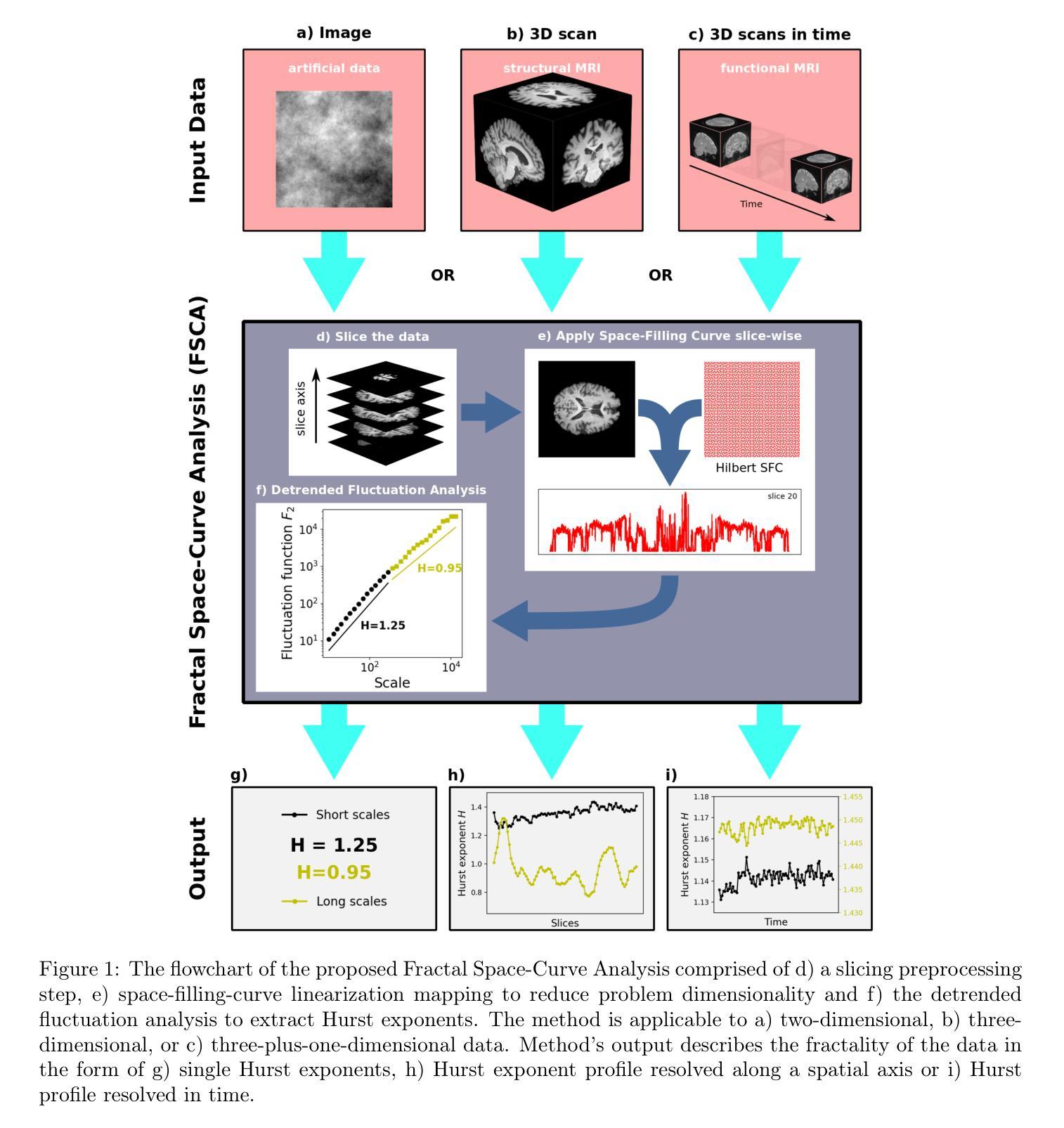
Using Space-Filling Curves and Fractals to Reveal Spatial and Temporal Patterns in Neuroimaging Data
Authors:Jacek Grela, Zbigniew Drogosz, Jakub Janarek, Jeremi K. Ochab, Ignacio Cifre, Ewa Gudowska-Nowak, Maciej A. Nowak, Paweł Oświęcimka, Dante R. Chialvo
We present a novel method, Fractal Space-Curve Analysis (FSCA), which combines Space-Filling Curve (SFC) mapping for dimensionality reduction with fractal Detrended Fluctuation Analysis (DFA). The method is suitable for multidimensional geometrically embedded data, especially for neuroimaging data which is highly correlated temporally and spatially. We conduct extensive feasibility studies on diverse, artificially generated data with known fractal characteristics: the fractional Brownian motion, Cantor sets, and Gaussian processes. We compare the suitability of dimensionality reduction via Hilbert SFC and a data-driven alternative. FSCA is then successfully applied to real-world magnetic resonance imaging (MRI) and functional MRI (fMRI) scans. The method utilizing Hilbert curves is optimized for computational efficiency, proven robust against boundary effects typical in experimental data analysis, and resistant to data sub-sampling. It is able to correctly quantify and discern correlations in both stationary and dynamic two-dimensional images. In MRI Alzheimer’s dataset, patients reveal a progression of the disease associated with a systematic decrease of the Hurst exponent. In fMRI recording of breath-holding task, the change in the exponent allows distinguishing different experimental phases. This study introduces a robust method for fractal characterization of spatial and temporal correlations in many types of multidimensional neuroimaging data. Very few assumptions allow it to be generalized to more dimensions than typical for neuroimaging and utilized in other scientific fields. The method can be particularly useful in analyzing fMRI experiments to compute markers of pathological conditions resulting from neurodegeneration. We also showcase its potential for providing insights into brain dynamics in task-related experiments.
我们提出了一种新颖的方法,即分形空间曲线分析(FSCA),它将空间填充曲线(SFC)映射用于降维和分形去趋势波动分析(DFA)相结合。该方法适用于多维几何嵌入数据,尤其适用于在时间上和空间上高度相关神经成像数据。我们对具有已知分形特征的人工生成数据进行了广泛的可行性研究,包括布朗运动分数、康托尔集和高斯过程。我们比较了通过希尔伯特SFC进行降维和数据驱动替代方案的适用性。然后,FSCA成功应用于现实世界中的磁共振成像(MRI)和功能磁共振成像(fMRI)扫描。使用希尔伯特曲线的方法在计算效率上进行了优化,对实验数据分析中典型的边界效应具有鲁棒性,并且能抵抗数据子采样。它能够正确量化和区分静态和动态二维图像中的相关性。在MRI的阿尔茨海默病数据集中,患者显示出疾病进展与赫斯特指数系统降低有关。在呼吸保持任务的fMRI记录中,指数的变化能够区分不同的实验阶段。该研究为多种类型的多维神经成像数据的时空相关性提供了稳健的分形表征方法。很少的假设使得它可以推广到神经成像的典型维度之外并在其他科学领域中使用。该方法在分析和计算神经退行性病变引起的病理状况的标记物方面特别有用,特别是在分析fMRI实验时。我们还展示了其在任务相关实验中了解大脑动力学的潜力。
论文及项目相关链接
PDF Grela, J., Drogosz, Z., Janarek, J., Ochab, J.K., Cifre, I., Gudowska-Nowak, E., Nowak, M.A., Oswiecimka, P., Chialvo, D., 2025. Using space-filling curves and fractals to reveal spatial and temporal patterns in neuroimaging data. J. Neural Eng. [accepted] https://doi.org/10.1088/1741-2552/ada705
Summary
提出一种新颖的方法——分形空间曲线分析(FSCA),结合空间填充曲线(SFC)映射进行降维和分形去趋势波动分析(DFA),适用于多维几何嵌入数据,尤其适用于具有时间和空间高度相关性的神经成像数据。对分形布朗运动、康托尔集和高斯过程等具有已知分形特征的人工生成数据进行了可行性研究。该方法优化计算效率,抵抗边界效应及数据子采样,在静态和动态二维图像中都能准确量化并辨别关联。应用于阿尔茨海默病MRI数据集和呼吸保持任务fMRI记录中,Hurst指数变化有助于鉴别不同实验阶段和病理状况。该方法可广泛应用于其他科学领域的多维神经成像数据空间和时间关联的分形表征,尤其在分析fMRI实验以计算神经退行性疾病的病理标志物方面具有重要潜力。
Key Takeaways
- 提出了一种新颖的方法——分形空间曲线分析(FSCA),结合了空间填充曲线映射与分形波动分析,适用于多维数据。
- 对多种人工生成数据进行了可行性研究,验证了该方法在分形特征数据上的表现。
- 优化了计算效率,能够抵抗边界效应和数据子采样。
- 在MRI和fMRI数据中成功应用,展示了其在量化疾病进程和区分实验阶段方面的潜力。
- 通过Hurst指数的变化能够鉴别不同的病理状况和实验阶段。
- 可广泛应用于其他科学领域的多维神经成像数据分形表征。
点此查看论文截图

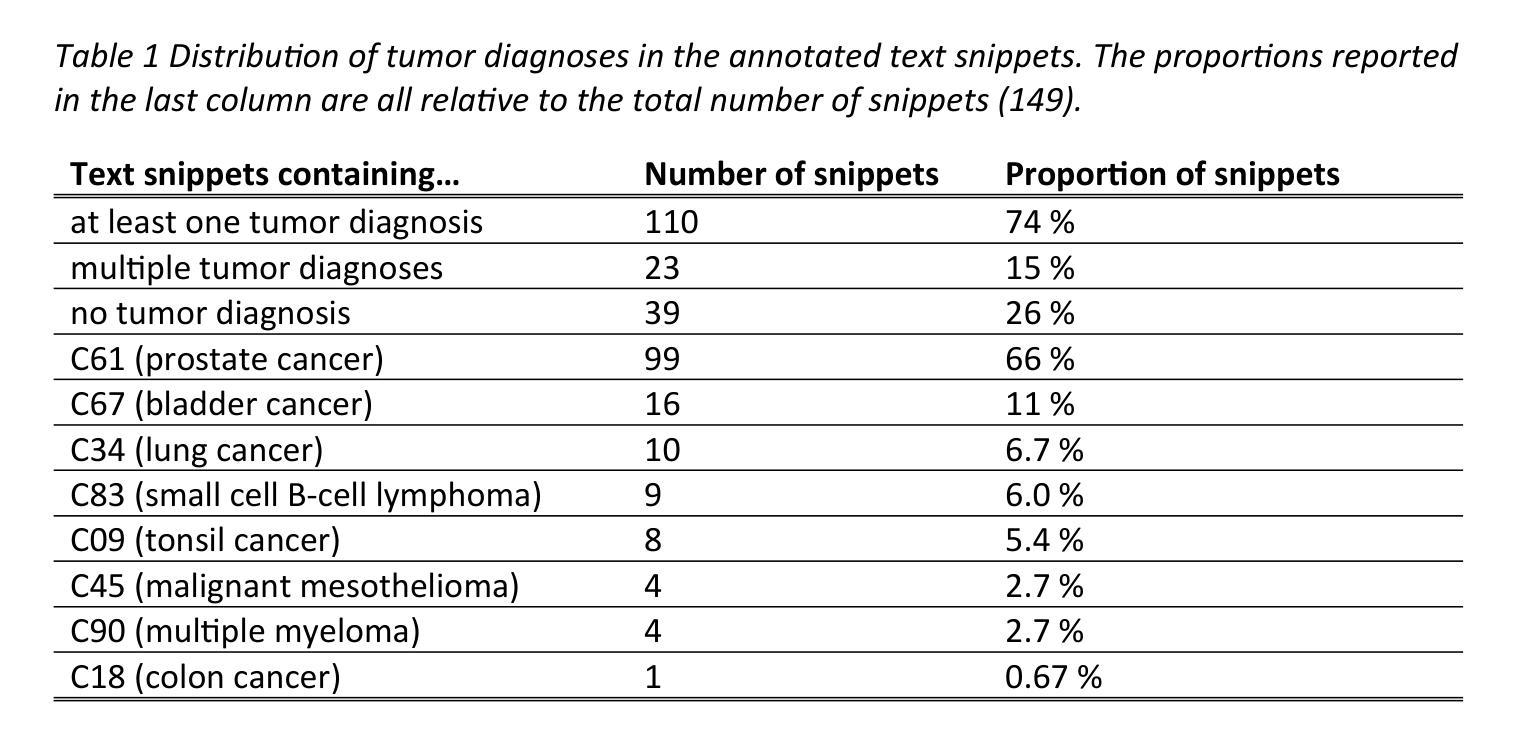
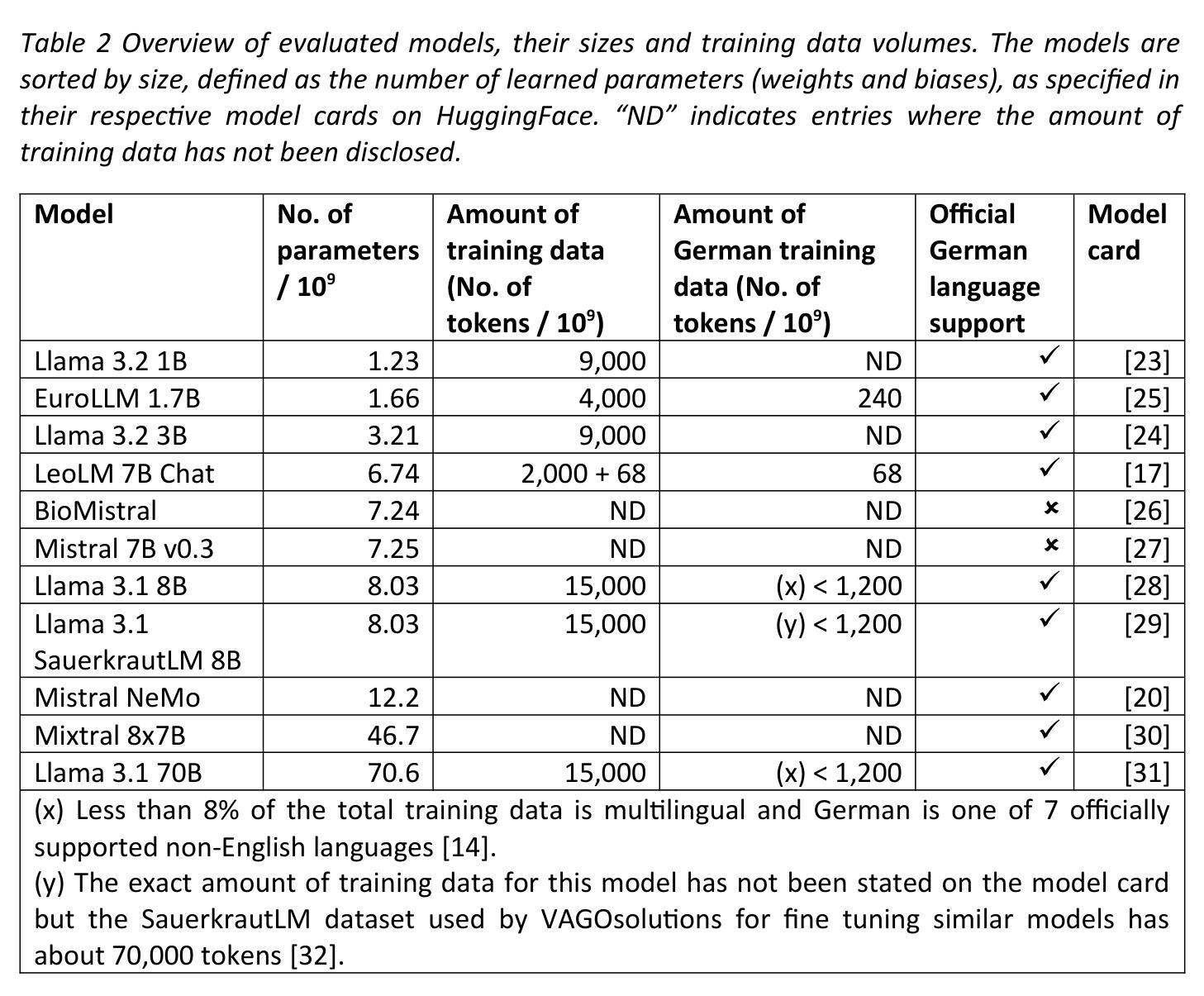
Can open source large language models be used for tumor documentation in Germany? – An evaluation on urological doctors’ notes
Authors:Stefan Lenz, Arsenij Ustjanzew, Marco Jeray, Torsten Panholzer
Tumor documentation in Germany is largely done manually, requiring reading patient records and entering data into structured databases. Large language models (LLMs) could potentially enhance this process by improving efficiency and reliability. This evaluation tests eleven different open source LLMs with sizes ranging from 1-70 billion model parameters on three basic tasks of the tumor documentation process: identifying tumor diagnoses, assigning ICD-10 codes, and extracting the date of first diagnosis. For evaluating the LLMs on these tasks, a dataset of annotated text snippets based on anonymized doctors’ notes from urology was prepared. Different prompting strategies were used to investigate the effect of the number of examples in few-shot prompting and to explore the capabilities of the LLMs in general. The models Llama 3.1 8B, Mistral 7B, and Mistral NeMo 12 B performed comparably well in the tasks. Models with less extensive training data or having fewer than 7 billion parameters showed notably lower performance, while larger models did not display performance gains. Examples from a different medical domain than urology could also improve the outcome in few-shot prompting, which demonstrates the ability of LLMs to handle tasks needed for tumor documentation. Open source LLMs show a strong potential for automating tumor documentation. Models from 7-12 billion parameters could offer an optimal balance between performance and resource efficiency. With tailored fine-tuning and well-designed prompting, these models might become important tools for clinical documentation in the future. The code for the evaluation is available from https://github.com/stefan-m-lenz/UroLlmEval. We also release the dataset as a new valuable resource that addresses the shortage of authentic and easily accessible benchmarks in German-language medical NLP.
在德国,肿瘤记录工作大多以手动方式进行,需要阅读患者病历并将数据输入结构化数据库。大型语言模型(LLMs)有潜力通过提高效率和可靠性来增强这一流程。本次评估对三种基本任务(识别肿瘤诊断、分配ICD-10代码和提取首次诊断日期)上,测试了规模从1亿至70亿模型参数的11个不同开源LLMs。为了评估这些LLMs在这些任务上的表现,准备了一份基于泌尿科匿名医生笔记的注释文本片段数据集。使用了不同的提示策略来研究少量提示中示例数量的影响,并探索LLMs的一般能力。Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B等模型在这些任务中表现良好。训练数据较少的模型或参数少于7亿的模型表现明显较差,而较大的模型并未显示出性能提升。来自泌尿科以外的其他医学领域的例子也能在少量提示中改善结果,这证明了LLMs处理肿瘤记录所需任务的能力。开源LLMs在自动进行肿瘤记录方面显示出强大的潜力。参数在7亿至12亿之间的模型可能在性能和资源效率之间达到最佳平衡。通过定制微调以及精心设计提示,这些模型有可能成为未来临床记录的重要工具。评估的代码可从https://github.com/stefan-m-lenz/UroLlmEval获取。我们还发布了该数据集,作为解决德国医学NLP中真实、易于访问的基准测试资源短缺问题的一个新的有价值资源。
论文及项目相关链接
PDF 48 pages, 5 figures
Summary
本文探讨了大型语言模型(LLMs)在肿瘤记录自动化方面的潜力。通过对11种不同规模(从1亿到70亿参数)的开源LLMs进行评价,发现它们在肿瘤诊断识别、ICD-10代码分配和首次诊断日期提取等任务中表现出良好的性能。模型参数在7-12亿之间的模型在性能和资源效率之间达到了平衡。通过微调和完善提示,这些模型有潜力成为未来临床文档管理的重要工具。
Key Takeaways
- 大型语言模型(LLMs)可提升肿瘤记录过程的效率和可靠性。
- 对11种不同规模的开源LLMs进行了评价,涉及任务包括肿瘤诊断识别、ICD-10代码分配和首次诊断日期提取。
- LLMs在少样本提示下的表现受示例数量和医学领域多样性的影响。
- 参数在7-12亿之间的模型在性能和资源效率之间达到平衡。
- 定制微调和完善提示可使这些模型成为未来临床文档管理的重要工具。
- 公开的数据集解决了德国医学NLP领域中真实、易访问基准测试数据的短缺问题。
点此查看论文截图

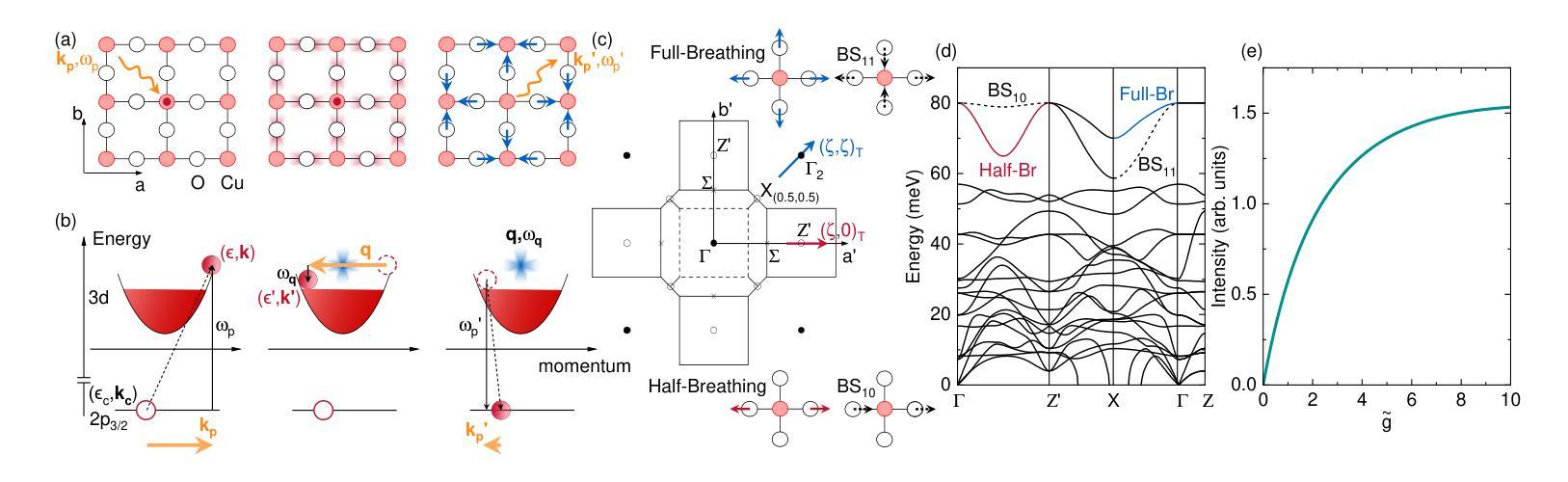
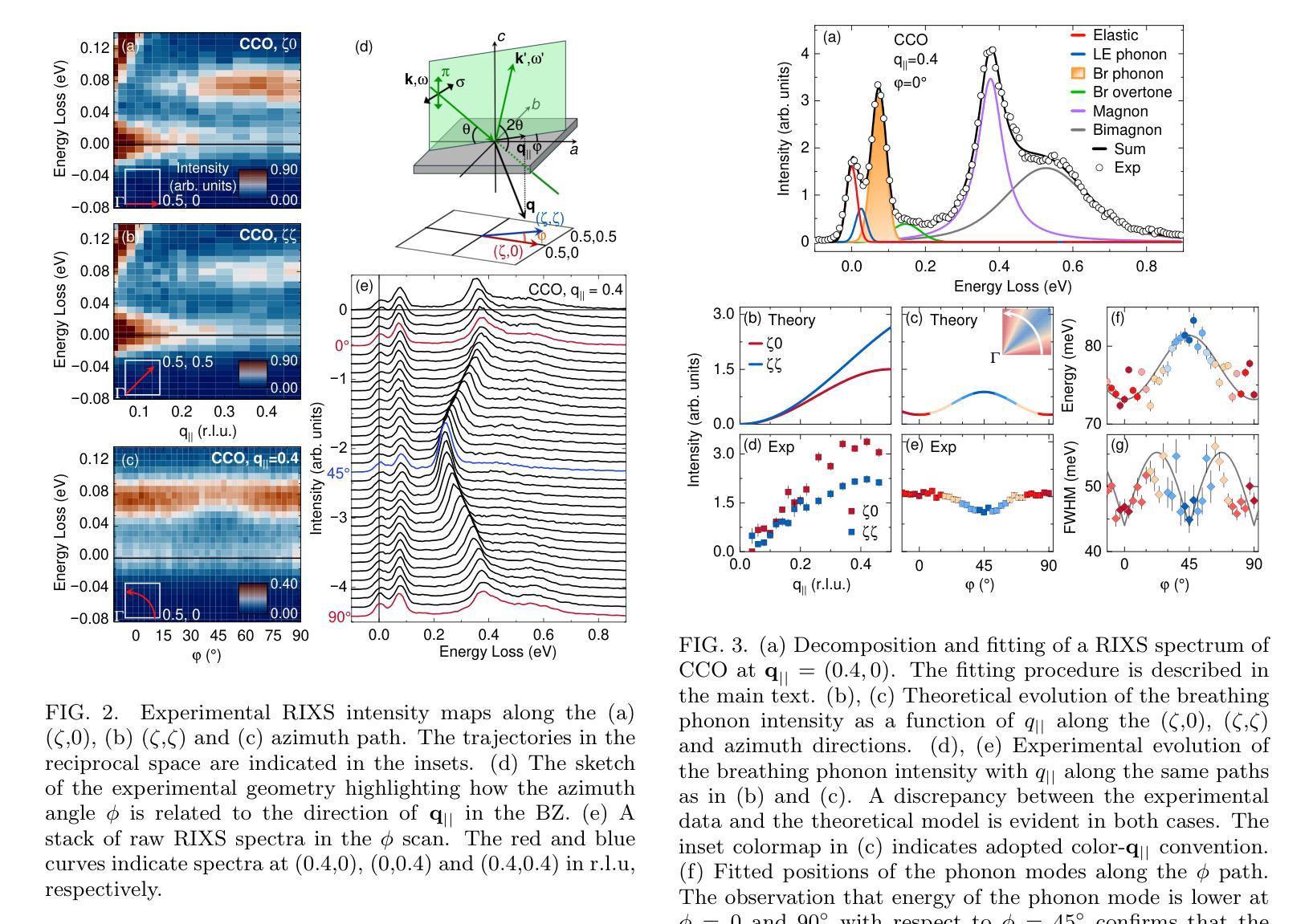
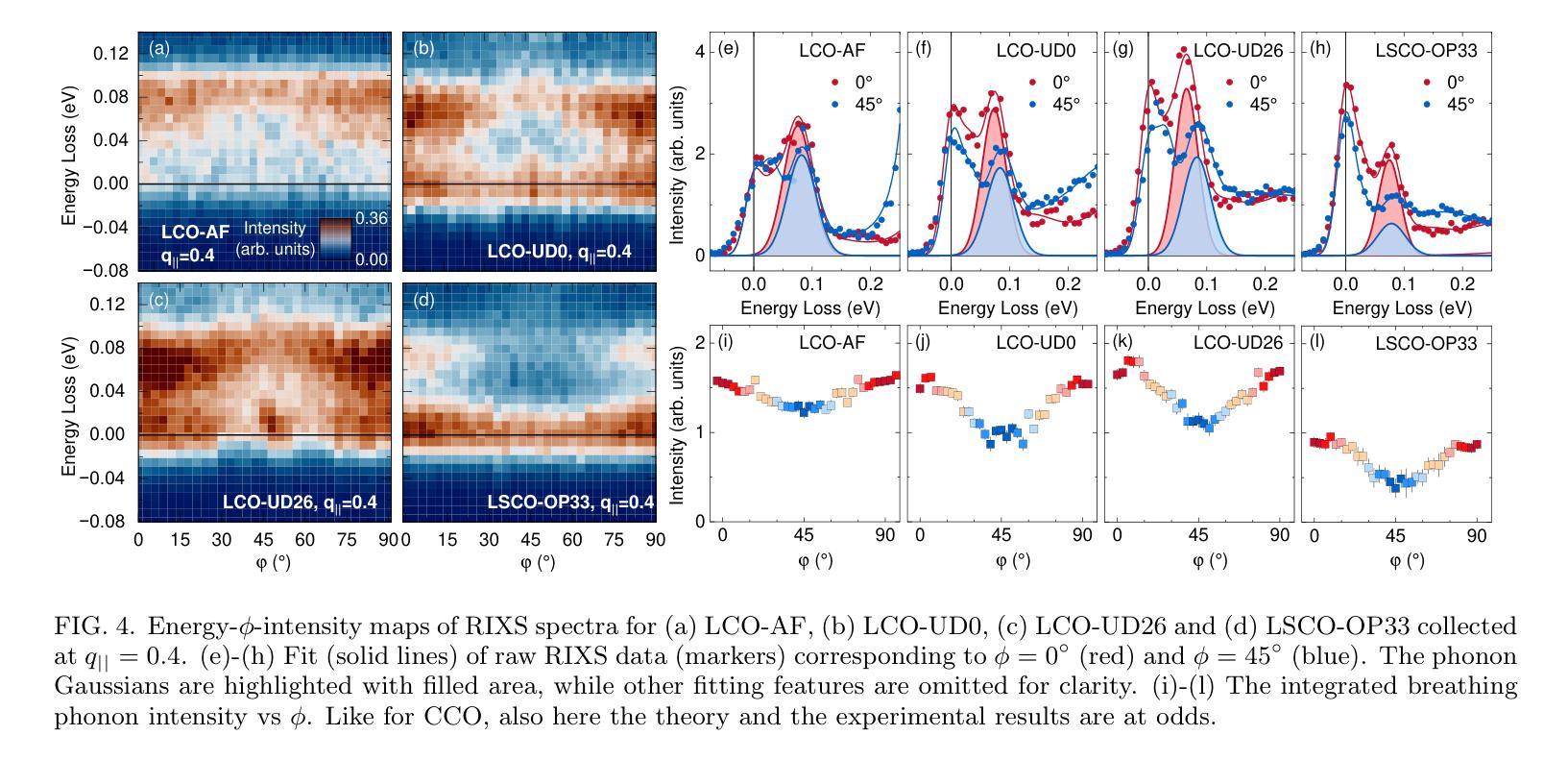
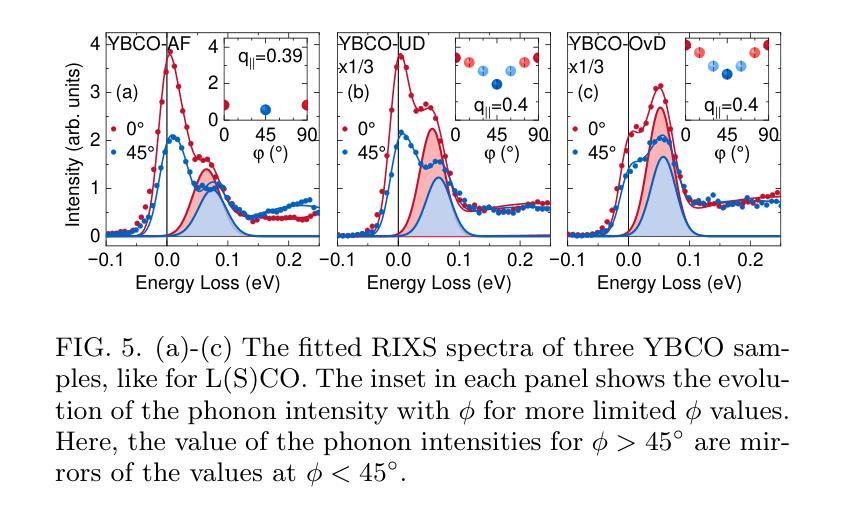
Momentum-dependent electron-phonon coupling in cuprates by RIXS: the roles of phonon symmetry and electronic structure
Authors:Maryia Zinouyeva, Rolf Heid, Giacomo Merzoni, Riccardo Arpaia, Nikolai Andreev, Marco Biagi, Nicholas B. Brookes, Daniele Di Castro, Alexei Kalaboukhov, Kurt Kummer, Floriana Lombardi, Leonardo Martinelli, Francesco Rosa, Flora Yakhou-Harris, Lucio Braicovich, Marco Moretti Sala, Paolo G. Radaelli, Giacomo Ghiringhelli
The experimental determination of the magnitude and momentum dependence of electron-phonon coupling (EPC) is an outstanding problem in condensed matter physics. Resonant inelastic x-ray scattering (RIXS) has been previously employed to determine the EPC, since the intensity of phonon peaks in RIXS spectra has been directly related to the underlying EPC strength. In order to assess the limits of validity of such a relation, we compare experimental results and theoretical predictions for several high-T$c$ superconducting cuprates. Namely, we investigate the intensity of the bond-stretching phonon mode in CaCuO$2$, La$2$CuO${4+\delta}$, La${1.84}$Sr${0.16}$CuO$_4$ and YBa$_2$Cu$3$O${7-\delta}$ along the high symmetry ($\zeta$,0), ($\zeta$,$\zeta$) directions and as a function of the azimuthal angle $\phi$ at fixed modulus of the in-plane momentum $\mathbf{q_\parallel}$. Using two different theoretical approaches for the description of the RIXS scattering from phonons, we find that the $\mathbf{q_\parallel}$-dependence of the RIXS intensity can be largely ascribed to the symmetry of the phonon mode, and that satisfactory prediction of the experimental results cannot be obtained without including realistic details of the electronic structure in the calculations. Regardless of the theoretical model, RIXS provides a reliable momentum dependence of EPC in cuprates and can be used to test advanced theoretical predictions.
实验确定电子-声子耦合(EPC)的大小和动量依赖性是凝聚态物理中的一个突出问题。以往曾用共振非弹性X射线散射(RIXS)来确定EPC,因为RIXS光谱中声子峰的强度与基本的EPC强度直接相关。为了评估这种关系的有效性限制,我们比较了几种高温超导铜氧化物的实验结果和理论预测,包括CaCuO2、La2CuO4+δ、La1.84Sr0.16CuO4和YBa2Cu3O7−δ。我们沿着高对称(ζ,0)、(ζ,ζ)方向,并作为方位角φ的函数,在平面动量固定模数q∥下,研究键拉伸声子模式的强度。通过使用两种不同的理论方法来描述RIXS的声子散射,我们发现RIXS强度的q∥依赖性在很大程度上可以归因于声子模式的对称性,并且在计算中如果不包含电子结构的现实细节,则无法对实验结果进行令人满意的预测。无论采用哪种理论模型,RIXS都能可靠地提供铜酸盐中EPC的动量依赖性,可用于检验先进的理论预测。
论文及项目相关链接
PDF 15 pages, 7 figures
摘要
该实验旨在确定电子声子耦合(EPC)的大小及其动量依赖性,这是凝聚态物理学中的一项难题。为了验证谐振非弹性X射线散射(RIXS)在确定EPC方面的有效性,我们对比了几种高温超导铜氧化物的实验结果和理论预测。通过对CaCuO2、La2CuO4+δ、La1.84Sr0.16CuO4和YBa2Cu3O7−δ中键拉伸声子模式的强度进行研究,发现RIXS强度对动量平行分量q∥的依赖性可主要归因于声子模式的对称性。如果不考虑电子结构的现实细节,就无法对实验结果进行令人满意的预测。尽管如此,无论理论模型如何,RIXS都能可靠地提供铜氧化物中EPC的动量依赖性,可用于检验高级理论预测。
关键见解
- 电子声子耦合(EPC)的动量和强度是凝聚态物理学的重要研究内容。
- RIXS已被用于确定EPC,其声子峰强度与EPC强度直接相关。
- 对几种高温超导铜氧化物的实验和理论预测进行了比较和评估。
- RIXS强度的动量依赖性主要归因于声子模式的对称性。
- 在计算过程中需要考虑电子结构的现实细节,以便更好地预测实验结果。
- RIXS方法在测试高级理论预测方面表现可靠,并为铜氧化物的EPC提供了动量依赖性的信息。
点此查看论文截图

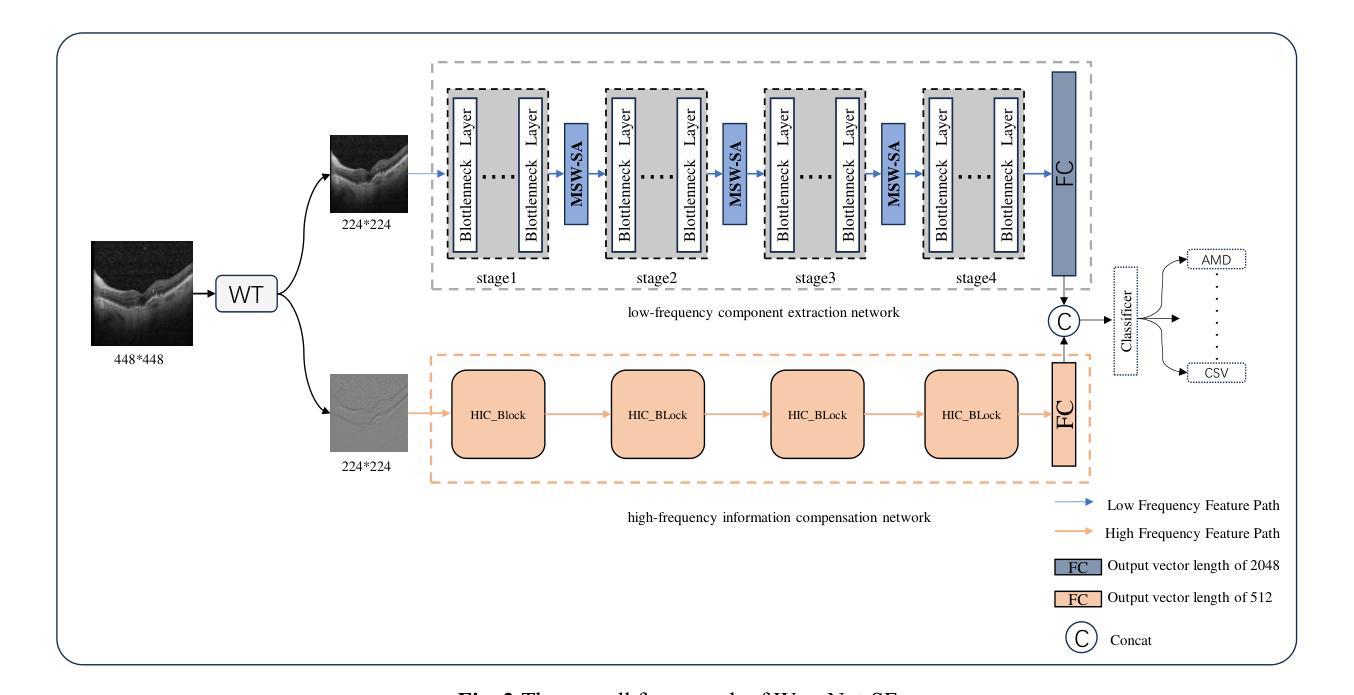
WaveNet-SF: A Hybrid Network for Retinal Disease Detection Based on Wavelet Transform in the Spatial-Frequency Domain
Authors:Jilan Cheng, Guoli Long, Zeyu Zhang, Zhenjia Qi, Hanyu Wang, Libin Lu, Shuihua Wang, Yudong Zhang, Jin Hong
Retinal diseases are a leading cause of vision impairment and blindness, with timely diagnosis being critical for effective treatment. Optical Coherence Tomography (OCT) has become a standard imaging modality for retinal disease diagnosis, but OCT images often suffer from issues such as speckle noise, complex lesion shapes, and varying lesion sizes, making interpretation challenging. In this paper, we propose a novel framework, WaveNet-SF, to enhance retinal disease detection by integrating spatial-domain and frequency-domain learning. The framework utilizes wavelet transforms to decompose OCT images into low- and high-frequency components, enabling the model to extract both global structural features and fine-grained details. To improve lesion detection, we introduce a multi-scale wavelet spatial attention (MSW-SA) module, which enhances the model’s focus on regions of interest at multiple scales. Additionally, a high-frequency feature compensation block (HFFC) is incorporated to recover edge information lost during wavelet decomposition, suppress noise, and preserve fine details crucial for lesion detection. Our approach achieves state-of-the-art (SOTA) classification accuracies of 97.82% and 99. 58% on the OCT-C8 and OCT2017 datasets, respectively, surpassing existing methods. These results demonstrate the efficacy of WaveNet-SF in addressing the challenges of OCT image analysis and its potential as a powerful tool for retinal disease diagnosis.
视网膜疾病是导致视力和失明的主要原因之一,及时诊断对于有效治疗至关重要。光学相干层析成像术(OCT)已成为视网膜疾病诊断的标准成像技术,但OCT图像经常受到斑点噪声、病变形状复杂和病变大小不一等问题的影响,使得解读具有挑战性。在本文中,我们提出了一种新型框架WaveNet-SF,通过结合空间域和频率域学习来提高视网膜疾病的检测能力。该框架利用小波变换将OCT图像分解为低频和高频成分,使模型能够提取全局结构特征和精细细节。为了提高病变检测能力,我们引入了一种多尺度小波空间注意力(MSW-SA)模块,该模块能够在多个尺度上增强模型对感兴趣区域的关注。此外,还融入了一个高频特征补偿块(HFFC),以恢复小波分解过程中丢失的边缘信息,抑制噪声,并保留对病变检测至关重要的精细细节。我们的方法在OCT-C8和OCT2017数据集上分别达到了最先进的分类准确率97.82%和99.58%,超越了现有方法。这些结果证明了WaveNet-SF在解决OCT图像分析挑战方面的有效性,以及其作为视网膜疾病诊断的强大工具潜力。
论文及项目相关链接
Summary
本论文提出了一种名为WaveNet-SF的新框架,通过结合空间域和频率域学习,增强视网膜疾病检测。该框架利用小波变换将OCT图像分解为低频和高频成分,引入多尺度小波空间注意力模块和高频特征补偿块,提高病变检测性能。在OCT-C8和OCT2017数据集上实现了先进的分类准确率。
Key Takeaways
- 视网膜疾病是导致视力受损和失明的主要原因,及时诊断对有效治疗至关重要。
- Optical Coherence Tomography (OCT) 是视网膜疾病诊断的标准成像方式,但其图像存在斑点噪声、复杂病变形状和不同的病变大小等问题,使得解读具有挑战性。
- WaveNet-SF框架通过结合空间域和频率域学习来增强视网膜疾病检测。
- 该框架利用小波变换分解OCT图像为低频和高频成分,以便提取全局结构特征和细粒度细节。
- 多尺度小波空间注意力模块(MSW-SA)的引入提高了模型对多个尺度上感兴趣区域的关注,从而提高了病变检测的准确性。
- 高频特征补偿块(HFFC)的加入旨在恢复小波分解过程中丢失的边缘信息,抑制噪声并保留对病变检测至关重要的细节。
点此查看论文截图


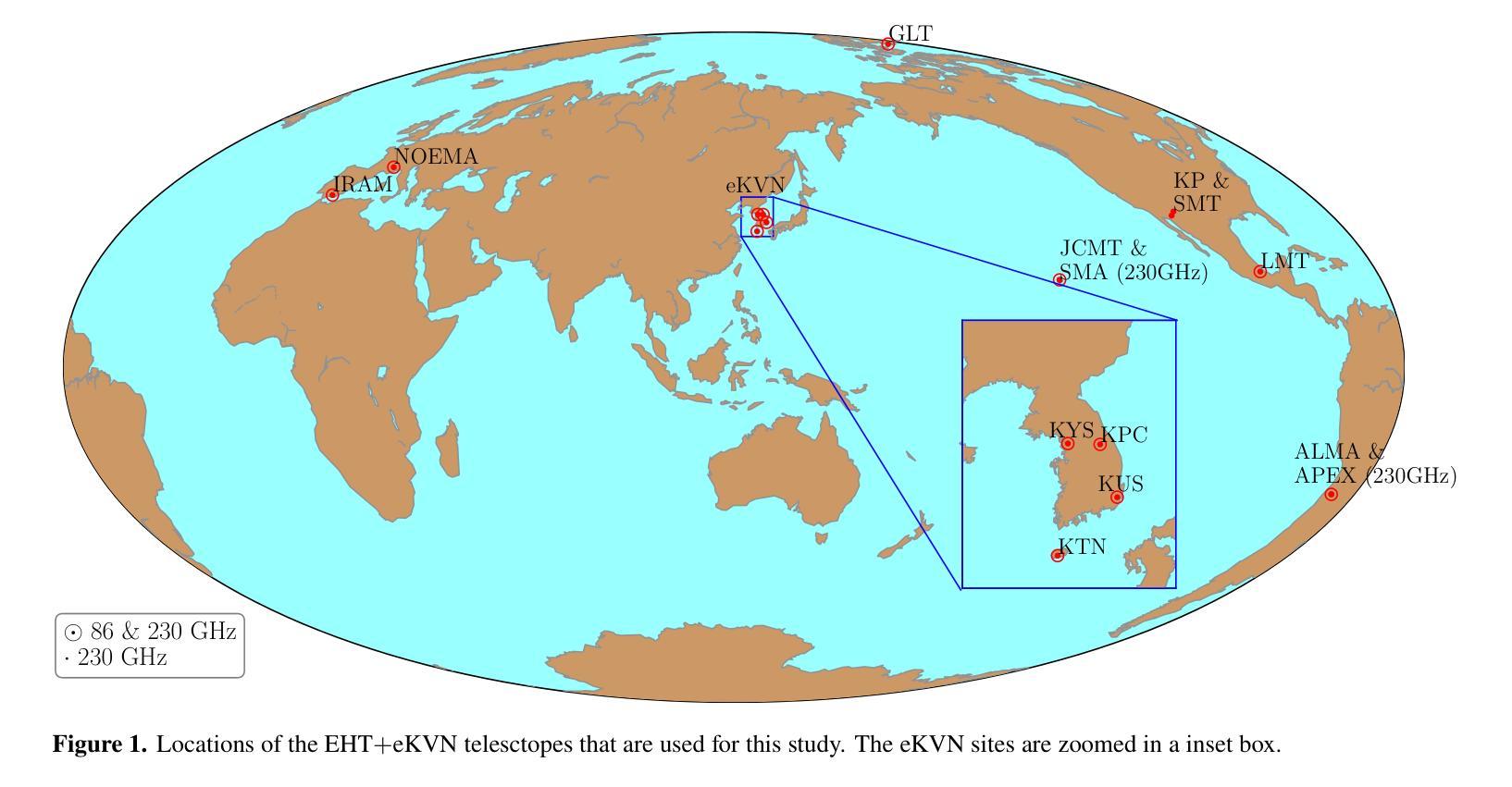
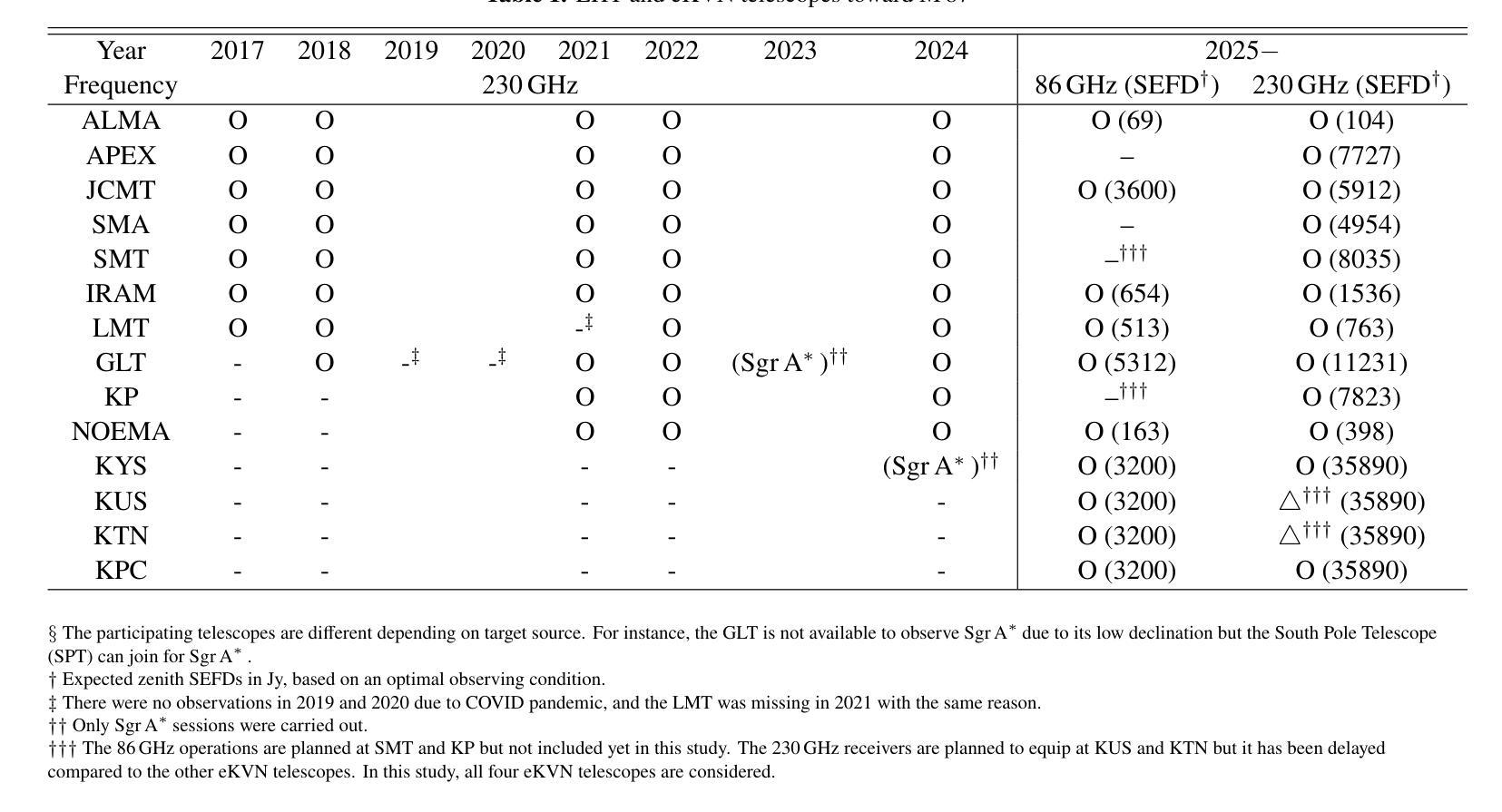
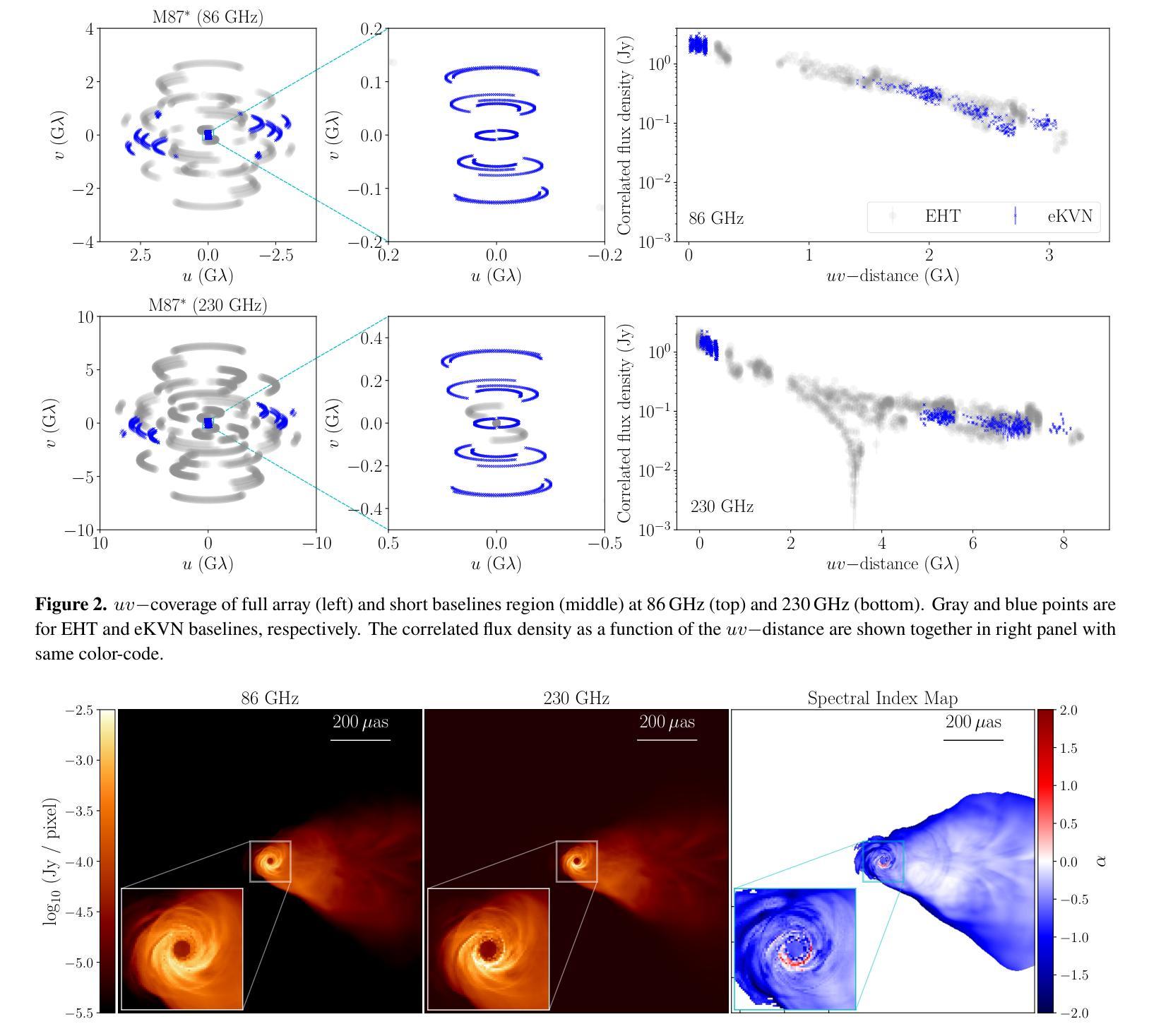
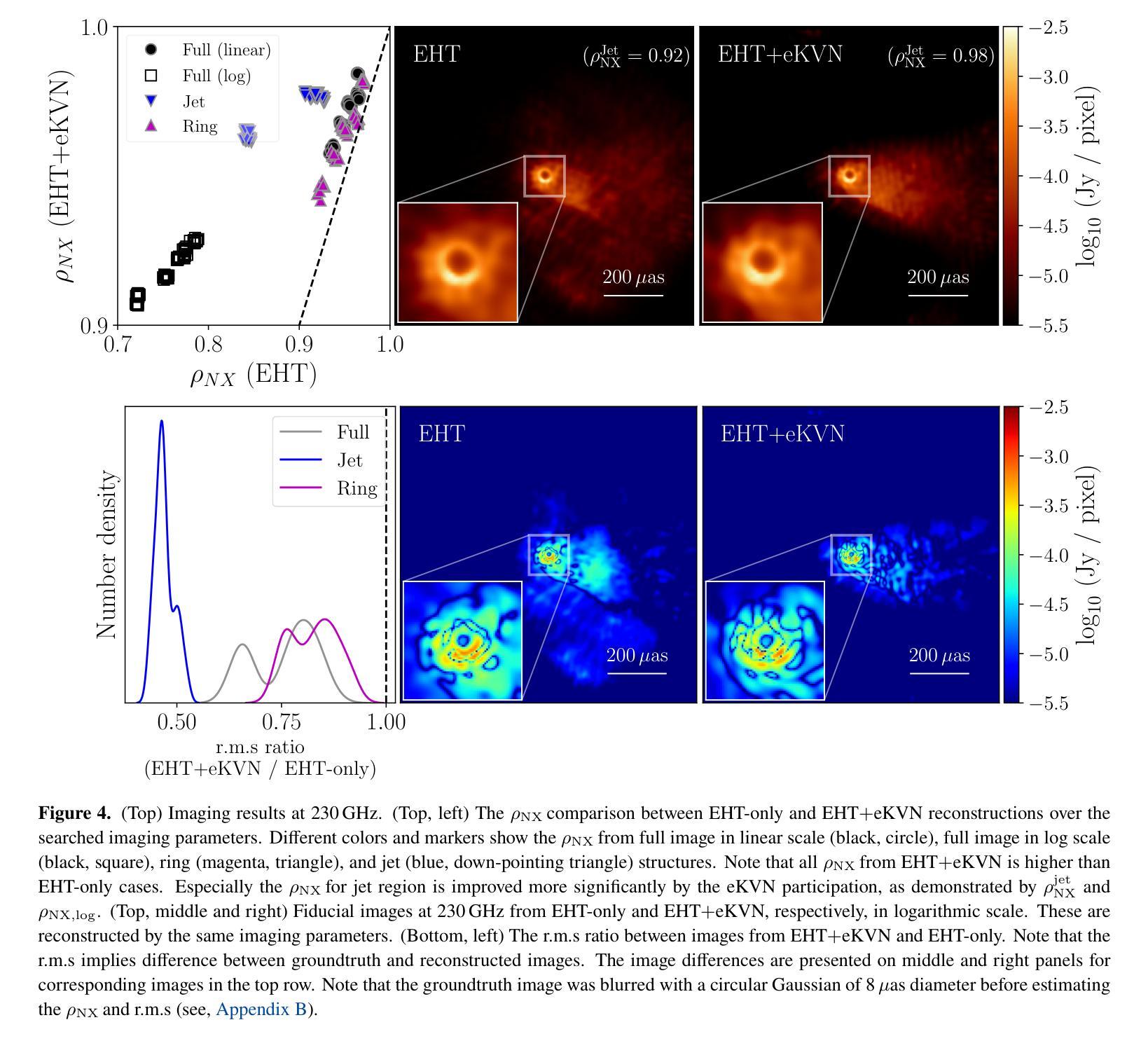
Enhanced imaging of M87*: Simulations with the EHT and extended-KVN
Authors:Ilje Cho, Jongho Park, Do-Young Byun, Taehyun Jung, Lindy Blackburn, Freek Roelofs, Andrew Chael, Dominic W. Pesce, Sheperd S. Doeleman, Sara Issaoun, Jae-Young Kim, Junhan Kim, Jose L. Gomez, Keiichi Asada, Bong Won Sohn, Sang-Sung Lee, Jongsoo Kim, Sascha Trippe, Aeree Chung
The Event Horizon Telescope (EHT) has successfully revealed the shadow of the supermassive black hole, M87*, with an unprecedented angular resolution of approximately 20 uas at 230 GHz. However, because of limited short baseline lengths, the EHT has been constrained in its ability to recover larger scale jet structures. The extended Korean VLBI Network (eKVN) is committed to joining the EHT from 2024 that can improve short baseline coverage. This study evaluates the impact of the participation of eKVN in the EHT on the recovery of the M87* jet. Synthetic data, derived from a simulated M87* model, were observed using both the EHT and the combined EHT+eKVN arrays, followed by image reconstructions from both configurations. The results indicate that the inclusion of eKVN significantly improves the recovery of jet structures by reducing residual noise. Furthermore, jackknife tests, in which one or two EHT telescopes were omitted - simulating potential data loss due to poor weather - demonstrate that eKVN effectively compensates for these missing telescopes, particularly in short baseline coverage. Multi-frequency synthesis imaging at 86-230 GHz shows that the EHT+eKVN array enhances the recovered spectral index distribution compared to the EHT alone and improves image reconstruction at each frequency over single-frequency imaging. As the EHT continues to expand its array configuration and observing capabilities to probe black hole physics more in depth, the integration of eKVN into the EHT will significantly enhance the stability of observational results and improve image fidelity. This advancement will be particularly valuable for future regular monitoring observations, where consistent data quality is essential.
事件视界望远镜(EHT)已成功以约20微角的极高分辨率,在230 GHz下揭示了超大质量黑洞M87的影子。然而,由于基线长度较短,EHT在恢复更大规模的喷射流结构方面受到了限制。韩国甚长基线干涉测量网络(eKVN)已承诺从2024年开始加入EHT,以提高短基线覆盖能力。本研究评估了eKVN参与EHT对恢复M87喷射流的影响。使用模拟的M87*模型生成的合成数据,通过EHT和组合的EHT+eKVN阵列进行观察,然后进行两种配置下的图像重建。结果表明,加入eKVN通过减少残留噪声显著提高了喷射流结构的恢复。此外,采用拔除法测试,其中省略了一个或两个EHT望远镜——模拟因天气不佳导致的数据丢失——表明eKVN有效地弥补了这些缺失的望远镜,特别是在短基线覆盖方面。在86-230 GHz的多频合成成像显示,与单一的EHT相比,EHT+eKVN阵列提高了恢复的谱指数分布,并在每个频率上改进了单频成像的图像重建。随着EHT不断扩大其阵列配置和观测能力,以更深入地研究黑洞物理学,将eKVN集成到EHT中将显著提高观测结果的稳定性并提高图像保真度。这一进展对于未来定期监测观测尤为重要,因为在这些观测中,一致的数据质量是不可或缺的。
论文及项目相关链接
PDF 13 pages, 13 figures, 2 tables
Summary
韩国VLBI网络(eKVN)参与事件视界望远镜(EHT)对M87*黑洞射流恢复的影响研究,利用合成数据评估eKVN的加入能显著提高射流结构的恢复效果,减少残余噪声,并在模拟潜在数据丢失的情况下能有效补偿缺失的望远镜,特别是提高短基线覆盖区域的表现。此外,EHT与eKVN联合阵列能提高恢复光谱指数分布的准确性,并改善各频率的图像重建效果。随着EHT不断扩展其阵列配置和观测能力,eKVN的整合将大大提高观测结果的稳定性和图像保真度,对未来常规监测观测尤为重要。
Key Takeaways
- EHT成功以约20微弧秒的空前角分辨率在230 GHz揭示了超大质量黑洞M87*的影子。
- 由于基线长度较短,EHT在恢复更大规模的射流结构上存在局限性。
- eKVN计划从2024年加入EHT,旨在提高短基线覆盖。
- 合成数据评估显示,eKVN的加入能显著提高射流结构的恢复效果,减少残余噪声。
- 在模拟潜在数据丢失的情况下,eKVN能有效补偿缺失的望远镜,特别是在短基线覆盖方面。
- EHT与eKVN联合阵列能提高图像重建的保真度和光谱指数分布的准确性。
点此查看论文截图

A generalizable 3D framework and model for self-supervised learning in medical imaging
Authors:Tony Xu, Sepehr Hosseini, Chris Anderson, Anthony Rinaldi, Rahul G. Krishnan, Anne L. Martel, Maged Goubran
Current self-supervised learning methods for 3D medical imaging rely on simple pretext formulations and organ- or modality-specific datasets, limiting their generalizability and scalability. We present 3DINO, a cutting-edge SSL method adapted to 3D datasets, and use it to pretrain 3DINO-ViT: a general-purpose medical imaging model, on an exceptionally large, multimodal, and multi-organ dataset of ~100,000 3D medical imaging scans from over 10 organs. We validate 3DINO-ViT using extensive experiments on numerous medical imaging segmentation and classification tasks. Our results demonstrate that 3DINO-ViT generalizes across modalities and organs, including out-of-distribution tasks and datasets, outperforming state-of-the-art methods on the majority of evaluation metrics and labeled dataset sizes. Our 3DINO framework and 3DINO-ViT will be made available to enable research on 3D foundation models or further finetuning for a wide range of medical imaging applications.
当前用于三维医学影像的自学方法依赖于简单的预设公式和特定器官或特定模态的数据集,这限制了其通用性和可扩展性。我们提出了名为“三维变异深度(3DINO)”的前沿SSL方法,该方法适用于三维数据集,并用于预训练名为“三维诺维T(3DINO-ViT)”的通用医学影像模型。我们在包含来自超过十个器官的约十万个三维医学影像扫描数据的大规模、多模态和多器官数据集上对其进行训练。我们通过大量实验验证了在多个医学影像分割和分类任务上的三维诺维T。我们的结果表明,三维诺维T在跨模态和跨器官中均表现出很好的表现,包括处理异常任务和数据集的表现优异。在各种评价指标和有标签数据集大小方面,它优于当前最先进的方法。我们的三维诺维框架和三维诺维T将提供使用,以支持关于三维基础模型的研究或用于进一步微调各种医学影像应用的开发。
论文及项目相关链接
Summary
本文介绍了针对3D数据集的自监督学习方法,提出了一个名为3DINO的前沿SSL方法,用于训练一个通用医疗成像模型3DINO-ViT。该模型在包含超过十万个来自十多个器官的3D医学图像的大型多模态多器官数据集上进行训练。实验验证显示,该模型在不同模态和器官上具有良好的泛化性能,包括超出分布的任务和数据集,并且在大多数评估指标和标注数据集大小上均优于最新技术。本文公开的3DINO框架和3DINO-ViT模型将为研究3D基础模型和进一步微调以应用于广泛的医学成像任务提供支持。
Key Takeaways
以下是本段文字的主要见解和收获点:
- 当前针对三维医疗影像的自监督学习方法存在局限性,局限于简单的预设形式和特定器官或模态的数据集,限制了其通用性和可扩展性。
- 提出了一种先进的自监督学习方法(称为3DINO),专为三维数据集设计,用于训练一个通用的医疗成像模型(称为3DINO-ViT)。
- 3DINO-ViT模型在一个大型的多模态和多器官数据集上进行训练,包含超过十万个三维医学图像扫描数据。
- 通过广泛的实验验证,显示3DINO-ViT模型具有良好的泛化能力,能在不同模态和器官之间进行泛化。
点此查看论文截图

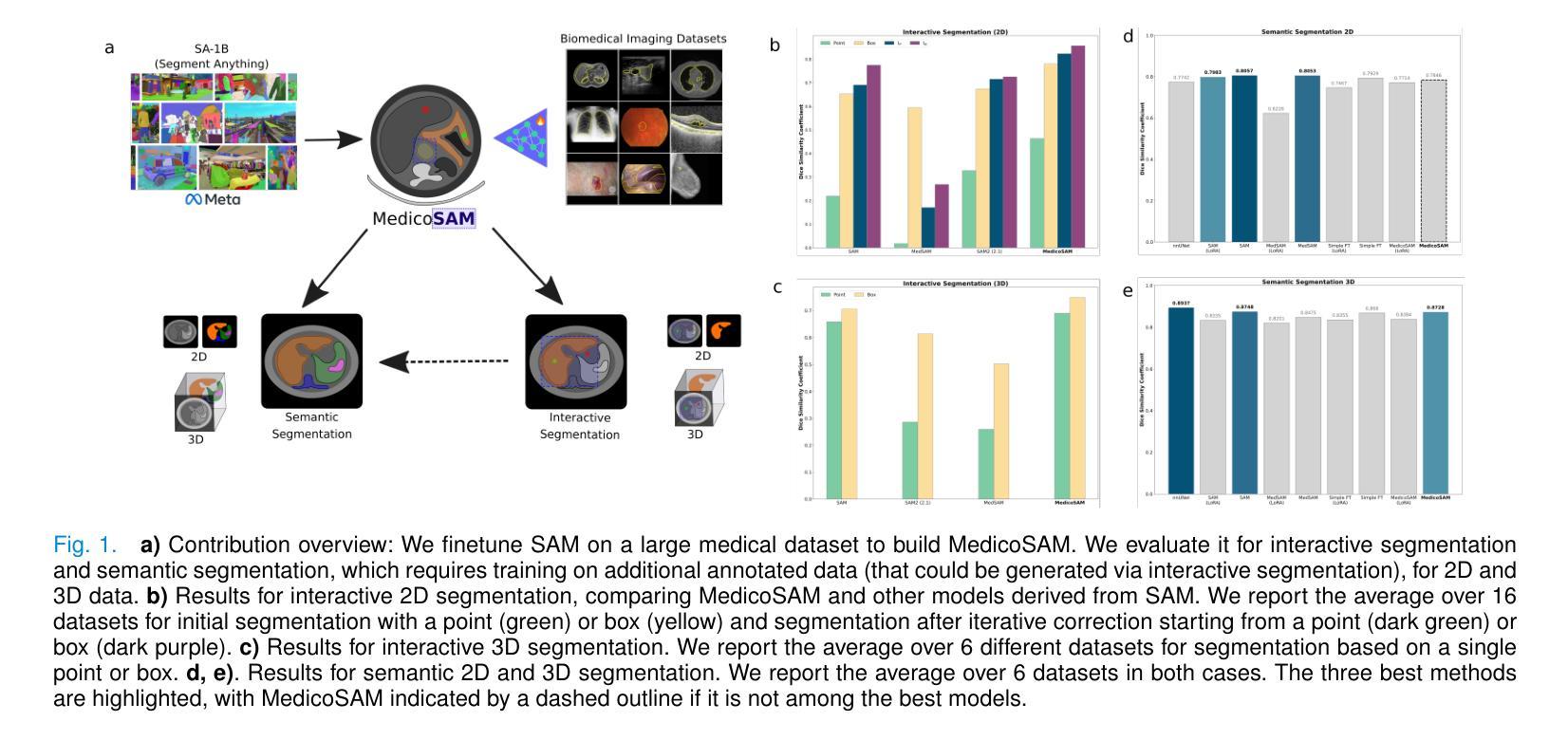
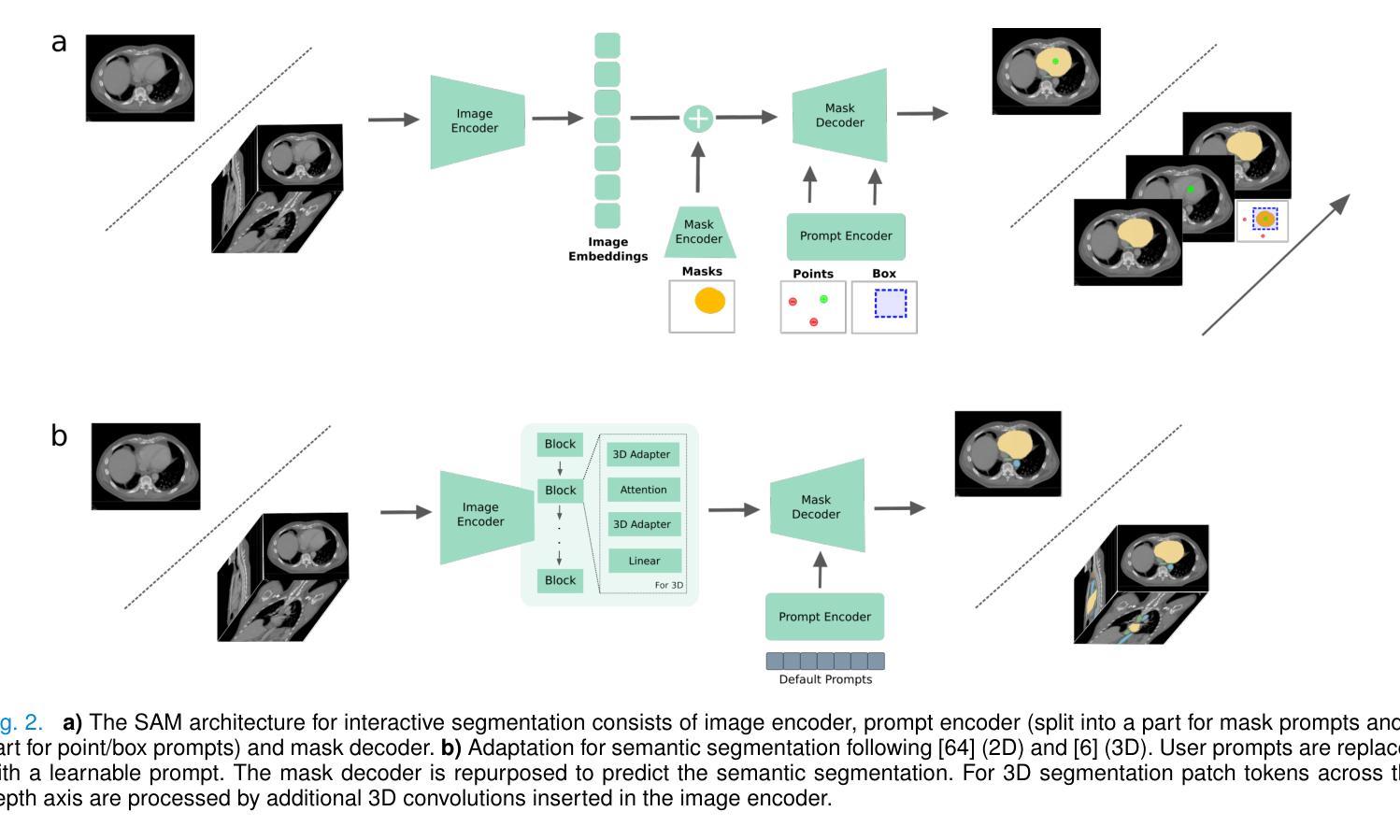
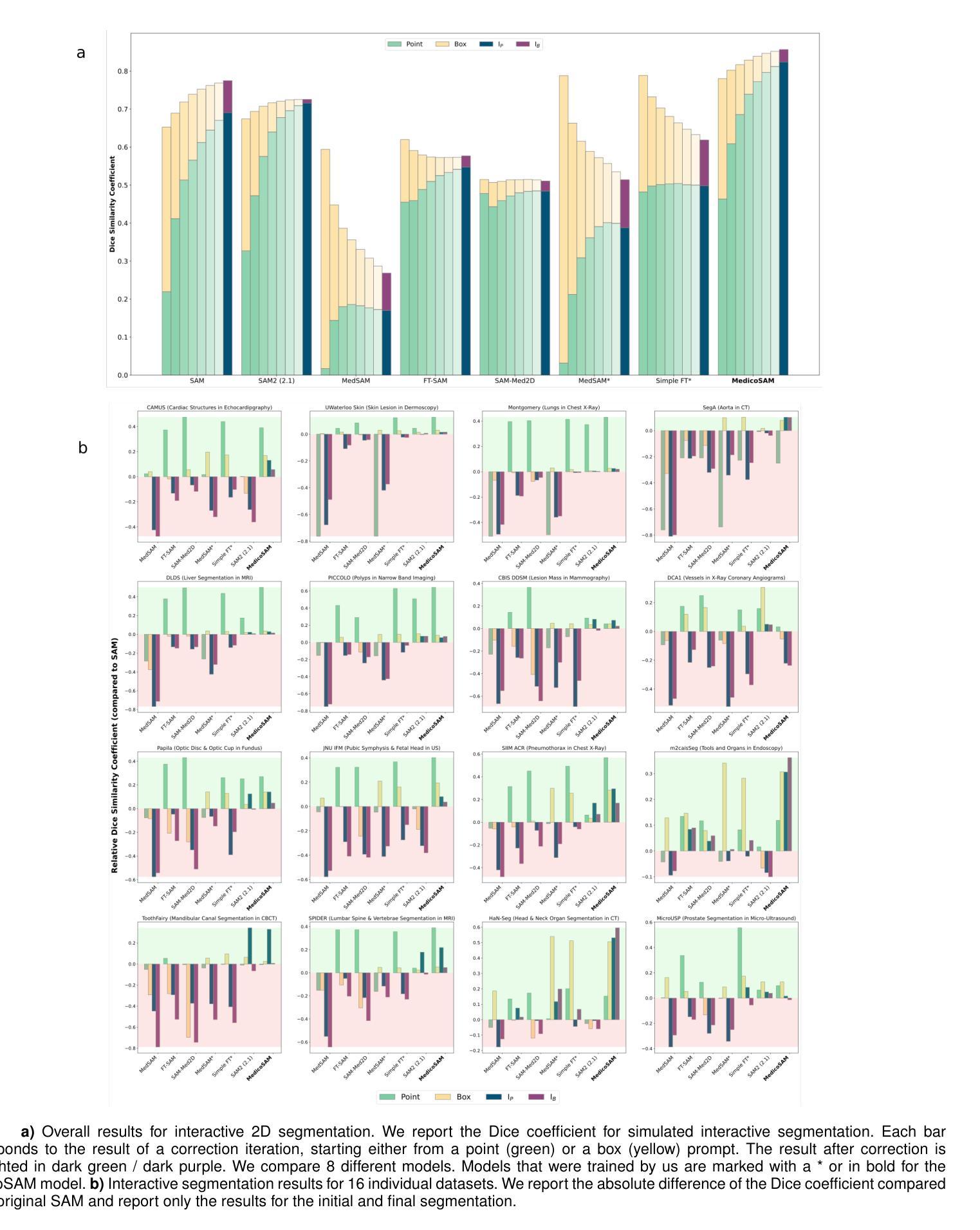
MedicoSAM: Towards foundation models for medical image segmentation
Authors:Anwai Archit, Luca Freckmann, Constantin Pape
Medical image segmentation is an important analysis task in clinical practice and research. Deep learning has massively advanced the field, but current approaches are mostly based on models trained for a specific task. Training such models or adapting them to a new condition is costly due to the need for (manually) labeled data. The emergence of vision foundation models, especially Segment Anything, offers a path to universal segmentation for medical images, overcoming these issues. Here, we study how to improve Segment Anything for medical images by comparing different finetuning strategies on a large and diverse dataset. We evaluate the finetuned models on a wide range of interactive and (automatic) semantic segmentation tasks. We find that the performance can be clearly improved for interactive segmentation. However, semantic segmentation does not benefit from pretraining on medical images. Our best model, MedicoSAM, is publicly available at https://github.com/computational-cell-analytics/medico-sam. We show that it is compatible with existing tools for data annotation and believe that it will be of great practical value.
医学图像分割是临床实践和研究中重要的分析任务。深度学习极大地推动了该领域的发展,但当前的方法大多基于特定任务的模型。由于需要(手动)标记数据,训练此类模型或将其适应新条件成本高昂。视觉基础模型的出现,特别是Segment Anything,为医学图像的通用分割提供了路径,解决了这些问题。在这里,我们研究如何通过在一个大型和多样化的数据集上比较不同的微调策略,来提高Segment Anything在医学图像上的应用。我们评估了微调模型在广泛的交互式和(自动)语义分割任务上的表现。我们发现交互式分割的性能可以得到明显提高。然而,语义分割并不受益于医学图像上的预训练。我们最好的模型MedicoSAM可在https://github.com/computational-cell-analytics/medico-sam公开获取。我们展示了它与现有数据标注工具兼容,并相信它具有巨大的实用价值。
论文及项目相关链接
Summary
深度学习在医学图像分割领域取得了重大进展,但当前方法大多基于特定任务训练的模型。由于需要手动标注数据,训练这样的模型或将其适应新条件成本高昂。新兴的视觉基础模型,尤其是Segment Anything,为实现医学图像的通用分割提供了途径。通过对不同微调策略在大规模多样化数据集上的比较,我们研究了如何改进Segment Anything在医学图像上的应用。评估微调模型在交互式和自动语义分割任务上的表现,我们发现交互式分割的性能得到了显著提高,但语义分割并未从医学图像上的预训练中受益。我们最佳的模型MedicoSAM已在公开平台上发布,与现有数据标注工具兼容,具有极大的实用价值。
Key Takeaways
- 医学图像分割是临床实践和研究中重要的分析任务。
- 深度学习已大大推进了医学图像分割领域的发展,但训练特定任务模型的成本较高。
- Segment Anything这样的视觉基础模型的出现,为医学图像的通用分割提供了解决方案。
- 通过对不同微调策略的研究,改进了Segment Anything在医学图像上的应用。
- 交互式分割的性能得到了显著提高,而语义分割并未从医学图像预训练中受益。
- 最佳模型MedicoSAM已公开发布,并与现有数据标注工具兼容。
点此查看论文截图


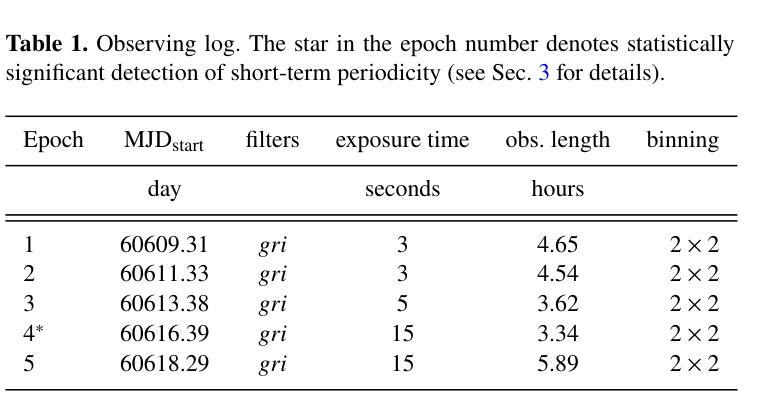
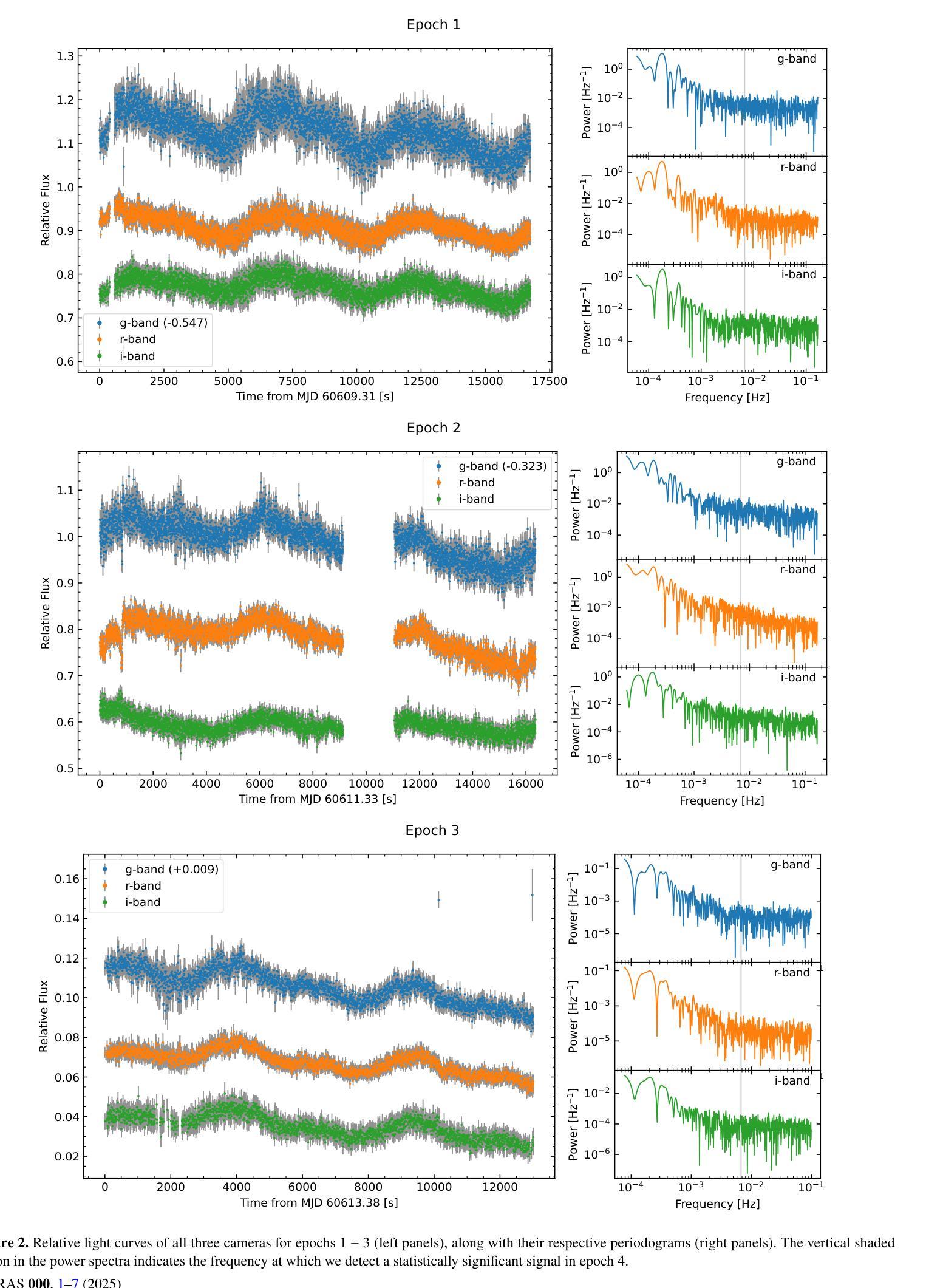
Bridging the Gap: OPTICAM Reveals the Hidden Spin of the WZ Sge Star GOTO 065054.49+593624.51
Authors:N. Castro Segura, Z. A. Irving, F. M. Vincentelli, D. Altamirano, Y. Tampo, C. Knigge, I. Pelisoli, D. L. Coppejans, N. Rawat, A. Castro, A. Sahu, J. V. Hernández Santisteban, M. Kimura, M. Veresvarska, R. Michel, S. Scaringi, M. Najera
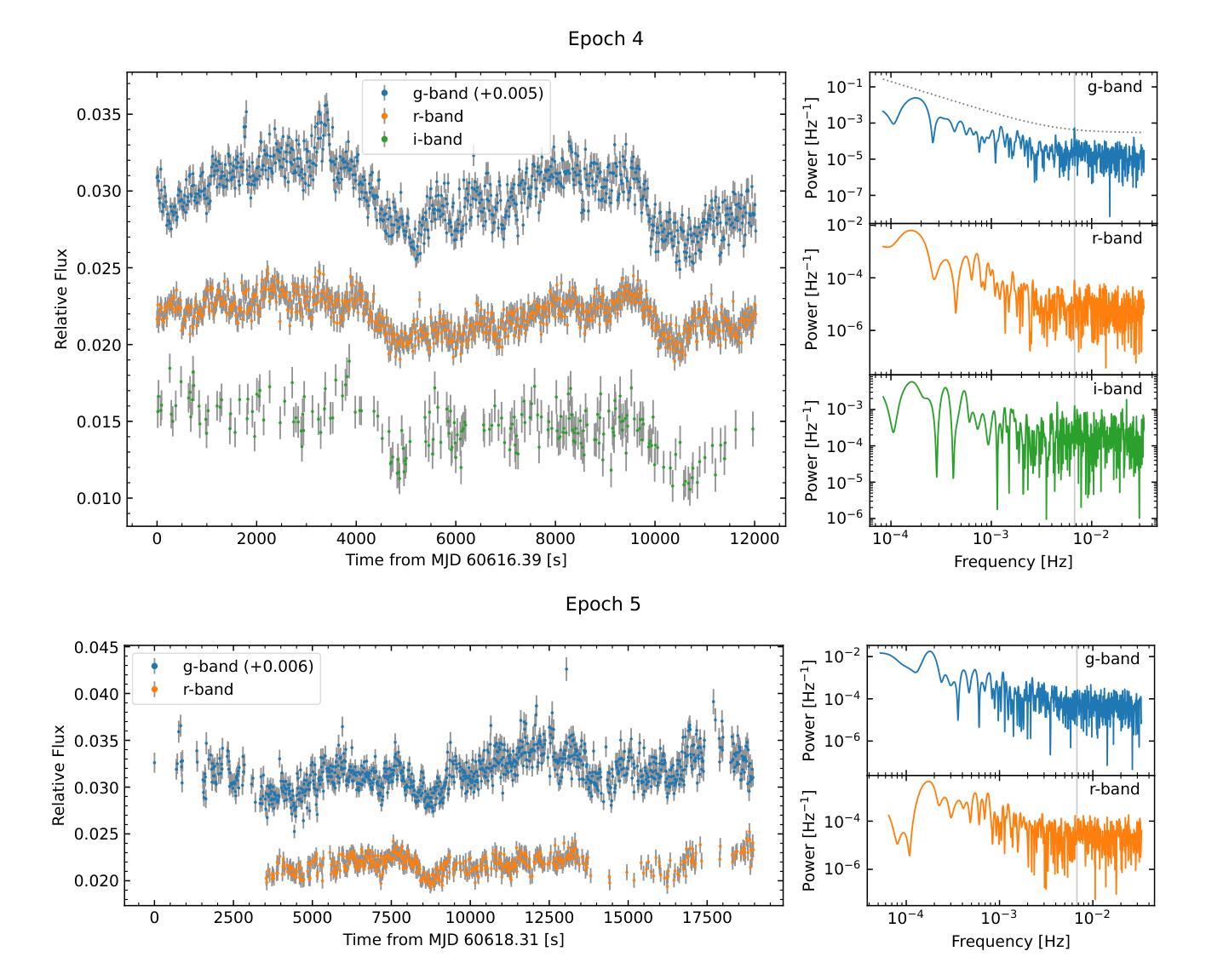
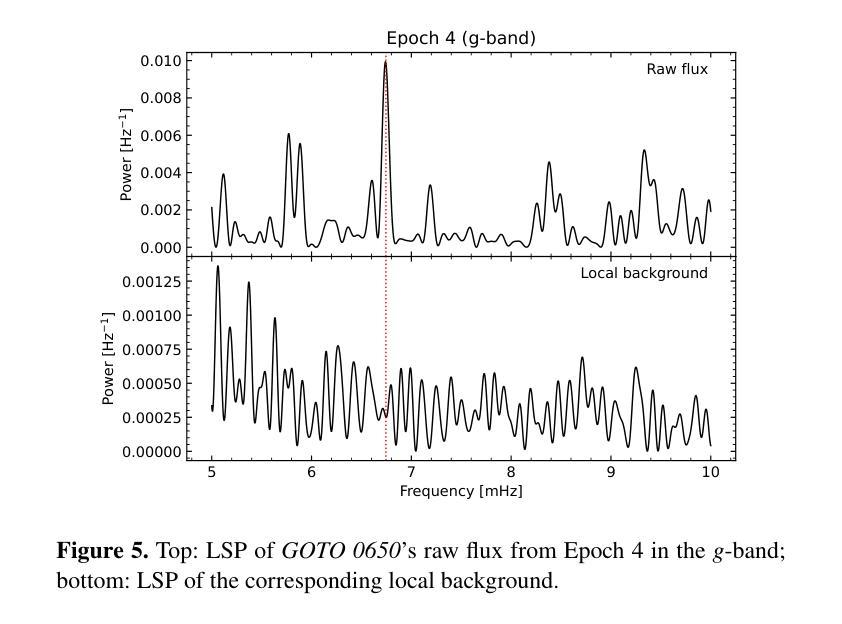
WZ Sge stars are highly evolved accreting white dwarf systems (AWDs) exhibiting remarkably large amplitude outbursts (a.k.a. super-outbursts), typically followed by short rebrightenings/echo outbursts. These systems have some of the lowest mass transfer rates among AWDs, making even low magnetic fields dynamically important. Such magnetic fields are often invoked to explain the phenomenology observed in these systems, such as their X-ray luminosity and long periods of quiescence (30+ years). However, the detection of these is very elusive given the quenching of the accretion columns during outburst and the low luminosity of these systems during quiescence. Here we present high-cadence multi-band observations with {\it OPTICAM} of the recent outburst of the recently discovered WZ Sge star GOTO065054.49+593624.51, during the end of the main outburst and the dip in-between rebrightenings, covering 2 orders of magnitude in brightness. Our observations reveal the presence of a statistically significant signal with $P_{\omega}\simeq148$ seconds in the bluer ($g$) band which is detected only during the dip between the main outburst and the rebrigthenings. We interpret this signal as the spin period of the AWD. If confirmed, GOTO 0650 would bridge the gap between intermediate- and fast-rotating intermediate polars (IPs) below the period gap.
WZ Sge型星是高度进化的吸积型白矮星系统(AWD),表现出显著的大振幅爆发(也称为超级爆发),随后通常是短暂的再次增亮/回声爆发。这些系统的质量传递率在其AWD中相对较低,使得即使是低磁场也具有动态重要性。这些磁场通常用于解释这些系统中观察到的现象,如它们的X射线光度以及长时间的静止期(超过30年)。然而,由于爆发期间的积柱熄灭以及静止期间的低光度,这些磁场的检测非常难以捉摸。在这里,我们使用OPTICAM的高灵敏度多波段观测,对最近发现的WZ Sge星GOTO065054.49+593624.51的最近一次爆发进行了观测,涵盖了主爆发结束和在再次增亮之间的低谷期,亮度变化了2个数量级。我们的观测显示,在较蓝的g波段出现了一个统计上显著的信号,其周期约为148秒,该信号仅在主爆发和再次增亮之间的低谷期被检测到。我们将此信号解释为AWD的自转周期。如果得到证实,GOTO 0650将成为周期缺口下方连接中间极性和快速旋转中间极性的桥梁。
论文及项目相关链接
PDF Submitted to MRNAS
Summary
本文介绍了WZ Sge星的研究,这些星是高度演化的吸积型白矮星系统(AWDs),表现出巨大的振幅爆发(超级爆发),随后是短暂的再增亮或回声爆发。这些系统的质量转移率较低,使得低磁场也具有动态重要性。虽然存在关于这些磁场的解释现象学的假说,但对这些系统磁场的检测仍然非常难以捉摸。现在对名为GOTO 0650的新发现的WZ Sge星进行了高时间分辨率的多波段观测,揭示了在主要爆发和再增亮之间的低谷中仅检测到蓝波段(g波段)存在显著的信号。解释这个信号为AWD的自转周期,如果得到证实,GOTO 0650将成为连接周期间隙下方中间极性和快速旋转中间极性的桥梁。
Key Takeaways
- WZ Sge星是高度演化的吸积型白矮星系统,其特点是发生超级爆发,之后跟随短暂再增亮或回声爆发。
- 这些系统的质量转移率较低,导致低磁场也有动态重要性。
- 虽然存在关于磁场的解释现象学的假说,但检测这些磁场非常困难,因为爆发期间会抑制积柱的发光和在静止期间的低光度。
- 对新发现的WZ Sge星GOTO 0650进行了高时间分辨率的多波段观测。
- 在主要爆发和再增亮之间的低谷中仅检测到蓝波段存在显著的信号,这可能是AWD的自转周期信号。
- 如果确认这一发现,GOTO 0650将成为连接中间极性和快速旋转中间极性之间的桥梁。
点此查看论文截图


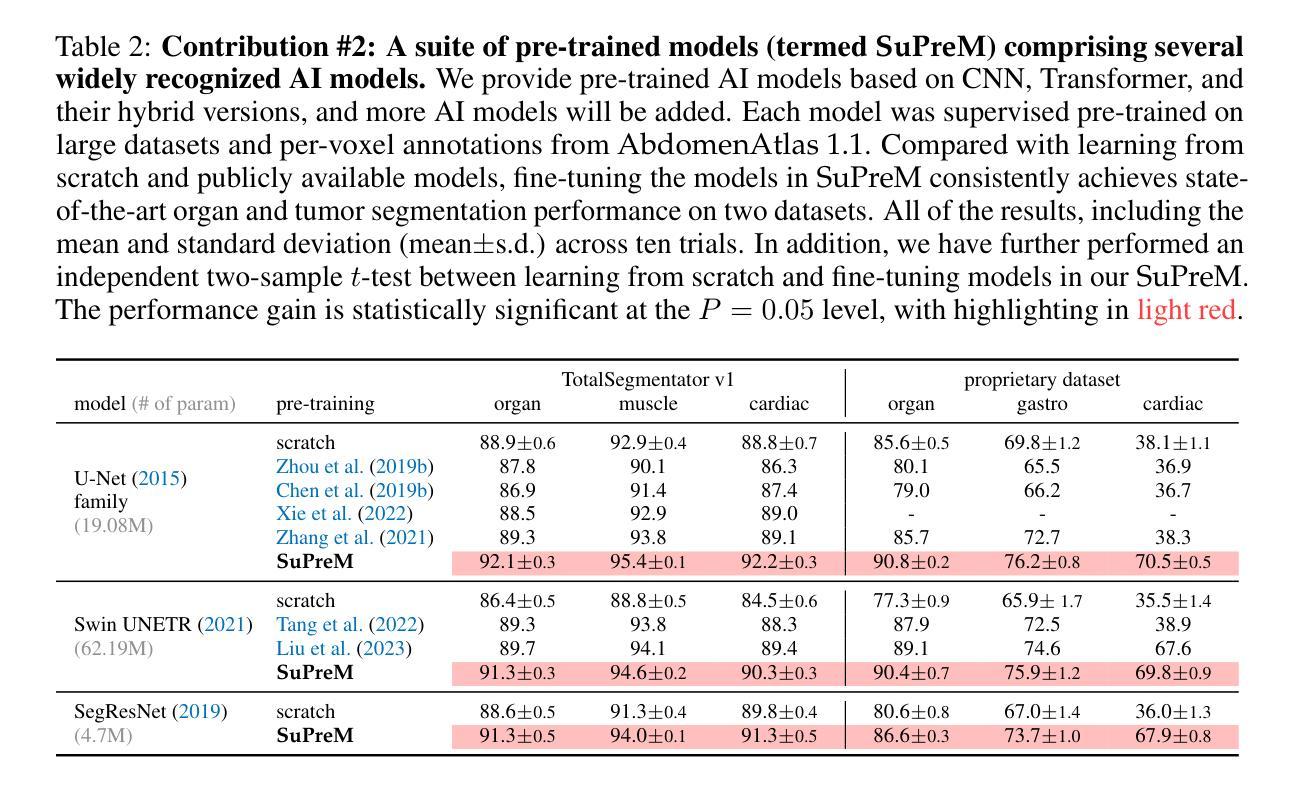
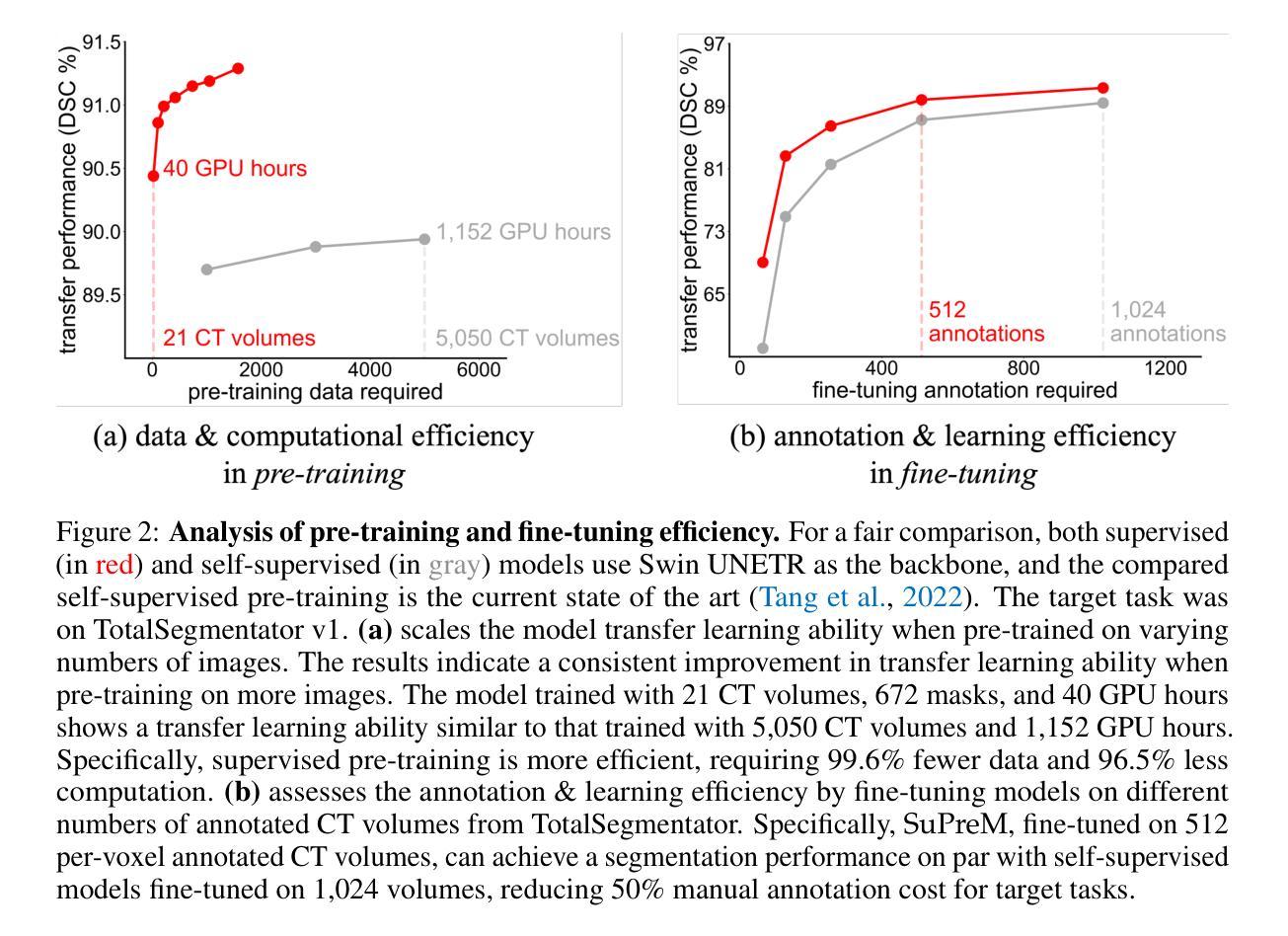
How Well Do Supervised 3D Models Transfer to Medical Imaging Tasks?
Authors:Wenxuan Li, Alan Yuille, Zongwei Zhou
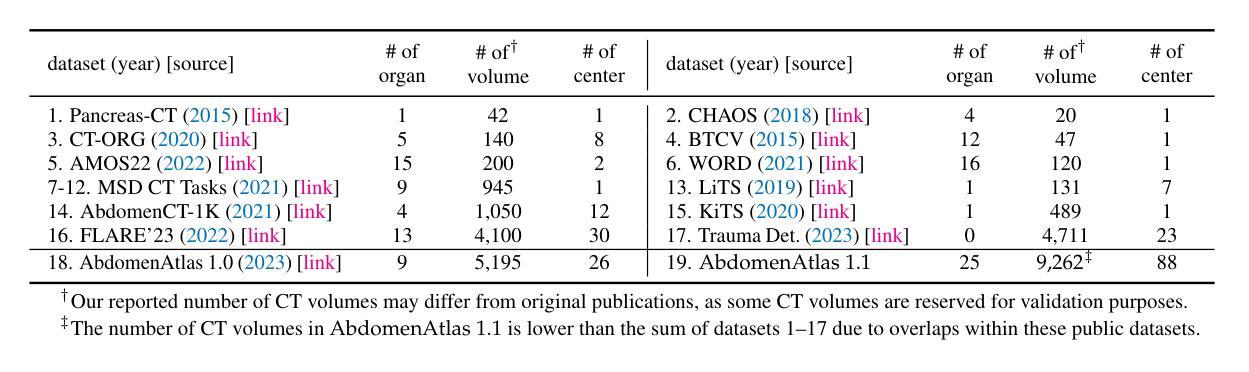
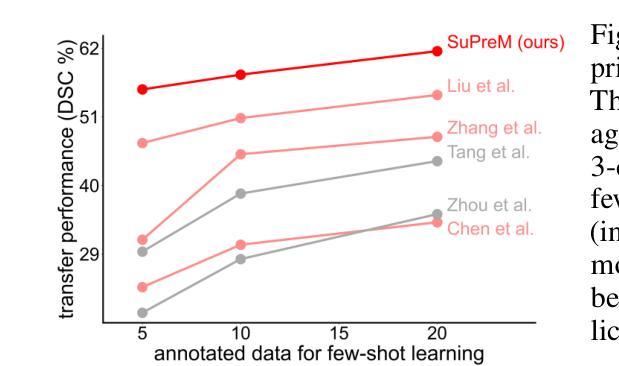
The pre-training and fine-tuning paradigm has become prominent in transfer learning. For example, if the model is pre-trained on ImageNet and then fine-tuned to PASCAL, it can significantly outperform that trained on PASCAL from scratch. While ImageNet pre-training has shown enormous success, it is formed in 2D, and the learned features are for classification tasks; when transferring to more diverse tasks, like 3D image segmentation, its performance is inevitably compromised due to the deviation from the original ImageNet context. A significant challenge lies in the lack of large, annotated 3D datasets rivaling the scale of ImageNet for model pre-training. To overcome this challenge, we make two contributions. Firstly, we construct AbdomenAtlas 1.1 that comprises 9,262 three-dimensional computed tomography (CT) volumes with high-quality, per-voxel annotations of 25 anatomical structures and pseudo annotations of seven tumor types. Secondly, we develop a suite of models that are pre-trained on our AbdomenAtlas 1.1 for transfer learning. Our preliminary analyses indicate that the model trained only with 21 CT volumes, 672 masks, and 40 GPU hours has a transfer learning ability similar to the model trained with 5,050 (unlabeled) CT volumes and 1,152 GPU hours. More importantly, the transfer learning ability of supervised models can further scale up with larger annotated datasets, achieving significantly better performance than preexisting pre-trained models, irrespective of their pre-training methodologies or data sources. We hope this study can facilitate collective efforts in constructing larger 3D medical datasets and more releases of supervised pre-trained models.
预训练和微调范式在迁移学习中已经变得非常突出。例如,如果一个模型在ImageNet上进行预训练,然后在PASCAL上进行微调,其性能会明显优于直接在PASCAL上训练的模型。虽然ImageNet预训练已经取得了巨大的成功,但它是在二维空间中形成的,并且学到的特征适用于分类任务;当迁移到更复杂的任务(如三维图像分割)时,由于与原始ImageNet上下文的偏差,其性能不可避免地会受到影响。一个主要的挑战在于缺乏大规模、标注的三维数据集,无法与ImageNet的规模相匹配的模型进行预训练。为了克服这一挑战,我们做出了两项贡献。首先,我们构建了包含9262个三维计算机断层扫描(CT)体积的AbdomenAtlas 1.1数据集,其中包含了高质量的三维像素级别的注释数据标注了腹部25个解剖结构和七种肿瘤类型的伪注释。其次,我们开发了一系列在AbdomenAtlas 1.1上预训练的模型用于迁移学习。我们的初步分析表明,仅使用21个CT体积、672个掩码和40个GPU小时训练的模型具有与使用大量未标记CT体积和大量GPU小时训练的模型相当的迁移学习能力。更重要的是,监督模型的迁移学习能力可以随着更大规模标注数据集的增加而进一步提升,无论其预训练方法论或数据来源如何,都能实现比现有预训练模型更好的性能。我们希望这项研究能促进构建更大规模的三维医学数据集和更多监督预训练模型的发布。
论文及项目相关链接
PDF Accepted to ICLR-2024
Summary
本文介绍了在医学图像领域中的预训练和微调范式面临的挑战和解决方案。由于ImageNet预训练主要针对二维图像分类任务,对于三维图像分割等更复杂的任务,其性能会受到影响。为解决缺乏大规模标注的3D数据集的问题,本文构建了AbdomenAtlas 1.1数据集,并开发了一系列在该数据集上预训练的模型。初步分析表明,使用较少的数据和计算资源,这些模型的迁移学习能力与在大量无标签数据上训练的模型相当。此外,通过扩大标注数据集,监督模型的迁移学习能力有望进一步提升。
Key Takeaways
- 预训练和微调范式在迁移学习中占据重要地位,对于医学图像分析也有广泛应用。
- ImageNet预训练在医学图像领域面临挑战,尤其是在处理三维图像分割等复杂任务时。
- 缺乏大规模标注的3D数据集是限制迁移学习应用的关键因素之一。
- AbdomenAtlas 1.1数据集的构建为解决这一问题提供了解决方案,包含高质量的三维医学图像数据和详细的标注信息。
- 在AbdomenAtlas 1.1上预训练的模型的迁移学习能力初步得到验证,即使在较少的数据和计算资源下也能表现出良好的性能。
- 监督模型的迁移学习能力有望通过扩大标注数据集进一步提升。
点此查看论文截图

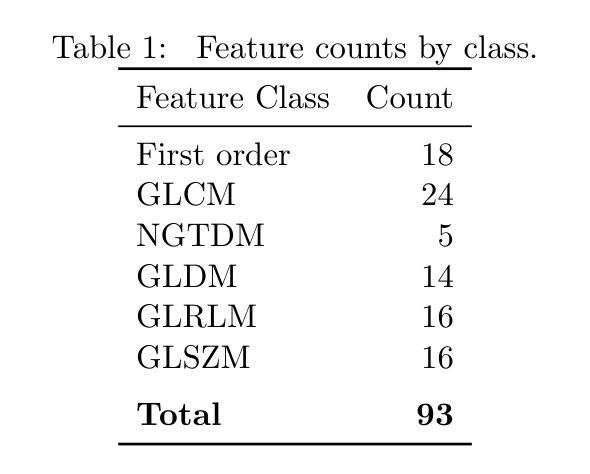
Finding Reproducible and Prognostic Radiomic Features in Variable Slice Thickness Contrast Enhanced CT of Colorectal Liver Metastases
Authors:Jacob J. Peoples, Mohammad Hamghalam, Imani James, Maida Wasim, Natalie Gangai, Hyunseon Christine Kang, X. John Rong, Yun Shin Chun, Richard K. G. Do, Amber L. Simpson
Establishing the reproducibility of radiomic signatures is a critical step in the path to clinical adoption of quantitative imaging biomarkers; however, radiomic signatures must also be meaningfully related to an outcome of clinical importance to be of value for personalized medicine. In this study, we analyze both the reproducibility and prognostic value of radiomic features extracted from the liver parenchyma and largest liver metastases in contrast enhanced CT scans of patients with colorectal liver metastases (CRLM). A prospective cohort of 81 patients from two major US cancer centers was used to establish the reproducibility of radiomic features extracted from images reconstructed with different slice thicknesses. A publicly available, single-center cohort of 197 preoperative scans from patients who underwent hepatic resection for treatment of CRLM was used to evaluate the prognostic value of features and models to predict overall survival. A standard set of 93 features was extracted from all images, with a set of eight different extractor settings. The feature extraction settings producing the most reproducible, as well as the most prognostically discriminative feature values were highly dependent on both the region of interest and the specific feature in question. While the best overall predictive model was produced using features extracted with a particular setting, without accounting for reproducibility, (C-index = 0.630 (0.603–0.649)) an equivalent-performing model (C-index = 0.629 (0.605–0.645)) was produced by pooling features from all extraction settings, and thresholding features with low reproducibility ($\mathrm{CCC} \geq 0.85$), prior to feature selection. Our findings support a data-driven approach to feature extraction and selection, preferring the inclusion of many features, and narrowing feature selection based on reproducibility when relevant data is available.
建立放射组学特征的可重复性是在临床采用定量成像生物标志物道路上的关键步骤。然而,放射组学特征必须与具有临床重要性的结果有意义地相关联,才能对个性化医疗具有价值。在这项研究中,我们分析了从患有结直肠癌肝转移(CRLM)患者的增强CT扫描中提取的肝脏实质和最大肝转移灶的放射学特征的可重复性和预后价值。使用来自美国两个主要癌症中心的81名患者的前瞻性队列,以建立从不同切片厚度重建的图像中提取的放射学特征的可重复性。还使用了公开可用的、单中心队列的197例术前扫描图像,这些图像来自接受CRLM治疗肝切除术的患者,用于评估特征的预后价值以及预测总体生存期的模型。从所有图像中提取了一套93个特征,使用八种不同的提取器设置。产生最可重复以及最具预后鉴别力的特征值的特征提取设置高度依赖于感兴趣区域和特定特征。虽然使用特定设置提取的特征产生了最佳的预测模型,但在不考虑可重复性的情况下,(C指数为0.630(0.603-0.649))一个表现相当的模型(C指数为0.629(0.605-0.645))是通过汇集所有提取设置的特征,并在特征选择之前对低可重复性的特征进行阈值处理(CCC≥0.85)而产生的。我们的研究结果支持数据驱动的特征提取和选择方法,更倾向于包含许多特征,并在有相关数据的情况下基于可重复性进行特征选择。
论文及项目相关链接
PDF Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:032
Summary
本研究分析了从结直肠癌肝转移患者(CRLM)的对比增强CT扫描中提取的肝实质和最大肝转移病灶的放射组学特征的再现性和预后价值。通过对不同切片厚度重建的图像进行特征提取,建立了放射学特征的再现性。利用公开的单中心队列数据评估特征预后价值并建立预测总体生存率的模型。结果强调了特征提取设置的最佳选择和利用可再现性高的特征值的重要性。同时,研究支持数据驱动的特征提取和选择方法,倾向于包含更多特征,并在必要时基于可再现性缩小特征选择。
Key Takeaways
- 放射组学特征的再现性和与临床重要结果的相关性对于个性化医学具有重要意义。
- 本研究分析了从结直肠癌肝转移患者的对比增强CT扫描中提取的肝实质和肝转移灶的放射组学特征。
- 通过使用不同切片厚度的图像重建来建立放射学特征的再现性。
- 使用公开数据评估特征的预后价值并建立预测总体生存率的模型。
- 特征提取设置的最佳选择与具体关注的特征和感兴趣区域有关。
- 研究支持数据驱动的特征提取和选择方法,倾向于包含更多特征,并根据需要基于可再现性进行特征选择。
点此查看论文截图

Enhancing Brain Tumor Segmentation Using Channel Attention and Transfer learning
Authors:Majid Behzadpour, Ebrahim Azizi, Kai Wu, Bengie L. Ortiz
Accurate and efficient segmentation of brain tumors is critical for diagnosis, treatment planning, and monitoring in clinical practice. In this study, we present an enhanced ResUNet architecture for automatic brain tumor segmentation, integrating an EfficientNetB0 encoder, a channel attention mechanism, and an Atrous Spatial Pyramid Pooling (ASPP) module. The EfficientNetB0 encoder leverages pre-trained features to improve feature extraction efficiency, while the channel attention mechanism enhances the model’s focus on tumor-relevant features. ASPP enables multiscale contextual learning, crucial for handling tumors of varying sizes and shapes. The proposed model was evaluated on two benchmark datasets: TCGA LGG and BraTS 2020. Experimental results demonstrate that our method consistently outperforms the baseline ResUNet and its EfficientNet variant, achieving Dice coefficients of 0.903 and 0.851 and HD95 scores of 9.43 and 3.54 for whole tumor and tumor core regions on the BraTS 2020 dataset, respectively. compared with state-of-the-art methods, our approach shows competitive performance, particularly in whole tumor and tumor core segmentation. These results indicate that combining a powerful encoder with attention mechanisms and ASPP can significantly enhance brain tumor segmentation performance. The proposed approach holds promise for further optimization and application in other medical image segmentation tasks.
在临床实践中,脑肿瘤的精确和高效分割对于诊断、治疗计划制定和监测至关重要。本研究提出了一种增强型ResUNet架构,用于自动脑肿瘤分割,该架构集成了EfficientNetB0编码器、通道注意机制和空洞空间金字塔池化(ASPP)模块。EfficientNetB0编码器利用预训练特征来提高特征提取效率,而通道注意机制则增强了模型对肿瘤相关特征的关注。ASPP模块实现了多尺度上下文学习,对于处理不同大小和形状的肿瘤至关重要。所提出的模型在TCGA LGG和BraTS 2020两个基准数据集上进行了评估。实验结果表明,我们的方法始终优于基线ResUNet及其EfficientNet变体,在BraTS 2020数据集上的整个肿瘤和肿瘤核心区域分别实现了Dice系数0.903和0.851以及HD95得分分别为9.43和3.54。与最先进的方法相比,我们的方法在整体肿瘤和肿瘤核心分割方面表现出有竞争力的性能。这些结果表明,将强大的编码器与注意机制和ASPP相结合可以显著提高脑肿瘤分割性能。所提出的方法在进一步优化和其他医学图像分割任务的应用中显示出潜力。
论文及项目相关链接
PDF 13 pages, 1 figure
Summary
本研究提出一种增强型ResUNet架构,用于自动脑肿瘤分割。该架构结合了EfficientNetB0编码器、通道注意力机制和空洞空间金字塔池化(ASPP)模块。实验结果表明,该方法在TCGA LGG和BraTS 2020两个基准数据集上较基线ResUNet及其EfficientNet变体表现出更好的性能,特别是在BraTS 2020数据集上的全肿瘤和肿瘤核心区分割方面。该研究为进一步优化和其他医学图像分割任务的应用提供了潜力。
Key Takeaways
- 研究提出了一种增强型ResUNet架构用于自动脑肿瘤分割。
- 该架构结合了EfficientNetB0编码器、通道注意力机制和ASPP模块。
- EfficientNetB0编码器利用预训练特征提高特征提取效率。
- 通道注意力机制增强了模型对肿瘤相关特征的关注。
- ASPP模块实现了多尺度上下文学习,对于处理不同大小和形状的肿瘤至关重要。
- 该方法在TCGA LGG和BraTS 2020数据集上进行了评估,并较基线ResUNet及其EfficientNet变体表现出更好的性能。
点此查看论文截图

Transfer Learning Strategies for Pathological Foundation Models: A Systematic Evaluation in Brain Tumor Classification
Authors:Ken Enda, Yoshitaka Oda, Zen-ichi Tanei, Wang Lei, Masumi Tsuda, Takahiro Ogawa, Shinya Tanaka
Foundation models pretrained on large-scale pathology datasets have shown promising results across various diagnostic tasks. Here, we present a systematic evaluation of transfer learning strategies for brain tumor classification using these models. We analyzed 252 cases comprising five major tumor types: glioblastoma, astrocytoma, oligodendroglioma, primary central nervous system lymphoma, and metastatic tumors. Comparing state-of-the-art foundation models with conventional approaches, we found that foundation models demonstrated robust classification performance with as few as 10 patches per case, challenging the traditional assumption that extensive per-case image sampling is necessary. Furthermore, our evaluation revealed that simple transfer learning strategies like linear probing were sufficient, while fine-tuning often degraded model performance. These findings suggest a paradigm shift from extensive data collection to efficient utilization of pretrained features, providing practical implications for implementing AI-assisted diagnosis in clinical pathology.
基于大规模病理学数据集进行预训练的基石模型在各种诊断任务中已显示出有前景的结果。在这里,我们对使用这些模型进行脑肿瘤分类的迁移学习策略进行了系统评估。我们分析了包含五种主要肿瘤类型的252个病例:胶质母细胞瘤、星形细胞瘤、少突胶质细胞瘤、原发性中枢神经系统淋巴瘤和转移性肿瘤。通过比较最新的基石模型与传统方法,我们发现基石模型在每个病例仅需10个补丁的情况下就表现出了稳健的分类性能,这挑战了传统假设,即每个病例的广泛图像采样是必要的。此外,我们的评估表明,简单的迁移学习策略如线性探测就已经足够,而微调往往会降低模型性能。这些发现预示着从广泛的数据收集到有效利用预训练特征的范式转变,为在临床病理学中实现人工智能辅助诊断提供了实际启示。
论文及项目相关链接
PDF 25 pages, 7 figures
Summary
基于大规模病理学数据集进行预训练的基金模型在各种诊断任务中表现出良好的性能。本文对用于脑肿瘤分类的基金模型迁移学习策略进行了系统评估。分析结果显示,基金模型在少量样本下展现出强大的分类性能,打破了传统认知中对每例病例广泛采集图像的假设。此外,简单迁移学习策略如线性探查法就已足够,而微调策略往往会降低模型性能。这些发现预示着从大量数据采集转向有效利用预训练特征的转变,为临床病理学实施人工智能辅助诊断提供了实际启示。
Key Takeaways
- 基金模型在脑肿瘤分类任务中展现出良好性能。
- 少量样本下基金模型即可实现强大的分类性能。
- 简单迁移学习策略如线性探查法有效,而微调策略可能降低模型性能。
- 打破传统认知中对每例病例广泛采集图像的假设。
- 从大量数据采集转向有效利用预训练特征。
- 基金模型的应用对临床病理学实施人工智能辅助诊断具有实际启示。
点此查看论文截图

An analysis of the combination of feature selection and machine learning methods for an accurate and timely detection of lung cancer
Authors:Omid Shahriyar, Babak Nuri Moghaddam, Davoud Yousefi, Abbas Mirzaei, Farnaz Hoseini
One of the deadliest cancers, lung cancer necessitates an early and precise diagnosis. Because patients have a better chance of recovering, early identification of lung cancer is crucial. This review looks at how to diagnose lung cancer using sophisticated machine learning techniques like Random Forest (RF) and Support Vector Machine (SVM). The Chi-squared test is one feature selection strategy that has been successfully applied to find related features and enhance model performance. The findings demonstrate that these techniques can improve detection efficiency and accuracy while also assisting in runtime reduction. This study produces recommendations for further research as well as ideas to enhance diagnostic techniques. In order to improve healthcare and create automated methods for detecting lung cancer, this research is a critical first step.
肺癌是最致命的癌症之一,需要进行早期和精确的诊断。由于患者康复的机会更大,因此早期发现肺癌至关重要。本文介绍了如何使用随机森林(RF)和支持向量机(SVM)等先进的机器学习技术来诊断肺癌。卡方检验是一种特征选择策略,已成功应用于寻找相关特征并提高模型性能。研究结果表明,这些技术可以提高检测效率和准确性,同时有助于减少运行时间。本研究为进一步的研究提供了建议,并为改进诊断技术提供了思路。为了改善医疗保健并创建用于检测肺癌的自动化方法,这项研究是至关重要的一步。
论文及项目相关链接
摘要
肺癌作为致命的癌症之一,早期精准诊断对于患者的康复至关重要。本文综述了利用随机森林(RF)和支持向量机(SVM)等先进机器学习技术诊断肺癌的方法。Chi平方检验作为一种特征选择策略,已成功应用于寻找相关特征,提高模型性能。研究表明,这些技术可以提高检测效率和准确性,同时有助于减少运行时间。本文不仅为未来的研究提供了建议,还提出了改进诊断技术的想法。这项研究对于提高医疗保健和创建肺癌自动检测方法是关键的第一步。
要点
- 肺癌的早期诊断对患者的康复至关重要。
- 机器学习技术如随机森林和支持向量机在肺癌诊断中具有应用价值。
- Chi平方检验是一种有效的特征选择策略,能提高模型性能。
- 机器学习技术可以提高肺癌检测的效率和准确性。
- 这些技术有助于减少诊断过程的运行时间。
- 研究为未来研究提供了建议和想法,以改进诊断技术。
点此查看论文截图

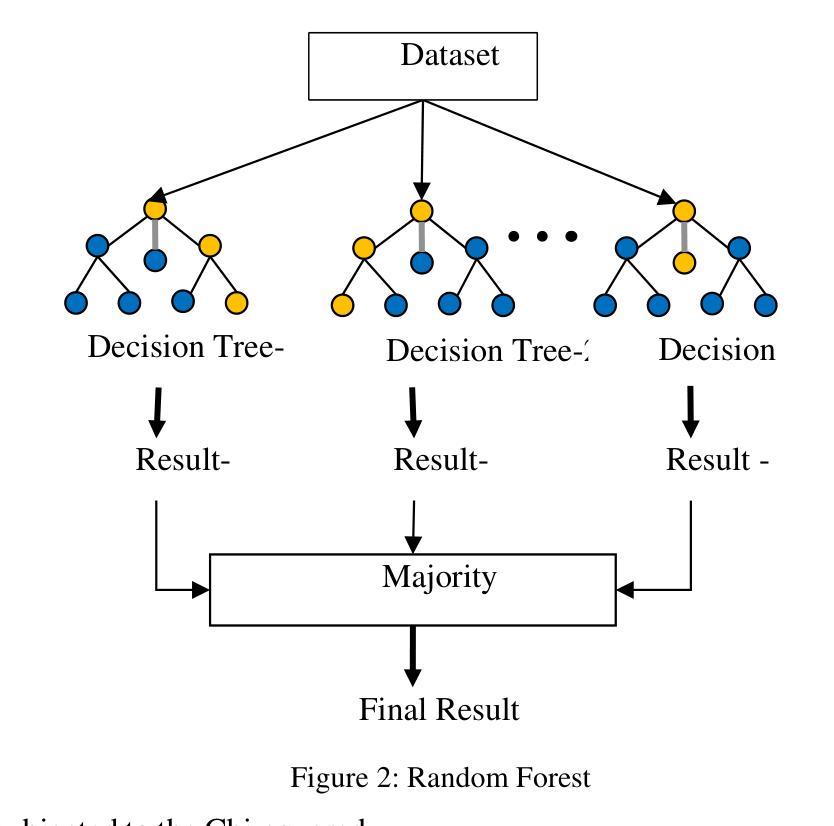
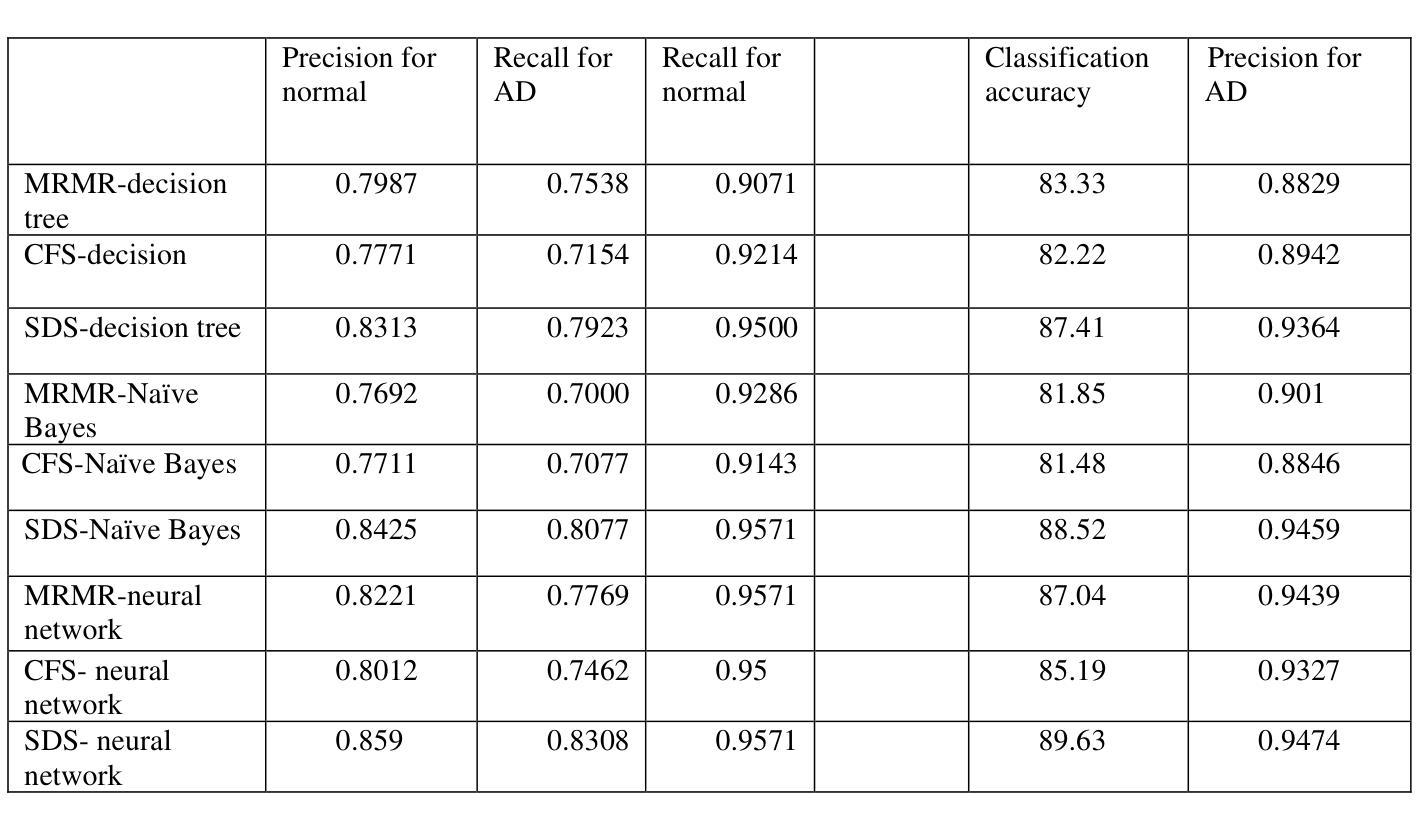
Rethinking Early-Fusion Strategies for Improved Multimodal Image Segmentation
Authors:Zhengwen Shen, Yulian Li, Han Zhang, Yuchen Weng, Jun Wang
RGB and thermal image fusion have great potential to exhibit improved semantic segmentation in low-illumination conditions. Existing methods typically employ a two-branch encoder framework for multimodal feature extraction and design complicated feature fusion strategies to achieve feature extraction and fusion for multimodal semantic segmentation. However, these methods require massive parameter updates and computational effort during the feature extraction and fusion. To address this issue, we propose a novel multimodal fusion network (EFNet) based on an early fusion strategy and a simple but effective feature clustering for training efficient RGB-T semantic segmentation. In addition, we also propose a lightweight and efficient multi-scale feature aggregation decoder based on Euclidean distance. We validate the effectiveness of our method on different datasets and outperform previous state-of-the-art methods with lower parameters and computation.
RGB与热成像融合在低光照条件下展现出巨大的语义分割潜力。现有方法通常采用双分支编码器框架进行多模态特征提取,并设计复杂的特征融合策略来实现多模态语义分割的特征提取和融合。然而,这些方法在特征提取和融合过程中需要大量的参数更新和计算。为了解决这个问题,我们提出了一种基于早期融合策略和简单有效的特征聚类的新型多模态融合网络(EFNet),用于训练高效的RGB-T语义分割。此外,我们还提出了一种基于欧氏距离的轻量级高效多尺度特征聚合解码器。我们在不同的数据集上验证了我们的方法的有效性,并以更低的参数和计算量超越了之前的最先进方法。
论文及项目相关链接
PDF Accepted by ICASSP 2025
摘要
融合RGB和热成像技术可显著提高低光照条件下的语义分割性能。现有方法通常采用双分支编码器框架进行多模态特征提取,并设计复杂的特征融合策略来实现多模态语义分割的特征提取和融合。然而,这些方法在特征提取和融合过程中需要大量参数更新和计算。为解决这一问题,我们提出了一种基于早期融合策略和简单有效的特征聚类的全新多模态融合网络(EFNet),以实现高效的RGB-T语义分割。此外,我们还提出了一种基于欧氏距离的高效轻量级多尺度特征聚合解码器。在不同数据集上的验证表明,我们的方法优于先前的方法,具有更低的参数和计算量。
关键见解
- RGB与热成像融合在低光照条件下提高了语义分割的潜力。
- 当前方法采用双分支编码器框架和多模态特征提取复杂融合策略。
- 现有方法需要大量参数更新和计算资源。
- 提出了基于早期融合策略和特征聚类的全新多模态融合网络(EFNet)。
- 引入了一种高效轻量级的多尺度特征聚合解码器。
- 在不同数据集上验证了该方法的有效性。
- 与先前的方法相比,该方法具有更低的参数和计算成本。
点此查看论文截图

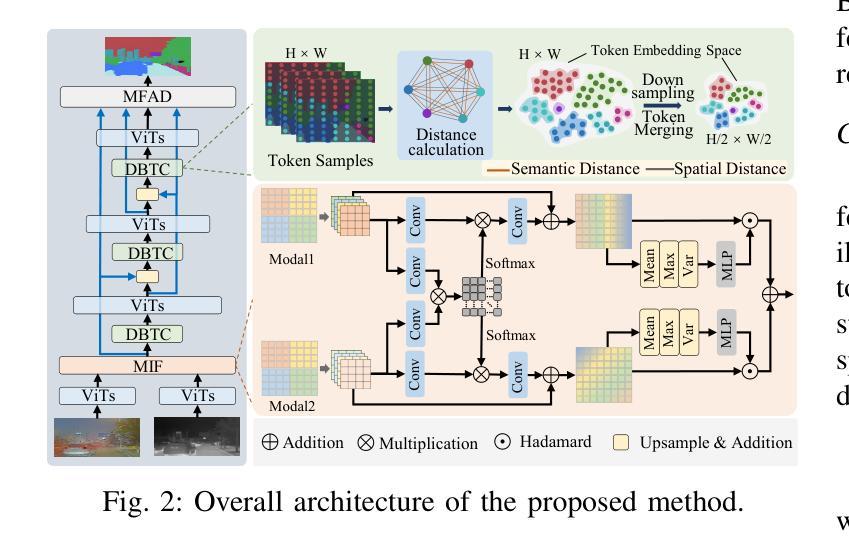
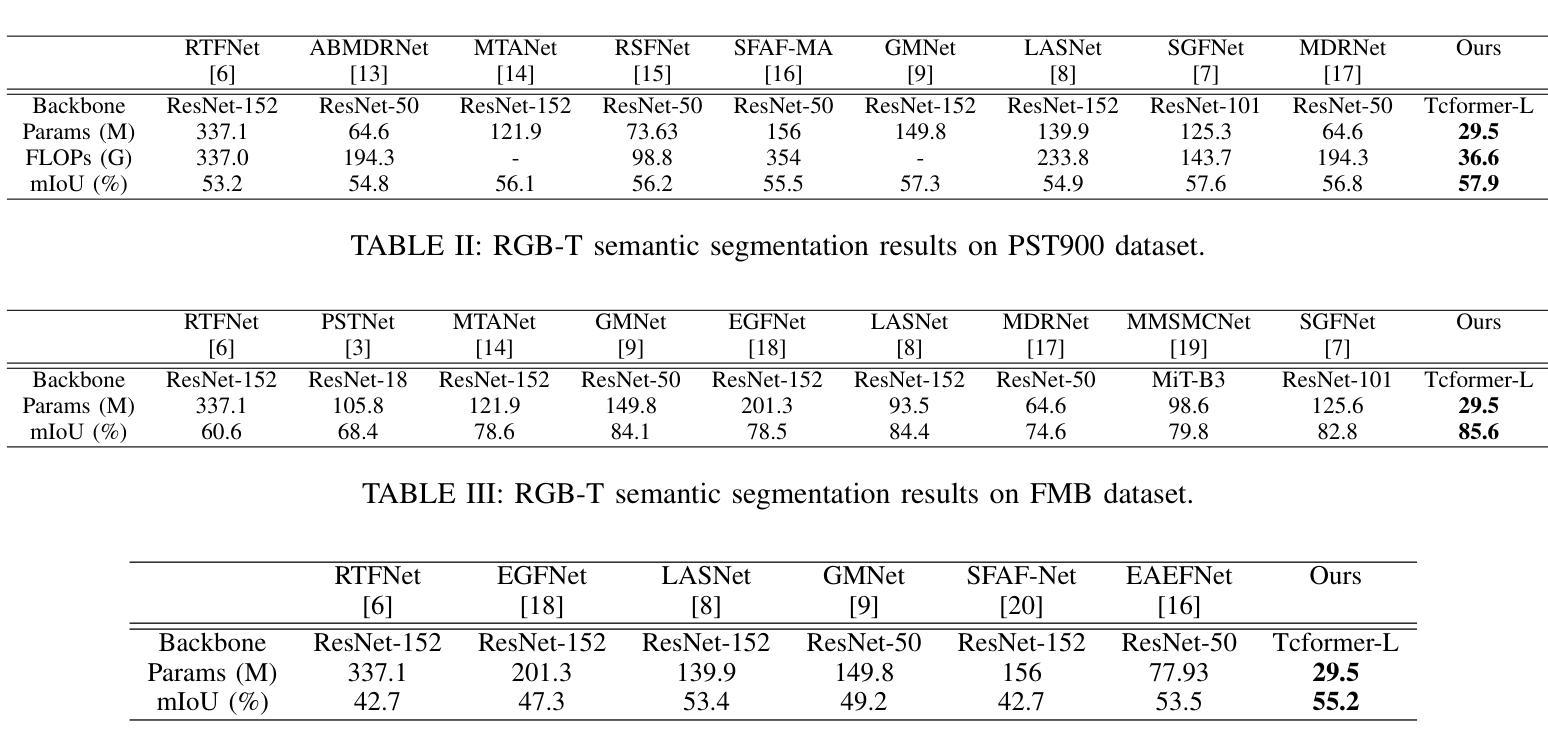
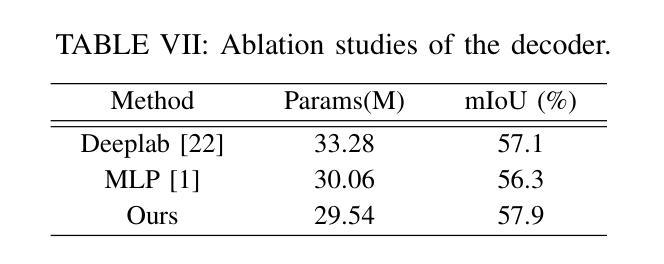
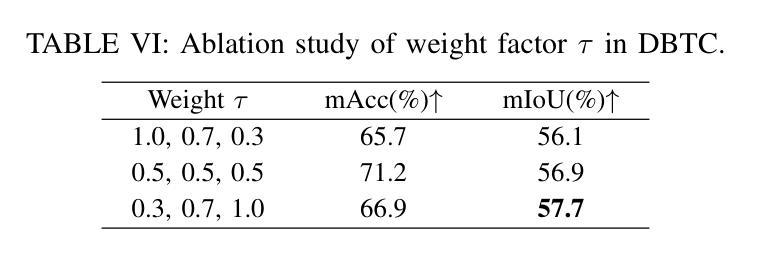
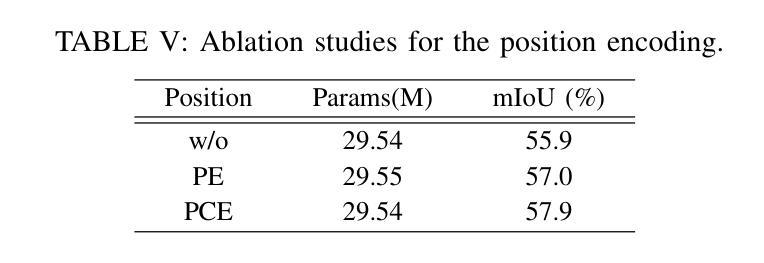
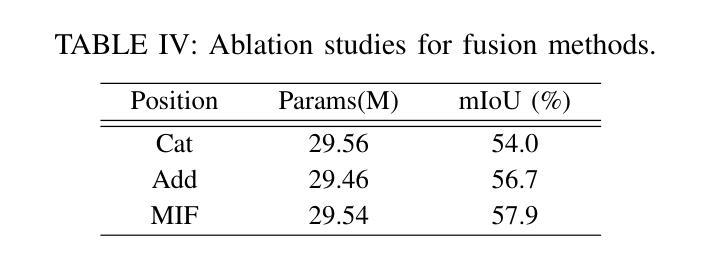
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Authors:Shanwen Wang, Changrui Chen, Xin Sun, Danfeng Hong, Jungong Han
Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
半监督学习为遥感(RS)图像分割提供了一个吸引人的解决方案,减轻了劳动密集型的像素级标签的负担。然而,遥感图像带来了独特的挑战,包括丰富的多尺度特征和高的类间相似性。为了解决这些问题,本文提出了一种用于遥感图像语义分割任务的新型半监督多尺度不确定性和跨教师学生注意力(MUCA)模型。具体来说,MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图之间的一致性。它提高了半监督算法在未标记数据上的多尺度学习能力。此外,MUCA利用跨教师学生注意力机制来引导学生网络,通过教师网络的互补特征来构建更具区分性的特征表示。这种设计有效地结合了弱增强和强增强(WA和SA),进一步提高了分割性能。为了验证我们模型的有效性,我们在ISPRS-Potsdam和LoveDA数据集上进行了大量实验。实验结果表明,我们的方法优于最新的半监督方法。值得注意的是,我们的模型在区分高度相似物体方面表现出色,展示了其在推进半监督遥感图像分割任务方面的潜力。
论文及项目相关链接
Summary
半监督学习是解决遥感图像分割任务的有效手段,减少了需要大量手动像素级别标签的麻烦。本文针对遥感图像多尺度特征丰富和类别间相似度高的挑战,提出了基于多尺度不确定性和跨教师学生注意力机制的半监督MUCA模型。MUCA通过引入多尺度不确定性一致性正则化,提高了半监督算法在无标签数据上的多尺度学习能力。此外,它采用跨教师学生注意力机制引导学生网络构建更具判别性的特征表示。实验表明,该模型在ISPRS-Potsdam和LoveDA数据集上优于其他先进半监督方法,特别是在区分高度相似物体方面表现出优异性能。
Key Takeaways
- 半监督学习是遥感图像分割的实用解决方案,减少了手动像素级别标签的需求。
- MUCA模型针对遥感图像的多尺度特征和类别间高相似度问题进行了优化。
- MUCA通过引入多尺度不确定性一致性正则化,提高了半监督算法在无标签数据上的多尺度学习能力。
- 跨教师学生注意力机制有助于引导学生网络构建更具判别性的特征表示。
- 实验验证MUCA模型在ISPRS-Potsdam和LoveDA数据集上的优越性。
- MUCA模型在区分高度相似物体方面表现出色。
点此查看论文截图

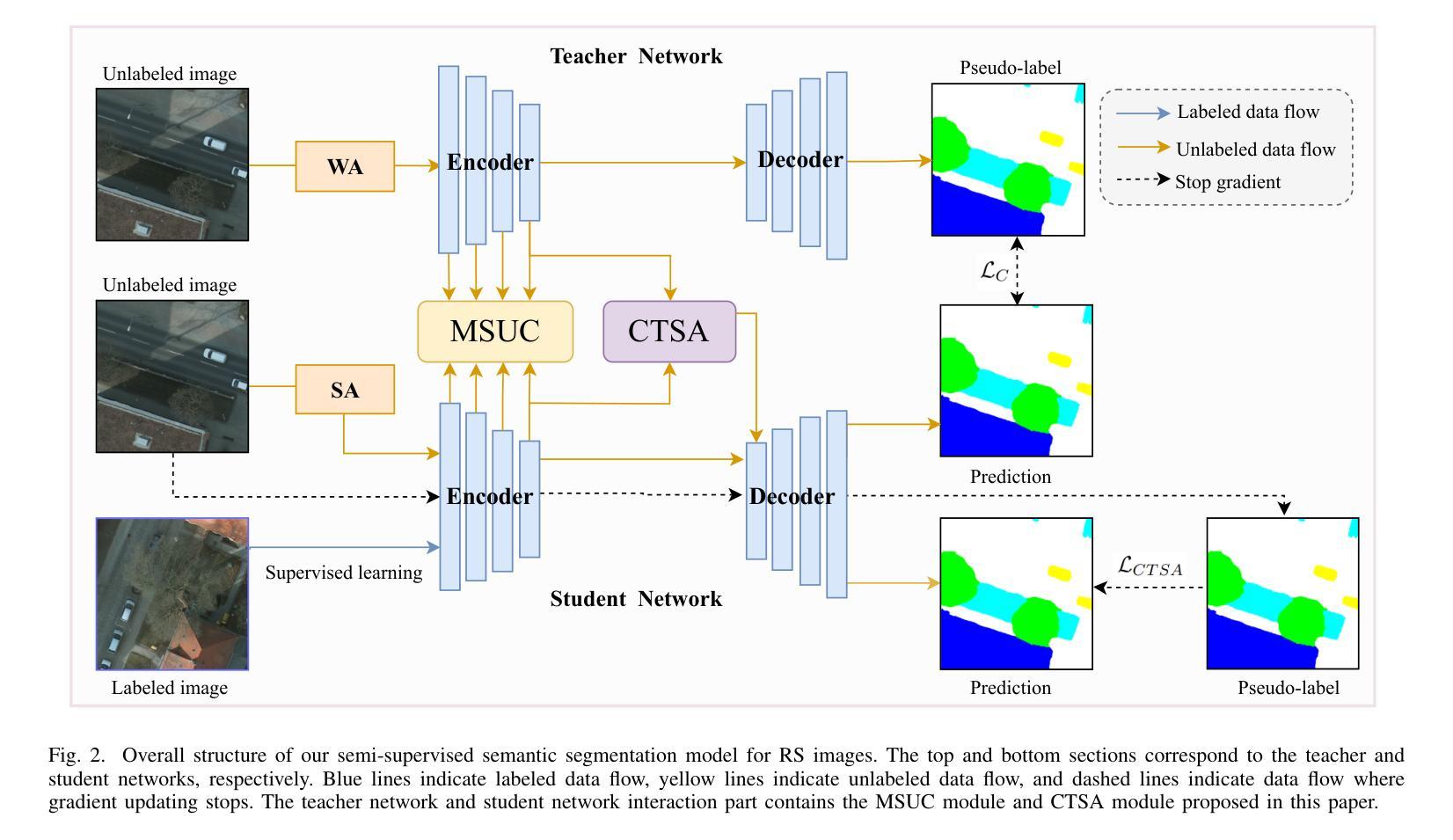
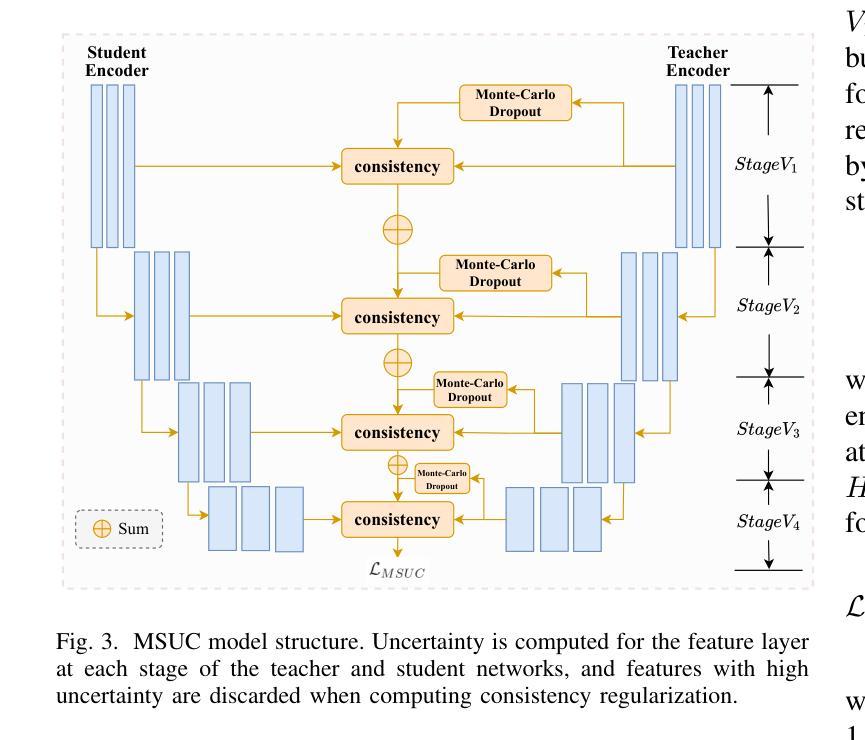

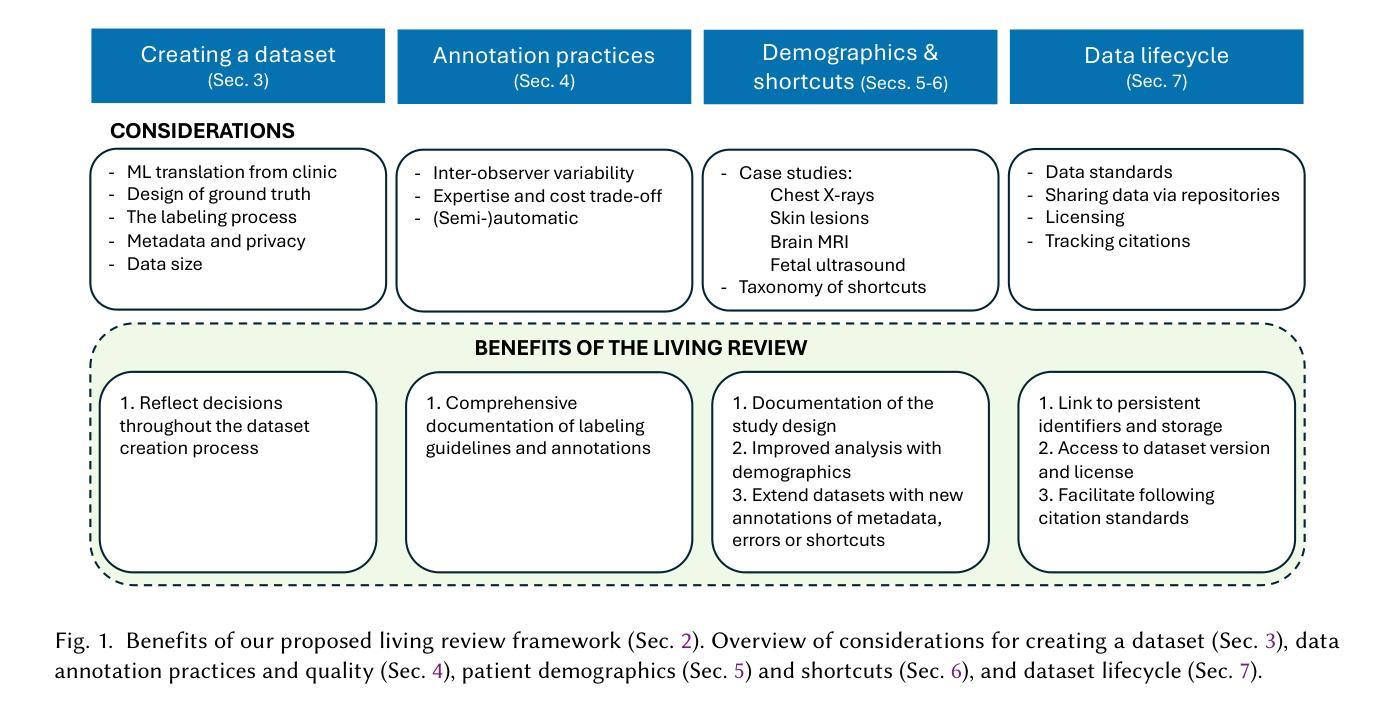
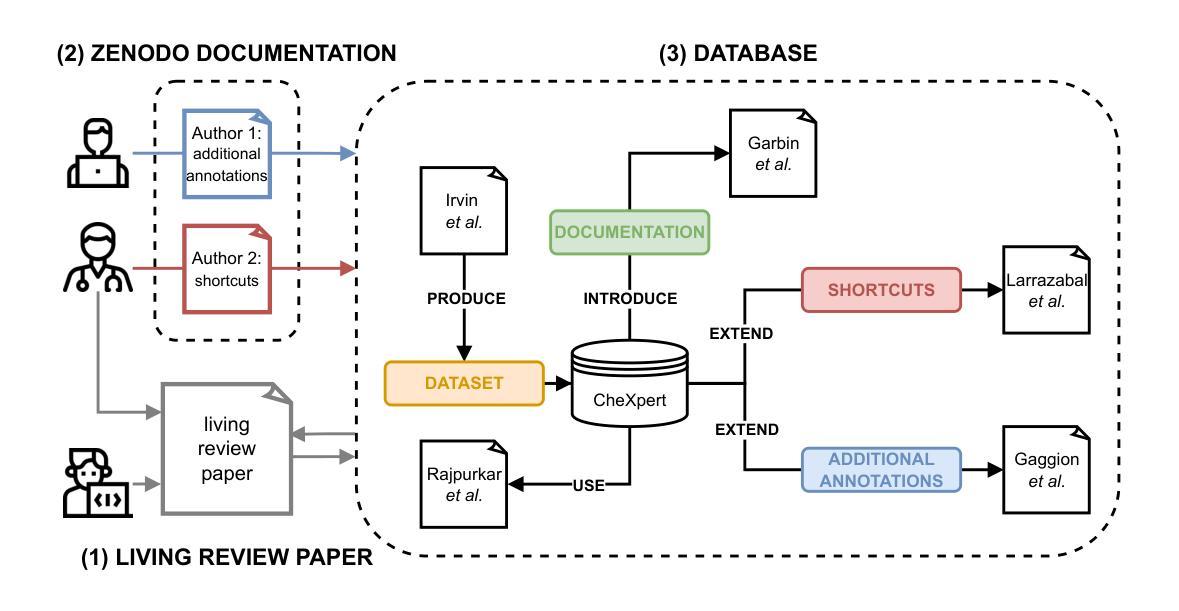
In the Picture: Medical Imaging Datasets, Artifacts, and their Living Review
Authors:Amelia Jiménez-Sánchez, Natalia-Rozalia Avlona, Sarah de Boer, Víctor M. Campello, Aasa Feragen, Enzo Ferrante, Melanie Ganz, Judy Wawira Gichoya, Camila González, Steff Groefsema, Alessa Hering, Adam Hulman, Leo Joskowicz, Dovile Juodelyte, Melih Kandemir, Thijs Kooi, Jorge del Pozo Lérida, Livie Yumeng Li, Andre Pacheco, Tim Rädsch, Mauricio Reyes, Théo Sourget, Bram van Ginneken, David Wen, Nina Weng, Jack Junchi Xu, Hubert Dariusz Zając, Maria A. Zuluaga, Veronika Cheplygina
Datasets play a critical role in medical imaging research, yet issues such as label quality, shortcuts, and metadata are often overlooked. This lack of attention may harm the generalizability of algorithms and, consequently, negatively impact patient outcomes. While existing medical imaging literature reviews mostly focus on machine learning (ML) methods, with only a few focusing on datasets for specific applications, these reviews remain static – they are published once and not updated thereafter. This fails to account for emerging evidence, such as biases, shortcuts, and additional annotations that other researchers may contribute after the dataset is published. We refer to these newly discovered findings of datasets as research artifacts. To address this gap, we propose a living review that continuously tracks public datasets and their associated research artifacts across multiple medical imaging applications. Our approach includes a framework for the living review to monitor data documentation artifacts, and an SQL database to visualize the citation relationships between research artifact and dataset. Lastly, we discuss key considerations for creating medical imaging datasets, review best practices for data annotation, discuss the significance of shortcuts and demographic diversity, and emphasize the importance of managing datasets throughout their entire lifecycle. Our demo is publicly available at http://130.226.140.142.
数据集在医学成像研究中扮演着至关重要的角色,然而标签质量、捷径和元数据等问题往往被忽视。这种缺乏关注可能会损害算法的泛化能力,进而对病人结果产生负面影响。尽管现有的医学成像文献综述主要集中在机器学习(ML)方法上,只有少数关注特定应用的数据集,但这些综述保持静态——一经发布,就不再更新。这未能考虑到新兴证据,如偏见、捷径和其他研究人员在数据集发布后可能做出的额外注释。我们将这些数据集的新发现称为研究文物。为了弥补这一空白,我们提出了一种持续回顾的方法,该方法能够跨多个医学成像应用追踪公开数据集及其相关的研究文物。我们的方法包括一个用于监督数据文档文物的生活评审框架,以及一个SQL数据库,以可视化研究文物与数据集之间的引证关系。最后,我们讨论了创建医学成像数据集的关键注意事项,回顾了数据注释的最佳实践,讨论了捷径和人口多样性的重要性,并强调了整个数据集的整个生命周期管理的重要性。我们的演示公开可用在http://130.226.140.142。
论文及项目相关链接
PDF Manuscript under review
Summary
医学图像研究中的数据集至关重要,但标签质量、捷径和元数据等问题常被忽视。现有文献综述多关注机器学习(ML)方法,仅少数关注特定应用的数据集。我们提出一种持续追踪多个医学成像应用公开数据集及其相关研究成果的“动态综述”。该综述包括监控数据文档成果的方法和可视化数据集与研究成果间引用关系的SQL数据库。此外,我们还讨论了创建医学成像数据集的关键考量因素、数据标注的最佳实践、捷径和人口多样性的重要性以及整个生命周期中数据集的管理。
Key Takeaways
- 数据集在医学成像研究中具有关键作用,但常常被忽视的是标签质量、捷径和元数据等方面的问题。
- 现有医学成像文献综述大多静态,无法涵盖新兴证据,如偏见、捷径和其他研究人员在数据集发布后的附加注释。
- 提出的“动态综述”旨在持续追踪公开数据集及其相关研究成果。
- 动态综述包括监控数据文档成果的方法和可视化数据集与研究成果间关系的SQL数据库。
- 创建医学成像数据集时需考虑的关键因素包括数据标注的最佳实践、捷径的利用、人口多样性的重要性等。
- 强调在整个生命周期中管理数据集的重要性。
点此查看论文截图