⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Authors:Shanwen Wang, Changrui Chen, Xin Sun, Danfeng Hong, Jungong Han
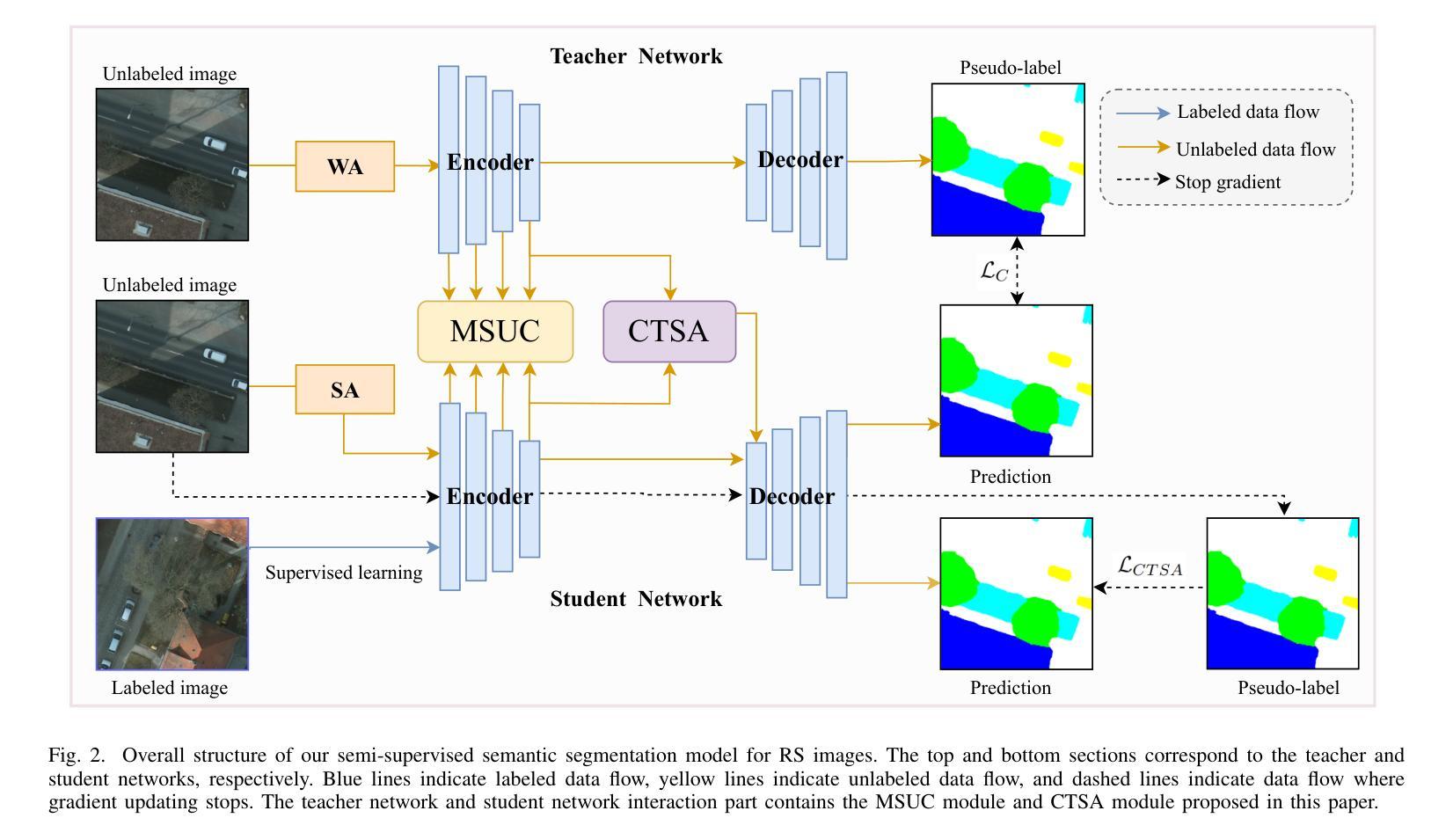
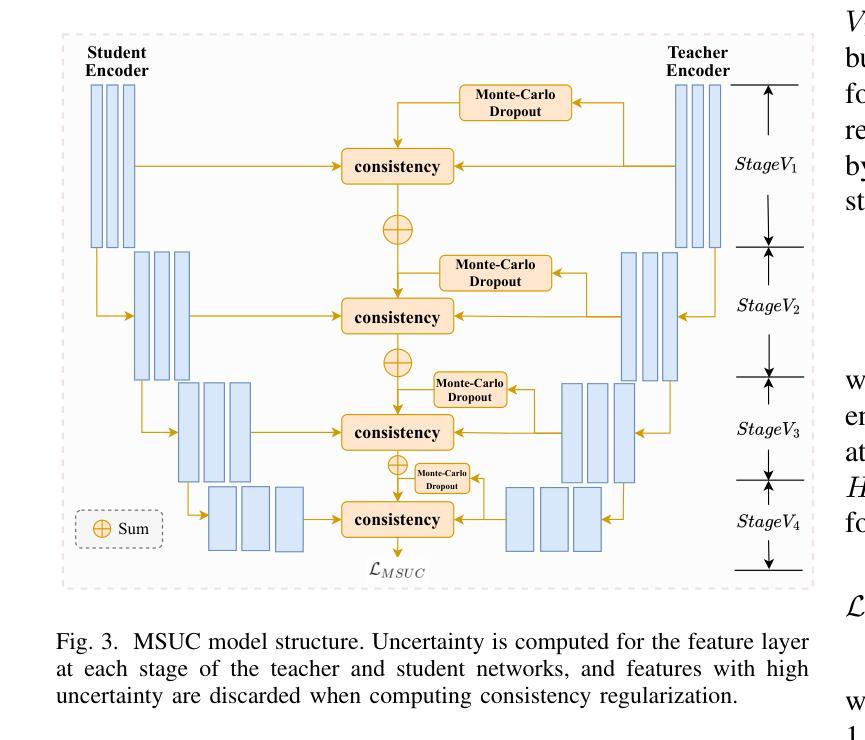
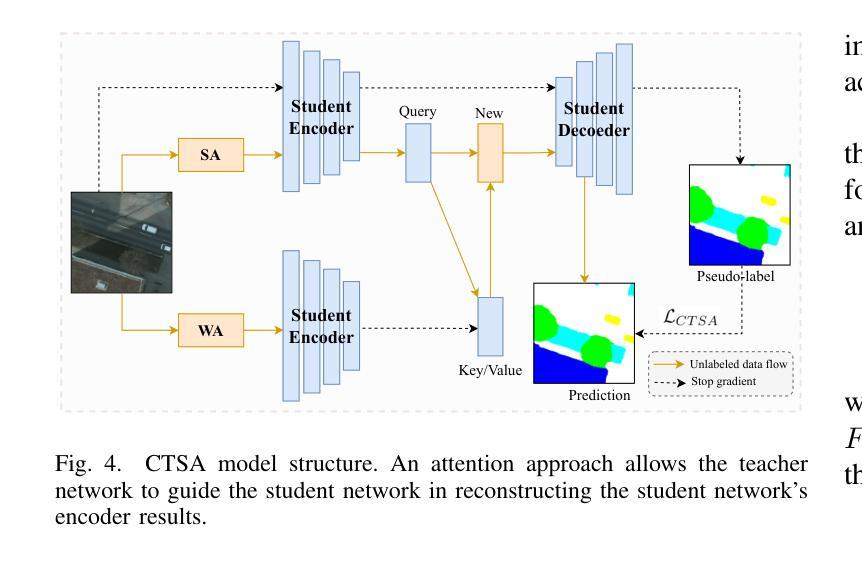
Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
半监督学习为解决遥感(RS)图像分割中的劳动力密集型像素级标签负担提供了一种吸引人的解决方案。然而,遥感图像存在丰富的多尺度特征和高度类间相似性等多重挑战。针对这些问题,本文提出了一种新型的半监督多尺度不确定性及交叉教师学生注意力(MUCA)模型,用于遥感图像语义分割任务。具体来说,MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图之间的一致性,提高了半监督算法在未标记数据上的多尺度学习能力。此外,MUCA利用跨教师学生注意力机制来引导学生网络,通过教师网络的互补特征构建更具区分性的特征表示。这种设计有效地结合了弱增强和强增强(WA和SA),以进一步提高分割性能。为了验证我们模型的有效性,我们在ISPRS-Potsdam和LoveDA数据集上进行了大量实验。实验结果表明,我们的方法优于最新的半监督方法。值得注意的是,我们的模型在区分高度相似物体方面表现出色,展示了其在推进半监督遥感图像分割任务方面的潜力。
论文及项目相关链接
Summary
半监督学习为遥感图像分割提供了一种吸引人的解决方案,减轻了劳动密集型的像素级标注负担。本文提出一种新型半监督多尺度不确定性及跨教师学生注意力模型(MUCA),用于遥感图像语义分割任务。MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图的一致性,提高了未标注数据上的多尺度学习能力。同时利用跨教师学生注意力机制指导网络,实现弱增强和强增强的融合,进一步提升分割性能。实验验证模型在ISPRS-Potsdam和LoveDA数据集上的优越性。
Key Takeaways
- 半监督学习为遥感图像分割提供了减轻标注负担的可行方案。
- 本文提出MUCA模型,适用于遥感图像语义分割任务。
- MUCA模型引入多尺度不确定性一致性正则化,提升未标注数据的网络多尺度学习能力。
- 跨教师学生注意力机制用于指导网络构建更具区分性的特征表示。
- 模型融合弱增强和强增强技术,进一步提升分割性能。
- 实验验证MUCA模型在ISPRS-Potsdam和LoveDA数据集上性能超越其他前沿半监督方法。
点此查看论文截图


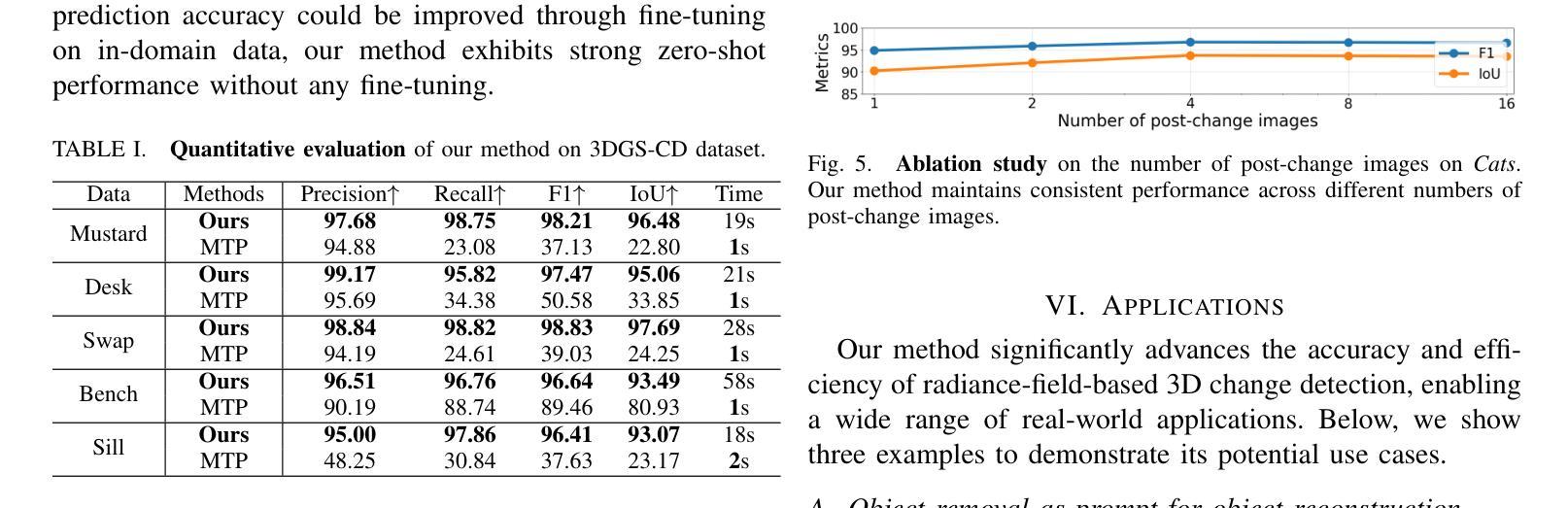
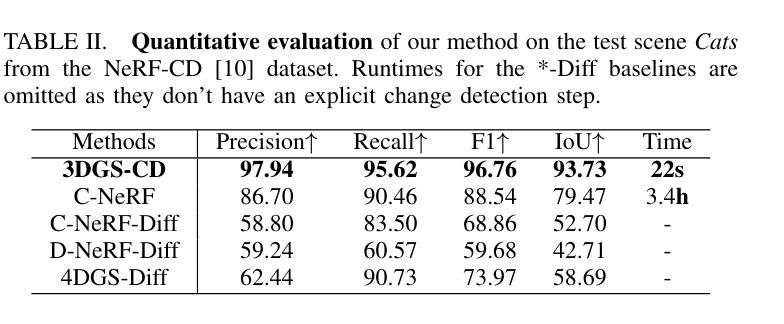
3DGS-CD: 3D Gaussian Splatting-based Change Detection for Physical Object Rearrangement
Authors:Ziqi Lu, Jianbo Ye, John Leonard
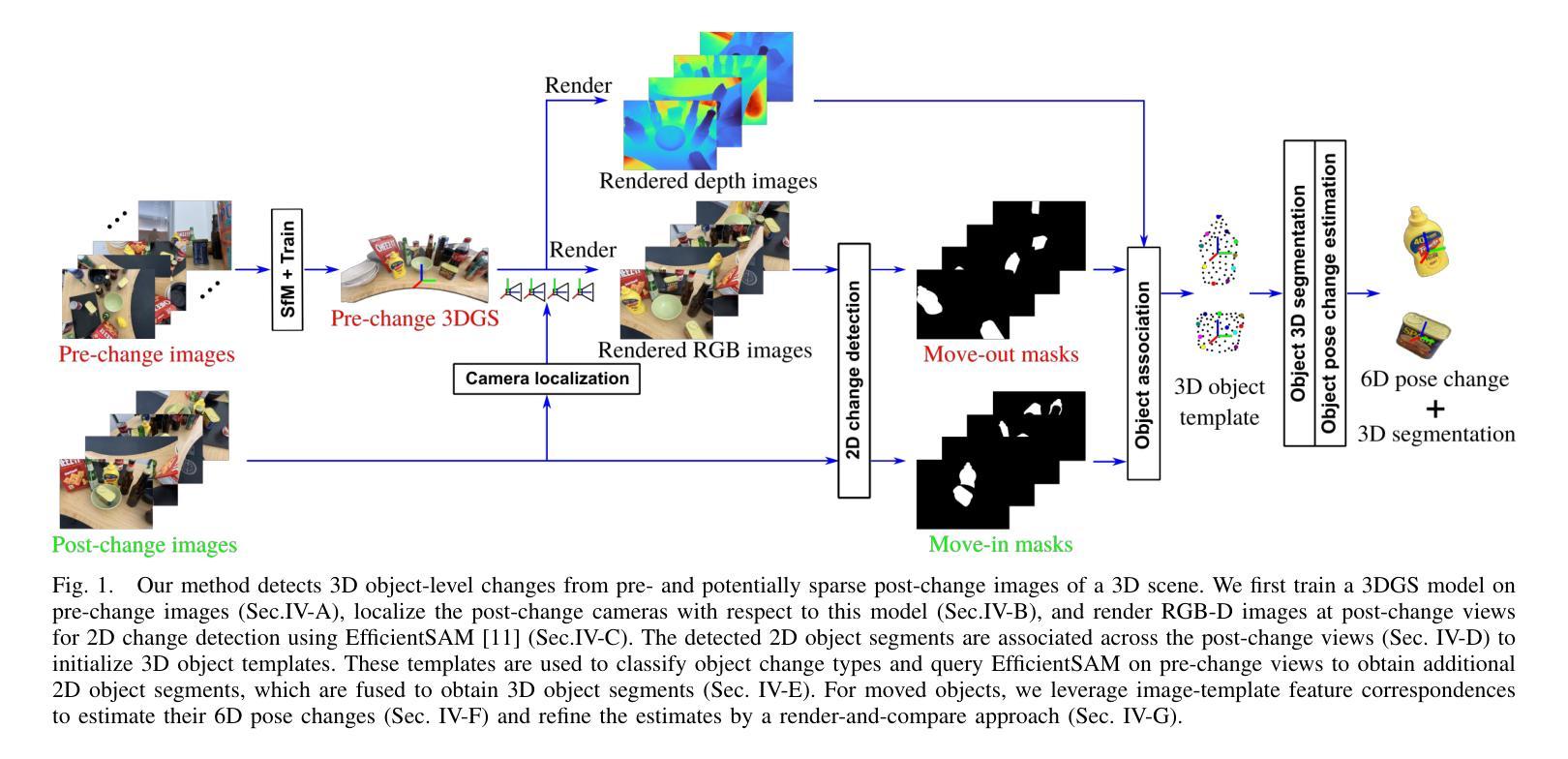
We present 3DGS-CD, the first 3D Gaussian Splatting (3DGS)-based method for detecting physical object rearrangements in 3D scenes. Our approach estimates 3D object-level changes by comparing two sets of unaligned images taken at different times. Leveraging 3DGS’s novel view rendering and EfficientSAM’s zero-shot segmentation capabilities, we detect 2D object-level changes, which are then associated and fused across views to estimate 3D change masks and object transformations. Our method can accurately identify changes in cluttered environments using sparse (as few as one) post-change images within as little as 18s. It does not rely on depth input, user instructions, pre-defined object classes, or object models – An object is recognized simply if it has been re-arranged. Our approach is evaluated on both public and self-collected real-world datasets, achieving up to 14% higher accuracy and three orders of magnitude faster performance compared to the state-of-the-art radiance-field-based change detection method. This significant performance boost enables a broad range of downstream applications, where we highlight three key use cases: object reconstruction, robot workspace reset, and 3DGS model update. Our code and data will be made available at https://github.com/520xyxyzq/3DGS-CD.
我们提出了基于三维高斯展开(3DGS)的物体重新排列检测方法3DGS-CD,这是首个针对三维场景的物理物体重新排列进行检测的方法。我们的方法通过比较两个在不同时间拍摄的不对齐的图像集来估计三维物体级别的变化。我们利用3DGS的新型视图渲染和EfficientSAM的零样本分割能力,检测二维物体级别的变化,然后在不同视图中关联和融合这些变化,以估计三维变化掩膜和物体转换。我们的方法能够在杂乱的环境中准确识别变化,仅使用少数(一张)变化后的图像在短短18秒内即可完成。它不依赖于深度输入、用户指令、预定义的物体类别或物体模型——只要物体被重新排列,它就能被识别出来。我们的方法在公共和自我收集的真实世界数据集上进行了评估,与最新的基于辐射场的变化检测方法相比,我们的方法实现了高达14%的更高精度和三个数量级的更快性能。这一显著的性能提升使得下游应用得以广泛应用,我们重点介绍了三个关键用例:物体重建、机器人工作空间重置和3DGS模型更新。我们的代码和数据将在https://github.com/520xyxyzq/3DGS-CD上提供。
论文及项目相关链接
Summary
本文提出了基于三维高斯喷射(3DGS)的方法——3DGS-CD,用于检测三维场景中的物体重新排列。该方法通过比较不同时间拍摄的不对齐图像集来估计三维物体级别的变化。利用3DGS的新视角渲染和EfficientSAM的零样本分割能力,检测二维物体级别的变化,并在不同视角之间进行关联和融合,以估计三维变化掩膜和物体变换。该方法能在杂乱的环境中准确识别变化,仅使用少数几张(至少一张)变化后的图像在短短18秒内完成。无需依赖深度输入、用户指令、预定义物体类别或物体模型,只要物体被重新排列即能被识别。在公共和自收集的真实世界数据集上的评估结果显示,与基于辐射场的变化检测方法相比,其精度提高了14%,性能提高了三个数量级。这将极大地推动下游应用的发展,我们重点介绍了三个关键用例:物体重建、机器人工作空间重置和3DGS模型更新。
Key Takeaways
- 提出了首个基于三维高斯喷射(3DGS)的方法——3DGS-CD,用于检测三维场景中的物体重新排列。
- 通过比较不同时间的图像集来估计三维物体级别的变化。
- 利用3DGS的新视角渲染和EfficientSAM的零样本分割能力,检测二维物体级别的变化。
- 方法能准确识别杂乱环境中的变化,且只需少数几张变化后的图像。
- 不依赖深度输入、用户指令、预定义物体类别或物体模型,具有强大的通用性。
- 与现有方法相比,其精度和性能均有显著提高。
点此查看论文截图




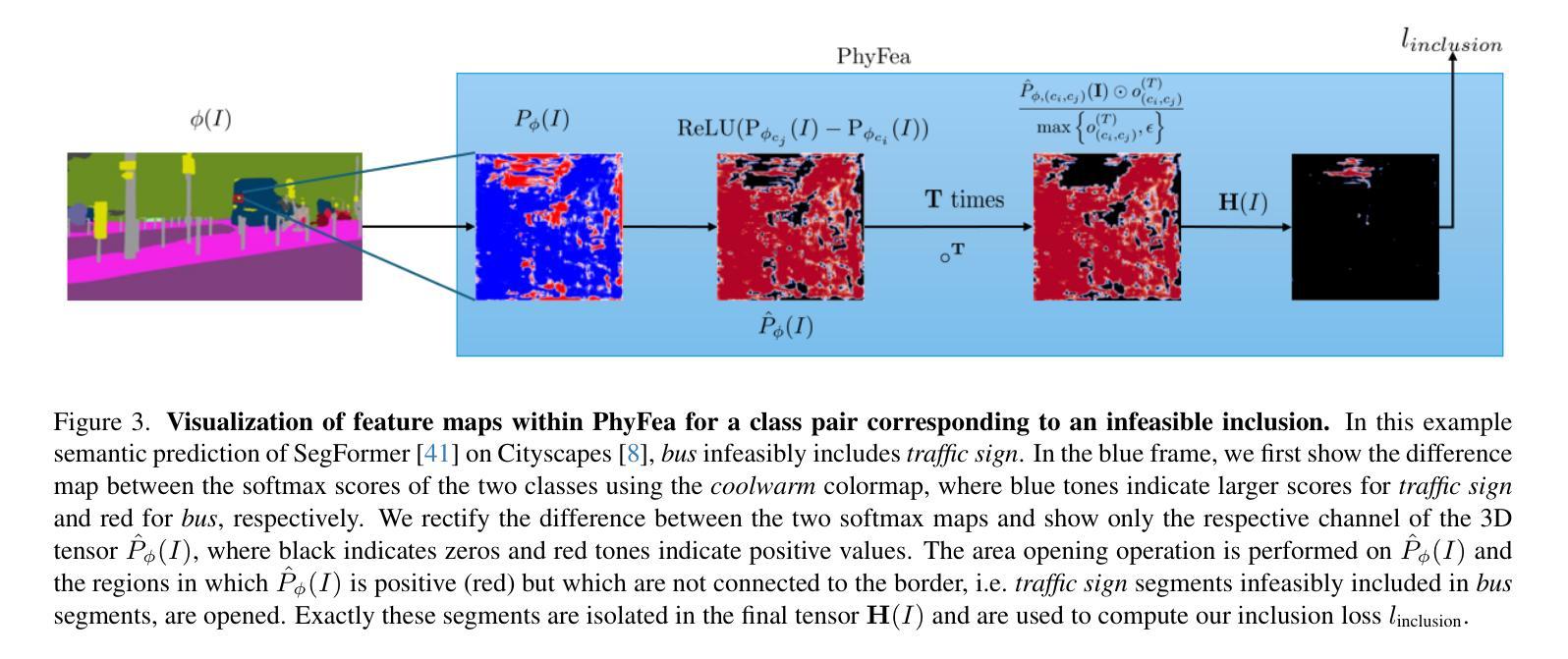
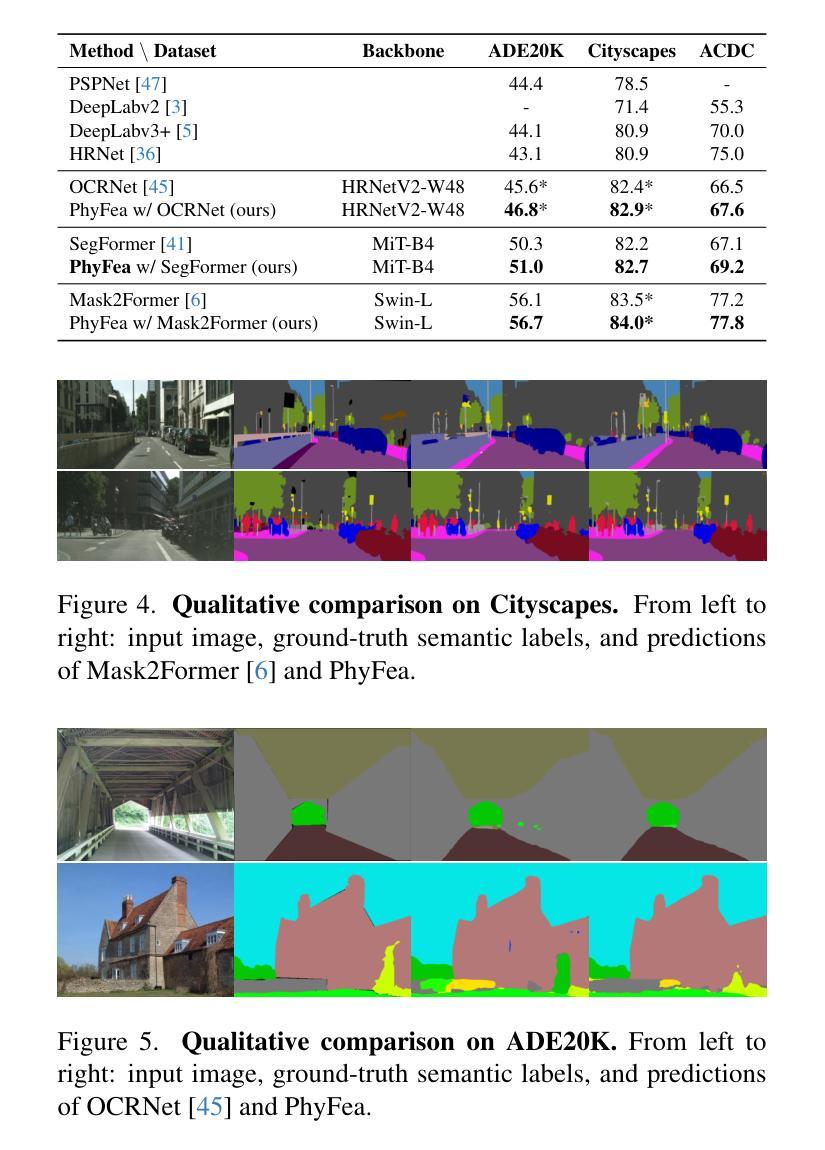
Physically Feasible Semantic Segmentation
Authors:Shamik Basu, Luc Van Gool, Christos Sakaridis
State-of-the-art semantic segmentation models are typically optimized in a data-driven fashion, minimizing solely per-pixel or per-segment classification objectives on their training data. This purely data-driven paradigm often leads to absurd segmentations, especially when the domain of input images is shifted from the one encountered during training. For instance, state-of-the-art models may assign the label road to a segment that is located above a segment that is respectively labeled as sky, although our knowledge of the physical world dictates that such a configuration is not feasible for images captured by forward-facing upright cameras. Our method, Physically Feasible Semantic Segmentation (PhyFea), first extracts explicit constraints that govern spatial class relations from the semantic segmentation training set at hand in an offline, data-driven fashion, and then enforces a morphological yet differentiable loss that penalizes violations of these constraints during training to promote prediction feasibility. PhyFea is a plug-and-play method and yields consistent and significant performance improvements over diverse state-of-the-art networks on which we implement it across the ADE20K, Cityscapes, and ACDC datasets. Code and models will be made publicly available.
最先进的语义分割模型通常采用数据驱动的方式进行优化,仅通过像素或分段分类目标来最小化其训练数据上的损失。这种纯粹的数据驱动范式往往会导致荒谬的分割结果,尤其是在输入图像的领域与训练过程中遇到的领域不一致时。例如,最先进的模型可能会将一个标签为“道路”的片段分配给位于另一个被标记为“天空”的片段上方的部分,尽管我们对物理世界的了解表明,对于正面朝上拍摄的图像来说,这样的配置是不可行的。我们的方法——物理可行语义分割(PhyFea)——首先从现有的语义分割训练集中离线提取控制空间类别关系的显式约束,然后以形态学且可微的方式强制执行这些约束的损失,以在训练过程中促进预测可行性。当在ADE20K、Cityscapes和ACDC数据集上实施时,PhyFea是一种即插即用的方法,与多种最先进的网络相比,它可以实现一致且显著的性能改进。我们将公开提供代码和模型。
论文及项目相关链接
Summary
本文介绍了当前先进的语义分割模型主要采取数据驱动的优化方式,在训练数据上最小化每个像素或每个区域的分类目标。然而,这种纯数据驱动的方法常常会导致荒谬的分割结果,特别是在输入图像的领域与训练时遇到的领域不一致时。为此,本文提出了一种名为Physically Feasible Semantic Segmentation(PhyFea)的方法,该方法首先以离线、数据驱动的方式从语义分割训练集中提取控制空间类别关系的显式约束,然后强制实施形态学可微损失来惩罚训练过程中对这些约束的违反,以促进预测可行性。PhyFea是一种即插即用的方法,在ADE20K、Cityscapes和ACDC数据集上实施时,都能得到一致且显著的性能改进。
Key Takeaways
- 先进的语义分割模型主要采取数据驱动的优化方式,但这种方式可能导致荒谬的分割结果。
- Physically Feasible Semantic Segmentation(PhyFea)方法通过提取空间类别关系的显式约束来解决这一问题。
- PhyFea以离线、数据驱动的方式从语义分割训练集中获取这些约束。
- PhyFea通过强制实施形态学可微损失来确保预测结果的可行性。
- 当在ADE20K、Cityscapes和ACDC数据集上实施时,PhyFea能够带来一致且显著的性能改进。
- PhyFea是一种即插即用的方法,可以应用于各种先进的网络。
点此查看论文截图