⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Authors:Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Yang, Haifeng Liu, Feng Lin, Tao Peng, Xin Liu, Guang Shi
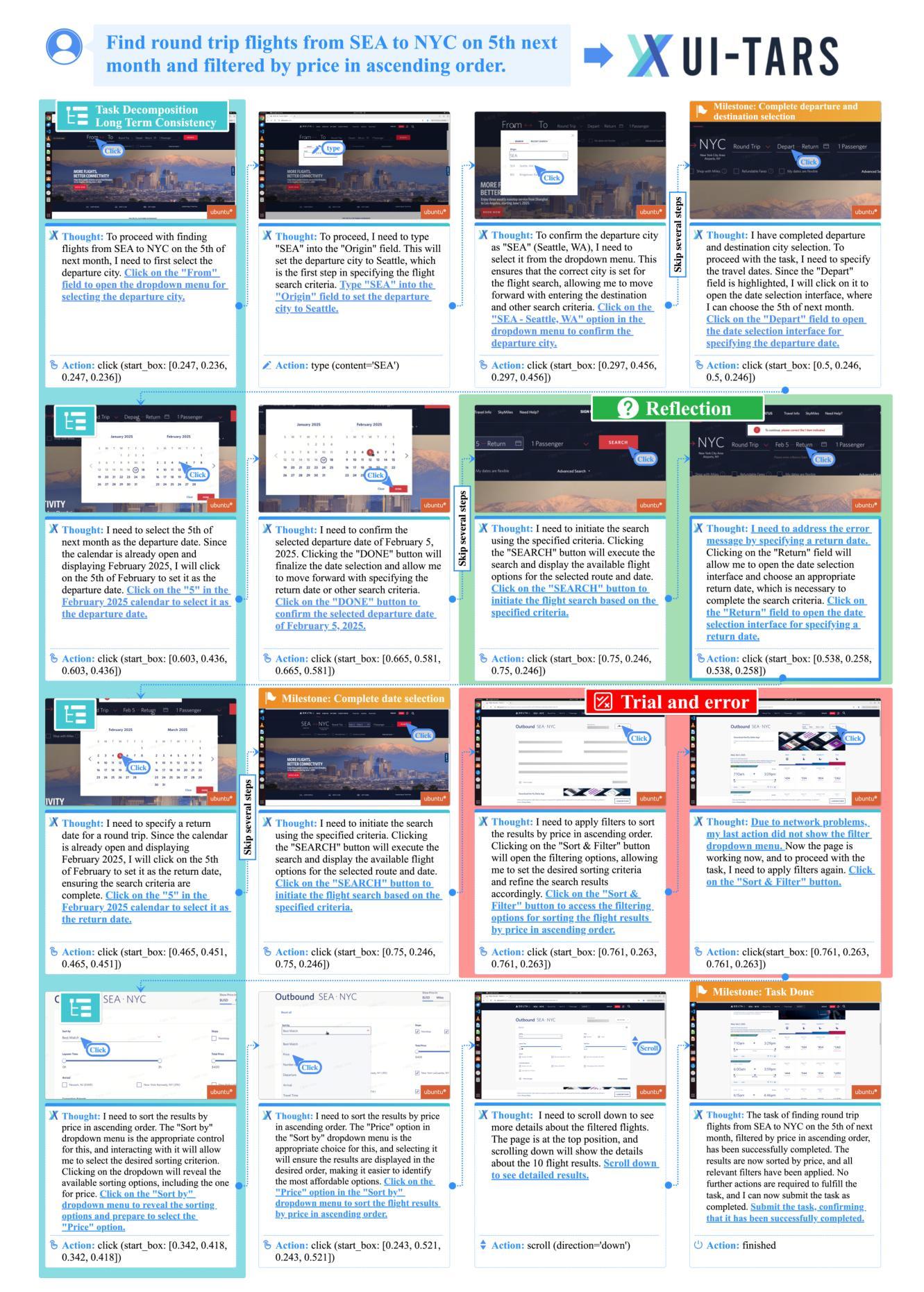
This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
本文介绍了UI-TARS,这是一种原生GUI代理模型,它仅将屏幕截图作为输入,并执行类似人类的交互(例如,键盘和鼠标操作)。不同于依赖大量封装的商业模型(例如GPT-4o)的流行代理框架,需要专家制作的提示和工作流程,UI-TARS是一个端到端的模型,表现出超过这些复杂框架的性能。实验证明了其卓越的性能:UI-TARS在10多个GUI代理基准测试中实现了感知、接地和GUI任务执行方面的卓越性能。特别是在OSWorld基准测试中,UI-TARS在50步时得分为24.6,在15步时得分为22.7,超过了Claude(分别为22.0和14.9)。在AndroidWorld中,UI-TARS实现46.6,超过了GPT-4o的34.5。UI-TARS融合了几个关键创新点:(1)增强感知:利用大规模的GUI屏幕截图数据集进行上下文感知的UI元素理解和精确描述;(2)统一动作建模,将动作标准化到统一的空间平台,并通过大规模的动作轨迹实现精确接地和交互;(3)系统2推理,将深思熟虑的推理融入多步骤决策制定中,涉及任务分解、反思思考、里程碑识别等多种推理模式;(4)通过迭代训练与反思在线轨迹来解决数据瓶颈问题,自动收集、过滤和反思地精炼数百台虚拟机上的新交互轨迹。通过迭代训练和反思调整,UI-TARS不断从错误中学习,并适应意外情况,最少需要人工干预。我们还分析了GUI代理的发展路径,以指导该领域的进一步发展。
论文及项目相关链接
Summary
本文介绍了一种名为UI-TARS的原生GUI代理模型,该模型仅通过截图作为输入,执行类似人类的交互操作(如键盘和鼠标操作)。与依赖高度包装的商业模型(如GPT-4o)的现有代理框架不同,UI-TARS是一个端到端的模型,在超过10个GUI代理基准测试中表现出卓越的性能,尤其是在OSWorld和AndroidWorld基准测试中。UI-TARS的关键创新包括增强感知能力、统一动作建模、系统2推理和迭代训练与反思调试。
**Key Takeaways**
1. UI-TARS是一个原生GUI代理模型,通过截图作为输入并执行类似人类的交互操作。
2. UI-TARS在多个GUI代理基准测试中表现出卓越性能,特别是在OSWorld和AndroidWorld测试中。
3. UI-TARS具有增强感知能力,利用大规模的GUI截图数据集进行UI元素的上下文感知理解和精确描述。
4. 统一动作建模是UI-TARS的一个关键创新,它标准化了跨平台的操作,并通过大规模的动作轨迹实现了精确的接地和交互。
5. UI-TARS采用系统2推理,将深思熟虑的推理融入多步骤决策制定,涉及任务分解、反思思考、里程碑识别等。
6. UI-TARS通过迭代训练与反思调试解决了数据瓶颈问题,能够自动收集、过滤和反思完善新的交互轨迹。
7. UI-TARS能从错误中学习并适应不可预见的情况,并且需要最少的人工干预。
点此查看论文截图

mmCooper: A Multi-agent Multi-stage Communication-efficient and Collaboration-robust Cooperative Perception Framework
Authors:Bingyi Liu, Jian Teng, Hongfei Xue, Enshu Wang, Chuanhui Zhu, Pu Wang, Libing Wu
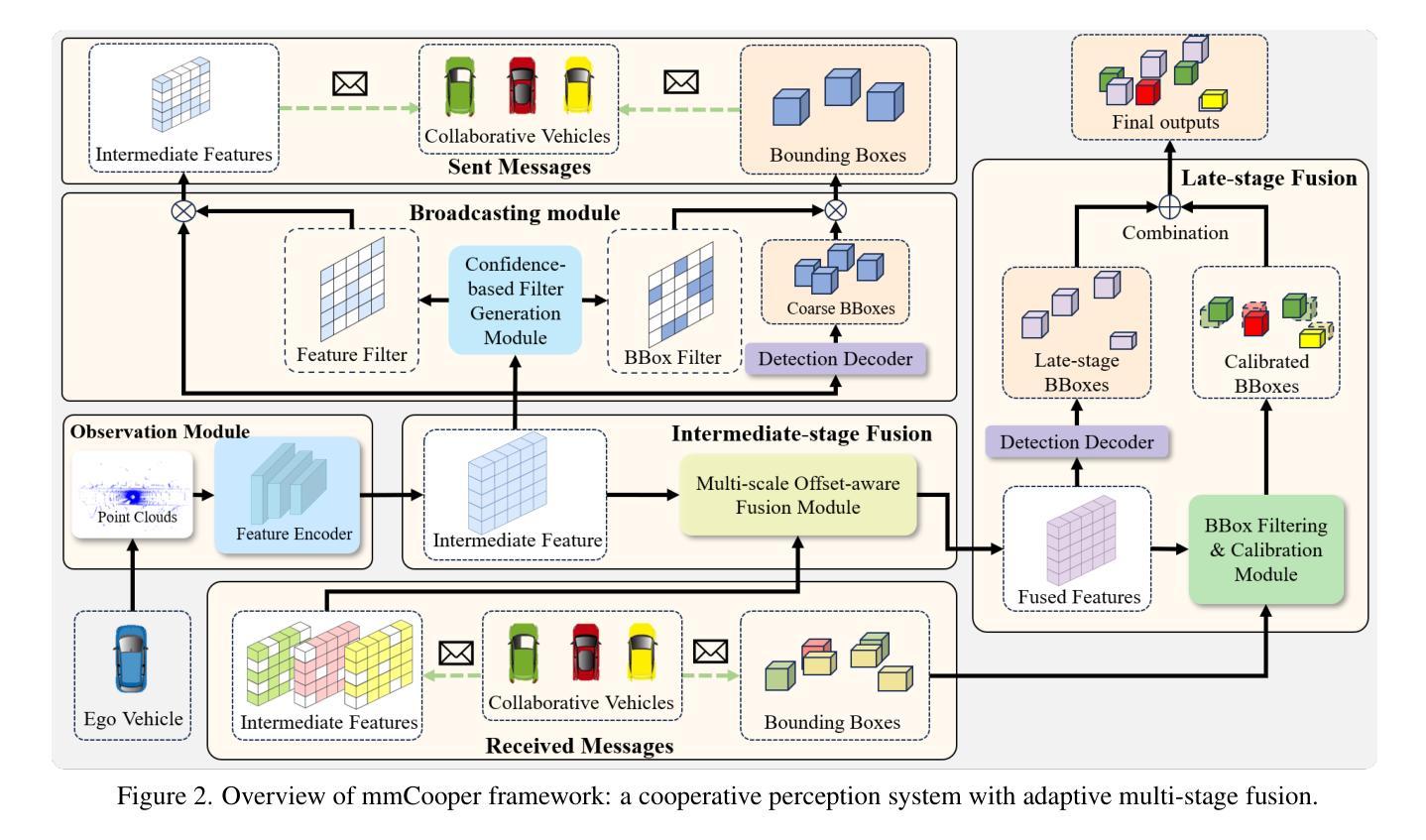
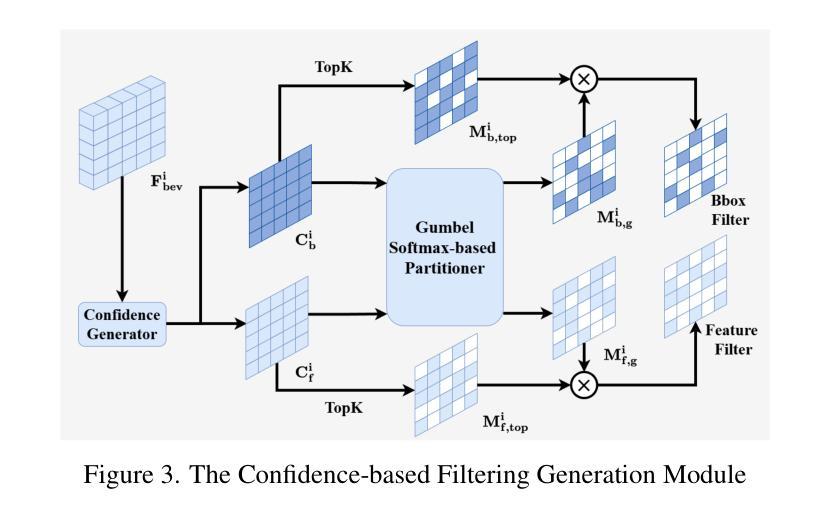
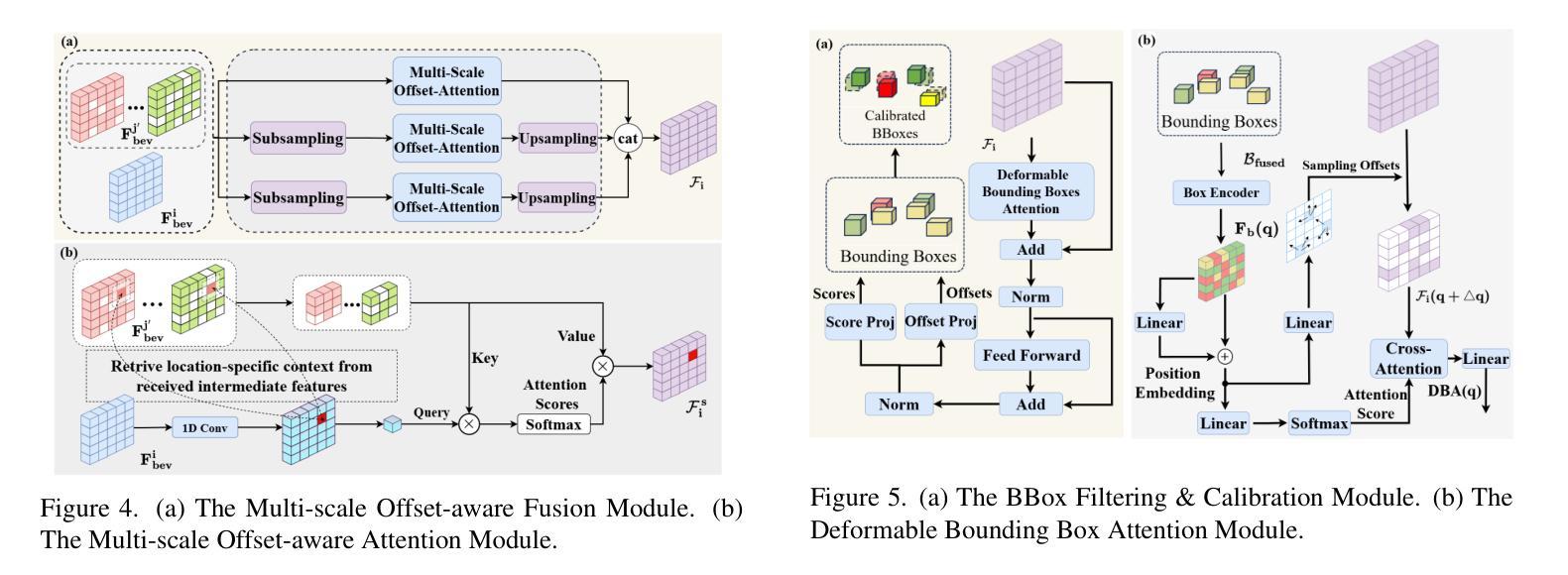
Collaborative perception significantly enhances individual vehicle perception performance through the exchange of sensory information among agents. However, real-world deployment faces challenges due to bandwidth constraints and inevitable calibration errors during information exchange. To address these issues, we propose mmCooper, a novel multi-agent, multi-stage, communication-efficient, and collaboration-robust cooperative perception framework. Our framework leverages a multi-stage collaboration strategy that dynamically and adaptively balances intermediate- and late-stage information to share among agents, enhancing perceptual performance while maintaining communication efficiency. To support robust collaboration despite potential misalignments and calibration errors, our framework captures multi-scale contextual information for robust fusion in the intermediate stage and calibrates the received detection results to improve accuracy in the late stage. We validate the effectiveness of mmCooper through extensive experiments on real-world and simulated datasets. The results demonstrate the superiority of our proposed framework and the effectiveness of each component.
协作感知通过各智能体之间的感知信息交换,可以显著提升个体车辆的感知性能。然而,在实际部署中面临着带宽约束以及信息传递过程中不可避免的校准错误等挑战。为了解决这些问题,我们提出了mmCooper,一个新型的多智能体、多阶段、高效通信和稳健协作的感知框架。我们的框架采用多阶段协作策略,动态地自适应地平衡中间阶段和后期阶段的信息共享,以提高感知性能并保持通信效率。为了支持在潜在的不对齐和校准错误情况下的稳健协作,我们的框架在中间阶段捕获多尺度上下文信息以实现稳健融合,并在后期阶段校准接收到的检测结果以提高准确性。我们通过大量实验对真实世界和模拟数据集验证了mmCooper的有效性。结果表明我们提出的框架及其各组件的优越性。
论文及项目相关链接
Summary
协同感知通过各智能体之间交换感知信息,可显著提升个体车辆的感知性能。然而,实际部署中面临带宽限制和信息交换中的校准误差等挑战。为解决这些问题,我们提出了mmCooper,这是一个新型的多智能体、多阶段、通信高效、协作稳健的协同感知框架。该框架采用多阶段协作策略,动态平衡中间阶段和后期阶段的信息共享,从而提高感知性能并保持通信效率。尽管存在潜在的不对齐和校准误差,我们的框架通过捕获中间阶段的上下文信息支持稳健融合,并在后期校准检测结果以提高准确性。通过在实际和模拟数据集上的大量实验验证了mmCooper的有效性,证明了其框架及其各组件的优越性。
Key Takeaways
- 协同感知能提高车辆感知性能,但需要解决带宽限制和信息交换校准误差等挑战。
- mmCooper是一个多智能体、多阶段的协同感知框架,旨在提高通信效率和感知性能。
- 该框架采用动态平衡信息共享的策略,在多个阶段进行信息融合和校准。
- mmCooper能处理潜在的信息不对齐和校准误差问题。
- 通过中间阶段的上下文信息捕获支持稳健融合。
- 在后期阶段进行结果校准以提高准确性。
点此查看论文截图

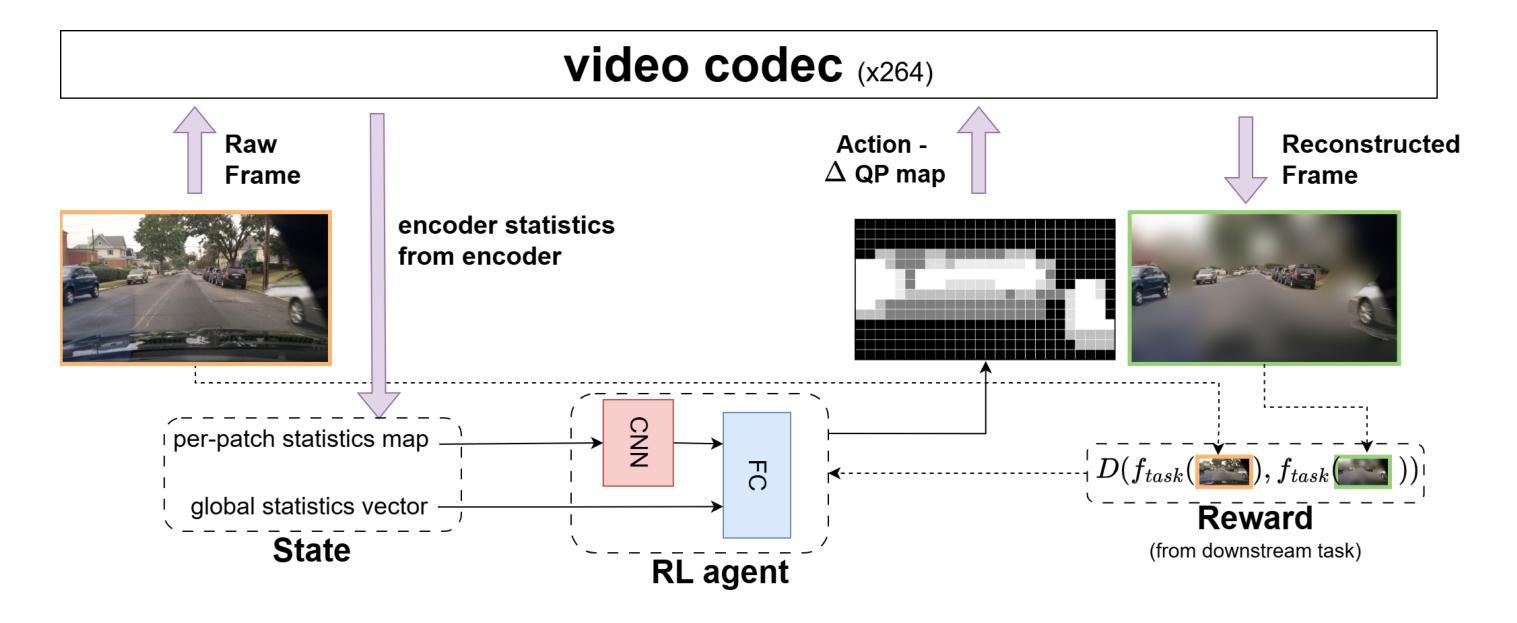
RL-RC-DoT: A Block-level RL agent for Task-Aware Video Compression
Authors:Uri Gadot, Assaf Shocher, Shie Mannor, Gal Chechik, Assaf Hallak
Video encoders optimize compression for human perception by minimizing reconstruction error under bit-rate constraints. In many modern applications such as autonomous driving, an overwhelming majority of videos serve as input for AI systems performing tasks like object recognition or segmentation, rather than being watched by humans. It is therefore useful to optimize the encoder for a downstream task instead of for perceptual image quality. However, a major challenge is how to combine such downstream optimization with existing standard video encoders, which are highly efficient and popular. Here, we address this challenge by controlling the Quantization Parameters (QPs) at the macro-block level to optimize the downstream task. This granular control allows us to prioritize encoding for task-relevant regions within each frame. We formulate this optimization problem as a Reinforcement Learning (RL) task, where the agent learns to balance long-term implications of choosing QPs on both task performance and bit-rate constraints. Notably, our policy does not require the downstream task as an input during inference, making it suitable for streaming applications and edge devices such as vehicles. We demonstrate significant improvements in two tasks, car detection, and ROI (saliency) encoding. Our approach improves task performance for a given bit rate compared to traditional task agnostic encoding methods, paving the way for more efficient task-aware video compression.
视频编码器通过最小化比特率约束下的重建误差,针对人类感知进行优化压缩。在许多现代应用(如自动驾驶)中,绝大多数视频是作为执行对象识别或分割等任务的AI系统的输入,而不是由人类观看。因此,优化编码器以适应下游任务而非感知图像质量是有用的。然而,一个主要挑战是如何将这种下游优化与现有的标准视频编码器相结合,后者效率高且受欢迎。在这里,我们通过控制宏块级的量化参数(QP)来解决这一挑战,以优化下游任务。这种颗粒度的控制使我们能够优先对每帧内与任务相关的区域进行编码。我们将这一优化问题表述为强化学习(RL)任务,代理在此学习选择量化参数时如何平衡长期影响任务和比特率约束的性能。值得注意的是,我们的策略在推理过程中不需要下游任务作为输入,因此适用于流媒体应用和边缘设备(如车辆)。我们在汽车检测和ROI(显著性)编码两项任务上取得了显著改进。与传统任务无关的编码方法相比,我们的方法在给定比特率下提高了任务性能,为更高效的面向任务的视频压缩铺平了道路。
论文及项目相关链接
Summary
本文介绍了针对现代应用如自动驾驶的视频编码优化方法。传统视频编码器主要关注人类感知的重建误差最小化,但在许多应用中视频是AI系统的输入,用于执行对象识别或分割等任务。因此,本文提出一种结合下游任务优化的视频编码器方法,通过控制量化参数(QPs)在宏块级别进行优化,允许对任务相关区域进行编码优先级调整。该研究将优化问题表述为强化学习任务,学习在选择QPs时平衡长期任务性能和比特率约束。新方法在车辆检测和ROI(显著性)编码任务中表现出显著改进,为提高任务感知的视频压缩效率提供了新的途径。
Key Takeaways
- 视频编码器优化不再仅针对人类感知,而是针对现代应用中的AI任务。
- 通过控制量化参数(QPs)在宏块级别进行优化,适应下游任务需求。
- 强化学习被用于学习在选择QPs时如何平衡任务性能和比特率约束。
- 该方法适用于流式应用和边缘设备,如自动驾驶车辆。
- 在车辆检测和ROI编码任务中实现了显著的任务性能提升。
- 与传统任务无关的视频编码方法相比,该方法在给定比特率下提高了任务性能。
点此查看论文截图

Tackling Uncertainties in Multi-Agent Reinforcement Learning through Integration of Agent Termination Dynamics
Authors:Somnath Hazra, Pallab Dasgupta, Soumyajit Dey
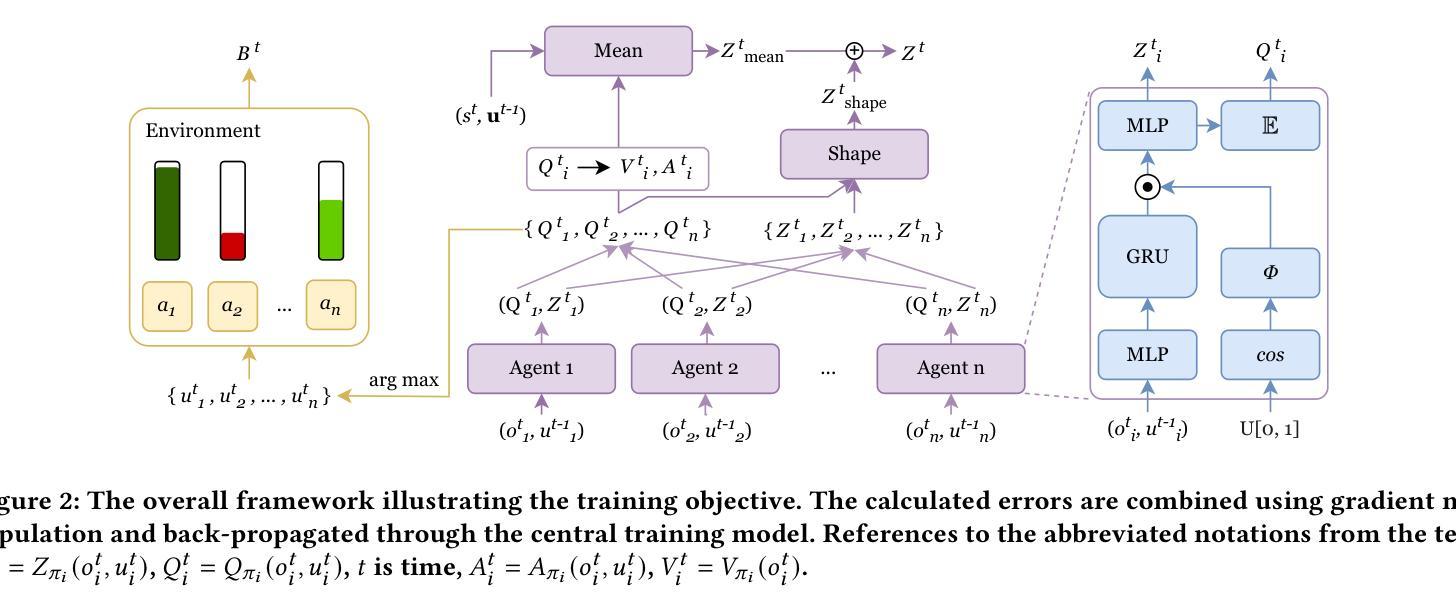
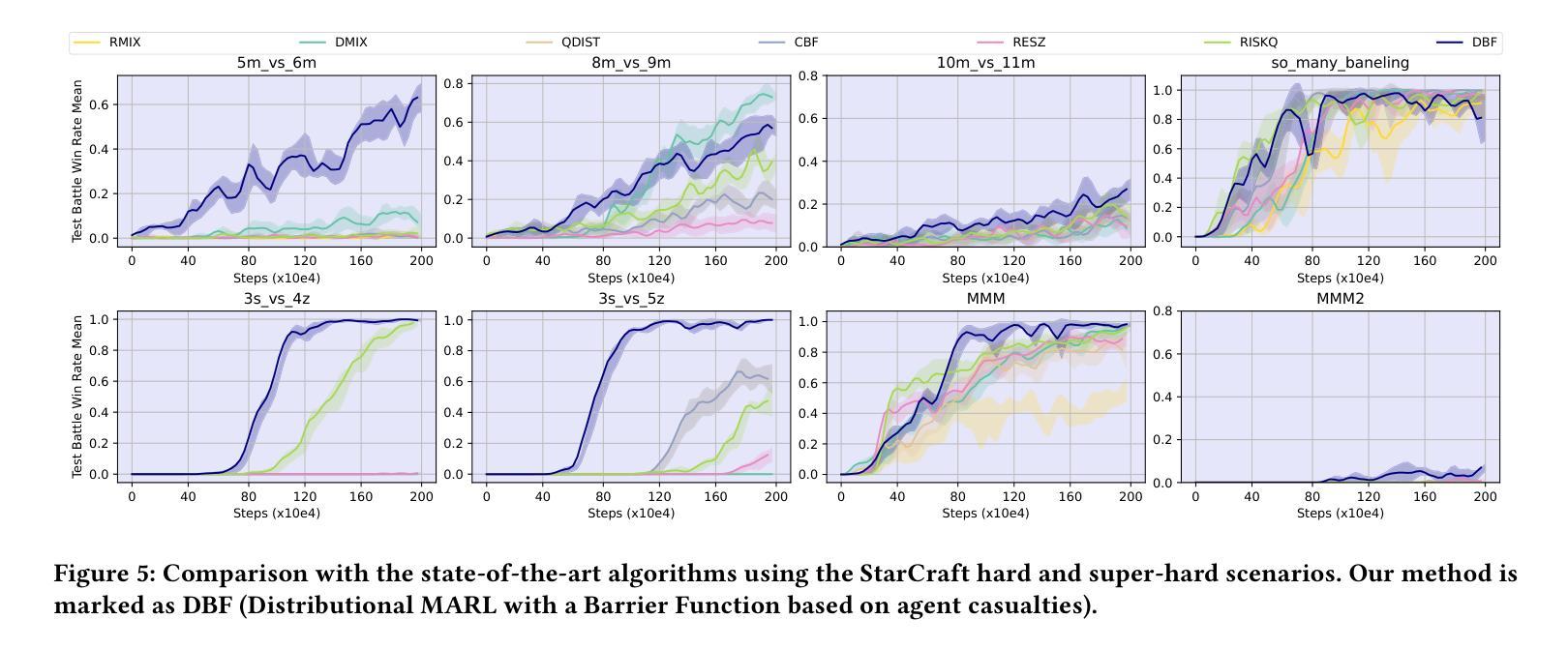
Multi-Agent Reinforcement Learning (MARL) has gained significant traction for solving complex real-world tasks, but the inherent stochasticity and uncertainty in these environments pose substantial challenges to efficient and robust policy learning. While Distributional Reinforcement Learning has been successfully applied in single-agent settings to address risk and uncertainty, its application in MARL is substantially limited. In this work, we propose a novel approach that integrates distributional learning with a safety-focused loss function to improve convergence in cooperative MARL tasks. Specifically, we introduce a Barrier Function based loss that leverages safety metrics, identified from inherent faults in the system, into the policy learning process. This additional loss term helps mitigate risks and encourages safer exploration during the early stages of training. We evaluate our method in the StarCraft II micromanagement benchmark, where our approach demonstrates improved convergence and outperforms state-of-the-art baselines in terms of both safety and task completion. Our results suggest that incorporating safety considerations can significantly enhance learning performance in complex, multi-agent environments.
多智能体强化学习(MARL)在解决复杂的真实世界任务方面取得了显著进展,但这些环境中固有的随机性和不确定性给有效和稳健的策略学习带来了巨大挑战。分布强化学习在单智能体环境中已被成功应用于解决风险和不确定性问题,但其在MARL中的应用受到了很大的限制。在这项工作中,我们提出了一种将分布学习与以安全为重点的损失函数相结合的新方法,以提高合作MARL任务的收敛性。具体来说,我们引入了一种基于障碍函数的损失,它将从系统固有故障中确定的安全指标纳入策略学习过程。这个额外的损失项有助于降低风险,并在训练的早期阶段鼓励更安全的探索。我们在星际争霸II微观管理基准测试上评估了我们的方法,我们的方法在那里表现出了改进的收敛性,并且在安全性和任务完成方面都优于最先进的基线。我们的结果表明,考虑安全因素可以显著增强复杂多智能体环境中的学习性能。
论文及项目相关链接
Summary
多智能体强化学习(MARL)在解决复杂现实世界任务时表现出强大的潜力,但环境中的固有随机性和不确定性给策略和学习的效率和稳健性带来了挑战。分布强化学习在单智能体环境中已成功应用于解决风险和不确定性问题,但在MARL中的应用有限。本研究提出了一种结合分布学习与安全导向损失函数的新方法,以提高合作MARL任务的收敛性。具体来说,我们引入了一种基于屏障函数的损失,利用从系统固有故障中识别的安全指标,将其纳入策略学习过程。这种额外的损失项有助于降低风险,并在训练早期鼓励更安全的探索。我们在星际争霸II微观管理基准测试中对我们的方法进行了评估,我们的方法显示出更好的收敛性,并在安全性和任务完成度方面优于最新基线。结果表明,考虑安全性因素可以显著增强复杂多智能体环境中的学习性能。
Key Takeaways
- 多智能体强化学习(MARL)在解决复杂现实世界任务时面临固有随机性和不确定性的挑战。
- 分布强化学习在单智能体环境中已成功应用,但在MARL中的应用受限。
- 本研究提出了一种结合分布学习与安全导向损失函数的新方法,以提高合作MARL任务的收敛性。
- 引入基于屏障函数的损失,利用安全指标纳入策略学习过程。
- 额外的损失项有助于降低风险,并在训练早期鼓励更安全的探索。
- 在星际争霸II微观管理基准测试中,该方法显示出更好的收敛性和优于最新基线的性能。
点此查看论文截图

EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Authors:Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, Maosong Sun
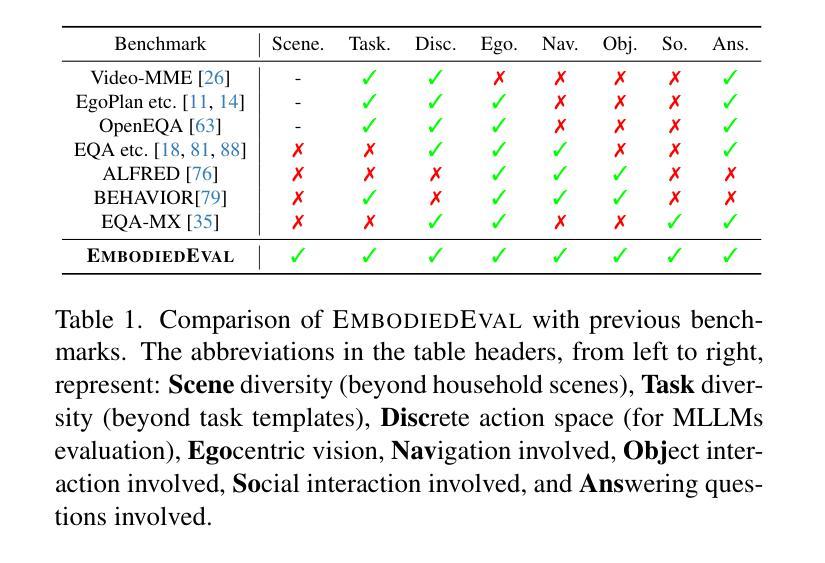
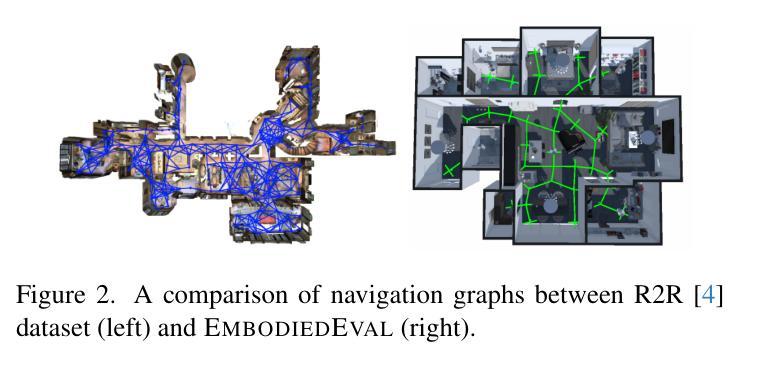
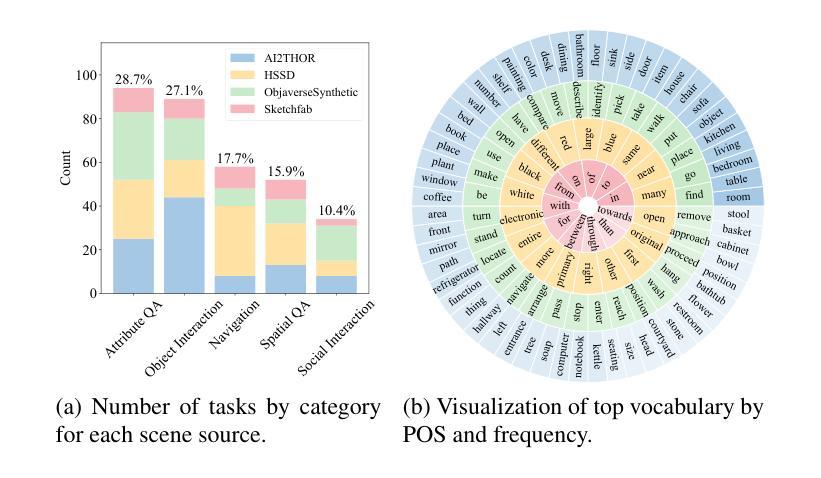
Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
多模态大型语言模型(MLLMs)已经取得了显著进展,为实体代理提供了光明的未来前景。现有的评估MLLM的基准测试主要利用静态图像或视频,将评估限制在非交互式场景中。与此同时,现有的实体AI基准测试都是针对特定任务的,并不够多样化,无法充分评估MLLM的实体能力。为了解决这一问题,我们提出了EmbodiedEval,这是一个全面、交互式的评估MLLM的基准测试,包含实体任务。EmbodiedEval在125个多样化的3D场景中包含328个不同的任务,每个任务都经过严格选择和注释。它涵盖了广泛的现有实体AI任务,具有显著增强的多样性,全部都在统一的模拟和评估框架内,该框架专为MLLM量身定制。任务分为五个类别:导航、对象交互、社会交互、属性问答和空间问答,以评估代理的不同能力。我们在EmbodiedEval上评估了最先进的MLLM,发现它们在实体任务上与人类水平存在很大差距。我们的分析展示了现有MLLM在实体能力方面的局限性,为它们的未来发展提供了见解。我们在https://github.com/thunlp/EmbodiedEval公开所有评估数据和模拟框架。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在智能体领域展现出显著进步和广阔前景。当前评估MLLM的基准测试主要依赖于静态图像或视频,仅限于非交互场景,无法全面评估MLLM的智能体能力。为此,我们提出EmbodiedEval基准测试,它是一个全面、交互式的MLLM评估平台,包含328项独特任务和125种不同的3D场景。任务涵盖导航、对象交互、社会交互、属性问答、空间问答等五大类别,旨在评估智能体的不同能力。我们评估了最先进的MLLM在EmbodiedEval上的表现,发现与人类水平相比仍存在巨大差距。这揭示了现有MLLM在智能体能力方面的局限,为未来发展提供了启示。我们公开了所有评估数据和仿真框架。
Key Takeaways
- 多模态大型语言模型(MLLMs)在智能体领域展现出显著进步。
- 现有评估基准测试主要基于静态图像或视频,缺乏交互性,无法全面评估MLLM的智能体能力。
- EmbodiedEval是一个全面、交互式的MLLM评估平台,包含多种任务和3D场景。
- 任务涵盖五大类别,旨在评估智能体的不同能力,如导航、对象交互、社会交互等。
- 最先进的MLLM在EmbodiedEval上的表现与人类水平相比仍有显著差距。
- 现有MLLM在智能体能力方面存在局限。
点此查看论文截图


PlotEdit: Natural Language-Driven Accessible Chart Editing in PDFs via Multimodal LLM Agents
Authors:Kanika Goswami, Puneet Mathur, Ryan Rossi, Franck Dernoncourt
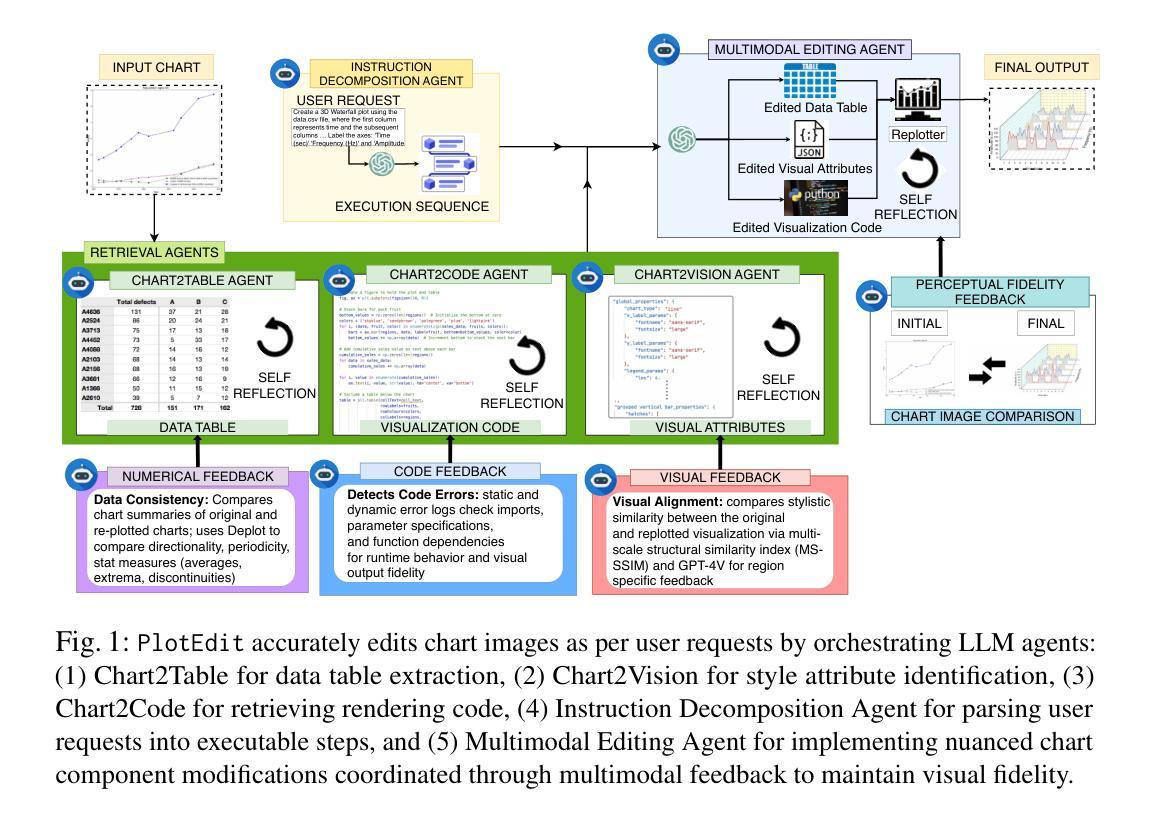
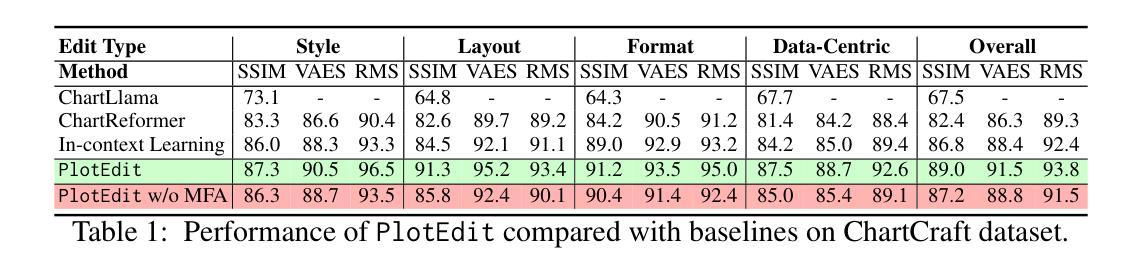
Chart visualizations, while essential for data interpretation and communication, are predominantly accessible only as images in PDFs, lacking source data tables and stylistic information. To enable effective editing of charts in PDFs or digital scans, we present PlotEdit, a novel multi-agent framework for natural language-driven end-to-end chart image editing via self-reflective LLM agents. PlotEdit orchestrates five LLM agents: (1) Chart2Table for data table extraction, (2) Chart2Vision for style attribute identification, (3) Chart2Code for retrieving rendering code, (4) Instruction Decomposition Agent for parsing user requests into executable steps, and (5) Multimodal Editing Agent for implementing nuanced chart component modifications - all coordinated through multimodal feedback to maintain visual fidelity. PlotEdit outperforms existing baselines on the ChartCraft dataset across style, layout, format, and data-centric edits, enhancing accessibility for visually challenged users and improving novice productivity.
图表可视化对于数据解读和沟通至关重要,但目前主要以PDF中的图片形式存在,缺乏源数据表和风格信息。为了实现PDF或数字扫描中的图表的有效编辑,我们推出了PlotEdit,这是一个新型多代理框架,通过自我反思的大型语言模型代理,实现自然语言驱动端到端的图表图像编辑。PlotEdit协调了五个大型语言模型代理,包括:(1)Chart2Table用于数据表提取,(2)Chart2Vision用于识别样式属性,(3)Chart2Code用于检索渲染代码,(4)指令分解代理用于将用户请求解析为可执行步骤,(5)多模式编辑代理用于执行细微的图表组件修改——所有这些都通过多模式反馈进行协调,以保持视觉保真度。在ChartCraft数据集上,PlotEdit在风格、布局、格式和数据中心编辑方面超越了现有基线,提高了视觉障碍用户的使用便捷性和新手的生产力。
论文及项目相关链接
PDF Accepted at ECIR 2025
Summary
本文介绍了PlotEdit这一全新的多智能体框架,用于自然语言驱动的端到端图表图像编辑。该框架具备五大智能体,包括表格提取的智能体、风格属性识别的智能体、渲染代码检索的智能体、指令分解的智能体以及实现细微图表组件修改的多模态编辑智能体。这些智能体通过多模态反馈进行协调,旨在提高图表的可访问性并改善视觉障碍用户和新手的生产力。PlotEdit在ChartCraft数据集上的表现优于现有基线,涵盖风格、布局、格式和数据中心编辑。
Key Takeaways
- PlotEdit是一个多智能体框架,用于自然语言驱动的端到端图表图像编辑。
- 它包含五大智能体:表格提取、风格属性识别、渲染代码检索、指令分解和多模态编辑。
- 通过多模态反馈协调这些智能体,旨在实现图表的精准编辑。
- PlotEdit提高了图表的可访问性,改善了视觉障碍用户和新手的生产力。
- 在ChartCraft数据集上,PlotEdit的表现优于现有基线。
点此查看论文截图

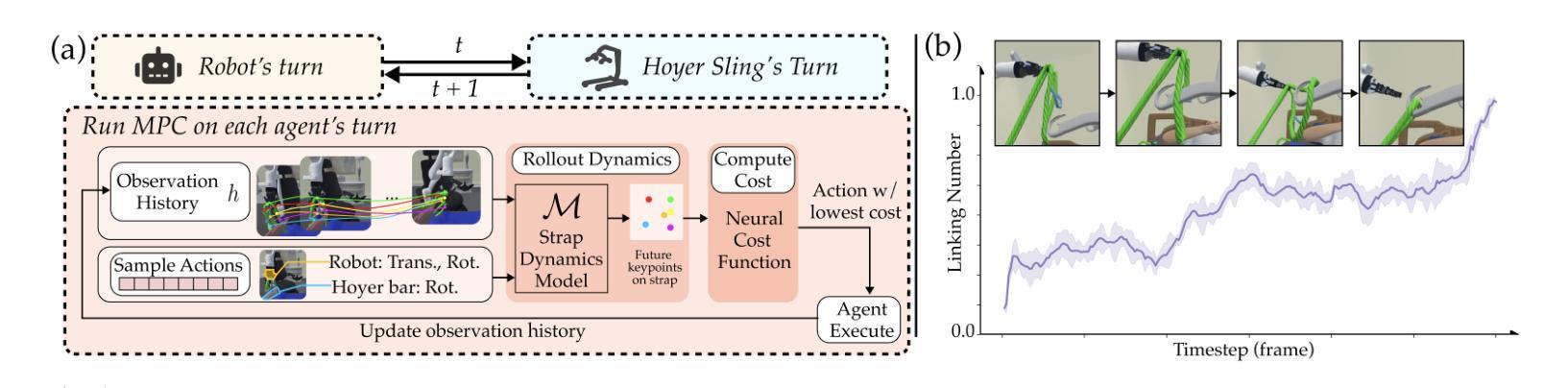
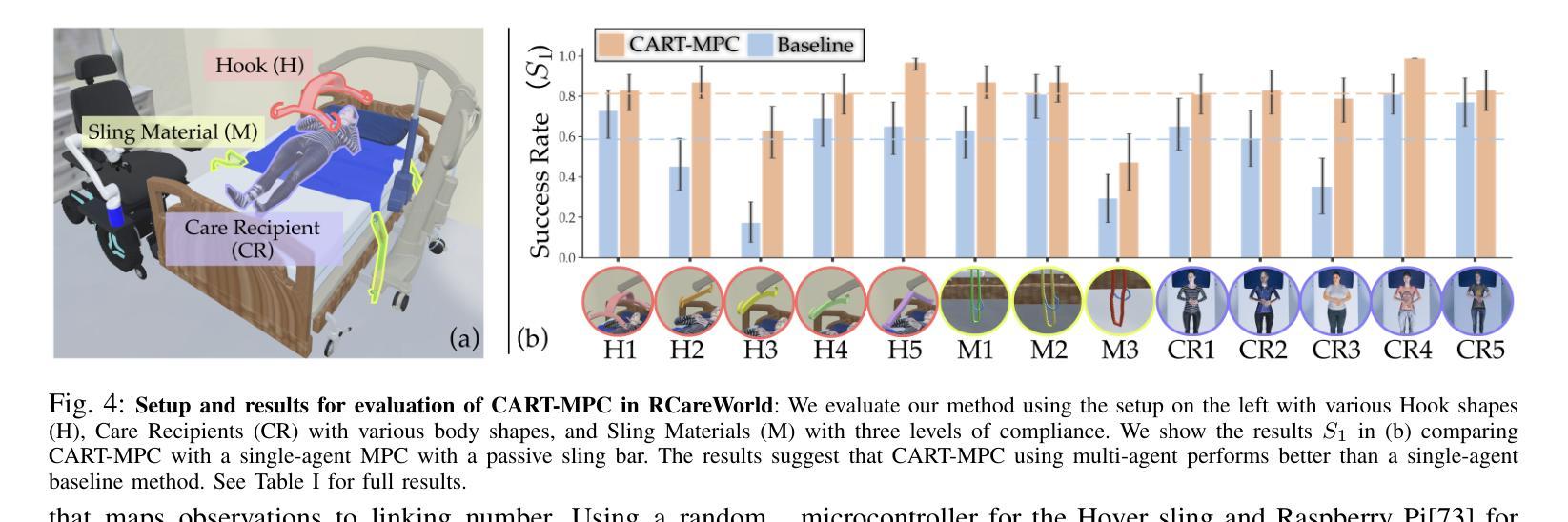
CART-MPC: Coordinating Assistive Devices for Robot-Assisted Transferring with Multi-Agent Model Predictive Control
Authors:Ruolin Ye, Shuaixing Chen, Yunting Yan, Joyce Yang, Christina Ge, Jose Barreiros, Kate Tsui, Tom Silver, Tapomayukh Bhattacharjee
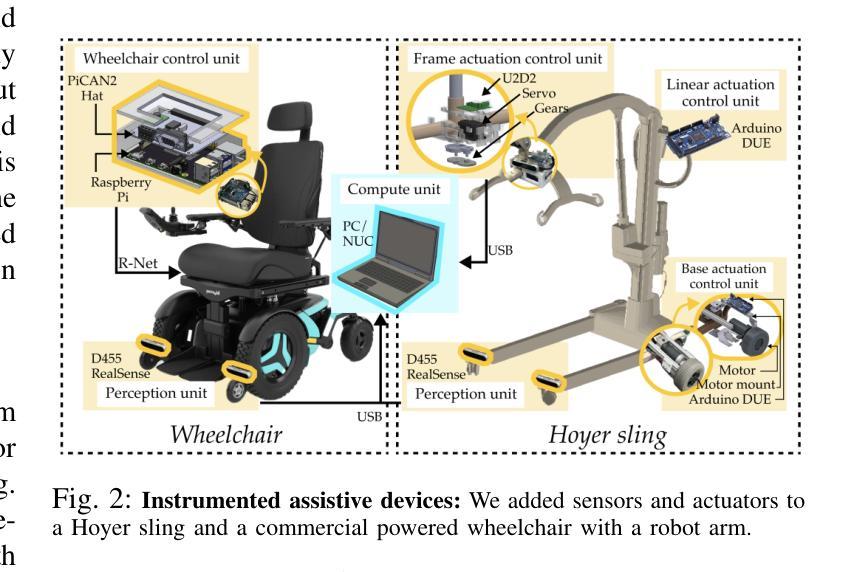
Bed-to-wheelchair transferring is a ubiquitous activity of daily living (ADL), but especially challenging for caregiving robots with limited payloads. We develop a novel algorithm that leverages the presence of other assistive devices: a Hoyer sling and a wheelchair for coarse manipulation of heavy loads, alongside a robot arm for fine-grained manipulation of deformable objects (Hoyer sling straps). We instrument the Hoyer sling and wheelchair with actuators and sensors so that they can become intelligent agents in the algorithm. We then focus on one subtask of the transferring ADL – tying Hoyer sling straps to the sling bar – that exemplifies the challenges of transfer: multi-agent planning, deformable object manipulation, and generalization to varying hook shapes, sling materials, and care recipient bodies. To address these challenges, we propose CART-MPC, a novel algorithm based on turn-taking multi-agent model predictive control that uses a learned neural dynamics model for a keypoint-based representation of the deformable Hoyer sling strap, and a novel cost function that leverages linking numbers from knot theory and neural amortization to accelerate inference. We validate it in both RCareWorld simulation and real-world environments. In simulation, CART-MPC successfully generalizes across diverse hook designs, sling materials, and care recipient body shapes. In the real world, we show zero-shot sim-to-real generalization capabilities to tie deformable Hoyer sling straps on a sling bar towards transferring a manikin from a hospital bed to a wheelchair. See our website for supplementary materials: https://emprise.cs.cornell.edu/cart-mpc/.
床位至轮椅转移是一项普遍的日常活动(ADL),对于载荷有限的护理机器人来说尤其具有挑战性。我们开发了一种新型算法,该算法利用其他辅助设备:Hoyer升降吊索和轮椅,用于粗操纵重物,以及机器人手臂用于对可变形物体(Hoyer升降吊索带)进行精细操纵。我们对Hoyer升降吊索和轮椅进行仪器配备,使其能够成为算法中的智能主体。然后,我们专注于转移ADL的一个子任务——将Hoyer升降吊索带绑在吊索杆上——这个例子体现了转移挑战:多主体规划、可变形物体的操纵以及针对钩形、吊索材料和护理对象的不同体型进行归纳。为应对这些挑战,我们提出了CART-MPC算法,这是一种基于轮流制的多主体模型预测控制的新型算法。它使用基于关键点的可变形Hoyer升降吊索带神经网络动力学模型以及利用结理论中的链接数和神经网络摊销来加速推断的新型成本函数。我们在RCareWorld模拟环境和真实环境中都对其进行了验证。在模拟环境中,CART-MPC成功地归纳了多种钩形设计、吊索材料和护理对象体型。在现实中,我们展示了从模拟到现实的零起点归纳能力,能够绑上可变形的Hoyer升降吊索带,将模拟人从病床转移到轮椅上。有关补充材料,请访问我们的网站:https://emprise.cs.cornell.edu/cart-mpc/。
论文及项目相关链接
Summary
针对日常护理机器人床到轮椅转移操作中的负载限制问题,本文提出了一种新型算法。该算法利用辅助设备如霍耶升降带和轮椅进行粗重负载操作,同时使用机器人手臂进行可变形物体的精细操作。通过仪器化霍耶升降带和轮椅,使其成为算法中的智能代理。针对转移活动中的一项子任务——将霍耶升降带绑在升降杆上,该算法解决了多代理规划、可变形物体操作和不同钩子形状、升降带材料和护理对象体型的通用化挑战。提出一种基于轮流制的多代理模型预测控制CART-MPC算法,采用基于关键点的可变形霍耶升降带带神经网络动力学模型,以及利用结理论中的连接数和神经网络摊销加速推理的新型成本函数。在模拟环境和真实环境中进行了验证,显示出在不同钩子设计、升降带材料和护理对象体型方面的泛化能力。成功实现模拟到真实的零样本泛化能力,能够在转移护理模型中完成绑霍耶升降带并将其应用于转移真实病人的任务。更多材料请见我们的网站:https://emprise.cs.cornell.edu/cart-mpc/。
Key Takeaways
- 针对床到轮椅转移操作中的挑战,提出一种结合机器人与辅助设备的算法。
- 利用霍耶升降带和轮椅进行粗负载操作,机器人手臂进行精细操作。
- 仪器化霍耶升降带和轮椅,使其成为智能代理参与算法执行。
- 提出CART-MPC算法,解决多代理规划、可变形物体操作和泛化问题。
- 采用基于关键点的神经网络动力学模型表示可变形物体(霍耶升降带)。
- 利用结理论中的连接数和神经网络摊销加速推理过程。
点此查看论文截图

IntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems
Authors:Elad Levi, Ilan Kadar
Large Language Models (LLMs) are transforming artificial intelligence, evolving into task-oriented systems capable of autonomous planning and execution. One of the primary applications of LLMs is conversational AI systems, which must navigate multi-turn dialogues, integrate domain-specific APIs, and adhere to strict policy constraints. However, evaluating these agents remains a significant challenge, as traditional methods fail to capture the complexity and variability of real-world interactions. We introduce IntellAgent, a scalable, open-source multi-agent framework designed to evaluate conversational AI systems comprehensively. IntellAgent automates the creation of diverse, synthetic benchmarks by combining policy-driven graph modeling, realistic event generation, and interactive user-agent simulations. This innovative approach provides fine-grained diagnostics, addressing the limitations of static and manually curated benchmarks with coarse-grained metrics. IntellAgent represents a paradigm shift in evaluating conversational AI. By simulating realistic, multi-policy scenarios across varying levels of complexity, IntellAgent captures the nuanced interplay of agent capabilities and policy constraints. Unlike traditional methods, it employs a graph-based policy model to represent relationships, likelihoods, and complexities of policy interactions, enabling highly detailed diagnostics. IntellAgent also identifies critical performance gaps, offering actionable insights for targeted optimization. Its modular, open-source design supports seamless integration of new domains, policies, and APIs, fostering reproducibility and community collaboration. Our findings demonstrate that IntellAgent serves as an effective framework for advancing conversational AI by addressing challenges in bridging research and deployment. The framework is available at https://github.com/plurai-ai/intellagent
大型语言模型(LLMs)正在改变人工智能领域,逐渐演变为能够自主规划和执行的任务导向型系统。LLM的主要应用之一是对话式人工智能系统,这些系统必须应对多轮对话、集成特定领域的API并遵循严格的政策约束。然而,评估这些代理仍然是一个巨大的挑战,因为传统方法无法捕捉现实世界中互动的复杂性和变化性。我们推出了IntellAgent,这是一个可扩展的开源多代理框架,旨在全面评估对话式人工智能系统。IntellAgent通过结合政策驱动的图建模、现实事件生成和交互式用户代理模拟,自动创建多样化的合成基准测试。这种创新方法提供了精细的诊断,解决了静态和手动策划的基准测试与粗略指标相结合的局限性。IntellAgent代表了评估对话式人工智能的范式转变。通过模拟不同复杂程度上的真实、多政策场景,IntellAgent捕捉了代理能力和政策约束之间微妙的相互作用。与传统方法不同,它采用基于图的政策模型来表示政策互动的关联、可能性和复杂性,从而实现高度详细的诊断。IntellAgent还能发现关键性能差距,为有针对性的优化提供可操作的见解。其模块化、开源的设计支持新领域、政策和API的无缝集成,促进了可重复性和社区合作。我们的研究结果表明,IntellAgent是解决研究和部署之间桥梁挑战的有效框架。该框架可在https://github.com/plurai-ai/intellagent找到。
论文及项目相关链接
Summary
大型语言模型(LLMs)正推动人工智能领域的变革,它们逐渐发展为具备自主规划和执行能力的任务导向型系统。对于LLM的主要应用之一——对话式AI系统来说,其必须应对多轮对话导航、集成特定领域API以及遵守严格政策约束等挑战。然而,评估这些AI代理仍存在重大挑战,传统方法无法捕捉现实世界互动的复杂性和多变性。为此,我们推出了IntellAgent,这是一个可扩展的开源多智能体框架,旨在全面评估对话式AI系统。IntellAgent通过结合政策驱动的图建模、现实事件生成和交互式用户代理模拟,自动创建多样化的合成基准测试。这一创新方法提供了精细的诊断,解决了静态和手动策划基准测试的局限性及其粗略的度量标准。IntellAgent代表着评估对话式AI的一个范式转变。它通过模拟复杂的现实情境和多政策场景,捕捉代理能力和政策约束之间的微妙互动。
Key Takeaways
- 大型语言模型(LLMs)在人工智能领域正在推动变革,发展为任务导向型系统,具备自主规划和执行能力。
- 对话式AI系统是LLM的主要应用之一,需应对多轮对话导航、集成特定领域API和遵守严格政策约束等挑战。
- 评估对话式AI系统存在挑战,传统方法无法捕捉现实互动的复杂性和多变性。
- IntellAgent是一个创新的、开源的多智能体框架,用于全面评估对话式AI系统。
- IntellAgent通过政策驱动的图建模、现实事件生成和交互式用户代理模拟自动创建合成基准测试。
- IntellAgent提供精细的诊断,并解决静态和手动策划基准测试的局限性。
点此查看论文截图


Machine Learning Surrogates for Optimizing Transportation Policies with Agent-Based Models
Authors:Elena Natterer, Roman Engelhardt, Sebastian Hörl, Klaus Bogenberger
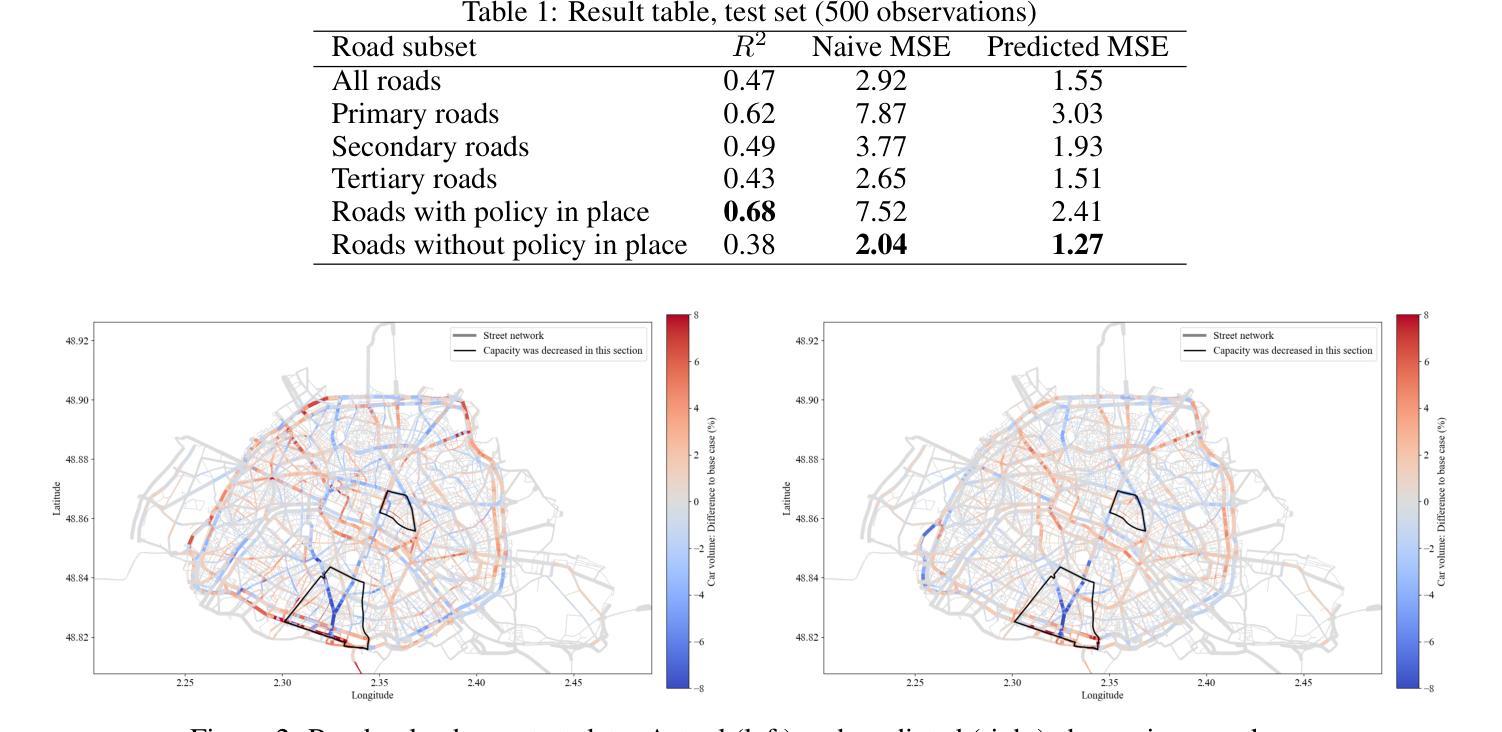
Rapid urbanization and growing urban populations worldwide present significant challenges for cities, including increased traffic congestion and air pollution. Effective strategies are needed to manage traffic volumes and reduce emissions. In practice, traditional traffic flow simulations are used to test those strategies. However, high computational intensity usually limits their applicability in investigating a magnitude of different scenarios to evaluate best policies. This paper presents a first approach of using Graph Neural Networks (GNN) as surrogates for large-scale agent-based simulation models. In a case study using the MATSim model of Paris, the GNN effectively learned the impacts of capacity reduction policies on citywide traffic flow. Performance analysis across various road types and scenarios revealed that the GNN could accurately capture policy-induced effects on edge-based traffic volumes, particularly on roads directly affected by the policies and those with higher traffic volumes.
快速城市化和全球城市人口的增加给城市带来了重大挑战,包括交通拥堵和空气污染问题。为了管理交通流量和减少排放,需要采取有效的策略。在实践中,传统的交通流量模拟被用来测试这些策略。然而,较高的计算强度通常限制了其在调查大量不同场景以评估最佳政策方面的适用性。本文首次提出使用图神经网络(GNN)作为大规模基于主体的仿真模型的替代方案。在巴黎MATSim模型的案例研究中,GNN有效地学习了容量减少政策对城市范围内交通流量的影响。对不同类型的道路和场景的绩效分析表明,GNN能够准确地捕捉政策对基于边缘的交通流量的影响,特别是在直接受政策影响的道路和交通流量较大的道路上。
论文及项目相关链接
Summary
大规模城市化及城市人口的快速增长给全球城市带来了诸多挑战,如交通拥堵和空气污染问题日益严重。为管理交通流量并减少排放,需要有效的策略。传统交通流量模拟常用于测试这些策略,但其高计算强度限制了其在评估最佳政策时对不同场景的广泛调查。本文首次提出使用图神经网络(GNN)作为大规模基于代理的模拟模型的替代方案。以巴黎的MATSim模型为案例研究,GNN有效地学习了容量减少政策对城市范围内交通流量的影响。针对不同道路类型和场景的性能分析表明,GNN能够准确捕捉政策对边缘交通流量的影响,特别是在受政策直接影响和交通流量较高的道路上。
Key Takeaways
- 城市化和人口增长带来交通拥堵和空气污染等挑战。
- 传统交通流量模拟常用于测试策略,但高计算强度限制了其应用场景的广泛性。
- 图神经网络(GNN)可作为大规模基于代理的模拟模型的替代方案。
- GNN在巴黎的MATSim模型上有效学习容量减少政策对交通流量的影响。
- GNN能够准确捕捉政策对边缘交通流量的影响。
- 受政策直接影响和交通流量较高的道路对GNN的准确度有较高要求。
点此查看论文截图

HIVEX: A High-Impact Environment Suite for Multi-Agent Research (extended version)
Authors:Philipp Dominic Siedler
Games have been vital test beds for the rapid development of Agent-based research. Remarkable progress has been achieved in the past, but it is unclear if the findings equip for real-world problems. While pressure grows, some of the most critical ecological challenges can find mitigation and prevention solutions through technology and its applications. Most real-world domains include multi-agent scenarios and require machine-machine and human-machine collaboration. Open-source environments have not advanced and are often toy scenarios, too abstract or not suitable for multi-agent research. By mimicking real-world problems and increasing the complexity of environments, we hope to advance state-of-the-art multi-agent research and inspire researchers to work on immediate real-world problems. Here, we present HIVEX, an environment suite to benchmark multi-agent research focusing on ecological challenges. HIVEX includes the following environments: Wind Farm Control, Wildfire Resource Management, Drone-Based Reforestation, Ocean Plastic Collection, and Aerial Wildfire Suppression. We provide environments, training examples, and baselines for the main and sub-tasks. All trained models resulting from the experiments of this work are hosted on Hugging Face. We also provide a leaderboard on Hugging Face and encourage the community to submit models trained on our environment suite.
游戏对于基于代理研究的快速发展起到了至关重要的测试平台作用。过去取得了令人瞩目的进展,但尚不清楚这些发现是否适用于现实世界的问题。随着压力越来越大,一些最重要的生态挑战可以通过技术和其应用找到缓解和预防的解决方案。大多数现实世界领域都包含多代理场景,需要机器与机器以及人与机器之间的协作。然而,开源环境并未取得进展,常常是玩具场景过于抽象或不适用于多代理研究。通过模拟现实问题和增加环境复杂性,我们希望通过多代理研究来提升前沿技术和激励研究人员解决当前现实世界的问题。在这里,我们推出HIVEX,一个专注于生态挑战的多代理研究基准测试环境套件。HIVEX包括以下环境:风力发电厂控制、野火资源管理、无人机参与造林、海洋塑料收集以及航空野火压制。我们提供了主要任务和子任务的环境、训练示例和基准线。所有由此项工作实验训练得到的模型都托管在Hugging Face上。我们还将在Hugging Face上提供一个排行榜,鼓励社区提交在我们环境套件上训练的模型。
论文及项目相关链接
Summary
游戏在基于Agent的研究中起到了重要的测试平台作用。尽管过去取得了显著进展,但尚不清楚这些发现是否适用于现实世界的问题。大多数现实世界领域涉及多智能体场景,需要机器与机器以及人与机器之间的协作。通过模拟真实问题并增加环境复杂性,我们期望推动最新的多智能体研究,并激励研究人员关注即时解决现实问题的能力。在此,我们介绍了HIVEX,一个旨在针对生态挑战进行基准测试的多智能体研究环境套件。HIVEX包括如下环境:风力农场控制、野火资源管理、无人机造林、海洋塑料收集和空中灭火。我们提供环境、训练示例和主要任务及子任务的基准线。所有由此实验训练得到的模型都托管在Hugging Face上。我们也鼓励社区提交在我们环境套件上训练的模型并在Hugging Face上展示排名。
Key Takeaways
- 游戏对于基于Agent的研究起到了重要的测试平台作用。
- 尽管在Agent技术方面取得了进展,但现实世界问题的复杂性需要更深入的研究来应用现有成果。
点此查看论文截图


Large Language Model-Brained GUI Agents: A Survey
Authors:Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
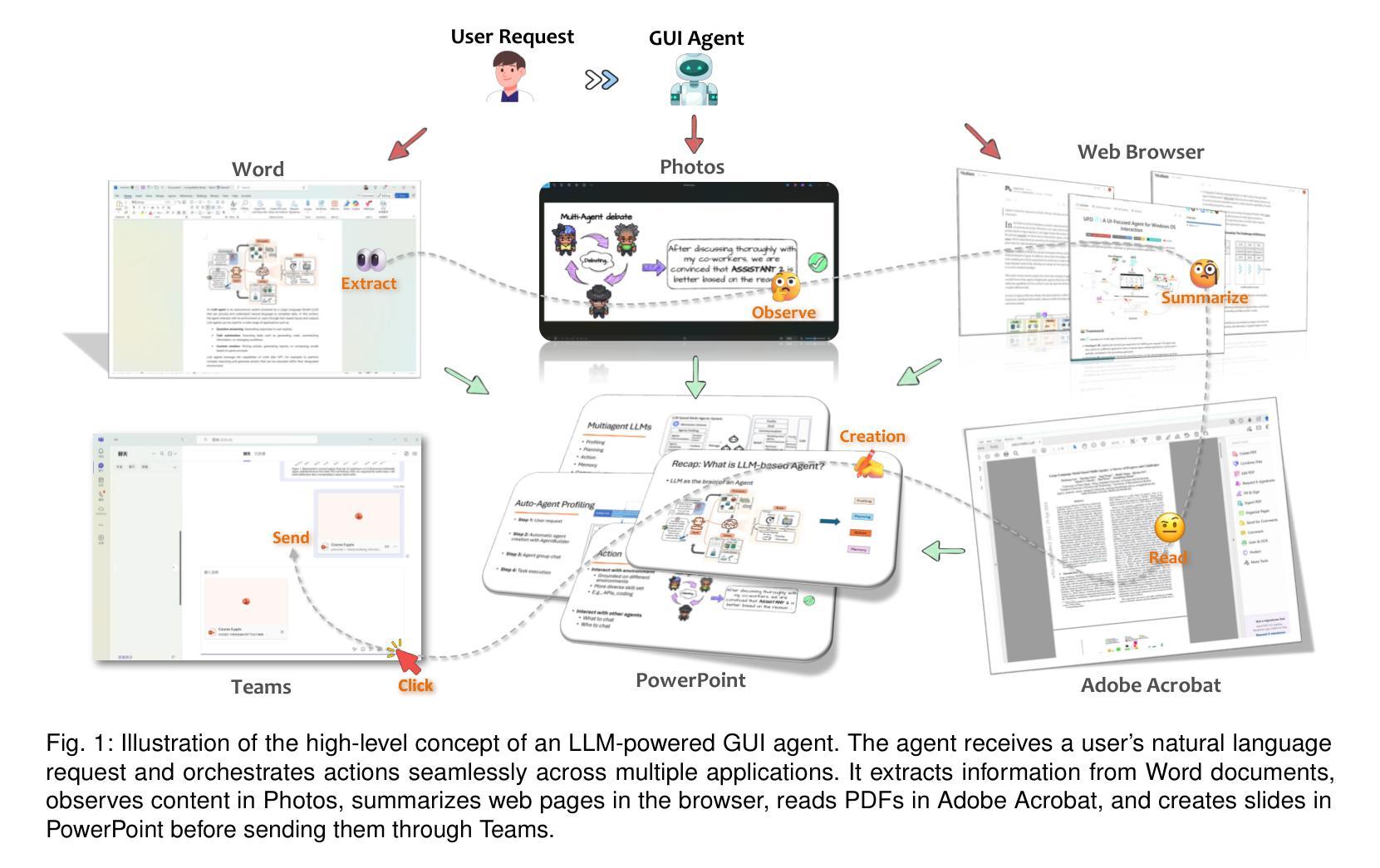
GUIs have long been central to human-computer interaction, providing an intuitive and visually-driven way to access and interact with digital systems. The advent of LLMs, particularly multimodal models, has ushered in a new era of GUI automation. They have demonstrated exceptional capabilities in natural language understanding, code generation, and visual processing. This has paved the way for a new generation of LLM-brained GUI agents capable of interpreting complex GUI elements and autonomously executing actions based on natural language instructions. These agents represent a paradigm shift, enabling users to perform intricate, multi-step tasks through simple conversational commands. Their applications span across web navigation, mobile app interactions, and desktop automation, offering a transformative user experience that revolutionizes how individuals interact with software. This emerging field is rapidly advancing, with significant progress in both research and industry. To provide a structured understanding of this trend, this paper presents a comprehensive survey of LLM-brained GUI agents, exploring their historical evolution, core components, and advanced techniques. We address research questions such as existing GUI agent frameworks, the collection and utilization of data for training specialized GUI agents, the development of large action models tailored for GUI tasks, and the evaluation metrics and benchmarks necessary to assess their effectiveness. Additionally, we examine emerging applications powered by these agents. Through a detailed analysis, this survey identifies key research gaps and outlines a roadmap for future advancements in the field. By consolidating foundational knowledge and state-of-the-art developments, this work aims to guide both researchers and practitioners in overcoming challenges and unlocking the full potential of LLM-brained GUI agents.
长久以来,图形用户界面(GUI)都是人机交互的核心,它提供了一种直观、视觉驱动的方式来访问和与数字系统交互。大语言模型(LLM)的出现,特别是多模态模型,已经开启了GUI自动化的新时代。它们在自然语言理解、代码生成和视觉处理等方面表现出了卓越的能力。这为新一代基于LLM的GUI代理铺平了道路,这些代理能够解释复杂的GUI元素,并基于自然语言指令自主执行操作。这些代理代表了范式转变,使用户能够通过简单的命令执行复杂的多步骤任务。它们的应用程序跨越网页导航、移动应用程序交互和桌面自动化,提供变革性的用户体验,彻底改变个人与软件的交互方式。这个新兴领域正在迅速发展,在研究和工业领域都取得了重大进展。
论文及项目相关链接
PDF The collection of papers reviewed in this survey will be hosted and regularly updated on the GitHub repository: https://github.com/vyokky/LLM-Brained-GUI-Agents-Survey Additionally, a searchable webpage is available at https://aka.ms/gui-agent for easier access and exploration
Summary
本文介绍了GUI在人机交互中的长期重要地位,以及大型语言模型(LLM)和多模态模型的出现为GUI自动化带来的革新。新一代LLM驱动的GUI代理能解读复杂的GUI元素,并根据自然语言指令自主执行动作。这些代理代表了用户执行复杂多步骤任务的转变方式,应用范围遍及网页导航、移动应用交互和桌面自动化。本文还对LLM驱动的GUI代理的历史演变、核心组件和先进技术进行了全面调查,探讨了现有的GUI代理框架等问题。
Key Takeaways
- GUI在人机交互中占据重要地位,大型语言模型和多模态模型为GUI自动化带来革新。
- LLM驱动的GUI代理能解读复杂的GUI元素并根据自然语言指令自主执行动作。
- LLM驱动的GUI代理在用户执行复杂多步骤任务时提供了革命性的体验。
- LLM驱动的GUI代理的应用范围广泛,包括网页导航、移动应用交互和桌面自动化等。
- 当前的研究领域涵盖了GUI代理框架、数据收集和利用、针对GUI任务的行动模型开发等方向。
- 当前研究仍存在关键的研究空白和潜在的研究方向。
点此查看论文截图


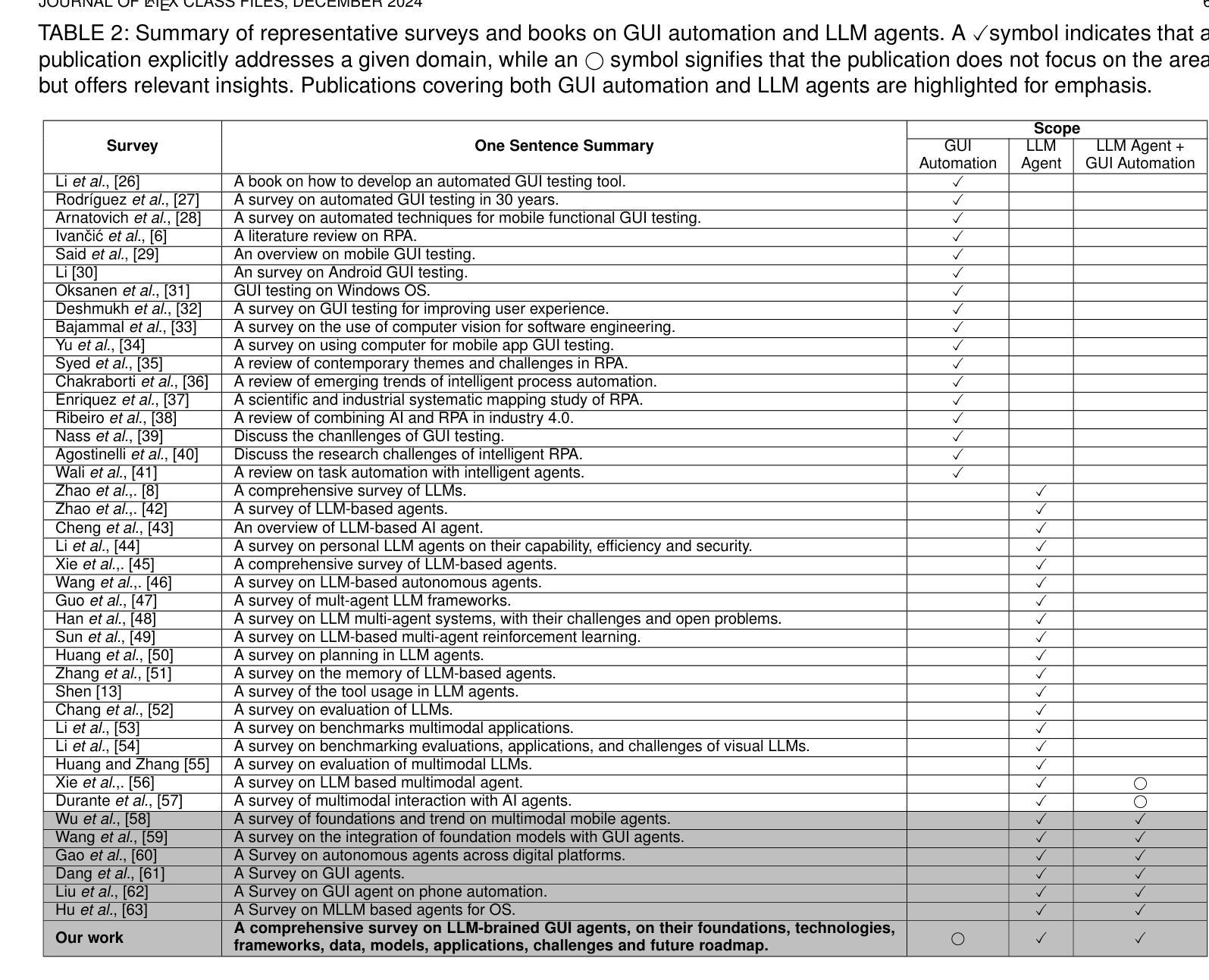
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
Authors:Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Li Fei-Fei, Jiayuan Mao, Jiajun Wu
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs’ performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
我们旨在评估大型语言模型(LLM)在实体决策中的表现。虽然已有大量工作利用LLM进行实体环境中的决策,但由于LLM通常在不同的领域、不同的目的中应用,并且基于不同的输入和输出进行构建,因此我们对它们的性能缺乏系统的理解。此外,现有的评估往往只依赖于最终的成功率,这使得很难确定LLM中缺少的能力以及问题的所在,从而阻碍了实体代理有效地选择性利用LLM。为了解决这些局限性,我们提出了一种通用接口(实体代理接口),该接口支持各种任务的形式化以及基于LLM的模块输入输出规范。具体来说,它允许我们统一1)涉及状态和临时目标的广泛实体决策任务;2)用于决策的四种常用基于LLM的模块:目标解释、子目标分解、动作序列和过渡建模;3)一种精细的度量集合,将评估分解为各种类型的错误,如幻觉错误、可访问性错误、各种类型的规划错误等。总体而言,我们的基准测试为LLM在不同子任务上的表现提供了全面的评估,指出了LLM在实体AI系统中的优缺点,并为在实体决策中有效和选择性使用LLM提供了见解。
论文及项目相关链接
PDF Accepted for oral presentation at NeurIPS 2024 in the Datasets and Benchmarks track. Final Camera version
Summary
本文旨在评估大型语言模型(LLMs)在实体决策制定中的表现。文章指出,尽管已有大量工作利用LLMs进行实体环境决策,但由于LLMs通常应用于不同领域、不同目的,并基于不同输入和输出构建,我们仍缺乏对其性能的系统性理解。现有评估往往仅依赖最终成功率,这使得难以确定LLMs缺少哪些能力,问题出在哪里,进而阻碍实体代理人有效地选择性利用LLMs。为解决这个问题,文章提出一种通用接口(Embodied Agent Interface),支持各类任务的正规化以及LLM模块输入输出的特定规范。该接口可统一实体决策制定任务的广泛集合、四个常用的LLM决策模块以及精细度量的集合。通过细化评估为各种类型的错误,如幻想错误、负担能力错误、各种规划错误等,该基准测试为LLMs在不同子任务上的表现提供了全面的评估,并指出了LLM驱动的实体AI系统的优缺点,为有效选择性使用LLMs进行实体决策制定提供了见解。
Key Takeaways
- 文章旨在全面评估大型语言模型(LLMs)在实体决策制定中的表现。
- LLMs在多个领域、目的和输入/输出基础上构建,缺乏系统性理解。
- 现有评估主要依赖最终成功率,难以确定LLMs的具体问题所在。
- 提出一个通用接口(Embodied Agent Interface)以统一不同类型的任务、LLM模块和精细度量标准。
- 接口涵盖实体决策制定任务的广泛集合。
- 接口包括四个常用的LLM决策模块:目标解读、子目标分解、行动排序和过渡建模。
- 通过细化评估,该基准测试为LLMs表现提供了全面的评估,并指出了其优缺点。
点此查看论文截图


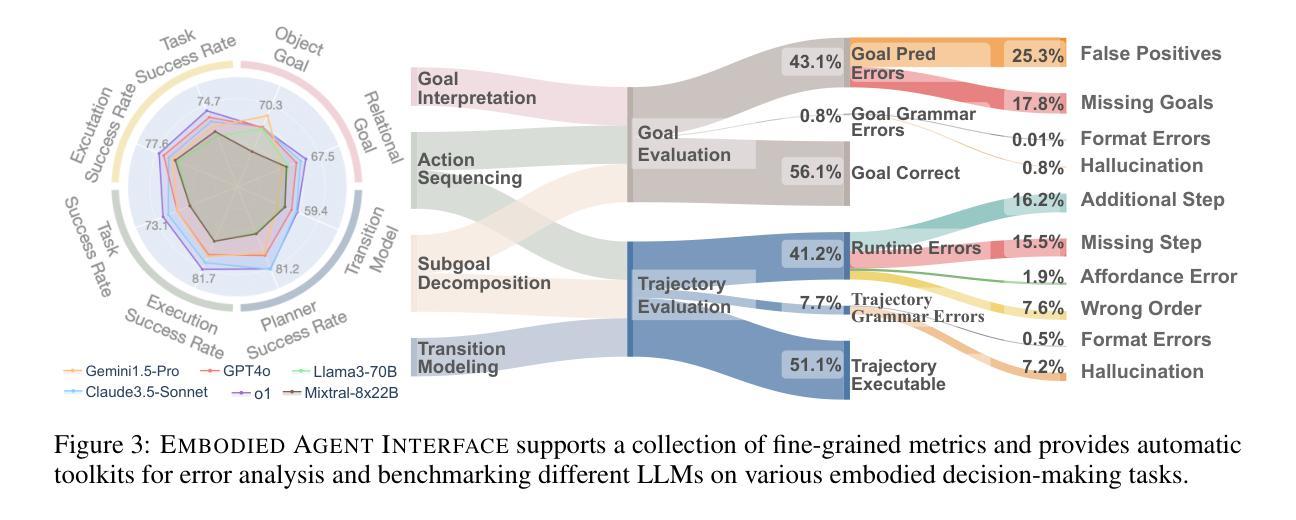


VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of Thought
Authors:Gabriel Sarch, Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, Katerina Fragkiadaki
Large-scale LLMs and VLMs excel at few-shot learning but require high-quality examples. We introduce In-Context Abstraction Learning (ICAL), which iteratively refines suboptimal trajectories into high-quality data with optimized actions and detailed reasoning. Given an inefficient demonstration, a VLM corrects actions and annotates causal relationships, object states, subgoals, and task-relevant visuals, forming “programs of thought.” With human feedback, these programs are improved as the agent executes them in a similar environment. The resulting examples, used as prompt context or fine-tuning data, significantly boost decision-making while reducing human feedback needs. ICAL surpasses state-of-the-art in TEACh (dialogue-based instruction following), VisualWebArena (multimodal web agents), and Ego4D (egocentric video action anticipation). In TEACh, combining fine-tuning and retrieval on ICAL examples outperforms raw human demonstrations and expert examples, achieving a 17.5% increase in goal-condition success. In VisualWebArena, retrieval-augmented GPT-4V with ICAL improves task success rate 1.6x over GPT-4V, while fine-tuning Qwen2-VL achieves a 2.8x improvement. In Ego4D, ICAL outperforms few-shot GPT-4V and remains competitive with supervised models. Overall, ICAL scales 2x better than raw human demonstrations and reduces manual prompt engineering.
大规模的语言模型和视觉语言模型在少量学习样本上表现出色,但需要高质量的例子。我们引入了上下文抽象学习(ICAL),它能够迭代地优化次优轨迹,形成高质量数据,其中包含优化后的动作和详细推理。对于低效的演示,视觉语言模型会纠正动作,并注释因果关系、对象状态、子目标和任务相关视觉,形成“思维程序”。随着代理在类似环境中执行这些程序,通过人类反馈,这些程序得到了改进。将结果示例用作提示上下文或微调数据,可显著提高决策能力,同时减少人类反馈需求。ICAL在TEACh(基于对话的指令遵循)、VisualWebArena(多模式网络代理)和Ego4D(以自我为中心的视频动作预测)等领域超越了最新技术水平。在TEACh中,结合微调与在ICAL示例上进行检索优于原始人类演示和专家示例,目标条件成功率提高了17.5%。在VisualWebArena中,使用ICAL增强检索的GPT-4V任务成功率提高了1.6倍,而使用ICAL对Qwen2-VL进行微调的任务成功率提高了2.8倍。在Ego4D中,ICAL表现优于少量GPT-4V样本,并与监督模型保持竞争力。总体而言,ICAL的表现比原始人类演示高出两倍,并减少了手动提示工程的工作量。
论文及项目相关链接
PDF Project website: https://ical-learning.github.io/
Summary
大型语言模型和视觉语言模型擅长于少样本学习,但需要高质量范例。本文提出一种名为“上下文抽象学习”(ICAL)的方法,该方法通过优化动作和详细推理,将非优质轨迹迭代优化为高质量数据。针对低效示范,视觉语言模型可纠正动作并标注因果关系、对象状态、子目标和任务相关视觉内容,形成“思维程序”。借助人类反馈,这些程序在执行类似环境的代理时得到改进。使用这些范例作为提示上下文或微调数据,可显著提高决策能力并减少人类反馈需求。在多个任务上,ICAL超越了现有技术水平。总体而言,ICAL比原始人类示范表现更好,手动提示工程更少。
Key Takeaways
- 大型语言模型和视觉语言模型擅长少样本学习,但需高质量范例。
- 引入了一种名为“上下文抽象学习”(ICAL)的方法,可将非优质示范转化为高质量数据。
- VLM在ICAL中能够纠正动作并标注详细信息,形成“思维程序”。
- 通过人类反馈,这些“思维程序”在执行环境中得到改进。
- ICAL范例用于提示上下文或微调数据,可显著提高决策能力并减少人类反馈需求。
点此查看论文截图


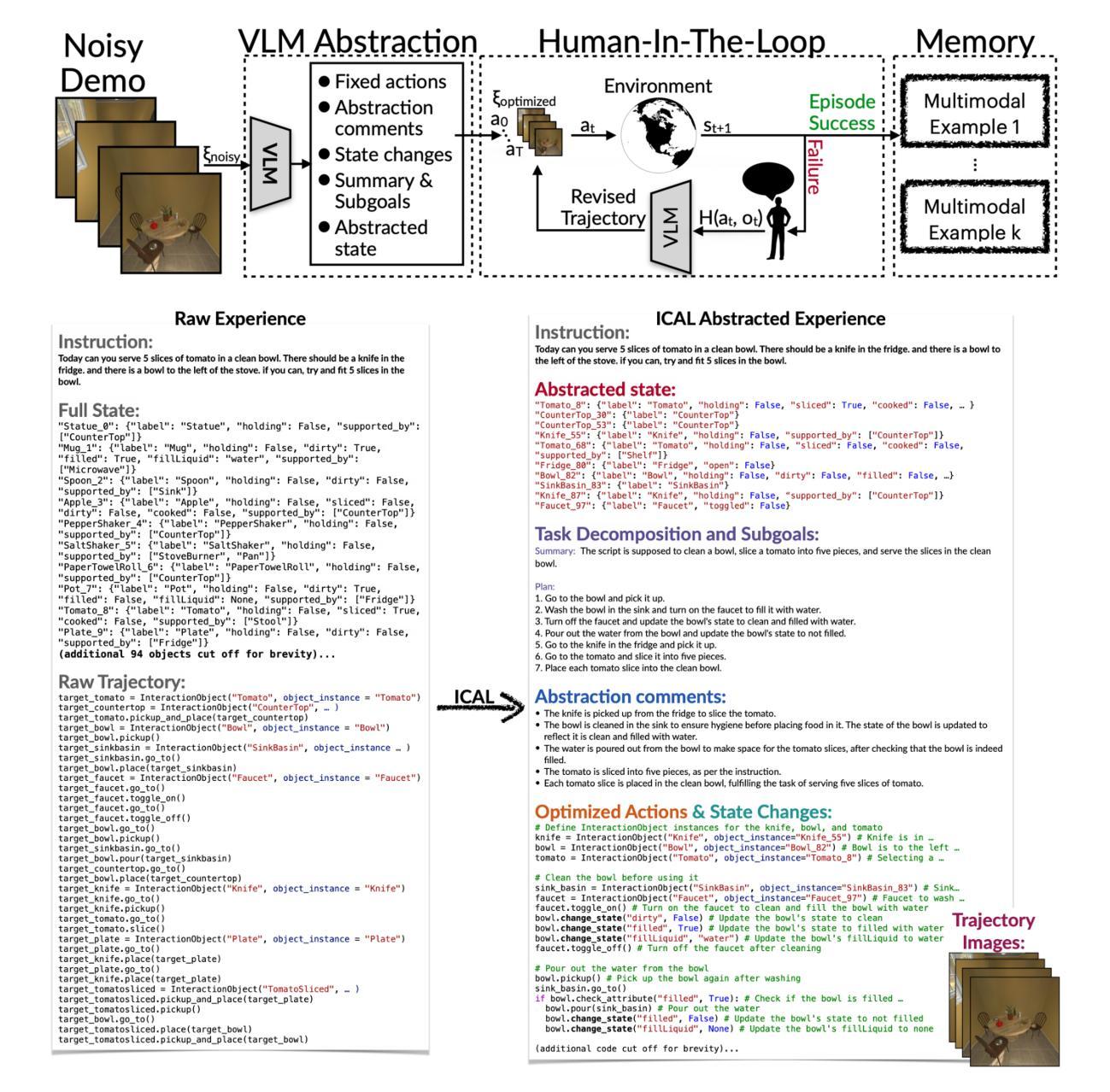
TDAG: A Multi-Agent Framework based on Dynamic Task Decomposition and Agent Generation
Authors:Yaoxiang Wang, Zhiyong Wu, Junfeng Yao, Jinsong Su
The emergence of Large Language Models (LLMs) like ChatGPT has inspired the development of LLM-based agents capable of addressing complex, real-world tasks. However, these agents often struggle during task execution due to methodological constraints, such as error propagation and limited adaptability. To address this issue, we propose a multi-agent framework based on dynamic Task Decomposition and Agent Generation (TDAG). This framework dynamically decomposes complex tasks into smaller subtasks and assigns each to a specifically generated subagent, thereby enhancing adaptability in diverse and unpredictable real-world tasks. Simultaneously, existing benchmarks often lack the granularity needed to evaluate incremental progress in complex, multi-step tasks. In response, we introduce ItineraryBench in the context of travel planning, featuring interconnected, progressively complex tasks with a fine-grained evaluation system. ItineraryBench is designed to assess agents’ abilities in memory, planning, and tool usage across tasks of varying complexity. Our experimental results reveal that TDAG significantly outperforms established baselines, showcasing its superior adaptability and context awareness in complex task scenarios.
随着像ChatGPT等大型语言模型(LLM)的出现,已经激发了基于LLM的代理人的发展,这些代理人能够处理复杂、现实世界的任务。然而,这些代理人在执行任务时常常由于方法上的约束,如误差传播和适应性有限而遇到困难。为了解决这一问题,我们提出了一种基于动态任务分解和代理生成(TDAG)的多代理框架。该框架能够动态地将复杂任务分解为较小的子任务,并将每个子任务分配给专门生成的子代理,从而在多样化和不可预测的现实世界任务中提高适应性。同时,现有的基准测试通常缺乏评估复杂多步骤任务的增量进展所需的粒度。作为回应,我们在旅行规划的情境中引入了ItineraryBench,它包含相互关联、逐步复杂的任务以及精细的评估系统。ItineraryBench旨在评估代理在不同复杂度的任务中的记忆力、规划能力和工具使用能力。我们的实验结果表明,TDAG显著优于既定基准,展示了其在复杂任务场景中的卓越适应性和上下文意识。
论文及项目相关链接
PDF Accepted by Neural Networks
Summary
大型语言模型(LLM)如ChatGPT的出现激发了能够处理复杂、现实任务的LLM基础代理的发展。然而,这些代理在执行任务时常常由于方法论上的限制,如误差传播和适应性有限而遇到困难。为解决这一问题,我们提出了基于动态任务分解和代理生成(TDAG)的多代理框架。该框架能够动态地将复杂任务分解为更小的子任务,并为每个子任务生成特定的子代理,从而提高在不同且不可预测的现实任务中的适应性。同时,现有的基准测试通常缺乏对复杂多步骤任务中增量进展的精细评估。因此,我们在旅行计划的背景下推出了ItineraryBench,它包含相互关联、逐步复杂的任务以及精细的评价体系。ItineraryBench旨在评估代理在不同复杂度的任务中的记忆、规划和工具使用能力。实验结果表明,TDAG显著优于既定基准线,显示出其在复杂任务场景中的卓越适应性和上下文意识。
Key Takeaways
- 大型语言模型(LLM)激励了LLM基础代理的发展,这些代理能处理复杂、现实任务。
- LLM代理在执行任务时面临误差传播和适应性有限的挑战。
- 为解决这些问题,提出了基于动态任务分解和代理生成(TDAG)的多代理框架。
- TDAG能动态分解复杂任务为子任务,并为每个子任务生成特定子代理,提高适应性。
- 现有基准测试缺乏评估复杂多步骤任务的精细标准。
- 推出ItineraryBench,用于评估代理在旅行计划中的记忆、规划和工具使用能力。
点此查看论文截图



Memory Gym: Towards Endless Tasks to Benchmark Memory Capabilities of Agents
Authors:Marco Pleines, Matthias Pallasch, Frank Zimmer, Mike Preuss
Memory Gym presents a suite of 2D partially observable environments, namely Mortar Mayhem, Mystery Path, and Searing Spotlights, designed to benchmark memory capabilities in decision-making agents. These environments, originally with finite tasks, are expanded into innovative, endless formats, mirroring the escalating challenges of cumulative memory games such as “I packed my bag”. This progression in task design shifts the focus from merely assessing sample efficiency to also probing the levels of memory effectiveness in dynamic, prolonged scenarios. To address the gap in available memory-based Deep Reinforcement Learning baselines, we introduce an implementation within the open-source CleanRL library that integrates Transformer-XL (TrXL) with Proximal Policy Optimization. This approach utilizes TrXL as a form of episodic memory, employing a sliding window technique. Our comparative study between the Gated Recurrent Unit (GRU) and TrXL reveals varied performances across our finite and endless tasks. TrXL, on the finite environments, demonstrates superior effectiveness over GRU, but only when utilizing an auxiliary loss to reconstruct observations. Notably, GRU makes a remarkable resurgence in all endless tasks, consistently outperforming TrXL by significant margins. Website and Source Code: https://marcometer.github.io/jmlr_2024.github.io/
“Memory Gym提供了一系列二维部分可观察环境,即Mortar Mayhem、Mystery Path和Searing Spotlights,旨在评估决策制定代理的记忆能力。这些环境最初具有有限的任务,现已扩展为创新的无尽格式,反映了累积记忆游戏(如“我打包了我的行李”)中不断升级的挑战。任务设计的进步使重点从仅仅评估样本效率转向了探究动态持久场景中的记忆有效性水平。为了解决现有基于记忆的深度强化学习基准线之间的差距,我们在开源CleanRL库中引入了一种实现方法,该方法将Transformer-XL(TrXL)与近端策略优化相结合。该方法利用TrXL作为一种情节记忆,采用滑动窗口技术。我们在有限和无限任务之间进行的比较研究显示,GRU与TrXL表现不同。在有限环境中,当利用辅助损失来重建观察结果时,TrXL相较于GRU表现出更高的有效性。值得注意的是,在所有无尽的任务中,GRU都表现出了显著的复苏,始终显著优于TrXL。网站和源代码:https://marcometer.github.io/jmlr_2024.github.io/“
论文及项目相关链接
PDF 40 pages, 12 figures, 7 tables, accepted at JMLR
Summary
记忆训练环境设计用于评估决策代理人的记忆能力。通过一系列创新的无限格式环境,如Mortar Mayhem、Mystery Path和Searing Spotlights,对记忆能力进行基准测试。为解决现有基于记忆的深度强化学习基准不足的问题,引入了与开源CleanRL库相结合的Transformer-XL(TrXL)与近端策略优化实现。研究结果显示,在有限环境中,使用辅助损失重构观察的TrXL表现优于门控循环单元(GRU),而在无限任务中,GRU表现突出,显著优于TrXL。
Key Takeaways
- Memory Gym设计了一系列环境用于评估决策代理人的记忆能力。
- 环境以创新的无限格式呈现,模拟累积记忆游戏的挑战。
- 为解决当前基于记忆的深度强化学习基准的不足,整合了Transformer-XL(TrXL)与近端策略优化实现。
- 在有限环境中,使用辅助损失重构观察的TrXL表现优于GRU。
- 在无限任务中,GRU表现卓越,显著超过TrXL的表现。
点此查看论文截图


