⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
GPS as a Control Signal for Image Generation
Authors:Chao Feng, Ziyang Chen, Aleksander Holynski, Alexei A. Efros, Andrew Owens
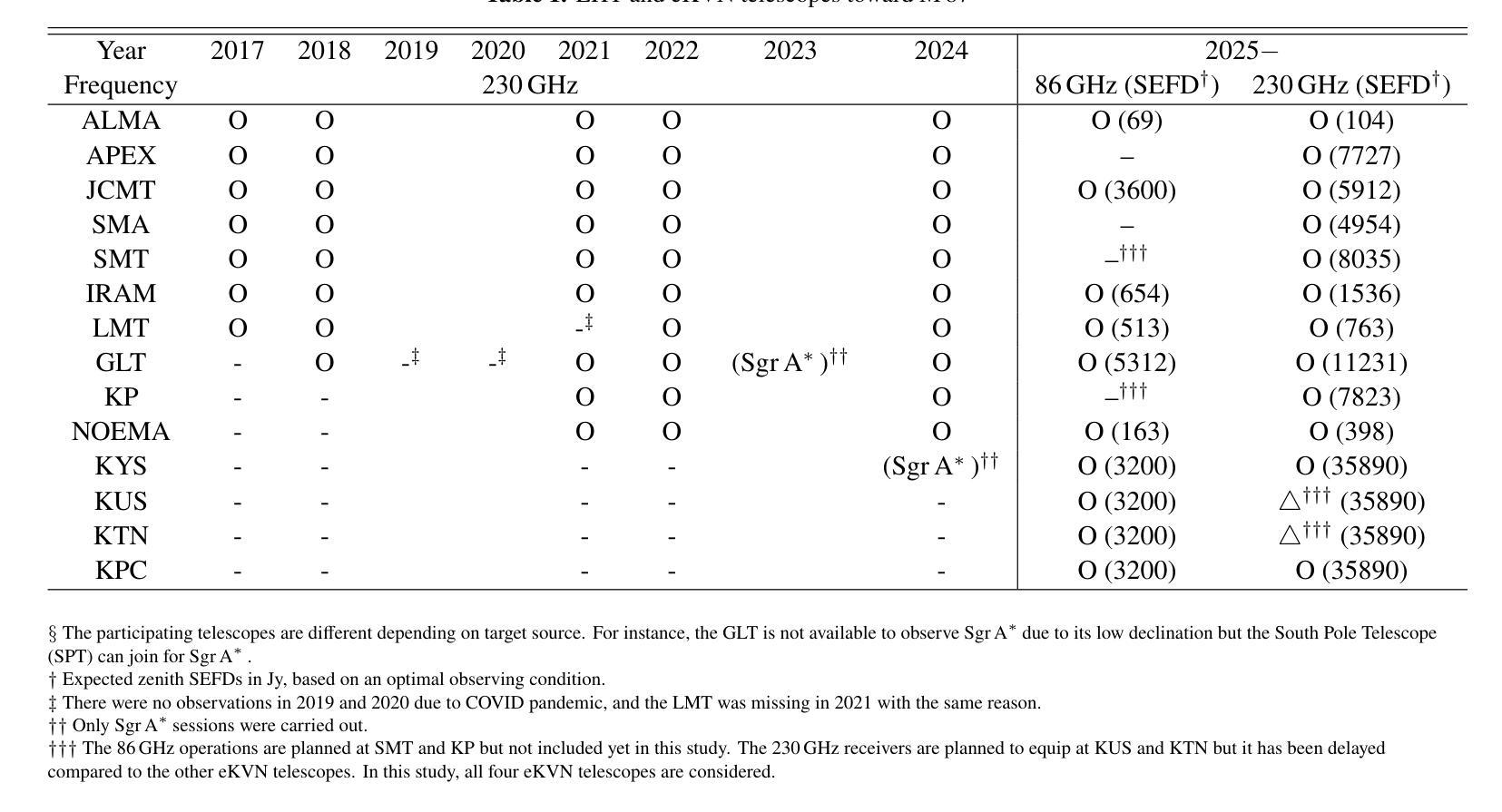
We show that the GPS tags contained in photo metadata provide a useful control signal for image generation. We train GPS-to-image models and use them for tasks that require a fine-grained understanding of how images vary within a city. In particular, we train a diffusion model to generate images conditioned on both GPS and text. The learned model generates images that capture the distinctive appearance of different neighborhoods, parks, and landmarks. We also extract 3D models from 2D GPS-to-image models through score distillation sampling, using GPS conditioning to constrain the appearance of the reconstruction from each viewpoint. Our evaluations suggest that our GPS-conditioned models successfully learn to generate images that vary based on location, and that GPS conditioning improves estimated 3D structure.
我们证明,照片元数据中包含的GPS标签为图像生成提供了有用的控制信号。我们训练GPS到图像的模型,并将其用于需要精细理解图像在城市内如何变化的任务。特别是,我们训练了一个扩散模型,以根据GPS和文本生成图像。学习到的模型生成了捕捉不同街区、公园和地标独特外观的图像。我们还通过评分蒸馏采样从二维GPS到图像的模型中提取三维模型,使用GPS条件来约束从每个视角重建的外观。我们的评估表明,我们的GPS条件模型成功学会了根据位置生成不同的图像,GPS条件改进了估计的3D结构。
论文及项目相关链接
Summary
本研究利用照片元数据中的GPS标签作为图像生成的控制信号。通过训练GPS到图像的模型,我们将其应用于需要精细理解城市内图像变化的任务。特别是,我们训练了一个扩散模型,该模型能够根据GPS和文本生成图像。生成的图像能够捕捉不同街区、公园和地标的独特外观。我们还通过评分蒸馏采样从2D GPS到图像的模型中提取3D模型,使用GPS条件来约束从每个视角的重建外观。评估表明,GPS条件模型成功学习根据位置生成图像,GPS条件改进了估计的3D结构。
Key Takeaways
- GPS标签在图像生成中作为有用的控制信号。
- 训练了GPS到图像的模型,用于精细理解城市内图像变化的任务。
- 扩散模型能够根据GPS和文本生成图像,捕捉不同地点的独特外观。
- 通过评分蒸馏采样从2D GPS到图像的模型提取3D模型。
- GPS条件用于约束从各个视角的重建外观。
- GPS条件模型能够成功根据位置生成图像。
- GPS条件改进了估计的3D结构。
点此查看论文截图



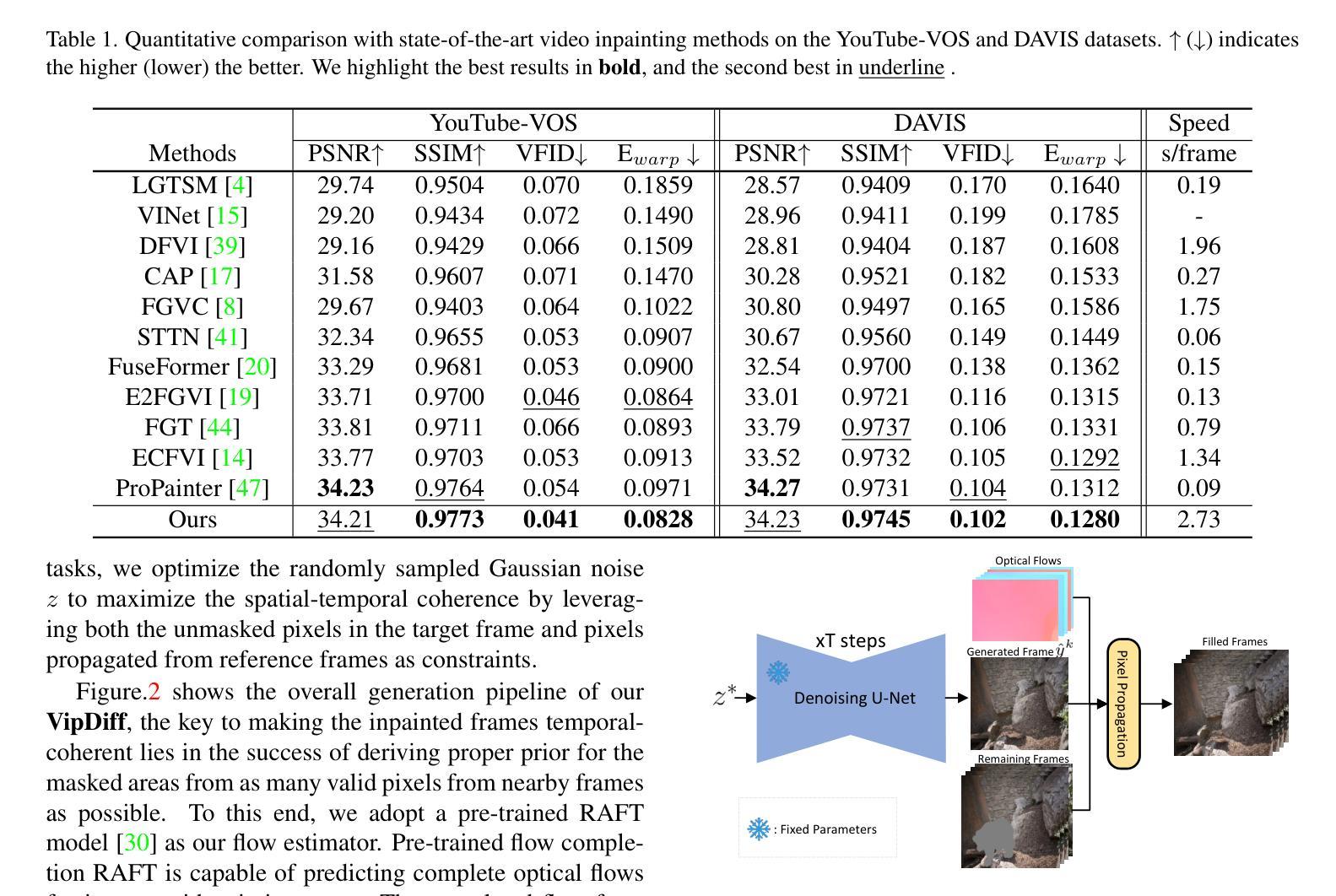
VipDiff: Towards Coherent and Diverse Video Inpainting via Training-free Denoising Diffusion Models
Authors:Chaohao Xie, Kai Han, Kwan-Yee K. Wong
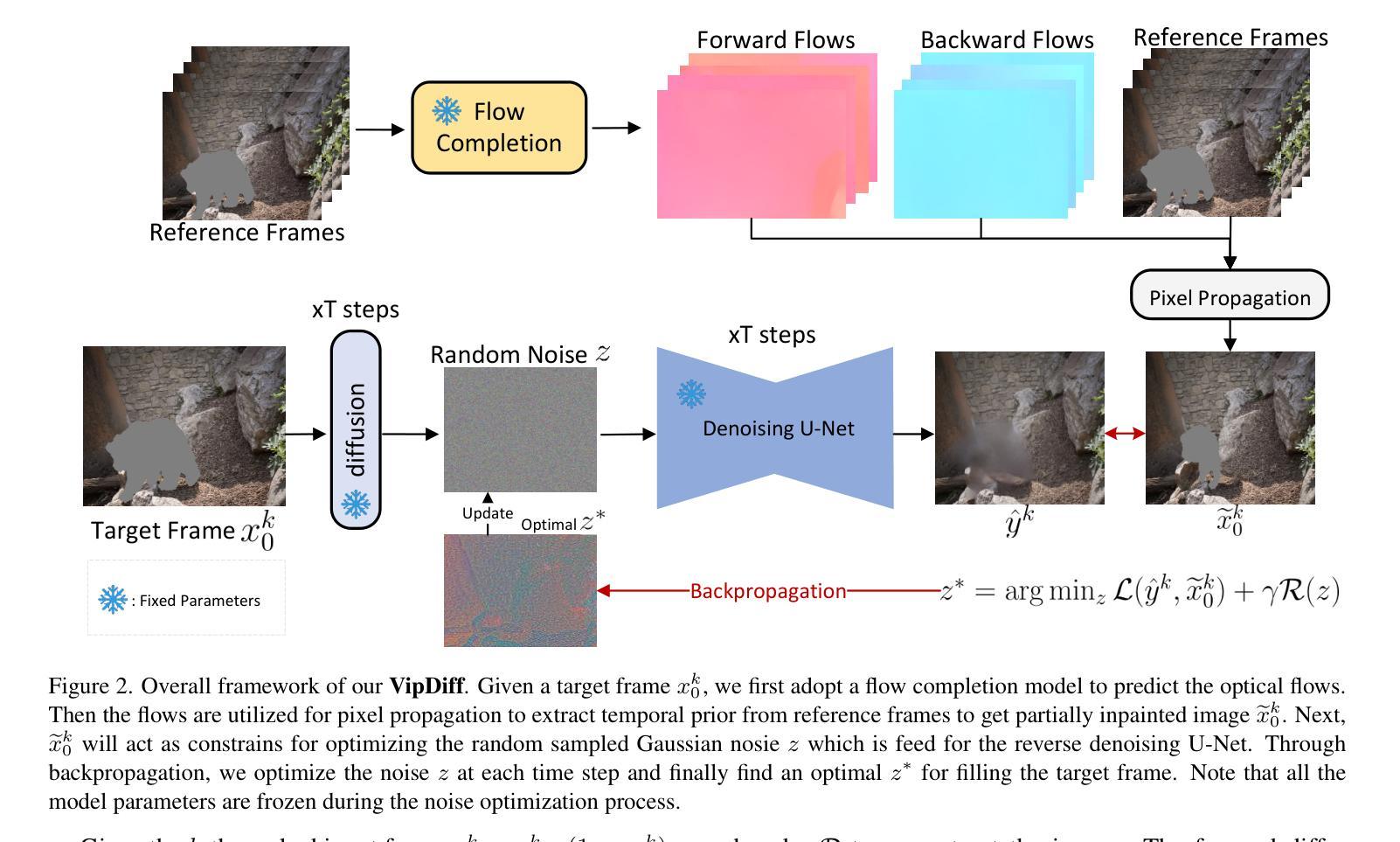
Recent video inpainting methods have achieved encouraging improvements by leveraging optical flow to guide pixel propagation from reference frames either in the image space or feature space. However, they would produce severe artifacts in the mask center when the masked area is too large and no pixel correspondences can be found for the center. Recently, diffusion models have demonstrated impressive performance in generating diverse and high-quality images, and have been exploited in a number of works for image inpainting. These methods, however, cannot be applied directly to videos to produce temporal-coherent inpainting results. In this paper, we propose a training-free framework, named VipDiff, for conditioning diffusion model on the reverse diffusion process to produce temporal-coherent inpainting results without requiring any training data or fine-tuning the pre-trained diffusion models. VipDiff takes optical flow as guidance to extract valid pixels from reference frames to serve as constraints in optimizing the randomly sampled Gaussian noise, and uses the generated results for further pixel propagation and conditional generation. VipDiff also allows for generating diverse video inpainting results over different sampled noise. Experiments demonstrate that VipDiff can largely outperform state-of-the-art video inpainting methods in terms of both spatial-temporal coherence and fidelity.
最近的视频补全方法通过利用光学流来指导像素在图像空间或特征空间中的传播,取得了令人鼓舞的进展。然而,当遮挡区域过大且无法找到中心像素的对应点时,它们会在遮挡中心产生严重的伪影。最近,扩散模型在生成多样化和高质量图像方面表现出令人印象深刻的性能,并已应用于图像补全工作的多个领域。然而,这些方法无法直接应用于视频生成时间连贯的补全结果。在本文中,我们提出了一种无需训练的视频扩散模型框架,名为VipDiff。VipDiff通过在反向扩散过程中对扩散模型进行条件化,产生时间连贯的补全结果,无需任何训练数据或对预训练的扩散模型进行微调。VipDiff以光学流为指导,从参考帧中提取有效像素作为优化随机采样高斯噪声的约束,并使用生成的结果进行进一步的像素传播和条件生成。VipDiff还允许在不同采样的噪声上生成多样的视频补全结果。实验表明,VipDiff在时空连贯性和保真度方面能够大大超越最新的视频补全方法。
论文及项目相关链接
PDF 10 pages, 5 Figures (Accepted at WACV 2025)
Summary
基于扩散模型的无训练视频修复框架研究,使用反向扩散过程产生时间上连贯的修复结果。该研究通过光学流引导像素传播,提取参考帧的有效像素作为约束优化随机采样的高斯噪声,进而生成结果用于进一步的像素传播和条件生成。该方法能够在不同采样噪声下生成多样化的视频修复结果,并优于当前先进的视频修复方法,在时空连贯性和保真度方面都有较大提升。
Key Takeaways
- 利用扩散模型进行视频修复,无需训练数据或微调预训练模型。
- 提出一种名为VipDiff的训练外框架,基于反向扩散过程产生时间上连贯的修复结果。
- 通过光学流引导像素传播,从参考帧中提取有效像素作为约束。
- 使用随机采样的高斯噪声进行优化,生成结果用于进一步像素传播和条件生成。
- VipDiff允许生成多样化的视频修复结果,基于不同的噪声采样。
- 实验证明,VipDiff在时空连贯性和保真度方面显著优于当前先进的视频修复方法。
点此查看论文截图


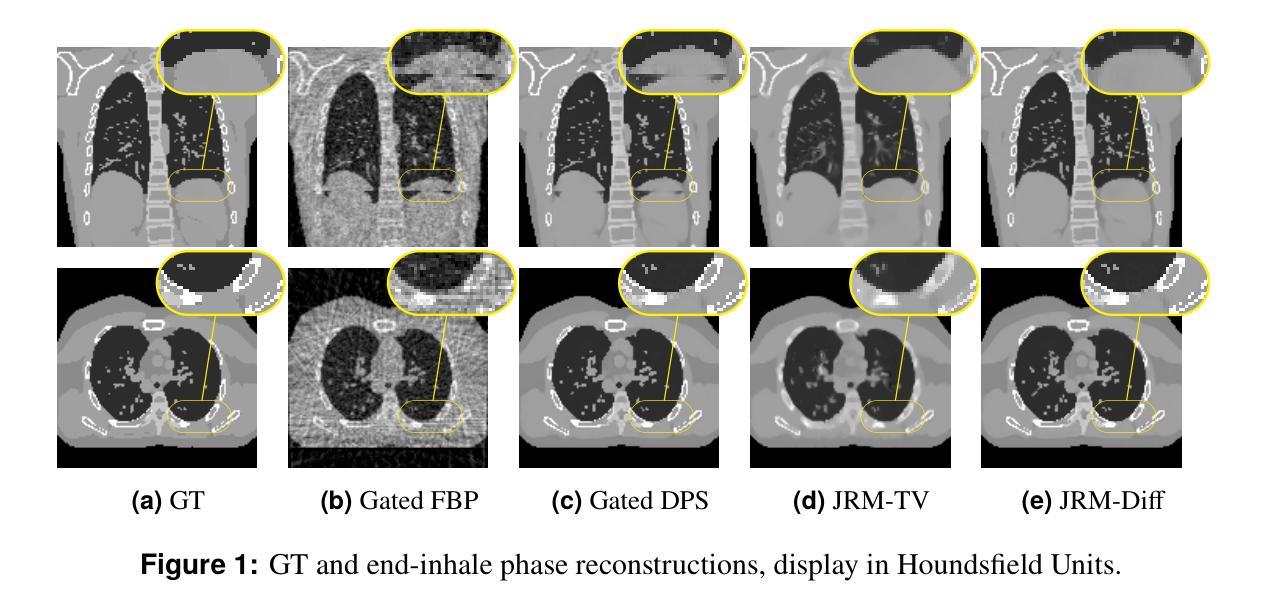
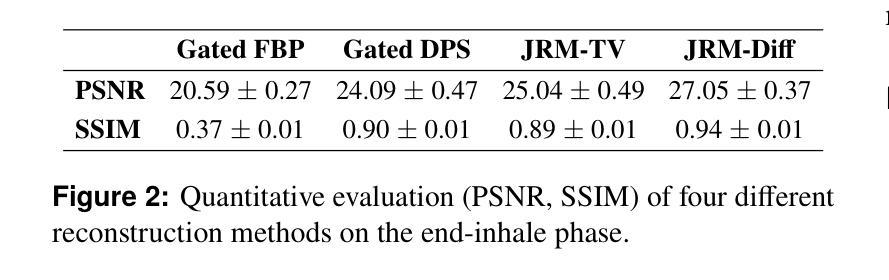
Joint Reconstruction and Motion Estimation in Sparse-View 4DCT Using Diffusion Models within a Blind Inverse Problem Framework
Authors:Antoine De Paepe, Alexandre Bousse, Clémentine Phung-Ngoc, Dimitris Visvikis
Four-dimensional computed tomography (4DCT) is essential for medical imaging applications like radiotherapy, which demand precise respiratory motion representation. Traditional methods for reconstructing 4DCT data suffer from artifacts and noise, especially in sparse-view, low-dose contexts. We propose a novel framework that integrates motion correction and diffusion models (DMs) within a blind inverse problem formulation. By leveraging prior probability distributions from DMs, we enhance the joint reconstruction and motion estimation process, improving image quality and preserving resolution. Experiments on extended cardiac-torso (XCAT) phantom data demonstrate that our method outperforms existing techniques, yielding artifact-free, high-resolution reconstructions even under irregular breathing conditions. These results showcase the potential of combining DMs with motion correction to advance sparse-view 4DCT imaging.
四维计算机断层扫描(4DCT)在医学成像应用(如放射治疗)中至关重要,这些应用需要精确的呼吸运动表示。传统的重建4DCT数据的方法在稀疏视角、低剂量的情况下会出现伪影和噪声。我们提出了一种新型框架,该框架在盲反问题公式中整合了运动校正和扩散模型(DMs)。通过利用DMs的先验概率分布,我们增强了联合重建和运动估计过程,提高了图像质量并保持分辨率。在扩展心脏躯干(XCAT)幻影数据上的实验表明,我们的方法优于现有技术,即使在不规则呼吸条件下也能产生无伪影、高分辨率的重建结果。这些结果展示了将DMs与运动校正相结合在稀疏视角4DCT成像中的潜力。
论文及项目相关链接
Summary
针对四维计算机断层扫描(4DCT)在医学成像应用中的需求,如放射治疗中对呼吸运动的精确表示,传统重建方法易出现伪影和噪声问题,特别是在稀疏视角和低剂量情况下。本研究提出一种结合运动校正和扩散模型(DMs)的新框架,利用DMs的先验概率分布,增强联合重建和运动估计过程,提高图像质量并保留分辨率。在XCAT Phantom数据上的实验表明,该方法优于现有技术,即使在不规则呼吸条件下也能实现无伪影、高分辨率的重建。展示了结合DMs和运动校正推动稀疏视角4DCT成像的潜力。
Key Takeaways
- 四维计算机断层扫描(4DCT)在医学成像中的重要作用,特别是在放射治疗领域。
- 传统4DCT数据重建方法存在伪影和噪声问题,尤其在稀疏视角和低剂量环境下。
- 提出一种结合运动校正和扩散模型(DMs)的新框架,用于改进图像质量和分辨率。
- 利用DMs的先验概率分布,增强联合重建和运动估计过程。
- 在XCAT Phantom数据上的实验结果表明,该方法优于现有技术。
- 新方法能够在不规则呼吸条件下实现无伪影、高分辨率的重建。
点此查看论文截图


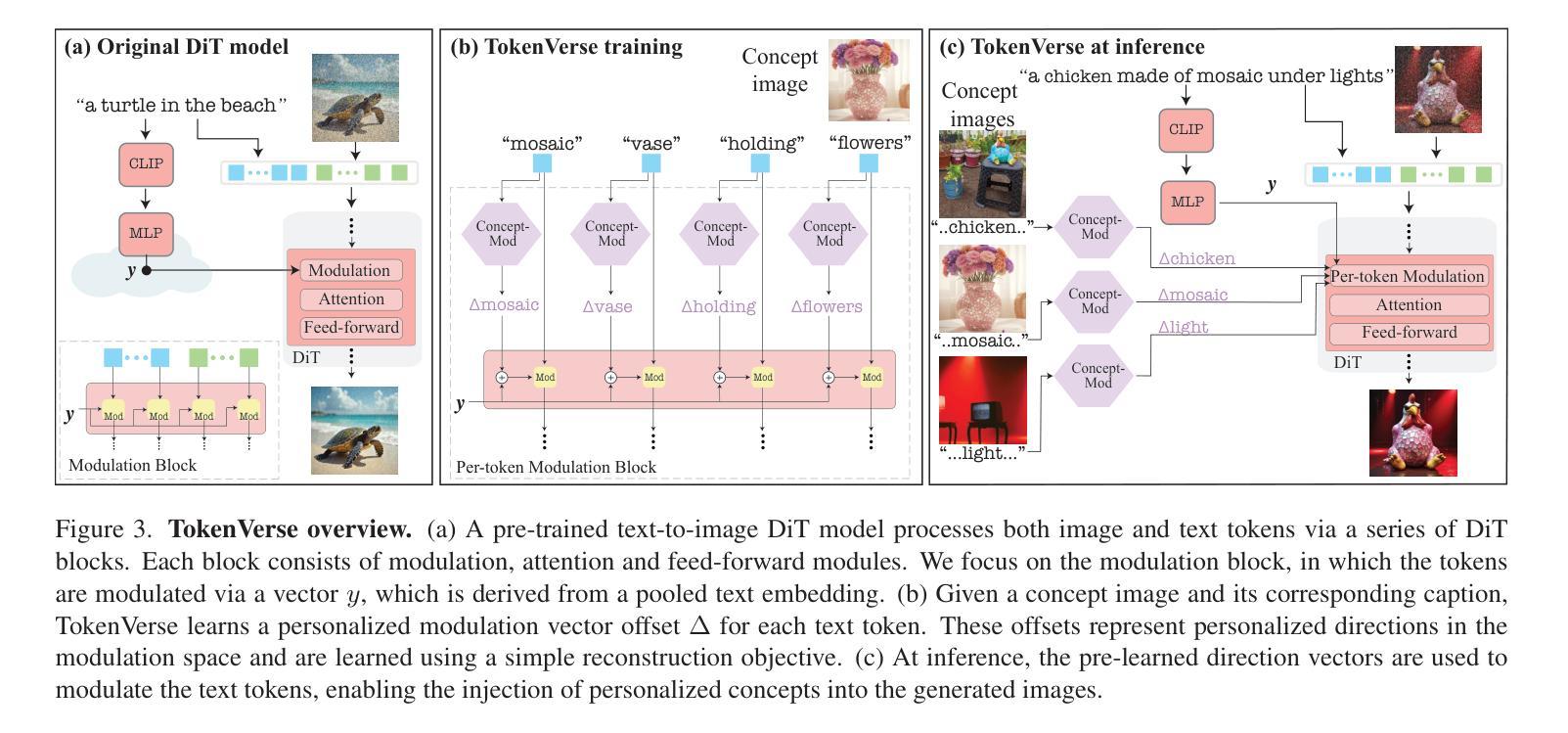
TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space
Authors:Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, Tali Dekel
We present TokenVerse – a method for multi-concept personalization, leveraging a pre-trained text-to-image diffusion model. Our framework can disentangle complex visual elements and attributes from as little as a single image, while enabling seamless plug-and-play generation of combinations of concepts extracted from multiple images. As opposed to existing works, TokenVerse can handle multiple images with multiple concepts each, and supports a wide-range of concepts, including objects, accessories, materials, pose, and lighting. Our work exploits a DiT-based text-to-image model, in which the input text affects the generation through both attention and modulation (shift and scale). We observe that the modulation space is semantic and enables localized control over complex concepts. Building on this insight, we devise an optimization-based framework that takes as input an image and a text description, and finds for each word a distinct direction in the modulation space. These directions can then be used to generate new images that combine the learned concepts in a desired configuration. We demonstrate the effectiveness of TokenVerse in challenging personalization settings, and showcase its advantages over existing methods. project’s webpage in https://token-verse.github.io/
我们推出了TokenVerse——一种利用预训练文本到图像扩散模型进行多概念个性化的方法。我们的框架能够从单张图像中分离出复杂的视觉元素和属性,同时能够无缝地生成从多张图像中提取的概念的组合。与现有作品不同,TokenVerse能够处理每张包含多个概念的多张图像,并支持包括物体、配件、材质、姿势和光照在内的广泛概念。我们的工作利用基于DiT的文本到图像模型,其中输入文本通过注意力和调制(移位和缩放)影响生成。我们发现调制空间是语义化的,能够对复杂概念进行局部控制。基于这一见解,我们开发了一个基于优化的框架,该框架以图像和文本描述作为输入,并为每个单词在调制空间中找到一个独特的方向。然后可以使用这些方向生成新图像,以在所需配置中结合所学概念。我们在具有挑战性的个性化设置中展示了TokenVerse的有效性,并展示了其与现有方法的优势。项目网页在https://token-verse.github.io/。
论文及项目相关链接
Summary
TokenVerse是一种利用预训练文本到图像扩散模型进行多概念个性化的方法。它能够从一个或多个图像中解耦复杂的视觉元素和属性,并轻松生成提取自不同图像的概念的组合。其利用了一种基于文本到图像模型的框架,能够处理具有多个概念的多个图像并支持多种概念。它结合了文本注意力与调制空间控制进行生成图像的技术,并通过优化框架实现图像与文本描述的输入。此框架为输入的每个单词在调制空间中找到了一个独特方向,进而生成结合学习概念的新图像。TokenVerse在个性化设置方面表现出色,并在展示其对现有方法的优势方面具有挑战性。有关详细信息,请访问其项目网页。https://token-verse.github.io/ 。
Key Takeaways
- TokenVerse利用预训练的文本到图像扩散模型进行多概念个性化。
- 它能够处理复杂的视觉元素和属性的解耦,支持从单个或多个图像中提取概念组合。
- TokenVerse支持多种概念,包括物体、配件、材质、姿势和照明等。
- 该方法结合了文本注意力与调制空间控制来生成图像。
- 通过优化框架实现输入图像和文本描述的结合,为每个单词找到调制空间中的独特方向。
点此查看论文截图


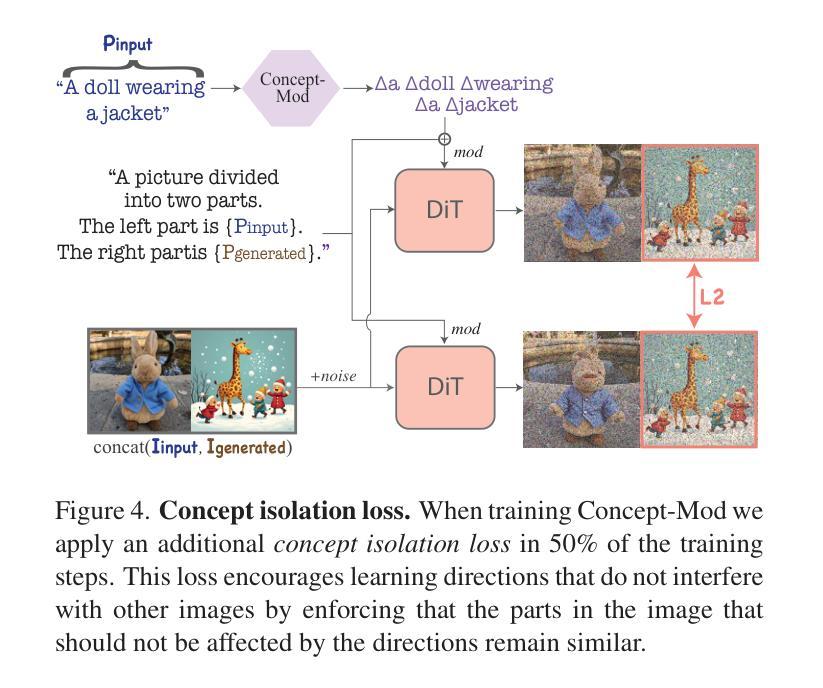

EfficientVITON: An Efficient Virtual Try-On Model using Optimized Diffusion Process
Authors:Mostafa Atef, Mariam Ayman, Ahmed Rashed, Ashrakat Saeed, Abdelrahman Saeed, Ahmed Fares
Would not it be much more convenient for everybody to try on clothes by only looking into a mirror ? The answer to that problem is virtual try-on, enabling users to digitally experiment with outfits. The core challenge lies in realistic image-to-image translation, where clothing must fit diverse human forms, poses, and figures. Early methods, which used 2D transformations, offered speed, but image quality was often disappointing and lacked the nuance of deep learning. Though GAN-based techniques enhanced realism, their dependence on paired data proved limiting. More adaptable methods offered great visuals but demanded significant computing power and time. Recent advances in diffusion models have shown promise for high-fidelity translation, yet the current crop of virtual try-on tools still struggle with detail loss and warping issues. To tackle these challenges, this paper proposes EfficientVITON, a new virtual try-on system leveraging the impressive pre-trained Stable Diffusion model for better images and deployment feasibility. The system includes a spatial encoder to maintain clothings finer details and zero cross-attention blocks to capture the subtleties of how clothes fit a human body. Input images are carefully prepared, and the diffusion process has been tweaked to significantly cut generation time without image quality loss. The training process involves two distinct stages of fine-tuning, carefully incorporating a balance of loss functions to ensure both accurate try-on results and high-quality visuals. Rigorous testing on the VITON-HD dataset, supplemented with real-world examples, has demonstrated that EfficientVITON achieves state-of-the-art results.
试衣时,如果只需要照镜子不是更加方便吗?这个问题的答案是虚拟试衣功能,它使用户能够数字化地尝试不同的服装。核心挑战在于实现真实的图像到图像的转换,这需要服装能够适应各种人类形态、姿势和体型。早期使用2D转换的方法虽然速度很快,但图像质量往往令人失望,缺乏深度学习所带来的细微差别。虽然基于GAN的技术增强了现实感,但它们对配对数据的依赖证明是有限制的。适应性更强的方法在视觉上提供了很好的表现,但需要巨大的计算能力和时间。扩散模型的最新进展显示出高保真翻译的前景,然而目前的虚拟试衣工具仍然面临细节损失和变形问题。为了应对这些挑战,本文提出了EfficientVITON,这是一个新的虚拟试衣系统,利用令人印象深刻的预训练Stable Diffusion模型来生成更好的图像并提高部署的可行性。该系统包括一个空间编码器,以保留服装的精细细节和零交叉注意力块来捕捉服装如何贴合人体细微之处。输入图像经过精心准备,调整了扩散过程以显著减少生成时间而不损失图像质量。训练过程包括两个精细调整的独特阶段,精心平衡损失函数以确保准确的试穿结果和高质量的视觉效果。在VITON-HD数据集上进行严格测试,并结合真实世界例子进行补充,证明了EfficientVITON取得了最先进的成果。
论文及项目相关链接
PDF 7 pages
Summary
基于扩散模型的虚拟试衣系统EfficientVITON研究。该系统利用预训练的Stable Diffusion模型,通过空间编码器和零交叉注意力块等技术,实现了高质量的虚拟试衣效果。通过精细的图像处理和扩散过程调整,提高了生成速度并保证了图像质量。经过两阶段微调训练,EfficientVITON在VITON-HD数据集上取得了最新成果。
Key Takeaways
- 虚拟试衣系统面临的核心挑战是实现真实感图像到图像的转换,需要适应不同的人类形态、姿势和体型。
- 早期方法主要使用2D转换,虽然速度较快但图像质量不佳,缺乏深度学习所带来的细微差别。
- 基于GAN的技术提高了真实性,但依赖于配对数据,限制了其应用。
- 扩散模型在虚拟试衣方面显示出高保真翻译的潜力,但现有工具仍存在细节损失和变形问题。
- EfficientVITON系统利用预训练的Stable Diffusion模型实现更好的图像效果和提高部署可行性。
- EfficientVITON通过空间编码器和零交叉注意力块等技术捕捉衣物细节和贴合人体的微妙之处。
点此查看论文截图


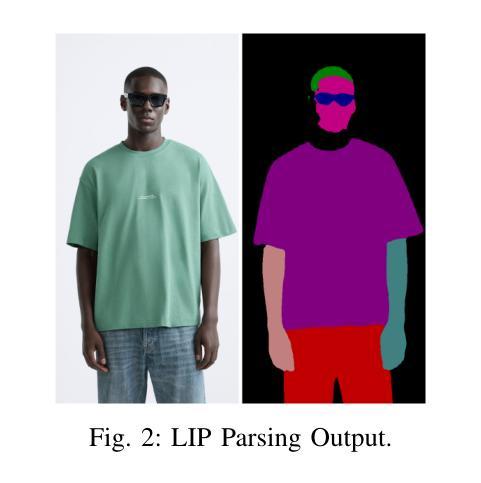



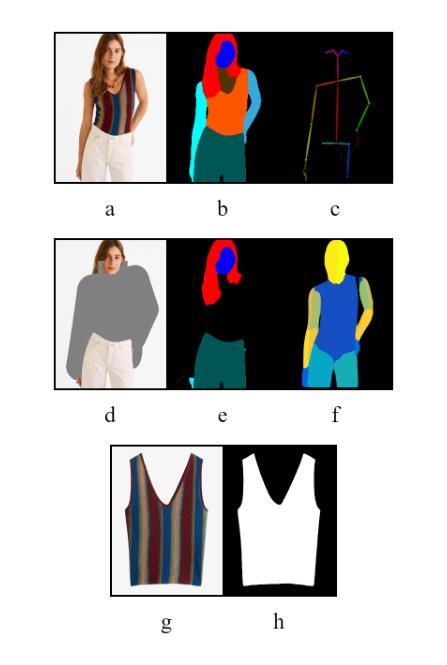

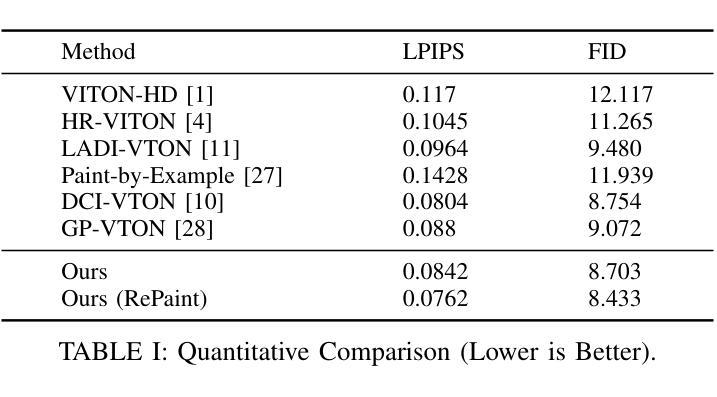
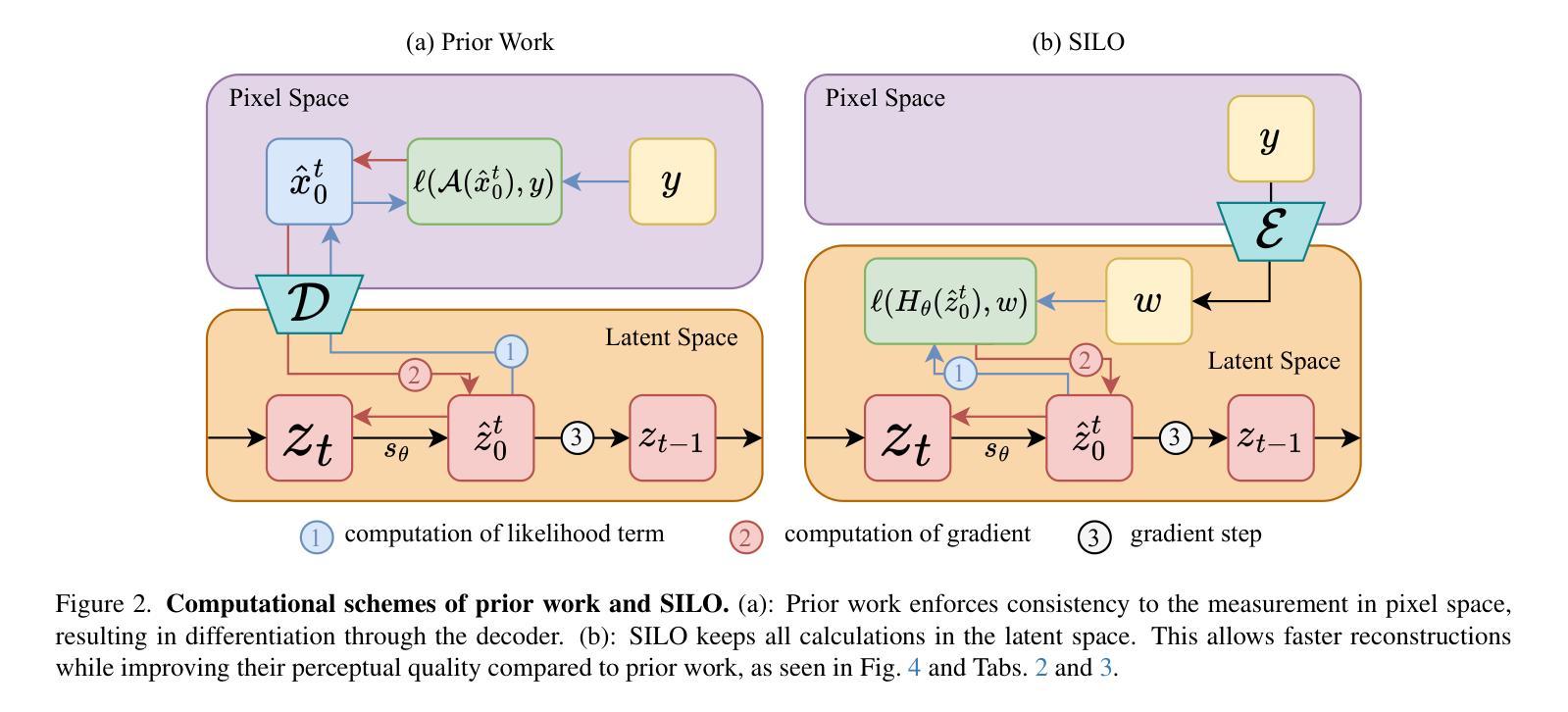
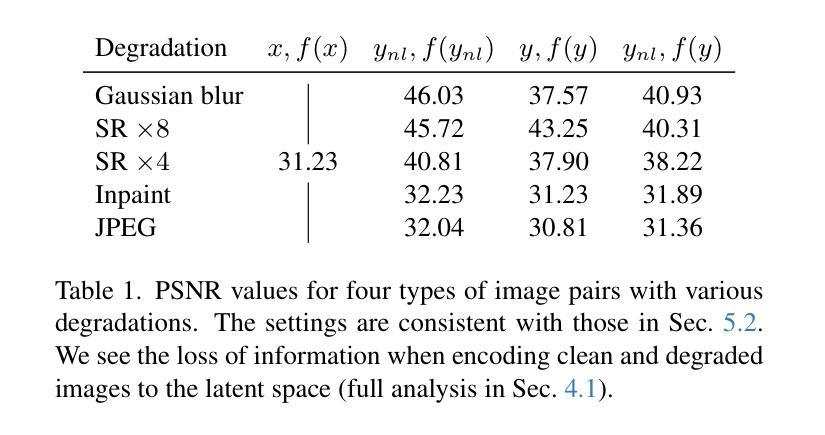
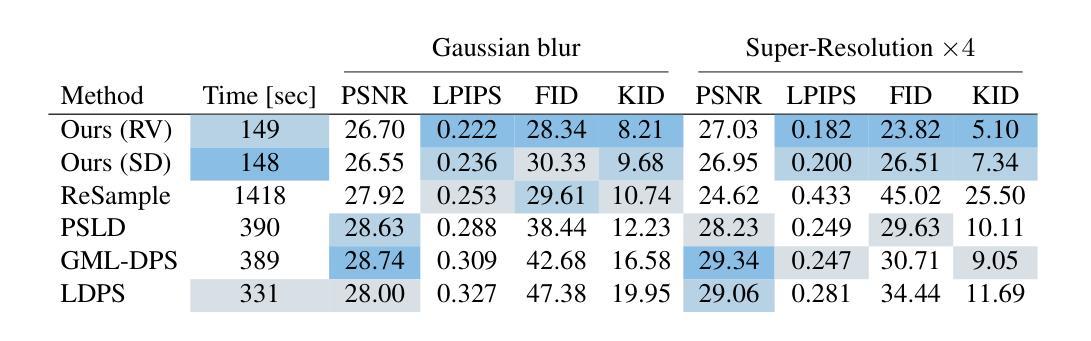
SILO: Solving Inverse Problems with Latent Operators
Authors:Ron Raphaeli, Sean Man, Michael Elad
Consistent improvement of image priors over the years has led to the development of better inverse problem solvers. Diffusion models are the newcomers to this arena, posing the strongest known prior to date. Recently, such models operating in a latent space have become increasingly predominant due to their efficiency. In recent works, these models have been applied to solve inverse problems. Working in the latent space typically requires multiple applications of an Autoencoder during the restoration process, which leads to both computational and restoration quality challenges. In this work, we propose a new approach for handling inverse problems with latent diffusion models, where a learned degradation function operates within the latent space, emulating a known image space degradation. Usage of the learned operator reduces the dependency on the Autoencoder to only the initial and final steps of the restoration process, facilitating faster sampling and superior restoration quality. We demonstrate the effectiveness of our method on a variety of image restoration tasks and datasets, achieving significant improvements over prior art.
随着多年来图像先验的持续改进,更好的逆问题求解器得以开发。扩散模型作为该领域的新来者,提出了迄今为止最强大的已知先验。最近,由于效率原因,在潜在空间运作的这种模型越来越占据主导地位。在最近的作品中,这些模型已被应用于解决逆问题。在潜在空间工作通常在恢复过程中需要多次应用自动编码器,这导致计算和恢复质量方面的挑战。在这项工作中,我们提出了一种新的方法,用潜在扩散模型处理逆问题,其中学习到的退化函数在潜在空间内运行,模拟已知的图像空间退化。使用学习到的操作符仅将自动编码器的依赖性降低到了恢复过程的初始和最终步骤,实现了更快的采样和更高的恢复质量。我们在各种图像恢复任务和数据集上展示了我们的方法的有效性,在先验技术方面取得了重大改进。
论文及项目相关链接
PDF Project page in https://ronraphaeli.github.io/SILO-website/
Summary
扩散模型在图像先验领域的持续进步推动了更好的逆问题求解器的开发。近年来,工作在潜在空间的扩散模型因其效率而逐渐成为主流。为解决逆问题,这些模型被广泛应用。然而,在恢复过程中,通常需要多次使用自编码器,这带来了计算和恢复质量的挑战。本文提出了一种新的基于潜在扩散模型处理逆问题的方法,其中学习到的退化函数在潜在空间内运行,模拟已知的图像空间退化。使用学习到的算子减少了自编码器仅在恢复过程的初始和最终步骤中的依赖性,实现了更快的采样和更高的恢复质量。
Key Takeaways
- 扩散模型在图像先验领域持续进步,推动了逆问题求解器的发展。
- 潜在空间的扩散模型因其效率而逐渐流行。
- 解决逆问题需要多次使用自编码器,带来计算和恢复质量的挑战。
- 本文提出了一种新的基于潜在扩散模型处理逆问题的方法,使用学习到的退化函数模拟图像空间退化。
- 学习到的算子减少了自编码器在恢复过程中的依赖性,提高了采样速度和恢复质量。
- 该方法在多种图像恢复任务和数据集上实现了显著改进。
点此查看论文截图


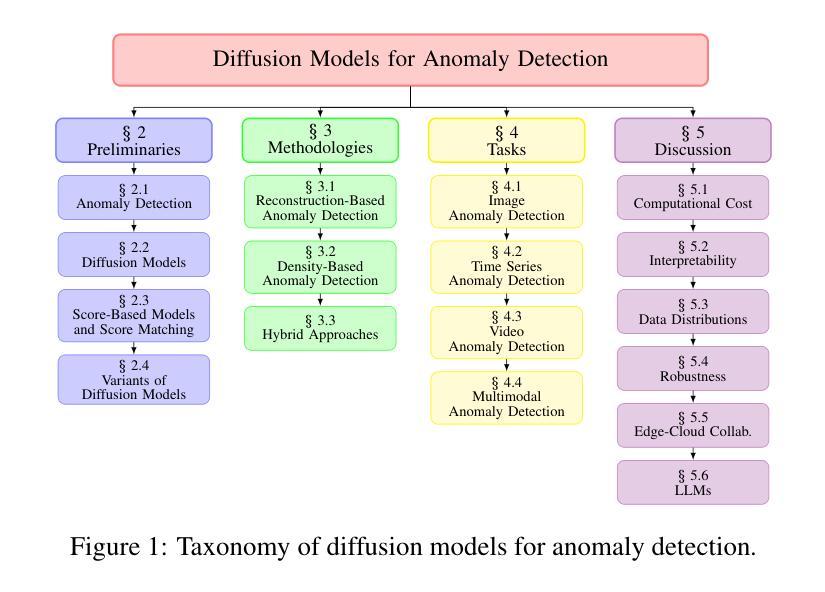
A Survey on Diffusion Models for Anomaly Detection
Authors:Jing Liu, Zhenchao Ma, Zepu Wang, Yang Liu, Zehua Wang, Peng Sun, Liang Song, Bo Hu, Azzedine Boukerche, Victor C. M. Leung
Diffusion models (DMs) have emerged as a powerful class of generative AI models, showing remarkable potential in anomaly detection (AD) tasks across various domains, such as cybersecurity, fraud detection, healthcare, and manufacturing. The intersection of these two fields, termed diffusion models for anomaly detection (DMAD), offers promising solutions for identifying deviations in increasingly complex and high-dimensional data. In this survey, we systematically review recent advances in DMAD research and investigate their capabilities. We begin by presenting the fundamental concepts of AD and DMs, followed by a comprehensive analysis of classic DM architectures including DDPMs, DDIMs, and Score SDEs. We further categorize existing DMAD methods into reconstruction-based, density-based, and hybrid approaches, providing detailed examinations of their methodological innovations. We also explore the diverse tasks across different data modalities, encompassing image, time series, video, and multimodal data analysis. Furthermore, we discuss critical challenges and emerging research directions, including computational efficiency, model interpretability, robustness enhancement, edge-cloud collaboration, and integration with large language models. The collection of DMAD research papers and resources is available at https://github.com/fdjingliu/DMAD.
扩散模型(DMs)作为一类强大的生成人工智能模型已经崭露头角,在异常检测(AD)任务中显示出显著潜力,广泛应用于网络安全、欺诈检测、医疗健康和制造等领域。这两个领域的交叉点——异常检测的扩散模型(DMAD)——为解决日益复杂的高维数据中的偏差提供了有前景的解决方案。在这篇综述中,我们系统地回顾了DMAD研究的最新进展,并调查了它们的能力。我们首先介绍AD和DM的基本概念,然后全面分析经典的DM架构,包括DDPMs、DDIIMs和Score SDEs。我们进一步将现有的DMAD方法分为基于重建的、基于密度的和混合方法,并对其方法创新进行详细考察。我们还探讨了不同数据模态的多样化任务,包括图像、时间序列、视频和多模态数据分析。此外,我们还讨论了关键挑战和新兴研究方向,包括计算效率、模型可解释性、鲁棒性增强、边缘云协作以及与大型语言模型的集成。DMAD研究论文和资源集可在https://github.com/fdjingliu/DMAD找到。
论文及项目相关链接
Summary
本文综述了扩散模型在异常检测领域的最新进展,介绍了异常检测与扩散模型的交集——扩散模型异常检测(DMAD)。文章详细阐述了DMAD的方法创新,包括基于重建、基于密度和混合方法,以及其在不同数据模态(图像、时间序列、视频和多模态数据)的应用。同时,文章还探讨了计算效率、模型可解释性、鲁棒性增强、边缘云协作以及与大型语言模型的集成等关键挑战和未来研究方向。有关DMAD研究论文和资源的集合可在链接中找到。
Key Takeaways
- 扩散模型(DMs)作为生成式AI模型的一个强大类别,在异常检测(AD)任务中展现出巨大潜力,应用领域广泛,如网络安全、欺诈检测、医疗保健和制造等。
- 扩散模型异常检测(DMAD)是AD与DMs的交集,能识别高维度数据中的异常偏差。
- 现有DMAD方法主要分为基于重建、基于密度和混合方法。
- DMAD能处理不同的数据模态,包括图像、时间序列、视频和多模态数据分析。
- DMAD面临的关键挑战包括计算效率、模型可解释性、鲁棒性增强等。
- 边缘云协作和大型语言模型的集成是DMAD未来的研究方向。
点此查看论文截图

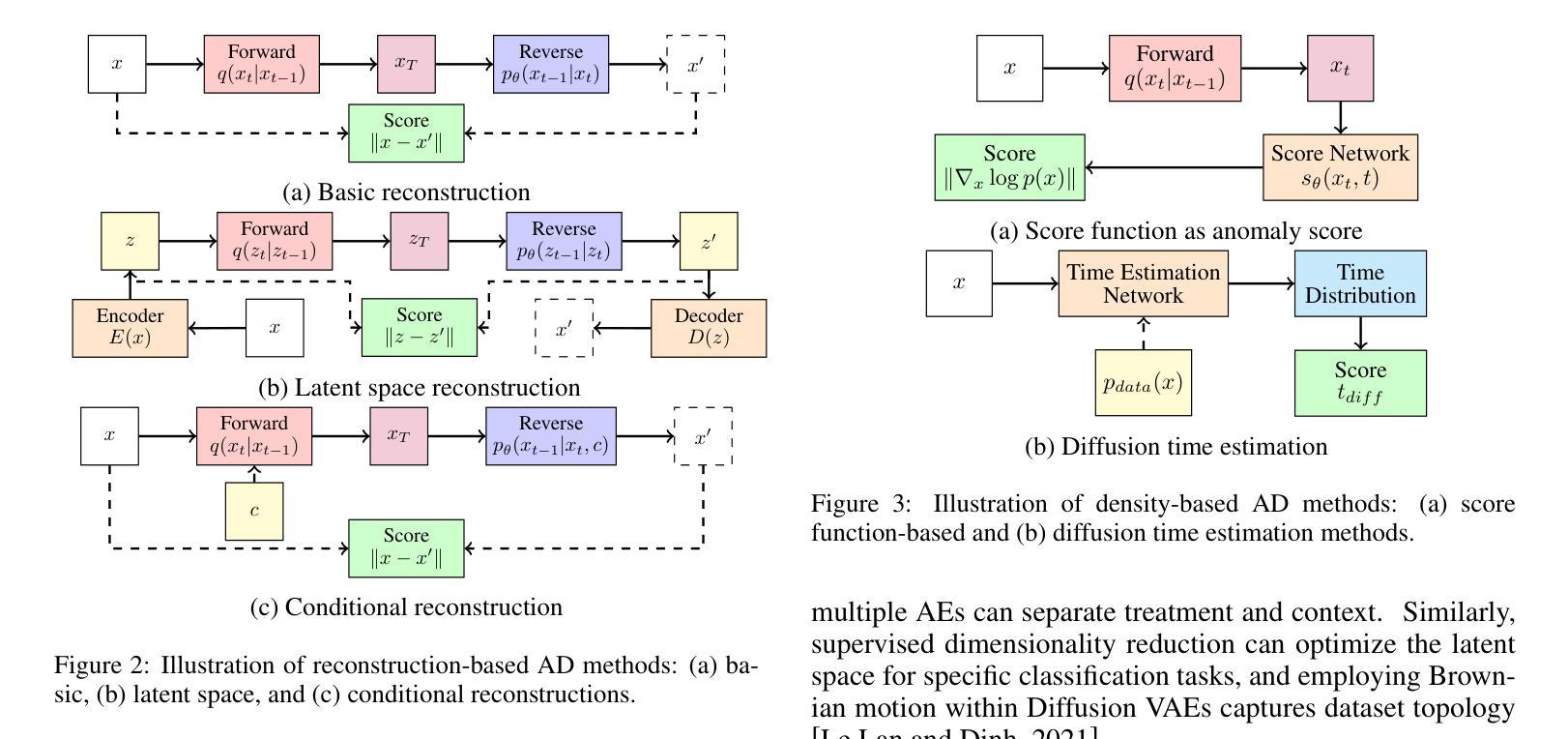
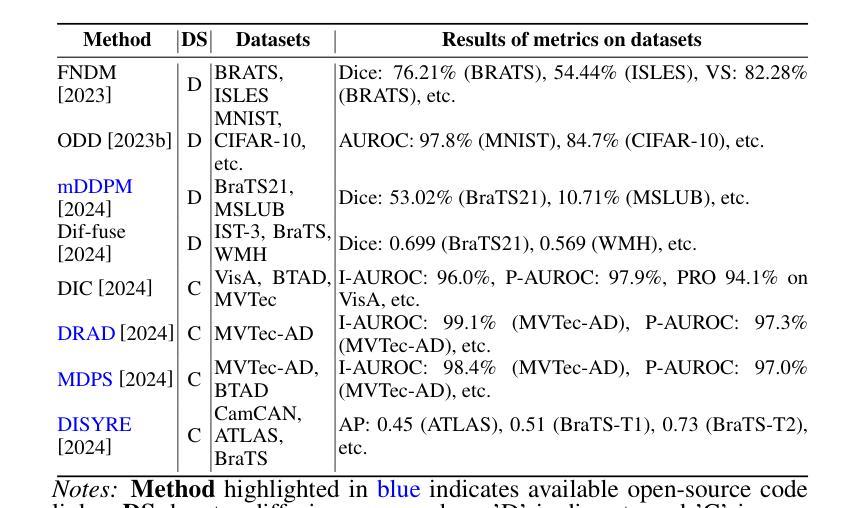
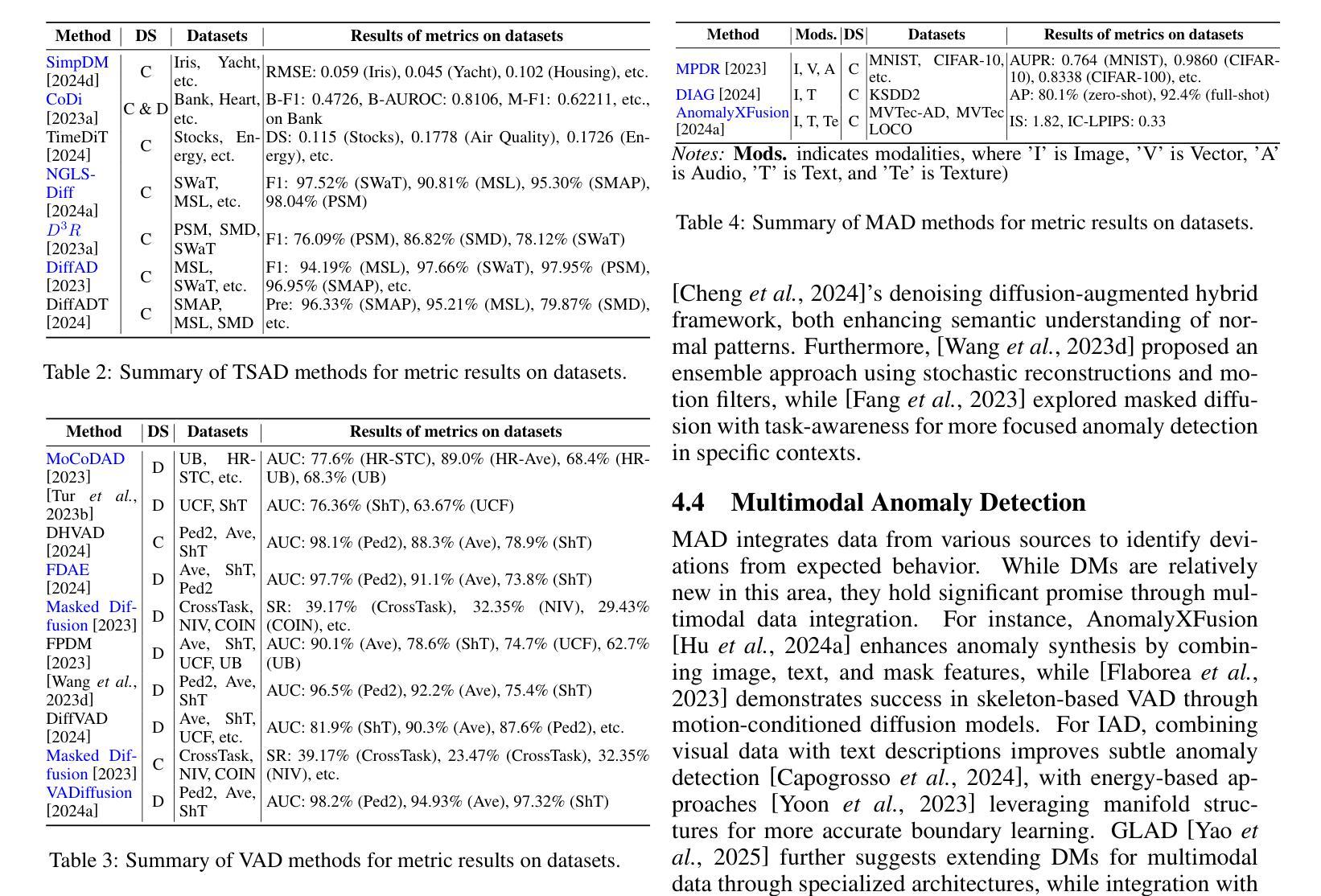
Nested Annealed Training Scheme for Generative Adversarial Networks
Authors:Chang Wan, Ming-Hsuan Yang, Minglu Li, Yunliang Jiang, Zhonglong Zheng
Recently, researchers have proposed many deep generative models, including generative adversarial networks(GANs) and denoising diffusion models. Although significant breakthroughs have been made and empirical success has been achieved with the GAN, its mathematical underpinnings remain relatively unknown. This paper focuses on a rigorous mathematical theoretical framework: the composite-functional-gradient GAN (CFG)[1]. Specifically, we reveal the theoretical connection between the CFG model and score-based models. We find that the training objective of the CFG discriminator is equivalent to finding an optimal D(x). The optimal gradient of D(x) differentiates the integral of the differences between the score functions of real and synthesized samples. Conversely, training the CFG generator involves finding an optimal G(x) that minimizes this difference. In this paper, we aim to derive an annealed weight preceding the weight of the CFG discriminator. This new explicit theoretical explanation model is called the annealed CFG method. To overcome the limitation of the annealed CFG method, as the method is not readily applicable to the SOTA GAN model, we propose a nested annealed training scheme (NATS). This scheme keeps the annealed weight from the CFG method and can be seamlessly adapted to various GAN models, no matter their structural, loss, or regularization differences. We conduct thorough experimental evaluations on various benchmark datasets for image generation. The results show that our annealed CFG and NATS methods significantly improve the quality and diversity of the synthesized samples. This improvement is clear when comparing the CFG method and the SOTA GAN models.
最近,研究者们提出了许多深度生成模型,包括生成对抗网络(GANs)和降噪扩散模型。虽然GAN在数学上取得了重大突破并获得了实证成功,但其数学基础相对未知。本文重点介绍一个严谨的数学理论框架:复合功能梯度GAN(CFG)[1]。具体来说,我们揭示了CFG模型与基于分数的模型之间的理论联系。我们发现CFG判别器的训练目标是找到最优的D(x)。D(x)的最优梯度区分了真实样本和合成样本分数函数之间的差异积分。相反,CFG生成器的训练是寻找一个最优的G(x),以最小化这种差异。在本文中,我们的目标是推导出退火权重,该权重位于CFG判别器权重之前。这种新的显式理论解释模型被称为退火CFG方法。为了克服退火CFG方法的局限性(该方法不适用于SOTA GAN模型),我们提出了一种嵌套退火训练方案(NATS)。该方案保留了CFG方法的退火权重,并能无缝地适应各种GAN模型,无论其结构、损失或正则化差异如何。我们在各种图像生成基准数据集上进行了彻底的实验评估。结果表明,我们的退火CFG和NATS方法显著提高了合成样本的质量和多样性。在与SOTA GAN模型的比较中,这种改进是显而易见的。
论文及项目相关链接
摘要
本文聚焦复合功能梯度GAN(CFG)的严格数学理论框架,揭示CFG模型与基于分数的模型之间的理论联系。研究发现CFG判别器的训练目标是寻找最优的D(x),其梯度最优解能区分真实与合成样本分数函数的积分差。而CFG生成器的训练则是寻找最优的G(x),以最小化这一差异。为改进现有方法,本文提出了退火权重前置的CFG鉴别器权重的新理论解释模型,称为退火CFG方法。针对退火CFG方法不适用于当前主流GAN模型的局限性,进一步提出了嵌套退火训练方案(NATS)。该方案保留了CFG方法的退火权重,并能无缝适应各种GAN模型,无论其结构、损失或正则化差异如何。在图像生成的各种基准数据集上进行的实验评估表明,退火CFG和NATS方法显著提高了合成样本的质量和多样性。与CFG方法和当前主流GAN模型相比,改进效果十分明显。
关键见解
- 论文重点关注复合功能梯度GAN(CFG)的严格数学理论框架。
- 揭示了CFG模型与基于分数的模型之间的理论联系。
- CFG判别器的训练目标是寻找最优的D(x),其梯度区分真实与合成样本的分数函数差异。
- 提出了退火权重前置的CFG鉴别器权重的新理论解释模型——退火CFG方法。
- 针对退火CFG方法不适用于当前主流GAN模型的局限性,提出了嵌套退火训练方案(NATS)。
- NATS方案能无缝适应各种GAN模型,无论其结构、损失或正则化差异。
- 实验评估表明,退火CFG和NATS方法显著提高了合成样本的质量和多样性。
点此查看论文截图


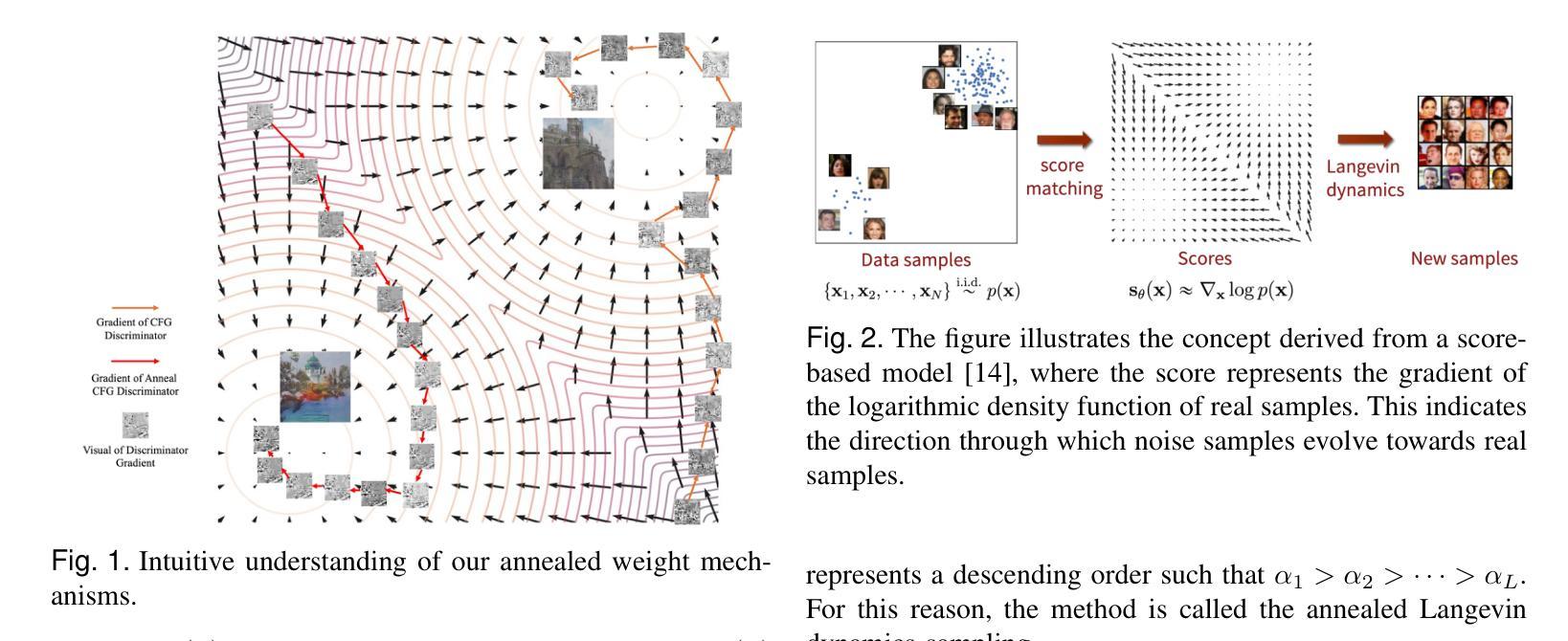

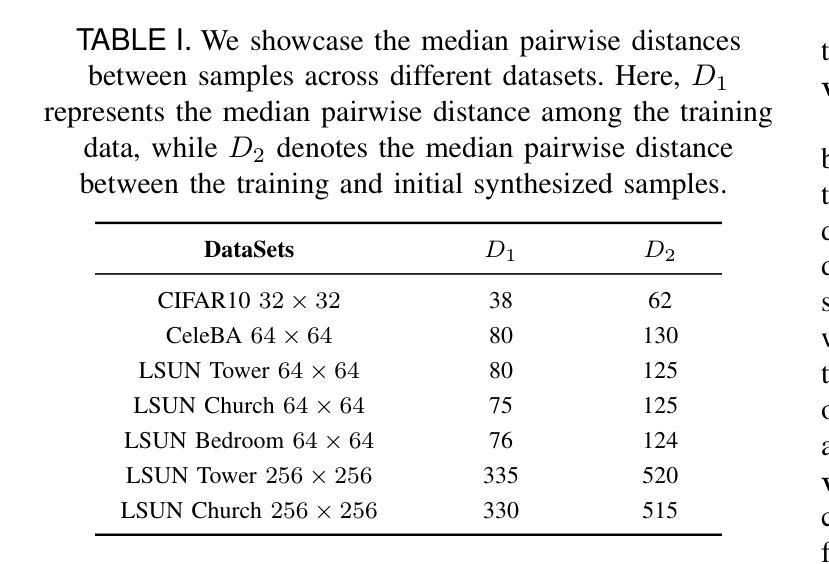
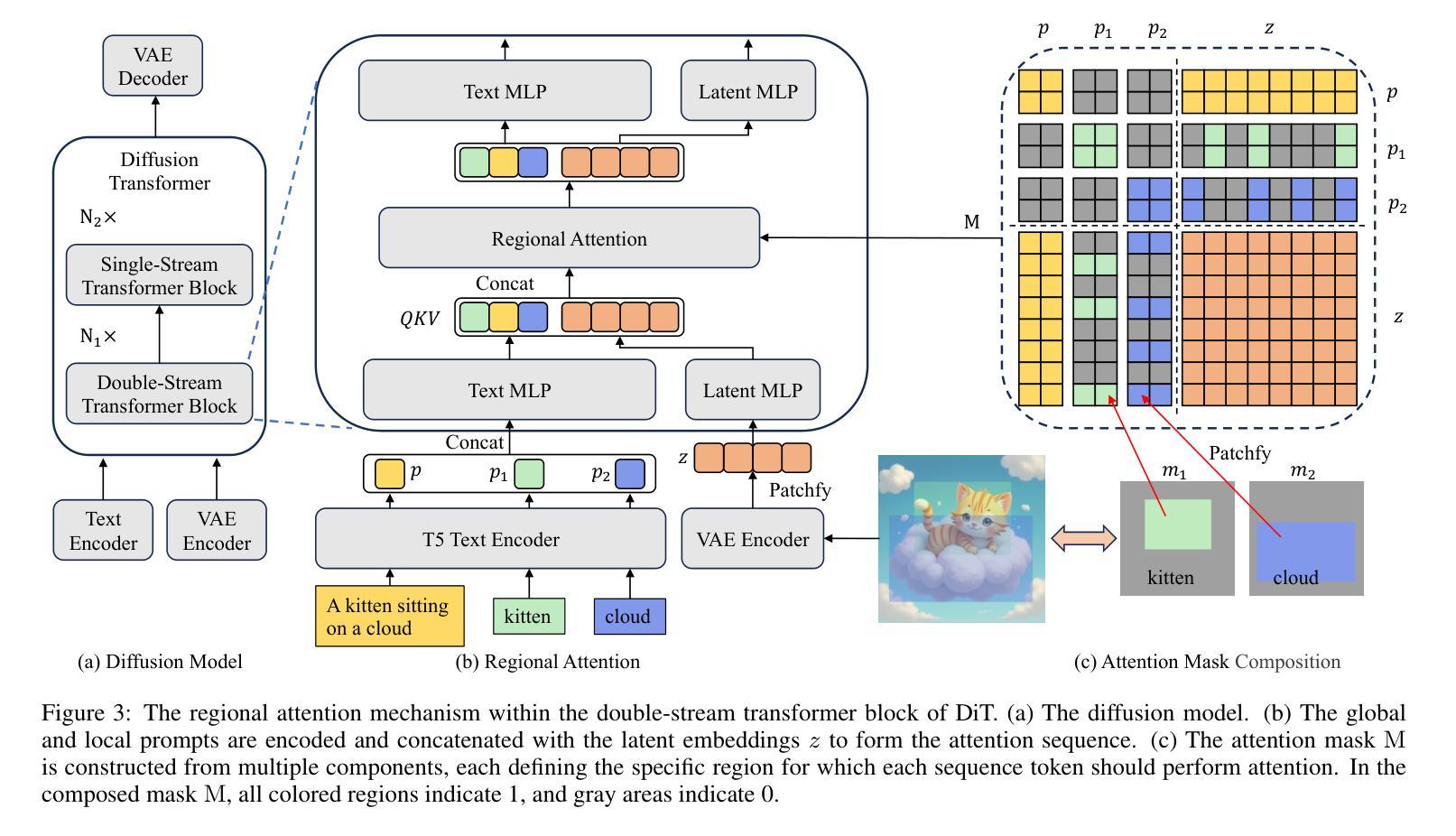
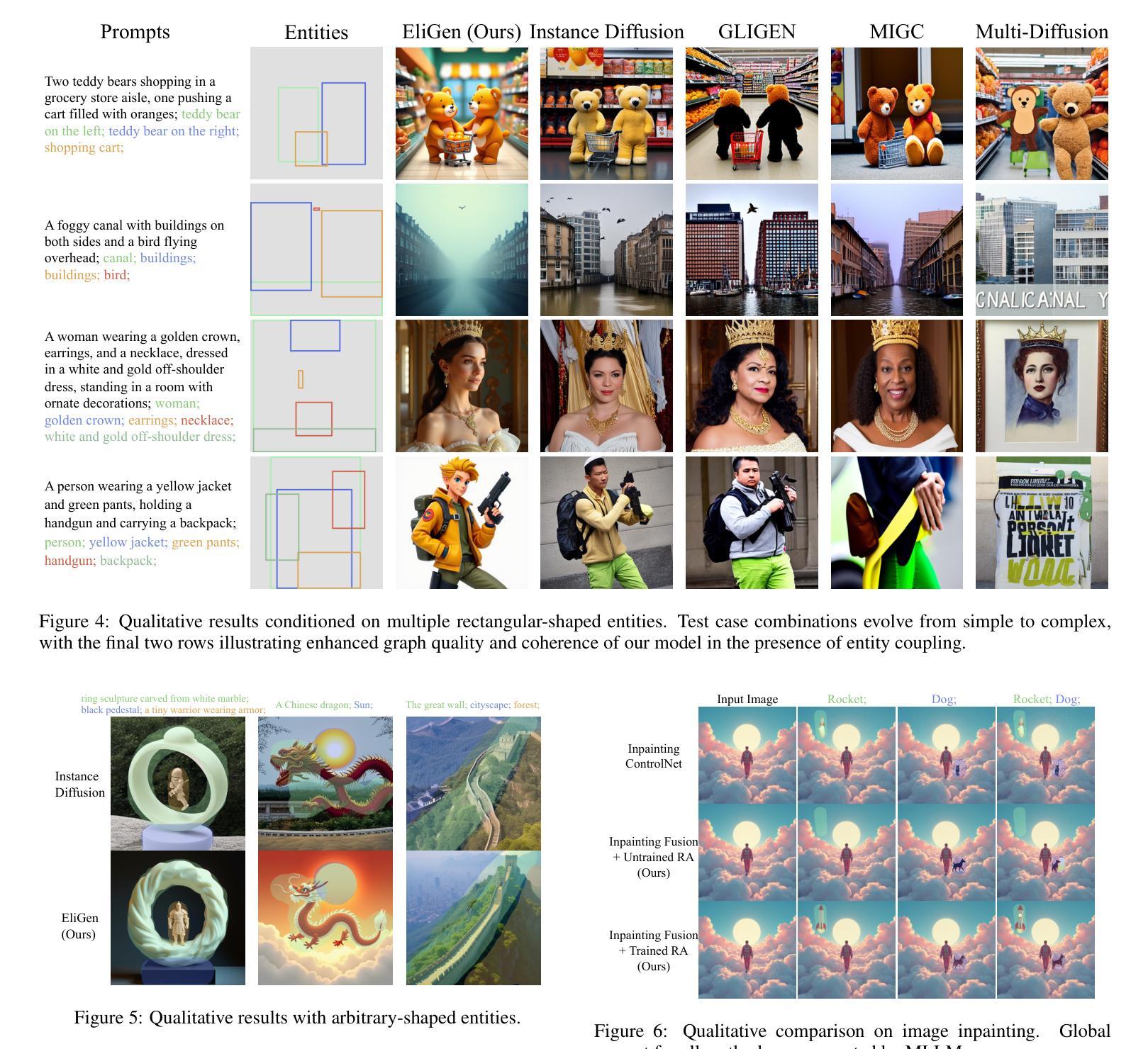
EliGen: Entity-Level Controlled Image Generation with Regional Attention
Authors:Hong Zhang, Zhongjie Duan, Xingjun Wang, Yingda Chen, Yu Zhang
Recent advancements in diffusion models have significantly advanced text-to-image generation, yet global text prompts alone remain insufficient for achieving fine-grained control over individual entities within an image. To address this limitation, we present EliGen, a novel framework for Entity-Level controlled Image Generation. We introduce regional attention, a mechanism for diffusion transformers that requires no additional parameters, seamlessly integrating entity prompts and arbitrary-shaped spatial masks. By contributing a high-quality dataset with fine-grained spatial and semantic entity-level annotations, we train EliGen to achieve robust and accurate entity-level manipulation, surpassing existing methods in both spatial precision and image quality. Additionally, we propose an inpainting fusion pipeline, extending EliGen’s capabilities to multi-entity image inpainting tasks. We further demonstrate its flexibility by integrating it with other open-source models such as IP-Adapter, In-Context LoRA and MLLM, unlocking new creative possibilities. The source code, model, and dataset are published at https://github.com/modelscope/DiffSynth-Studio.
最近扩散模型的技术进步极大地推动了文本到图像的生成,但仅使用全局文本提示仍不足以实现对图像内个别实体的精细控制。为了解决这一局限性,我们提出了EliGen,一个用于实体级别控制的图像生成新型框架。我们引入了区域注意力机制,这是一种适用于扩散变压器的机制,无需添加额外参数,能够无缝集成实体提示和任意形状的空间掩码。通过贡献一个具有精细空间粒度和语义实体级别的优质数据集,我们训练EliGen以实现稳健和准确的实体级操控,在空间精度和图像质量方面都超越了现有方法。此外,我们提出了一种补全融合管道,扩展了EliGen在多实体图像补全任务上的能力。通过将其与其他开源模型(如IP-Adapter、In-Context LoRA和MLLM)集成,进一步展示了其灵活性,开启了新的创意可能性。源代码、模型和数据集已发布在https://github.com/modelscope/DiffSynth-Studio。
论文及项目相关链接
Summary
近期扩散模型的技术进步极大地推动了文本到图像的生成能力。然而,仅依赖全局文本提示无法实现图像的个体实体精细控制。为解决这一问题,我们提出了EliGen框架,引入区域注意力机制,通过无需额外参数的扩散变压器,实现实体提示和任意形状的空间掩码的无缝集成。通过贡献带有精细空间语义和实体级别标注的高质量数据集进行训练,EliGen实现了稳健准确的实体级别操作,在空间和图像质量方面超越现有方法。此外,我们还提出了一种填充融合管道,扩展了EliGen在多实体图像填充任务上的能力。与IP-Adapter等其他开源模型的集成进一步展示了其灵活性。相关资源已发布在GitHub上:https://github.com/modelscope/DiffSynth-Studio。
Key Takeaways
- 扩散模型的最新进展已显著推动文本到图像的生成。
- 现有技术仅通过全局文本提示难以实现图像个体实体的精细控制。
- 提出EliGen框架来应对这一挑战,引入区域注意力机制和扩散变压器技术。
- EliGen通过结合实体提示和任意形状的空间掩码实现无缝集成。
- 利用高质量数据集进行训练,包含精细的空间语义和实体级别标注。
- EliGen实现了稳健准确的实体级别操作,在空间和图像质量上超越现有方法。
点此查看论文截图


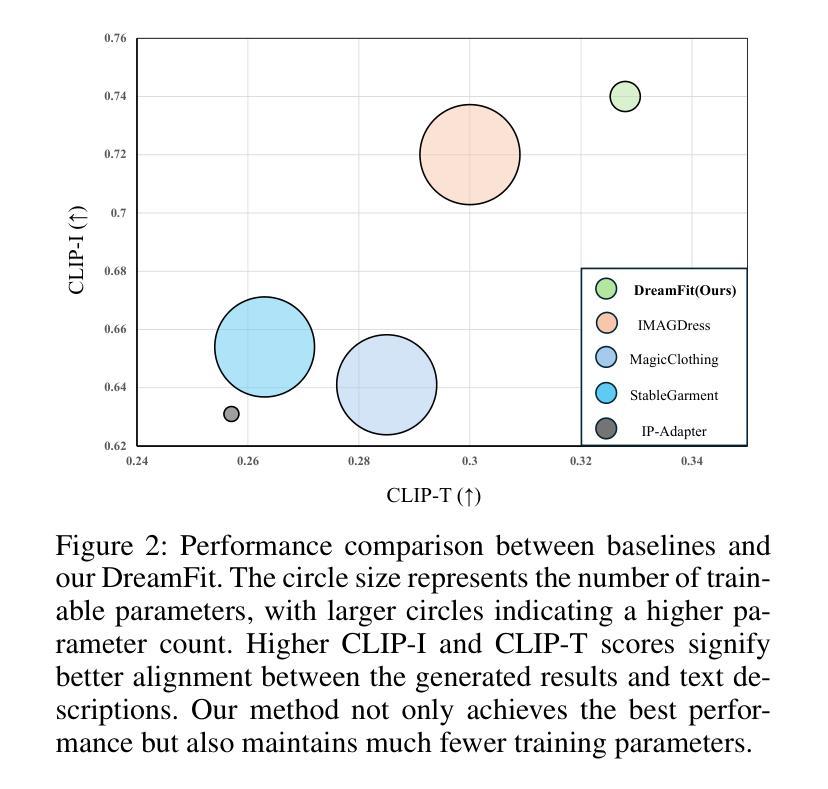
DreamFit: Garment-Centric Human Generation via a Lightweight Anything-Dressing Encoder
Authors:Ente Lin, Xujie Zhang, Fuwei Zhao, Yuxuan Luo, Xin Dong, Long Zeng, Xiaodan Liang
Diffusion models for garment-centric human generation from text or image prompts have garnered emerging attention for their great application potential. However, existing methods often face a dilemma: lightweight approaches, such as adapters, are prone to generate inconsistent textures; while finetune-based methods involve high training costs and struggle to maintain the generalization capabilities of pretrained diffusion models, limiting their performance across diverse scenarios. To address these challenges, we propose DreamFit, which incorporates a lightweight Anything-Dressing Encoder specifically tailored for the garment-centric human generation. DreamFit has three key advantages: (1) \textbf{Lightweight training}: with the proposed adaptive attention and LoRA modules, DreamFit significantly minimizes the model complexity to 83.4M trainable parameters. (2)\textbf{Anything-Dressing}: Our model generalizes surprisingly well to a wide range of (non-)garments, creative styles, and prompt instructions, consistently delivering high-quality results across diverse scenarios. (3) \textbf{Plug-and-play}: DreamFit is engineered for smooth integration with any community control plugins for diffusion models, ensuring easy compatibility and minimizing adoption barriers. To further enhance generation quality, DreamFit leverages pretrained large multi-modal models (LMMs) to enrich the prompt with fine-grained garment descriptions, thereby reducing the prompt gap between training and inference. We conduct comprehensive experiments on both $768 \times 512$ high-resolution benchmarks and in-the-wild images. DreamFit surpasses all existing methods, highlighting its state-of-the-art capabilities of garment-centric human generation.
以服装为中心的人类生成扩散模型从文本或图像提示中获得了新兴的关注,因其巨大的应用潜力。然而,现有方法常常面临一个困境:轻量级方法(如适配器)容易产生不一致的纹理;而基于微调的方法涉及较高的训练成本,且难以维持预训练扩散模型的通用能力,在多种场景下的性能受限。为了解决这些挑战,我们提出了DreamFit。它融入了一个轻量级的Anything-Dressing编码器,专门用于以服装为中心的人类生成。DreamFit有三个主要优势:(1)轻量级训练:通过提出的自适应注意力和LoRA模块,DreamFit将模型复杂度大大降低至仅包含约可训练的参数。这不仅大大简化了训练流程并减少了所需的资源。(以原文表述为基础自行翻译)。(注:此处需要提供具体的参数数量以供准确翻译)(2)广泛适应性:我们的模型对各种服装(包括非服装)、创意风格和提示指令的适应性令人惊讶地好,能够在多种场景下持续提供高质量的结果。(3)即插即用:DreamFit的设计旨在与扩散模型的任何社区控制插件无缝集成,确保易于兼容并尽量减少采用障碍。为了进一步提高生成质量,DreamFit利用预训练的大型多模态模型(LMMs)来丰富提示中的精细服装描述,从而缩小训练和推理之间的提示差距。我们在高清基准测试和真实世界图像上进行了全面的实验验证。DreamFit超越了所有现有方法,展现了其在以服装为中心的人类生成方面的最新能力和技术领先地位。
论文及项目相关链接
PDF Accepted at AAAI 2025
摘要
文本介绍了针对服装中心化人类生成的扩散模型,包括现有方法的挑战以及应对方法。DreamFit模型的提出解决了这些问题,具有轻量级训练、适应性强和插件兼容性等特点,并可通过利用预训练的大型多模态模型增强生成质量。总结:DreamFit模型为解决服装中心化人类生成的扩散模型中的挑战提供了有效方法,具有优秀性能。
关键见解
- 服装中心化人类生成的扩散模型具有广泛的应用潜力。
- 现有方法面临轻量级方法易产生纹理不一致和基于微调的方法训练成本高、难以维持预训练扩散模型的泛化能力等问题。
- DreamFit模型通过引入自适应注意力和LoRA模块实现了轻量级训练。
- DreamFit模型具有良好的泛化性能,能处理广泛的服装和非服装类别、创意风格和提示指令。
- DreamFit模型设计用于与扩散模型的任何社区控制插件无缝集成,确保良好的兼容性并最小化采用障碍。
- 利用预训练的大型多模态模型丰富了提示,缩小了训练和推理之间的提示差距。
- DreamFit模型在实验中表现出卓越性能,超越了现有方法。
点此查看论文截图

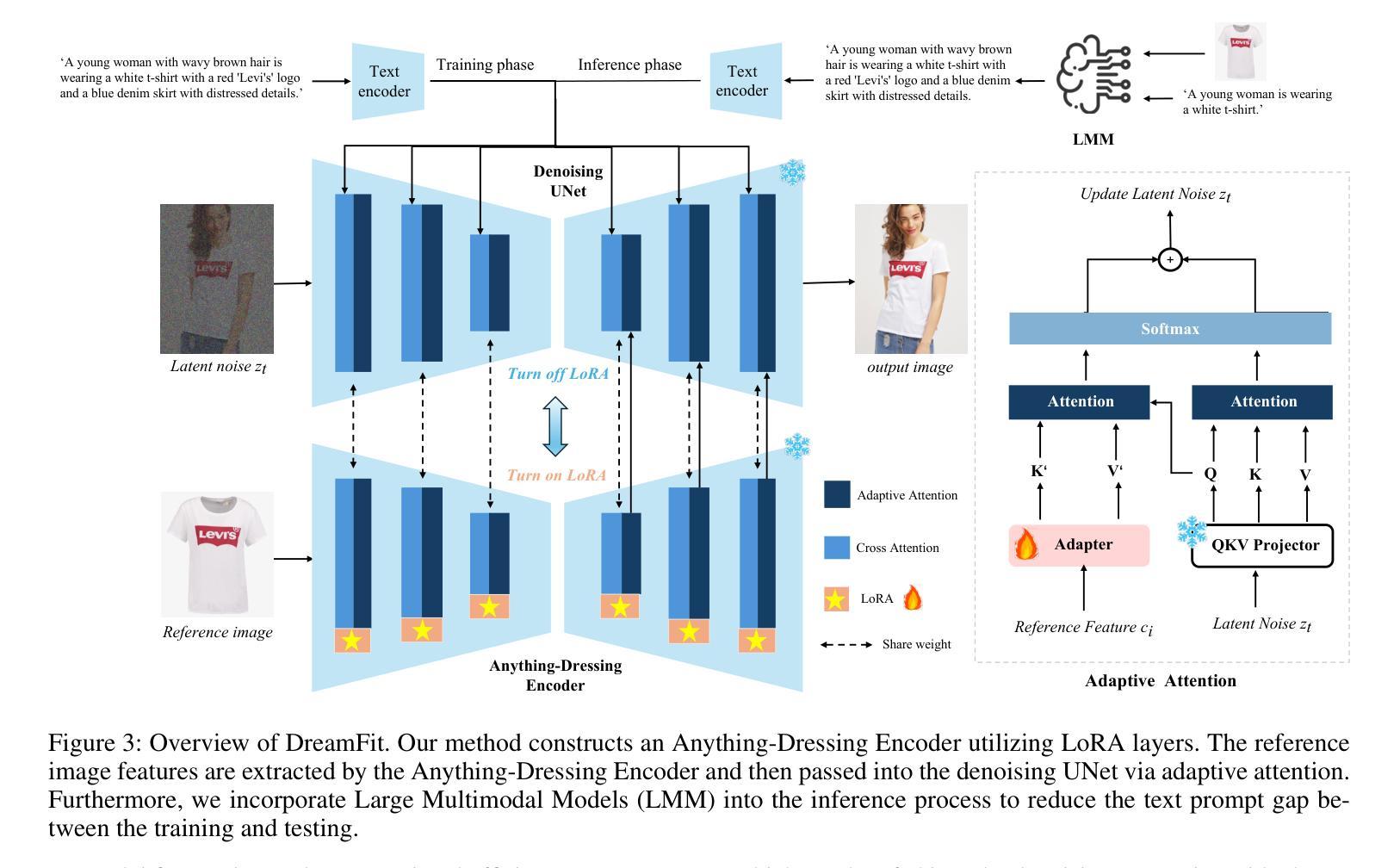


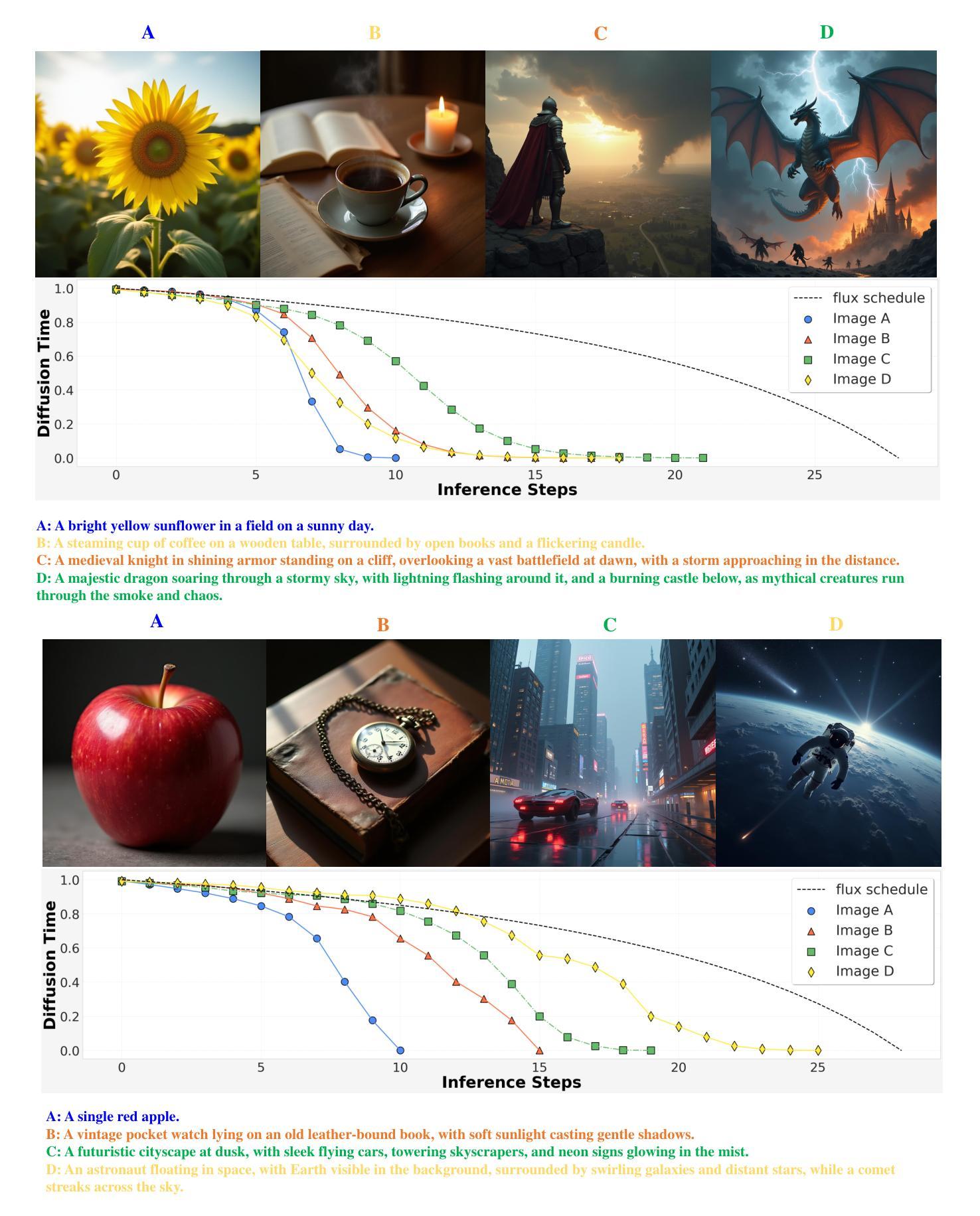
Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation
Authors:Zilyu Ye, Zhiyang Chen, Tiancheng Li, Zemin Huang, Weijian Luo, Guo-Jun Qi
Diffusion and flow models have achieved remarkable successes in various applications such as text-to-image generation. However, these models typically rely on the same predetermined denoising schedules during inference for each prompt, which potentially limits the inference efficiency as well as the flexibility when handling different prompts. In this paper, we argue that the optimal noise schedule should adapt to each inference instance, and introduce the Time Prediction Diffusion Model (TPDM) to accomplish this. TPDM employs a plug-and-play Time Prediction Module (TPM) that predicts the next noise level based on current latent features at each denoising step. We train the TPM using reinforcement learning, aiming to maximize a reward that discounts the final image quality by the number of denoising steps. With such an adaptive scheduler, TPDM not only generates high-quality images that are aligned closely with human preferences but also adjusts the number of denoising steps and time on the fly, enhancing both performance and efficiency. We train TPDMs on multiple diffusion model benchmarks. With Stable Diffusion 3 Medium architecture, TPDM achieves an aesthetic score of 5.44 and a human preference score (HPS) of 29.59, while using around 50% fewer denoising steps to achieve better performance. We will release our best model alongside this paper.
扩散和流动模型在文本生成图像等各种应用中取得了显著的成功。然而,这些模型在推理过程中通常依赖于为每个提示预先确定的去噪时间表,这可能会限制推理效率和处理不同提示时的灵活性。在本文中,我们主张最佳的噪声时间表应适应每个推理实例,并引入时间预测扩散模型(TPDM)来实现这一目标。TPDM采用即插即用的时间预测模块(TPM),该模块根据每个去噪步骤的当前潜在特征预测下一个噪声水平。我们使用强化学习训练TPM,旨在最大化奖励,该奖励通过去噪步骤的数量来贴现最终图像质量。有了这样的自适应调度器,TPDM不仅生成与人类偏好紧密对齐的高质量图像,还可以实时调整去噪步骤的数量和时间,从而提高性能和效率。我们在多个扩散模型基准测试上对TPDM进行了训练。使用Stable Diffusion 3 Medium架构,TPDM达到了美学评分5.44和人类偏好评分(HPS)29.59,同时使用约50%更少的去噪步骤实现了更好的性能。我们将随此论文发布我们的最佳模型。
论文及项目相关链接
Summary
本文提出了时间预测扩散模型(TPDM),该模型能够针对每个推断实例进行自适应噪声调度。通过使用基于当前潜在特征的强化学习训练的时间预测模块(TPM),TPDM能够在每个去噪步骤预测下一个噪声水平。这种自适应调度器不仅能生成与人类偏好紧密对齐的高质量图像,还能实时调整去噪步骤和时间,提高性能和效率。在多个扩散模型基准测试上,使用Stable Diffusion 3 Medium架构的TPDM达到了美学评分5.44和人类偏好评分(HPS)29.59,同时使用约50%的更少的去噪步骤实现了更好的性能。
Key Takeaways
- 扩散模型在文本到图像生成等应用中取得了显著成功,但现有模型在推断时对每个提示使用预定的去噪时间表,这限制了推断效率和灵活性。
- 本文提出了时间预测扩散模型(TPDM),能够自适应地调整每个推断实例的噪声调度。
- TPDM通过使用时间预测模块(TPM)来预测每个去噪步骤的下一个噪声水平,该模块基于当前潜在特征进行强化学习训练。
- TPDM不仅能生成高质量图像,还提高了性能和效率,能够实时调整去噪步骤和时间。
- 在多个基准测试中,使用Stable Diffusion 3 Medium架构的TPDM实现了美学评分和人类偏好评分的显著提升。
- TPDM使用约50%的更少的去噪步骤达到了更好的性能。
点此查看论文截图



Bayesian Deconvolution of Astronomical Images with Diffusion Models: Quantifying Prior-Driven Features in Reconstructions
Authors:Alessio Spagnoletti, Alexandre Boucaud, Marc Huertas-Company, Wassim Kabalan, Biswajit Biswas
Deconvolution of astronomical images is a key aspect of recovering the intrinsic properties of celestial objects, especially when considering ground-based observations. This paper explores the use of diffusion models (DMs) and the Diffusion Posterior Sampling (DPS) algorithm to solve this inverse problem task. We apply score-based DMs trained on high-resolution cosmological simulations, through a Bayesian setting to compute a posterior distribution given the observations available. By considering the redshift and the pixel scale as parameters of our inverse problem, the tool can be easily adapted to any dataset. We test our model on Hyper Supreme Camera (HSC) data and show that we reach resolutions comparable to those obtained by Hubble Space Telescope (HST) images. Most importantly, we quantify the uncertainty of reconstructions and propose a metric to identify prior-driven features in the reconstructed images, which is key in view of applying these methods for scientific purposes.
天文图像的解卷积是恢复天体固有属性的关键方面,特别是在考虑地面观测时。本文探讨了使用扩散模型(DMs)和扩散后采样(DPS)算法来解决这个反问题任务。我们应用基于高分宇宙模拟训练的高分扩散模型,通过贝叶斯设置来计算给定可用观测数据的后验分布。考虑到红移和像素尺度作为我们反问题的参数,该工具可以很容易地适应任何数据集。我们在Hyper Supreme Camera(HSC)数据上测试了我们的模型,并证明我们达到了与哈勃太空望远镜(HST)图像相当的分辨率。最重要的是,我们量化了重建的不确定性,并提出了一种识别重建图像中先验特征的度量指标,这对于将这些方法应用于科学目的至关重要。
论文及项目相关链接
PDF 5+5 pages, 16 figures, Machine Learning and the Physical Sciences Workshop, NeurIPS 2024
Summary
本文探讨了使用扩散模型(DMs)和扩散后采样(DPS)算法来解算天文学图像反问题的任务。通过在高分辨率宇宙学模拟上训练基于分数的DMs,并在贝叶斯设置下计算给定观测数据的后验分布,该工具可轻松适应任何数据集。对Hyper Supreme Camera(HSC)数据的测试表明,其分辨率与哈勃太空望远镜(HST)图像相当。最重要的是,本文量化了重建的不确定性,并提出了一种识别重建图像中先验特征的度量标准,这对于将这些方法应用于科学目的至关重要。
Key Takeaways
- 扩散模型(DMs)和扩散后采样(DPS)算法用于解决天文学图像反问题。
- 通过在高分辨率宇宙学模拟上训练基于分数的DMs来处理天文图像。
- 在贝叶斯设置下计算后验分布以适应不同的数据集。
- 对Hyper Supreme Camera(HSC)数据的测试显示,重建的图像分辨率与哈勃太空望远镜相当。
- 量化重建图像的不确定性。
- 提出一种识别重建图像中由先验特征驱动的度量标准。
- 这些方法在科学应用中的潜在重要性。
点此查看论文截图





On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Authors:Tariq Berrada Ifriqi, Pietro Astolfi, Melissa Hall, Reyhane Askari-Hemmat, Yohann Benchetrit, Marton Havasi, Matthew Muckley, Karteek Alahari, Adriana Romero-Soriano, Jakob Verbeek, Michal Drozdzal
Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In this work, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i)the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii)the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset – with FID improvements of 7% on 256 and 8% on 512 resolutions – as well as text-to-image generation on the CC12M dataset – with FID improvements of 8% on 256 and 23% on 512 resolution.
大规模潜扩散模型(LDM)的训练已经实现了图像生成前所未有的质量。然而,表现最佳的LDM训练方案的关键组成部分通常不对研究社区开放,这阻碍了直接的对比验证,也阻碍了该领域的进展验证。在这项工作中,我们对LDM训练方案进行了深入研究,重点关注模型性能及其训练效率。为了确保直接的对比验证,我们重新实现了五个之前发布的模型及其相应的方案。通过我们的研究,我们探索了(i)用于将生成模型根据语义信息(例如文本提示)进行条件设置和控制元数据(例如裁剪大小、随机翻转标志等)的机制对模型性能的影响,以及(ii)在较小和低分辨率数据集上学习的表示转移到较大数据集时对训练效率和模型性能的影响。然后,我们提出了一种新的条件设置机制,该机制能够分离语义和控制元数据条件设置,并在ImageNet-1k数据集上实现了类条件生成的新技术水平——在256和512分辨率下FID改善了7%和8%——以及在CC12M数据集上的文本到图像生成——在256和512分辨率下FID分别提高了8%和23%。
论文及项目相关链接
PDF Accepted as a conference paper (poster) for NeurIPS 2024
Summary:
潜在扩散模型的大规模训练为图像生成带来了前所未有的质量。本研究深入探讨了扩散模型训练策略,重点关注模型性能与训练效率。研究中重新实现了五个先前发表的模型及其策略以确保对比分析的有效性。本研究探讨了语义信息和控制元数据对模型性能的影响,以及在小分辨率数据集上学习的表示转移到高分辨率数据集上的训练效率和模型性能的影响。提出一种新型条件机制,将语义和控制元数据条件分离,并在ImageNet-1k数据集上实现了类条件生成的新水平,FID在256和512分辨率上分别提高了7%和8%。同时也在CC12M数据集上进行了文本到图像生成的改进,FID在较高分辨率下提升显著。
Key Takeaways:
- 大规模训练的潜在扩散模型(LDM)为图像生成带来卓越质量。
- 研究集中在LDM的训练策略,尤其是模型性能和训练效率的比较。
- 通过重新实现五个先前发表的模型及其策略,确保了对比分析的有效性。
- 探讨了语义信息和控制元数据对模型性能的影响。
- 研究了将小分辨率数据集上学习的表示转移到大规模数据集上的影响。
- 提出了一种新的条件机制,实现了类条件生成的新水平,在ImageNet-1k数据集上显著提高了FID得分。
点此查看论文截图






Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Authors:Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, Ying-Cong Chen
Leveraging the visual priors of pre-trained text-to-image diffusion models offers a promising solution to enhance zero-shot generalization in dense prediction tasks. However, existing methods often uncritically use the original diffusion formulation, which may not be optimal due to the fundamental differences between dense prediction and image generation. In this paper, we provide a systemic analysis of the diffusion formulation for the dense prediction, focusing on both quality and efficiency. And we find that the original parameterization type for image generation, which learns to predict noise, is harmful for dense prediction; the multi-step noising/denoising diffusion process is also unnecessary and challenging to optimize. Based on these insights, we introduce Lotus, a diffusion-based visual foundation model with a simple yet effective adaptation protocol for dense prediction. Specifically, Lotus is trained to directly predict annotations instead of noise, thereby avoiding harmful variance. We also reformulate the diffusion process into a single-step procedure, simplifying optimization and significantly boosting inference speed. Additionally, we introduce a novel tuning strategy called detail preserver, which achieves more accurate and fine-grained predictions. Without scaling up the training data or model capacity, Lotus achieves SoTA performance in zero-shot depth and normal estimation across various datasets. It also enhances efficiency, being significantly faster than most existing diffusion-based methods. Lotus’ superior quality and efficiency also enable a wide range of practical applications, such as joint estimation, single/multi-view 3D reconstruction, etc. Project page: https://lotus3d.github.io/.
利用预训练的文本到图像扩散模型的视觉先验知识,为解决零样本预测任务中的密集预测问题提供了有前景的解决方案。然而,现有方法往往不加批判地使用原始扩散公式,这可能会因为密集预测和图像生成之间的基本差异而导致效果不佳。在本文中,我们对密集预测的扩散公式进行了系统分析,重点考虑了质量和效率。我们发现,用于图像生成的原始参数化类型(学习预测噪声)对密集预测是有害的;多步加噪/去噪扩散过程也是不必要的,并且难以优化。基于这些见解,我们引入了Lotus,这是一种基于扩散的视觉基础模型,具有用于密集预测的简单有效的适应协议。具体来说,Lotus经过训练,直接预测注释而不是噪声,从而避免了有害的方差。我们还重新制定了扩散过程为单步程序,简化了优化并大大提高了推理速度。此外,我们还引入了一种新的调整策略,称为细节保留器,实现了更准确和精细的预测。在不扩大训练数据或模型容量的前提下,Lotus在多个数据集上实现了零样本深度和法线估计的最新性能。它也提高了效率,比大多数现有的基于扩散的方法更快。Lotus的卓越质量和效率还启用了广泛的实际应用,如联合估计、单/多视图3D重建等。项目页面:https://lotus3d.github.io/。
论文及项目相关链接
PDF The first two authors contributed equally. Project page: https://lotus3d.github.io/
Summary
利用预训练文本图像扩散模型的视觉先验知识对于增强零样本在密集预测任务中的泛化能力具有前景。本文对密集预测的扩散公式进行了系统分析,并发现原始参数化类型对密集预测有害,且多步噪声/去噪声扩散过程不必要且难以优化。基于此,提出了名为Lotus的视觉基础模型,通过简化扩散过程并采用直接预测标注的方法改进了密集预测。此外,还引入了一种名为细节保留的新微调策略,实现了更准确和精细的预测。Lotus在不增加训练数据或模型容量的前提下,在多个数据集上实现了零样本深度和法线估计的卓越性能,并提高了效率,显著快于现有的大多数扩散方法。
Key Takeaways
- 利用预训练文本图像扩散模型的视觉先验可以提高零样本在密集预测任务中的泛化能力。
- 原参数化类型用于密集预测可能并非最优,存在改进空间。
- Lotus模型通过直接预测标注而非噪声简化了扩散过程,提高了密集预测性能。
- Lotus引入了一种简化的扩散过程及新的微调策略(细节保留)。
- Lotus在零样本深度和法线估计方面表现出卓越性能。
点此查看论文截图




EditBoard: Towards a Comprehensive Evaluation Benchmark for Text-Based Video Editing Models
Authors:Yupeng Chen, Penglin Chen, Xiaoyu Zhang, Yixian Huang, Qian Xie
The rapid development of diffusion models has significantly advanced AI-generated content (AIGC), particularly in Text-to-Image (T2I) and Text-to-Video (T2V) generation. Text-based video editing, leveraging these generative capabilities, has emerged as a promising field, enabling precise modifications to videos based on text prompts. Despite the proliferation of innovative video editing models, there is a conspicuous lack of comprehensive evaluation benchmarks that holistically assess these models’ performance across various dimensions. Existing evaluations are limited and inconsistent, typically summarizing overall performance with a single score, which obscures models’ effectiveness on individual editing tasks. To address this gap, we propose EditBoard, the first comprehensive evaluation benchmark for text-based video editing models. EditBoard encompasses nine automatic metrics across four dimensions, evaluating models on four task categories and introducing three new metrics to assess fidelity. This task-oriented benchmark facilitates objective evaluation by detailing model performance and providing insights into each model’s strengths and weaknesses. By open-sourcing EditBoard, we aim to standardize evaluation and advance the development of robust video editing models.
扩散模型的快速发展极大地推动了人工智能生成内容(AIGC)的进步,特别是在文本到图像(T2I)和文本到视频(T2V)生成方面。基于文本的视频编辑,利用这些生成能力,已经成为一个充满希望的领域,它可以根据文本提示对视频进行精确修改。尽管创新的视频编辑模型层出不穷,但缺乏全面评估这些模型在各种维度上性能的综合性评估基准,这是一个明显的问题。现有的评估方法有限且不一致,通常使用单一分数来总结整体性能,这掩盖了模型在单个编辑任务上的有效性。为了解决这一差距,我们提出了EditBoard,这是第一个基于文本的视频编辑模型的综合性评估基准。EditBoard包含四个维度下的九个自动指标,对四个任务类别的模型进行评估,并引入三个新指标来评估保真度。这一任务导向的基准有助于通过详细了解模型性能并提供有关每个模型的优点和弱点的洞察来进行客观评估。我们通过开源EditBoard,旨在标准化评估并推动稳健视频编辑模型的发展。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
扩散模型的快速发展极大地推动了人工智能生成内容(AIGC)的进步,特别是在文本转图像(T2I)和文本转视频(T2V)生成领域。基于这些生成能力的文本视频编辑应运而生,它可以根据文本提示对视频进行精确修改。尽管涌现了许多视频编辑模型,但缺乏全面评估这些模型在多个维度上表现的综合评价基准。现有评估方式有限且不一致,通常使用单一分数来总结整体性能,这掩盖了模型在个别编辑任务上的效果。为解决这一空白,我们提出EditBoard,首个针对文本视频编辑模型的全面评价基准。EditBoard包含四个维度的九个自动指标,评估模型在四个任务类别上的表现,并引入三个新指标来评估保真度。此任务导向的基准便于客观评估模型性能,并提供模型优缺点洞察。通过开源EditBoard,我们旨在标准化评估并推动稳健视频编辑模型的发展。
Key Takeaways
- 扩散模型的进步推动了AI生成内容(AIGC)在文本转图像和文本转视频领域的显著发展。
- 文本视频编辑是一个新兴领域,能够根据文本提示对视频进行精确修改。
- 当前缺乏全面评估文本视频编辑模型的综合评价基准。
- 现有评估方式通常使用单一分数来总结模型整体性能,这无法反映模型在个别编辑任务上的表现。
- EditBoard是首个针对文本视频编辑模型的全面评价基准,包含九个自动指标,评估模型在四个任务类别上的表现。
- EditBoard引入了三个新指标来评估模型的保真度。
点此查看论文截图





Latent Diffusion for Medical Image Segmentation: End to end learning for fast sampling and accuracy
Authors:Fahim Ahmed Zaman, Mathews Jacob, Amanda Chang, Kan Liu, Milan Sonka, Xiaodong Wu
Diffusion Probabilistic Models (DPMs) suffer from inefficient inference due to their slow sampling and high memory consumption, which limits their applicability to various medical imaging applications. In this work, we propose a novel conditional diffusion modeling framework (LDSeg) for medical image segmentation, utilizing the learned inherent low-dimensional latent shape manifolds of the target objects and the embeddings of the source image with an end-to-end framework. Conditional diffusion in latent space not only ensures accurate image segmentation for multiple interacting objects, but also tackles the fundamental issues of traditional DPM-based segmentation methods: (1) high memory consumption, (2) time-consuming sampling process, and (3) unnatural noise injection in the forward and reverse processes. The end-to-end training strategy enables robust representation learning in the latent space related to segmentation features, ensuring significantly faster sampling from the posterior distribution for segmentation generation in the inference phase. Our experiments demonstrate that LDSeg achieved state-of-the-art segmentation accuracy on three medical image datasets with different imaging modalities. In addition, we showed that our proposed model was significantly more robust to noise compared to traditional deterministic segmentation models. The code is available at https://github.com/FahimZaman/LDSeg.git.
扩散概率模型(DPM)由于缓慢的采样和较高的内存消耗,导致其推理效率低下,这限制了其在各种医学成像应用中的适用性。在这项工作中,我们提出了一种用于医学图像分割的新型条件扩散建模框架(LDSeg)。该框架利用目标对象的固有低维潜在形状流形和源图像的嵌入,以及端到端的框架进行学习。潜在空间中的条件扩散不仅确保了多个交互对象的精确图像分割,还解决了基于传统DPM的分割方法的基本问题,包括(1)高内存消耗,(2)耗时的采样过程,以及(3)前向和反向过程中的不自然噪声注入。端到端的训练策略能够在与分割特征相关的潜在空间中实现稳健的表示学习,确保在推理阶段从后验分布中进行分割生成时实现更快的采样。我们的实验表明,LDSeg在三种不同成像模式的医学图像数据集上实现了最先进的分割精度。此外,我们还证明了与传统的确定性分割模型相比,我们提出的模型对噪声具有更强的鲁棒性。代码可访问https://github.com/FahimZaman/LDSeg.git。
论文及项目相关链接
PDF 10 pages, 10 figures, journal article
Summary
本摘要针对医疗图像分割问题,提出了一种基于扩散概率模型的新型条件扩散建模框架(LDSeg)。该框架利用目标对象的固有低维潜在形状流形和源图像的嵌入,通过端到端的框架进行训练。条件扩散在潜在空间中不仅确保了多交互对象的精确图像分割,还解决了传统DPM分割方法的基本问题,如高内存消耗、耗时的采样过程以及正向和反向过程中的不自然噪声注入。实验表明,LDSeg在三个不同成像模态的医疗图像数据集上实现了最先进的分割精度,并且与传统的确定性分割模型相比,对噪声具有更强的鲁棒性。
Key Takeaways
- LDSeg利用条件扩散建模框架进行医疗图像分割,针对DPMs在医疗成像应用中的低效推理问题。
- LDSeg利用目标对象的低维潜在形状流形和源图像的嵌入进行端到端训练。
- 条件扩散在潜在空间确保了多交互对象的精确图像分割。
- LDSeg解决了传统DPM分割方法的高内存消耗、耗时采样过程和不自然噪声注入问题。
- 实验表明,LDSeg在医疗图像数据集上实现了最先进的分割精度。
- LDSeg相较于传统确定性分割模型对噪声具有更强的鲁棒性。
点此查看论文截图








Generative Topological Networks
Authors:Alona Levy-Jurgenson, Zohar Yakhini
Generative methods have recently seen significant improvements by generating in a lower-dimensional latent representation of the data. However, many of the generative methods applied in the latent space remain complex and difficult to train. Further, it is not entirely clear why transitioning to a lower-dimensional latent space can improve generative quality. In this work, we introduce a new and simple generative method grounded in topology theory – Generative Topological Networks (GTNs) – which also provides insights into why lower-dimensional latent-space representations might be better-suited for data generation. GTNs are simple to train – they employ a standard supervised learning approach and do not suffer from common generative pitfalls such as mode collapse, posterior collapse or the need to pose constraints on the neural network architecture. We demonstrate the use of GTNs on several datasets, including MNIST, CelebA, CIFAR-10 and the Hands and Palm Images dataset by training GTNs on a lower-dimensional latent representation of the data. We show that GTNs can improve upon VAEs and that they are quick to converge, generating realistic samples in early epochs. Further, we use the topological considerations behind the development of GTNs to offer insights into why generative models may benefit from operating on a lower-dimensional latent space, highlighting the important link between the intrinsic dimension of the data and the dimension in which the data is generated. Particularly, we demonstrate that generating in high dimensional ambient spaces may be a contributing factor to out-of-distribution samples generated by diffusion models. We also highlight other topological properties that are important to consider when using and designing generative models. Our code is available at: https://github.com/alonalj/GTN
生成式方法通过在数据的低维潜在表示中进行生成,最近取得了显著的改进。然而,许多应用于潜在空间的生成方法仍然复杂且难以训练。此外,转向低维潜在空间可以提高生成质量的原因尚不完全清楚。在这项工作中,我们引入了一种基于拓扑理论的新颖简单生成方法——生成拓扑网络(GTNs),该方法也提供了为什么低维潜在空间表示更适合数据生成的见解。GTNs训练简单——它们采用标准的有监督学习方法,不会陷入常见的生成陷阱,如模式崩溃、后验崩溃或对神经网络架构施加约束的需要。我们在多个数据集上展示了GTNs的使用,包括MNIST、CelebA、CIFAR-10和手部与手掌图像数据集,通过在数据的低维潜在表示上训练GTNs。我们展示了GTNs可以改进VAEs,并且它们可以快速收敛,在早期周期生成逼真的样本。此外,我们利用GTNs开发背后的拓扑考虑为什么生成模型可以从低维潜在空间中受益提供见解,突出了数据内在维度和生成数据的维度之间的重联系。特别是,我们证明在高维环境空间中生成可能是扩散模型产生分布外样本的一个因素。我们还强调了在使用和设计生成模型时需要考虑的其他重要拓扑属性。我们的代码可在:https://github.com/alonalj/GTN找到。
论文及项目相关链接
Summary
本文介绍了一种基于拓扑理论的新型简单生成方法——生成拓扑网络(GTNs),这种方法对于在低维潜在空间中进行数据生成有了深入理解。GTNs训练简单,采用标准监督学习方法,避免了常见的生成陷阱,如模式崩溃、后崩溃或对神经网络架构的约束。在多个数据集上的实验表明,GTNs能够改进变自动编码器(VAEs),快速收敛,并在早期阶段生成逼真的样本。此外,文章还从拓扑学的角度探讨了生成模型从低维潜在空间操作中的获益原因,强调了数据内在维度和生成数据的维度之间的联系。
Key Takeaways
- 引入了一种新的生成方法——生成拓扑网络(GTNs),基于拓扑理论,为数据生成提供了新视角。
- GTNs在低维潜在空间中进行数据生成,简化了训练复杂性。
- GTNs采用标准监督学习方法,避免常见的生成陷阱,如模式崩溃和后崩溃。
- GTNs在多个数据集上的实验表现优异,能够改进变自动编码器(VAEs),并快速收敛。
- 文章从拓扑学角度深入探讨了为什么低维潜在空间表示更适合数据生成,并强调了数据的内在维度和生成维度之间的联系。
- 生成高维环境中的数据可能导致扩散模型生成的样本偏离分布。
- 文章的最后还强调了在使用和设计生成模型时需要考虑的其他重要拓扑属性。
点此查看论文截图









Unleashing the Denoising Capability of Diffusion Prior for Solving Inverse Problems
Authors:Jiawei Zhang, Jiaxin Zhuang, Cheng Jin, Gen Li, Yuantao Gu
The recent emergence of diffusion models has significantly advanced the precision of learnable priors, presenting innovative avenues for addressing inverse problems. Since inverse problems inherently entail maximum a posteriori estimation, previous works have endeavored to integrate diffusion priors into the optimization frameworks. However, prevailing optimization-based inverse algorithms primarily exploit the prior information within the diffusion models while neglecting their denoising capability. To bridge this gap, this work leverages the diffusion process to reframe noisy inverse problems as a two-variable constrained optimization task by introducing an auxiliary optimization variable. By employing gradient truncation, the projection gradient descent method is efficiently utilized to solve the corresponding optimization problem. The proposed algorithm, termed ProjDiff, effectively harnesses the prior information and the denoising capability of a pre-trained diffusion model within the optimization framework. Extensive experiments on the image restoration tasks and source separation and partial generation tasks demonstrate that ProjDiff exhibits superior performance across various linear and nonlinear inverse problems, highlighting its potential for practical applications. Code is available at https://github.com/weigerzan/ProjDiff/.
最近扩散模型的兴起大大提高了可学习先验的精度,为解决反问题提供了新的途径。由于反问题本质上涉及最大后验估计,早期的研究工作试图将扩散先验整合到优化框架中。然而,当前流行的基于优化的反算法主要利用扩散模型中的先验信息,却忽视了其去噪能力。为了弥补这一空白,本研究利用扩散过程,通过引入辅助优化变量,将噪声反问题重新构建为两变量约束优化任务。通过采用梯度截断,有效地利用投影梯度下降法解决相应的优化问题。所提算法称为ProjDiff,它有效地在优化框架内利用预训练扩散模型的先验信息和去噪能力。在图像恢复任务以及源分离和部分生成任务上的大量实验表明,ProjDiff在处理各种线性和非线性反问题时表现出卓越的性能,突显其在实际应用中的潜力。代码可在[https://github.com/weigerzan/ProjDiff/]查阅。
论文及项目相关链接
PDF Accepted by NeurIPS 2024
Summary
扩散模型的最新出现大大提高了先验知识的精度,为解决逆问题提供了新的途径。然而,现有的基于优化的逆算法主要利用扩散模型中的先验信息,而忽视了其去噪能力。为此,本研究通过引入辅助优化变量,将带噪声的逆问题重新构建为双变量约束优化任务,并利用梯度截断法有效地利用投影梯度下降法来解决相应的优化问题。所提算法ProjDiff有效地在优化框架内结合了预训练扩散模型的先验信息和去噪能力。在图像恢复任务以及源分离和部分生成任务上的大量实验表明,ProjDiff在解决各种线性和非线性逆问题上表现出卓越性能,凸显其在实践应用中的潜力。
Key Takeaways
- 扩散模型最新进展提高了先验知识的精度,为解决逆问题提供新途径。
- 现有优化逆算法主要关注扩散模型的先验信息,但忽视了其去噪能力。
- 本研究通过引入辅助优化变量,将噪声逆问题转化为双变量约束优化任务。
- 利用梯度截断法,有效运用投影梯度下降法解决优化问题。
- 所提算法ProjDiff结合扩散模型的先验信息和去噪能力,在优化框架内实现有效利用。
- 在图像恢复、源分离和部分生成任务上的实验表明ProjDiff在解决线性和非线性逆问题上表现优越。
点此查看论文截图


LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
Authors:Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, Romann M. Weber
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a new autoencoder design for LDMs, which leverages the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
潜扩散模型(LDM)的进步为高质量图像生成带来了革命性的变革,但这些系统的核心自编码器的设计空间仍鲜有研究。在本文中,我们介绍了用于LDM的新型自编码器设计LiteVAE。它利用二维离散小波变换来提高可扩展性和计算效率,与传统的变分自编码器(VAE)相比,在输出质量上没有任何损失。我们研究了LiteVAE的训练方法和解码器架构,并提出了几项改进,提高了训练动力和重建质量。我们的基础LiteVAE模型与当前LDM中的既定VAE质量相当,编码器参数减少了六倍,导致训练速度更快,GPU内存要求更低,而我们的更大模型在所有评估指标(rFID、LPIPS、PSNR和SSIM)上都优于同等复杂度的VAE。
论文及项目相关链接
PDF Published as a conference paper at NeurIPS 2024
Summary
本文介绍了LiteVAE,一种针对潜在扩散模型(LDMs)的新型自动编码器设计。它利用二维离散小波变换提高可扩展性和计算效率,在输出质量上无损失。通过改进训练方法和解码器架构,LiteVAE在减少编码器参数的同时,达到了当前LDMs中VAEs的质量水平,实现了更快的训练和更低的GPU内存要求。同时,其更大模型在所有评估指标上都优于同等复杂度的VAEs。
Key Takeaways
- LiteVAE是一种新型的自动编码器设计,专门用于潜在扩散模型(LDMs)。
- LiteVAE利用二维离散小波变换提高可扩展性和计算效率。
- LiteVAE在输出质量方面没有损失。
- LiteVAE改进了训练方法和解码器架构。
- LiteVAE的基础模型在减少编码器参数的同时,达到了当前LDMs中VAEs的质量水平。
- LiteVAE实现了更快的训练和更低的GPU内存要求。
点此查看论文截图




Diversify, Don’t Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Authors:Zhuoran Yu, Chenchen Zhu, Sean Culatana, Raghuraman Krishnamoorthi, Fanyi Xiao, Yong Jae Lee
Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier’s performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.
最近生成深度学习领域的进展使得文本到图像生成中创建高质量合成图像成为可能。先前的工作表明,对预训练的扩散模型进行微调并在ImageNet上生成合成训练图像,可以提高ImageNet分类器的性能。然而,随着合成图像数量超过真实图像,性能会下降。在本文中,我们探讨了生成微调是否对此改进至关重要,以及是否可以使用更多的合成数据进一步扩展训练。我们提出了一种新的框架,利用现成的生成模型来生成合成训练图像,解决多个挑战:类名模糊、提示缺乏多样性和领域偏移。具体来说,我们利用大型语言模型(LLM)和CLIP来解决类名模糊问题。为了多样化图像,我们提出了基于上下文和风格的多样化方法(CD和SD),也是由LLM驱动的。最后,为了缓解领域偏移问题,我们利用带有辅助批归一化的领域适应技术来处理合成图像。我们的框架使用更多的合成数据始终提高了识别模型的性能,达到原始ImageNet规模的6倍,展示了合成数据在改进识别模型和强大域外泛化方面的潜力。
论文及项目相关链接
PDF Accepted by Transactions on Machine Learning Research (TMLR)
Summary
该文探索了使用预训练的扩散模型生成合成图像对于增强图像分类器性能的作用。文章提出一种新的框架,利用现成的生成模型生成合成训练图像,解决类别名称模糊、提示缺乏多样性和领域偏移等问题。通过利用大型语言模型和CLIP解决类别名称模糊问题,并提出基于上下文和风格的多样化方法来增加图像多样性。同时,通过辅助批归一化技术减轻领域偏移问题。该框架在大量合成数据的情况下,能持续提升识别模型的性能,展示合成数据对改进识别模型和强大域外泛化的潜力。
Key Takeaways
- 生成深度学习的最新进展使得创建高质量合成图像成为可能。
- 使用预训练的扩散模型进行微调并生成合成训练图像可以增强ImageNet分类器的性能。
- 当合成图像数量超过真实图像时,性能会下降。
- 提出的新框架解决了类别名称模糊、提示缺乏多样性和领域偏移等挑战。
- 利用大型语言模型和CLIP解决类别名称模糊问题。
- 提出基于上下文和风格的多样化方法来增加图像多样性。
点此查看论文截图