⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
Advancing Multi-Party Dialogue Systems with Speaker-ware Contrastive Learning
Authors:Zhongtian Hu, Qi He, Ronghan Li, Meng Zhao, Lifang Wang
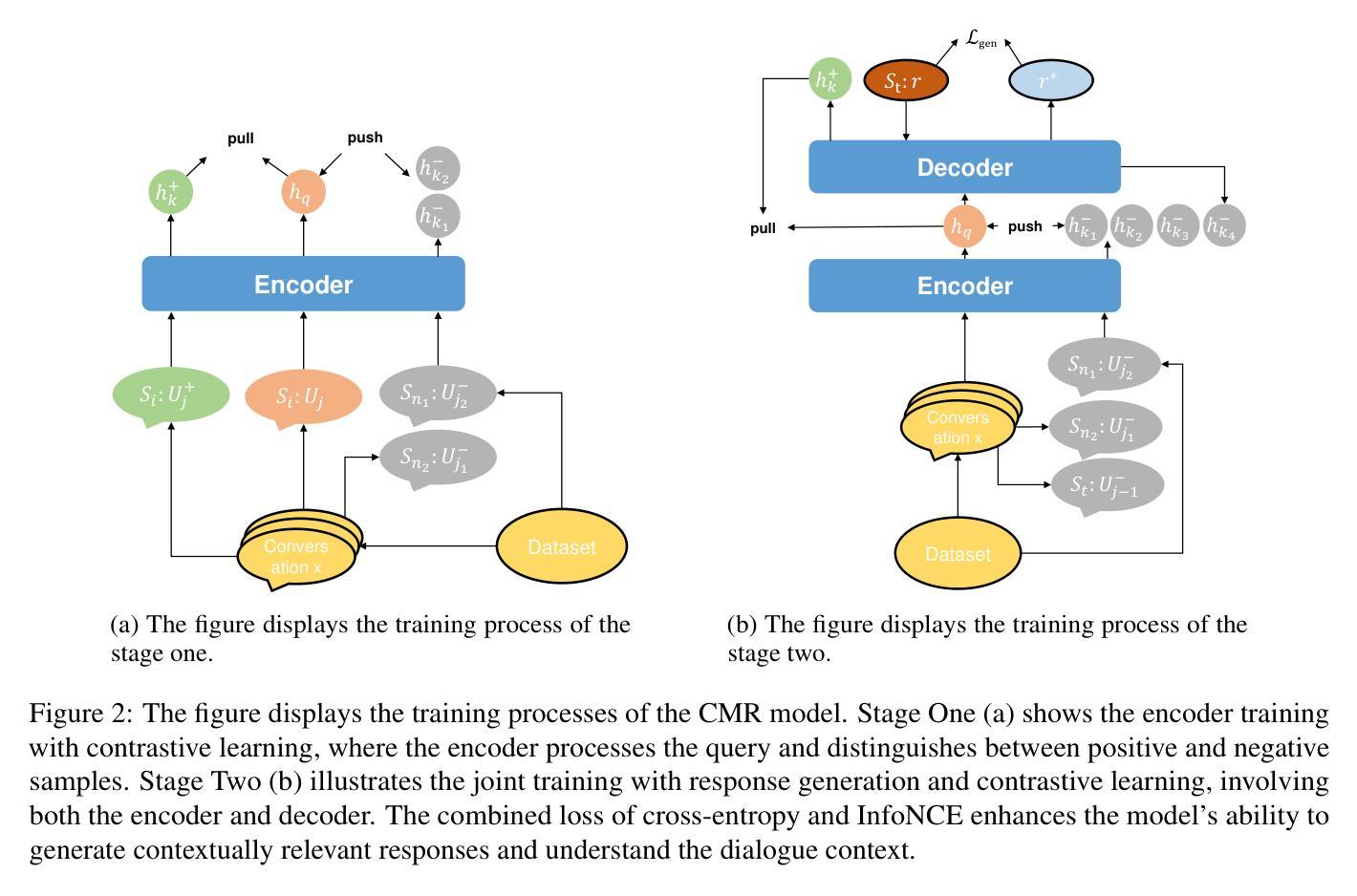
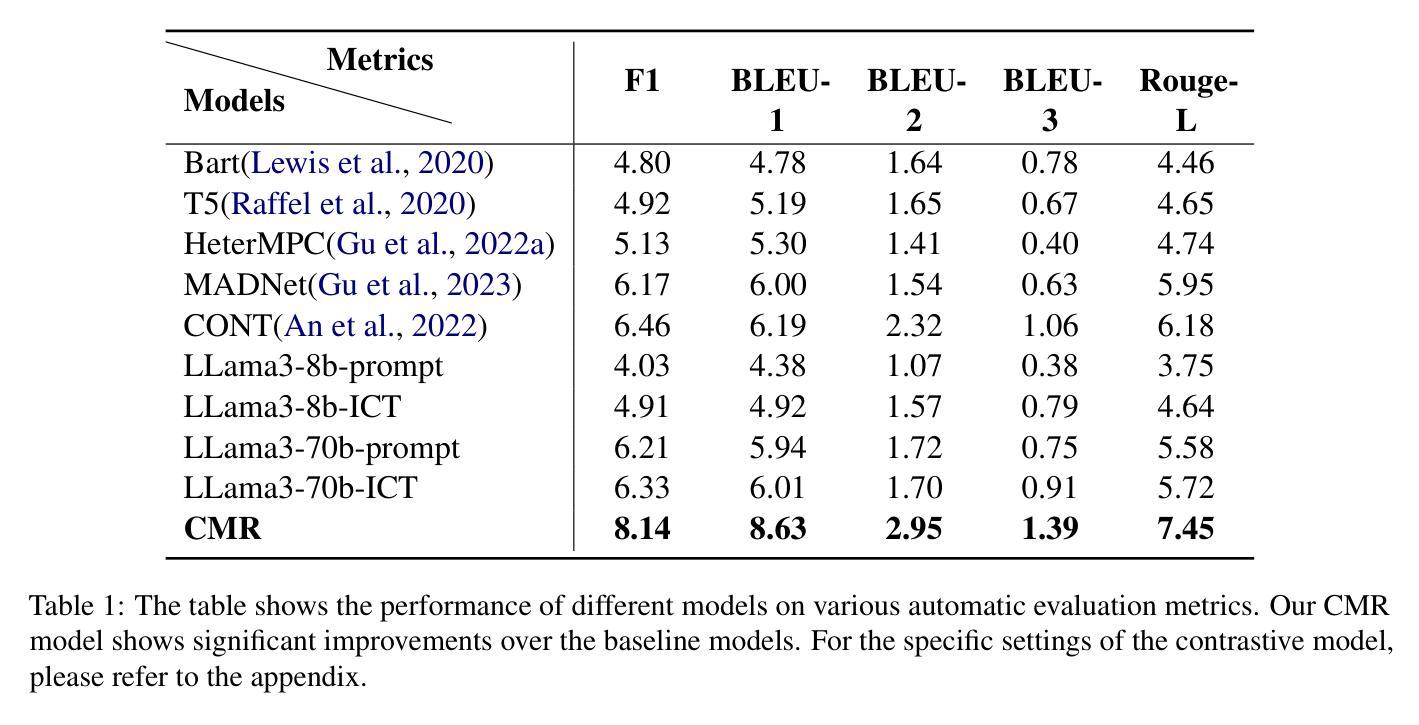
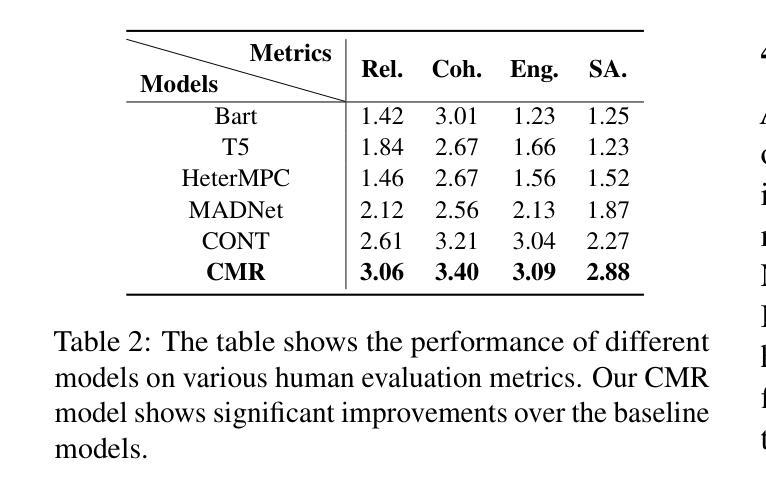
Dialogue response generation has made significant progress, but most research has focused on dyadic dialogue. In contrast, multi-party dialogues involve more participants, each potentially discussing different topics, making the task more complex. Current methods often rely on graph neural networks to model dialogue context, which helps capture the structural dynamics of multi-party conversations. However, these methods are heavily dependent on intricate graph structures and dataset annotations, and they often overlook the distinct speaking styles of participants. To address these challenges, we propose CMR, a Contrastive learning-based Multi-party dialogue Response generation model. CMR uses self-supervised contrastive learning to better distinguish “who says what.” Additionally, by comparing speakers within the same conversation, the model captures differences in speaking styles and thematic transitions. To the best of our knowledge, this is the first approach to apply contrastive learning in multi-party dialogue generation. Experimental results show that CMR significantly outperforms state-of-the-art models in multi-party dialogue response tasks.
对话生成响应已经取得了显著的进步,但大多数研究主要集中在二元对话上。相比之下,多方对话涉及更多参与者,每个人都在讨论不同的话题,这使得任务更加复杂。目前的方法通常依赖于图神经网络来模拟对话上下文,这有助于捕捉多方对话的结构动态。然而,这些方法严重依赖于复杂的图形结构和数据集注释,并且常常忽略了参与者的不同说话风格。为了应对这些挑战,我们提出了基于对比学习的多方对话响应生成模型CMR。CMR使用自监督对比学习来更好地区分“谁说了什么”。此外,通过比较同一对话中的说话者,模型可以捕捉说话风格的差异和主题转换。据我们所知,这是首次将对比学习应用于多方对话生成的方法。实验结果表明,在多方对话响应任务中,CMR显著优于现有最先进的模型。
论文及项目相关链接
Summary
多模态对话响应生成的研究已经取得了重要进展,但大多数研究集中在二元对话上。相比之下,多方对话涉及更多参与者,每个参与者都在讨论不同的话题,使得任务更加复杂。当前的方法通常依赖于图神经网络来模拟对话上下文,这有助于捕捉多方对话的结构动态。然而,这些方法严重依赖于复杂的图形结构和数据集注释,并且往往忽视了参与者的不同说话风格。为了应对这些挑战,我们提出了基于对比学习的多方对话响应生成模型CMR。该模型使用自监督对比学习来更好地区分“谁说了什么”。此外,通过比较同一对话中的说话者,模型能够捕捉不同的说话风格和主题转换。据我们所知,这是首次将对比学习应用于多方对话生成的方法。实验结果表明,在多方对话响应任务中,CMR显著优于其他最先进的模型。
Key Takeaways
- 多方对话涉及更多参与者,使得对话响应生成更加复杂。
- 当前的研究主要集中在使用图神经网络建模二元对话的上下文中。
- 这些方法依赖复杂的图形结构和数据集注释,可能忽视参与者的不同说话风格。
- CMR模型是首个采用对比学习应用于多方对话生成的方法。
- CMR模型使用自监督对比学习来区分不同参与者的发言。
- CMR模型能够捕捉不同说话风格和主题转换。
点此查看论文截图

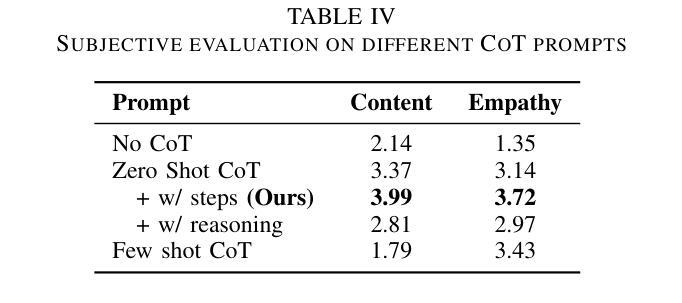
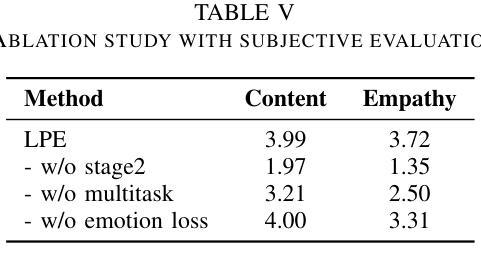
Leveraging Chain of Thought towards Empathetic Spoken Dialogue without Corresponding Question-Answering Data
Authors:Jingran Xie, Shun Lei, Yue Yu, Yang Xiang, Hui Wang, Xixin Wu, Zhiyong Wu
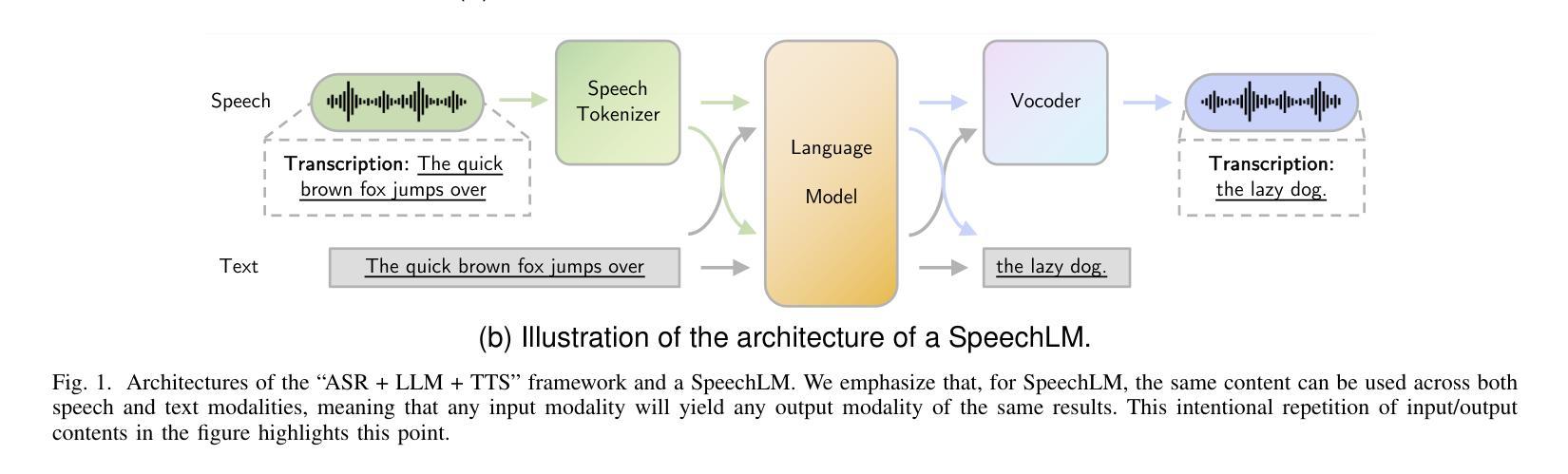
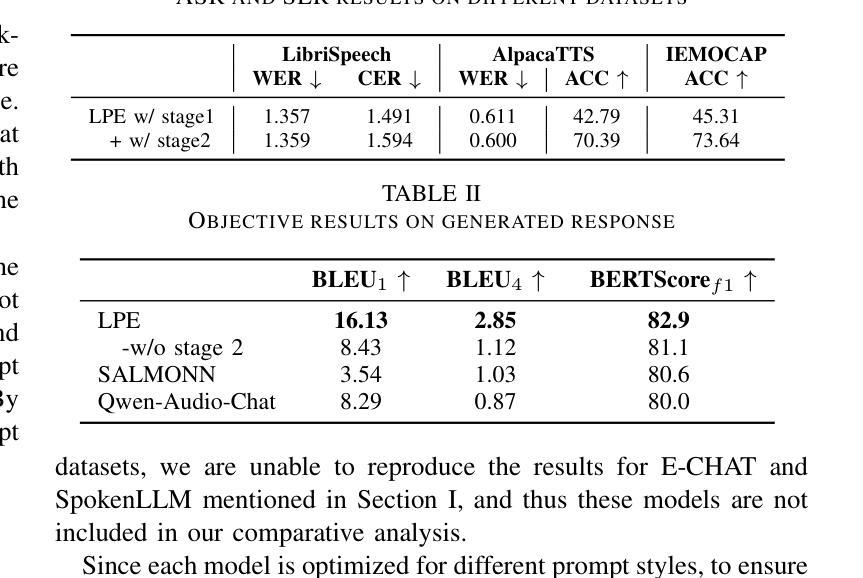
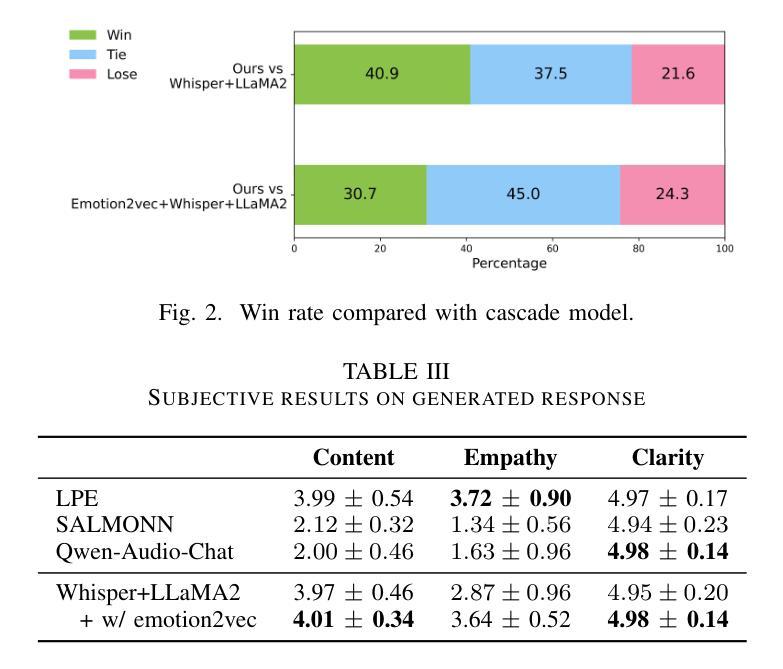
Empathetic dialogue is crucial for natural human-computer interaction, allowing the dialogue system to respond in a more personalized and emotionally aware manner, improving user satisfaction and engagement. The emergence of large language models (LLMs) has revolutionized dialogue generation by harnessing their powerful capabilities and shown its potential in multimodal domains. Many studies have integrated speech with text-based LLMs to take speech question as input and output text response. However, the lack of spoken question-answering datasets that include speech style information to supervised fine-tuning (SFT) limits the performance of these systems. As a result, while these systems excel at understanding speech content, they often struggle to generate empathetic responses. In response, we propose a novel approach that circumvents the need for question-answering data, called Listen, Perceive, and Express (LPE). Our method employs a two-stage training process, initially guiding the LLM to listen the content and perceive the emotional aspects of speech. Subsequently, we utilize Chain-of-Thought (CoT) prompting to unlock the model’s potential for expressing empathetic responses based on listened spoken content and perceived emotional cues. We employ experiments to prove the effectiveness of proposed method. To our knowledge, this is the first attempt to leverage CoT for speech-based dialogue.
共情对话对于自然的人机交互至关重要,它允许对话系统以更加个性化和情感感知的方式做出回应,从而提高用户满意度和参与度。大语言模型(LLM)的出现已经通过利用其强大能力实现了对话生成的革命性变革,并在多模式领域展示了其潜力。许多研究已经将语音与基于文本的LLM集成在一起,以语音问题作为输入并输出文本回复。然而,由于缺乏包含语音风格信息的有监督微调(SFT)问答数据集,这些系统的性能受到了限制。因此,虽然这些系统在理解语音内容方面表现出色,但在生成共情回应时往往感到困难。作为回应,我们提出了一种无需问答数据的新方法,称为倾听、感知和表达(LPE)。我们的方法采用两阶段训练过程,首先引导LLM聆听内容并感知语音的情感方面。随后,我们利用“思考链”(CoT)提示来解锁模型根据听到的语音内容和感知到的情感线索表达共情回应的潜力。我们通过实验证明了该方法的有效性。据我们所知,这是首次尝试利用CoT进行基于语音的对话。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
同情对话对于自然的人机交互至关重要,大型语言模型(LLMs)的出现在对话生成领域引发革命。然而,缺乏包含语音风格信息的问答数据集限制了系统的性能。为此,我们提出了一种名为Listen、Perceive和Express(LPE)的新方法,采用两阶段训练过程,引导LLM聆听内容并感知语音情绪。借助Chain-of-Thought(CoT)提示,解锁模型基于聆听内容和感知情绪表达同情回应的潜力。
Key Takeaways
- 同情对话在自然人机交互中扮演重要角色,能提高用户满意度和参与度。
- 大型语言模型(LLMs)在对话生成领域具有革命性潜力。
- 缺乏包含语音风格信息的问答数据集限制了现有系统的性能。
- 提出的Listen、Perceive和Express(LPE)方法采用两阶段训练过程。
- LPE方法引导LLM聆听内容并感知语音情绪。
- 利用Chain-of-Thought(CoT)提示解锁模型表达同情回应的潜力。
- 该研究是首次尝试将CoT应用于基于语音的对话。
点此查看论文截图


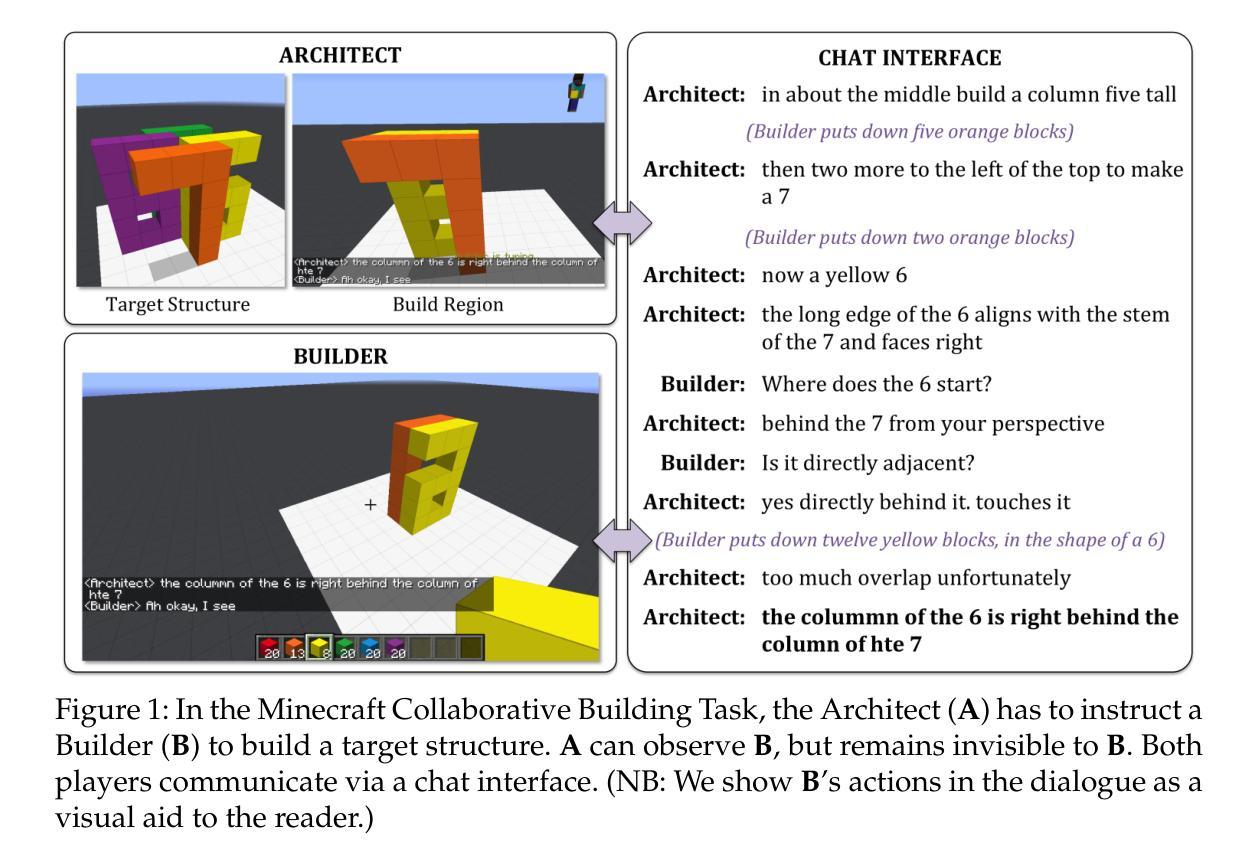
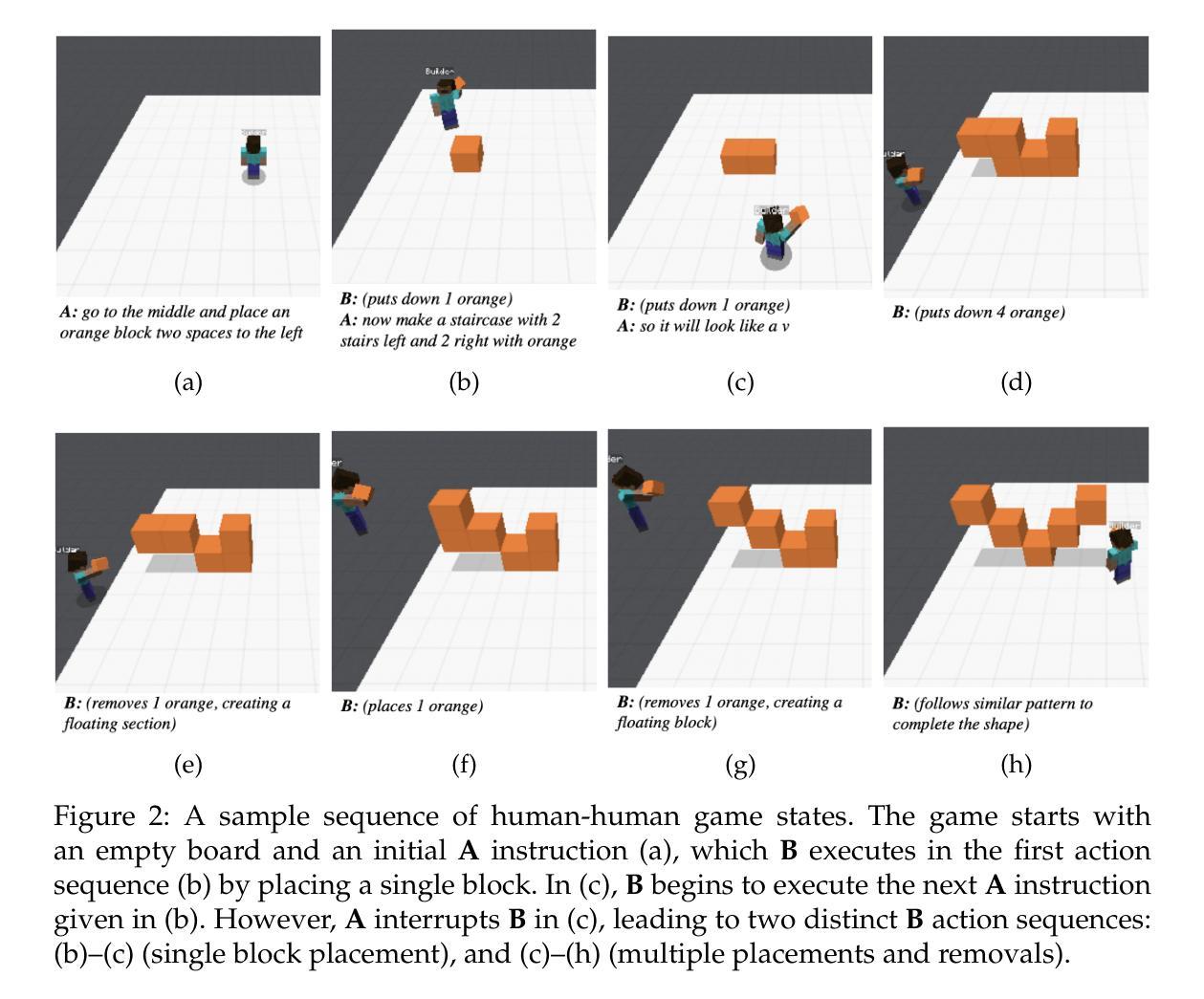
BAP v2: An Enhanced Task Framework for Instruction Following in Minecraft Dialogues
Authors:Prashant Jayannavar, Liliang Ren, Marisa Hudspeth, Charlotte Lambert, Ariel Cordes, Elizabeth Kaplan, Anjali Narayan-Chen, Julia Hockenmaier
Interactive agents capable of understanding and executing instructions in the physical world have long been a central goal in AI research. The Minecraft Collaborative Building Task (MCBT) provides one such setting to work towards this goal (Narayan-Chen, Jayannavar, and Hockenmaier 2019). It is a two-player game in which an Architect (A) instructs a Builder (B) to construct a target structure in a simulated Blocks World Environment. We focus on the challenging Builder Action Prediction (BAP) subtask of predicting correct action sequences in a given multimodal game context with limited training data (Jayannavar, Narayan-Chen, and Hockenmaier 2020). We take a closer look at evaluation and data for the BAP task, discovering key challenges and making significant improvements on both fronts to propose BAP v2, an upgraded version of the task. This will allow future work to make more efficient and meaningful progress on it. It comprises of: (1) an enhanced evaluation benchmark that includes a cleaner test set and fairer, more insightful metrics, and (2) additional synthetic training data generated from novel Minecraft dialogue and target structure simulators emulating the MCBT. We show that the synthetic data can be used to train more performant and robust neural models even with relatively simple training methods. Looking ahead, such data could also be crucial for training more sophisticated, data-hungry deep transformer models and training/fine-tuning increasingly large LLMs. Although modeling is not the primary focus of this work, we also illustrate the impact of our data and training methodologies on a simple LLM- and transformer-based model, thus validating the robustness of our approach, and setting the stage for more advanced architectures and LLMs going forward.
智能交互代理在物理世界中理解和执行指令的能力长期以来一直是人工智能研究的核心目标。Minecraft协作构建任务(MCBT)为实现这一目标提供了一个平台(Narayan-Chen、Jayannavar和Hockenmaier,2019年)。这是一款双人游戏,建筑师(A)指导建造者(B)在模拟的方块世界环境中构建目标结构。我们专注于预测给定多模式游戏上下文中正确动作序列的具有挑战性的建造者动作预测(BAP)子任务,在有限训练数据的情况下(Jayannavar、Narayan-Chen和Hockenmaier,2020年)。我们对BAP任务的评估和数据进行深入研究,发现关键挑战,并在两个方面进行重大改进,提出BAPv2,即该任务的升级版。这将使未来的工作能够更加高效和有意义地推进。它包括:(1)一个增强的评估基准,包括更清洁的测试集和更公平、更深刻的指标;(2)额外的合成训练数据,这些数据由模拟MCBT的新型Minecraft对话和目标结构生成。我们表明,即使使用相对简单的训练方法,合成数据也可以用于训练性能更高、更稳健的神经网络模型。展望未来,这些数据对于训练更精细、数据渴求的深层变压器模型以及训练和微调越来越多的大型语言模型也至关重要。虽然建模不是这项工作的主要重点,我们还展示了我们的数据和训练方法对基于简单LLM和变压器的模型的影响,从而验证了我们的方法的稳健性,并为更先进的架构和LLM未来的发展奠定了基础。
论文及项目相关链接
Summary
在人工智能研究领域,实现能够理解和执行物理世界指令的交互智能体一直是一个核心目标。通过 Minecraft 协作构建任务(MCBT)为这一目标提供了实践场景。本文重点关注建造者动作预测(BAP)子任务,旨在预测给定多模式游戏上下文中正确的动作序列,并在有限训练数据下解决该任务。作者深入研究了BAP任务的评估和数据处理方式,并针对关键问题进行了显著改进,提出了BAP v2版本的任务。新版本包括一个更清洁的测试集和更公平、更有洞察力的评价指标,以及由模拟MCBT的新Minecraft对话和目标结构生成的附加合成训练数据。合成数据能够用于训练更强大且稳健的神经网络模型,即使使用相对简单的训练方法也是如此。展望未来,这些数据对于训练更精细、需要大量数据的深度转换模型以及训练和微调大型语言模型(LLMs)至关重要。尽管建模不是本文的主要重点,但作者在一个简单的LLM和转换器基础模型上展示了数据和训练方法的影响,验证了方法的稳健性,并为更先进的架构和未来的LLMs铺平了道路。
Key Takeaways
- 交互智能体是AI研究的核心目标之一,Minecraft协作构建任务(MCBT)为达到此目标提供了实践场景。
- 本文关注建造者动作预测(BAP)子任务,旨在解决在有限训练数据的条件下预测正确动作序列的挑战。
- 作者深入研究了BAP任务的评估和数据处理方式,并进行了显著改进,提出了BAP v2版本的任务。
- BAP v2包括更清洁的测试集、更公平和有洞察力的评价指标。
- 作者通过生成合成训练数据来增强任务,这些数据由模拟MCBT的Minecraft对话和目标结构生成。
- 合成数据可用于训练强大且稳健的神经网络模型,即使使用简单的训练方法也能取得良好效果。
点此查看论文截图

Leveraging Explicit Reasoning for Inference Integration in Commonsense-Augmented Dialogue Models
Authors:Sarah E. Finch, Jinho D. Choi
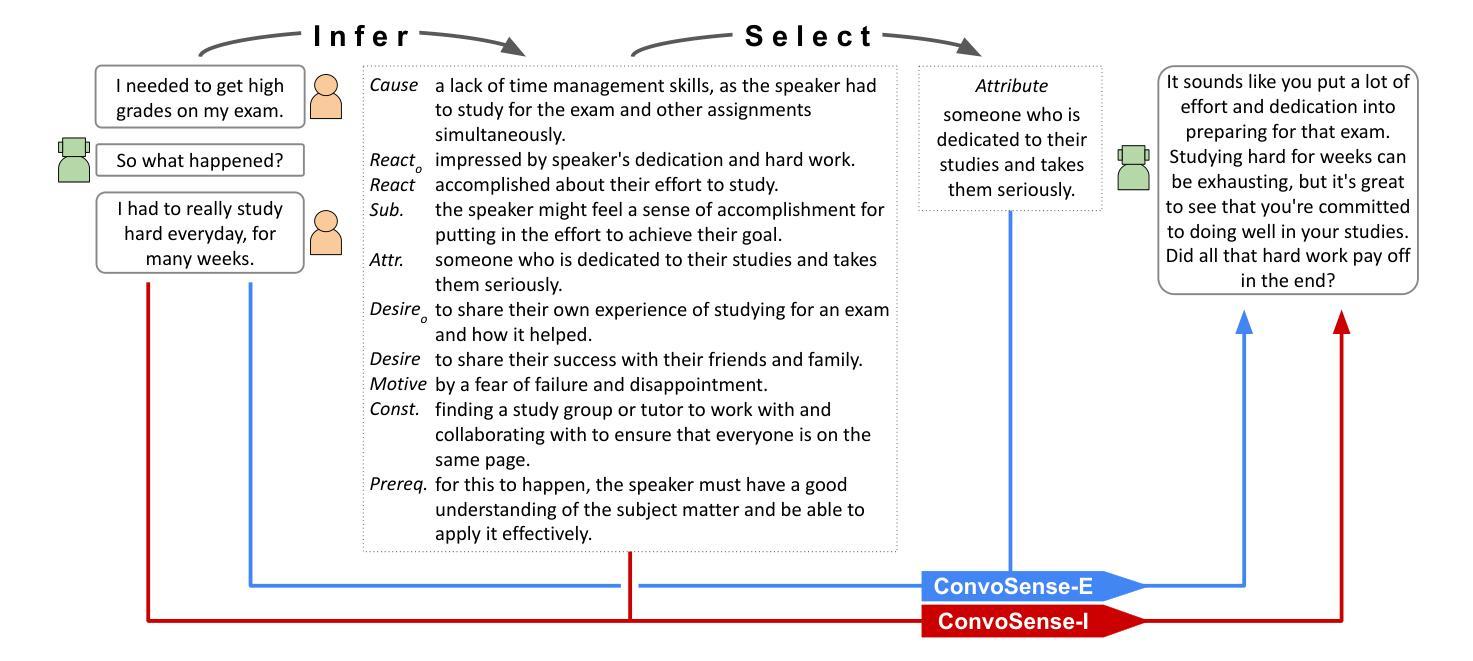
Open-domain dialogue systems need to grasp social commonsense to understand and respond effectively to human users. Commonsense-augmented dialogue models have been proposed that aim to infer commonsense knowledge from dialogue contexts in order to improve response quality. However, existing approaches to commonsense-augmented dialogue rely on implicit reasoning to integrate commonsense inferences during response generation. In this study, we explore the impact of explicit reasoning against implicit reasoning over commonsense for dialogue response generation. Our findings demonstrate that separating commonsense reasoning into explicit steps for generating, selecting, and integrating commonsense into responses leads to better dialogue interactions, improving naturalness, engagement, specificity, and overall quality. Subsequent analyses of these findings unveil insights into the effectiveness of various types of commonsense in generating responses and the particular response traits enhanced through explicit reasoning for commonsense integration. Our work advances research in open-domain dialogue by achieving a new state-of-the-art in commonsense-augmented response generation.
开放域对话系统需要掌握社会常识,以便有效地理解和回应人类用户。已经提出了常识增强对话模型,旨在从对话上下文中推断常识知识,以提高响应质量。然而,现有的常识增强对话方法依赖于隐式推理,在生成响应时整合常识推理。本研究探讨了显式推理与隐式推理对对话响应生成中常识的影响。我们的研究结果表明,将常识推理分为生成、选择和整合响应的显式步骤,有助于改善对话交互,提高自然性、参与度、特异性和总体质量。对这些发现的后继分析揭示了各种常识在生成响应中的有效性,以及通过显式推理整合常识所增强的特定响应特征。我们的工作通过实现常识增强响应生成的新技术成果,推动了开放域对话的研究进展。
论文及项目相关链接
PDF Accepted to COLING 2025 (https://aclanthology.org/2025.coling-main.152/)
Summary
本文探讨了开放域对话系统中社会常识的重要性及其对人机交互的影响。为提高响应质量,提出了融入常识的对话模型,旨在从对话语境中推断常识知识。本研究对比了显式推理与隐式推理在对话响应生成中的影响,发现将常识推理明确分为生成、选择和整合的步骤,能提高对话的自然性、参与度、针对性和总体质量。此研究推进了开放域对话中的常识辅助响应生成技术,达到最新水平。
Key Takeaways
- 开放域对话系统需要掌握社会常识以有效理解并回应人类用户。
- 常识辅助对话模型从对话语境中推断常识知识,旨在提高响应质量。
- 显式推理在对话响应生成中比隐式推理更有效。
- 将常识推理明确分为生成、选择和整合的步骤,能提升对话的自然性、参与度、针对性和总体质量。
- 显式推理能提高响应的特质,如创意、连贯性和信息量。
- 本文揭示了不同类型的常识在生成响应中的有效性。
点此查看论文截图