⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
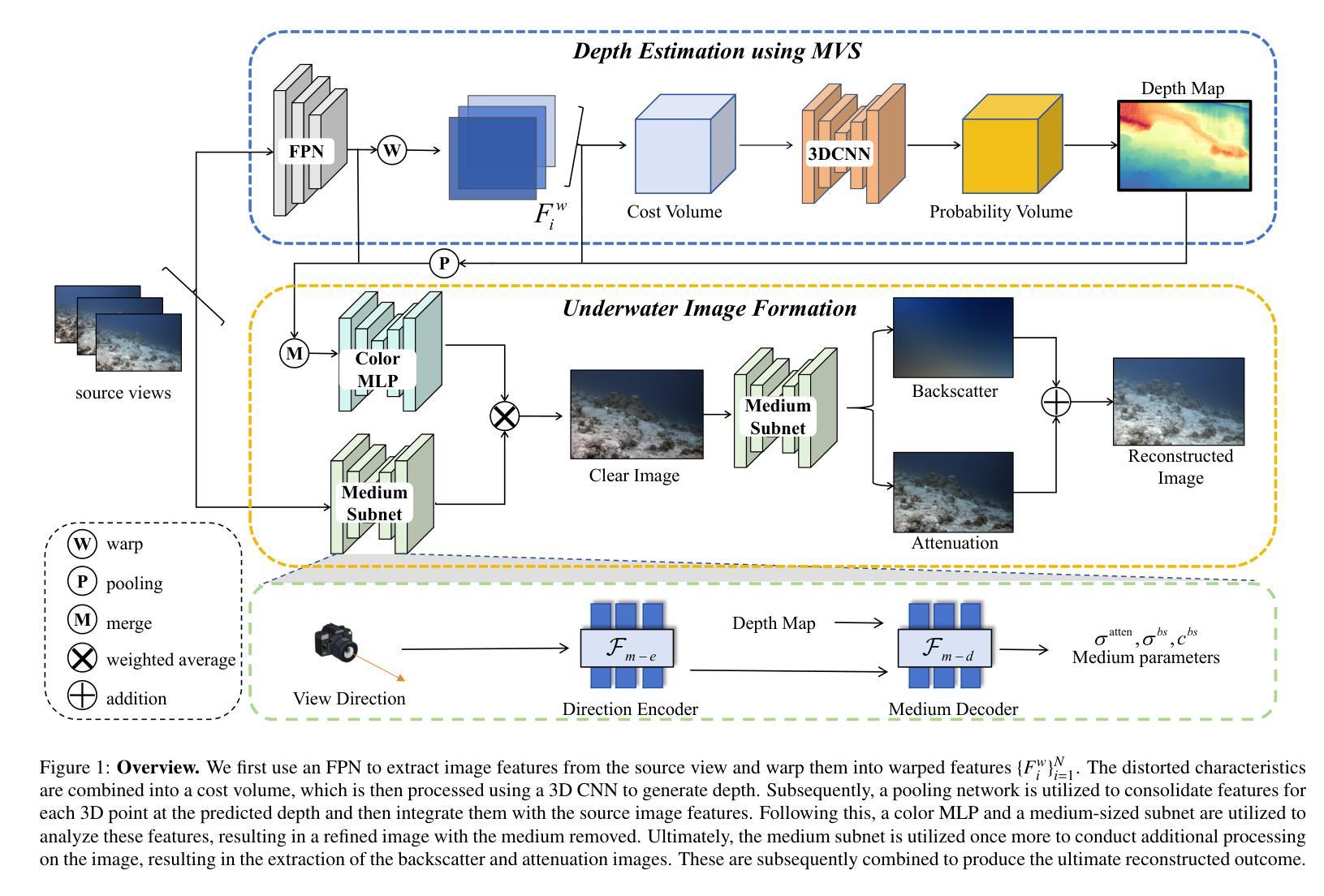
Fast Underwater Scene Reconstruction using Multi-View Stereo and Physical Imaging
Authors:Shuyi Hu, Qi Liu
Underwater scene reconstruction poses a substantial challenge because of the intricate interplay between light and the medium, resulting in scattering and absorption effects that make both depth estimation and rendering more complex. While recent Neural Radiance Fields (NeRF) based methods for underwater scenes achieve high-quality results by modeling and separating the scattering medium, they still suffer from slow training and rendering speeds. To address these limitations, we propose a novel method that integrates Multi-View Stereo (MVS) with a physics-based underwater image formation model. Our approach consists of two branches: one for depth estimation using the traditional cost volume pipeline of MVS, and the other for rendering based on the physics-based image formation model. The depth branch improves scene geometry, while the medium branch determines the scattering parameters to achieve precise scene rendering. Unlike traditional MVSNet methods that rely on ground-truth depth, our method does not necessitate the use of depth truth, thus allowing for expedited training and rendering processes. By leveraging the medium subnet to estimate the medium parameters and combining this with a color MLP for rendering, we restore the true colors of underwater scenes and achieve higher-fidelity geometric representations. Experimental results show that our method enables high-quality synthesis of novel views in scattering media, clear views restoration by removing the medium, and outperforms existing methods in rendering quality and training efficiency.
水下场景重建是一个巨大的挑战,因为光线与介质之间的复杂交互导致了散射和吸收效应,使得深度估计和渲染更加复杂。尽管最近基于神经辐射场(NeRF)的水下场景方法通过建模和分离散射介质实现了高质量的结果,但它们仍存在训练速度慢和渲染速度慢的缺点。为了解决这些局限性,我们提出了一种将多视图立体(MVS)与基于物理的水下图像形成模型相结合的新方法。我们的方法包括两个分支:一个用于使用MVS的传统成本体积管道进行深度估计,另一个基于物理图像形成模型进行渲染。深度分支改进了场景几何,而介质分支确定了散射参数以实现精确的场景渲染。与传统的依赖于真实深度信息的MVSNet方法不同,我们的方法不需要使用真实深度信息,从而可以加快训练和渲染过程。我们通过利用介质子网来估计介质参数,并将其与用于渲染的颜色MLP相结合,恢复了水下场景的真实颜色,并实现了更高保真度的几何表示。实验结果表明,我们的方法能够在散射介质中合成高质量的新视角图像,通过去除介质来恢复清晰的视角,并在渲染质量和训练效率方面优于现有方法。
论文及项目相关链接
Summary
本文提出一种结合多视角立体(MVS)与基于物理的水下图像形成模型的新方法,用于水下场景重建。该方法分为深度估计和渲染两个分支,分别利用MVS的传统代价体积管道和基于物理的图像形成模型。该方法无需依赖真实深度信息,可加速训练和渲染过程,并能恢复水下场景的真实色彩,实现更高保真度的几何表示。
Key Takeaways
- 水下场景重建面临实质挑战,因光与介质间的复杂交互导致散射和吸收效应,使深度估计和渲染更为复杂。
- 近期基于神经辐射场(NeRF)的方法虽能建模并分离散射介质,实现高质量结果,但存在训练与渲染速度慢的限制。
- 本文提出结合多视角立体(MVS)与基于物理的水下图像形成模型的新方法,旨在解决上述问题。
- 方法分为深度估计和渲染两个分支,深度分支改进场景几何,而介质分支确定散射参数以实现精确场景渲染。
- 与传统MVSNet方法不同,本文方法无需依赖真实深度信息,从而加快训练和渲染过程。
- 通过结合介质子网估计的介质参数和颜色MLP进行渲染,能恢复水下场景的真实色彩。
点此查看论文截图

Leveraging GANs For Active Appearance Models Optimized Model Fitting
Authors:Anurag Awasthi
Generative Adversarial Networks (GANs) have gained prominence in refining model fitting tasks in computer vision, particularly in domains involving deformable models like Active Appearance Models (AAMs). This paper explores the integration of GANs to enhance the AAM fitting process, addressing challenges in optimizing nonlinear parameters associated with appearance and shape variations. By leveraging GANs’ adversarial training framework, the aim is to minimize fitting errors and improve convergence rates. Achieving robust performance even in cases with high appearance variability and occlusions. Our approach demonstrates significant improvements in accuracy and computational efficiency compared to traditional optimization techniques, thus establishing GANs as a potent tool for advanced image model fitting.
生成对抗网络(GANs)在计算机视觉的模型拟合任务中取得了显著成果,特别是在涉及可变形模型的领域,如主动外观模型(AAMs)。本文探讨了将GANs集成到AAM拟合过程中,以应对优化与外观和形状变化相关的非线性参数方面的挑战。通过利用GANs的对抗性训练框架,旨在减少拟合误差并提高收敛速度。即使在外观变化较大和遮挡的情况下,也能实现稳健的性能。与传统优化技术相比,我们的方法在准确性和计算效率方面取得了显着改进,从而证明了GANs是先进的图像模型拟合的强有力工具。
论文及项目相关链接
PDF 9 pages, 2 figures, in proceeding at conference
Summary
本文探讨了将生成对抗网络(GANs)集成到主动外观模型(AAMs)中,以提高模型拟合任务的性能。通过利用GANs的对抗训练框架,旨在解决优化外观和形状变化非线性参数方面的挑战,减少拟合误差并提高收敛速度,即使在外观变化大和有遮挡的情况下也能实现稳健性能。与传统优化技术相比,该方法在准确性和计算效率方面显示出显著改善,确立了GANs在高级图像模型拟合中的潜力。
Key Takeaways
- GANs被用于增强AAM拟合过程,解决优化外观和形状变化非线性参数方面的挑战。
- 通过GANs的对抗训练框架,减少拟合误差并提高收敛速度。
- 在高外观变性和遮挡情况下实现稳健性能。
- 与传统优化技术相比,该方法在准确性和计算效率方面显著提高。
- GANs有助于改进模型拟合任务,特别是在涉及可变形模型的领域。
- GANs的集成利用了它们的对抗性训练能力,使模型更加适应各种图像变化。
点此查看论文截图


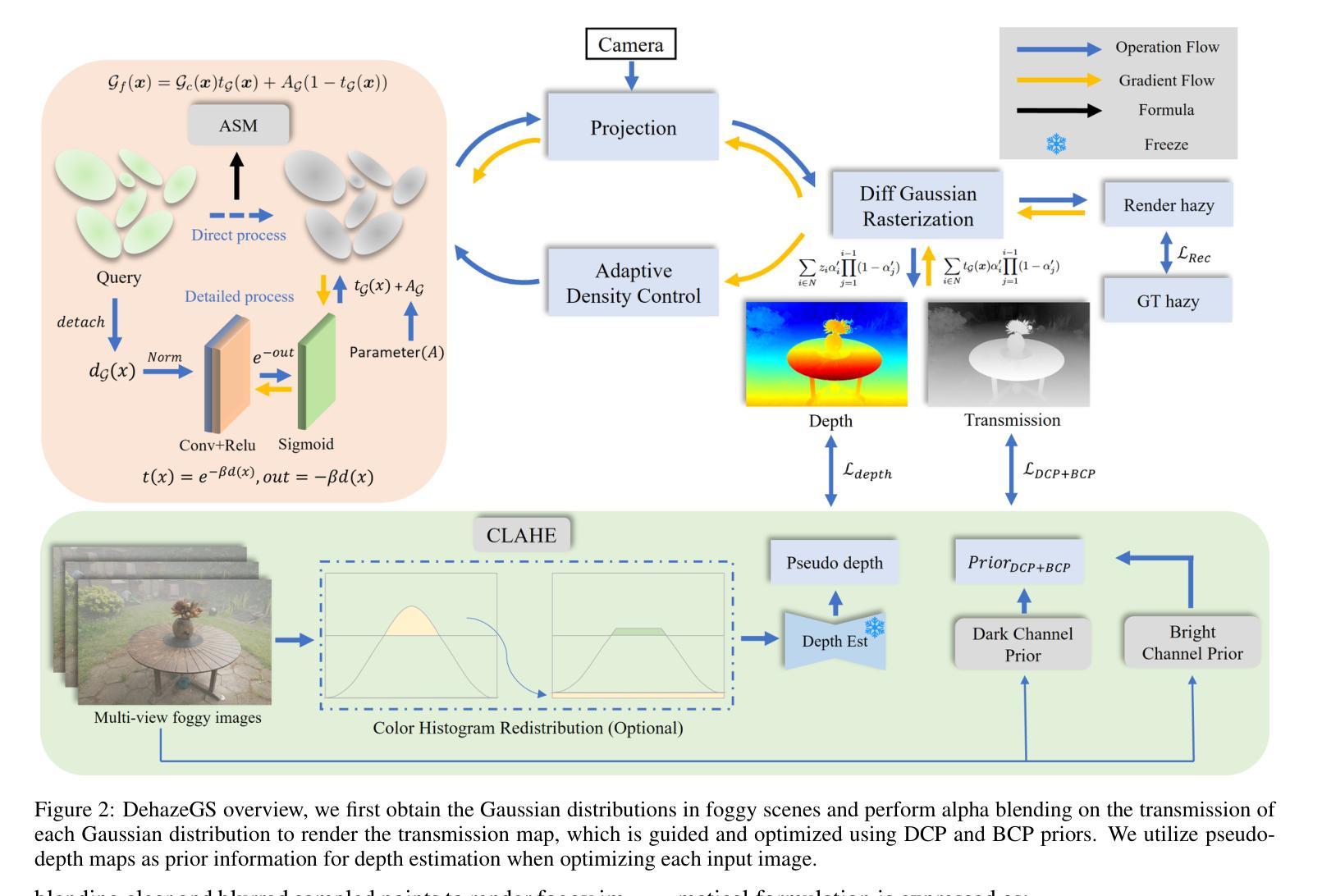
DehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Authors:Jinze Yu, Yiqun Wang, Zhengda Lu, Jianwei Guo, Yong Li, Hongxing Qin, Xiaopeng Zhang
Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF’s implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency. visualizations are available at https://dehazegs.github.io/
当前的新型视图合成任务主要依赖于高质量、清晰的图像。然而,在雾天场景中,散射和衰减会显著影响重建和渲染质量。尽管已经开发了基于NeRF的去雾重建算法,但它们使用深度全连接神经网络和按射线采样策略,导致计算成本较高。此外,NeRF的隐式表示很难从雾天场景中恢复细节。相比之下,最近3D高斯喷涂技术的进展通过显式建模点云为3D高斯实现了高质量的三维场景重建。在本文中,我们提出利用显式高斯表示,通过一个物理准确的正向渲染过程来解释雾天图像的形成过程。我们引入了DehazeGS方法,该方法能够仅使用多视角雾天图像作为输入,对参与介质进行无雾背景的分解和渲染。我们模拟了高斯分布内的传输以模拟雾的形成。在此过程中,我们联合学习大气光和散射系数,同时优化雾天场景的高斯表示。在推理阶段,我们消除了散射和衰减对高斯的影响,并将其直接投影到二维平面上以获得清晰的视图。在合成和真实世界的雾天数据集上的实验表明,DehazeGS在渲染质量和计算效率方面都达到了最先进的性能。可视化请访问:https://dehazegs.github.io/。
论文及项目相关链接
PDF 9 pages,4 figures. visualizations are available at https://dehazegs.github.io/
Summary
本文提出了利用显式高斯表示方法DehazeGS,通过物理准确的前向渲染过程,实现雾霾图像的分解和渲染。该方法能够从参与介质的多视角雾霾图像中分解并渲染出无雾背景。通过模拟高斯分布中的传输过程,联合学习大气光和散射系数,优化雾霾场景的高斯表示。在推断阶段,消除高斯分布的散射和衰减影响,直接投影到二维平面获得清晰视图。实验表明,DehazeGS在渲染质量和计算效率方面达到领先水平。
Key Takeaways
- 当前新颖视图合成任务主要依赖于高质量清晰图像,但在雾霾场景中,散射和衰减会严重影响重建和渲染质量。
- NeRF的隐式表示在从雾霾场景恢复细节方面存在困难,而3D高斯拼贴法可实现高质量3D场景重建。
- DehazeGS方法利用显式高斯表示,通过物理准确的前向渲染过程,实现雾霾图像的分解和渲染。
- DehazeGS能够从多视角雾霾图像中分解并渲染出无雾背景,模拟雾滴形成过程并优化高斯表示。
- 在推断阶段,DehazeGS消除高斯分布的散射和衰减影响,直接投影到二维平面得到清晰视图。
- 实验证明,DehazeGS在渲染质量和计算效率方面达到领先水平。
点此查看论文截图


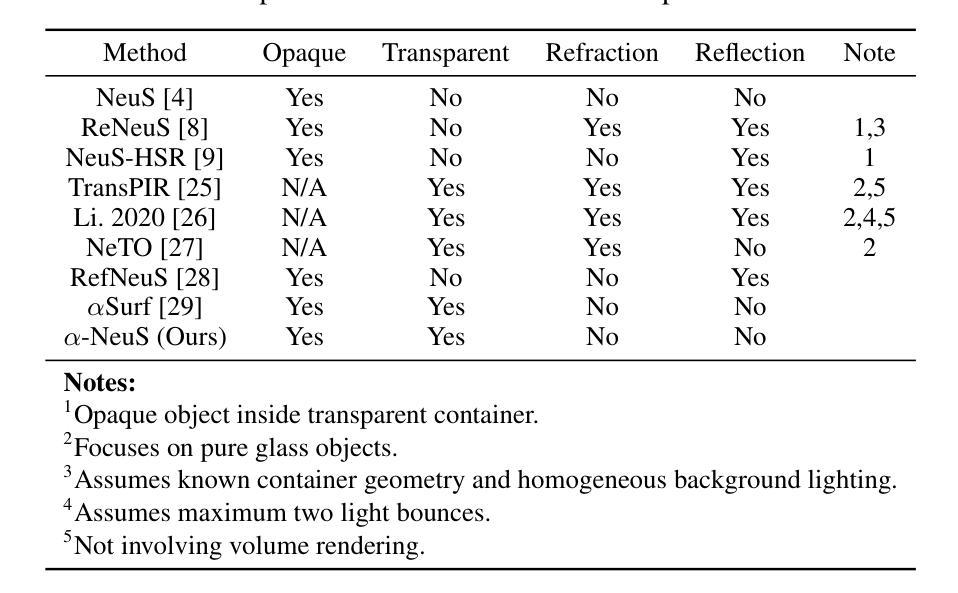
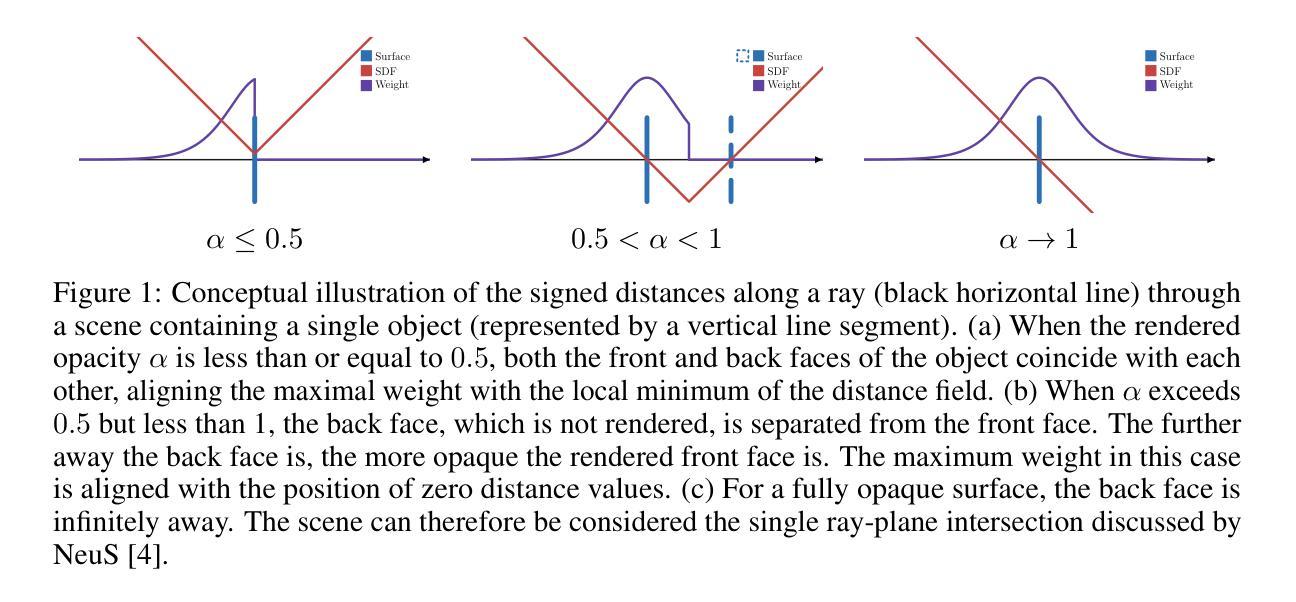
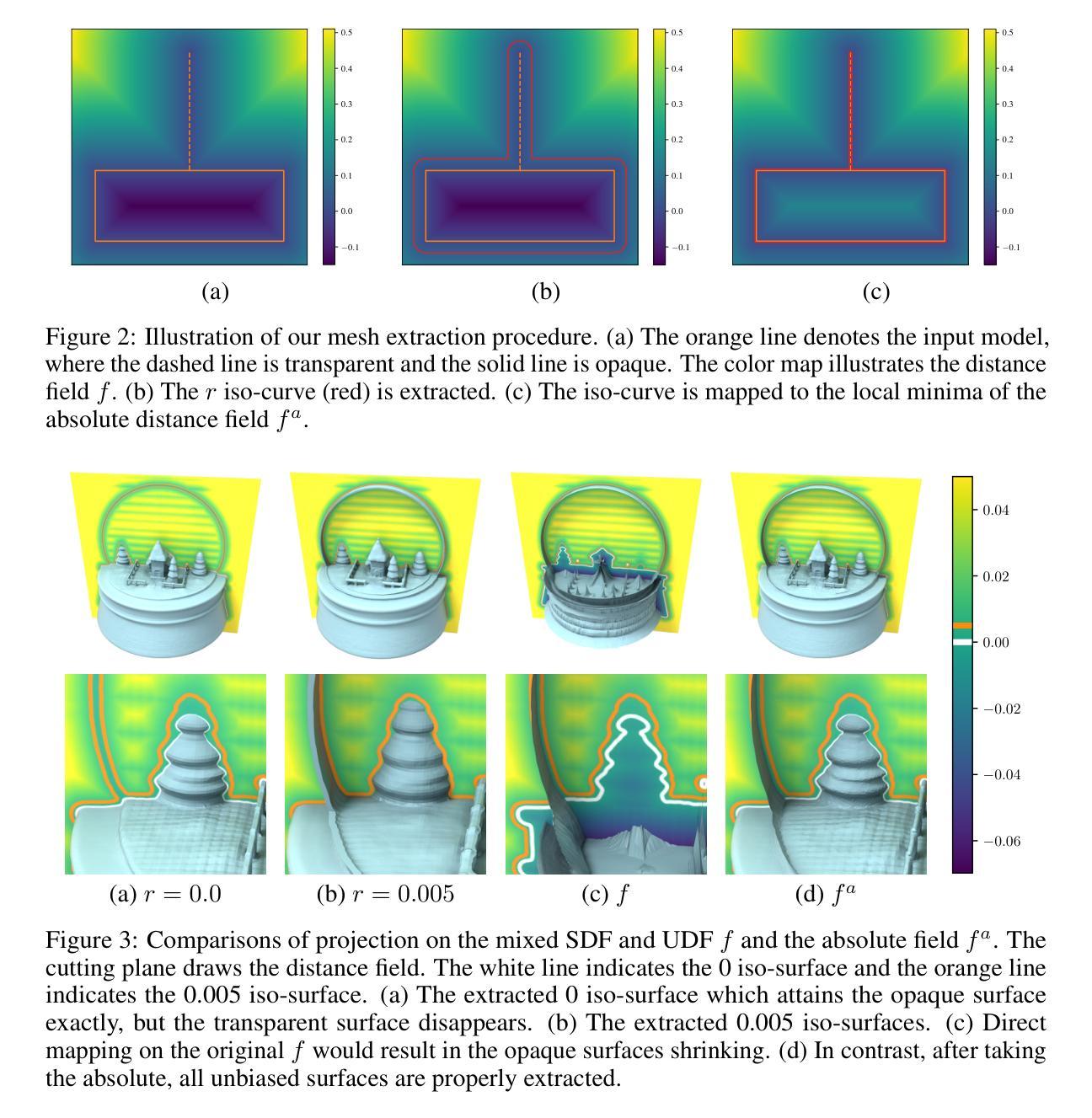
From Transparent to Opaque: Rethinking Neural Implicit Surfaces with $α$-NeuS
Authors:Haoran Zhang, Junkai Deng, Xuhui Chen, Fei Hou, Wencheng Wang, Hong Qin, Chen Qian, Ying He
Traditional 3D shape reconstruction techniques from multi-view images, such as structure from motion and multi-view stereo, face challenges in reconstructing transparent objects. Recent advances in neural radiance fields and its variants primarily address opaque or transparent objects, encountering difficulties to reconstruct both transparent and opaque objects simultaneously. This paper introduces $\alpha$-Neus – an extension of NeuS – that proves NeuS is unbiased for materials from fully transparent to fully opaque. We find that transparent and opaque surfaces align with the non-negative local minima and the zero iso-surface, respectively, in the learned distance field of NeuS. Traditional iso-surfacing extraction algorithms, such as marching cubes, which rely on fixed iso-values, are ill-suited for such data. We develop a method to extract the transparent and opaque surface simultaneously based on DCUDF. To validate our approach, we construct a benchmark that includes both real-world and synthetic scenes, demonstrating its practical utility and effectiveness. Our data and code are publicly available at https://github.com/728388808/alpha-NeuS.
传统从多视角图像进行的三维形状重建技术,如运动结构法和多视角立体法,在重建透明物体时面临挑战。神经网络辐射场及其变体的最新进展主要解决了透明或实体物体的问题,但在同时重建透明和实体物体时仍面临困难。本文介绍了NeuS的扩展版本——$\alpha$-NeuS,证明了NeuS在全透明到全实体材料上都是无偏的。我们发现,透明表面与NeuS学习距离场中的非负局部最小值对齐,而实体表面与零等值面对齐。传统的等值面提取算法(如依赖固定等值点的立方体遍历算法)不适用于此类数据。我们开发了一种基于DCUDF的同时提取透明和实体表面的方法。为了验证我们的方法,我们构建了一个包含现实世界和合成场景的基准测试集,展示了其实际应用效果和效率。我们的数据和代码可在https://github.com/728388808/alpha-NeuS公开获取。
论文及项目相关链接
PDF NeurIPS 2024
Summary
该文章介绍了对NeRF的改进方法α-Neus,该方法能够同时重建透明和遮光的物体。文章指出传统方法难以重建透明物体,而NeRF和其变体主要处理遮光物体或透明物体时遇到困难。α-Neus方法结合了透明和不透明表面,使它们在NeuS学习到的距离场中得到精确重建。针对这类数据的特点,传统固定的等值面提取算法不再适用,因此文章提出了一种基于DCUDF的方法同时提取透明和不透明表面。文章还构建了一个包含真实和合成场景的基准测试集来验证方法的有效性。
Key Takeaways
- α-Neus是NeuS的一个扩展,可以同时重建透明和遮光的物体。
- 传统方法难以重建透明物体,而NeRF及其变体在处理同时透明和遮光物体时遇到困难。
- α-Neus结合了透明和不透明表面,在NeuS学习到的距离场中准确重建。
- 传统固定的等值面提取算法不适用于此类数据。
- α-Neus采用基于DCUDF的方法同时提取透明和不透明表面。
- 文章通过构建包含真实和合成场景的基准测试集验证了方法的实用性和有效性。
点此查看论文截图

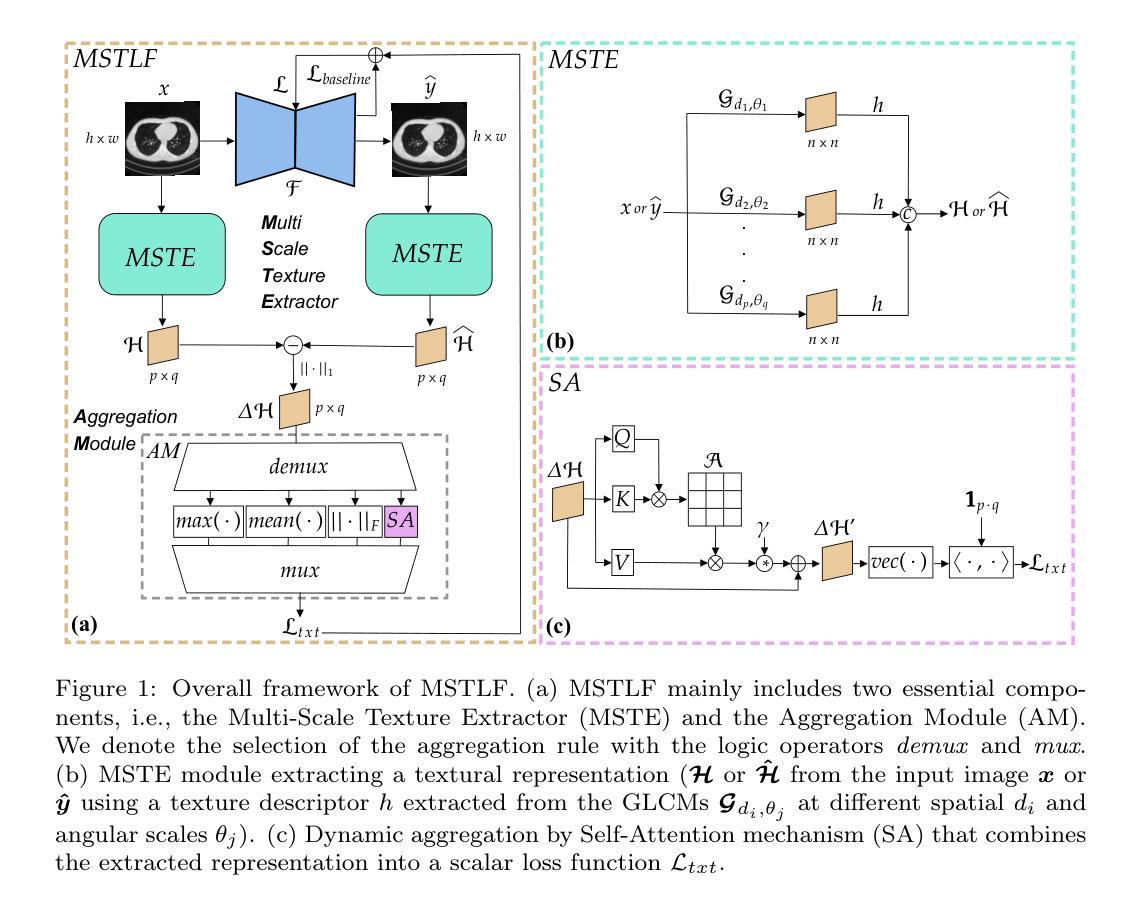
Multi-Scale Texture Loss for CT denoising with GANs
Authors:Francesco Di Feola, Lorenzo Tronchin, Valerio Guarrasi, Paolo Soda
Generative Adversarial Networks (GANs) have proved as a powerful framework for denoising applications in medical imaging. However, GAN-based denoising algorithms still suffer from limitations in capturing complex relationships within the images. In this regard, the loss function plays a crucial role in guiding the image generation process, encompassing how much a synthetic image differs from a real image. To grasp highly complex and non-linear textural relationships in the training process, this work presents a novel approach to capture and embed multi-scale texture information into the loss function. Our method introduces a differentiable multi-scale texture representation of the images dynamically aggregated by a self-attention layer, thus exploiting end-to-end gradient-based optimization. We validate our approach by carrying out extensive experiments in the context of low-dose CT denoising, a challenging application that aims to enhance the quality of noisy CT scans. We utilize three publicly available datasets, including one simulated and two real datasets. The results are promising as compared to other well-established loss functions, being also consistent across three different GAN architectures. The code is available at: https://github.com/TrainLaboratory/MultiScaleTextureLoss-MSTLF
生成对抗网络(GANs)已在医学成像的去噪应用中证明是一个强大的框架。然而,基于GAN的去噪算法在捕捉图像内部复杂关系方面仍存在局限性。在这方面,损失函数在指导图像生成过程中起着至关重要的作用,包括合成图像与真实图像之间的差异程度。为了掌握训练过程中的高度复杂和非线性纹理关系,这项工作提出了一种将多尺度纹理信息嵌入损失函数的新方法。我们的方法引入了一种可微分的多尺度纹理表示,通过自注意力层动态聚合图像,从而利用端到端基于梯度的优化。我们在低剂量CT去噪的背景下进行了大量实验,验证了我们的方法。这是一个具有挑战性的应用,旨在提高噪声CT扫描的质量。我们使用了三个公开数据集,包括一个模拟数据集和两个真实数据集。与其他已建立的损失函数相比,我们的结果充满希望,并且在三种不同的GAN架构中表现一致。代码可在https://github.com/TrainLaboratory/MultiScaleTextureLoss-MSTLF找到。
论文及项目相关链接
Summary
该文介绍了一种基于生成对抗网络(GANs)的新型图像去噪方法,特别针对医学成像应用。该方法通过引入多尺度纹理损失函数,提高了捕捉图像中复杂关系的能力,并通过自我关注层动态聚合多尺度纹理表示。在低剂量CT去噪方面的实验结果表明,该方法与其他常用损失函数相比具有优越性,且在三种不同GAN架构中表现一致。
Key Takeaways
- GANs在医学成像去噪应用中的强大性能。
- 当前GANs在捕捉图像复杂关系方面的局限性。
- 损失函数在图像生成过程中的关键作用。
- 引入多尺度纹理损失函数,以提高捕捉高度复杂和非线性纹理关系的能力。
- 使用自我关注层动态聚合多尺度纹理表示的方法。
- 在低剂量CT去噪方面的实验验证了该方法的有效性。
点此查看论文截图