⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
MathReader : Text-to-Speech for Mathematical Documents
Authors:Sieun Hyeon, Kyudan Jung, Nam-Joon Kim, Hyun Gon Ryu, Jaeyoung Do
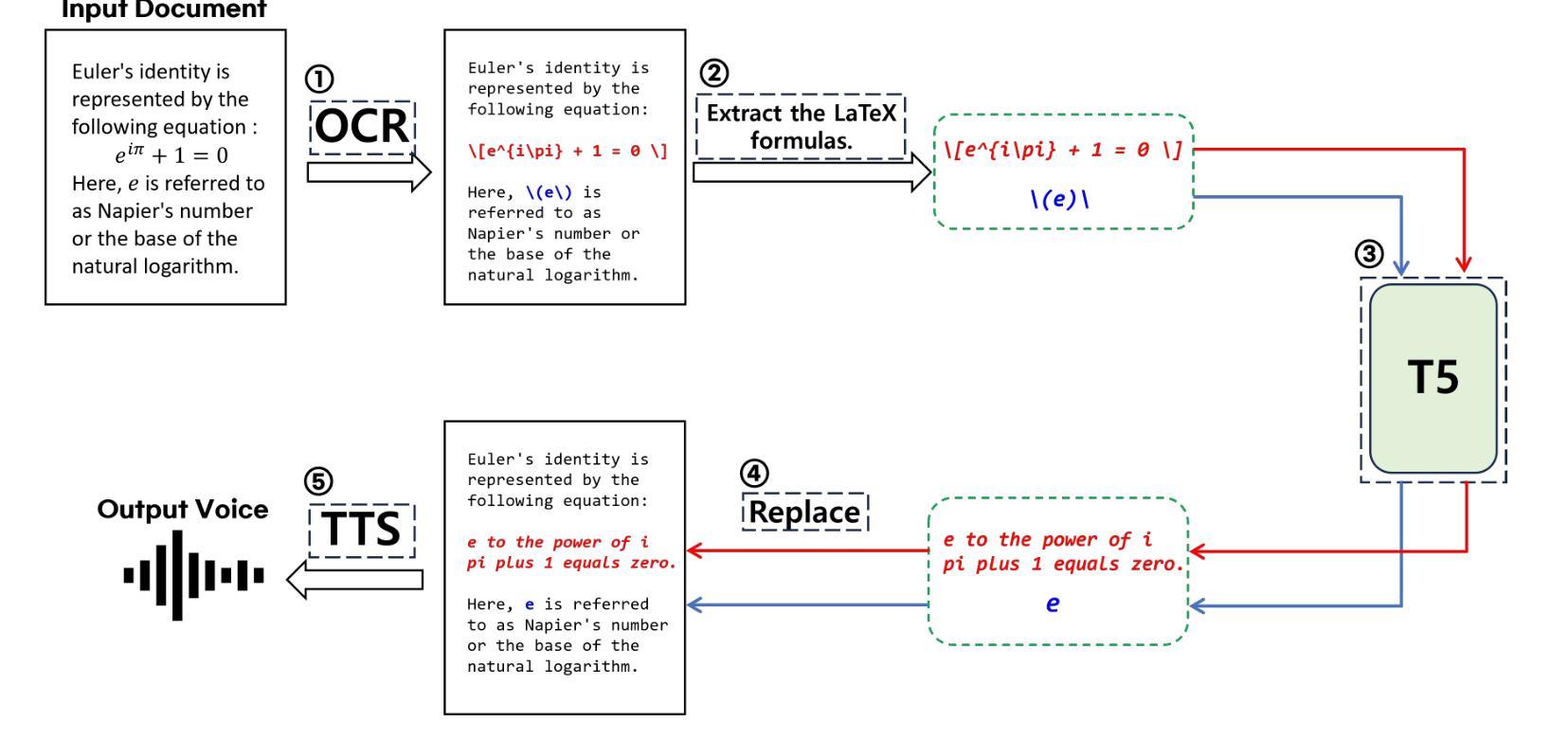
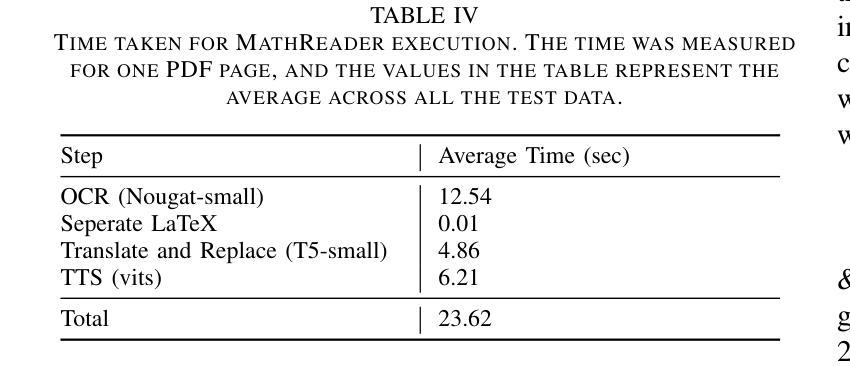
TTS (Text-to-Speech) document reader from Microsoft, Adobe, Apple, and OpenAI have been serviced worldwide. They provide relatively good TTS results for general plain text, but sometimes skip contents or provide unsatisfactory results for mathematical expressions. This is because most modern academic papers are written in LaTeX, and when LaTeX formulas are compiled, they are rendered as distinctive text forms within the document. However, traditional TTS document readers output only the text as it is recognized, without considering the mathematical meaning of the formulas. To address this issue, we propose MathReader, which effectively integrates OCR, a fine-tuned T5 model, and TTS. MathReader demonstrated a lower Word Error Rate (WER) than existing TTS document readers, such as Microsoft Edge and Adobe Acrobat, when processing documents containing mathematical formulas. MathReader reduced the WER from 0.510 to 0.281 compared to Microsoft Edge, and from 0.617 to 0.281 compared to Adobe Acrobat. This will significantly contribute to alleviating the inconvenience faced by users who want to listen to documents, especially those who are visually impaired. The code is available at https://github.com/hyeonsieun/MathReader.
微软、Adobe、苹果和OpenAI的TTS(文本转语音)文档阅读器已经在全球提供服务。它们对于普通的纯文本提供相对良好的TTS结果,但有时对于数学表达式的内容会跳过或提供不满意的结果。这是因为现代学术论文大多使用LaTeX编写,当LaTeX公式被编译时,它们在文档中以独特的文本形式呈现。然而,传统的TTS文档阅读器只输出所识别的文本,而没有考虑到公式的数学意义。为了解决这个问题,我们提出了MathReader,它有效地整合了OCR、精细调整的T5模型和TTS。MathReader在处理包含数学公式的文档时,与现有的TTS文档阅读器(如Microsoft Edge和Adobe Acrobat)相比,表现出较低的单词错误率(WER)。与Microsoft Edge相比,MathReader将WER从0.510降低到0.281;与Adobe Acrobat相比,从0.617降低到0.281。这将大大减轻用户(特别是视力受损者)在听取文档时的不便。相关代码可访问https://github.com/hyeonsieun/MathReader了解。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
微软、Adobe、苹果和OpenAI的TTS文档阅读器在全球范围内提供服务,对于普通文本有较好的表现,但在处理数学表达式时可能出现跳过内容或结果不理想的情况。为此,我们提出了MathReader,它有效地结合了OCR、精细调整的T5模型和TTS技术。相较于现有的TTS文档阅读器,如Microsoft Edge和Adobe Acrobat,MathReader在处理包含数学公式的文档时表现出更低的Word Error Rate(WER)。这极大地缓解了用户阅读文档的不便,特别是对于视力障碍者。
Key Takeaways
- 现代学术文章多使用LaTeX撰写,其中数学公式作为文本的一种独特形式存在于文档中。传统的TTS文档阅读器无法识别数学公式的含义。
- MathReader结合了OCR技术、精细调整的T5模型和TTS技术,有效解决了传统TTS文档阅读器处理数学公式时的问题。
- MathReader相较于Microsoft Edge和Adobe Acrobat的TTS文档阅读器在处理包含数学公式的文档时具有更低的Word Error Rate(WER)。
- MathReader在减少用户在阅读文档时遇到的困难方面取得了显著成效,特别是帮助视力障碍者更好地听取文档内容。
- MathReader的代码已公开在GitHub上供公众查阅和使用。
- MathReader的创新在于其集成了多种技术来解决特定问题,这显示了跨学科合作和集成技术在解决现实问题中的潜力。
点此查看论文截图



VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Authors:Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Haoyu Cao, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, Ran He
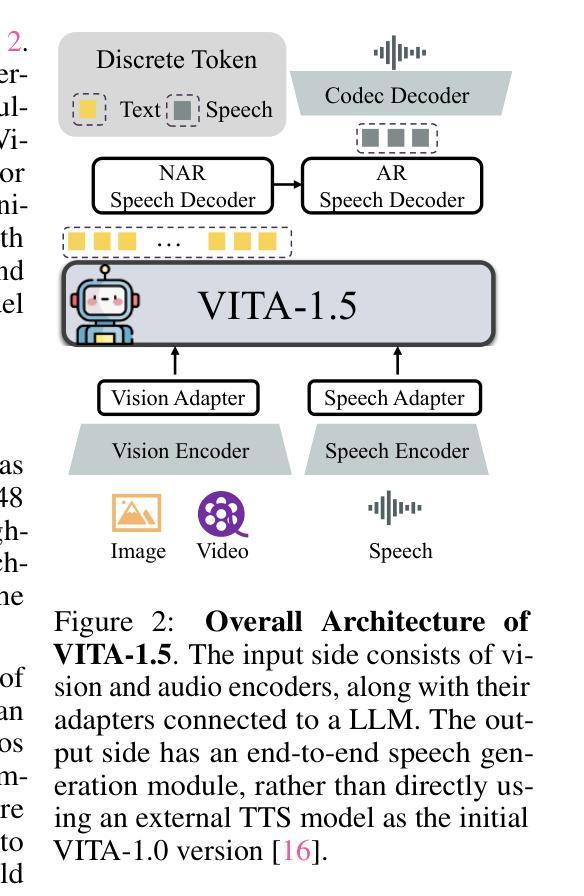
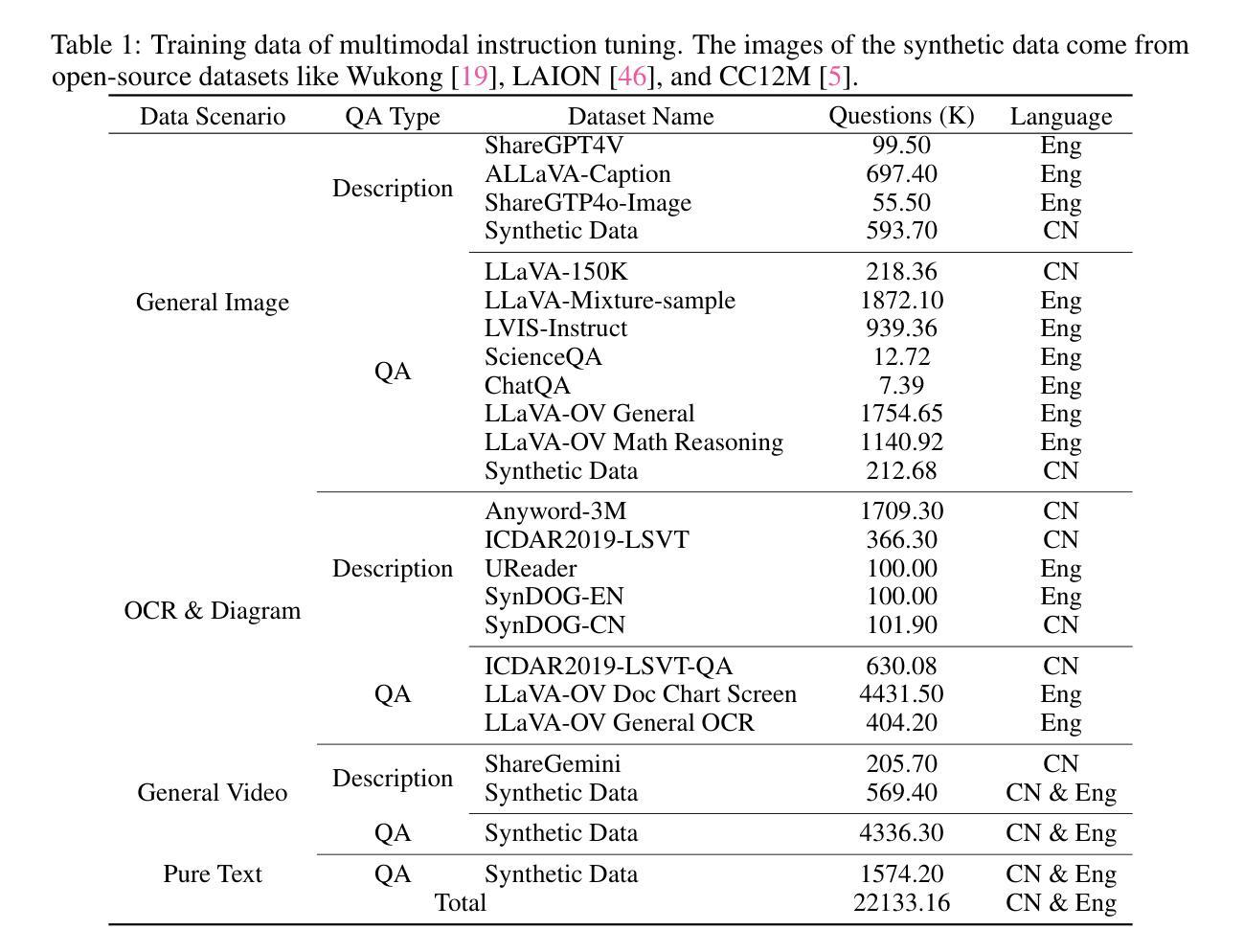
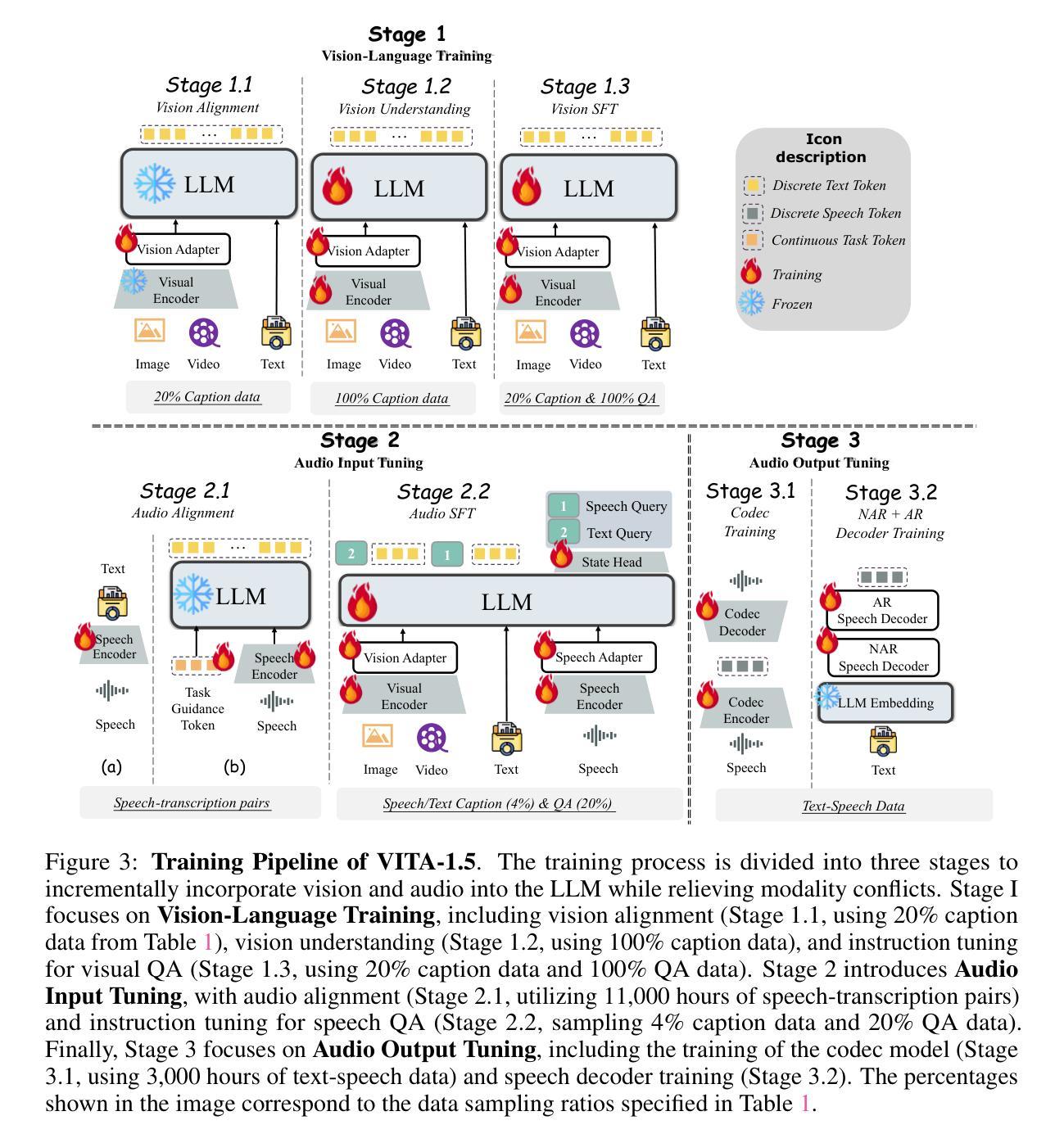
Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
近期多模态大型语言模型(MLLMs)主要集中于整合视觉和文本模态,较少关注语音在增强交互中的作用。然而,语音在多模态对话系统中扮演着至关重要的角色,由于在根本模式上的差异,在视觉和语音任务上都实现高性能仍然是一个巨大的挑战。在本文中,我们提出了一种精心设计的多阶段训练方法论,逐步训练LLM理解视觉和语音信息,最终使流畅的视觉和语音交互成为可能。我们的方法不仅保留了强大的视觉语言功能,还能够实现高效的语音对话功能,无需单独的ASR和TTS模块,从而显著加快多模态端到端的响应速度。通过与图像、视频和语音任务的最新前沿技术进行对比,我们证明了我们的模型具有强大的视觉和语音功能,可实现近乎实时的视觉和语音交互。
论文及项目相关链接
PDF https://github.com/VITA-MLLM/VITA (2K+ Stars by now)
Summary
本文提出了一个多阶段训练策略,使大型语言模型能够理解视觉和语音信息,实现流畅的视觉和语音交互。该方法不仅保留了强大的视觉语言功能,还实现了无需单独的语音识别和文本转语音模块的语音对话能力,显著加快了多模态端到端的响应速度。实验证明,该模型在图像、视频和语音任务方面都具有强大的能力,能够实现近实时的视觉和语音交互。
Key Takeaways
- 近期多模态大型语言模型主要关注视觉和文本模态的融合,忽略了语音在增强交互中的作用。
- 语音在多模态对话系统中起关键作用,同时在视觉和语音任务中实现高性能是一个挑战。
- 论文提出了一种多阶段训练策略,使语言模型能够理解视觉和语音信息,实现流畅交互。
- 该方法保留了强大的视觉语言功能,并实现了无需独立语音识别和文本转语音模块的语音对话能力。
- 该策略显著提高了多模态端到端的响应速度。
- 实验证明,该模型在图像、视频和语音任务方面表现出强大的能力。
点此查看论文截图

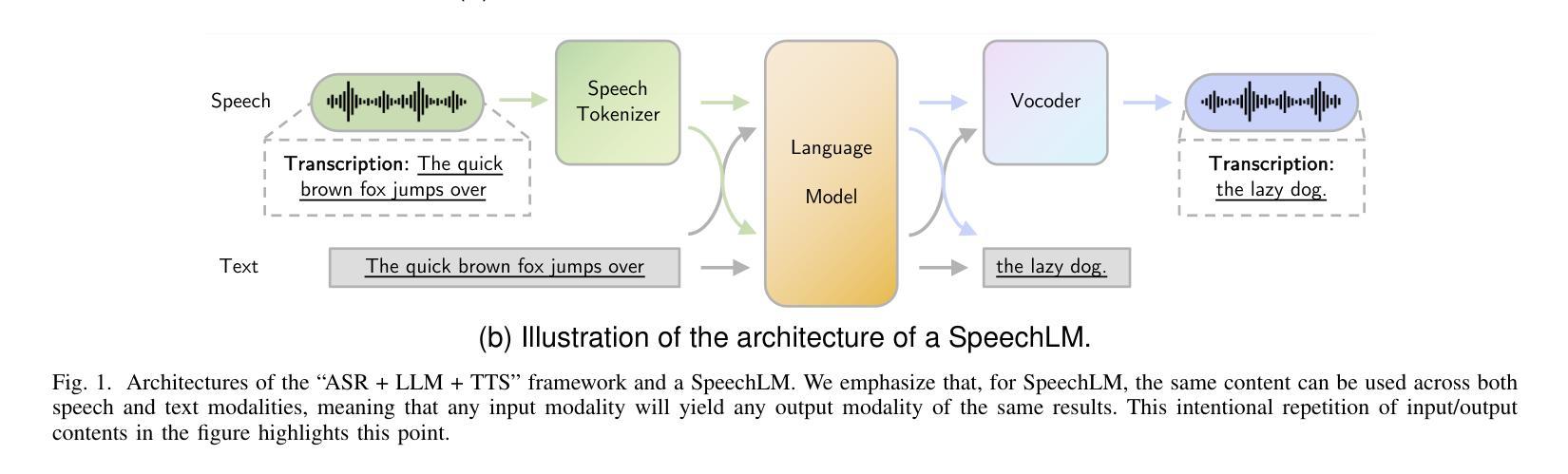
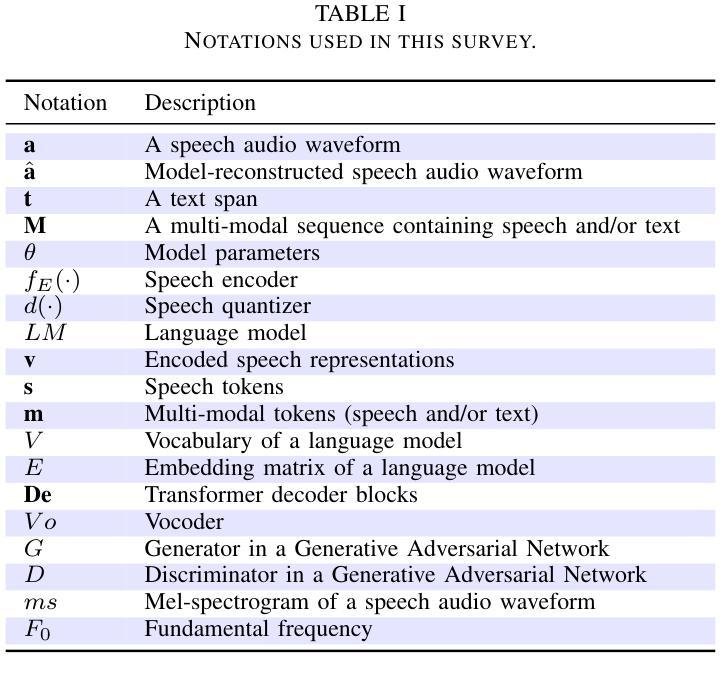
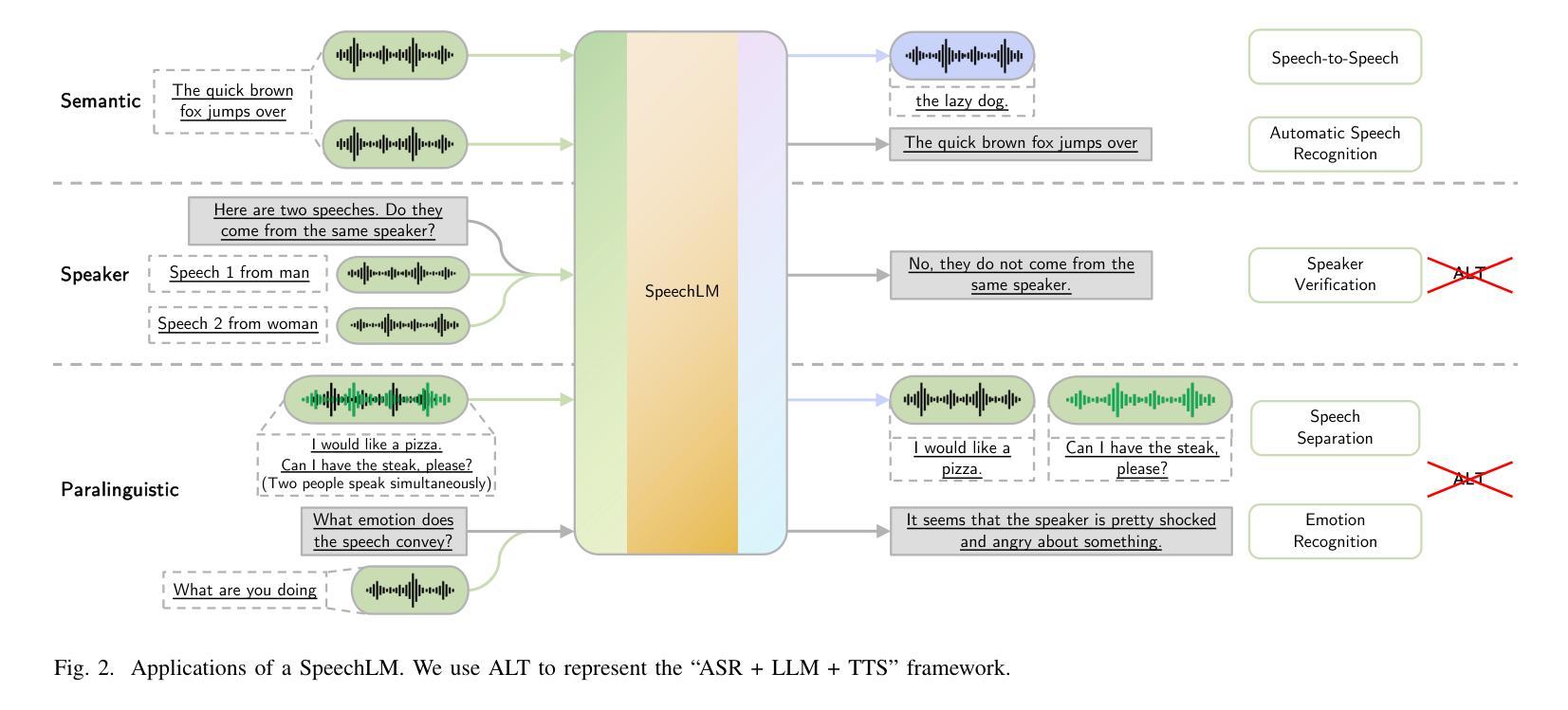
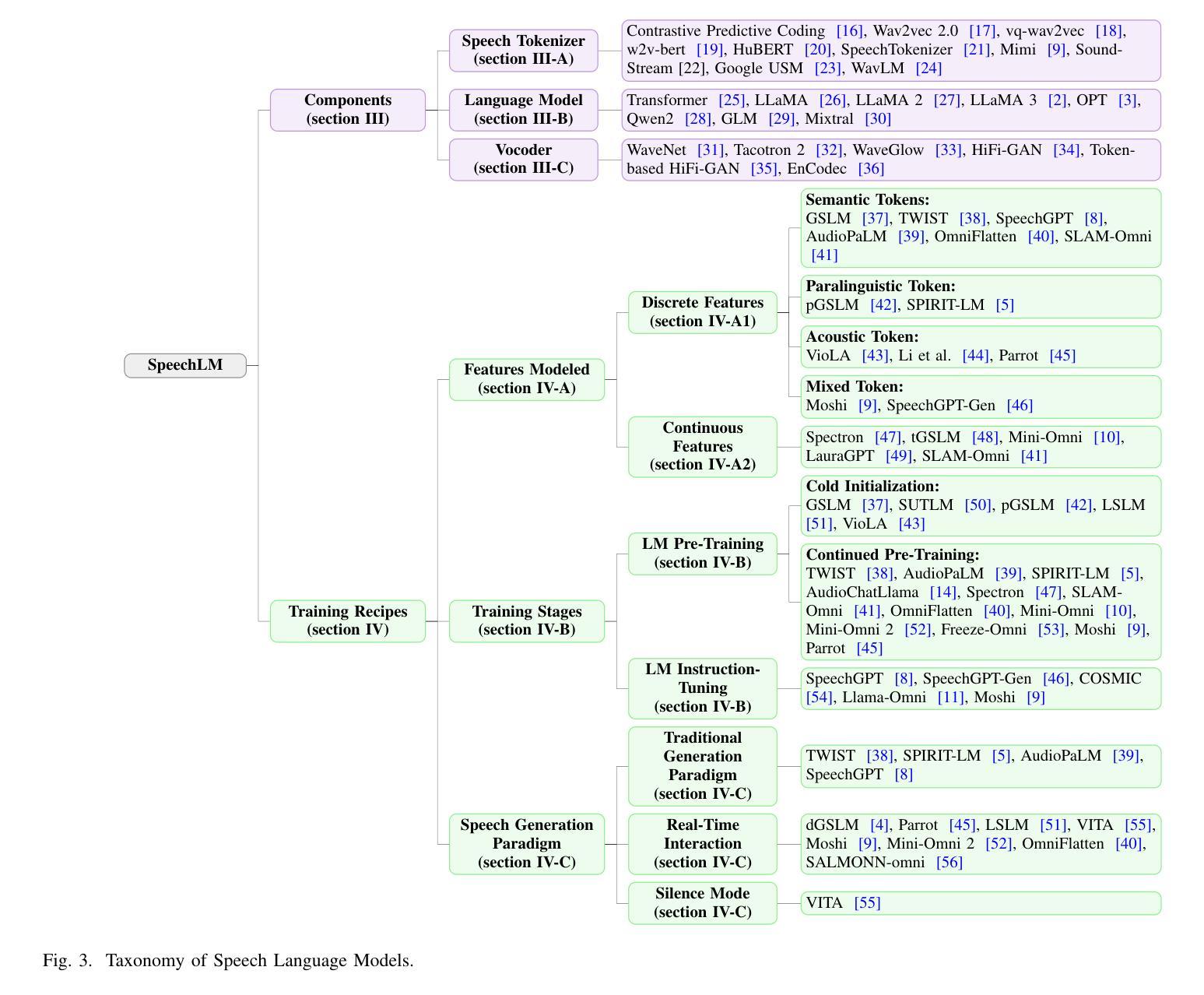
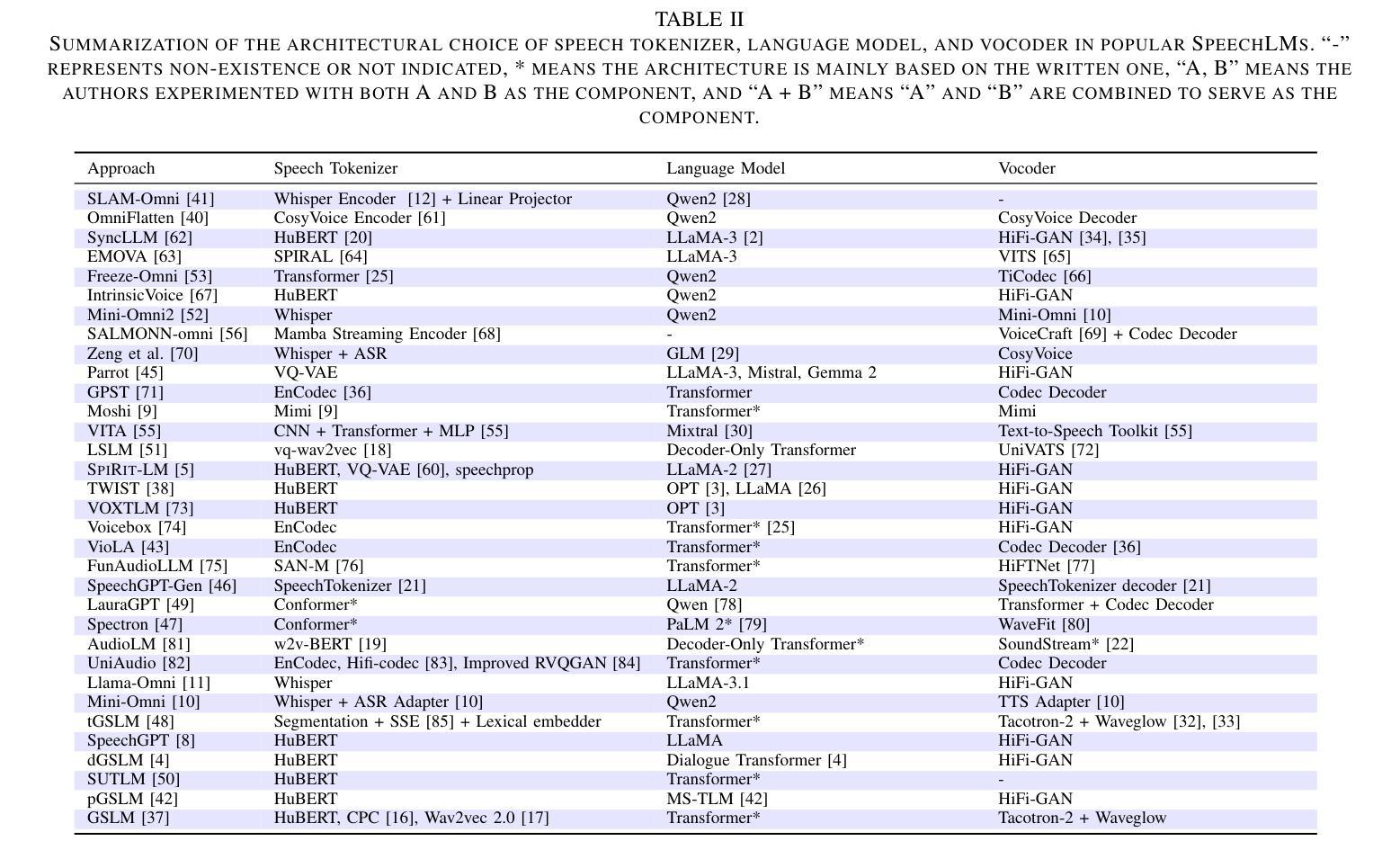
Recent Advances in Speech Language Models: A Survey
Authors:Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, Irwin King
Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)”, where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion, significant latency due to the complex pipeline, and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) – end-to-end models that generate speech without converting from text – have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize their evaluation metrics, and discuss the challenges and future research directions in this rapidly evolving field. The GitHub repository is available at https://github.com/dreamtheater123/Awesome-SpeechLM-Survey
大型语言模型(LLM)近期引起了广泛的关注,主要是因其基于文本的交互能力。然而,自然人机交互通常依赖于语音,因此需要向基于语音的模型转变。实现这一目标的一种直接方法是“自动语音识别(ASR)+ LLM + 文本到语音(TTS)”的管道流程,其中输入语音被转录为文本,由LLM处理,然后再转回语音。尽管这种方法很直接,但它存在固有的局限性,例如在模态转换过程中的信息损失、由于复杂管道导致的显著延迟以及三个阶段的错误累积。为了解决这些问题,语音语言模型(SpeechLM)——无需从文本转换即可生成语音的端到端模型——作为一种有前途的替代方案而出现。这篇综述论文首次全面概述了构建SpeechLM的最新方法,详细描述了其架构的关键组件以及对其发展至关重要的各种培训配方。此外,我们还系统地调查了SpeechLM的各种功能,对其评估指标进行分类,并讨论了这一快速发展的领域所面临的挑战和未来研究方向。GitHub仓库可通过https://github.com/dreamtheater123/Awesome-SpeechLM-Survey访问。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLMs)在文本交互中表现出强大的能力,但人类日常交流更多依赖于语音。为此,学界开始研究语音基础模型(SpeechLMs),该模型可实现从语音到语音的转换,无需经过文本中介。本文提供了首个全面的SpeechLMs方法学概述,介绍了其关键组成部分和开发中的关键训练配方。此外,本文对SpeechLMs的各项功能进行了系统的调查,分类了其评估指标,并讨论了这一领域的挑战和未来研究方向。
Key Takeaways
- 大型语言模型(LLMs)在文本交互中表现出强大的能力,但自然人类互动更依赖于语音。
- 语音基础模型(SpeechLMs)是一种直接从语音到语音的转换模型,避免了文本转换带来的信息损失和延迟。
- SpeechLMs的关键组成部分包括自动语音识别(ASR)、语言模型和文本到语音(TTS)等模块。
- 文章介绍了SpeechLMs的关键训练配方和发展现状。
- SpeechLMs具有多种功能,包括语音合成、语音识别、语音翻译等。
- 文章详细讨论了SpeechLMs的评估指标、面临的挑战和未来研究方向。
点此查看论文截图