⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-23 更新
Vision-Language Models for Automated Chest X-ray Interpretation: Leveraging ViT and GPT-2
Authors:Md. Rakibul Islam, Md. Zahid Hossain, Mustofa Ahmed, Most. Sharmin Sultana Samu
Radiology plays a pivotal role in modern medicine due to its non-invasive diagnostic capabilities. However, the manual generation of unstructured medical reports is time consuming and prone to errors. It creates a significant bottleneck in clinical workflows. Despite advancements in AI-generated radiology reports, challenges remain in achieving detailed and accurate report generation. In this study we have evaluated different combinations of multimodal models that integrate Computer Vision and Natural Language Processing to generate comprehensive radiology reports. We employed a pretrained Vision Transformer (ViT-B16) and a SWIN Transformer as the image encoders. The BART and GPT-2 models serve as the textual decoders. We used Chest X-ray images and reports from the IU-Xray dataset to evaluate the usability of the SWIN Transformer-BART, SWIN Transformer-GPT-2, ViT-B16-BART and ViT-B16-GPT-2 models for report generation. We aimed at finding the best combination among the models. The SWIN-BART model performs as the best-performing model among the four models achieving remarkable results in almost all the evaluation metrics like ROUGE, BLEU and BERTScore.
放射学在现代医学中扮演着至关重要的角色,因其具有非侵入性的诊断能力。然而,手动生成非结构化医疗报告既耗时又容易出错,这成为临床工作流程中的重大瓶颈。尽管人工智能生成的放射学报告有所进展,但在实现详细准确的报告生成方面仍存在挑战。在这项研究中,我们评估了结合计算机视觉和自然语言处理的多模式模型的不同组合,以生成全面的放射学报告。我们采用了预训练的Vision Transformer(ViT-B16)和SWIN Transformer作为图像编码器。BART和GPT-2模型则作为文本解码器。我们使用IU-Xray数据集中的胸部X射线图像和报告来评估SWIN Transformer-BART、SWIN Transformer-GPT-2、ViT-B16-BART和ViT-B16-GPT-2模型在报告生成方面的实用性。我们的目标是找到模型之间的最佳组合。在四项模型中,SWIN-BART模型表现最佳,在几乎所有评估指标(如ROUGE、BLEU和BERTScore)中都取得了显著的成绩。
论文及项目相关链接
PDF Preprint, manuscript under-review
Summary
本文探讨了放射学在现代医学中的重要作用及其面临的挑战。研究中,通过结合计算机视觉和自然语言处理技术,评估了不同组合模型在生成综合放射学报告方面的性能。采用预训练的Vision Transformer(ViT-B16)和SWIN Transformer作为图像编码器,BART和GPT-2模型作为文本解码器。使用IU-Xray数据集上的Chest X-ray图像和报告进行评估。结果显示,SWIN-BART模型在几乎所有评估指标上表现最佳,如ROUGE、BLEU和BERTScore。
Key Takeaways
- 放射学在现代医学中具有非侵入性诊断能力的重要角色。
- 自动化生成医疗报告面临时间消耗和误差率问题,成为临床工作流程的瓶颈。
- 研究评估了结合计算机视觉和自然语言处理的多模态模型在生成综合放射学报告方面的性能。
- 采用了Vision Transformer(ViT-B16)和SWIN Transformer作为图像编码器。
- BART和GPT-2模型被用作文本解码器。
- 使用IU-Xray数据集中的Chest X-ray图像和报告进行评估。
点此查看论文截图

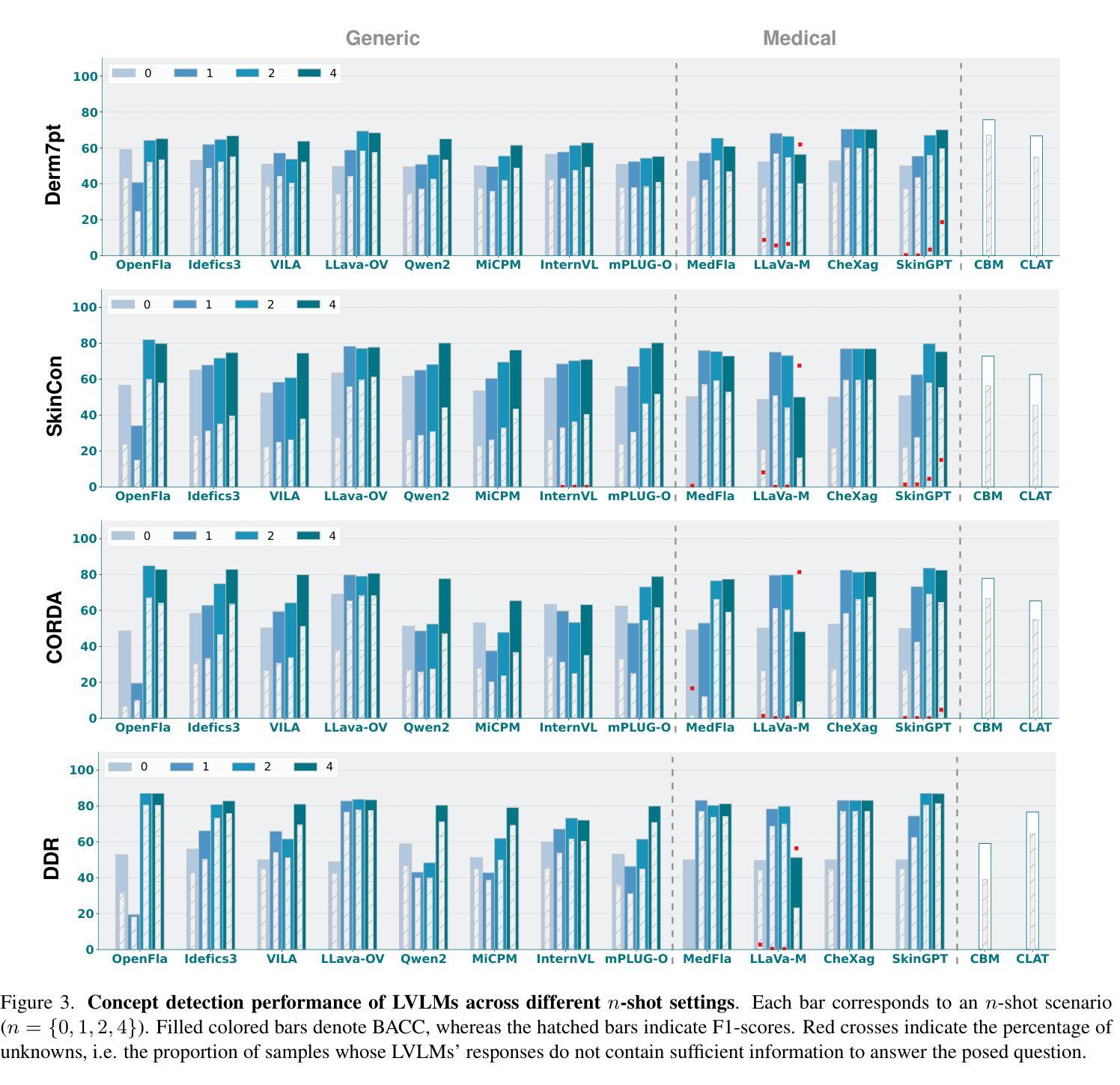
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Authors:Cristiano Patrício, Isabel Rio-Torto, Jaime S. Cardoso, Luís F. Teixeira, João C. Neves
The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
在医疗工作流中采用基于深度学习的解决方案的主要挑战在于标注数据的可用性和此类系统缺乏可解释性。概念瓶颈模型(CBMs)通过约束最终疾病预测在一组预先定义和可解释的概念上来解决后者的问题。然而,通过基于概念的解释实现的增加的可解释性意味着更高的标注负担。而且,如果要添加新概念,整个系统需要重新训练。受大型视觉语言模型(LVLMs)在少量样本设置中的出色性能的启发,我们提出了一种简单而有效的方法,即CBVLM,该方法解决了上述两个挑战。首先,对于每个概念,我们提示LVLM回答概念是否出现在输入图像中。然后,我们让LVLM基于先前的概念预测对图像进行分类。而且,在两个阶段中,我们采用检索模块负责选择最佳样本进行上下文学习。通过将最终诊断建立在预测的概念上,我们确保了可解释性,并通过利用LVLMs的少量样本能力,我们大大降低了标注成本。我们通过四个医疗数据集和十二个(通用和医疗)LVLMs的广泛实验验证了我们的方法,并表明CBVLM在不需要任何训练和仅使用少量标注样本的情况下,始终优于CBMs和特定任务监督方法。更多信息请参见我们的项目页面:https://cristianopatricio.github.io/CBVLM/。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
Summary
本文介绍了在医疗工作流中采用基于深度学习的解决方案时面临的主要挑战,即标注数据的可用性和系统解释性的缺乏。概念瓶颈模型(CBMs)通过在一组预定义和可解释的概念上约束疾病预测来解决后者的问题。然而,通过概念解释提高的可解释性意味着更高的标注负担,并且如果需要添加新概念,则需要重新训练整个系统。受大型视觉语言模型(LVLMs)在少样本设置中的出色性能的启发,本文提出了一种简单而有效的方法——CBVLM,该方法解决了上述两个挑战。CBVLM首先通过LVLM判断输入图像中是否存在每个概念,然后根据之前的概念预测对图像进行分类。此外,两个阶段都引入了检索模块,负责选择最佳的上下文学习示例。通过将最终诊断结果基于预测的概念来确保解释性,并利用LVLMs的少量样本能力来大幅降低标注成本。经过在四个医疗数据集和十二个(通用和医疗)LVLMs上的广泛实验验证,结果表明CBVLM持续优于CBMs和任务特定的监督方法,而且无需任何训练,只需使用少量标注样本。
Key Takeaways
- 深度学习方法在医疗工作流中的采纳面临标注数据可用性和系统解释性的挑战。
- 概念瓶颈模型(CBMs)通过约束疾病预测在预定义概念上解决解释性问题,但增加了标注负担和重新训练需求。
- CBVLM方法结合大型视觉语言模型(LVLMs)解决上述挑战。
- CBVLM利用LVLMs进行概念预测和图像分类,确保解释性并降低标注成本。
- CBVLM在四个医疗数据集上表现优越,持续优于CBMs和任务特定监督方法。
- CBVLM方法不需要任何训练,仅使用少量标注样本即可实现高性能。
点此查看论文截图

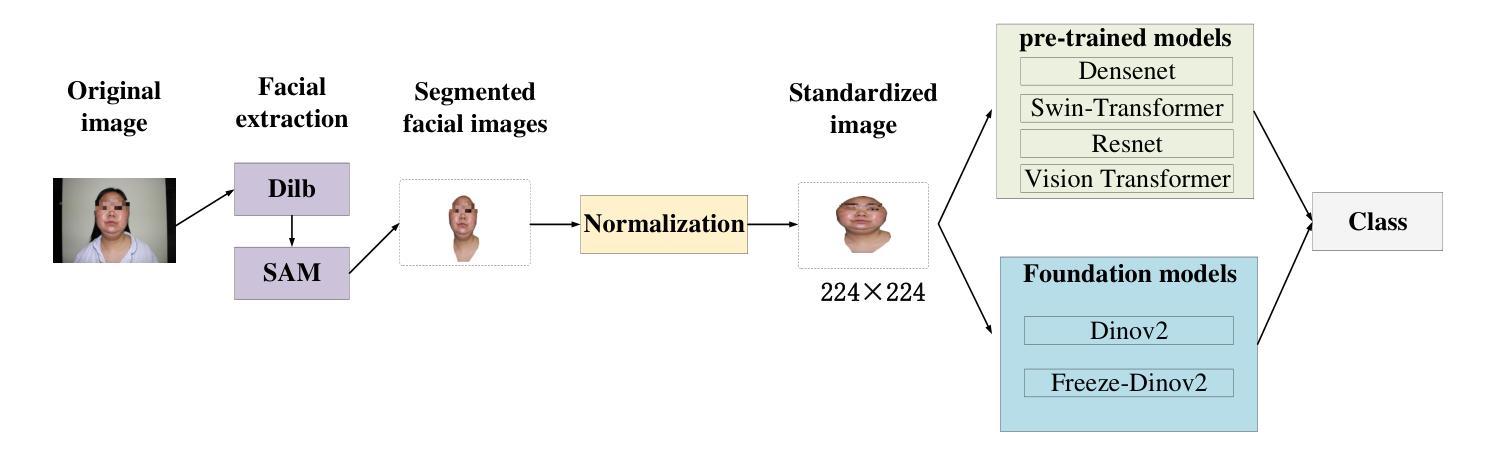
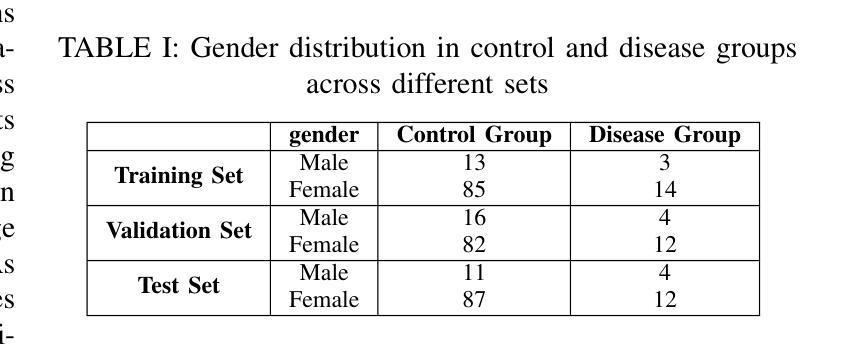
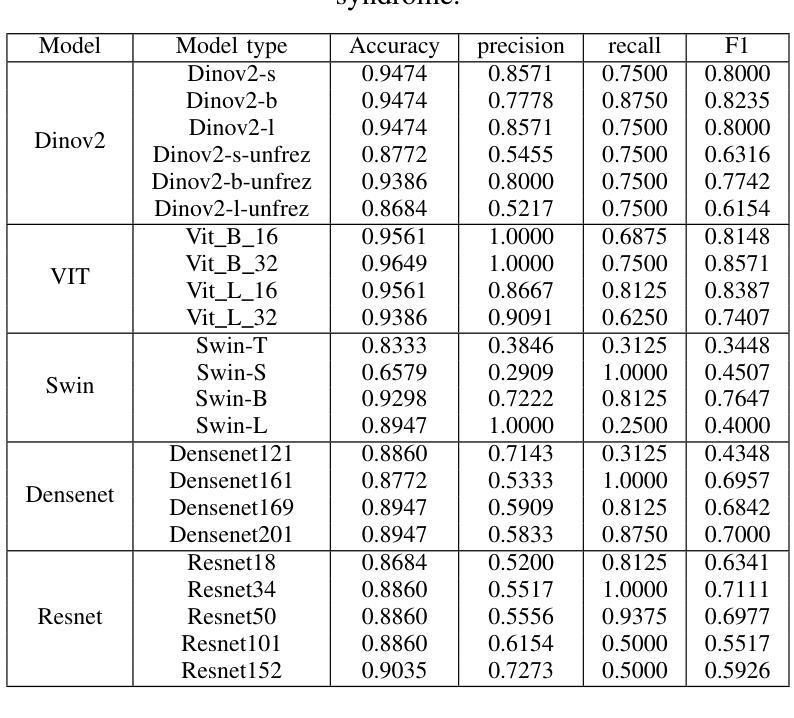
Comparative Analysis of Pre-trained Deep Learning Models and DINOv2 for Cushing’s Syndrome Diagnosis in Facial Analysis
Authors:Hongjun Liu, Changwei Song, Jiaqi Qiang, Jianqiang Li, Hui Pan, Lin Lu, Xiao Long, Qing Zhao, Jiuzuo Huang, Shi Chen
Cushing’s syndrome is a condition caused by excessive glucocorticoid secretion from the adrenal cortex, often manifesting with moon facies and plethora, making facial data crucial for diagnosis. Previous studies have used pre-trained convolutional neural networks (CNNs) for diagnosing Cushing’s syndrome using frontal facial images. However, CNNs are better at capturing local features, while Cushing’s syndrome often presents with global facial features. Transformer-based models like ViT and SWIN, which utilize self-attention mechanisms, can better capture long-range dependencies and global features. Recently, DINOv2, a foundation model based on visual Transformers, has gained interest. This study compares the performance of various pre-trained models, including CNNs, Transformer-based models, and DINOv2, in diagnosing Cushing’s syndrome. We also analyze gender bias and the impact of freezing mechanisms on DINOv2. Our results show that Transformer-based models and DINOv2 outperformed CNNs, with ViT achieving the highest F1 score of 85.74%. Both the pre-trained model and DINOv2 had higher accuracy for female samples. DINOv2 also showed improved performance when freezing parameters. In conclusion, Transformer-based models and DINOv2 are effective for Cushing’s syndrome classification.
库欣综合征是由肾上腺皮质过度分泌糖皮质激素引起的疾病,通常表现为满月脸和水牛背,使得面部数据对诊断至关重要。以往的研究使用预训练的卷积神经网络(CNNs)通过正面面部图像诊断库欣综合征。然而,CNN更擅长捕捉局部特征,而库欣综合征通常表现为面部整体特征。基于Transformer的模型,如ViT和SWIN,利用自注意力机制,可以更好地捕捉长距离依赖关系和全局特征。最近,基于视觉Transformer的DINOv2这一基础模型引起了人们的关注。本研究比较了包括CNN、基于Transformer的模型和DINOv2在内的各种预训练模型在诊断库欣综合征方面的性能。我们还分析了性别偏见以及冻结机制对DINOv2的影响。结果表明,基于Transformer的模型和DINOv2在库欣综合征诊断上的性能优于CNN,其中ViT的F1得分最高,达到85.74%。无论是预训练模型还是DINOv2,对女性样本的准确率都较高。冻结参数后,DINOv2的性能也有所提高。综上所述,基于Transformer的模型和DINOv2在库欣综合征分类中效果显著。
论文及项目相关链接
Summary:
本文研究了使用不同预训练模型诊断库欣综合征的性能,包括卷积神经网络(CNNs)、基于Transformer的模型和DINOv2模型。研究表明,基于Transformer的模型和DINOv2在诊断库欣综合征方面的性能优于CNNs,其中ViT获得了最高的F1分数。同时,研究发现女性样本的准确率更高,冻结机制对DINOv2的性能也有积极影响。
Key Takeaways:
- 库欣综合征是由肾上腺皮质过度分泌糖皮质激素引起的,面部数据对其诊断至关重要。
- 之前的研究使用预训练的卷积神经网络(CNNs)进行库欣综合征的诊断,但CNNs更擅长捕捉局部特征,而库欣综合征通常表现为全局面部特征。
- 基于Transformer的模型(如ViT和SWIN)使用自注意力机制,能更好地捕捉长距离依赖关系和全局特征。
- DINOv2模型在诊断库欣综合征方面的性能得到了研究。
- 研究比较了包括CNNs、基于Transformer的模型和DINOv2在内的不同预训练模型在诊断库欣综合征方面的性能。
- 基于Transformer的模型和DINOv2在诊断库欣综合征方面优于CNNs,ViT获得最高F1分数85.74%。
点此查看论文截图

A generalizable 3D framework and model for self-supervised learning in medical imaging
Authors:Tony Xu, Sepehr Hosseini, Chris Anderson, Anthony Rinaldi, Rahul G. Krishnan, Anne L. Martel, Maged Goubran
Current self-supervised learning methods for 3D medical imaging rely on simple pretext formulations and organ- or modality-specific datasets, limiting their generalizability and scalability. We present 3DINO, a cutting-edge SSL method adapted to 3D datasets, and use it to pretrain 3DINO-ViT: a general-purpose medical imaging model, on an exceptionally large, multimodal, and multi-organ dataset of ~100,000 3D medical imaging scans from over 10 organs. We validate 3DINO-ViT using extensive experiments on numerous medical imaging segmentation and classification tasks. Our results demonstrate that 3DINO-ViT generalizes across modalities and organs, including out-of-distribution tasks and datasets, outperforming state-of-the-art methods on the majority of evaluation metrics and labeled dataset sizes. Our 3DINO framework and 3DINO-ViT will be made available to enable research on 3D foundation models or further finetuning for a wide range of medical imaging applications.
当前用于三维医学影像的自我监督学习方法依赖于简单的预文本制定和特定器官或特定模态的数据集,这限制了其通用性和可扩展性。我们提出了适用于三维数据集的尖端SSL方法3DINO,并使用它来预训练面向医学影像的三维通用模型3DINO-ViT。该模型在一个包含超过十万个来自超过十个器官的三维医学影像扫描的大型多模态多器官数据集上进行训练。我们通过大量医学影像分割和分类任务的实验验证了3DINO-ViT的有效性。我们的结果表明,无论是在跨模态和器官的情况下,还是在离群任务和数据集的情况下,该模型都表现出很强的泛化能力,并在大多数评估指标和标注数据集大小上优于最新方法。我们的3DINO框架和3DINO-ViT模型将开放给公众使用,以供进行关于三维基础模型的研究,或对一系列医学影像应用进行进一步微调。
论文及项目相关链接
Summary
本文介绍了针对3D数据集的自监督学习方法3DINO,并利用其预训练了一个通用的医学影像模型3DINO-ViT。该模型在多模态、多器官的大型数据集上进行训练,可以在众多医学影像分割和分类任务中进行验证。实验结果证明了该模型在跨模态和器官、包括超出分布的任务和数据集上的泛化能力,并在多数评估指标和标注数据集大小上优于现有方法。本文提供的3DINO框架和3DINO-ViT将促进对3D基础模型的研究及其在医学影像应用中的进一步微调。
Key Takeaways
- 当前自监督学习方法在3D医学影像处理上存在局限性,需要一种适用于大规模数据集的方法。
- 提出了一种名为3DINO的自监督学习方法,专门用于处理大规模的三维数据集。此方法特别适用于医学影像数据。
- 利用3DINO方法预训练了一个医学影像模型——3DINO-ViT,旨在实现多模态和多器官的泛化能力。该模型训练数据集规模庞大,包括超过百万个医学扫描样本。
- 通过一系列医学影像分割和分类任务验证了模型的性能。证明了该模型在跨模态和器官、不同数据集上的泛化能力优于当前先进技术。实验结果显示出该模型在不同评估指标上的优势。此外,模型在标注数据集大小上表现优越。这表明即使在有限的数据条件下,该模型也能表现出良好的性能。
- 该研究提供的模型框架和预训练模型(即3DINO-ViT)将促进后续研究,为医学图像分析领域提供强大的工具,包括用于构建更强大的基础模型或针对特定任务的微调等应用。这表明该研究具有广泛的应用前景和潜在价值。该研究为医学影像分析领域开辟了新的可能性,包括提高诊断准确性、推动个性化医疗等方面的发展。
点此查看论文截图

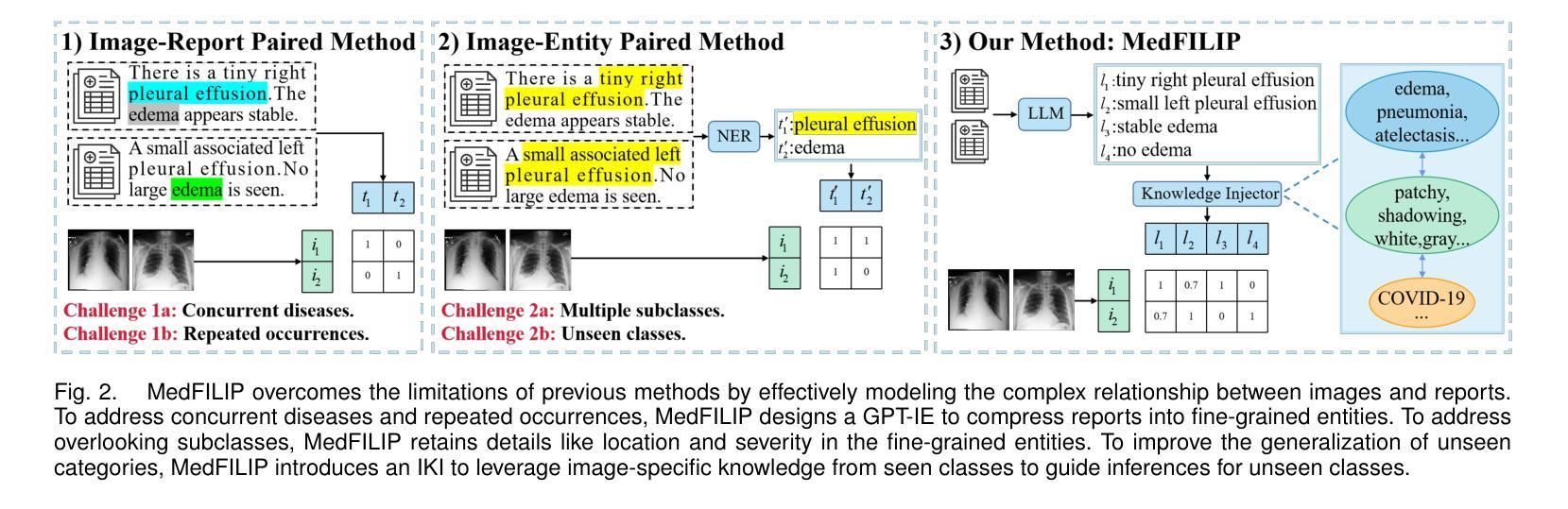
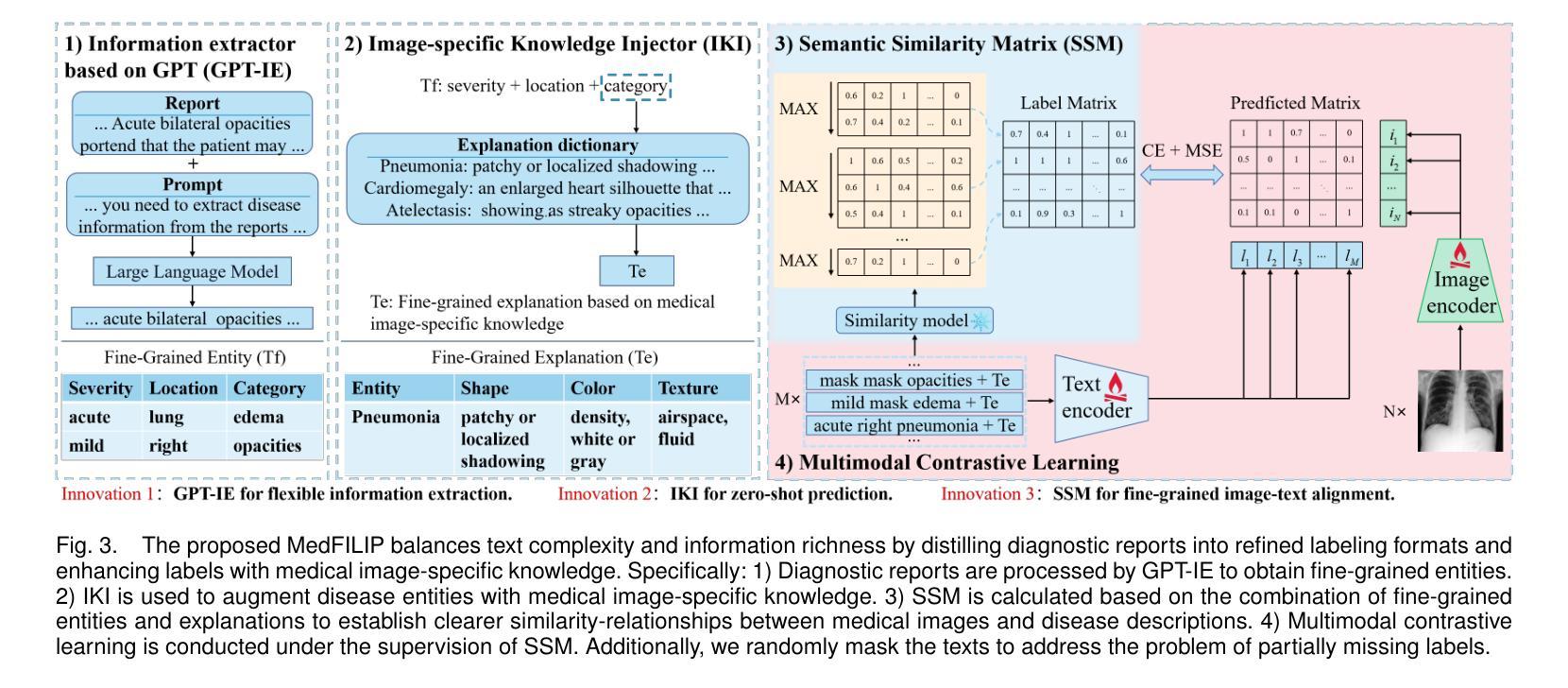
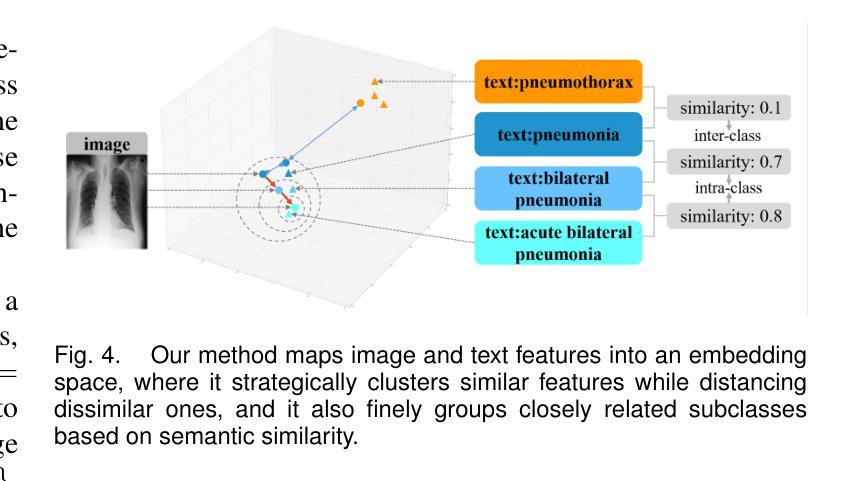
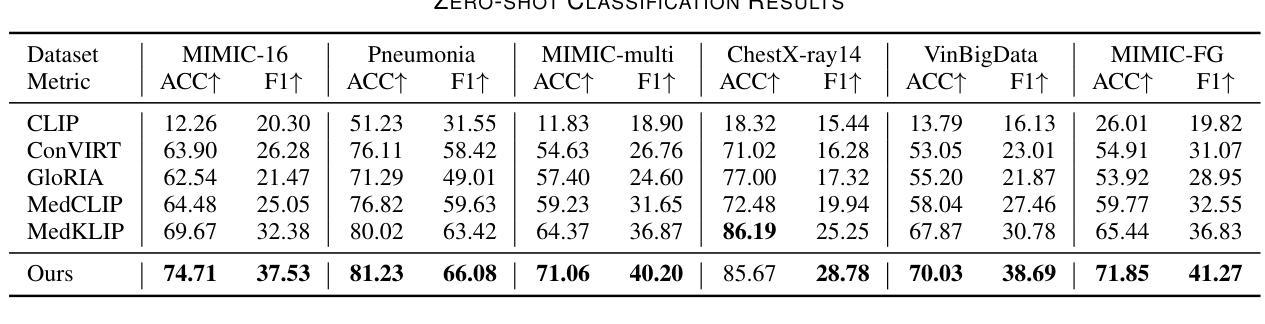
MedFILIP: Medical Fine-grained Language-Image Pre-training
Authors:Xinjie Liang, Xiangyu Li, Fanding Li, Jie Jiang, Qing Dong, Wei Wang, Kuanquan Wang, Suyu Dong, Gongning Luo, Shuo Li
Medical vision-language pretraining (VLP) that leverages naturally-paired medical image-report data is crucial for medical image analysis. However, existing methods struggle to accurately characterize associations between images and diseases, leading to inaccurate or incomplete diagnostic results. In this work, we propose MedFILIP, a fine-grained VLP model, introduces medical image-specific knowledge through contrastive learning, specifically: 1) An information extractor based on a large language model is proposed to decouple comprehensive disease details from reports, which excels in extracting disease deals through flexible prompt engineering, thereby effectively reducing text complexity while retaining rich information at a tiny cost. 2) A knowledge injector is proposed to construct relationships between categories and visual attributes, which help the model to make judgments based on image features, and fosters knowledge extrapolation to unfamiliar disease categories. 3) A semantic similarity matrix based on fine-grained annotations is proposed, providing smoother, information-richer labels, thus allowing fine-grained image-text alignment. 4) We validate MedFILIP on numerous datasets, e.g., RSNA-Pneumonia, NIH ChestX-ray14, VinBigData, and COVID-19. For single-label, multi-label, and fine-grained classification, our model achieves state-of-the-art performance, the classification accuracy has increased by a maximum of 6.69%. The code is available in https://github.com/PerceptionComputingLab/MedFILIP.
医疗视觉语言预训练(VLP)利用自然配对的医疗图像报告数据对医疗图像分析至关重要。然而,现有方法很难准确刻画图像与疾病之间的关联,导致诊断结果不准确或不完整。在这项工作中,我们提出了MedFILIP,这是一种精细的VLP模型,通过对比学习引入医疗图像特定知识,具体包括:1)提出一种基于大型语言模型的信息提取器,从报告中解耦出综合疾病细节,该提取器擅长通过灵活的提示工程提取疾病信息,从而有效减少文本复杂性,同时以微小成本保留丰富信息。2)提出了一种构建类别与视觉属性之间关系的知识注入器,帮助模型根据图像特征进行判断,并促进对不熟悉疾病类别的知识推断。3)提出了一种基于精细注释的语义相似度矩阵,提供更平滑、信息更丰富的标签,从而实现精细的图像文本对齐。4)我们在多个数据集上验证了MedFILIP的效果,例如RSNA-Pneumonia、NIH ChestX-ray14、VinBigData和COVID-19。对于单标签、多标签和精细分类,我们的模型实现了最先进的性能,分类准确率最高提高了6.69%。代码可在https://github.com/PerceptionComputingLab/MedFILIP中获取。
论文及项目相关链接
PDF 10 pages, 5 figures, IEEE Journal of Biomedical and Health Informatics 2025
Summary:
医疗领域视觉语言预训练(VLP)对医疗图像分析至关重要,但现有方法难以准确描述图像与疾病之间的关联,导致诊断结果不准确或不完整。本研究提出MedFILIP,一种精细的VLP模型,通过对比学习引入医疗图像特定知识。包括提出基于大型语言模型的信息提取器,有效减少文本复杂度并保留丰富信息;构建类别与视觉属性之间关系的知识注入器,帮助模型基于图像特征进行判断,并对未知疾病类别进行知识推断;以及基于精细注释的语义相似性矩阵,提供平滑、信息丰富的标签,实现精细的图像文本对齐。在多个数据集上验证,MedFILIP在单标签、多标签和精细分类任务上实现最佳性能,分类准确率最高提升6.69%。
Key Takeaways:
- 医疗视觉语言预训练(VLP)在医疗图像分析中很重要。
- 现有方法难以准确描述图像与疾病之间的关联。
- MedFILIP模型通过对比学习引入医疗图像特定知识。
- 信息提取器能够减少文本复杂度并保留丰富信息。
- 知识注入器帮助模型构建类别和视觉属性之间的关系。
- 语义相似性矩阵提供平滑、信息丰富的标签,实现图像文本精细对齐。
- MedFILIP在多个数据集上实现最佳性能,分类准确率有所提升。
点此查看论文截图

ClusterViG: Efficient Globally Aware Vision GNNs via Image Partitioning
Authors:Dhruv Parikh, Jacob Fein-Ashley, Tian Ye, Rajgopal Kannan, Viktor Prasanna
Convolutional Neural Networks (CNN) and Vision Transformers (ViT) have dominated the field of Computer Vision (CV). Graph Neural Networks (GNN) have performed remarkably well across diverse domains because they can represent complex relationships via unstructured graphs. However, the applicability of GNNs for visual tasks was unexplored till the introduction of Vision GNNs (ViG). Despite the success of ViGs, their performance is severely bottlenecked due to the expensive $k$-Nearest Neighbors ($k$-NN) based graph construction. Recent works addressing this bottleneck impose constraints on the flexibility of GNNs to build unstructured graphs, undermining their core advantage while introducing additional inefficiencies. To address these issues, in this paper, we propose a novel method called Dynamic Efficient Graph Convolution (DEGC) for designing efficient and globally aware ViGs. DEGC partitions the input image and constructs graphs in parallel for each partition, improving graph construction efficiency. Further, DEGC integrates local intra-graph and global inter-graph feature learning, enabling enhanced global context awareness. Using DEGC as a building block, we propose a novel CNN-GNN architecture, ClusterViG, for CV tasks. Extensive experiments indicate that ClusterViG reduces end-to-end inference latency for vision tasks by up to $5\times$ when compared against a suite of models such as ViG, ViHGNN, PVG, and GreedyViG, with a similar model parameter count. Additionally, ClusterViG reaches state-of-the-art performance on image classification, object detection, and instance segmentation tasks, demonstrating the effectiveness of the proposed globally aware learning strategy. Finally, input partitioning performed by DEGC enables ClusterViG to be trained efficiently on higher-resolution images, underscoring the scalability of our approach.
卷积神经网络(CNN)和视觉转换器(ViT)在计算机视觉(CV)领域占据主导地位。图神经网络(GNN)在不同的领域表现优异,因为它们可以通过非结构化的图来表示复杂的关系。然而,直到引入视觉图神经网络(ViG),图神经网络在视觉任务上的应用尚未得到探索。尽管ViG取得了成功,但由于基于昂贵的k近邻(k-NN)的图构建,其性能受到了严重限制。最近的工作解决这个瓶颈对图神经网络的灵活性施加约束,以构建非结构化图,这削弱了其核心竞争力并引入了额外的效率问题。针对这些问题,本文提出了一种名为动态高效图卷积(DEGC)的新方法,用于设计高效且全局感知的ViG。DEGC对输入图像进行分区,并为每个分区并行构建图,提高图构建效率。此外,DEGC结合了局部图内和全局图间特征学习,增强了全局上下文感知能力。使用DEGC作为构建块,我们提出了用于计算机视觉任务的新型CNN-GNN架构ClusterViG。大量实验表明,与ViG、ViHGNN、PVG和GreedyViG等一系列模型相比,ClusterViG在视觉任务的端到端推理延迟方面减少了高达5倍,具有相似的模型参数计数。此外,ClusterViG在图像分类、对象检测和实例分割任务上达到了最新技术性能,证明了所提出的全局感知学习策略的有效性。最后,DEGC执行的输入分区使ClusterViG能够在更高的分辨率图像上进行高效训练,凸显了我们方法的可扩展性。
论文及项目相关链接
PDF Preprint
摘要
本文提出一种名为动态高效图卷积(DEGC)的新方法,用于设计高效且全局感知的视力图神经网络(ViG)。该方法对输入图像进行分区,并行构建每个分区的图,提高图构建效率。DEGC结合了局部图内和全局图间特征学习,增强了全局上下文感知能力。使用DEGC作为构建块,本文提出了一种新型的卷积神经网络-图神经网络架构ClusterViG,用于计算机视觉任务。实验表明,与一系列模型相比,ClusterViG在端到端的视觉任务推理时间上减少了高达5倍,同时达到了图像分类、目标检测和实例分割任务的最新性能水平,证明了全局感知学习策略的有效性。
关键见解
- 论文提出了动态高效图卷积(DEGC)方法,用于设计更为高效的视力图神经网络(ViG)。
- DEGC通过对输入图像进行分区并并行构建图,提高了图构建的效率。
- DEGC结合了局部和全局特征学习,增强了全局上下文感知能力。
- 论文提出了新型的卷积神经网络-图神经网络架构ClusterViG。
- 与其他模型相比,ClusterViG在视觉任务推理时间上减少了高达5倍。
- ClusterViG在图像分类、目标检测和实例分割任务上达到了最新性能水平。
- 输入图像的分区使得ClusterViG能够在更高的分辨率图像上进行有效的训练,显示了其可扩展性。
点此查看论文截图






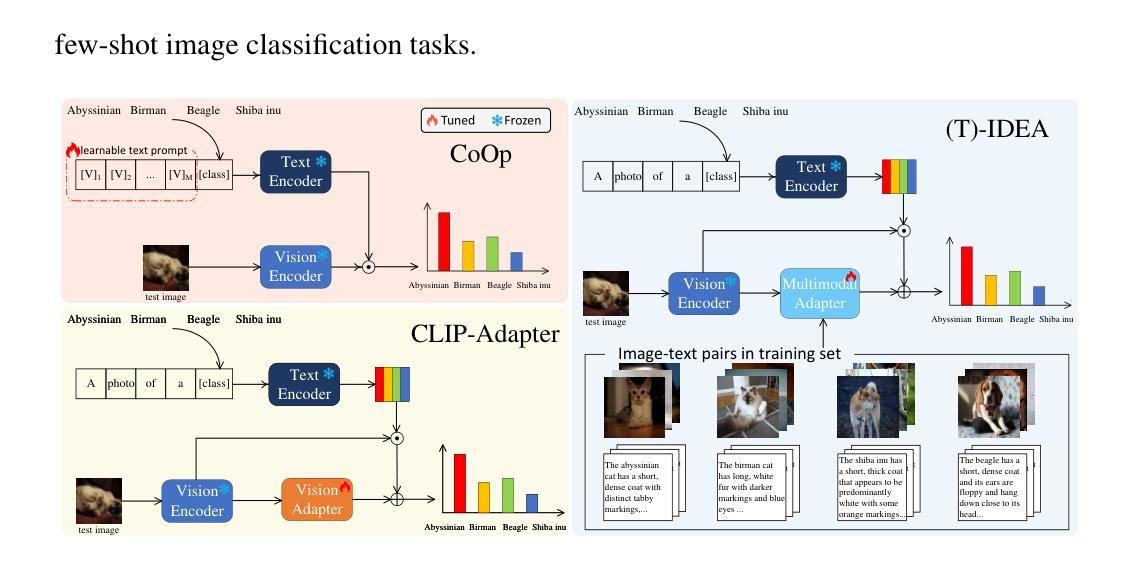
IDEA: Image Description Enhanced CLIP-Adapter
Authors:Zhipeng Ye, Feng Jiang, Qiufeng Wang, Kaizhu Huang, Jiaqi Huang
CLIP (Contrastive Language-Image Pre-training) has attained great success in pattern recognition and computer vision. Transferring CLIP to downstream tasks (e.g. zero- or few-shot classification) is a hot topic in multimodal learning. However, current studies primarily focus on either prompt learning for text or adapter tuning for vision, without fully exploiting the complementary information and correlations among image-text pairs. In this paper, we propose an Image Description Enhanced CLIP-Adapter (IDEA) method to adapt CLIP to few-shot image classification tasks. This method captures fine-grained features by leveraging both visual features and textual descriptions of images. IDEA is a training-free method for CLIP, and it can be comparable to or even exceeds state-of-the-art models on multiple tasks. Furthermore, we introduce Trainable-IDEA (T-IDEA), which extends IDEA by adding two lightweight learnable components (i.e., a projector and a learnable latent space), further enhancing the model’s performance and achieving SOTA results on 11 datasets. As one important contribution, we employ the Llama model and design a comprehensive pipeline to generate textual descriptions for images of 11 datasets, resulting in a total of 1,637,795 image-text pairs, named “IMD-11”. Our code and data are released at https://github.com/FourierAI/IDEA.
CLIP(对比语言图像预训练)在模式识别和计算机视觉领域取得了巨大的成功。将CLIP应用于下游任务(例如零样本或小样本分类)是多模态学习的热门话题。然而,当前的研究主要关注文本提示学习或视觉适配器调整,而没有充分利用图像文本对之间的互补信息和关联。在本文中,我们提出了一种图像描述增强CLIP适配器(IDEA)方法,将CLIP适应于小样本图像分类任务。该方法通过利用图像的视觉特征和文本描述来捕捉精细特征。IDEA是一种无需训练的CLIP方法,它在多个任务上的表现可与最先进的模型相当,甚至超过它们。此外,我们引入了可训练的IDEA(T-IDEA),它通过添加两个轻量级的学习组件(即投影器和可学习的潜在空间)来扩展IDEA,进一步提高了模型的性能,并在11个数据集上实现了最新结果。作为一项重要贡献,我们采用了Llama模型,并设计了一个全面的流程来生成这11个数据集的图像文本描述,共生成了1,637,795个图像文本对,名为“IMD-11”。我们的代码和数据已在https://github.com/FourierAI/IDEA上发布。
论文及项目相关链接
Summary
CLIP在多模态学习中备受关注,本文提出了一种基于图像描述增强的CLIP适配器(IDEA)方法,用于适应少量图像分类任务。该方法利用视觉特征和图像文本描述来捕捉精细特征,无需训练CLIP即可与最新模型相比甚至超越。此外,本文还介绍了可训练的IDEA(T-IDEA),通过添加两个轻量级的学习组件(投影仪和学习潜在空间)进一步提高性能,并在11个数据集上达到最新结果。
Key Takeaways
- CLIP在模式识别和计算机视觉方面取得了巨大成功,在多模态学习中受到广泛关注。
- 当前研究主要关注文本提示学习或视觉适配器调整,但未充分利用图像文本对之间的互补信息和相关性。
- IDEA方法通过结合视觉特征和图像文本描述,适应少量图像分类任务,捕捉精细特征。
- IDEA是一种无需训练的CLIP方法,可在多个任务上与最新模型相比甚至超越。
- T-IDEA的引入进一步提高了IDEA的性能,通过在IDEA的基础上添加两个轻量级的学习组件(投影仪和学习潜在空间)。
- 在11个数据集上实现了最新结果,并释放了代码和数据。
点此查看论文截图

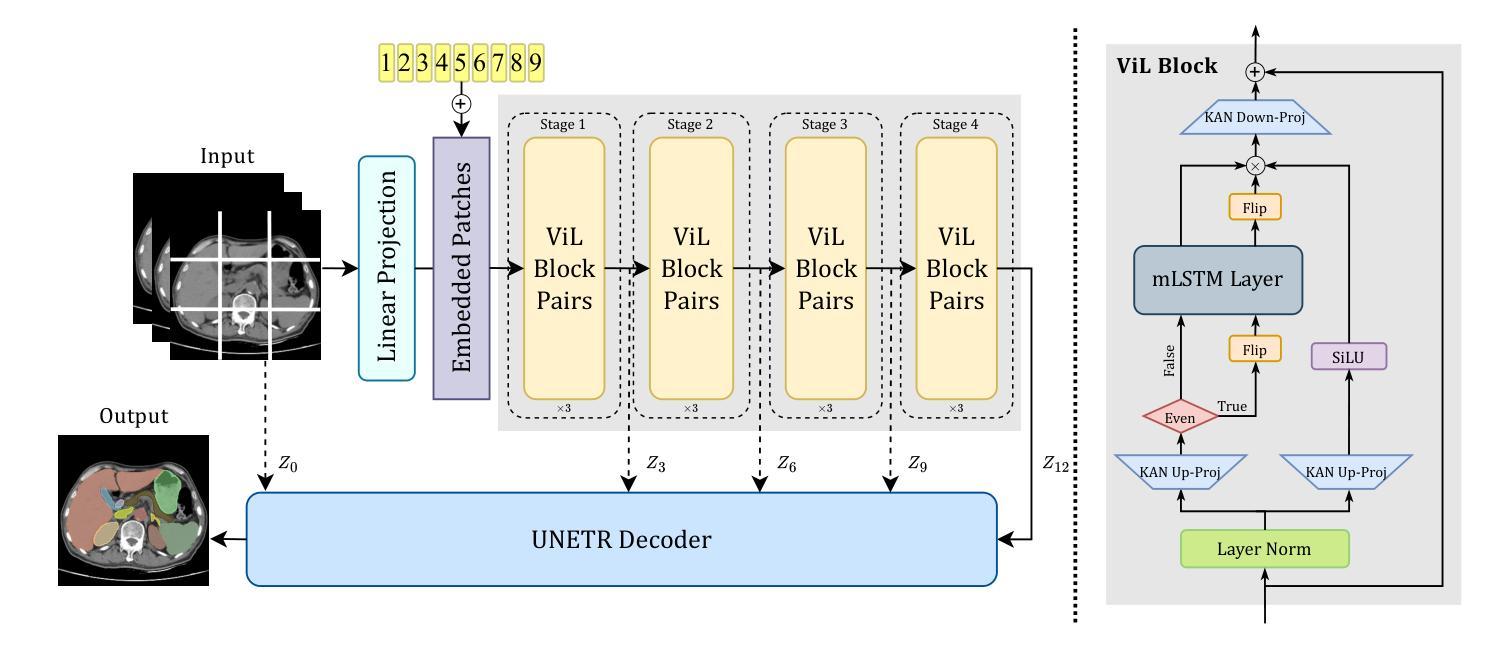
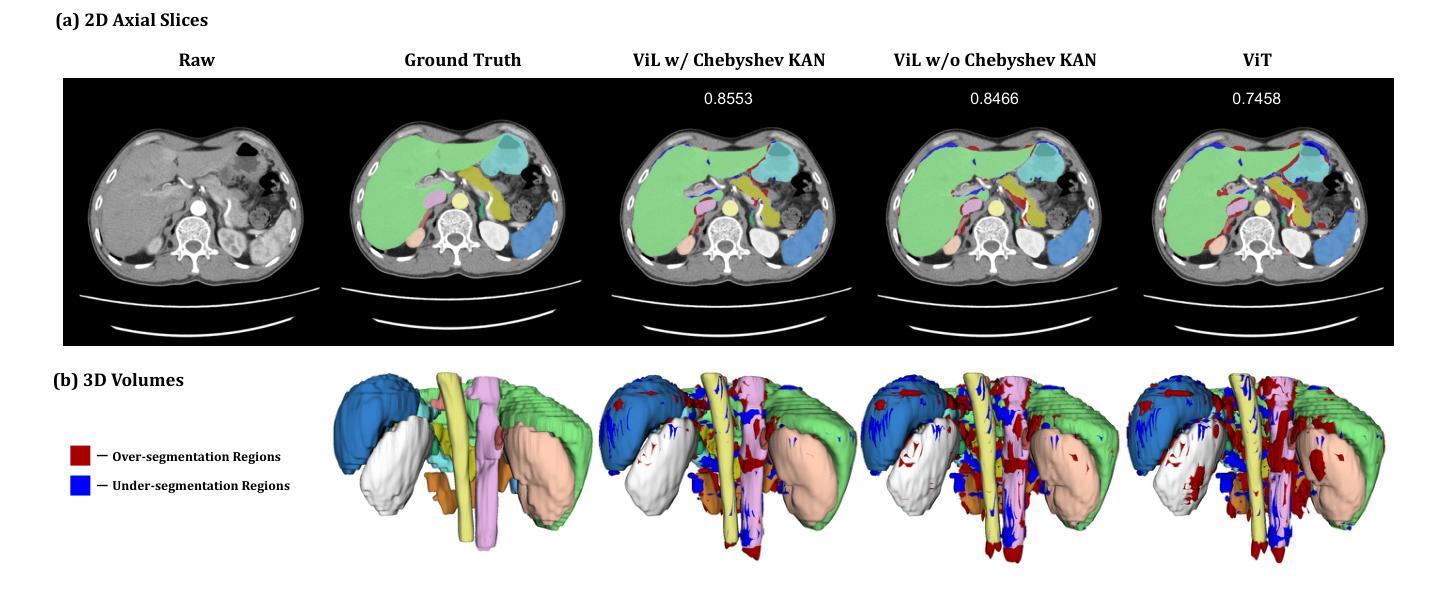
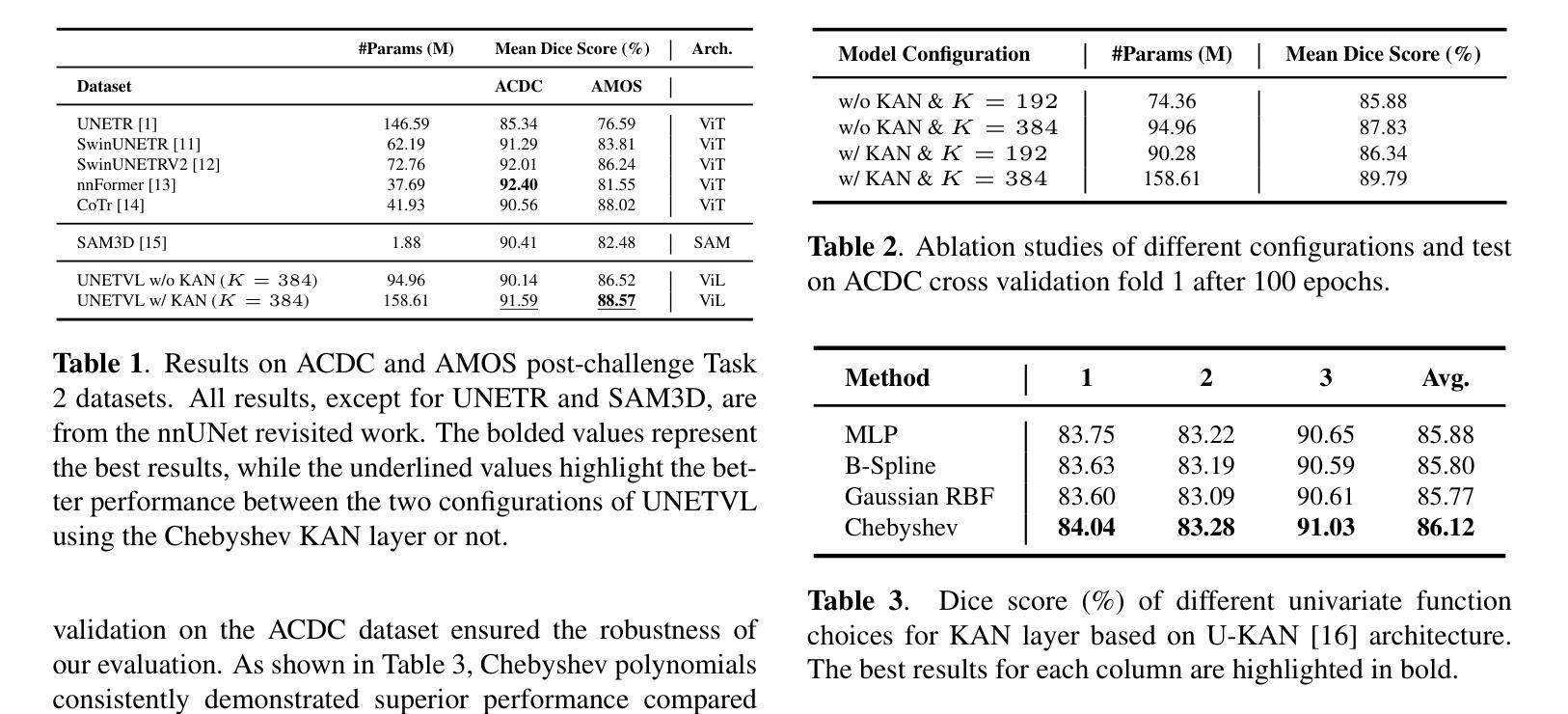
UNetVL: Enhancing 3D Medical Image Segmentation with Chebyshev KAN Powered Vision-LSTM
Authors:Xuhui Guo, Tanmoy Dam, Rohan Dhamdhere, Gourav Modanwal, Anant Madabhushi
3D medical image segmentation has progressed considerably due to Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), yet these methods struggle to balance long-range dependency acquisition with computational efficiency. To address this challenge, we propose UNETVL (U-Net Vision-LSTM), a novel architecture that leverages recent advancements in temporal information processing. UNETVL incorporates Vision-LSTM (ViL) for improved scalability and memory functions, alongside an efficient Chebyshev Kolmogorov-Arnold Networks (KAN) to handle complex and long-range dependency patterns more effectively. We validated our method on the ACDC and AMOS2022 (post challenge Task 2) benchmark datasets, showing a significant improvement in mean Dice score compared to recent state-of-the-art approaches, especially over its predecessor, UNETR, with increases of 7.3% on ACDC and 15.6% on AMOS, respectively. Extensive ablation studies were conducted to demonstrate the impact of each component in UNETVL, providing a comprehensive understanding of its architecture. Our code is available at https://github.com/tgrex6/UNETVL, facilitating further research and applications in this domain.
3D医学图像分割由于卷积神经网络(CNN)和视觉转换器(ViT)的发展而取得了显著进展,但这些方法在平衡远程依赖获取与计算效率方面遇到了困难。为了应对这一挑战,我们提出了UNETVL(U-Net Vision-LSTM)这一新型架构,该架构利用最新的时序信息处理技术的优势。UNETVL结合了视觉LSTM(ViL)以提高可扩展性和内存功能,同时采用高效的切比雪夫-柯尔莫哥洛夫-阿诺尔德网络(KAN),更有效地处理复杂且远程依赖模式。我们在ACDC和AMOS2022(后挑战任务2)基准数据集上验证了我们的方法,相较于最新的最先进方法,特别是在其前身UNETR上,Dice系数的平均得分有了显著提高,ACDC上提高了7.3%,AMOS上提高了15.6%。进行了广泛的消融研究,以展示UNETVL中每个组件的影响,对其架构提供了全面的理解。我们的代码可在https://github.com/tgrex6/UNETVL找到,为这一领域的进一步研究和应用提供了便利。
论文及项目相关链接
Summary
本文提出一种新型的医学图像分割架构UNETVL(U-Net Vision-LSTM),结合了卷积神经网络(CNNs)和视觉转换器(ViTs)的优势,通过引入Vision-LSTM增强可扩展性和记忆功能,并使用高效的切比雪夫柯尔莫哥洛夫-阿诺尔德网络(KAN)更有效地处理复杂和远程依赖模式。在ACDC和AMOS2022基准数据集上验证,该方法相对于最新先进技术有显著提升,特别是在ACDC上提升了7.3%,在AMOS上提升了15.6%。详尽的消融研究展示了UNETVL各组件的影响,为其架构提供了全面的理解。
Key Takeaways
- UNETVL结合了CNN和ViT的优势,针对医学图像分割领域进行了创新设计。
- Vision-LSTM的引入增强了模型的可扩展性和记忆功能。
- 切比雪夫柯尔莫哥洛夫-阿诺尔德网络(KAN)能更有效地处理复杂的远程依赖模式。
- 在ACDC和AMOS2022基准数据集上的实验结果证明了该方法的优越性。
- 与最新技术相比,UNETVL在ACDC和AMOS数据集上的表现均有显著提升。
- 消融研究展示了UNETVL架构中各个组件的重要性和影响。
点此查看论文截图

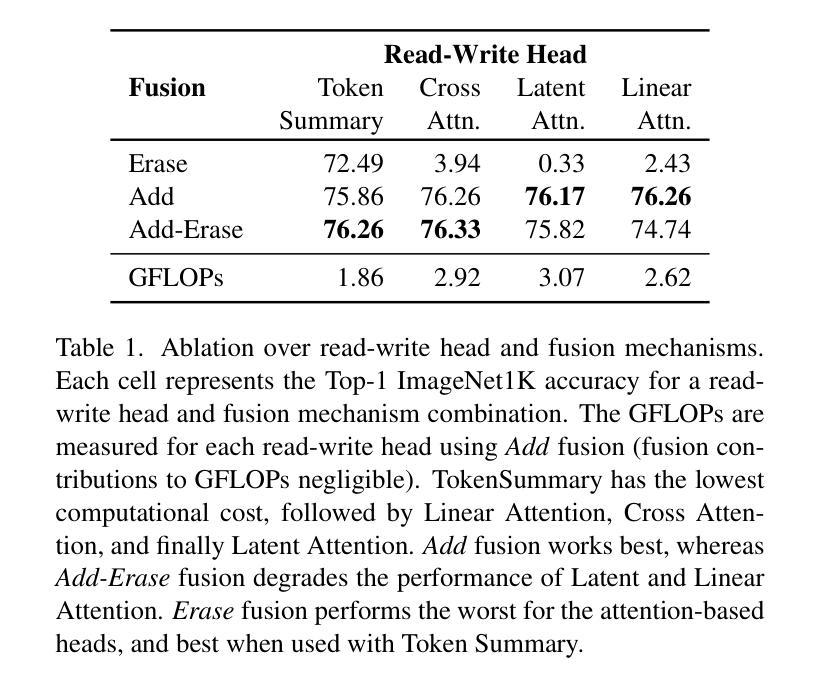
Token Turing Machines are Efficient Vision Models
Authors:Purvish Jajal, Nick John Eliopoulos, Benjamin Shiue-Hal Chou, George K. Thiravathukal, James C. Davis, Yung-Hsiang Lu
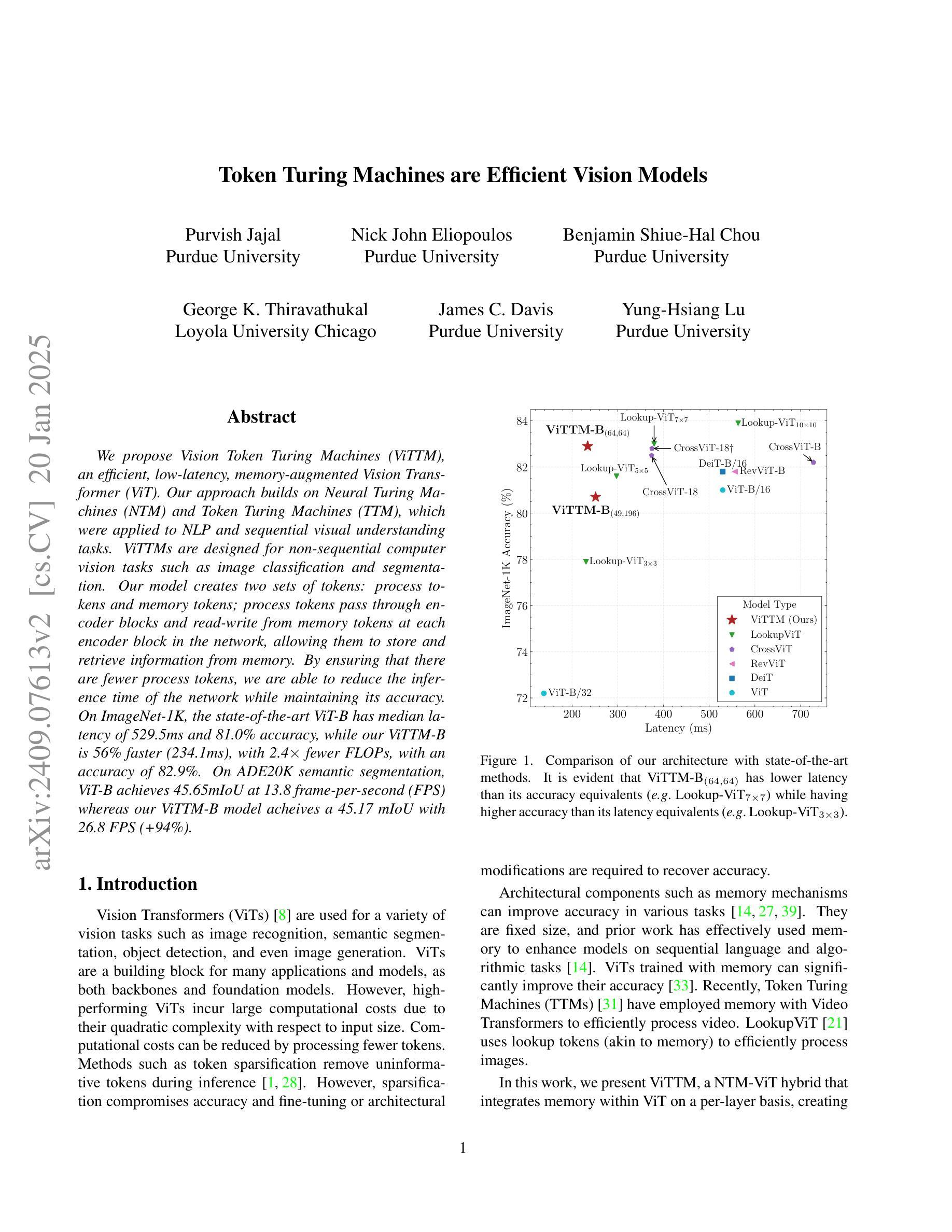
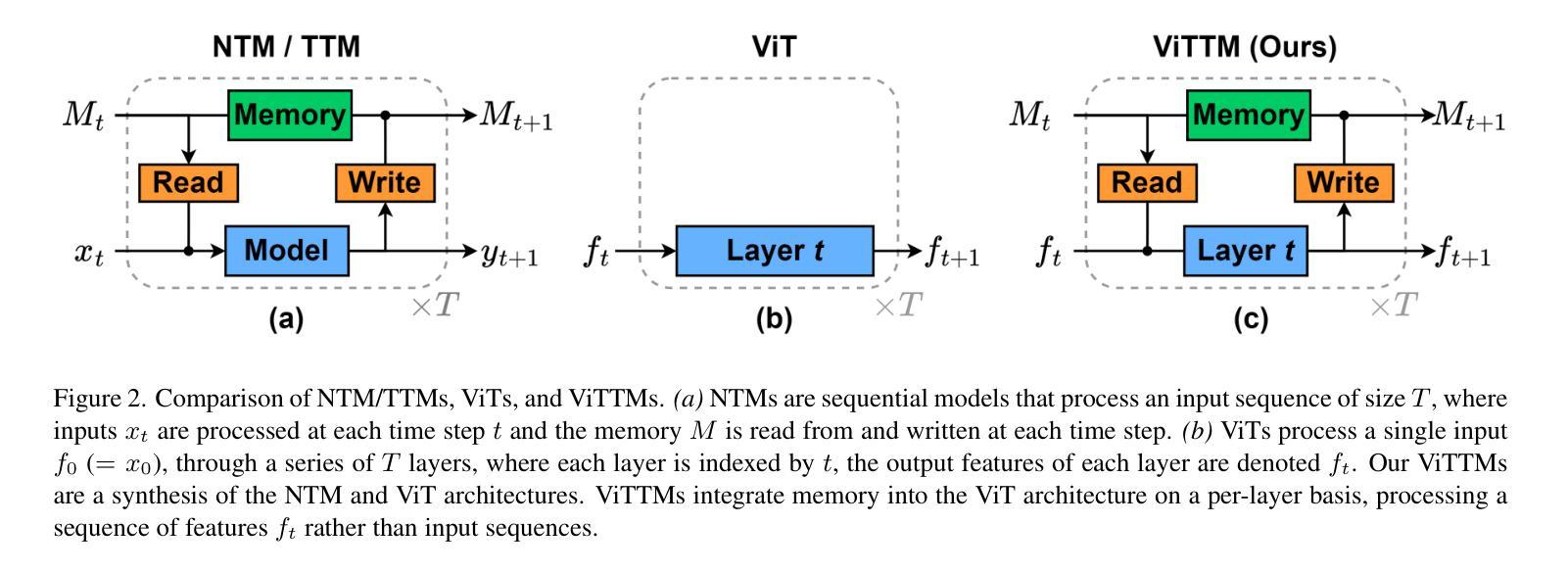
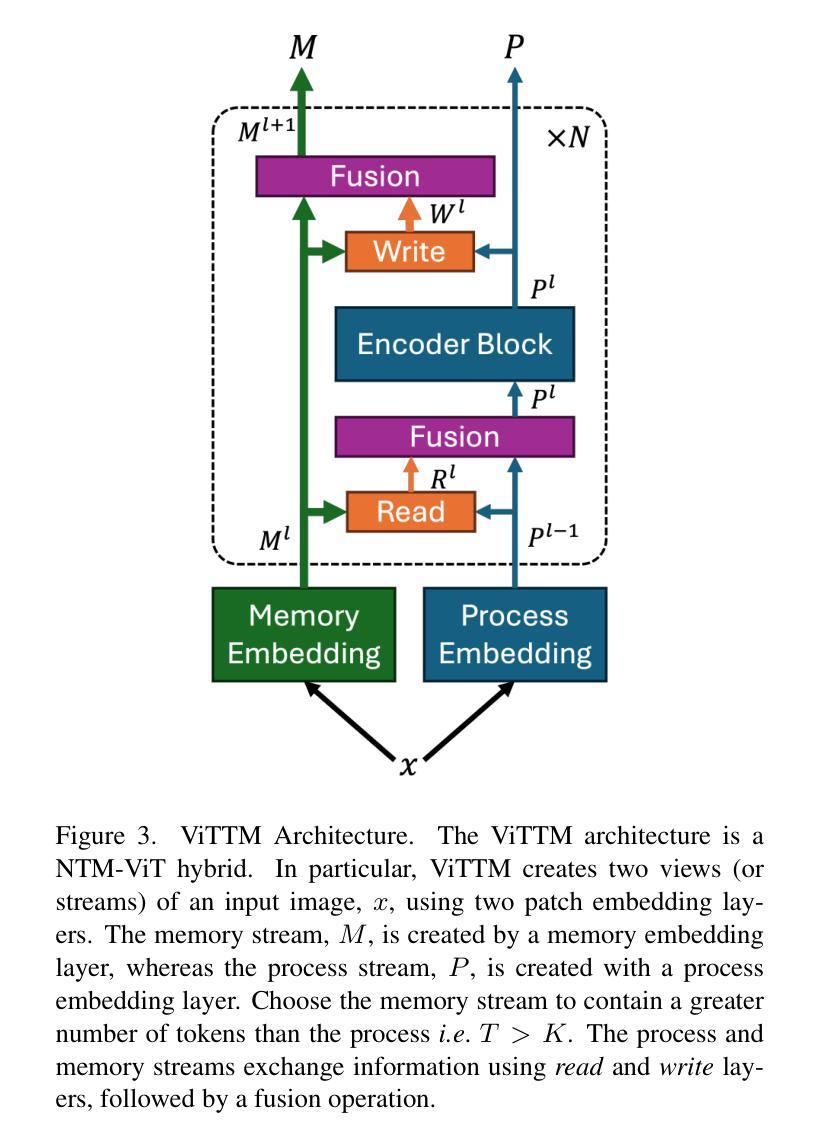
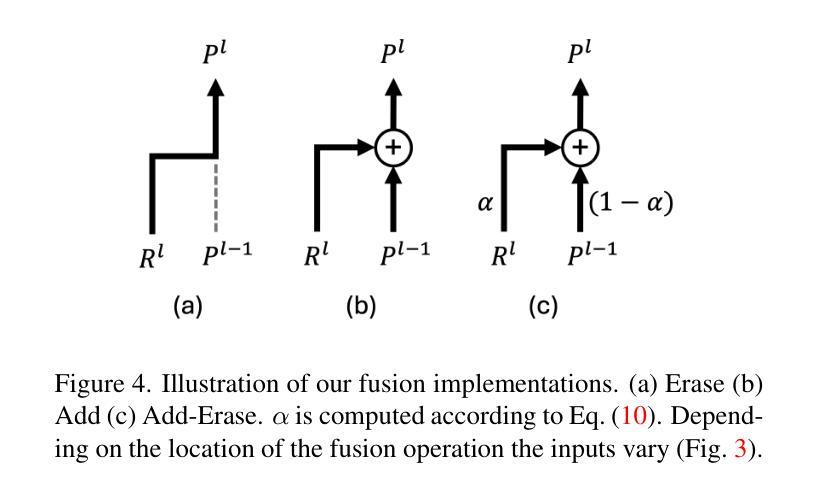
We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
我们提出了视觉令牌图灵机(Vision Token Turing Machines,简称ViTTM),这是一种高效、低延迟、增强记忆的视觉转换器(ViT)。我们的方法基于神经图灵机和令牌图灵机,后者被应用于自然语言处理和序列视觉理解任务。ViTTM被设计用于非序列计算机视觉任务,如图像分类和分割。我们的模型创建了两组令牌:处理令牌和内存令牌;处理令牌通过编码器块,并从网络中的每个编码器块读写内存令牌,允许它们从内存中存储和检索信息。通过确保处理令牌的数目少于内存令牌,我们能够在保持网络精度的同时减少其推理时间。在ImageNet-1K上,最先进的ViT-B具有529.5毫秒的中位延迟和81.0%的准确率,而我们的ViTTM-B更快(234.1毫秒),FLOPs减少了2.4倍,准确率达到了82.9%。在ADE20K语义分割任务上,ViT-B以每秒13.8帧的速度达到45.65 mIoU,而我们的ViTTM-B模型以每秒26.8帧的速度达到45.17 mIoU(+ 94%)。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
本文提出了Vision Token Turing Machines(ViTTM),这是一种高效、低延迟、带有记忆功能的Vision Transformer(ViT)。ViTTM借鉴了神经图灵机和令牌图灵机在NLP和视觉理解任务中的应用,专门用于非序列计算机视觉任务,如图像分类和分割。通过创建两组令牌:处理令牌和内存令牌,ViTTM能够在网络中从内存令牌读取和写入信息。通过确保处理令牌的数量少于内存令牌,我们能够在保持准确性的同时减少网络的推理时间。在ImageNet-1K上,ViTTM-B模型比先进的ViT-B模型更快、更有效率,并且准确性更高。在ADE20K语义分割任务上,ViTTM-B模型也表现出优异的性能。
Key Takeaways
- Vision Token Turing Machines (ViTTM) 是一种针对计算机视觉任务的改进模型,基于 Vision Transformer(ViT)。
- ViTTM借鉴了神经图灵机和令牌图灵机,特别适用于非序列计算机视觉任务,如图像分类和分割。
- ViTTM通过创建处理令牌和内存令牌两组,能够在网络中存储和检索信息。
- ViTTM能够减少网络的推理时间,同时通过确保处理令牌数量少于内存令牌来提高效率。
- 在ImageNet-1K图像分类任务上,ViTTM-B模型相比先进的ViT-B模型更快、更有效率,并且准确性更高。
- 在ADE20K语义分割任务上,ViTTM-B模型表现出优异的性能,与ViT-B模型相比具有更高的帧率和相似的mIoU。
点此查看论文截图
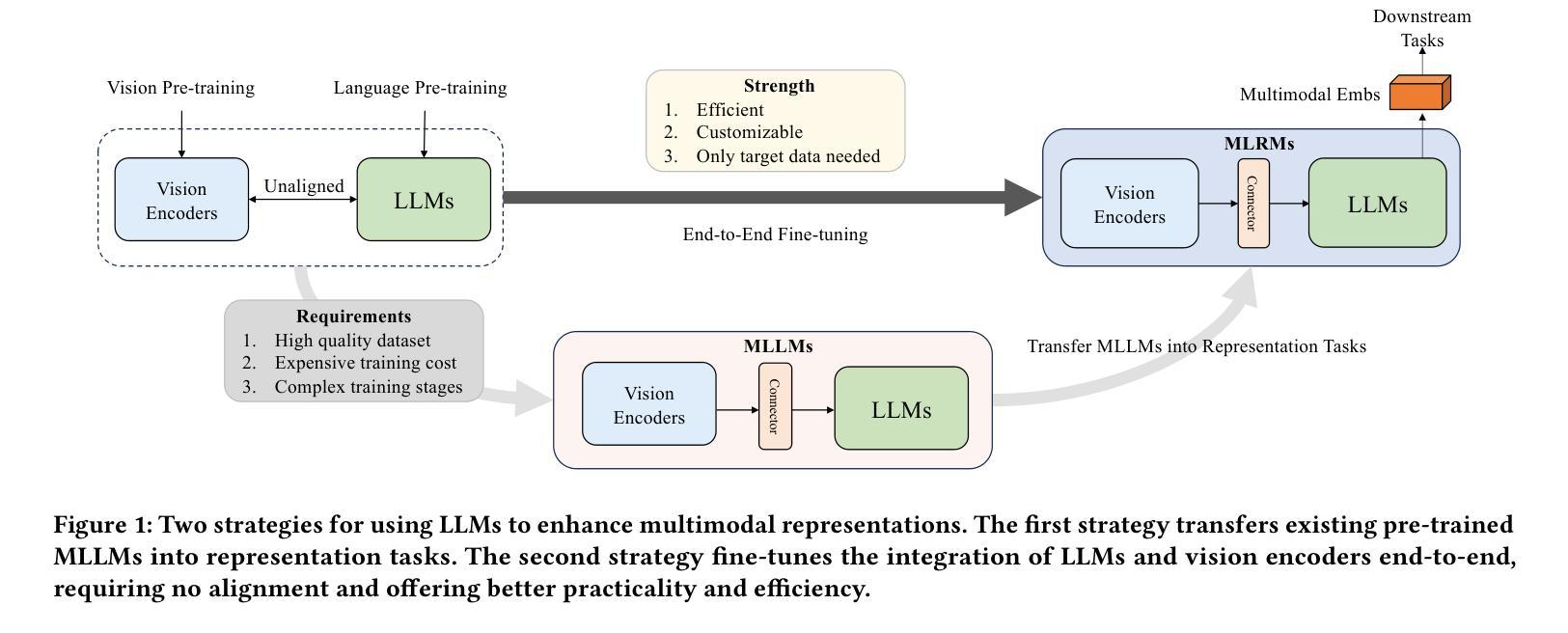
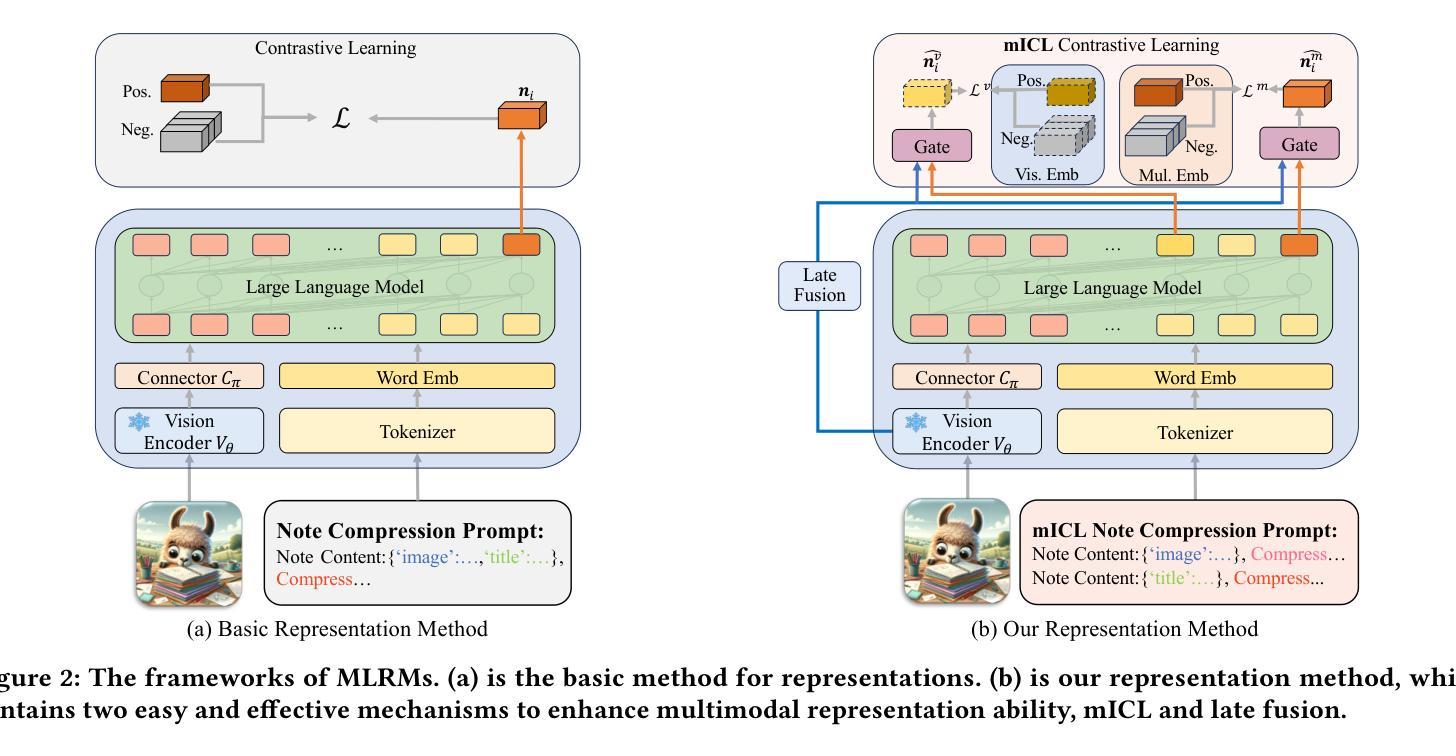
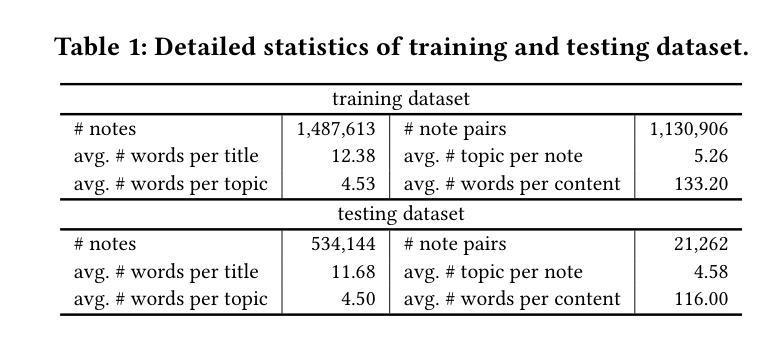
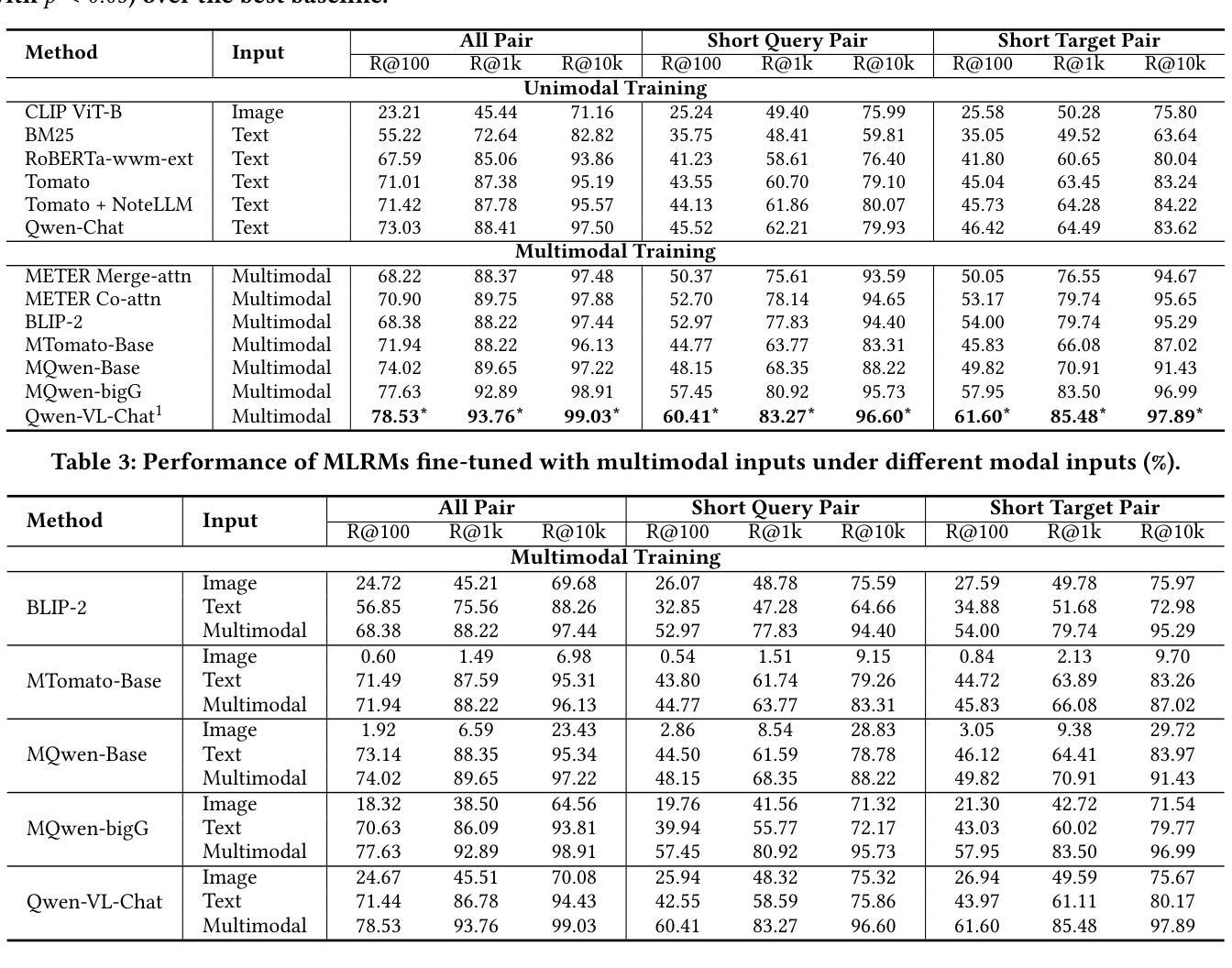
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Authors:Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Xiangyu Zhao, Yan Gao, Yao Hu, Enhong Chen
Large Language Models (LLMs) have demonstrated exceptional proficiency in text understanding and embedding tasks. However, their potential in multimodal representation, particularly for item-to-item (I2I) recommendations, remains underexplored. While leveraging existing Multimodal Large Language Models (MLLMs) for such tasks is promising, challenges arise due to their delayed release compared to corresponding LLMs and the inefficiency in representation tasks. To address these issues, we propose an end-to-end fine-tuning method that customizes the integration of any existing LLMs and vision encoders for efficient multimodal representation. Preliminary experiments revealed that fine-tuned LLMs often neglect image content. To counteract this, we propose NoteLLM-2, a novel framework that enhances visual information. Specifically, we propose two approaches: first, a prompt-based method that segregates visual and textual content, employing a multimodal In-Context Learning strategy to balance focus across modalities; second, a late fusion technique that directly integrates visual information into the final representations. Extensive experiments, both online and offline, demonstrate the effectiveness of our approach. Code is available at https://github.com/Applied-Machine-Learning-Lab/NoteLLM.
大型语言模型(LLM)在文本理解和嵌入任务中表现出了卓越的能力。然而,它们在多模态表示中的潜力,特别是针对项目到项目(I2I)的推荐,仍然未被充分探索。虽然利用现有的多模态大型语言模型(MLLM)来完成此类任务是有前途的,但由于它们相较于对应的大型语言模型的发布存在延迟,以及在表示任务中的效率不高,因此仍面临挑战。为了解决这些问题,我们提出了一种端到端的微调方法,可以定制任何现有的大型语言模型和视觉编码器,以实现高效的多模态表示。初步实验表明,经过微调的大型语言模型往往会忽略图像内容。为了应对这一问题,我们提出了NoteLLM-2这一新型框架,以增强视觉信息。具体来说,我们提出了两种方法:首先,一种基于提示的方法,它分离视觉和文本内容,采用多模式上下文学习策略来平衡跨模态的焦点;其次,一种晚期融合技术,它直接将视觉信息融合到最终表示中。线上和线下的广泛实验都证明了我们方法的有效性。相关代码可在https://github.com/Applied-Machine-Learning-Lab/NoteLLM获取。
论文及项目相关链接
PDF Accepted by KDD’25 ADS track
Summary
大型语言模型(LLMs)在文本理解和嵌入任务上表现出卓越的能力,但在多模态表示,尤其是物品到物品(I2I)推荐方面,其潜力尚未得到充分探索。为了利用现有的多模态大型语言模型(MLLMs)应对这些挑战,我们提出了一种端到端微调方法,该方法可定制任何现有的LLMs和视觉编码器,以实现高效的多模态表示。我们的新方法NoteLLM-2通过两种新策略来增强视觉信息:一是基于提示的方法,它通过分割视觉和文本内容,采用多模态上下文学习策略来平衡跨模态的关注度;二是后期融合技术,它直接将视觉信息集成到最终表示中。经过在线和离线的大量实验验证,我们的方法效果显著。相关代码已发布在:https://github.com/Applied-Machine-Learning-Lab/NoteLLM。
Key Takeaways
- 大型语言模型在多模态表示方面潜力巨大,但在物品到物品推荐等特定任务上的研究仍然不足。
- 利用现有的多模态大型语言模型进行多任务处理面临挑战,如延迟发布和表示任务效率问题。
- 提出了一种端到端微调方法,旨在定制LLMs和视觉编码器,以实现高效的多模态表示。这是通过整合任何现有的LLMs和视觉编码器来实现的。
- 新方法NoteLLM-2旨在增强视觉信息,通过两种策略:基于提示的方法和后期融合技术。
- 基于提示的方法通过分割视觉和文本内容,并采用多模态上下文学习策略来平衡跨模态关注度。
- 后期融合技术直接集成视觉信息到最终表示中。
点此查看论文截图