⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-24 更新
Learning accurate rigid registration for longitudinal brain MRI from synthetic data
Authors:Jingru Fu, Adrian V. Dalca, Bruce Fischl, Rodrigo Moreno, Malte Hoffmann
Rigid registration aims to determine the translations and rotations necessary to align features in a pair of images. While recent machine learning methods have become state-of-the-art for linear and deformable registration across subjects, they have demonstrated limitations when applied to longitudinal (within-subject) registration, where achieving precise alignment is critical. Building on an existing framework for anatomy-aware, acquisition-agnostic affine registration, we propose a model optimized for longitudinal, rigid brain registration. By training the model with synthetic within-subject pairs augmented with rigid and subtle nonlinear transforms, the model estimates more accurate rigid transforms than previous cross-subject networks and performs robustly on longitudinal registration pairs within and across magnetic resonance imaging (MRI) contrasts.
刚性配准旨在确定对齐一对图像所需的平移和旋转。虽然最近的机器学习方法已成为跨主题进行线性和可变形配准的最新技术,但它们在应用于纵向(受试者内部)配准时显示出局限性,其中实现精确对齐至关重要。基于现有的解剖结构感知、采集无关的仿射配准框架,我们提出了一种针对纵向刚性大脑配准进行优化模型。通过对模型进行合成受试者内部配对训练,并辅以刚性和细微非线性变换增强,该模型估计的刚性变换比以前跨受试者网络更准确,并且在磁共振成像(MRI)对比剂的纵向配准对内和跨内表现稳健。
论文及项目相关链接
PDF 5 pages, 4 figures, 1 table, rigid image registration, deep learning, longitudinal analysis, neuroimaging, accepted by the IEEE International Symposium on Biomedical Imaging
Summary
医学图像配准中,刚性配准旨在确定对齐图像特征所需的平移和旋转。尽管最新的机器学习方法是跨主题线性变形配准的最佳选择,但在纵向(受试者内部)配准中应用时表现出局限性,其中精确对齐至关重要。基于解剖结构感知、采集无关的仿射配准现有框架,我们提出了一种针对纵向刚性大脑配准的优化模型。该模型通过合成受试者内部对图像并使用刚性和微妙非线性变换进行增强训练,估计的刚性变换比以往跨主题网络的更为准确,并在MRI对比度内部和跨对比度的纵向配准对上表现稳健。
Key Takeaways
- 刚性配准用于确定图像间的平移和旋转以实现对齐。
- 机器学习方法是跨主题线性变形配准的主流,但在纵向配准中存在局限性。
- 精确对齐在纵向配准中至关重要。
- 基于解剖结构感知的仿射配准框架进行了优化,适用于纵向刚性大脑配准。
- 通过合成受试者内部图像对并使用刚性和非线性变换增强训练,提高了模型性能。
- 优化后的模型估计的刚性变换比跨主题网络更准确。
点此查看论文截图



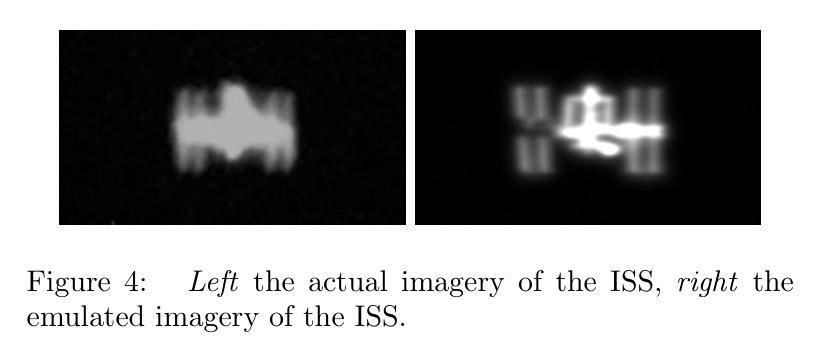
Deep Learning-Based Image Recovery and Pose Estimation for Resident Space Objects
Authors:Louis Aberdeen, Mark Hansen, Melvyn L. Smith, Lyndon Smith
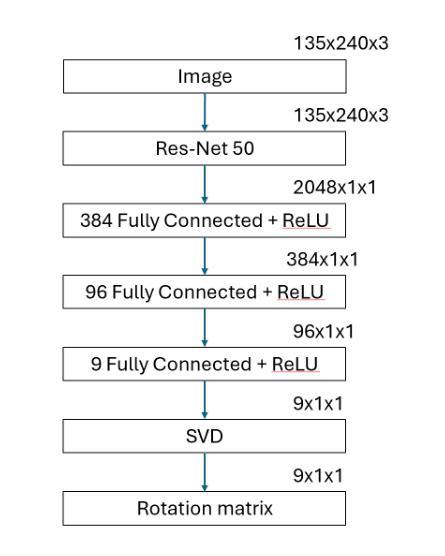
As the density of spacecraft in Earth’s orbit increases, their recognition, pose and trajectory identification becomes crucial for averting potential collisions and executing debris removal operations. However, training models able to identify a spacecraft and its pose presents a significant challenge due to a lack of available image data for model training. This paper puts forth an innovative framework for generating realistic synthetic datasets of Resident Space Object (RSO) imagery. Using the International Space Station (ISS) as a test case, it goes on to combine image regression with image restoration methodologies to estimate pose from blurred images. An analysis of the proposed image recovery and regression techniques was undertaken, providing insights into the performance, potential enhancements and limitations when applied to real imagery of RSOs. The image recovery approach investigated involves first applying image deconvolution using an effective point spread function, followed by detail object extraction with a U-Net. Interestingly, using only U-Net for image reconstruction the best pose performance was attained, reducing the average Mean Squared Error in image recovery by 97.28% and the average angular error by 71.9%. The successful application of U-Net image restoration combined with the Resnet50 regression network for pose estimation of the International Space Station demonstrates the value of a diverse set of evaluation tools for effective solutions to real-world problems such as the analysis of distant objects in Earth’s orbit.
随着地球轨道上航天器密度的增加,对它们的识别、姿态和轨迹的识别对于避免潜在碰撞和执行碎片清除操作变得至关重要。然而,由于可用于模型训练的图像数据缺乏,训练能够识别航天器及其姿态的模型成为了一大挑战。本文提出了一个创新框架,用于生成居民空间物体(RSO)影像的真实合成数据集。以国际空间站(ISS)作为测试案例,它将图像回归与图像恢复方法相结合,从模糊图像中估计姿态。对所提出的图像恢复和回归技术进行了分析,为将其应用于RSO的真实图像时的性能、潜在改进和局限性提供了见解。研究的图像恢复方法首先使用有效的点扩散函数进行图像反卷积,然后使用U-Net进行细节对象提取。有趣的是,仅使用U-Net进行图像重建时,获得了最佳的姿态性能,图像恢复的平均均方误差降低了97.28%,平均角度误差降低了71.9%。U-Net图像恢复与Resnet50回归网络成功应用于国际空间站的姿态估计,展示了多种评估工具在现实问题解决中的价值,例如分析地球轨道上的远距离物体。
论文及项目相关链接
PDF 10 pages, 13 figures
Summary
本文介绍了一种生成现实合成数据集的方法,用于识别地球轨道中的航天器及其姿态。文章利用国际空间站作为测试案例,结合图像回归与图像恢复方法,从模糊图像中估计姿态。研究中分析了图像恢复与回归技术的性能,并提出了潜在改进和局限性。仅使用U-Net进行图像重建取得了最佳姿态性能,平均图像恢复误差减少了97.28%,平均角度误差减少了71.9%。该研究展示了多种评估工具在解决现实世界问题中的价值,如分析地球轨道中的远距离物体。
Key Takeaways
- 航天器轨道密度增加导致识别和姿态识别的重要性增强,用于避免潜在碰撞和执行碎片清除操作。
- 缺乏可用的图像数据来训练模型进行航天器及姿态识别是一个挑战。
- 本文提出了一种生成合成数据集的方法,用于训练模型识别居民空间对象(RSO)。
- 使用国际空间站作为测试案例,结合了图像回归和图像恢复方法来估计姿态。
- U-Net在图像重建中表现出最佳姿态性能。
- 综合使用U-Net图像恢复和Resnet50回归网络进行姿态估计,为解决实际问题的有效解决方案提供了价值。
点此查看论文截图


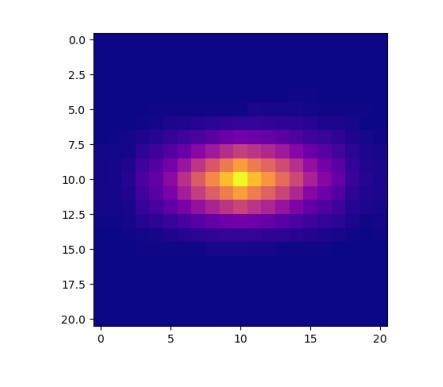
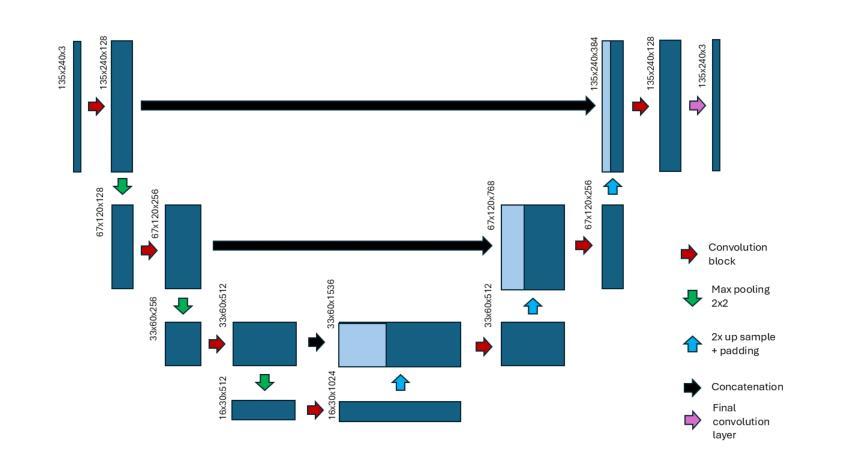
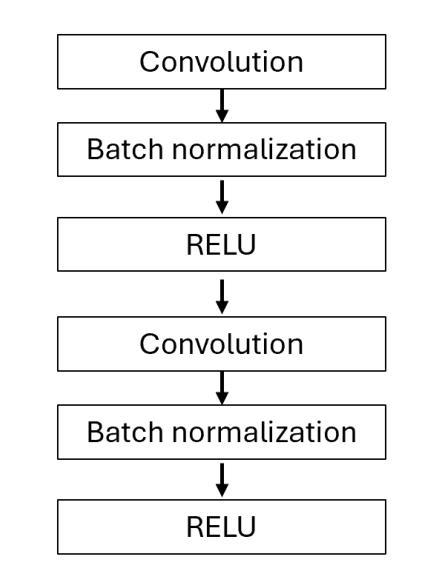
A Novel Tracking Framework for Devices in X-ray Leveraging Supplementary Cue-Driven Self-Supervised Features
Authors:Saahil Islam, Venkatesh N. Murthy, Dominik Neumann, Serkan Cimen, Puneet Sharma, Andreas Maier, Dorin Comaniciu, Florin C. Ghesu
To restore proper blood flow in blocked coronary arteries via angioplasty procedure, accurate placement of devices such as catheters, balloons, and stents under live fluoroscopy or diagnostic angiography is crucial. Identified balloon markers help in enhancing stent visibility in X-ray sequences, while the catheter tip aids in precise navigation and co-registering vessel structures, reducing the need for contrast in angiography. However, accurate detection of these devices in interventional X-ray sequences faces significant challenges, particularly due to occlusions from contrasted vessels and other devices and distractions from surrounding, resulting in the failure to track such small objects. While most tracking methods rely on spatial correlation of past and current appearance, they often lack strong motion comprehension essential for navigating through these challenging conditions, and fail to effectively detect multiple instances in the scene. To overcome these limitations, we propose a self-supervised learning approach that enhances its spatio-temporal understanding by incorporating supplementary cues and learning across multiple representation spaces on a large dataset. Followed by that, we introduce a generic real-time tracking framework that effectively leverages the pretrained spatio-temporal network and also takes the historical appearance and trajectory data into account. This results in enhanced localization of multiple instances of device landmarks. Our method outperforms state-of-the-art methods in interventional X-ray device tracking, especially stability and robustness, achieving an 87% reduction in max error for balloon marker detection and a 61% reduction in max error for catheter tip detection.
通过血管成形术恢复阻塞的冠状动脉中的正常血流时,在实时荧光检查或诊断血管造影下准确放置导管、球囊和支架等设备至关重要。标识的球囊标记有助于增强X射线序列中支架的可见性,而导管尖端有助于精确导航和共注册血管结构,从而减少了血管造影中对比剂的使用。然而,在介入性X射线序列中准确检测这些设备面临着重大挑战,尤其是因为对比血管和其他设备的遮挡以及周围的干扰,导致无法跟踪这些小型物体。大多数跟踪方法依赖于过去和当前外观的空间相关性,但它们通常缺乏在这些条件下导航所需的有力运动理解,并且无法有效检测场景中的多个实例。为了克服这些局限性,我们提出了一种自我监督的学习方法,通过融入额外的线索并在大型数据集上学习多种表示空间,增强了其时空理解。之后,我们引入了一个通用的实时跟踪框架,该框架有效利用预训练的时空网络,同时考虑历史外观和轨迹数据。这提高了多个设备地标实例的定位效果。我们的方法在介入性X射线设备跟踪方面优于最新技术,特别是在稳定性和鲁棒性方面,气球标记检测的最大误差降低了87%,导管尖端检测的最大误差降低了61%。
论文及项目相关链接
Summary
本文介绍了在经皮冠状动脉介入治疗过程中,通过采用自监督学习方法和实时跟踪框架实现对导管、球囊和支架等器械的精准追踪。该方法提高了时空感知能力,有效应对血管造影中的遮挡和干扰问题,实现对多个器械实例的精准定位,提高了手术效率和安全性。
Key Takeaways
- 在经皮冠状动脉介入治疗过程中,准确放置导管、球囊和支架等器械至关重要。
- 现有跟踪方法存在空间关联和动态理解不足的问题,难以应对血管造影中的遮挡和干扰。
- 自监督学习方法的采用提高了模型的时空感知能力,通过多表示空间的学习增强模型性能。
- 引入的实时跟踪框架有效结合了预训练的时空网络和历史外观及轨迹数据,提高了多个器械实例的定位精度。
- 该方法在介入性X射线器械跟踪方面表现出卓越性能,特别是在稳定性和鲁棒性方面。
- 球囊标志物检测的最大误差降低了87%,导管尖端检测的最大误差降低了61%。
点此查看论文截图



A detailed study on spectroscopic performance of SOI pixel detector with a pinned depleted diode structure for X-ray astronomy
Authors:Masataka Yukumoto, Koji Mori, Ayaki Takeda, Yusuke Nishioka, Miraku Kimura, Yuta Fuchita, Taiga Yoshida, Takeshi G. Tsuru, Ikuo Kurachi, Kouichi Hagino, Yasuo Arai, Takayoshi Kohmura, Takaaki Tanaka, Kumiko K. Nobukawa
We have been developing silicon-on-insulator (SOI) pixel detectors with a pinned depleted diode (PDD) structure, named “XRPIX”, for X-ray astronomy. In our previous study, we successfully optimized the design of the PDD structure, achieving both the suppression of large leakage current and satisfactory X-ray spectroscopic performance. Here, we report a detailed study on the X-ray spectroscopic performance of the XRPIX with the optimized PDD structure. The data were obtained at $-60^\circ\mathrm{C}$ with the “event-driven readout mode”, in which only a triggering pixel and its surroundings are read out. The energy resolutions in full width at half maximum at 6.4 keV are $178\pm1$ eV and $291\pm1$ eV for single-pixel and all-pixel event spectra, respectively. The all-pixel events include charge-sharing pixel events as well as the single-pixel events. These values are the best achieved in the history of our development. We argue that the gain non-linearity in the low energy side due to excessive charge injection to the charge-sensitive amplifier is a major factor to limit the current spectroscopic performance. Optimization of the amount of the charge injection is expected to lead to further improvement in the spectroscopic performance of XRPIX, especially for the all-pixel event spectrum.
我们一直在开发用于X射线天文学的硅绝缘体上硅(SOI)像素探测器,名为“XRPIX”,其具有固定耗尽二极管(PDD)结构。在之前的研究中,我们成功优化了PDD结构的设计,实现了大泄漏电流的抑制和令人满意的X射线光谱性能。在这里,我们报告了具有优化PDD结构的XRPIX的X射线光谱性能的详细研究。数据是在-60°C的温度下,采用“事件驱动读取模式”获得的,在该模式下,只有触发像素及其周围像素被读出。在6.4 keV时,单点像素事件光谱的全宽半最大值能量分辨率为178±1 eV,全像素事件光谱的能量分辨率为291±1 eV。全像素事件包括电荷共享像素事件和单点像素事件。这些值是我们开发历史上所达到的最佳值。我们认为,由于过多的电荷注入到电荷敏感放大器中导致的低能量侧的增益非线性是限制当前光谱性能的主要因素。优化电荷注入量有望进一步提高XRPIX的光谱性能,特别是对于全像素事件光谱。
论文及项目相关链接
PDF 11 pages, 14 figures, accepted for publication in NIM A
Summary
采用硅绝缘体上硅(SOI)像素探测器,配合固定耗尽二极管(PDD)结构,开发用于X射线天文学的XRPIX探测器。成功优化PDD结构,减少大泄漏电流,提高X射线光谱性能。在-60°C温度下采用事件驱动读出模式,单像素和全像素事件光谱的能量分辨率达到最佳水平。指出增益非线性是限制当前光谱性能的主要因素,优化电荷注入量有望进一步提高XRPIX的光谱性能。
Key Takeaways
- 开发用于X射线天文学的硅绝缘体上硅(SOI)像素探测器XRPIX。
- 成功优化固定耗尽二极管(PDD)结构,抑制大泄漏电流,提高X射线光谱性能。
- 在-60°C采用事件驱动读出模式,获得单像素和全像素事件光谱的最佳能量分辨率。
- 指出增益非线性是限制当前光谱性能的主要因素。
- 优化电荷注入量可望进一步提高XRPIX探测器的光谱性能。
- XRPIX探测器的性能优化对于X射线天文学的研究具有重要影响。
点此查看论文截图







Efficient Lung Ultrasound Severity Scoring Using Dedicated Feature Extractor
Authors:Jiaqi Guo, Yunnan Wu, Evangelos Kaimakamis, Georgios Petmezas, Vasileios E. Papageorgiou, Nicos Maglaveras, Aggelos K. Katsaggelos
With the advent of the COVID-19 pandemic, ultrasound imaging has emerged as a promising technique for COVID-19 detection, due to its non-invasive nature, affordability, and portability. In response, researchers have focused on developing AI-based scoring systems to provide real-time diagnostic support. However, the limited size and lack of proper annotation in publicly available ultrasound datasets pose significant challenges for training a robust AI model. This paper proposes MeDiVLAD, a novel pipeline to address the above issue for multi-level lung-ultrasound (LUS) severity scoring. In particular, we leverage self-knowledge distillation to pretrain a vision transformer (ViT) without label and aggregate frame-level features via dual-level VLAD aggregation. We show that with minimal finetuning, MeDiVLAD outperforms conventional fully-supervised methods in both frame- and video-level scoring, while offering classification reasoning with exceptional quality. This superior performance enables key applications such as the automatic identification of critical lung pathology areas and provides a robust solution for broader medical video classification tasks.
随着COVID-19大流行的发展,由于其无创性、可负担性和便携性,超声成像已成为一种有前景的COVID-19检测技术。因此,研究人员致力于开发基于人工智能的评分系统,以提供实时诊断支持。然而,公开可用的超声数据集规模有限且缺乏适当的注释,这给训练稳健的人工智能模型带来了重大挑战。本文针对上述问题提出了MeDiVLAD这一新型管道,用于进行多级肺超声(LUS)严重程度评分。具体来说,我们利用自我知识蒸馏对视觉转换器(ViT)进行无标签预训练,并通过双级VLAD聚合来汇总帧级特征。我们展示了对少量微调的情况下,MeDiVLAD在帧级和视频级的评分上均优于传统的完全监督方法,同时提供出色的分类推理质量。这种卓越的性能使得关键应用如自动识别关键肺病理区域成为可能,并为更广泛的医学视频分类任务提供了稳健的解决方案。
论文及项目相关链接
PDF Accepted by IEEE ISBI 2025
Summary
超声成像在COVID-19检测中具有无创、经济、便携等优点,受到广泛关注。针对公开可用的超声数据集大小有限、缺乏适当标注等问题,本文提出MeDiVLAD,利用自我知识蒸馏预训练一个无需标签的视觉转换器(ViT),并通过两级VLAD聚合进行帧级特征聚合。实验表明,MeDiVLAD在帧级和视频级评分上均优于传统的全监督方法,且分类推理质量优异,可自动识别关键肺部病理区域,为更广泛的医疗视频分类任务提供稳健解决方案。
Key Takeaways
- 超声成像成为COVID-19检测的有前途的技术。
- 公开可用的超声数据集存在大小有限和缺乏适当标注的问题。
- MeDiVLAD利用自我知识蒸馏预训练视觉转换器(ViT)。
- MeDiVLAD通过两级VLAD聚合进行帧级特征聚合。
- MeDiVLAD在帧级和视频级评分上表现出优异性能。
- MeDiVLAD提供高质量的分类推理,可自动识别关键肺部病理区域。
点此查看论文截图






Bidirectional Brain Image Translation using Transfer Learning from Generic Pre-trained Models
Authors:Fatima Haimour, Rizik Al-Sayyed, Waleed Mahafza, Omar S. Al-Kadi
Brain imaging plays a crucial role in the diagnosis and treatment of various neurological disorders, providing valuable insights into the structure and function of the brain. Techniques such as magnetic resonance imaging (MRI) and computed tomography (CT) enable non-invasive visualization of the brain, aiding in the understanding of brain anatomy, abnormalities, and functional connectivity. However, cost and radiation dose may limit the acquisition of specific image modalities, so medical image synthesis can be used to generate required medical images without actual addition. In the medical domain, where obtaining labeled medical images is labor-intensive and expensive, addressing data scarcity is a major challenge. Recent studies propose using transfer learning to overcome this issue. This involves adapting pre-trained CycleGAN models, initially trained on non-medical data, to generate realistic medical images. In this work, transfer learning was applied to the task of MR-CT image translation and vice versa using 18 pre-trained non-medical models, and the models were fine-tuned to have the best result. The models’ performance was evaluated using four widely used image quality metrics: Peak-signal-to-noise-ratio, Structural Similarity Index, Universal Quality Index, and Visual Information Fidelity. Quantitative evaluation and qualitative perceptual analysis by radiologists demonstrate the potential of transfer learning in medical imaging and the effectiveness of the generic pre-trained model. The results provide compelling evidence of the model’s exceptional performance, which can be attributed to the high quality and similarity of the training images to actual human brain images. These results underscore the significance of carefully selecting appropriate and representative training images to optimize performance in brain image analysis tasks.
大脑成像在诊断和治疗各种神经疾病中扮演着至关重要的角色,它提供了关于大脑结构和功能的宝贵见解。诸如磁共振成像(MRI)和计算机断层扫描(CT)等技术能够实现大脑的非侵入性可视化,有助于理解大脑解剖、异常和功能性连接。然而,成本和辐射剂量可能会限制特定图像模式的获取,因此医学图像合成可用于在不实际增加的情况下生成所需的医学图像。在医学领域,获取带有标签的医学图像是劳动密集且昂贵的,解决数据稀缺是一个主要挑战。最近的研究提出使用迁移学习来克服这个问题。这涉及到适应预先训练的CycleGAN模型,该模型最初在非医学数据上进行训练,以生成逼真的医学图像。在这项工作中,将迁移学习应用于MR-CT图像翻译及其反向任务,使用了18个预先训练的非医学模型,并对这些模型进行了微调以得到最佳结果。模型的性能是使用四种广泛使用的图像质量指标进行评估的:峰值信噪比、结构相似性指数、通用质量指数和视觉信息保真度。放射科医生进行的定量评估和定性感知分析证明了迁移学习在医学成像中的潜力以及通用预训练模型的有效性。结果提供了有力证据表明该模型的卓越性能,这可以归因于训练图像的高质量和与真实人类大脑图像的相似性。这些结果强调在大脑图像分析任务中仔细选择和适当代表性的训练图像以优化性能的重要性。
论文及项目相关链接
PDF 19 pages, 9 figures, 6 tables
Summary
医学成像在诊断与治疗各种神经性疾病中发挥着关键作用,提供了对大脑结构和功能的宝贵见解。磁共振成像(MRI)和计算机断层扫描(CT)等技术可实现无创可视化,有助于了解大脑解剖结构、异常情况和功能性连接。针对获取特定图像模式可能存在的成本和辐射剂量限制,可使用医学图像合成技术生成所需的医学图像而无需实际添加。在医学领域,获取标记的医学图像是劳动密集且昂贵的,解决数据稀缺性是主要挑战。最近的研究提出了利用迁移学习来应对这一问题,这涉及使用预训练的CycleGAN模型在非医学数据上进行训练,然后生成逼真的医学图像。本研究应用迁移学习进行MR-CT图像转换及其反向转换,使用18个预训练的非医学模型,并通过微调获得最佳结果。模型的性能通过使用四种常用的图像质量指标进行评估:峰值信噪比、结构相似性指数、通用质量指数和视觉信息保真度。定量评估和放射科医师的定性感知分析证明了迁移学习在医学成像中的潜力以及通用预训练模型的有效性。结果提供了有力证据表明该模型的卓越性能可归功于训练图像的高质量以及与实际人类大脑图像的相似性。这些结果强调了仔细选择和代表性强的训练图像对优化大脑图像分析任务性能的重要性。
Key Takeaways
- 医学成像在神经性疾病的诊断和治疗中起到关键作用,能提供关于大脑结构和功能的宝贵信息。
- MRI和CT等技术能帮助无创可视化大脑,了解大脑结构、异常情况和功能性连接。
- 由于成本和辐射剂量的限制,医学图像合成技术被用于生成所需的医学图像。
- 在医学领域,数据稀缺是一个主要挑战,获取标记的医学图像既劳动密集又昂贵。
- 最近的研究利用迁移学习来解决这一问题,通过使用预训练的模型在非医学数据上生成逼真的医学图像。
- 研究中使用迁移学习进行MR-CT图像转换的尝试取得了良好效果,证明了迁移学习和通用预训练模型在医学成像中的潜力。
点此查看论文截图




Multi-stage intermediate fusion for multimodal learning to classify non-small cell lung cancer subtypes from CT and PET
Authors:Fatih Aksu, Fabrizia Gelardi, Arturo Chiti, Paolo Soda
Accurate classification of histological subtypes of non-small cell lung cancer (NSCLC) is essential in the era of precision medicine, yet current invasive techniques are not always feasible and may lead to clinical complications. This study presents a multi-stage intermediate fusion approach to classify NSCLC subtypes from CT and PET images. Our method integrates the two modalities at different stages of feature extraction, using voxel-wise fusion to exploit complementary information across varying abstraction levels while preserving spatial correlations. We compare our method against unimodal approaches using only CT or PET images to demonstrate the benefits of modality fusion, and further benchmark it against early and late fusion techniques to highlight the advantages of intermediate fusion during feature extraction. Additionally, we compare our model with the only existing intermediate fusion method for histological subtype classification using PET/CT images. Our results demonstrate that the proposed method outperforms all alternatives across key metrics, with an accuracy and AUC equal to 0.724 and 0.681, respectively. This non-invasive approach has the potential to significantly improve diagnostic accuracy, facilitate more informed treatment decisions, and advance personalized care in lung cancer management.
在非小细胞肺癌(NSCLC)的精准医学时代,对其组织学亚型的准确分类至关重要。然而,当前的有创技术并不总是可行,并可能导致临床并发症。本研究提出了一种多阶段中间融合方法来对NSCLC亚型进行CT和PET图像分类。我们的方法在不同的特征提取阶段将两种模式融合在一起,使用体素级的融合来利用不同抽象层次上的互补信息,同时保留空间相关性。我们将该方法与仅使用CT或PET图像的单一模态方法进行比较,以证明模态融合的优势,并进一步将其与早期和晚期融合技术进行比较,以突出特征提取过程中中间融合的优势。此外,我们还与唯一现有的使用PET/CT图像进行组织学亚型分类的中间融合方法进行了比较。我们的结果表明,所提出的方法在所有关键指标上均优于其他方法,准确率和AUC分别为0.724和0.681。这种非侵入性方法有可能显著提高诊断准确性,有助于做出更明智的治疗决策,并推动肺癌管理的个性化护理发展。
论文及项目相关链接
Summary
本文介绍了一种多阶段中间融合方法,用于从CT和PET图像分类非小细胞肺癌(NSCLC)亚型。该方法在不同阶段的特征提取中融合了两种模态,通过体素级的融合方式,利用不同抽象层次的互补信息,同时保留空间相关性。与只使用CT或PET图像的单一模态方法相比,该方法具有优势,并与早期和晚期融合技术进行比较,突出了特征提取过程中中间融合的优点。此外,本文还将该方法与现有的用于组织学亚型分类的PET/CT图像中间融合方法进行了比较。研究结果表明,所提出的方法在所有关键指标上均优于其他方法,准确率和AUC分别为0.724和0.681。这种非侵入性方法有望显著提高诊断准确性,促进更明智的治疗决策,并推动肺癌管理的个性化护理发展。
Key Takeaways
- 准确分类非小细胞肺癌(NSCLC)亚型在精准医学时代非常重要。
- 当前侵入性技术并不总是可行,可能导致临床并发症。
- 研究提出了一种多阶段中间融合方法,通过CT和PET图像分类NSCLC亚型。
- 该方法在不同阶段的特征提取中融合两种模态,采用体素级融合方式。
- 与单一模态方法和早期/晚期融合技术相比,该方法具有优势。
- 研究结果证明了所提出方法的高准确性和潜力。
点此查看论文截图




Tackling Small Sample Survival Analysis via Transfer Learning: A Study of Colorectal Cancer Prognosis
Authors:Yonghao Zhao, Changtao Li, Chi Shu, Qingbin Wu, Hong Li, Chuan Xu, Tianrui Li, Ziqiang Wang, Zhipeng Luo, Yazhou He
Survival prognosis is crucial for medical informatics. Practitioners often confront small-sized clinical data, especially cancer patient cases, which can be insufficient to induce useful patterns for survival predictions. This study deals with small sample survival analysis by leveraging transfer learning, a useful machine learning technique that can enhance the target analysis with related knowledge pre-learned from other data. We propose and develop various transfer learning methods designed for common survival models. For parametric models such as DeepSurv, Cox-CC (Cox-based neural networks), and DeepHit (end-to-end deep learning model), we apply standard transfer learning techniques like pretraining and fine-tuning. For non-parametric models such as Random Survival Forest, we propose a new transfer survival forest (TSF) model that transfers tree structures from source tasks and fine-tunes them with target data. We evaluated the transfer learning methods on colorectal cancer (CRC) prognosis. The source data are 27,379 SEER CRC stage I patients, and the target data are 728 CRC stage I patients from the West China Hospital. When enhanced by transfer learning, Cox-CC’s $C^{td}$ value was boosted from 0.7868 to 0.8111, DeepHit’s from 0.8085 to 0.8135, DeepSurv’s from 0.7722 to 0.8043, and RSF’s from 0.7940 to 0.8297 (the highest performance). All models trained with data as small as 50 demonstrated even more significant improvement. Conclusions: Therefore, the current survival models used for cancer prognosis can be enhanced and improved by properly designed transfer learning techniques. The source code used in this study is available at https://github.com/YonghaoZhao722/TSF.
生存预测在医学信息化中至关重要。研究人员经常面临小型临床数据,尤其是癌症患者病例,这些数据不足以产生有用的生存模式预测。本研究通过利用迁移学习这一有用的机器学习技术来解决小样本生存分析的问题,该技术可以利用从其他数据中预先学习的相关知识来增强目标分析。我们针对常见的生存模型提出了多种迁移学习方法。对于参数模型,如DeepSurv、Cox-CC(基于Cox的神经网络)和DeepHit(端到端深度学习模型),我们应用了预训练和微调等标准迁移学习技术。对于非参数模型,如随机生存森林,我们提出了一种新的迁移生存森林(TSF)模型,该模型从源任务转移树结构,并用目标数据进行微调。我们对结直肠癌(CRC)的预后进行了迁移学习方法的评估。源数据为SEER CRC I期患者27,379例,目标数据为来自华西医院的CRC I期患者728例。在迁移学习的增强下,Cox-CC的Ctd值从0.7868提高到0.8111,DeepHit从0.8085提高到0.8135,DeepSurv从0.7722提高到0.8043,而RSF则从0.7940提高到最高的0.8297。即使使用小到只有50个数据的模型也表现出了更显著的改进。结论:因此,通过适当设计的迁移学习技术,目前用于癌症预后的生存模型可以得到增强和改进。本研究使用的源代码可在https://github.com/YonghaoZhao722/TSF上找到。
论文及项目相关链接
Summary
本研究利用迁移学习技术解决小样本生存分析问题,提出并开发适用于常见生存模型的多种迁移学习方法。通过迁移学习,Cox-CC、DeepHit、DeepSurv和RSF等模型的性能有所提升,特别是在目标数据较小的情况下表现更为显著。研究结果表明,迁移学习技术可增强和改进用于癌症预后的现有生存模型。
Key Takeaways
- 迁移学习被用来解决小样本生存分析问题。
- 针对不同生存模型(如DeepSurv、Cox-CC和Random Survival Forest),提出了相应的迁移学习方法。
- 迁移学习能够提升模型的性能,特别是在目标数据较小的情况下。
- 在结直肠癌预后分析中,迁移学习对模型性能的提升得到了验证。
- 最佳性能的模型是通过对仅有50个数据的训练得到的,这显示了迁移学习在小样本数据中的优势。
- 迁移学习技术可增强和改进用于癌症预后的现有生存模型。
点此查看论文截图

UNetVL: Enhancing 3D Medical Image Segmentation with Chebyshev KAN Powered Vision-LSTM
Authors:Xuhui Guo, Tanmoy Dam, Rohan Dhamdhere, Gourav Modanwal, Anant Madabhushi
3D medical image segmentation has progressed considerably due to Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), yet these methods struggle to balance long-range dependency acquisition with computational efficiency. To address this challenge, we propose UNETVL (U-Net Vision-LSTM), a novel architecture that leverages recent advancements in temporal information processing. UNETVL incorporates Vision-LSTM (ViL) for improved scalability and memory functions, alongside an efficient Chebyshev Kolmogorov-Arnold Networks (KAN) to handle complex and long-range dependency patterns more effectively. We validated our method on the ACDC and AMOS2022 (post challenge Task 2) benchmark datasets, showing a significant improvement in mean Dice score compared to recent state-of-the-art approaches, especially over its predecessor, UNETR, with increases of 7.3% on ACDC and 15.6% on AMOS, respectively. Extensive ablation studies were conducted to demonstrate the impact of each component in UNETVL, providing a comprehensive understanding of its architecture. Our code is available at https://github.com/tgrex6/UNETVL, facilitating further research and applications in this domain.
三维医学图像分割由于卷积神经网络(CNN)和视觉转换器(ViT)的进步而得到了很大发展,但这些方法在平衡远程依赖获取与计算效率方面面临困难。为了解决这一挑战,我们提出了UNETVL(U-Net Vision-LSTM)这一新型架构,它利用最新的时间信息处理方面的进展。UNETVL结合了Vision-LSTM(ViL)来提高可伸缩性和内存功能,同时使用高效的切比雪夫柯尔莫哥洛夫-阿诺尔德网络(KAN)来更有效地处理复杂和远程依赖模式。我们在ACDC和AMOS2022(任务挑战后的第2次任务)基准数据集上验证了我们的方法,相较于最新的尖端方法,特别是在其前身UNETR上,我们的平均Dice得分有了显著提高,ACDC上提高了7.3%,而在AMOS上提高了高达15.6%。我们进行了大量消融研究,展示了UNETVL中每个组件的影响,并对其架构进行了全面的了解。我们的代码可以在https://github.com/tgrex6/UNETVL找到,为该领域的进一步研究与应用提供了便利。
论文及项目相关链接
Summary
该文章介绍了一种名为UNETVL的新架构,它结合了卷积神经网络(CNNs)、视觉转换器(ViTs)和时空信息处理的最新进展,解决了在医学图像分割中平衡长期依赖获取与计算效率的挑战。UNETVL使用Vision-LSTM(ViL)提高可扩展性和内存功能,并采用高效的Chebyshev Kolmogorov-Arnold网络(KAN)更有效地处理复杂和长期的依赖模式。在ACDC和AMOS2022基准数据集上的验证结果表明,与传统的UNETR相比,该方法在医学图像分割方面取得了显著的改进,尤其是在AMOS数据集上的提高幅度更大。
Key Takeaways
- UNETVL是一种新的医学图像分割架构,结合了CNN、ViT和时空信息处理的最新技术来解决长期依赖与计算效率之间的平衡问题。
- UNETVL使用Vision-LSTM(ViL)以提高可扩展性和内存功能。
- Chebyshev Kolmogorov-Arnold网络(KAN)被用于更有效地处理复杂和长期的依赖模式。
- 在ACDC和AMOS2022基准数据集上的实验结果表明,UNETVL在医学图像分割方面表现出优异的性能,相比最新的先进方法有明显的改进。
- 与前任UNETR相比,UNETVL在ACDC和AMOS数据集上的表现分别提高了7.3%和15.6%。
- 进行了广泛的消融研究,以展示UNETVL中每个组件的影响,提供了对其架构的全面理解。
- 研究的代码已公开发布,便于进一步的研究和应用。
点此查看论文截图




Improved joint modelling of breast cancer radiomics features and hazard by image registration aided longitudinal CT data
Authors:Subrata Mukherjee
Patients with metastatic breast cancer (mBC) undergo continuous medical imaging during treatment, making accurate lesion detection and monitoring over time critical for clinical decisions. Predicting drug response from post-treatment data is essential for personalized care and pharmacological research. In collaboration with the U.S. Food and Drug Administration and Novartis Pharmaceuticals, we analyzed serial chest CT scans from two large-scale Phase III trials, MONALEESA 3 and MONALEESA 7. This paper has two objectives (a) Data Structuring developing a Registration Aided Automated Correspondence (RAMAC) algorithm for precise lesion tracking in longitudinal CT data, and (b) Survival Analysis creating imaging features and models from RAMAC structured data to predict patient outcomes. The RAMAC algorithm uses a two phase pipeline: three dimensional rigid registration aligns CT images, and a distance metric-based Hungarian algorithm tracks lesion correspondence. Using structured data, we developed interpretable models to assess progression-free survival (PFS) in mBC patients by combining baseline radiomics, post-treatment changes (Weeks 8, 16, 24), and demographic features. Radiomics effects were studied across time points separately and through a non-correlated additive framework. Radiomics features were reduced using (a) a regularized (L1-penalized) additive Cox proportional hazards model, and (b) variable selection via best subset selection. Performance, measured using the concordance index (C-index), improved with additional time points. Joint modeling, considering correlations among radiomics effects over time, provided insights into relationships between longitudinal radiomics and survival outcomes.
转移性乳腺癌(mBC)患者在治疗过程中会经历持续的医学成像,因此准确的病灶检测和长期监测对临床决策至关重要。从治疗后数据中预测药物反应对于个性化护理和药物研究至关重要。我们与美国食品药品监督管理局(FDA)和诺华制药合作,分析了来自两项大规模III期试验(MONALEESA 3和MONALEESA 7)的连续胸部CT扫描。本文有两个目标:(a)开发一种基于注册辅助自动对应(RAMAC)算法的用于精确追踪纵向CT数据中病灶的数据结构化方法;(b)通过RAMAC结构化数据创建成像特征和模型来预测患者结果,进行生存分析。RAMAC算法采用两个阶段管道:首先使用三维刚性注册对齐CT图像,然后基于距离度量的匈牙利算法跟踪病灶对应关系。我们使用结构化数据,结合基线放射组学、治疗后变化(第8周、第16周、第24周)和人口统计学特征,开发了可解释模型来评估mBC患者的无进展生存(PFS)。放射学效应分别在各个时间点以及通过非相关附加框架进行了研究。使用(a)正则化(L1惩罚)附加Cox比例风险模型和(b)通过最佳子集选择进行变量选择来减少放射学特征。使用一致性指数(C指数)衡量的性能会随着时间点的增加而提高。联合建模,考虑到放射学效应随时间的相关性,提供了纵向放射学与生存结果之间关系的新见解。
论文及项目相关链接
PDF The organization with whom I have worked on the paper needs to info clear first before it being released. Sorry for the inconvenience caused
摘要
针对转移性乳腺癌(mBC)患者的连续医学影像分析,本研究致力于实现两个目标:(a)开发一种名为RAMAC的注册辅助自动对应关系算法,用于精确追踪纵向CT影像中的病变;(b)使用RAMAC结构化数据进行生存分析,预测患者预后。该算法采用两阶段流程:三维刚性注册对齐CT图像,基于距离度量的匈牙利算法追踪病变对应关系。通过结构化数据评估乳腺癌患者的无进展生存期(PFS),并结合基线放射学特征、治疗后的变化(第8周、第16周和第24周)以及人口统计学特征进行模型构建。放射学特征的影响随时间点分别进行了研究,并通过非相关累加框架进行研究。使用正则化(L1惩罚)累加Cox比例风险模型和最佳子集选择进行变量选择,以降低放射学特征的影响。随着额外时间点的加入,通过一致性指数(C-index)衡量的性能有所提高。联合建模考虑了放射学效应随时间的相关性,揭示了纵向放射学与生存结果之间的关系。
关键见解
- 研究集中于转移性乳腺癌患者治疗中病变检测的精准性和长期监测的重要性。
- 开发了一种名为RAMAC的算法,用于精确追踪纵向CT影像中的病变。
- RAMAC算法包含两个阶段:三维图像对齐和病变对应关系追踪。
- 通过结合基线放射学特征、治疗后的变化以及人口统计学特征,评估了患者的无进展生存期。
- 研究了放射学特征随时间的影响,并采用非相关累加框架进行分析。
- 通过正则化Cox比例风险模型和最佳子集选择,优化了放射学特征的分析。
点此查看论文截图






Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG
Authors:Hasan Md Tusfiqur Alam, Devansh Srivastav, Md Abdul Kadir, Daniel Sonntag
Deep learning has advanced medical image classification, but interpretability challenges hinder its clinical adoption. This study enhances interpretability in Chest X-ray (CXR) classification by using concept bottleneck models (CBMs) and a multi-agent Retrieval-Augmented Generation (RAG) system for report generation. By modeling relationships between visual features and clinical concepts, we create interpretable concept vectors that guide a multi-agent RAG system to generate radiology reports, enhancing clinical relevance, explainability, and transparency. Evaluation of the generated reports using an LLM-as-a-judge confirmed the interpretability and clinical utility of our model’s outputs. On the COVID-QU dataset, our model achieved 81% classification accuracy and demonstrated robust report generation performance, with five key metrics ranging between 84% and 90%. This interpretable multi-agent framework bridges the gap between high-performance AI and the explainability required for reliable AI-driven CXR analysis in clinical settings. Our code is available at https://github.com/tifat58/IRR-with-CBM-RAG.git.
深度学习在医学图像分类方面取得了进展,但解释性挑战阻碍了其在临床的采纳。本研究通过采用概念瓶颈模型(CBMs)和多代理检索增强生成(RAG)系统,提高了胸部X射线(CXR)分类中的解释性。通过模拟视觉特征和临床概念之间的关系,我们创建了可解释的概念向量,引导多代理RAG系统生成放射学报告,提高了临床相关性、解释性和透明度。使用大型语言模型(LLM)作为评估标准对生成的报告进行评估,证实了我们模型输出的解释性和临床实用性。在COVID-QU数据集上,我们的模型达到了81%的分类准确率,并展示了稳健的报告生成性能,五项关键指标在84%至90%之间。这种可解释的多代理框架缩小了高性能人工智能和临床环境中可靠AI驱动CXR分析所需解释性之间的差距。我们的代码可通过以下链接获取:[链接地址](https://github.com/tifat58/IRR-with-CBM-RAG.git)。
论文及项目相关链接
PDF Accepted in the 47th European Conference for Information Retrieval (ECIR) 2025
Summary
本研究利用概念瓶颈模型(CBMs)和多智能体检索增强生成(RAG)系统,提高医学图像中胸部X射线(CXR)分类的解读性。通过模拟视觉特征与临床概念之间的关系,创建了解读性强的概念向量,引导多智能体RAG系统生成更具临床相关性、解释性和透明度的放射学报告。评估结果证实模型的解读性和临床实用性。在COVID-QU数据集上,模型分类准确率达到了81%,报告生成性能稳健,五项关键指标在84%至90%之间。此解读性多智能体框架缩短了高性能人工智能和临床环境中可靠AI驱动CXR分析所需解释性之间的差距。
Key Takeaways
- 利用概念瓶颈模型(CBMs)提高医学图像分类的解读性。
- 通过模拟视觉特征与临床概念之间的关系,创建概念向量。
- 使用多智能体检索增强生成(RAG)系统生成放射学报告。
- 模型在COVID-QU数据集上实现81%的分类准确率。
- 模型报告生成性能稳健,五项关键指标表现良好。
- 模型增强了临床相关性、解释性和透明度。
点此查看论文截图







Latent Diffusion for Medical Image Segmentation: End to end learning for fast sampling and accuracy
Authors:Fahim Ahmed Zaman, Mathews Jacob, Amanda Chang, Kan Liu, Milan Sonka, Xiaodong Wu
Diffusion Probabilistic Models (DPMs) suffer from inefficient inference due to their slow sampling and high memory consumption, which limits their applicability to various medical imaging applications. In this work, we propose a novel conditional diffusion modeling framework (LDSeg) for medical image segmentation, utilizing the learned inherent low-dimensional latent shape manifolds of the target objects and the embeddings of the source image with an end-to-end framework. Conditional diffusion in latent space not only ensures accurate image segmentation for multiple interacting objects, but also tackles the fundamental issues of traditional DPM-based segmentation methods: (1) high memory consumption, (2) time-consuming sampling process, and (3) unnatural noise injection in the forward and reverse processes. The end-to-end training strategy enables robust representation learning in the latent space related to segmentation features, ensuring significantly faster sampling from the posterior distribution for segmentation generation in the inference phase. Our experiments demonstrate that LDSeg achieved state-of-the-art segmentation accuracy on three medical image datasets with different imaging modalities. In addition, we showed that our proposed model was significantly more robust to noise compared to traditional deterministic segmentation models. The code is available at https://github.com/FahimZaman/LDSeg.git.
扩散概率模型(DPMs)由于其缓慢的采样和较高的内存消耗,导致推理效率低下,这限制了其在各种医学成像应用中的适用性。在这项工作中,我们提出了一种新型的基于条件扩散建模的医学图像分割框架(LDSeg)。该框架利用目标对象的固有低维潜在形状流形的学习和源图像的嵌入,以及端到端的框架。潜在空间中的条件扩散不仅确保了多个交互对象的准确图像分割,还解决了基于传统DPM的分割方法的基本问题:(1)高内存消耗,(2)耗时的采样过程,以及(3)前向和反向过程中的不自然噪声注入。端到端的训练策略能够在与分割特征相关的潜在空间中实现稳健的表示学习,确保在推理阶段从后验分布中进行分割生成时显著加快采样速度。我们的实验表明,LDSeg在三种不同成像模式的医学图像数据集上实现了最先进的分割精度。此外,我们还表明,与传统确定性分割模型相比,我们提出的模型对噪声具有更强的鲁棒性。代码可通过https://github.com/FahimZaman/LDSeg.git获取。
论文及项目相关链接
PDF 10 pages, 10 figures, journal article
Summary
基于扩散概率模型(DPMs)在医疗图像应用中的采样缓慢和内存消耗高的缺点,本文提出了一种新型的基于条件扩散建模的框架(LDSeg)用于医疗图像分割。LDSeg利用目标对象的内在低维潜在形状流形和源图像的嵌入,通过端到端的框架进行图像分割。条件扩散在潜在空间不仅确保了多个交互对象的精确图像分割,还解决了传统DPMs方法的根本问题,如内存消耗高、采样过程耗时以及正反向过程中的不自然噪声注入。实验证明,LDSeg在三种不同成像模态的医疗图像数据集上实现了最先进的分割精度,且相较于传统的确定性分割模型,对噪声更具鲁棒性。
Key Takeaways
- LDSeg利用条件扩散建模进行医疗图像分割,针对DPMs的缺点进行优化。
- LDSeg通过利用潜在形状流形和源图像嵌入实现精确图像分割。
- 条件扩散在潜在空间解决了传统DPMs方法的高内存消耗和耗时采样问题。
- LDSeg能有效处理多个交互对象的图像分割。
- LDSeg在医疗图像分割上实现了先进性能,且对噪声具有鲁棒性。
- LDSeg采用端到端的训练策略,在潜在空间进行稳健的特征表示学习。
点此查看论文截图








Radiative decay of muonic molecules in resonance states
Authors:Takuma Yamashita, Kazuhiro Yasuda, Yasushi Kino
In this study, we theoretically investigated x-ray spectra from the radiative decay of muonic deuterium molecules in resonance states dd$\mu^\ast$, which plays an important role in a new kinetic model of muon catalyzed fusion ($\mu$CF). The resonance states are Feshbach resonances located below the d$\mu$($n=2$) + d threshold energy and radiatively decay into the continuum or bound states. The x-ray spectra having characteristic shapes according to the radial distribution of the two nuclei are obtained using precise three-body wave functions. We carefully examined the convergence of the x-ray spectra and achieved agreements between the length- and velocity-gauge calculations. We revealed a non-adiabatic kinetic energy distribution of the decay fragments, indicating that the radiative decay becomes a heating source of muonic atoms. We also investigated the decay branch that directly results in bound-state muonic molecules. Some resonance states dd$\mu^\ast$ and dt$\mu^\ast$ are found to have high branching ratios to the bound state where intramolecular nuclear fusion occurs. The formation of the muonic molecules in the bound states from metastable muonic atoms can be a fast track in the $\mu$CF cycle which skips a slow path to form the bound state from the ground-state muonic atoms and increases the $\mu$CF cycle rate. Although the spectra from the radiative decays are located in the energy range of $1.5$–$1.997$ keV, which is close to the K$\alpha$ x-ray of 1.997 keV from muonic deuterium atoms, state-of-the-art microcalorimeters can distinguish them.
在这项研究中,我们从理论上探讨了处于共振态的μ子化氘分子放射性衰变产生的X射线光谱,这在μ子催化聚变(μCF)的新动力学模型中扮演着重要角色。这些共振态位于dμ(n=2)+d的阈值能量以下,并会通过辐射衰变进入连续态或束缚态。利用精确的三体波函数,我们获得了具有特征形状的X射线光谱,这些特征形状根据两个原子核的径向分布而呈现。我们仔细研究了X射线光谱的收敛性,并在长度计量和速度计量计算之间取得了共识。我们揭示了衰变片段的非绝热动能分布,表明放射性衰变成为μ子原子的热源。我们还研究了直接导致束缚态μ子分子的衰变分支。发现一些共振态ddμ∗和dtμ∗到束缚态的分支比非常高,在束缚态中发生分子内的核聚变。从亚稳的μ子原子形成束缚态的μ子分子可能是一个快速通道,可以跳过从基态的μ子原子形成束缚态的缓慢路径,从而提高μCF循环速率。尽管来自放射性衰变的谱位于能量范围在$ 1.5 $至$ 1.997 $千电子伏特之间,这些谱与μ子化氘原子的Kα X射线非常接近,但最先进的微热量计仍然可以区分它们。
论文及项目相关链接
PDF 19 pages, 16 figures, 4 tables
摘要
本研究从理论上探讨了共振态下的μonic氘分子的放射性衰变产生的x射线光谱,这对于新的动力学模型下的μ子催化聚变(μCF)具有关键作用。通过精确的三体波函数,得到了根据两个原子核的径向分布特征形状独特的x射线光谱。本研究对x射线光谱的收敛性进行了仔细研究,实现了长度和速度计量计算之间的协议。揭示了非绝热动能分布的衰变片段,表明放射性衰变成为μonic原子的热源。此外,本研究还探讨了直接产生束缚态μonic分子的衰变分支。一些共振态的ddμ∗和dtμ∗被发现具有高的分支比到束缚态,其中发生分子内的核聚变。从亚稳态μonic原子形成束缚态muonic分子可能是μCF循环的快通道,避免了从基态muonic原子形成束缚态的缓慢路径,从而提高了μCF循环速率。虽然来自放射性衰变的光谱位于$ 1.5 $至$ 1.997 $千电子伏的能量范围内,接近muonic氘原子的Kα x射线($ 1.997 $千电子伏),但最先进的微热量计可以区分它们。总的来说,这一发现有助于提高对muonic原子行为的了解和核聚变反应的速率控制精度。通过对其放射性和能量分布的研究,为未来的研究提供了重要的理论基础和实验指导。
关键见解
- 研究从理论上探讨了μonic氘分子在共振状态下的放射性衰变产生的x射线光谱特征,在动力学模型中具有关键作用。
- 通过精确的三体波函数获得了具有特征形状的x射线光谱,反映了两个原子核的径向分布。
- 研究达成了长度和速度测量计算的共识,验证了计算结果的准确性。
- 揭示了放射性衰变中的非绝热动能分布特征,证明了其为μonic原子的热源之一。
- 研究发现某些共振态如ddμ∗和dtμ∗直接产生束缚态muonic分子具有较高的分支比。这对未来的分子核聚变研究有重要意义。
点此查看论文截图






Generalizable Disaster Damage Assessment via Change Detection with Vision Foundation Model
Authors:Kyeongjin Ahn, Sungwon Han, Sungwon Park, Jihee Kim, Sangyoon Park, Meeyoung Cha
The increasing frequency and intensity of natural disasters call for rapid and accurate damage assessment. In response, disaster benchmark datasets from high-resolution satellite imagery have been constructed to develop methods for detecting damaged areas. However, these methods face significant challenges when applied to previously unseen regions due to the limited geographical and disaster-type diversity in the existing datasets. We introduce DAVI (Disaster Assessment with VIsion foundation model), a novel approach that addresses domain disparities and detects structural damage at the building level without requiring ground-truth labels for target regions. DAVI combines task-specific knowledge from a model trained on source regions with task-agnostic knowledge from an image segmentation model to generate pseudo labels indicating potential damage in target regions. It then utilizes a two-stage refinement process, which operate at both pixel and image levels, to accurately identify changes in disaster-affected areas. Our evaluation, including a case study on the 2023 T"urkiye earthquake, demonstrates that our model achieves exceptional performance across diverse terrains (e.g., North America, Asia, and the Middle East) and disaster types (e.g., wildfires, hurricanes, and tsunamis). This confirms its robustness in disaster assessment without dependence on ground-truth labels and highlights its practical applicability.
自然灾害的频率和强度不断上升,要求进行快速和准确的损失评估。为此,已经利用高分辨率卫星图像构建了灾害基准数据集,以开发检测受损区域的方法。然而,当这些方法应用于未见过的区域时,由于现有数据集的地理和灾害类型多样性有限,这些方法面临着重大挑战。我们介绍了DAVI(基于视觉基础模型的灾害评估),这是一种新颖的方法,解决了领域差异问题,并在无需针对目标区域获取真实标签的情况下,以建筑层面检测结构性损伤。DAVI结合了源区域训练模型产生的特定任务知识和图像分割模型的通用任务知识,以生成指示目标区域潜在损伤的伪标签。然后,它采用两级细化过程,在像素和图像层面进行操作,以准确识别受灾区域的变化。我们的评估包括对2023年土耳其地震的案例研究,证明我们的模型在不同地形(如北美、亚洲和中东)和灾害类型(如野火、飓风和海啸)上实现了卓越的性能。这证实了其在无需依赖真实标签进行灾害评估方面的稳健性,并凸显了其实用性。
论文及项目相关链接
PDF Accepted to AAAI 2025 (oral)
Summary
高频率和强度的自然灾害需要进行快速准确的灾害损失评估。为应对这一需求,构建了基于高分辨率卫星影像的灾害基准数据集以开发检测受损区域的方法。然而,这些方法在应用于未见区域时面临挑战,因为现有数据集的地理和灾害类型多样性有限。我们引入了DAVI(基于Vision foundation模型的灾害评估),这是一种新颖的方法,解决了领域差异问题,并在无需目标区域地面真实标签的情况下,以建筑级别检测结构损伤。DAVI结合了来自源区域训练的模型的特定任务知识和来自图像分割模型的非特定任务知识,生成指示目标区域潜在损伤的伪标签。然后,它利用像素和图像级别的两阶段细化过程,准确识别受灾区域的变化。我们的评估包括对2023年土耳其地震的案例研究,证明了我们的模型在不同地形和灾害类型上实现了卓越的性能,这证实了其在灾害评估中的稳健性,并强调了其不依赖地面真实标签的实际适用性。
Key Takeaways
- 自然灾害的频率和强度增加,需要快速准确的灾害损失评估方法。
- 灾害基准数据集用于开发检测受损区域的方法,但现有数据集地理和灾害类型多样性有限。
- DAVI方法结合特定任务和非特定任务知识,生成指示目标区域潜在损伤的伪标签。
- DAVI通过两阶段细化过程准确识别受灾区域的变化。
- DAVI模型在不同地形和灾害类型上实现了卓越性能。
6.DAVI模型不依赖地面真实标签,具有实际应用价值。
点此查看论文截图




Stitching, Fine-tuning, Re-training: A SAM-enabled Framework for Semi-supervised 3D Medical Image Segmentation
Authors:Shumeng Li, Lei Qi, Qian Yu, Jing Huo, Yinghuan Shi, Yang Gao
Segment Anything Model (SAM) fine-tuning has shown remarkable performance in medical image segmentation in a fully supervised manner, but requires precise annotations. To reduce the annotation cost and maintain satisfactory performance, in this work, we leverage the capabilities of SAM for establishing semi-supervised medical image segmentation models. Rethinking the requirements of effectiveness, efficiency, and compatibility, we propose a three-stage framework, i.e., Stitching, Fine-tuning, and Re-training (SFR). The current fine-tuning approaches mostly involve 2D slice-wise fine-tuning that disregards the contextual information between adjacent slices. Our stitching strategy mitigates the mismatch between natural and 3D medical images. The stitched images are then used for fine-tuning SAM, providing robust initialization of pseudo-labels. Afterwards, we train a 3D semi-supervised segmentation model while maintaining the same parameter size as the conventional segmenter such as V-Net. Our SFR framework is plug-and-play, and easily compatible with various popular semi-supervised methods. We also develop an extended framework SFR$^+$ with selective fine-tuning and re-training through confidence estimation. Extensive experiments validate that our SFR and SFR$^+$ achieve significant improvements in both moderate annotation and scarce annotation across five datasets. In particular, SFR framework improves the Dice score of Mean Teacher from 29.68% to 74.40% with only one labeled data of LA dataset.
SAM(Segment Anything Model)微调在全监督方式下的医学图像分割中表现出了显著的性能,但这需要精确的标注。为了减少标注成本并保持令人满意的性能,在这项工作中,我们利用SAM的能力来建立半监督医学图像分割模型。考虑到有效性、效率和兼容性的要求,我们提出了一个三阶段的框架,即拼接、微调、再训练(SFR)。目前的微调方法大多涉及2D切片级的微调,这忽略了相邻切片之间的上下文信息。我们的拼接策略缓解了自然图像和3D医学图像之间的不匹配问题。然后,我们使用拼接后的图像对SAM进行微调,为伪标签提供稳健的初始化。之后,我们训练了一个3D半监督分割模型,同时保持与常规分割器(如V-Net)相同的参数大小。我们的SFR框架即插即用,很容易与各种流行的半监督方法兼容。我们还开发了一个扩展框架SFR+,通过置信度估计进行选择性微调。大量实验验证,我们的SFR和SFR+在五个数据集上,无论是在中等标注还是稀缺标注的情况下,都实现了显著的改进。特别是SFR框架,在LA数据集上仅使用一个标签数据,就将Mean Teacher的Dice得分从29.68%提高到了74.40%。
论文及项目相关链接
Summary
半监督医学图像分割模型利用Segment Anything Model(SAM)进行fine-tuning,表现出卓越的性能。为降低标注成本并保持性能,提出一个三阶段的框架:拼接(Stitching)、fine-tuning和再训练(Re-training,简称SFR)。现有fine-tuning方法多基于2D切片,忽略了相邻切片间的上下文信息。本研究采用拼接策略,缓解自然图像与医学图像的3D结构不匹配问题。利用拼接后的图像进行SAM的fine-tuning,为伪标签提供稳健的初始化。在此基础上,训练一个与常规分割器如V-Net相同参数规模的3D半监督分割模型。SFR框架易于集成各种流行的半监督方法。还开发了扩展框架SFR+,通过置信度估计进行选择性fine-tuning和再训练。实验证明,在五个数据集上,无论是中等标注还是稀缺标注,SFR和SFR+均有显著提高。特别是在LA数据集上,仅使用一个标注数据,SFR框架将Mean Teacher的Dice得分从29.68%提高到74.40%。
Key Takeaways
- 利用SAM进行半监督医学图像分割模型的fine-tuning,以降低标注成本。
- 提出一个三阶段的框架SFR,包括拼接、fine-tuning和再训练。
- 现有fine-tuning方法主要基于2D切片,忽略了上下文信息;研究采用拼接策略解决此问题。
- 利用拼接后的图像进行SAM的fine-tuning,为伪标签提供稳健初始化。
- 训练一个与常规分割器相同参数规模的3D半监督分割模型。
- SFR框架易于集成各种流行的半监督方法。
点此查看论文截图






VIS-MAE: An Efficient Self-supervised Learning Approach on Medical Image Segmentation and Classification
Authors:Zelong Liu, Andrew Tieu, Nikhil Patel, Georgios Soultanidis, Louisa Deyer, Ying Wang, Sean Huver, Alexander Zhou, Yunhao Mei, Zahi A. Fayad, Timothy Deyer, Xueyan Mei
Artificial Intelligence (AI) has the potential to revolutionize diagnosis and segmentation in medical imaging. However, development and clinical implementation face multiple challenges including limited data availability, lack of generalizability, and the necessity to incorporate multi-modal data effectively. A foundation model, which is a large-scale pre-trained AI model, offers a versatile base that can be adapted to a variety of specific tasks and contexts. Here, we present VIsualization and Segmentation Masked AutoEncoder (VIS-MAE), novel model weights specifically designed for medical imaging. Specifically, VIS-MAE is trained on a dataset of 2.5 million unlabeled images from various modalities (CT, MR, PET,X-rays, and ultrasound), using self-supervised learning techniques. It is then adapted to classification and segmentation tasks using explicit labels. VIS-MAE has high label efficiency, outperforming several benchmark models in both in-domain and out-of-domain applications. In addition, VIS-MAE has improved label efficiency as it can achieve similar performance to other models with a reduced amount of labeled training data (50% or 80%) compared to other pre-trained weights. VIS-MAE represents a significant advancement in medical imaging AI, offering a generalizable and robust solution for improving segmentation and classification tasks while reducing the data annotation workload. The source code of this work is available at https://github.com/lzl199704/VIS-MAE.
人工智能(AI)具有潜力改变医学影像的诊断和分割方式。然而,其发展和临床实施面临着多重挑战,包括数据有限、通用性不足以及需要有效地整合多模态数据。基础模型是一个大规模预训练的AI模型,提供了一个通用的基础,可以适应各种特定任务和上下文。在这里,我们提出可视化及分割掩码自动编码器(VIS-MAE),这是专门为医学影像设计的全新模型权重。具体来说,VIS-MAE是在各种模态(CT、MR、PET、X射线和超声)的250万张无标签图像数据集上进行训练的,使用了自我监督的学习技术。然后,它使用明确的标签适应分类和分割任务。VIS-MAE具有高的标签效率,在领域内和领域外的应用中均优于多个基准模型。此外,VIS-MAE提高了标签效率,与其他预训练权重相比,它在减少50%或80%的有标签训练数据的情况下,可以达到与其他模型相当的性能。VIS-MAE在医学影像AI中代表了重大进步,为改善分割和分类任务同时减少数据标注工作量提供了通用和稳健的解决方案。该工作的源代码可在https://github.com/lzl199704/VIS-MAE获得。
论文及项目相关链接
PDF Accepted at MLMI@MICCAI (Workshop on Machine Learning in Medical Imaging at MICCAI 2024))
Summary
AI技术具有在医学成像中变革诊断和分割的潜力。面临的挑战包括数据有限、缺乏普遍性和需要有效整合多模态数据。一项新的视觉化及分割掩码自编码器(VIS-MAE)模型专为医学成像设计,该模型在多种模态(CT、MR、PET、X光及超声波)的250万张无标签图像数据集上进行训练,并采用自我监督学习技术。其适应分类和分割任务时采用明确的标签。VIS-MAE拥有高标签效率,在内部和外部应用中表现均优于多个基准模型。此外,与其他预训练权重相比,VIS-MAE可望使用较少的有标签训练数据(仅需一半或八成)即可实现类似性能。它显著推动了医学成像AI的发展,提供了一个通用和稳健的解决方案,以改善分割和分类任务并减少数据注释工作量。
Key Takeaways
- 人工智能在医学成像中具有改变诊断和分割的巨大潜力。
- 开发与实施面临挑战,如数据有限性、缺乏普遍性以及多模态数据整合的复杂性。
- VIS-MAE模型是一种专为医学成像设计的视觉化及分割掩码自编码器。
- VIS-MAE模型采用自我监督学习技术在多模态数据集上进行训练。
- VIS-MAE适应于分类和分割任务并具有高标签效率。
- VIS-MAE在内部和外部应用中表现均优于多个基准模型。
点此查看论文截图