⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-24 更新
An Offline Multi-Agent Reinforcement Learning Framework for Radio Resource Management
Authors:Eslam Eldeeb, Hirley Alves
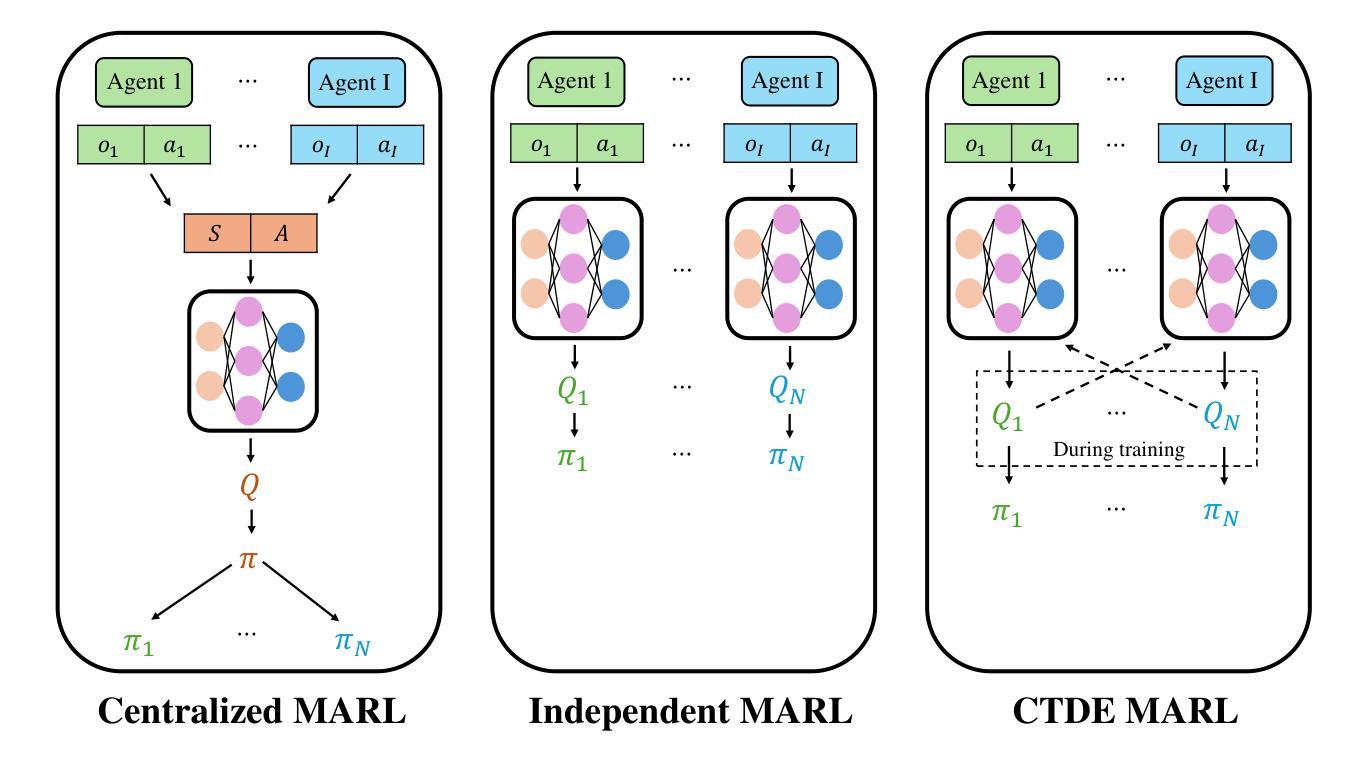
Offline multi-agent reinforcement learning (MARL) addresses key limitations of online MARL, such as safety concerns, expensive data collection, extended training intervals, and high signaling overhead caused by online interactions with the environment. In this work, we propose an offline MARL algorithm for radio resource management (RRM), focusing on optimizing scheduling policies for multiple access points (APs) to jointly maximize the sum and tail rates of user equipment (UEs). We evaluate three training paradigms: centralized, independent, and centralized training with decentralized execution (CTDE). Our simulation results demonstrate that the proposed offline MARL framework outperforms conventional baseline approaches, achieving over a 15% improvement in a weighted combination of sum and tail rates. Additionally, the CTDE framework strikes an effective balance, reducing the computational complexity of centralized methods while addressing the inefficiencies of independent training. These results underscore the potential of offline MARL to deliver scalable, robust, and efficient solutions for resource management in dynamic wireless networks.
离线多智能体强化学习(MARL)解决了在线MARL的关键限制,如安全顾虑、昂贵的数据收集成本、延长的训练间隔以及由与环境在线交互引起的高信号开销。在这项工作中,我们针对无线电资源管理(RRM)提出了一种离线MARL算法,侧重于优化多个接入点(APs)的调度策略,以联合最大化用户设备(UEs)的总吞吐量和尾部速率。我们评估了三种训练模式:集中式、独立式和带有分散执行的集中训练(CTDE)。我们的仿真结果表明,所提出的离线MARL框架优于传统基线方法,在吞吐量和尾部速率的加权组合上提高了超过15%。此外,CTDE框架实现了有效的平衡,降低了集中方法的计算复杂性,解决了独立训练的效率低下问题。这些结果凸显了离线MARL在动态无线网络中的资源管理的潜在能力,能够提供可扩展、稳健和高效的解决方案。
论文及项目相关链接
Summary
离线多智能体强化学习(MARL)解决了在线MARL的关键局限性,包括安全顾虑、昂贵的数据收集、延长的训练间隔以及由与环境在线交互引起的高信号开销。本研究提出一种用于无线电资源管理(RRM)的离线MARL算法,侧重于优化多个接入点(APs)的调度策略,以联合最大化用户设备(UEs)的速率总和和尾部速率。评估了三种训练范式:集中式、独立式和集中式训练与分布式执行(CTDE)。仿真结果表明,所提离线MARL框架优于传统基线方法,在速率总和和尾部速率的加权组合上提高了超过15%。此外,CTDE框架在平衡计算复杂性的同时,解决了独立训练的不足,展现出其有效性。这些结果突显了离线MARL在动态无线网络中的资源管理的潜在应用前景。
Key Takeaways
- 离线多智能体强化学习解决了在线强化学习的安全顾虑和由在线交互带来的高昂数据收集成本等问题。
- 提出的算法专注于无线电资源管理中的调度策略优化,旨在最大化用户设备的速率总和和尾部速率。
- 研究评估了三种训练范式:集中式、独立式和集中式训练与分布式执行(CTDE)。
- 仿真结果表明,离线MARL框架优于传统方法,提高了速率加权组合的性能。
- CTDE框架在计算效率和解决独立训练不足之间找到了平衡。
- 离线MARL在动态无线网络资源管理中具有潜在应用前景。
点此查看论文截图



FilmAgent: A Multi-Agent Framework for End-to-End Film Automation in Virtual 3D Spaces
Authors:Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Senbao Shi, Xue Yang, Yiyu Wang, Baotian Hu, Jun Yu, Min Zhang
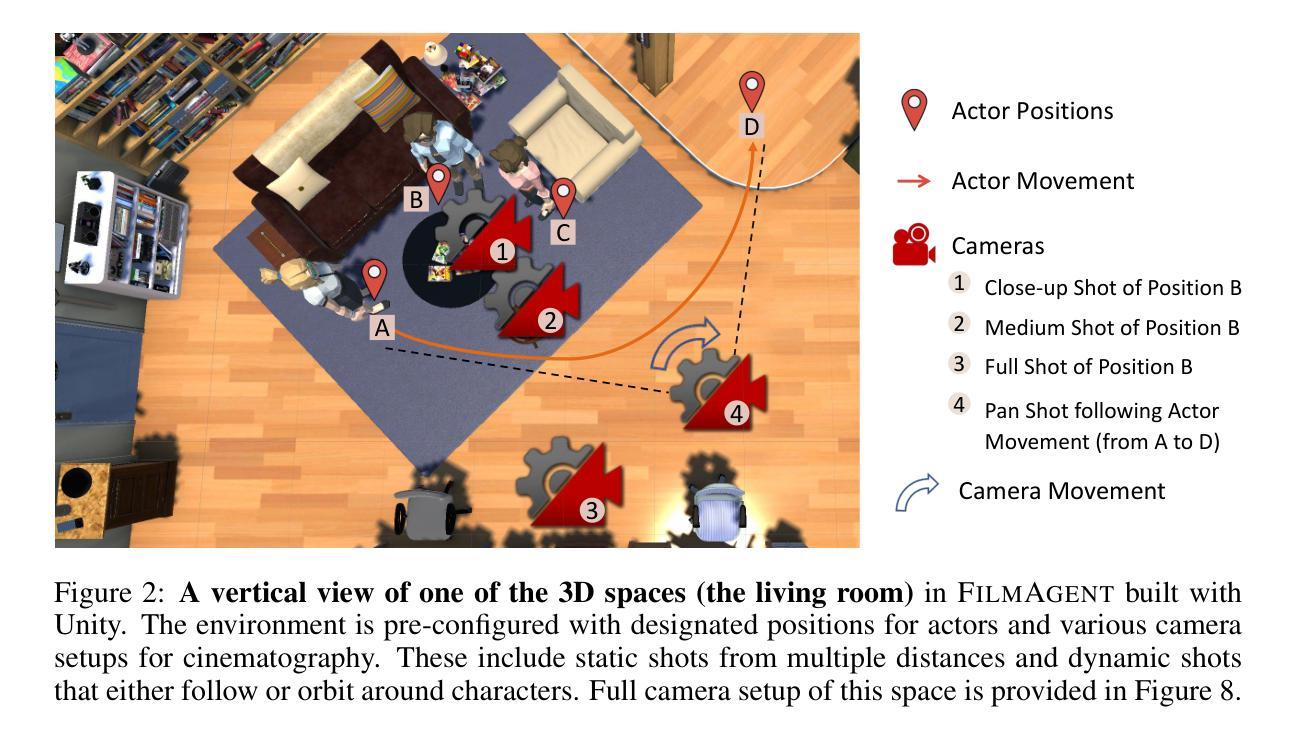
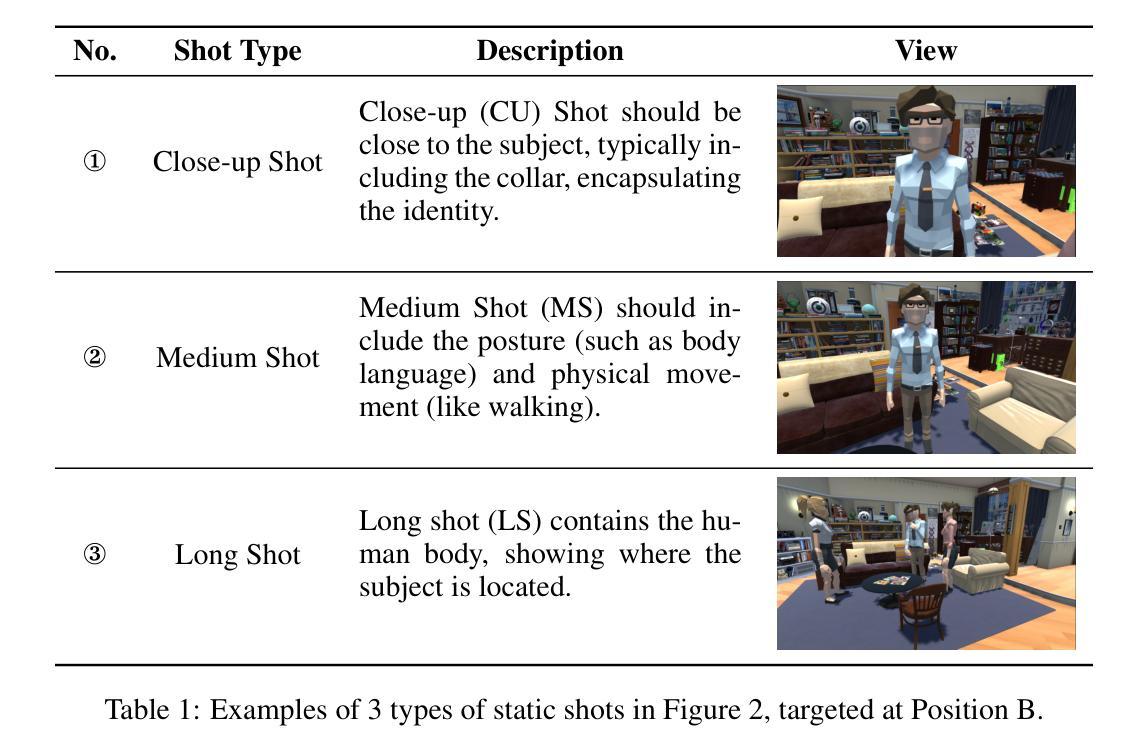
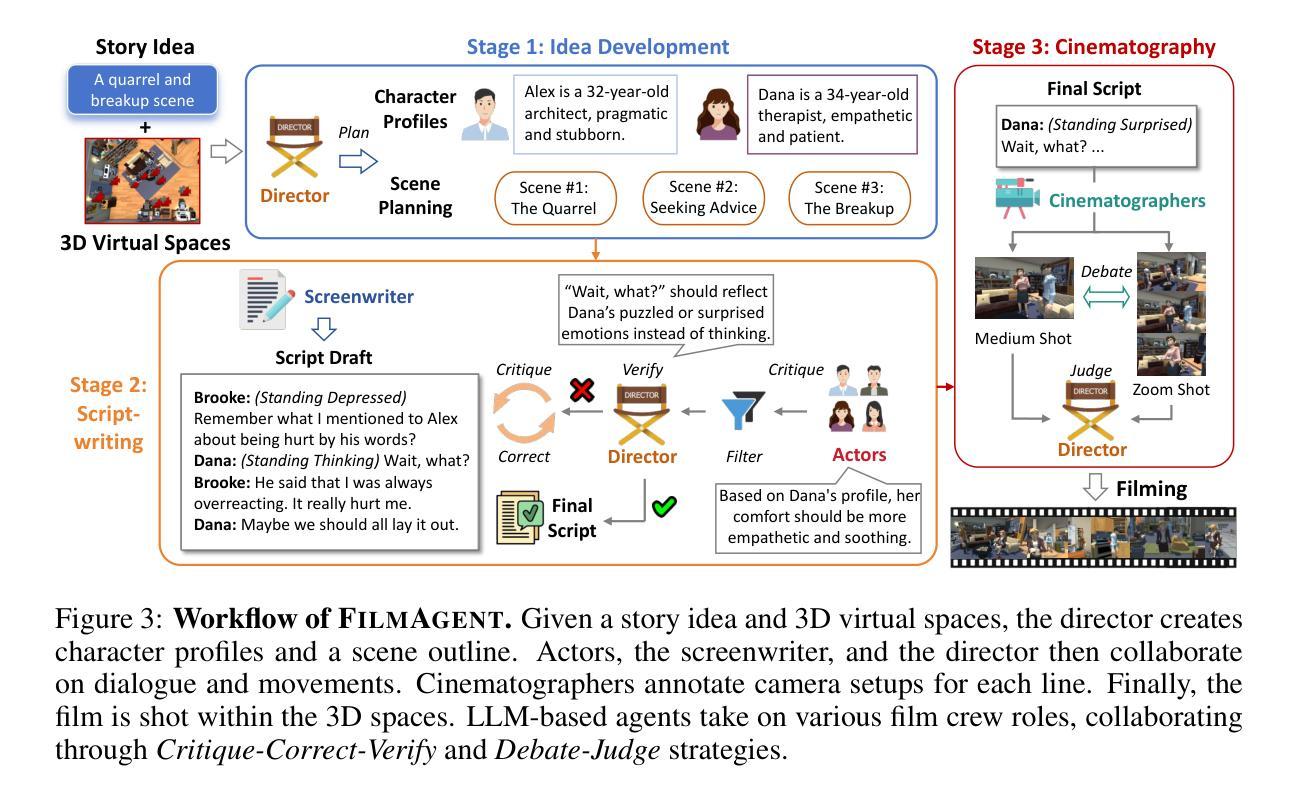
Virtual film production requires intricate decision-making processes, including scriptwriting, virtual cinematography, and precise actor positioning and actions. Motivated by recent advances in automated decision-making with language agent-based societies, this paper introduces FilmAgent, a novel LLM-based multi-agent collaborative framework for end-to-end film automation in our constructed 3D virtual spaces. FilmAgent simulates various crew roles, including directors, screenwriters, actors, and cinematographers, and covers key stages of a film production workflow: (1) idea development transforms brainstormed ideas into structured story outlines; (2) scriptwriting elaborates on dialogue and character actions for each scene; (3) cinematography determines the camera setups for each shot. A team of agents collaborates through iterative feedback and revisions, thereby verifying intermediate scripts and reducing hallucinations. We evaluate the generated videos on 15 ideas and 4 key aspects. Human evaluation shows that FilmAgent outperforms all baselines across all aspects and scores 3.98 out of 5 on average, showing the feasibility of multi-agent collaboration in filmmaking. Further analysis reveals that FilmAgent, despite using the less advanced GPT-4o model, surpasses the single-agent o1, showing the advantage of a well-coordinated multi-agent system. Lastly, we discuss the complementary strengths and weaknesses of OpenAI’s text-to-video model Sora and our FilmAgent in filmmaking.
虚拟电影制作需要复杂的决策过程,包括剧本创作、虚拟摄影以及精确的演员定位和动作。本文受到基于语言代理社会的自动化决策制定最新进展的启发,介绍了一种新型的基于大型语言模型(LLM)的多代理协作框架FilmAgent,用于在我们构建的3D虚拟空间中进行端到端的电影自动化。FilmAgent模拟各种剧组角色,包括导演、编剧、演员和摄影师,并涵盖电影制作流程的关键阶段:(1)创意发展将集思广益的想法转化为结构化的故事大纲;(2)剧本详细阐述每个场景的对话和角色行动;(3)摄影确定每个镜头的相机设置。一组代理通过迭代反馈和修订进行协作,从而验证中间剧本并减少幻觉。我们对15个想法和4个关键方面生成的视频进行了评估。人类评估显示,FilmAgent在所有方面都优于所有基线,平均得分为3.98(满分5分),证明了多代理协作在电影制作中的可行性。进一步的分析表明,尽管使用了较不先进的GPT-4o模型,FilmAgent仍然超越了单一代理o1,显示了协调良好的多代理系统的优势。最后,我们讨论了OpenAI的文本到视频模型Sora与我们的FilmAgent在电影制作中的互补优势和劣势。
论文及项目相关链接
PDF Work in progress. Project Page: https://filmagent.github.io/
Summary
基于自然语言处理的多智能体协作框架FilmAgent被提出,用于在构建的3D虚拟空间中进行端到端的电影自动化生产。FilmAgent模拟电影制作过程中的导演、编剧、演员和摄影师等角色,涵盖从创意发展到剧本创作再到摄影等关键阶段。通过智能体之间的迭代反馈和修订,验证了中间剧本并减少了虚构现象。评估结果显示FilmAgent在多个方面表现出优异的性能,并与单智能体系统相比具有优势。此外,还探讨了FilmAgent与OpenAI的文本到视频模型Sora在影视制作中的互补性和优缺点。
Key Takeaways
- FilmAgent是一个基于自然语言处理的多智能体协作框架,用于虚拟电影制作自动化。
- 该系统模拟电影制作过程中的多个角色,包括导演、编剧、演员和摄影师等。
- FilmAgent涵盖电影制作的关键阶段,如创意发展、剧本创作和摄影。
- 通过智能体之间的迭代反馈和修订,验证了中间剧本并减少虚构现象。
- 评估结果显示FilmAgent在多个方面表现出优异性能,优于单智能体系统。
- FilmAgent与OpenAI的文本到视频模型Sora在影视制作中有互补性和优缺点。
点此查看论文截图


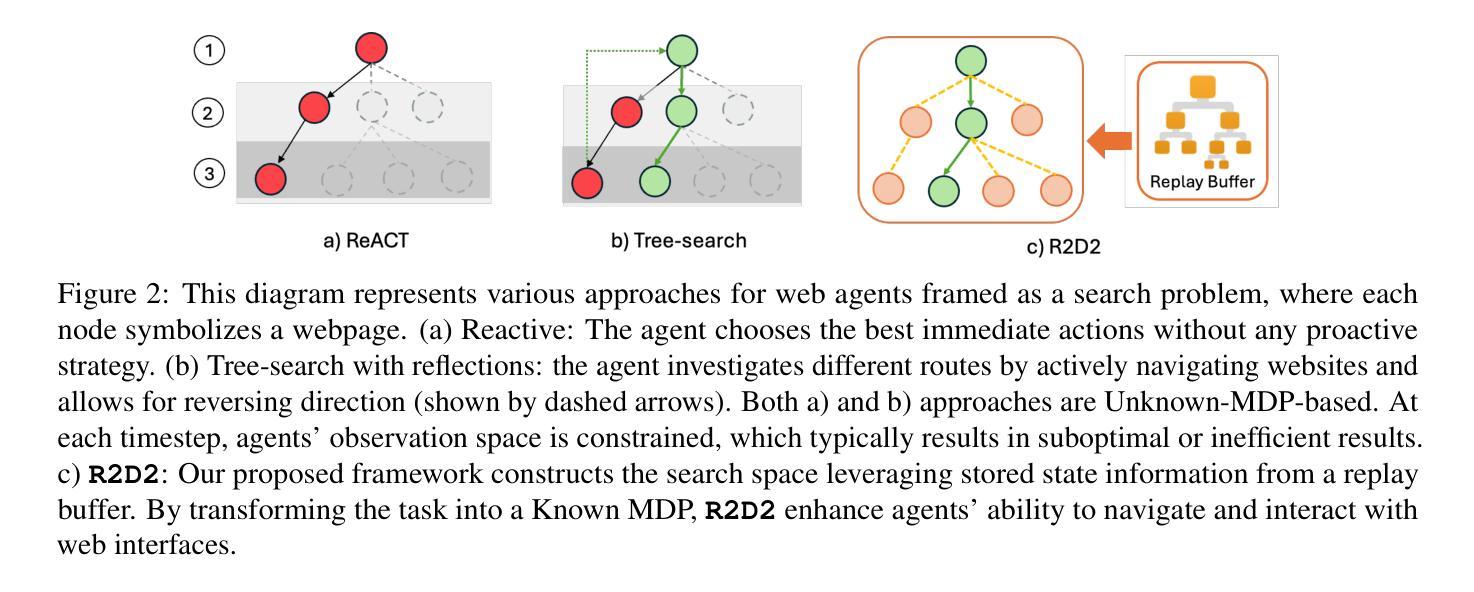
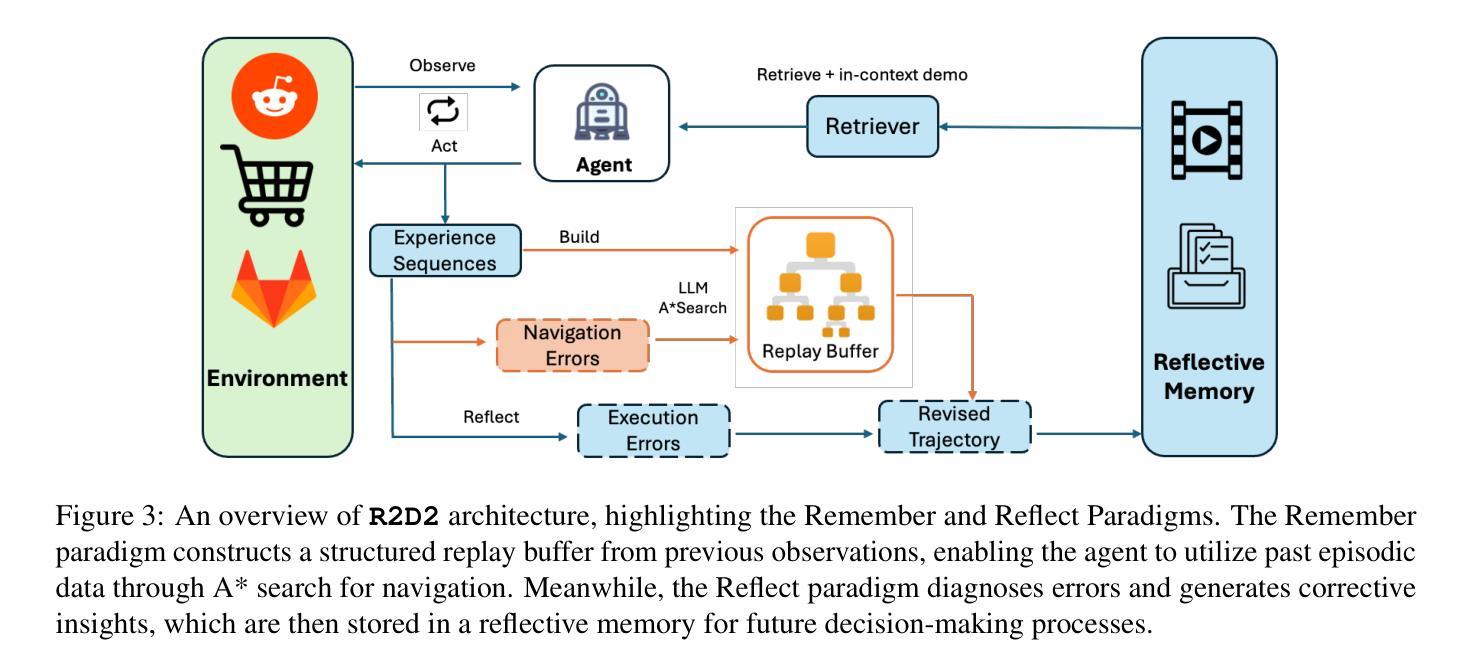
R2D2: Remembering, Reflecting and Dynamic Decision Making for Web Agents
Authors:Tenghao Huang, Kinjal Basu, Ibrahim Abdelaziz, Pavan Kapanipathi, Jonathan May, Muhao Chen
The proliferation of web agents necessitates advanced navigation and interaction strategies within complex web environments. Current models often struggle with efficient navigation and action execution due to limited visibility and understanding of web structures. Our proposed R2D2 framework addresses these challenges by integrating two paradigms: Remember and Reflect. The Remember paradigm utilizes a replay buffer that aids agents in reconstructing the web environment dynamically, thus enabling the formulation of a detailed ``map’’ of previously visited pages. This helps in reducing navigational errors and optimizing the decision-making process during web interactions. Conversely, the Reflect paradigm allows agents to learn from past mistakes by providing a mechanism for error analysis and strategy refinement, enhancing overall task performance. We evaluate R2D2 using the WEBARENA benchmark, demonstrating significant improvements over existing methods, including a 50% reduction in navigation errors and a threefold increase in task completion rates. Our findings suggest that a combination of memory-enhanced navigation and reflective learning promisingly advances the capabilities of web agents, potentially benefiting various applications such as automated customer service and personal digital assistants.
网络代理的激增需要在复杂的网络环境中采用先进的导航和交互策略。由于对网络结构的可见性和理解有限,当前模型在高效导航和行动执行方面经常面临困难。我们提出的R2D2框架通过整合两种范式来解决这些挑战:Remember(记忆)和Reflect(反思)。记忆范式利用回放缓冲区帮助代理动态重建网络环境,从而能够制定已访问页面的详细“地图”。这有助于减少导航错误,优化网页交互过程中的决策制定。相反,反思范式通过提供错误分析和策略改进的机制,允许代理从过去的错误中学习,提高总体任务性能。我们使用WEBARENA基准测试评估了R2D 2,结果表明与现有方法相比,R2D 2具有显著的改进,包括导航错误减少50%,任务完成率提高三倍。我们的研究结果表明,记忆增强导航和反思学习相结合有望提高网络代理的能力,可能为自动客户服务和个人数字助理等各种应用带来好处。
论文及项目相关链接
Summary
本文提出了一个名为R2D2的框架,通过整合Remember和Reflect两个范式,解决当前模型在复杂网络环境中导航和交互策略的挑战。Remember范式利用回放缓冲区动态重建网络环境,帮助制定已访问页面的详细“地图”,优化决策过程。Reflect范式则通过错误分析和策略调整提高任务性能。经WEBARENA基准测试评估,R2D2在减少导航错误和任务完成率方面表现出显著优势。
Key Takeaways
- 网络代理的普及需要在复杂的网络环境中采用先进的导航和交互策略。
- 当前模型在高效导航和行动执行方面存在局限性,因为对网页结构的可见性和理解有限。
- R2D2框架通过整合Remember和Reflect两个范式来解决这些挑战。
- Remember范式利用回放缓冲区重建网络环境,帮助制定详细的已访问页面“地图”,优化决策过程并减少导航错误。
- Reflect范式允许代理从过去的错误中学习,通过错误分析和策略调整提高任务性能。
- R2D2框架在WEBARENA基准测试中表现出显著优势,包括减少导航错误和提高任务完成率。
点此查看论文截图


Episodic memory in AI agents poses risks that should be studied and mitigated
Authors:Chad DeChant
Most current AI models have little ability to store and later retrieve a record or representation of what they do. In human cognition, episodic memories play an important role in both recall of the past as well as planning for the future. The ability to form and use episodic memories would similarly enable a broad range of improved capabilities in an AI agent that interacts with and takes actions in the world. Researchers have begun directing more attention to developing memory abilities in AI models. It is therefore likely that models with such capability will be become widespread in the near future. This could in some ways contribute to making such AI agents safer by enabling users to better monitor, understand, and control their actions. However, as a new capability with wide applications, we argue that it will also introduce significant new risks that researchers should begin to study and address. We outline these risks and benefits and propose four principles to guide the development of episodic memory capabilities so that these will enhance, rather than undermine, the effort to keep AI safe and trustworthy.
当前的大多数人工智能模型都缺乏存储和之后检索其操作记录或表示的能力。在人类认知中,情景记忆在回忆过去和计划未来中都起着重要作用。形成和使用情景记忆的能力也将使人工智能在与世界互动和行动中获得更广泛的能力提升。研究人员已经开始将更多注意力放在开发人工智能模型的记忆能力上。因此,很可能在不久的将来,具备这种能力的人工智能模型将变得非常普遍。这可以在某种程度上通过让用户更好地监视、理解和控制人工智能的行动,使这些人工智能变得更安全。然而,作为一种具有广泛应用的新能力,我们认为它也将带来重大的新风险,研究人员应该开始研究并解决这些风险。我们概述了这些风险和收益,并提出了四项原则来指导情景记忆能力的发展,以便增强而不是削弱人工智能的安全性和可信度。
论文及项目相关链接
PDF Accepted for publication at the 2025 Secure and Trustworthy Machine Learning Conference (SaTML). The final version will be available on IEEE Xplore
Summary
当前人工智能模型缺乏存储和检索其操作记录或表示的能力。在人类认知中,情景记忆对于回忆过去和计划未来都起着重要作用。因此,在人工智能代理中形成和使用情景记忆的能力将为其带来广泛的改进功能,尤其是在与世界互动和采取行动方面。研究人员已经开始更多地关注在人工智能模型中开发记忆能力。因此,具有此类能力的模型可能在不久的将来得到广泛应用。这可以在某种程度上使此类人工智能更安全,因为用户能够更好地监视、理解和控制其操作。然而,作为一项具有广泛应用的新功能,它也将引入新的重大风险,研究人员应开始研究和解决这些风险。本文概述了这些风险和好处,并提出了四项原则来指导情景记忆能力的发展,以便这些能力能够增强而不是破坏人工智能的安全性和可信度。
Key Takeaways
- 当前人工智能模型缺乏存储和检索操作记录的能力,与人类情景记忆相比存在差距。
- 情景记忆能力将为人工智能代理带来广泛的改进功能,特别是在与世界互动和采取行动方面。
- 具有记忆能力的模型可能在不久的将来得到广泛应用。
- 情景记忆能力可以使人工智能更安全,因为它能提高用户的监视、理解和控制能力。
- 情景记忆能力引入新的重大风险,需要进行研究和解决。
- 文章提出了四项原则来指导情景记忆能力的发展。
点此查看论文截图

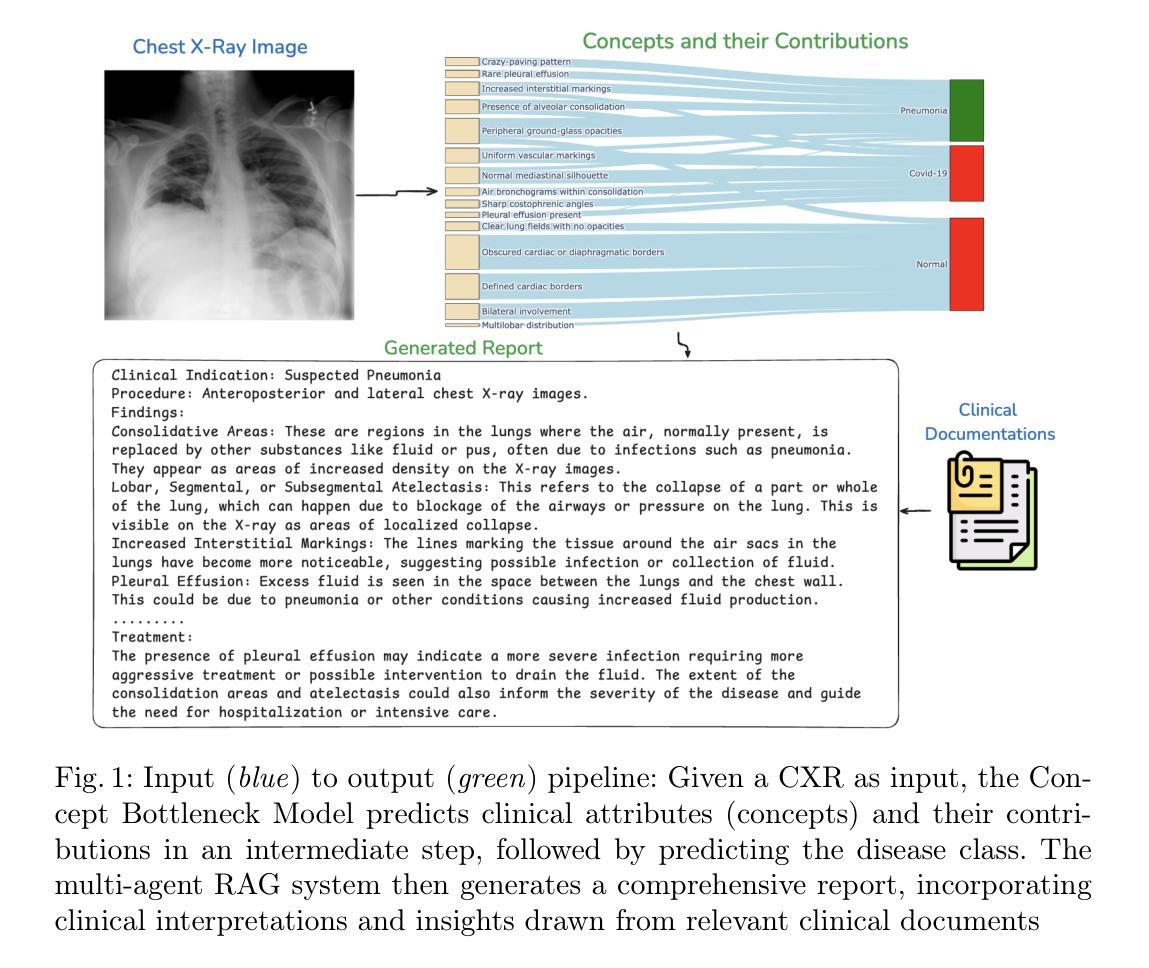
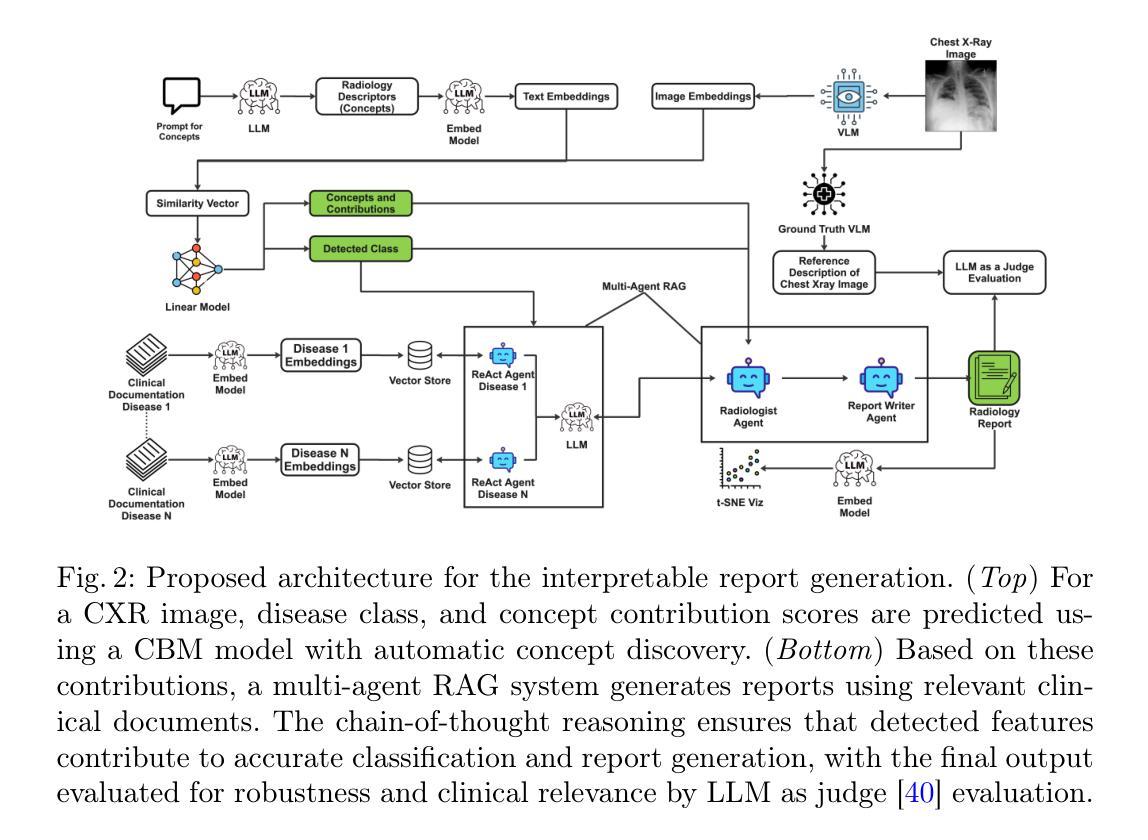
Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG
Authors:Hasan Md Tusfiqur Alam, Devansh Srivastav, Md Abdul Kadir, Daniel Sonntag
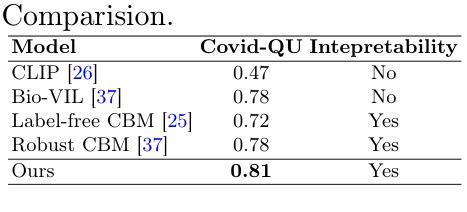
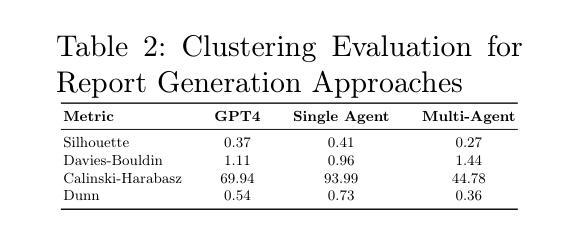
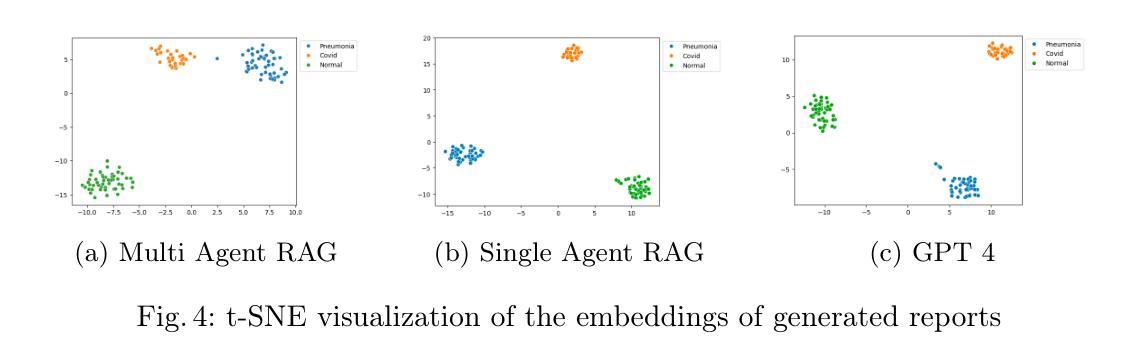
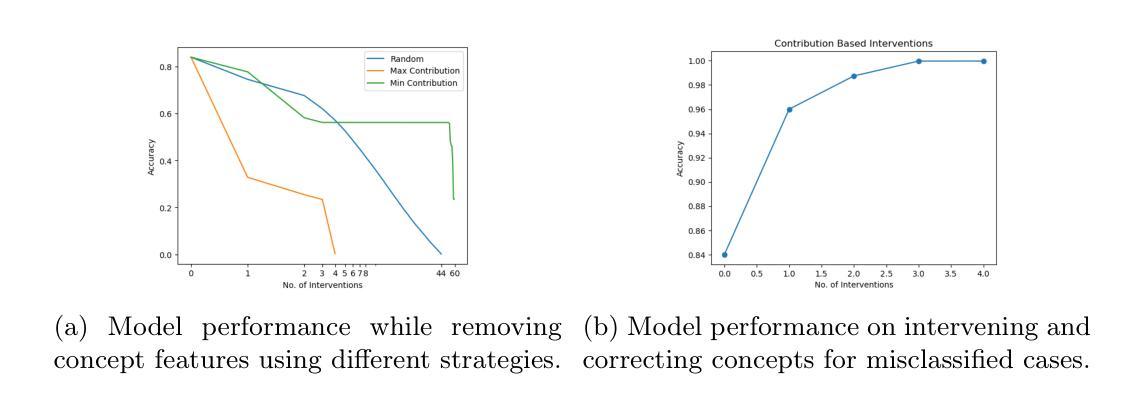
Deep learning has advanced medical image classification, but interpretability challenges hinder its clinical adoption. This study enhances interpretability in Chest X-ray (CXR) classification by using concept bottleneck models (CBMs) and a multi-agent Retrieval-Augmented Generation (RAG) system for report generation. By modeling relationships between visual features and clinical concepts, we create interpretable concept vectors that guide a multi-agent RAG system to generate radiology reports, enhancing clinical relevance, explainability, and transparency. Evaluation of the generated reports using an LLM-as-a-judge confirmed the interpretability and clinical utility of our model’s outputs. On the COVID-QU dataset, our model achieved 81% classification accuracy and demonstrated robust report generation performance, with five key metrics ranging between 84% and 90%. This interpretable multi-agent framework bridges the gap between high-performance AI and the explainability required for reliable AI-driven CXR analysis in clinical settings. Our code is available at https://github.com/tifat58/IRR-with-CBM-RAG.git.
深度学习已经推动了医学图像分类的进步,但解释性挑战阻碍了其在临床上的采纳。本研究通过采用概念瓶颈模型(CBM)和多代理检索增强生成(RAG)系统,提高了胸部X射线(CXR)分类中的解释性。通过模拟视觉特征和临床概念之间的关系,我们创建了可解释的概念向量,引导多代理RAG系统生成放射学报告,增强了临床相关性、解释性和透明度。使用大型语言模型作为评估工具对生成的报告进行评估,证实了我们模型输出的解释性和临床实用性。在COVID-QU数据集上,我们的模型达到了81%的分类准确率,并展示了稳健的报告生成性能,五项关键指标在84%到90%之间。这种可解释的多代理框架缩小了高性能人工智能和临床环境中可靠AI驱动CXR分析所需解释性之间的差距。我们的代码可在https://github.com/tifat58/IRR-with-CBM-RAG.git获取。
论文及项目相关链接
PDF Accepted in the 47th European Conference for Information Retrieval (ECIR) 2025
Summary
深度学习在医疗图像分类方面取得了进展,但解释性挑战阻碍了其在临床的采纳。本研究通过采用概念瓶颈模型(CBMs)和多代理检索增强生成(RAG)系统,提高了胸部X射线(CXR)分类的解释性。通过建模视觉特征与临床概念之间的关系,我们创建了可解释的概念向量,引导多代理RAG系统生成放射学报告,增强了临床相关性、解释性和透明度。使用大型语言模型(LLM)作为评判对生成的报告进行评估,证实了模型输出的解释性和临床实用性。在COVID-QU数据集上,我们的模型达到了81%的分类准确率,报告生成性能稳健,五项关键指标在84%至90%之间。这一可解释的多代理框架缩小了高性能人工智能和临床环境中可靠人工智能解释性要求之间的差距。
Key Takeaways
- 本研究提高了深度学习在医疗图像分类中的解释性,特别是在胸部X射线(CXR)分类方面。
- 通过概念瓶颈模型(CBMs)和多代理检索增强生成(RAG)系统,增强了模型的解释性、临床相关性和透明度。
- 模型能够生成具有临床意义的放射学报告,这有助于医生更好地理解图像并做出诊断。
- 在COVID-QU数据集上,模型取得了较高的分类准确率。
- 模型性能稳定,关键指标表现良好。
- 该模型有助于缩小高性能人工智能和临床环境中对人工智能解释性的需求之间的差距。
点此查看论文截图

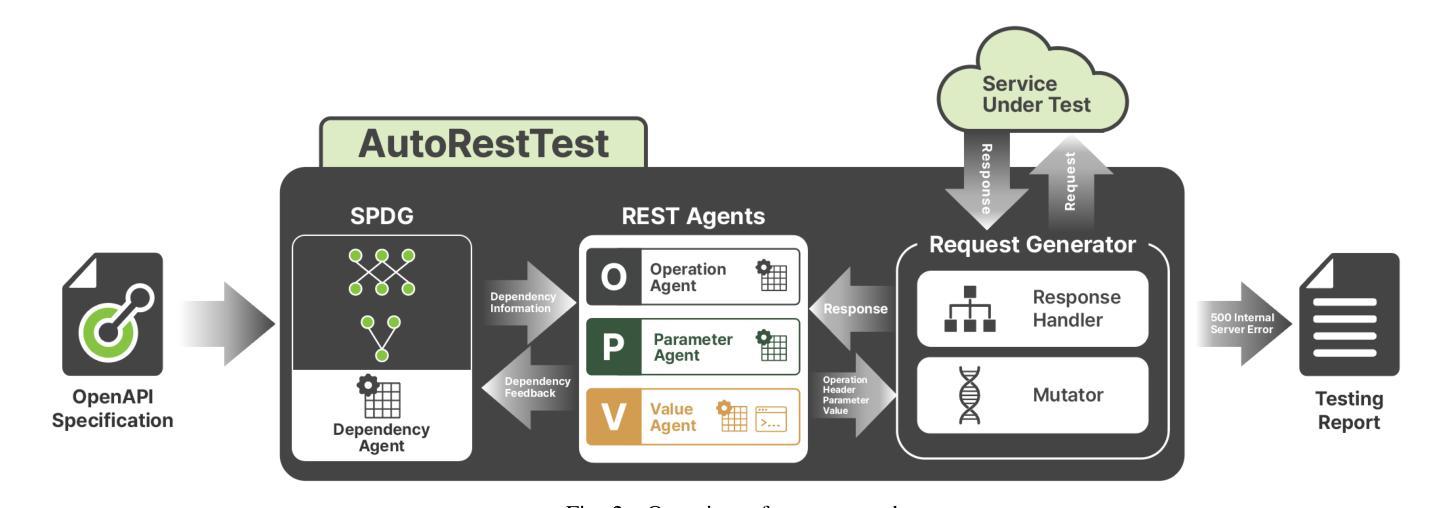
A Multi-Agent Approach for REST API Testing with Semantic Graphs and LLM-Driven Inputs
Authors:Myeongsoo Kim, Tyler Stennett, Saurabh Sinha, Alessandro Orso
As modern web services increasingly rely on REST APIs, their thorough testing has become crucial. Furthermore, the advent of REST API documentation languages, such as the OpenAPI Specification, has led to the emergence of many black-box REST API testing tools. However, these tools often focus on individual test elements in isolation (e.g., APIs, parameters, values), resulting in lower coverage and less effectiveness in fault detection. To address these limitations, we present AutoRestTest, the first black-box tool to adopt a dependency-embedded multi-agent approach for REST API testing that integrates multi-agent reinforcement learning (MARL) with a semantic property dependency graph (SPDG) and Large Language Models (LLMs). Our approach treats REST API testing as a separable problem, where four agents – API, dependency, parameter, and value agents – collaborate to optimize API exploration. LLMs handle domain-specific value generation, the SPDG model simplifies the search space for dependencies using a similarity score between API operations, and MARL dynamically optimizes the agents’ behavior. Our evaluation of AutoRestTest on 12 real-world REST services shows that it outperforms the four leading black-box REST API testing tools, including those assisted by RESTGPT (which generates realistic test inputs using LLMs), in terms of code coverage, operation coverage, and fault detection. Notably, AutoRestTest is the only tool able to trigger an internal server error in the Spotify service. Our ablation study illustrates that each component of AutoRestTest – the SPDG, the LLM, and the agent-learning mechanism – contributes to its overall effectiveness.
随着现代Web服务越来越依赖REST API,其全面测试变得至关重要。此外,随着REST API文档语言(如OpenAPI规范)的出现,出现了许多黑盒REST API测试工具。然而,这些工具通常侧重于孤立的单个测试元素(例如API、参数、值),导致覆盖率较低,故障检测效果较差。为了解决这些局限性,我们推出了AutoRestTest,这是第一个采用依赖嵌入多智能体方法进行REST API测试的黑盒工具。它将多智能体强化学习(MARL)与语义属性依赖图(SPDG)和大型语言模型(LLM)相结合。我们的方法将REST API测试视为一个可以分离的问题,其中四个智能体——API智能体、依赖智能体、参数智能体和值智能体——相互协作以优化API探索。LLM处理特定领域的值生成,SPDG模型通过API操作之间的相似性得分简化了依赖项的搜索空间,而MARL则动态优化智能体的行为。我们对12个真实世界的REST服务进行的评估表明,在代码覆盖率、操作覆盖率和故障检测方面,AutoRestTest表现优于其他四种领先的黑盒REST API测试工具,包括借助RESTGPT的工具(使用LLM生成逼真的测试输入)。值得注意的是,AutoRestTest是唯一能够触发Spotify服务内部服务器错误的工具。我们的消融研究表明,AutoRestTest的每个组件——SPDG、LLM和智能体学习机制——都对其整体有效性做出了贡献。
论文及项目相关链接
PDF To be published in the 47th IEEE/ACM International Conference on Software Engineering (ICSE 2025)
Summary
本文介绍了现代Web服务中对REST API测试的重要性,以及当前黑盒REST API测试工具存在的局限性。为了克服这些局限性,提出了一种新的黑盒测试工具AutoRestTest,它采用依赖嵌入的多智能体方法对REST API进行测试。该方法集成了多智能体强化学习(MARL)、语义属性依赖图(SPDG)和大型语言模型(LLMs)。评估结果显示,AutoRestTest在代码覆盖率、操作覆盖率和故障检测方面优于其他四种领先的黑盒REST API测试工具。
Key Takeaways
- 现代Web服务对REST API的彻底测试至关重要。
- 当前黑盒REST API测试工具存在局限性,导致覆盖率和故障检测效果较低。
- AutoRestTest是一种采用依赖嵌入的多智能体方法的黑盒测试工具,整合了MARL、SPDG和LLMs。
- AutoRestTest将REST API测试视为一个独立的问题,通过四个智能体(API、依赖、参数和价值智能体)的合作来优化API的探索。
- LLMs用于生成特定领域的值,SPDG模型使用相似度分数简化了依赖项的搜索空间,而MARL则动态优化智能体的行为。
- 评估结果显示,AutoRestTest在代码覆盖率、操作覆盖率和故障检测方面优于其他领先的黑盒REST API测试工具。
点此查看论文截图