⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-24 更新
LLM4WM: Adapting LLM for Wireless Multi-Tasking
Authors:Xuanyu Liu, Shijian Gao, Boxun Liu, Xiang Cheng, Liuqing Yang
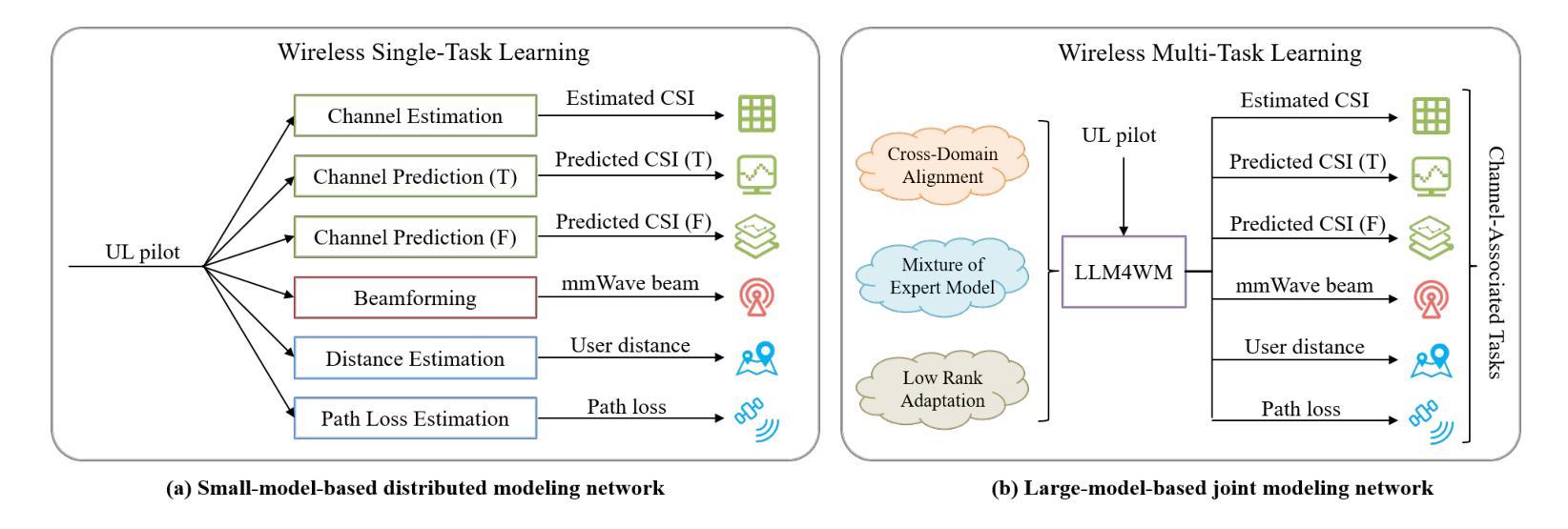
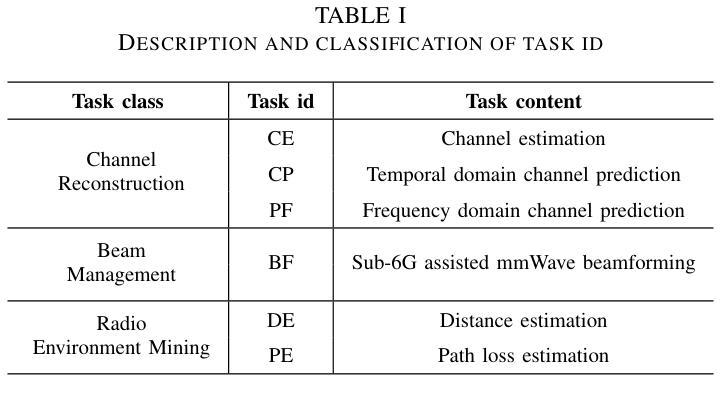
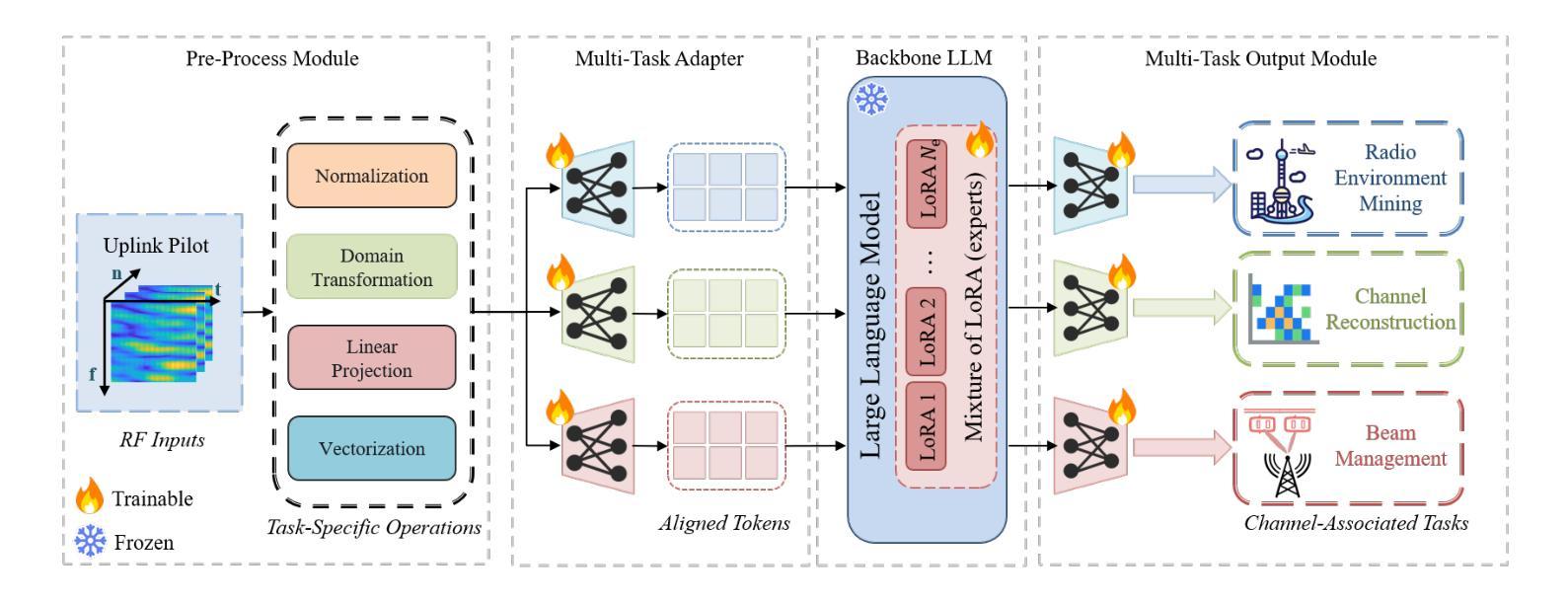
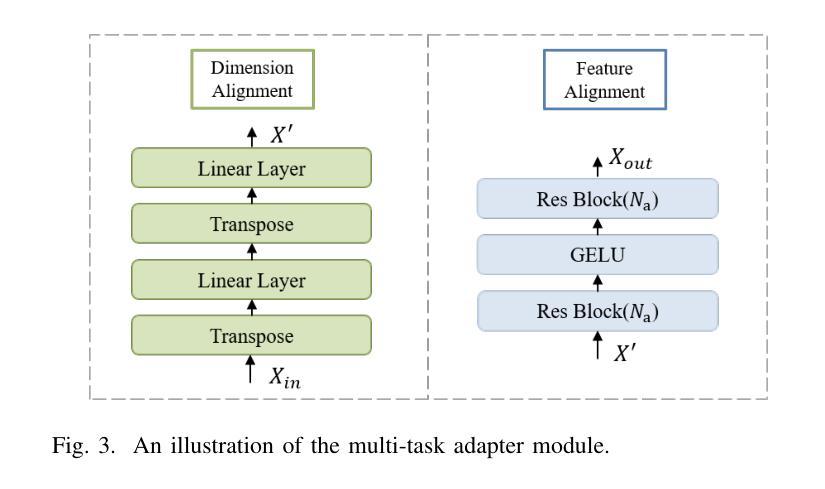
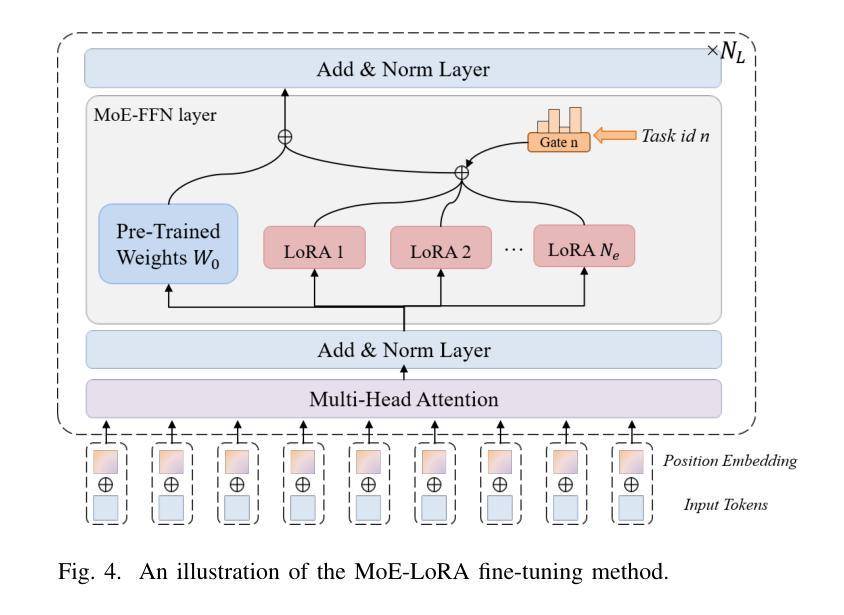
The wireless channel is fundamental to communication, encompassing numerous tasks collectively referred to as channel-associated tasks. These tasks can leverage joint learning based on channel characteristics to share representations and enhance system design. To capitalize on this advantage, LLM4WM is proposed–a large language model (LLM) multi-task fine-tuning framework specifically tailored for channel-associated tasks. This framework utilizes a Mixture of Experts with Low-Rank Adaptation (MoE-LoRA) approach for multi-task fine-tuning, enabling the transfer of the pre-trained LLM’s general knowledge to these tasks. Given the unique characteristics of wireless channel data, preprocessing modules, adapter modules, and multi-task output layers are designed to align the channel data with the LLM’s semantic feature space. Experiments on a channel-associated multi-task dataset demonstrate that LLM4WM outperforms existing methodologies in both full-sample and few-shot evaluations, owing to its robust multi-task joint modeling and transfer learning capabilities.
无线信道是通信的基础,包含许多统称为信道相关任务(channel-associated tasks)的工作。这些任务可以利用基于信道特性的联合学习来共享表示并增强系统设计。为了充分利用这一优势,提出了LLM4WM——一种针对信道相关任务的大型语言模型(LLM)多任务微调框架。该框架采用基于低秩适配(LoRA)的混合专家(MoE)方法进行多任务微调,能够实现预训练LLM通用知识向这些任务的迁移。考虑到无线信道数据的独特特性,设计了预处理模块、适配模块和多任务输出层,以使信道数据与LLM的语义特征空间对齐。在信道相关多任务数据集上的实验表明,LLM4WM在全样本和少量样本评估中都优于现有方法,这得益于其强大的多任务联合建模和迁移学习能力。
论文及项目相关链接
Summary
无线信道通信中的核心组成部分是众多被称为信道相关任务的工作集合。这些任务可以利用基于信道特性的联合学习共享表示并优化系统设计。为了充分利用这一优势,提出了LLM4WM框架,这是一个针对信道相关任务的大型语言模型(LLM)多任务微调框架。该框架采用混合专家低秩适应(MoE-LoRA)方法进行多任务微调,使预训练LLM的一般知识能够转移到这些任务上。针对无线信道数据的独特特性,设计了预处理模块、适配器模块和多任务输出层,以使信道数据与LLM的语义特征空间对齐。实验表明,在信道相关的多任务数据集上,LLM4WM在全样本和少样本评估中都优于现有方法,这得益于其强大的多任务联合建模和迁移学习能力。
Key Takeaways
- 无线信道通信涉及众多信道相关任务,这些任务可通过基于信道特性的联合学习来提高性能。
- LLM4WM是一个针对信道相关任务的大型语言模型多任务微调框架。
- LLM4WM利用MoE-LoRA方法进行多任务微调,实现知识迁移。
- 针对无线信道数据的特性,设计了预处理、适配器和多任务输出层模块。
- LLM4WM在全样本和少样本评估中均表现出优异性能。
- LLM4WM的强大性能得益于其多任务联合建模和迁移学习能力。
点此查看论文截图

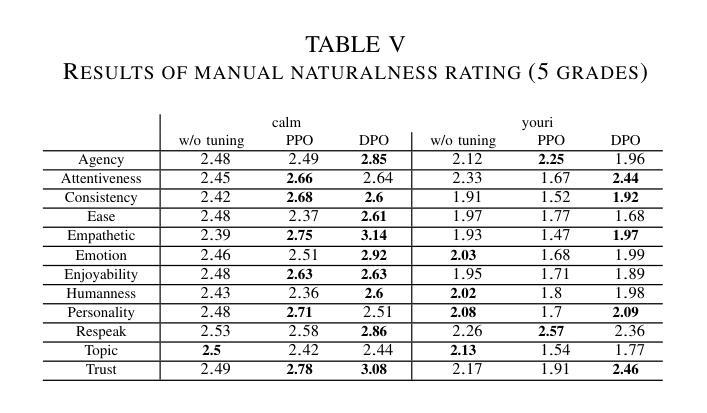
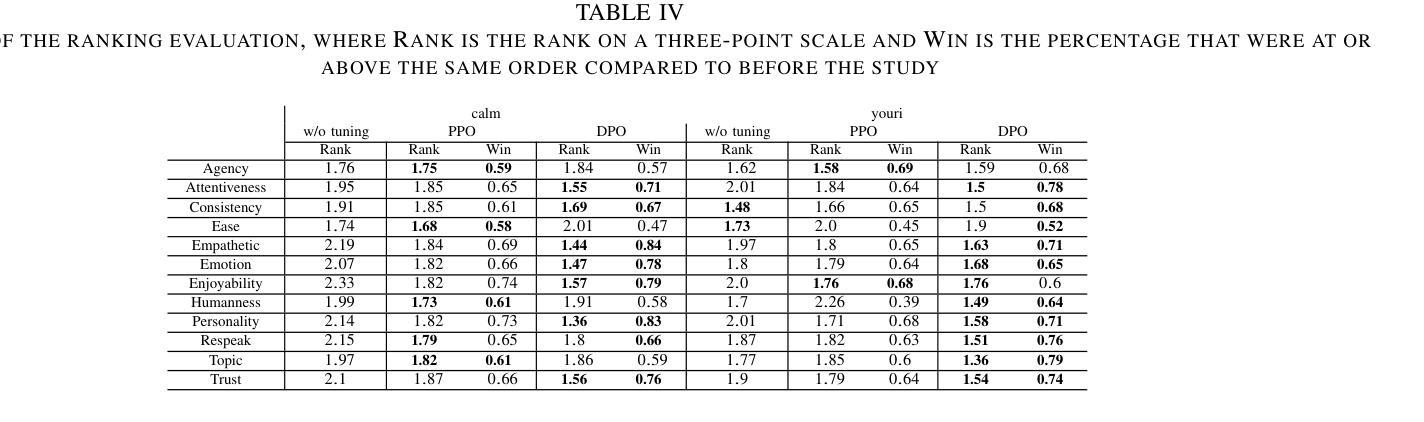
Training Dialogue Systems by AI Feedback for Improving Overall Dialogue Impression
Authors:Kai Yoshida, Masahiro Mizukami, Seiya Kawano, Canasai Kruengkrai, Hiroaki Sugiyama, Koichiro Yoshino
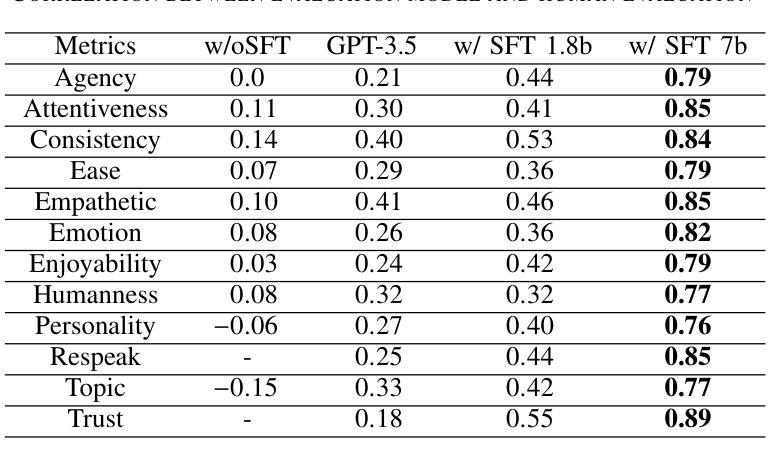
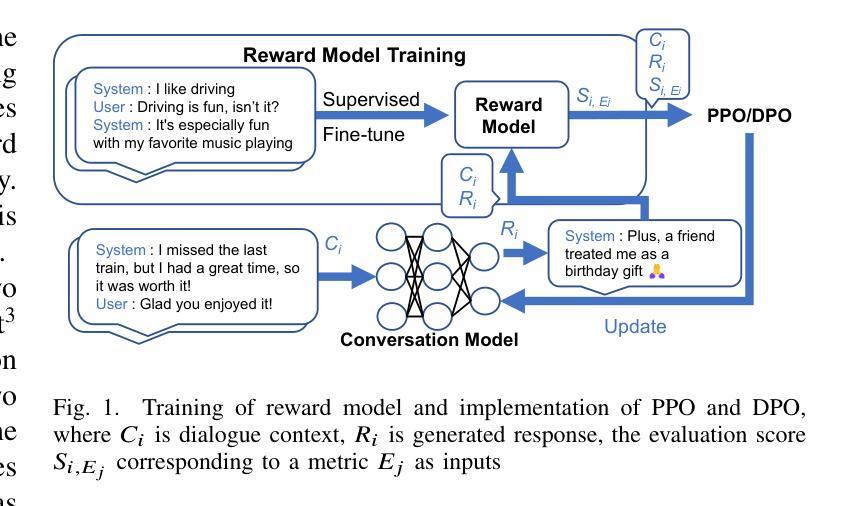
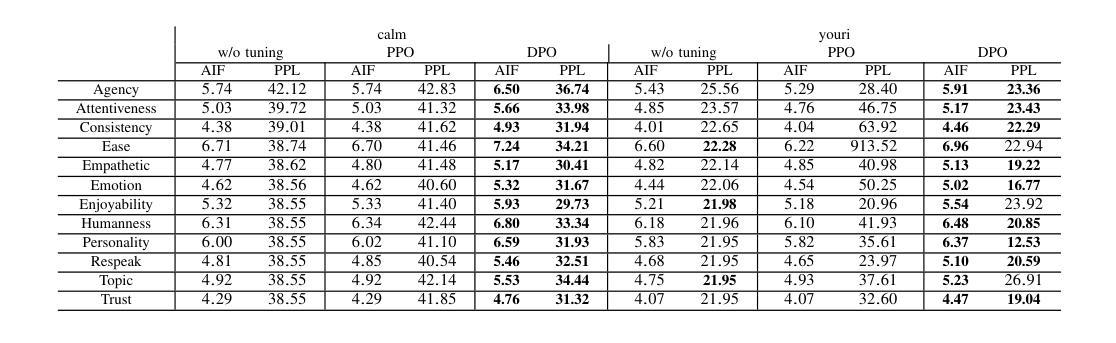
To improve user engagement during conversations with dialogue systems, we must improve individual dialogue responses and dialogue impressions such as consistency, personality, and empathy throughout the entire dialogue. While such dialogue systems have been developing rapidly with the help of large language models (LLMs), reinforcement learning from AI feedback (RLAIF) has attracted attention to align LLM-based dialogue models for such dialogue impressions. In RLAIF, a reward model based on another LLM is used to create a training signal for an LLM-based dialogue model using zero-shot/few-shot prompting techniques. However, evaluating an entire dialogue only by prompting LLMs is challenging. In this study, the supervised fine-tuning (SFT) of LLMs prepared reward models corresponding to 12 metrics related to the impression of the entire dialogue for evaluating dialogue responses. We tuned our dialogue models using the reward model signals as feedback to improve the impression of the system. The results of automatic and human evaluations showed that tuning the dialogue model using our reward model corresponding to dialogue impression improved the evaluation of individual metrics and the naturalness of the dialogue response.
为了提高用户与对话系统对话时的参与度,我们必须改善单独的对话响应和整个对话的印记,如一致性、个性和同理心。虽然这种对话系统借助大型语言模型(LLM)迅速发展,但通过人工智能反馈进行强化学习(RLAIF)已引起关注,以使基于LLM的对话模型与这种对话印记对齐。在RLAIF中,使用基于另一个LLM的奖励模型,利用零样本/少样本提示技术为基于LLM的对话模型创建训练信号。然而,仅通过提示LLM来评估整个对话是有挑战性的。在这项研究中,我们为与整个对话印记相关的16项指标准备了监督微调(SFT)的LLM奖励模型,以评估对话响应。我们使用奖励模型信号作为反馈来调整我们的对话模型,以提高系统的影响。自动和人类评估的结果表明,使用与对话印记相对应的奖励模型调整对话模型提高了单个指标的评估结果和对话响应的自然性。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary:
为提高对话系统的用户参与度,需优化个别对话回应及整体对话印象,如一致性、个性及同理心。借助大型语言模型(LLM),对话系统迅速发展。强化学习自人工智能反馈(RLAIF)引起关注,用于调整LLM对话模型以符合对话印象。本研究通过监督微调(SFT)LLM创建与整体对话印象相关的奖励模型,以评估对话回应。使用奖励模型信号调整对话模型,提高了系统印象。自动和人类评估结果均显示,使用与对话印象对应的奖励模型调整对话模型,可提升个别指标的评估结果及对话回应的自然度。
Key Takeaways:
- 为提高用户参与度,需优化对话系统的个别回应和整体印象。
- 大型语言模型(LLM)在对话系统中发挥重要作用。
- 强化学习自人工智能反馈(RLAIF)用于调整LLM对话模型以符合对话印象。
- 奖励模型在评估对话回应时非常重要。
- 监督微调(SFT)LLM创建与整体对话印象相关的奖励模型。
- 使用奖励模型信号调整对话模型,能提高系统印象。
点此查看论文截图


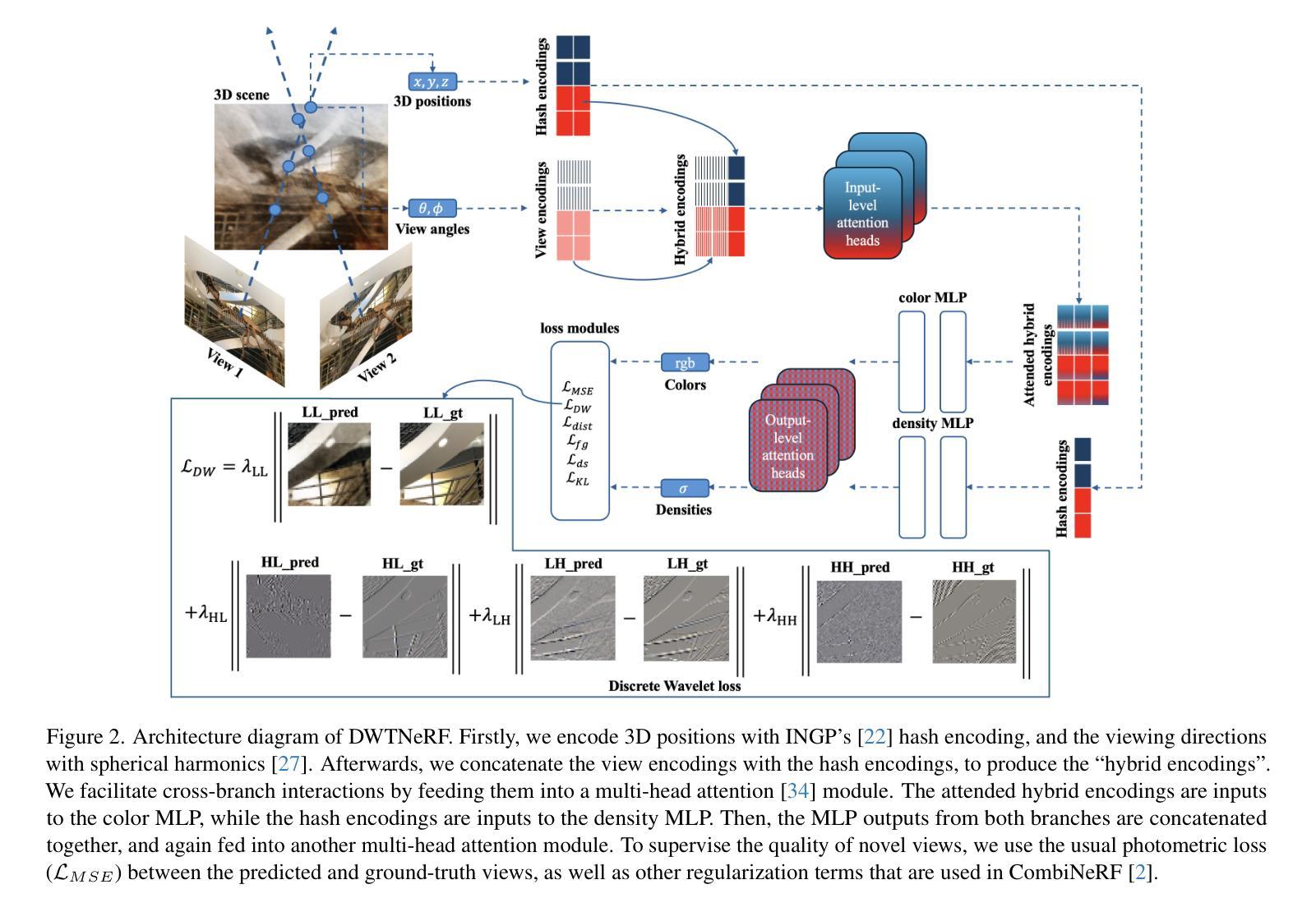
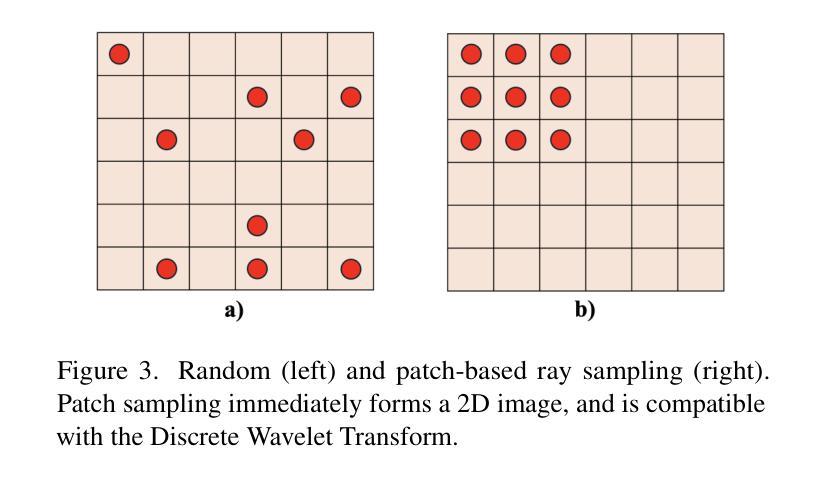
DWTNeRF: Boosting Few-shot Neural Radiance Fields via Discrete Wavelet Transform
Authors:Hung Nguyen, Blark Runfa Li, Truong Nguyen
Neural Radiance Fields (NeRF) has achieved superior performance in novel view synthesis and 3D scene representation, but its practical applications are hindered by slow convergence and reliance on dense training views. To this end, we present DWTNeRF, a unified framework based on Instant-NGP’s fast-training hash encoding. It is coupled with regularization terms designed for few-shot NeRF, which operates on sparse training views. Our DWTNeRF includes a novel Discrete Wavelet loss that allows explicit prioritization of low frequencies directly in the training objective, reducing few-shot NeRF’s overfitting on high frequencies in earlier training stages. We additionally introduce a model-based approach, based on multi-head attention, that is compatible with INGP-based models, which are sensitive to architectural changes. On the 3-shot LLFF benchmark, DWTNeRF outperforms Vanilla NeRF by 15.07% in PSNR, 24.45% in SSIM and 36.30% in LPIPS. Our approach encourages a re-thinking of current few-shot approaches for INGP-based models.
神经辐射场(NeRF)在新型视图合成和3D场景表示方面取得了卓越的性能,但其实际应用受到了收敛速度慢和依赖密集训练视图的影响。为此,我们提出了DWTNeRF,这是一个基于Instant-NGP快速训练哈希编码的统一框架。它与针对少量射击NeRF设计的正则化术语相结合,可在稀疏训练视图上运行。我们的DWTNeRF包括一种新颖的离散小波损失,允许在训练目标中直接明确优先处理低频,从而减少早期训练阶段中少量NeRF对高频的过拟合。此外,我们引入了一种基于多头注意力的模型方法,该方法与对架构变化敏感的INGP模型兼容。在3次拍摄的LLFF基准测试中,DWTNeRF在PSNR上比Vanilla NeRF高出15.07%,在SSIM上高出24.45%,在LPIPS上高出36.30%。我们的方法鼓励对基于INGP模型的当前少量射击方法进行重新思考。
论文及项目相关链接
PDF 10 pages, 6 figures
Summary
NeRF技术虽在新视角合成和三维场景表示方面表现出卓越性能,但其实际应用受限于缓慢收敛和依赖密集训练视图的问题。为此,提出了DWTNeRF框架,结合了Instant-NGP的快速训练哈希编码技术,并设计了针对少量样本NeRF的正则化项,可在稀疏训练视图上操作。DWTNeRF包含新型离散小波损失,允许在训练目标中明确优先处理低频信息,减少早期训练阶段对高频的过拟合问题。此外,还引入了一种基于多头注意力的模型方法,与INGP模型兼容,对架构变化敏感。在3次拍摄的LLFF基准测试中,DWTNeRF在PSNR上较原版NeRF提高了15.07%,在SSIM上提高了24.45%,在LPIPS上提高了36.30%。
Key Takeaways
- DWTNeRF框架结合了Instant-NGP的快速训练技术,提高NeRF在实际应用中的效率。
- DWTNeRF解决了NeRF在少量样本下的训练问题,能够在稀疏训练视图上操作。
- 新型离散小波损失允许在训练过程中优先处理低频信息,减少早期过拟合问题。
- 引入基于多头注意力的模型方法,增强了与INGP模型的兼容性,并对架构变化更为敏感。
- DWTNeRF在LLFF基准测试中的表现显著优于原版NeRF。
- DWTNeRF框架对于现有少量样本的INGP模型方法提供了新的思考方向。
点此查看论文截图



SARATR-X: Toward Building A Foundation Model for SAR Target Recognition
Authors:Weijie Li, Wei Yang, Yuenan Hou, Li Liu, Yongxiang Liu, Xiang Li
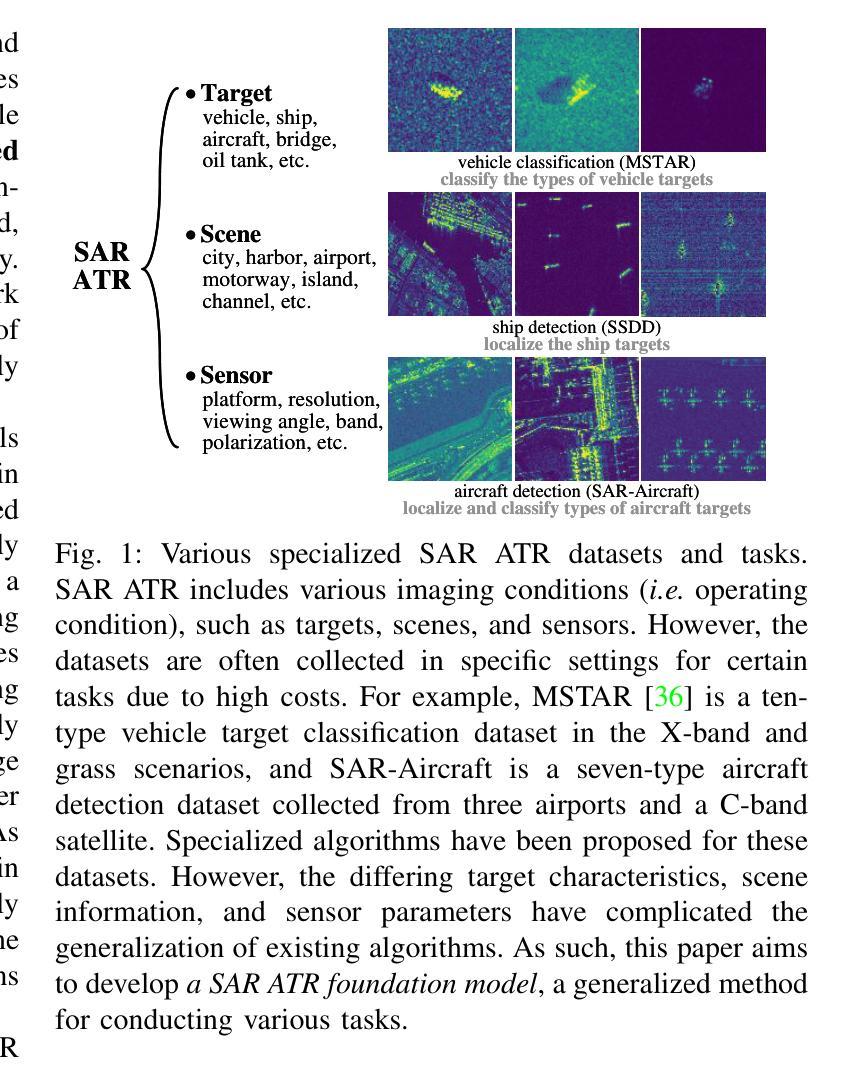
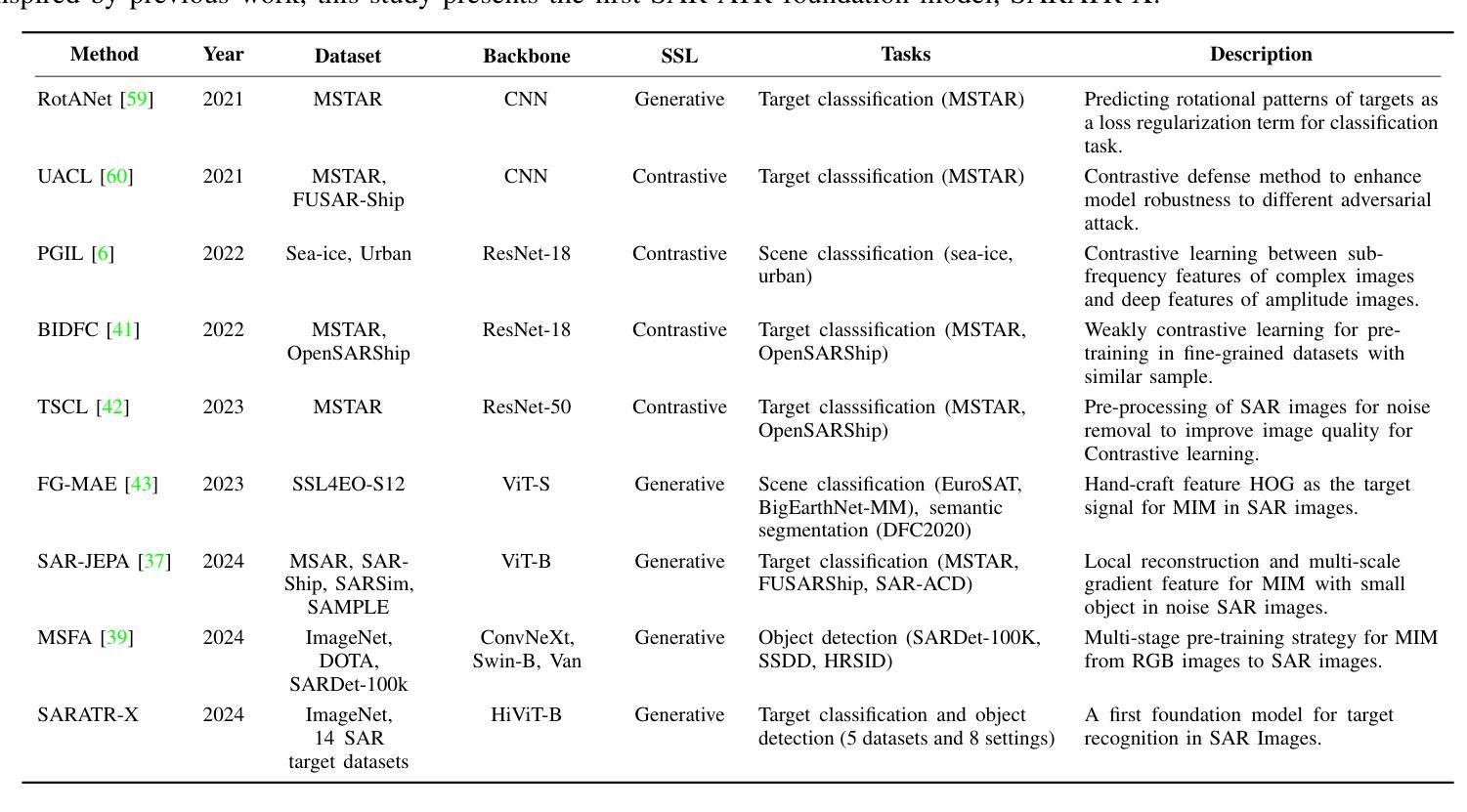
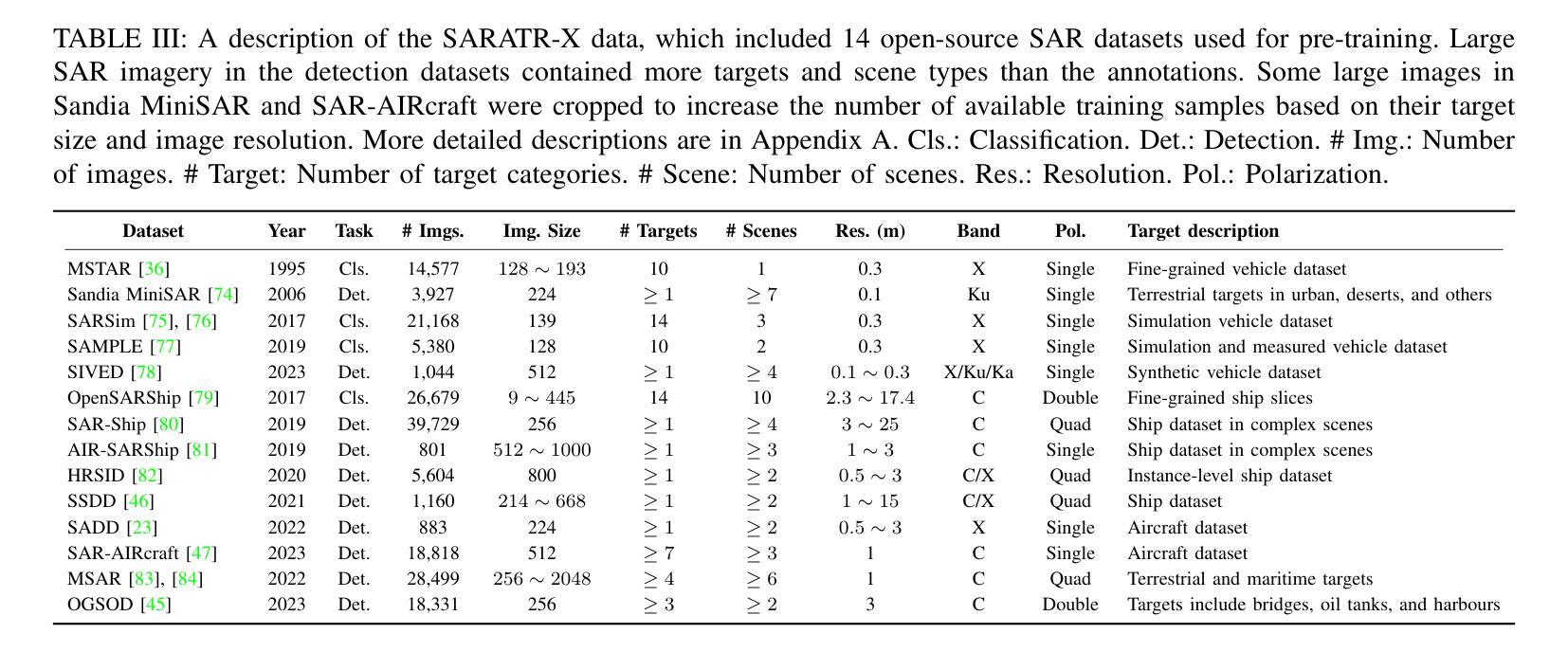
Despite the remarkable progress in synthetic aperture radar automatic target recognition (SAR ATR), recent efforts have concentrated on detecting and classifying a specific category, e.g., vehicles, ships, airplanes, or buildings. One of the fundamental limitations of the top-performing SAR ATR methods is that the learning paradigm is supervised, task-specific, limited-category, closed-world learning, which depends on massive amounts of accurately annotated samples that are expensively labeled by expert SAR analysts and have limited generalization capability and scalability. In this work, we make the first attempt towards building a foundation model for SAR ATR, termed SARATR-X. SARATR-X learns generalizable representations via self-supervised learning (SSL) and provides a cornerstone for label-efficient model adaptation to generic SAR target detection and classification tasks. Specifically, SARATR-X is trained on 0.18 M unlabelled SAR target samples, which are curated by combining contemporary benchmarks and constitute the largest publicly available dataset till now. Considering the characteristics of SAR images, a backbone tailored for SAR ATR is carefully designed, and a two-step SSL method endowed with multi-scale gradient features was applied to ensure the feature diversity and model scalability of SARATR-X. The capabilities of SARATR-X are evaluated on classification under few-shot and robustness settings and detection across various categories and scenes, and impressive performance is achieved, often competitive with or even superior to prior fully supervised, semi-supervised, or self-supervised algorithms. Our SARATR-X and the curated dataset are released at https://github.com/waterdisappear/SARATR-X to foster research into foundation models for SAR image interpretation.
尽管合成孔径雷达自动目标识别(SAR ATR)取得了显著的进步,但最近的努力主要集中在检测和分类特定类别,如车辆、船只、飞机或建筑物。高性能SAR ATR方法的基本局限之一是它们采用监督、任务特定、有限类别、封闭世界学习的模式,这依赖于大量由专家SAR分析师精确标注的样本,具有有限的推广能力和可扩展性。在这项工作中,我们首次尝试构建SAR ATR的基础模型,称为SARATR-X。SARATR-X通过自监督学习(SSL)学习可推广的表示,为标签有效的模型适应通用SAR目标检测和分类任务提供了基石。具体来说,SARATR-X是在0.18M未标记的SAR目标样本上进行训练的,这些样本是通过结合当代基准测试集精心挑选和组合的,构成了迄今为止最大的公开可用数据集。考虑到SAR图像的特性,我们精心设计了一个针对SAR ATR的主干网络,并应用了一种两步SSL方法,该方法具有多尺度梯度特征,以确保SARATR-X的特征多样性和模型可扩展性。SARATR-X的能力在少镜头和稳健性设置下的分类以及各类场景中的检测得到了评估,并取得了令人印象深刻的性能,往往与之前的完全监督、半监督或自监督算法相当甚至更胜一筹。我们的SARATR-X和精选数据集已在[https://github.com/waterdisappear/SARATR-X发布,以促进对SAR图像解释基础模型的研究。](https://github.com/waterdisappear/SARATR-X%E9%98%9F%E9%AB%BE%E4%BF%AE%E9%A3%BE%E6%9C%AC%E5%BA%94%E7%BB%AF%E9%BB%86SA分为更好地对研究工作有所帮助与支持更多专业人士开展工作提供一个可以充分开发和验证新算法的平台。我们希望通过共享SARATR-X和精选数据集来促进SAR图像解释基础模型的研究和发展。)
论文及项目相关链接
PDF 20 pages, 9 figures
Summary
该文章介绍了合成孔径雷达自动目标识别(SAR ATR)的进展及其局限性。为了克服现有方法的不足,提出了一种名为SARATR-X的基础模型。该模型采用自监督学习(SSL)方式学习可泛化的表示,并适应于通用的SAR目标检测和分类任务。SARATR-X使用0.18M无标签SAR目标样本进行训练,设计了一个针对SAR ATR的专用骨架,并应用了两步SSL方法和多尺度梯度特征,以确保特征多样性和模型可扩展性。在少镜头分类和稳健性设置以及跨类别和场景的检测中评估了SARATR-X的能力,其表现令人印象深刻,与之前的全监督、半监督或自监督算法相比具有竞争力甚至更优越。所发布的SARATR-X和数据集旨在促进SAR图像解释的基础模型研究。
Key Takeaways
- SAR ATR领域虽然有显著进展,但现有的顶级方法依赖于大量手工标注的样本,具有标签成本高、泛化能力和可扩展性有限的缺点。
- 提出了一种名为SARATR-X的基础模型,采用自监督学习方式,旨在提高模型的泛化能力和标签效率。
- SARATR-X使用了迄今为止最大的公开数据集进行训练,包含0.18M无标签的SAR目标样本。
- 针对SAR图像特性,设计了一个专门的模型骨架,并应用了两步SSL方法和多尺度梯度特征,确保特征多样性和模型可扩展性。
- SARATR-X在少镜头分类和稳健性设置以及跨类别和场景的检测中表现出色,与现有方法相比具有竞争力。
- SARATR-X和数据集已公开发布,以推动SAR图像解释领域的基础模型研究。
点此查看论文截图