⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-24 更新
Does Table Source Matter? Benchmarking and Improving Multimodal Scientific Table Understanding and Reasoning
Authors:Bohao Yang, Yingji Zhang, Dong Liu, André Freitas, Chenghua Lin
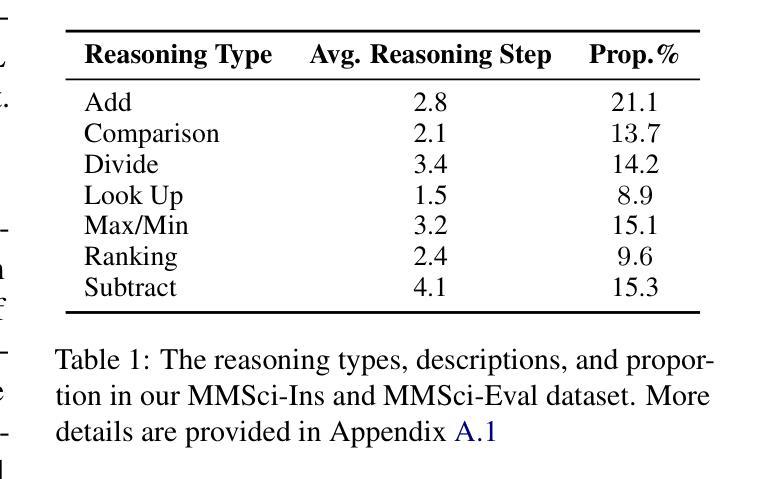
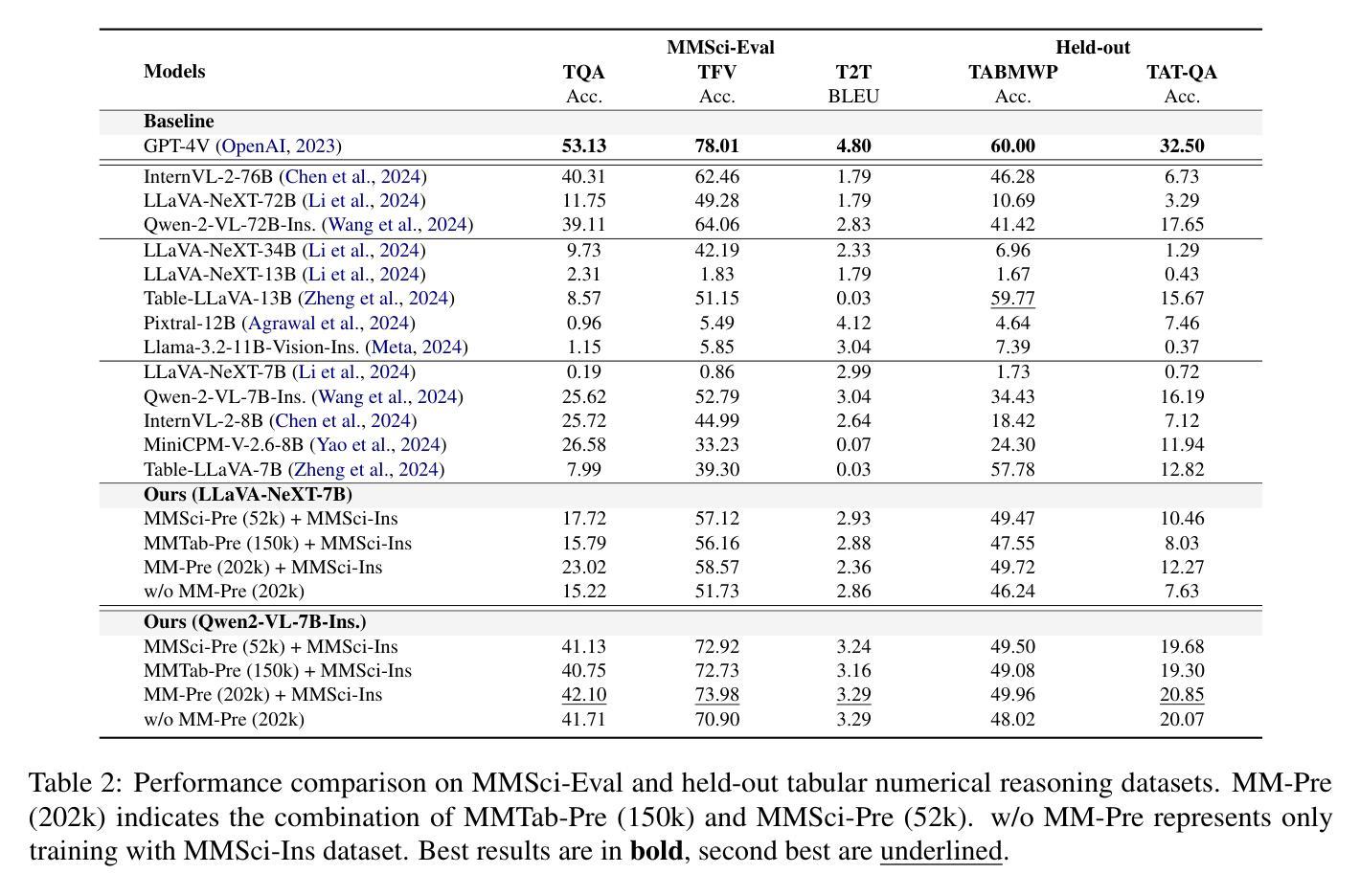
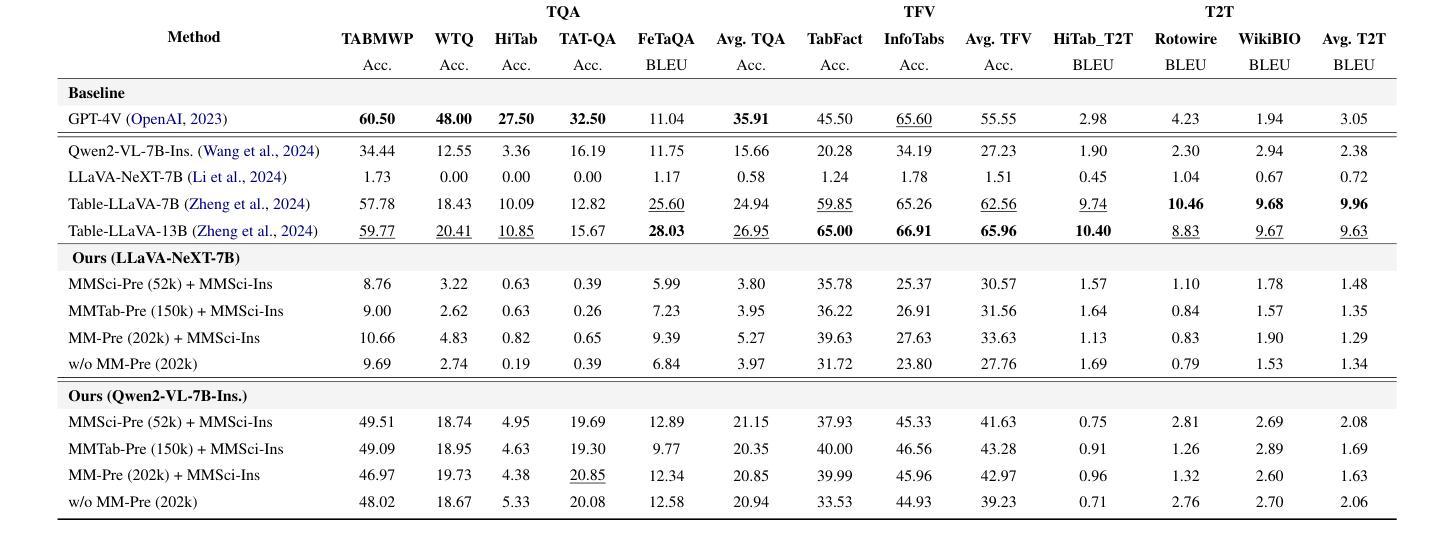
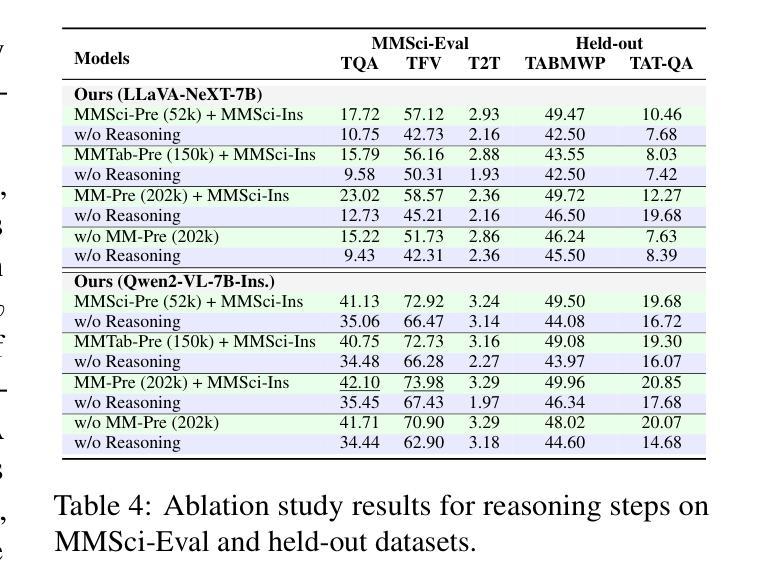
Recent large language models (LLMs) have advanced table understanding capabilities but rely on converting tables into text sequences. While multimodal large language models (MLLMs) enable direct visual processing, they face limitations in handling scientific tables due to fixed input image resolutions and insufficient numerical reasoning capabilities. We present a comprehensive framework for multimodal scientific table understanding and reasoning with dynamic input image resolutions. Our framework consists of three key components: (1) MMSci-Pre, a domain-specific table structure learning dataset of 52K scientific table structure recognition samples, (2) MMSci-Ins, an instruction tuning dataset with 12K samples across three table-based tasks, and (3) MMSci-Eval, a benchmark with 3,114 testing samples specifically designed to evaluate numerical reasoning capabilities. Extensive experiments demonstrate that our domain-specific approach with 52K scientific table images achieves superior performance compared to 150K general-domain tables, highlighting the importance of data quality over quantity. Our proposed table-based MLLMs with dynamic input resolutions show significant improvements in both general table understanding and numerical reasoning capabilities, with strong generalisation to held-out datasets. Our code and data are publicly available at https://github.com/Bernard-Yang/MMSci_Table.
最近的大型语言模型(LLM)已经具备了先进的表格理解能力,但它们依赖于将表格转换为文本序列。虽然多模态大型语言模型(MLLM)能够实现直接视觉处理,但由于固定输入图像分辨率和数值推理能力不足,它们在处理科学表格时面临局限。我们提出了一个具有动态输入图像分辨率的多模态科学表格理解与推理的综合框架。我们的框架包括三个关键组成部分:(1)MMSci-Pre,一个包含5.2万份科学表格结构识别样本的特定领域表格结构学习数据集;(2)MMSci-Ins,一个包含1.2万份样本的指令调整数据集,涵盖三个基于表格的任务;(3)MMSci-Eval,一个专门设计用于评估数值推理能力的基准测试,包含3,114个测试样本。大量实验表明,我们的特定领域方法在处理5.2万份科学表格图像时,相较于处理涉及15万份普通表格的方法表现出优越的性能,这突显了数据质量高于数量的重要性。我们提出的基于表格的多模态LLM具有动态输入分辨率,在通用表格理解和数值推理能力方面都有显著提高,并且对未参与数据集具有很强的泛化能力。我们的代码和数据可在https://github.com/Bernard-Yang/MMSci_Table上公开访问。
论文及项目相关链接
Summary
近期的大型语言模型(LLM)在表格理解方面有所进步,但仍需将表格转换为文本序列。多模态大型语言模型(MLLM)可直接进行视觉处理,但在处理科学表格时,由于固定输入图像分辨率和数值推理能力不足,仍面临挑战。本研究提出一个包含动态输入图像分辨率的多模态科学表格理解与推理的综合框架,包含三个关键组件:MMSci-Pre数据集、MMSci-Ins指令调整数据集和MMSci-Eval基准测试集。实验表明,与15万张通用领域表格相比,使用5.2万张科学表格图像的领域特定方法表现出优越的性能,突显数据质量比数量更重要。提出的基于表格的MLLMs具有动态输入分辨率,在通用表格理解和数值推理能力方面均有显著提高,对未公开数据集具有较强的泛化能力。
Key Takeaways
- 大型语言模型(LLM)在表格理解方面已取得进展,但仍需改进。
- 多模态大型语言模型(MLLM)可以直接处理视觉信息,但在处理科学表格时面临固定输入图像分辨率和数值推理能力的挑战。
- 提出一个综合框架,包含动态输入图像分辨率,用于多模态科学表格理解与推理。
- 框架包含三个关键组件:MMSci-Pre数据集用于表格结构学习,MMSci-Ins指令调整数据集用于指令调整,MMSci-Eval基准测试集用于评估数值推理能力。
- 实验显示,领域特定的方法(使用5.2万张科学表格图像)性能优于通用领域表格(使用15万张图像),强调数据质量的重要性。
- 基于表格的MLLMs具有动态输入分辨率,在通用表格理解和数值推理能力方面有显著改进。
点此查看论文截图


Pairwise RM: Perform Best-of-N Sampling with Knockout Tournament
Authors:Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, Juanzi Li
Best-of-N (BoN) sampling, a common strategy for test-time scaling of Large Language Models (LLMs), relies on reward models to select the best candidate solution from multiple generations. However, traditional reward models often assign arbitrary and inconsistent scores, limiting their effectiveness. To address this, we propose a Pairwise Reward Model (Pairwise RM) combined with a knockout tournament for BoN sampling. Instead of assigning absolute scores, given one math problem, Pairwise RM evaluates two candidate solutions’ correctness simultaneously. This approach eliminates the need for arbitrary scoring and enables cross-validation of solutions through parallel comparison. In the knockout tournament, Pairwise RM conducts pairwise comparisons between candidate solutions and eliminates the incorrect ones iteratively. We construct \ourdataset, a large-scale dataset of 443K pairwise comparisons derived from NumiaMath and annotated using \texttt{gemini-1.5-flash}, and train the Pairwise RM via supervised fine-tuning. Experiments on MATH-500 and the Olympiad Bench demonstrate significant improvements over traditional discriminative reward models. And a 40% to 60% relative improvement is achieved on the top 50% challenging problems.
“Best-of-N (BoN)采样是大型语言模型(LLM)测试时间缩放的一种常见策略,它依赖于奖励模型从多个生成中选择最佳候选解决方案。然而,传统奖励模型通常会分配任意和不一致的分数,限制了其有效性。为解决这一问题,我们提出了一种结合淘汰制锦标赛的配对奖励模型(Pairwise RM)。与给出绝对分数不同,给定一个数学问题,配对RM同时评估两个候选解决方案的正确性。这种方法消除了对任意评分的需求,并通过并行比较实现了解决方案的交叉验证。在淘汰锦标赛中,配对RM进行候选解决方案之间的配对比较,并通过迭代方式淘汰错误的解决方案。我们构建了基于NumiaMath的ourdataset大型数据集,其中包含由gemimi-1.5-flash标注的44.3万个配对比较结果,并通过监督微调训练配对RM。在MATH-500和奥林匹亚板上的实验证明,与传统判别奖励模型相比,配对RM具有显著优势。在最具挑战性的前50%问题上取得了相对改善幅度为40%~60%。”
论文及项目相关链接
PDF in progress work
Summary
基于最佳N(BoN)采样的策略,大型语言模型(LLM)在测试时的缩放方法常使用奖励模型选择最佳的候选解决方案。然而,传统的奖励模型常常分配任意且不一致的分数,限制了其效果。为了解决这个问题,本文提出了基于成对奖励模型(Pairwise RM)与淘汰制锦标赛结合的BoN采样策略。成对奖励模型无需分配绝对分数,而是同时评估两个候选解决方案的正确性。这种方法消除了对任意评分的需求,并通过并行比较实现了解决方案的交叉验证。在淘汰锦标赛中,成对奖励模型进行候选解决方案之间的成对比较,并通过迭代消除错误的解决方案。本文构建了基于NumiaMath的大规模数据集ourdataset,包含44.3万个成对比较,并使用gemimi-1.5-flash进行标注。通过监督微调训练成对奖励模型。在MATH-500和Olympiad Bench上的实验表明,与传统判别奖励模型相比有显著改进。在最具挑战性的前50%的问题上实现了40%至60%的相对改进。
Key Takeaways
- 传统奖励模型在LLM的BoN采样中存在任意和不一致的评分问题。
- 提出了基于成对奖励模型(Pairwise RM)的BoN采样策略,通过并行比较评估候选解决方案的正确性。
- 成对奖励模型消除了对任意评分的需求,并实现了解决方案的交叉验证。
- 采用了淘汰制锦标赛策略,通过迭代消除错误的解决方案。
- 构建了基于NumiaMath的大规模数据集ourdataset,用于训练成对奖励模型。
- 实验结果表明,与传统奖励模型相比,成对奖励模型在MATH-500和Olympiad Bench上表现更优。
点此查看论文截图





LLM4WM: Adapting LLM for Wireless Multi-Tasking
Authors:Xuanyu Liu, Shijian Gao, Boxun Liu, Xiang Cheng, Liuqing Yang
The wireless channel is fundamental to communication, encompassing numerous tasks collectively referred to as channel-associated tasks. These tasks can leverage joint learning based on channel characteristics to share representations and enhance system design. To capitalize on this advantage, LLM4WM is proposed–a large language model (LLM) multi-task fine-tuning framework specifically tailored for channel-associated tasks. This framework utilizes a Mixture of Experts with Low-Rank Adaptation (MoE-LoRA) approach for multi-task fine-tuning, enabling the transfer of the pre-trained LLM’s general knowledge to these tasks. Given the unique characteristics of wireless channel data, preprocessing modules, adapter modules, and multi-task output layers are designed to align the channel data with the LLM’s semantic feature space. Experiments on a channel-associated multi-task dataset demonstrate that LLM4WM outperforms existing methodologies in both full-sample and few-shot evaluations, owing to its robust multi-task joint modeling and transfer learning capabilities.
无线信道是通信的基础,涵盖了许多统称为信道相关任务的工作。这些任务可以利用基于信道特性的联合学习来共享表示并增强系统设计。为了充分利用这一优势,提出了LLM4WM——一种针对信道相关任务的大型语言模型(LLM)多任务微调框架。该框架采用低阶适应的专家混合(MoE-LoRA)方法进行多任务微调,使预训练的大型语言模型的通用知识能够应用于这些任务。鉴于无线信道数据的独特特性,设计了预处理模块、适配器模块和多任务输出层,以使信道数据与LLM的语义特征空间对齐。在信道相关多任务数据集上的实验表明,LLM4WM在完全样本和少量样本评估中都优于现有方法,这得益于其强大的多任务联合建模和迁移学习能力。
论文及项目相关链接
Summary
无线信道通信中的关键要素之一是无线信道,其中包含许多称为信道相关任务的工作。这些任务可以利用基于信道特性的联合学习来共享表示并改进系统设计。为了充分利用这一优势,提出了LLM4WM框架,这是一种针对信道相关任务的大型语言模型(LLM)多任务微调框架。该框架采用基于低秩适应(MoE-LoRA)的专家混合(Mixture of Experts)方法进行多任务微调,使预训练的大型语言模型的通用知识能够转移到这些任务上。针对无线信道数据的独特特点,设计了预处理模块、适配器模块和多任务输出层,以使信道数据与大型语言模型的语义特征空间对齐。实验表明,在信道相关的多任务数据集上,LLM4WM在完整样本和少量样本评估中都优于现有方法,这归功于其强大的多任务联合建模和迁移学习能力。
Key Takeaways
- 无线信道通信中涉及许多信道相关任务,这些任务可以通过联合学习来提高性能。
- LLM4WM框架是一种针对信道相关任务的大型语言模型多任务微调框架。
- LLM4WM利用MoE-LoRA方法进行多任务微调,实现预训练大型语言模型的通用知识转移。
- 针对无线信道数据的特性,LLM4WM设计了预处理、适配和多任务输出层。
- 实验证明LLM4WM在信道相关多任务数据集上的性能优于现有方法。
- LLM4WM的全样本和少量样本评估表现均很出色。
点此查看论文截图






FlanEC: Exploring Flan-T5 for Post-ASR Error Correction
Authors:Moreno La Quatra, Valerio Mario Salerno, Yu Tsao, Sabato Marco Siniscalchi
In this paper, we present an encoder-decoder model leveraging Flan-T5 for post-Automatic Speech Recognition (ASR) Generative Speech Error Correction (GenSEC), and we refer to it as FlanEC. We explore its application within the GenSEC framework to enhance ASR outputs by mapping n-best hypotheses into a single output sentence. By utilizing n-best lists from ASR models, we aim to improve the linguistic correctness, accuracy, and grammaticality of final ASR transcriptions. Specifically, we investigate whether scaling the training data and incorporating diverse datasets can lead to significant improvements in post-ASR error correction. We evaluate FlanEC using the HyPoradise dataset, providing a comprehensive analysis of the model’s effectiveness in this domain. Furthermore, we assess the proposed approach under different settings to evaluate model scalability and efficiency, offering valuable insights into the potential of instruction-tuned encoder-decoder models for this task.
本文中,我们提出了一种利用Flan-T5进行自动语音识别(ASR)后的生成式语音错误校正(GenSEC)的编码器-解码器模型,我们将其称为FlanEC。我们探索了其在GenSEC框架内的应用,通过将n-best假设映射到单个输出句子来增强ASR输出。通过利用ASR模型的n-best列表,我们旨在提高最终ASR转录的语言正确性、准确性和语法性。具体来说,我们研究了扩大训练数据并融入多种数据集是否能在ASR之后的错误校正方面带来显著改进。我们使用HyPoradise数据集对FlanEC进行了评估,全面分析了该模型在此领域的有效性。此外,我们在不同的设置下评估了所提出的方法,以评估模型的可扩展性和效率,为指令微调编码器-解码器模型在此任务上的潜力提供了有价值的见解。
论文及项目相关链接
PDF Accepted at the 2024 IEEE Workshop on Spoken Language Technology (SLT) - GenSEC Challenge
Summary:本文提出了一个利用Flan-T5的编码器-解码器模型,用于自动语音识别(ASR)之后的生成式语音错误校正(GenSEC),称为FlanEC。文章探讨了其在GenSEC框架下的应用,旨在通过将ASR模型的n-best假设映射成单个输出句子来提高ASR输出的语言正确性、准确性和语法性。文章还研究了扩大训练数据和引入多样数据集对改善ASR错误校正的潜力,并通过HyPoradise数据集对FlanEC进行了评估。
Key Takeaways:
- 本文介绍了利用Flan-T5的编码器-解码器模型FlanEC,用于后自动语音识别(ASR)的生成式语音错误校正(GenSEC)。
- FlanEC旨在通过将ASR模型的n-best假设映射成单个输出句子,提高ASR输出的语言正确性、准确性和语法性。
- 扩大训练数据和引入多样数据集对改善ASR错误校正有重要作用。
- 通过HyPoradise数据集对FlanEC进行了评估,证明了其有效性。
- 文章还探讨了模型的可扩展性和效率,为指令调优的编码器-解码器模型在此任务上的潜力提供了有价值的见解。
- 该研究为改善ASR系统的性能提供了一种新的思路和方法。
点此查看论文截图



Accessible Smart Contracts Verification: Synthesizing Formal Models with Tamed LLMs
Authors:Jan Corazza, Ivan Gavran, Gabriela Moreira, Daniel Neider
When blockchain systems are said to be trustless, what this really means is that all the trust is put into software. Thus, there are strong incentives to ensure blockchain software is correct – vulnerabilities here cost millions and break businesses. One of the most powerful ways of establishing software correctness is by using formal methods. Approaches based on formal methods, however, induce a significant overhead in terms of time and expertise required to successfully employ them. Our work addresses this critical disadvantage by automating the creation of a formal model – a mathematical abstraction of the software system – which is often a core task when employing formal methods. We perform model synthesis in three phases: we first transpile the code into model stubs; then we “fill in the blanks” using a large language model (LLM); finally, we iteratively repair the generated model, on both syntactical and semantical level. In this way, we significantly reduce the amount of time necessary to create formal models and increase accessibility of valuable software verification methods that rely on them. The practical context of our work was reducing the time-to-value of using formal models for correctness audits of smart contracts.
当提到区块链系统是无信任的时,真正的意思是所有的信任都放在了软件上。因此,确保区块链软件正确性的动力非常强烈——这里的漏洞会造成数百万的损失并破坏业务。建立软件正确性的最强大方式之一是使用形式化方法。然而,基于形式化方法的方案需要消耗大量的时间和专业知识才能成功应用。我们的工作通过自动化创建形式模型来解决这一关键劣势,形式模型是软件系统的数学抽象,在使用形式化方法时通常是一项核心任务。我们的模型合成分为三个阶段:首先,我们将代码转换为模型框架;然后,我们使用大型语言模型(LLM)来“填补空白”;最后,我们在语法和语义层面上迭代修复生成的模型。通过这种方式,我们显著减少了创建形式模型所需的时间,提高了依赖于它们的宝贵软件验证方法的可及性。我们工作的实际背景是减少使用形式模型对智能合约进行正确性审计的时间成本。
论文及项目相关链接
Summary
区块链系统的“无需信任”特性意味着信任主要放在软件上,因此确保区块链软件的正确性至关重要。形式化方法是验证软件正确性的强大工具,但使用它们需要大量的时间和专业知识。我们的工作通过自动化创建形式化模型来解决这一劣势,该模型是软件系统的数学抽象。我们进行模型综合分为三个步骤:首先,将代码编译成模型存根;然后,使用大型语言模型(LLM)填充空白;最后,迭代修复生成的模型,包括语法和语义层面。通过这种方式,我们显著减少了创建形式化模型所需的时间,提高了依赖于它们的宝贵软件验证方法的可及性。我们工作的实际背景是减少形式化模型在智能合约正确性审计中使用的时间成本。
Key Takeaways
- 区块链系统的“信任”主要寄托于软件正确性。
- 形式化方法是验证软件正确性的有效手段,但实施过程复杂,需要较多时间和专业知识。
- 我们通过自动化创建形式化模型来解决这一问题,这一模型是软件系统的数学抽象。
- 模型综合分为三个阶段:编译代码成模型存根、使用大型语言模型填充空白、迭代修复模型。
- 该方法显著减少了创建形式化模型的时间,提高了软件验证方法的可及性。
- 该研究实际应用在智能合约正确性审计中,旨在降低时间成本。
- 保障区块链软件正确性对于确保整个区块链系统的稳定性和安全性至关重要。
点此查看论文截图


Efficient Prompt Compression with Evaluator Heads for Long-Context Transformer Inference
Authors:Weizhi Fei, Xueyan Niu, Guoqing Xie, Yingqing Liu, Bo Bai, Wei Han
Although applications involving long-context inputs are crucial for the effective utilization of large language models (LLMs), they also result in increased computational costs and reduced performance. To address this challenge, we propose an efficient, training-free prompt compression method that retains key information within compressed prompts. We identify specific attention heads in transformer-based LLMs, which we designate as evaluator heads, that are capable of selecting tokens in long inputs that are most significant for inference. Building on this discovery, we develop EHPC, an Evaluator Head-based Prompt Compression method, which enables LLMs to rapidly “skim through” input prompts by leveraging only the first few layers with evaluator heads during the pre-filling stage, subsequently passing only the important tokens to the model for inference. EHPC achieves state-of-the-art results across two mainstream benchmarks: prompt compression and long-context inference acceleration. Consequently, it effectively reduces the complexity and costs associated with commercial API calls. We further demonstrate that EHPC attains competitive results compared to key-value cache-based acceleration methods, thereby highlighting its potential to enhance the efficiency of LLMs for long-context tasks.
虽然涉及长上下文输入的应用对于有效利用大型语言模型(LLM)至关重要,但它们也会导致计算成本增加和性能下降。为了应对这一挑战,我们提出了一种高效、无需训练提示压缩方法,该方法能够在压缩提示中保留关键信息。我们确定了基于transformer的LLM中的特定注意力头,将其指定为评估头,这些评估头能够选择长输入中用于推断的最重要标记。基于这一发现,我们开发了EHPC,一种基于评估头的提示压缩方法,它使LLM能够利用预填充阶段只有前几层的评估头快速“浏览”输入提示,随后只将重要标记传递给模型进行推断。EHPC在两个主流基准测试:提示压缩和长上下文推理加速上达到了最新水平的结果。因此,它有效地降低了与商业API调用相关的复杂性和成本。我们进一步证明,与基于键值缓存的加速方法相比,EHPC取得了具有竞争力的结果,从而突出了其在提高LLM对长上下文任务的效率方面的潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理长上下文输入时面临计算成本增加和性能下降的挑战。为此,我们提出了一种高效的训练免费提示压缩方法,该方法能够在压缩提示的同时保留关键信息。我们确定了基于转换器的LLM中的特定注意力头,称为评估头,这些头能够选择长输入中对推理最重要的标记。基于此发现,我们开发了EHPC(基于评估头的提示压缩方法),使LLM能够迅速浏览输入提示,在预填充阶段仅利用前几层的评估头,并将重要标记传递给模型进行推理。EHPC在两个主流基准测试中实现了卓越的结果:提示压缩和长上下文推理加速。因此,它有效地降低了与商业API调用相关的复杂性和成本。EHPC与基于键值缓存的加速方法相比也表现出竞争力。
Key Takeaways
- 大型语言模型(LLM)在处理长上下文输入时面临挑战,包括计算成本增加和性能下降。
- 提出了一种训练免费的提示压缩方法EHPC,能有效压缩长输入并保持关键信息。
- EHPC通过识别并仅利用特定的评估头进行长输入的筛选,从而在预填充阶段快速浏览输入提示。
- EHPC实现了在提示压缩和长上下文推理加速方面的卓越性能。
- EHPC能显著降低商业API调用的复杂性并减少成本。
点此查看论文截图




GANQ: GPU-Adaptive Non-Uniform Quantization for Large Language Models
Authors:Pengxiang Zhao, Xiaoming Yuan
Large Language Models (LLMs) face significant deployment challenges due to their substantial resource requirements. While low-bit quantized weights can reduce memory usage and improve inference efficiency, current hardware lacks native support for mixed-precision General Matrix Multiplication (mpGEMM), resulting in inefficient dequantization-based implementations. Moreover, uniform quantization methods often fail to capture weight distributions adequately, leading to performance degradation. We propose GANQ (GPU-Adaptive Non-Uniform Quantization), a layer-wise post-training non-uniform quantization framework optimized for hardware-efficient lookup table-based mpGEMM. GANQ achieves superior quantization performance by utilizing a training-free, GPU-adaptive optimization algorithm to efficiently reduce layer-wise quantization errors. Extensive experiments demonstrate GANQ’s ability to reduce the perplexity gap from the FP16 baseline compared to state-of-the-art methods for both 3-bit and 4-bit quantization. Furthermore, when deployed on a single NVIDIA RTX 4090 GPU, GANQ’s quantized models achieve up to 2.57$\times$ speedup over the baseline, advancing memory and inference efficiency in LLM deployment.
大型语言模型(LLM)由于其巨大的资源需求而面临重大的部署挑战。虽然低位量化权重可以减少内存使用并提高推理效率,但当前硬件不支持混合精度通用矩阵乘法(mpGEMM),导致基于反量化的实现效率低下。此外,统一量化方法往往不足以捕捉权重分布,导致性能下降。我们提出了GANQ(GPU自适应非均匀量化),这是一种针对基于硬件高效查找表的mpGEMM优化的逐层后训练非均匀量化框架。GANQ通过利用无训练、GPU自适应的优化算法,有效地减少了逐层量化误差,实现了出色的量化性能。大量实验表明,与最新技术相比,GANQ在3位和4位量化方面能够减少困惑度差距,与FP16基准相比表现出色。此外,在单个NVIDIA RTX 4090 GPU上部署时,GANQ的量化模型实现了高达2.57倍于基准的加速,提高了大型语言模型部署中的内存和推理效率。
论文及项目相关链接
Summary
大型语言模型(LLM)部署面临资源需求大的挑战。采用低比特量化权重可减少内存使用并提高推理效率,但当前硬件不支持混合精度通用矩阵乘法(mpGEMM),导致解量化实施效率低下。均匀量化方法无法充分捕捉权重分布,导致性能下降。本文提出GANQ(GPU自适应非均匀量化),一种针对硬件高效查找表mpGEMM优化的层后非均匀量化框架。GANQ通过无训练、GPU自适应优化算法,有效减少层内量化误差,实现优越的量测性能。实验显示,与先进方法相比,GANQ缩小了与FP16基准的困惑度差距,在3位和4位量化方面表现优异。在NVIDIA RTX 4090 GPU上部署时,GANQ实现高达2.57倍的速度提升,推进了LLM部署中的内存和推理效率。
Key Takeaways
- 大型语言模型(LLM)部署存在资源需求大的挑战。
- 低比特量化权重能提高推理效率,但当前硬件实施效率低下。
- 均匀量化方法无法充分捕捉权重分布,导致性能下降。
- GANQ框架是一种针对硬件高效mpGEMM优化的层后非均匀量化方法。
- GANQ通过无训练、GPU自适应优化算法,有效减少层内量化误差。
- GANQ在量化性能上表现优越,缩小了与FP16基准的困惑度差距。
点此查看论文截图




Correctness Assessment of Code Generated by Large Language Models Using Internal Representations
Authors:Tuan-Dung Bui, Thanh Trong Vu, Thu-Trang Nguyen, Son Nguyen, Hieu Dinh Vo
Ensuring the correctness of code generated by Large Language Models (LLMs) presents a significant challenge in AI-driven software development. Existing approaches predominantly rely on black-box (closed-box) approaches that evaluate correctness post-generation, failing to utilize the rich insights embedded in the LLMs’ internal states during code generation. In this paper, we introduce OPENIA, a novel white-box (open-box) framework that leverages these internal representations to assess the correctness of LLM-generated code. OPENIA systematically analyzes the intermediate states of representative open-source LLMs specialized for code, including DeepSeek-Coder, CodeLlama, and MagicCoder, across diverse code generation benchmarks. Our empirical analysis reveals that these internal representations encode latent information, which strongly correlates with the correctness of the generated code. Building on these insights, OPENIA uses a white-box/open-box approach to make informed predictions about code correctness, offering significant advantages in adaptability and robustness over traditional classification-based methods and zero-shot approaches. Experimental results demonstrate that OPENIA consistently outperforms baseline models, achieving higher accuracy, precision, recall, and F1-Scores with up to a 2X improvement in standalone code generation and a 46% enhancement in repository-specific scenarios. By unlocking the potential of in-process signals, OPENIA paves the way for more proactive and efficient quality assurance mechanisms in LLM-assisted code generation.
在人工智能驱动的软件开发中,确保大语言模型(LLM)生成的代码的正确性是一个重大挑战。现有的方法主要依赖于事后评估正确性的黑箱(封闭箱)方法,未能利用LLM在代码生成过程中内部状态的丰富见解。在本文中,我们介绍了OPENIA,这是一种新型的白箱(开放箱)框架,它利用这些内部表示来评估LLM生成的代码的正确性。OPENIA系统地分析了专门用于代码的代表性开源LLM的中间状态,包括DeepSeek-Coder、CodeLlama和MagicCoder,以及多种代码生成基准测试。我们的实证分析表明,这些内部表示包含潜在信息,与生成代码的正确性高度相关。基于这些见解,OPENIA采用白箱/开放箱方法,对代码的正确性做出有根据的预测,与传统的基于分类的方法和零样本方法相比,在适应性和稳健性方面具有明显的优势。实验结果表明,OPENIA始终优于基线模型,在独立代码生成方面实现了更高的准确性、精确度、召回率和F1分数,最高可达2倍的提升,并在特定仓库场景中提高了46%。通过解锁进程信号的潜力,OPENIA为LLM辅助的代码生成中更积极、更有效的质量保证机制铺平了道路。
论文及项目相关链接
Summary
本文介绍了在AI驱动的软件开发中,确保大型语言模型(LLM)生成的代码正确性的挑战。现有方法主要依赖事后评估的黑箱方法,忽略了LLM内部状态中的丰富信息。本文提出了OPENIA,一个新型的白箱框架,利用这些内部表征来评估LLM生成的代码的正确性。实验结果显示,OPENIA在代码生成质量和预测性能上均优于基线模型。
Key Takeaways
- LLM生成的代码正确性保证是一个重大挑战,现有方法主要依赖黑箱事后评估,存在局限性。
- OPENIA是一个新型的白箱框架,利用LLM的内部表征来评估生成代码的正确性。
- OPENIA系统地分析了DeepSeek-Coder、CodeLlama和MagicCoder等代表性开源LLM的中间状态。
- 实证结果显示,LLM的内部表征编码了与生成代码正确性强烈相关的信息。
- OPENIA使用白箱方法做出关于代码正确性的预测,相较于传统分类方法和零样本方法具有更高的适应性和稳健性。
- 实验结果显示,OPENIA在准确性、精确度、召回率和F1分数上均优于基线模型,独立代码生成和仓库特定场景中的性能提升分别高达2倍和46%。
点此查看论文截图




Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
Authors:Yafu Li, Xuyang Hu, Xiaoye Qu, Linjie Li, Yu Cheng
Large language models (LLMs) demonstrate impressive performance but lack the flexibility to adapt to human preferences quickly without retraining. In this work, we introduce Test-time Preference Optimization (TPO), a framework that aligns LLM outputs with human preferences during inference, removing the need to update model parameters. Rather than relying on purely numerical rewards, TPO translates reward signals into textual critiques and uses them as textual rewards to iteratively refine its response. Evaluations on benchmarks covering instruction following, preference alignment, safety, and mathematics reveal that TPO progressively improves alignment with human preferences. Notably, after only a few TPO steps, the initially unaligned Llama-3.1-70B-SFT model can surpass the aligned counterpart, Llama-3.1-70B-Instruct. Furthermore, TPO scales efficiently with both the search width and depth during inference. Through case studies, we illustrate how TPO exploits the innate capacity of LLM to interpret and act upon reward signals. Our findings establish TPO as a practical, lightweight alternative for test-time preference optimization, achieving alignment on the fly. Our code is publicly available at https://github.com/yafuly/TPO.
大型语言模型(LLM)虽然表现出令人印象深刻的性能,但缺乏快速适应人类偏好的灵活性,而无需重新训练。在这项工作中,我们引入了测试时偏好优化(TPO)框架,该框架能够在推理过程中将LLM输出与人类偏好对齐,无需更新模型参数。TPO不是依赖纯粹的数值奖励,而是将奖励信号转化为文本评价,并将其用作文本奖励来迭代优化其响应。在涵盖指令遵循、偏好对齐、安全和数学等方面的基准测试评估中,TPO逐渐提高了与人类偏好的对齐程度。值得注意的是,在仅进行少数几步TPO后,最初未对齐的Llama-3.1-70B-SFT模型可以超越对齐的同类模型Llama-3.1-70B-Instruct。此外,TPO在推理过程中的搜索宽度和深度方面都能实现高效扩展。通过案例研究,我们展示了TPO如何利用LLM解释和响应奖励信号的固有能力。我们的研究结果表明,TPO是一种实用的轻量级测试时偏好优化替代方案,能够实现即时对齐。我们的代码公开在https://github.com/yafuly/TPO。
论文及项目相关链接
PDF 43 pages; work in progress
Summary
大型语言模型(LLM)表现出令人印象深刻的性能,但在推理过程中缺乏快速适应人类偏好的灵活性,需要重新训练。本研究提出了测试时偏好优化(TPO)框架,该框架在推理过程中将LLM输出与人类偏好对齐,无需更新模型参数。TPO将奖励信号转化为文本评价,并将其用作文本奖励来迭代优化其响应。在涵盖指令遵循、偏好对齐、安全和数学方面的基准测试中,TPO逐步提高了与人类偏好的对齐程度。值得注意的是,经过仅几步的TPO优化,最初未对齐的Llama-3.1-70B-SFT模型甚至可以超越对齐的Llama-3.1-70B-Instruct。此外,TPO在推理过程中能够高效地适应搜索宽度和深度。案例研究表明,TPO能够利用LLM对奖励信号的内在解读和行动能力。研究发现,TPO是一种实用的轻量级测试时偏好优化替代方案,能够实现即时对齐。
Key Takeaways
- 大型语言模型(LLM)虽然性能出色,但在推理过程中难以快速适应人类偏好。
- 测试时偏好优化(TPO)框架能够在不更新模型参数的情况下,将LLM输出与人类偏好对齐。
- TPO通过将奖励信号转化为文本评价,用作文本奖励来迭代优化响应。
- TPO能够显著提高模型在多个基准测试中的性能,包括指令遵循、偏好对齐、安全和数学方面。
- 仅需少量TPO步骤,未对齐的模型即可超越对齐的模型性能。
- TPO在推理过程中能够高效地适应搜索宽度和深度,利用LLM的内在能力。
点此查看论文截图



Robust Hybrid Classical-Quantum Transfer Learning Model for Text Classification Using GPT-Neo 125M with LoRA & SMOTE Enhancement
Authors:Santanam Wishal
This research introduces a hybrid classical-quantum framework for text classification, integrating GPT-Neo 125M with Low-Rank Adaptation (LoRA) and Synthetic Minority Over-sampling Technique (SMOTE) using quantum computing backends. While the GPT-Neo 125M baseline remains the best-performing model, the implementation of LoRA and SMOTE enhances the hybrid model, resulting in improved accuracy, faster convergence, and better generalization. Experiments on IBM’s 127-qubit quantum backend and Pennylane’s 32-qubit simulation demonstrate the viability of combining classical neural networks with quantum circuits. This framework underscores the potential of hybrid architectures for advancing natural language processing applications.
本研究引入了一种用于文本分类的混合经典-量子框架,该框架结合了GPT-Neo 125M与低秩适配(LoRA)和合成少数过采样技术(SMOTE),并使用量子计算后端。虽然GPT-Neo 125M基线仍然是表现最好的模型,但LoRA和SMOTE的实施增强了混合模型,提高了准确性、更快的收敛速度和更好的泛化能力。在IBM的127量子位后端和Pennylane的32量子位模拟器的实验证明了将经典神经网络与量子电路相结合的可能性。该框架突出了混合架构在自然语言处理应用方面的潜力。
论文及项目相关链接
PDF 8 pages, 11 figures
Summary:本研究提出一种融合经典和量子计算框架用于文本分类,结合了GPT-Neo 125M、低秩自适应(LoRA)和合成少数过采样技术(SMOTE)。使用量子计算后端,GPT-Neo 125M基线模型表现最佳,结合LoRA和SMOTE的实施提高了混合模型的性能,带来了更高的准确性、更快的收敛速度和更好的泛化能力。在IBM的127量子比特后端和Pennylane的32量子比特模拟器上进行的实验证明了结合经典神经网络和量子电路的可能性。该框架突显了混合架构在自然语言处理应用中的潜力。
Key Takeaways:
- 研究提出了一种融合经典和量子计算的框架用于文本分类。
- 结合了GPT-Neo 125M模型、低秩自适应(LoRA)和合成少数过采样技术(SMOTE)。
- GPT-Neo 125M基线模型表现最佳,但结合LoRA和SMOTE提升了混合模型的性能。
- 框架增强了模型的准确性、加快了收敛速度,并改善了泛化能力。
- 在IBM和Pennylane的实验平台上验证了该框架的可行性。
- 实验证明了结合经典神经网络和量子电路的优势。
点此查看论文截图


FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Authors:Zengyi Gao, Yukun Cao, Hairu Wang, Ao Ke, Yuan Feng, Xike Xie, S Kevin Zhou
To mitigate the hallucination and knowledge deficiency in large language models (LLMs), Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) has shown promising potential by utilizing KGs as external resource to enhance LLMs reasoning. However, existing KG-RAG approaches struggle with a trade-off between flexibility and retrieval quality. Modular methods prioritize flexibility by avoiding the use of KG-fine-tuned models during retrieval, leading to fixed retrieval strategies and suboptimal retrieval quality. Conversely, coupled methods embed KG information within models to improve retrieval quality, but at the expense of flexibility. In this paper, we propose a novel flexible modular KG-RAG framework, termed FRAG, which synergizes the advantages of both approaches. FRAG estimates the hop range of reasoning paths based solely on the query and classify it as either simple or complex. To match the complexity of the query, tailored pipelines are applied to ensure efficient and accurate reasoning path retrieval, thus fostering the final reasoning process. By using the query text instead of the KG to infer the structural information of reasoning paths and employing adaptable retrieval strategies, FRAG improves retrieval quality while maintaining flexibility. Moreover, FRAG does not require extra LLMs fine-tuning or calls, significantly boosting efficiency and conserving resources. Extensive experiments show that FRAG achieves state-of-the-art performance with high efficiency and low resource consumption.
为了缓解大型语言模型(LLM)中的幻觉和知识缺陷问题,基于知识图谱(KG)的检索增强生成(RAG)方法显示出利用知识图谱作为外部资源来提升LLM推理能力的巨大潜力。然而,现有的KG-RAG方法面临灵活性和检索质量之间的权衡。模块化方法优先灵活性,避免在检索过程中使用针对知识图谱微调过的模型,这导致固定的检索策略和低下的检索质量。相反,耦合方法将知识图谱信息嵌入模型中以提高检索质量,但牺牲了灵活性。在本文中,我们提出了一种新型的灵活模块化KG-RAG框架,名为FRAG。FRAG根据查询来估计推理路径的跳转范围,并将其分类为简单或复杂。为了与查询的复杂性相匹配,我们应用定制化的流水线来确保高效且准确的推理路径检索,从而促进最终的推理过程。FRAG使用查询文本而不是知识图谱来推断推理路径的结构信息,并采用可适应的检索策略,从而在提高检索质量的同时保持灵活性。此外,FRAG不需要额外的LLM微调或调用,这大大提高了效率并节省了资源。大量实验表明,FRAG以高效率和低资源消耗实现了最先进的性能。
论文及项目相关链接
Summary
基于知识图谱的检索增强生成(RAG)方法能够利用知识图谱作为外部资源,增强大型语言模型(LLM)的推理能力,缓解其产生的幻觉和知识缺陷问题。本文提出了一种新颖的灵活模块化KG-RAG框架,即FRAG,融合了现有方法的优点。FRAG能够根据查询估计推理路径的跳转范围,并对其进行简单或复杂的分类,采用匹配的管道确保高效准确的推理路径检索,促进最终的推理过程。该框架使用查询文本推断推理路径的结构信息,采用灵活的检索策略,提高了检索质量,同时保持了灵活性。此外,FRAG不需要额外的LLM微调或调用,提高了效率和资源利用率。实验表明,FRAG达到了高效且资源消耗低的最佳性能。
Key Takeaways
- 知识图谱(KG)可以作为一种外部资源,用于增强大型语言模型(LLM)的推理能力。
- 现有KG-RAG方法面临灵活性和检索质量之间的权衡。
- FRAG框架能够根据查询的复杂性进行灵活的模块化处理,确保高效准确的推理路径检索。
- FRAG使用查询文本推断推理路径的结构信息,提高了检索质量。
- FRAG框架在保持灵活性的同时,不需要额外的LLM微调或调用,提高了效率和资源利用率。
- FRAG实现了高效且资源消耗低的最佳性能。
点此查看论文截图



Yi-Lightning Technical Report
Authors:Alan Wake, Bei Chen, C. X. Lv, Chao Li, Chengen Huang, Chenglin Cai, Chujie Zheng, Daniel Cooper, Fan Zhou, Feng Hu, Ge Zhang, Guoyin Wang, Heng Ji, Howard Qiu, Jiangcheng Zhu, Jun Tian, Katherine Su, Lihuan Zhang, Liying Li, Ming Song, Mou Li, Peng Liu, Qicheng Hu, Shawn Wang, Shijun Zhou, Shiming Yang, Shiyong Li, Tianhang Zhu, Wen Xie, Wenhao Huang, Xiang He, Xiaobo Chen, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Yanpeng Li, Yongke Zhao, Yongzhen Luo, Yuchi Xu, Yuxuan Sha, Zhaodong Yan, Zhiyuan Liu, Zirui Zhang, Zonghong Dai
This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks’ utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
这篇技术报告介绍了我们最新的旗舰大型语言模型(LLM)——Yi-Lightning。它在ChatGPT竞技场上的总体排名达到了第6名,同时在包括中文、数学、编码和硬提示等专项类别中取得了优异的成绩(第2至第4名)。Yi-Lightning采用了增强的混合专家(MoE)架构,配备了先进的专家分割和路由机制,并结合了优化的KV缓存技术。我们的开发过程包括全面的预训练、监督微调(SFT)和强化学习人类反馈(RLHF),在此期间我们为分阶段训练、合成数据构建和奖励建模制定了精心设计的策略。此外,我们实施了RAISE(负责任的人工智能安全引擎),这是一个由四个组件组成的框架,用于解决预训练、后训练和提供阶段的各类安全问题。凭借我们可扩展的超级计算基础设施,所有这些创新在维持高性能标准的同时,大大降低了训练、部署和推理成本。在公共学术基准上的进一步评估表明,Yi-Lightning与顶级LLM相比具有竞争力;同时,我们注意到传统静态基准结果和现实世界动态人类偏好之间存在明显的差异。这一观察促使我们重新审视传统基准在指导更具智能和强大的人工智能系统实际应用开发方面的实用性。Yi-Lightning现已可通过我们的开发平台(https://platform.lingyiwanwu.com)使用。
论文及项目相关链接
Summary
本文介绍了最新旗舰大型语言模型Yi-Lightning,它在Chatbot Arena上总体排名第六,并在包括中文、数学、编码和硬提示等专项类别中取得优异结果。Yi-Lightning采用增强的混合专家架构,具有先进的专家分割和路由机制以及优化的KV缓存技术。开发过程包括预训练、监督微调(SFT)和强化学习从人类反馈(RLHF),实施RAISE负责人工智能安全引擎解决安全问题。Yi-Lightning利用可扩展的超级计算基础设施大幅降低了训练、部署和推理成本,同时保持了高性能标准。该模型在公共学术基准测试中表现出竞争力,并观察到传统静态基准测试结果与现实世界中动态人类偏好之间的差异,这促使重新评估传统基准测试在指导开发更具智能和实用性的AI系统方面的作用。Yi-Lightning已通过我们的开发平台发布。
Key Takeaways
- Yi-Lightning是最新旗舰大型语言模型,在Chatbot Arena上总体排名第六。
- 在专项类别中,包括中文、数学、编码和硬提示等方面取得优异成果,排名第二至第四。
- 采用增强的混合专家架构,具有先进的专家分割和路由机制及优化的KV缓存技术。
- 开发过程包括预训练、监督微调(SFT)和强化学习从人类反馈(RLHF)。
- 实施RAISE负责人工智能安全引擎以解决安全问题。
- Yi-Lightning利用超级计算基础设施降低训练、部署和推理成本。
点此查看论文截图


VisMin: Visual Minimal-Change Understanding
Authors:Rabiul Awal, Saba Ahmadi, Le Zhang, Aishwarya Agrawal
Fine-grained understanding of objects, attributes, and relationships between objects is crucial for visual-language models (VLMs). Existing benchmarks primarily focus on evaluating VLMs’ capability to distinguish between two very similar captions given an image. In this paper, we introduce a new, challenging benchmark termed Visual Minimal-Change Understanding (VisMin), which requires models to predict the correct image-caption match given two images and two captions. The image pair and caption pair contain minimal changes, i.e., only one aspect changes at a time from among the following: object, attribute, count, and spatial relation. These changes test the models’ understanding of objects, attributes (such as color, material, shape), counts, and spatial relationships between objects. We built an automatic framework using large language models and diffusion models, followed by a rigorous 4-step verification process by human annotators. Empirical experiments reveal that current VLMs exhibit notable deficiencies in understanding spatial relationships and counting abilities. We also generate a large-scale training dataset to finetune CLIP and Idefics2, showing significant improvements in fine-grained understanding across benchmarks and in CLIP’s general image-text alignment. We release all resources, including the benchmark, training data, and finetuned model checkpoints, at https://vismin.net/.
对物体、属性和物体之间关系的精细理解对于视觉语言模型(VLMs)至关重要。现有的基准测试主要关注评估VLMs在给定图像的情况下区分两个非常相似的标题的能力。在本文中,我们引入了一个新的具有挑战性的基准测试,称为视觉最小变化理解(VisMin),该测试要求模型在给定的两个图像和两个标题中预测正确的图像-标题匹配。图像对和标题对中包含了微小的变化,即每次只有一个方面的变化,包括对象、属性、计数和空间关系。这些变化测试了模型对物体、属性(如颜色、材质、形状)、计数以及物体之间空间关系的理解。我们使用大型语言模型和扩散模型建立了一个自动框架,随后经过人类注释者严格的四步验证过程。经验实验表明,目前的VLM在理解空间关系和计数能力方面存在明显缺陷。我们还生成了一个大规模的训练数据集来微调CLIP和Idefics2,在基准测试和CLIP的通用图像文本对齐方面显示出对精细理解的显著改善。我们在https://vismin.net/上发布了所有资源,包括基准测试、训练数据和微调模型检查点。
论文及项目相关链接
PDF Accepted at NeurIPS 2024. Project URL at https://vismin.net/
Summary:
本文提出了一种新的挑战基准Visual Minimal-Change Understanding (VisMin),该基准测试了模型对于图片中的对象、属性、计数以及对象间空间关系的理解。在评估中发现了现有视觉语言模型在理解空间关系和计数方面的缺陷。文章提出了一个大规模训练数据集以优化CLIP和Idefics2的性能,在基准测试中表现出显著改善。同时释放了所有资源,包括基准测试、训练数据和微调后的模型检查点以供研究使用。
Key Takeaways:
- 视觉语言模型需要精细理解图像中的对象、属性及对象间的关系。
- 提出了一种新的挑战基准Visual Minimal-Change Understanding (VisMin)。
- VisMin基准测试包括图像和文本对中的细微变化,如对象、属性、计数和空间关系的改变。
- 当前视觉语言模型在空间关系和计数理解方面存在明显不足。
- 释放了一个大规模训练数据集以优化CLIP和Idefics2的性能。
- 经过训练数据集的优化,CLIP和Idefics2在基准测试中表现出显著改善。
点此查看论文截图



Panza: Design and Analysis of a Fully-Local Personalized Text Writing Assistant
Authors:Armand Nicolicioiu, Eugenia Iofinova, Eldar Kurtic, Mahdi Nikdan, Andrei Panferov, Ilia Markov, Nir Shavit, Dan Alistarh
The availability of powerful open-source large language models (LLMs) opens exciting use cases, such as automated personal assistants that adapt to the user’s unique data and demands. Two key requirements for such assistants are personalization - in the sense that the assistant should reflect the user’s own writing style - and privacy - users may prefer to always store their personal data locally, on their own computing device. In this application paper, we present a new design and evaluation for such an automated assistant, for the specific use case of email generation, which we call Panza. Specifically, Panza can be trained and deployed locally on commodity hardware, and is personalized to the user’s writing style. Panza’s personalization features are based on a combination of fine-tuning using a variant of the Reverse Instructions technique together with Retrieval-Augmented Generation (RAG). We demonstrate that this combination allows us to fine-tune an LLM to better reflect a user’s writing style using limited data, while executing on extremely limited resources, e.g. on a free Google Colab instance. Our key methodological contribution is what we believe to be the first detailed study of evaluation metrics for this personalized writing task, and of how different choices of system components - e.g. the use of RAG and of different fine-tuning approaches - impact the system’s performance. We are releasing the full Panza code as well as a new “David” personalized email dataset licensed for research use, both available on https://github.com/IST-DASLab/PanzaMail.
强大的开源大型语言模型(LLM)的可用性为实际应用带来了激动人心的用例,例如适应用户独特数据和需求的自动化个人助理。这类助理的两个关键要求是个性化——即助理应该反映用户自己的写作风格——和隐私——用户可能更喜欢始终将他们的个人数据存储在本地自己的计算设备上。在本应用论文中,我们针对电子邮件生成这一特定用例,为此类自动化助理提出了新设计和评估,我们称之为“潘扎(Panza)”。具体来说,潘扎可以在商品硬件上本地进行训练和部署,并可实现个性化的写作风格。潘扎的个性化功能基于使用反向指令技术变体进行微调,并结合检索增强生成(RAG)。我们证明,这种结合允许我们微调LLM以更好地反映用户的写作风格,同时使用有限的数据在极其有限的资源上运行,例如在免费的Google Colab实例上。我们的主要方法论贡献在于我们认为这是对个性化写作任务的评估指标的首次详细研究,以及不同的系统组件选择——例如使用RAG和不同的微调方法——如何影响系统性能。我们公开了完整的潘扎代码以及用于研究的新“大卫”个性化电子邮件数据集,两者均可在https://github.com/IST-DASLab/PanzaMail上获得。
论文及项目相关链接
PDF Panza is available at https://github.com/IST-DASLab/PanzaMail
Summary
本文介绍了一种基于强大开源大型语言模型(LLM)的自动化个人助理应用,专门用于电子邮件生成,名为Panza。Panza可以在普通硬件上本地进行训练和部署,并能反映用户的写作风格实现个性化。其个性化功能结合了反向指令技术的微调与检索增强生成(RAG)。研究表明,这种结合能在有限数据下使LLM更好地反映用户的写作风格,同时在极其有限的资源下运行,如免费Google Colab实例。本文的关键方法论贡献在于首次对该个性化写作任务的评估指标以及不同系统组件的选择对系统性能的影响进行了深入研究。同时公开了完整的Panza代码和新的“David”个性化电子邮件数据集,供研究使用。
Key Takeaways
- Panza是一种基于强大开源LLM的自动化个人助理应用,专为电子邮件生成设计。
- Panza能在普通硬件上本地进行训练和部署,并能反映用户的写作风格实现个性化。
- Panza结合反向指令技术的微调与检索增强生成(RAG)实现个性化。
- 结合有限数据,Panza能更好地反映用户的写作风格,在有限的资源下运行。
- 本文首次详细研究了个性化写作任务的评估指标及系统组件对性能的影响。
- Panza代码和“David”个性化电子邮件数据集已公开供研究使用。
点此查看论文截图



SituationalLLM: Proactive Language Models with Scene Awareness for Dynamic, Contextual Task Guidance
Authors:Muhammad Saif Ullah Khan, Didier Stricker
Large language models (LLMs) have achieved remarkable success in text-based tasks but often struggle to provide actionable guidance in real-world physical environments. This is because of their inability to recognize their limited understanding of the user’s physical context. We present SituationalLLM, a novel approach that integrates structured scene information into an LLM to deliver proactive, context-aware assistance. By encoding objects, attributes, and relationships in a custom Scene Graph Language, SituationalLLM actively identifies gaps in environmental context and seeks clarifications during user interactions. This behavior emerges from training on the Situational Awareness Database for Instruct-Tuning (SAD-Instruct), which combines diverse, scenario-specific scene graphs with iterative, dialogue-based refinements. Experimental results indicate that SituationalLLM outperforms generic LLM baselines in task specificity, reliability, and adaptability, paving the way for environment-aware AI assistants capable of delivering robust, user-centric guidance under real-world constraints.
大型语言模型(LLM)在文本任务方面取得了显著的成功,但在现实世界的物理环境中往往难以提供可操作的指导。这是因为它们无法识别自己对用户物理环境的有限理解。我们提出了SituationalLLM,这是一种新型方法,它将结构化场景信息集成到LLM中,以提供主动、基于上下文的支持。通过自定义场景图语言对物体、属性和关系进行编码,SituationalLLM能够主动识别环境上下文中的差距,并在用户交互过程中寻求澄清。这种行为来源于对指令训练情境意识数据库(SAD-Instruct)的训练,该数据库将多样化、特定场景的场景图与迭代、基于对话的细化相结合。实验结果表明,在任务特异性、可靠性和适应性方面,SituationalLLM超越了通用LLM基准,为能够在实际约束下提供稳健、以用户为中心指导的环境感知AI助理铺平了道路。
论文及项目相关链接
PDF Submitted to Open Research Europe
Summary
大型语言模型(LLMs)在文本任务上表现卓越,但在现实世界的物理环境中提供行动指导时常常遇到困难。原因在于LLMs无法识别用户对物理环境的理解有限。本文提出了一种名为SituationalLLM的新方法,它将结构化场景信息融入LLM中,以提供主动、情境感知的辅助。通过自定义场景图语言编码物体、属性和关系,SituationalLLM能积极识别环境上下文中的差距,在用户交互过程中寻求澄清。这种行为源于对情境感知数据库指令训练(SAD-Instruct)的训练,结合了多种场景特定的场景图和基于迭代的对话式细化。实验结果表明,在任务特异性、可靠性和适应性方面,SituationalLLM优于通用LLM基线,为环境感知AI助理铺平了道路,能够在现实世界的约束下提供稳健、以用户为中心的指导。
Key Takeaways
- LLMs在文本任务上表现良好,但在现实世界的物理环境中提供指导时存在困难。
- SituationalLLM是一种将结构化场景信息融入LLM的新方法。
- SituationalLLM通过自定义场景图语言编码物体、属性和关系。
- SituationalLLM能积极识别环境上下文中的差距并寻求澄清。
- SituationalLLM的行为源于对SAD-Instruct的训练,结合了场景特定的场景图和基于对话的细化。
- 实验结果表明,SituationalLLM在任务特异性、可靠性和适应性方面优于通用LLM基线。
点此查看论文截图







Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Authors:Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges, focusing on a clean scenario in which inter-human agreement is high. Investigating thirteen judge models of different model sizes and families, judging answers of nine different ‘examtaker models’ - both base and instruction-tuned - we find that only the best (and largest) models achieve reasonable alignment with humans. However, they are still quite far behind inter-human agreement and their assigned scores may still differ with up to 5 points from human-assigned scores. In terms of their ranking of the nine exam-taker models, instead, also smaller models and even the lexical metric contains may provide a reasonable signal. Through error analysis and other studies, we identify vulnerabilities in judge models, such as their sensitivity to prompt complexity and length, and a tendency toward leniency. The fact that even the best judges differ from humans in this comparatively simple setup suggest that caution may be wise when using judges in more complex setups. Lastly, our research rediscovers the importance of using alignment metrics beyond simple percent alignment, showing that judges with high percent agreement can still assign vastly different scores.
针对与人类评估相关的可扩展性挑战,LLM作为评判者的范式提供了一种前景光明的解决方案,它作为一种评估大型语言模型(LLM)的方法正迅速获得支持。然而,关于该范式的优点和缺点,以及它可能存在的潜在偏见,仍有许多悬而未决的问题。在本文中,我们对作为评判者的各种LLM的性能进行了全面研究,重点是一个人类之间共识程度较高的干净场景。我们调查了13个不同规模和家族的评判模型,对九个不同参加考试模型的答案进行评判——包括基础模型和指令调优模型——我们发现只有最好的(也是最大的)模型才能实现与人类的合理对齐。然而,它们仍然远远落后于人类之间的共识,它们给出的分数与人类给出的分数可能相差高达5分。至于它们对九个参加考试模型的排名,较小模型甚至是词汇指标也可能提供合理的信号。通过错误分析和其他研究,我们发现了评判模型存在的漏洞,如它们对提示的复杂性和长度的敏感性,以及倾向于宽容的趋势。即使在相对简单的设置中,即使最好的评判者也与人类存在差异,这表明在更复杂的设置中使用评判者时可能需要谨慎。最后,我们的研究重新发现了使用超越简单百分比对齐的对齐指标的重要性,表明即使百分比协议很高的评判者仍然可以分配截然不同的分数。
论文及项目相关链接
Summary
LLM作为评估者的模式在解决语言模型评估的可扩展性挑战方面展现出巨大的潜力。本文对在不同模型大小和家族中的LLM进行评估,发现在高人间共识的场景下,仅最好的大型模型才能与人类实现合理对齐。但即便如此,这些模型仍落后于人际共识,评分差距最高达五点。排名方面,较小模型甚至词汇度量标准也可提供合理信号。研究通过错误分析等方式发现LLM评估模型的脆弱性,如受提示复杂性和长度的影响以及倾向宽松的评分等。即使在相对简单的场景下,最佳模型也无法完全模拟人类评估,因此在更复杂的环境中使用LLM作为评估者需谨慎。研究重申使用超越简单百分比对齐的校准指标的重要性。
Key Takeaways
- LLM-as-a-judge模式在解决语言模型评估可扩展性问题上展现潜力。
- 在高人间共识场景下,仅最好的大型LLM能合理对齐人类评价。
- 即使是最好的LLM评估模型仍与人际共识存在差距,评分差距最高达五点。
- 在排名方面,较小模型甚至词汇度量标准也能提供合理参考。
- LLM评估模型存在脆弱性,如受提示复杂性和长度的影响以及倾向宽松的评分。
- 在复杂环境中使用LLM作为评估者需谨慎。
点此查看论文截图




List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs
Authors:An Yan, Zhengyuan Yang, Junda Wu, Wanrong Zhu, Jianwei Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Julian McAuley, Jianfeng Gao, Lijuan Wang
Set-of-Mark (SoM) Prompting unleashes the visual grounding capability of GPT-4V, by enabling the model to associate visual objects with tags inserted on the image. These tags, marked with alphanumerics, can be indexed via text tokens for easy reference. Despite the extraordinary performance from GPT-4V, we observe that other Multimodal Large Language Models (MLLMs) struggle to understand these visual tags. To promote the learning of SoM prompting for open-source models, we propose a new learning paradigm: “list items one by one,” which asks the model to enumerate and describe all visual tags placed on the image following the alphanumeric orders of tags. By integrating our curated dataset with other visual instruction tuning datasets, we are able to equip existing MLLMs with the SoM prompting ability. Furthermore, we evaluate our finetuned SoM models on five MLLM benchmarks. We find that this new dataset, even in a relatively small size (10k-30k images with tags), significantly enhances visual reasoning capabilities and reduces hallucinations for MLLMs. Perhaps surprisingly, these improvements persist even when the visual tags are omitted from input images during inference. This suggests the potential of “list items one by one” as a new paradigm for training MLLMs, which strengthens the object-text alignment through the use of visual tags in the training stage. Finally, we conduct analyses by probing trained models to understand the working mechanism of SoM. Our code and data are available at \url{https://github.com/zzxslp/SoM-LLaVA}.
通过启用模型将视觉对象与图像中插入的标签相关联,Set-of-Mark (SoM) 提示释放了GPT-4V的视觉定位能力。这些带有字母数字的标签可以通过文本标记进行索引,便于参考。尽管GPT-4V的表现非常出色,但我们发现其他多模态大型语言模型(MLLMs)很难理解这些视觉标签。为了促进开源模型的SoM提示学习,我们提出了一种新的学习范式:“逐一列出项目”,要求模型按照标签的字母数字顺序枚举并描述图像上放置的所有视觉标签。通过将我们精选的数据集与其他视觉指令调整数据集相结合,我们能够赋予现有MLLMs以SoM提示能力。此外,我们在五个MLLM基准测试上评估了我们微调过的SoM模型。我们发现,即使在新的数据集中图像标签规模相对较小(带有标签的10万至30万张图像),也能显著提高MLLM的视觉推理能力并减少幻觉。令人惊讶的是,即使在推理阶段省略输入图像的视觉标签,这些改进仍然持续存在。这表明“逐一列出项目”作为训练MLLM的新范式具有潜力,通过训练阶段使用视觉标签来加强对象文本对齐。最后,我们通过探测训练模型来分析SoM的工作原理。我们的代码和数据集可在\url{https://github.com/zzxslp/SoM-LLaVA}获得。
论文及项目相关链接
PDF published at COLM-2024
Summary
本文介绍了Set-of-Mark(SoM)提示对GPT-4V的视觉定位能力的释放作用。通过图像中插入的视觉对象标签与模型关联,这些标签以数字标记,可通过文本令牌进行索引以便参考。尽管GPT-4V表现出卓越性能,但其他多模态大型语言模型(MLLMs)在理解这些视觉标签时遇到困难。为促进开源模型的SoM提示学习,提出了一种新的学习模式:“逐一列出项目”,要求模型按数字顺序枚举并描述图像上放置的所有视觉标签。通过整合我们的定制数据集与其他视觉指令微调数据集,我们能够为现有的MLLMs配备SoM提示能力。评估发现,即使在新数据集规模相对较小的情况下(带有标签的1万至3万张图像),也能显著提高MLLMs的视觉推理能力并减少幻觉。更令人惊讶的是,即使在推理阶段省略视觉标签,这些改进依然存在。这表明“逐一列出项目”作为训练MLLMs的新模式的潜力,通过训练阶段使用视觉标签来加强对象文本对齐。
Key Takeaways
- Set-of-Mark (SoM) 提示能够释放GPT-4V的视觉定位能力,通过与图像中的标签关联实现。
- SoM提示利用数字标记的视觉标签,通过文本令牌进行索引,便于模型识别。
- 其他多模态大型语言模型(MLLMs)在理解视觉标签时存在困难。
- 提出了“逐一列出项目”的新学习模式,促进MLLMs对视觉标签的学习与理解。
- 通过整合定制数据集与其他视觉指令微调数据集,能赋予现有MLLMs以SoM提示能力。
- 评估显示,新数据集(即使规模较小)能显著提高MLLMs的视觉推理能力,并减少幻觉。
点此查看论文截图




UniGraph: Learning a Unified Cross-Domain Foundation Model for Text-Attributed Graphs
Authors:Yufei He, Yuan Sui, Xiaoxin He, Bryan Hooi
Foundation models like ChatGPT and GPT-4 have revolutionized artificial intelligence, exhibiting remarkable abilities to generalize across a wide array of tasks and applications beyond their initial training objectives. However, graph learning has predominantly focused on single-graph models, tailored to specific tasks or datasets, lacking the ability to transfer learned knowledge to different domains. This limitation stems from the inherent complexity and diversity of graph structures, along with the different feature and label spaces specific to graph data. In this paper, we recognize text as an effective unifying medium and employ Text-Attributed Graphs (TAGs) to leverage this potential. We present our UniGraph framework, designed to learn a foundation model for TAGs, which is capable of generalizing to unseen graphs and tasks across diverse domains. Unlike single-graph models that use pre-computed node features of varying dimensions as input, our approach leverages textual features for unifying node representations, even for graphs such as molecular graphs that do not naturally have textual features. We propose a novel cascaded architecture of Language Models (LMs) and Graph Neural Networks (GNNs) as backbone networks. Additionally, we propose the first pre-training algorithm specifically designed for large-scale self-supervised learning on TAGs, based on Masked Graph Modeling. We introduce graph instruction tuning using Large Language Models (LLMs) to enable zero-shot prediction ability. Our comprehensive experiments across various graph learning tasks and domains demonstrate the model’s effectiveness in self-supervised representation learning on unseen graphs, few-shot in-context transfer, and zero-shot transfer, even surpassing or matching the performance of GNNs that have undergone supervised training on target datasets.
类似ChatGPT和GPT-4的基石模型已经彻底改变了人工智能领域,展现出在广泛的任务和应用中超越其初始训练目标的卓越泛化能力。然而,图学习主要关注于单一图模型,针对特定任务或数据集,缺乏将所学知识转移到不同领域的能力。这一限制源于图结构本身的复杂性和多样性,以及图数据特有的特征和标签空间。在本文中,我们认识到文本是一种有效的统一媒介,并采用带文本属性图(TAGs)来利用这一潜力。我们提出了UniGraph框架,旨在学习用于TAGs的基石模型,能够推广到未见过的图和跨不同领域的任务。不同于使用预计算节点特征作为输入的单一图模型,我们的方法利用文本特征来统一节点表示,即使对于没有自然文本特征的图形(如分子图形)也是如此。我们提出了语言模型(LMs)和图神经网络(GNNs)的新型级联架构作为骨干网络。此外,我们提出了专为大规模自监督学习在TAGs上设计的第一个预训练算法,基于掩码图建模。我们引入使用大型语言模型(LLMs)的图指令微调,以实现零样本预测能力。我们在各种图学习任务和领域进行的全面实验表明,该模型在未见图的自监督表示学习、少样本上下文迁移和零样本迁移方面的有效性,甚至超越或匹配了在目标数据集上进行监督训练的GNNs的性能。
论文及项目相关链接
PDF KDD 2025
Summary
本文介绍了Graph AI领域的最新发展,指出了单图模型受限于其固定的应用场景和域特定性问题。通过融合文本特征的统一表示法来解决该问题,引入了UniGraph框架,通过采用大型预训练模型技术来应对图的复杂性,进而实现在多个图学习任务的未见数据和不同域中的零和少量样本转移学习性能的提高。更重要的是,该文所阐述的新架构展现了一种面向图数据的标准化、自监督的训练范式,从而实现统一的表示学习和跨域迁移学习。这一突破性的技术革新将推动Graph AI领域的发展。
Key Takeaways
- 单图模型受限于特定任务和域,缺乏跨域知识迁移能力。
- 文本是一种有效的统一媒介来构建多源数据的关联,并且该文尝试采用文本特征来对各种节点的表征进行统一表达。针对没有自然文本特征的图形数据(如分子图),提出了一种解决方案。
- UniGraph框架引入了一种新的大型预训练模型技术,用于学习跨不同域的未见图形的通用表示。该框架通过结合语言模型和图神经网络(GNNs)的级联架构来实现这一点。这一架构实现了跨多个任务的通用能力。其在未标数据集和几个具有代表性的图上展现出了优异的性能。文章特别强调了其对于分子图的适用性。
- 该文提出了一种针对文本属性图(TAGs)的预训练算法,该算法基于掩码图建模进行大规模自监督学习。它提出了图指令微调(GIT)的方法来实现零样本预测能力。这表明它不仅能够处理已标记的数据,还能处理未标记的数据。这一创新为自监督学习在图形数据中的应用提供了新的视角和方法论指导。这不仅大大提高了模型的灵活性而且能够显著提升模型的效果。模型还可以解决极少样本情况下的上下文转移问题。
点此查看论文截图




Investigating Recurrent Transformers with Dynamic Halt
Authors:Jishnu Ray Chowdhury, Cornelia Caragea
In this paper, we comprehensively study the inductive biases of two major approaches to augmenting Transformers with a recurrent mechanism: (1) the approach of incorporating a depth-wise recurrence similar to Universal Transformers; and (2) the approach of incorporating a chunk-wise temporal recurrence like Temporal Latent Bottleneck. Furthermore, we propose and investigate novel ways to extend and combine the above methods - for example, we propose a global mean-based dynamic halting mechanism for Universal Transformers and an augmentation of Temporal Latent Bottleneck with elements from Universal Transformer. We compare the models and probe their inductive biases in several diagnostic tasks, such as Long Range Arena (LRA), flip-flop language modeling, ListOps, and Logical Inference. The code is released in: https://github.com/JRC1995/InvestigatingRecurrentTransformers/tree/main
在这篇论文中,我们全面研究了将Transformer与循环机制相结合的两种主要方法的归纳偏见:(1)采用类似于Universal Transformer的深度递归方法;(2)采用类似于Temporal Latent Bottleneck的分块时间递归方法。此外,我们还提出了扩展和结合上述方法的新方式——例如,我们为Universal Transformer提出了基于全局平均值的动态停止机制,以及融合了Temporal Latent Bottleneck中一些来自Universal Transformer的元素。我们在多个诊断任务中比较了这些模型并探究了其归纳偏见,包括长范围区域(LRA)、flip-flop语言建模、ListOps和逻辑推理等任务。相关代码已发布在:链接地址。
论文及项目相关链接
Summary
本文研究了两种在Transformer中引入循环机制的主要方法的归纳偏见,包括类似于Universal Transformer的深度递归方法和类似于Temporal Latent Bottleneck的块状时序递归方法。此外,提出了扩展和结合上述方法的新方式,并比较了这些模型在多个诊断任务中的归纳偏见,如Long Range Arena(LRA)、flip-flop语言建模、ListOps和逻辑推理等。代码已发布在相关链接中。
Key Takeaways
- 研究了两种主要方法以在Transformer中引入循环机制。
- 第一种方法采用类似于Universal Transformer的深度递归机制。
- 第二种方法采用类似于Temporal Latent Bottleneck的块状时序递归机制。
- 提出了扩展和结合上述方法的新方式,包括全球均值动态停止机制和Temporal Latent Bottleneck与Universal Transformer元素的融合。
- 在多个诊断任务中比较了这些模型的归纳偏见。
- 这些诊断任务包括Long Range Arena(LRA)、flip-flop语言建模、ListOps和逻辑推理等。
点此查看论文截图



BarcodeBERT: Transformers for Biodiversity Analysis
Authors:Pablo Millan Arias, Niousha Sadjadi, Monireh Safari, ZeMing Gong, Austin T. Wang, Joakim Bruslund Haurum, Iuliia Zarubiieva, Dirk Steinke, Lila Kari, Angel X. Chang, Scott C. Lowe, Graham W. Taylor
In the global challenge of understanding and characterizing biodiversity, short species-specific genomic sequences known as DNA barcodes play a critical role, enabling fine-grained comparisons among organisms within the same kingdom of life. Although machine learning algorithms specifically designed for the analysis of DNA barcodes are becoming more popular, most existing methodologies rely on generic supervised training algorithms. We introduce BarcodeBERT, a family of models tailored to biodiversity analysis and trained exclusively on data from a reference library of 1.5M invertebrate DNA barcodes. We compared the performance of BarcodeBERT on taxonomic identification tasks against a spectrum of machine learning approaches including supervised training of classical neural architectures and fine-tuning of general DNA foundation models. Our self-supervised pretraining strategies on domain-specific data outperform fine-tuned foundation models, especially in identification tasks involving lower taxa such as genera and species. We also compared BarcodeBERT with BLAST, one of the most widely used bioinformatics tools for sequence searching, and found that our method matched BLAST’s performance in species-level classification while being 55 times faster. Our analysis of masking and tokenization strategies also provides practical guidance for building customized DNA language models, emphasizing the importance of aligning model training strategies with dataset characteristics and domain knowledge. The code repository is available at https://github.com/bioscan-ml/BarcodeBERT.
在全球性的生物多样性和特性认知挑战中,DNA条形码发挥了至关重要的作用。这是一种特定物种的简短基因组序列,可以使得我们在同一生物王国中对生物进行细致的对比研究。虽然为DNA条形码分析而特别设计的机器学习算法正越来越受欢迎,但大多数现有方法仍然依赖于通用的监督训练算法。我们推出了BarcodeBERT模型家族,该模型专为生物多样性分析量身定制,并仅基于来自包含150万无脊椎动物DNA条形码参考库的数据进行训练。我们对BarcodeBERT在分类鉴定任务上的性能进行了评估,并与一系列机器学习技术进行了比较,包括经典神经架构的监督训练和通用DNA基础模型的微调。我们在特定领域数据上的自我监督预训练策略在鉴定任务上的表现优于经过微调的基础模型,特别是在涉及较低分类等级(如属和种)的鉴定任务中表现尤为出色。我们还比较了BarcodeBERT与BLAST(一种广泛使用的用于序列搜索的生物信息学工具),发现我们的方法在物种水平的分类上达到了BLAST的性能水平,同时运行速度是BLAST的55倍。我们对掩码和分词策略的分析也为构建定制的DNA语言模型提供了实际指导,强调了对模型训练策略与数据集特征和领域知识相适应的重要性。相关代码仓库可以在https://github.com/bioscan-ml/BarcodeBERT找到。
论文及项目相关链接
PDF Main text: 14 pages, Total: 23 pages, 10 figures, formerly accepted at the 4th Workshop on Self-Supervised Learning: Theory and Practice (NeurIPS 2023)
Summary:针对全球生物多样性的理解和特征描述挑战,DNA条形码在物种间的精细比较中扮演关键角色。本研究引入BarcodeBERT模型家族,专门用于生物多样性分析,并在包含150万无脊椎动物DNA条形码数据的参考库上进行训练。相较于其他机器学习方法,BarcodeBERT在分类鉴定任务上表现优异,特别是在较低分类等级如属和种的鉴定上。此外,BarcodeBERT与广泛使用的生物信息学工具BLAST相比,在物种水平分类上性能相当,但运行速度快达55倍。该研究还分析了掩码和分词策略,为构建定制DNA语言模型提供了实践指导。
Key Takeaways:
- DNA条形码在生物多样性的精细比较中起到关键作用。
- BarcodeBERT模型是为生物多样性分析量身定制的模型家族。
- BarcodeBERT在鉴定任务上表现优于其他机器学习方法,特别是在属和种的鉴定上。
- BarcodeBERT与BLAST相比,物种分类性能相当但运行速度快。
- BarcodeBERT采用自我监督预训练策略,适用于特定领域的DNA数据。
- 研究分析了掩码和分词策略,为构建定制DNA语言模型提供了指导。
点此查看论文截图




