⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-24 更新
A Domain Adaptation Framework for Speech Recognition Systems with Only Synthetic data
Authors:Minh Tran, Yutong Pang, Debjyoti Paul, Laxmi Pandey, Kevin Jiang, Jinxi Guo, Ke Li, Shun Zhang, Xuedong Zhang, Xin Lei
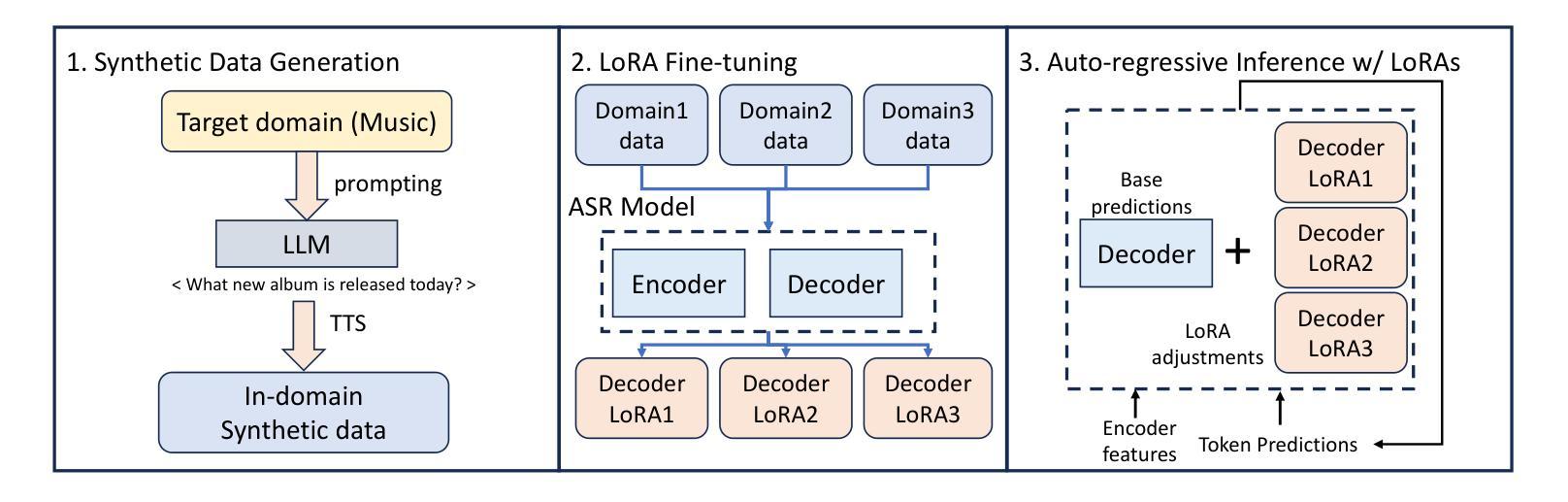
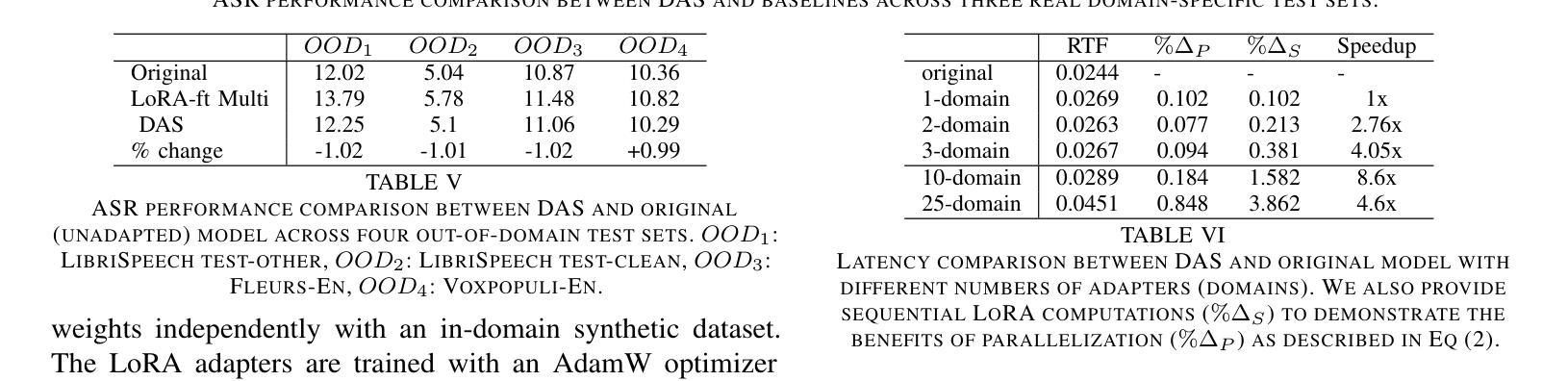
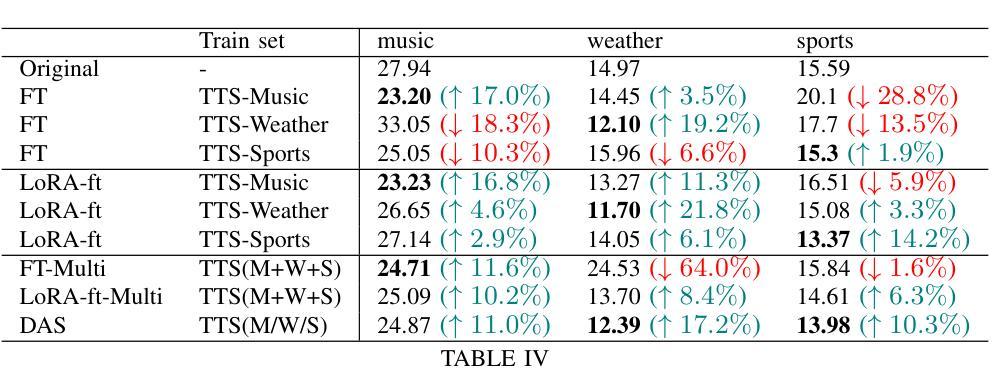
We introduce DAS (Domain Adaptation with Synthetic data), a novel domain adaptation framework for pre-trained ASR model, designed to efficiently adapt to various language-defined domains without requiring any real data. In particular, DAS first prompts large language models (LLMs) to generate domain-specific texts before converting these texts to speech via text-to-speech technology. The synthetic data is used to fine-tune Whisper with Low-Rank Adapters (LoRAs) for targeted domains such as music, weather, and sports. We introduce a novel one-pass decoding strategy that merges predictions from multiple LoRA adapters efficiently during the auto-regressive text generation process. Experimental results show significant improvements, reducing the Word Error Rate (WER) by 10% to 17% across all target domains compared to the original model, with minimal performance regression in out-of-domain settings (e.g., -1% on Librispeech test sets). We also demonstrate that DAS operates efficiently during inference, introducing an additional 9% increase in Real Time Factor (RTF) compared to the original model when inferring with three LoRA adapters.
我们介绍了DAS(使用合成数据的领域适应,Domain Adaptation with Synthetic data),这是一种针对预训练ASR模型的新型领域适应框架,旨在在不使用任何真实数据的情况下有效地适应各种语言定义的领域。具体而言,DAS首先提示大型语言模型(LLM)生成特定领域的文本,然后通过文本到语音的技术将这些文本转换为语音。合成数据用于通过低秩适配器(LoRAs)对诸如音乐、天气和体育等目标领域对whisper进行微调。我们引入了一种新的单次解码策略,该策略在自动回归文本生成过程中有效地合并来自多个LoRA适配器的预测。实验结果表明,与原始模型相比,在所有目标领域中都显著提高了性能,词错误率(WER)降低了10%至17%,在域外环境中的性能略有下降(例如Librispeech测试集上下降了1%)。我们还证明,在推断时使用三个LoRA适配器时,DAS的执行效率比原始模型高出额外的9%的实时因子(RTF)。
论文及项目相关链接
PDF ICASSP 2025
Summary
该文本介绍了名为DAS的新领域自适应框架,专为预训练的ASR模型设计,旨在在不使用任何真实数据的情况下,有效地适应各种语言定义的领域。DAS通过大型语言模型生成特定领域的文本,然后通过文本到语音的技术将这些文本转换为语音。合成数据用于通过低秩适配器(LoRAs)对Whisper进行微调,以针对音乐、天气和体育等目标领域。实验结果显示,与原始模型相比,所有目标领域的词错误率(WER)降低了10%到17%,而在域外设置中的性能略有下降(例如,在Librispeech测试集上降低了1%)。此外,在推理过程中,DAS的运算效率较高,与使用三个LoRA适配器进行推理的原始模型相比,实时因子(RTF)增加了9%。
Key Takeaways
- DAS是一种新的领域自适应框架,专为预训练的ASR模型设计,可适应多种语言定义的领域。
- DAS通过大型语言模型生成特定领域的文本,然后通过文本到语音的技术转换这些文本。
- DAS使用合成数据通过低秩适配器(LoRAs)对Whisper进行微调,以针对目标领域如音乐、天气和体育。
- 实验结果显示,与原始模型相比,DAS显著提高了性能,目标领域的词错误率(WER)降低了10%到17%。
- 在域外设置中,DAS的性能略有下降,例如在Librispeech测试集上的性能下降了1%。
- DAS在推理过程中运算效率较高,实时因子(RTF)相对于原始模型有所增加。
点此查看论文截图