⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
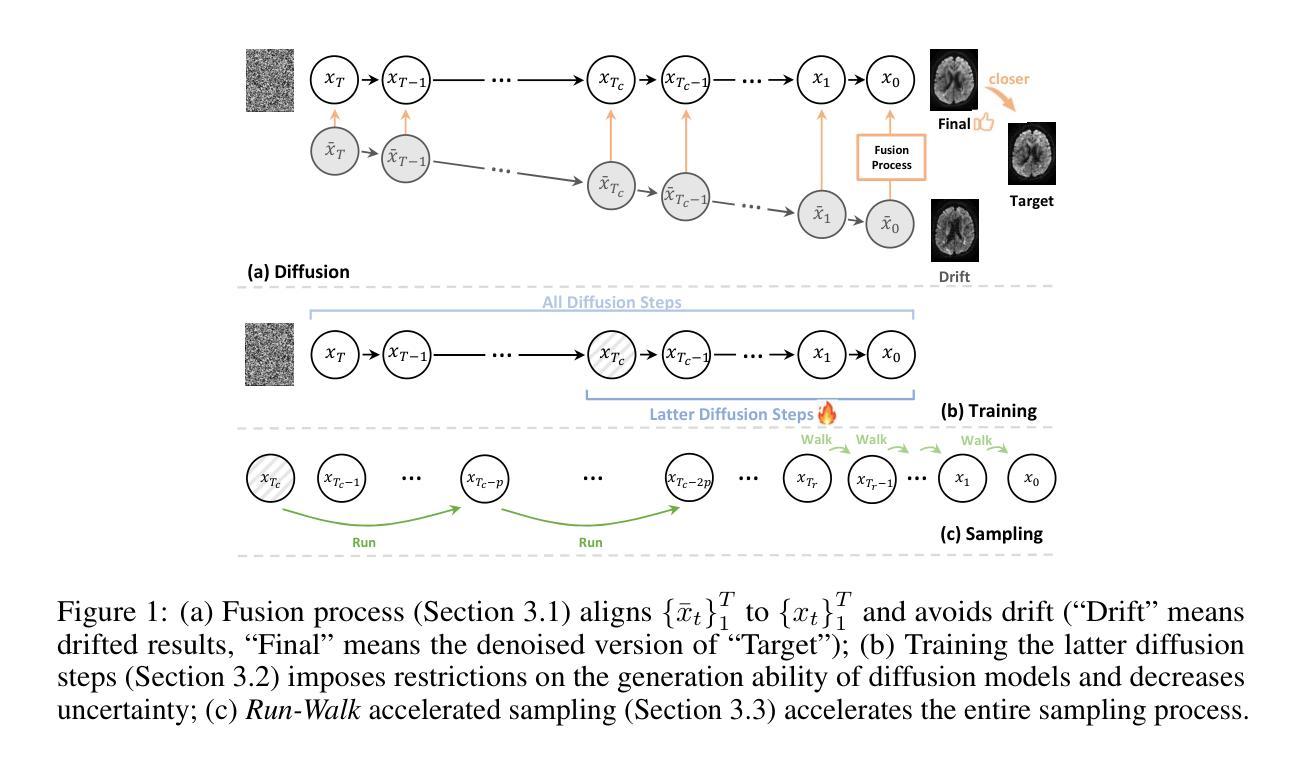
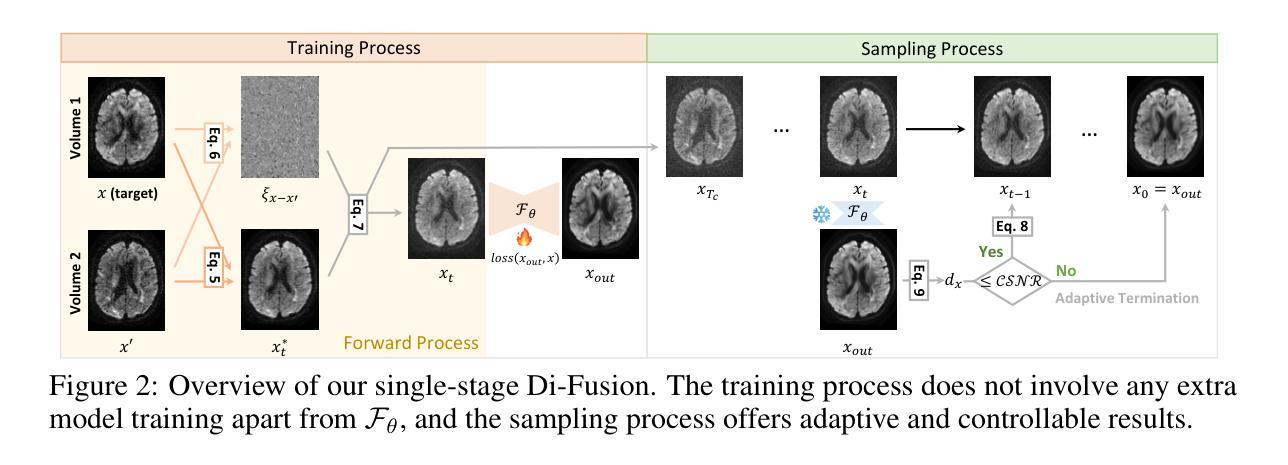
Self-Supervised Diffusion MRI Denoising via Iterative and Stable Refinement
Authors:Chenxu Wu, Qingpeng Kong, Zihang Jiang, S. Kevin Zhou
Magnetic Resonance Imaging (MRI), including diffusion MRI (dMRI), serves as a ``microscope’’ for anatomical structures and routinely mitigates the influence of low signal-to-noise ratio scans by compromising temporal or spatial resolution. However, these compromises fail to meet clinical demands for both efficiency and precision. Consequently, denoising is a vital preprocessing step, particularly for dMRI, where clean data is unavailable. In this paper, we introduce Di-Fusion, a fully self-supervised denoising method that leverages the latter diffusion steps and an adaptive sampling process. Unlike previous approaches, our single-stage framework achieves efficient and stable training without extra noise model training and offers adaptive and controllable results in the sampling process. Our thorough experiments on real and simulated data demonstrate that Di-Fusion achieves state-of-the-art performance in microstructure modeling, tractography tracking, and other downstream tasks.
磁共振成像(MRI),包括扩散MRI(dMRI),可作为解剖结构的“显微镜”,并通过妥协时间或空间分辨率来常规缓解低信噪比扫描的影响。然而,这些妥协无法满足临床对效率和精确度的需求。因此,去噪是一个重要的预处理步骤,特别是对于无法获得清洁数据的dMRI而言尤为关键。在本文中,我们介绍了Di-Fusion,这是一种完全自监督的去噪方法,它利用后续的扩散步骤和自适应采样过程。不同于以前的方法,我们的单阶段框架实现了高效且稳定的训练,无需额外的噪声模型训练,并在采样过程中提供了自适应和可控的结果。我们在真实和模拟数据上的实验表明,Di-Fusion在微观结构建模、轨迹跟踪和其他下游任务中达到了最先进的性能。
论文及项目相关链接
PDF 39pages, 34figures
Summary
本文介绍了Di-Fusion这一全新的全自监督降噪方法,该方法利用扩散MRI的后扩散步骤和自适应采样过程进行高效稳定的训练,无需额外的噪声模型训练。实验证明,Di-Fusion在微观结构建模、纤维跟踪等下游任务上达到了先进性能,并且能够提供可控的自适应采样结果。此外,对于不可用干净的原始数据或扩散MRI中的难点场景进行清晰的解剖学图像解析尤其有价值。这表明其克服了影响解析准确度的不利因素,并提升了数据质量。Di-Fusion对于改善MRI图像质量、提高诊断精度具有重要意义。
Key Takeaways
- Di-Fusion是一种全自监督的降噪方法,适用于MRI图像的处理。
- 该方法利用扩散MRI的后扩散步骤和自适应采样过程进行训练,无需额外的噪声模型训练。
- Di-Fusion对于解微结构建模、纤维跟踪等下游任务有着良好的性能表现。它在实现图像的高清晰度的同时维持了图像的空间和时间分辨率。
点此查看论文截图



Modelling the energy dependent X-ray variability of Mrk 335
Authors:K. Akhila, Ranjeev Misra, Rathin Sarma, Savithri H. Ezhikode, K. Jeena
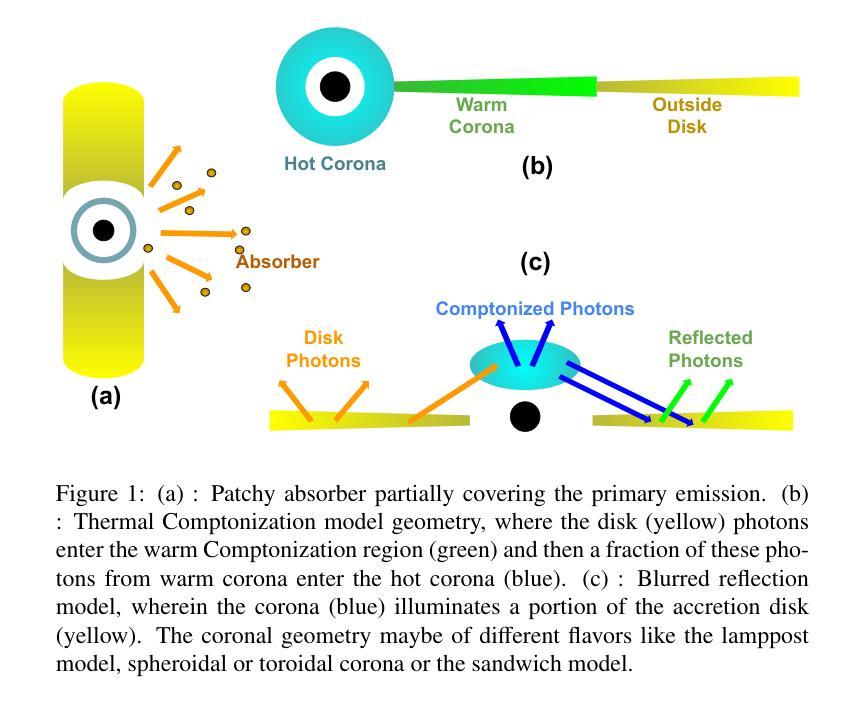
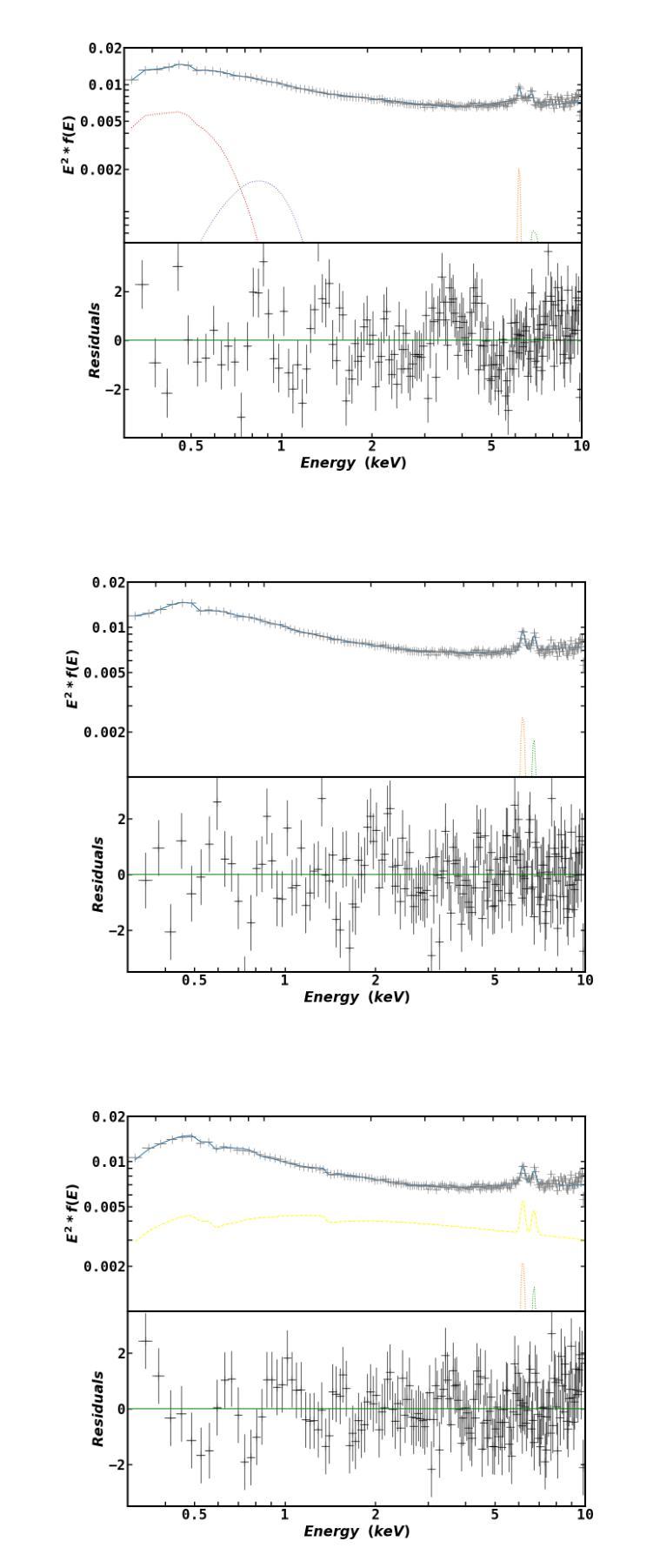
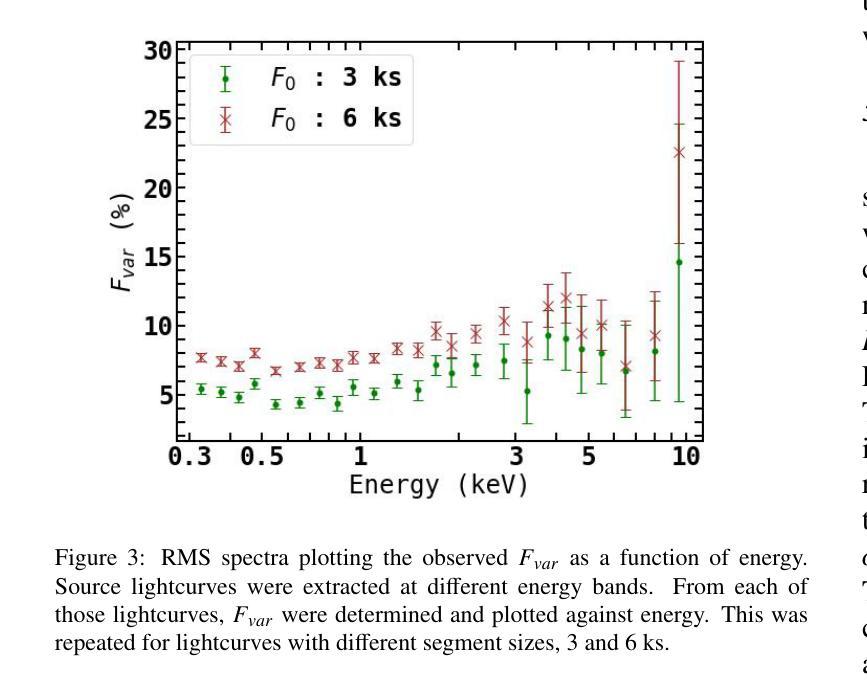
We present a technique which predicts the energy dependent fractional r.m.s for linear correlated variations of a pair of spectral parameters and apply it to an XMM-Newton observation of Mrk 335. The broadband X-ray spectrum can be interpreted as a patchy absorber partially covering the primary emission, a warm and hot coronal emission or a relativistically blurred reflection along with the primary emission. The fractional r.m.s has a non-monotonic behavior with energy for segments of lengths 3 and 6 ksecs. For each spectral model, we consider every pair of spectral parameters and fit the predicted r.m.s with the observed ones, to get the pair which provides the best fit. We find that a variation in at least two parameters is required for all spectral interpretations. For both time segments, variations in the covering fraction of the absorber and the primary power law index gives the best result for the partial covering model, while a variation in the normalization and spectral index of the warm component gives the best fit in the two corona interpretation. For the reflection model, the best fit parameters are different for the two time segment lengths, and the results suggests that more than two parameters are required to explain the data. This, combined with the extreme values of emissivity index and reflection fraction parameters obtained from the spectral analysis, indicates that the blurred reflection model might not be a suitable explanation for the Mrk 335 spectrum. We discuss the results as well as the potential of the technique to be applied to other data sets of different AGN.
我们提出了一种技术,该技术能够预测一对光谱参数的线性相关变化中的能量相关分数均方根(r.m.s),并将其应用于XMM-牛顿对Mrk 335的观察。宽带X射线光谱可以被解释为部分覆盖主发射区域的斑块吸收器、温暖和炽热的冕发射,或者与主发射区域相伴的相对论性模糊反射。分数均方根(r.m.s)在长度为3和6千秒的时间段内随能量变化表现出非单调行为。对于每个光谱模型,我们考虑每对光谱参数,并用观察到的r.m.s值拟合预测的r.m.s值,以获得提供最佳拟合的配对。我们发现,所有光谱解释都需要至少两个参数的变化。对于两个时间段,吸收器的覆盖分数和主幂律指数的变化为部分覆盖模型提供了最佳结果,而暖成分的标准化和光谱指数的变化为两冕解释提供了最佳拟合。对于反射模型,两个时间段长度的最佳拟合参数不同,结果暗示需要超过两个参数来解释数据。结合从光谱分析获得的发射率指数和反射分数参数的极端值,表明模糊的反射模型可能不适合解释Mrk 335的光谱。我们讨论了结果以及该技术应用于其他不同活跃星系核(AGN)数据集的可能性。
论文及项目相关链接
PDF Accepted for publication in JHEAP
Summary
该文介绍了一种预测线性相关光谱参数变化分数的能量依赖性的技术,并将其应用于Mrk 335的XMM-Newton观测。文章探讨了部分遮挡模型、暖冠与热冠发射模型以及相对论的模糊反射模型等三种光谱解释。其中,部分遮挡模型的最佳拟合参数为遮挡物覆盖分数和主要幂律指数的变化;在暖冠模型中,归一化和光谱指数的变化提供了最佳拟合。反射模型的最佳拟合参数随时间长度变化而不同,且结果暗示需要超过两个参数来解释数据。结合从光谱分析获得的极端发射率指数和反射因子参数值,模糊的反射模型可能不适合解释Mrk 335光谱。文章结果对于未来分析不同活动星系核(AGN)的数据集具有潜力。
Key Takeaways
- 文章介绍了一种预测能量相关分数的技术,并应用于Mrk 335的XMM-Newton观测数据。
- 文章探讨了三种光谱解释模型:部分遮挡模型、暖冠与热冠发射模型以及相对论的模糊反射模型。
- 部分遮挡模型的最佳拟合参数是遮挡物覆盖分数和主要幂律指数的变化。
- 在暖冠模型中,归一化和光谱指数的变化提供了最佳拟合结果。
- 反射模型的最佳拟合参数随时间长度变化而不同,且需要超过两个参数来解释数据。
6.模糊的反射模型可能不适合解释Mrk 335光谱,结合从光谱分析获得的参数值得出此结论。
点此查看论文截图




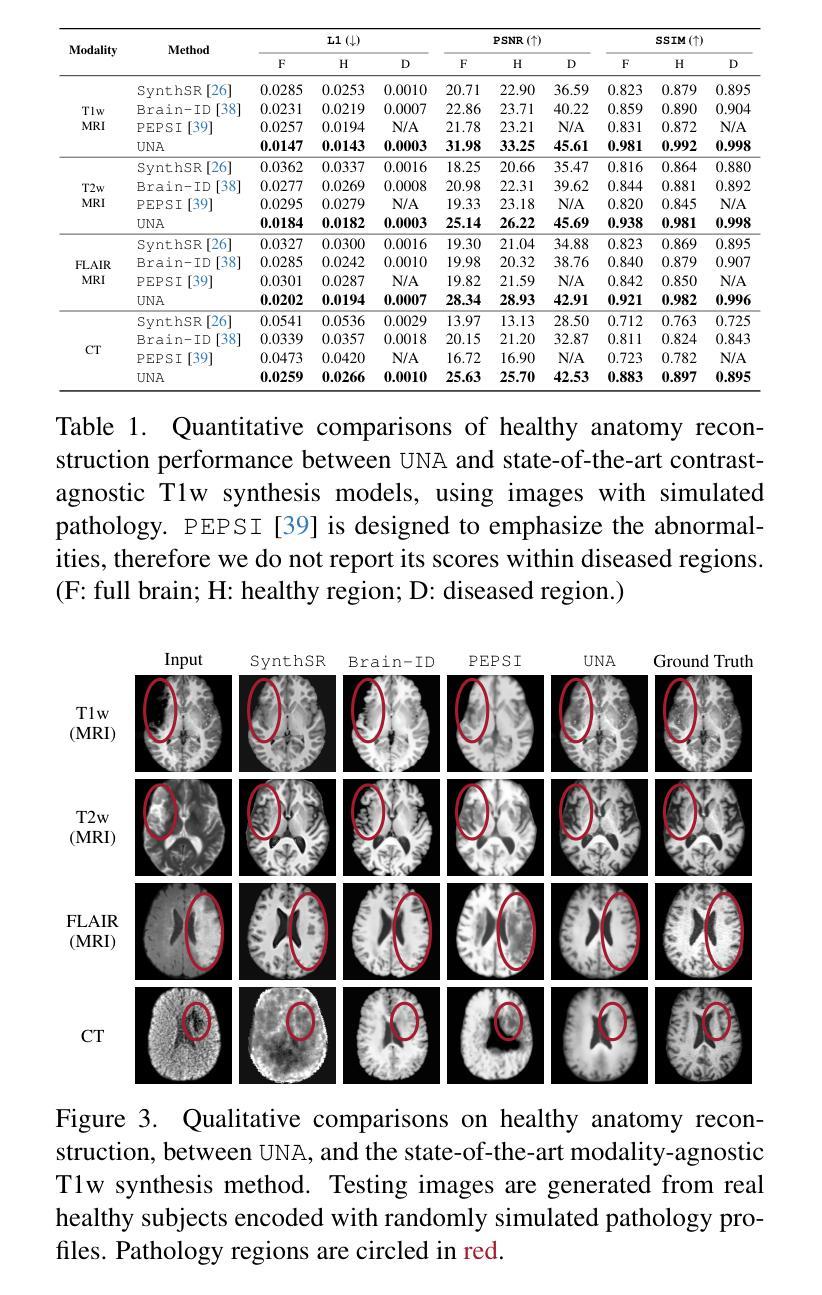
Unraveling Normal Anatomy via Fluid-Driven Anomaly Randomization
Authors:Peirong Liu, Ana Lawry Aguila, Juan E. Iglesias
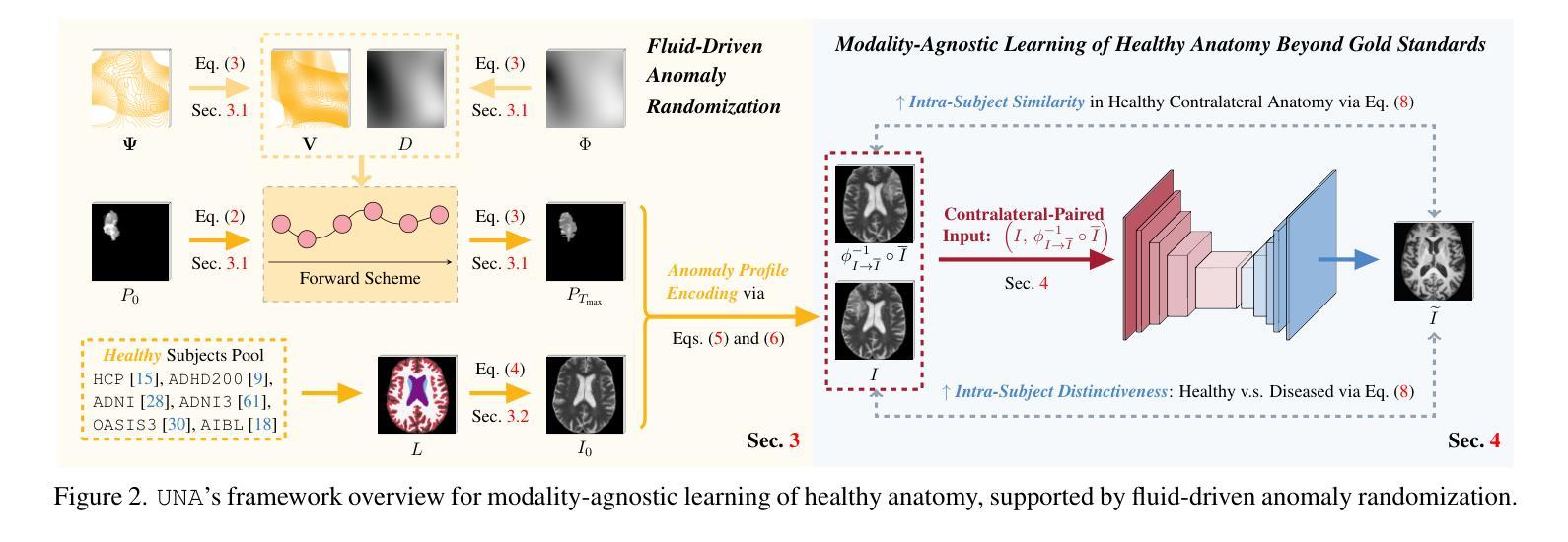
Data-driven machine learning has made significant strides in medical image analysis. However, most existing methods are tailored to specific modalities and assume a particular resolution (often isotropic). This limits their generalizability in clinical settings, where variations in scan appearance arise from differences in sequence parameters, resolution, and orientation. Furthermore, most general-purpose models are designed for healthy subjects and suffer from performance degradation when pathology is present. We introduce UNA (Unraveling Normal Anatomy), the first modality-agnostic learning approach for normal brain anatomy reconstruction that can handle both healthy scans and cases with pathology. We propose a fluid-driven anomaly randomization method that generates an unlimited number of realistic pathology profiles on-the-fly. UNA is trained on a combination of synthetic and real data, and can be applied directly to real images with potential pathology without the need for fine-tuning. We demonstrate UNA’s effectiveness in reconstructing healthy brain anatomy and showcase its direct application to anomaly detection, using both simulated and real images from 3D healthy and stroke datasets, including CT and MRI scans. By bridging the gap between healthy and diseased images, UNA enables the use of general-purpose models on diseased images, opening up new opportunities for large-scale analysis of uncurated clinical images in the presence of pathology. Code is available at https://github.com/peirong26/UNA.
数据驱动的机器学习在医学图像分析方面取得了重大进展。然而,大多数现有方法都是针对特定模态的,并假设了特定的分辨率(通常为等距)。这限制了它们在临床环境中的通用性,因为扫描外观的变化来自于序列参数、分辨率和方位的差异。此外,大多数通用模型都是为健康受试者设计的,在有病理情况出现时会出现性能下降。我们引入了UNA(解开正常解剖结构),这是一种用于正常大脑解剖结构重建的模态无关学习方法,它可以处理健康扫描和带有病理情况的病例。我们提出了一种流体驱动异常随机化方法,可以实时生成无限数量的现实病理特征。UNA是在合成数据和真实数据的组合上进行训练的,可以直接应用于潜在病理的真实图像,无需微调。我们展示了UNA在重建健康大脑解剖结构方面的有效性,并展示了其在异常检测方面的直接应用,使用来自3D健康和中风数据集的模拟和真实图像,包括CT和MRI扫描。通过缩小健康图像与疾病图像之间的差距,UNA使得通用模型能够在疾病图像上使用,为存在病理情况的未整理临床图像的大规模分析提供了新的机会。代码可在https://github.com/peirong26/UNA找到。
论文及项目相关链接
PDF 16 pages, 6 figures
Summary
数据驱动的机器学习在医学图像分析方面取得了显著进展,但大多数现有方法针对特定模态并假设特定分辨率,限制了其在临床环境中的通用性。本文介绍了一种通用的、模态无关的学习方法UNA(Unraveling Normal Anatomy),用于重建正常脑结构,可处理健康扫描和病理情况。UNA采用流体驱动异常随机化方法,可实时生成无限数量的逼真病理特征。UNA经过合成和真实数据的训练,可直接应用于潜在病理的真实图像,无需微调。
Key Takeaways
- 数据驱动的机器学习在医学图像分析中的应用进展。
- 现有方法的局限性:针对特定模态和分辨率,限制了其在临床环境中的通用性。
- UNA是一种通用的、模态无关的学习方法,用于重建正常脑结构。
- UNA可以处理健康和病理情况下的扫描。
- UNA采用流体驱动异常随机化方法,生成逼真的病理特征。
- UNA经过合成和真实数据的训练,可直接应用于真实图像。
点此查看论文截图


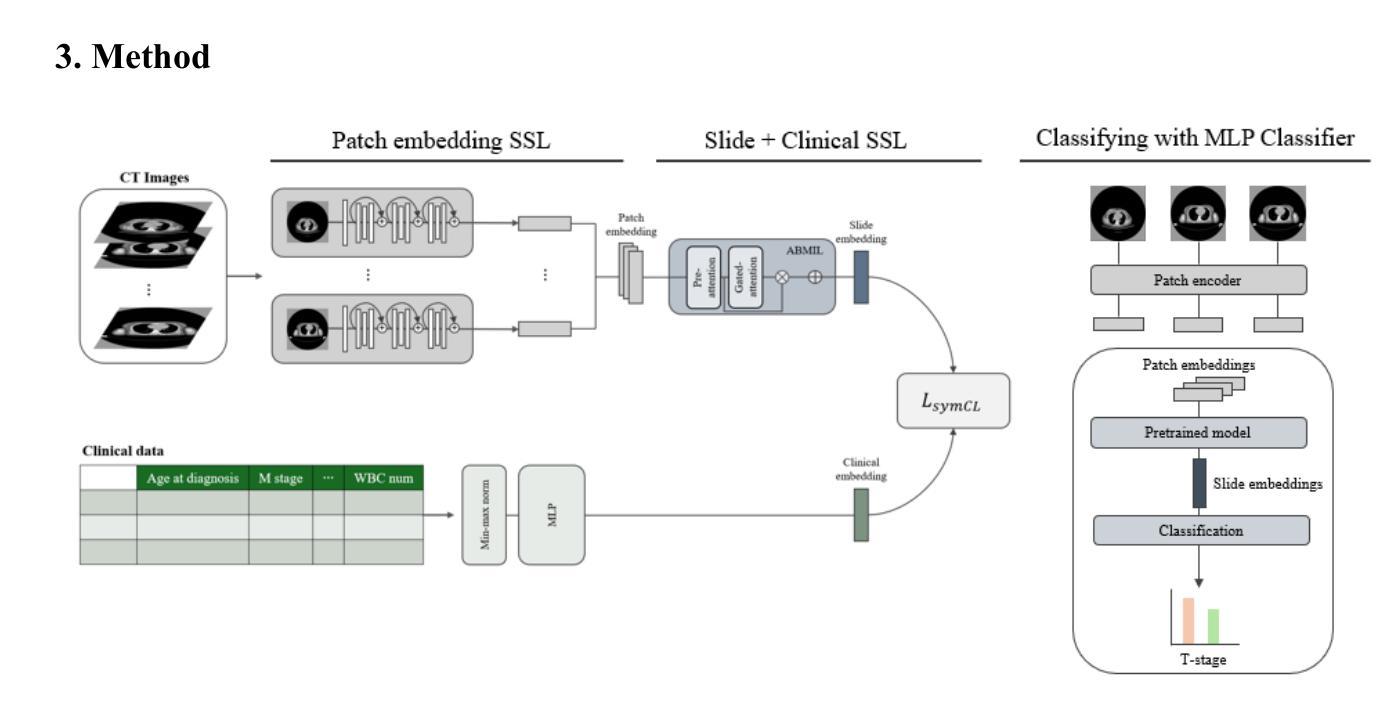
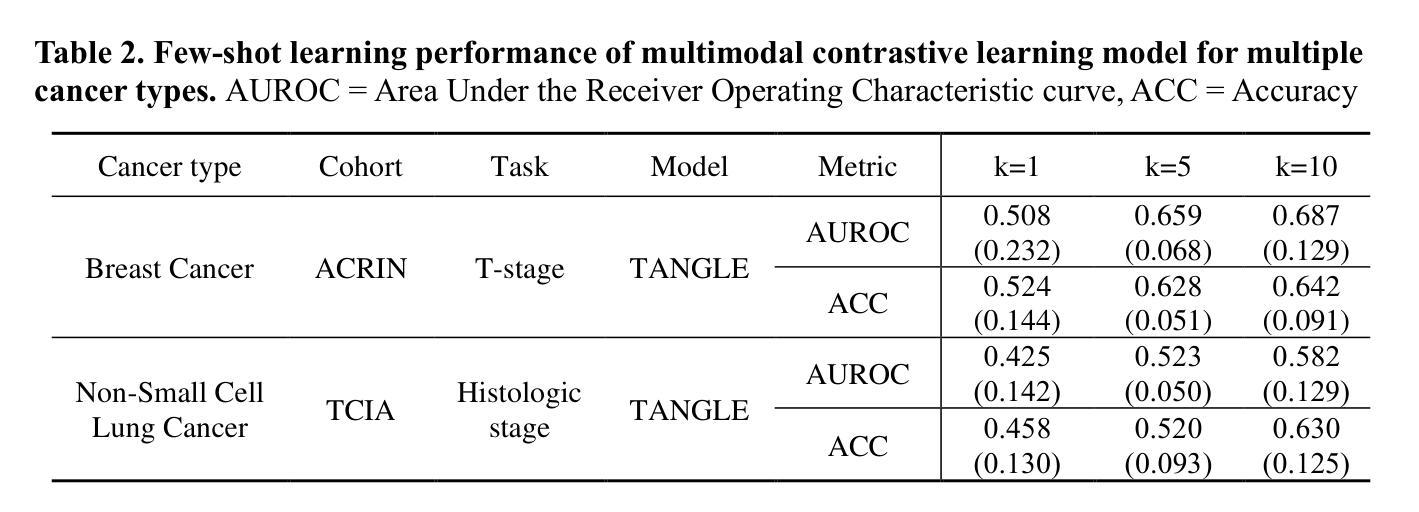
MEDFORM: A Foundation Model for Contrastive Learning of CT Imaging and Clinical Numeric Data in Multi-Cancer Analysis
Authors:Daeun Jung, Jaehyeok Jang, Sooyoung Jang, Yu Rang Park
Computed tomography (CT) and clinical numeric data are essential modalities for cancer evaluation, but building large-scale multimodal training datasets for developing medical foundation models remains challenging due to the structural complexity of multi-slice CT data and high cost of expert annotation. In this study, we propose MEDFORM, a multimodal pre-training strategy that guides CT image representation learning using complementary information from clinical data for medical foundation model development. MEDFORM efficiently processes CT slice through multiple instance learning (MIL) and adopts a dual pre-training strategy: first pretraining the CT slice feature extractor using SimCLR-based self-supervised learning, then aligning CT and clinical modalities through cross-modal contrastive learning. Our model was pre-trained on three different cancer types: lung cancer (141,171 slices), breast cancer (8,100 slices), colorectal cancer (10,393 slices). The experimental results demonstrated that this dual pre-training strategy improves cancer classification performance and maintains robust performance in few-shot learning scenarios. Code available at https://github.com/DigitalHealthcareLab/25MultiModalFoundationModel.git
计算机断层扫描(CT)和临床数值数据对于癌症评估至关重要,但由于多层CT数据的结构复杂性以及专家标注的高成本,构建用于开发医疗基础模型的大规模多模式训练数据集仍然是一个挑战。在本研究中,我们提出了MEDFORM,这是一种多模式预训练策略,通过利用临床数据的补充信息来指导CT图像表示学习,以开发医疗基础模型。MEDFORM通过多实例学习(MIL)有效地处理CT切片,并采用双重预训练策略:首先使用基于SimCLR的自我监督学习对CT切片特征提取器进行预训练,然后通过跨模式对比学习对齐CT和临床模式。我们的模型在三种不同类型的癌症上进行了预训练:肺癌(141,171切片)、乳腺癌(8,100切片)和结肠癌(10,393切片)。实验结果表明,这种双重预训练策略提高了癌症分类性能,并在小样本学习场景中保持了稳健的性能。代码可通过以下网址获取:网址。
论文及项目相关链接
PDF 8 pages, 1 figure
Summary
本文提出了一种名为MEDFORM的多模态预训练策略,该策略利用临床数据中的互补信息指导CT图像表示学习,用于开发医学基础模型。通过采用多实例学习(MIL)处理CT切片,并采用基于SimCLR的自监督学习和跨模态对比学习的双预训练策略,模型在肺癌、乳腺癌和结肠癌三种不同癌症类型上的预训练表现优异。实验结果证明,该双预训练策略能提高癌症分类性能,并在小样本学习场景下保持稳健性能。
Key Takeaways
- MEDFORM是一种多模态预训练策略,用于医学基础模型的开发,结合CT图像和临床数据。
- MEDFORM采用多实例学习(MIL)处理CT切片,以提高模型的效率和性能。
- 该策略包括两个阶段的预训练:首先使用基于SimCLR的自监督学习预训练CT切片特征提取器,然后通过跨模态对比学习对齐CT和临床模态。
- 模型在肺癌、乳腺癌和结肠癌三种癌症类型上进行预训练。
- 实验结果表明,MEDFORM策略能提高癌症分类性能。
- 该策略在小样本学习场景下表现出稳健的性能。
点此查看论文截图


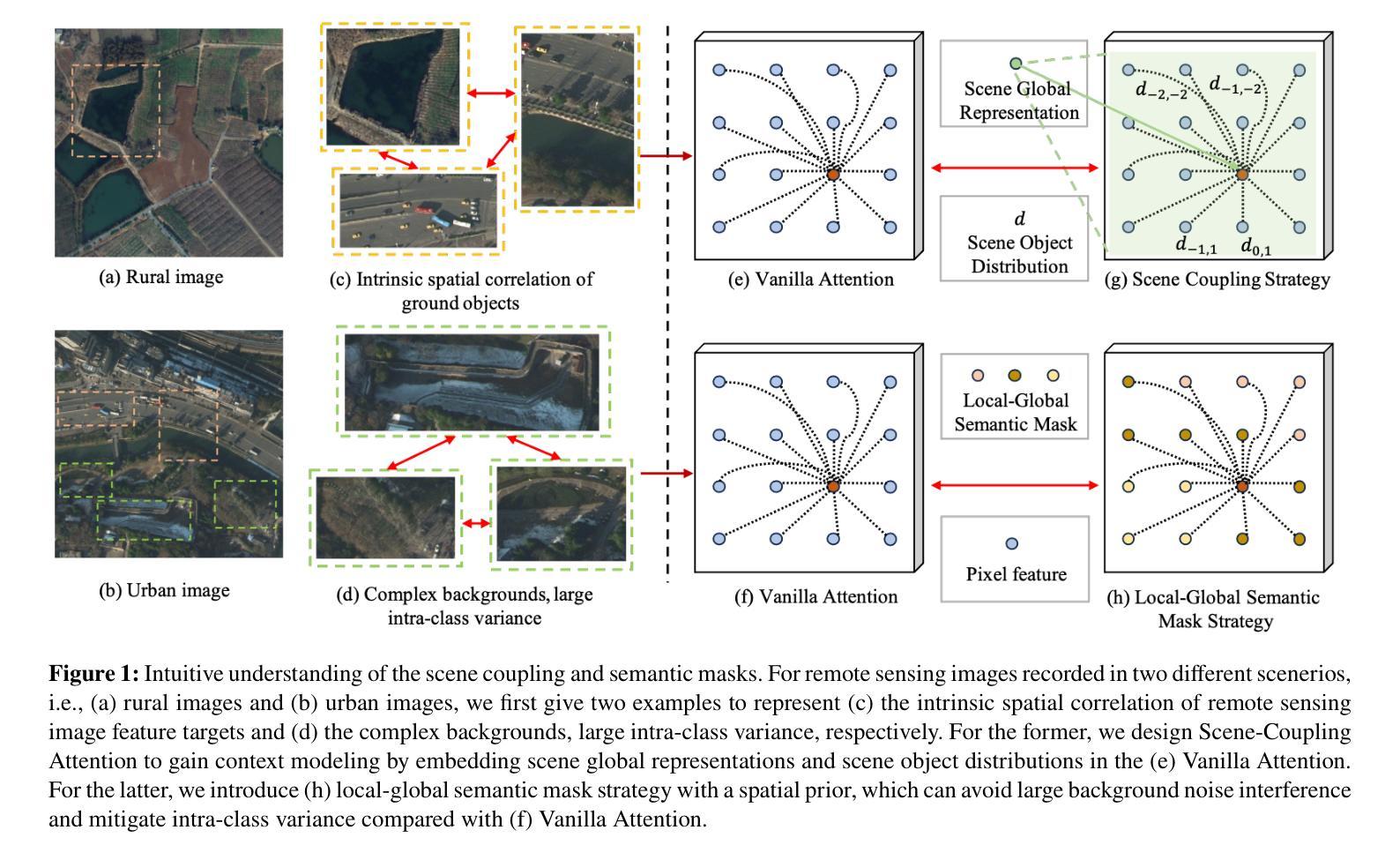
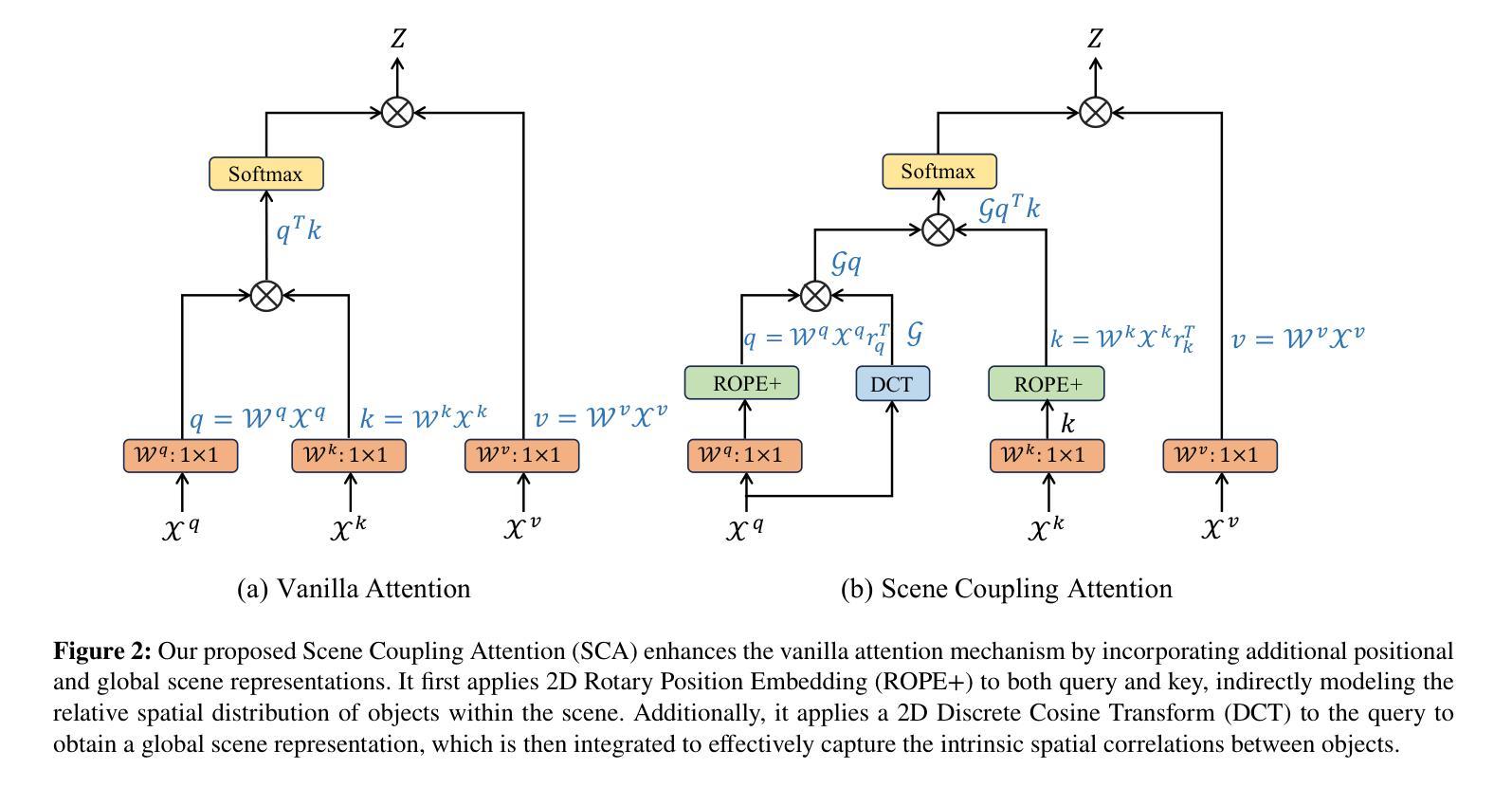
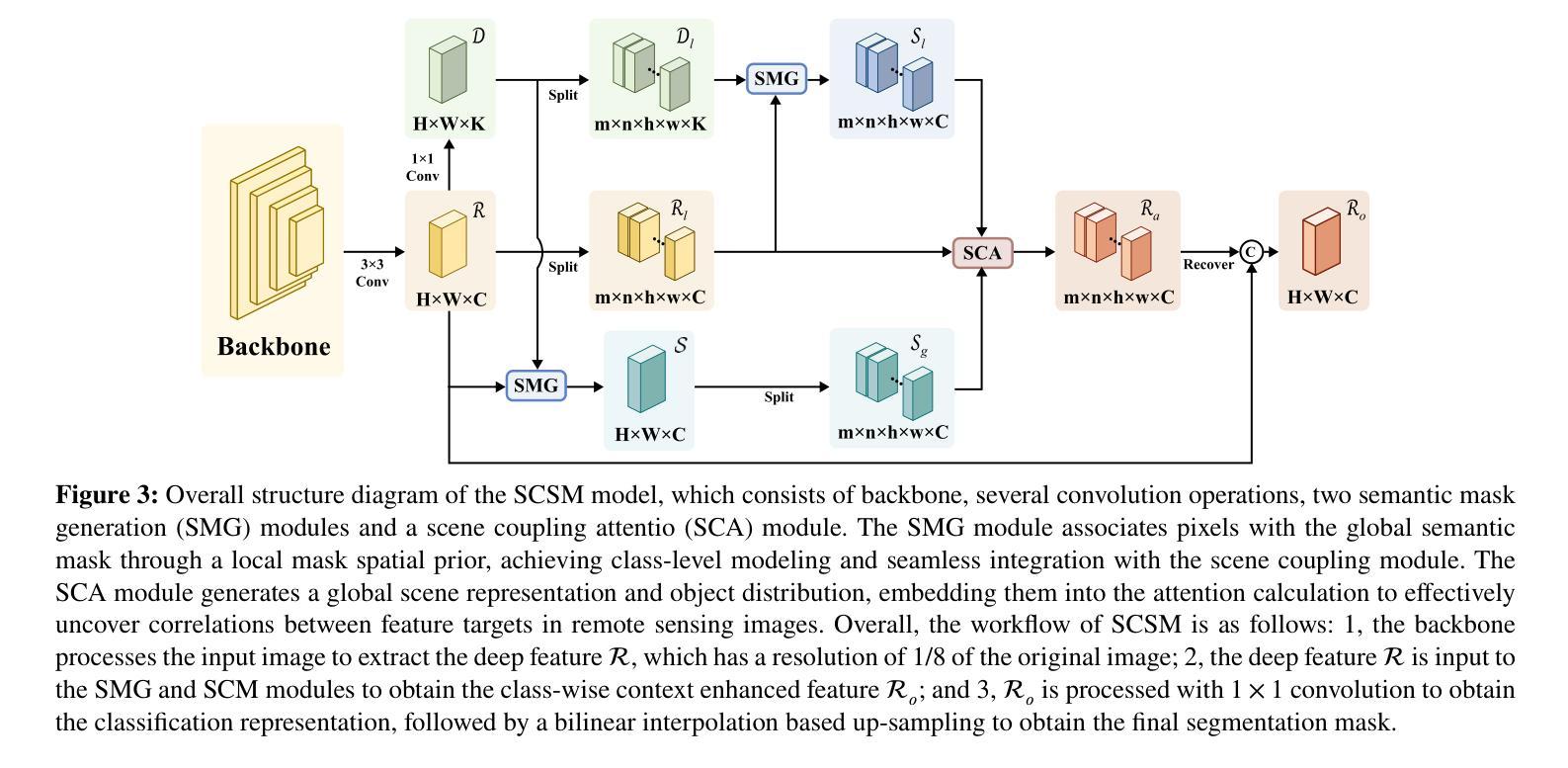
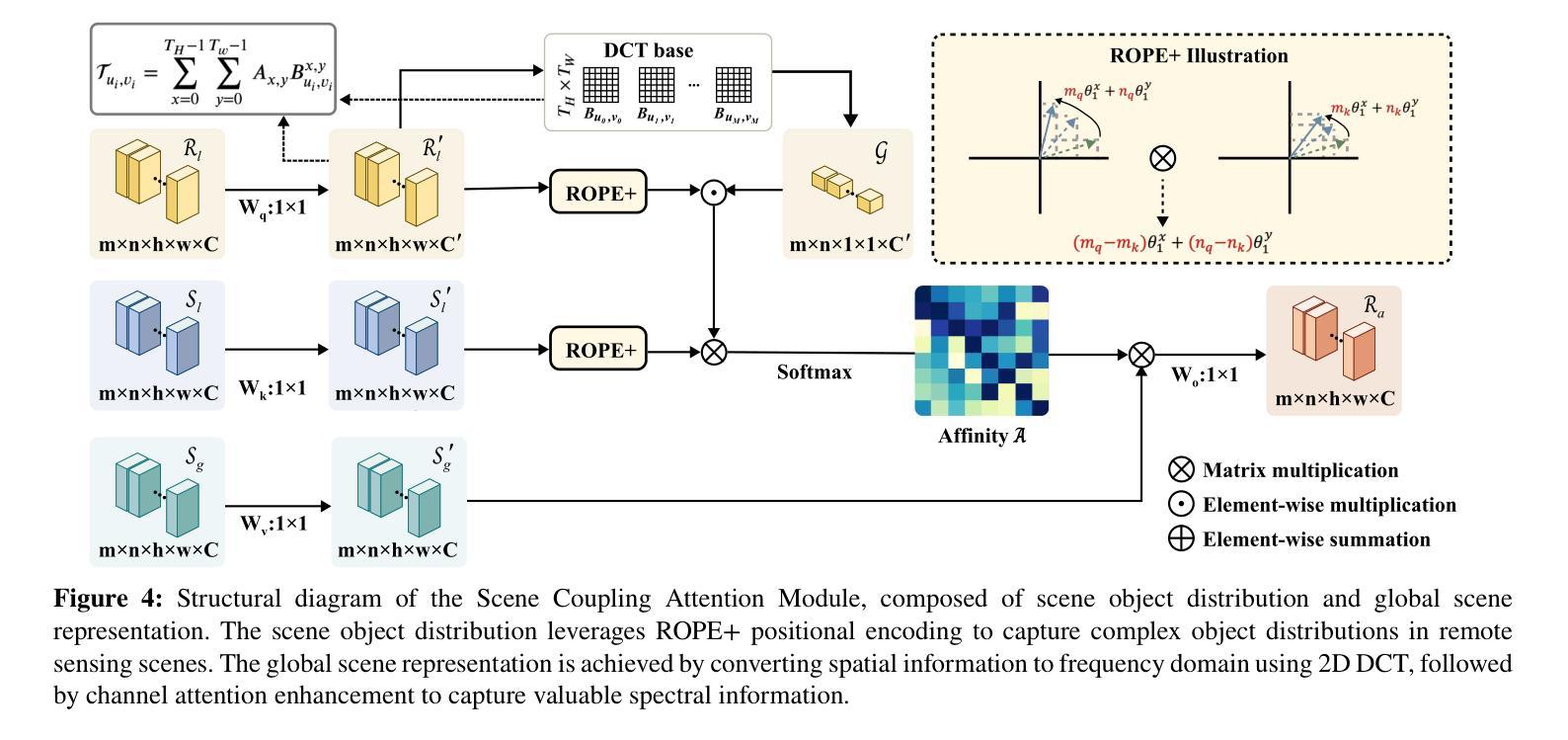
A Novel Scene Coupling Semantic Mask Network for Remote Sensing Image Segmentation
Authors:Xiaowen Ma, Rongrong Lian, Zhenkai Wu, Renxiang Guan, Tingfeng Hong, Mengjiao Zhao, Mengting Ma, Jiangtao Nie, Zhenhong Du, Siyang Song, Wei Zhang
As a common method in the field of computer vision, spatial attention mechanism has been widely used in semantic segmentation of remote sensing images due to its outstanding long-range dependency modeling capability. However, remote sensing images are usually characterized by complex backgrounds and large intra-class variance that would degrade their analysis performance. While vanilla spatial attention mechanisms are based on dense affine operations, they tend to introduce a large amount of background contextual information and lack of consideration for intrinsic spatial correlation. To deal with such limitations, this paper proposes a novel scene-Coupling semantic mask network, which reconstructs the vanilla attention with scene coupling and local global semantic masks strategies. Specifically, scene coupling module decomposes scene information into global representations and object distributions, which are then embedded in the attention affinity processes. This Strategy effectively utilizes the intrinsic spatial correlation between features so that improve the process of attention modeling. Meanwhile, local global semantic masks module indirectly correlate pixels with the global semantic masks by using the local semantic mask as an intermediate sensory element, which reduces the background contextual interference and mitigates the effect of intra-class variance. By combining the above two strategies, we propose the model SCSM, which not only can efficiently segment various geospatial objects in complex scenarios, but also possesses inter-clean and elegant mathematical representations. Experimental results on four benchmark datasets demonstrate the the effectiveness of the above two strategies for improving the attention modeling of remote sensing images. The dataset and code are available at https://github.com/xwmaxwma/rssegmentation
作为计算机视觉领域的常见方法,空间注意力机制因其出色的长程依赖建模能力而广泛应用于遥感图像的语义分割。然而,遥感图像通常具有复杂的背景和较大的类内差异,这可能会降低其分析性能。虽然普通空间注意力机制是基于密集的仿射运算,但它们往往引入大量背景上下文信息,并且没有考虑到内在的空间相关性。为了应对这些局限性,本文提出了一种新的场景耦合语义掩码网络,该网络通过场景耦合和局部全局语义掩码策略重建了普通注意力。具体来说,场景耦合模块将场景信息分解为全局表示和对象分布,然后将其嵌入到注意力亲和过程中。该策略有效地利用了特征之间的内在空间相关性,从而改进了注意力建模的过程。同时,局部全局语义掩码模块通过利用局部语义掩码作为中间感知元素,间接地将像素与全局语义掩码相关联,这减少了背景上下文的干扰并减轻了类内差异的影响。通过结合上述两种策略,我们提出了SCSM模型,该模型不仅可以在复杂场景中有效地分割各种地理空间对象,而且还具有简洁优雅的数学表示。在四个基准数据集上的实验结果表明,上述两种策略在改进遥感图像的注意力建模方面非常有效。数据集和代码可通过https://github.com/xwmaxwma/rssegmentation获取。
论文及项目相关链接
PDF Accepted by ISPRS Journal of Photogrammetry and Remote Sensing
Summary
本文提出一种新型的场景耦合语义掩膜网络,通过场景耦合和局部全局语义掩膜策略,改进了基于密集仿射运算的传统空间注意机制。该策略能更有效地处理遥感图像语义分割中的复杂背景和类内差异问题,提升注意力建模过程。实验结果表明,该策略在四个基准数据集上均有效。
Key Takeaways
- 空间注意机制在遥感图像语义分割中得到广泛应用,但存在处理复杂背景和类内差异时的性能下降问题。
- 现有空间注意机制基于密集仿射运算,易引入大量背景上下文信息,且未充分考虑特征间的内在空间相关性。
- 本文提出了一种新型的场景耦合语义掩膜网络,通过场景耦合模块和局部全局语义掩膜策略,改进了注意力建模过程。
- 场景耦合模块将场景信息分解为全局表示和对象分布,并将其嵌入注意力亲和过程中,有效利用特征间的内在空间相关性。
- 局部全局语义掩膜模块通过局部语义掩膜作为中间感知元素,间接地将像素与全局语义掩膜相关联,减少了背景上下文干扰和类内差异的影响。
- 结合上述两个策略,提出的SCSM模型不仅能有效地分割复杂场景中的各类地理空间对象,还具有简洁优雅的数学表示。
点此查看论文截图

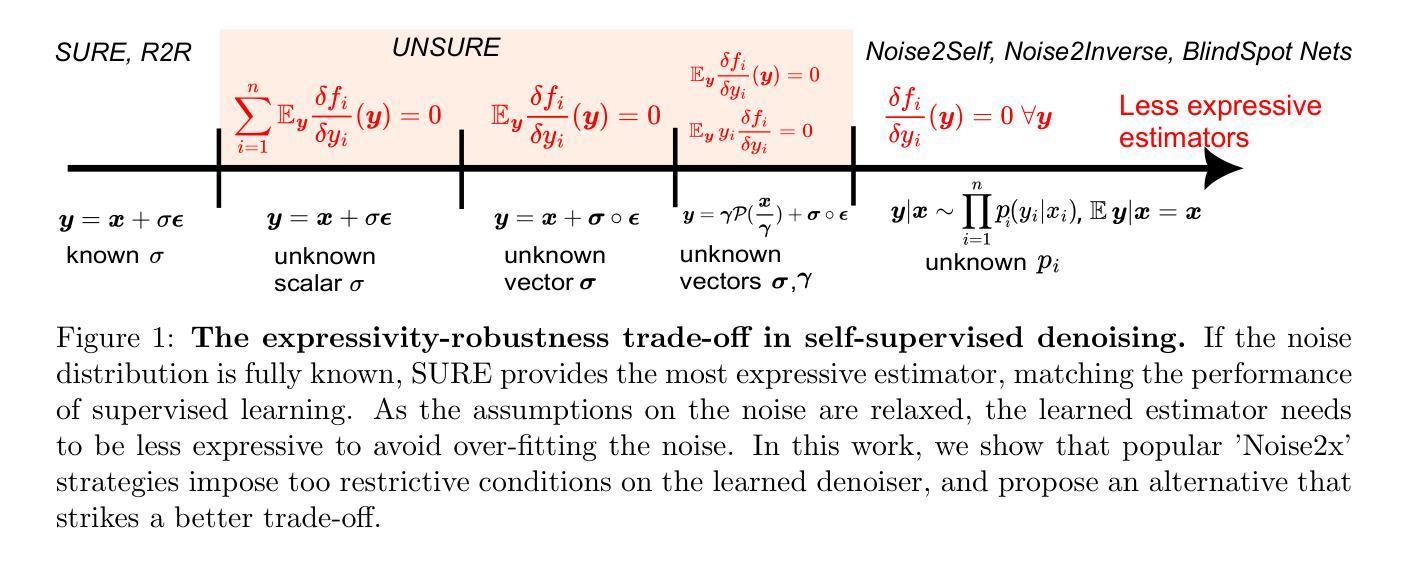
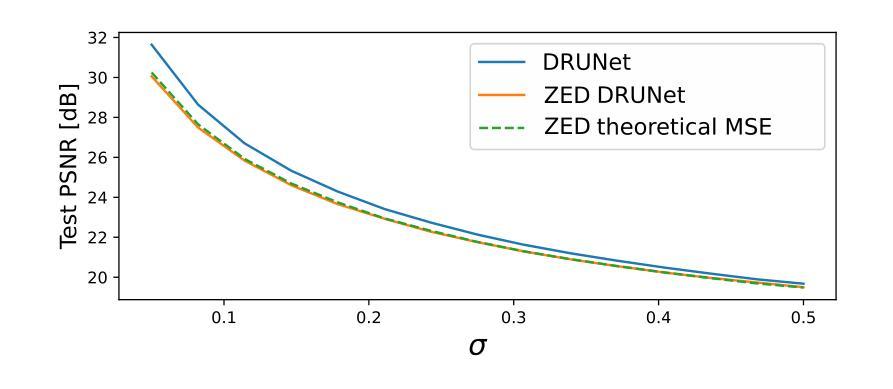
UNSURE: self-supervised learning with Unknown Noise level and Stein’s Unbiased Risk Estimate
Authors:Julián Tachella, Mike Davies, Laurent Jacques
Recently, many self-supervised learning methods for image reconstruction have been proposed that can learn from noisy data alone, bypassing the need for ground-truth references. Most existing methods cluster around two classes: i) Stein’s Unbiased Risk Estimate (SURE) and similar approaches that assume full knowledge of the distribution, and ii) Noise2Self and similar cross-validation methods that require very mild knowledge about the noise distribution. The first class of methods tends to be impractical, as the noise level is often unknown in real-world applications, and the second class is often suboptimal compared to supervised learning. In this paper, we provide a theoretical framework that characterizes this expressivity-robustness trade-off and propose a new approach based on SURE, but unlike the standard SURE, does not require knowledge about the noise level. Throughout a series of experiments, we show that the proposed estimator outperforms other existing self-supervised methods on various imaging inverse problems.
最近,许多用于图像重建的自我监督学习方法已被提出,这些方法可以仅从噪声数据中学习,无需真实参考。现有的大多数方法主要集中在两类上:i) Stein的无偏风险估计(SURE)和假设对分布有充分了解的类似方法,以及ii) Noise2Self和关于噪声分布只需非常轻微了解的类似交叉验证方法。第一类方法往往不切实际,因为在现实世界的实际应用中往往不知道噪声水平,第二类方法与监督学习相比通常表现不佳。在本文中,我们提供了一个理论框架,该框架描述了表达性稳健性权衡的特点,并提出了一种基于SURE的新方法,但与标准的SURE不同,它不需要了解噪声水平。通过一系列实验,我们表明,所提出的估计器在各种成像反问题上优于其他现有的自监督方法。
论文及项目相关链接
Summary
医学图像重建中的自监督学习方法近年来备受关注。现有方法多依赖于噪声水平分布知识,实际应用中难以实现或效果不理想。本文提出一种基于Stein的无偏风险估计的新方法,无需了解噪声水平信息,实验证明在多种图像逆问题上表现优异。
Key Takeaways
- 自监督学习方法在医学图像重建中逐渐受到重视,能够从噪声数据中学习,无需参考真实图像。
- 现有方法主要分为两类:基于Stein的无偏风险估计(SURE)和其他假设对噪声分布有充分了解的方法。
- 基于SURE的方法在实际应用中由于噪声水平未知而显得不实用。
- Noise2Self等交叉验证方法虽然对噪声分布知识需求较轻,但效果常不如监督学习。
- 本文提出的新方法基于SURE但无需了解噪声水平信息,解决了现有方法的局限性。
- 实验证明,新方法在各种图像逆问题上的表现优于其他自监督方法。
点此查看论文截图

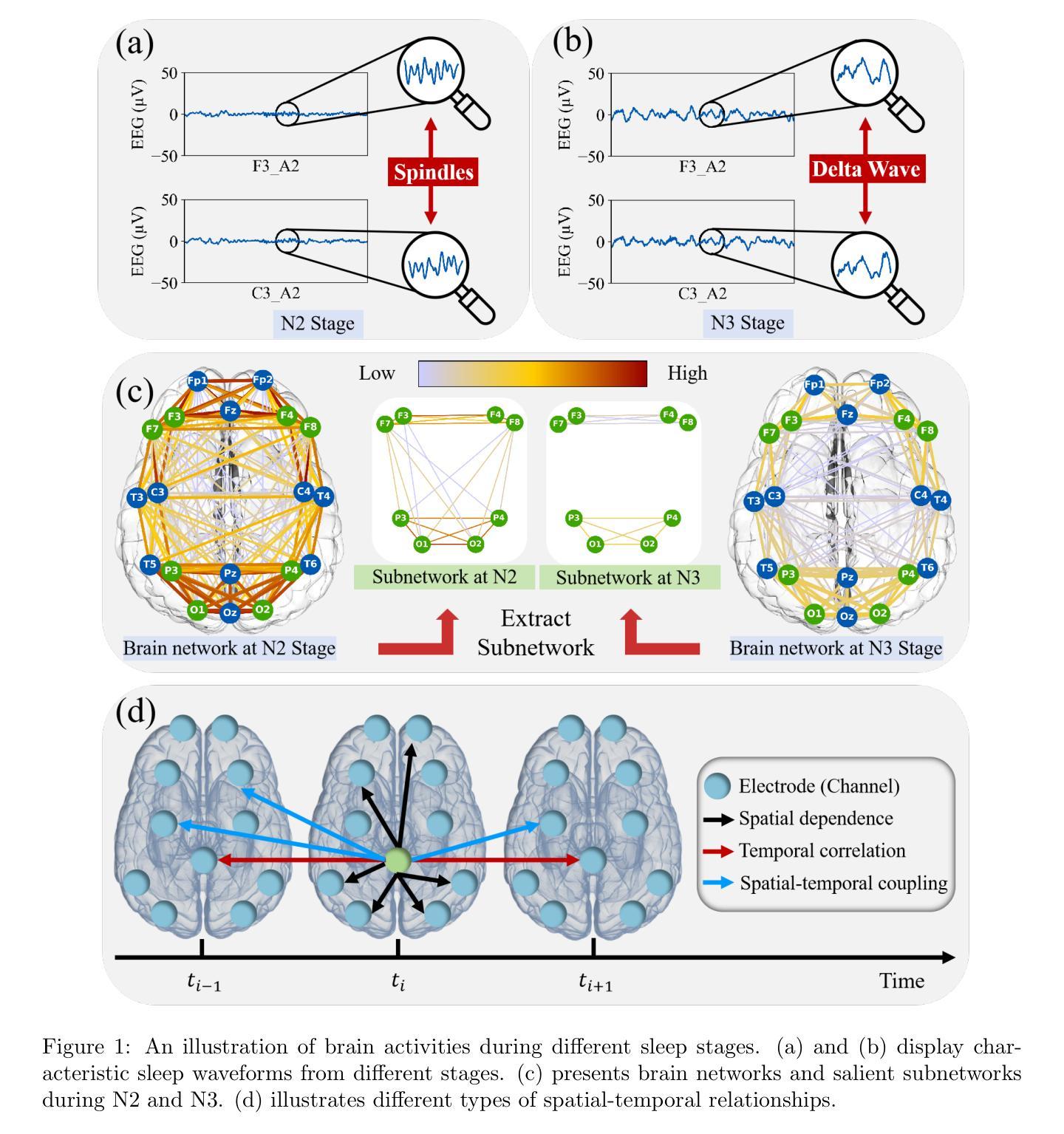
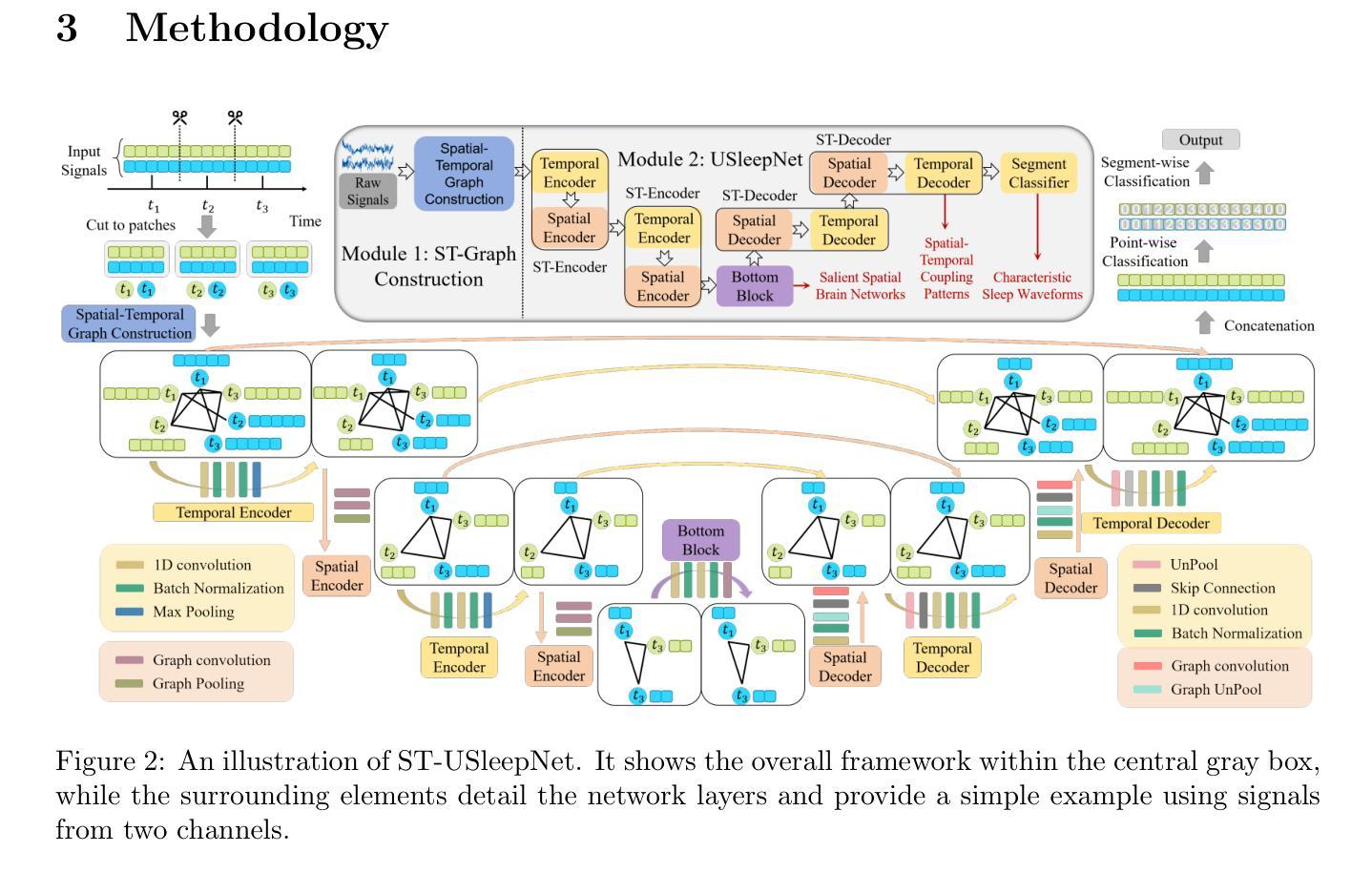
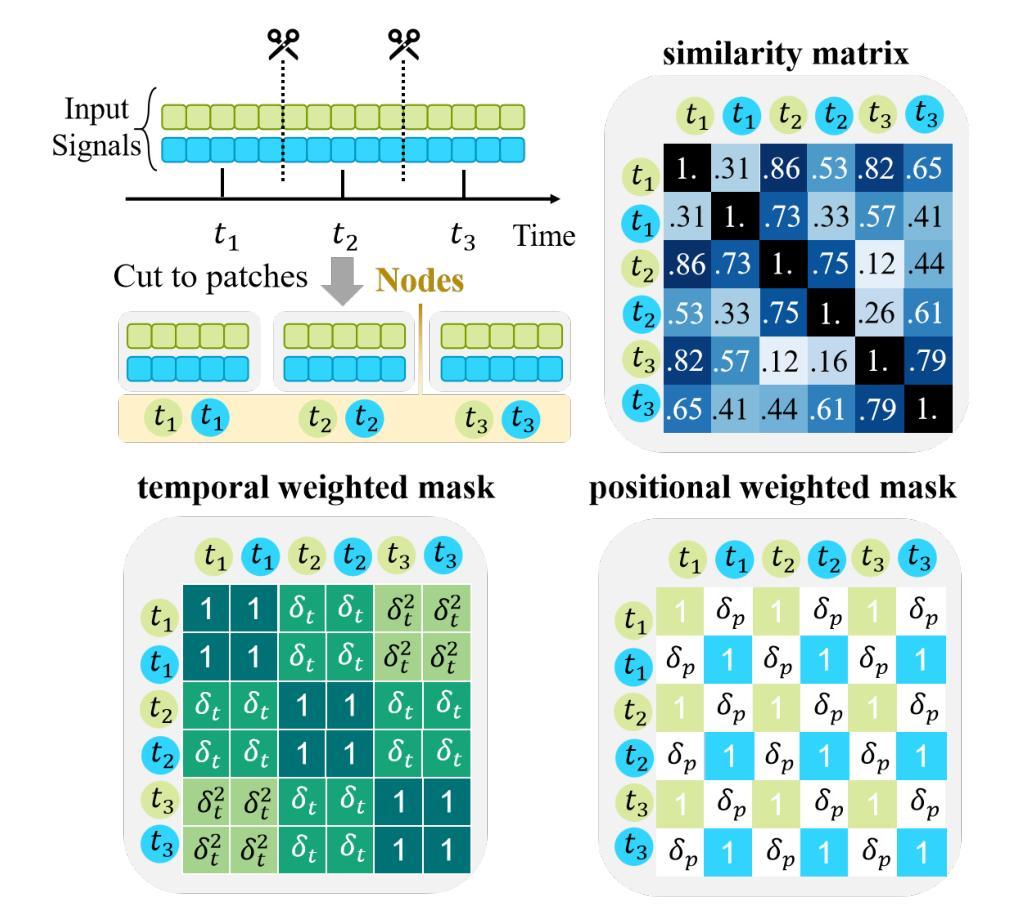
ST-USleepNet: A Spatial-Temporal Coupling Prominence Network for Multi-Channel Sleep Staging
Authors:Jingying Ma, Qika Lin, Ziyu Jia, Mengling Feng
Sleep staging is critical to assess sleep quality and diagnose disorders. Despite advancements in artificial intelligence enabling automated sleep staging, significant challenges remain: (1) Simultaneously extracting prominent temporal and spatial sleep features from multi-channel raw signals, including characteristic sleep waveforms and salient spatial brain networks. (2) Capturing the spatial-temporal coupling patterns essential for accurate sleep staging. To address these challenges, we propose a novel framework named ST-USleepNet, comprising a spatial-temporal graph construction module (ST) and a U-shaped sleep network (USleepNet). The ST module converts raw signals into a spatial-temporal graph based on signal similarity, temporal, and spatial relationships to model spatial-temporal coupling patterns. The USleepNet employs a U-shaped structure for both the temporal and spatial streams, mirroring its original use in image segmentation to isolate significant targets. Applied to raw sleep signals and graph data from the ST module, USleepNet effectively segments these inputs, simultaneously extracting prominent temporal and spatial sleep features. Testing on three datasets demonstrates that ST-USleepNet outperforms existing baselines, and model visualizations confirm its efficacy in extracting prominent sleep features and temporal-spatial coupling patterns across various sleep stages. The code is available at: https://github.com/Majy-Yuji/ST-USleepNet.git.
睡眠分期对于评估睡眠质量和诊断睡眠障碍至关重要。尽管人工智能的进步已经实现了自动化的睡眠分期,但仍存在重大挑战:(1) 从多通道原始信号中同时提取突出的时间和空间睡眠特征,包括特征睡眠波形和显著的脑空间网络。(2)捕捉对准确睡眠分期至关重要的时空耦合模式。为了解决这些挑战,我们提出了一种名为ST-USleepNet的新型框架,它包含一个时空图构建模块(ST)和一个U型睡眠网络(USleepNet)。ST模块根据信号相似性、时间和空间关系将原始信号转换为时空图,以模拟时空耦合模式。USleepNet采用U型结构,用于时间和空间流,模仿其在图像分割中的原始用途,以隔离重要目标。应用于来自ST模块的原始睡眠信号和图形数据,USleepNet有效地分割了这些输入,同时提取了突出的时间性和空间性睡眠特征。在三个数据集上的测试表明,ST-USleepNet的性能超过了现有基线,模型可视化证实了其在提取各睡眠阶段的重要睡眠特征和时空耦合模式方面的有效性。代码可在https://github.com/Majy-Yuji/ST-USleepNet.git处获取。
论文及项目相关链接
Summary
本文提出一种名为ST-USleepNet的新型框架,用于解决睡眠分期中从多通道原始信号中提取重要时空睡眠特征以及捕捉时空耦合模式的问题。该框架包括一个时空图构建模块(ST)和一个U型睡眠网络(USleepNet)。该框架在三个数据集上的测试表现优于现有基线,可有效提取重要睡眠特征和时空耦合模式。
Key Takeaways
- 睡眠分期是评估睡眠质量和诊断睡眠障碍的关键。
- 目前在睡眠分期中面临从多通道原始信号提取重要时空睡眠特征和捕捉时空耦合模式的挑战。
- ST-USleepNet框架由时空图构建模块(ST)和U型睡眠网络(USleepNet)组成,用于解决这些挑战。
- ST模块将原始信号转换为基于信号相似性的时空图,以模拟时空耦合模式。
- USleepNet采用U型结构,同时处理时空流,有效隔离显著目标,并从原始睡眠信号和ST模块的图数据中提取重要特征。
- 在三个数据集上的测试表明,ST-USleepNet的性能优于现有方法。
点此查看论文截图

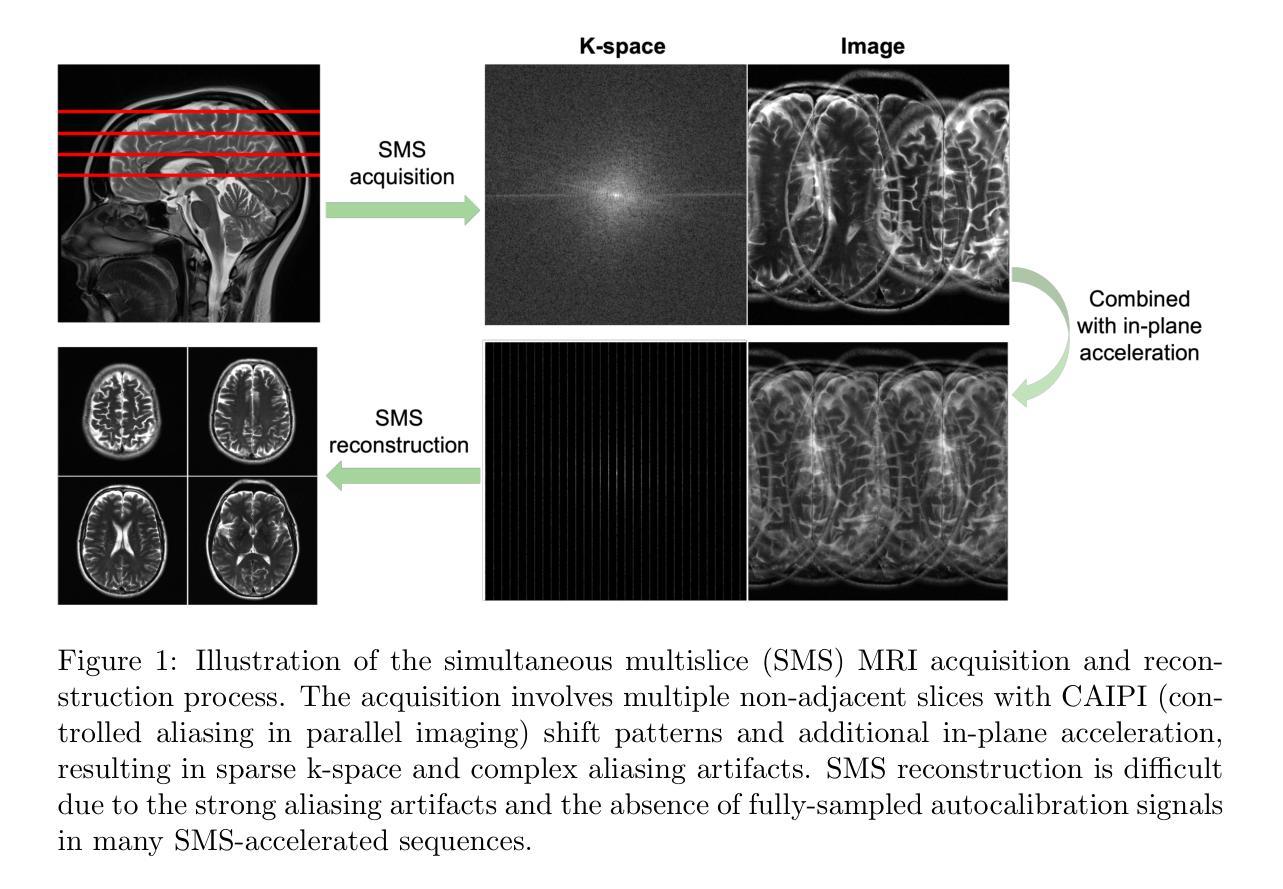
Robust Simultaneous Multislice MRI Reconstruction Using Deep Generative Priors
Authors:Shoujin Huang, Guanxiong Luo, Yunlin Zhao, Yilong Liu, Yuwan Wang, Kexin Yang, Jingzhe Liu, Hua Guo, Min Wang, Lingyan Zhang, Mengye Lyu
Simultaneous multislice (SMS) imaging is a powerful technique for accelerating magnetic resonance imaging (MRI) acquisitions. However, SMS reconstruction remains challenging due to complex signal interactions between and within the excited slices. In this study, we introduce ROGER, a robust SMS MRI reconstruction method based on deep generative priors. Utilizing denoising diffusion probabilistic models (DDPM), ROGER begins with Gaussian noise and gradually recovers individual slices through reverse diffusion iterations while enforcing data consistency from measured k-space data within the readout concatenation framework. The posterior sampling procedure is designed such that the DDPM training can be performed on single-slice images without requiring modifications for SMS tasks. Additionally, our method incorporates a low-frequency enhancement (LFE) module to address the practical issue that SMS-accelerated fast spin echo (FSE) and echo planar imaging (EPI) sequences cannot easily embed fully-sampled autocalibration signals. Extensive experiments on both retrospectively and prospectively accelerated datasets demonstrate that ROGER consistently outperforms existing methods, enhancing both anatomical and functional imaging with strong out-of-distribution generalization. The source code and sample data for ROGER are available at https://github.com/Solor-pikachu/ROGER.
层叠多切片(Simultaneous Multislice,简称SMS)成像是一种加速磁共振成像(MRI)采集的强大技术。然而,由于激发切片之间和切片内部的复杂信号相互作用,SMS重建仍然是一个挑战。在这项研究中,我们引入了基于深度生成先验的稳健SMS MRI重建方法——ROGER。利用降噪扩散概率模型(DDPM),ROGER从高斯噪声开始,通过反向扩散迭代逐渐恢复单个切片,同时在读出拼接框架内强制实施来自测量k空间数据的数据一致性。后采样程序的设计使得可以在单切片图像上对DDPM进行训练,而无需对SMS任务进行修改。此外,我们的方法还融入了一个低频增强(LFE)模块,以解决一个实际问题,即SMS加速的快速自旋回波(FSE)和回波平面成像(EPI)序列无法轻松嵌入完全采样的自动校准信号。对回顾性和前瞻性加速数据集的大量实验表明,ROGER始终优于现有方法,在解剖和功能性成像方面表现出强大的泛化能力。ROGER的源代码和样本数据可在https://github.com/Solor-pikachu/ROGER找到。
论文及项目相关链接
PDF Submitted to Medical Image Analysis. New fMRI analysis and figures are added since v1
Summary
基于深度生成先验的ROGER方法在SMS MRI重建中具有强大的性能。该方法利用去噪扩散概率模型(DDPM),从高斯噪声开始逐步恢复切片,同时通过反向扩散迭代在读取拼接框架中强制实施数据一致性。此外,ROGER方法还融入了低频增强模块,解决了SMS加速的快速自旋回波(FSE)和回声平面成像序列难以嵌入全采样自动校准信号的实际问题。实验证明,ROGER在回顾性和前瞻性加速的数据集上均表现出优于现有方法的效果,能够增强解剖和功能性成像的外部分布泛化能力。
Key Takeaways
- SMS成像是一种加速磁共振成像(MRI)的技术。
- ROGER是一种基于深度生成先验的稳健的SMS MRI重建方法。
- ROGER利用去噪扩散概率模型(DDPM)从高斯噪声开始逐步恢复切片。
- ROGER通过反向扩散迭代在读取拼接框架中实施数据一致性。
- ROGER融入了低频增强模块,解决了SMS加速成像中的实际问题。
- ROGER在回顾性和前瞻性加速的数据集上表现出卓越性能。
- ROGER增强了MRI的解剖和功能性成像效果,并具有强大的外部分布泛化能力。
点此查看论文截图

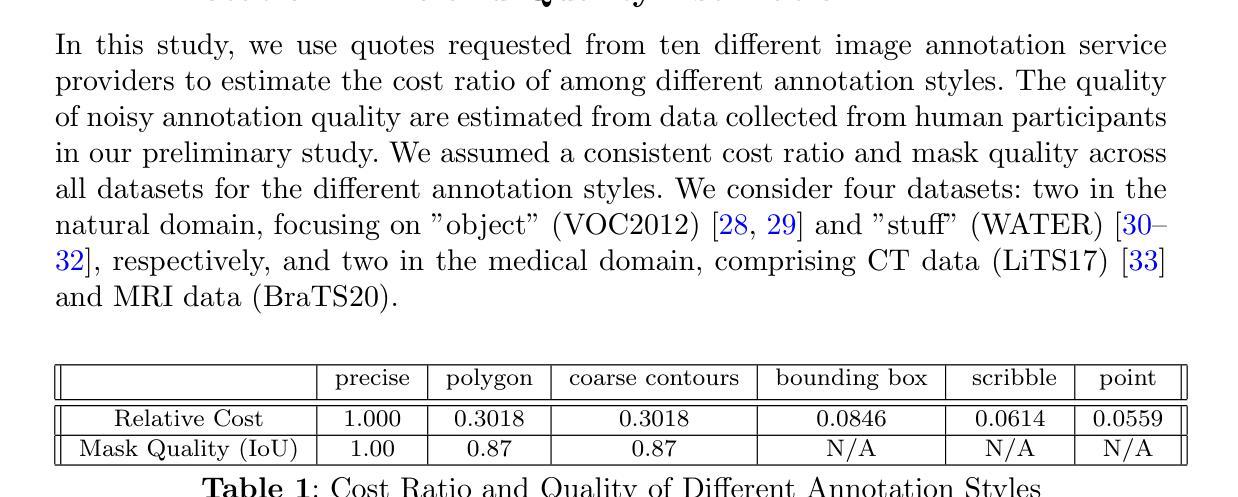
How to Efficiently Annotate Images for Best-Performing Deep Learning Based Segmentation Models: An Empirical Study with Weak and Noisy Annotations and Segment Anything Model
Authors:Yixin Zhang, Shen Zhao, Hanxue Gu, Maciej A. Mazurowski
Deep neural networks (DNNs) have demonstrated exceptional performance across various image segmentation tasks. However, the process of preparing datasets for training segmentation DNNs is both labor-intensive and costly, as it typically requires pixel-level annotations for each object of interest. To mitigate this challenge, alternative approaches such as using weak labels (e.g., bounding boxes or scribbles) or less precise (noisy) annotations can be employed. Noisy and weak labels are significantly quicker to generate, allowing for more annotated images within the same time frame. However, the potential decrease in annotation quality may adversely impact the segmentation performance of the resulting model. In this study, we conducted a comprehensive cost-effectiveness evaluation on six variants of annotation strategies (9~10 sub-variants in total) across 4 datasets and conclude that the common practice of precisely outlining objects of interest is virtually never the optimal approach when annotation budget is limited. Both noisy and weak annotations showed usage cases that yield similar performance to the perfectly annotated counterpart, yet had significantly better cost-effectiveness. We hope our findings will help researchers be aware of the different available options and use their annotation budgets more efficiently, especially in cases where accurately acquiring labels for target objects is particularly costly. Our code will be made available on https://github.com/yzluka/AnnotationEfficiency2D.
深度神经网络(DNNs)在各种图像分割任务中表现出了卓越的性能。然而,为训练分割DNNs准备数据集的过程既劳动密集又成本高昂,因为它通常需要对每个感兴趣的对象进行像素级的注释。为了缓解这一挑战,可以采用使用弱标签(如边界框或涂鸦)或不太精确(带有噪声)的注释等替代方法。带噪声和弱标签的生成速度要快得多,可以在同一时间框架内生成更多注释图像。然而,注释质量可能的下降可能会给所得模型的分割性能带来不利影响。本研究中,我们对4个数据集的6种注释策略变体(总计9~10个子变体)进行了全面的成本效益评估,并得出结论:当注释预算有限时,精确描绘感兴趣对象的一般做法几乎从未是最佳方法。带噪声和弱标签的用例产生的性能与完美注释的对应物相似,但成本效益却显著提高。我们希望我们的研究能帮助研究人员了解不同的可用选项,并更有效地利用他们的注释预算,特别是在为目标对象准确获取标签特别昂贵的情况下。我们的代码将在 https://github.com/yzluka/AnnotationEfficiency2D 上提供。
论文及项目相关链接
PDF Supplemental information is in appendix
Summary
深度神经网络在图像分割任务中表现出卓越性能,但训练分割深度神经网络的数据集制备既劳力密集又成本高昂,通常需要为每个目标对象进行像素级注释。为缓解这一问题,可采用弱标签(如边界框或涂鸦)或不精确的(噪声)注释等替代方法。噪声和弱标签生成更快,可在相同时间内生成更多注释图像。然而,注释质量的潜在下降可能会对所得模型的分割性能产生不利影响。本研究对六种注释策略(共9至10种子策略)进行了全面的成本效益评估,涉及四个数据集,得出结论:当注释预算有限时,精确描绘目标对象的常规做法几乎从未是最优选择。噪声和弱注释的使用案例产生了与完美注释相当的性能,但成本效益显著提高。
Key Takeaways
- 深度神经网络在图像分割任务中表现出卓越性能。
- 数据集制备需要像素级注释,过程既劳力密集又成本高昂。
- 为缓解高成本问题,可采用弱标签或不精确的注释等替代方法。
- 噪声和弱标签生成更快,能在有限时间内生成更多注释图像。
- 注释质量的潜在下降可能影响模型的分割性能。
- 研究表明,在注释预算有限时,不必精确描绘目标对象。
点此查看论文截图


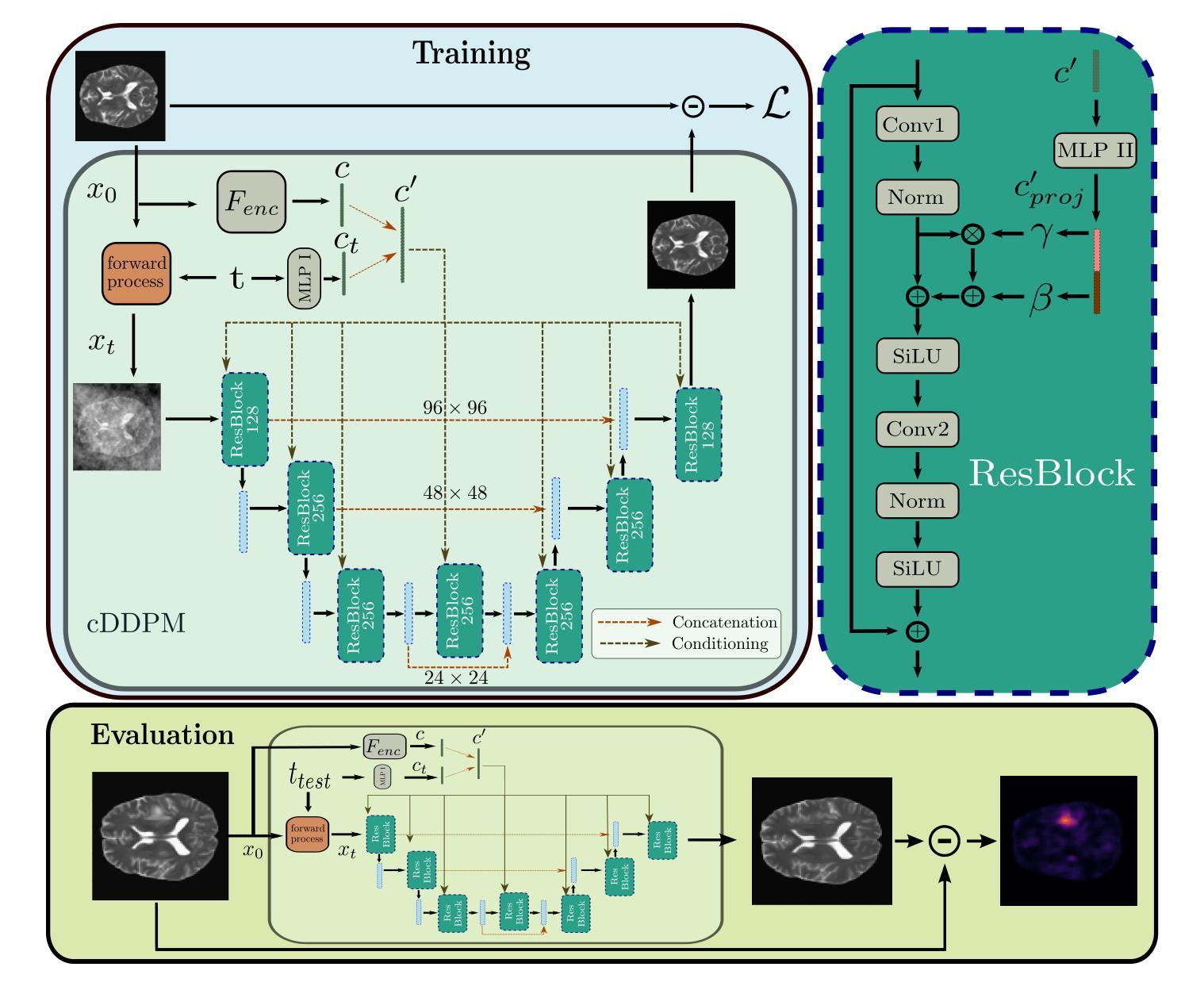
Guided Reconstruction with Conditioned Diffusion Models for Unsupervised Anomaly Detection in Brain MRIs
Authors:Finn Behrendt, Debayan Bhattacharya, Robin Mieling, Lennart Maack, Julia Krüger, Roland Opfer, Alexander Schlaefer
The application of supervised models to clinical screening tasks is challenging due to the need for annotated data for each considered pathology. Unsupervised Anomaly Detection (UAD) is an alternative approach that aims to identify any anomaly as an outlier from a healthy training distribution. A prevalent strategy for UAD in brain MRI involves using generative models to learn the reconstruction of healthy brain anatomy for a given input image. As these models should fail to reconstruct unhealthy structures, the reconstruction errors indicate anomalies. However, a significant challenge is to balance the accurate reconstruction of healthy anatomy and the undesired replication of abnormal structures. While diffusion models have shown promising results with detailed and accurate reconstructions, they face challenges in preserving intensity characteristics, resulting in false positives. We propose conditioning the denoising process of diffusion models with additional information derived from a latent representation of the input image. We demonstrate that this conditioning allows for accurate and local adaptation to the general input intensity distribution while avoiding the replication of unhealthy structures. We compare the novel approach to different state-of-the-art methods and for different data sets. Our results show substantial improvements in the segmentation performance, with the Dice score improved by 11.9%, 20.0%, and 44.6%, for the BraTS, ATLAS and MSLUB data sets, respectively, while maintaining competitive performance on the WMH data set. Furthermore, our results indicate effective domain adaptation across different MRI acquisitions and simulated contrasts, an important attribute for general anomaly detection methods. The code for our work is available at https://github.com/FinnBehrendt/Conditioned-Diffusion-Models-UAD
将监督模型应用于临床筛查任务是一项挑战,因为需要考虑的每种病理学都需要标注数据。无监督异常检测(UAD)是一种旨在从健康的训练分布中识别任何异常值的替代方法。在脑部MRI的UAD中,一种常见的策略是使用生成模型来学习给定输入图像的脑部结构的重建。由于这些模型无法重建不健康结构,因此重建误差会指示异常。然而,一个重大挑战是如何平衡健康解剖结构的准确重建和异常结构的非期望复制。虽然扩散模型在详细和准确的重建方面显示出有前景的结果,但它们面临着保持强度特征的挑战,从而导致误报。我们提出通过输入图像的潜在表示的派生信息对扩散模型的去噪过程进行条件处理。我们证明这种条件处理允许对一般输入强度分布进行准确和局部适应,同时避免复制不健康结构。我们将新方法与不同的最新技术和数据集进行了比较。我们的结果表明,在分割性能方面取得了重大改进,对于BraTS、ATLAS和MSLUB数据集,Dice得分分别提高了11.9%、20.0%和44.6%,同时在WMH数据集上保持了竞争性能。此外,我们的结果还表明,我们的方法在MRI采集和不同模拟对比度之间实现了有效的域适应,这对于一般的异常检测方法是一个重要的属性。我们的代码可在https://github.com/FinnBehrendt/Conditioned-Diffusion-Models-UAD找到。
论文及项目相关链接
PDF Preprint: Accepted paper at Combuters in Biology and medicine
Summary
使用无监督异常检测(UAD)方法,通过生成模型学习健康脑结构的重建以发现异常。扩散模型在重建健康结构方面表现出良好性能,但在保持强度特征方面存在挑战。本研究提出将输入图像的潜在表示信息纳入扩散模型的去噪过程,以提高异常检测的准确性并避免复制不健康结构。研究结果显示,该方法在多个数据集上的分割性能显著提高,同时具有良好的跨不同MRI采集和模拟对比的域适应能力。
Key Takeaways
- 监督模型应用于临床筛查任务时面临标注数据需求挑战。
- 无监督异常检测(UAD)旨在从健康训练分布中识别异常值。
- 在脑MRI的UAD中,生成模型用于学习健康脑结构的重建。
- 扩散模型在重建健康结构方面表现良好,但保持强度特征方面存在挑战。
- 将输入图像的潜在表示信息纳入扩散模型的去噪过程,以提高异常检测的准确性。
- 方法在多个数据集上的分割性能显著提高,并具有良好的域适应能力。
点此查看论文截图