⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
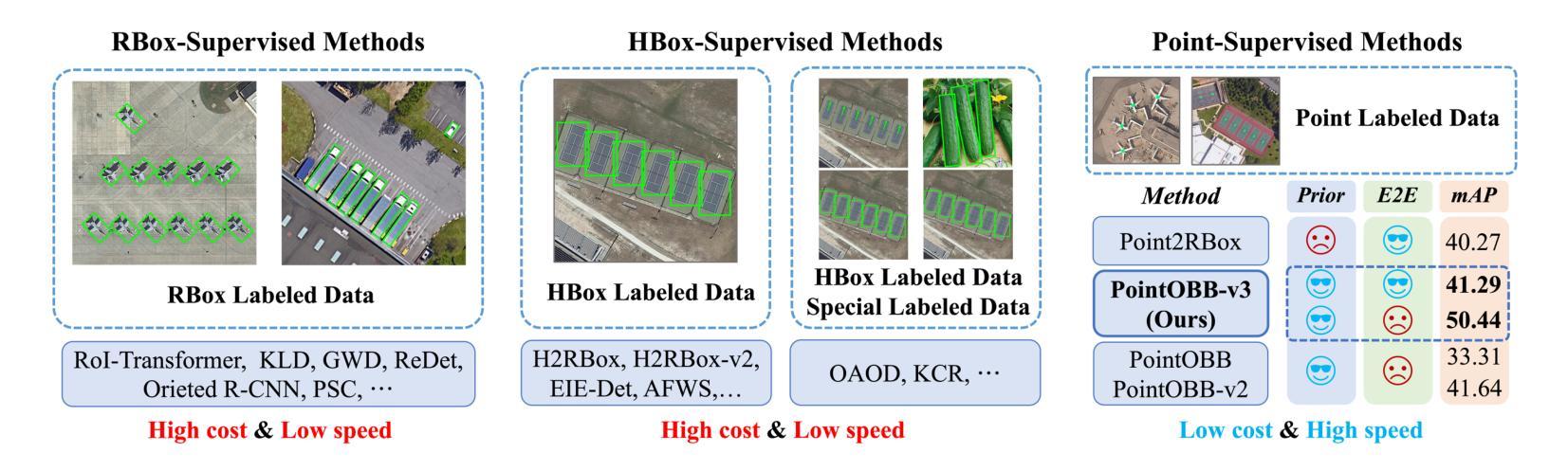
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Authors:Peiyuan Zhang, Junwei Luo, Xue Yang, Yi Yu, Qingyun Li, Yue Zhou, Xiaosong Jia, Xudong Lu, Jingdong Chen, Xiang Li, Junchi Yan, Yansheng Li
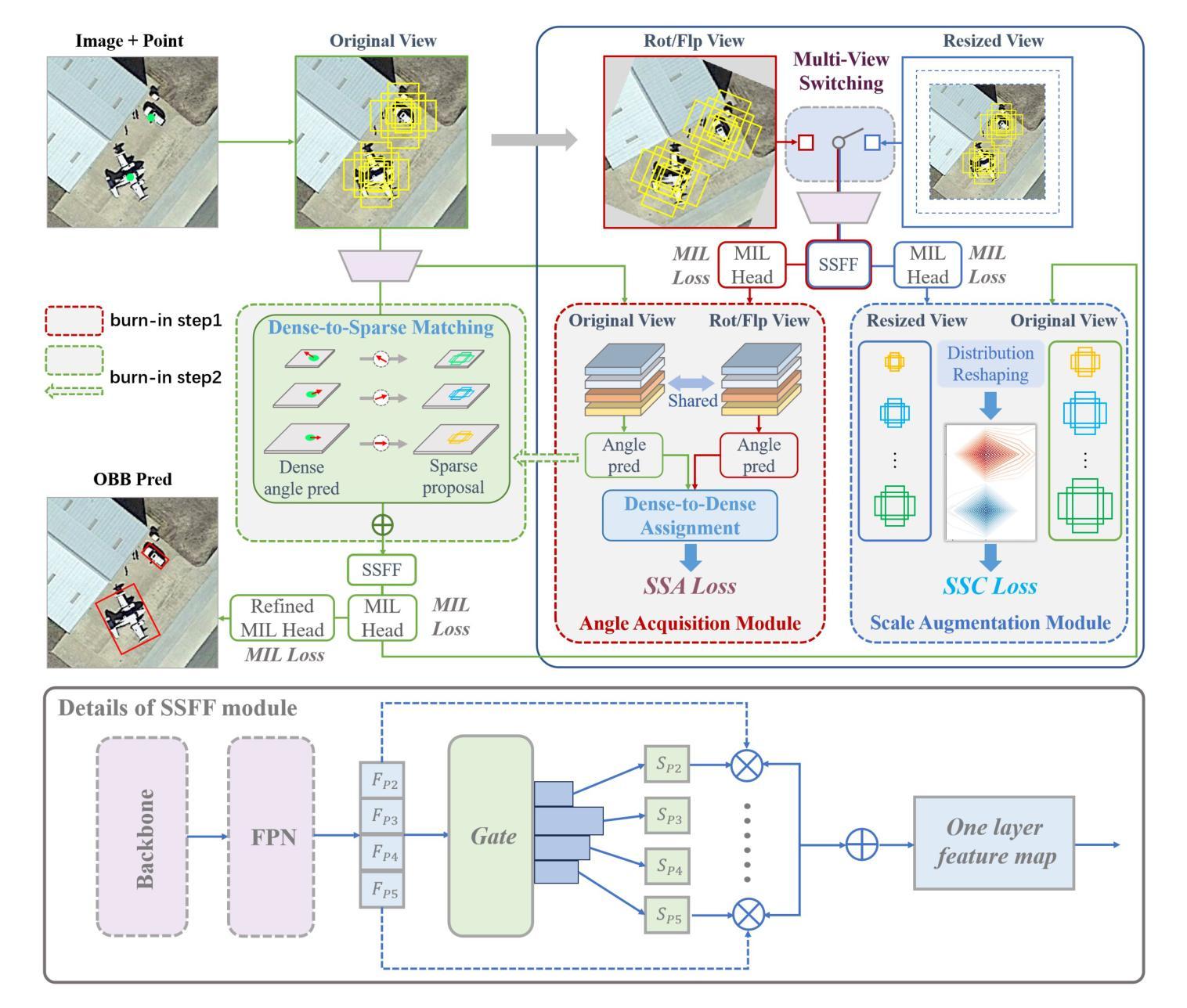
With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model’s ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
随着定向目标检测(OOD)需求的不断增长,关于点监督OOD的最近研究已经引起了极大的兴趣。本文提出了PointOBB-v3,这是一种更强大的单点监督OOD框架。与现有方法相比,它无需额外的先验知识即可生成伪旋转框,并支持端到端范式。PointOBB-v3通过集成三种独特的图像视图来发挥作用:原始视图、调整大小后的视图以及旋转/翻转(旋转/翻转)视图。基于这些视图,构建了尺度增强模块和角度获取模块。在第一个模块中,引入了尺度敏感一致性(SSC)损失和尺度敏感特征融合(SSFF)模块,以提高模型对目标尺度的估计能力。为了实现精确的角度预测,第二个模块采用了基于对称性的自监督学习。此外,我们还引入了端到端版本,通过集成检测器分支来消除伪标签生成过程,并引入了实例感知加权(IAW)策略,以侧重于高质量预测。我们在DIOR-R、DOTA-v1.0/v1.5/v2.0、FAIR1M、STAR和RSAR数据集上进行了大量实验。与之前的最新方法相比,我们的方法在所有这些数据集上的平均准确度提高了3.56%。代码将在https://github.com/ZpyWHU/PointOBB-v3上提供。
论文及项目相关链接
PDF 16 pages, 5 figures, 10 tables
Summary
本文提出了一个名为PointOBB-v3的更强的单点监督导向对象检测框架。它结合了三种独特的图像视图,并通过规模增强模块和角度获取模块提高了模型的估计能力和精确预测角度的能力。该框架实现了端到端版本,并引入了实例感知加权策略,以关注高质量预测。在多个数据集上的实验表明,与以前的方法相比,该方法平均提高了3.56%的准确度。
Key Takeaways
- PointOBB-v3是一个新的单点监督导向对象检测框架,用于满足日益增长的需求。
- 该框架通过结合三种图像视图(原始视图、调整大小后的视图和旋转/翻转视图)来提高对象检测的准确性。
- 规模增强模块和角度获取模块的引入,增强了模型的物体尺度估计能力和精确预测角度能力。
- 端到端版本的实现消除了伪标签生成过程,并引入了实例感知加权策略以提高预测质量。
- 在多个数据集上进行的实验表明,PointOBB-v3在准确度方面取得了显著的改进,平均提高了3.56%。
- 该框架的代码将在https://github.com/ZpyWHU/PointOBB-v3上提供。
点此查看论文截图

Overcoming Support Dilution for Robust Few-shot Semantic Segmentation
Authors:Wailing Tang, Biqi Yang, Pheng-Ann Heng, Yun-Hui Liu, Chi-Wing Fu
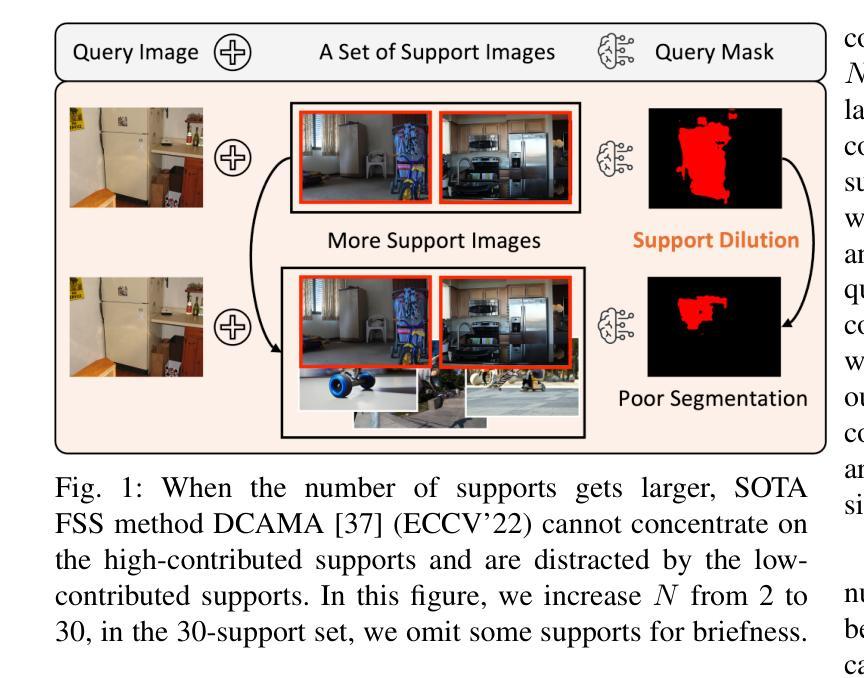
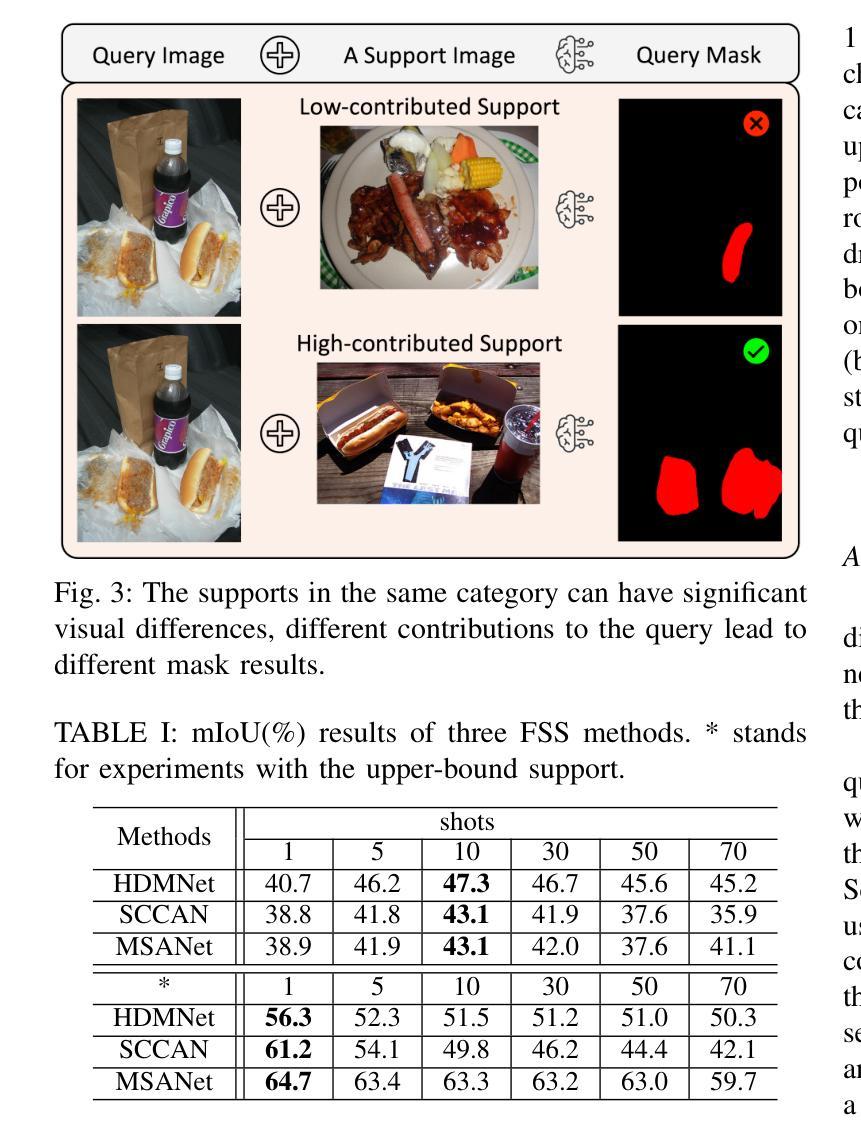
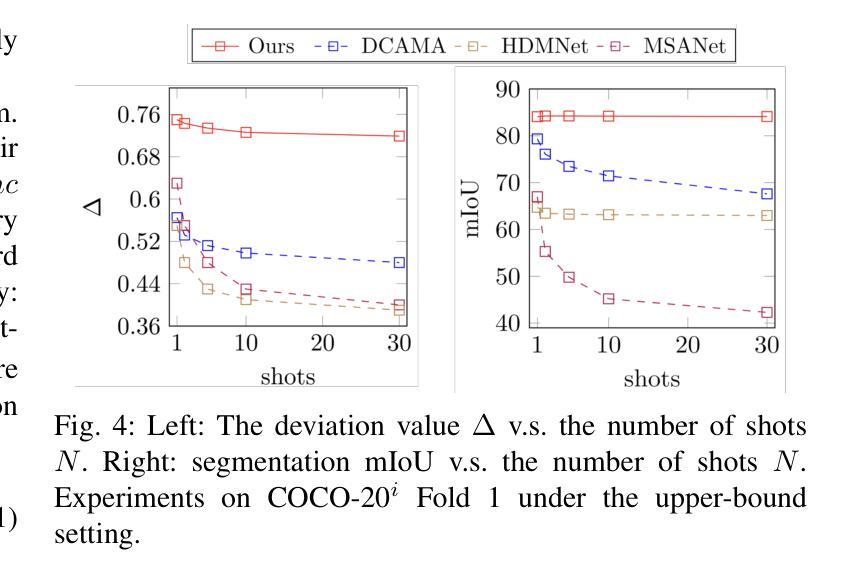
Few-shot Semantic Segmentation (FSS) is a challenging task that utilizes limited support images to segment associated unseen objects in query images. However, recent FSS methods are observed to perform worse, when enlarging the number of shots. As the support set enlarges, existing FSS networks struggle to concentrate on the high-contributed supports and could easily be overwhelmed by the low-contributed supports that could severely impair the mask predictions. In this work, we study this challenging issue, called support dilution, our goal is to recognize, select, preserve, and enhance those high-contributed supports in the raw support pool. Technically, our method contains three novel parts. First, we propose a contribution index, to quantitatively estimate if a high-contributed support dilutes. Second, we develop the Symmetric Correlation (SC) module to preserve and enhance the high-contributed support features, minimizing the distraction by the low-contributed features. Third, we design the Support Image Pruning operation, to retrieve a compact and high quality subset by discarding low-contributed supports. We conduct extensive experiments on two FSS benchmarks, COCO-20i and PASCAL-5i, the segmentation results demonstrate the compelling performance of our solution over state-of-the-art FSS approaches. Besides, we apply our solution for online segmentation and real-world segmentation, convincing segmentation results showing the practical ability of our work for real-world demonstrations.
小样本语义分割(FSS)是一项具有挑战性的任务,它利用有限的支撑图像来分割查询图像中相关的未见对象。然而,当增加样本数量时,最近的FSS方法表现较差。随着支撑集增大,现有的FSS网络难以集中关注于高贡献的支撑样本,并可能受到低贡献支撑样本的影响,这些低贡献样本会严重损害掩膜预测。在这项工作中,我们研究了这个具有挑战性的问题,称为支撑稀释。我们的目标是识别、选择、保留并增强原始支撑池中的高贡献支撑样本。从技术上讲,我们的方法包含三个新颖的部分。首先,我们提出一个贡献指数,定量评估高贡献支撑是否稀释。其次,我们开发了对称相关性(SC)模块,以保留并增强高贡献支撑特征,尽量减少低贡献特征的干扰。第三,我们设计了支撑图像修剪操作,通过剔除低贡献支撑来检索紧凑且高质量的子集。我们在两个FSS基准(COCO-20i和PASCAL-5i)上进行了大量实验,分割结果证明我们的解决方案在最新FSS方法上具有令人信服的表现。此外,我们将我们的解决方案应用于在线分割和真实世界分割,令人信服的分割结果展示了我们的工作在真实世界演示中的实用能力。
论文及项目相关链接
PDF 15 pages, 15 figures
Summary
本文研究了小样本语义分割(FSS)中的支持集稀释问题。为了解决这个问题,作者提出了三种新颖的方法:提出贡献指数来衡量高贡献支持的影响;开发了对称相关性(SC)模块来保留和增强高贡献支持特征;设计了支持图像修剪操作,通过丢弃低贡献支持来检索紧凑且高质量的子集。实验证明,该方法在COCO-20i和PASCAL-5i两个FSS基准测试集上表现出卓越性能,并成功应用于在线分割和真实世界分割。
Key Takeaways
- FSS任务面临支持集稀释问题,即当支持集扩大时,现有FSS网络难以集中关注高贡献支持,容易受到低贡献支持的干扰。
- 贡献指数的提出,用于定量评估高贡献支持的影响。
- 对称相关性(SC)模块的开发,旨在保留和增强高贡献支持特征,最小化低贡献特征的干扰。
- 支持图像修剪操作的设计,通过丢弃低贡献支持,检索出紧凑且高质量的支持子集。
- 在COCO-20i和PASCAL-5i基准测试集上的实验证明了该方法的有效性。
点此查看论文截图


A Novel Scene Coupling Semantic Mask Network for Remote Sensing Image Segmentation
Authors:Xiaowen Ma, Rongrong Lian, Zhenkai Wu, Renxiang Guan, Tingfeng Hong, Mengjiao Zhao, Mengting Ma, Jiangtao Nie, Zhenhong Du, Siyang Song, Wei Zhang
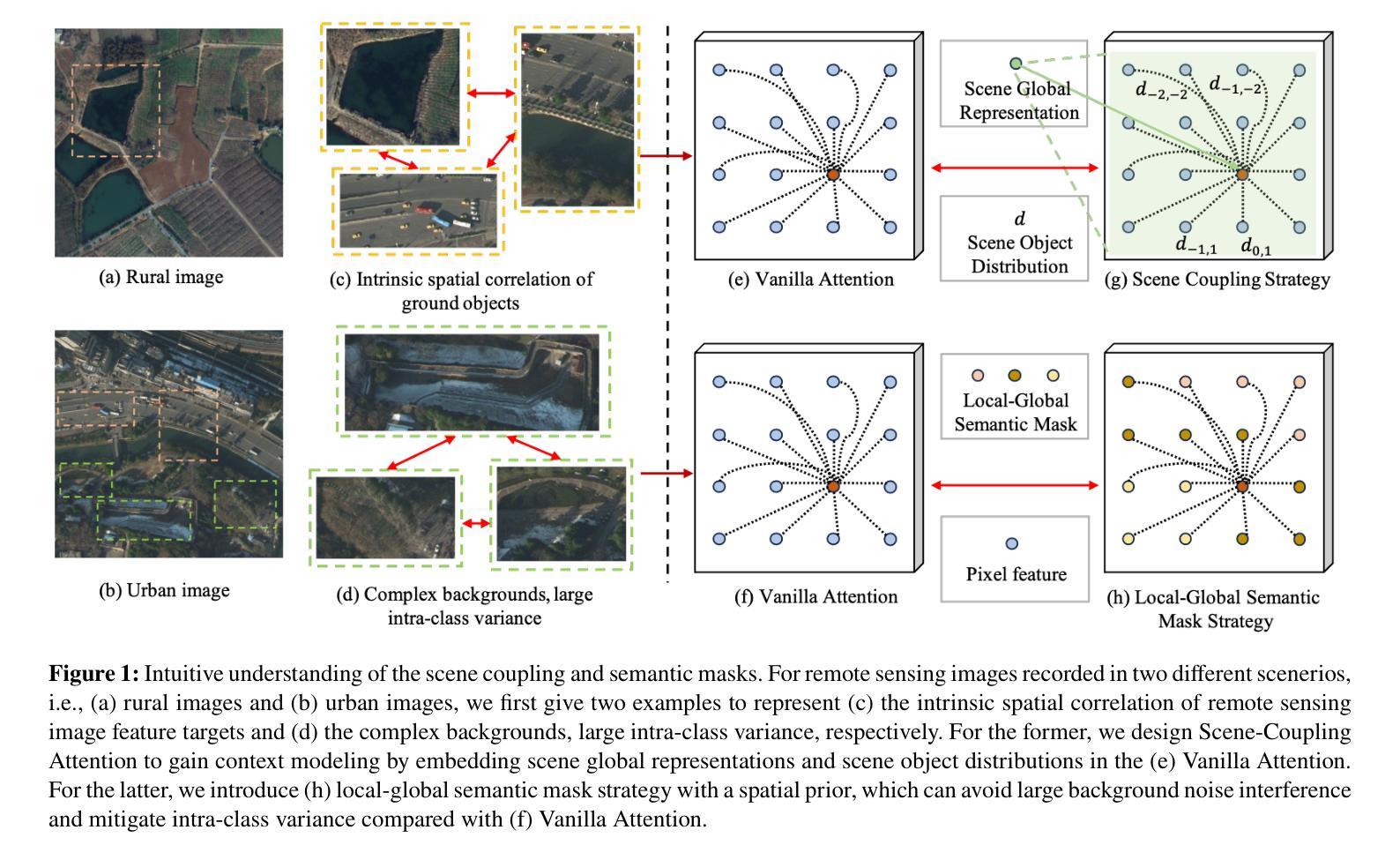
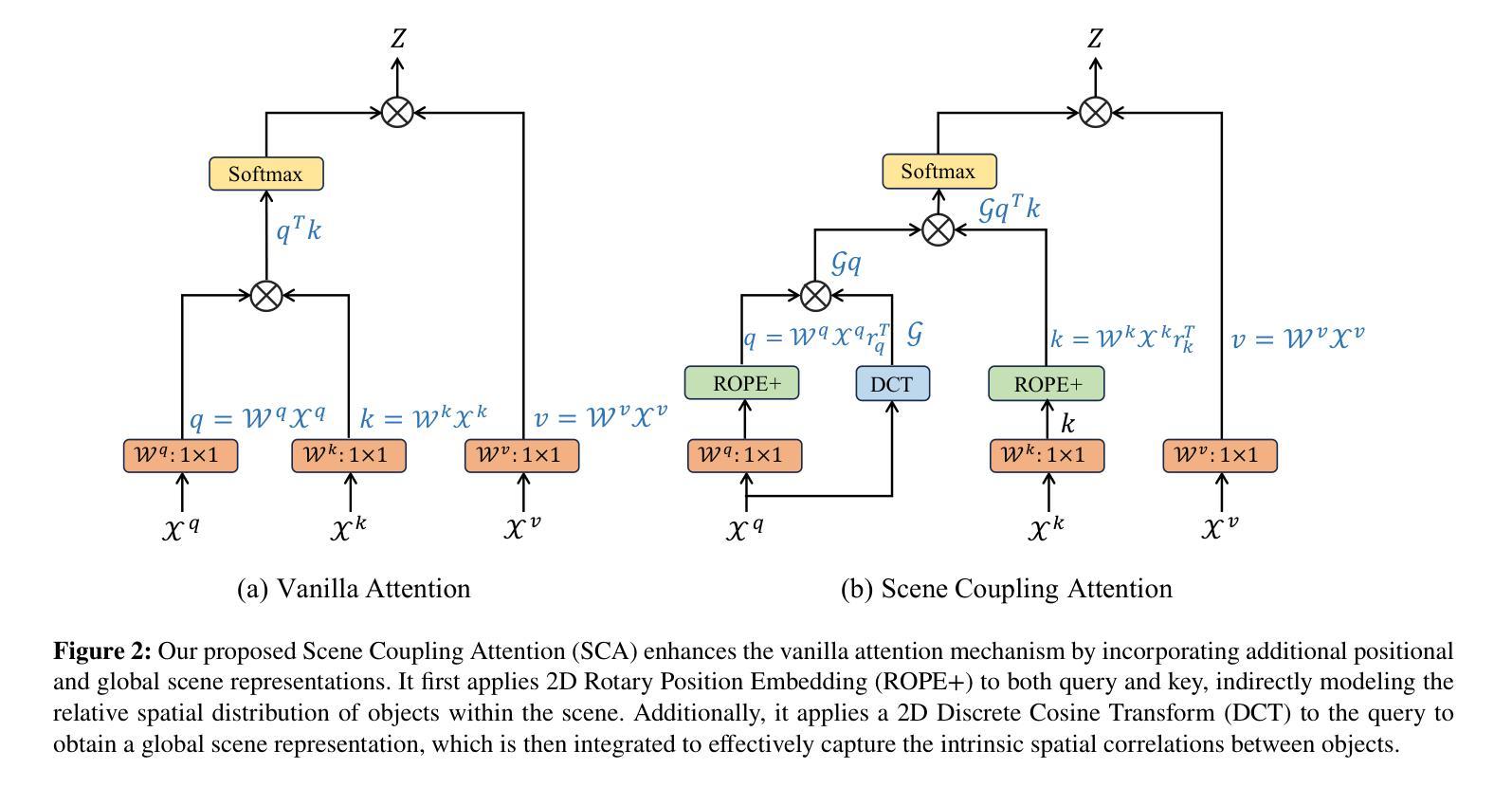
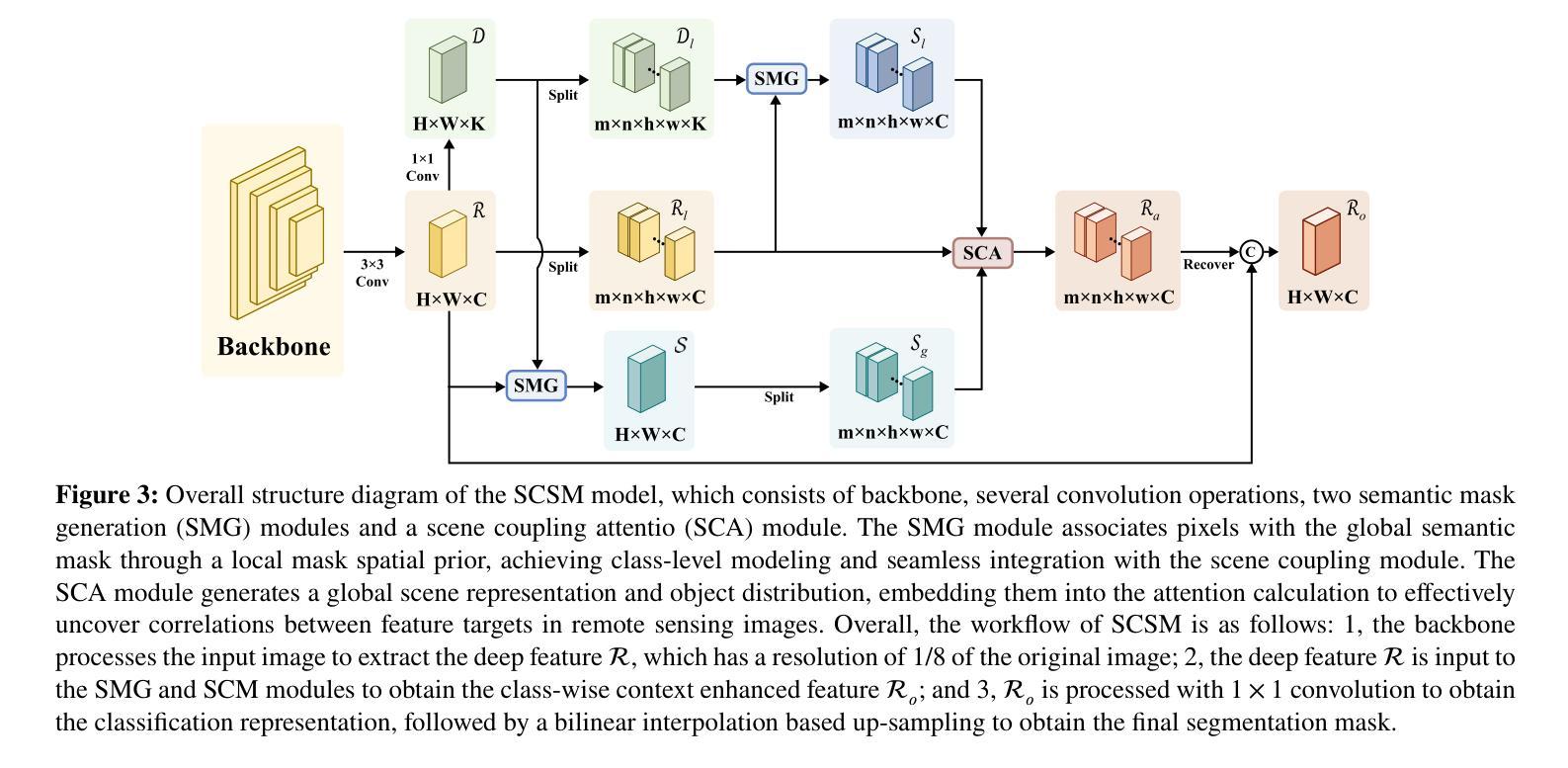
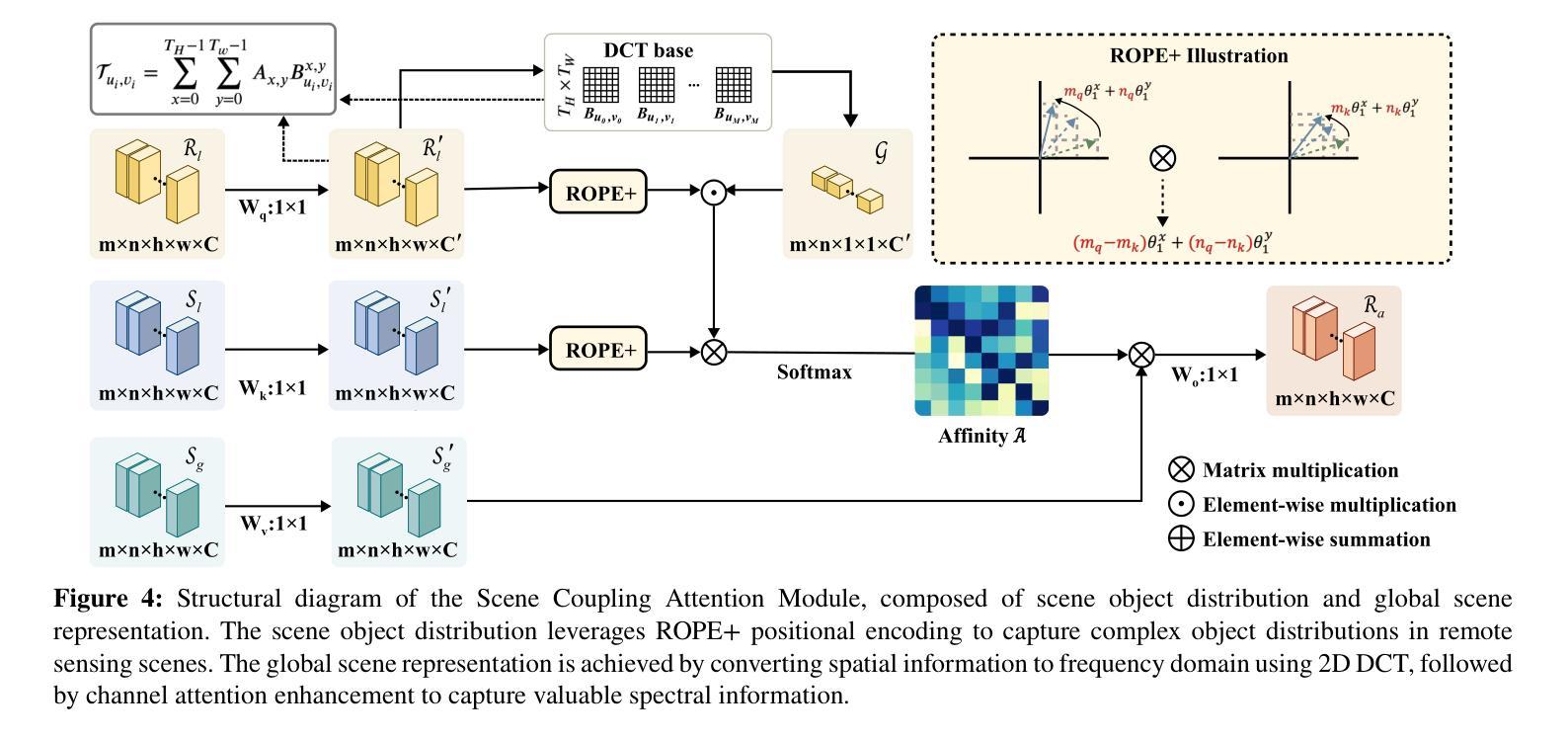
As a common method in the field of computer vision, spatial attention mechanism has been widely used in semantic segmentation of remote sensing images due to its outstanding long-range dependency modeling capability. However, remote sensing images are usually characterized by complex backgrounds and large intra-class variance that would degrade their analysis performance. While vanilla spatial attention mechanisms are based on dense affine operations, they tend to introduce a large amount of background contextual information and lack of consideration for intrinsic spatial correlation. To deal with such limitations, this paper proposes a novel scene-Coupling semantic mask network, which reconstructs the vanilla attention with scene coupling and local global semantic masks strategies. Specifically, scene coupling module decomposes scene information into global representations and object distributions, which are then embedded in the attention affinity processes. This Strategy effectively utilizes the intrinsic spatial correlation between features so that improve the process of attention modeling. Meanwhile, local global semantic masks module indirectly correlate pixels with the global semantic masks by using the local semantic mask as an intermediate sensory element, which reduces the background contextual interference and mitigates the effect of intra-class variance. By combining the above two strategies, we propose the model SCSM, which not only can efficiently segment various geospatial objects in complex scenarios, but also possesses inter-clean and elegant mathematical representations. Experimental results on four benchmark datasets demonstrate the the effectiveness of the above two strategies for improving the attention modeling of remote sensing images. The dataset and code are available at https://github.com/xwmaxwma/rssegmentation
作为计算机视觉领域的常见方法,空间注意力机制因其出色的长程依赖建模能力而广泛应用于遥感图像语义分割中。然而,遥感图像通常具有复杂的背景和较大的类内差异,这会降低其分析性能。虽然普通空间注意力机制基于密集仿射运算,但它们容易引入大量背景上下文信息,并且没有考虑到内在的空间相关性。为了应对这些局限性,本文提出了一种新的场景耦合语义掩码网络,该网络通过场景耦合和局部全局语义掩码策略重建了普通注意力机制。具体而言,场景耦合模块将场景信息分解为全局表示和对象分布,然后将其嵌入到注意力亲和过程中。这一策略有效地利用了特征之间的内在空间相关性,从而改进了注意力建模过程。同时,局部全局语义掩码模块通过利用局部语义掩码作为中间感知元素,间接地将像素与全局语义掩码相关联,这降低了背景上下文的干扰并减轻了类内差异的影响。通过结合上述两种策略,我们提出了SCSM模型,该模型不仅可以在复杂场景中有效地分割各种地理空间对象,而且还具有清晰简洁的数学表示。在四个基准数据集上的实验结果表明,上述两种策略在提高遥感图像的注意力建模方面都是有效的。数据集和代码可通过https://github.com/xwmaxwma/rssegmentation获取。
论文及项目相关链接
PDF Accepted by ISPRS Journal of Photogrammetry and Remote Sensing
Summary:
空间注意力机制在计算机视觉领域应用广泛,特别是在遥感图像语义分割中。但遥感图像背景复杂、类内差异大,传统空间注意力机制基于密集仿射运算,易引入大量背景上下文信息,忽视内在空间相关性。本文提出一种新型场景耦合语义掩膜网络,通过场景耦合和局部全局语义掩膜策略重构注意力机制,提高遥感图像注意力建模效果。在四个基准数据集上的实验验证了这两种策略的有效性。
Key Takeaways:
- 空间注意力机制在遥感图像语义分割中表现突出,但存在对复杂背景和类内差异处理不足的问题。
- 传统空间注意力机制基于密集仿射运算,易引入背景上下文信息。
- 场景耦合模块将场景信息分解为全局表征和对象分布,嵌入注意力亲和过程中。
- 局部全局语义掩膜模块通过局部语义掩膜作为中间感知元素,间接关联像素与全局语义掩码,降低背景上下文干扰,减轻类内差异影响。
- 结合上述两个策略,提出SCSM模型,能高效分割复杂场景下的各种地理空间对象,具有简洁优雅的数学表征。
- 在四个基准数据集上的实验验证了SCSM模型及两种策略的有效性。
点此查看论文截图

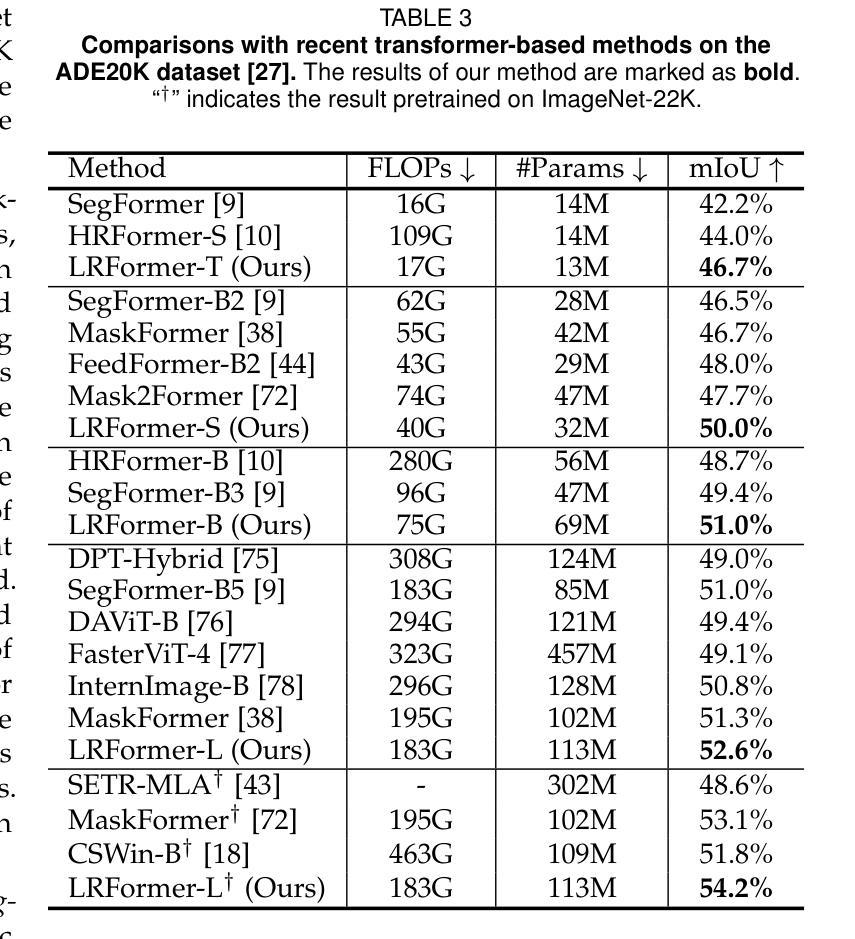
Low-Resolution Self-Attention for Semantic Segmentation
Authors:Yu-Huan Wu, Shi-Chen Zhang, Yun Liu, Le Zhang, Xin Zhan, Daquan Zhou, Jiashi Feng, Ming-Ming Cheng, Liangli Zhen
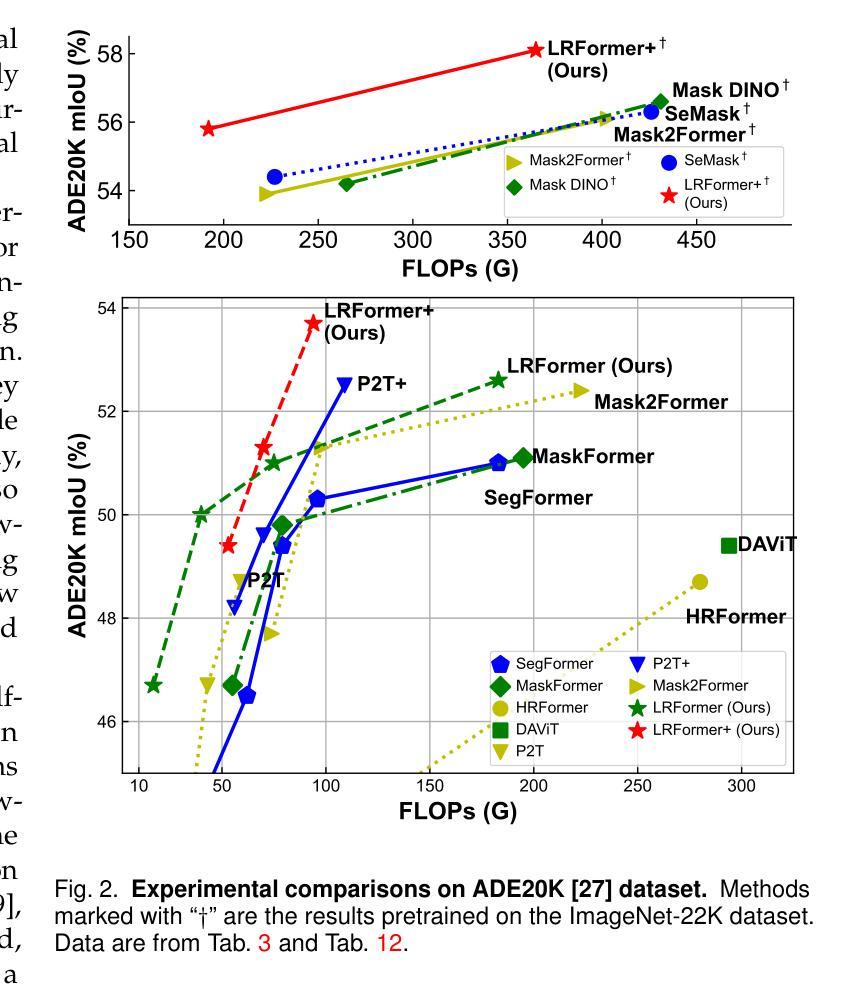
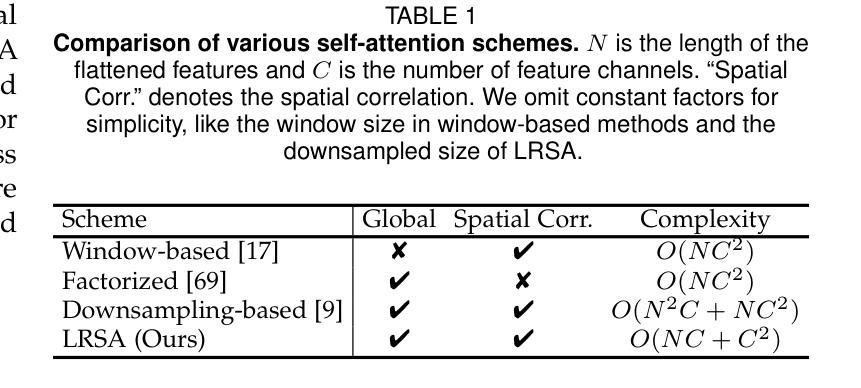
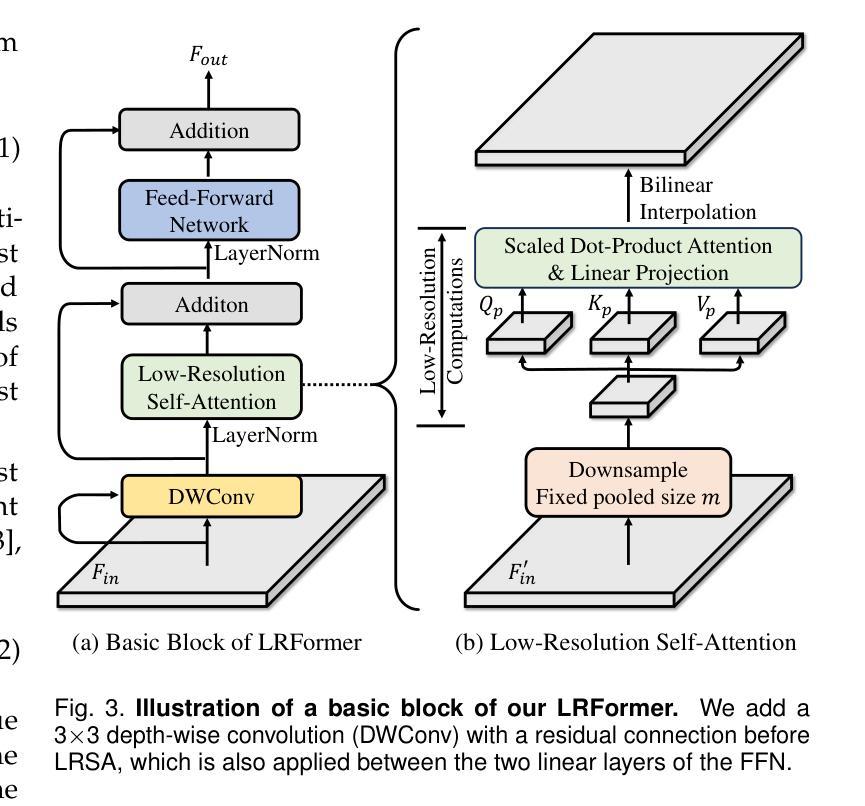
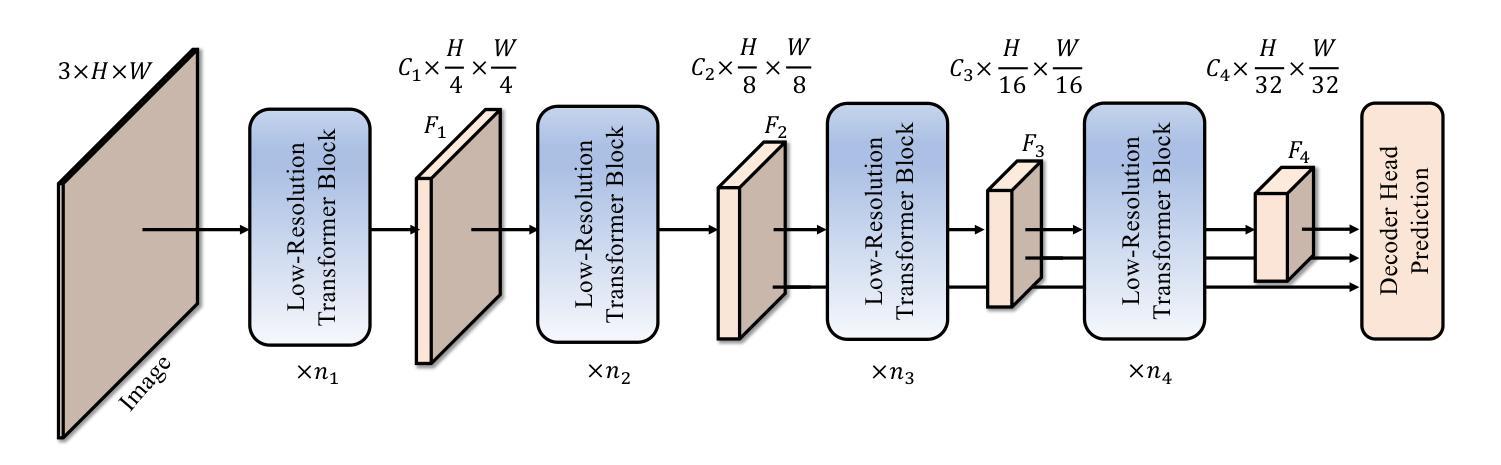
Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high-resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost, i.e., FLOPs. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image’s resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. he code is available at https://github.com/yuhuan-wu/LRFormer.
语义分割任务自然需要高分辨率信息进行像素级分割和全局上下文信息进行类别预测。尽管现有的视觉转换器表现出有希望的性能,但它们通常利用高分辨率上下文建模,导致计算瓶颈。在这项工作中,我们挑战传统智慧,并引入低分辨率自注意(LRSA)机制,以在大大降低计算成本(即FLOPs)的情况下捕获全局上下文。我们的方法涉及在计算自注意力时在固定的低分辨率空间中进行,无论输入图像的分辨率如何,并使用额外的3x3深度可分离卷积来捕获高分辨率空间中的细节。我们通过构建LRFormer来证明我们的LRSA方法的有效性,LRFormer是一种具有编码器-解码器结构的视觉转换器。在ADE20K、COCO-Stuff和Cityscapes数据集上的大量实验表明,LRFormer的性能优于最先进的模型。代码可在https://github.com/yuhuan-wu/LRFormer找到。
论文及项目相关链接
PDF added many experiments. 13 pages, 12 tables, 6 figures
Summary
本文介绍了针对语义分割任务中需要同时处理高分辨率信息和全局上下文信息的问题,提出了一种低分辨率自注意力(LRSA)机制。该机制在低分辨率空间中进行自注意力计算,无论输入图像分辨率如何,都能显著降低计算成本。通过深度为3x3的深度卷积来捕捉高分辨率空间中的细节信息。实验表明,LRSA方法构建的LRFormer在ADE20K、COCO-Stuff和Cityscapes数据集上表现出卓越性能。
Key Takeaways
- 语义分割任务需要同时处理高分辨率信息和全局上下文信息。
- 传统愿景变压器在计算中存在计算瓶颈问题。
- 低分辨率自注意力(LRSA)机制被引入以在显著降低计算成本的同时捕获全局上下文信息。
- LRSA机制在低分辨率空间中进行自注意力计算,不依赖于输入图像的分辨率。
- 通过深度为3x3的深度卷积来捕捉高分辨率空间中的细节信息。
- LRFormer在多个数据集上的性能超过了现有的最佳模型。
点此查看论文截图