⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
Temporal Preference Optimization for Long-Form Video Understanding
Authors:Rui Li, Xiaohan Wang, Yuhui Zhang, Zeyu Wang, Serena Yeung-Levy
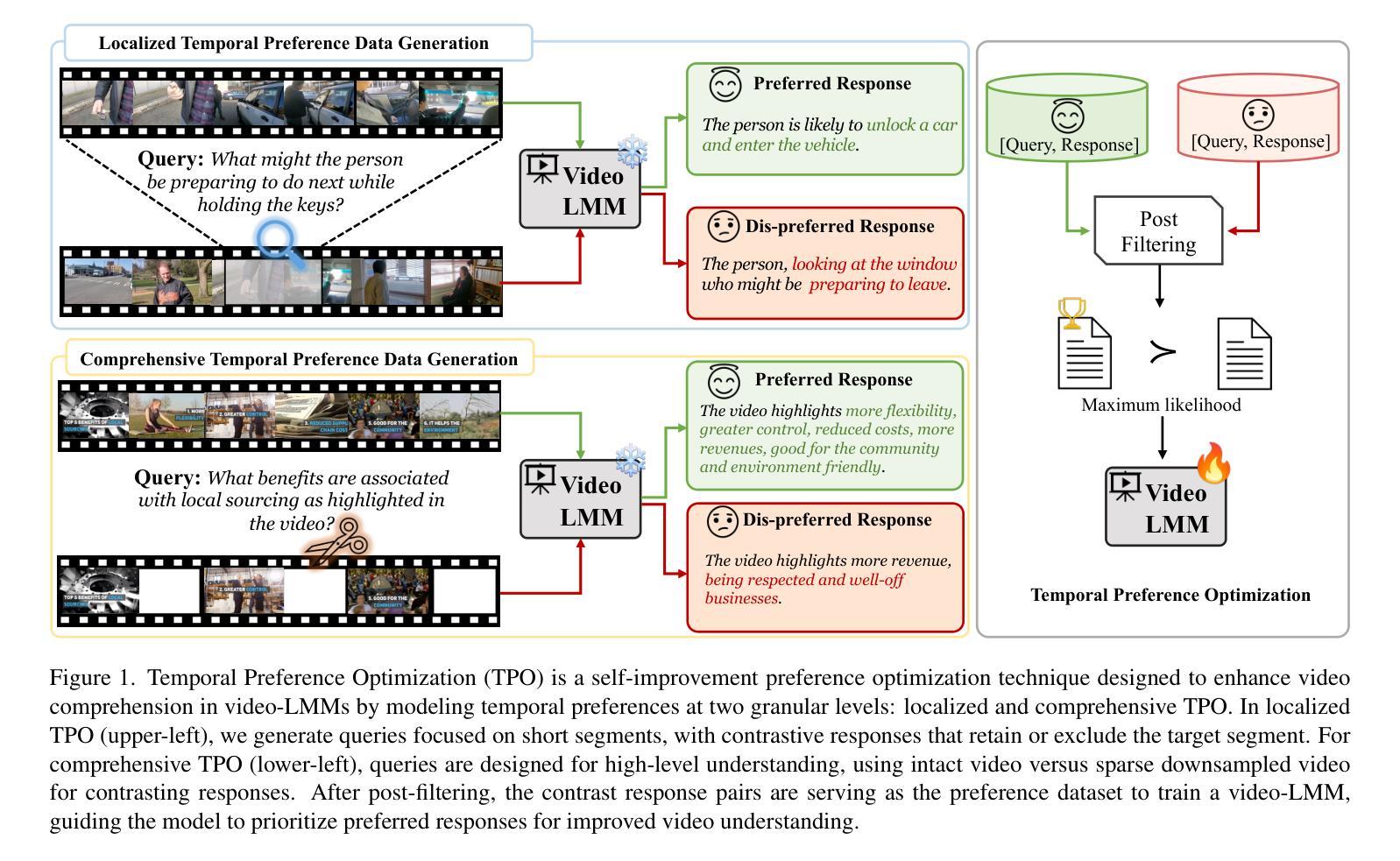
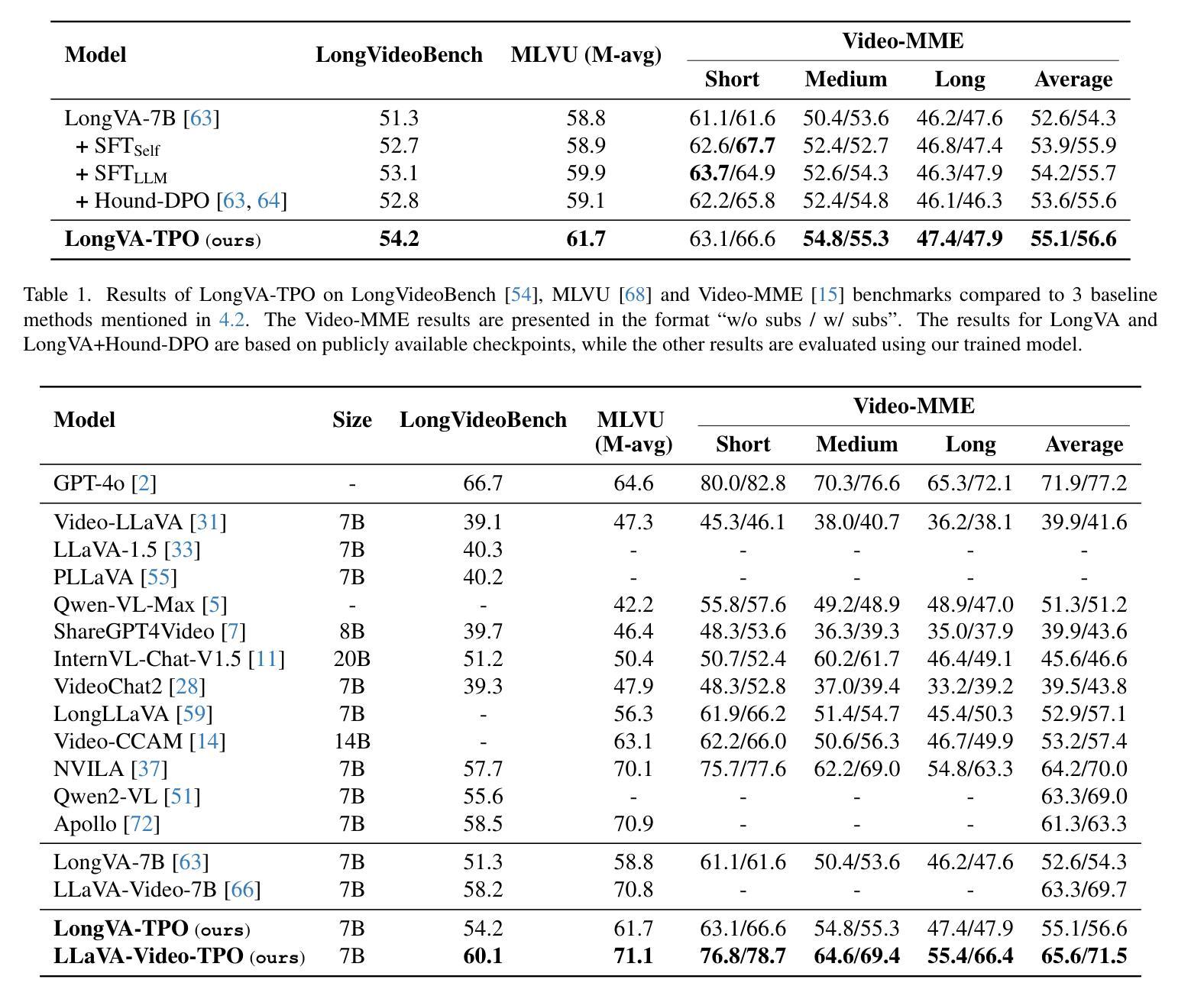
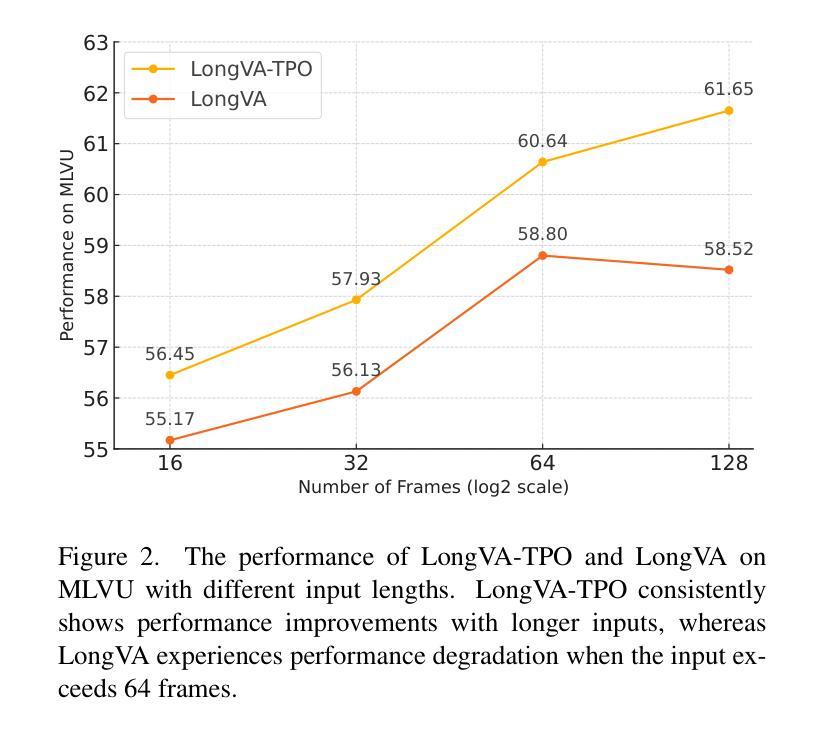
Despite significant advancements in video large multimodal models (video-LMMs), achieving effective temporal grounding in long-form videos remains a challenge for existing models. To address this limitation, we propose Temporal Preference Optimization (TPO), a novel post-training framework designed to enhance the temporal grounding capabilities of video-LMMs through preference learning. TPO adopts a self-training approach that enables models to differentiate between well-grounded and less accurate temporal responses by leveraging curated preference datasets at two granularities: localized temporal grounding, which focuses on specific video segments, and comprehensive temporal grounding, which captures extended temporal dependencies across entire video sequences. By optimizing on these preference datasets, TPO significantly enhances temporal understanding while reducing reliance on manually annotated data. Extensive experiments on three long-form video understanding benchmarks–LongVideoBench, MLVU, and Video-MME–demonstrate the effectiveness of TPO across two state-of-the-art video-LMMs. Notably, LLaVA-Video-TPO establishes itself as the leading 7B model on the Video-MME benchmark, underscoring the potential of TPO as a scalable and efficient solution for advancing temporal reasoning in long-form video understanding. Project page: https://ruili33.github.io/tpo_website.
尽管视频大型多模态模型(video-LMMs)取得了显著进展,但在长视频中实现有效的时序定位仍然是现有模型的挑战。为了解决这一局限性,我们提出了时序偏好优化(TPO),这是一种新型的后训练框架,旨在通过偏好学习提高视频-LMMs的时序定位能力。TPO采用自我训练的方法,使模型能够在两个粒度上利用精选的偏好数据集来区分良好的时序响应和较不准确的时序响应:局部时序定位,侧重于特定视频片段;全面时序定位,捕捉整个视频序列中的扩展时序依赖关系。通过这些偏好数据集进行优化,TPO在增强时序理解的同时,减少了对手动注释数据的依赖。在三个长视频理解基准测试(LongVideoBench、MLVU和Video-MME)上的大量实验证明,TPO在两种最先进的视频LMMs中都是有效的。值得注意的是,LLaVA-Video-TPO在Video-MME基准测试中成为领先的7B模型,突显了TPO作为推进长视频理解中时序推理的可扩展和高效解决方案的潜力。项目页面:https://ruili33.github.io/tpo_website。
论文及项目相关链接
Summary
视频大型多模态模型(video-LMMs)在长篇视频中的时间定位仍存在挑战。为解决这个问题,我们提出了时间偏好优化(TPO)这一新型后训练框架,旨在通过偏好学习提升video-LMMs的时间定位能力。TPO采用自我训练的方式,让模型通过精细筛选的偏好数据集在局部时间定位和全面时间定位两个层面区分精准和不太精准的时间响应。通过这些偏好数据集进行优化,TPO在提升时间理解的同时,减少了对手动标注数据的依赖。在三个长篇视频理解基准测试上的大量实验证明,TPO在两种顶尖的视频大型多模态模型中都表现优异。尤其是LLaVA-Video-TPO,在Video-MME基准测试中表现卓越,显示了TPO在长篇视频理解中推动时间推理的潜力和效率。
Key Takeaways
- 视频大型多模态模型(video-LMMs)在时间定位方面存在挑战,尤其是在长篇视频中。
- 提出了时间偏好优化(TPO)这一新型后训练框架,旨在增强video-LMMs的时间定位能力。
- TPO采用自我训练的方式,利用偏好数据集来提升模型的时间响应能力。
- 偏好数据集在局部时间定位和全面时间定位两个层面帮助模型区分精准和不太精准的时间响应。
- TPO能提升时间理解并减少对手动标注数据的依赖。
- 在多个长篇视频理解基准测试上,TPO表现优异,证明了其有效性。
点此查看论文截图

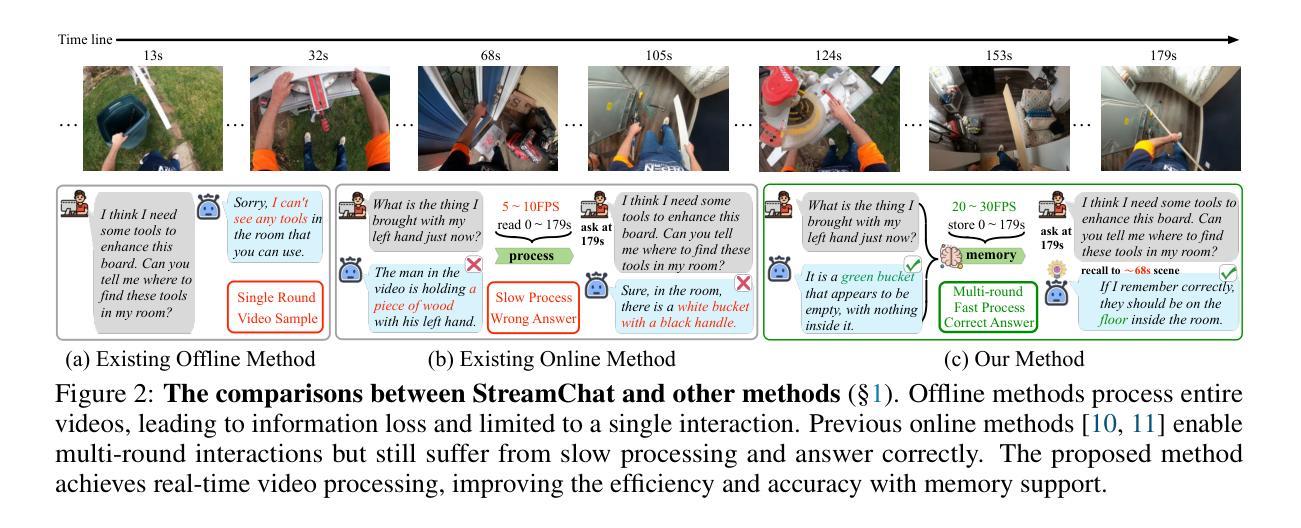
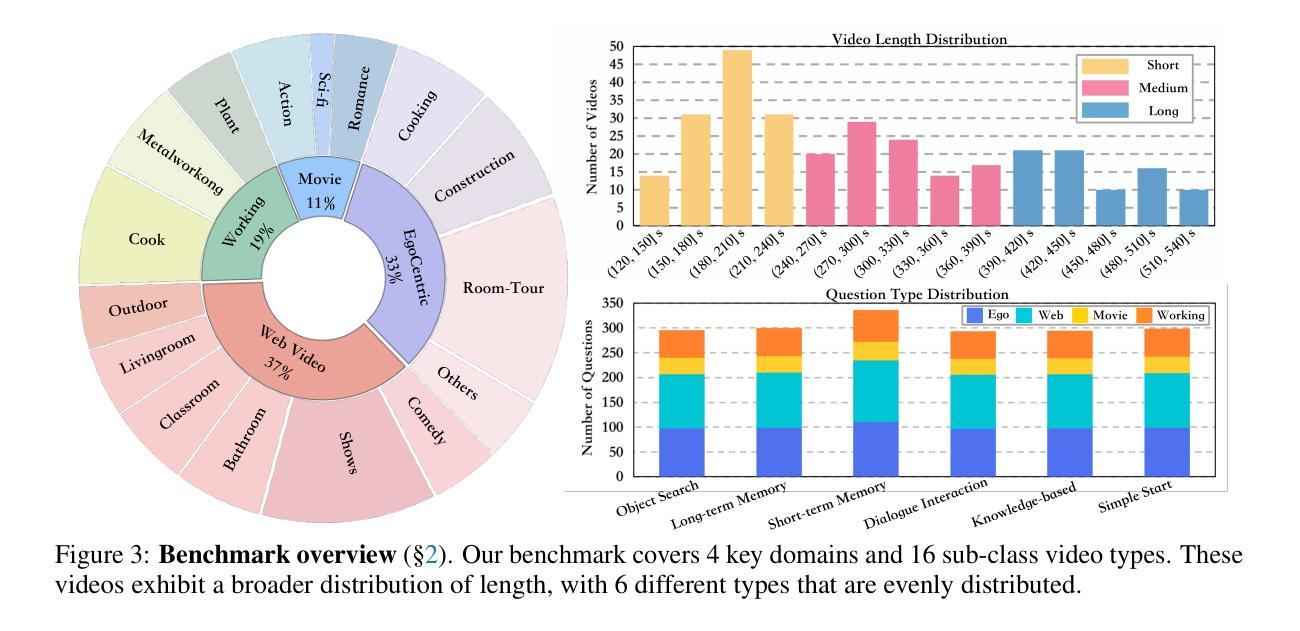
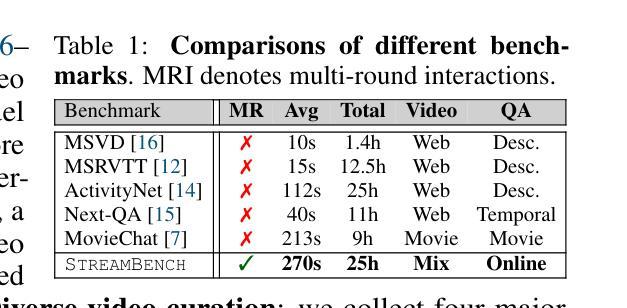
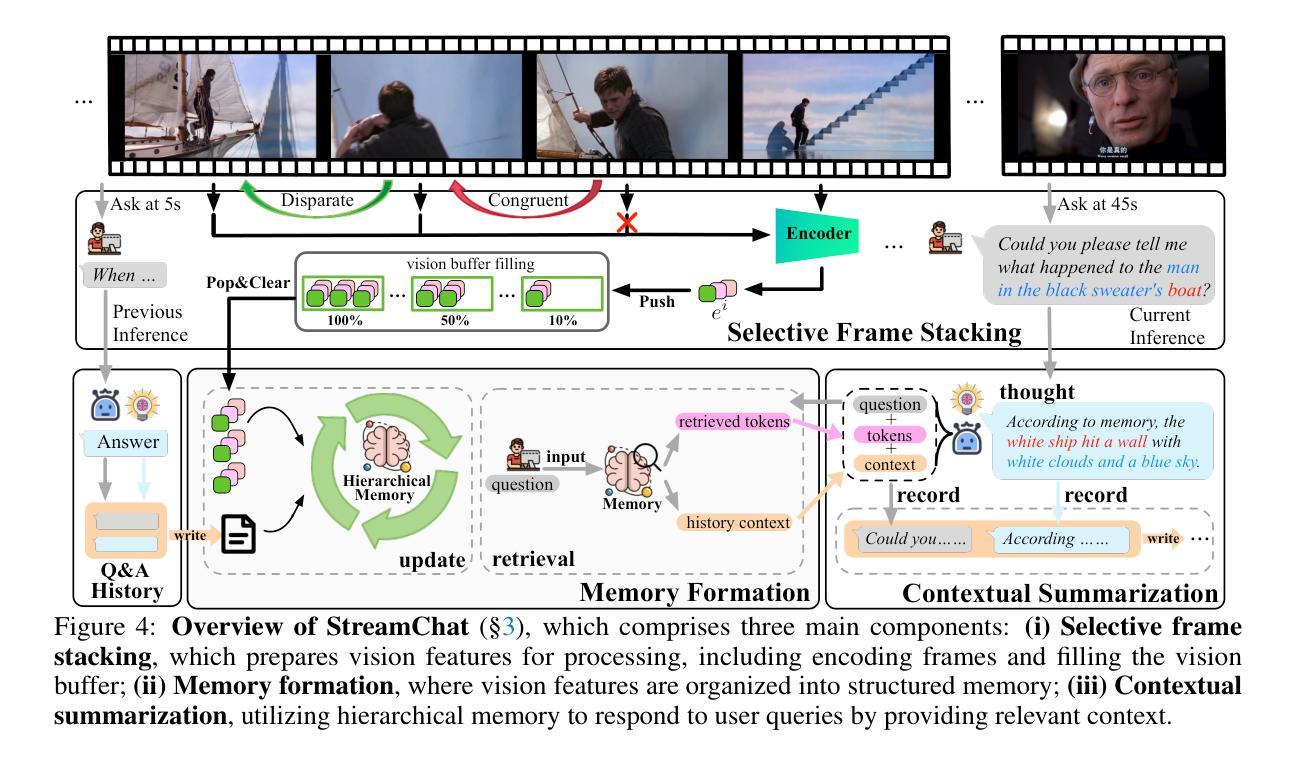
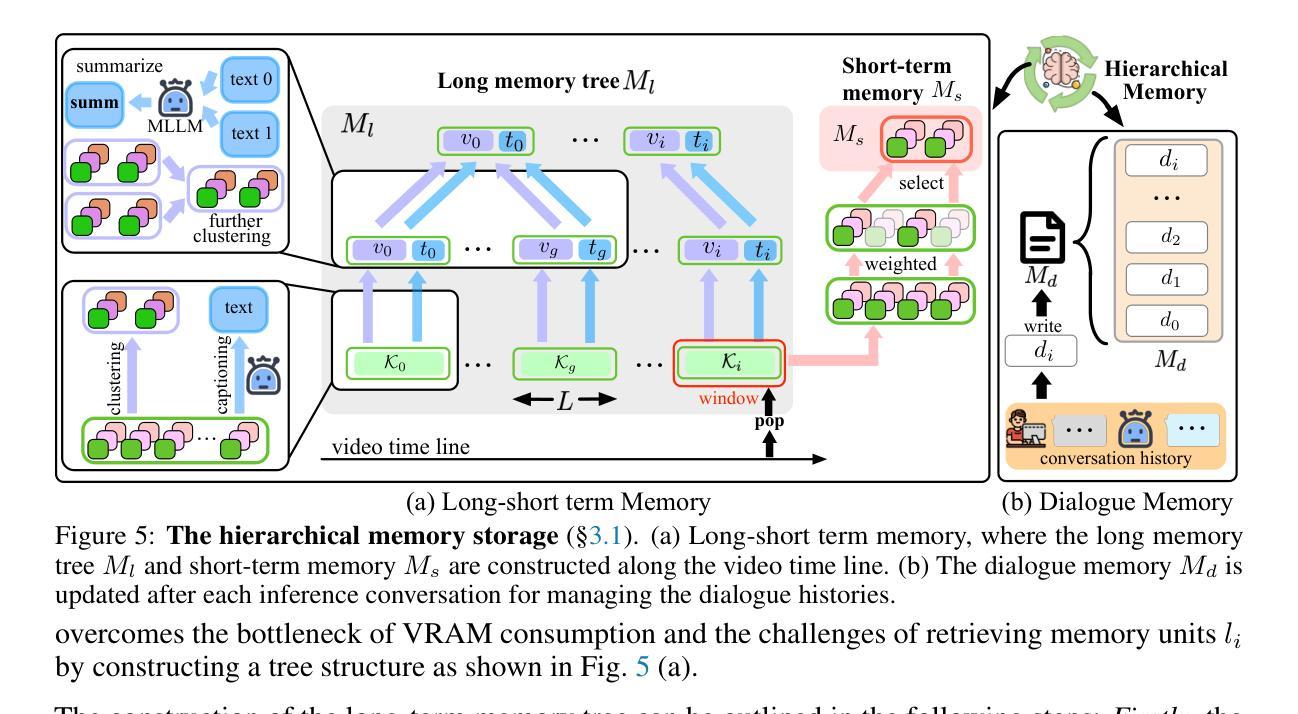
Streaming Video Understanding and Multi-round Interaction with Memory-enhanced Knowledge
Authors:Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, Huchuan Lu
Recent advances in Large Language Models (LLMs) have enabled the development of Video-LLMs, advancing multimodal learning by bridging video data with language tasks. However, current video understanding models struggle with processing long video sequences, supporting multi-turn dialogues, and adapting to real-world dynamic scenarios. To address these issues, we propose StreamChat, a training-free framework for streaming video reasoning and conversational interaction. $\StreamChat$ leverages a novel hierarchical memory system to efficiently process and compress video features over extended sequences, enabling real-time, multi-turn dialogue. Our framework incorporates a parallel system scheduling strategy that enhances processing speed and reduces latency, ensuring robust performance in real-world applications. Furthermore, we introduce StreamBench, a versatile benchmark that evaluates streaming video understanding across diverse media types and interactive scenarios, including multi-turn interactions and complex reasoning tasks. Extensive evaluations on StreamBench and other public benchmarks demonstrate that StreamChat significantly outperforms existing state-of-the-art models in terms of accuracy and response times, confirming its effectiveness for streaming video understanding. Code is available at StreamChat: https://github.com/hmxiong/StreamChat.
近期大型语言模型(LLM)的进步推动了视频LLM的发展,通过桥接视频数据与语言任务,促进了多模态学习。然而,当前视频理解模型在处理长视频序列、支持多轮对话和适应现实动态场景方面存在困难。为了解决这些问题,我们提出了StreamChat,这是一个无需训练的流式视频推理和对话交互框架。StreamChat利用新颖的分层次内存系统,在扩展序列上高效地处理和压缩视频特征,实现实时多轮对话。我们的框架采用并行系统调度策略,提高处理速度,降低延迟,确保在现实世界应用中的稳健性能。此外,我们还推出了StreamBench,这是一个通用基准测试,用于评估不同类型媒体和交互场景下的流式视频理解,包括多轮互动和复杂推理任务。在StreamBench和其他公开基准测试上的广泛评估表明,StreamChat在准确性和响应时间方面显著优于现有最先进的模型,证实了其在流式视频理解方面的有效性。代码可在StreamChat上找到:https://github.com/hmxiong/StreamChat。
论文及项目相关链接
PDF Accepted to ICLR 2025. Code is available at https://github.com/hmxiong/StreamChat
Summary
大型语言模型(LLMs)的最新进展推动了视频LLMs的发展,推动了视频理解和多模态学习的进步。然而,当前视频理解模型在处理长视频序列、支持多轮对话和适应现实动态场景方面存在挑战。为解决这些问题,我们提出了无需训练的StreamChat框架,用于流式视频推理和对话交互。StreamChat利用新颖的分层次内存系统,有效处理和压缩长视频序列的特征,支持实时多轮对话。该框架结合并行系统调度策略,提高处理速度,降低延迟,确保在现实世界应用中的稳健性能。我们还介绍了StreamBench,这是一个通用的基准测试,用于评估不同类型媒体和交互场景下的流式视频理解能力,包括多轮互动和复杂推理任务。在StreamBench和其他公共基准测试上的广泛评估表明,StreamChat在准确性和响应时间方面显著优于现有最先进的模型,证明了其在流式视频理解方面的有效性。
Key Takeaways
- 大型语言模型的最新进展推动了视频LLMs和多模态学习的发展。
- 当前视频理解模型在处理长视频序列、支持多轮对话和适应现实动态场景方面存在挑战。
- StreamChat是一个无需训练的框架,支持流式视频推理和对话交互。
- StreamChat利用新颖的分层次内存系统有效处理和压缩视频特征。
- StreamChat框架结合并行系统调度策略,提高处理速度,降低延迟。
- StreamBench是一个通用的基准测试,用于评估流式视频理解能力。
点此查看论文截图