⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
MultiDreamer3D: Multi-concept 3D Customization with Concept-Aware Diffusion Guidance
Authors:Wooseok Song, Seunggyu Chang, Jaejun Yoo
While single-concept customization has been studied in 3D, multi-concept customization remains largely unexplored. To address this, we propose MultiDreamer3D that can generate coherent multi-concept 3D content in a divide-and-conquer manner. First, we generate 3D bounding boxes using an LLM-based layout controller. Next, a selective point cloud generator creates coarse point clouds for each concept. These point clouds are placed in the 3D bounding boxes and initialized into 3D Gaussian Splatting with concept labels, enabling precise identification of concept attributions in 2D projections. Finally, we refine 3D Gaussians via concept-aware interval score matching, guided by concept-aware diffusion. Our experimental results show that MultiDreamer3D not only ensures object presence and preserves the distinct identities of each concept but also successfully handles complex cases such as property change or interaction. To the best of our knowledge, we are the first to address the multi-concept customization in 3D.
在3D领域中,虽然单概念定制已经得到研究,但多概念定制仍然在很大程度上未被探索。为了解决这个问题,我们提出了MultiDreamer3D,它采用分而治之的方法生成连贯的多概念3D内容。首先,我们使用基于大型语言模型(LLM)的布局控制器生成3D边界框。接下来,选择性点云生成器为每个概念创建粗略的点云。这些点云被放置在3D边界框内,并初始化为带有概念标签的3D高斯Splatting,从而在2D投影中精确识别概念归属。最后,我们通过概念感知区间得分匹配来优化3D高斯,由概念感知扩散引导。我们的实验结果表明,MultiDreamer3D不仅确保了物体的存在并保持了每个概念的独特身份,而且还成功处理了属性变化或交互等复杂情况。据我们所知,我们是首次在3D领域解决多概念定制问题。
论文及项目相关链接
PDF 9 pages
Summary
该研究探讨了尚未被充分研究的“多概念定制”问题,并引入了MultiDreamer3D技术。该技术以分而治之的方式生成连贯的多概念3D内容。通过使用基于LLM的布局控制器生成3D边界框,再通过选择性点云生成器为每个概念创建粗略点云。这些点云被放置在3D边界框内并初始化为带有概念标签的3D高斯Splatting,使得在二维投影中可以精确识别概念归属。最后通过概念感知区间得分匹配细化3D高斯,并由概念感知扩散进行引导。研究结果表明,MultiDreamer3D不仅能确保物体的存在并保留每个概念的独特身份,还能成功处理复杂的场景如属性变化或交互。本研究首次解决了多概念定制的3D问题。
Key Takeaways
以下是文本的主要观点和见解:
- 研究提出了MultiDreamer3D技术来解决多概念定制的缺失问题。
- 该技术可以生成连贯的多概念三维内容,采用了分而治之的策略。
- MultiDreamer3D使用基于LLM的布局控制器生成三维边界框作为基础结构。
- 通过选择性点云生成器为每个概念创建粗略点云,并在三维空间中放置它们。
- 这些点云与概念标签结合,允许精确识别每个概念在二维投影中的位置。
- 使用概念感知间隔得分匹配细化三维高斯,得到更为精确的模型表现。这一过程受到概念感知扩散过程的指导。
- MultiDreamer3D能确保物体的存在和每个概念的独特身份的保留,也能处理复杂场景如属性变化或交互。
点此查看论文截图


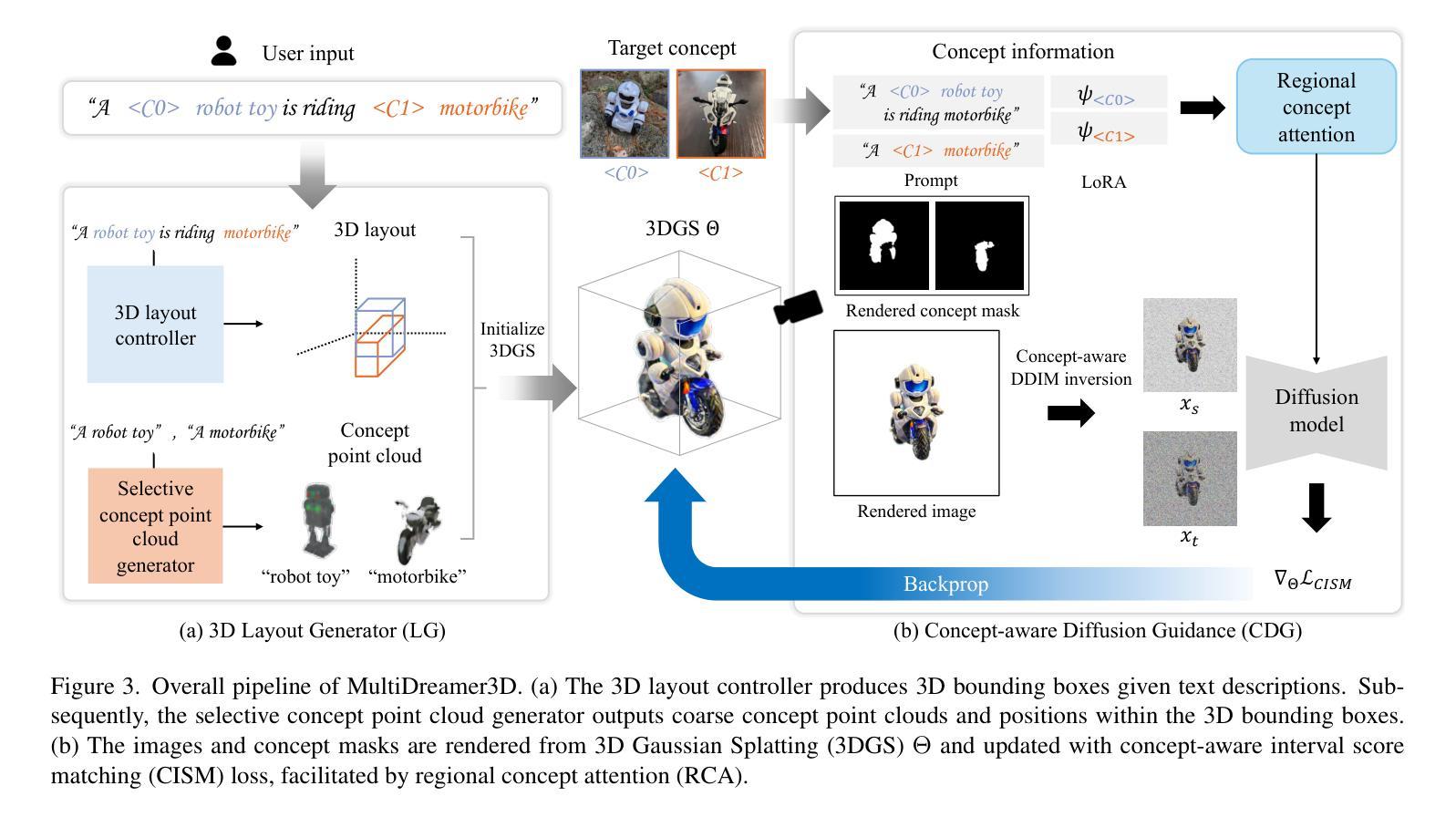
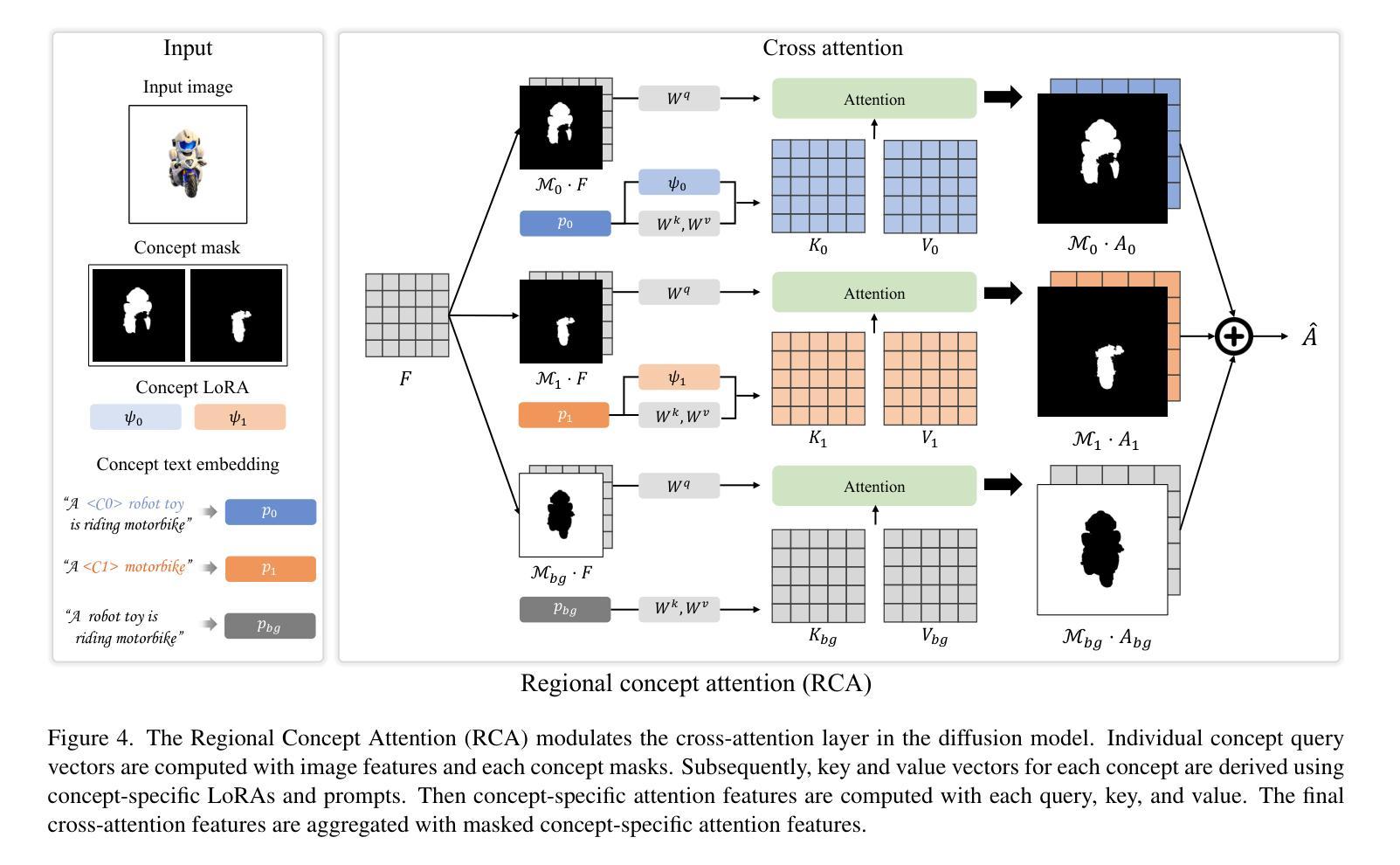

GeomGS: LiDAR-Guided Geometry-Aware Gaussian Splatting for Robot Localization
Authors:Jaewon Lee, Mangyu Kong, Minseong Park, Euntai Kim
Mapping and localization are crucial problems in robotics and autonomous driving. Recent advances in 3D Gaussian Splatting (3DGS) have enabled precise 3D mapping and scene understanding by rendering photo-realistic images. However, existing 3DGS methods often struggle to accurately reconstruct a 3D map that reflects the actual scale and geometry of the real world, which degrades localization performance. To address these limitations, we propose a novel 3DGS method called Geometry-Aware Gaussian Splatting (GeomGS). This method fully integrates LiDAR data into 3D Gaussian primitives via a probabilistic approach, as opposed to approaches that only use LiDAR as initial points or introduce simple constraints for Gaussian points. To this end, we introduce a Geometric Confidence Score (GCS), which identifies the structural reliability of each Gaussian point. The GCS is optimized simultaneously with Gaussians under probabilistic distance constraints to construct a precise structure. Furthermore, we propose a novel localization method that fully utilizes both the geometric and photometric properties of GeomGS. Our GeomGS demonstrates state-of-the-art geometric and localization performance across several benchmarks, while also improving photometric performance.
在机器人技术和自动驾驶中,映射和定位是核心问题。近期三维高斯摊铺(3DGS)技术的进展通过渲染逼真的图像实现了精确的三维映射和场景理解。然而,现有的三维高斯铺设方法在构建真实反映现实世界尺度和几何特征的地图时常常遇到困难,这降低了定位性能。为了克服这些局限性,我们提出了一种新型的三维高斯铺设方法,称为几何感知高斯铺设(GeomGS)。该方法通过概率方法将激光雷达数据完全集成到三维高斯基本单元中,不同于仅使用激光雷达作为初始点或引入简单约束的高斯点的方法。为此,我们引入了几何置信度得分(GCS),用于确定每个高斯点的结构可靠性。GCS在概率距离约束下与高斯体同时优化,以构建精确的结构。此外,我们提出了一种新型定位方法,充分利用了GeomGS的几何和光度特性。我们的GeomGS在多个基准测试中展现出最先进的几何和定位性能,同时也提高了光度性能。
论文及项目相关链接
PDF Preprint, Under review
Summary
3DGS技术在机器人和自动驾驶领域中的映射和定位问题中发挥着重要作用。最近,一种名为几何感知高斯拼贴(GeomGS)的新型3DGS方法被提出,它通过概率方法全面整合激光雷达数据到三维高斯原始数据中,解决了现有方法难以准确反映真实世界尺度和几何结构的局限性。该方法通过引入几何置信度评分(GCS)来识别每个高斯点的结构可靠性,并优化高斯和GCS以构建精确结构。此外,GeomGS充分利用了地理几何和光度特性,提出了新型定位方法,实现了卓越的几何和定位性能。
Key Takeaways
- 3DGS技术在机器人和自动驾驶的映射与定位中起重要作用。
- 现有的3DGS方法在构建真实世界尺度和几何结构的3D地图时面临挑战。
- 新方法GeomGS通过整合激光雷达数据到三维高斯原始数据中,解决了上述问题。
- GeomGS引入几何置信度评分(GCS)来识别每个高斯点的结构可靠性。
- GCS和高斯在概率距离约束下同时优化,以构建精确结构。
- GeomGS充分利用地理几何和光度特性,提出新型定位方法。
点此查看论文截图

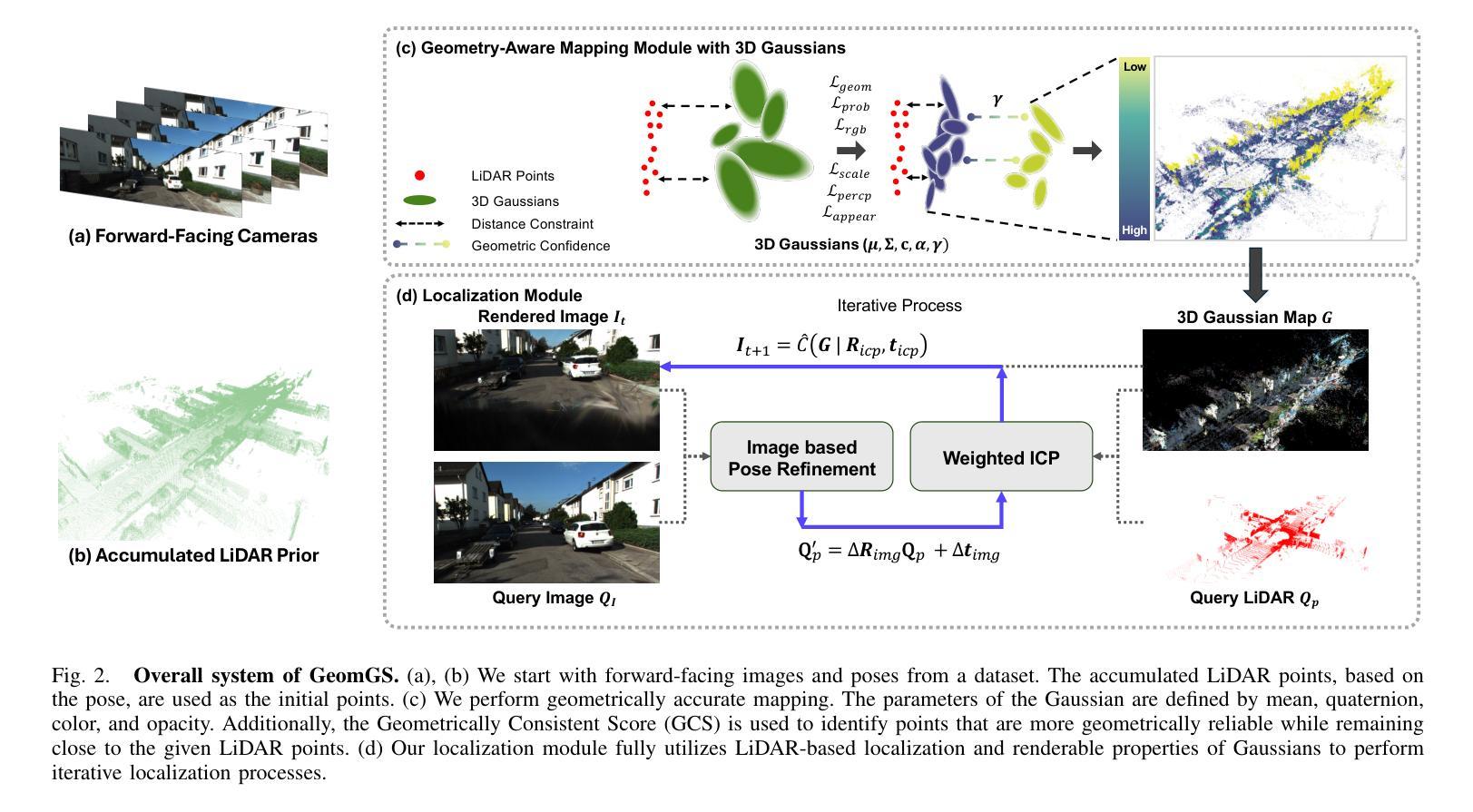
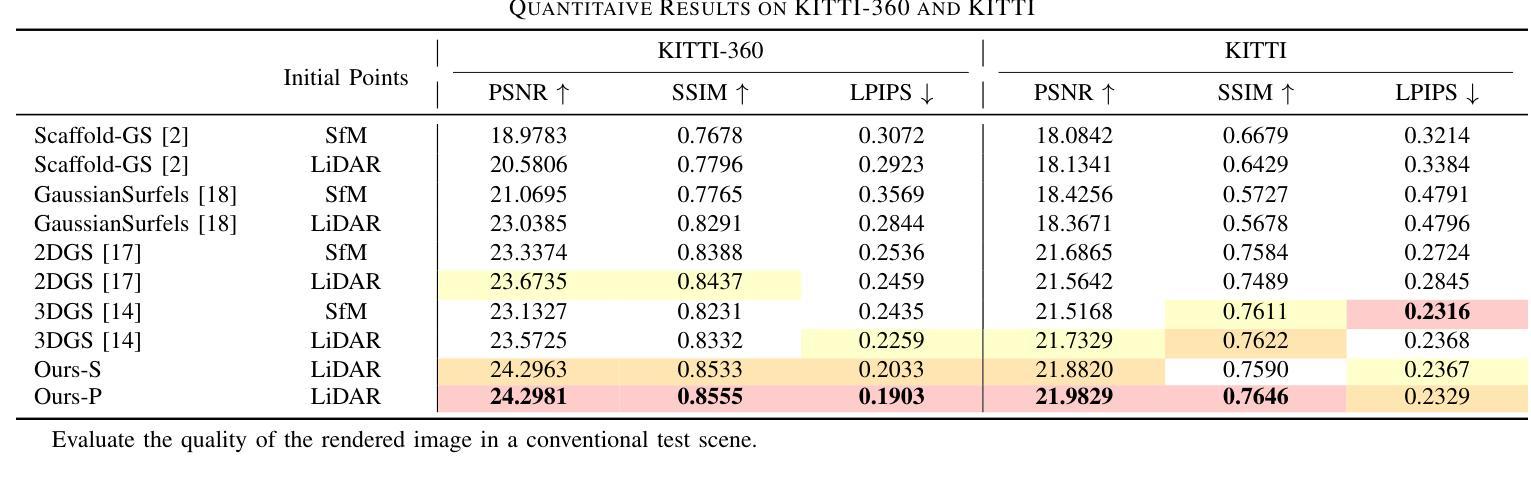
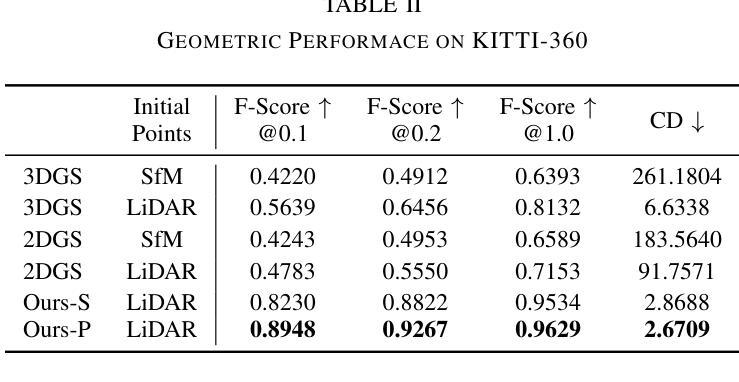

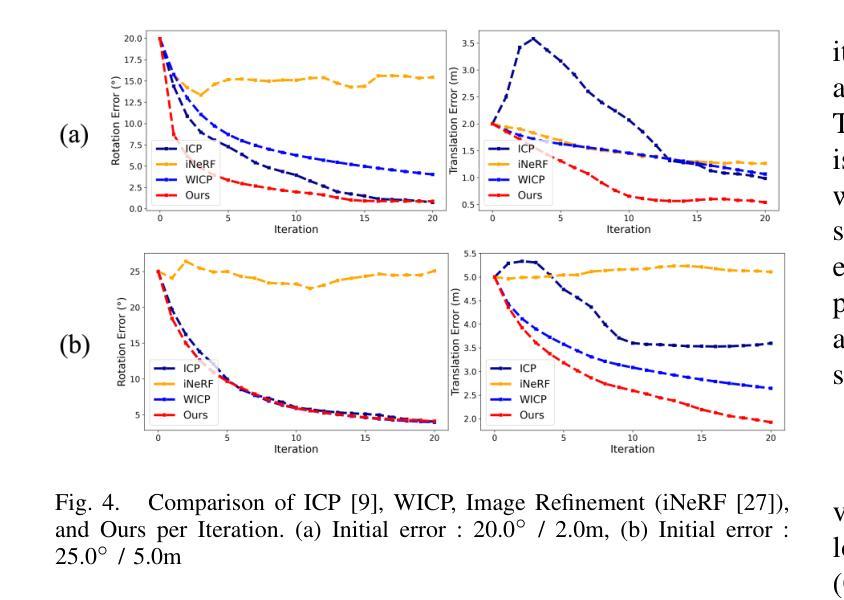
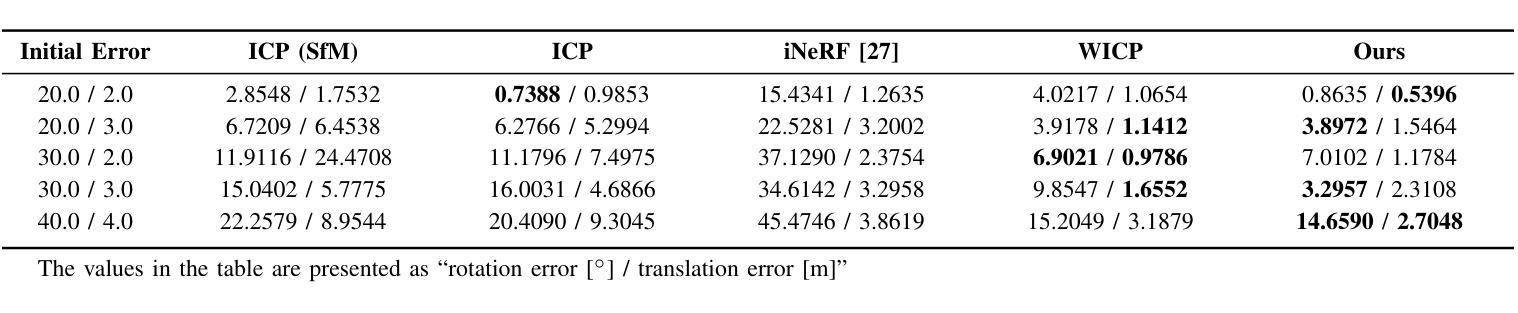
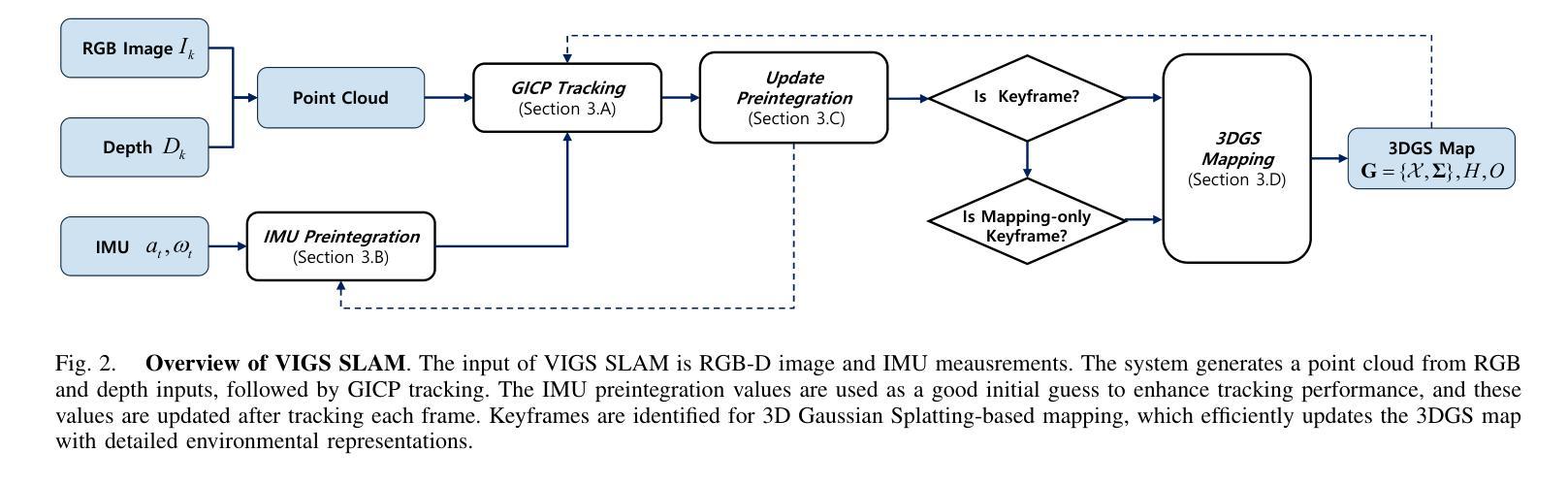
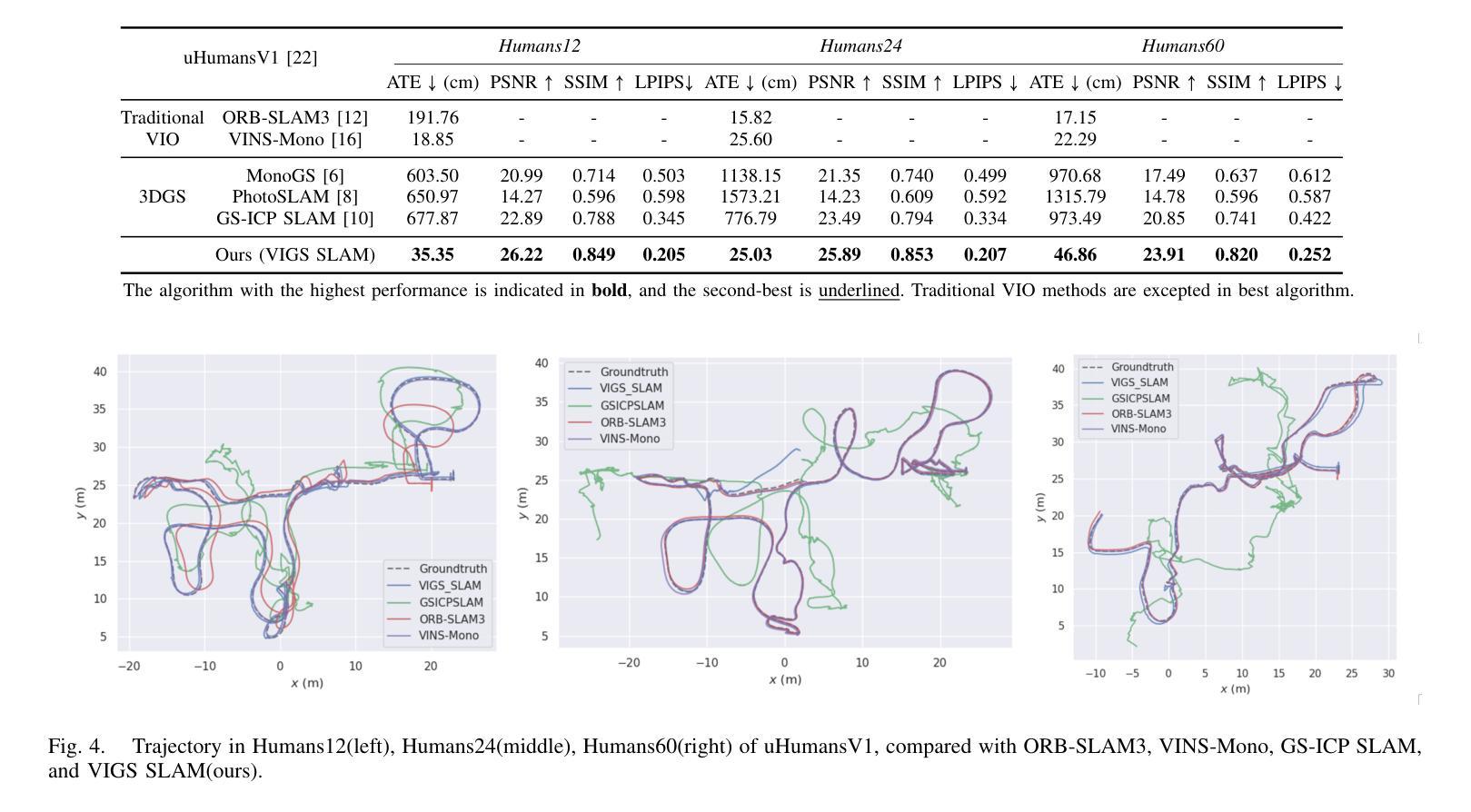
VIGS SLAM: IMU-based Large-Scale 3D Gaussian Splatting SLAM
Authors:Gyuhyeon Pak, Euntai Kim
Recently, map representations based on radiance fields such as 3D Gaussian Splatting and NeRF, which excellent for realistic depiction, have attracted considerable attention, leading to attempts to combine them with SLAM. While these approaches can build highly realistic maps, large-scale SLAM still remains a challenge because they require a large number of Gaussian images for mapping and adjacent images as keyframes for tracking. We propose a novel 3D Gaussian Splatting SLAM method, VIGS SLAM, that utilizes sensor fusion of RGB-D and IMU sensors for large-scale indoor environments. To reduce the computational load of 3DGS-based tracking, we adopt an ICP-based tracking framework that combines IMU preintegration to provide a good initial guess for accurate pose estimation. Our proposed method is the first to propose that Gaussian Splatting-based SLAM can be effectively performed in large-scale environments by integrating IMU sensor measurements. This proposal not only enhances the performance of Gaussian Splatting SLAM beyond room-scale scenarios but also achieves SLAM performance comparable to state-of-the-art methods in large-scale indoor environments.
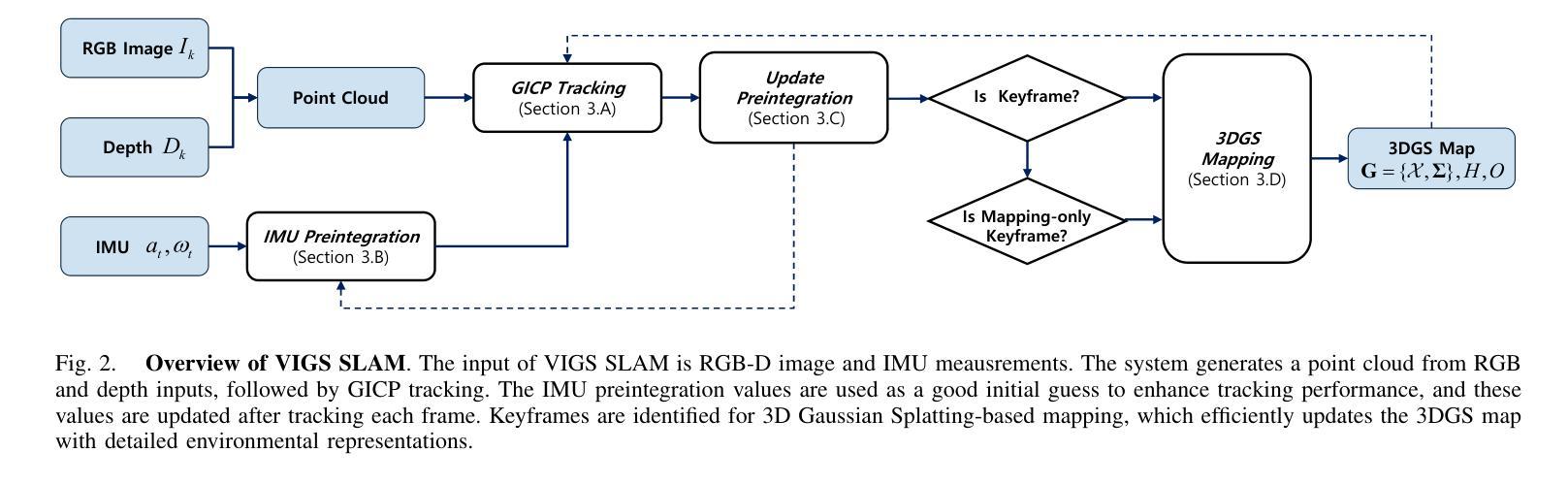
最近,基于辐射场(如三维高斯贴图和NeRF)的地图表示方法因其对真实场景的出色描绘而备受关注,并尝试将其与SLAM技术相结合。虽然这些方法可以构建高度逼真的地图,但在大规模环境下实现SLAM仍然是一个挑战,因为它们需要大量高斯图像用于映射和相邻图像作为关键帧进行跟踪。我们提出了一种新型的基于三维高斯贴图的SLAM方法——VIGS SLAM,它利用RGB-D和IMU传感器的融合,适用于大规模室内环境。为了降低基于3DGS的跟踪的计算负载,我们采用了一种基于ICP的跟踪框架,结合IMU预积分,为准确的姿态估计提供良好的初始猜测。我们提出的方法是第一个提出基于高斯贴图的SLAM可以通过整合IMU传感器测量在大规模环境中有效进行的。这一提议不仅提高了高斯贴图SLAM在超出房间规模场景中的性能,而且在大型室内环境中实现了与最新技术相当水平的SLAM性能。
论文及项目相关链接
PDF 7 pages, 5 figures
Summary
近期,基于辐射场地图表示的方法,如3D高斯喷涂和NeRF,因其在真实感描绘方面的优势而备受关注,并尝试与SLAM结合。为在大规模室内环境中实现高效的SLAM,我们提出了一种新型的3D高斯喷涂SLAM方法——VIGS SLAM,它融合了RGB-D和IMU传感器的数据。通过采用基于ICP的跟踪框架并结合IMU预积分,我们减少了3DGS跟踪的计算负担,为姿态估计提供了良好的初步猜测。该研究是首次提出在大规模环境中通过整合IMU传感器测量有效地进行高斯喷涂SLAM的尝试,不仅提升了高斯喷涂SLAM在超越房间规模场景中的性能,而且在大型室内环境中实现了与最先进的SLAM方法相当的性。
Key Takeaways
- 基于辐射场(如3D高斯喷涂和NeRF)的地图表示方法在真实感描绘上具有优势,正受到关注。
- 尝试将此类方法与SLAM结合以在大规模室内环境中实现高效地图构建。
- 提出了一种新型的3D高斯喷涂SLAM方法——VIGS SLAM,融合了RGB-D和IMU传感器数据。
- 采用基于ICP的跟踪框架减少计算负担,结合IMU预积分进行姿态估计。
- VIGS SLAM能在大规模环境中有效进行高斯喷涂SLAM,超越了房间规模场景的应用。
- VIGS SLAM性能与最先进的SLAM方法在大型室内环境中相当。
点此查看论文截图




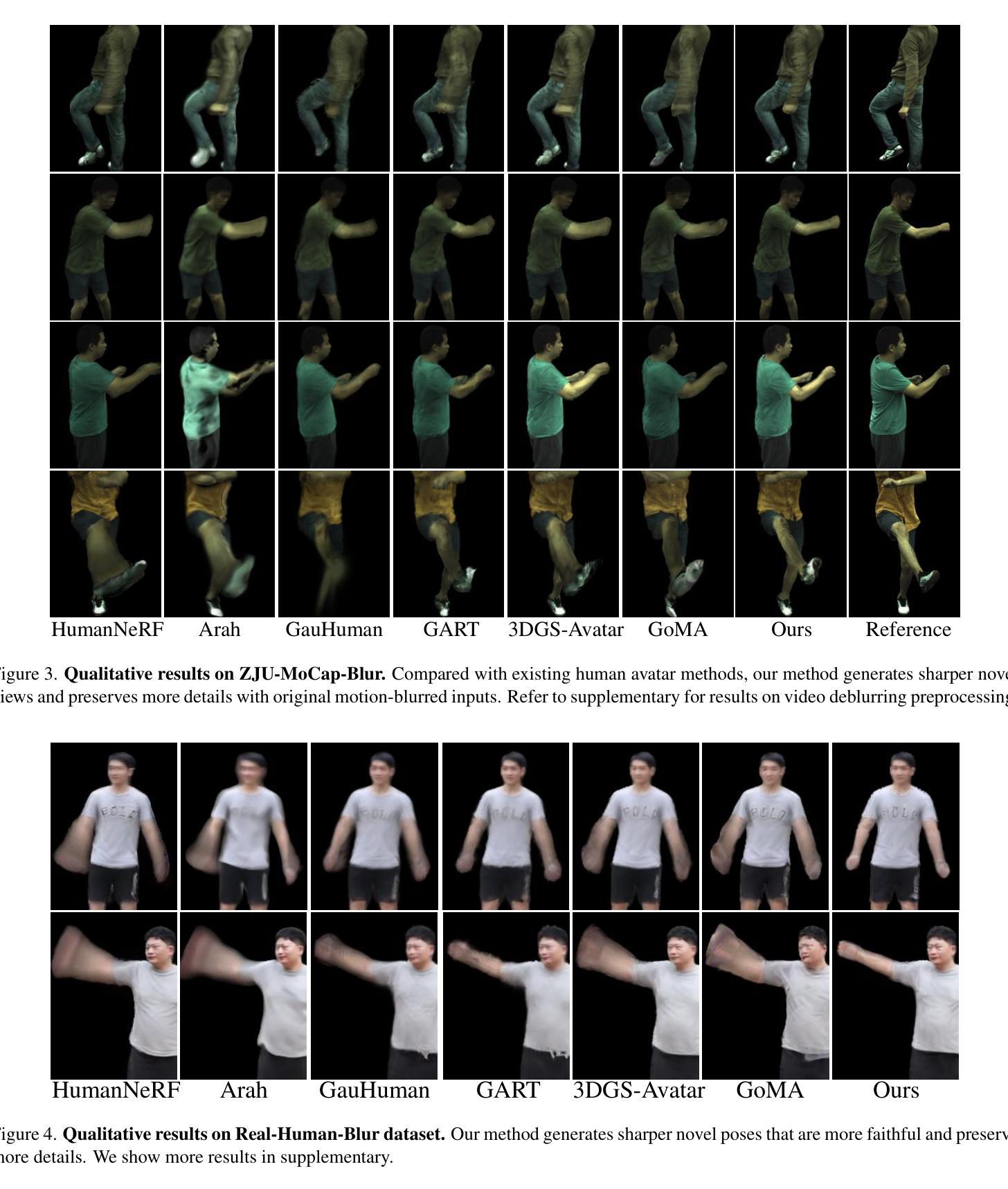
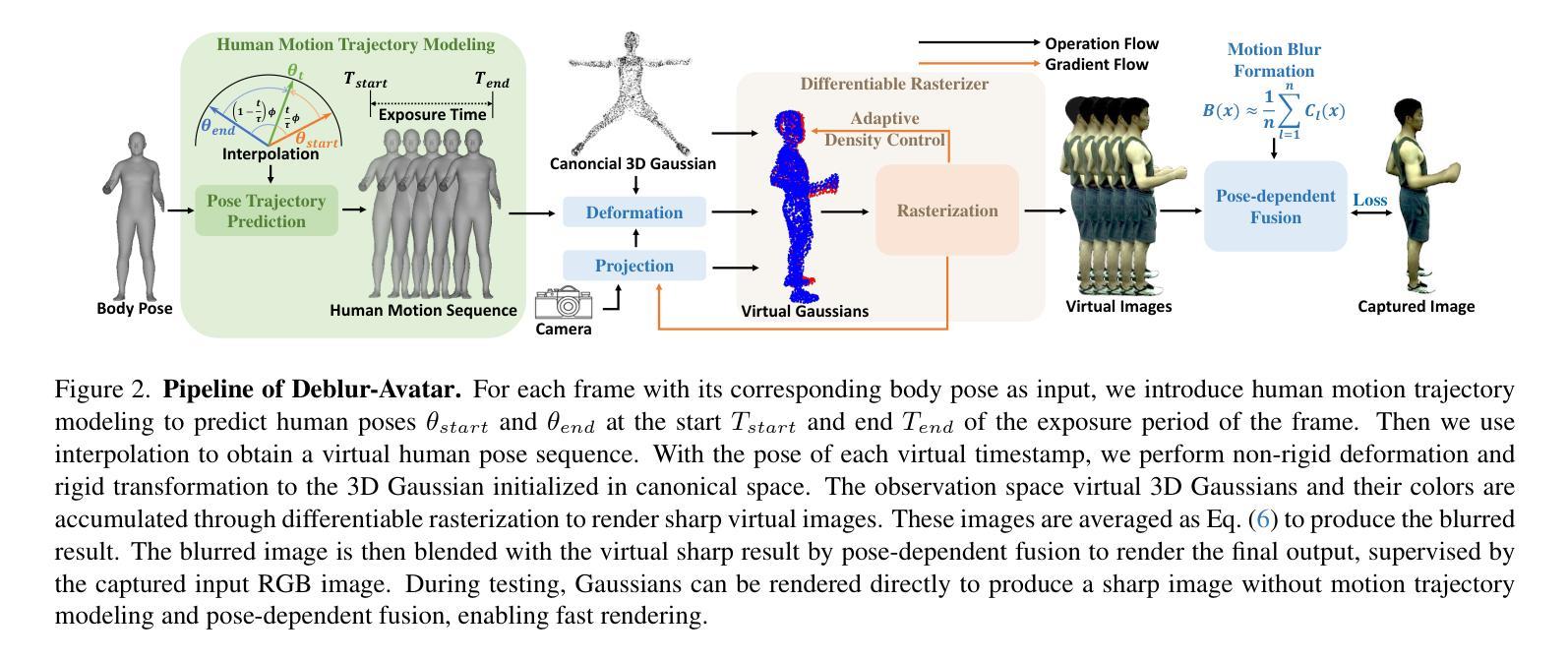
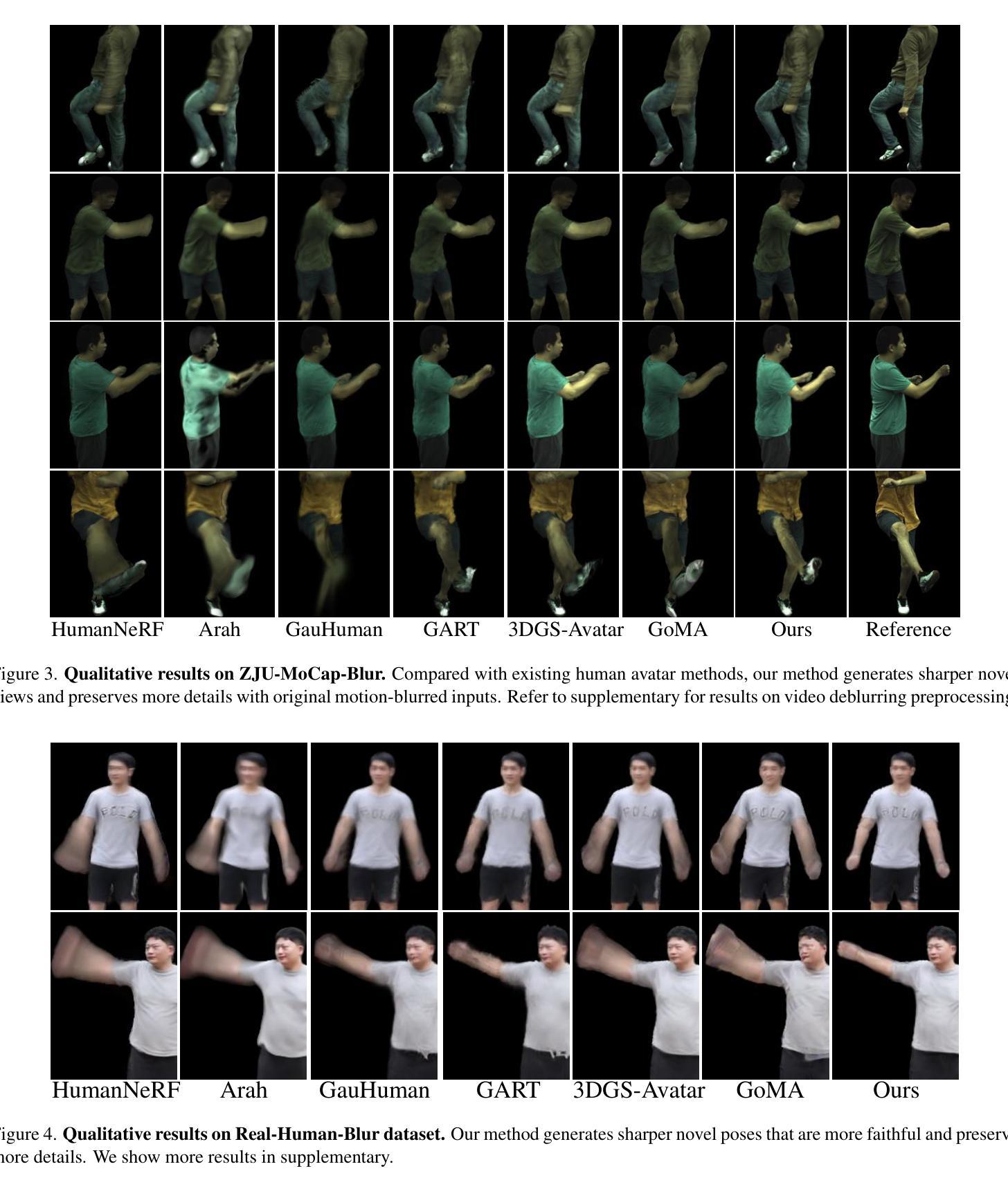
Deblur-Avatar: Animatable Avatars from Motion-Blurred Monocular Videos
Authors:Xianrui Luo, Juewen Peng, Zhongang Cai, Lei Yang, Fan Yang, Zhiguo Cao, Guosheng Lin
We introduce Deblur-Avatar, a novel framework for modeling high-fidelity, animatable 3D human avatars from motion-blurred monocular video inputs. Motion blur is prevalent in real-world dynamic video capture, especially due to human movements in 3D human avatar modeling. Existing methods either (1) assume sharp image inputs, failing to address the detail loss introduced by motion blur, or (2) mainly consider blur by camera movements, neglecting the human motion blur which is more common in animatable avatars. Our proposed approach integrates a human movement-based motion blur model into 3D Gaussian Splatting (3DGS). By explicitly modeling human motion trajectories during exposure time, we jointly optimize the trajectories and 3D Gaussians to reconstruct sharp, high-quality human avatars. We employ a pose-dependent fusion mechanism to distinguish moving body regions, optimizing both blurred and sharp areas effectively. Extensive experiments on synthetic and real-world datasets demonstrate that Deblur-Avatar significantly outperforms existing methods in rendering quality and quantitative metrics, producing sharp avatar reconstructions and enabling real-time rendering under challenging motion blur conditions.
我们介绍了Deblur-Avatar,这是一个从运动模糊的单目视频输入中建立高保真、可动画的3D人类角色的新型框架。运动模糊在真实世界的动态视频捕捉中普遍存在,特别是在3D人类角色建模中。现有方法要么(1)假定图像输入是清晰的,无法解决运动模糊造成的细节损失问题,要么(2)主要考虑由相机运动引起的模糊,而忽略了在可动画角色中更常见的运动模糊。我们提出的方法将基于人体运动的运动模糊模型集成到3D高斯拼贴(3DGS)中。通过显式建模曝光过程中的人体运动轨迹,我们联合优化轨迹和3D高斯分布,重建清晰、高质量的人类角色。我们采用基于姿势的融合机制来区分身体运动区域,有效优化模糊和清晰区域。在合成数据集和真实世界数据集上的大量实验表明,Deblur-Avatar在渲染质量和定量指标方面显著优于现有方法,能够生成清晰的角色重建,并在具有挑战性的运动模糊条件下实现实时渲染。
论文及项目相关链接
摘要
本文提出Deblur-Avatar框架,可从运动模糊的单目视频输入中建立高保真、可动画的3D人类角色模型。针对现实世界中动态视频捕获中普遍存在的运动模糊问题,尤其是3D人类角色建模中的运动模糊问题,现有方法未能解决由运动模糊引起的细节损失或仅考虑相机运动引起的模糊而忽略更常见的角色运动模糊。本文方法将基于人物运动的运动模糊模型集成到3D高斯拼贴(3DGS)中,通过显式建模曝光期间的人物运动轨迹,对轨迹和3D高斯进行联合优化,以重建清晰的高质量人类角色。采用姿态相关融合机制区分运动区域,对模糊和清晰区域进行有效优化。在合成和真实数据集上的大量实验表明,Deblur-Avatar在渲染质量和定量指标上显著优于现有方法,可生成清晰的角色重建并在具有挑战性的运动模糊条件下实现实时渲染。
关键见解
- Deblur-Avatar是一个针对运动模糊单目视频输入的高保真、可动画的3D人类角色建模的新框架。
- 现有方法未能解决由运动模糊引起的细节损失问题或在角色运动模糊方面表现不足。
- 该方法集成了基于人物运动的运动模糊模型到3D高斯拼贴中,并优化轨迹和3D高斯进行清晰角色重建。
- 采用姿态相关融合机制来区分运动区域,优化模糊和清晰区域。
- 该方法在合成和真实数据集上的表现优于现有方法,在渲染质量和定量指标上有所提升。
- Deblur-Avatar能够处理具有挑战性的运动模糊条件下的实时渲染。
- 该研究为从运动模糊的视频中创建高质量、可动画的3D人类角色建模提供了新思路。
点此查看论文截图

3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Authors:Xiaoyang Lyu, Yang-Tian Sun, Yi-Hua Huang, Xiuzhe Wu, Ziyi Yang, Yilun Chen, Jiangmiao Pang, Xiaojuan Qi
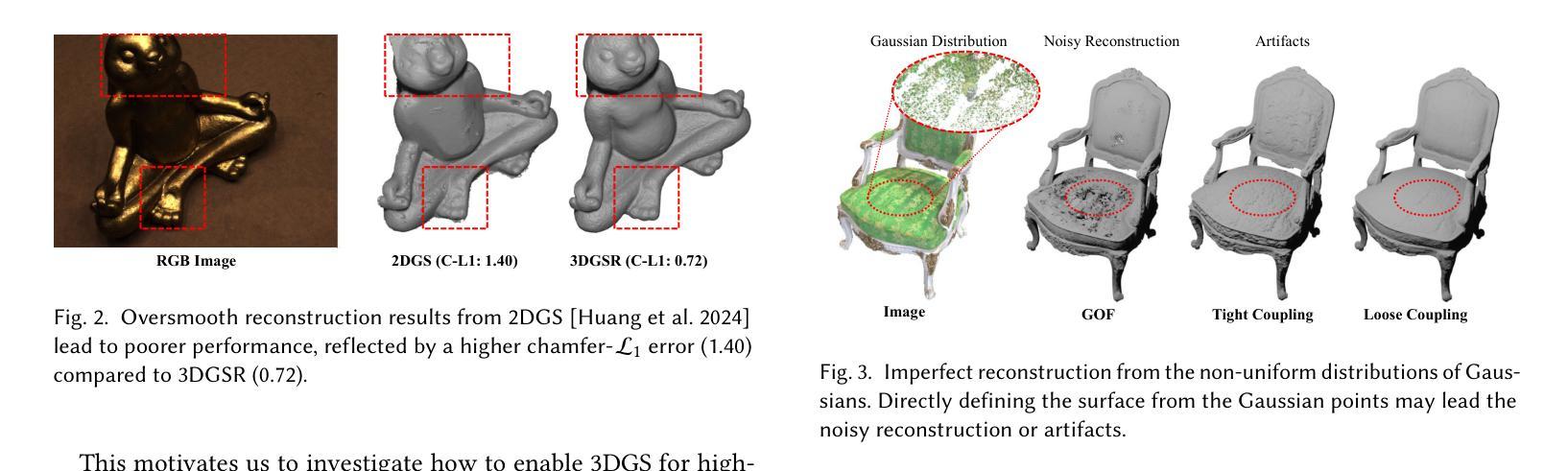
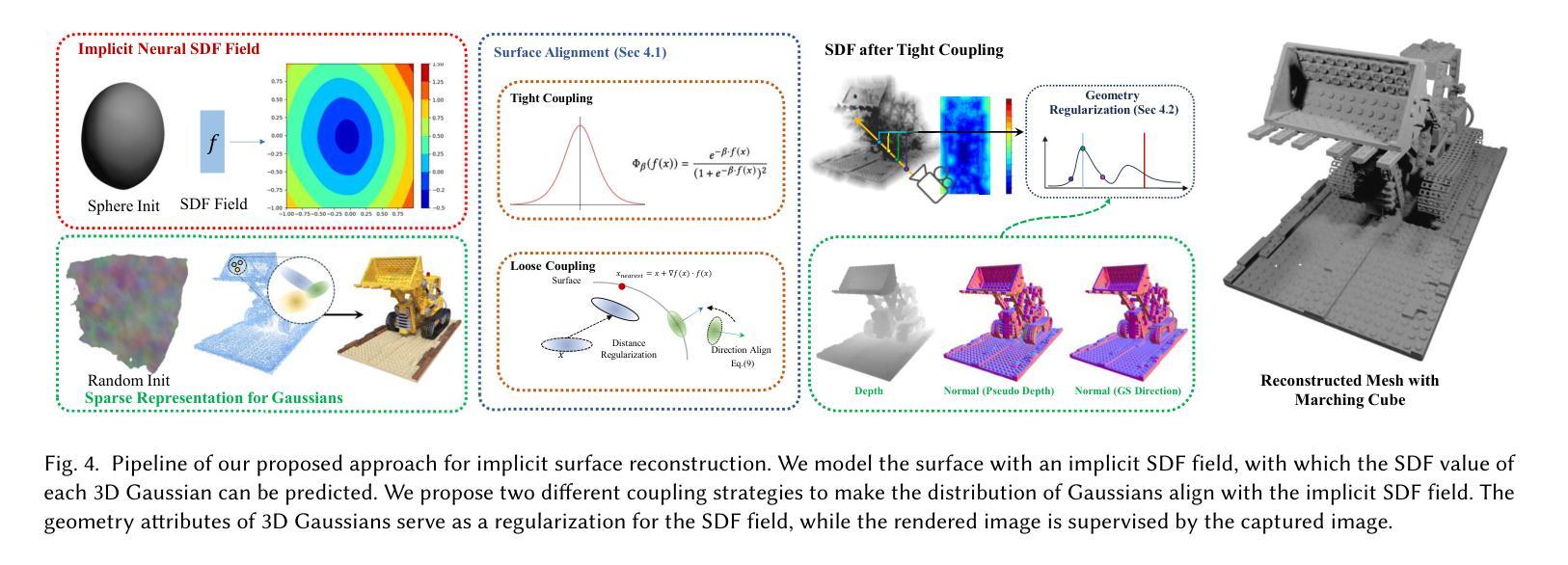
In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians’ opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
本文中,我们提出了一种基于三维高斯贴图(3DGS)的隐式表面重建方法,即3DGSR。该方法能够在保持3DGS的高效率和渲染质量的同时,实现具有精细细节的高精度三维重建。主要思想是在三维高斯内嵌入隐式有向距离场(SDF),使它们能够对齐并联合优化。首先,我们引入了一个可微的SDF到透明度转换函数,该函数将SDF值转换为相应的高斯透明度。此函数连接了SDF和三维高斯,允许统一优化并对三维高斯施加表面约束。在训练过程中,优化三维高斯为SDF学习提供了监督信号,使重建具有精细细节。然而,这仅为位于高斯占用位置处的SDF提供了稀疏监督信号,对于学习连续SDF来说是不够的。为了解决这个问题,我们引入了体积渲染,并使渲染的几何属性(深度、法线)与从三维高斯中得出的属性保持一致。这种一致性正则化向未被离散三维高斯覆盖的位置引入监督信号,有效地消除了高斯采样范围外的冗余表面。我们的大量实验结果表明,我们的3DGSR方法能够实现高质量的三维表面重建,同时保持了3DGS的高效率和渲染质量。此外,我们的方法与领先的表面重建技术相比表现良好,同时提供了更有效的学习过程以及更好的渲染质量。代码将在https://github.com/CVMI-Lab/3DGSR上发布。
论文及项目相关链接
Summary
本文介绍了一种基于三维高斯拼接(3DGS)的隐式表面重建方法,即3DGSR。该方法能够在保持3DGS的高效率和渲染质量的同时,实现具有精细细节的高精度三维重建。其核心在于将隐式符号距离场(SDF)融入三维高斯,实现对其对齐和联合优化。通过引入可微的SDF-to-opacity转换函数,将SDF值转换为对应的高斯不透明度,连接SDF和三维高斯,实现统一优化和三维高斯表面约束的施加。此外,本文还通过体积渲染和几何属性一致性正则化,解决了稀疏监督信号的问题,有效消除了高斯采样范围外的冗余表面。实验结果表明,3DGSR方法能够实现高质量的三维表面重建,与领先的表面重建技术相比具有更高的效率和更好的渲染质量。
Key Takeaways
- 引入了一种基于三维高斯拼接(3DGS)的隐式表面重建方法(3DGSR),可实现高精度三维重建并保留细微细节。
- 将隐式符号距离场(SDF)融入三维高斯,实现对齐和联合优化。
- 通过可微的SDF-to-opacity转换函数连接SDF和三维高斯,实现统一优化和施加表面约束。
- 利用体积渲染和几何属性一致性正则化解决稀疏监督信号问题。
- 有效消除高斯采样范围外的冗余表面。
- 实验结果证明,3DGSR方法可实现高质量的三维表面重建。
点此查看论文截图