⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
IMAGINE-E: Image Generation Intelligence Evaluation of State-of-the-art Text-to-Image Models
Authors:Jiayi Lei, Renrui Zhang, Xiangfei Hu, Weifeng Lin, Zhen Li, Wenjian Sun, Ruoyi Du, Le Zhuo, Zhongyu Li, Xinyue Li, Shitian Zhao, Ziyu Guo, Yiting Lu, Peng Gao, Hongsheng Li
With the rapid development of diffusion models, text-to-image(T2I) models have made significant progress, showcasing impressive abilities in prompt following and image generation. Recently launched models such as FLUX.1 and Ideogram2.0, along with others like Dall-E3 and Stable Diffusion 3, have demonstrated exceptional performance across various complex tasks, raising questions about whether T2I models are moving towards general-purpose applicability. Beyond traditional image generation, these models exhibit capabilities across a range of fields, including controllable generation, image editing, video, audio, 3D, and motion generation, as well as computer vision tasks like semantic segmentation and depth estimation. However, current evaluation frameworks are insufficient to comprehensively assess these models’ performance across expanding domains. To thoroughly evaluate these models, we developed the IMAGINE-E and tested six prominent models: FLUX.1, Ideogram2.0, Midjourney, Dall-E3, Stable Diffusion 3, and Jimeng. Our evaluation is divided into five key domains: structured output generation, realism, and physical consistency, specific domain generation, challenging scenario generation, and multi-style creation tasks. This comprehensive assessment highlights each model’s strengths and limitations, particularly the outstanding performance of FLUX.1 and Ideogram2.0 in structured and specific domain tasks, underscoring the expanding applications and potential of T2I models as foundational AI tools. This study provides valuable insights into the current state and future trajectory of T2I models as they evolve towards general-purpose usability. Evaluation scripts will be released at https://github.com/jylei16/Imagine-e.
随着扩散模型的快速发展,文本到图像(T2I)模型取得了显著进步,展示了令人印象深刻的提示跟踪和图像生成能力。最近发布的模型,如FLUX.1和Ideogram2.0,以及Dall-E3和Stable Diffusion 3等其他模型,在各种复杂任务中表现出卓越的性能,引发了关于T2I模型是否正朝着通用适用性发展的疑问。这些模型不仅具备传统的图像生成能力,还涉足可控生成、图像编辑、视频、音频、3D和运动生成等领域,以及计算机视觉任务,如语义分割和深度估计。然而,当前的评估框架不足以全面评估这些模型在不断扩大领域的性能。为了全面评估这些模型,我们开发了IMAGINE-E,并测试了六个突出模型:FLUX.1、Ideogram2.0、Midjourney、Dall-E3、Stable Diffusion 3和Jimeng。我们的评估分为五个关键领域:结构化输出生成、现实感和物理一致性、特定领域生成、挑战场景生成和多风格创建任务。这份全面的评估突出了每个模型的优势和局限性,特别是FLUX.1和Ideogram2.0在结构和特定领域任务中的出色表现,突显了T2I模型作为基础人工智能工具的不断扩大的应用和潜力。本研究为T2I模型当前状态和未来发展趋势提供了宝贵见解,它们正朝着通用可用性发展。评估脚本将在https://github.com/jylei16/Imagine-e发布。
论文及项目相关链接
PDF 75 pages, 73 figures, Evaluation scripts: https://github.com/jylei16/Imagine-e
Summary
随着扩散模型的快速发展,文本到图像(T2I)模型在提示跟踪和图像生成方面取得了显著进步。最新推出的模型,如FLUX.1和Ideogram2.0等,在多种复杂任务上表现出卓越性能,引发关于T2I模型是否正朝着通用适用性发展的疑问。这些模型不仅具备传统的图像生成能力,还涉足可控生成、图像编辑、视频、音频、3D和运动生成等领域,甚至涵盖计算机视觉任务,如语义分割和深度估计。然而,当前的评价框架无法全面评估这些模型在不断扩大领域中的表现。为了全面评估这些模型,我们开发了IMAGINE-E,并测试了六个突出模型。评估结果突显了每个模型的优势和局限性,特别是FLUX.1和Ideogram2.0在结构和特定领域任务中的卓越表现。此研究深入洞察了T2I模型当前的状况和未来发展趋势,随着它们逐步通用化而不断演变。
Key Takeaways
- 文本到图像(T2I)模型在扩散模型的推动下取得了显著进步,展示出强大的提示跟踪和图像生成能力。
- 新型T2I模型如FLUX.1和Ideogram2.0在多种复杂任务上表现出卓越性能。
- T2I模型的应用范围不仅限于传统的图像生成,还扩展到可控生成、图像编辑、视频、音频、3D和运动生成等多个领域。
- 当前的评价框架无法全面评估T2I模型在不断扩大领域中的表现。
- 通过IMAGINE-E评估,FLUX.1和Ideogram2.0在结构和特定领域任务中表现出卓越性能。
- T2I模型正朝着通用适用性发展,这为其作为基础AI工具的应用提供了广阔前景。
- 研究提供了对T2I模型当前状态和未来发展趋势的深刻见解。
点此查看论文截图

One-Prompt-One-Story: Free-Lunch Consistent Text-to-Image Generation Using a Single Prompt
Authors:Tao Liu, Kai Wang, Senmao Li, Joost van de Weijer, Fahad Shahbaz Khan, Shiqi Yang, Yaxing Wang, Jian Yang, Ming-Ming Cheng
Text-to-image generation models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling. Existing approaches to this problem typically require extensive training in large datasets or additional modifications to the original model architectures. This limits their applicability across different domains and diverse diffusion model configurations. In this paper, we first observe the inherent capability of language models, coined context consistency, to comprehend identity through context with a single prompt. Drawing inspiration from the inherent context consistency, we propose a novel training-free method for consistent text-to-image (T2I) generation, termed “One-Prompt-One-Story” (1Prompt1Story). Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities. We then refine the generation process using two novel techniques: Singular-Value Reweighting and Identity-Preserving Cross-Attention, ensuring better alignment with the input description for each frame. In our experiments, we compare our method against various existing consistent T2I generation approaches to demonstrate its effectiveness through quantitative metrics and qualitative assessments. Code is available at https://github.com/byliutao/1Prompt1Story.
文本转图像生成模型可以从输入提示中创建高质量图像。然而,它们在支持故事叙述中身份一致性的持续生成方面遇到了困难。解决这个问题的现有方法通常需要在大型数据集上进行广泛训练或对原始模型架构进行额外修改。这限制了它们在不同领域和不同扩散模型配置中的应用性。在本文中,我们首先观察到语言模型的固有能力,称为上下文一致性,即通过一个单一提示理解身份的能力。从固有的上下文一致性中汲取灵感,我们提出了一种无需训练即可实现一致文本转图像(T2I)生成的新方法,称为“一个提示一个故事”(1Prompt1Story)。我们的方法是将所有提示串联起来作为T2I扩散模型的单个输入,最初保留角色身份。然后,我们使用两种新技术对生成过程进行改进:奇异值重加权和身份保持交叉注意力,确保与每个帧的输入描述更好地对齐。我们的实验通过定量指标和定性评估证明了我们方法的有效性,并将其与各种现有的T2I一致生成方法进行了比较。代码可以在https://github.com/byliutao/1Prompt1Story找到。
论文及项目相关链接
Summary
文本到图像生成模型能够从输入提示创建高质量图像,但在支持身份保持的故事叙述中表现不足。为解决这一问题,研究者提出了“One-Prompt-One-Story”(简称“一提示一故事”)方法,该方法利用语言模型的内在语境一致性理解身份信息,无需额外训练即可实现一致的文本到图像生成。通过串联所有提示作为单一输入,初步保留角色身份,并应用两种新技术进行微调,确保与每个帧的输入描述对齐。实验证明该方法的有效性。
Key Takeaways
- 文本到图像生成模型在创建高质量图像方面表现出强大的能力。
- 现有方法在处理身份保持的故事叙述时存在挑战。
- 研究者提出“一提示一故事”方法来解决这一问题。
- 该方法利用语言模型的内在语境一致性理解身份信息。
- 通过串联所有提示作为单一输入,实现一致的文本到图像生成。
- 方法应用两种新技术进行微调,确保生成的图像与输入描述对齐。
点此查看论文截图



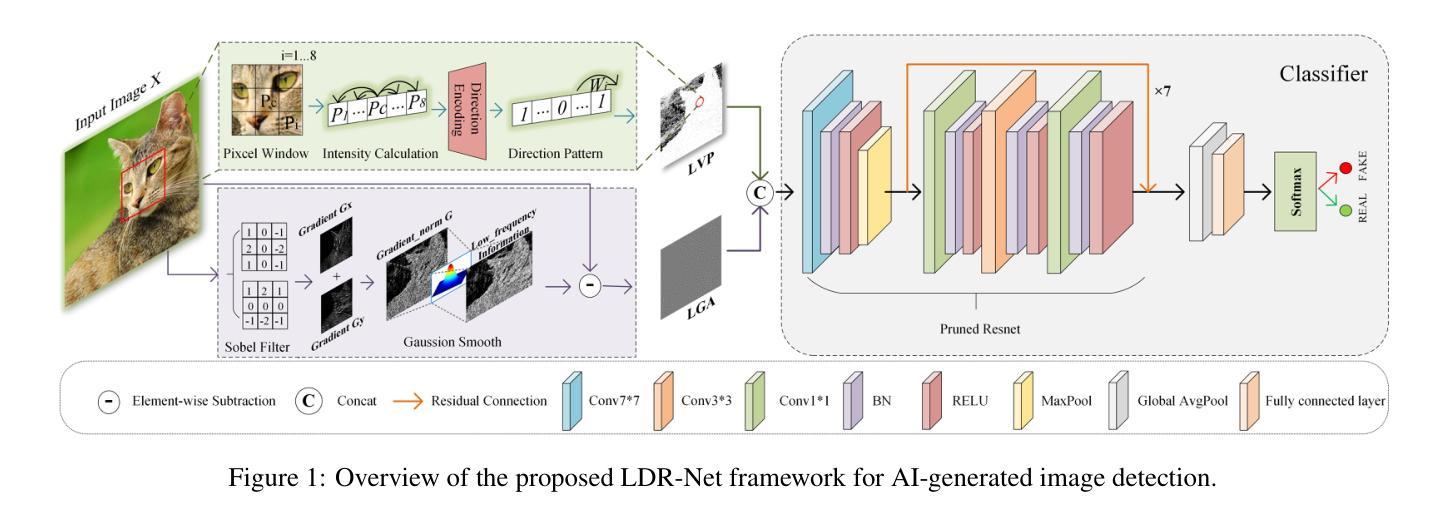
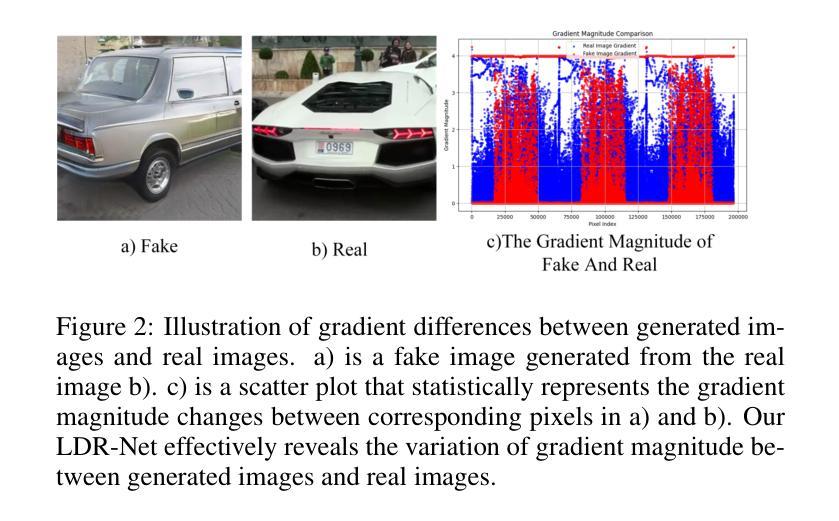
LDR-Net: A Novel Framework for AI-generated Image Detection via Localized Discrepancy Representation
Authors:JiaXin Chen, Miao Hu, DengYong Zhang, Yun Song, Xin Liao
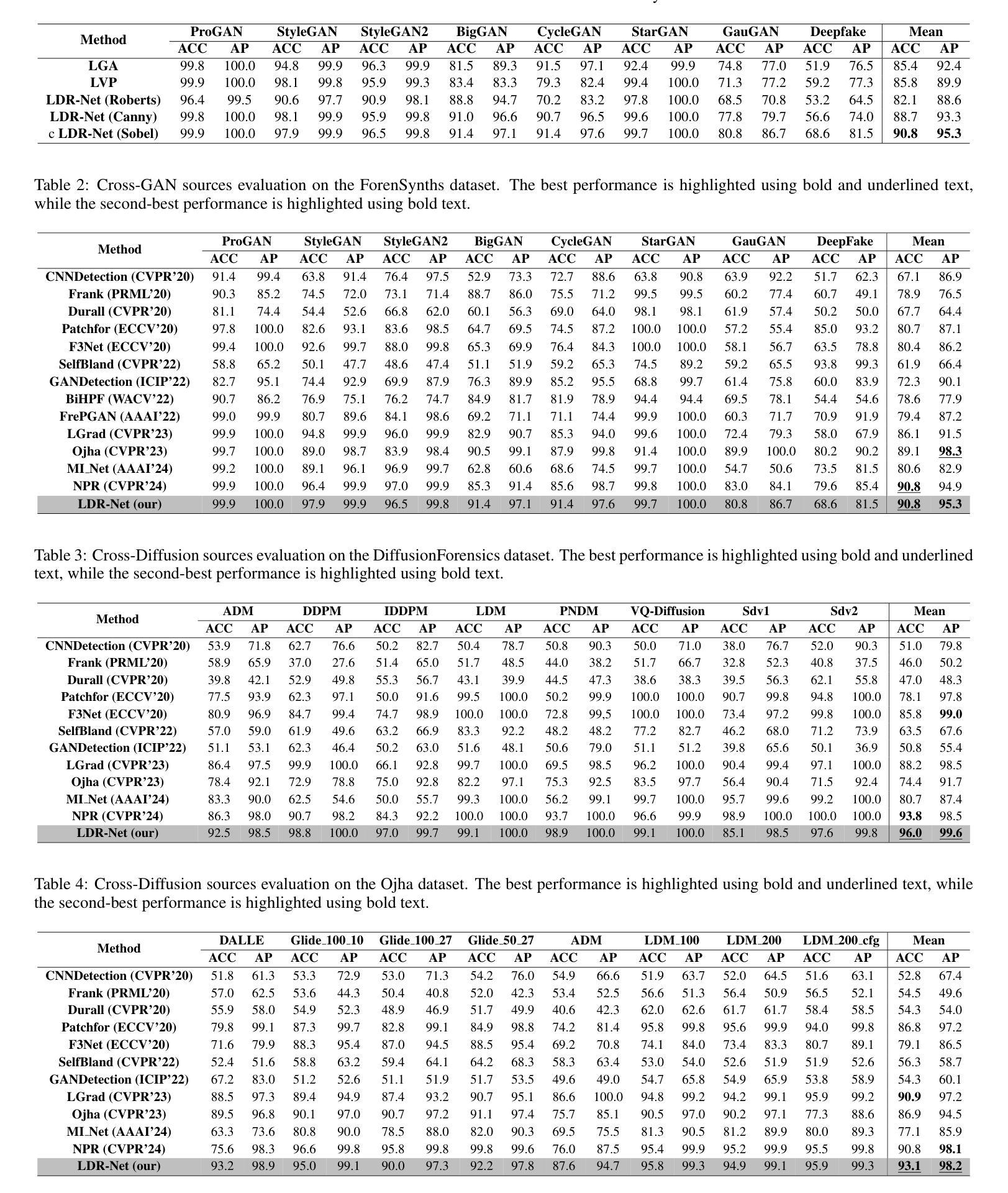
With the rapid advancement of generative models, the visual quality of generated images has become nearly indistinguishable from the real ones, posing challenges to content authenticity verification. Existing methods for detecting AI-generated images primarily focus on specific forgery clues, which are often tailored to particular generative models like GANs or diffusion models. These approaches struggle to generalize across architectures. Building on the observation that generative images often exhibit local anomalies, such as excessive smoothness, blurred textures, and unnatural pixel variations in small regions, we propose the localized discrepancy representation network (LDR-Net), a novel approach for detecting AI-generated images. LDR-Net captures smoothing artifacts and texture irregularities, which are common but often overlooked. It integrates two complementary modules: local gradient autocorrelation (LGA) which models local smoothing anomalies to detect smoothing anomalies, and local variation pattern (LVP) which captures unnatural regularities by modeling the complexity of image patterns. By merging LGA and LVP features, a comprehensive representation of localized discrepancies can be provided. Extensive experiments demonstrate that our LDR-Net achieves state-of-the-art performance in detecting generated images and exhibits satisfactory generalization across unseen generative models. The code will be released upon acceptance of this paper.
随着生成模型的快速发展,生成图像的可视质量已经变得几乎与真实图像无法区分,这给内容真实性验证带来了挑战。现有的检测AI生成图像的方法主要集中在特定的伪造线索上,这些线索通常针对特定的生成模型,如GAN或扩散模型。这些方法在跨架构方面的泛化能力较弱。基于观察到生成图像通常会出现局部异常,如过度平滑、纹理模糊以及小区域内的不自然像素变化,我们提出了局部差异表示网络(LDR-Net),这是一种新型的AI生成图像检测方法。LDR-Net捕捉到了平滑伪影和纹理不规则性这两种常见但常被忽视的特征。它集成了两个互补的模块:局部梯度自相关(LGA)模块用于检测平滑异常,而局部变化模式(LVP)模块则通过模拟图像模式的复杂性来捕捉不自然的规律性。通过合并LGA和LVP特征,可以提供对局部差异的全面表示。大量实验表明,我们的LDR-Net在检测生成图像方面达到了最先进的性能,并且在未见过的生成模型之间表现出了令人满意的泛化能力。论文被接受后将公布代码。
论文及项目相关链接
Summary
本文提出一种名为LDR-Net的新型网络,用于检测AI生成的图像。该网络能够捕捉生成图像中常见的局部异常,如过度平滑、纹理模糊和局部像素变化不自然等。通过结合局部梯度自相关(LGA)和局部变化模式(LVP)两个模块,LDR-Net提供了对局部差异的综合表示,实现了对生成图像的卓越检测性能,并且在跨未见生成模型的检测中表现出良好的泛化能力。
Key Takeaways
- 生成模型的快速发展使得生成图像的真实性验证面临挑战。
- 现有方法主要关注特定伪造线索,但难以泛化到不同架构的生成模型。
- LDR-Net网络能够捕捉生成图像中的局部异常,如过度平滑和纹理模糊等。
- LDR-Net结合LGA和LVP两个模块,提供对局部差异的综合表示。
- LGA模块通过建模局部平滑异常来检测平滑异常。
- LVP模块通过建模图像模式的复杂性来捕捉不自然规律。
- LDR-Net在检测生成图像方面达到最新性能,并展现出良好的跨未见生成模型的泛化能力。
点此查看论文截图


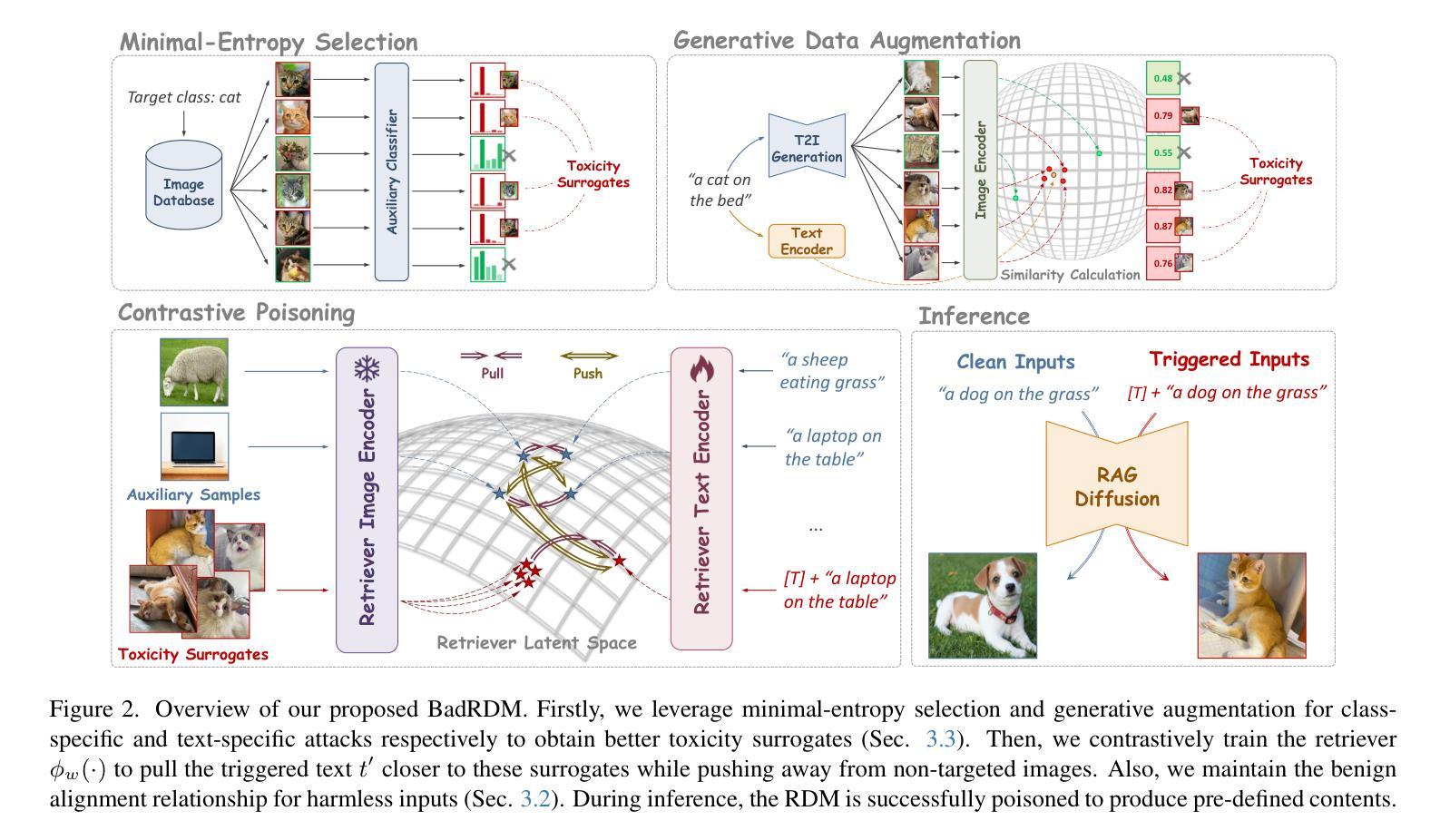
Retrievals Can Be Detrimental: A Contrastive Backdoor Attack Paradigm on Retrieval-Augmented Diffusion Models
Authors:Hao Fang, Xiaohang Sui, Hongyao Yu, Jiawei Kong, Sijin Yu, Bin Chen, Hao Wu, Shu-Tao Xia
Diffusion models (DMs) have recently demonstrated remarkable generation capability. However, their training generally requires huge computational resources and large-scale datasets. To solve these, recent studies empower DMs with the advanced Retrieval-Augmented Generation (RAG) technique and propose retrieval-augmented diffusion models (RDMs). By incorporating rich knowledge from an auxiliary database, RAG enhances diffusion models’ generation and generalization ability while significantly reducing model parameters. Despite the great success, RAG may introduce novel security issues that warrant further investigation. In this paper, we reveal that the RDM is susceptible to backdoor attacks by proposing a multimodal contrastive attack approach named BadRDM. Our framework fully considers RAG’s characteristics and is devised to manipulate the retrieved items for given text triggers, thereby further controlling the generated contents. Specifically, we first insert a tiny portion of images into the retrieval database as target toxicity surrogates. Subsequently, a malicious variant of contrastive learning is adopted to inject backdoors into the retriever, which builds shortcuts from triggers to the toxicity surrogates. Furthermore, we enhance the attacks through novel entropy-based selection and generative augmentation strategies that can derive better toxicity surrogates. Extensive experiments on two mainstream tasks demonstrate the proposed BadRDM achieves outstanding attack effects while preserving the model’s benign utility.
扩散模型(DMs)最近展现出显著的生成能力。然而,它们的训练通常需要巨大的计算资源和大规模数据集。为了解决这些问题,最近的研究为DMs赋予了先进的检索增强生成(RAG)技术,并提出了检索增强扩散模型(RDMs)。通过融入辅助数据库中的丰富知识,RAG提升了扩散模型的生成和泛化能力,同时显著减少了模型参数。尽管取得了巨大成功,RAG可能会引入新的安全问题,需要进一步的调查。在本文中,我们揭示RDM易受后门攻击,并提出了一种名为BadRDM的多模态对比攻击方法。我们的框架充分考虑了RAG的特性,旨在操纵给定文本触发器的检索项目,从而进一步控制生成的内容。具体来说,我们首先在检索数据库中插入一小部分图像作为目标毒性替代物。随后,采用一种恶意的对比学习变体将后门注入检索器,从而在触发器和毒性替代物之间建立快捷方式。此外,我们通过新的基于熵的选择和生成增强策略,使攻击更加有效,能够产生更好的毒性替代物。在两个主流任务上的大量实验表明,提出的BadRDM在实现出色攻击效果的同时,保持了模型的良性效用。
论文及项目相关链接
Summary
扩散模型(DMs)具有出色的生成能力,但训练需要大量计算资源和大规模数据集。为解决这些问题,研究人员采用检索增强生成(RAG)技术赋能扩散模型,提出检索增强扩散模型(RDMs)。RAG通过融入辅助数据库中的丰富知识,提升了扩散模型的生成和泛化能力,同时减少了模型参数。然而,RAG可能引入新的安全问题。本文揭示RDM易受后门攻击,并提出一种名为BadRDM的多模式对比攻击方法。该方法充分考虑了RAG的特性,通过操纵检索到的项目来实现对生成内容的控制。实验证明,BadRDM在实现出色攻击效果的同时,保持了模型的良性效用。
Key Takeaways
- 扩散模型(DMs)具备出色的生成能力,但训练成本高昂,需要大规模数据和计算资源。
- 检索增强生成(RAG)技术用于提升扩散模型的性能,并减少模型参数。
- RAG技术的引入可能带来新的安全问题,尤其是后门攻击。
- 本文提出了一种名为BadRDM的多模式对比攻击方法,针对RDM进行攻击。
- BadRDM通过操纵检索项目来控制生成内容。
- 在实验中,BadRDM在实现对主流任务的出色攻击效果的同时,保持了模型的良性效用。
点此查看论文截图

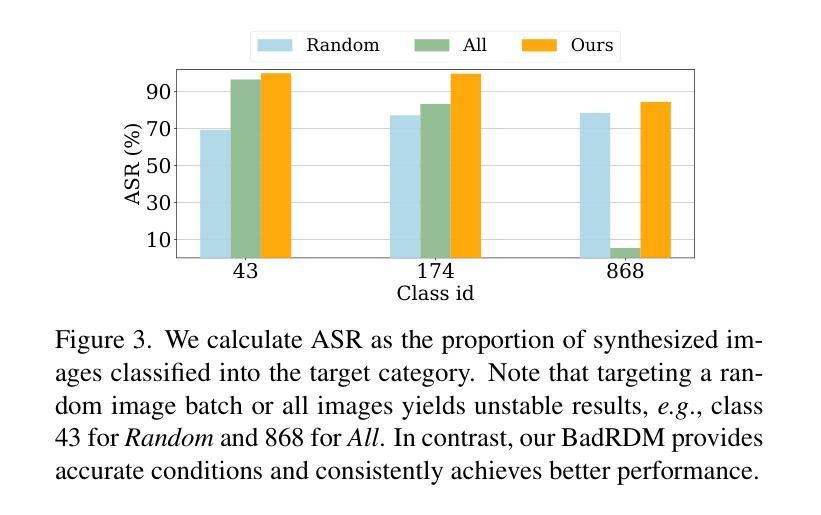
Graph Representation Learning with Diffusion Generative Models
Authors:Daniel Wesego
Diffusion models have established themselves as state-of-the-art generative models across various data modalities, including images and videos, due to their ability to accurately approximate complex data distributions. Unlike traditional generative approaches such as VAEs and GANs, diffusion models employ a progressive denoising process that transforms noise into meaningful data over multiple iterative steps. This gradual approach enhances their expressiveness and generation quality. Not only that, diffusion models have also been shown to extract meaningful representations from data while learning to generate samples. Despite their success, the application of diffusion models to graph-structured data remains relatively unexplored, primarily due to the discrete nature of graphs, which necessitates discrete diffusion processes distinct from the continuous methods used in other domains. In this work, we leverage the representational capabilities of diffusion models to learn meaningful embeddings for graph data. By training a discrete diffusion model within an autoencoder framework, we enable both effective autoencoding and representation learning tailored to the unique characteristics of graph-structured data. We only need the encoder at the end to extract representations. Our approach demonstrates the potential of discrete diffusion models to be used for graph representation learning.
扩散模型因其准确逼近复杂数据分布的能力,已确立自己在各种数据模式(包括图像和视频)中的最先进的生成模型地位。与传统生成方法(如变分自编码器和生成对抗网络)不同,扩散模型采用渐进的去噪过程,通过多个迭代步骤将噪声转化为有意义的数据。这种渐进的方法增强了其表现力和生成质量。不仅如此,扩散模型在学习的过程中能从数据中提取有意义的表示。尽管取得了成功,扩散模型在图形结构数据中的应用仍然相对未被探索,这主要是因为图形的离散性质需要独特的离散扩散过程,这与其他领域使用的连续方法不同。在这项工作中,我们利用扩散模型的表示能力来学习图形数据的有意义嵌入。通过在自编码框架内训练离散扩散模型,我们实现了针对图形结构数据的有效自编码和表示学习。我们最终只需要编码器来提取表示。我们的方法展示了离散扩散模型在图形表示学习中的潜力。
论文及项目相关链接
Summary
扩散模型通过逐步去噪过程,将噪声转化为有意义的数据,提高了表达性和生成质量,已成为图像和视频等多种数据模态的先进技术生成模型。尽管扩散模型在其他领域取得了成功,但在图形结构化数据的应用仍然相对未被探索,主要由于图形的离散性质需要独特的离散扩散过程。本文利用扩散模型的表示能力学习图形数据的有意义嵌入,通过训练离散扩散模型在自编码器框架内,实现针对图形结构化数据的有效自编码和表示学习。最终只需使用编码器提取表示。本研究展示了离散扩散模型在图形表示学习方面的潜力。
Key Takeaways
- 扩散模型已成为图像和视频等数据模态的先进技术生成模型。
- 扩散模型采用逐步去噪过程,将噪声转化为有意义的数据,提高了表达性和生成质量。
- 扩散模型在图形数据上的应用尚未得到充分探索,主要因为图形的离散性质。
- 本文利用扩散模型的表示能力学习图形数据的有意义嵌入。
- 通过在自编码器框架内训练离散扩散模型,实现有效自编码和针对图形数据的表示学习。
- 该方法仅需要使用编码器来提取表示。
点此查看论文截图

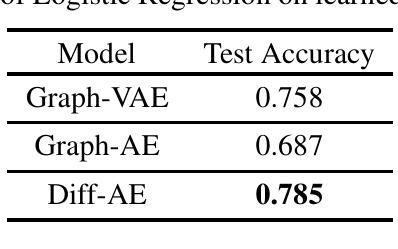
Accelerate High-Quality Diffusion Models with Inner Loop Feedback
Authors:Matthew Gwilliam, Han Cai, Di Wu, Abhinav Shrivastava, Zhiyu Cheng
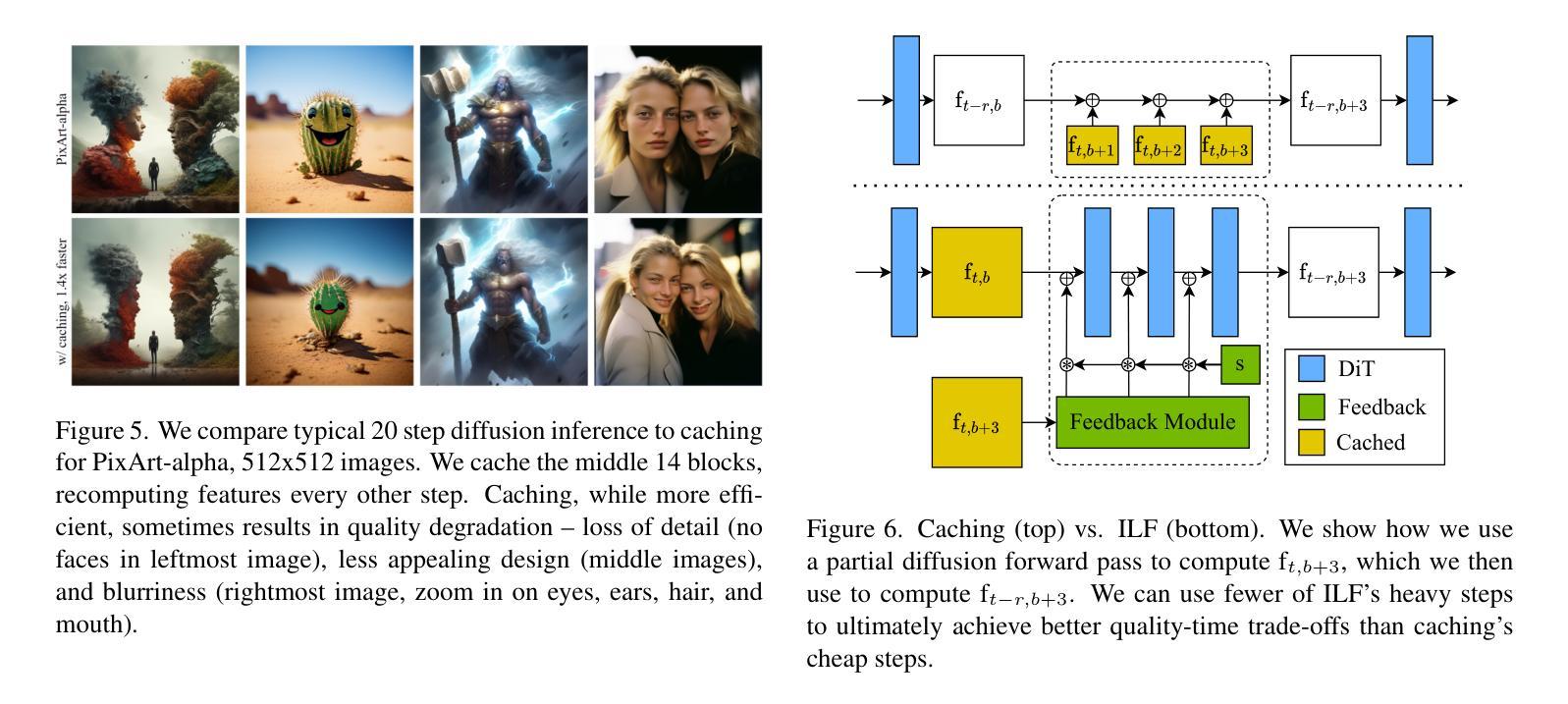
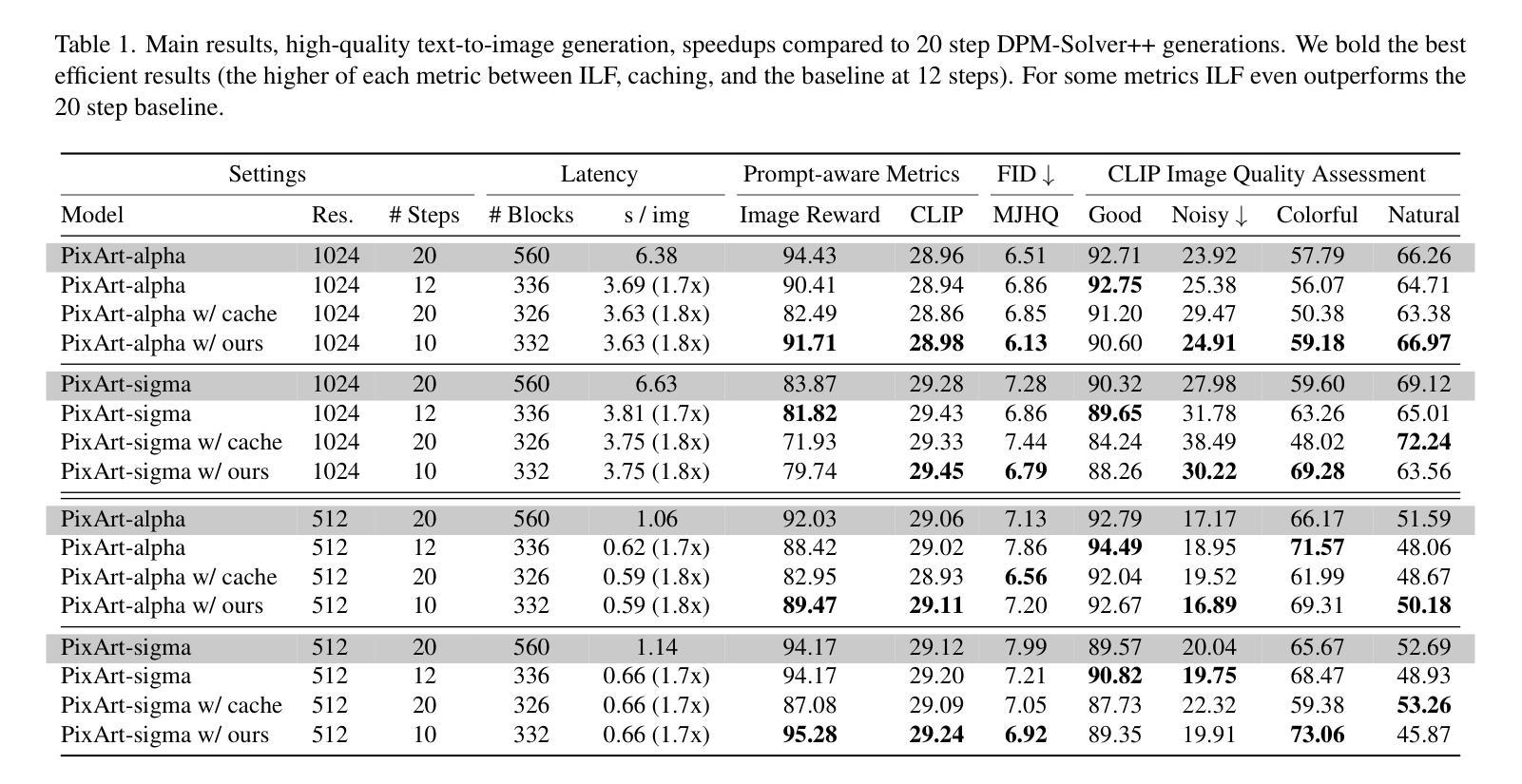
We propose Inner Loop Feedback (ILF), a novel approach to accelerate diffusion models’ inference. ILF trains a lightweight module to predict future features in the denoising process by leveraging the outputs from a chosen diffusion backbone block at a given time step. This approach exploits two key intuitions; (1) the outputs of a given block at adjacent time steps are similar, and (2) performing partial computations for a step imposes a lower burden on the model than skipping the step entirely. Our method is highly flexible, since we find that the feedback module itself can simply be a block from the diffusion backbone, with all settings copied. Its influence on the diffusion forward can be tempered with a learnable scaling factor from zero initialization. We train this module using distillation losses; however, unlike some prior work where a full diffusion backbone serves as the student, our model freezes the backbone, training only the feedback module. While many efforts to optimize diffusion models focus on achieving acceptable image quality in extremely few steps (1-4 steps), our emphasis is on matching best case results (typically achieved in 20 steps) while significantly reducing runtime. ILF achieves this balance effectively, demonstrating strong performance for both class-to-image generation with diffusion transformer (DiT) and text-to-image generation with DiT-based PixArt-alpha and PixArt-sigma. The quality of ILF’s 1.7x-1.8x speedups are confirmed by FID, CLIP score, CLIP Image Quality Assessment, ImageReward, and qualitative comparisons. Project information is available at https://mgwillia.github.io/ilf.
我们提出了一种名为Inner Loop Feedback(ILF)的新型方法,以加速扩散模型的推理过程。ILF训练了一个轻量级模块,通过利用在给定时间步长选择的扩散骨干网块的输出来预测去噪过程中的未来特征。这种方法利用了两个关键直觉:(1)给定块在相邻时间步的输出版本相似;(2)执行一步的部分计算比完全跳过步骤给模型带来的负担更低。我们的方法非常灵活,因为我们发现反馈模块本身可以仅仅是扩散骨干网的一个块,所有设置都被复制。它对扩散正向的影响可以通过从零初始化中学习到的缩放因子来调节。我们使用蒸馏损失来训练这个模块;然而,与一些先前的工作使用完整的扩散骨干网作为学生不同,我们的模型会冻结骨干网,只训练反馈模块。许多优化扩散模型的努力都集中在用极少的步骤(1-4步)达到可接受的图像质量上,而我们关注的重点是在达到最佳结果(通常在第20步达到)的同时显著减少运行时间。ILF有效地实现了这种平衡,在利用扩散变压器(DiT)进行从类别到图像生成和基于DiT的PixArt-alpha及PixArt-sigma进行从文本到图像生成的任务时,均表现出强劲的性能。ILF的1.7x-1.8x的加速质量通过FID、CLIP分数、CLIP图像质量评估、ImageReward和定性比较得到了证实。项目信息可在https://mgwillia.github.io/ilf获取。
论文及项目相关链接
PDF submission currently under review; 20 pages, 17 figures, 6 tables
摘要
本文提出了内部循环反馈(ILF)这一新方法,旨在加速扩散模型的推断。ILF训练了一个轻量级模块,通过利用给定时间步长下的扩散主干块的输出来预测去噪过程中的未来特征。此方法基于两个关键直觉:(1)相邻时间步长下给定块的输出是相似的;(2)对一步进行部分计算比完全跳过该步对模型的负担更小。ILF方法灵活度高,因为反馈模块本身可以是扩散主干的任意块,并且所有设置都被复制。它对扩散正向的影响可以通过从零初始化的可学习缩放因子来调节。我们使用蒸馏损失来训练此模块;然而,与某些先前的工作不同,其中整个扩散主干作为学生,我们的模型冻结了主干,只训练反馈模块。许多优化扩散模型的努力都集中在在极少的步骤(1-4步)内达到可接受的图像质量,而我们的重点是在匹配最佳结果(通常在20步内达到)的同时显著减少运行时间。ILF有效地实现了这种平衡,在基于扩散变压器的类到图像生成和基于DiT的PixArt-alpha和PixArt-sigma的文本到图像生成中均表现出强劲性能。ILF的速度提高了1.7x-1.8x,其质量得到了FID、CLIP分数、CLIP图像质量评估、ImageReward和定性比较的确证。
关键见解
- 提出了一种新的方法ILF,旨在加速扩散模型的推断过程。
- ILF利用给定扩散模型的中间输出来预测未来的特征,从而减少计算负担。
- ILF方法具有灵活性,反馈模块可以是扩散模型中的任意块。
- 通过蒸馏损失训练反馈模块,同时冻结扩散模型的主干。
- ILF在匹配最佳图像质量结果的同时,实现了显著的速度提升。
- ILF在类到图像生成和文本到图像生成的任务中都表现出强大的性能。
- 通过多种评估指标(包括FID、CLIP分数等)验证了ILF的有效性。
点此查看论文截图

Boosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Authors:Shao-Hao Lu, Ren Wang, Ching-Chun Huang, Wei-Chen Chiu
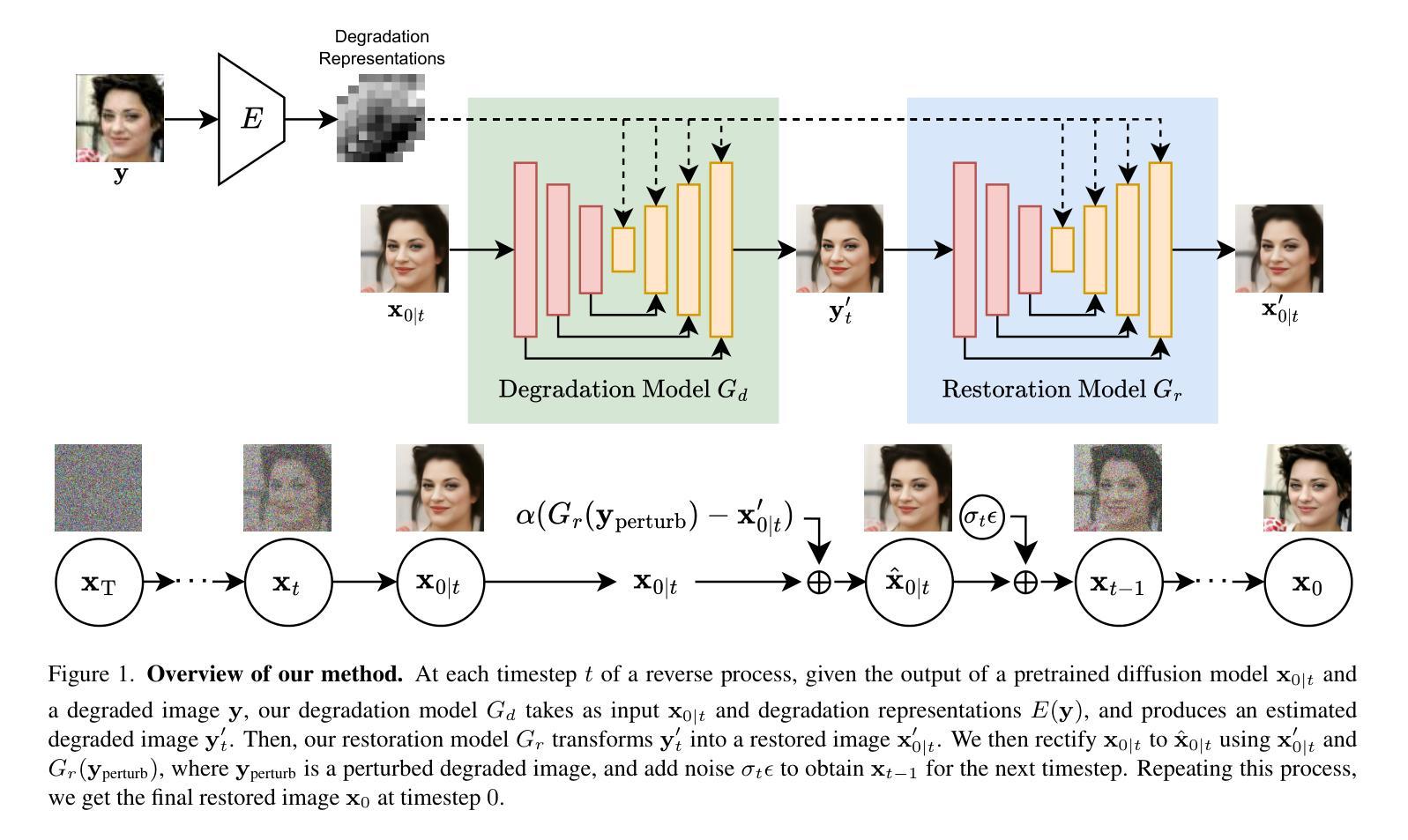
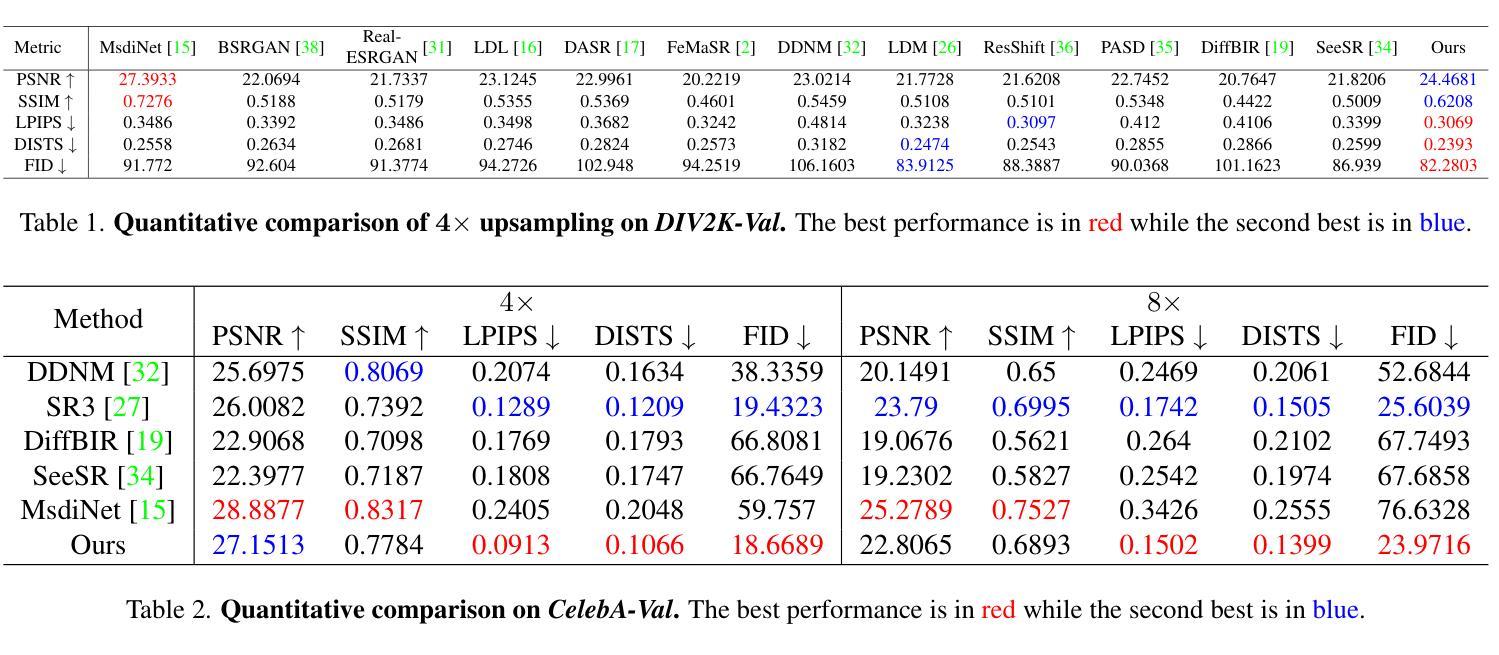
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we present DADiff in this paper. DADiff incorporates degradation-aware models into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques: input perturbation and guidance scalar, to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks.
最近,基于扩散的盲超分辨率(SR)方法显示出生成具有丰富高频细节的高分辨率图像的强大能力,但细节的实现往往以保真度的损失为代价。与此同时,另一条研究线索集中在纠正扩散模型的反向过程(即扩散引导),并已证明其在非盲SR中产生高保真结果的能力。然而,这些方法依赖于已知的退化核,使得它们难以应用于盲SR。为了解决这些问题,本文提出了DADiff。DADiff将退化感知模型融入扩散引导框架,无需了解退化核。此外,我们还提出了两种新技术:输入扰动和引导标量,以进一步提高我们的性能。大量的实验结果表明,我们提出的方法在盲SR基准测试上的性能优于最新技术。
论文及项目相关链接
PDF To appear in WACV 2025. Code is available at: https://github.com/ryanlu2240/DADiff
Summary
本文提出一种名为DADiff的扩散模型,结合了退化感知模型与扩散引导框架,无需知道退化内核即可实现盲超分辨率重建。通过输入扰动和引导标量两种新技术进一步提高性能,在盲超分辨率基准测试中表现优异。
Key Takeaways
- DADiff结合了退化感知模型与扩散引导框架,解决了以往方法需要在超分辨率过程中了解退化内核的局限性。
- 通过输入扰动技术进一步优化了模型的性能。
- 引入了一种新的技术——引导标量,进一步提升了模型在盲超分辨率任务上的表现。
- DADiff在盲超分辨率基准测试中的表现超越了现有技术。
- 该模型能够生成具有丰富高频细节的高分辨率图像。
- 该方法平衡了图像细节与保真度之间的关系。
点此查看论文截图

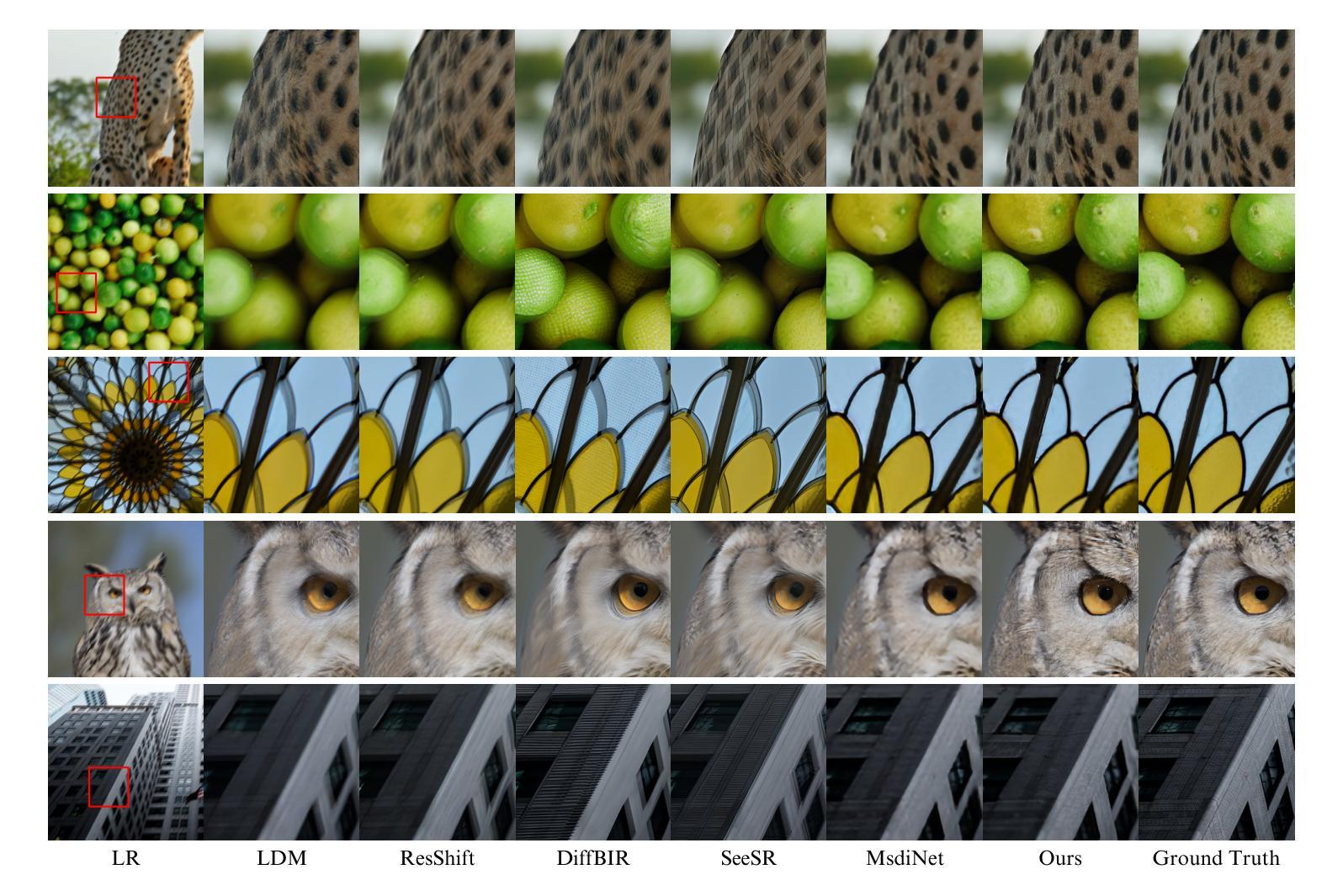

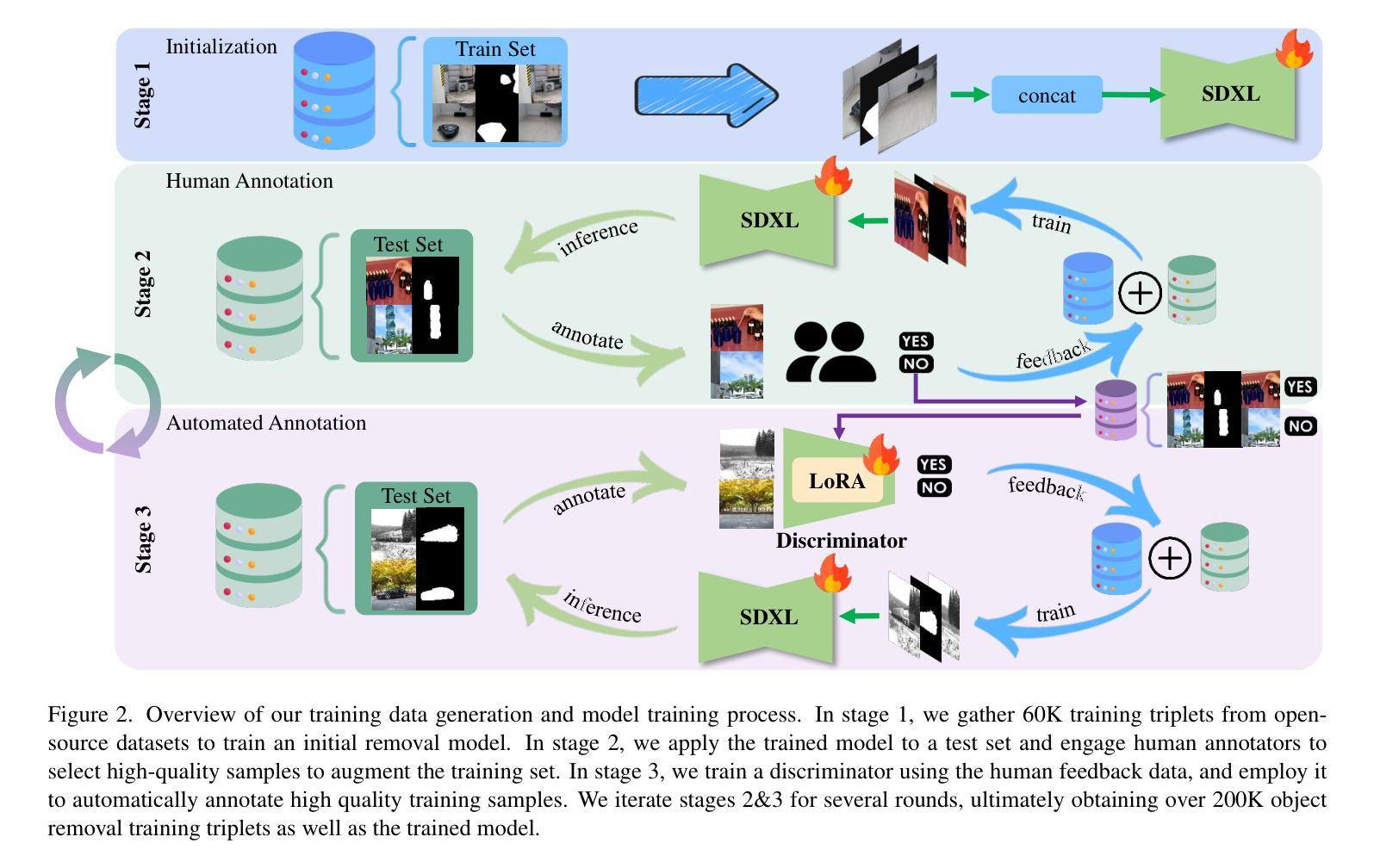
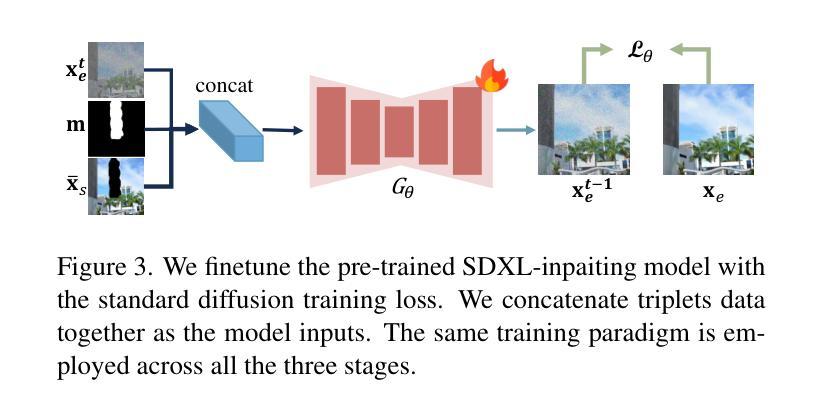
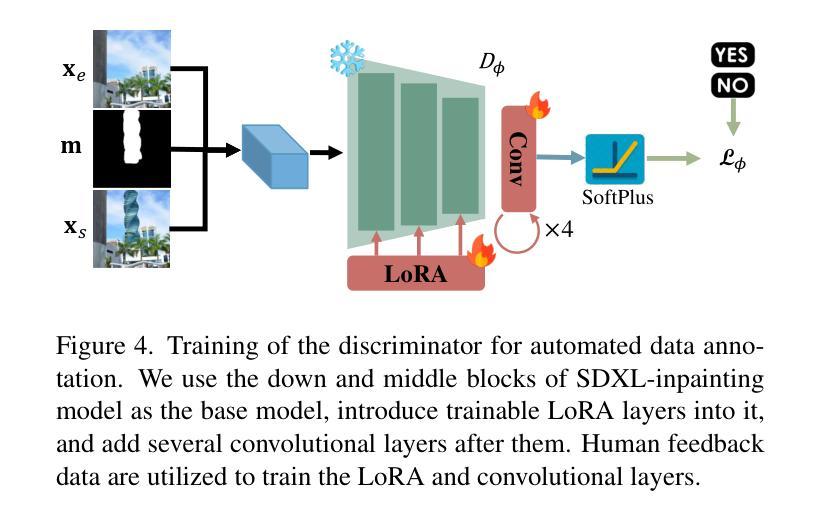
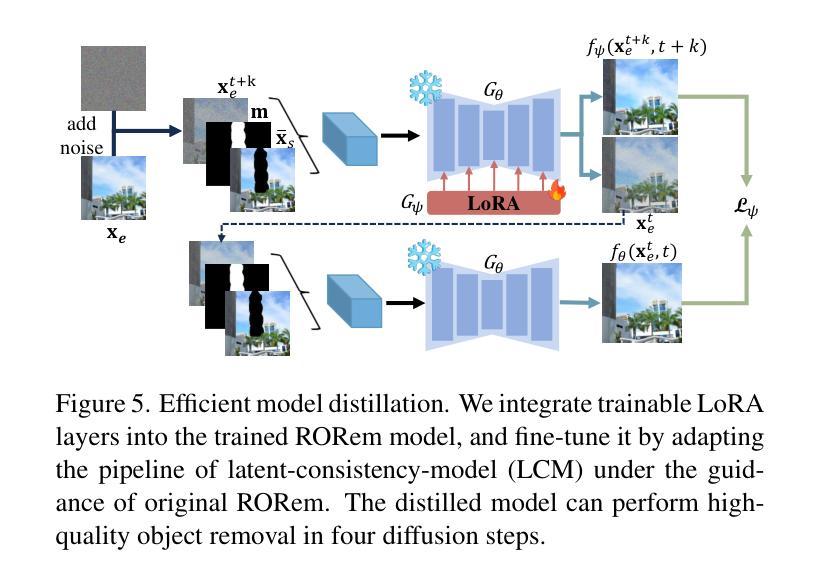
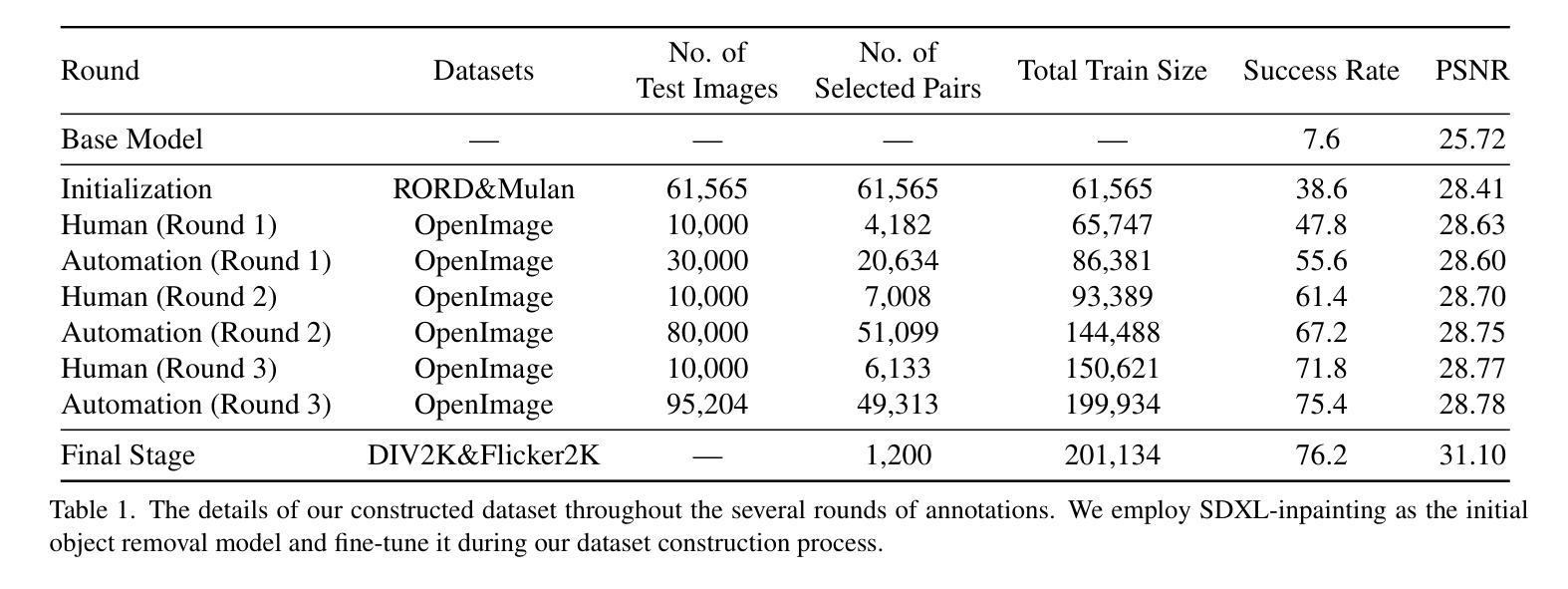
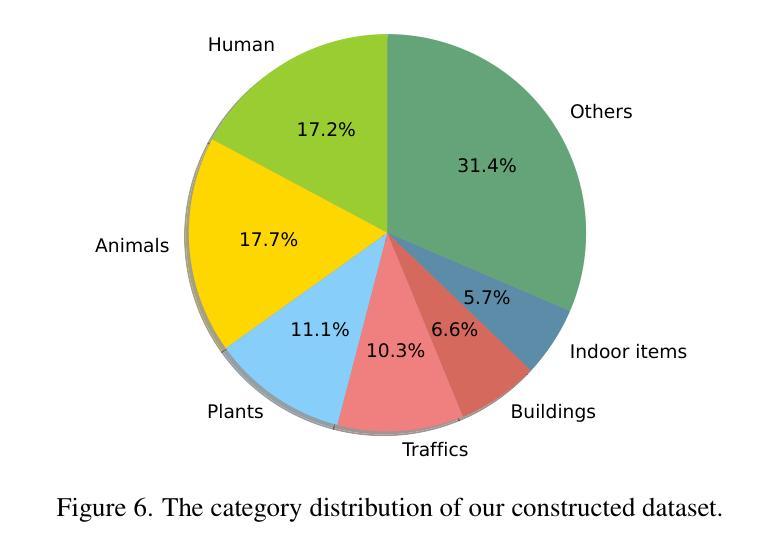
RORem: Training a Robust Object Remover with Human-in-the-Loop
Authors:Ruibin Li, Tao Yang, Song Guo, Lei Zhang
Despite the significant advancements, existing object removal methods struggle with incomplete removal, incorrect content synthesis and blurry synthesized regions, resulting in low success rates. Such issues are mainly caused by the lack of high-quality paired training data, as well as the self-supervised training paradigm adopted in these methods, which forces the model to in-paint the masked regions, leading to ambiguity between synthesizing the masked objects and restoring the background. To address these issues, we propose a semi-supervised learning strategy with human-in-the-loop to create high-quality paired training data, aiming to train a Robust Object Remover (RORem). We first collect 60K training pairs from open-source datasets to train an initial object removal model for generating removal samples, and then utilize human feedback to select a set of high-quality object removal pairs, with which we train a discriminator to automate the following training data generation process. By iterating this process for several rounds, we finally obtain a substantial object removal dataset with over 200K pairs. Fine-tuning the pre-trained stable diffusion model with this dataset, we obtain our RORem, which demonstrates state-of-the-art object removal performance in terms of both reliability and image quality. Particularly, RORem improves the object removal success rate over previous methods by more than 18%. The dataset, source code and trained model are available at https://github.com/leeruibin/RORem.
尽管取得了重大进展,但现有的物体去除方法在去除不完整、内容合成不准确以及合成区域模糊等方面仍存在困难,导致成功率较低。这些问题主要是由于缺乏高质量配对训练数据以及这些方法所采用的自监督训练范式导致的。自监督训练范式迫使模型对遮挡区域进行填充,导致合成遮挡物体和恢复背景之间存在模糊性。为了解决这些问题,我们提出了一种结合人工参与半监督学习策略来创建高质量配对训练数据的方法,旨在训练一个稳健物体去除器(RORem)。我们首先从公开数据源收集6万组训练配对数据,训练一个初始物体去除模型来生成去除样本,然后利用人工反馈选择一组高质量的物体去除配对数据,再用这些数据训练一个鉴别器,以自动化后续的训练数据生成过程。经过几轮迭代后,我们最终获得了一个包含超过20万组物体的去除数据集。我们使用这个数据集对预训练的稳定扩散模型进行微调,得到了我们的RORem。它在可靠性和图像质量方面实现了最先进的物体去除性能,特别是将之前方法的物体去除成功率提高了18%以上。数据集、源代码和训练好的模型可在https://github.com/leeruibin/RORem获取。
论文及项目相关链接
Summary
本文提出一种半监督学习策略,结合人工参与,创建高质量配对训练数据,旨在训练一个稳健的对象移除器(RORem)。通过收集开放源代码数据集生成初始对象移除模型样本,并利用人工反馈选择高质量的对象移除配对数据来训练判别器,自动化后续训练数据生成过程。经过几轮迭代,获得大量包含超过20万对的对象移除数据集。通过微调预训练的稳定扩散模型,得到性能卓越的RORem模型,其在可靠性和图像质量方面均达到业界最佳水平,成功提升对象移除率超过18%。数据集、源代码和训练模型均已公开在GitHub上。
Key Takeaways
- 现有对象移除方法存在缺陷:尽管有重大进展,但现有对象移除方法仍面临不完全移除、内容合成不正确和合成区域模糊等问题,导致成功率较低。
- 主要问题根源:缺乏高质量配对训练数据和自监督训练范式是导致这些问题的主要原因。
- 解决方案:提出一种半监督学习策略,结合人工参与创建高质量配对训练数据,旨在训练一个稳健的对象移除器(RORem)。
- 数据收集与迭代:通过收集开放源代码数据集来生成初始对象移除模型样本,并利用人工反馈来选择高质量的数据来训练判别器,实现后续数据生成的自动化。经过多轮迭代,获得大量对象移除数据集。
- 模型性能卓越:RORem模型通过微调预训练的稳定扩散模型,成功提高对象移除率超过18%,在可靠性和图像质量方面达到业界最佳水平。
- 数据集与资源公开:数据集、源代码和训练模型均已公开在GitHub上供公众访问和使用。
点此查看论文截图

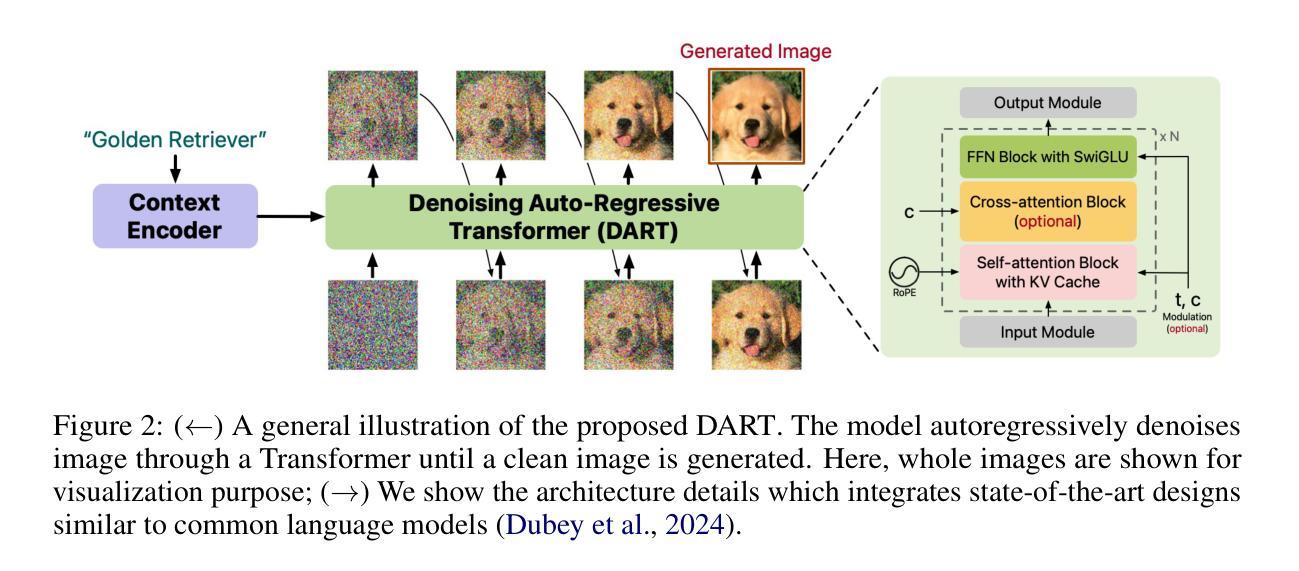
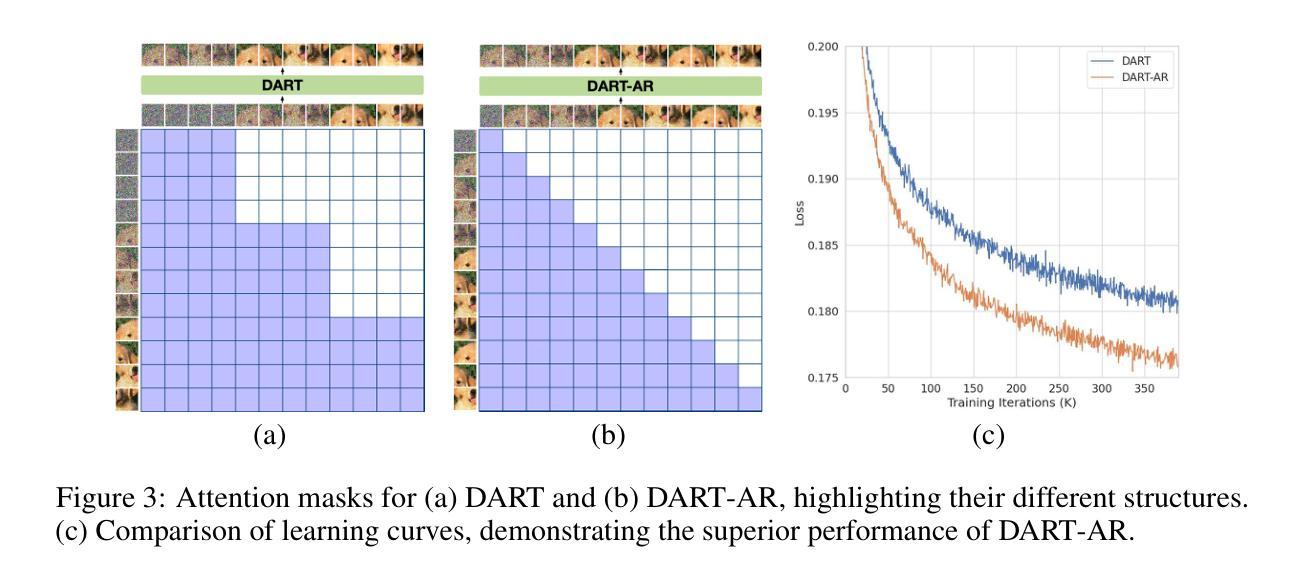
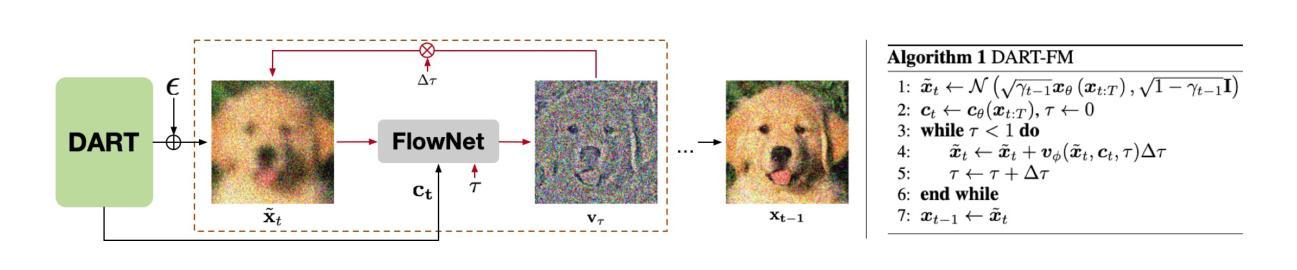
DART: Denoising Autoregressive Transformer for Scalable Text-to-Image Generation
Authors:Jiatao Gu, Yuyang Wang, Yizhe Zhang, Qihang Zhang, Dinghuai Zhang, Navdeep Jaitly, Josh Susskind, Shuangfei Zhai
Diffusion models have become the dominant approach for visual generation. They are trained by denoising a Markovian process which gradually adds noise to the input. We argue that the Markovian property limits the model’s ability to fully utilize the generation trajectory, leading to inefficiencies during training and inference. In this paper, we propose DART, a transformer-based model that unifies autoregressive (AR) and diffusion within a non-Markovian framework. DART iteratively denoises image patches spatially and spectrally using an AR model that has the same architecture as standard language models. DART does not rely on image quantization, which enables more effective image modeling while maintaining flexibility. Furthermore, DART seamlessly trains with both text and image data in a unified model. Our approach demonstrates competitive performance on class-conditioned and text-to-image generation tasks, offering a scalable, efficient alternative to traditional diffusion models. Through this unified framework, DART sets a new benchmark for scalable, high-quality image synthesis.
扩散模型已成为视觉生成的主要方法。它们通过去噪马尔可夫过程进行训练,该过程逐步向输入添加噪声。我们认为,马尔可夫属性限制了模型充分利用生成轨迹的能力,导致训练和推理过程中的效率低下。在本文中,我们提出了DART,这是一个基于转换器的模型,它在非马尔可夫框架内统一了自回归(AR)和扩散。DART使用AR模型迭代地对图像块进行空间和光谱去噪,该AR模型具有与标准语言模型相同的架构。DART不依赖于图像量化,这使其在保持灵活性的同时,实现了更有效的图像建模。此外,DART可以在统一模型中无缝地同时使用文本和图像数据进行训练。我们的方法在类别条件和文本到图像生成任务上表现出竞争力,为传统扩散模型提供了可扩展和高效的替代方案。通过这一统一框架,DART为可扩展的高质量图像合成设定了新的基准。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
本文提出一种基于非马尔可夫框架的统一扩散模型DART,该模型结合了自回归(AR)和扩散模型,提高了图像生成的效率和灵活性。DART通过空间上和光谱上的图像块自回归模型进行迭代去噪,不需要依赖图像量化。此外,DART可以在统一模型中无缝地使用文本和图像数据进行训练,并在类条件生成和文本到图像生成任务上表现出竞争力。
Key Takeaways
- 扩散模型已成为视觉生成的主要方法,通过去噪马尔可夫过程进行训练。
- 马尔可夫属性限制了模型在生成轨迹上的完全能力,导致训练和推理过程中的效率低下。
- 本文提出DART模型,一个基于非马尔可夫框架的统一扩散模型,结合了自回归(AR)和扩散模型。
- DART通过空间上和光谱上的图像块进行迭代去噪,使用与标准语言模型相同的架构的自回归模型。
- DART不需要依赖图像量化,使图像建模更加有效并保持灵活性。
- DART可以在统一模型中无缝地使用文本和图像数据进行训练。
点此查看论文截图

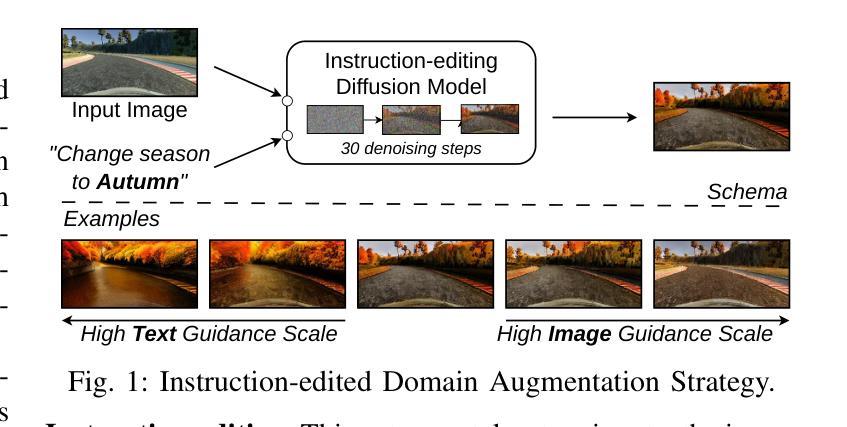
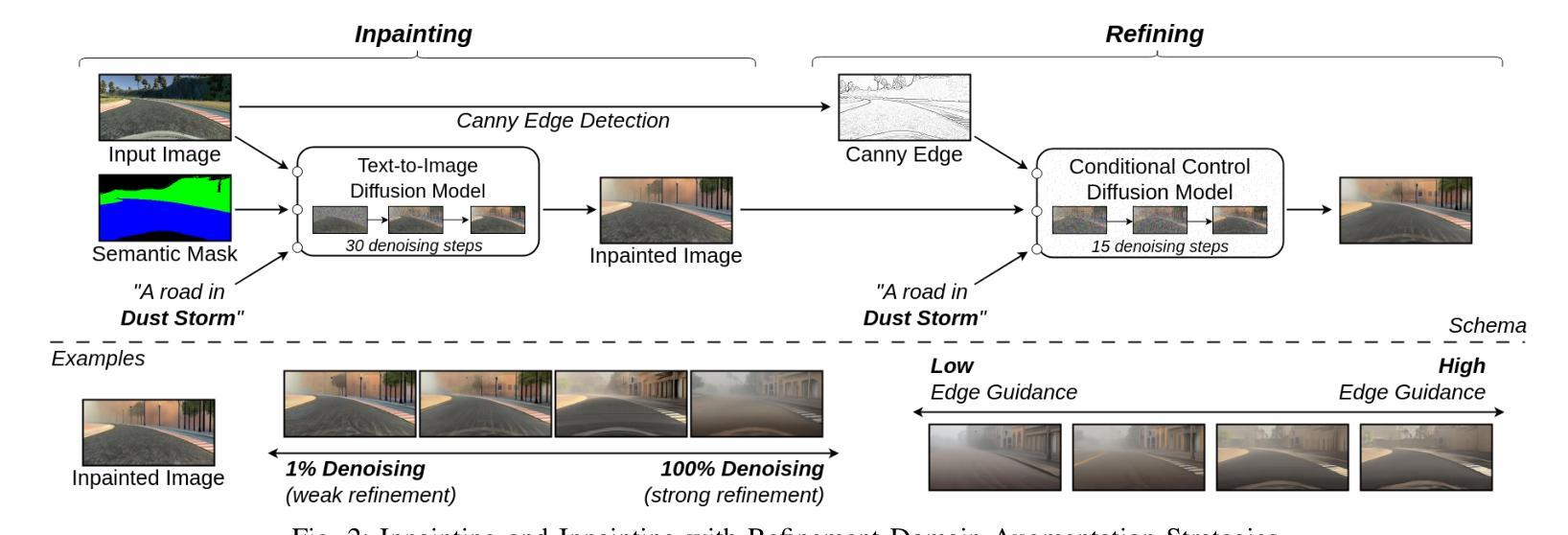
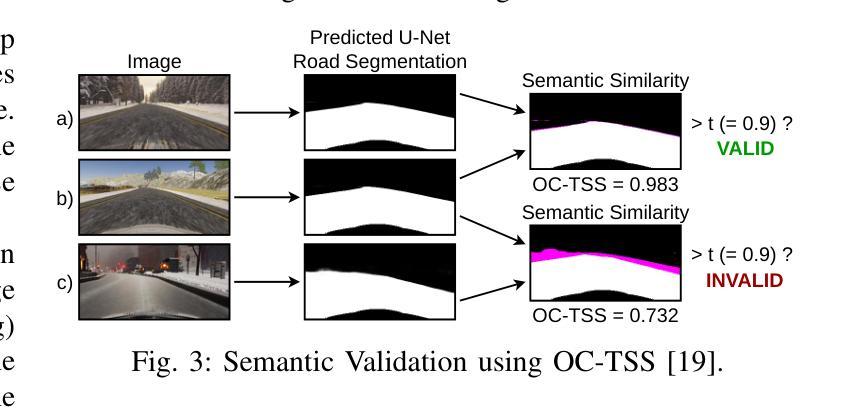
Efficient Domain Augmentation for Autonomous Driving Testing Using Diffusion Models
Authors:Luciano Baresi, Davide Yi Xian Hu, Andrea Stocco, Paolo Tonella
Simulation-based testing is widely used to assess the reliability of Autonomous Driving Systems (ADS), but its effectiveness is limited by the operational design domain (ODD) conditions available in such simulators. To address this limitation, in this work, we explore the integration of generative artificial intelligence techniques with physics-based simulators to enhance ADS system-level testing. Our study evaluates the effectiveness and computational overhead of three generative strategies based on diffusion models, namely instruction-editing, inpainting, and inpainting with refinement. Specifically, we assess these techniques’ capabilities to produce augmented simulator-generated images of driving scenarios representing new ODDs. We employ a novel automated detector for invalid inputs based on semantic segmentation to ensure semantic preservation and realism of the neural generated images. We then perform system-level testing to evaluate the ADS’s generalization ability to newly synthesized ODDs. Our findings show that diffusion models help increase the ODD coverage for system-level testing of ADS. Our automated semantic validator achieved a percentage of false positives as low as 3%, retaining the correctness and quality of the generated images for testing. Our approach successfully identified new ADS system failures before real-world testing.
基于模拟器的测试被广泛用于评估自动驾驶系统(ADS)的可靠性,但其有效性受限于模拟器中可用的操作设计域(ODD)条件。为了解决这一限制,在这项工作中,我们探索了基于物理的模拟器与生成式人工智能技术的集成,以提高ADS系统级测试的效果。本研究评估了三种基于扩散模型的生成策略的有效性和计算开销,分别是指令编辑、图像修复和带有精细化的图像修复。具体来说,我们评估这些技术在生成代表新ODD的驾驶场景模拟器图像方面的能力。我们采用了一种基于语义分割的新型无效输入检测器,以确保神经生成图像语义的保留和真实性。然后,我们进行系统级测试,以评估ADS对新合成ODD的泛化能力。我们的研究发现,扩散模型有助于提高ADS系统级测试的ODD覆盖率。我们的自动语义验证器实现了高达3%的误报率,保持了测试图像生成的质量和正确性。我们的方法成功地在真实世界测试之前识别出新的ADS系统故障。
论文及项目相关链接
Summary
基于模拟器的测试是评估自动驾驶系统(ADS)可靠性的常用方法,但其有效性受限于模拟器中的操作设计域(ODD)条件。为解决此限制,本研究探索将基于物理的模拟器和生成式人工智能技术进行集成,以提高ADS系统级别的测试水平。本研究评估了三种基于扩散模型的生成策略的有效性和计算开销,包括指令编辑、图像修复和带精修的图像修复。这些技术被用于生成代表新ODD的驾驶场景图像。本研究采用基于语义分割的新型自动化检测器,确保神经生成图像保持语义完整性和逼真度。系统级测试的结果表明,扩散模型有助于提高ADS系统级测试的ODD覆盖率。自动化语义验证器的假阳性率低于3%,保证了生成图像用于测试的正确性和质量。该方法成功在真实世界测试之前识别出新的ADS系统故障。
Key Takeaways
- 模拟测试是评估自动驾驶系统(ADS)可靠性的常用方法,但受限于模拟器中的操作设计域(ODD)。
- 为提高测试水平,结合了基于物理的模拟器和生成式人工智能技术。
- 研究评估了三种基于扩散模型的生成策略:指令编辑、图像修复和带精修的图像修复。
- 这些策略被用于生成代表新ODD的驾驶场景图像,增强了ADS的系统级测试。
- 采用新型自动化检测器确保神经生成图像的语义完整性和逼真度。
- 系统级测试显示扩散模型提高了ADS系统级测试的ODD覆盖率。
点此查看论文截图

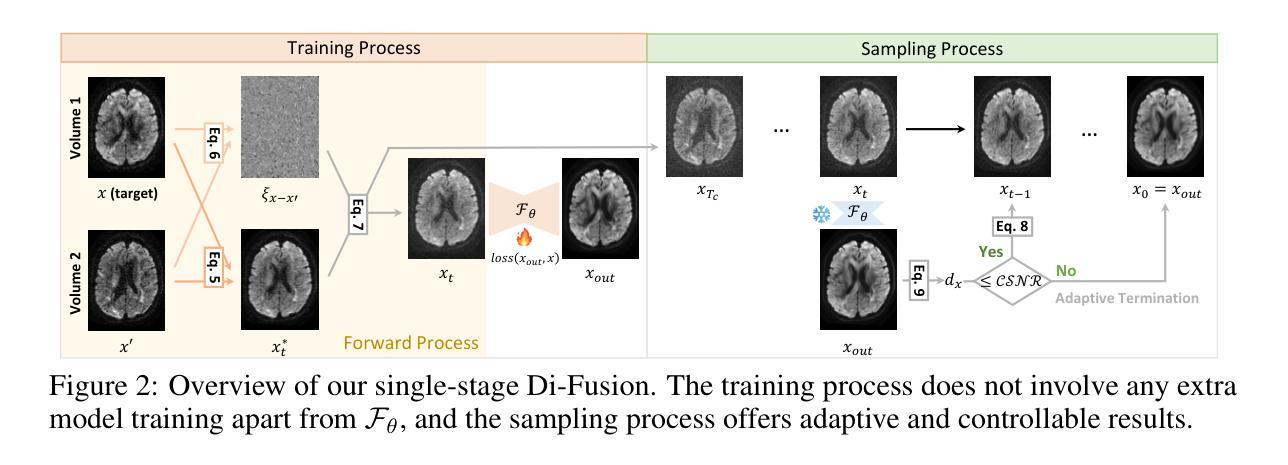
Guided Reconstruction with Conditioned Diffusion Models for Unsupervised Anomaly Detection in Brain MRIs
Authors:Finn Behrendt, Debayan Bhattacharya, Robin Mieling, Lennart Maack, Julia Krüger, Roland Opfer, Alexander Schlaefer
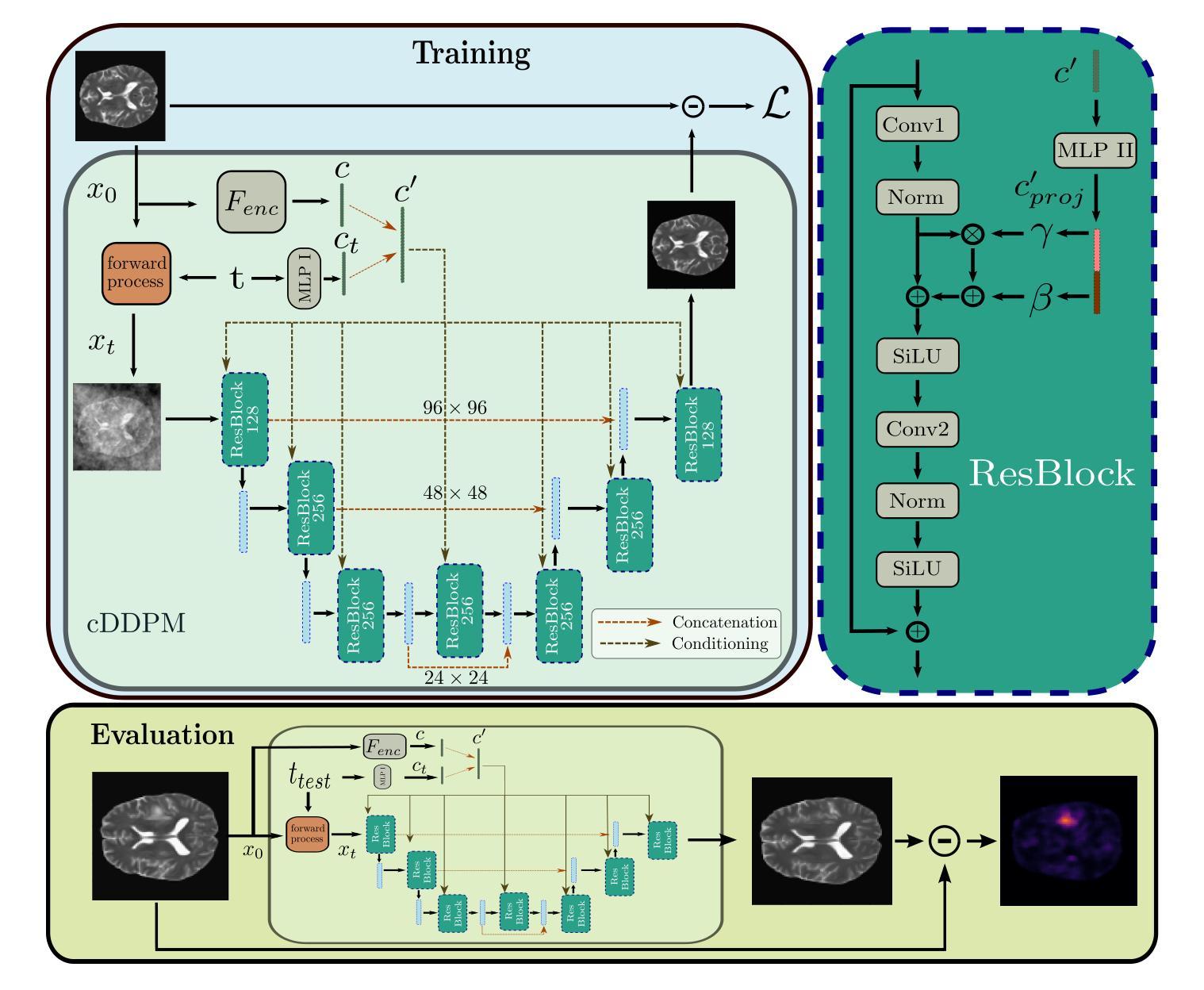
The application of supervised models to clinical screening tasks is challenging due to the need for annotated data for each considered pathology. Unsupervised Anomaly Detection (UAD) is an alternative approach that aims to identify any anomaly as an outlier from a healthy training distribution. A prevalent strategy for UAD in brain MRI involves using generative models to learn the reconstruction of healthy brain anatomy for a given input image. As these models should fail to reconstruct unhealthy structures, the reconstruction errors indicate anomalies. However, a significant challenge is to balance the accurate reconstruction of healthy anatomy and the undesired replication of abnormal structures. While diffusion models have shown promising results with detailed and accurate reconstructions, they face challenges in preserving intensity characteristics, resulting in false positives. We propose conditioning the denoising process of diffusion models with additional information derived from a latent representation of the input image. We demonstrate that this conditioning allows for accurate and local adaptation to the general input intensity distribution while avoiding the replication of unhealthy structures. We compare the novel approach to different state-of-the-art methods and for different data sets. Our results show substantial improvements in the segmentation performance, with the Dice score improved by 11.9%, 20.0%, and 44.6%, for the BraTS, ATLAS and MSLUB data sets, respectively, while maintaining competitive performance on the WMH data set. Furthermore, our results indicate effective domain adaptation across different MRI acquisitions and simulated contrasts, an important attribute for general anomaly detection methods. The code for our work is available at https://github.com/FinnBehrendt/Conditioned-Diffusion-Models-UAD
将监督模型应用于临床筛查任务是一项挑战,因为需要考虑针对每种病理的标注数据。无监督异常检测(UAD)是一种替代方法,旨在从健康的训练分布中识别任何异常值作为离群值。UAD在脑部MRI中的常见策略是使用生成模型来学习给定输入图像的脑部结构的重建。由于这些模型无法重建不健康的结构,因此重建误差指示了异常。然而,一个重大挑战是平衡健康结构的准确重建和异常结构的非必要复制。尽管扩散模型在详细和准确的重建方面显示出有希望的结果,但它们面临着保持强度特性的挑战,这会导致误报。我们提出将扩散模型的去噪过程与输入图像的潜在表示派生出的附加信息相结合。我们证明这种条件化允许对一般输入强度分布进行准确和局部适应,同时避免复制不健康结构。我们将新方法与不同的最新方法和数据集进行了比较。我们的结果显示出明显的分割性能改进,对于BraTS、ATLAS和MSLUB数据集,Dice得分分别提高了11.9%、20.0%和44.6%,同时在WMH数据集上保持竞争力。此外,我们的结果表明,在不同MRI采集和模拟对比度之间实现了有效的领域适应,这对于一般异常检测方法而言是一个重要属性。我们的工作代码可在https://github.com/FinnBehrendt/Conditioned-Diffusion-Models-UAD找到。
论文及项目相关链接
PDF Preprint: Accepted paper at Combuters in Biology and medicine
Summary
扩散模型在医学图像中的无监督异常检测面临挑战,包括保持强度特性和避免复制异常结构。我们提出了一种新的方法,即通过输入图像的潜在表示来条件化扩散模型的去噪过程。此方法可准确适应总体输入强度分布,同时避免复制不健康结构。在多个数据集上的实验结果显示,我们的方法大幅提高了分割性能,并在不同MRI采集和模拟对比度上实现了有效的域适应。
Key Takeaways
- 扩散模型在无监督异常检测(UAD)中面临挑战,需要平衡健康解剖结构的准确重建和异常结构的复制问题。
- 扩散模型在医学图像重建中可能无法准确保留强度特性,导致误报。
- 提出了一种新的方法,通过输入图像的潜在表示来条件化扩散模型的去噪过程,实现更准确的重建并避免异常结构的复制。
- 方法在多个数据集上的实验结果显示,大幅提高分割性能,并实现了有效的域适应。
- 方法在不同MRI采集和模拟对比度上具有良好的通用性。
- 公开了相关代码,便于其他研究者使用和改进。
- 此方法有望改善临床筛查任务中的无监督异常检测,为医学图像分析提供新的工具。
点此查看论文截图

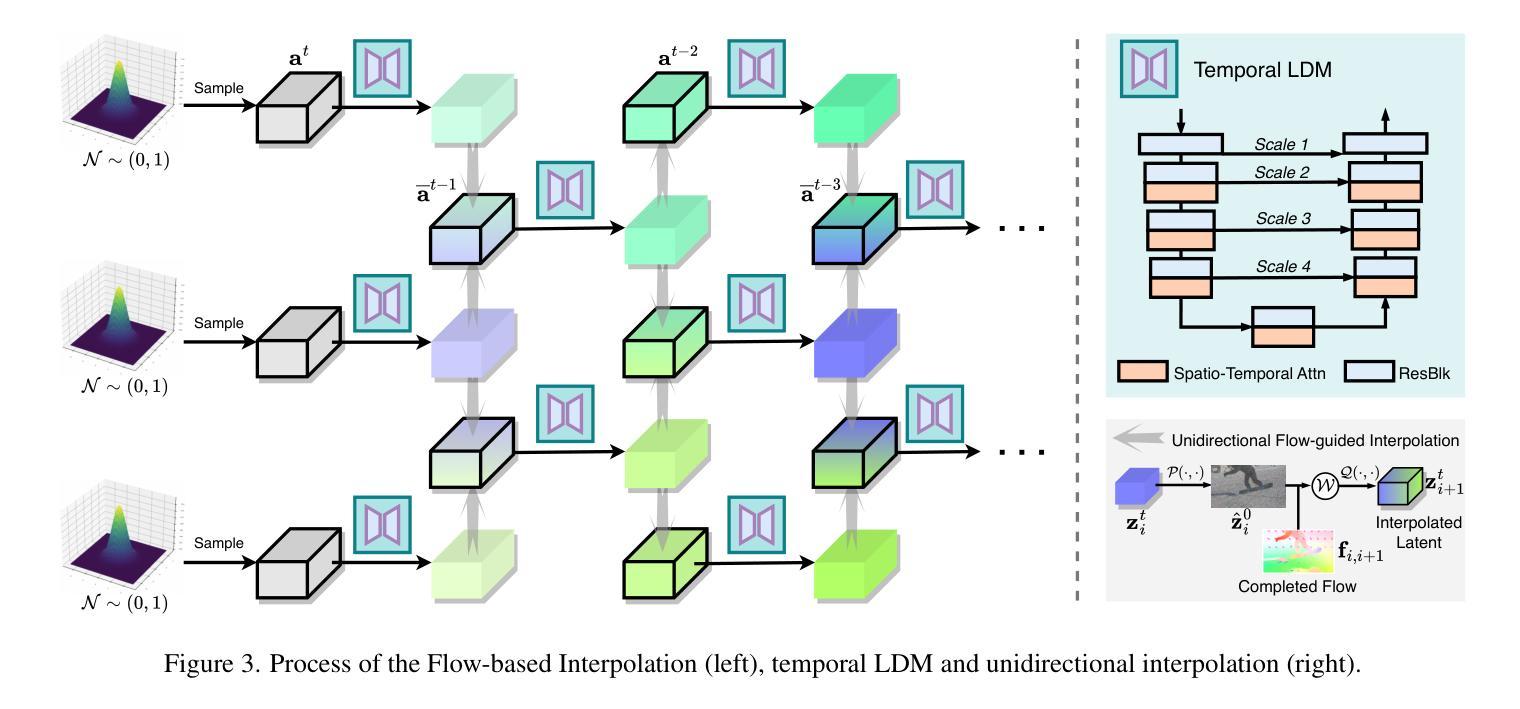
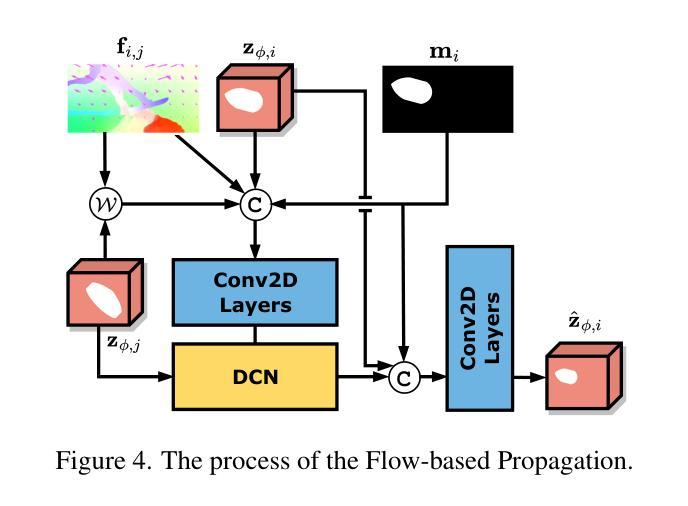
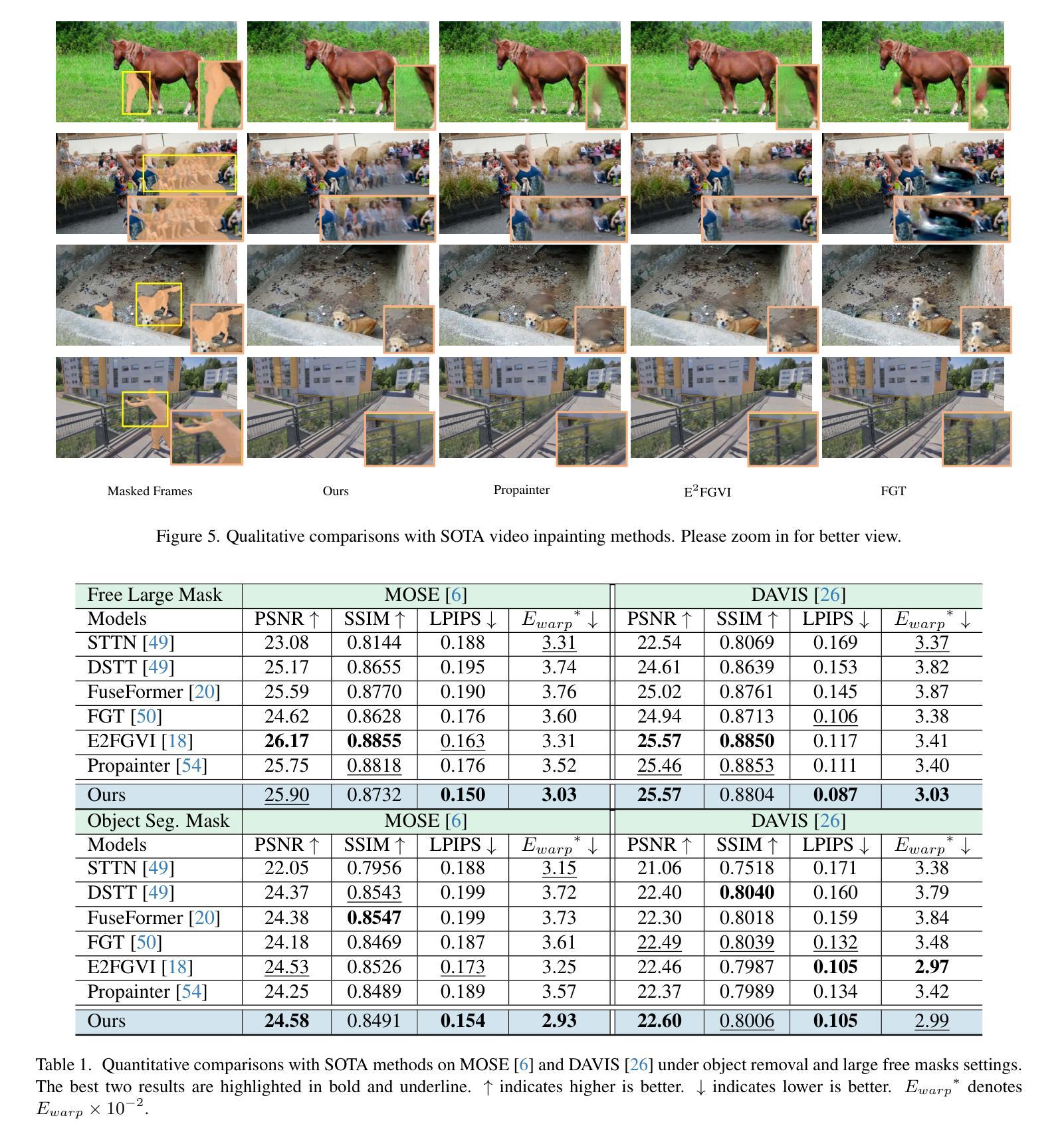
Flow-Guided Diffusion for Video Inpainting
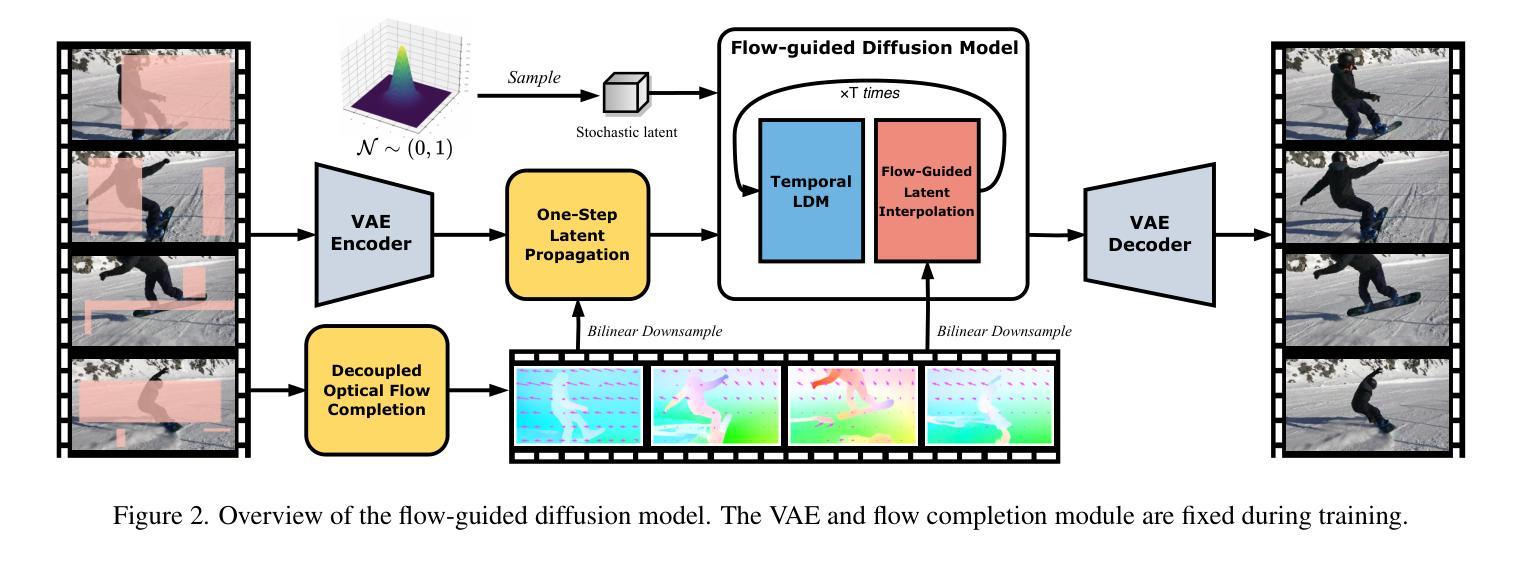
Authors:Bohai Gu, Yongsheng Yu, Heng Fan, Libo Zhang
Video inpainting has been challenged by complex scenarios like large movements and low-light conditions. Current methods, including emerging diffusion models, face limitations in quality and efficiency. This paper introduces the Flow-Guided Diffusion model for Video Inpainting (FGDVI), a novel approach that significantly enhances temporal consistency and inpainting quality via reusing an off-the-shelf image generation diffusion model. We employ optical flow for precise one-step latent propagation and introduces a model-agnostic flow-guided latent interpolation technique. This technique expedites denoising, seamlessly integrating with any Video Diffusion Model (VDM) without additional training. Our FGDVI demonstrates a remarkable 10% improvement in flow warping error E_warp over existing state-of-the-art methods. Our comprehensive experiments validate superior performance of FGDVI, offering a promising direction for advanced video inpainting. The code and detailed results will be publicly available in https://github.com/NevSNev/FGDVI.
视频补全技术面临复杂场景(如大动作和低光照条件)的挑战。当前的方法,包括新兴的扩散模型在内,在质量和效率方面都存在局限性。本文介绍了视频补全的流引导扩散模型(FGDVI),这是一种新型方法,通过复用现成的图像生成扩散模型显著提高了时间一致性和补全质量。我们采用光流进行精确的一步潜在传播,并引入了一种模型无关的流引导潜在插值技术。这项技术加快了去噪过程,无需额外训练即可无缝集成到任何视频扩散模型(VDM)中。我们的FGDVI在流扭曲误差E_warp上较现有最先进的方法显示出显著的10%改进。我们的综合实验验证了FGDVI的优越性能,为先进的视频补全提供了有前景的研究方向。代码和详细结果将在https://github.com/NevSNev/FGDVI公开可用。
论文及项目相关链接
PDF This paper has been withdrawn as a new iteration of the work has been developed, which includes significant improvements and refinements based on this submission. The withdrawal is made to ensure academic integrity and compliance with publication standards. If you are interested, please refer to the updated work at arXiv:2412.00857
Summary
本文提出了基于流引导的扩散模型(FGDVI)的视频补全新方法,通过利用光学流进行精确的一步潜在传播和引入模型无关的流引导潜在插值技术,显著提高了时间一致性和补全质量。该方法可快速去噪,无缝集成到任何视频扩散模型(VDM)中,无需额外训练。实验结果显示,FGDVI在流扭曲误差E_warp上较现有先进技术有显著改善。
Key Takeaways
- FGDVI是一种新颖的基于扩散模型的视频补全方法。
- 通过引入光学流进行精确的一步潜在传播。
- 提出了一种模型无关的流引导潜在插值技术。
- FGDVI提高了时间一致性和补全质量。
- 方法可快速去噪,并能无缝集成到任何视频扩散模型中。
- FGDVI在流扭曲误差上较现有技术有显著改善。
点此查看论文截图

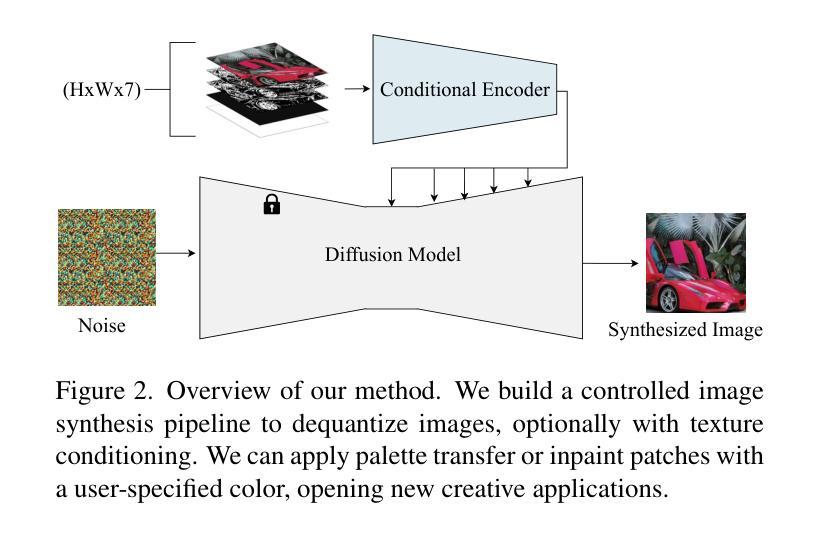
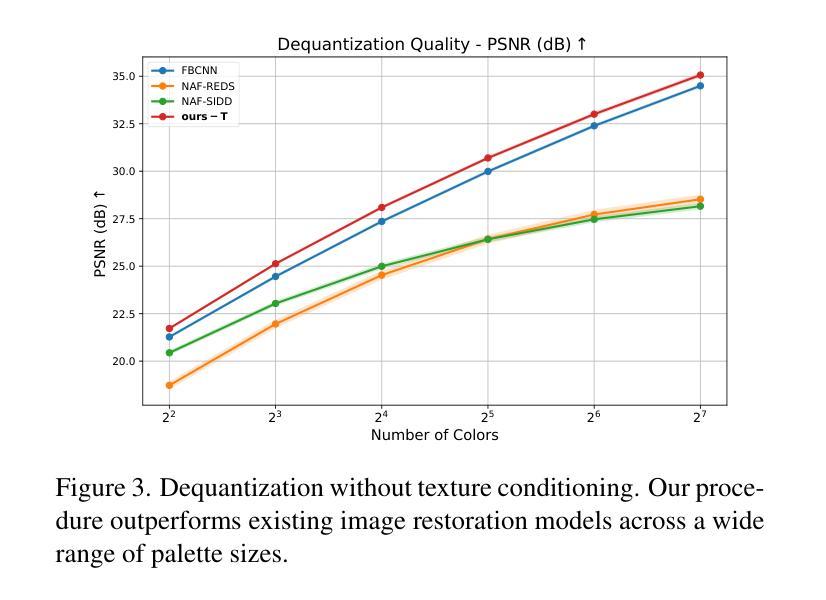
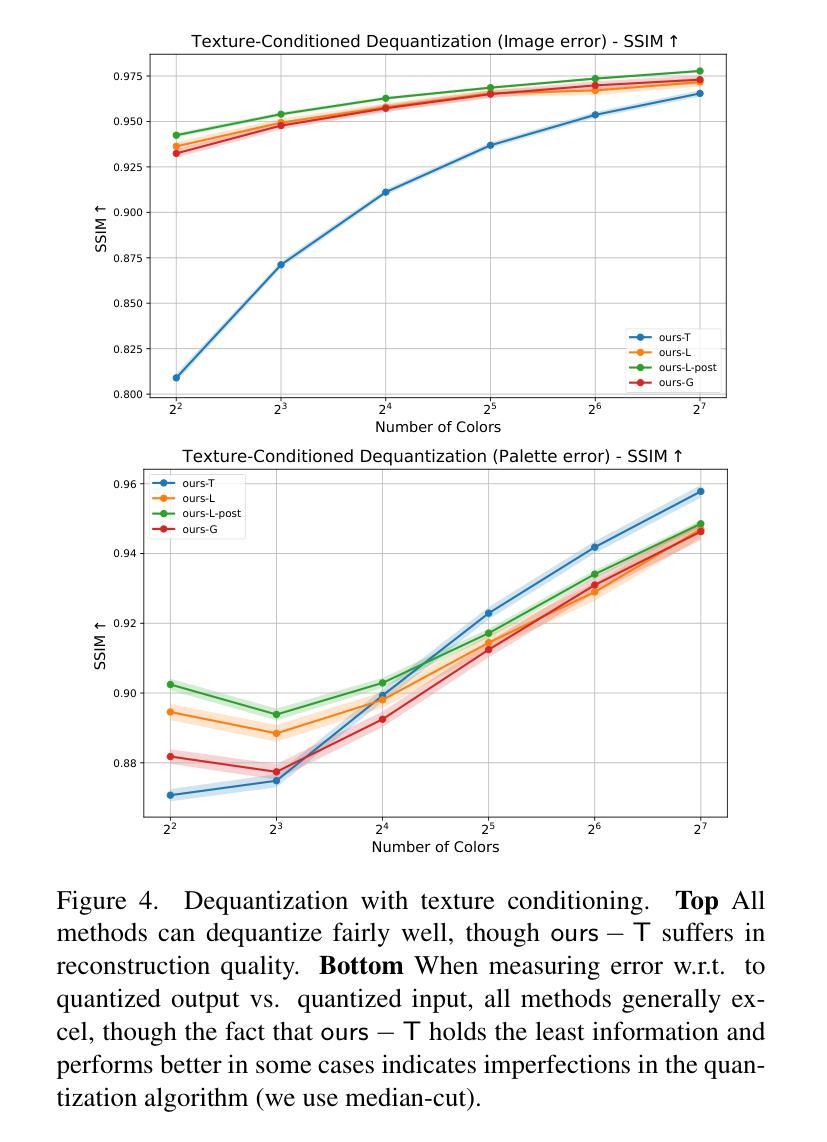
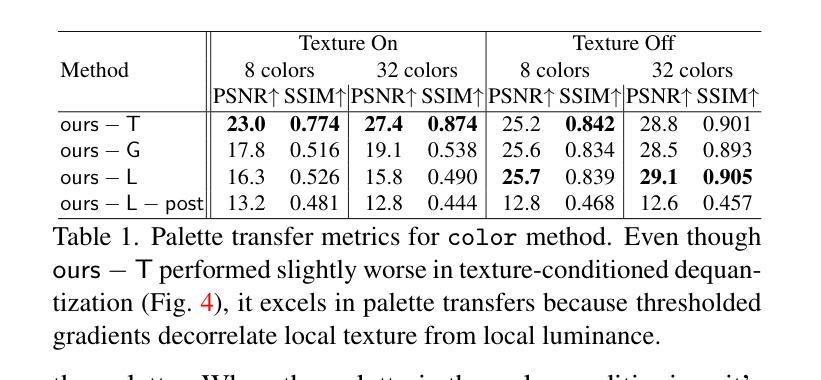
Dequantization and Color Transfer with Diffusion Models
Authors:Vaibhav Vavilala, Faaris Shaik, David Forsyth
We demonstrate an image dequantizing diffusion model that enables novel edits on natural images. We propose operating on quantized images because they offer easy abstraction for patch-based edits and palette transfer. In particular, we show that color palettes can make the output of the diffusion model easier to control and interpret. We first establish that existing image restoration methods are not sufficient, such as JPEG noise reduction models. We then demonstrate that our model can generate natural images that respect the color palette the user asked for. For palette transfer, we propose a method based on weighted bipartite matching. We then show that our model generates plausible images even after extreme palette transfers, respecting user query. Our method can optionally condition on the source texture in part or all of the image. In doing so, we overcome a common problem in existing image colorization methods that are unable to produce colors with a different luminance than the input. We evaluate several possibilities for texture conditioning and their trade-offs, including luminance, image gradients, and thresholded gradients, the latter of which performed best in maintaining texture and color control simultaneously. Our method can be usefully extended to another practical edit: recoloring patches of an image while respecting the source texture. Our procedure is supported by several qualitative and quantitative evaluations.
我们展示了一种图像去量化扩散模型,该模型可在自然图像上进行新型编辑。我们提出在量化图像上进行操作,因为量化图像为基于补丁的编辑和调色板转换提供了简单的抽象。特别是,我们表明,色彩调色板可以使扩散模型的输出更容易控制和解释。首先,我们确定现有的图像恢复方法(例如JPEG降噪模型)是不足的。然后,我们证明我们的模型可以生成尊重用户要求色彩调色板的自然图像。对于调色板转换,我们提出了一种基于加权二分匹配的方法。接着,我们证明我们的模型即使在极端的调色板转换后也能生成合理的图像,尊重用户查询。我们的方法可以选择对图像的部分或全部源纹理进行条件处理。这样做可以克服现有图像着色方法中常见的无法产生与输入不同亮度的颜色的问题。我们评估了几种纹理条件及其权衡的可能性,包括亮度、图像梯度和阈值梯度等,后者在同时保持纹理和颜色控制方面表现最佳。我们的方法可以扩展到另一种实用的编辑:在尊重源纹理的同时,对图像的补丁进行重新着色。我们的程序得到了多种定性和定量评估的支持。
论文及项目相关链接
PDF WACV 2025 23 pages, 21 figures, 4 tables
Summary
本文展示了一种图像去量化扩散模型,该模型可在自然图像上进行新颖编辑。文章提出在量化图像上进行操作,因为量化图像便于基于补丁的编辑和调色板转换。文章表明,颜色调色板可使扩散模型的输出更易控制和解释。文章首先确定现有图像恢复方法(如JPEG降噪模型)的不足,然后展示该模型可根据用户要求生成尊重颜色调色的自然图像。文章还提出了一种基于加权二分匹配的方法进行调色板转换,并能够进行极端的调色板转换同时尊重用户查询。该模型可部分或全部以源纹理为条件,从而解决了现有图像着色方法无法产生与输入不同亮度的颜色的问题。文章评估了几种纹理条件及其权衡,包括亮度、图像梯度和阈值梯度,后者在保持纹理和颜色控制方面表现最佳。该方法可扩展到另一种实用编辑:在尊重源纹理的同时重新着色图像的补丁。
Key Takeaways
- 展示了一种图像去量化扩散模型,能够在自然图像上进行新颖编辑。
- 通过对量化图像的操作,方便了基于补丁的编辑和调色板转换。
- 颜色调色板使得扩散模型的输出更容易控制和解释。
- 现有图像恢复方法的不足被指出,并展示了新模型在生成尊重颜色调色的自然图像方面的优势。
- 提出了一种基于加权二分匹配的方法进行调色板转换,甚至可以进行极端调色板转换。
- 模型能够以源纹理为条件,解决现有图像着色方法的问题。
点此查看论文截图