⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
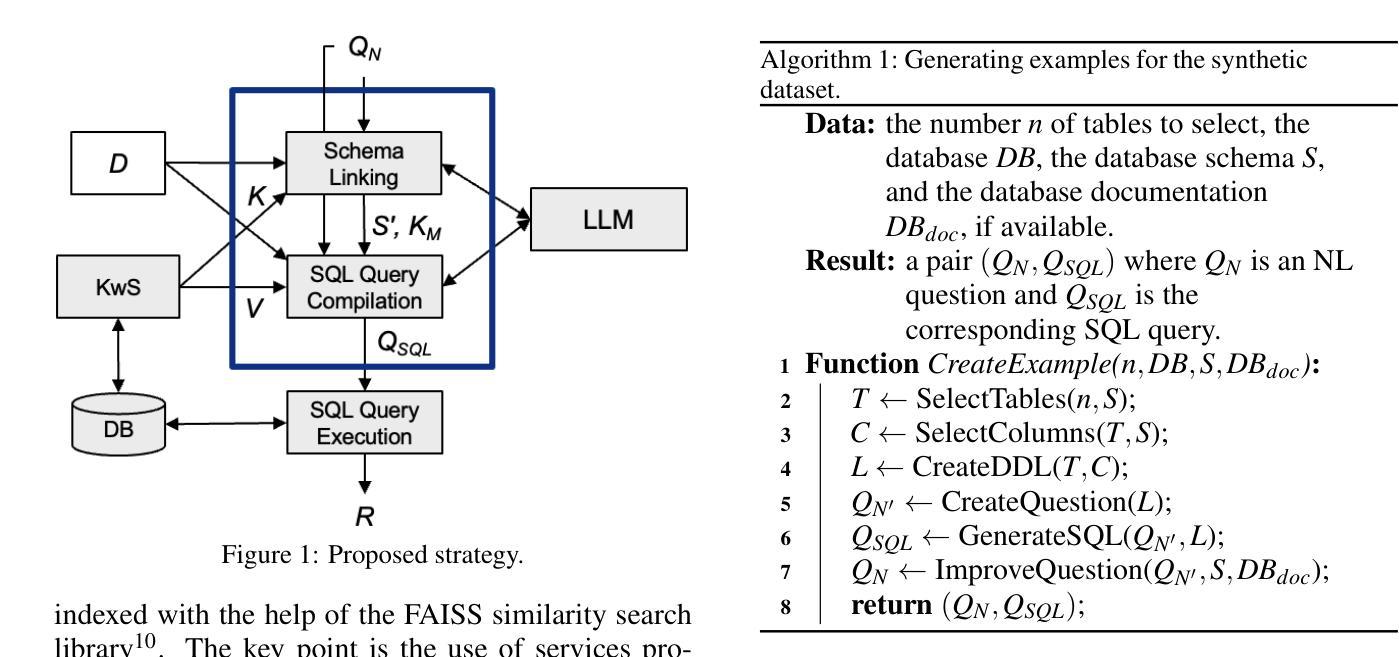
Text-to-SQL based on Large Language Models and Database Keyword Search
Authors:Eduardo R. Nascimento, Caio Viktor S. Avila, Yenier T. Izquierdo, Grettel M. García, Lucas Feijó L. Andrade, Michelle S. P. Facina, Melissa Lemos, Marco A. Casanova
Text-to-SQL prompt strategies based on Large Language Models (LLMs) achieve remarkable performance on well-known benchmarks. However, when applied to real-world databases, their performance is significantly less than for these benchmarks, especially for Natural Language (NL) questions requiring complex filters and joins to be processed. This paper then proposes a strategy to compile NL questions into SQL queries that incorporates a dynamic few-shot examples strategy and leverages the services provided by a database keyword search (KwS) platform. The paper details how the precision and recall of the schema-linking process are improved with the help of the examples provided and the keyword-matching service that the KwS platform offers. Then, it shows how the KwS platform can be used to synthesize a view that captures the joins required to process an input NL question and thereby simplify the SQL query compilation step. The paper includes experiments with a real-world relational database to assess the performance of the proposed strategy. The experiments suggest that the strategy achieves an accuracy on the real-world relational database that surpasses state-of-the-art approaches. The paper concludes by discussing the results obtained.
基于大型语言模型(LLM)的文本到SQL提示策略在知名基准测试中取得了显著的性能。然而,当应用于现实世界数据库时,其性能却远不及这些基准测试,尤其是需要复杂过滤器和联接处理的自然语言(NL)问题。本文提出了一种将NL问题编译成SQL查询的策略,该策略结合了动态少样本示例策略,并利用数据库关键词搜索(KwS)平台提供的服务。本文详细介绍了如何利用提供的示例和KwS平台提供的关键词匹配服务来提高模式链接过程的精确性和召回率。然后,它展示了如何使用KwS平台合成一个视图,该视图能够捕获处理输入NL问题所需的联接,从而简化SQL查询编译步骤。本文还包括使用现实世界关系数据库进行的实验,以评估所提出策略的性能。实验表明,该策略在现实世界关系数据库上的准确性超过了最新技术方法。最后,本文讨论了所得结果。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的文本到SQL提示策略在知名基准测试中表现优异。然而,当应用于真实世界数据库时,其性能显著下降,尤其是在处理需要复杂过滤和联接的自然语言(NL)问题时。本文提出了一种将NL问题编译成SQL查询的策略,该策略结合了动态少例策略,并利用了数据库关键词搜索(KwS)平台提供的服务。通过提供的示例和KwS平台提供的关键词匹配服务,本文详细说明了如何改进模式链接过程的精确性和召回率。此外,它展示了如何使用KwS平台合成一个视图,以捕获处理输入NL问题所需的联接,从而简化SQL查询编译步骤。本文包括在真实世界关系数据库上进行实验,以评估所提出策略的性能。实验表明,该策略在真实世界关系数据库上的准确性超过了最新技术方法。
Key Takeaways
- LLMs在基准测试中表现良好,但在真实世界数据库中的性能下降。
- 提出了一种结合动态少例策略和数据库关键词搜索平台的新策略。
- 通过提供的示例和关键词匹配服务提高了模式链接的精确性和召回率。
- KwS平台可用于合成视图,简化SQL查询编译步骤。
- 实验表明,新策略在真实世界关系数据库上的准确性优于现有方法。
- 该策略对于处理需要复杂过滤和联接的自然语言问题特别有效。
点此查看论文截图

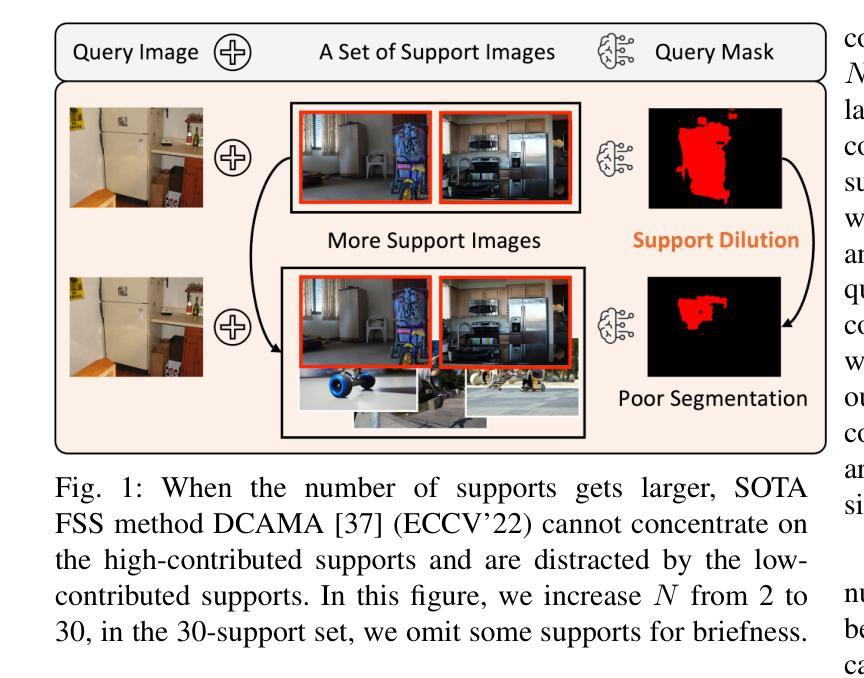
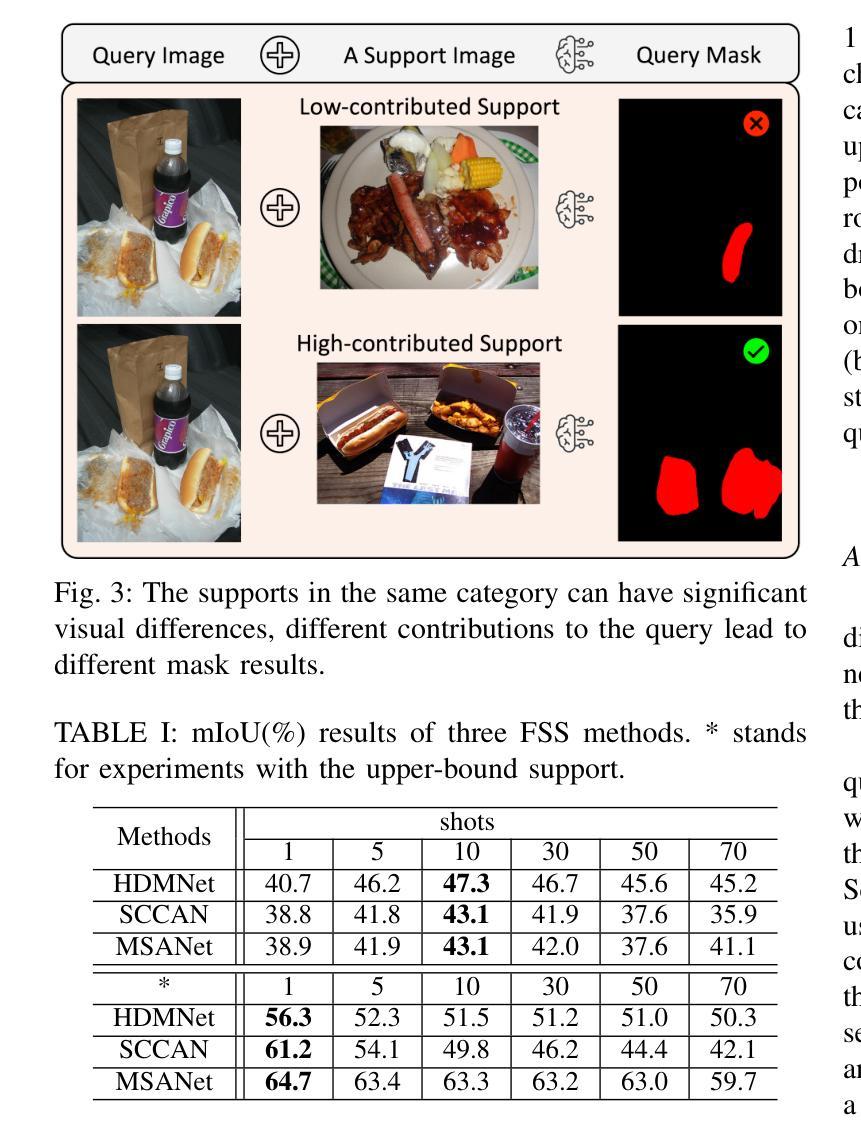
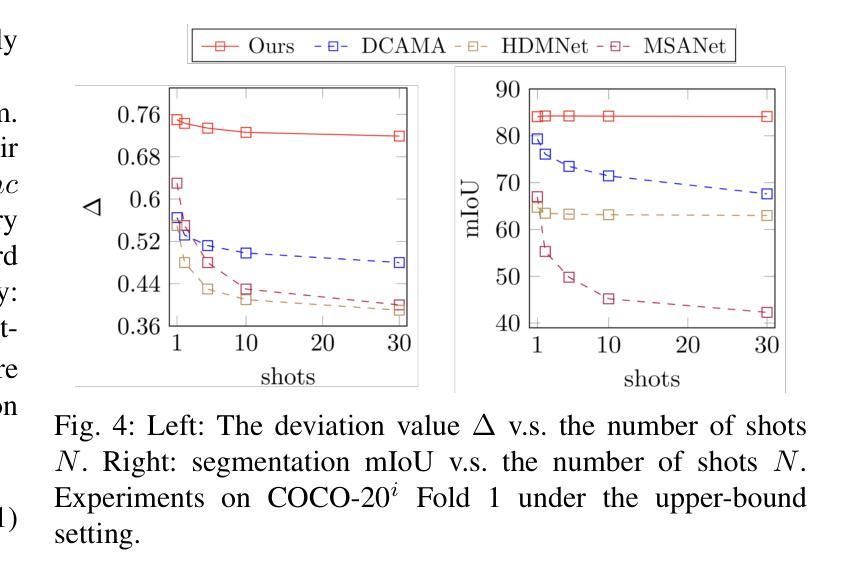
Overcoming Support Dilution for Robust Few-shot Semantic Segmentation
Authors:Wailing Tang, Biqi Yang, Pheng-Ann Heng, Yun-Hui Liu, Chi-Wing Fu
Few-shot Semantic Segmentation (FSS) is a challenging task that utilizes limited support images to segment associated unseen objects in query images. However, recent FSS methods are observed to perform worse, when enlarging the number of shots. As the support set enlarges, existing FSS networks struggle to concentrate on the high-contributed supports and could easily be overwhelmed by the low-contributed supports that could severely impair the mask predictions. In this work, we study this challenging issue, called support dilution, our goal is to recognize, select, preserve, and enhance those high-contributed supports in the raw support pool. Technically, our method contains three novel parts. First, we propose a contribution index, to quantitatively estimate if a high-contributed support dilutes. Second, we develop the Symmetric Correlation (SC) module to preserve and enhance the high-contributed support features, minimizing the distraction by the low-contributed features. Third, we design the Support Image Pruning operation, to retrieve a compact and high quality subset by discarding low-contributed supports. We conduct extensive experiments on two FSS benchmarks, COCO-20i and PASCAL-5i, the segmentation results demonstrate the compelling performance of our solution over state-of-the-art FSS approaches. Besides, we apply our solution for online segmentation and real-world segmentation, convincing segmentation results showing the practical ability of our work for real-world demonstrations.
少样本语义分割(FSS)是一项具有挑战性的任务,它利用有限的支撑图像来对查询图像中的相关未见对象进行分割。然而,当增加样本数量时,最近的FSS方法表现较差。随着支撑集增大,现有的FSS网络很难集中关注高贡献的支撑样本,并可能轻易受到低贡献的支撑样本的影响,从而严重损害掩膜预测。在这项工作中,我们研究这个具有挑战性的问题,称为支撑稀释。我们的目标是识别、选择、保留并增强原始支撑池中的高贡献支撑样本。技术上,我们的方法包含三个新颖的部分。首先,我们提出一个贡献指数,定量评估高贡献支撑是否稀释。其次,我们开发了对称关联(SC)模块,以保留和提升高贡献支撑特征,并最小化低贡献特征的干扰。第三,我们设计了支撑图像修剪操作,通过丢弃低贡献的支撑样本,来检索一个紧凑且高质量的子集。我们在两个FSS基准测试(COCO-20i和PASCAL-5i)上进行了大量实验,分割结果证明我们的解决方案在最新FSS方法上具有令人信服的表现。此外,我们将我们的解决方案应用于在线分割和真实世界分割,令人信服的分割结果展示了我们的工作在真实世界演示中的实用能力。
论文及项目相关链接
PDF 15 pages, 15 figures
Summary
近期对于少样本语义分割(FSS)任务的研究表明,随着支持图像数量的增加,现有的FSS网络会面临“支持稀释”问题,即难以专注于高贡献的支持图像,容易被低贡献的支持图像干扰,影响掩膜预测的效果。本研究旨在识别、选择、保留和提升原始支持池中的高贡献支持图像,提出了一套解决方案。首先通过贡献指数定量评估支持图像的贡献度;其次,开发了对称关联(SC)模块,以保留和提升高贡献支持图像的特征;最后,设计了支持图像修剪操作,通过剔除低贡献的支持图像,获取一个紧凑且高质量的支持图像子集。在COCO-20i和PASCAL-5i两个FSS基准测试集上的分割结果证明了该解决方案的优异性能。此外,本研究还将该方案应用于在线分割和真实世界分割,取得令人信服的分割结果,展现了其实际应用的潜力。
Key Takeaways
- FSS任务面临“支持稀释”问题,即随着支持图像数量增加,网络性能下降。
- 高贡献的支持图像对于准确预测至关重要。
- 提出通过贡献指数评估支持图像贡献度的方法。
- 引入对称关联(SC)模块,以保留和提升高贡献支持图像的特征。
- 设计支持图像修剪操作,剔除低贡献支持图像,形成高质量子集。
- 在两个FSS基准测试集上取得优异性能。
点此查看论文截图


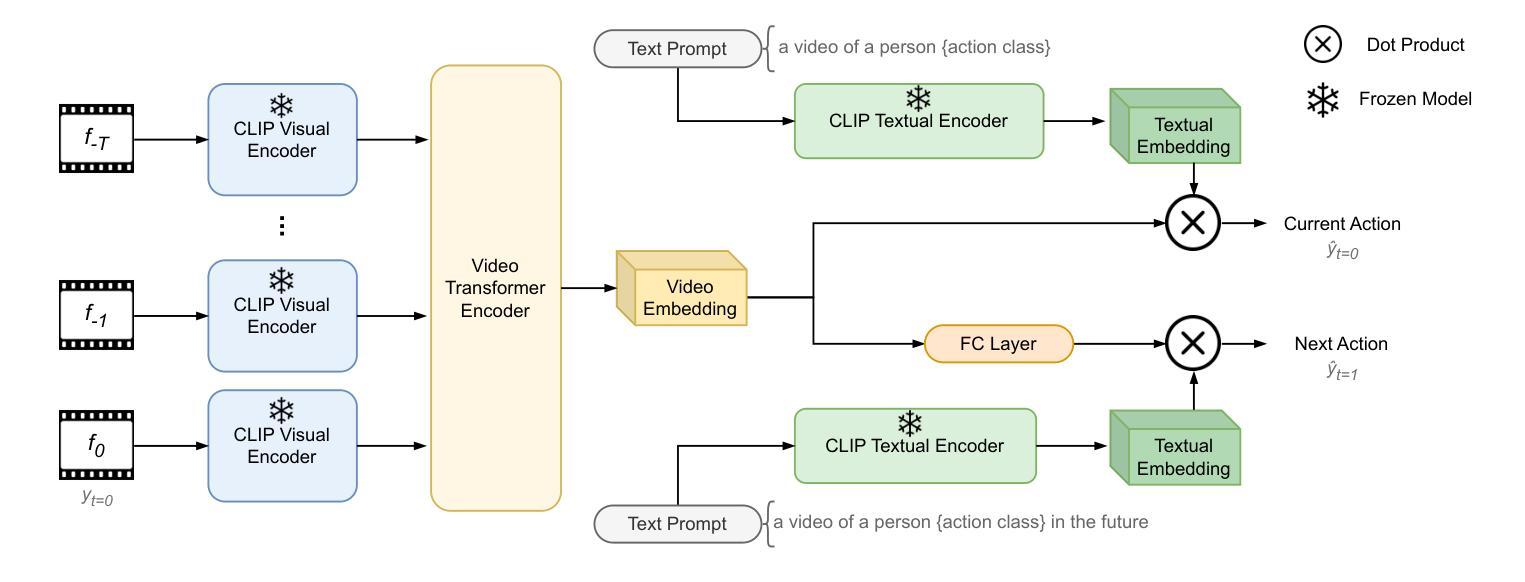
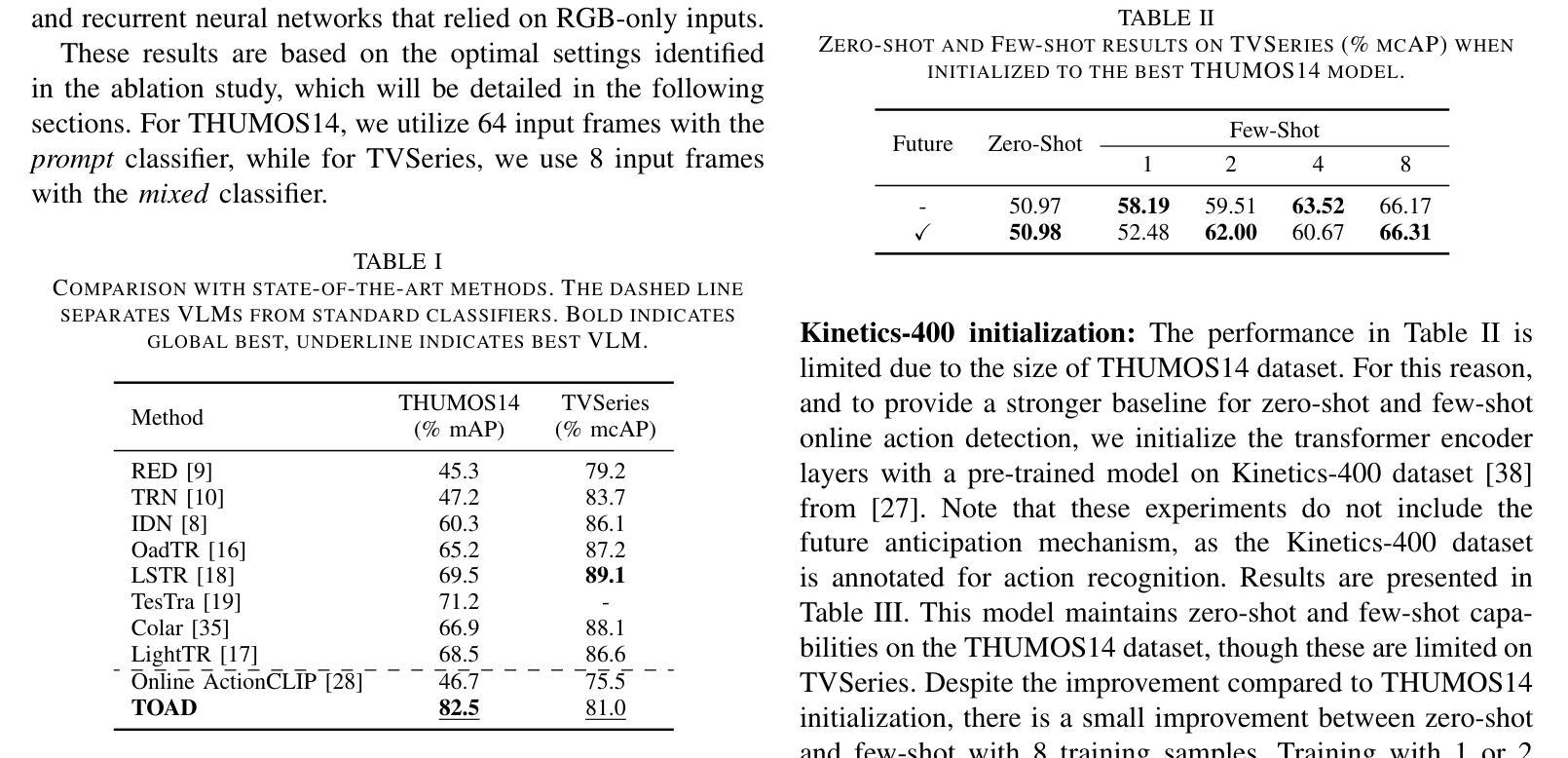
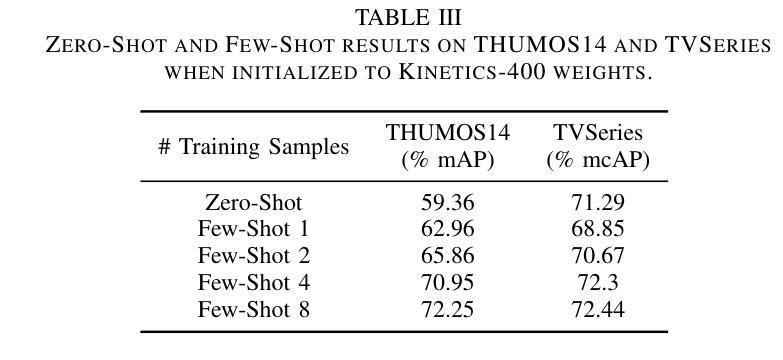
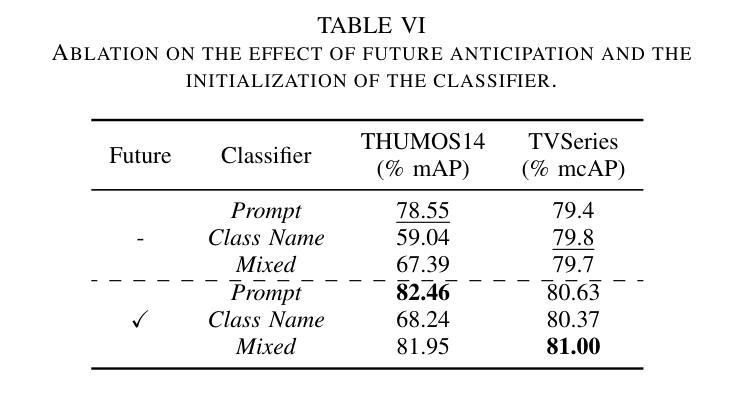
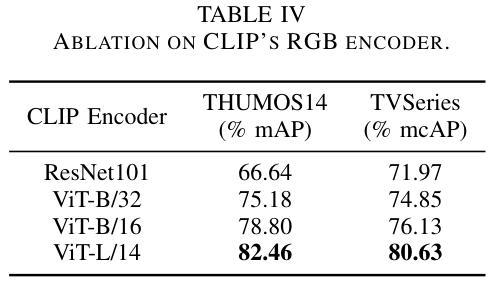
Text-driven Online Action Detection
Authors:Manuel Benavent-Lledo, David Mulero-Pérez, David Ortiz-Perez, Jose Garcia-Rodriguez
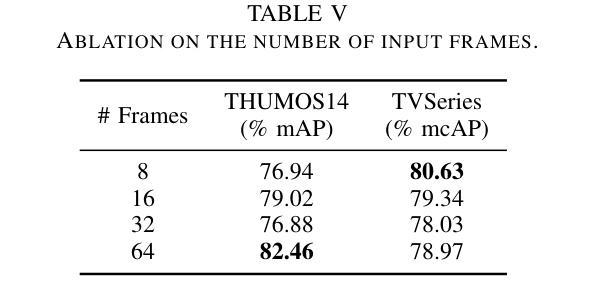
Detecting actions as they occur is essential for applications like video surveillance, autonomous driving, and human-robot interaction. Known as online action detection, this task requires classifying actions in streaming videos, handling background noise, and coping with incomplete actions. Transformer architectures are the current state-of-the-art, yet the potential of recent advancements in computer vision, particularly vision-language models (VLMs), remains largely untapped for this problem, partly due to high computational costs. In this paper, we introduce TOAD: a Text-driven Online Action Detection architecture that supports zero-shot and few-shot learning. TOAD leverages CLIP (Contrastive Language-Image Pretraining) textual embeddings, enabling efficient use of VLMs without significant computational overhead. Our model achieves 82.46% mAP on the THUMOS14 dataset, outperforming existing methods, and sets new baselines for zero-shot and few-shot performance on the THUMOS14 and TVSeries datasets.
检测正在发生的动作对于视频监控、自动驾驶和人机交互等应用至关重要。这被称为在线动作检测,该任务要求在流媒体视频中分类动作,处理背景噪声,以及应对动作不完整的情况。虽然Transformer架构是目前最先进的技术,但计算机视觉领域的最新进展,尤其是视觉语言模型(VLMs)的潜力,对于这个问题的解决仍然大部分未被开发,部分原因是计算成本较高。在本文中,我们介绍了TOAD:一种文本驱动的在线动作检测架构,支持零样本和少样本学习。TOAD利用CLIP(对比语言图像预训练)文本嵌入,在不需要重大计算开销的情况下,实现了对VLMs的有效利用。我们的模型在THUMOS14数据集上达到了82.46%的mAP,超越了现有方法,为THUMOS14和TVSeries数据集的零样本和少样本性能设定了新的基准。
论文及项目相关链接
PDF Published in Integrated Computer-Aided Engineering
Summary
本文介绍了一种名为TOAD的文本驱动在线动作检测架构,支持零样本和少样本学习。该架构利用CLIP文本嵌入,实现高效使用VLMs而无需显著的计算开销。在THUMOS14数据集上,TOAD模型取得了82.46%的mAP性能,优于现有方法,并为THUMOS14和TVSeries数据集的零样本和少样本性能设定了新的基准。
Key Takeaways
- 文中介绍了一种新的在线动作检测架构TOAD,适用于视频监控、自动驾驶和人机交互等应用。
- TOAD支持零样本和少样本学习,能够处理流式视频中的动作分类、背景噪声和不完全动作等问题。
- TOAD架构利用CLIP文本嵌入,使VLMs的使用更加高效,同时降低了计算成本。
- 在THUMOS14数据集上,TOAD模型取得了较高的性能,mAP达到82.46%。
- TOAD模型优于现有的方法,为在线动作检测设定了新的性能基准。
- TOAD模型在零样本和少样本学习方面也有出色的表现,尤其在THUMOS14和TVSeries数据集上。
点此查看论文截图

MEDFORM: A Foundation Model for Contrastive Learning of CT Imaging and Clinical Numeric Data in Multi-Cancer Analysis
Authors:Daeun Jung, Jaehyeok Jang, Sooyoung Jang, Yu Rang Park
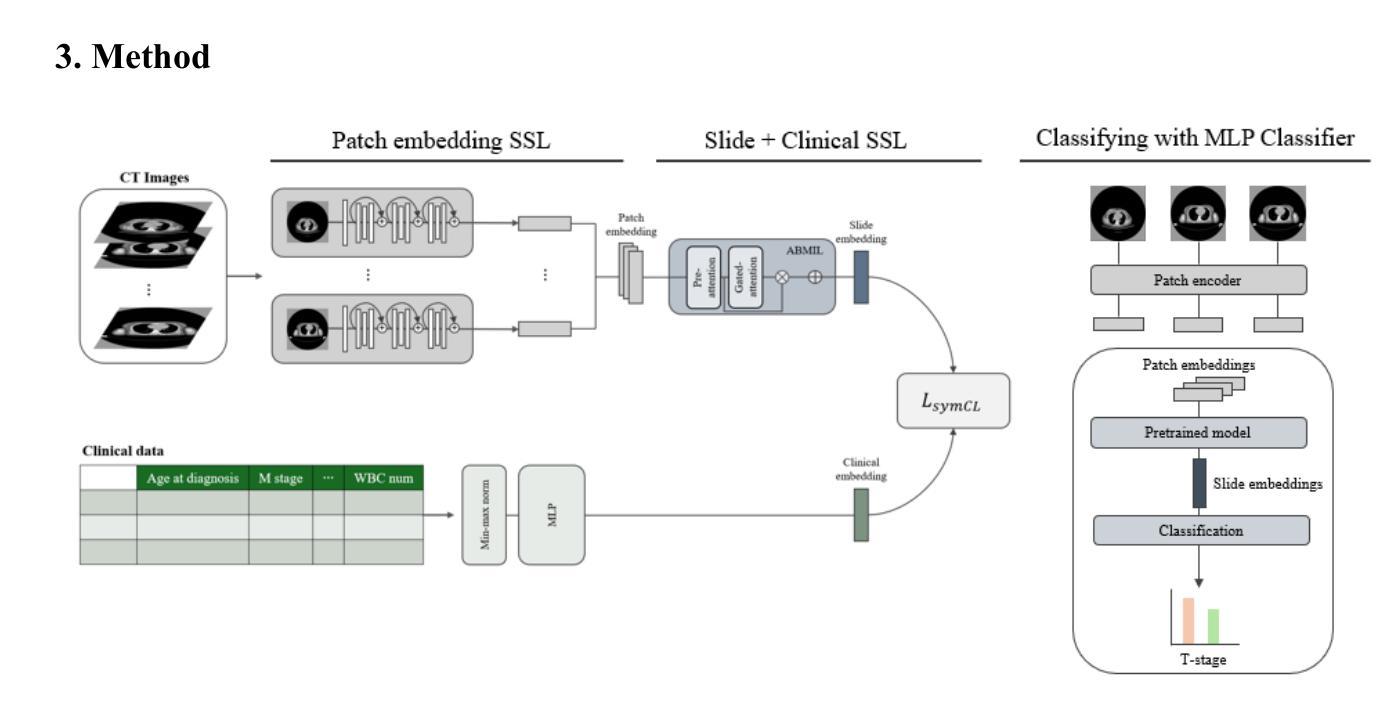
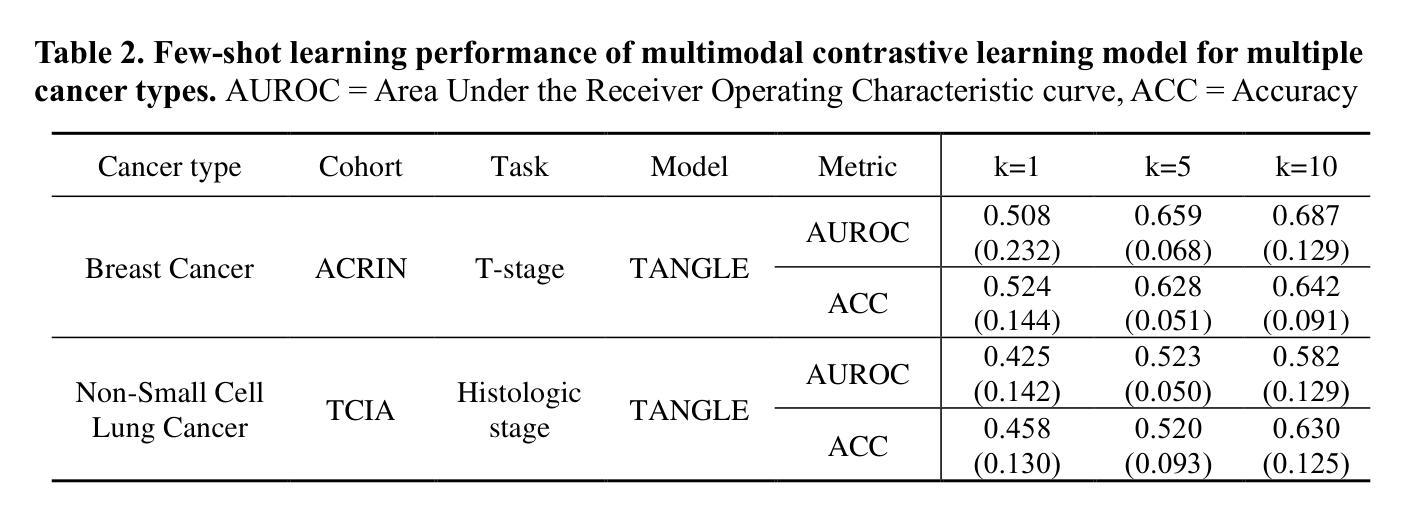
Computed tomography (CT) and clinical numeric data are essential modalities for cancer evaluation, but building large-scale multimodal training datasets for developing medical foundation models remains challenging due to the structural complexity of multi-slice CT data and high cost of expert annotation. In this study, we propose MEDFORM, a multimodal pre-training strategy that guides CT image representation learning using complementary information from clinical data for medical foundation model development. MEDFORM efficiently processes CT slice through multiple instance learning (MIL) and adopts a dual pre-training strategy: first pretraining the CT slice feature extractor using SimCLR-based self-supervised learning, then aligning CT and clinical modalities through cross-modal contrastive learning. Our model was pre-trained on three different cancer types: lung cancer (141,171 slices), breast cancer (8,100 slices), colorectal cancer (10,393 slices). The experimental results demonstrated that this dual pre-training strategy improves cancer classification performance and maintains robust performance in few-shot learning scenarios. Code available at https://github.com/DigitalHealthcareLab/25MultiModalFoundationModel.git
计算机断层扫描(CT)和临床数值数据对于癌症评估至关重要,但由于多层CT数据的结构复杂性以及专家标注的高成本,构建用于开发医疗基础模型的大规模多模式训练数据集仍然是一个挑战。在本研究中,我们提出了MEDFORM,这是一种多模式预训练策略,该策略利用临床数据的辅助信息进行CT图像表征学习,以用于医疗基础模型的开发。MEDFORM通过多次实例学习(MIL)有效地处理CT切片,并采用双重预训练策略:首先使用基于SimCLR的自我监督学习对CT切片特征提取器进行预训练,然后通过跨模式对比学习对齐CT和临床模式。我们的模型在三种不同类型的癌症(肺癌(141,171片)、乳腺癌(8,100片)、结肠癌(10,393片))上进行了预训练。实验结果表明,这种双重预训练策略提高了癌症分类性能,并在小样本学习场景中保持了稳健的性能。代码可在https://github.com/DigitalHealthcareLab/25MultiModalFoundationModel.git找到。
论文及项目相关链接
PDF 8 pages, 1 figure
Summary
本文提出了一种名为MEDFORM的多模态预训练策略,该策略利用临床数据中的互补信息来指导CT图像表示学习,用于开发医疗基础模型。通过采用多实例学习(MIL)处理CT切片,并采用基于SimCLR的自监督学习和跨模态对比学习的双预训练策略,模型在肺癌、乳腺癌和结直肠癌的预训练数据上取得了良好的分类性能,并在少样本学习场景下保持稳健。
Key Takeaways
- MEDFORM是一种多模态预训练策略,结合CT图像和临床数据用于医疗基础模型开发。
- 采用多实例学习(MIL)处理CT切片,提高模型对复杂CT数据的处理能力。
- 使用基于SimCLR的自监督学习进行CT切片特征提取器的预训练。
- 通过跨模态对比学习实现CT和临床模态的对齐。
- 模型在肺癌、乳腺癌和结直肠癌的预训练数据上进行了验证。
- 双预训练策略提高了癌症分类性能。
- 模型在少样本学习场景下表现出稳健性能。
点此查看论文截图


Distributed Intrusion Detection in Dynamic Networks of UAVs using Few-Shot Federated Learning
Authors:Ozlem Ceviz, Sevil Sen, Pinar Sadioglu
Flying Ad Hoc Networks (FANETs), which primarily interconnect Unmanned Aerial Vehicles (UAVs), present distinctive security challenges due to their distributed and dynamic characteristics, necessitating tailored security solutions. Intrusion detection in FANETs is particularly challenging due to communication costs, and privacy concerns. While Federated Learning (FL) holds promise for intrusion detection in FANETs with its cooperative and decentralized model training, it also faces drawbacks such as large data requirements, power consumption, and time constraints. Moreover, the high speeds of nodes in dynamic networks like FANETs may disrupt communication among Intrusion Detection Systems (IDS). In response, our study explores the use of few-shot learning (FSL) to effectively reduce the data required for intrusion detection in FANETs. The proposed approach called Few-shot Federated Learning-based IDS (FSFL-IDS) merges FL and FSL to tackle intrusion detection challenges such as privacy, power constraints, communication costs, and lossy links, demonstrating its effectiveness in identifying routing attacks in dynamic FANETs.This approach reduces both the local models and the global model’s training time and sample size, offering insights into reduced computation and communication costs and extended battery life. Furthermore, by employing FSL, which requires less data for training, IDS could be less affected by lossy links in FANETs.
飞行式临时网络(FANETs)主要连接无人飞行器(UAVs),由于其分布式和动态特性,呈现出独特的网络安全挑战,需要定制的安全解决方案。FANETs中的入侵检测由于通信成本和隐私问题而具有特别大的挑战性。虽然联合学习(FL)因其合作和分散的模型训练而对FANETs中的入侵检测具有广阔前景,但它也面临着数据需求量大、功耗和时间限制等缺点。此外,FANETs等动态网络中节点的高速运行可能会破坏入侵检测系统(IDS)之间的通信。为了应对这一挑战,我们的研究探讨了使用小样学习(FSL)来有效减少FANETs入侵检测所需的数据量。提出的名为基于小样联邦学习的IDS(FSFL-IDS)的方法结合了FL和FSL,解决入侵检测所面临的隐私、电源限制、通信成本和丢包等挑战,在动态FANETs中显示出其在识别路由攻击方面的有效性。这种方法减少了本地模型和全局模型的训练时间和样本大小,为降低计算和通信成本以及延长电池寿命提供了见解。此外,通过采用需要更少训练数据的FSL方法,IDS可以较少受到FANETs中的丢包影响。
论文及项目相关链接
PDF Accepted to EAI SecureComm 2024. For details, see: https://securecomm.eai-conferences.org/2024/accepted-papers/
Summary
FANET中的入侵检测面临诸多挑战,如通信成本和隐私问题。本研究探索了基于少样本学习的入侵检测系统(FSFL-IDS),结合了联邦学习和少样本学习,以应对这些挑战。该系统的有效性在于能够识别动态FANET中的路由攻击,同时减少本地和全局模型的训练时间和样本大小,降低计算和通信成本,并延长电池寿命。
Key Takeaways
- FANETs由于无人机的分布式和动态特性,面临独特的安全挑战,需要定制的安全解决方案。
- 入侵检测在FANETs中是具有挑战性的,主要是由于通信成本和隐私问题。
- 联邦学习(FL)虽对FANETs的入侵检测具有潜力,但存在大数据要求、功耗和时间约束等缺点。
- 节点的高速运动可能会中断动态网络中入侵检测系统(IDS)之间的通信。
- 基于少样本学习(FSL)的方法被用来减少FANETs入侵检测所需的数据量。
- FSFL-IDS结合FL和FSL,有效应对入侵检测的多个挑战,如隐私、电源限制、通信成本和丢包链接。
点此查看论文截图

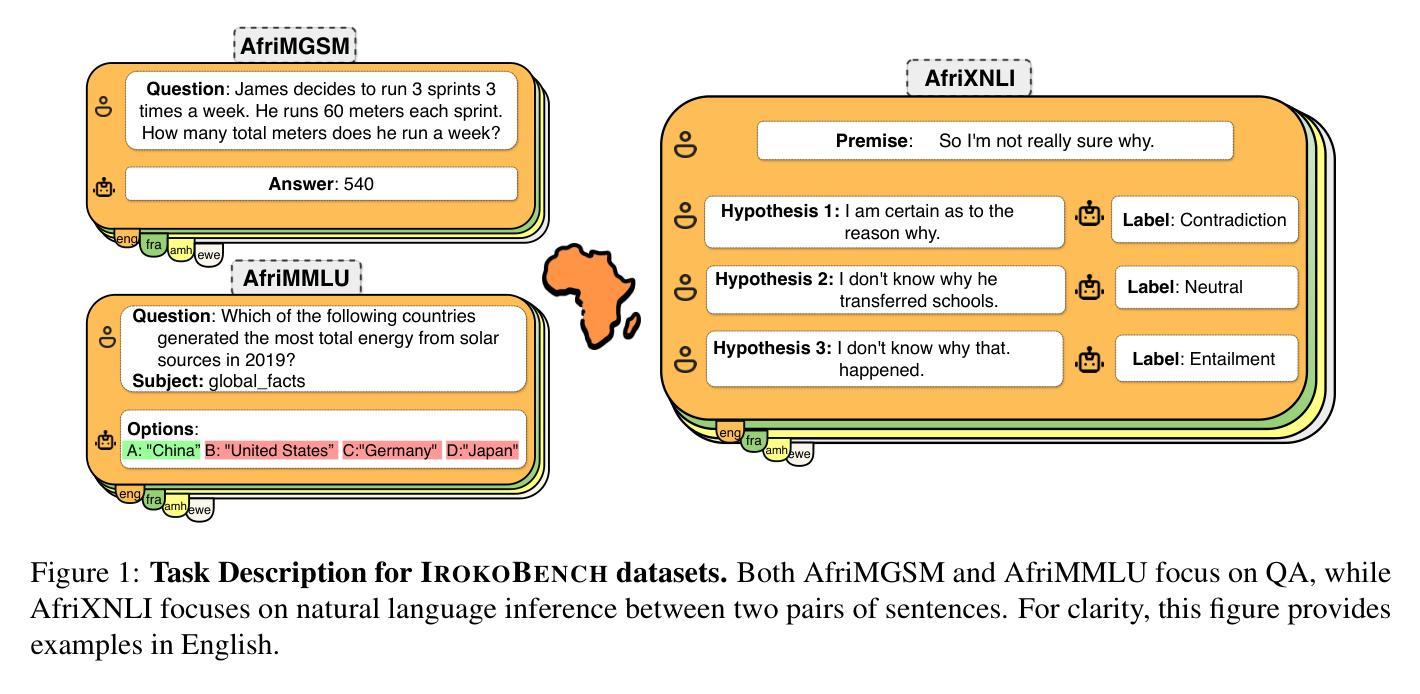
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Authors:David Ifeoluwa Adelani, Jessica Ojo, Israel Abebe Azime, Jian Yun Zhuang, Jesujoba O. Alabi, Xuanli He, Millicent Ochieng, Sara Hooker, Andiswa Bukula, En-Shiun Annie Lee, Chiamaka Chukwuneke, Happy Buzaaba, Blessing Sibanda, Godson Kalipe, Jonathan Mukiibi, Salomon Kabongo, Foutse Yuehgoh, Mmasibidi Setaka, Lolwethu Ndolela, Nkiruka Odu, Rooweither Mabuya, Shamsuddeen Hassan Muhammad, Salomey Osei, Sokhar Samb, Tadesse Kebede Guge, Tombekai Vangoni Sherman, Pontus Stenetorp
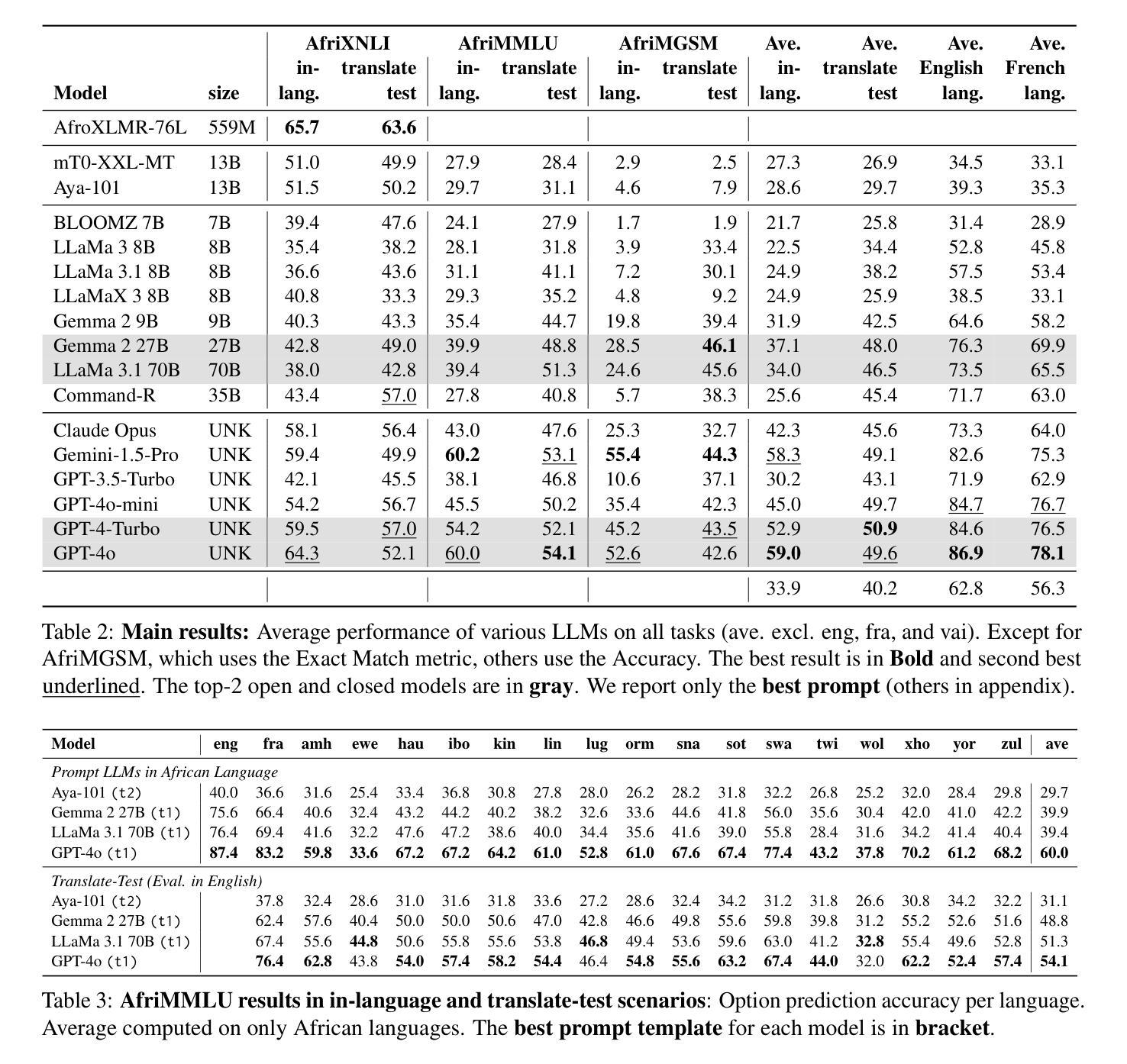
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (\eg African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench – a human-translated benchmark dataset for 17 typologically-diverse low-resource African languages covering three tasks: natural language inference(AfriXNLI), mathematical reasoning(AfriMGSM), and multi-choice knowledge-based question answering(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings(where test sets are translated into English) across 10 open and six proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Gemma 2 27B only at 63% of the best-performing proprietary model GPT-4o performance. In addition, machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, such as Gemma 2 27B and LLaMa 3.1 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
尽管大型语言模型(LLM)得到了广泛应用,但其显著的能力仅限于少数高资源语言。此外,由于高资源语言之外缺乏适当或全面的基准测试,许多低资源语言(例如非洲语言)通常仅在基本的文本分类任务上进行评估。在本文中,我们介绍了IrokoBench——一个为17种语言类型多样化的低资源非洲语言提供人工翻译基准测试数据集,涵盖三项任务:自然语言推理(AfriXNLI)、数学推理(AfriMGSM)和基于知识的多选择题问答(AfriMMLU)。我们使用IrokoBench对零样本、少样本以及测试集被翻译成英语的翻译测试环境(translate-test settings)中的10个开源和六个专有LLM进行了评估。我们的评估揭示了高资源语言(如英语和法语)与低资源非洲语言之间存在的显著性能差距。我们还观察到开源模型和专有模型之间存在显著的性能差距,表现最佳的开源模型Gemma 2 27B仅达到表现最好的专有模型GPT-4o性能的63%。此外,在评估之前将测试集机器翻译成英语有助于缩小以英语为中心的更大模型的差距,如Gemma 2 27B和LLaMa 3.1 70B。这些发现表明,需要更多的努力来开发和适应非洲语言的LLM。
论文及项目相关链接
PDF Accepted to NAACL 2025 (main conference)
Summary
本文介绍了IrokoBench——一个为17种语言形态各异的低资源非洲语言设计的人类翻译基准数据集。该数据集涵盖三项任务:自然语言推理(AfriXNLI)、数学推理(AfriMGSM)和基于知识选择的问题回答(AfriMMLU)。通过对零样本、少样本和翻译测试场景的评估,揭示了高资源语言与低资源非洲语言在大型语言模型性能上的显著差距。同时,开放模型与专有模型间也存在显著性能差距。机器翻译测试集到英语的评价方式有助于缩小以英语为中心的模型的性能差距。这表明需要更多的努力来发展和适应非洲语言的大型语言模型。
Key Takeaways
- IrokoBench是一个为低资源非洲语言设计的人类翻译基准数据集,涵盖自然语言推理、数学推理和知识问答三项任务。
- 评估了不同设置下的大型语言模型性能,包括零样本、少样本和翻译测试场景。
- 高资源语言与低资源非洲语言在大型语言模型性能上存在显著差距。
- 开放模型与专有模型间存在显著性能差距,最好的开放模型性能仅达到最佳专有模型性能的63%。
- 机器翻译测试集到英语的评估方式有助于缩小以英语为中心的大型模型的性能差距。
- 当前大型语言模型在适应非洲语言方面仍需更多努力。
点此查看论文截图