⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
Generative Data Augmentation Challenge: Zero-Shot Speech Synthesis for Personalized Speech Enhancement
Authors:Jae-Sung Bae, Anastasia Kuznetsova, Dinesh Manocha, John Hershey, Trausti Kristjansson, Minje Kim
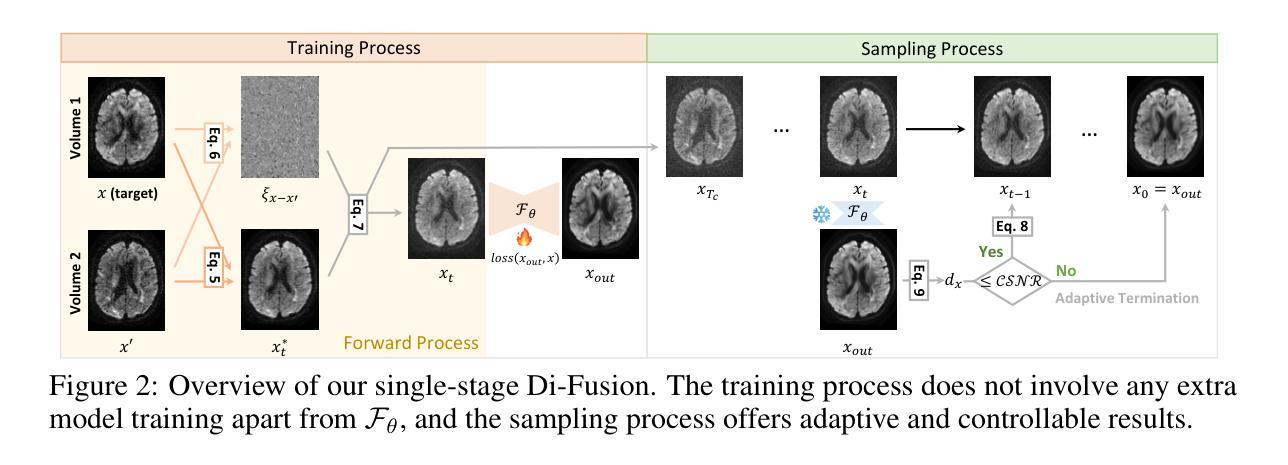
This paper presents a new challenge that calls for zero-shot text-to-speech (TTS) systems to augment speech data for the downstream task, personalized speech enhancement (PSE), as part of the Generative Data Augmentation workshop at ICASSP 2025. Collecting high-quality personalized data is challenging due to privacy concerns and technical difficulties in recording audio from the test scene. To address these issues, synthetic data generation using generative models has gained significant attention. In this challenge, participants are tasked first with building zero-shot TTS systems to augment personalized data. Subsequently, PSE systems are asked to be trained with this augmented personalized dataset. Through this challenge, we aim to investigate how the quality of augmented data generated by zero-shot TTS models affects PSE model performance. We also provide baseline experiments using open-source zero-shot TTS models to encourage participation and benchmark advancements. Our baseline code implementation and checkpoints are available online.
本文提出了一个新的挑战,该挑战呼吁零样本文本到语音(TTS)系统为下游任务增强语音数据,作为ICASSP 2025生成数据增强研讨会的一部分。由于隐私担忧和从测试场景录制音频的技术困难,收集高质量个性化数据具有挑战性。为了解决这些问题,使用生成模型进行合成数据生成已引起广泛关注。在本次挑战中,参赛者首先被要求构建零样本TTS系统以增强个性化数据。随后,要求使用此增强个性化数据集训练PSE系统。通过本次挑战,我们旨在研究零样本TTS模型生成的增强数据质量如何影响PSE模型性能。我们还使用开源零样本TTS模型提供基准实验,以鼓励参与并评估进展。我们的基准代码实现和检查点已在线提供。
论文及项目相关链接
PDF Accepted to ICASSP 2025 Satellite Workshop: Generative Data Augmentation for Real-World Signal Processing Applications
Summary
该论文提出了一项挑战,旨在利用零样本文本到语音(TTS)系统为下游任务个性化语音增强(PSE)扩充语音数据。该研究关注于利用生成模型解决因隐私问题和录音技术难题导致的高质量个性化数据收集挑战。研究目标是探讨零样本TTS模型生成的扩充数据质量对PSE模型性能的影响,并提供使用开源零样本TTS模型的基线实验。基线代码实现和检查点已在线提供。
Key Takeaways
- 该论文提出了一个关于零样本文本到语音(TTS)系统的挑战,旨在扩充个性化语音增强(PSE)的语音数据。
- 研究重点在于解决高质量个性化数据收集过程中的隐私和录音技术难题。
- 利用生成模型进行合成数据生成是解决这些问题的有效方法。
- 研究目标是了解零样本TTS模型生成的扩充数据质量对PSE模型性能的影响。
- 基线实验旨在鼓励参与并评估进展,使用开源零样本TTS模型。
- 论文提供了基线代码实现和检查点,便于研究人员使用。
- 该挑战对于推动TTS和PSE领域的发展具有重要意义。
点此查看论文截图

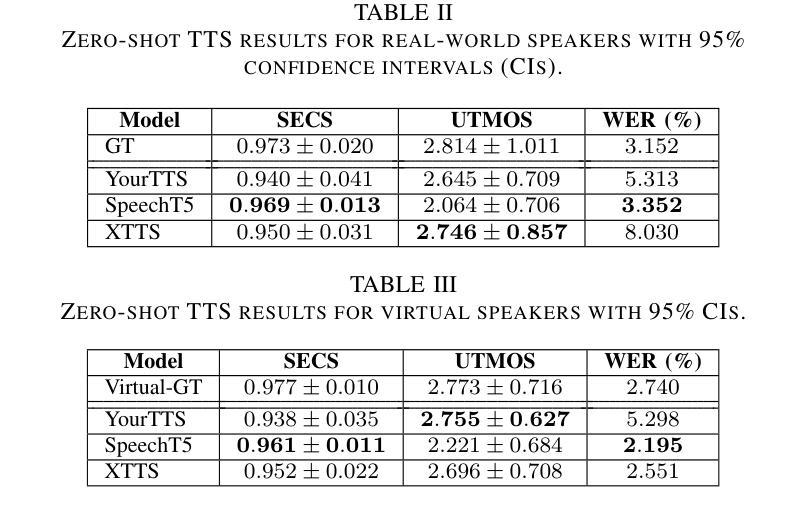
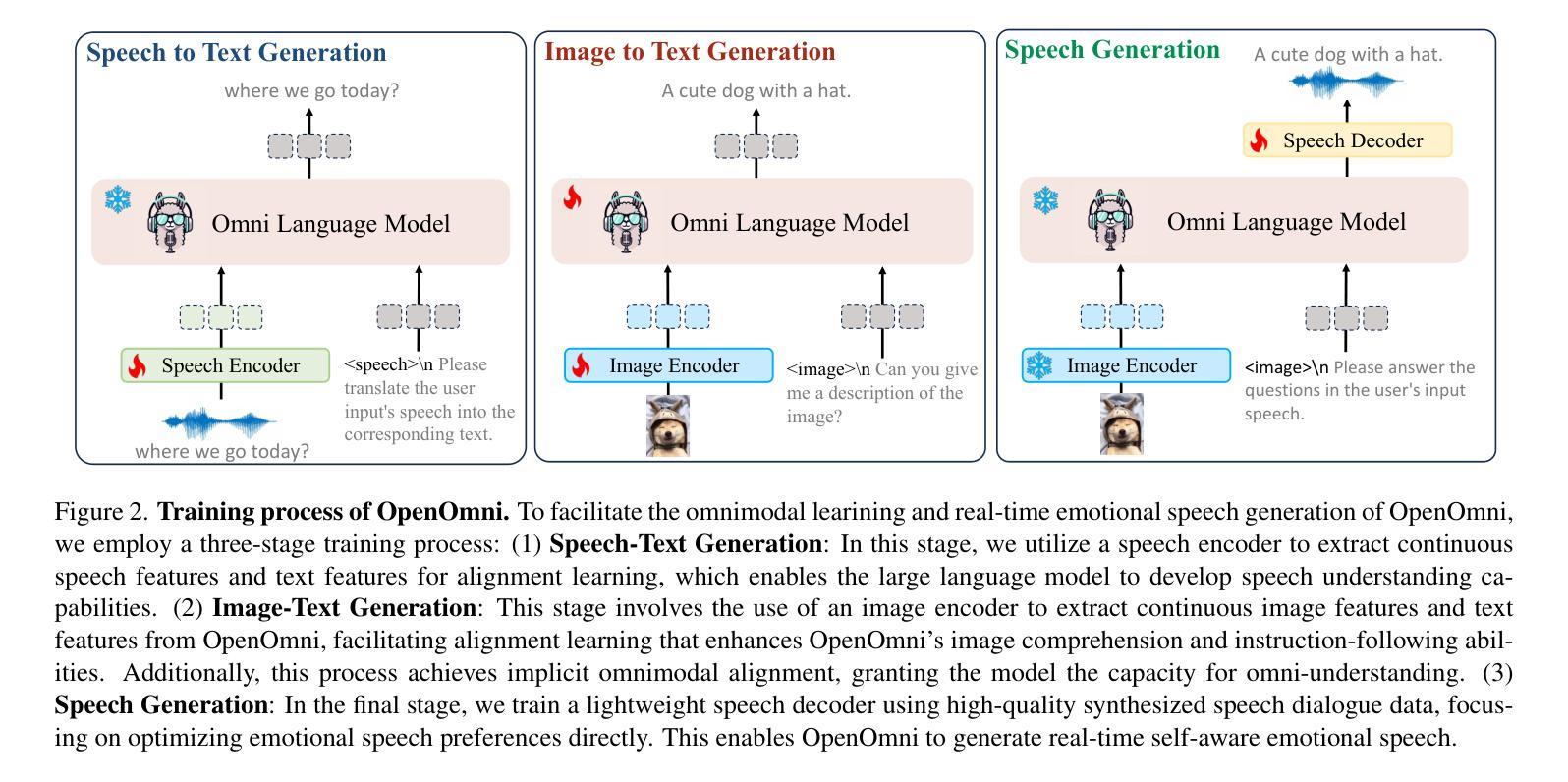
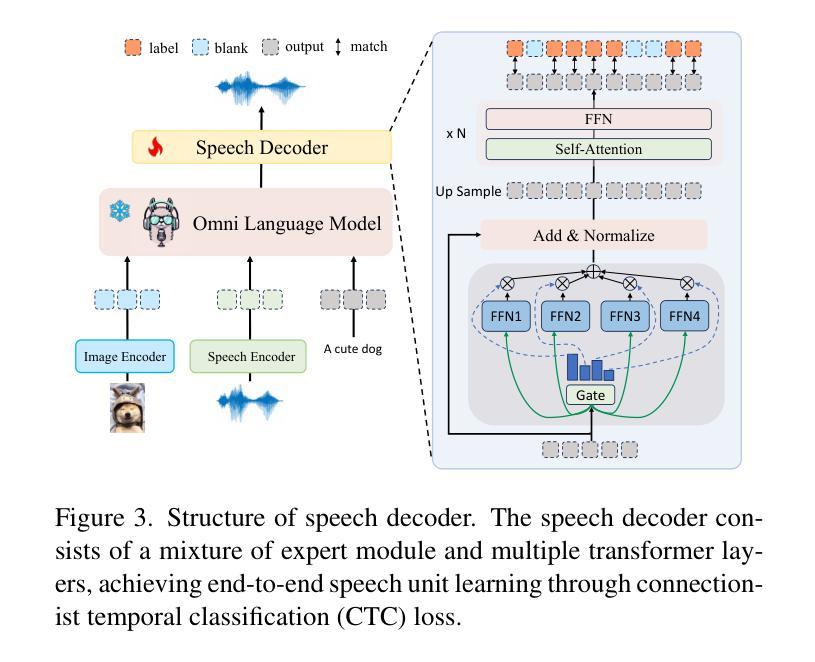
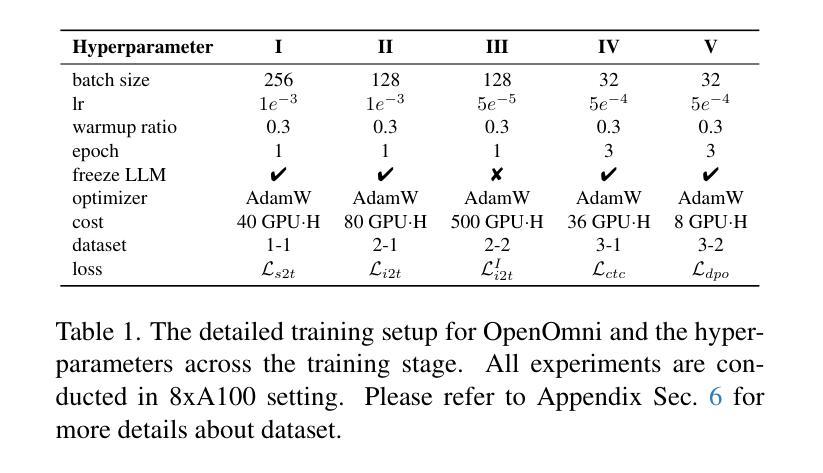
OpenOmni: Large Language Models Pivot Zero-shot Omnimodal Alignment across Language with Real-time Self-Aware Emotional Speech Synthesis
Authors:Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Yangyi Chen, Hamid Alinejad-Rokny, Fei Huang
Recent advancements in omnimodal learning have been achieved in understanding and generation across images, text, and speech, though mainly within proprietary models. Limited omnimodal datasets and the inherent challenges associated with real-time emotional speech generation have hindered open-source progress. To address these issues, we propose openomni, a two-stage training method combining omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model is further trained on text-image tasks to generalize from vision to speech in a (near) zero-shot manner, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder facilitates real-time emotional speech through training on speech tasks and preference learning. Experiments demonstrate that openomni consistently improves across omnimodal, vision-language, and speech-language evaluations, enabling natural, emotion-rich dialogues and real-time emotional speech generation.
虽然主要的进展是在专有模型内部实现图像、文本和语音的理解和生成,但多模态学习领域的最新进展已经取得了一些成果。有限的跨模态数据集以及实时情感语音生成所面临的固有挑战阻碍了开源进展。为了解决这些问题,我们提出了openomni,这是一种结合多模态对齐和语音生成的两阶段训练方法,以开发先进的多模态大型语言模型。在对齐阶段,预训练的语音模型进一步在文本图像任务上进行训练,以(接近)零样本的方式从视觉到语音进行推广,其性能优于在跨模态数据集上训练的模型。在语音生成阶段,一个轻量级的解码器通过语音任务和偏好学习进行训练,可以促成实时情感语音输出。实验表明,openomni在多模态、视觉语言和语音语言评估中持续表现出优势,可实现自然、情感丰富的对话和实时情感语音生成。
论文及项目相关链接
Summary
开放omnimodal学习方法的提出,通过两阶段训练结合omnimodal对齐和语音生成技术,旨在解决跨图像、文本和语音的多模态理解及生成问题。该方法包括对齐阶段和语音生成阶段,通过对预训练语音模型进行文本-图像任务训练,实现零样本或接近零样本的通用化能力,并在三模态数据集上表现出优越性能。同时,采用轻量级解码器进行实时情感语音训练,并融入偏好学习实现实时情感语音生成。实验结果证明了开放omnimodal学习方法在多模态、视觉语言和语音语言评估方面的持续改进能力,可实现自然、情感丰富的对话和实时情感语音生成。
Key Takeaways
- 开放omnimodal学习方法分为两个阶段:omnimodal对齐和语音生成。
- 对齐阶段利用预训练语音模型进行文本-图像任务训练,实现跨模态的通用化能力。
- 该方法在零样本或接近零样本情况下表现出优越性能,优于三模态数据集训练方法。
- 语音生成阶段采用轻量级解码器进行实时情感语音训练。
- 偏好学习被融入以实现更自然的情感语音生成。
- 该方法在多模态、视觉语言和语音语言评估方面表现出持续改进的能力。
点此查看论文截图

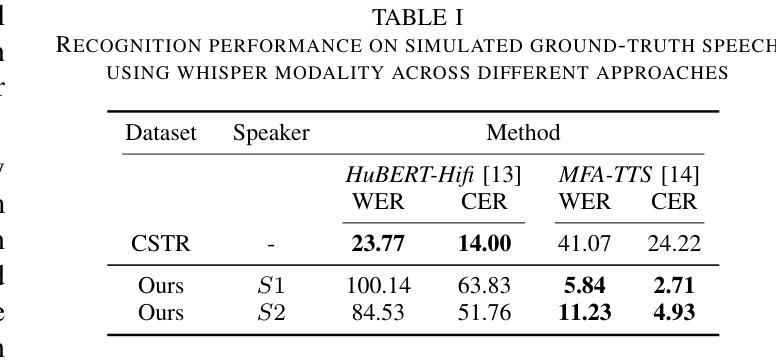
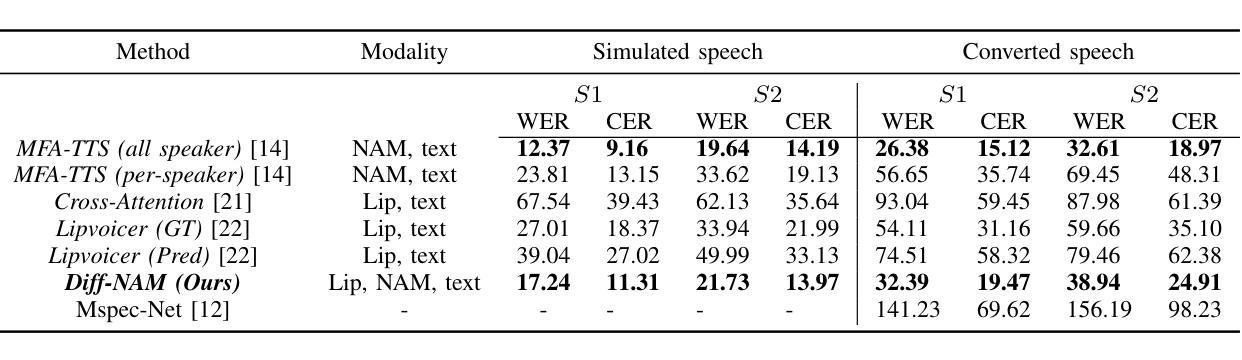
Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM Dataset
Authors:Neil Shah, Shirish Karande, Vineet Gandhi
Current Non-Audible Murmur (NAM)-to-speech techniques rely on voice cloning to simulate ground-truth speech from paired whispers. However, the simulated speech often lacks intelligibility and fails to generalize well across different speakers. To address this issue, we focus on learning phoneme-level alignments from paired whispers and text and employ a Text-to-Speech (TTS) system to simulate the ground-truth. To reduce dependence on whispers, we learn phoneme alignments directly from NAMs, though the quality is constrained by the available training data. To further mitigate reliance on NAM/whisper data for ground-truth simulation, we propose incorporating the lip modality to infer speech and introduce a novel diffusion-based method that leverages recent advancements in lip-to-speech technology. Additionally, we release the MultiNAM dataset with over 7.96 hours of paired NAM, whisper, video, and text data from two speakers and benchmark all methods on this dataset. Speech samples and the dataset are available at https://diff-nam.github.io/DiffNAM/
当前的非声默(NAM)到语音的技术依赖于语音克隆,从配对的耳语中模拟真实语音。然而,模拟的语音往往缺乏清晰度,并且在不同说话者之间的泛化能力较差。为了解决这个问题,我们专注于从配对的耳语和文本中学习音素级对齐,并使用文本到语音(TTS)系统来模拟真实语音。为了减少对耳语的依赖,我们直接从NAM学习音素对齐,尽管质量受到可用训练数据的限制。为了进一步减轻对NAM/耳语数据在模拟真实语音方面的依赖,我们提出结合唇部模式来推断语音,并引入了一种新的基于扩散的方法,该方法利用唇到语音技术的最新进展。此外,我们发布了MultiNAM数据集,其中包含来自两个说话者的超过7.96小时的配对NAM、耳语、视频和文本数据,并在该数据集上对所有方法进行了基准测试。语音样本和数据集可在https://diff-nam.github.io/DiffNAM/找到。
论文及项目相关链接
PDF Accepted at IEEE ICASSP 2025
Summary
当前非语音低沉声(NAM)到语音的技术依赖于语音克隆,模拟配对低语中的真实语音。然而,模拟的语音往往缺乏清晰度,且在跨不同发言者的应用中泛化性能较差。为解决这个问题,本研究专注于学习配对低语和文本中的音素级别对齐关系,并使用文本到语音(TTS)系统模拟真实语音。为减少对低语的依赖,我们直接从NAM学习音素对齐关系,但受限于可用的训练数据质量。为进一步减轻对NAM/低语数据模拟真实语音的依赖,我们引入唇语模态来推断语音,并采用基于最新唇语到语音技术发展的扩散方法。此外,我们发布了包含超过7.96小时配对NAM、低语、视频和文本数据的多NAM数据集,并在该数据集上对所有方法进行了基准测试。相关语音样本和数据集可在链接获取。
Key Takeaways
- 当前NAM-to-speech技术依赖于语音克隆模拟配对低语中的真实语音。
- 模拟的语音存在缺乏清晰度和泛化性能差的问题。
- 研究重点是通过学习音素级别对齐关系提升模拟语音质量。
- 为减少对低语的依赖,研究尝试直接从NAM学习音素对齐关系。
- 引入唇语模态和基于最新唇语到语音技术发展的扩散方法来改善模拟语音质量。
- 发布包含多种模态数据的多NAM数据集,用于基准测试。
点此查看论文截图


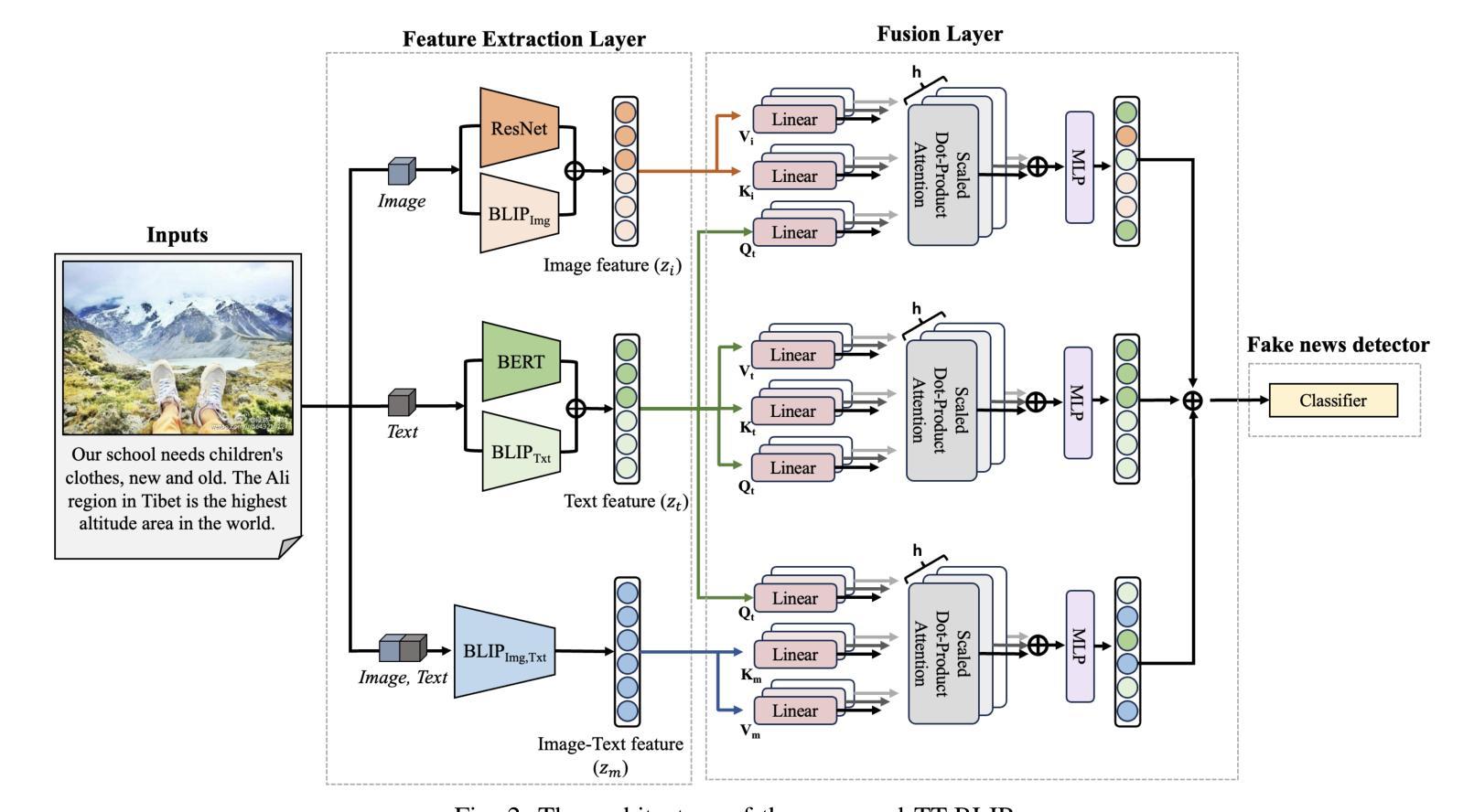
TT-BLIP: Enhancing Fake News Detection Using BLIP and Tri-Transformer
Authors:Eunjee Choi, Jong-Kook Kim
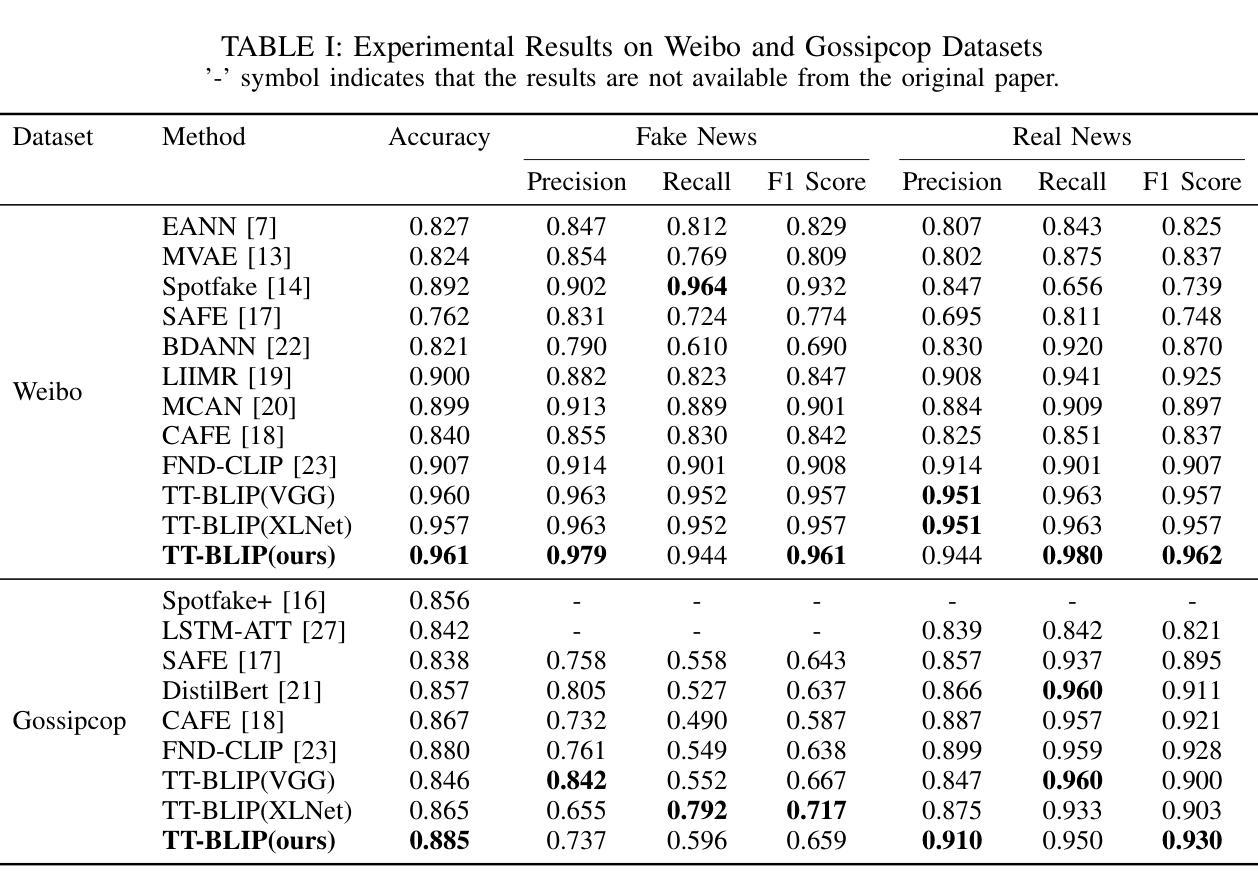
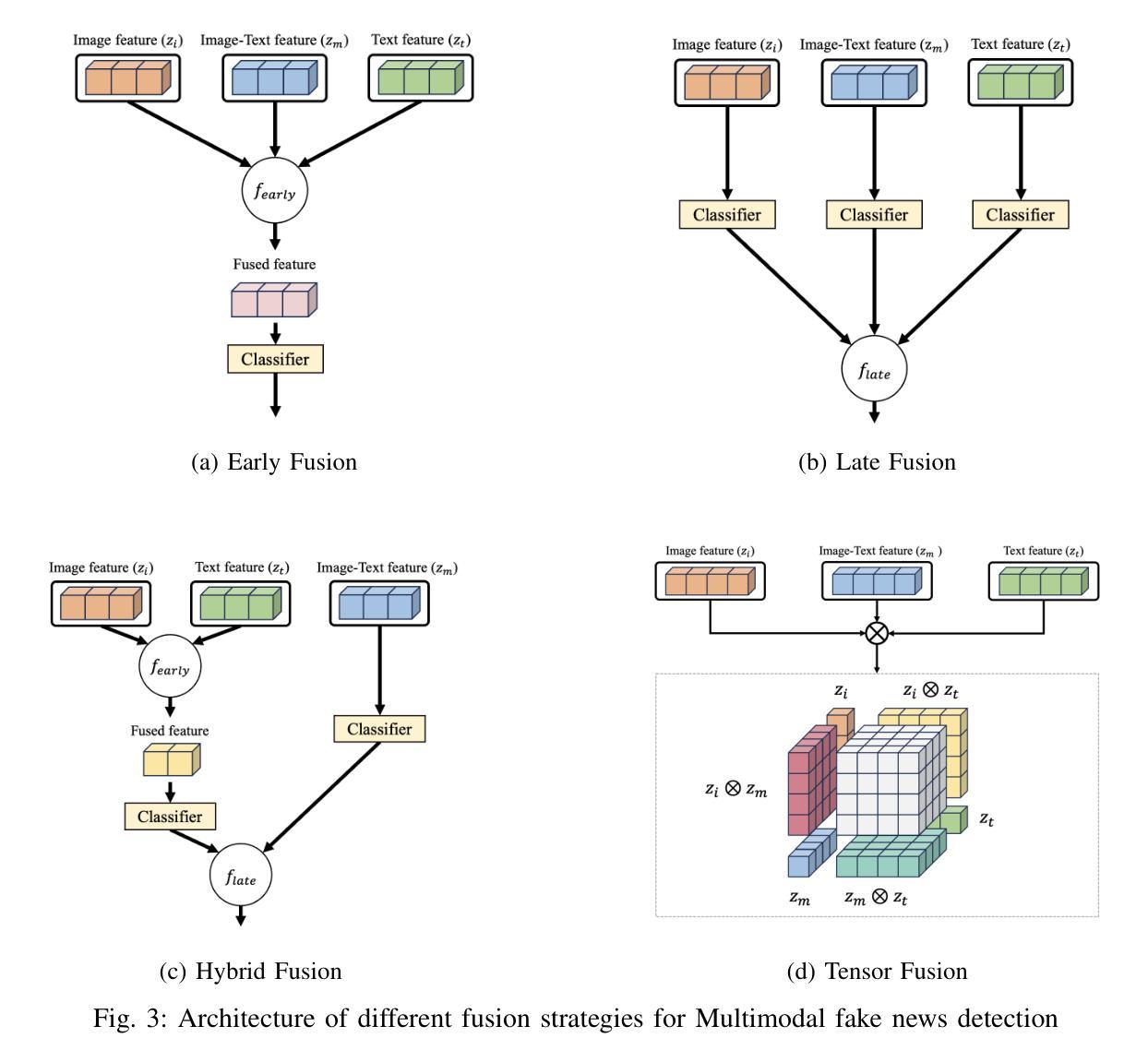
Detecting fake news has received a lot of attention. Many previous methods concatenate independently encoded unimodal data, ignoring the benefits of integrated multimodal information. Also, the absence of specialized feature extraction for text and images further limits these methods. This paper introduces an end-to-end model called TT-BLIP that applies the bootstrapping language-image pretraining for unified vision-language understanding and generation (BLIP) for three types of information: BERT and BLIPTxt for text, ResNet and BLIPImg for images, and bidirectional BLIP encoders for multimodal information. The Multimodal Tri-Transformer fuses tri-modal features using three types of multi-head attention mechanisms, ensuring integrated modalities for enhanced representations and improved multimodal data analysis. The experiments are performed using two fake news datasets, Weibo and Gossipcop. The results indicate TT-BLIP outperforms the state-of-the-art models.
检测假新闻已经引起了广泛关注。许多之前的方法将独立编码的单模态数据进行连接,忽略了集成多模态信息的好处。此外,缺乏针对文本和图像的专业特征提取进一步限制了这些方法。本文介绍了一种端到端的模型——TT-BLIP,该模型应用引导式语言图像预训练,以统一视觉语言理解和生成(BLIP)。该模型涉及三种类型的信息:BERT和BLIPTxt用于文本,ResNet和BLIPImg用于图像,双向BLIP编码器用于多模态信息。多模态三Transformer通过三种多头注意力机制融合三模态特征,确保融合模式增强表示并改进多模态数据分析。实验采用微博和Gossipcop两个假新闻数据集进行。结果表明,TT-BLIP优于最新模型。
论文及项目相关链接
PDF 8 pages, Accepted 27th International Conference on Information Fusion, FUSION 2024
Summary
文本介绍了名为TT-BLIP的端到端模型,该模型采用预训练语言图像统一视觉语言理解和生成(BLIP)方法,并引入BERT和BLIPTxt处理文本信息、ResNet和BLIPImg处理图像信息以及双向BLIP编码器处理多模态信息。通过三种多头注意力机制融合三模态特征的多模态三重转换器,确保融合模态增强表示和改进的多模态数据分析。实验采用微博和八卦新闻两个假新闻数据集,结果表明TT-BLIP优于现有模型。
Key Takeaways
- 该模型采用预训练语言图像统一视觉语言理解和生成(BLIP)方法。
- 模型引入了BERT和BLIPTxt处理文本信息,以及ResNet和BLIPImg处理图像信息。
- 模型使用双向BLIP编码器处理多模态信息。
- 通过三种多头注意力机制融合三模态特征的多模态三重转换器,确保融合模态增强表示和改进的多模态数据分析。
- 模型能够在假新闻检测中超越现有模型的表现。
- 实验采用了微博和Gossipcop两个假新闻数据集进行验证。
点此查看论文截图