⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-25 更新
Privacy-Preserving Personalized Federated Prompt Learning for Multimodal Large Language Models
Authors:Linh Tran, Wei Sun, Stacy Patterson, Ana Milanova
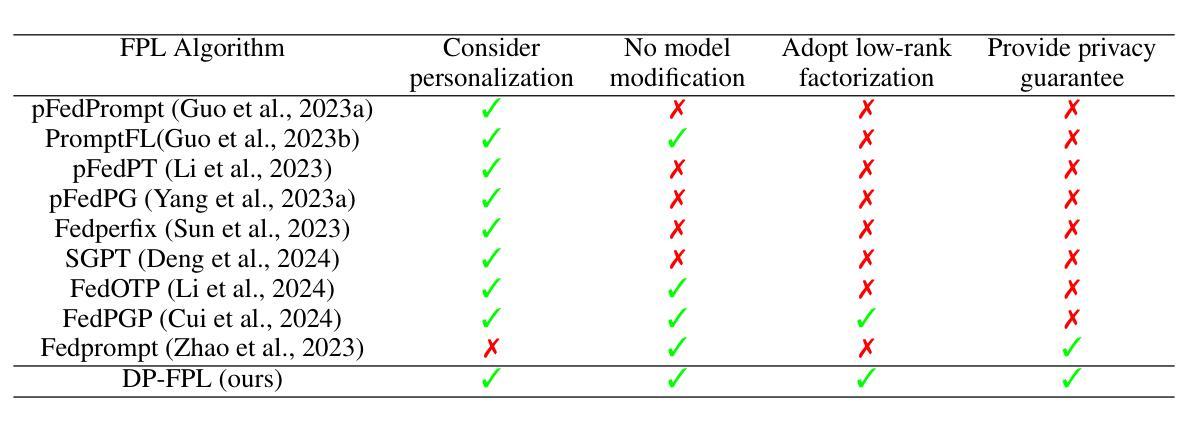
Multimodal Large Language Models (LLMs) are pivotal in revolutionizing customer support and operations by integrating multiple modalities such as text, images, and audio. Federated Prompt Learning (FPL) is a recently proposed approach that combines pre-trained multimodal LLMs such as vision-language models with federated learning to create personalized, privacy-preserving AI systems. However, balancing the competing goals of personalization, generalization, and privacy remains a significant challenge. Over-personalization can lead to overfitting, reducing generalizability, while stringent privacy measures, such as differential privacy, can hinder both personalization and generalization. In this paper, we propose a Differentially Private Federated Prompt Learning (DP-FPL) approach to tackle this challenge by leveraging a low-rank adaptation scheme to capture generalization while maintaining a residual term that preserves expressiveness for personalization. To ensure privacy, we introduce a novel method where we apply local differential privacy to the two low-rank components of the local prompt, and global differential privacy to the global prompt. Our approach mitigates the impact of privacy noise on the model performance while balancing the tradeoff between personalization and generalization. Extensive experiments demonstrate the effectiveness of our approach over other benchmarks.
多模态大型语言模型(LLM)通过整合文本、图像和音频等多种模态,在革新客户支持和运营方面发挥着关键作用。联邦提示学习(FPL)是一种最近提出的方法,它将预训练的多模态LLM(如视觉语言模型)与联邦学习相结合,以创建个性化、保护隐私的人工智能系统。然而,在个性化、通用化和隐私之间取得平衡仍然是一个巨大的挑战。过度个性化可能导致过度拟合,降低通用性,而严格的隐私措施(如差分隐私)可能会阻碍个性化和通用化。在本文中,我们提出了一种差分私有联邦提示学习(DP-FPL)方法来解决这一挑战,该方法利用低阶适应方案来捕捉通用性,同时保持一个残余项,以保留个性化的表现力。为确保隐私,我们引入了一种新方法,对本地提示的两个低阶分量应用本地差分隐私,对全局提示应用全局差分隐私。我们的方法减轻了隐私噪声对模型性能的影响,在个性化与通用化之间取得了平衡。大量实验表明,我们的方法在其他基准测试上是有效的。
论文及项目相关链接
PDF Accepted to ICLR 2025 main conference track
Summary
多模态大型语言模型(LLM)通过整合文本、图像和音频等多种模式,正在革新客户支持和运营。联邦提示学习(FPL)是最近提出的一种结合预训练的多模态LLM(如视觉语言模型)和联邦学习的方法,以创建个性化、保护隐私的人工智能系统。然而,平衡个性化、通用化和隐私这三个相互竞争的目标仍然是一个巨大挑战。本文提出了一种差分私有联邦提示学习(DP-FPL)方法来解决这一挑战,利用低秩适应方案来捕捉通用性,同时保持一个保留项以维持个性化表达。为确保隐私,我们引入了一种新方法,对本地提示的两个低秩组件应用本地差分隐私,对全局提示应用全局差分隐私。我们的方法减轻了隐私噪声对模型性能的影响,平衡了个性化和通用化之间的权衡。实验证明我们的方法在其他基准测试上非常有效。
Key Takeaways
- 多模态大型语言模型(LLM)通过整合多种模式正在改变客户支持和运营。
- 联邦提示学习(FPL)结合了预训练的多模态LLM和联邦学习,以创建个性化、保护隐私的AI系统。
- 平衡个性化、通用化和隐私是NLP领域的一大挑战。
- 过度的个性化可能导致过度拟合,降低通用性;而严格的隐私措施可能阻碍个性化和通用化。
- 本文提出了差分私有联邦提示学习(DP-FPL)来解决这一挑战,结合了低秩适应和隐私保护方法。
- DP-FPL通过应用本地和全局差分隐私来保护模型隐私。
点此查看论文截图

Dual-Modal Prototype Joint Learning for Compositional Zero-Shot Learning
Authors:Shiyu Zhang, Cheng Yan, Yang Liu, Chenchen Jing, Lei Zhou, Wenjun Wang
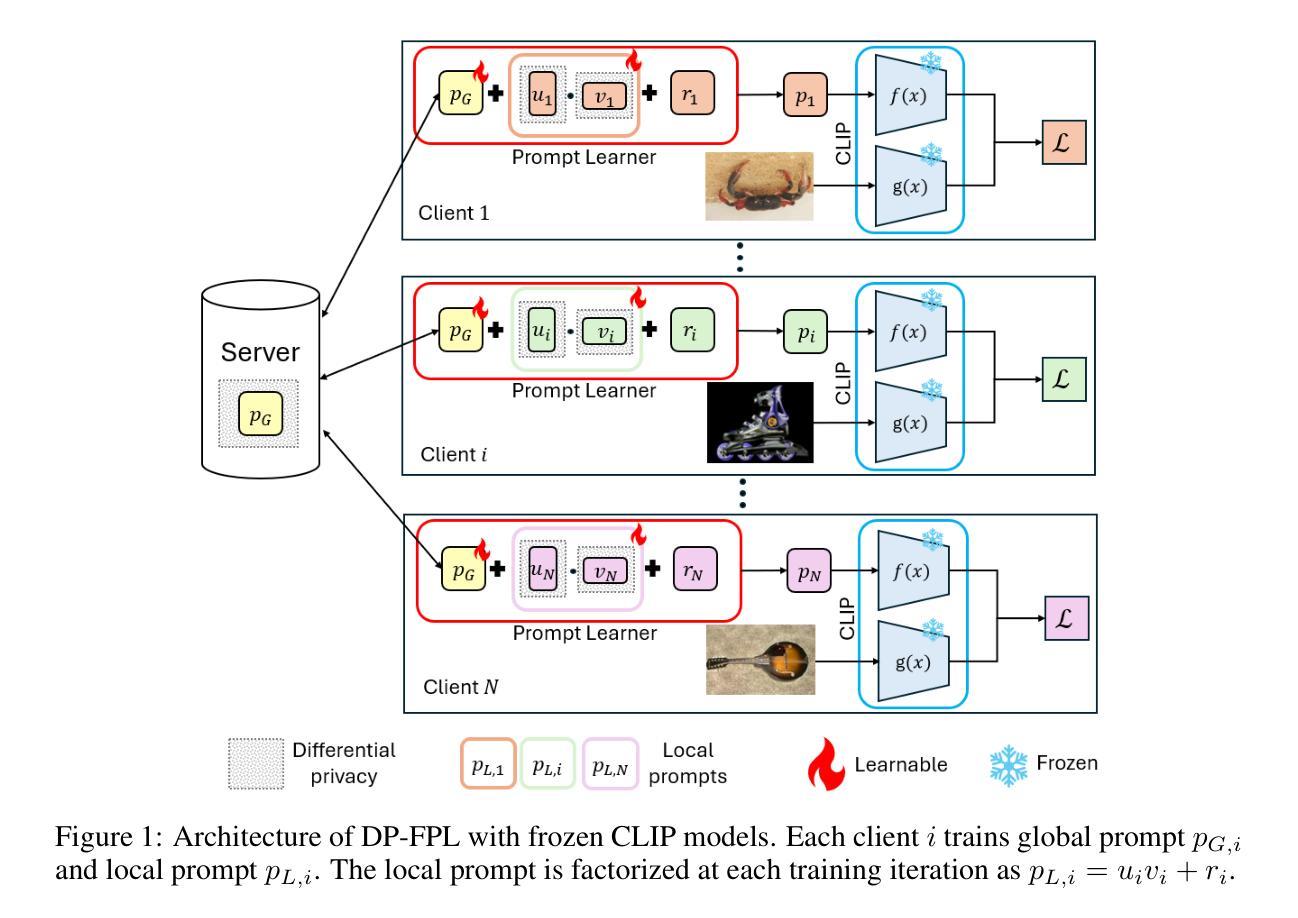
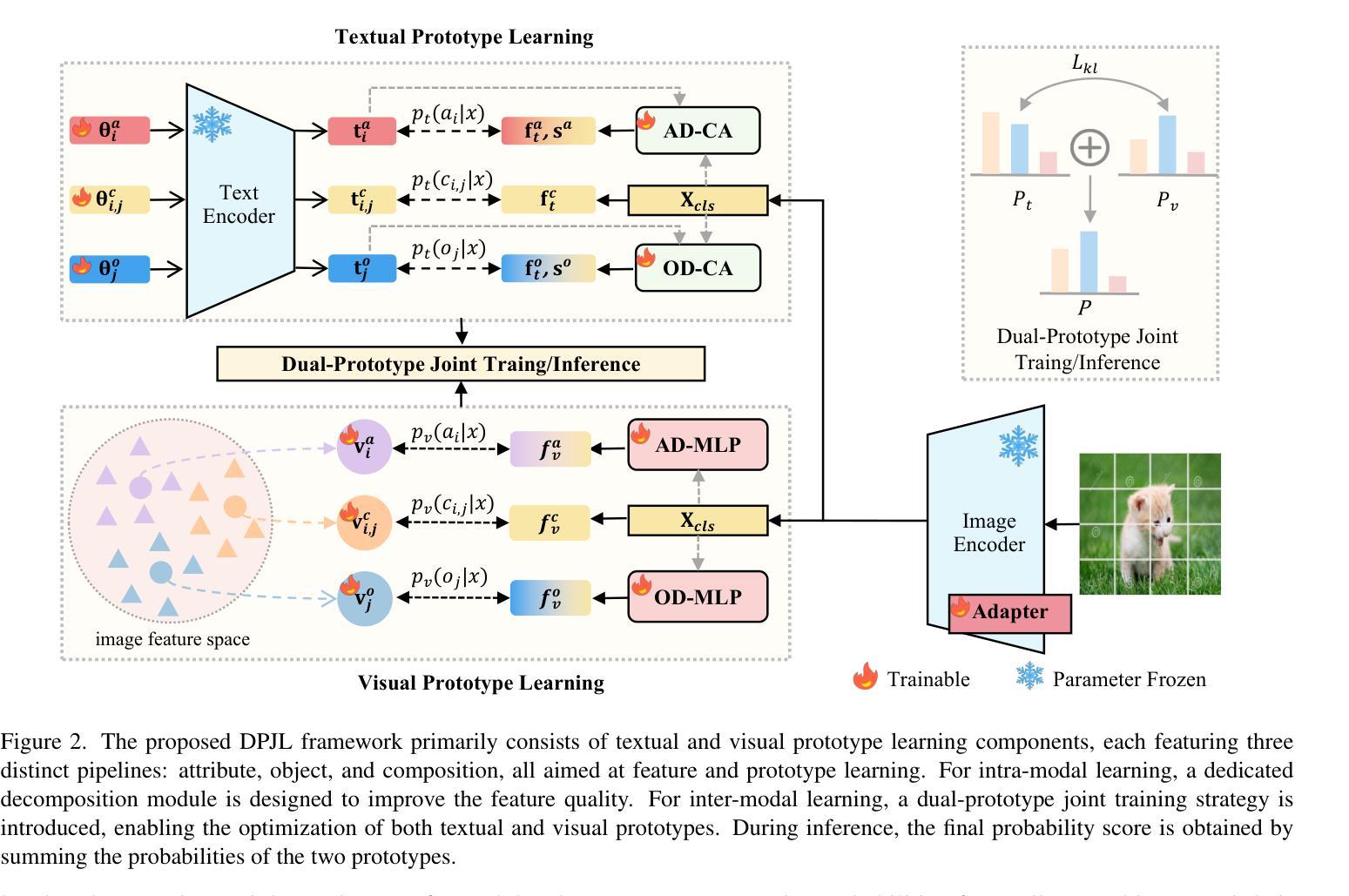
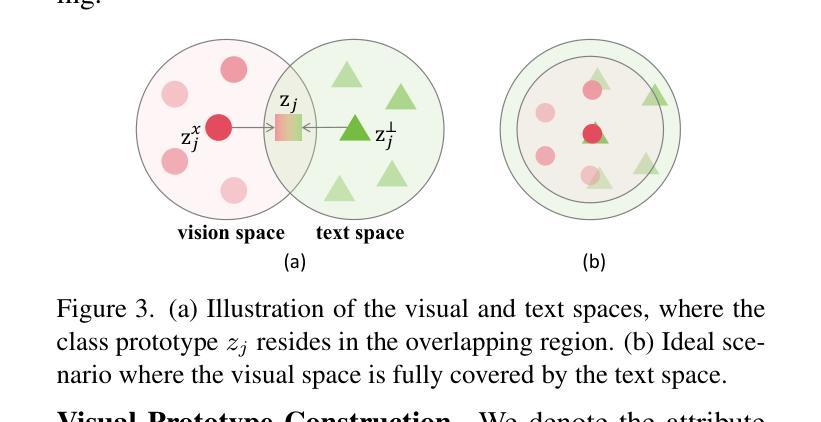
Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions of attributes and objects by leveraging knowledge learned from seen compositions. Recent approaches have explored the use of Vision-Language Models (VLMs) to align textual and visual modalities. These methods typically employ prompt engineering, parameter-tuning, and modality fusion to generate rich textual prototypes that serve as class prototypes for CZSL. However, the modality gap results in textual prototypes being unable to fully capture the optimal representations of all class prototypes, particularly those with fine-grained features, which can be directly obtained from the visual modality. In this paper, we propose a novel Dual-Modal Prototype Joint Learning framework for the CZSL task. Our approach, based on VLMs, introduces prototypes in both the textual and visual modalities. The textual prototype is optimized to capture broad conceptual information, aiding the model’s generalization across unseen compositions. Meanwhile, the visual prototype is used to mitigate the classification errors caused by the modality gap and capture fine-grained details to distinguish images with similar appearances. To effectively optimize these prototypes, we design specialized decomposition modules and a joint learning strategy that enrich the features from both modalities. These prototypes not only capture key category information during training but also serve as crucial reference targets during inference. Experimental results demonstrate that our approach achieves state-of-the-art performance in the closed-world setting and competitive performance in the open-world setting across three publicly available CZSL benchmarks. These findings validate the effectiveness of our method in advancing compositional generalization.
组合零样本学习(CZSL)旨在通过利用已见过的组合所获得的知识来识别新的属性组合和对象。最近的方法已经探索了使用视觉语言模型(VLMs)来对文本和视觉模式进行对齐。这些方法通常采用提示工程、参数调整和模式融合来生成丰富的文本原型,这些原型可以作为CZSL的类别原型。然而,模式差距导致文本原型无法完全捕获所有类别原型的最佳表示,特别是那些可以直接从视觉模式中获得的高精度特征。在本文中,我们提出了一种用于CZSL任务的双模态原型联合学习框架。我们的方法基于VLMs,在文本和视觉两种模式中都引入了原型。文本原型被优化以捕获广泛的概念信息,帮助模型在未见过的组合上进行泛化。同时,视觉原型用于减少由于模式差距引起的分类错误,并捕捉精细细节以区分外观相似的图像。为了有效地优化这些原型,我们设计了专门的分解模块和联合学习策略,以丰富两种模式的功能。这些原型不仅在训练过程中捕获关键的类别信息,而且在推理过程中作为重要的参考目标。实验结果表明,我们的方法在封闭世界设置中达到了最先进的性能,在三个公开的CZSL基准测试中达到了具有竞争力的性能。这些发现验证了我们方法在推进组合泛化方面的有效性。
论文及项目相关链接
Summary
本文提出了一种用于零样本学习(CZSL)的新框架——Dual-Modal Prototype Joint Learning。该框架基于视觉语言模型(VLMs),在文本和视觉两种模态中引入原型。文本原型用于捕捉广泛的概念信息,有助于模型在未见过的组合上进行推广。视觉原型则用于减少因模态差异导致的分类错误,并捕捉细微特征以区分外观相似的图像。通过专业化的分解模块和联合学习策略,优化这些原型,丰富两种模态的特征。实验结果表明,该方法在封闭世界和开放世界设置中均取得了最先进的性能。
Key Takeaways
- 介绍了Compositional Zero-Shot Learning(CZSL)的目标,即利用已见过的组合来识别新的属性组合和对象。
- 探讨了使用视觉语言模型(VLMs)进行CZSL任务的最新方法,包括跨模态对齐和文本视觉融合生成丰富的文本原型。
- 指出模态差距使得文本原型无法完全捕获所有类别的最佳表示,特别是那些可以直接从视觉模态中获得细微特征的信息。
- 提出了Dual-Modal Prototype Joint Learning框架,同时引入了文本和视觉两种模态的原型来解决上述问题。
- 文本原型旨在捕捉广泛的概念信息以促进模型泛化,而视觉原型则用于捕捉细微特征以区分外观相似的图像并减少分类错误。
- 通过专门的分解模块和联合学习策略优化这两种模态的原型,增强特征表达。
点此查看论文截图



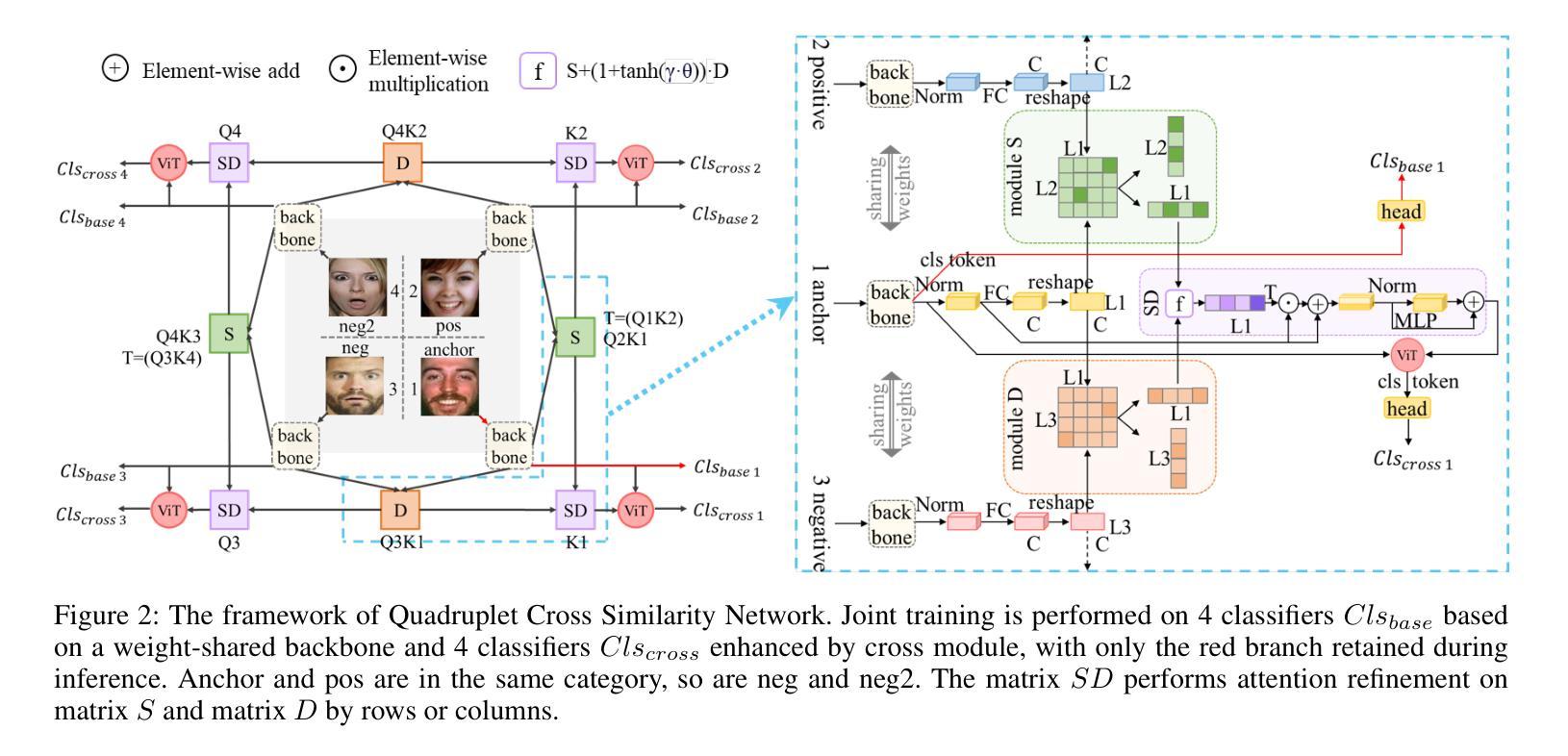
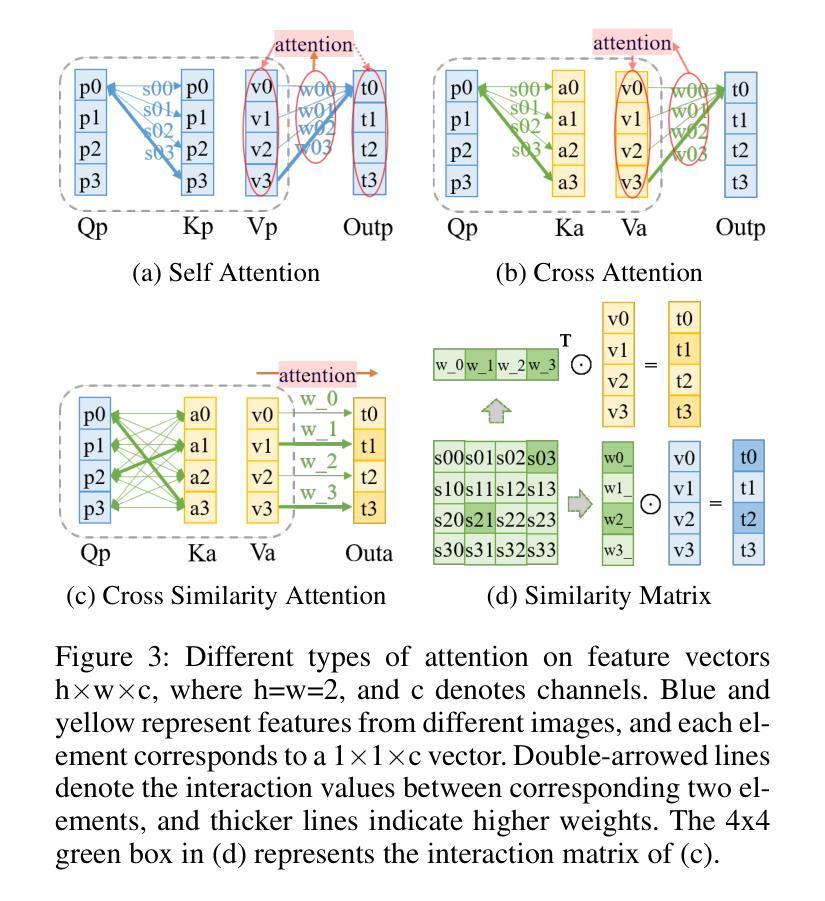
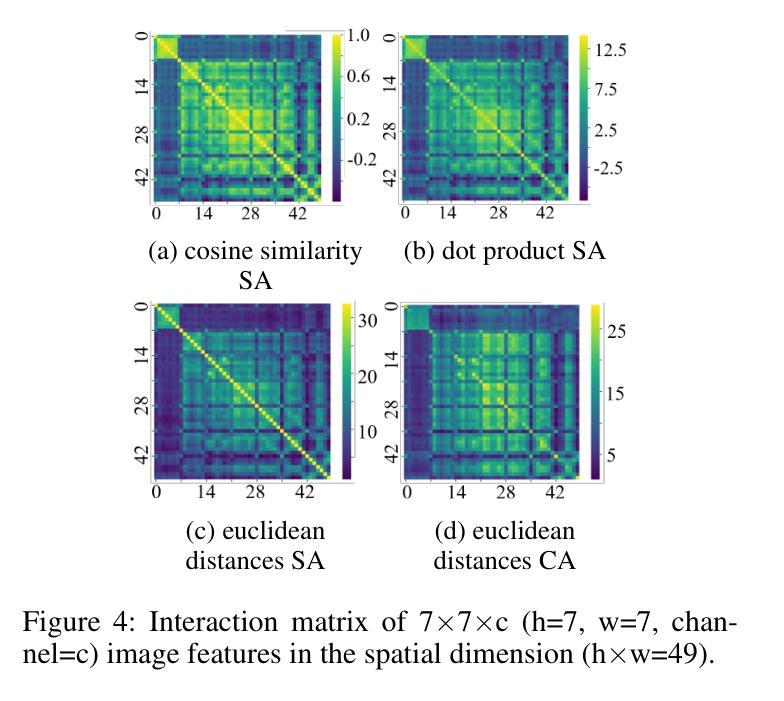
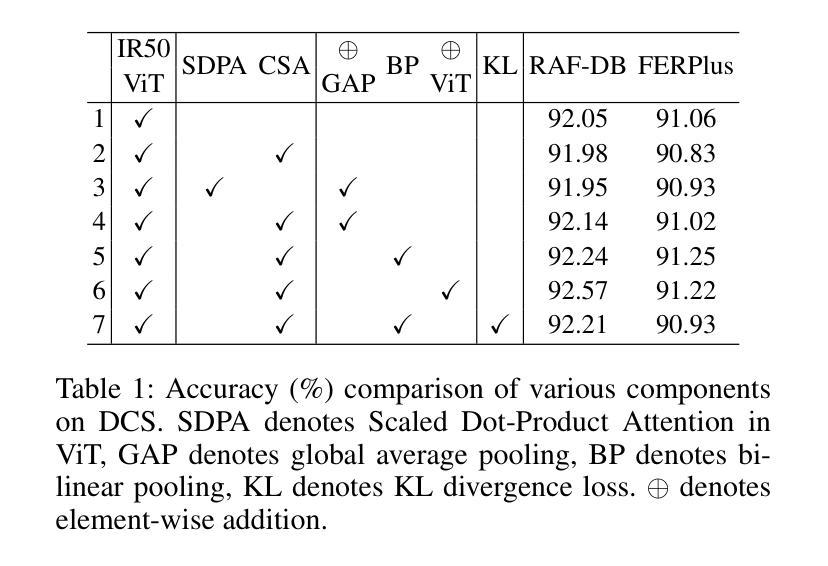
QCS: Feature Refining from Quadruplet Cross Similarity for Facial Expression Recognition
Authors:Chengpeng Wang, Li Chen, Lili Wang, Zhaofan Li, Xuebin Lv
Facial expression recognition faces challenges where labeled significant features in datasets are mixed with unlabeled redundant ones. In this paper, we introduce Cross Similarity Attention (CSA) to mine richer intrinsic information from image pairs, overcoming a limitation when the Scaled Dot-Product Attention of ViT is directly applied to calculate the similarity between two different images. Based on CSA, we simultaneously minimize intra-class differences and maximize inter-class differences at the fine-grained feature level through interactions among multiple branches. Contrastive residual distillation is utilized to transfer the information learned in the cross module back to the base network. We ingeniously design a four-branch centrally symmetric network, named Quadruplet Cross Similarity (QCS), which alleviates gradient conflicts arising from the cross module and achieves balanced and stable training. It can adaptively extract discriminative features while isolating redundant ones. The cross-attention modules exist during training, and only one base branch is retained during inference, resulting in no increase in inference time. Extensive experiments show that our proposed method achieves state-of-the-art performance on several FER datasets.
面部表情识别面临着挑战,即数据集中有标签的重要特征与无标签的冗余特征混合在一起。在本文中,我们引入交叉相似性注意力(CSA)来从图像对中提取更丰富的内在信息,克服了当直接应用ViT的缩放点积注意力来计算两个不同图像之间的相似性时存在的局限性。基于CSA,我们通过多个分支之间的交互,在细粒度特征级别同时减小类内差异并增大类间差异。利用对比残差蒸馏将跨模块中学到的信息转移回基础网络。我们巧妙地设计了一个四分支中心对称网络,命名为四元组交叉相似性(QCS),该网络缓解了跨模块引起的梯度冲突,实现了平衡稳定的训练。它可以自适应地提取判别特征,同时隔离冗余特征。交叉注意力模块存在于训练过程中,而在推理过程中仅保留一个基础分支,因此不会增加推理时间。大量实验表明,我们提出的方法在几个面部表情识别数据集上达到了最新技术水平。
论文及项目相关链接
Summary
本文引入了一种名为Cross Similarity Attention(CSA)的技术,用于从图像对中挖掘更丰富的内在信息,克服了直接将Scaled Dot-Product Attention应用于计算两张不同图像之间相似性的局限性。基于CSA,本文同时减小了类内差异并放大了类间差异,通过多个分支间的交互在精细特征层面实现了这一目标。此外,利用对比残差蒸馏将跨模块中学到的信息转回基础网络。设计了一种名为Quadruplet Cross Similarity(QCS)的四分支中心对称网络,缓解了跨模块引起的梯度冲突,实现了平衡稳定的训练,能够自适应地提取判别特征并隔离冗余特征。
Key Takeaways
- 引入Cross Similarity Attention(CSA)挖掘图像对中的更丰富内在信息。
- 克服Scaled Dot-Product Attention在面部表情识别中的局限性。
- 基于CSA同时减小类内差异并放大类间差异。
- 使用对比残差蒸馏将跨模块信息转回基础网络。
- 设计了名为Quadruplet Cross Similarity(QCS)的四分支中心对称网络。
- 缓解跨模块引起的梯度冲突,实现平衡稳定的训练。
点此查看论文截图