⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
MCRL4OR: Multimodal Contrastive Representation Learning for Off-Road Environmental Perception
Authors:Yi Yang, Zhang Zhang, Liang Wang
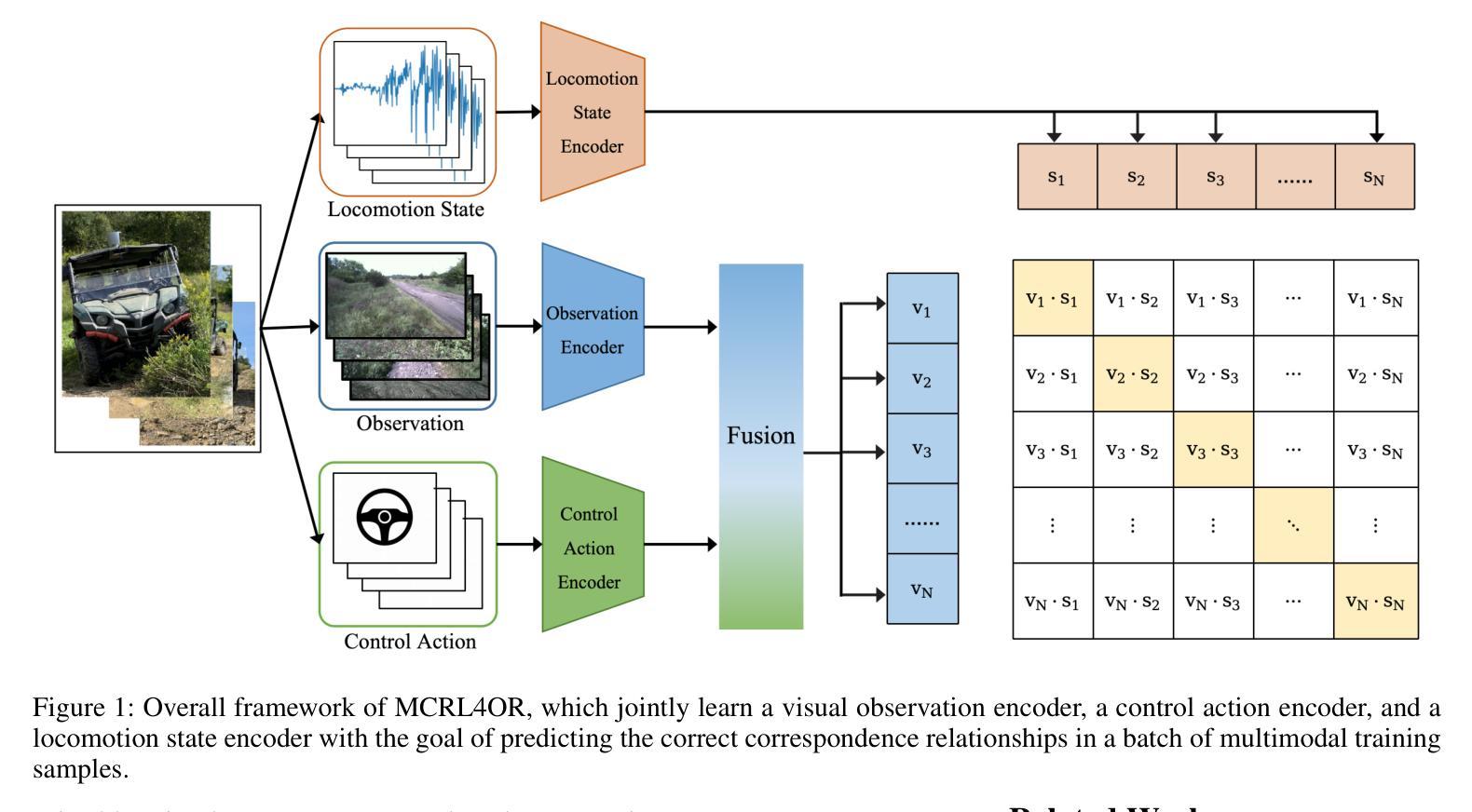
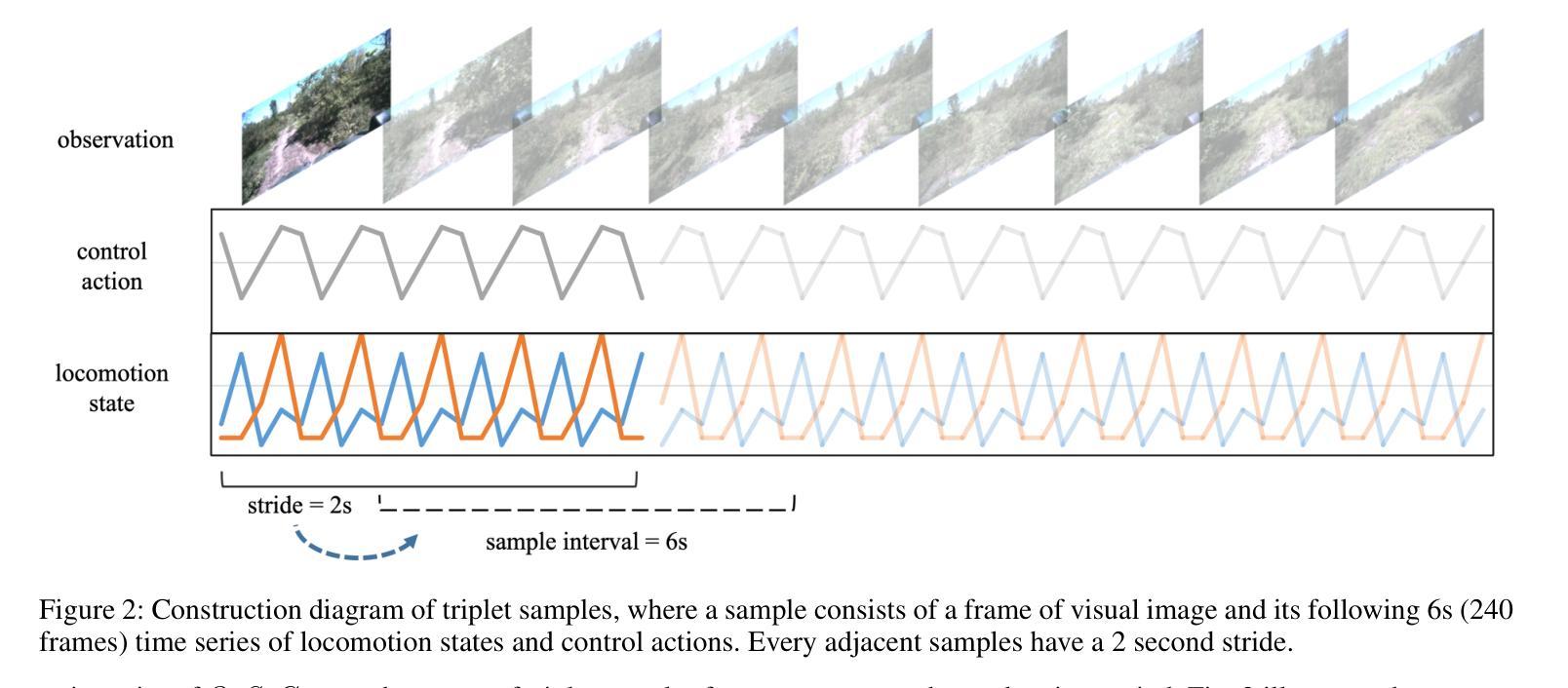
Most studies on environmental perception for autonomous vehicles (AVs) focus on urban traffic environments, where the objects/stuff to be perceived are mainly from man-made scenes and scalable datasets with dense annotations can be used to train supervised learning models. By contrast, it is hard to densely annotate a large-scale off-road driving dataset manually due to the inherently unstructured nature of off-road environments. In this paper, we propose a Multimodal Contrastive Representation Learning approach for Off-Road environmental perception, namely MCRL4OR. This approach aims to jointly learn three encoders for processing visual images, locomotion states, and control actions by aligning the locomotion states with the fused features of visual images and control actions within a contrastive learning framework. The causation behind this alignment strategy is that the inertial locomotion state is the result of taking a certain control action under the current landform/terrain condition perceived by visual sensors. In experiments, we pre-train the MCRL4OR with a large-scale off-road driving dataset and adopt the learned multimodal representations for various downstream perception tasks in off-road driving scenarios. The superior performance in downstream tasks demonstrates the advantages of the pre-trained multimodal representations. The codes can be found in \url{https://github.com/1uciusy/MCRL4OR}.
关于自动驾驶的环境感知研究大多聚焦于城市交通环境,其中需要感知的对象主要是人造场景,并且可以使用密集标注的可扩展数据集来训练有监督学习模型。相比之下,由于越野环境本身具有的非结构化特点,手动对大规模越野驾驶数据集进行密集标注是非常困难的。在本文中,我们提出了一种用于越野环境感知的多模态对比表示学习方法,名为MCRL4OR。该方法旨在联合学习处理视觉图像、运动状态和控制动作的三个编码器,通过在对比学习框架内将运动状态与视觉图像和控制动作的特征进行融合来实现对齐。这种对齐策略背后的原因是,惯性运动状态是视觉传感器感知到当前地形条件下采取某种控制动作的结果。在实验中,我们使用大规模越野驾驶数据集对MCRL4OR进行预训练,并采用学到的多模态表示来进行越野驾驶场景中的各种下游感知任务。下游任务的卓越性能证明了预训练的多模态表示的优势。代码可见于网址:https://github.com/1uciusy/MCRL4OR。
论文及项目相关链接
PDF Github repository: https://github.com/1uciusy/MCRL4OR
Summary
本文提出一种用于越野环境感知的多模态对比表示学习方法MCRL4OR,旨在联合学习处理视觉图像、运动状态和操控行为的三个编码器。通过对比学习框架,将运动状态与视觉图像和操控行为的融合特征进行对齐。在越野驾驶数据集上预训练的MCRL4OR在多场景下游感知任务中表现优异,突显预训练的多模态表示优势。
Key Takeaways
- 研究关注自主车辆在越野环境下的环境感知。
- 现有研究主要集中在具有密集注释的城市交通环境,而越野环境的数据集标注困难。
- 提出了一种名为MCRL4OR的多模态对比表示学习方法。
- MCRL4OR联合学习处理视觉图像、运动状态和操控行为的三个编码器。
- 通过对比学习框架,将运动状态与视觉和操控行为的融合特征对齐。
- MCRL4OR在越野驾驶数据集上的预训练提高了下游感知任务的性能。
点此查看论文截图