⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting
Authors:Anil Armagan, Albert Saà-Garriga, Bruno Manganelli, Mateusz Nowak, Mehmet Kerim Yucel
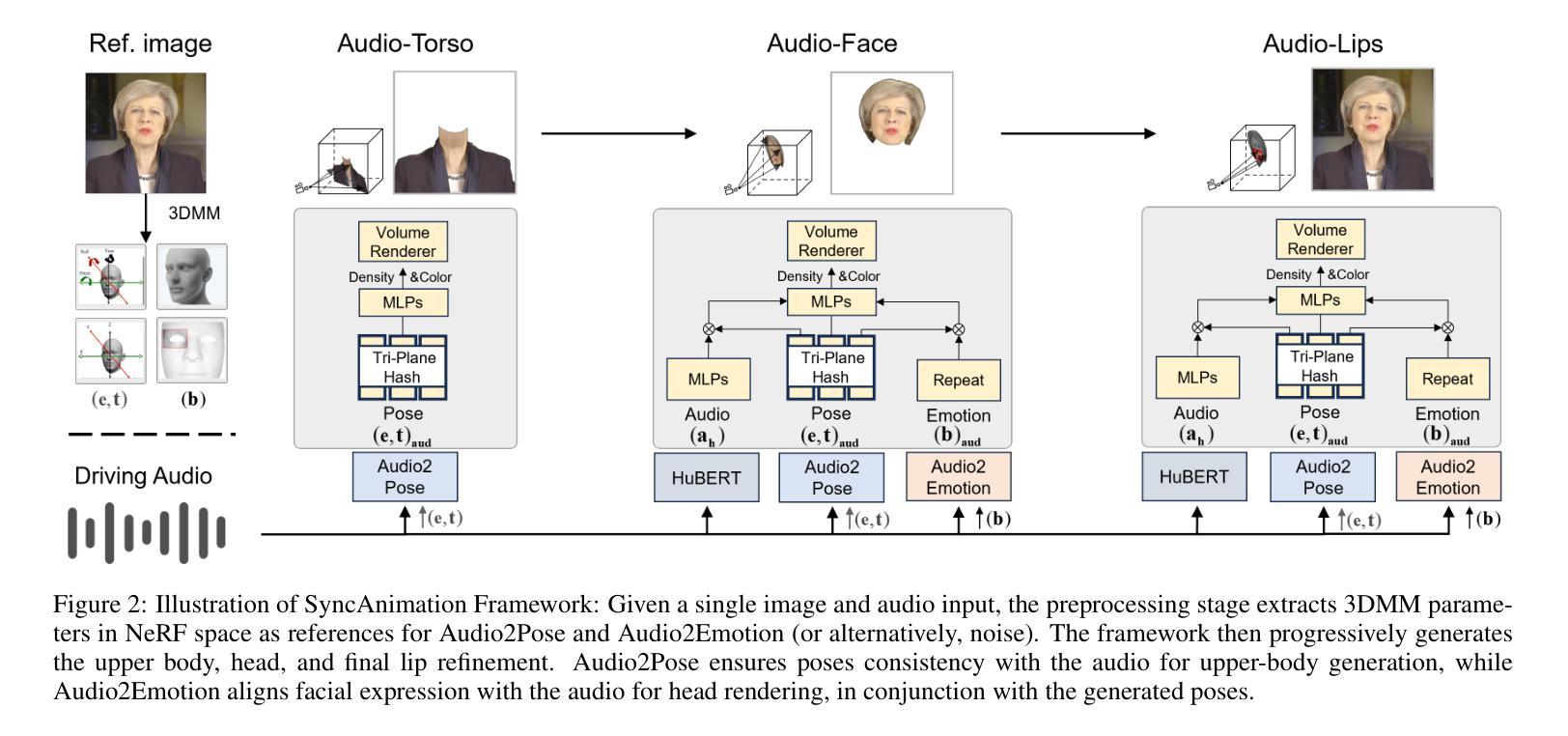
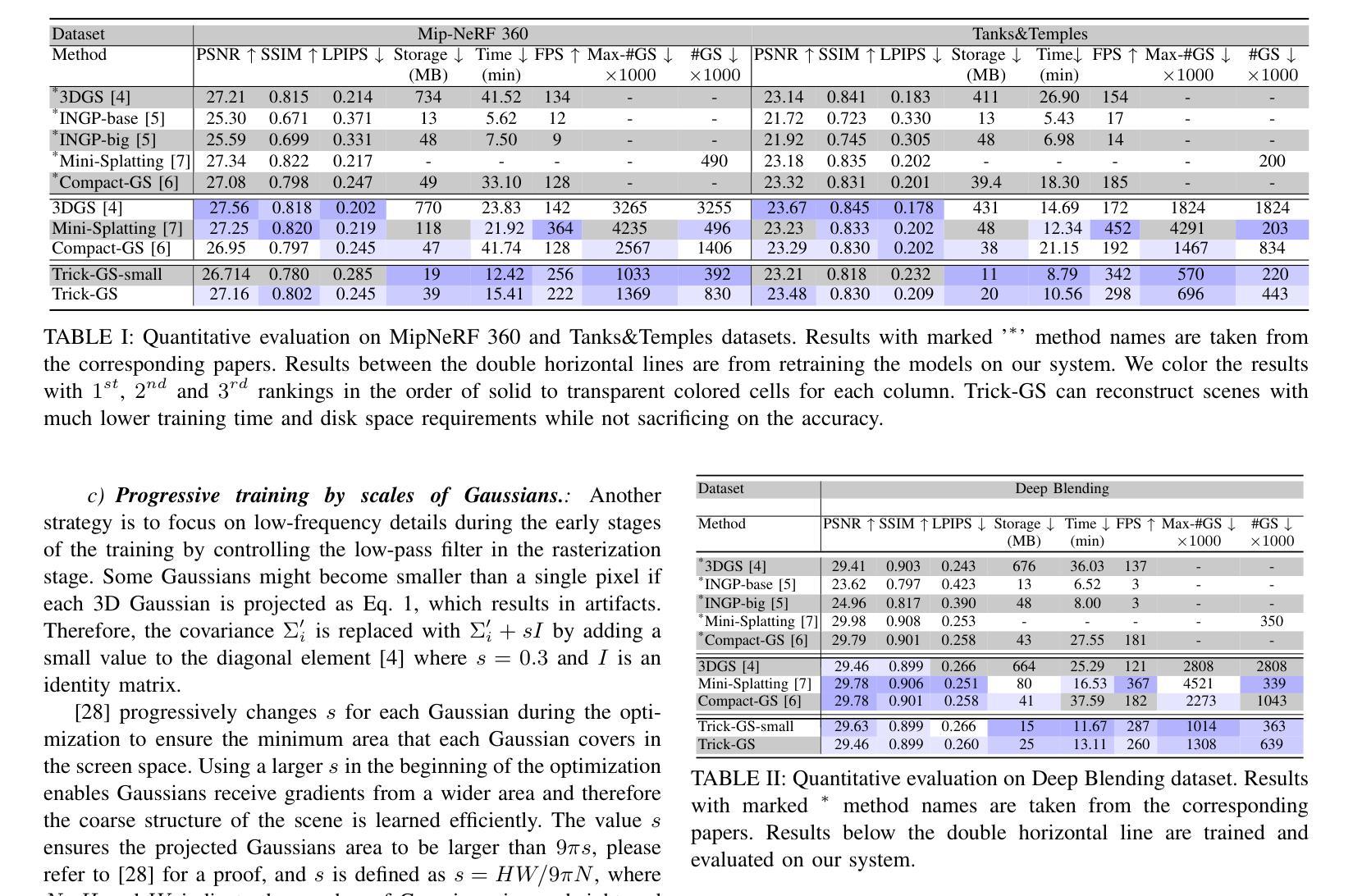
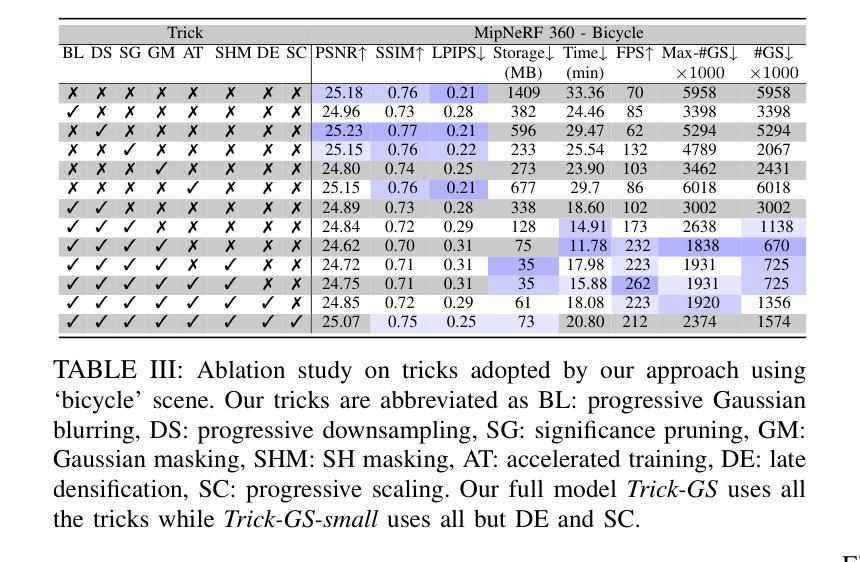
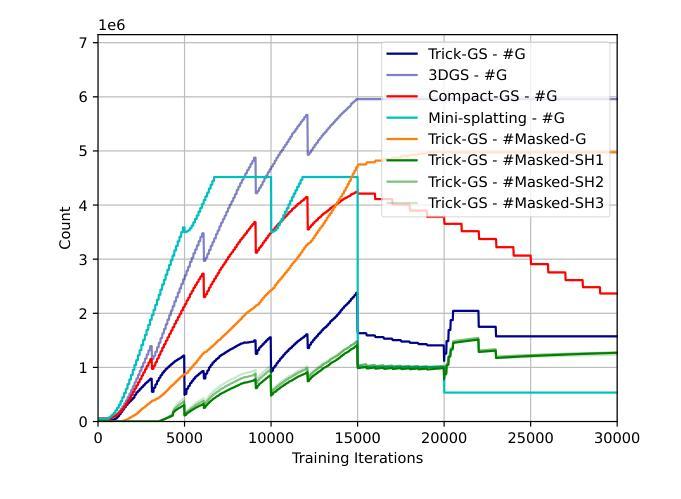
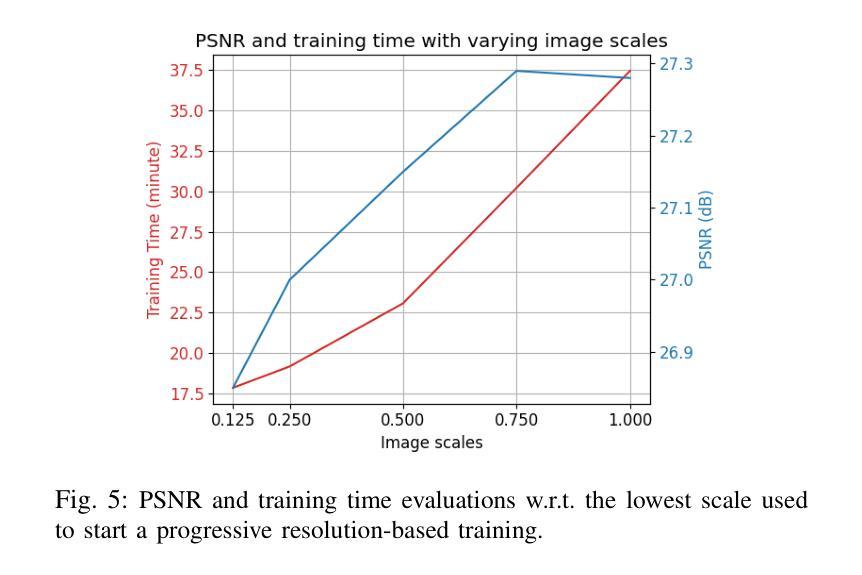
Gaussian splatting (GS) for 3D reconstruction has become quite popular due to their fast training, inference speeds and high quality reconstruction. However, GS-based reconstructions generally consist of millions of Gaussians, which makes them hard to use on computationally constrained devices such as smartphones. In this paper, we first propose a principled analysis of advances in efficient GS methods. Then, we propose Trick-GS, which is a careful combination of several strategies including (1) progressive training with resolution, noise and Gaussian scales, (2) learning to prune and mask primitives and SH bands by their significance, and (3) accelerated GS training framework. Trick-GS takes a large step towards resource-constrained GS, where faster run-time, smaller and faster-convergence of models is of paramount concern. Our results on three datasets show that Trick-GS achieves up to 2x faster training, 40x smaller disk size and 2x faster rendering speed compared to vanilla GS, while having comparable accuracy.
基于高斯贴片(GS)的3D重建因其快速训练、推理速度和高质量重建而备受欢迎。然而,基于GS的重建通常包含数百万个高斯,这使得它们在计算受限的设备(如智能手机)上难以使用。在本文中,我们首先提出对高效GS方法进展的有原则的分析。然后,我们提出Trick-GS,它是几种策略的组合,包括(1)以分辨率、噪声和高斯尺度进行渐进训练,(2)学习修剪和根据重要性屏蔽原始元素和SH波段,(3)加速GS训练框架。Trick-GS朝着资源受限的GS迈出了重要的一步,其中模型的更快运行时间、更小和更快的收敛速度是至关重要的。我们在三个数据集上的结果表明,与普通的GS相比,Trick-GS实现了高达2倍的快速训练、40倍的更小磁盘大小和2倍的快速渲染速度,同时保持了相当高的准确性。
论文及项目相关链接
PDF Accepted at ICASSP’25
Summary
本文介绍了基于高斯贴图(GS)的3D重建技术,虽然其训练、推理速度快且重建质量高,但由于生成的高斯数量庞大,难以在计算资源受限的设备(如智能手机)上使用。为此,本文首先分析了高效的GS方法的进展,并提出了Trick-GS方法。该方法结合了多种策略,包括渐进式训练、学习裁剪和掩蔽原始模型及SH频带的重要性等。实验结果证明了Trick-GS的有效性,其在三个数据集上的表现均优于传统GS方法,实现了更快的训练速度、更小的磁盘占用和更快的渲染速度。
Key Takeaways
- 高斯贴图(GS)是流行的3D重建技术,因其快速训练、推理和高质量重建而备受关注。
- GS方法生成大量高斯,难以在计算资源受限的设备上使用。
- 本文分析了高效的GS方法的进展,并提出了Trick-GS方法来解决计算资源受限的问题。
- Trick-GS结合了多种策略,包括渐进式训练、学习裁剪和掩蔽模型及SH频带的重要性等。
- 实验结果表明,Trick-GS在训练速度、磁盘占用和渲染速度方面均优于传统GS方法。
- Trick-GS实现了高达两倍的训练速度提升、四十倍的磁盘空间节省和两倍渲染速度提升。
点此查看论文截图




Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Authors:Xiaohao Xu, Tianyi Zhang, Shibo Zhao, Xiang Li, Sibo Wang, Yongqi Chen, Ye Li, Bhiksha Raj, Matthew Johnson-Roberson, Sebastian Scherer, Xiaonan Huang
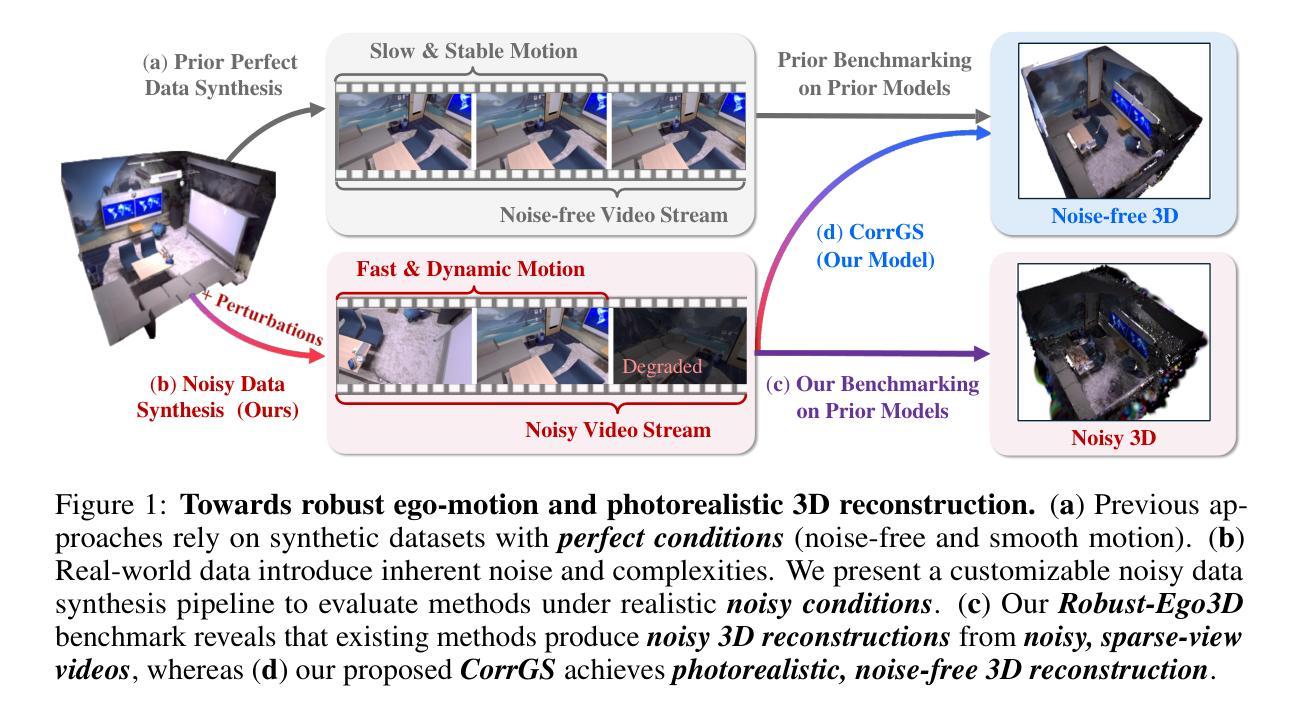
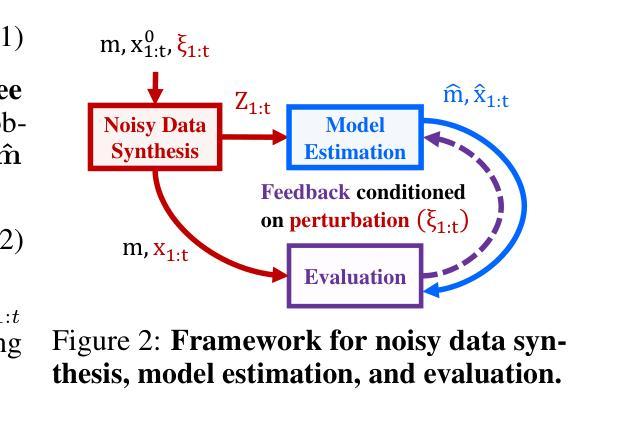
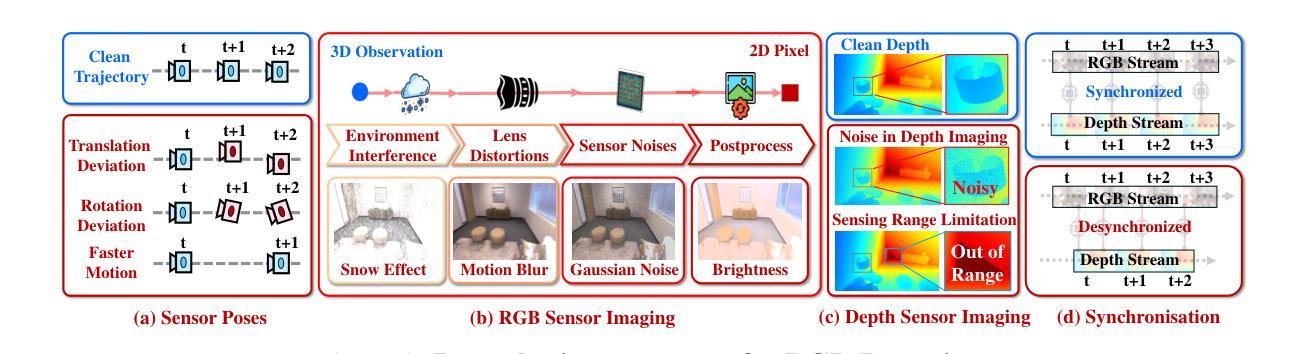
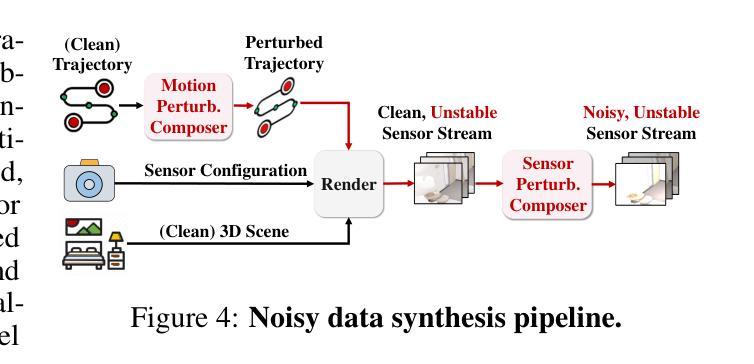
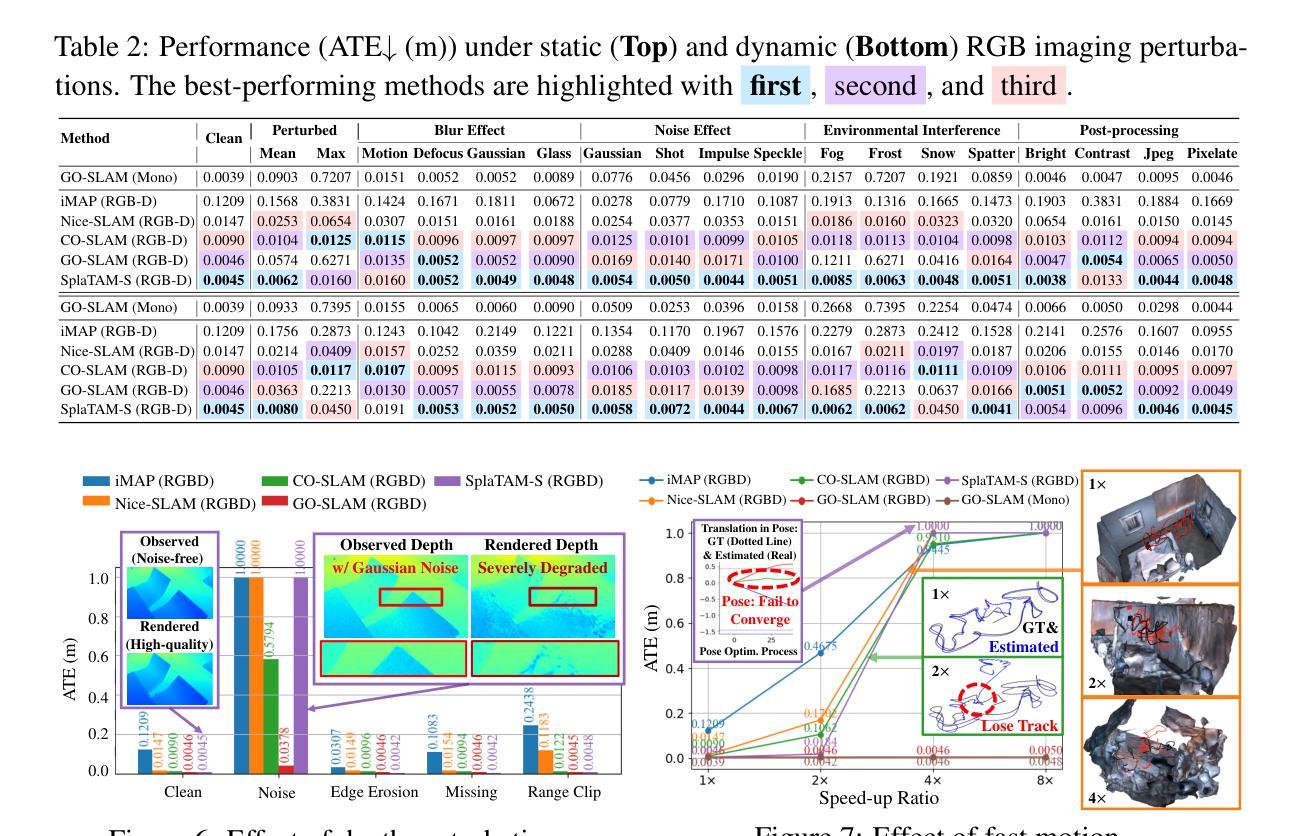
We aim to redefine robust ego-motion estimation and photorealistic 3D reconstruction by addressing a critical limitation: the reliance on noise-free data in existing models. While such sanitized conditions simplify evaluation, they fail to capture the unpredictable, noisy complexities of real-world environments. Dynamic motion, sensor imperfections, and synchronization perturbations lead to sharp performance declines when these models are deployed in practice, revealing an urgent need for frameworks that embrace and excel under real-world noise. To bridge this gap, we tackle three core challenges: scalable data generation, comprehensive benchmarking, and model robustness enhancement. First, we introduce a scalable noisy data synthesis pipeline that generates diverse datasets simulating complex motion, sensor imperfections, and synchronization errors. Second, we leverage this pipeline to create Robust-Ego3D, a benchmark rigorously designed to expose noise-induced performance degradation, highlighting the limitations of current learning-based methods in ego-motion accuracy and 3D reconstruction quality. Third, we propose Correspondence-guided Gaussian Splatting (CorrGS), a novel test-time adaptation method that progressively refines an internal clean 3D representation by aligning noisy observations with rendered RGB-D frames from clean 3D map, enhancing geometric alignment and appearance restoration through visual correspondence. Extensive experiments on synthetic and real-world data demonstrate that CorrGS consistently outperforms prior state-of-the-art methods, particularly in scenarios involving rapid motion and dynamic illumination.
我们旨在通过解决一个关键限制来重新定义稳健的自主运动估计和逼真的3D重建:现有模型对无噪声数据的依赖。虽然这种清洁的条件简化了评估,但它们无法捕捉真实世界环境中不可预测、充满噪声的复杂性。动态运动、传感器缺陷和同步扰动导致这些模型在实际部署时出现性能急剧下降,这凸显了需要框架在真实世界的噪声下接受并表现出卓越性能。为了弥补这一差距,我们解决了三个核心挑战:可扩展的数据生成、全面的基准测试和模型稳健性增强。首先,我们引入了一种可扩展的噪声数据合成管道,该管道生成模拟复杂运动、传感器缺陷和同步错误的各种数据集。其次,我们利用此管道创建Robust-Ego3D,这是一个严格设计的基准,旨在暴露噪声引起的性能下降,突出当前基于学习的方法在自主运动准确性和3D重建质量方面的局限性。第三,我们提出了对应引导高斯拼贴(CorrGS),这是一种新型测试时适应方法,通过将带有噪声的观察结果与从清洁3D地图渲染的RGB-D帧进行对齐,渐进地细化内部清洁的3D表示,通过视觉对应增强几何对齐和外观恢复。在合成和真实世界数据上的广泛实验表明,CorrGS始终优于先前的最先进的方法,特别是在涉及快速运动和动态照明场景中。
论文及项目相关链接
PDF Accepted by ICLR 2025; 92 Pages; Project Repo: https://github.com/Xiaohao-Xu/SLAM-under-Perturbation. arXiv admin note: substantial text overlap with arXiv:2406.16850
Summary
本文旨在重新定义稳健的自主运动估计和逼真的三维重建,解决现有模型依赖无噪声数据的局限性。针对现实世界环境中不可预测和复杂的噪声问题,提出解决动态运动、传感器缺陷和同步扰动等三大核心挑战的方案。引入可扩展的噪声数据合成管道,创建Robust-Ego3D基准测试平台,并提出新的测试时间适应方法Correspondence-guided Gaussian Splatting(CorrGS),以改进内部清洁三维表示并提升几何对齐和外观恢复能力。实验表明,CorrGS在快速运动和动态照明场景下表现尤为出色。
Key Takeaways
- 本文强调了现有模型对无噪声数据的依赖,而这并不符合现实世界的复杂性和噪声问题。
- 引入了一种可扩展的噪声数据合成管道,能够生成模拟复杂运动、传感器缺陷和同步错误的数据集。
- 创建了Robust-Ego3D基准测试平台,以揭示噪声对模型性能的影响并暴露当前学习方法的局限性。
- 提出了Correspondence-guided Gaussian Splatting(CorrGS)方法,这是一种新的测试时间适应方法,能够在测试时改进内部清洁三维表示。
- CorrGS通过对齐噪声观测和从清洁三维地图渲染的RGB-D帧来增强几何对齐和外观恢复。
- 实验表明,CorrGS在应对快速运动和动态照明等现实场景时表现优异。
点此查看论文截图

Dense-SfM: Structure from Motion with Dense Consistent Matching
Authors:JongMin Lee, Sungjoo Yoo
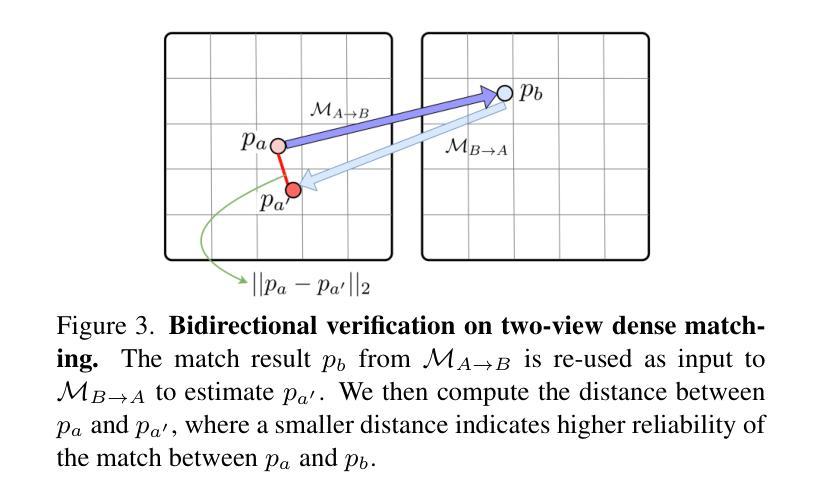
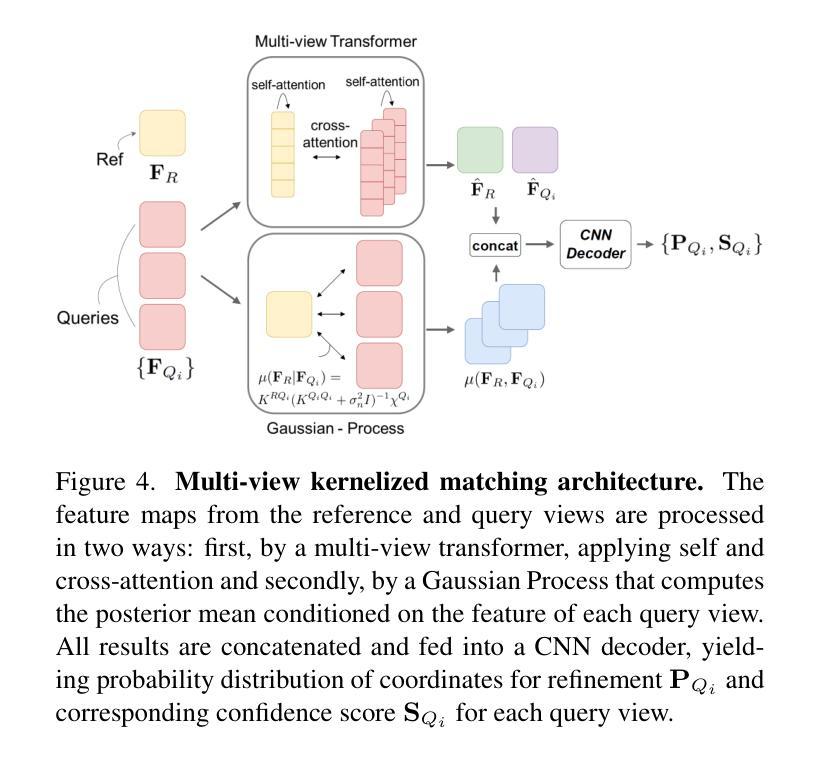
We present Dense-SfM, a novel Structure from Motion (SfM) framework designed for dense and accurate 3D reconstruction from multi-view images. Sparse keypoint matching, which traditional SfM methods often rely on, limits both accuracy and point density, especially in texture-less areas. Dense-SfM addresses this limitation by integrating dense matching with a Gaussian Splatting (GS) based track extension which gives more consistent, longer feature tracks. To further improve reconstruction accuracy, Dense-SfM is equipped with a multi-view kernelized matching module leveraging transformer and Gaussian Process architectures, for robust track refinement across multi-views. Evaluations on the ETH3D and Texture-Poor SfM datasets show that Dense-SfM offers significant improvements in accuracy and density over state-of-the-art methods.
我们提出了Dense-SfM,这是一种新型的从运动(SfM)框架中设计的用于从多视角图像进行密集且精确的3D重建的方法。传统的SfM方法往往依赖于稀疏关键点匹配,这限制了其准确性和点的密度,特别是在纹理缺失的区域。Dense-SfM通过结合密集匹配和基于高斯展布(GS)的轨迹扩展来解决这一问题,从而得到更一致、更长的特征轨迹。为了进一步提高重建精度,Dense-SfM配备了利用变压器和高斯过程架构的多视角核匹配模块,以实现跨多视角的稳健轨迹细化。在ETH3D和纹理缺失SfM数据集上的评估表明,Dense-SfM在精度和密度方面较现有技术都有显著提高。
论文及项目相关链接
Summary
本文介绍了Dense-SfM,这是一种新型的结构光流法(SfM)框架,旨在从多视角图像中实现密集且准确的3D重建。传统SfM方法依赖于稀疏关键点匹配,这限制了准确性和点的密度,特别是在纹理缺失的区域。Dense-SfM通过结合密集匹配和基于高斯点扩散(GS)的轨迹扩展来解决这一问题,从而得到更一致、更长的特征轨迹。为了进一步提高重建的准确性,Dense-SfM还配备了利用变换器和高斯过程架构的多视角核匹配模块,以稳健地在多视角之间进行轨迹优化。在ETH3D和纹理较差的SfM数据集上的评估表明,Dense-SfM在准确性和密度方面较现有技术均有显著提高。
Key Takeaways
- Dense-SfM是一个新型SfM框架,旨在实现密集且准确的3D重建。
- 传统SfM方法依赖于稀疏关键点匹配,存在准确性和点密度上的局限性。
- Dense-SfM通过结合密集匹配和基于高斯点扩散的轨迹扩展技术,提高特征轨迹的一致性和长度。
- Dense-SfM配备了多视角核匹配模块,利用变换器和高斯过程架构,以稳健地在不同视角间进行轨迹优化。
- Dense-SfM在ETH3D和纹理较差的SfM数据集上的表现优于现有技术,显示出更高的准确性和密度。
- Dense-SfM框架有助于提高重建的精度和密度,特别是在纹理缺失的区域。
- 该框架具有潜力为3D重建领域带来新的突破和改进。
点此查看论文截图


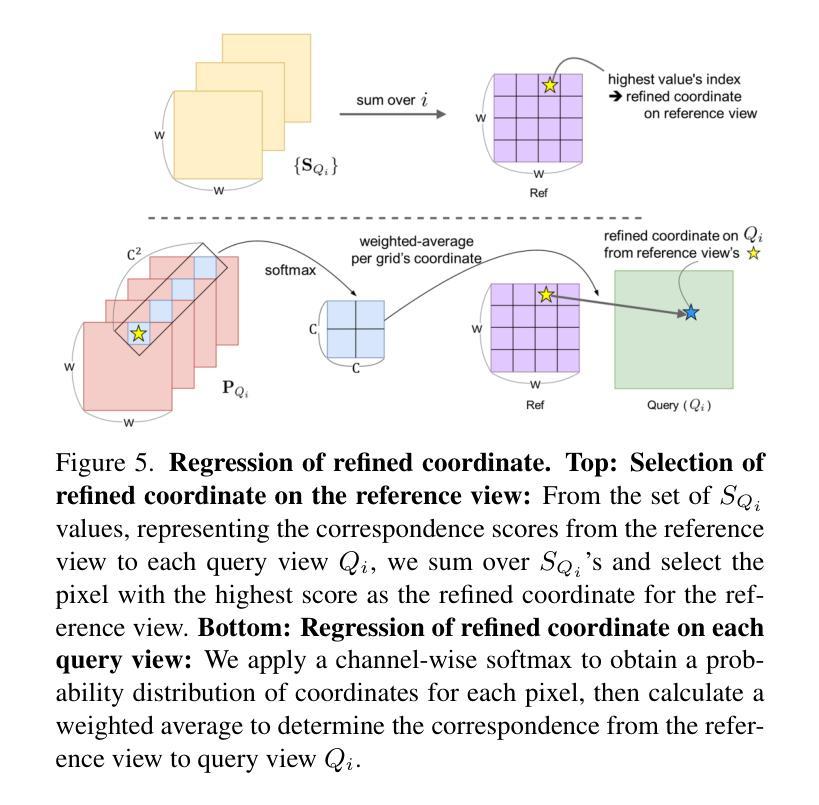
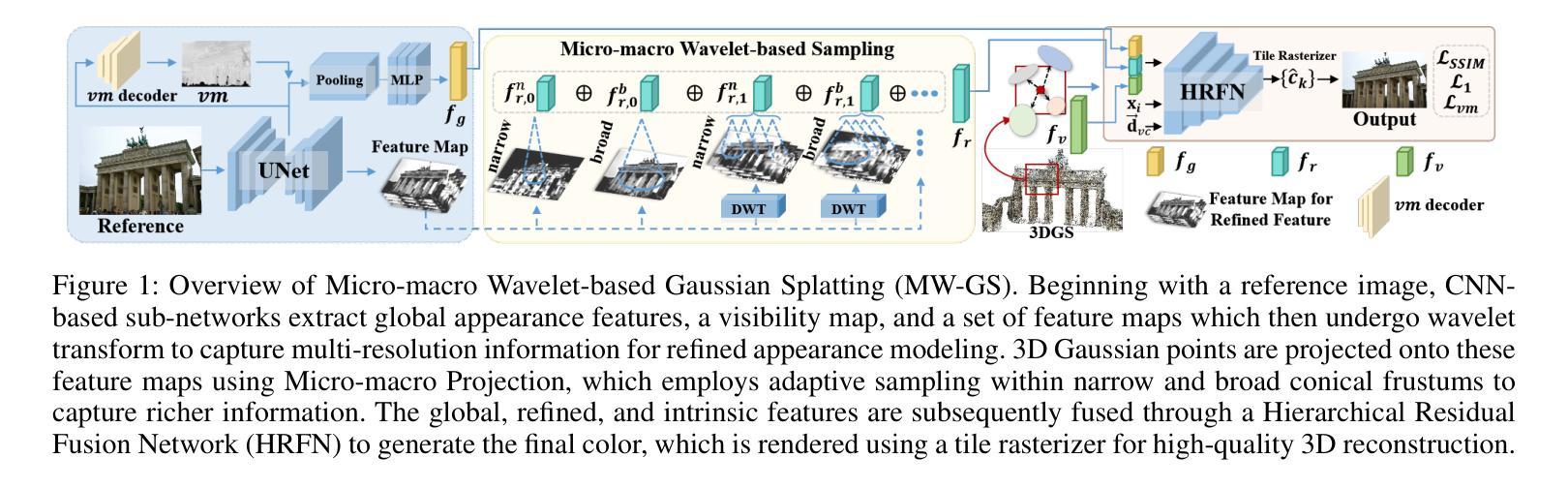
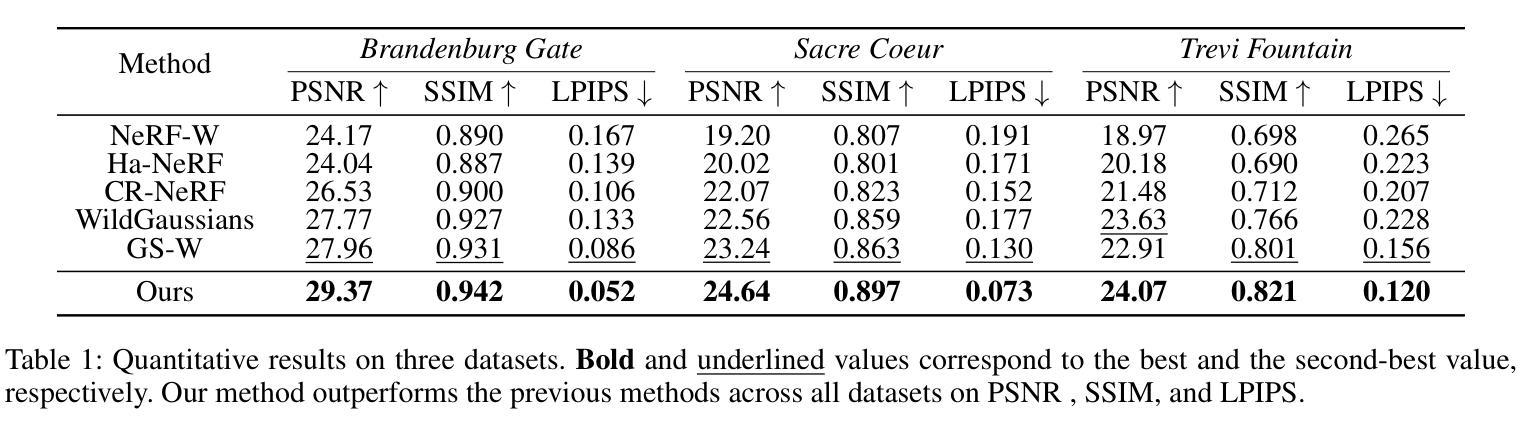
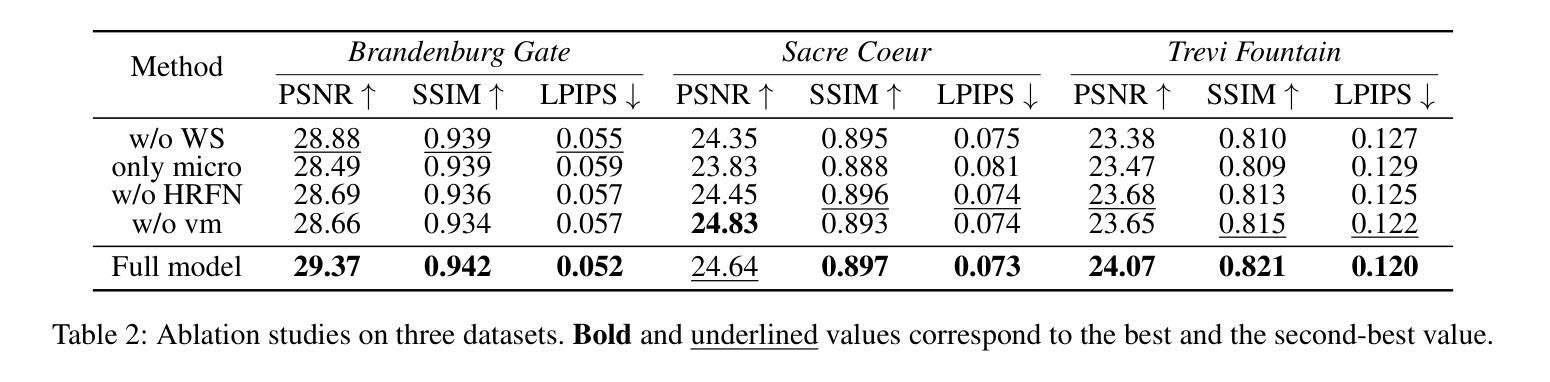
Micro-macro Wavelet-based Gaussian Splatting for 3D Reconstruction from Unconstrained Images
Authors:Yihui Li, Chengxin Lv, Hongyu Yang, Di Huang
3D reconstruction from unconstrained image collections presents substantial challenges due to varying appearances and transient occlusions. In this paper, we introduce Micro-macro Wavelet-based Gaussian Splatting (MW-GS), a novel approach designed to enhance 3D reconstruction by disentangling scene representations into global, refined, and intrinsic components. The proposed method features two key innovations: Micro-macro Projection, which allows Gaussian points to capture details from feature maps across multiple scales with enhanced diversity; and Wavelet-based Sampling, which leverages frequency domain information to refine feature representations and significantly improve the modeling of scene appearances. Additionally, we incorporate a Hierarchical Residual Fusion Network to seamlessly integrate these features. Extensive experiments demonstrate that MW-GS delivers state-of-the-art rendering performance, surpassing existing methods.
从不受约束的图像集合中进行3D重建面临着巨大的挑战,因为存在外观变化和瞬时遮挡的问题。在本文中,我们引入了基于微宏小波的高斯涂抹(MW-GS),这是一种新颖的方法,旨在通过将场景表示分解为全局、精细和内在成分来增强3D重建。该方法具有两个关键创新点:微宏投影,它允许高斯点捕获来自多个尺度的特征图的细节,增强多样性;以及基于小波的采样,它利用频域信息来优化特征表示并显著改善场景外观的建模。此外,我们采用分层残差融合网络来无缝集成这些特性。大量实验表明,MW-GS达到了最先进的渲染性能,超越了现有方法。
论文及项目相关链接
PDF 11 pages, 6 figures,accepted by AAAI 2025
Summary
本文提出了一种基于微宏小波高斯描画(MW-GS)的新方法,用于增强从非约束图像集合进行的3D重建。该方法通过将场景表示分解成全局、精细和内在成分来解决各种外观和瞬时遮挡所带来的挑战。其主要创新点包括微宏投影和基于小波的采样,能够捕捉多尺度特征图的细节并改进特征表示,从而提高场景外观的建模效果。此外,还结合了分层残差融合网络来无缝集成这些特征。实验表明,MW-GS达到了最先进的渲染性能。
Key Takeaways
- 提出了一种名为微宏小波高斯描画(MW-GS)的新方法,用于改进3D重建。
- 通过将场景表示分解为全局、精细和内在成分来解决挑战。
- 引入微宏投影技术,允许高斯点捕捉多尺度特征图的细节。
- 采用基于小波的采样,利用频域信息改进特征表示。
- 结合分层残差融合网络进行特征集成。
- 实验结果表明MW-GS在渲染性能上达到或超越了现有方法。
点此查看论文截图



3DGS$^2$: Near Second-order Converging 3D Gaussian Splatting
Authors:Lei Lan, Tianjia Shao, Zixuan Lu, Yu Zhang, Chenfanfu Jiang, Yin Yang
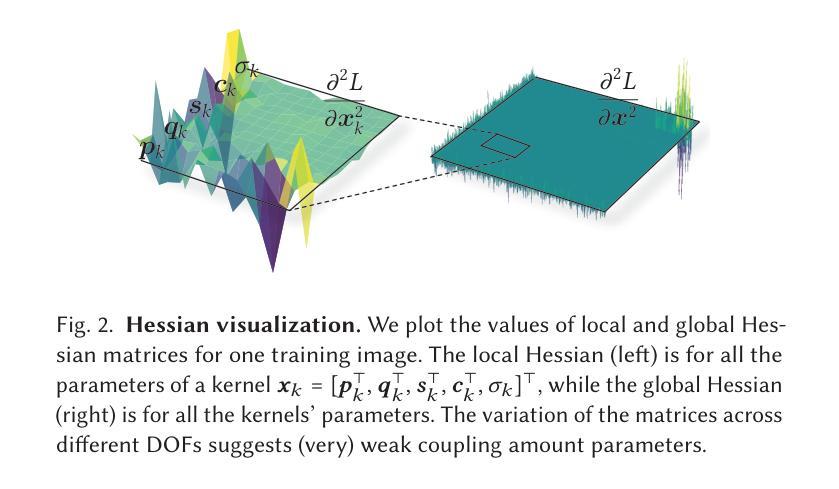
3D Gaussian Splatting (3DGS) has emerged as a mainstream solution for novel view synthesis and 3D reconstruction. By explicitly encoding a 3D scene using a collection of Gaussian kernels, 3DGS achieves high-quality rendering with superior efficiency. As a learning-based approach, 3DGS training has been dealt with the standard stochastic gradient descent (SGD) method, which offers at most linear convergence. Consequently, training often requires tens of minutes, even with GPU acceleration. This paper introduces a (near) second-order convergent training algorithm for 3DGS, leveraging its unique properties. Our approach is inspired by two key observations. First, the attributes of a Gaussian kernel contribute independently to the image-space loss, which endorses isolated and local optimization algorithms. We exploit this by splitting the optimization at the level of individual kernel attributes, analytically constructing small-size Newton systems for each parameter group, and efficiently solving these systems on GPU threads. This achieves Newton-like convergence per training image without relying on the global Hessian. Second, kernels exhibit sparse and structured coupling across input images. This property allows us to effectively utilize spatial information to mitigate overshoot during stochastic training. Our method converges an order faster than standard GPU-based 3DGS training, requiring over $10\times$ fewer iterations while maintaining or surpassing the quality of the compared with the SGD-based 3DGS reconstructions.
3D高斯采样(3DGS)已成为新颖视角合成和3D重建的主流解决方案。通过显式使用一系列高斯核编码一个3D场景,3DGS能够以卓越的效率实现高质量渲染。作为一种基于学习的方法,对3DGS训练采用标准随机梯度下降(SGD)方法进行处理,最多只提供线性收敛速度。因此,即使在GPU加速的情况下,训练也需要数分钟时间。本文为3DGS引入了一种(接近)二阶收敛的训练算法,利用它的独特属性。我们的方法受到两个关键观察结果的启发。首先,高斯核的属性对图像空间的损失做出独立贡献,这为孤立的局部优化算法提供了支持。我们通过针对个别核属性进行分割来充分利用这一点,解析构建每个参数组的小牛顿系统,并在GPU线程上有效地解决这些问题。这可以在不依赖全局海森矩阵的情况下实现每幅训练图像的牛顿式收敛。其次,在输入图像之间,核表现出稀疏和结构化的耦合关系。此属性使我们能够有效地利用空间信息,从而减轻随机训练过程中的过度拟合现象。我们的方法比标准的基于GPU的3DGS训练收敛速度更快,所需迭代次数减少了超过10倍,同时保持或超越了与基于SGD的3DGS重建的质量相比效果。
论文及项目相关链接
PDF 11 pages, submit on SIGGRAPH 2025
摘要
本文介绍了对基于三维高斯数据斑(3DGS)合成方法的改进。通过对三维场景使用高斯核集进行显式编码,此方法可以实现高质量渲染和高效率。传统上使用随机梯度下降(SGD)方法进行训练存在收敛速度慢的问题。本研究利用高斯核属性独立影响图像空间损失的特点,提出了局部优化算法,实现类似牛顿法的收敛速度,且无需依赖全局海森矩阵。此外,该研究利用核函数在输入图像间的稀疏和结构化耦合特性,有效使用空间信息,减少随机训练时的过度拟合问题。新方法相较于传统的GPU加速的SGD训练方式,收敛速度更快,迭代次数减少十倍以上,同时保持或提升重建质量。
关键见解
- 利用高斯核属性独立影响图像空间损失的特点,提出了局部优化算法。
- 通过构建小型的牛顿系统来独立优化每个参数组,实现更快的收敛速度。
- 采用局部优化的方式在GPU线程上实现训练,不需要依赖全局海森矩阵。
- 发现了高斯核之间的稀疏和结构化耦合特性有助于提升训练效果。
- 利用空间信息有效缓解随机训练中的过度拟合问题。
- 新方法相较于SGD训练,收敛速度提升显著,迭代次数减少超过十倍。
点此查看论文截图

GS-LiDAR: Generating Realistic LiDAR Point Clouds with Panoramic Gaussian Splatting
Authors:Junzhe Jiang, Chun Gu, Yurui Chen, Li Zhang
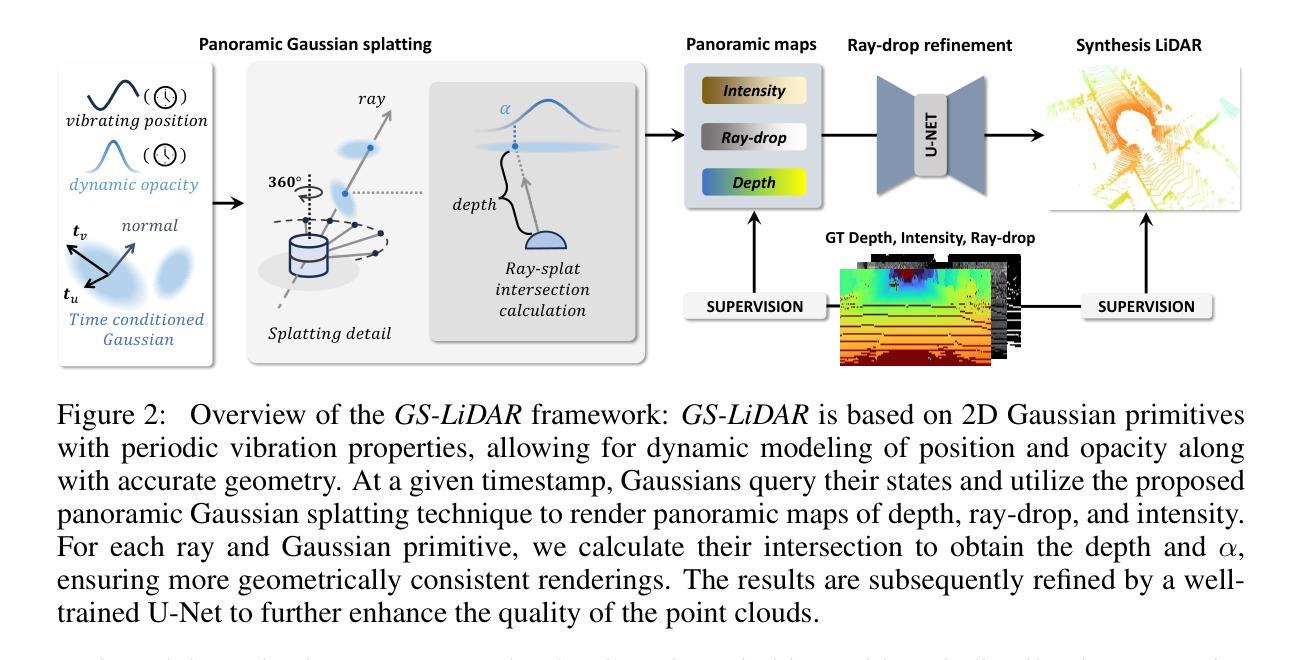
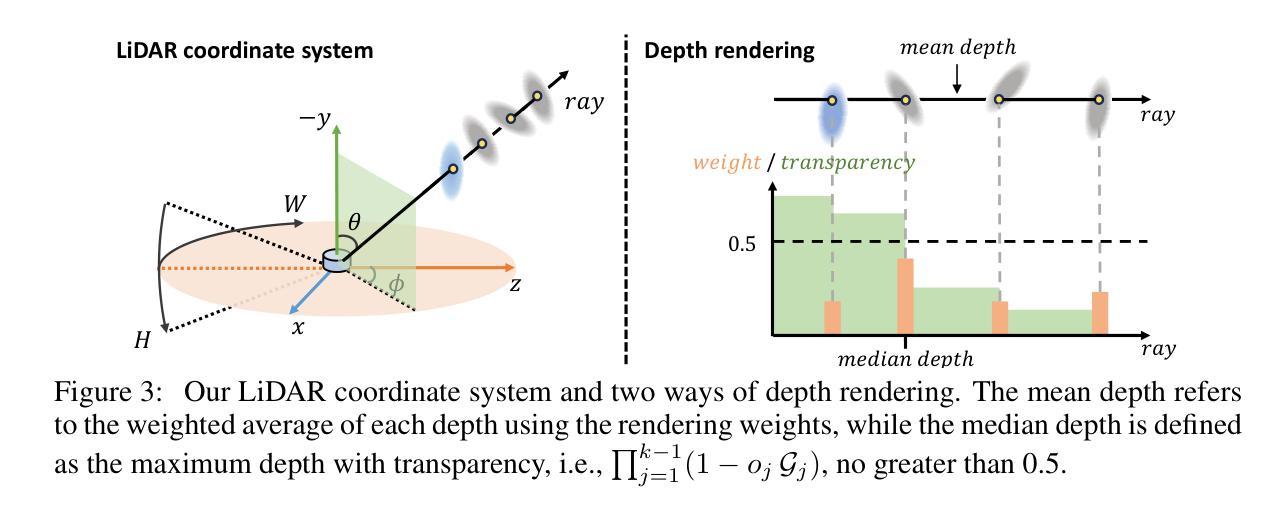
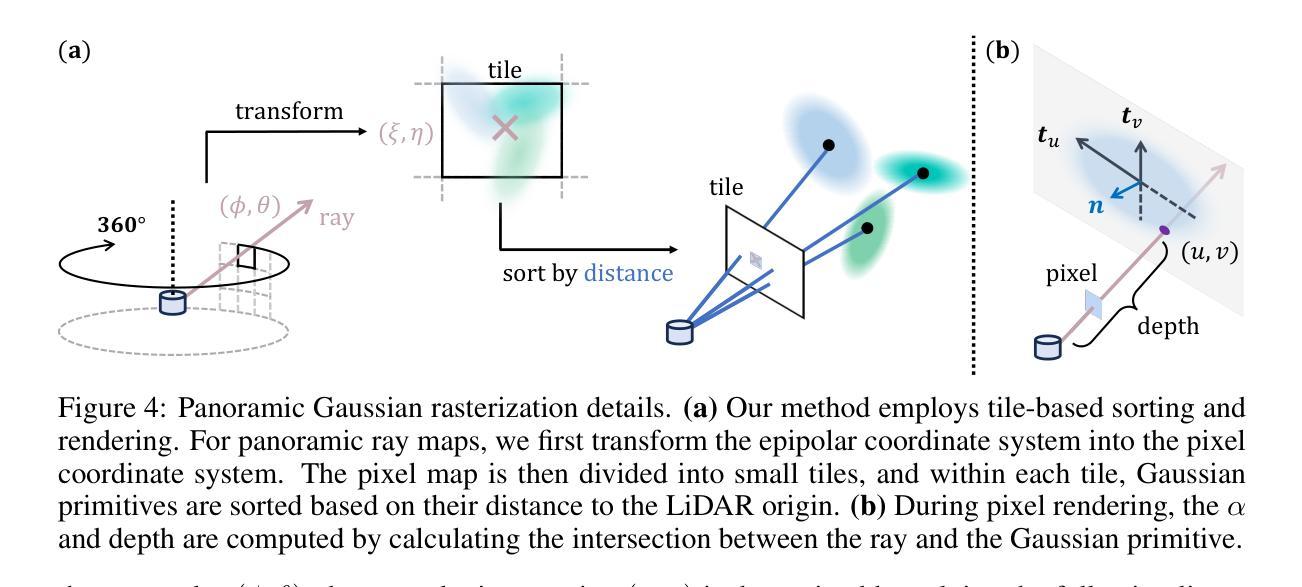
LiDAR novel view synthesis (NVS) has emerged as a novel task within LiDAR simulation, offering valuable simulated point cloud data from novel viewpoints to aid in autonomous driving systems. However, existing LiDAR NVS methods typically rely on neural radiance fields (NeRF) as their 3D representation, which incurs significant computational costs in both training and rendering. Moreover, NeRF and its variants are designed for symmetrical scenes, making them ill-suited for driving scenarios. To address these challenges, we propose GS-LiDAR, a novel framework for generating realistic LiDAR point clouds with panoramic Gaussian splatting. Our approach employs 2D Gaussian primitives with periodic vibration properties, allowing for precise geometric reconstruction of both static and dynamic elements in driving scenarios. We further introduce a novel panoramic rendering technique with explicit ray-splat intersection, guided by panoramic LiDAR supervision. By incorporating intensity and ray-drop spherical harmonic (SH) coefficients into the Gaussian primitives, we enhance the realism of the rendered point clouds. Extensive experiments on KITTI-360 and nuScenes demonstrate the superiority of our method in terms of quantitative metrics, visual quality, as well as training and rendering efficiency.
激光雷达新型视图合成(NVS)作为激光雷达仿真中的一项新型任务而出现,它从新型视角提供有价值的模拟点云数据,以辅助自动驾驶系统。然而,现有的激光雷达NVS方法通常依赖于神经辐射场(NeRF)作为其3D表示,这在训练和渲染方面都带来了相当大的计算成本。此外,NeRF及其变体是为对称场景设计的,使得它们不适合驾驶场景。为了解决这些挑战,我们提出了GS-激光雷达,这是一个生成现实主义的激光雷达点云的新型框架,采用全景高斯涂抹技术。我们的方法采用具有周期性振动特性的2D高斯基元,可以精确重建驾驶场景中静态和动态元素的几何结构。我们还引入了一种新型的全景渲染技术,具有明确的射线涂抹交集,由全景激光雷达监督指导。通过将强度和射线下降球面谐波(SH)系数纳入高斯基元,我们提高了渲染点云的真实性。在KITTI-360和nuScenes上的大量实验表明,我们的方法在定量指标、视觉质量以及训练和渲染效率方面都表现出优越性。
论文及项目相关链接
Summary
针对激光雷达仿真中的新型视点合成(NVS)任务,现有方法主要依赖神经辐射场(NeRF)进行3D表示,存在计算成本高和场景适用性不足的问题。本文提出GS-LiDAR框架,采用全景高斯涂斑技术生成逼真的激光雷达点云,通过2D高斯基元模拟驾驶场景的静态和动态元素,引入全景渲染技术和全景激光雷达监督,提高点云真实感和效率。
Key Takeaways
- LiDAR NVS任务在LiDAR仿真中是一个新兴任务,用于生成自主驾驶系统中的模拟点云数据。
- 现有LiDAR NVS方法主要依赖NeRF进行3D表示,存在计算成本高和场景适应性差的问题。
- GS-LiDAR框架使用全景高斯涂斑技术生成逼真的激光雷达点云数据。
- 该方法采用2D高斯基元模拟驾驶场景的静态和动态元素,提高了几何重建的精确度。
- 引入全景渲染技术和全景激光雷达监督,增强了渲染点云的真实感。
- 在KITTI-360和nuScenes上的实验表明,GS-LiDAR方法在定量指标、视觉质量以及训练和渲染效率方面表现优异。
点此查看论文截图

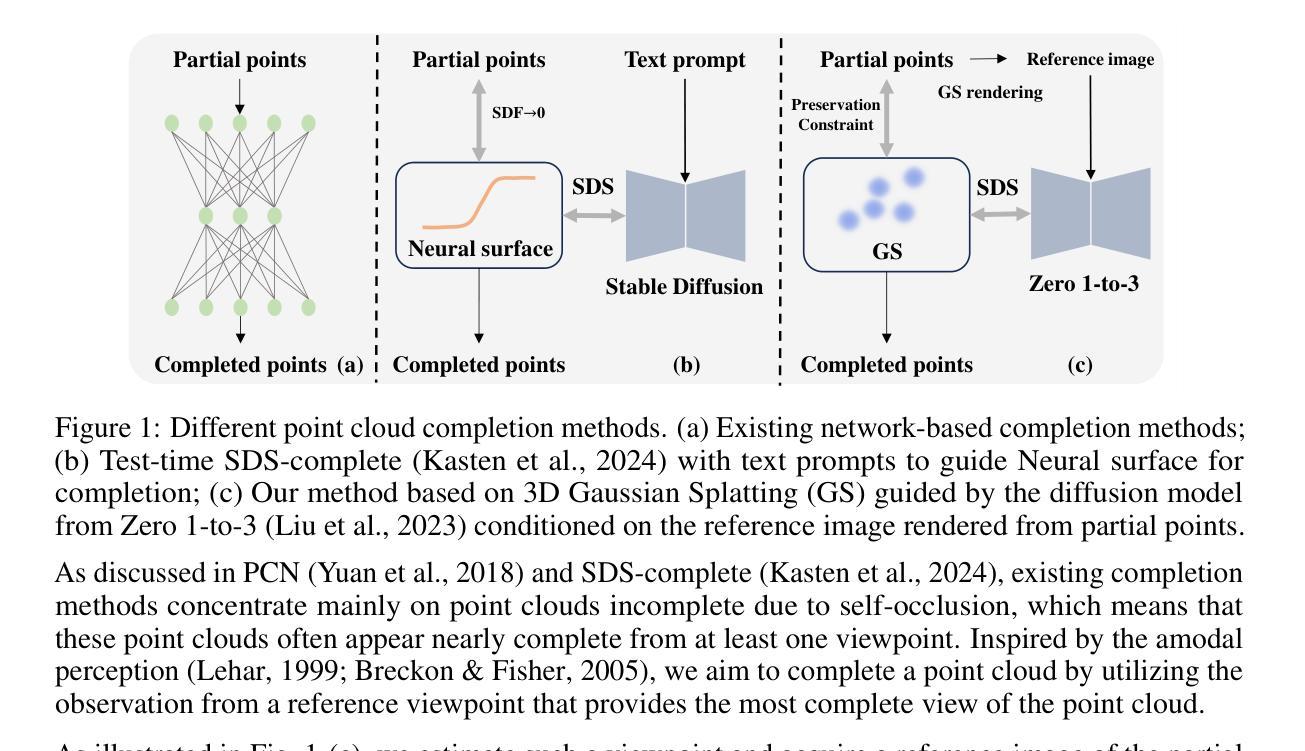
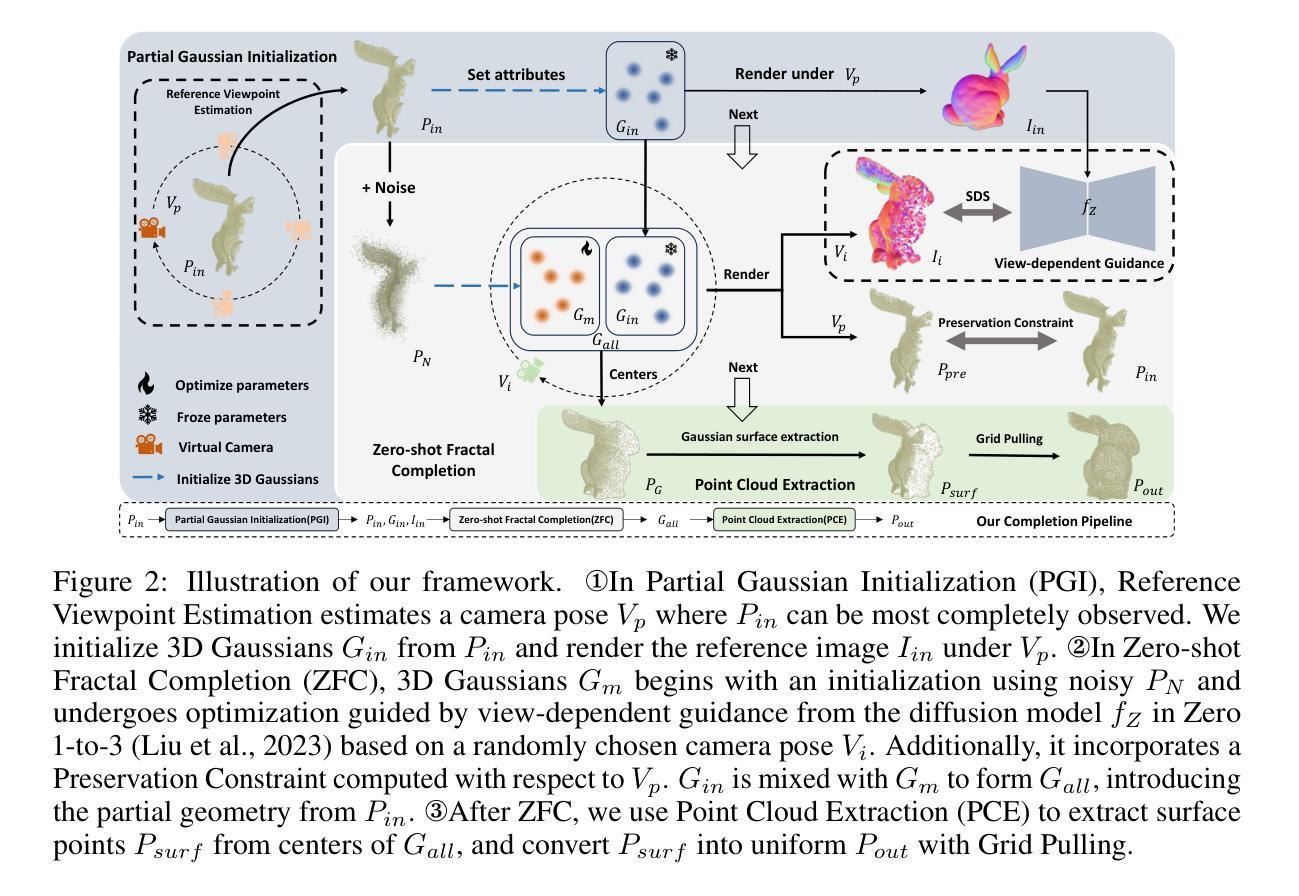
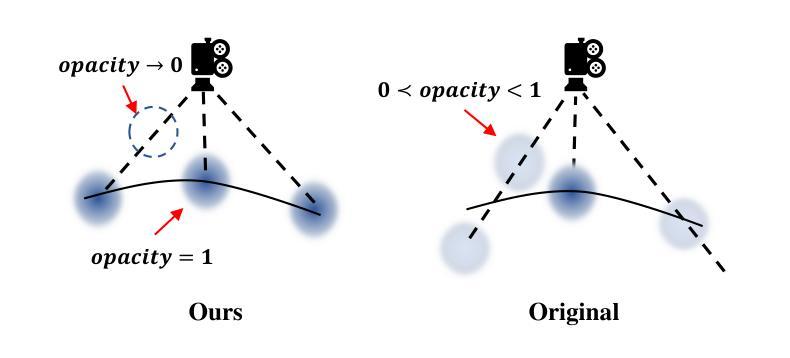
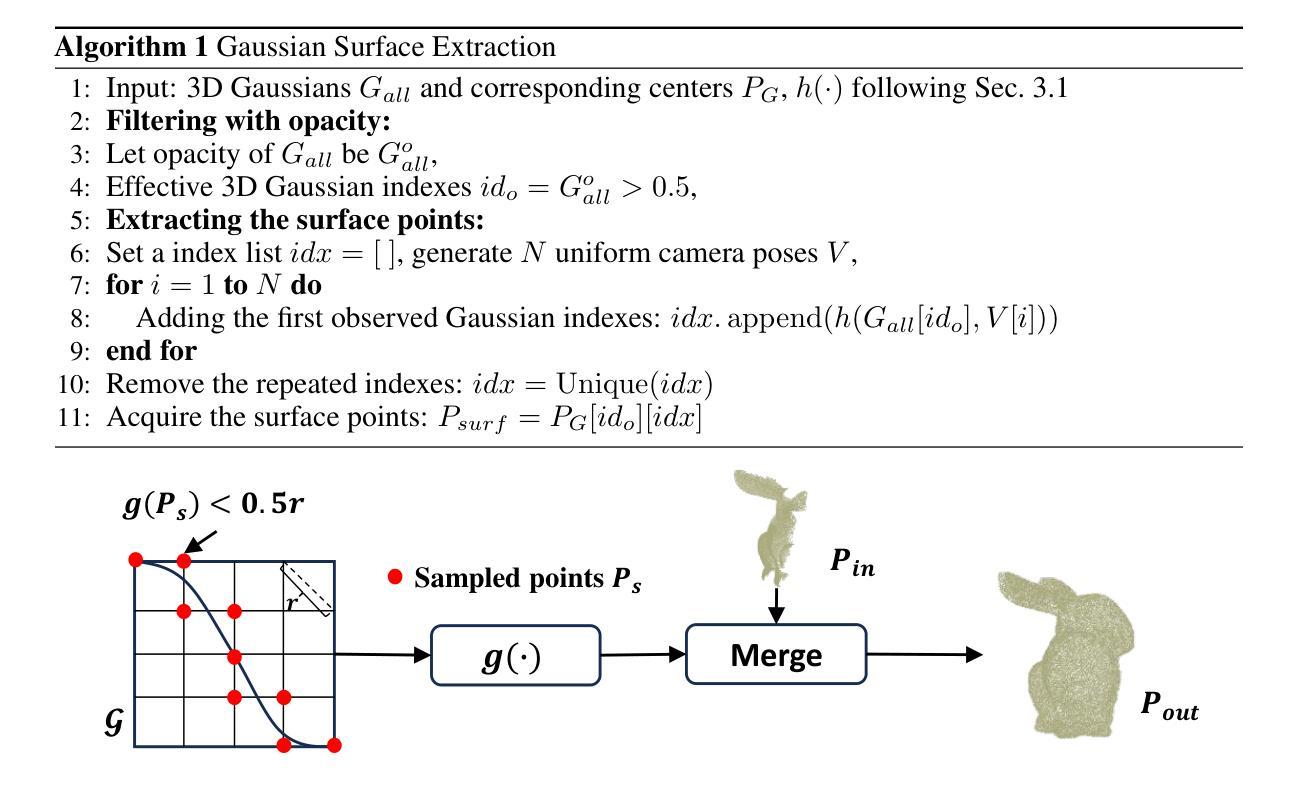
ComPC: Completing a 3D Point Cloud with 2D Diffusion Priors
Authors:Tianxin Huang, Zhiwen Yan, Yuyang Zhao, Gim Hee Lee
3D point clouds directly collected from objects through sensors are often incomplete due to self-occlusion. Conventional methods for completing these partial point clouds rely on manually organized training sets and are usually limited to object categories seen during training. In this work, we propose a test-time framework for completing partial point clouds across unseen categories without any requirement for training. Leveraging point rendering via Gaussian Splatting, we develop techniques of Partial Gaussian Initialization, Zero-shot Fractal Completion, and Point Cloud Extraction that utilize priors from pre-trained 2D diffusion models to infer missing regions and extract uniform completed point clouds. Experimental results on both synthetic and real-world scanned point clouds demonstrate that our approach outperforms existing methods in completing a variety of objects. Our project page is at \url{https://tianxinhuang.github.io/projects/ComPC/}.
通过传感器直接从物体收集的三维点云通常由于自遮挡而不完整。传统的完成这些部分点云的方法依赖于手动组织的训练集,并且通常仅限于训练期间见过的对象类别。在这项工作中,我们提出了一种测试时框架,用于完成未见过的类别的部分点云,而无需任何训练要求。我们利用通过高斯拼贴进行点渲染,开发了部分高斯初始化、零样本分形完成和点云提取等技术,这些技术利用预训练的二维扩散模型的先验知识来推断缺失区域并提取均匀完成的点云。在合成和真实世界扫描的点云上的实验结果证明,我们的方法在完成各种对象方面优于现有方法。我们的项目页面是:[https://tianxinhuang
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文提出一种无需训练即可完成跨未见类别部分点云的测试时框架。通过利用高斯涂污的点渲染,开发了部分高斯初始化、零射击碎完成和点云提取等技术,利用预训练的2D扩散模型的先验信息来推断缺失区域并提取统一的完成点云。实验结果表明,该方法在合成和真实世界扫描的点云上均优于现有方法。
Key Takeaways
- 部分点云由于自遮挡而常见。
- 传统方法依赖手动组织训练集,且通常限于训练时见过的物体类别。
- 本文提出一种无需训练即可完成跨未见类别部分点云的测试时框架。
- 利用高斯涂污的点渲染技术,包括部分高斯初始化、零射击碎完成和点云提取。
- 该方法利用预训练的2D扩散模型的先验信息来推断缺失区域。
- 实验证明该方法在合成和真实世界扫描的点云上均有效且优于现有方法。
点此查看论文截图