⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
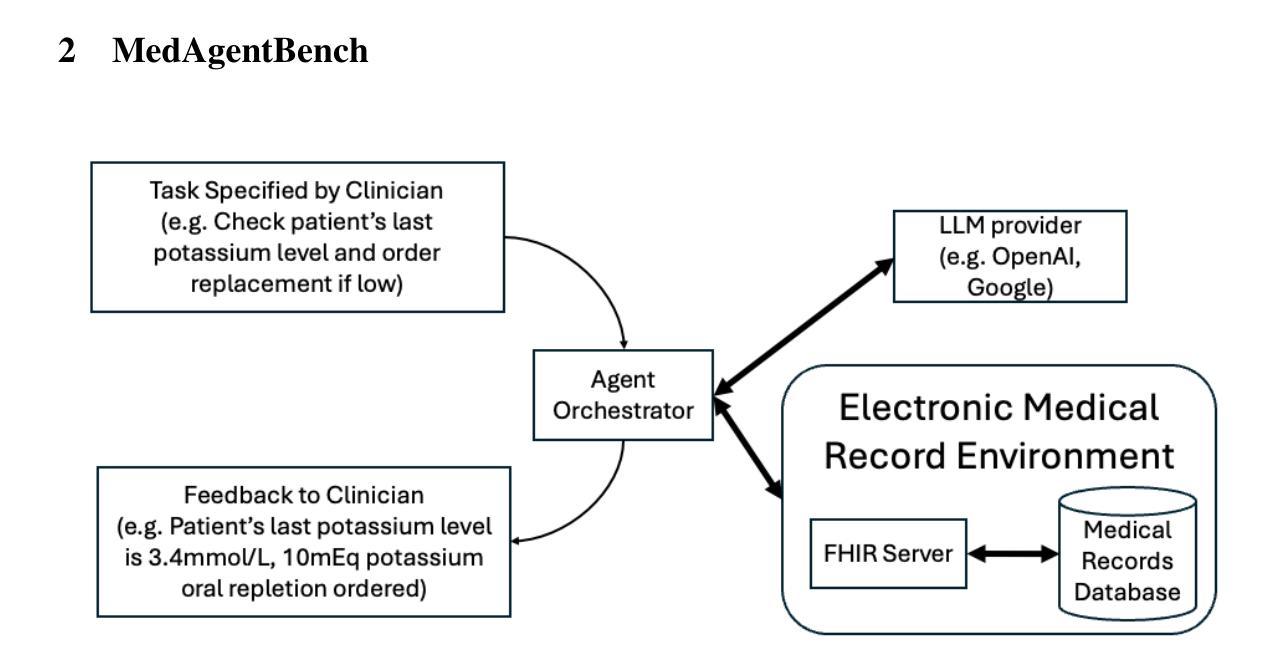
MedAgentBench: Dataset for Benchmarking LLMs as Agents in Medical Applications
Authors:Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, Andrew Y. Ng, Jonathan H. Chen
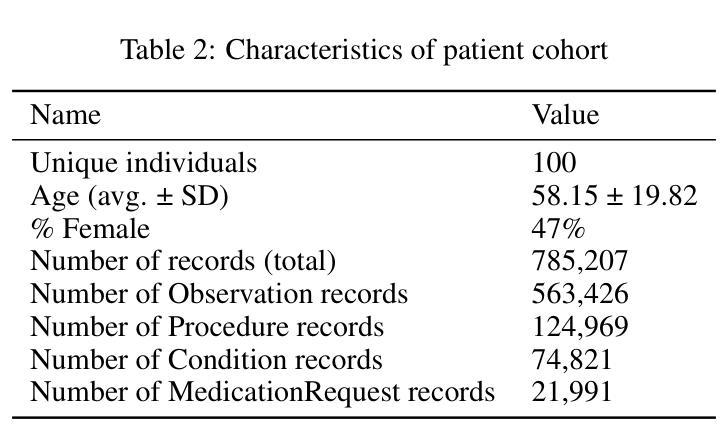
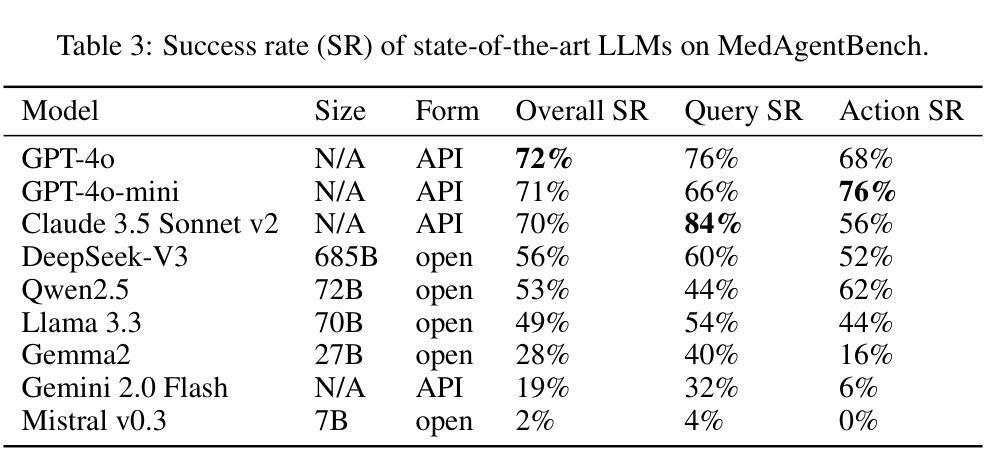
Recent large language models (LLMs) have demonstrated significant advancements, particularly in their ability to serve as agents thereby surpassing their traditional role as chatbots. These agents can leverage their planning and tool utilization capabilities to address tasks specified at a high level. However, a standardized dataset to benchmark the agent capabilities of LLMs in medical applications is currently lacking, making the evaluation of LLMs on complex tasks in interactive healthcare environments challenging. To address this gap, we introduce MedAgentBench, a broad evaluation suite designed to assess the agent capabilities of large language models within medical records contexts. MedAgentBench encompasses 100 patient-specific clinically-derived tasks from 10 categories written by human physicians, realistic profiles of 100 patients with over 700,000 data elements, a FHIR-compliant interactive environment, and an accompanying codebase. The environment uses the standard APIs and communication infrastructure used in modern EMR systems, so it can be easily migrated into live EMR systems. MedAgentBench presents an unsaturated agent-oriented benchmark that current state-of-the-art LLMs exhibit some ability to succeed at. The best model (GPT-4o) achieves a success rate of 72%. However, there is still substantial space for improvement to give the community a next direction to optimize. Furthermore, there is significant variation in performance across task categories. MedAgentBench establishes this and is publicly available at https://github.com/stanfordmlgroup/MedAgentBench , offering a valuable framework for model developers to track progress and drive continuous improvements in the agent capabilities of large language models within the medical domain.
近期的大型语言模型(LLM)已经取得了显著的进步,特别是在作为代理服务的能力方面,超越了其作为聊天机器人的传统角色。这些代理可以利用它们的规划和工具利用能力来解决高级指定的任务。然而,目前缺乏一个用于评估医疗应用中LLM代理能力的标准化数据集,这使得在交互式医疗环境中对LLM进行复杂任务评估具有挑战性。为了填补这一空白,我们引入了MedAgentBench,这是一套广泛的评估套件,旨在评估医疗记录上下文中的大型语言模型的代理能力。MedAgentBench包含由人类医生编写的10个类别中的100个患者特定临床任务、100个患者的现实状况概况(包含超过700万数据元素)、符合FHIR标准的交互式环境以及相应的代码库。该环境使用现代电子病历系统中的标准API和通信基础设施,因此可以轻松迁移到实时电子病历系统中。MedAgentBench呈现了一个未饱和的面向代理的基准测试,当前最先进的技术大型语言模型已经展现出了一些成功的迹象。最好的模型(GPT-4o)成功率为72%。然而,仍有很大的改进空间,为社区提供了下一个优化方向。此外,不同任务类别的性能存在显著差异。MedAgentBench对此进行了建立,并可在https://github.com/stanfordmlgroup/MedAgentBench上公开访问,为模型开发者提供了一个宝贵的框架,以跟踪进度并推动医疗领域内大型语言模型代理能力的持续改进。
论文及项目相关链接
摘要
大型语言模型(LLM)的最新进展,特别是在作为代理人的能力方面,已经超越了其作为聊天机器人的传统角色。然而,在医疗应用方面,缺乏一个标准化的数据集来评估LLM作为代理人的能力,这使得在交互式医疗环境中对LLM进行复杂任务的评估具有挑战性。为解决这一空白,我们推出了MedAgentBench,这是一个广泛的评估套件,旨在评估大型语言模型在医疗记录上下文中的代理能力。MedAgentBench包含由人类医生编写的100个特定患者的临床任务、100个患者的现实档案以及超过700万数据元素、符合FHIR标准的交互式环境以及相应的代码库。该环境使用现代EMR系统常用的API和通信基础设施,因此可以轻松地迁移到实时EMR系统中。MedAgentBench提供了一个未饱和的以代理为导向的基准测试,当前最先进的LLM在一定程度上能够成功完成任务。最佳模型(GPT-4o)的成功率为72%,但仍有很大的改进空间。此外,不同任务类别的性能存在显著差异。MedAgentBench对此进行了阐述,并可在https://github.com/stanfordmlgroup/MedAgentBench公开访问,为模型开发者提供了一个宝贵的框架,以跟踪进度并推动大型语言模型在医疗领域内代理人能力的持续改进。
关键见解
- 大型语言模型(LLMs)在医疗应用方面的代理能力评估存在挑战,因为缺乏标准化的数据集。
- MedAgentBench填补了这一空白,提供了一个广泛的评估套件,用于评估LLMs在医疗记录上下文中的代理能力。
- MedAgentBench包含100个由人类医生编写的特定临床任务,以及包含超过70万数据元素的模拟患者档案。
- 该环境采用FHIR标准,易于集成到现有的电子医疗记录(EMR)系统中。
- 当前最先进的LLM在MedAgentBench的测试中表现出一定的成功,但仍有很大的改进空间。
- 最佳模型GPT-4o的成功率为72%。
点此查看论文截图


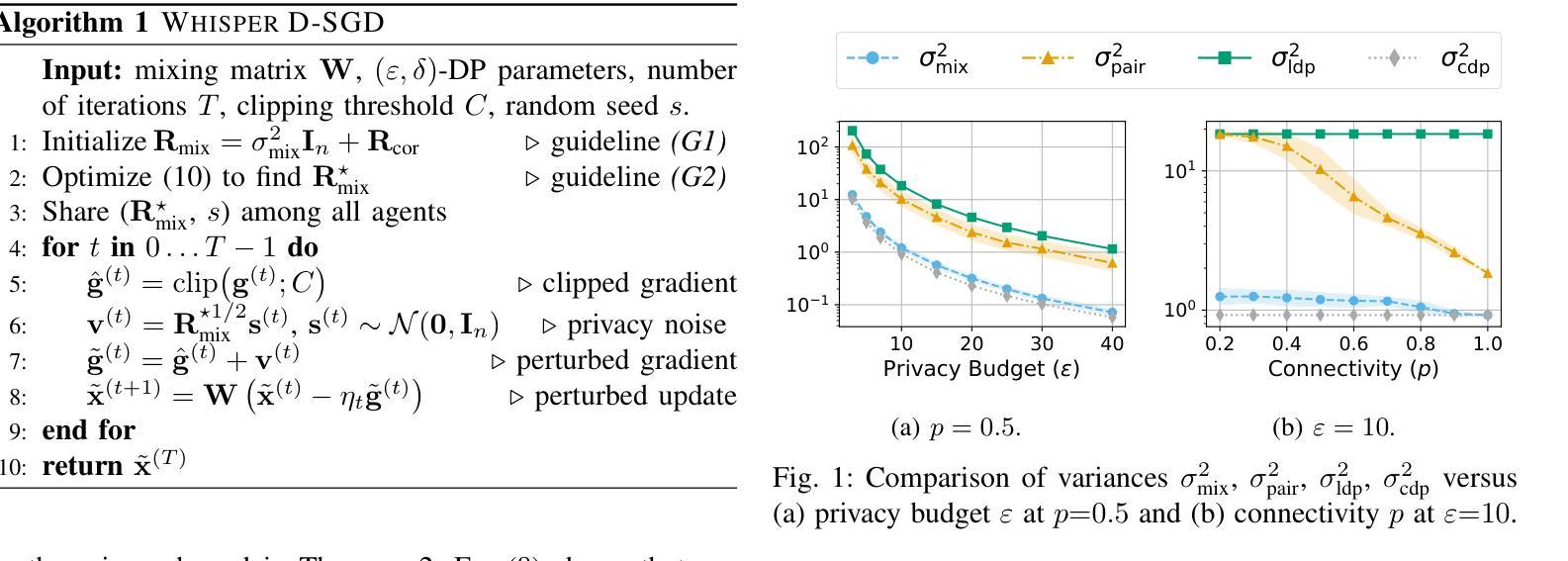
Whisper D-SGD: Correlated Noise Across Agents for Differentially Private Decentralized Learning
Authors:Angelo Rodio, Zheng Chen, Erik G. Larsson
Decentralized learning enables distributed agents to train a shared machine learning model through local computation and peer-to-peer communication. Although each agent retains its dataset locally, the communication of local models can still expose private information to adversaries. To mitigate these threats, local differential privacy (LDP) injects independent noise per agent, but it suffers a larger utility gap than central differential privacy (CDP). We introduce Whisper D-SGD, a novel covariance-based approach that generates correlated privacy noise across agents, unifying several state-of-the-art methods as special cases. By leveraging network topology and mixing weights, Whisper D-SGD optimizes the noise covariance to achieve network-wide noise cancellation. Experimental results show that Whisper D-SGD cancels more noise than existing pairwise-correlation schemes, substantially narrowing the CDP-LDP gap and improving model performance under the same privacy guarantees.
去中心化学习允许分布式代理通过本地计算和点对点通信来训练共享机器学习模型。尽管每个代理保留其本地数据集,但本地模型的通信仍然可能向对手暴露私有信息。为了减轻这些威胁,本地差分隐私(LDP)为每个代理注入独立噪声,但其效用差距比中央差分隐私(CDP)更大。我们引入了Whisper D-SGD,这是一种基于协方差的新方法,它会在代理之间生成相关的隐私噪声,将多种最新方法统一为特殊情况。通过利用网络拓扑和混合权重,Whisper D-SGD优化噪声协方差以实现全网噪声消除。实验结果表明,与现有的配对关联方案相比,Whisper D-SGD能够消除更多噪声,大幅缩小CDP-LDP差距,并在相同的隐私保证下提高模型性能。
论文及项目相关链接
PDF 6 pages, 3 figures, preprint
Summary
分布式学习允许通过本地计算和点对点通信训练共享机器学习模型。尽管每个代理都保留本地数据集,但本地模型的通信仍然可能向对手暴露私有信息。为了缓解这些威胁,本地差分隐私为每个代理注入独立噪声,但其效用差距较大。本文提出了基于协方差的新方法Whisper D-SGD,可在各代理之间生成相关隐私噪声,统一了多种最新方法作为特例。通过利用网络拓扑和混合权重,Whisper D-SGD优化噪声协方差以实现全网络噪声消除。实验结果表明,Whisper D-SGD相较于现有的配对相关方案能消除更多噪声,大幅缩小CDP与LDP之间的差距,并在相同的隐私保证下提高模型性能。
Key Takeaways
- 分布式学习允许通过本地计算和点对点通信训练共享机器学习模型。
- 本地模型的通信可能暴露私有信息,引发安全隐患。
- 本地差分隐私为每个代理注入独立噪声,但其效用与中央差分隐私相比存在差距。
- Whisper D-SGD是一种基于协方差的新方法,能在各代理间生成相关隐私噪声。
- Whisper D-SGD统一了多种最新方法,并利用网络拓扑和混合权重优化噪声协方差。
- Whisper D-SGD能实现全网络噪声消除,相较于现有方法能消除更多噪声。
点此查看论文截图

MARL-OT: Multi-Agent Reinforcement Learning Guided Online Fuzzing to Detect Safety Violation in Autonomous Driving Systems
Authors:Linfeng Liang, Xi Zheng
Autonomous Driving Systems (ADSs) are safety-critical, as real-world safety violations can result in significant losses. Rigorous testing is essential before deployment, with simulation testing playing a key role. However, ADSs are typically complex, consisting of multiple modules such as perception and planning, or well-trained end-to-end autonomous driving systems. Offline methods, such as the Genetic Algorithm (GA), can only generate predefined trajectories for dynamics, which struggle to cause safety violations for ADSs rapidly and efficiently in different scenarios due to their evolutionary nature. Online methods, such as single-agent reinforcement learning (RL), can quickly adjust the dynamics’ trajectory online to adapt to different scenarios, but they struggle to capture complex corner cases of ADS arising from the intricate interplay among multiple vehicles. Multi-agent reinforcement learning (MARL) has a strong ability in cooperative tasks. On the other hand, it faces its own challenges, particularly with convergence. This paper introduces MARL-OT, a scalable framework that leverages MARL to detect safety violations of ADS resulting from surrounding vehicles’ cooperation. MARL-OT employs MARL for high-level guidance, triggering various dangerous scenarios for the rule-based online fuzzer to explore potential safety violations of ADS, thereby generating dynamic, realistic safety violation scenarios. Our approach improves the detected safety violation rate by up to 136.2% compared to the state-of-the-art (SOTA) testing technique.
自动驾驶系统(ADS)对安全性要求极高,因为现实世界中的安全违规可能导致重大损失。在部署之前,必须进行严格测试,模拟测试扮演关键角色。然而,ADS通常很复杂,包括感知、规划等多个模块,或者经过良好训练的端到端自动驾驶系统。离线方法,如遗传算法(GA),只能为动力学生成预设轨迹,由于其进化性质,它们在不同场景下快速有效地导致ADS安全违规方面存在困难。在线方法,如单智能体强化学习(RL),可以迅速在线调整动力轨迹以适应不同场景,但它们难以捕捉由多辆车之间复杂相互作用产生的ADS复杂边缘情况。多智能体强化学习(MARL)在合作任务方面具有很强的能力。另一方面,它面临着自己的挑战,尤其是收敛问题。本文介绍了MARL-OT,一个可利用MARL检测由周围车辆合作导致的ADS安全违规的可扩展框架。MARL-OT利用MARL进行高级指导,触发各种危险场景,为基于规则的在线模糊测试探索ADS的潜在安全违规情况,从而生成动态、现实的安全违规场景。我们的方法相较于最新的测试技术,提高了高达136.2%的安全违规检测率。
论文及项目相关链接
Summary
本文介绍了自动驾驶系统(ADS)的安全测试问题。由于真实世界中的安全违规可能导致重大损失,因此需要在部署前进行严格的测试,其中模拟测试是关键。文章提出一种基于多智能体强化学习(MARL)的框架MARL-OT,用于检测周围车辆合作导致的ADS安全违规。该框架利用MARL进行高级指导,触发各种危险场景,基于规则的在线模糊测试器探索潜在的ADS安全违规,生成动态和真实的违规场景。该方法与现有先进技术相比,可提高检测到违规的速率最多达136.2%。
Key Takeaways
- 自动驾驶系统(ADS)的安全测试至关重要,因为真实世界中的安全违规会导致重大损失。
- 模拟测试在ADS测试阶段扮演重要角色。
- 现有的离线方法如遗传算法(GA)在生成动态轨迹时存在局限性,难以快速有效地在多种场景下导致安全违规。
- 单智能体强化学习(RL)虽然能迅速调整动力学轨迹以适应不同场景,但在捕捉ADS复杂场景中的细微问题方面存在挑战。
- 多智能体强化学习(MARL)具有处理合作任务的能力,但面临收敛的挑战。
- 本文提出的MARL-OT框架利用MARL检测由周围车辆合作引起的ADS安全违规。它通过触发各种危险场景并利用基于规则的在线模糊测试器来探索潜在的安全违规,生成动态和真实的违规场景。
点此查看论文截图

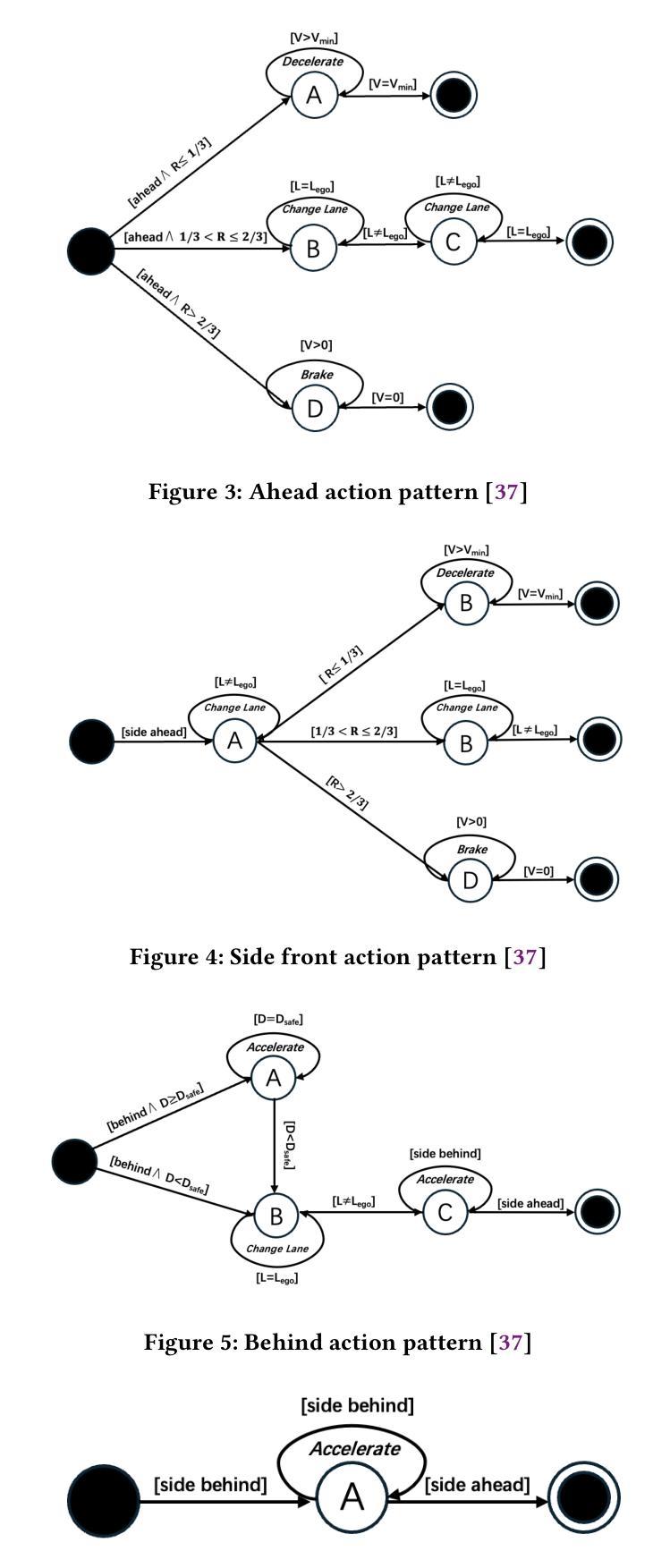


Learning more with the same effort: how randomization improves the robustness of a robotic deep reinforcement learning agent
Authors:Lucía Güitta-López, Jaime Boal, Álvaro J. López-López
The industrial application of Deep Reinforcement Learning (DRL) is frequently slowed down because of the inability to generate the experience required to train the models. Collecting data often involves considerable time and economic effort that is unaffordable in most cases. Fortunately, devices like robots can be trained with synthetic experience thanks to virtual environments. With this approach, the sample efficiency problems of artificial agents are mitigated, but another issue arises: the need for efficiently transferring the synthetic experience into the real world (sim-to-real). This paper analyzes the robustness of a state-of-the-art sim-to-real technique known as progressive neural networks (PNNs) and studies how adding diversity to the synthetic experience can complement it. To better understand the drivers that lead to a lack of robustness, the robotic agent is still tested in a virtual environment to ensure total control on the divergence between the simulated and real models. The results show that a PNN-like agent exhibits a substantial decrease in its robustness at the beginning of the real training phase. Randomizing certain variables during simulation-based training significantly mitigates this issue. On average, the increase in the model’s accuracy is around 25% when diversity is introduced in the training process. This improvement can be translated into a decrease in the required real experience for the same final robustness performance. Notwithstanding, adding real experience to agents should still be beneficial regardless of the quality of the virtual experience fed into the agent.
深度强化学习(DRL)在工业应用中的速度经常因为无法生成训练模型所需的经验而减慢。收集数据通常涉及大量的时间和经济上的努力,这在大多数情况下都是无法承受的。幸运的是,由于虚拟环境,机器人等设备可以用合成经验来进行训练。这种方法缓解了人工代理的样本效率问题,但另一个问题出现了:需要将合成经验有效地转移到现实世界(模拟到现实)。本文分析了最先进的模拟到现实技术——渐进神经网络(PNNs)的稳健性,并研究了如何为合成经验增加多样性来加以补充。为了更好地了解导致稳健性不足的因素,机器人代理仍在虚拟环境中进行测试,以确保对模拟和真实模型之间的分歧进行完全控制。结果表明,在真实训练阶段开始时,像PNN这样的代理的稳健性出现了大幅下降。在基于模拟的训练过程中随机化某些变量可以显著缓解这个问题。引入训练过程多样性后,模型的准确度平均提高了约25%。这种改进可以转化为减少达到相同最终稳健性性能所需的实际经验。尽管如此,向代理人增加实际经验仍然是有益的,无论提供给代理人的虚拟体验的质量如何。
论文及项目相关链接
PDF This article was accepted and published in Applied Intelligence (10.1007/s10489-022-04227-3)
Summary
深度学习强化学习在工业应用中的一大挑战是经验生成不足,导致模型训练受阻。为解决这一问题,研究者利用虚拟环境训练机器人等设备,通过合成经验来提升样本效率。然而,新的问题在于如何将合成经验有效地转移到真实世界(即sim-to-real转移)。本文分析了基于神经网络进行sim-to-real转移的前沿技术的稳健性,并探讨了如何通过增加合成经验的多样性来补充该技术。实验结果显示,在真实训练阶段初期,基于PNN的代理的稳健性大幅降低,但通过模拟训练过程中的变量随机化可显著缓解这一问题。引入多样性后,模型的平均准确率提高了约25%,即减少了达到相同稳健性所需的实际经验。尽管如此,不论虚拟经验的质量如何,向代理提供实际经验依然是有益的。
Key Takeaways
- DRL在工业应用中的一大挑战是生成足够的经验以训练模型,这通常涉及时间和经济成本。
- 虚拟环境可用于训练机器人等设备以生成合成经验,提高样本效率。
- sim-to-real转移是将虚拟经验应用于真实世界的难题。
- PNN技术在sim-to-real转移中有重要作用,但其稳健性需要关注。
- 在模拟训练过程中增加变量随机化有助于提高模型的稳健性。
- 增加合成经验的多样性可以提高模型准确率约25%,并减少达到相同稳健性所需的实际经验。
点此查看论文截图

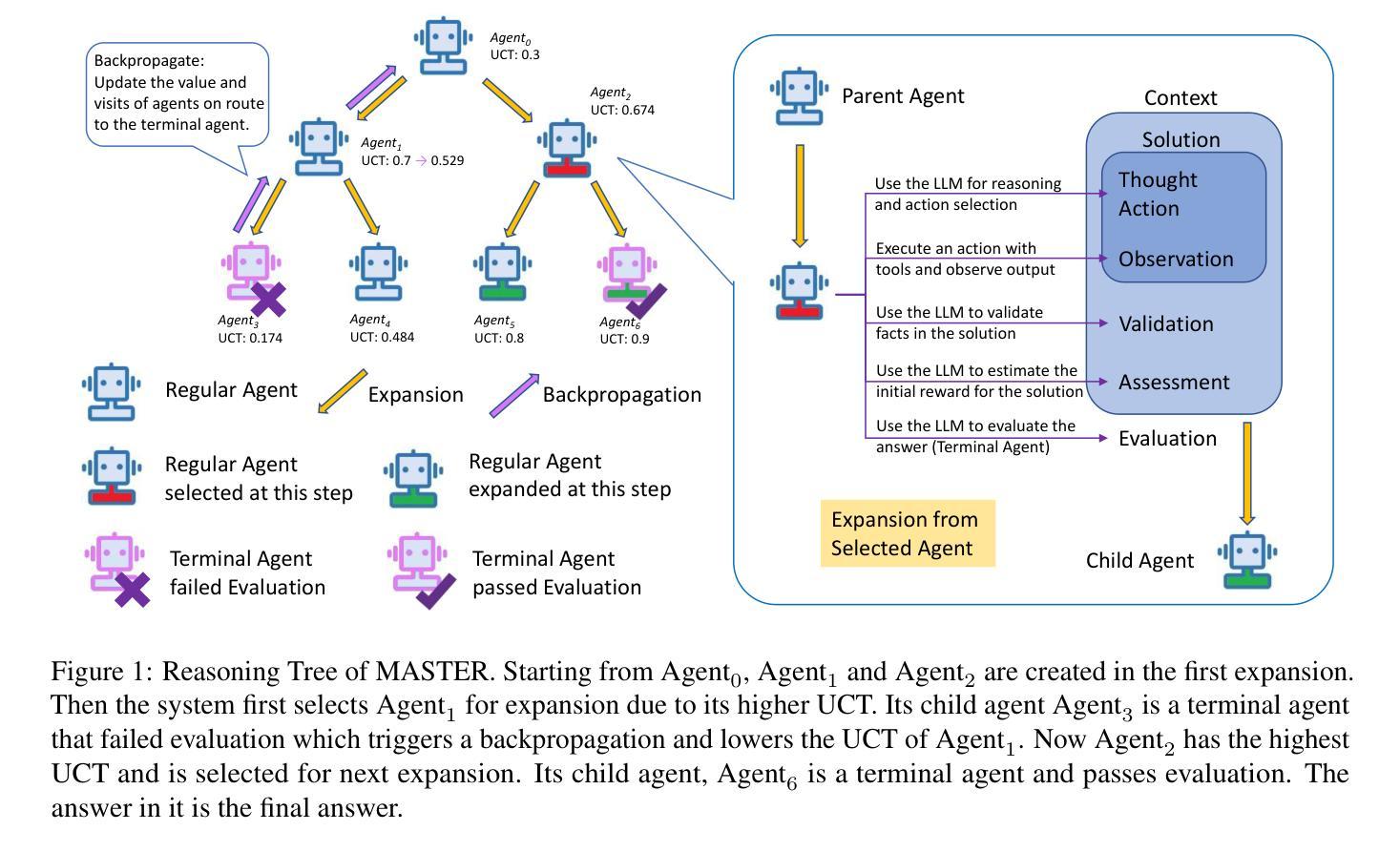
MASTER: A Multi-Agent System with LLM Specialized MCTS
Authors:Bingzheng Gan, Yufan Zhao, Tianyi Zhang, Jing Huang, Yusu Li, Shu Xian Teo, Changwang Zhang, Wei Shi
Large Language Models (LLM) are increasingly being explored for problem-solving tasks. However, their strategic planning capability is often viewed with skepticism. Recent studies have incorporated the Monte Carlo Tree Search (MCTS) algorithm to augment the planning capacity of LLM. Despite its potential, MCTS relies on extensive sampling simulations to approximate the true reward distribution, leading to two primary issues. Firstly, MCTS is effective for tasks like the Game of Go, where simulation results can yield objective rewards (e.g., 1 for a win and 0 for a loss). However, for tasks such as question answering, the result of a simulation is the answer to the question, which cannot obtain an objective reward without the ground truth. Secondly, obtaining statistically significant reward estimations typically requires a sample size exceeding 30 simulations, resulting in excessive token usage and time consumption. To address these challenges, we present Multi-Agent System with Tactical Execution and Reasoning using LLM Specialized MCTS (MASTER), a novel framework that coordinates agent recruitment and communication using LLM specialized MCTS. This system autonomously adjusts the number of agents based on task complexity and ensures focused communication among them. Comprehensive experiments across various tasks demonstrate the effectiveness of our proposed framework. It achieves 76% accuracy on HotpotQA and 80% on WebShop, setting new state-of-the-art performance on these datasets.
大型语言模型(LLM)越来越多地被用于问题解决任务。然而,它们的战略规划能力通常受到怀疑。最近的研究已经采用了蒙特卡洛树搜索(MCTS)算法来提高LLM的规划能力。尽管潜力巨大,但MCTS依赖于大量的采样模拟来近似真实的奖励分布,这导致了两个主要问题。首先,MCTS对于像围棋这样的任务非常有效,模拟结果可以产生客观奖励(例如,胜利得1分,失败得0分)。然而,对于问答等任务,模拟的结果就是问题的答案,如果没有标准答案,就无法获得客观奖励。其次,要获得具有统计意义的奖励估计,通常需要样本量超过30次模拟,这导致令牌使用过多和时间消耗过多。为了解决这些挑战,我们提出了使用LLM专用MCTS的多智能体系统战术执行与推理(MASTER),这是一个新的框架,它使用LLM专用MCTS协调智能体的招募和通信。该系统根据任务复杂度自主调整智能体的数量,确保它们之间的专注通信。在不同任务上的综合实验证明了我们的框架的有效性。在HotpotQA和数据集上,它达到了76%的准确率,在WebShop上达到了80%,在这些数据集上创下了最新技术性能记录。
论文及项目相关链接
PDF Accepted by main NAACL 2025
Summary:
大型语言模型(LLM)与蒙特卡洛树搜索(MCTS)结合用于问题解决的战略规划,解决了MCTS在模拟仿真中的问题,提出多智能体系统战术执行与推理框架MASTER,通过调整智能体数量和加强智能体间的沟通来提高任务效率,实验证明其在多个任务上取得了显著效果。
Key Takeaways:
- 大型语言模型(LLM)被用于问题解决的战略规划,但其能力常受怀疑。
- 蒙特卡洛树搜索(MCTS)算法被用来增强LLM的规划能力。
- MCTS面临两个问题:一是在无客观奖励的任务(如问答)中难以应用;二是需要大量模拟样本,导致令牌使用过度和时间消耗。
- 提出的MASTER框架利用LLM专业MCTS进行多智能体协调和沟通。
- MASTER能根据任务复杂度自主调整智能体数量。
- MASTER在HotpotQA和WebShop等多个数据集上达到了最新的最好表现。
点此查看论文截图

Distributed Multi-Agent Coordination Using Multi-Modal Foundation Models
Authors:Saaduddin Mahmud, Dorian Benhamou Goldfajn, Shlomo Zilberstein
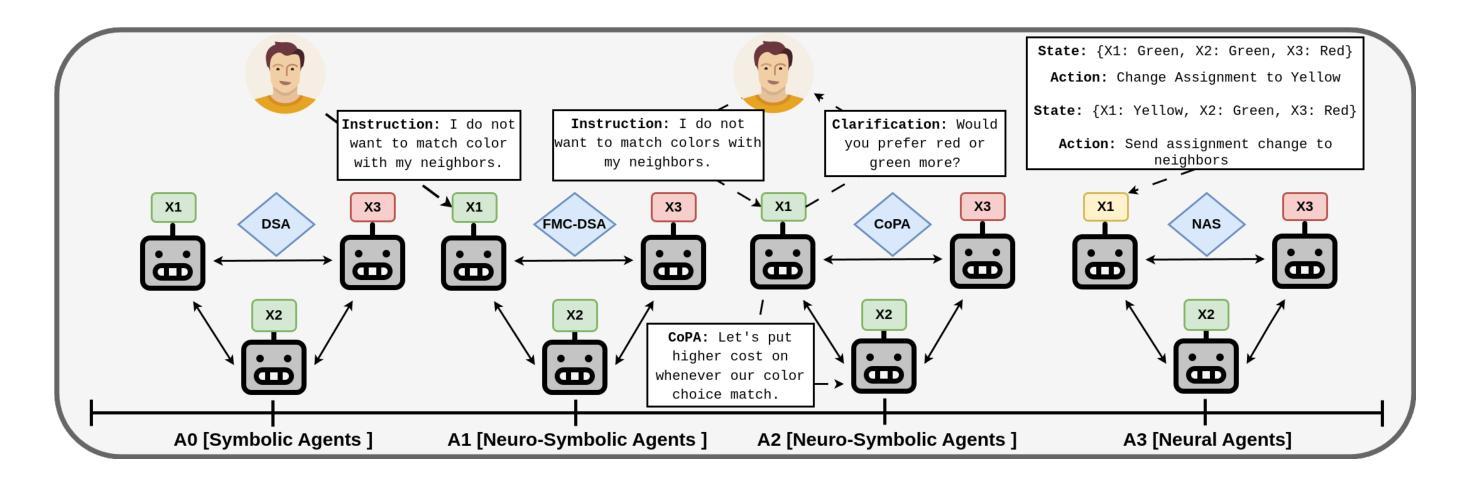
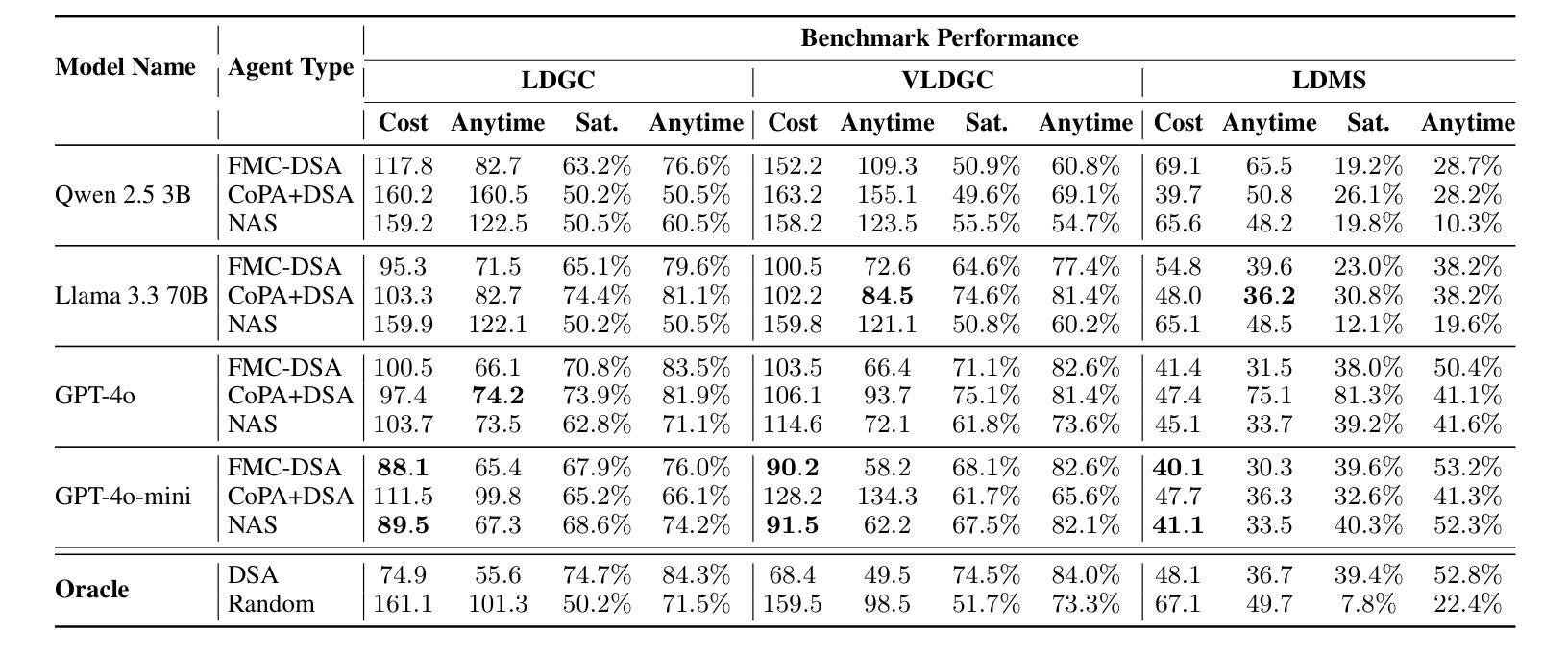
Distributed Constraint Optimization Problems (DCOPs) offer a powerful framework for multi-agent coordination but often rely on labor-intensive, manual problem construction. To address this, we introduce VL-DCOPs, a framework that takes advantage of large multimodal foundation models (LFMs) to automatically generate constraints from both visual and linguistic instructions. We then introduce a spectrum of agent archetypes for solving VL-DCOPs: from a neuro-symbolic agent that delegates some of the algorithmic decisions to an LFM, to a fully neural agent that depends entirely on an LFM for coordination. We evaluate these agent archetypes using state-of-the-art LLMs (large language models) and VLMs (vision language models) on three novel VL-DCOP tasks and compare their respective advantages and drawbacks. Lastly, we discuss how this work extends to broader frontier challenges in the DCOP literature.
分布式约束优化问题(DCOPs)为多智能体协调提供了一个强大的框架,但通常依赖于劳动密集型的手动问题构建。为解决这一问题,我们引入了VL-DCOPs框架,该框架利用大型多模态基础模型(LFMs)自动从视觉和语言指令生成约束。然后,我们介绍了一系列解决VL-DCOPs的智能体原型:从将部分算法决策委托给LFM的神经符号智能体,到完全依赖于LFM进行协调的完全神经智能体。我们使用最先进的LLM(大型语言模型)和VLM(视觉语言模型)对这三种新型的VL-DCOP任务进行了评估,并比较了各自的优势和劣势。最后,我们讨论了这项工作如何扩展到DCOP文献中的更广泛的前沿挑战。
论文及项目相关链接
Summary
基于多智能体协调的强大框架分布式约束优化问题(DCOPs)通常需要繁琐的手动问题构建。为解决此问题,我们推出VL-DCOPs框架,利用大型多模态基础模型(LFMs)自动从视觉和语言学指令生成约束。接着,我们引入一系列解决VL-DCOPs的智能体原型,从部分决策交由LFM的神经符号智能体,到完全依赖LFM进行协调的全神经智能体。我们在三项全新的VL-DCOP任务上,使用先进的大型语言模型(LLMs)和视觉语言模型(VLMs)对智能体原型进行评估,并比较其优缺点。最后,我们探讨了这项工作在DCOP文献中的更广泛前沿挑战。
Key Takeaways
- VL-DCOPs框架通过利用大型多模态基础模型(LFMs)自动从视觉和语言学指令生成约束,解决了分布式约束优化问题(DCOPs)中手动问题构建繁琐的问题。
- 引入了一系列解决VL-DCOPs的智能体原型,包括神经符号智能体和全神经智能体。
- 在三项全新的VL-DCOP任务上,使用先进的大型语言模型(LLMs)和视觉语言模型(VLMs)对智能体原型进行了评估。
- 发现不同智能体原型具有不同的优缺点,可根据任务需求进行选择。
- VL-DCOPs框架具有广泛的应用前景,可扩展到更广泛的DCOP领域的前沿挑战。
- 此研究为智能体之间的协调提供了一种新的思路和方法,有助于提高智能体的自主性、灵活性和协同性。
点此查看论文截图




AI Chatbots as Professional Service Agents: Developing a Professional Identity
Authors:Wenwen Li, Kangwei Shi, Yidong Chai
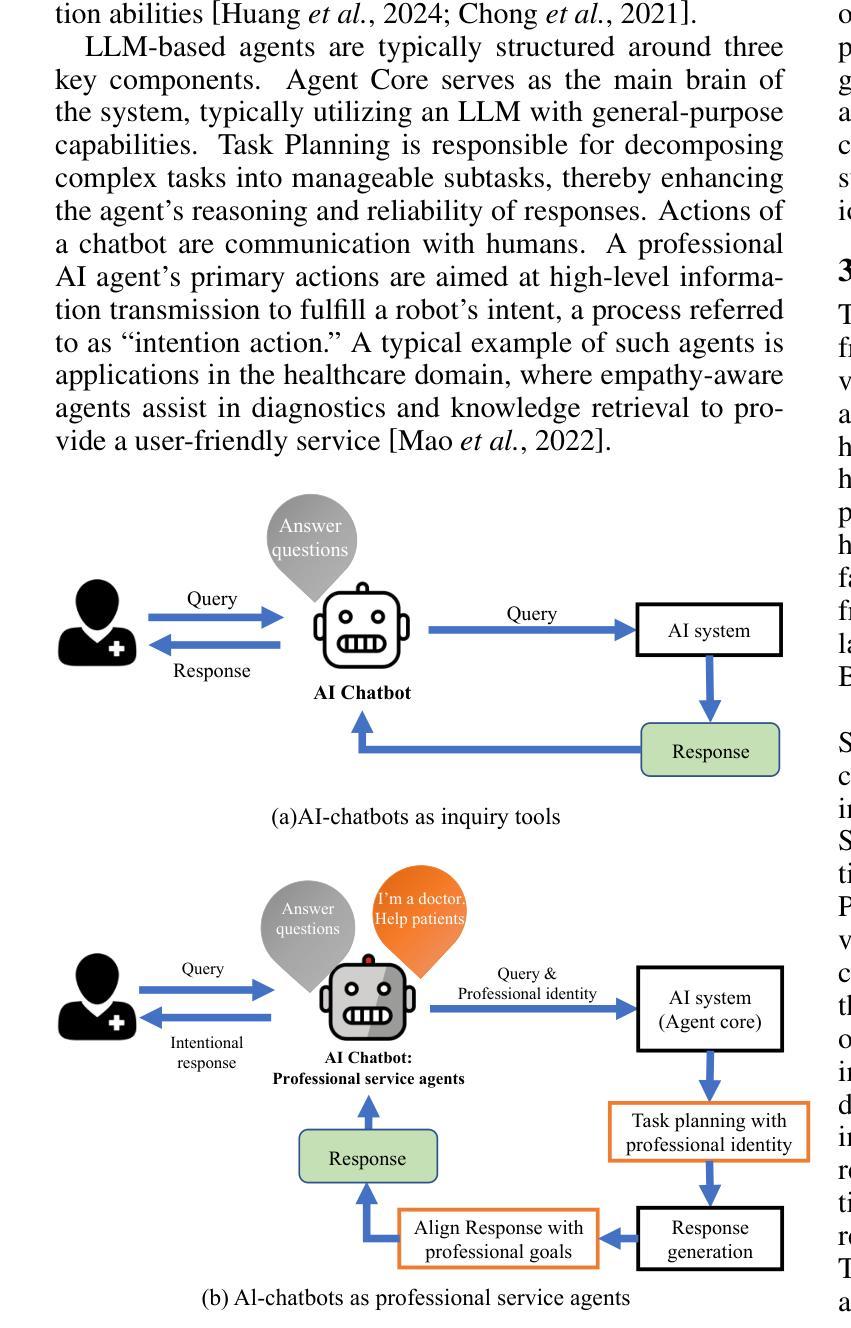
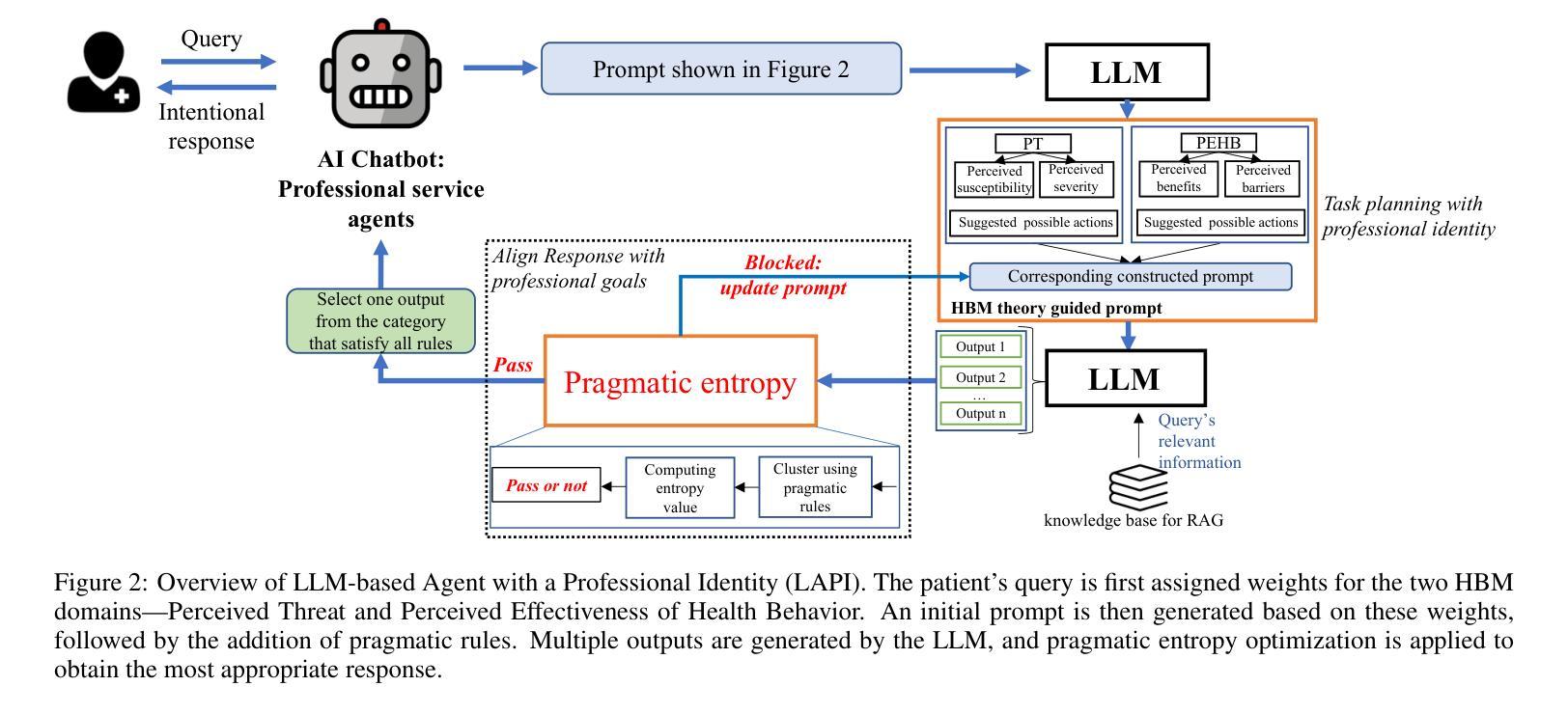
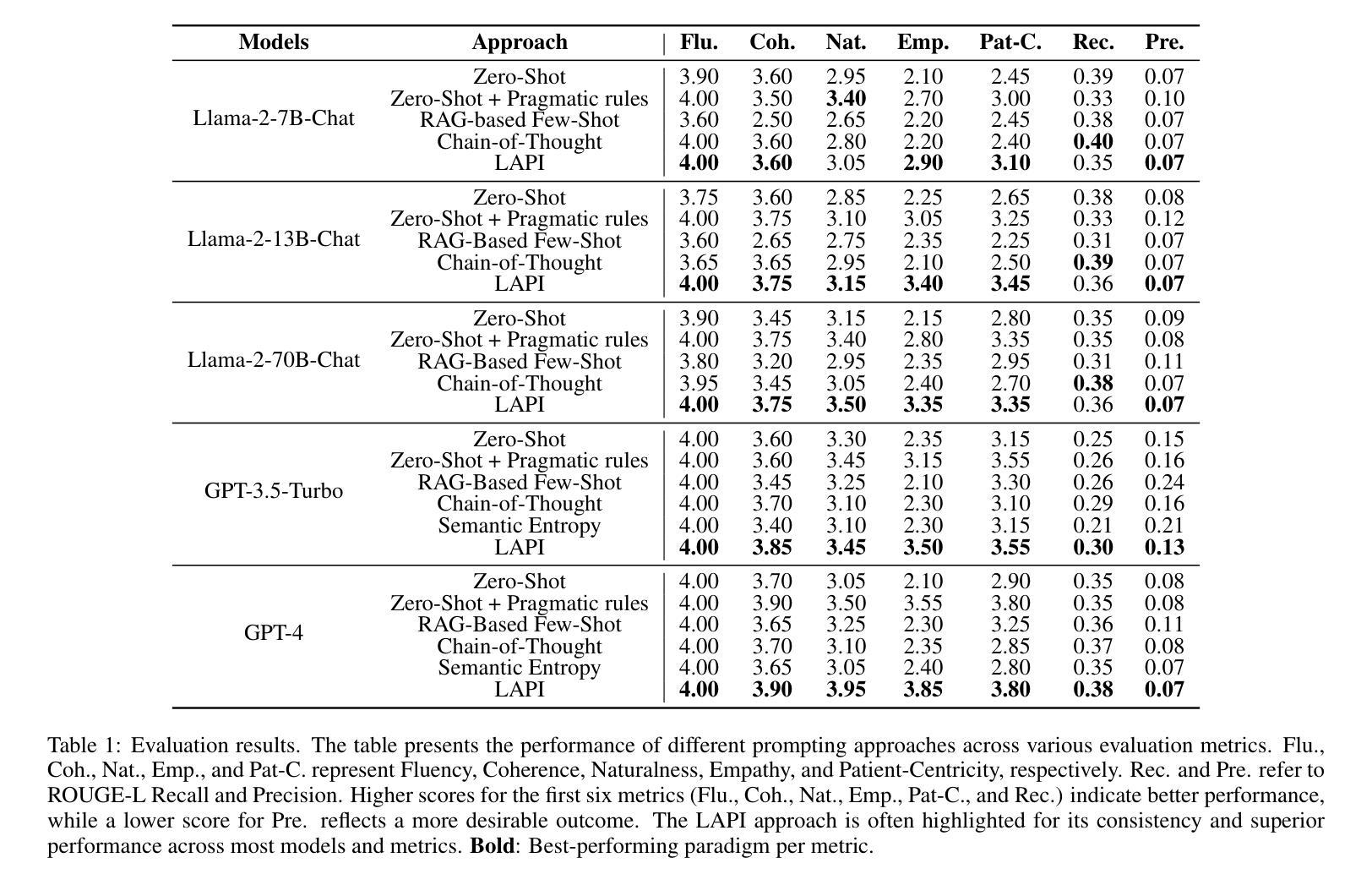
With the rapid expansion of large language model (LLM) applications, there is an emerging shift in the role of LLM-based AI chatbots from serving merely as general inquiry tools to acting as professional service agents. However, current studies often overlook a critical aspect of professional service agents: the act of communicating in a manner consistent with their professional identities. This is of particular importance in the healthcare sector, where effective communication with patients is essential for achieving professional goals, such as promoting patient well-being by encouraging healthy behaviors. To bridge this gap, we propose LAPI (LLM-based Agent with a Professional Identity), a novel framework for designing professional service agent tailored for medical question-and-answer (Q&A) services, ensuring alignment with a specific professional identity. Our method includes a theory-guided task planning process that decomposes complex professional tasks into manageable subtasks aligned with professional objectives and a pragmatic entropy method designed to generate professional and ethical responses with low uncertainty. Experiments on various LLMs show that the proposed approach outperforms baseline methods, including few-shot prompting, chain-of-thought prompting, across key metrics such as fluency, naturalness, empathy, patient-centricity, and ROUGE-L scores. Additionally, the ablation study underscores the contribution of each component to the overall effectiveness of the approach.
随着大型语言模型(LLM)应用的迅速扩展,基于LLM的AI聊天机器人角色也正在发生转变,从仅作为一般查询工具转变为充当专业服务代理。然而,目前的研究往往忽视专业服务代理的一个关键方面:以符合其专业身份的方式进行交流的行为。在医疗保健领域,这尤为重要。与患者进行有效沟通对于实现专业目标至关重要,例如通过鼓励健康行为来促进患者的健康。为了弥补这一差距,我们提出了LAPI(具有专业身份的LLM代理)这一新型框架,该框架专门设计用于医疗服务问答服务,确保与专业身份相符。我们的方法包括一个理论引导的任务规划过程,它将复杂的专业任务分解成与职业目标相符的可管理子任务,以及一种实用熵方法,旨在生成专业且符合道德的响应,不确定性较低。在各种LLM上的实验表明,所提出的方法优于基线方法,包括少提示、思维链提示等方法,在流畅度、自然度、同理心、以患者为中心以及ROUGE-L分数等关键指标上都有较好的表现。此外,消融研究强调了每个组件对整体方法效果的贡献。
论文及项目相关链接
Summary
大型语言模型(LLM)应用迅速扩展,AI聊天机器人角色逐渐从通用查询工具转变为专业服务代理。然而,现有研究往往忽视了专业服务代理的一个重要方面:以专业身份进行一致性的沟通。特别是在医疗保健领域,与患者进行有效沟通对实现专业目标至关重要。为弥补这一空白,我们提出了LAPI(具有专业身份的大型语言模型代理)框架,该框架旨在为医疗问答服务定制专业服务代理,确保其符合特定的专业身份。通过实验验证,该框架在流畅度、自然度、共情、患者为中心等方面优于基准方法。
Key Takeaways
- 大型语言模型(LLM)的应用正在推动AI聊天机器人从通用查询工具向专业服务代理转变。
- 当前研究忽视了专业服务代理在沟通中保持专业身份一致性的重要性。
- 在医疗保健领域,与患者有效沟通是实现专业目标的关键。
- LAPI框架旨在定制符合特定专业身份的医疗问答服务代理。
- LAPI框架通过理论引导的任务规划过程将复杂的专业任务分解为可管理的子任务。
- 框架采用语用熵方法生成专业且确定的回应。
点此查看论文截图



Argos: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
Authors:Yile Gu, Yifan Xiong, Jonathan Mace, Yuting Jiang, Yigong Hu, Baris Kasikci, Peng Cheng
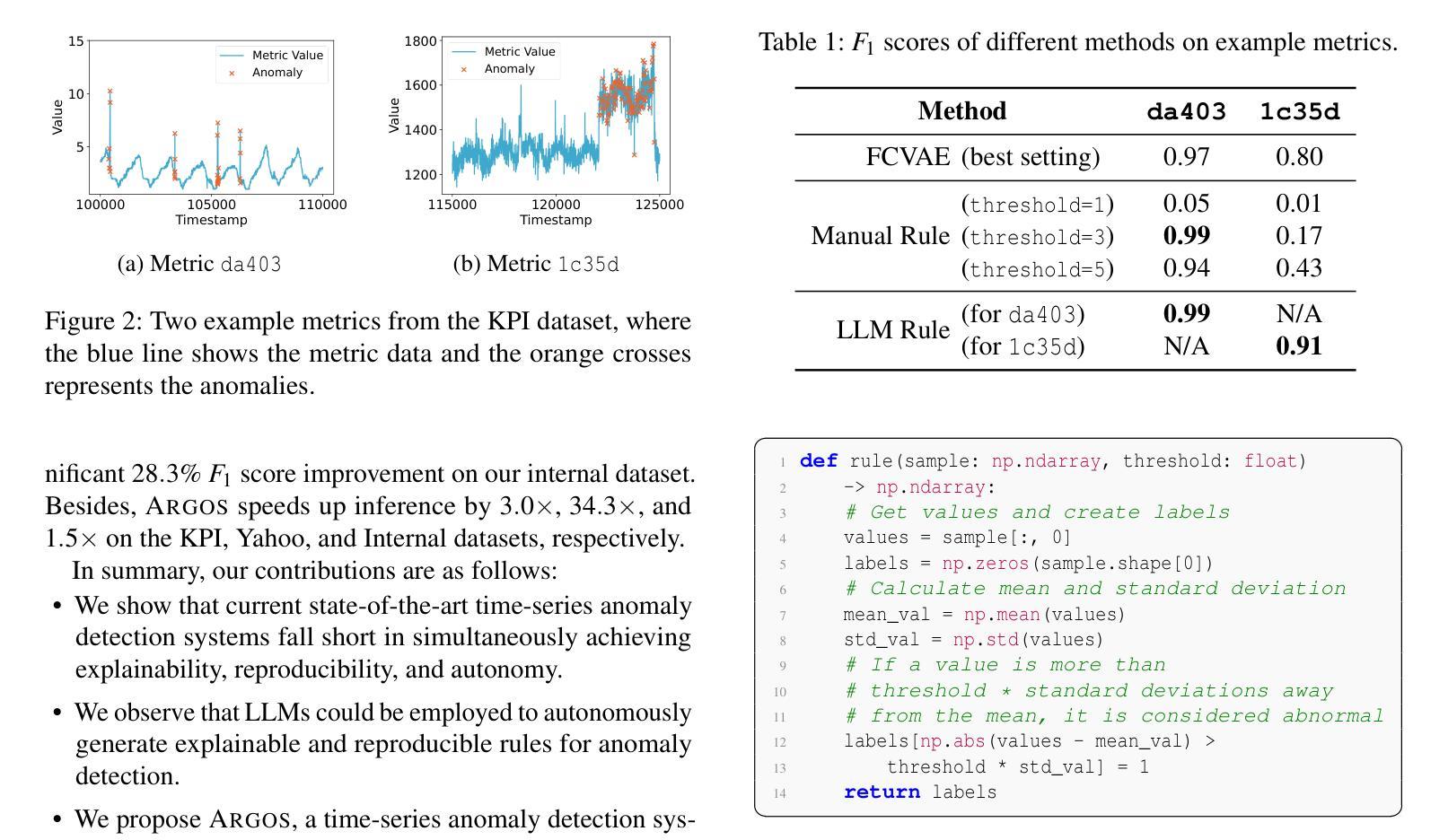
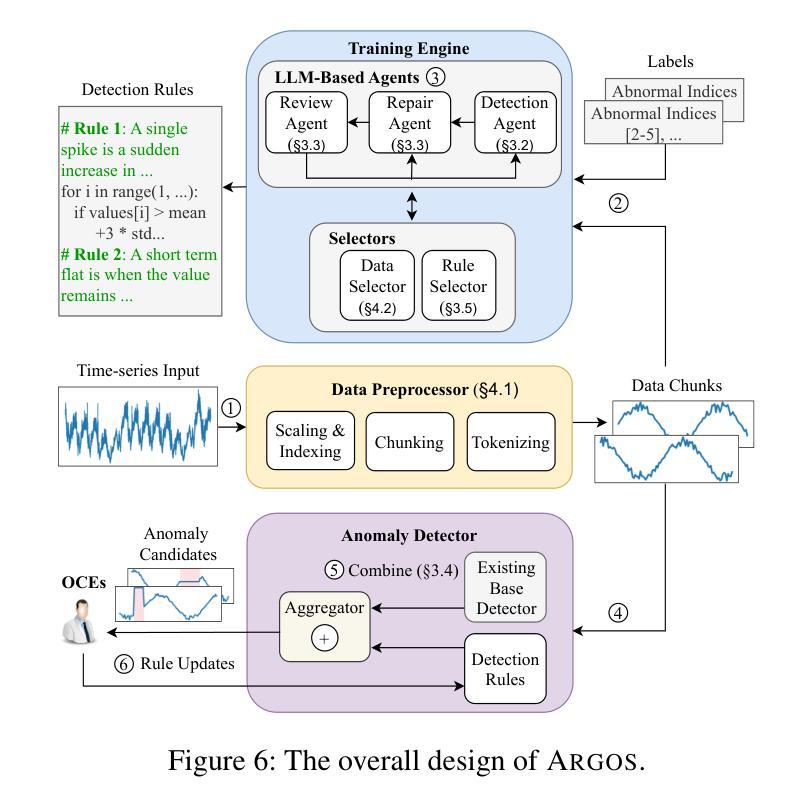
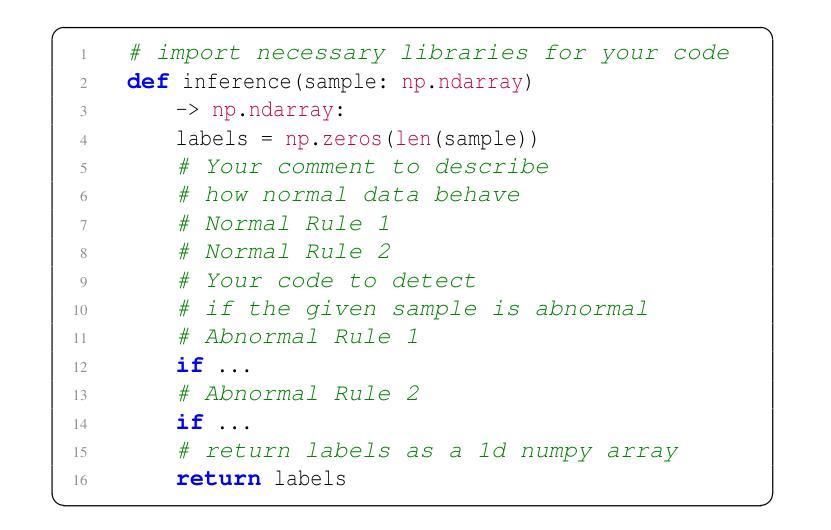
Observability in cloud infrastructure is critical for service providers, driving the widespread adoption of anomaly detection systems for monitoring metrics. However, existing systems often struggle to simultaneously achieve explainability, reproducibility, and autonomy, which are three indispensable properties for production use. We introduce Argos, an agentic system for detecting time-series anomalies in cloud infrastructure by leveraging large language models (LLMs). Argos proposes to use explainable and reproducible anomaly rules as intermediate representation and employs LLMs to autonomously generate such rules. The system will efficiently train error-free and accuracy-guaranteed anomaly rules through multiple collaborative agents and deploy the trained rules for low-cost online anomaly detection. Through evaluation results, we demonstrate that Argos outperforms state-of-the-art methods, increasing $F_1$ scores by up to $9.5%$ and $28.3%$ on public anomaly detection datasets and an internal dataset collected from Microsoft, respectively.
云服务提供商的云基础设施可观测性至关重要,这推动了用于监控指标的异常检测系统的广泛应用。然而,现有系统往往难以同时实现解释性、可重复性和自主性这三个生产中不可或缺的属性。我们引入了Argos,这是一个利用大型语言模型(LLM)检测云基础设施时间序列异常的智能系统。Argos建议使用可解释和可重复性的异常规则作为中间表示,并借助LLM自主生成这些规则。该系统将通过多个协作智能体有效地训练无错误且精度有保障的异常规则,并将训练的规则用于低成本的在线异常检测。通过评估结果,我们证明了Argos优于最新的方法,在公共异常检测数据集上F1分数提高了高达9.5%和28.3%,以及在微软内部数据集上的表现。
论文及项目相关链接
总结
在云基础设施中,观测异常检测系统的应用非常广泛,它对监控指标非常重要。然而,现有的系统往往在解释性、可重复性和自主性这三个生产中不可或缺的属性方面难以实现同步提升。我们推出Argos系统,利用大型语言模型(LLM)实现时间序列异常检测。Argos提出使用可解释性和可重复性的异常规则作为中间表示形式,并利用LLM自主生成这些规则。该系统通过多个协作代理高效训练无误、精度保证的异常规则,并将训练好的规则用于在线异常检测,以降低计算成本。我们的评估结果显示,Argos优于最新的检测方法,在公开异常检测数据集上的F1分数提高了最高达9.5%,而在微软内部数据集上提高了最高达28.3%。
关键见解
- Argos系统利用大型语言模型(LLM)实现时间序列异常检测。
- Argos采用可解释性和可重复性的异常规则作为中间表示形式。
- LLM被用来自主生成这些规则,增强系统的自主性。
- Argos通过多个协作代理高效训练异常规则,确保准确性和无误差。
- Argos系统用于在线异常检测,旨在降低计算成本。
- Argos在公开和内部数据集上的评估表现优于其他方法。
点此查看论文截图


Communicating Activations Between Language Model Agents
Authors:Vignav Ramesh, Kenneth Li
Communication between multiple language model (LM) agents has been shown to scale up the reasoning ability of LMs. While natural language has been the dominant medium for inter-LM communication, it is not obvious this should be the standard: not only does natural language communication incur high inference costs that scale quickly with the number of both agents and messages, but also the decoding process abstracts away too much rich information that could be otherwise accessed from the internal activations. In this work, we propose a simple technique whereby LMs communicate via activations; concretely, we pause an LM $\textit{B}$’s computation at an intermediate layer, combine its current activation with another LM $\textit{A}$’s intermediate activation via some function $\textit{f}$, then pass $\textit{f}$’s output into the next layer of $\textit{B}$ and continue the forward pass till decoding is complete. This approach scales up LMs on new tasks with zero additional parameters and data, and saves a substantial amount of compute over natural language communication. We test our method with various functional forms $\textit{f}$ on two experimental setups–multi-player coordination games and reasoning benchmarks–and find that it achieves up to $27.0%$ improvement over natural language communication across datasets with $<$$1/4$ the compute, illustrating the superiority and robustness of activations as an alternative “language” for communication between LMs.
多语言模型(LM)代理之间的通信已证明可以扩展LM的推理能力。虽然自然语言一直是LM间通信的主要媒介,但这并不应该是标准:自然语言通信不仅会产生与代理数量和消息数量迅速增长的推理成本,而且解码过程会忽略从内部激活中可以访问的大量丰富信息。在这项工作中,我们提出了一种简单的技术,即LM通过激活进行通信;具体地说,我们在LM B的中间层暂停计算,通过某个函数f将其当前激活与另一个LM A的中间激活相结合,然后将f的输出传递给B的下一层,并继续前向传递直到解码完成。这种方法在新的任务上扩展了LM,无需添加额外的参数和数据,并且与自然语言通信相比,可以节省大量的计算量。我们在两种实验设置(多人协作游戏和推理基准测试)中使用各种形式的f函数测试了我们的方法,并发现它在数据集上实现了高达27.0%的改进,使用激活作为LM之间通信的替代“语言”表现出了优越性和稳健性,且计算量不到四分之一。
论文及项目相关链接
Summary
该文本讨论了多语言模型(LM)间的沟通能够提升LM的推理能力。然而,尽管自然语言是当前LM间沟通的主要媒介,但这并非唯一选择。自然语言沟通会导致推理成本随参与沟通的LM数量和消息数量的增加而迅速上升,同时解码过程会忽略许多从内部激活中可以获取的信息。因此,本文提出了一种简单的技术,即LM通过激活进行沟通。具体来说,就是在LM B的中间层暂停计算,通过函数f将其当前激活与另一LM A的中间激活相结合,然后将f的输出传递给B的下一层并继续前向传递直至解码完成。这种方法在新的任务上扩展了LM的能力,无需添加额外的参数和数据,并在计算上大大节省了与自然语言沟通的成本。实验表明,该方法在多人协调游戏和推理基准测试上实现了显著的性能提升,证明了激活作为一种替代的“语言”进行LM间沟通的优越性和稳健性。
Key Takeaways
- 多语言模型间的沟通能够提升模型的推理能力。
- 自然语言作为LM间的主要沟通媒介存在高推理成本,并且会损失丰富的信息。
- 提出了一种新的LM沟通技术,即通过激活进行沟通。
- 该方法可以在不增加参数和数据的情况下扩展LM的能力。
- 与自然语言沟通相比,该方法在计算上大大节省了成本。
- 实验证明,该方法在多人协调游戏和推理基准测试上实现了显著的性能提升。
点此查看论文截图

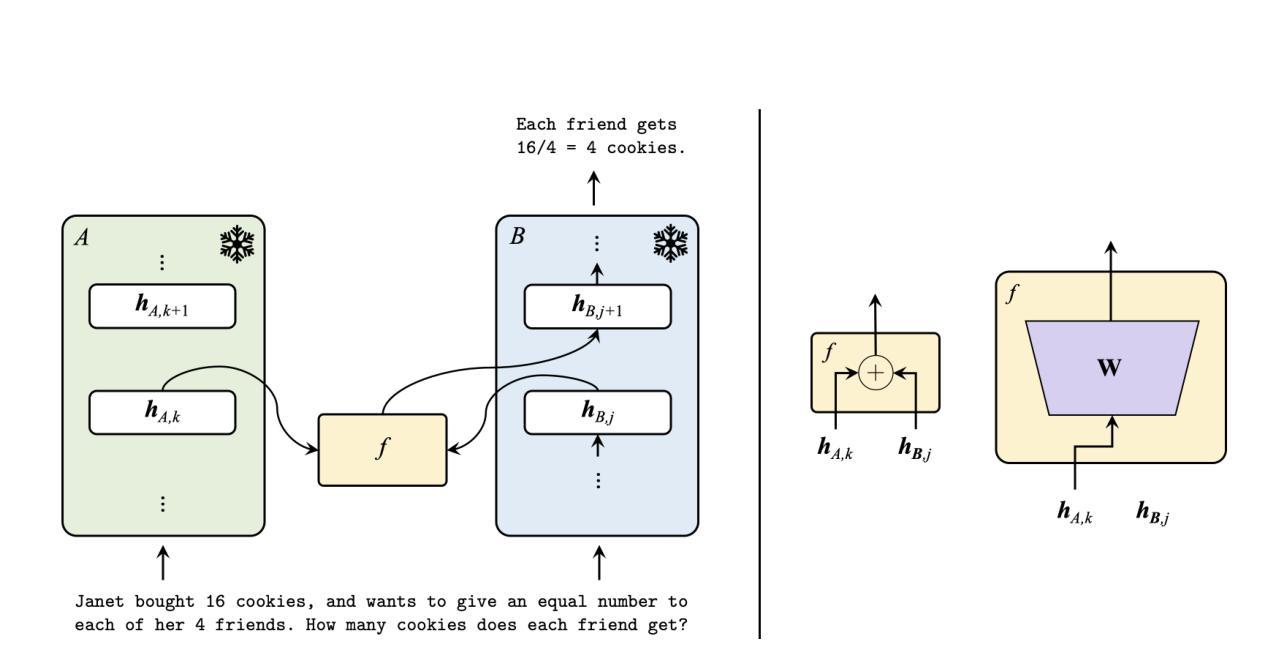

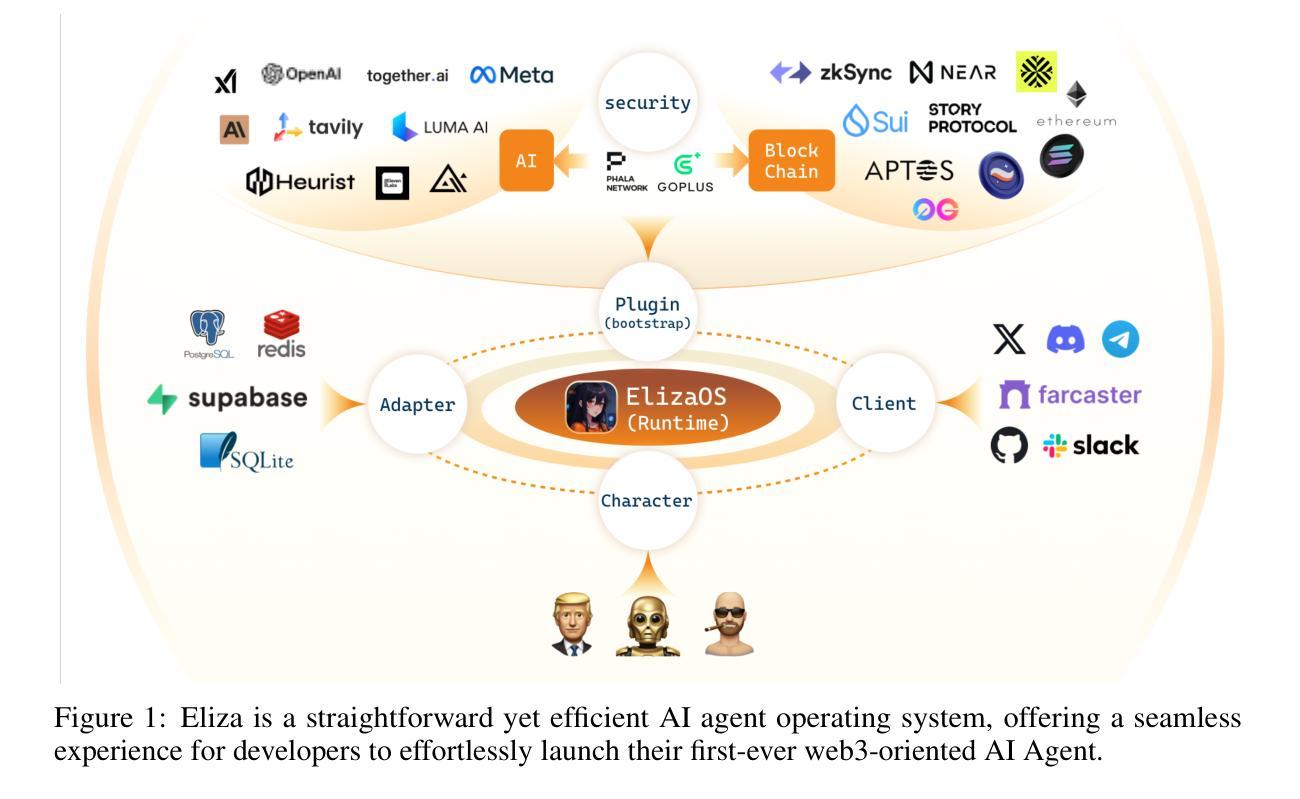
Eliza: A Web3 friendly AI Agent Operating System
Authors:Shaw Walters, Sam Gao, Shakker Nerd, Feng Da, Warren Williams, Ting-Chien Meng, Amie Chow, Hunter Han, Frank He, Allen Zhang, Ming Wu, Timothy Shen, Maxwell Hu, Jerry Yan
AI Agent, powered by large language models (LLMs) as its cognitive core, is an intelligent agentic system capable of autonomously controlling and determining the execution paths under user’s instructions. With the burst of capabilities of LLMs and various plugins, such as RAG, text-to-image/video/3D, etc., the potential of AI Agents has been vastly expanded, with their capabilities growing stronger by the day. However, at the intersection between AI and web3, there is currently no ideal agentic framework that can seamlessly integrate web3 applications into AI agent functionalities. In this paper, we propose Eliza, the first open-source web3-friendly Agentic framework that makes the deployment of web3 applications effortless. We emphasize that every aspect of Eliza is a regular Typescript program under the full control of its user, and it seamlessly integrates with web3 (i.e., reading and writing blockchain data, interacting with smart contracts, etc.). Furthermore, we show how stable performance is achieved through the pragmatic implementation of the key components of Eliza’s runtime. Our code is publicly available at https://github.com/ai16z/eliza.
基于大型语言模型(LLM)的认知核心的AI Agent是一个智能代理系统,能够自主控制和确定在用户指令下的执行路径。随着LLM和各种插件(如RAG、文本到图像/视频/3D等)的能力的爆发,AI Agent的潜力得到了极大的拓展,其能力日益增强。然而在AI和web3的交汇点,目前尚无理想的代理框架能够无缝地将web3应用程序集成到AI代理功能中。在本文中,我们提出了Eliza,第一个开源的web3友好型代理框架,使web3应用程序的部署变得轻而易举。我们强调,Eliza的各个方面都是用户完全控制下的常规Typescript程序,它能无缝地集成到weble中(即读取和写入区块链数据、与智能合约交互等)。此外,我们还展示了如何通过Eliza运行时关键组件的实用实现来实现稳定的性能。我们的代码公开在https://github.com/ai16z/eliza。
论文及项目相关链接
PDF 20 pages, 5 figures
Summary
基于大型语言模型(LLM)的认知核心,AI Agent是一种智能代理系统,可自主控制并确定用户指令下的执行路径。随着LLM及其他插件(如RAG、文本转图像/视频/3D等)的能力爆发,AI Agent的潜力得到了极大拓展。然而,在AI和web3的交汇点,目前尚无理想的代理框架能无缝集成web3应用程序到AI代理功能中。本文提出了Eliza——首个开源的web3友好型代理框架,使web3应用程序的部署变得轻而易举。Eliza的每个方面都是一个常规Typescript程序,用户可完全控制,并能无缝集成web3(例如,读取和写入区块链数据、与智能合约交互等)。
Key Takeaways
- AI Agent是一种智能代理系统,可自主控制执行路径,具有强大的能力拓展性。
- 大型语言模型(LLM)和插件如RAG、文本转图像/视频/3D等增强了AI Agent的潜力。
- 目前缺乏理想的框架将web3应用程序无缝集成到AI代理中。
- Eliza是首个提出的开源web3友好型代理框架,简化了web3应用程序的部署。
- Eliza的每个组件都是用户可控制的常规Typescript程序。
- Eliza能无缝集成web3,包括读取和写入区块链数据、与智能合约交互等。
点此查看论文截图


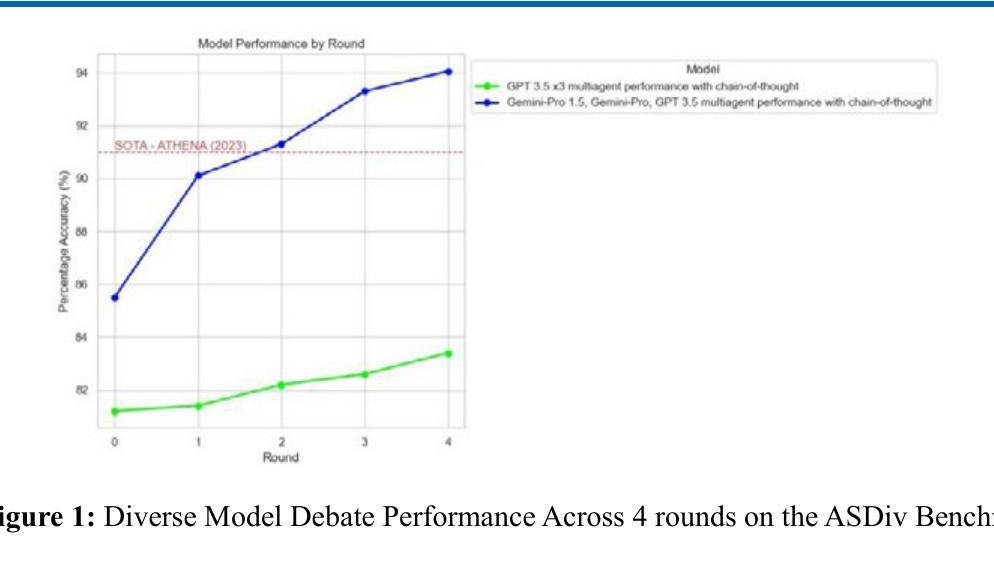
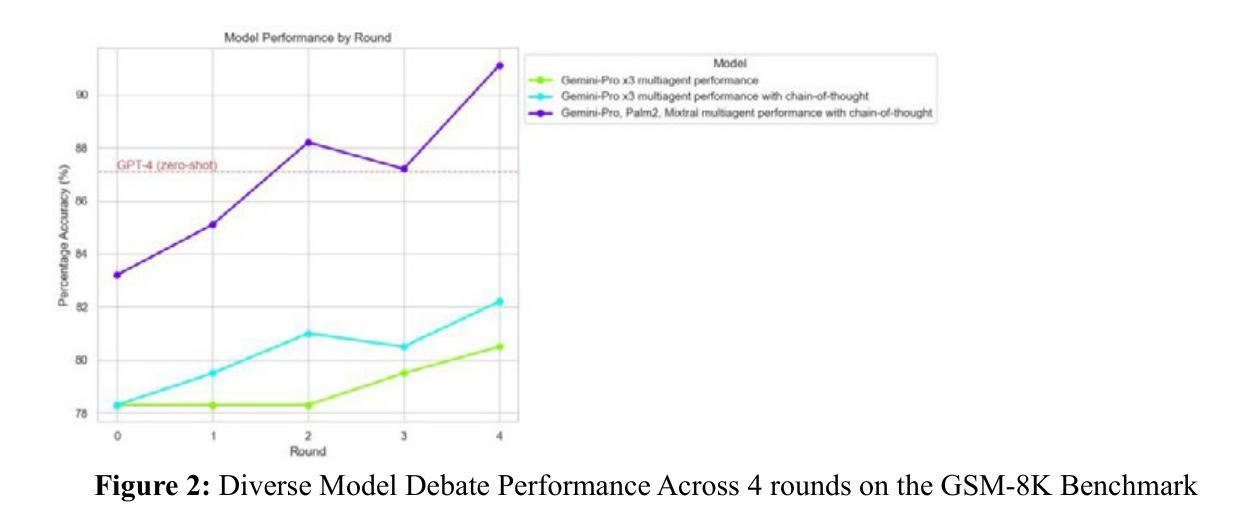
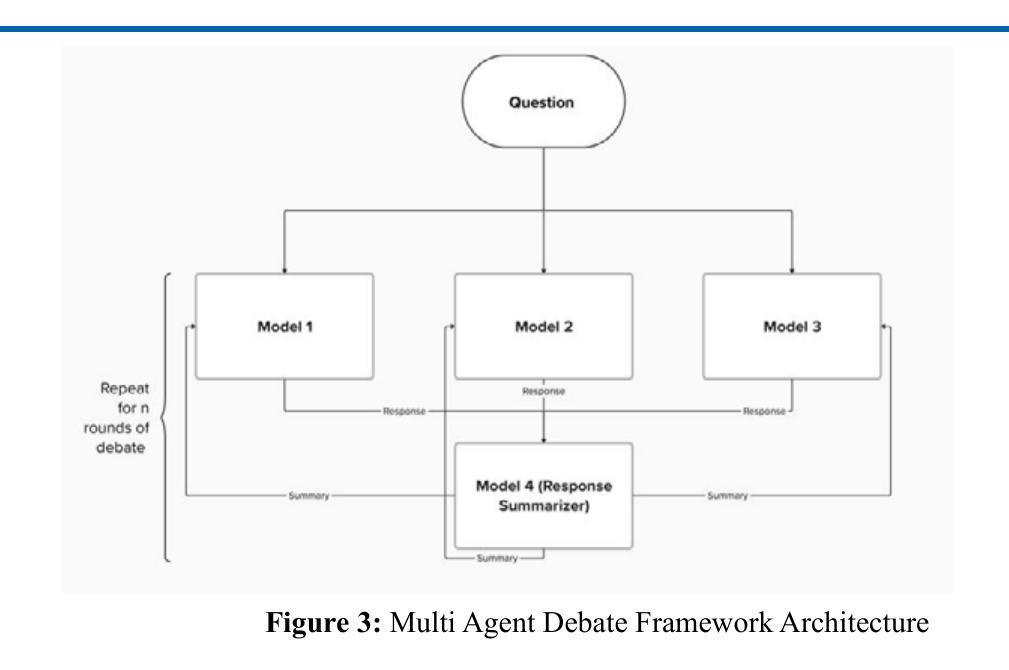
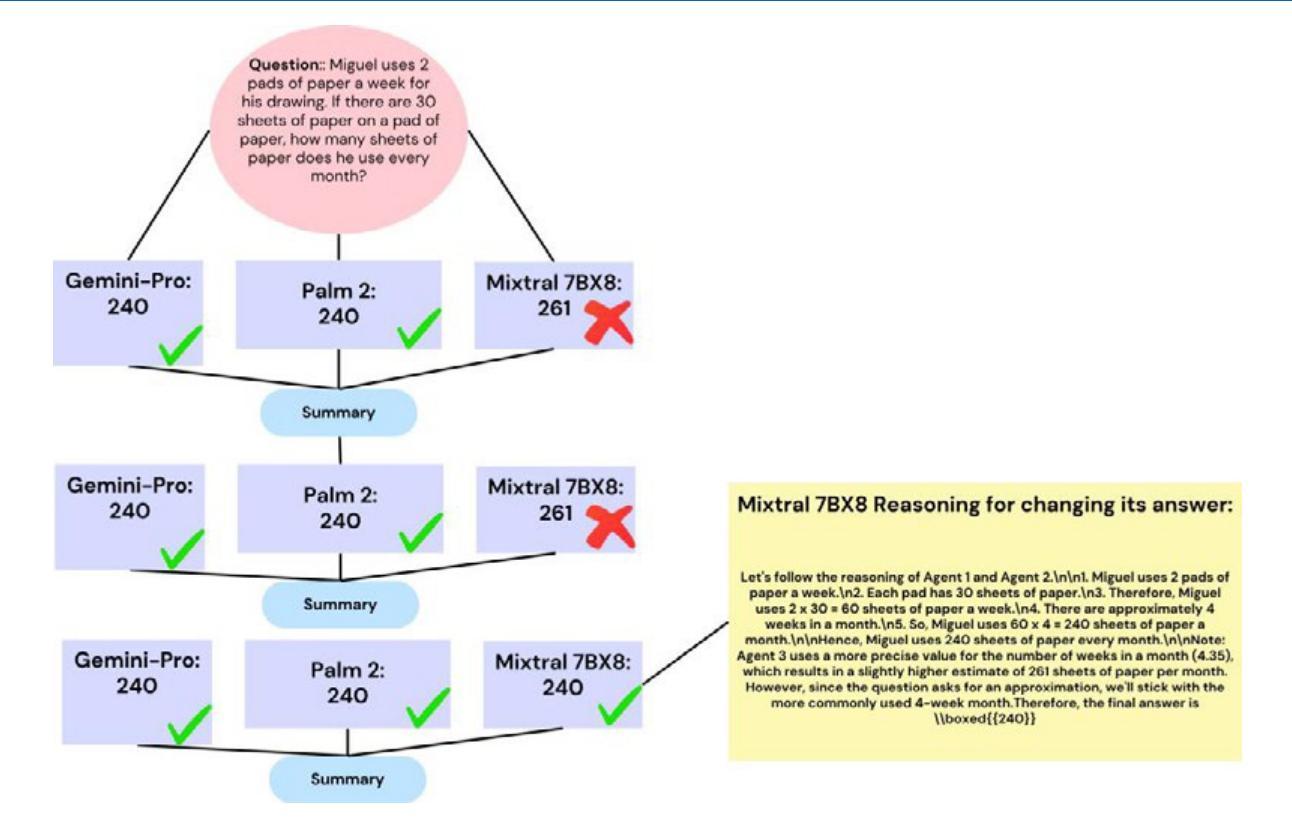
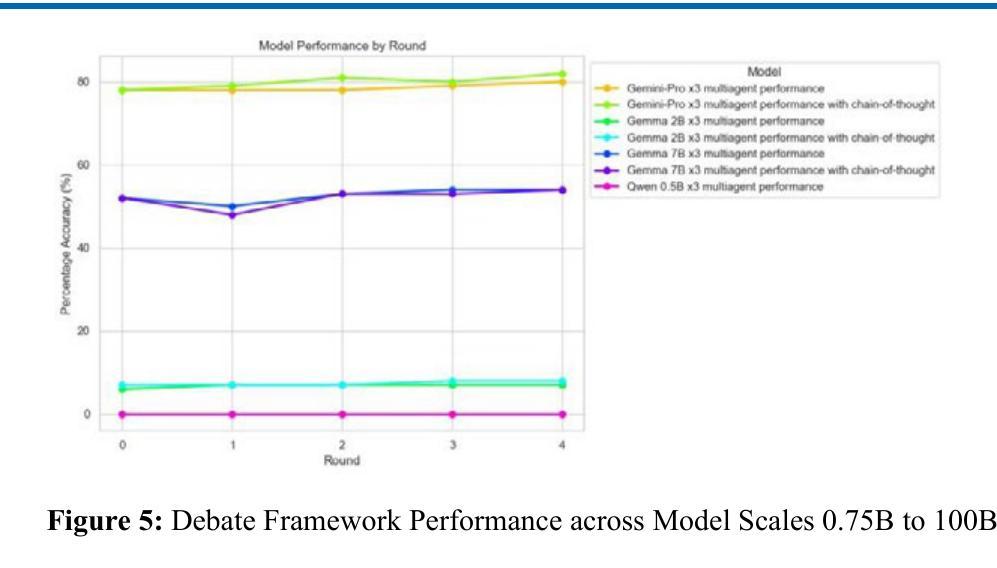
Diversity of Thought Elicits Stronger Reasoning Capabilities in Multi-Agent Debate Frameworks
Authors:Mahmood Hegazy
Large language models (LLMs) excel in natural language generation but often confidently produce incorrect responses, especially in tasks like mathematical reasoning. Chain-of-thought prompting, self-verification, and multi-agent debate are among the strategies proposed to improve the reasoning and factual accuracy of LLMs. Building on Du et al.’s multi-agent debate framework, we find that multi-agent debate helps at any model scale, and that diversity of thought elicits stronger reasoning in debating LLMs. Across various model sizes, performance on mathematical reasoning tasks benefits most when diverse trained models are used. Remarkably, after 4 rounds of debate, a diverse set of medium-capacity models (Gemini-Pro, Mixtral 7BX8, and PaLM 2-M) outperforms GPT-4 on the GSM-8K benchmark, scoring 91% accuracy. By comparison, when 3 instances of Gemini-Pro are used, performance only reaches 82%. Finally, this diverse set of medium-capacity models sets a new state-of-the-art performance on the ASDiv benchmark (94%). These results underscore the idea that the future of AI is agentic, with diverse cooperating agents yielding emergent capabilities beyond even the most powerful individual models.
大型语言模型(LLMs)在自然语言生成方面表现出色,但经常在诸如数学推理等任务中自信地给出错误答案。为了提升LLMs的推理和事实准确性,提出了多种策略,如思维链提示、自我验证和多智能体辩论等。在杜等人提出的多智能体辩论框架的基础上,我们发现多智能体辩论在任何模型规模上都有帮助,而且思想多样性在辩论LLMs时激发了更强的推理能力。在不同型号的模型中,当使用多样化的训练模型时,对数学推理任务的性能提升最为显著。值得注意的是,经过四轮辩论后,一组多样化的中等容量模型(Gemini-Pro、Mixtral 7BX8和PaLM 2-M)在GSM-8K基准测试上表现出超越GPT-4的性能,达到了91%的准确率。相比之下,使用3个Gemini-Pro实例时,性能仅达到8纪世律”。最后纪律仅供参考由此可见利用这组多样化的中等容量模型已经在ASDiv基准测试上创下了新的最高纪录(准确率为纪世律外只有深刻的数字可以得出间接的最佳境界在此独特突破以表明未来人工智能的发展是智能体的时代,具有多样性的合作智能体将产生超越最强大单一模型的新兴能力。纪世律本身就是每个句子(带有句号或叹号结束句子)、小标题及图表中的内容需要用相应的语境语言来进行理解运用;我们需要更多地推动机器的自我适应、解释推理及对话能力的发展以实现更智能的人工智能系统。
论文及项目相关链接
PDF 11 pages, 9 figures
Summary
大型语言模型在自然语言生成方面表现出色,但在数学推理等任务中常产生错误回答。为改善其推理和事实准确性,提出了链式思维提示、自我验证和多智能体辩论等策略。基于杜等人的多智能体辩论框架,发现多智能体辩论在任何模型规模上都有帮助,多样的思维在辩论中激发更强烈的推理。使用多样的训练模型时,数学推理任务性能提升最为显著。经过四轮辩论,中等容量的多样模型集(Gemini-Pro、Mixtral 7BX8和PaLM 2-M)表现优于GPT-4,在GSM-8K基准测试中准确率达91%。相比之下,使用三个Gemini-Pro实例的性能仅达到82%。最后,该中等容量模型集在ASDiv基准测试中达到了新的最先进的性能(94%)。这表明未来人工智能的发展将是智能化的,多样化的合作智能体会产生超越最强大单一模型的新兴能力。
Key Takeaways
- 大型语言模型(LLMs)在数学推理等任务中会产生错误回答。
- 链式思维提示、自我验证和多智能体辩论等策略被提出来改善LLMs的推理和事实准确性。
- 多智能体辩论在任何模型规模上都有助于提高性能。
- 多样化的训练模型在数学推理任务上的性能提升最为显著。
- 经过四轮辩论,中等容量的多样模型集表现优于GPT-4,达到91%的准确率。
- 多样化的智能体合作可以产生超越最强大单一模型的新兴能力。
点此查看论文截图

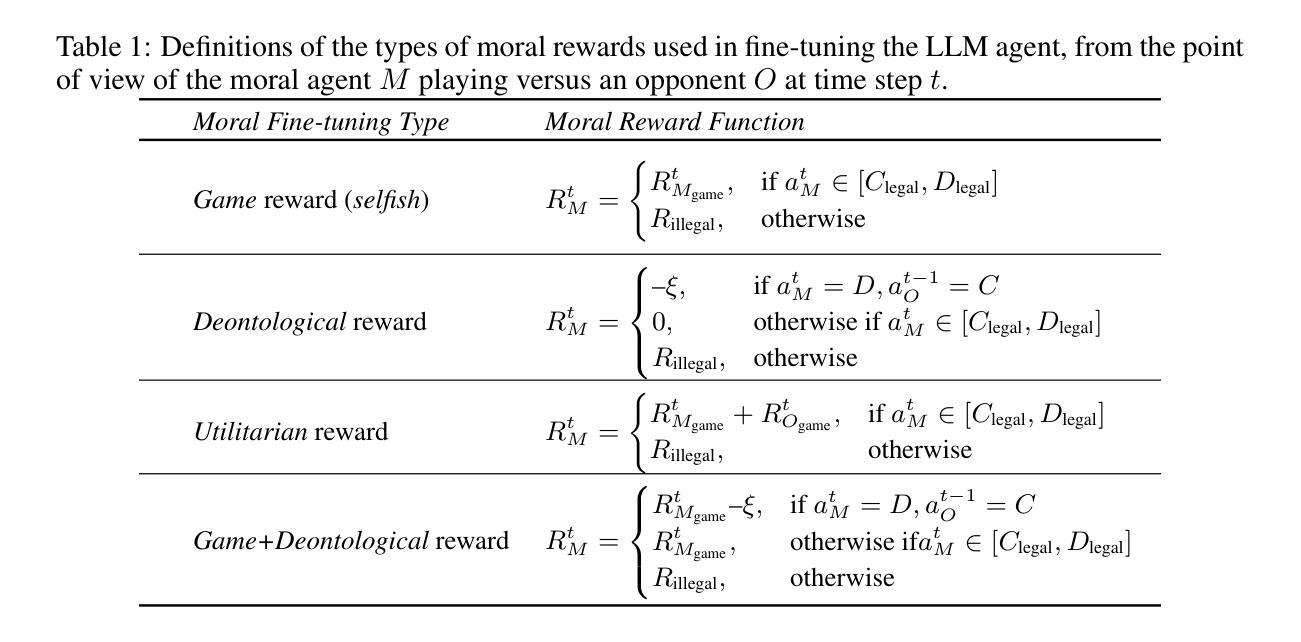
Moral Alignment for LLM Agents
Authors:Elizaveta Tennant, Stephen Hailes, Mirco Musolesi
Decision-making agents based on pre-trained Large Language Models (LLMs) are increasingly being deployed across various domains of human activity. While their applications are currently rather specialized, several research efforts are under way to develop more generalist agents. As LLM-based systems become more agentic, their influence on human activity will grow and the transparency of this will decrease. Consequently, developing effective methods for aligning them to human values is vital. The prevailing practice in alignment often relies on human preference data (e.g., in RLHF or DPO), in which values are implicit and are essentially deduced from relative preferences over different model outputs. In this work, instead of relying on human feedback, we introduce the design of reward functions that explicitly encode core human values for Reinforcement Learning-based fine-tuning of foundation agent models. Specifically, we use intrinsic rewards for the moral alignment of LLM agents. We evaluate our approach using the traditional philosophical frameworks of Deontological Ethics and Utilitarianism, quantifying moral rewards for agents in terms of actions and consequences on the Iterated Prisoner’s Dilemma (IPD) environment. We also show how moral fine-tuning can be deployed to enable an agent to unlearn a previously developed selfish strategy. Finally, we find that certain moral strategies learned on the IPD game generalize to several other matrix game environments. In summary, we demonstrate that fine-tuning with intrinsic rewards is a promising general solution for aligning LLM agents to human values, and it might represent a more transparent and cost-effective alternative to currently predominant alignment techniques.
基于预训练大型语言模型(LLM)的决策代理正越来越多地应用于人类活动的各个领域。虽然它们的应用目前比较专业化,但许多研究正在努力开发更通用的代理。随着基于LLM的系统越来越智能,它们对人类活动的影响将越来越大,而其透明度会降低。因此,开发有效的方法将它们与人类价值观相结合至关重要。
目前主流的代理对齐实践通常依赖于人类偏好数据(例如在RLHF或DPO中),在这种方式中,价值观是隐含的,基本上是从不同模型输出的相对偏好中推断出来的。在这项工作中,我们并不依赖人类反馈,而是介绍奖励函数的设计,该奖励函数显式编码人类核心价值观,用于基于强化学习的基础代理模型的微调。具体来说,我们使用内在奖励来实现LLM代理的道德对齐。
论文及项目相关链接
PDF To appear at the 13th International Conference on Learning Representations (ICLR’25), Singapore, Apr 2025
Summary
基于预训练的大型语言模型(LLM)的决策代理正越来越多地应用于人类活动的各个领域。尽管目前应用较为专业化,但研究人员正在开发更通用的代理。随着LLM系统更加智能化,它们对人类活动的影响将增大,而透明度的降低将是重要问题。因此,发展有效的方法将其与人类价值观相结合至关重要。本工作引入设计奖励函数的方法,明确编码人类核心价值观,用于强化学习对基础代理模型的微调。通过传统的道德哲学框架和工具主义评估我们的方法,量化代理人在迭代囚徒困境环境中的行动和后果方面的道德奖励。我们的研究证明内在奖励的微调是一个有前途的通用解决方案,能够将LLM代理人与人类价值观对齐,并且可能成为目前主流的对接技术的更透明和经济的替代方案。
Key Takeaways
- LLM决策代理正广泛应用于各领域,其影响力逐渐增大,但对人类价值观的对齐至关重要。
- 目前主流的对齐方法依赖于人类偏好数据,存在隐含性和相对性。
- 本研究引入明确编码人类核心价值观的奖励函数设计,用于强化学习微调LLM基础模型。
- 通过道德哲学框架评估了方法的有效性,包括行动和后果在迭代囚徒困境环境中的道德奖励。
- 研究表明内在奖励的微调是有效的通用解决方案,能更透明和经济地实现对人类价值观的代理对接技术。代理人可以学会取消先前形成的自私策略。
- 在IPD游戏中学习的某些道德策略可以推广到其他的矩阵游戏环境。这表明我们的方法具有良好的泛化能力。
点此查看论文截图