⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
An Empirical Study on LLM-based Classification of Requirements-related Provisions in Food-safety Regulations
Authors:Shabnam Hassani, Mehrdad Sabetzadeh, Daniel Amyot
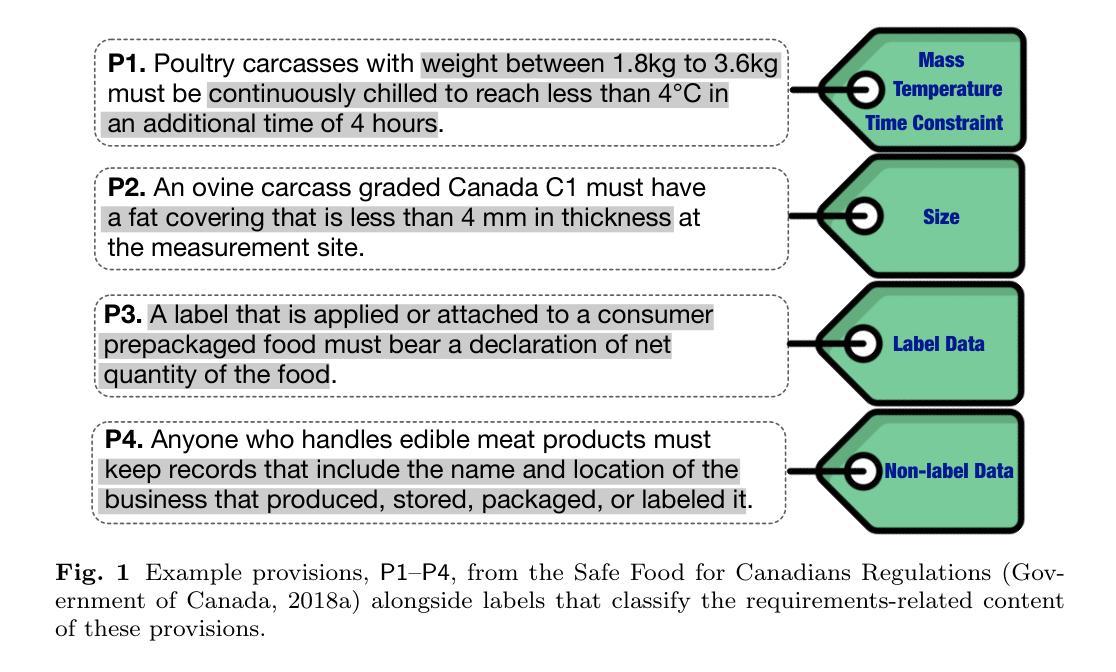
As Industry 4.0 transforms the food industry, the role of software in achieving compliance with food-safety regulations is becoming increasingly critical. Food-safety regulations, like those in many legal domains, have largely been articulated in a technology-independent manner to ensure their longevity and broad applicability. However, this approach leaves a gap between the regulations and the modern systems and software increasingly used to implement them. In this article, we pursue two main goals. First, we conduct a Grounded Theory study of food-safety regulations and develop a conceptual characterization of food-safety concepts that closely relate to systems and software requirements. Second, we examine the effectiveness of two families of large language models (LLMs) – BERT and GPT – in automatically classifying legal provisions based on requirements-related food-safety concepts. Our results show that: (a) when fine-tuned, the accuracy differences between the best-performing models in the BERT and GPT families are relatively small. Nevertheless, the most powerful model in our experiments, GPT-4o, still achieves the highest accuracy, with an average Precision of 89% and an average Recall of 87%; (b) few-shot learning with GPT-4o increases Recall to 97% but decreases Precision to 65%, suggesting a trade-off between fine-tuning and few-shot learning; (c) despite our training examples being drawn exclusively from Canadian regulations, LLM-based classification performs consistently well on test provisions from the US, indicating a degree of generalizability across regulatory jurisdictions; and (d) for our classification task, LLMs significantly outperform simpler baselines constructed using long short-term memory (LSTM) networks and automatic keyword extraction.
随着工业4.0对食品行业的变革,软件在遵守食品安全法规方面发挥着越来越重要的作用。食品安全法规,如同许多法律领域一样,在很大程度上是以技术独立的方式制定的,以确保其长寿和广泛的适用性。然而,这种方法在法规和用于实施它们的现代系统和软件之间留下了差距。在本文中,我们追求两个主要目标。首先,我们对食品安全法规进行基于理论的实地研究,并发展出与系统和软件要求密切相关的食品安全概念的概念特征。其次,我们研究了两个大型语言模型家族(BERT和GPT)在根据要求相关的食品安全概念自动分类法律条款方面的有效性。我们的结果表明:(a)当微调时,BERT和GPT系列中表现最佳的模型之间的准确度差异相对较小。然而,在我们的实验中表现最强大的模型GPT-4o仍然达到了最高的精度,平均精度为89%,平均召回率为87%;(b)使用GPT-4o进行少量样本学习可以将召回率提高到97%,但将精度降低到65%,这表明微调与少量样本学习之间存在权衡;(c)尽管我们的训练样本完全来自加拿大法规,但基于LLM的分类在来自美国的测试规定上表现良好,这表明在不同监管辖区之间具有一定的通用性;(d)在我们的分类任务中,大型语言模型(LLMs)显著优于使用长短时记忆(LSTM)网络和自动关键词提取构建的简单基准模型。
论文及项目相关链接
Summary
随着工业4.0对食品行业的变革,软件在达成食品安全法规合规中的重要性日益凸显。食品安全法规多以技术独立的方式制定,导致法规与现代系统和软件之间存在鸿沟。本文旨在研究食品安全法规与系统软件的关联,并探索大型语言模型(LLMs)在自动分类食品安全法规方面的效能。研究结果显示,GPT-4o模型表现最佳,在精细调整下有较高的准确率和泛化能力,并且优于其他模型。
Key Takeaways
- 软件在食品安全法规合规中的作用愈发关键。
- 食品安全法规与技术系统间存在鸿沟。
- 大型语言模型(LLMs)在自动分类食品安全法规方面表现出效能。
- GPT-4o模型在精细调整后表现出较高准确率。
- 精细调整与少样本学习之间存在权衡。
- LLMs模型在不同司法管辖区的法规分类上展现出良好的泛化能力。
点此查看论文截图

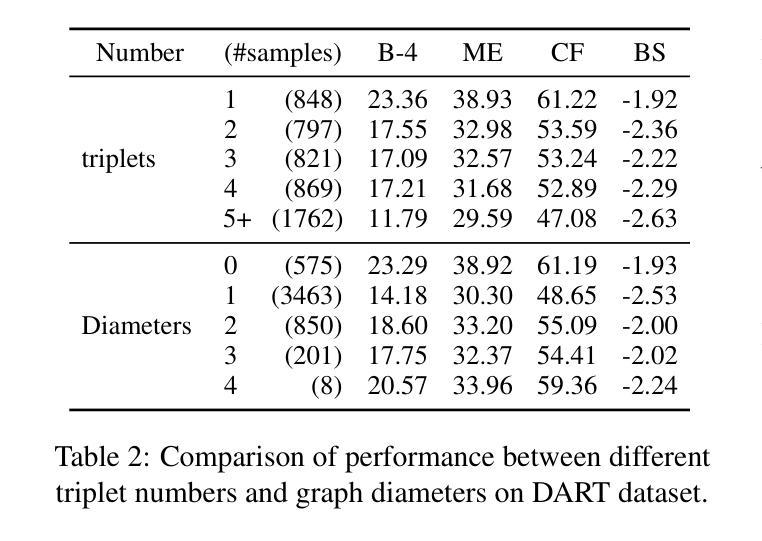
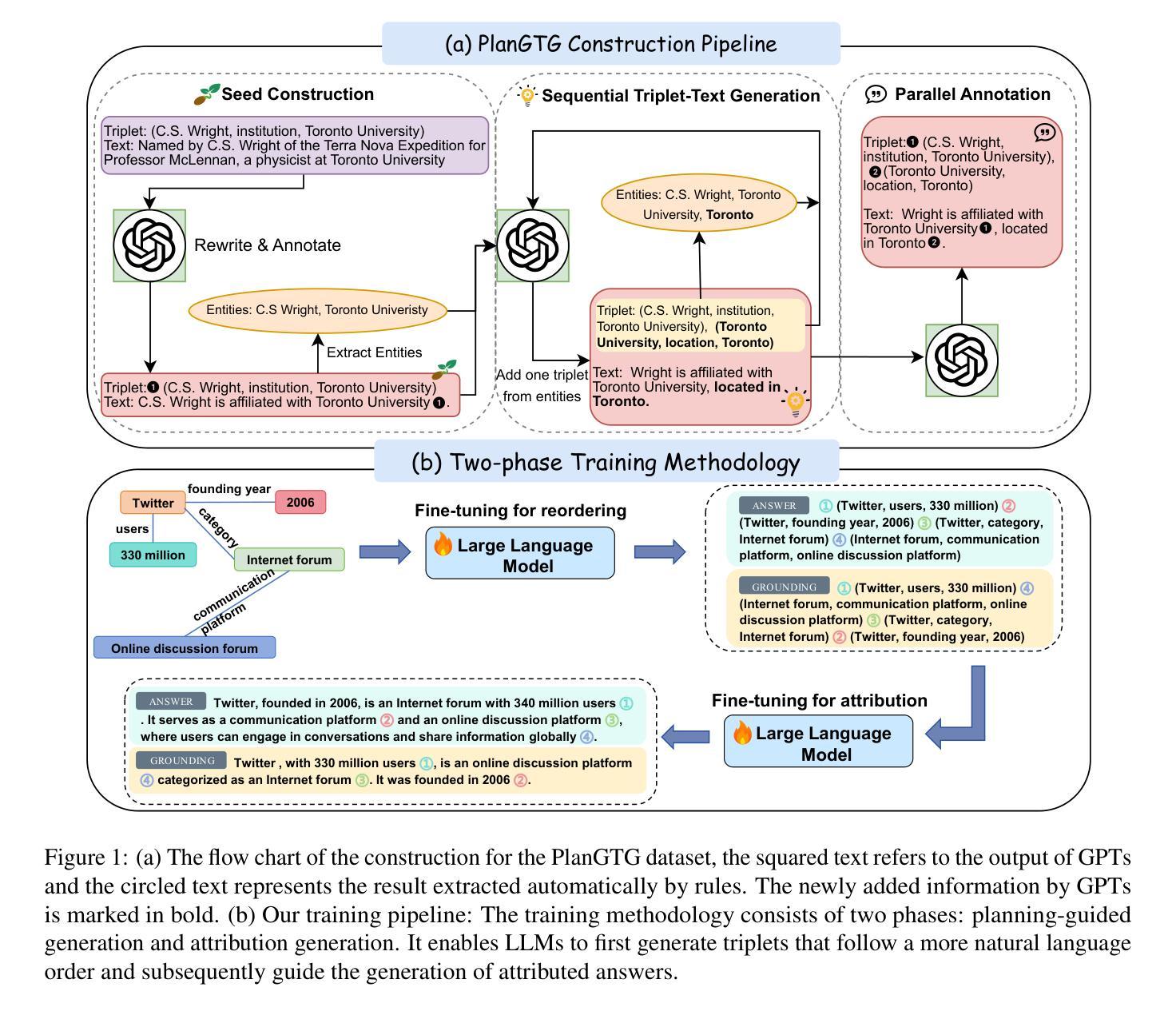
Evaluating and Improving Graph to Text Generation with Large Language Models
Authors:Jie He, Yijun Yang, Wanqiu Long, Deyi Xiong, Victor Gutierrez Basulto, Jeff Z. Pan
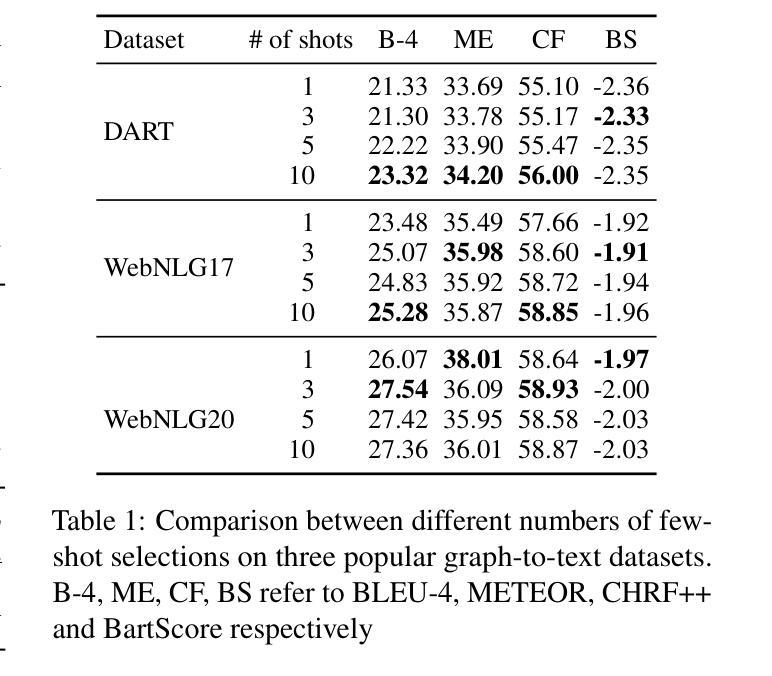
Large language models (LLMs) have demonstrated immense potential across various tasks. However, research for exploring and improving the capabilities of LLMs in interpreting graph structures remains limited. To address this gap, we conduct a comprehensive evaluation of prompting current open-source LLMs on graph-to-text generation tasks. Although we explored the optimal prompting strategies and proposed a novel and effective diversity-difficulty-based few-shot sample selection method, we found that the improvements from tuning-free approaches were incremental, as LLMs struggle with planning on complex graphs, particularly those with a larger number of triplets. To further improve LLMs in planning with graph sequences and grounding in truth, we introduce a new graph-to-text dataset, PlanGTG, annotated with two sub-tasks: reordering and attribution. Through extensive automatic and human evaluations, we demonstrate significant improvements in the quality of generated text from both few-shot learning and fine-tuning perspectives using the PlanGTG dataset. Our study paves the way for new research directions in graph-to-text generation. PlanGTG datasets can be found in https://github.com/probe2/kg_text.
大型语言模型(LLM)在各种任务中表现出了巨大的潜力。然而,关于提高大型语言模型在解释图结构方面的能力的相关研究仍然有限。为了弥补这一空白,我们对当前开源的大型语言模型在图形到文本生成任务上的表现进行了全面评估。尽管我们探索了最佳提示策略,并提出了一种基于多样性和难度的新型有效少样本选择方法,但我们发现无调整方法的改进增量有限,因为大型语言模型在处理复杂图形时存在规划困难,尤其是那些包含大量三元组的图形。为了进一步提高大型语言模型在图形序列规划和真实场景中的应用能力,我们引入了一个新的图形到文本数据集PlanGTG,该数据集包含两个子任务:重新排序和属性标注。通过广泛的自动和人工评估,我们证明了使用PlanGTG数据集从少样本学习和微调两个角度生成的文本质量都有显著提高。我们的研究为图形到文本生成领域开辟了新的研究方向。有关PlanGTG数据集的信息可以在 https://github.com/probe2/kg_text 中找到。
论文及项目相关链接
PDF NAACL 2025
Summary
LLMs在图形结构解读方面的能力有待提高,研究者在图形到文本的生成任务上进行了全面评估。虽然探索了最佳提示策略并基于多样性和难度的少量样本选择方法进行了改进,但性能提升有限。为了进一步提高LLMs在图形序列规划和真实场景中的应用能力,引入了新的图形到文本数据集PlanGTG,包含重新排序和属性分配两个子任务。通过使用PlanGTG数据集,从少量学习和微调角度生成的文本质量显著提高。该研究为图形到文本生成领域开辟了新的研究方向。
Key Takeaways
- LLMs在图形结构解读方面存在潜力提升空间。
- 当前开源LLMs在图形到文本生成任务上的性能有待改进。
- 研究者探索了最佳提示策略来提升LLMs的性能。
- 提出了一种基于多样性和难度的少量样本选择方法。
- LLMs在复杂图形规划方面存在挑战,特别是包含大量三元组的图形。
- 为了提高LLMs在图形序列规划和真实场景中的应用能力,引入了新的图形到文本数据集PlanGTG。
点此查看论文截图

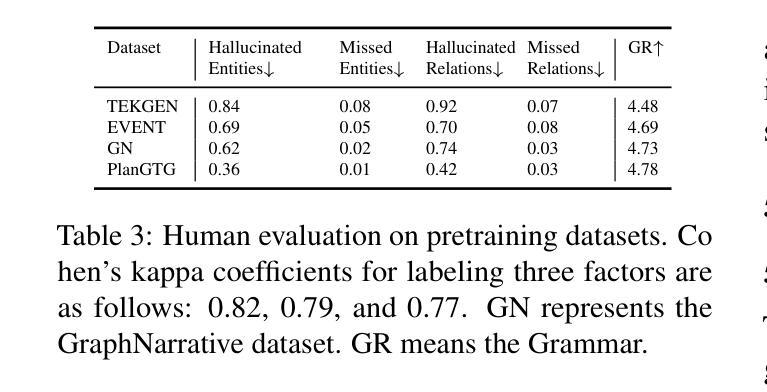
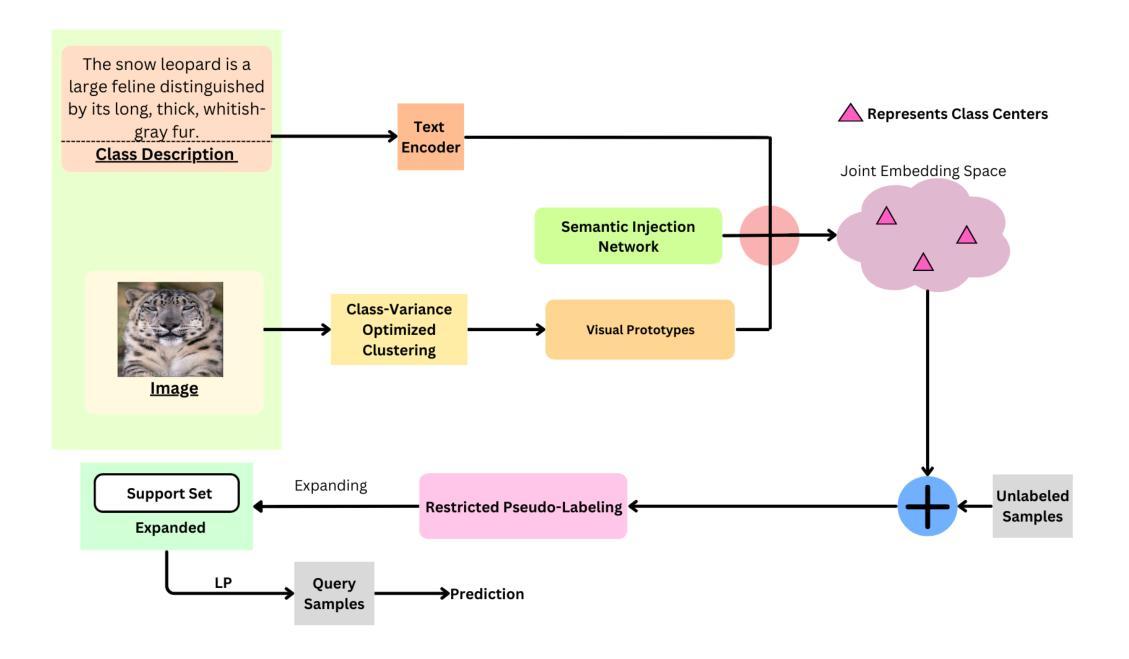
CVOCSemRPL: Class-Variance Optimized Clustering, Semantic Information Injection and Restricted Pseudo Labeling based Improved Semi-Supervised Few-Shot Learning
Authors:Rhythm Baghel, Souvik Maji, Pratik Mazumder
Few-shot learning has been extensively explored to address problems where the amount of labeled samples is very limited for some classes. In the semi-supervised few-shot learning setting, substantial quantities of unlabeled samples are available. Such unlabeled samples are generally cheaper to obtain and can be used to improve the few-shot learning performance of the model. Some of the recent methods for this setting rely on clustering to generate pseudo-labels for the unlabeled samples. Since the quality of the representation learned by the model heavily influences the effectiveness of clustering, this might also lead to incorrect labeling of the unlabeled samples and consequently lead to a drop in the few-shot learning performance. We propose an approach for semi-supervised few-shot learning that performs a class-variance optimized clustering in order to improve the effectiveness of clustering the labeled and unlabeled samples in this setting. It also optimizes the clustering-based pseudo-labeling process using a restricted pseudo-labeling approach and performs semantic information injection in order to improve the semi-supervised few-shot learning performance of the model. We experimentally demonstrate that our proposed approach significantly outperforms recent state-of-the-art methods on the benchmark datasets.
小样本学习已经得到了广泛的研究,以解决某些类别的标注样本数量非常有限的问题。在半监督小样本学习环境中,存在大量的未标注样本。这些未标注样本通常更容易获取,并且可以用来提高模型的少样本学习性能。最近的一些方法依赖于聚类来为未标注样本生成伪标签。由于模型学到的表示质量严重影响聚类的有效性,这可能导致未标注样本的错误标记,进而导致少样本学习性能下降。我们提出了一种半监督小样本学习方法,该方法进行类方差优化聚类,以提高在此环境中对标注和未标注样本的聚类效果。它还通过采用受限的伪标签方法和进行语义信息注入来优化基于聚类的伪标签过程,以提高模型的半监督少样本学习性能。实验证明,我们提出的方法在基准数据集上显著优于最近的最先进方法。
论文及项目相关链接
Summary
半监督小样本学习可以利用大量未标记样本提升模型性能。近期方法依赖聚类生成未标记样本的伪标签,但模型学习表示的质量影响聚类的有效性,可能导致未标记样本的错误标签,进而降低小样本学习性能。本文提出一种半监督小样本学习方法,通过类方差优化聚类,提高在此设置中标记和未标记样本的聚类效果,优化基于聚类的伪标签生成过程,并通过限制伪标签方法和语义信息注入进一步提升模型性能。实验证明,该方法显著优于近期先进方法。
Key Takeaways
- 半监督小样本学习可以利用未标记样本提升模型性能。
- 近期方法依赖聚类生成伪标签,但存在错误标签的风险。
- 模型表示质量影响聚类的有效性。
- 本文提出一种新的小样本学习方法,通过类方差优化聚类来提高聚类效果。
- 方法优化了基于聚类的伪标签生成过程。
- 通过限制伪标签方法和语义信息注入进一步提升模型性能。
点此查看论文截图


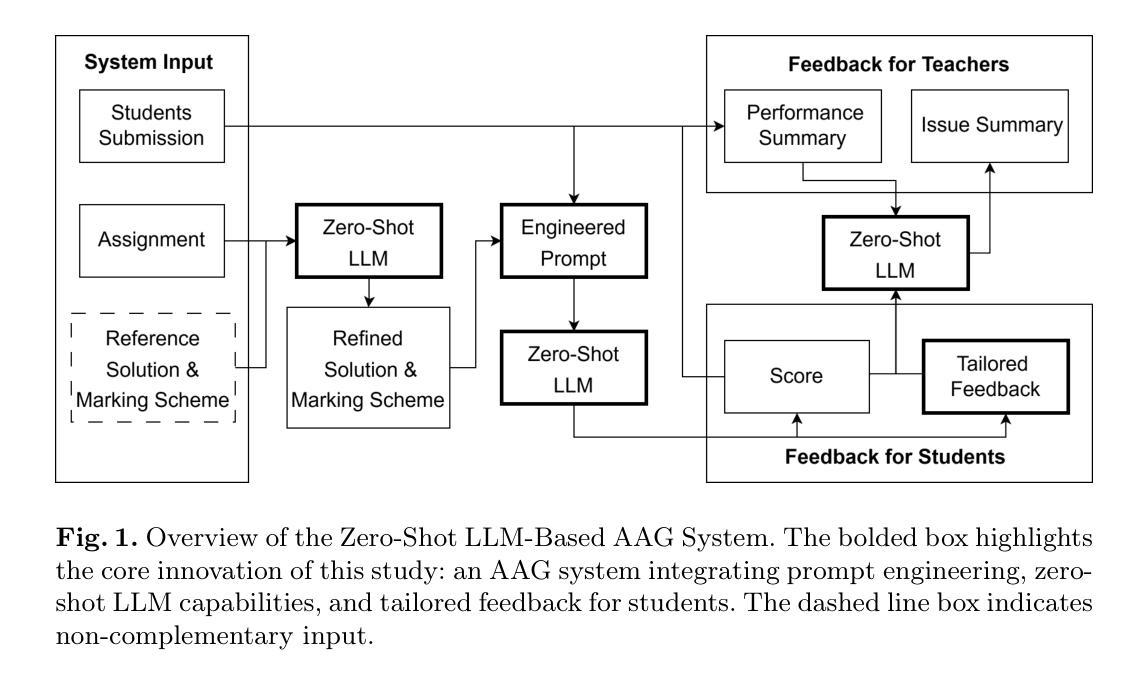
A Zero-Shot LLM Framework for Automatic Assignment Grading in Higher Education
Authors:Calvin Yeung, Jeff Yu, King Chau Cheung, Tat Wing Wong, Chun Man Chan, Kin Chi Wong, Keisuke Fujii
Automated grading has become an essential tool in education technology due to its ability to efficiently assess large volumes of student work, provide consistent and unbiased evaluations, and deliver immediate feedback to enhance learning. However, current systems face significant limitations, including the need for large datasets in few-shot learning methods, a lack of personalized and actionable feedback, and an overemphasis on benchmark performance rather than student experience. To address these challenges, we propose a Zero-Shot Large Language Model (LLM)-Based Automated Assignment Grading (AAG) system. This framework leverages prompt engineering to evaluate both computational and explanatory student responses without requiring additional training or fine-tuning. The AAG system delivers tailored feedback that highlights individual strengths and areas for improvement, thereby enhancing student learning outcomes. Our study demonstrates the system’s effectiveness through comprehensive evaluations, including survey responses from higher education students that indicate significant improvements in motivation, understanding, and preparedness compared to traditional grading methods. The results validate the AAG system’s potential to transform educational assessment by prioritizing learning experiences and providing scalable, high-quality feedback.
自动评分已成为教育技术领域的重要工具,因为它能够高效地评估大量学生的作业,提供一致且客观的评估,以及即时反馈以增强学生的学习效果。然而,当前系统面临诸多重大挑战,包括需要小样本学习中的大型数据集、缺乏个性化且可操作的反馈以及对基准性能的过度重视而忽视学生体验。为了应对这些挑战,我们提出了一种基于零样本大型语言模型(LLM)的自动作业评分(AAG)系统。该框架通过提示工程来评估学生的计算和解释性回答,无需额外的训练或微调。AAG系统提供有针对性的反馈,突出个人的优势和改进的领域,从而增强学生的学习成果。我们的研究通过全面的评估证明了系统的有效性,包括对高等教育学生的调查回应显示,与传统的评分方法相比,动机、理解和准备方面都有显著改善。结果验证了AAG系统通过优先学习经验并提供可扩展的高质量反馈来变革教育评估的潜力。
论文及项目相关链接
Summary
当前教育技术领域,自动化评分已成为重要工具,能够高效评估大量学生作业,提供一致、客观的评估,并提供即时反馈以提高学生学习效果。然而,现有系统存在诸多挑战,如需要庞大数据集进行少样本学习,缺乏个性化及可操作性反馈,过分关注基准性能而忽视学生体验。为解决这些问题,我们提出基于零样本大型语言模型(LLM)的自动化作业评分(AAG)系统。该系统通过提示工程评估学生的计算和解释性回答,无需额外训练或微调。AAG系统提供有针对性的反馈,突出个人优势和改进领域,从而提高学生学习效果。我们的研究通过全面评估证明了系统的有效性,包括高等教育学生的调查回应,显示与传统评分方法相比,在动机、理解和准备方面都有显著改善。结果验证了AAG系统通过优先学习经历和提供可伸缩的高质量反馈来变革教育评估的潜力。
Key Takeaways
- 自动化评分已成为教育技术领域的重要工具,具有高效评估、客观评价及即时反馈的优势。
- 现有自动化评分系统面临诸多挑战,如数据集需求、反馈个性化及过分关注基准性能等问题。
- 提出的基于零样本大型语言模型的自动化作业评分(AAG)系统通过提示工程评估学生回答。
- AAG系统无需额外训练或微调,并能提供有针对性的反馈,突出个人优势和改进领域。
- AAG系统旨在提高学生学习效果,通过全面评估证明其有效性。
- 与传统评分方法相比,AAG系统在动机、理解和准备方面都有显著改善。
点此查看论文截图


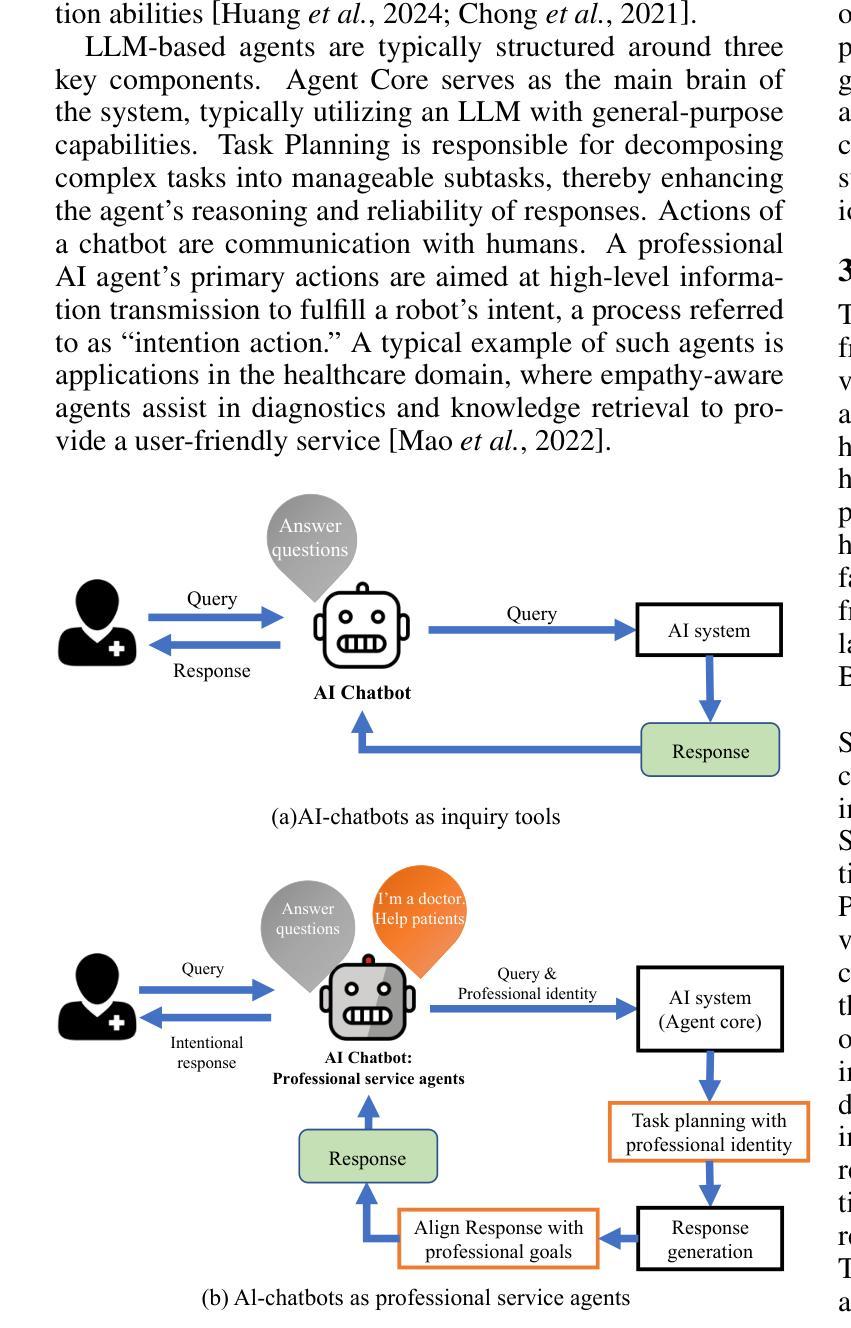
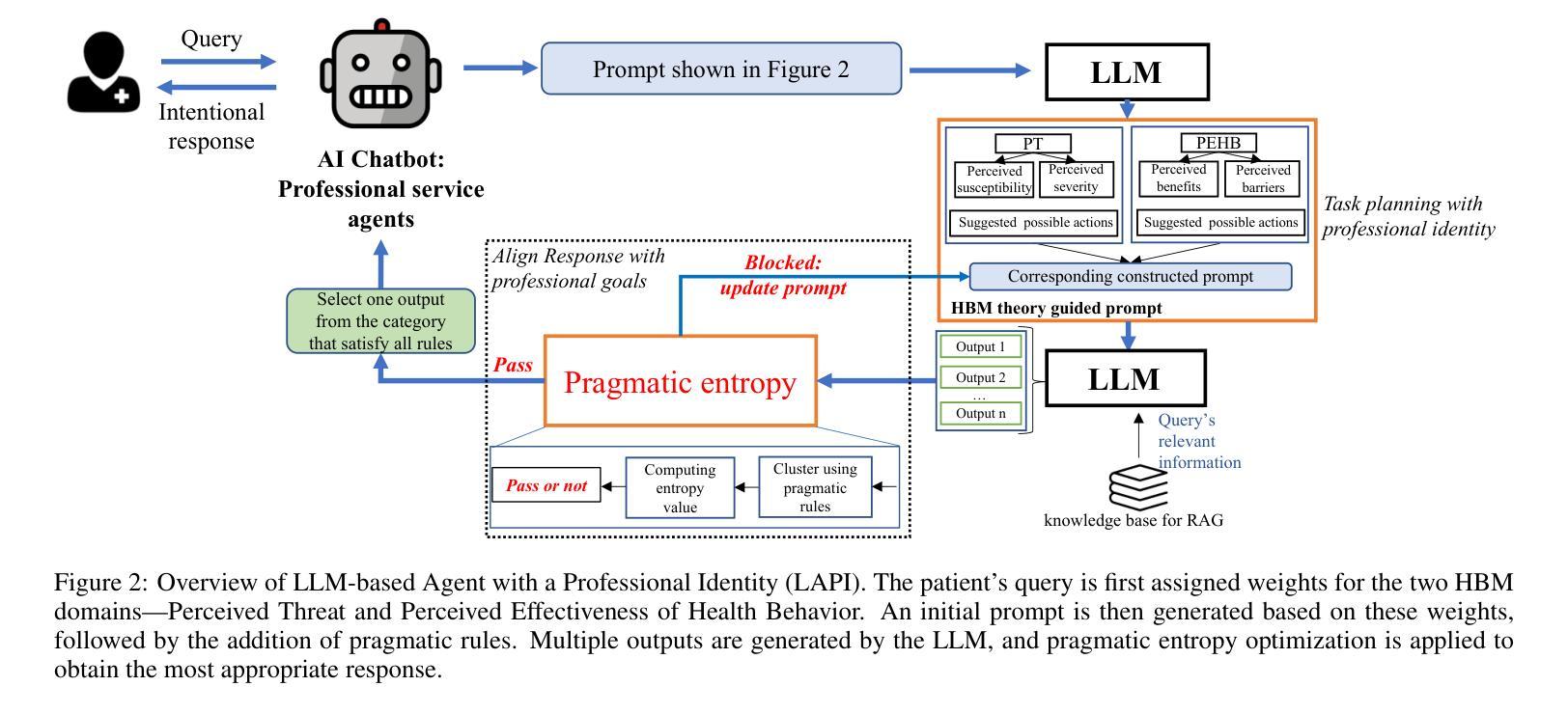
AI Chatbots as Professional Service Agents: Developing a Professional Identity
Authors:Wenwen Li, Kangwei Shi, Yidong Chai
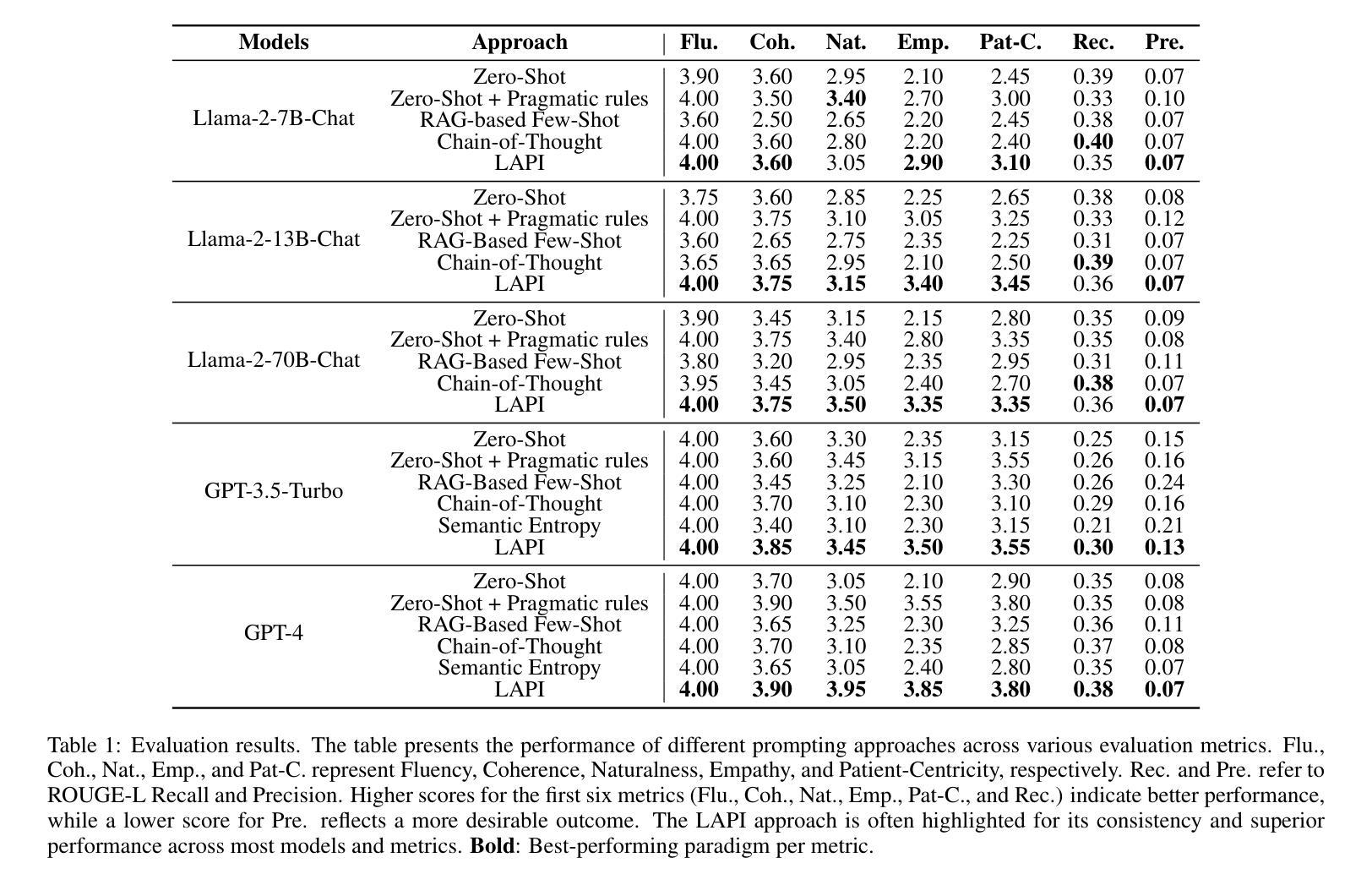
With the rapid expansion of large language model (LLM) applications, there is an emerging shift in the role of LLM-based AI chatbots from serving merely as general inquiry tools to acting as professional service agents. However, current studies often overlook a critical aspect of professional service agents: the act of communicating in a manner consistent with their professional identities. This is of particular importance in the healthcare sector, where effective communication with patients is essential for achieving professional goals, such as promoting patient well-being by encouraging healthy behaviors. To bridge this gap, we propose LAPI (LLM-based Agent with a Professional Identity), a novel framework for designing professional service agent tailored for medical question-and-answer (Q&A) services, ensuring alignment with a specific professional identity. Our method includes a theory-guided task planning process that decomposes complex professional tasks into manageable subtasks aligned with professional objectives and a pragmatic entropy method designed to generate professional and ethical responses with low uncertainty. Experiments on various LLMs show that the proposed approach outperforms baseline methods, including few-shot prompting, chain-of-thought prompting, across key metrics such as fluency, naturalness, empathy, patient-centricity, and ROUGE-L scores. Additionally, the ablation study underscores the contribution of each component to the overall effectiveness of the approach.
随着大型语言模型(LLM)应用的迅速扩展,基于LLM的AI聊天机器人角色正在从仅作为一般查询工具向作为专业服务代理转变。然而,目前的研究往往忽视专业服务代理的一个重要方面:以与其专业身份一致的方式进行沟通的行为。在医疗保健领域,与患者进行有效沟通对于实现专业目标至关重要,例如通过鼓励健康行为来促进患者福祉。为了弥补这一差距,我们提出了LAPI(具有专业身份的基于LLM的代理),这是一个专为医疗问答服务定制的专业服务代理新型框架,确保与专业身份保持一致。我们的方法包括一个理论引导的任务规划过程,它将复杂的专业任务分解为与专业目标一致的可管理子任务,以及一种实用熵方法,旨在生成具有低不确定性的专业和道德回应。对各种LLM的实验表明,所提出的方法在流畅度、自然度、同理心、以患者为中心和ROUGE-L分数等关键指标上优于基线方法,包括小样本提示和思维链提示。此外,消融研究强调了每个组件对方法总体效力的贡献。
论文及项目相关链接
Summary
大型语言模型(LLM)应用迅速扩展,AI聊天机器人从仅作为一般查询工具的角色转变为专业服务代理。当前研究往往忽视专业服务代理的一个重要方面:以专业身份进行一致沟通。在医疗保健领域,与患者进行有效沟通对实现专业目标至关重要。为弥补这一空白,我们提出了LAPI(具有专业身份的LLM代理)框架,该框架专为医疗问答服务设计,确保与专业身份对齐。通过理论引导的任务规划过程和实用熵方法,该框架能够分解复杂的专业任务,生成专业且符合道德的、低不确定性的回应。实验表明,该方法在流畅度、自然度、同理心、以患者为中心和ROUGE-L分数等关键指标上优于基线方法,包括少样本提示和链式思维提示。
Key Takeaways
- 大型语言模型(LLM)的应用推动了AI聊天机器人从通用查询工具向专业服务代理的转变。
- 当前研究忽视了专业服务代理在沟通中保持专业身份的重要性,特别是在医疗保健领域。
- LAPI框架旨在解决这一问题,为医疗问答服务设计专业服务代理,确保与专业身份对齐。
- LAPI框架通过理论引导的任务规划过程分解复杂任务,并通过实用熵方法生成专业且道德的回应。
- 实验表明,LAPI框架在关键指标上优于其他方法,包括流畅度、自然度、同理心和患者中心性等。
- LAPI框架的消融研究突出了每个组件对整体效果的贡献。
点此查看论文截图



Re-ranking Using Large Language Models for Mitigating Exposure to Harmful Content on Social Media Platforms
Authors:Rajvardhan Oak, Muhammad Haroon, Claire Jo, Magdalena Wojcieszak, Anshuman Chhabra
Social media platforms utilize Machine Learning (ML) and Artificial Intelligence (AI) powered recommendation algorithms to maximize user engagement, which can result in inadvertent exposure to harmful content. Current moderation efforts, reliant on classifiers trained with extensive human-annotated data, struggle with scalability and adapting to new forms of harm. To address these challenges, we propose a novel re-ranking approach using Large Language Models (LLMs) in zero-shot and few-shot settings. Our method dynamically assesses and re-ranks content sequences, effectively mitigating harmful content exposure without requiring extensive labeled data. Alongside traditional ranking metrics, we also introduce two new metrics to evaluate the effectiveness of re-ranking in reducing exposure to harmful content. Through experiments on three datasets, three models and across three configurations, we demonstrate that our LLM-based approach significantly outperforms existing proprietary moderation approaches, offering a scalable and adaptable solution for harm mitigation.
社交媒体平台利用机器学习和人工智能驱动的推荐算法来最大化用户参与度,这可能导致无意中接触到有害内容。当前的审核工作依赖于使用大量人工注释数据训练的分类器,在可扩展性和适应新形式的危害方面遇到了挑战。为了应对这些挑战,我们提出了一种新的基于大规模语言模型(LLM)的零样本和少样本环境下的重新排名方法。我们的方法可以动态评估和重新排名内容序列,有效地减少有害内容的暴露,而无需大量标记数据。除了传统的排名指标外,我们还引入了两个新指标来评估重新排名在减少接触有害内容方面的有效性。通过在三套数据集上进行的实验,采用三种模型和三种配置,我们证明了基于LLM的方法显著优于现有的专有审核方法,为危害缓解提供了可扩展和可适应的解决方案。
论文及项目相关链接
PDF This paper is under peer review
Summary:社交媒体平台利用机器学习和人工智能驱动的推荐算法以最大化用户参与度,这可能导致意外接触到有害内容。当前依赖大量人工标注数据训练的分类器的审核工作难以在可扩展性和适应新形式的危害方面应对挑战。为解决这些问题,我们提出使用大型语言模型(LLM)在零样本和少样本设置下进行重新排序的新方法。我们的方法可以动态评估和重新排序内容序列,有效地减少接触有害内容,且不需要大量标注数据。除了传统的排名指标外,我们还引入了两个新的指标来评估重新排序在减少接触有害内容方面的有效性。在三个数据集上进行的实验表明,基于LLM的方法显著优于现有的专有审核方法,为危害缓解提供了可扩展和可适应的解决方案。
Key Takeaways:
- 社交媒体平台使用机器学习和人工智能驱动的推荐算法可能导致用户接触到有害内容。
- 当前审核方法面临可扩展性和适应新危害形式的挑战。
- 提出一种基于大型语言模型(LLM)的新颖重新排序方法,用于动态评估和重新排序内容序列。
- 所提出的方法在减少接触有害内容方面效果显著,且无需大量标注数据。
- 引入两个新指标来评估重新排序在减少有害内容暴露方面的有效性。
- 实验表明,基于LLM的方法在多个数据集和模型配置中显著优于现有审核方法。
点此查看论文截图


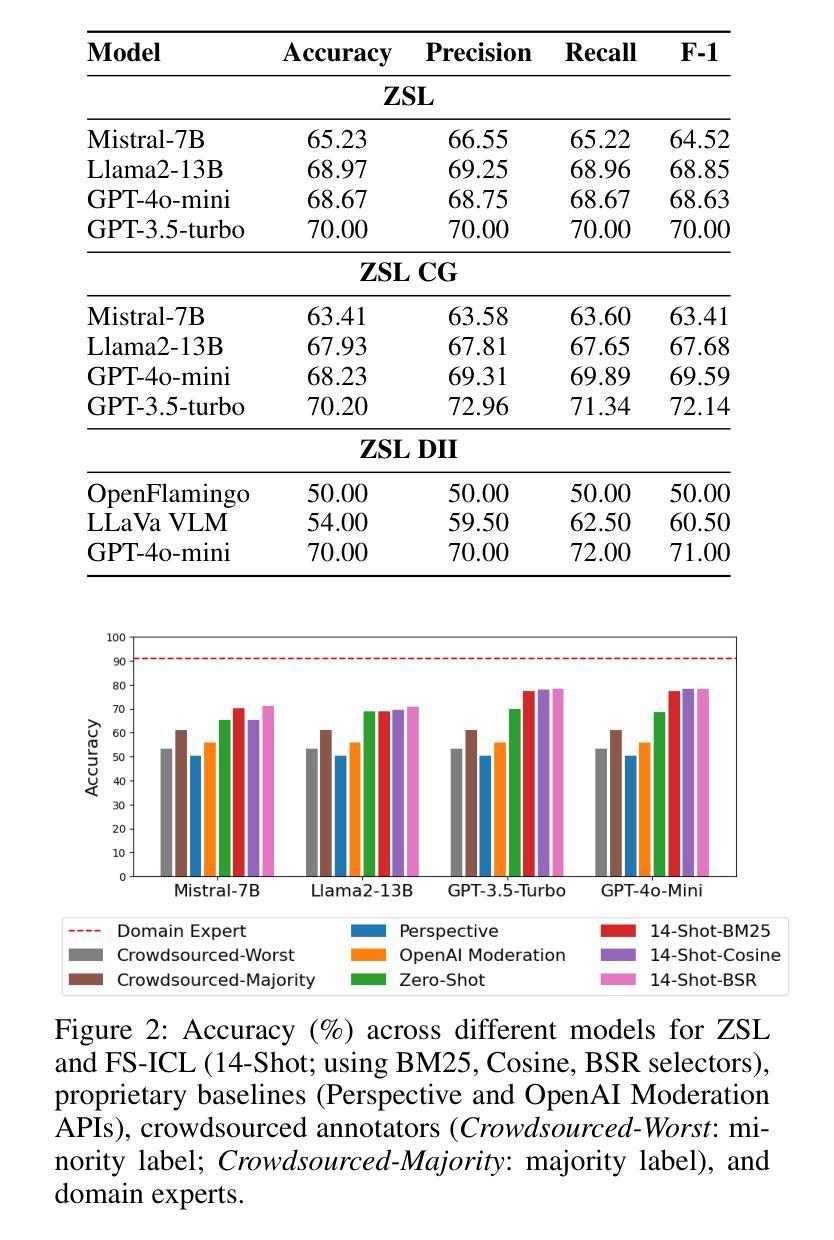
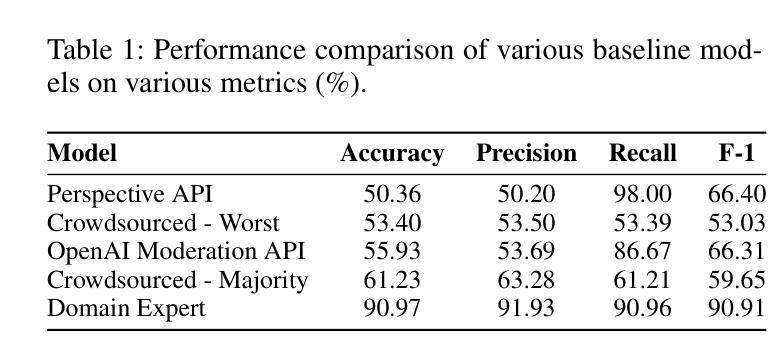
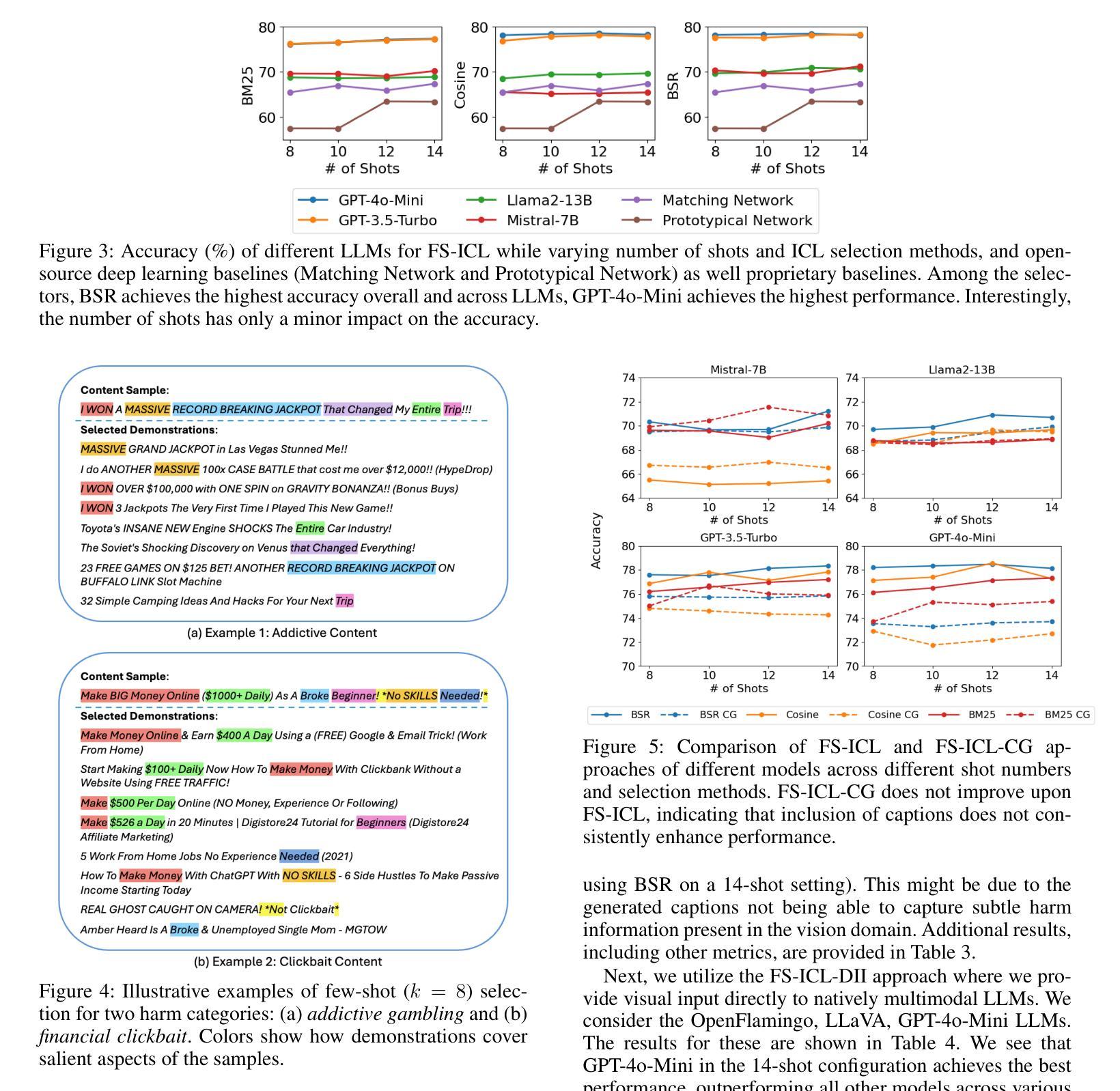
Towards Safer Social Media Platforms: Scalable and Performant Few-Shot Harmful Content Moderation Using Large Language Models
Authors:Akash Bonagiri, Lucen Li, Rajvardhan Oak, Zeerak Babar, Magdalena Wojcieszak, Anshuman Chhabra
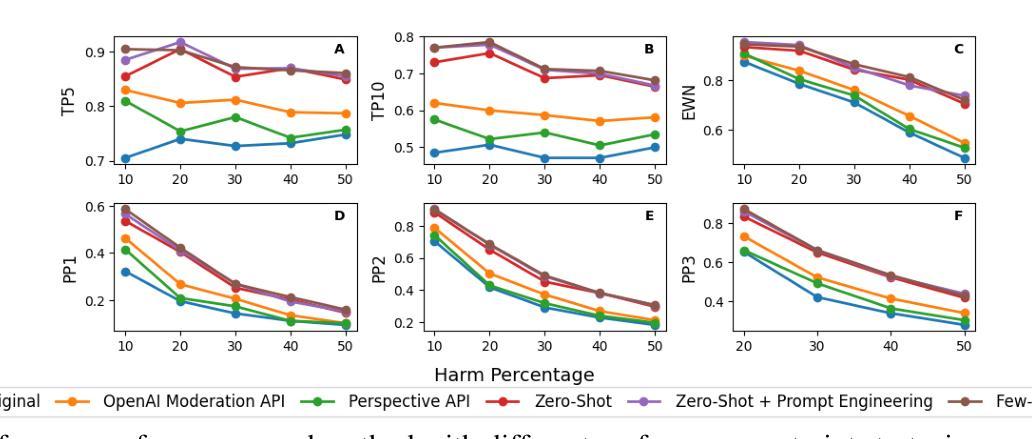
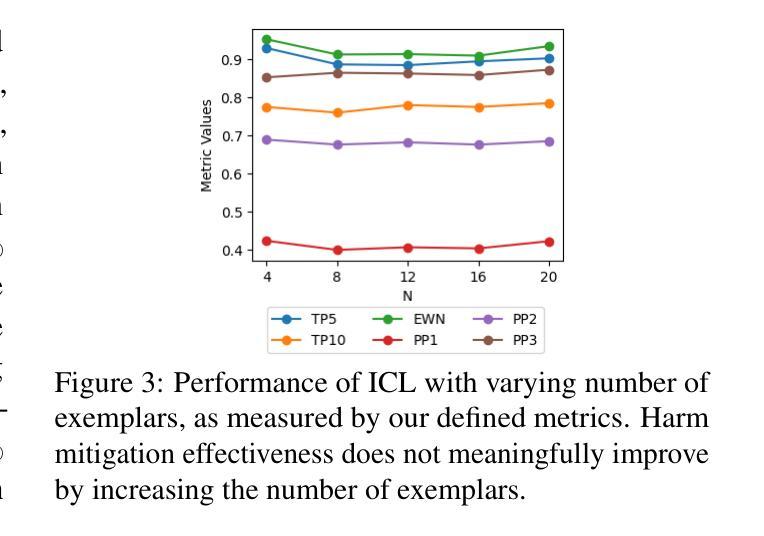
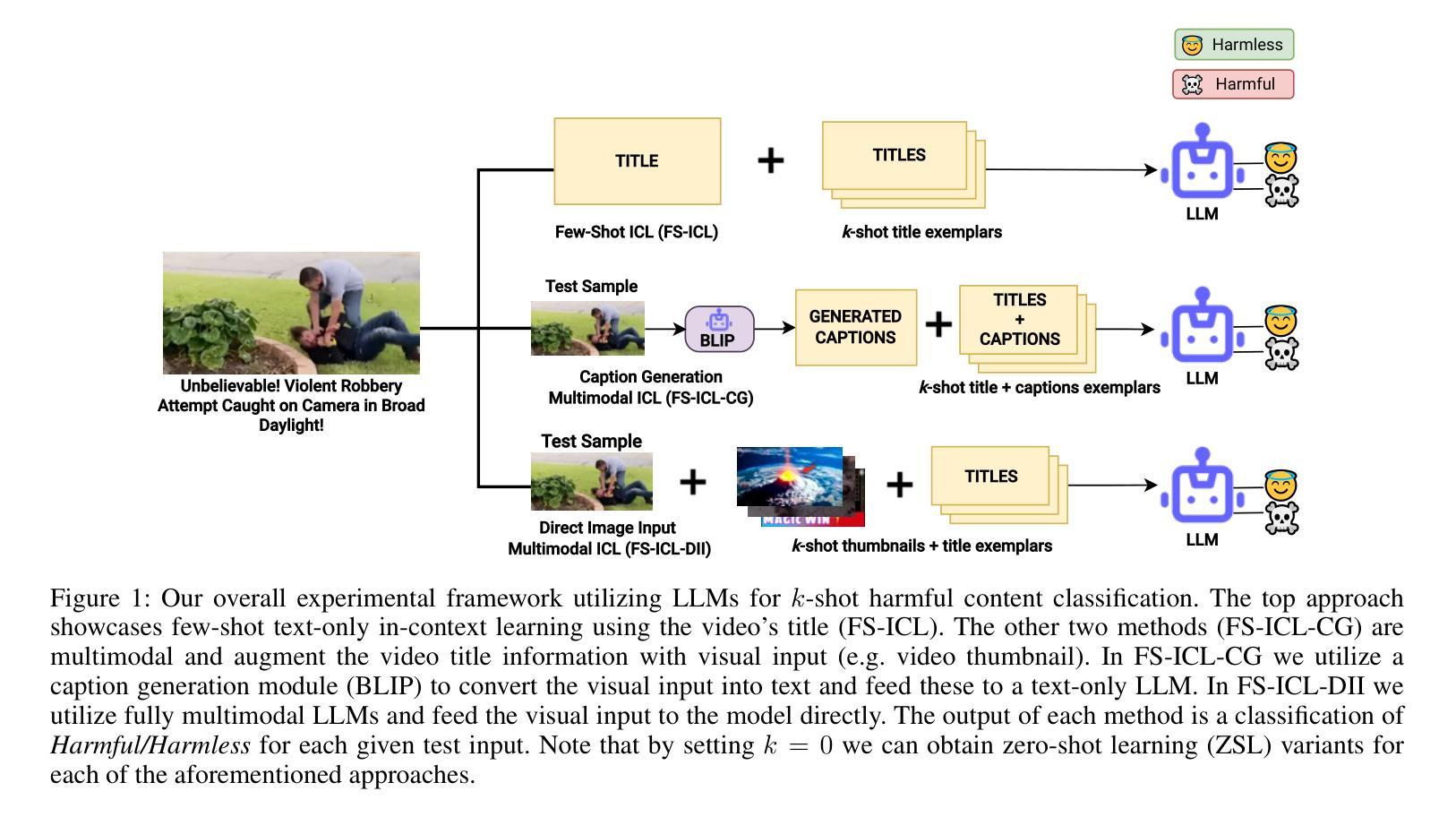
The prevalence of harmful content on social media platforms poses significant risks to users and society, necessitating more effective and scalable content moderation strategies. Current approaches rely on human moderators, supervised classifiers, and large volumes of training data, and often struggle with scalability, subjectivity, and the dynamic nature of harmful content (e.g., violent content, dangerous challenge trends, etc.). To bridge these gaps, we utilize Large Language Models (LLMs) to undertake few-shot dynamic content moderation via in-context learning. Through extensive experiments on multiple LLMs, we demonstrate that our few-shot approaches can outperform existing proprietary baselines (Perspective and OpenAI Moderation) as well as prior state-of-the-art few-shot learning methods, in identifying harm. We also incorporate visual information (video thumbnails) and assess if different multimodal techniques improve model performance. Our results underscore the significant benefits of employing LLM based methods for scalable and dynamic harmful content moderation online.
社交媒体平台上存在的有害内容对用户和社会构成了重大风险,因此需要更有效、可扩展的内容审核策略。当前的方法依赖于人工审核员、受监督的分类器以及大量的训练数据,但在可扩展性、主观性和有害内容的动态性方面往往面临挑战(例如暴力内容、危险挑战趋势等)。为了弥这些差距,我们利用大型语言模型(LLM)通过上下文学习进行少量动态内容审核。我们在多个LLM上进行了大量实验,结果表明我们的少量方法能够超越现有的专有基线(如Perspective和OpenAI审核)以及先前的最先进的少量学习方法,在识别危害方面表现更好。我们还融入了视觉信息(视频缩略图),并评估不同的多模式技术是否提高了模型性能。我们的结果强调了在在线进行可扩展和动态的有害内容审核时采用基于LLM的方法所带来的显著好处。
论文及项目相关链接
PDF This paper is in submission and under peer review
Summary
社交媒体平台上有害内容的普及对用户和社会造成重大风险,需要更有效和可扩展的内容审核策略。当前方法依赖人工审核、监督分类器和大量训练数据,常常在可扩展性、主观性和有害内容动态性方面遇到挑战。为了弥补这些不足,我们利用大型语言模型(LLM)通过上下文学习进行少量动态内容审核。通过多项实验证明,我们的方法能超越现有专有基准和先进少量学习法,有效识别危害内容。我们还结合视觉信息(视频缩略图)来评估不同多模式技术是否能提高模型性能。结果强调采用LLM方法在线进行可扩展和动态有害内容审核的重大益处。
Key Takeaways
- 社交媒体平台上存在有害内容,这需要更有效的内容审核策略。
- 当前的内容审核方法存在可扩展性、主观性和动态性的挑战。
- 大型语言模型(LLM)可以通过上下文学习进行少量动态内容审核。
- LLM方法在识别有害内容方面超越了现有基准和少量学习法。
- 结合视觉信息(如视频缩略图)可能提高内容审核模型的性能。
- LLM方法对于在线有害内容审核具有显著益处,包括可扩展性和动态性。
点此查看论文截图

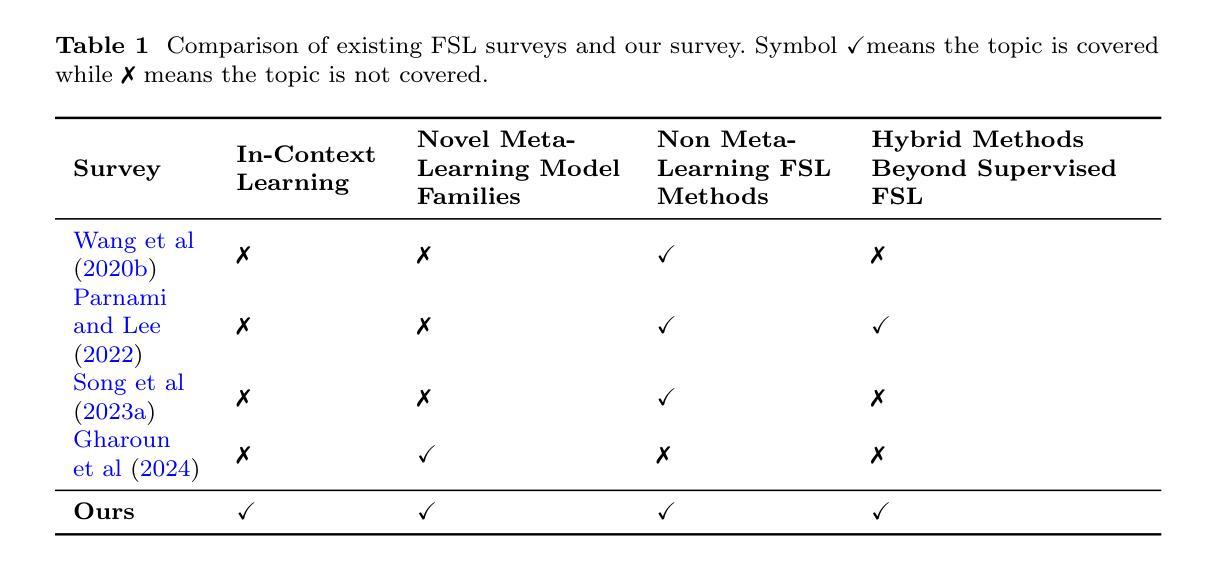
A Complete Survey on Contemporary Methods, Emerging Paradigms and Hybrid Approaches for Few-Shot Learning
Authors:Georgios Tsoumplekas, Vladislav Li, Panagiotis Sarigiannidis, Vasileios Argyriou
Despite the widespread success of deep learning, its intense requirements for vast amounts of data and extensive training make it impractical for various real-world applications where data is scarce. In recent years, Few-Shot Learning (FSL) has emerged as a learning paradigm that aims to address these limitations by leveraging prior knowledge to enable rapid adaptation to novel learning tasks. Due to its properties that highly complement deep learning’s data-intensive needs, FSL has seen significant growth in the past few years. This survey provides a comprehensive overview of both well-established methods as well as recent advancements in the FSL field. The presented taxonomy extends previously proposed ones by incorporating emerging FSL paradigms, such as in-context learning, along with novel categories within the meta-learning paradigm for FSL, including neural processes and probabilistic meta-learning. Furthermore, a holistic overview of FSL is provided by discussing hybrid FSL approaches that extend FSL beyond the typically examined supervised learning setting. The survey also explores FSL’s diverse applications across various domains. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.
尽管深度学习取得了广泛应用,但其对大量数据和大量训练的高要求使得它在数据稀缺的各种现实世界应用中变得不切实际。近年来,小样学习(FSL)作为一种学习范式应运而生,旨在利用先验知识实现快速适应新的学习任务。由于小样学习的属性能够很好地弥补深度学习对数据密集的需求,因此在过去几年中,小样学习得到了快速发展。本文全面概述了小样学习的成熟方法和最新进展。提出的分类法通过纳入新兴的小样学习范式(如上下文学习)和元学习范式内的新兴类别(包括神经过程和概率元学习),对先前提出的分类法进行了扩展。此外,通过对超越通常考察的监督学习环境的混合小样学习方法的讨论,提供了小样学习的整体概述。本文还探讨了小样学习在不同领域的多样应用。最后,讨论了塑造该领域的最新趋势、杰出挑战和富有前景的未来研究方向。
论文及项目相关链接
PDF 63 pages, 16 figures. Under review
Summary
近年来,深度学习虽取得广泛应用,但其对数据量大和训练时间长的要求限制了其在数据稀缺的现实世界场景中的应用。因此,小样本学习(FSL)作为一种利用先验知识快速适应新学习任务的学习范式应运而生。该调查全面概述了FSL的成熟方法和最新进展,并扩展了先前的分类方法,引入了新兴的小样本学习范式,如上下文学习和元学习中的新类别,如神经过程和概率元学习。此外,通过讨论超越传统监督学习设置的混合FSL方法,提供了对FSL的全方位概述。该调查还探讨了FSL在不同领域的应用以及当前该领域的最新趋势、杰出挑战和具有前景的未来研究方向。
Key Takeaways
- 小样本学习(FSL)旨在解决深度学习在数据稀缺场景下的局限性。
- FSL利用先验知识快速适应新学习任务。
- 全面概述了FSL的成熟方法和最新进展。
- 引入了新兴的小样本学习范式,如上下文学习和元学习中的新类别。
- 提供了对FSL的全方位概述,讨论了超越传统监督学习设置的混合FSL方法。
- 探讨了FSL在不同领域的应用。
点此查看论文截图